6.1. Discussion of Research Questions
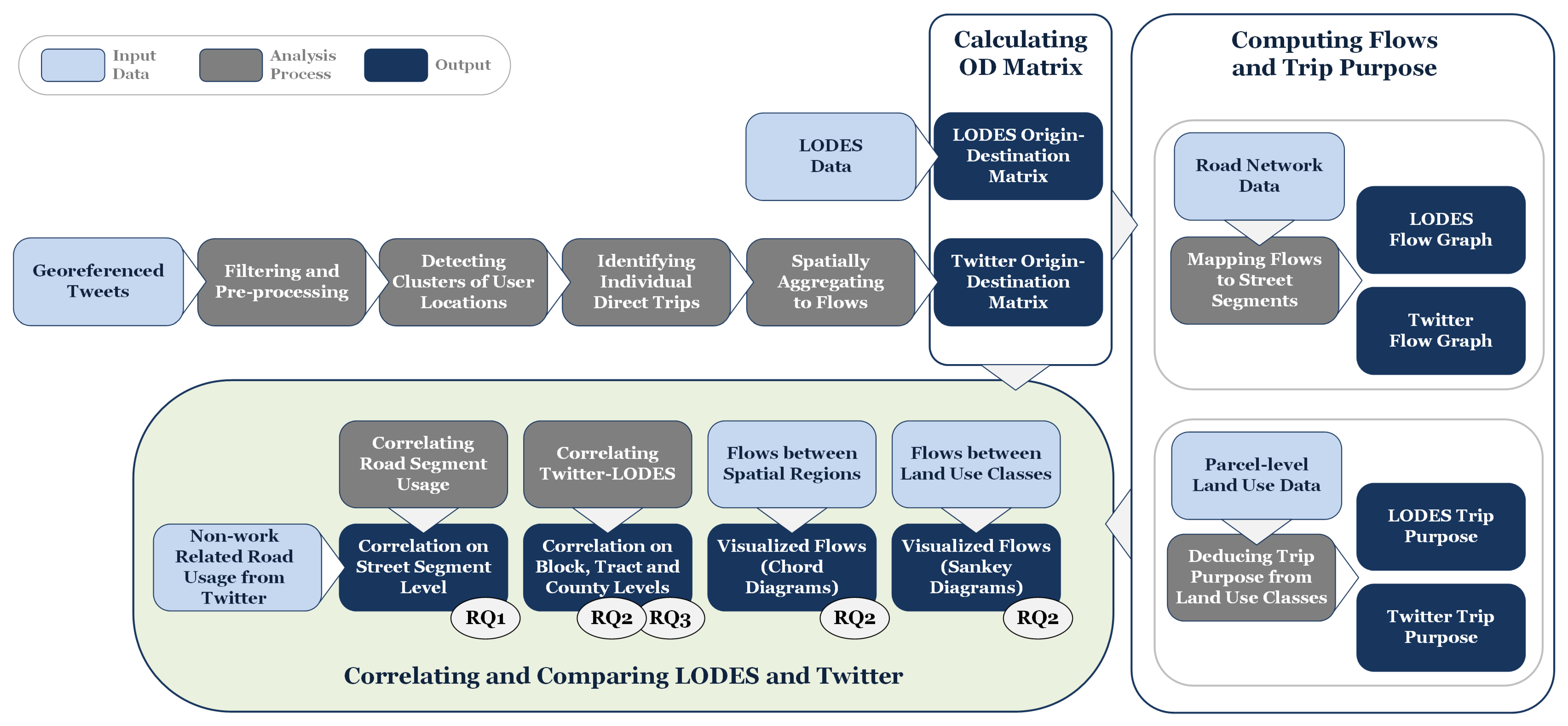
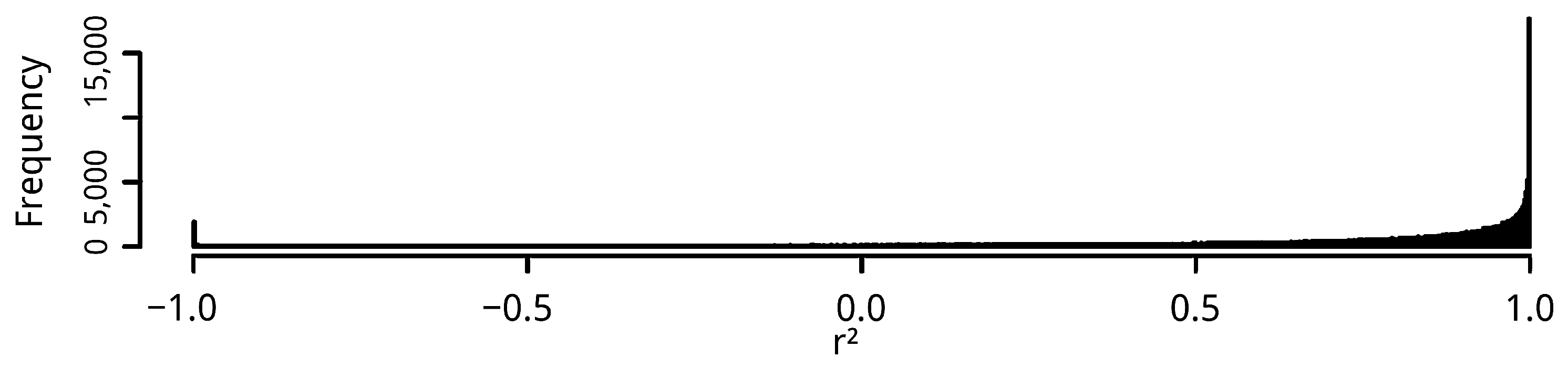
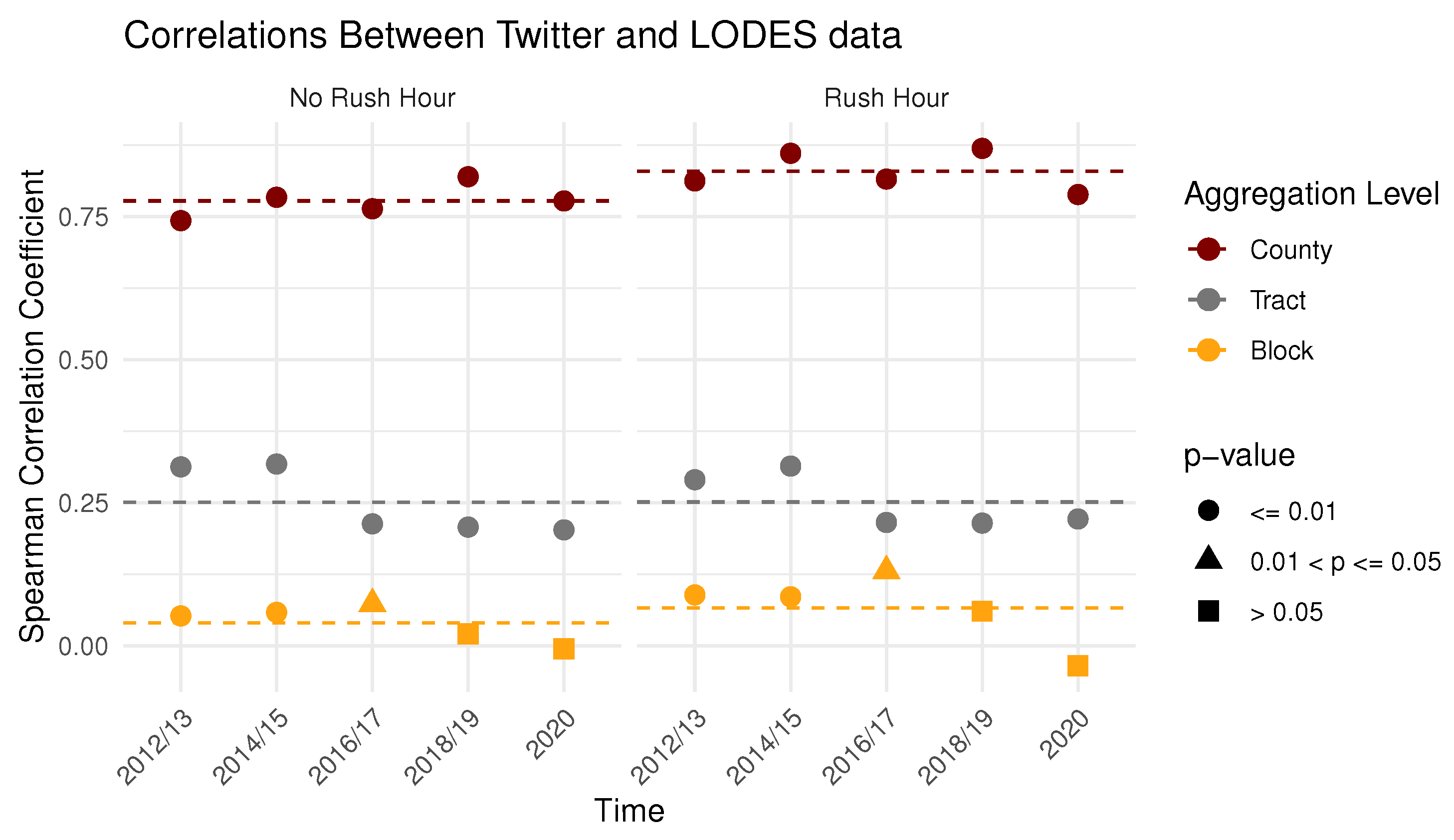
To address research question 1, to what degree do commuter flow patterns identified in GSND correlate with official LODES commuting data, we analyzed the correlations among the OD pairs of both data sources at multiple spatial scales. As confirmed by other county-level analyses of Twitter-based flow data, we found that there is a strong correlation at smaller spatial scales. In contrast, when we mapped the flows at highly localized to the street segment levels, we found indications that a large portion of Twitter flows are different from direct work trips. They tend to be significantly shorter, even if they occur during rush hour times.
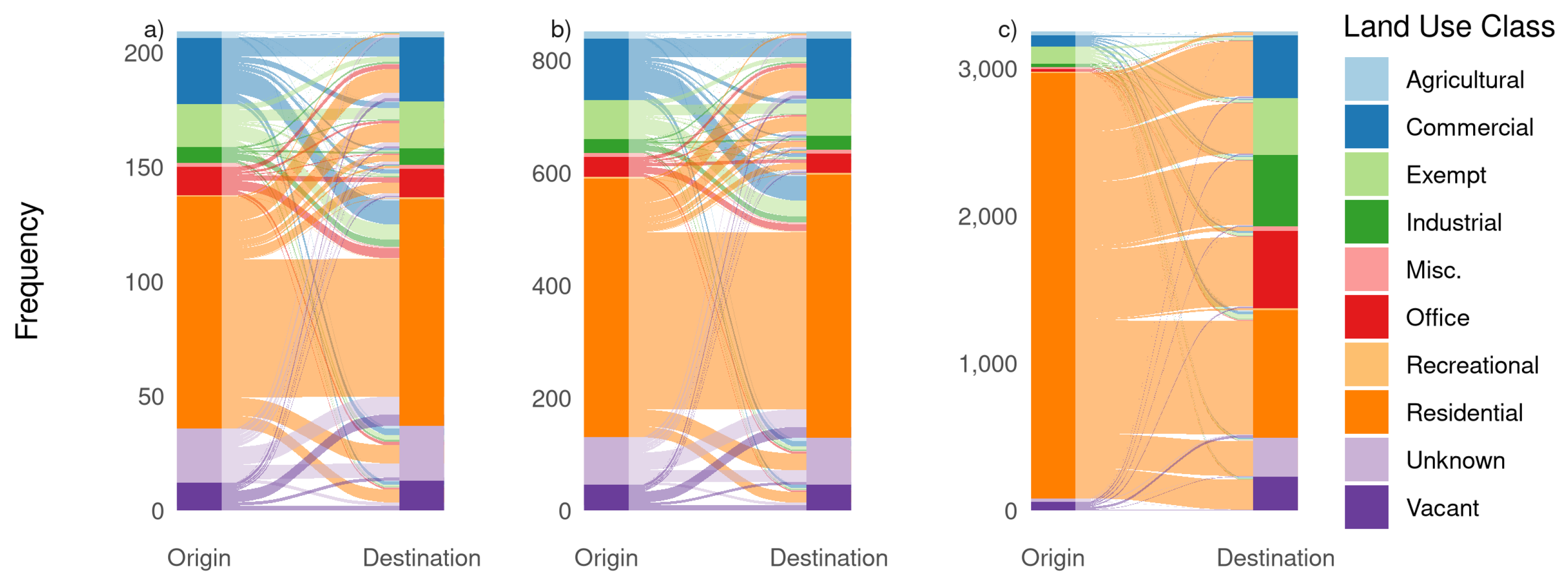
To address research question 2, which traffic flow information beyond commuting is contained in GSND, we used both destination land use classes as well as time stamps outside of typical rush hours to derive different trip populations. Both methods lead to clearly distinguishable movement patterns. Our assumption that LODES trips show a stronger linkage between residential and work-related land uses than non-commuter movements is confirmed by the comparison of parts (a) and (b) in the Sankey diagrams of
Figure 8.
To address research question 3, how strong is the influence of spatial scale on correlations between flows extracted from GSND and LODES commuting flows, we again refer to the correlation coefficients of Twitter and LODES flows at different times and on different spatial scales. The correlation coefficients show that for county-level mobility, Twitter and LODES exhibit robust, high correlations. This is consistent with a number of nation-wide, county-level resolution studies.
6.2. Discussion of Methods
For the purpose of this study, we focused on movements within our study area that a user visits repeatedly. We implemented this premise by only including fine-grained areas (no bigger than a census block) in which we detected spatiotemporal clusters of tweets by a given user. We implemented this constraint to ascertain that we capture routine travel behavior, which means that rarely visited locations have purposefully been excluded from this analysis. A built-in assumption here is that frequent visits to a location result in frequent tweets. This is a limitation that is not borne out of any particular conceptual model but based in the nature of the data. Another limitation of our work is that trip chains between home and work, in which the user makes regular stops at intermediate locations can be picked up as regularly occurring trips that skew the Twitter OD data away from the LODES data. This effect can also be beneficial, however, if the actual road use patterns created by commuters are of interest.
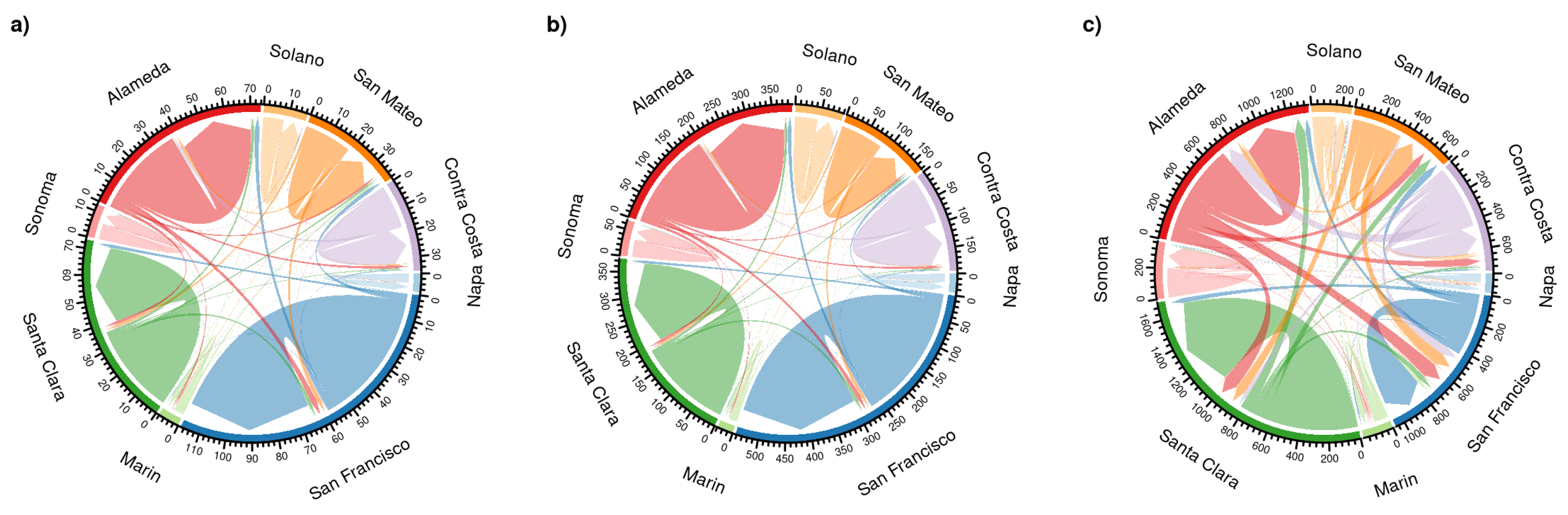
For our area-based approaches, we emphasize flow magnitudes, as well as the origin and destination areas. The direct comparisons of correlation coefficients result in simple summary statistics, which are compact and easy to compare, but do not provide deeper insights into the spatial characteristics of the results. This is compounded by the inherently binary nature of OD pair comparisons: Two OD pairs are either identical or they are not. This distorts the reality that each OD pair is a simplified representation of what is actually a route along a street network. Two OD pairs with starting or end points in close spatial proximity but in different area units, are likely to share some street segments in their routes. However, they are not identical and are therefore, a mismatch from an area-based perspective. This skews the correlation statistics towards low values, especially for smaller areas. The graph-based reasoning methods are better suited to capture such spatially similar but non-identical connections. This effect can be observed when comparing the region-based results in
Figure 6 with the graph-based ones from
Table 3. Although the median street segment length of
constitute a finer scale than the census block level, the predictive power is significantly higher. It is worth noting, however, that using a least-cost path algorithm to derive road segment usage from OD pairs assumes highly efficient travelling behavior, which might not be given.
Aside from road graphs, the finest area unit for direct comparisons of LODES and Twitter data used in this study is the census block. Georeferenced Twitter data typically derive their location from a mobile device’s Global Positioning System (GPS) sensor. Using GPS locations would potentially allow comparisons on an even finer spatial scale, however this would also require appropriate reference data. In the case of this study, we chose the census block scale of the LODES data as the limit.
A significant portion of the land-use class connections are residential to residential trips. This is not a surprising result for the Twitter flows, since we expected movement between different private residences as part of day-to-day social interactions. In the LODES data, however, this was unexpected, since we did not expect many residential areas to function as workplaces. We identified possible reasons for this discrepancy. Areas classified as residential areas in our land-use data could in fact be compound areas of different land-use classes. Also, by integrating the land-use data on the census block level, compound areas could have been aggregated to the most dominant land-use class, thereby obscuring some commercial land-use class parcels. A possible alternative would be to use a weighted approach to account for such areas.
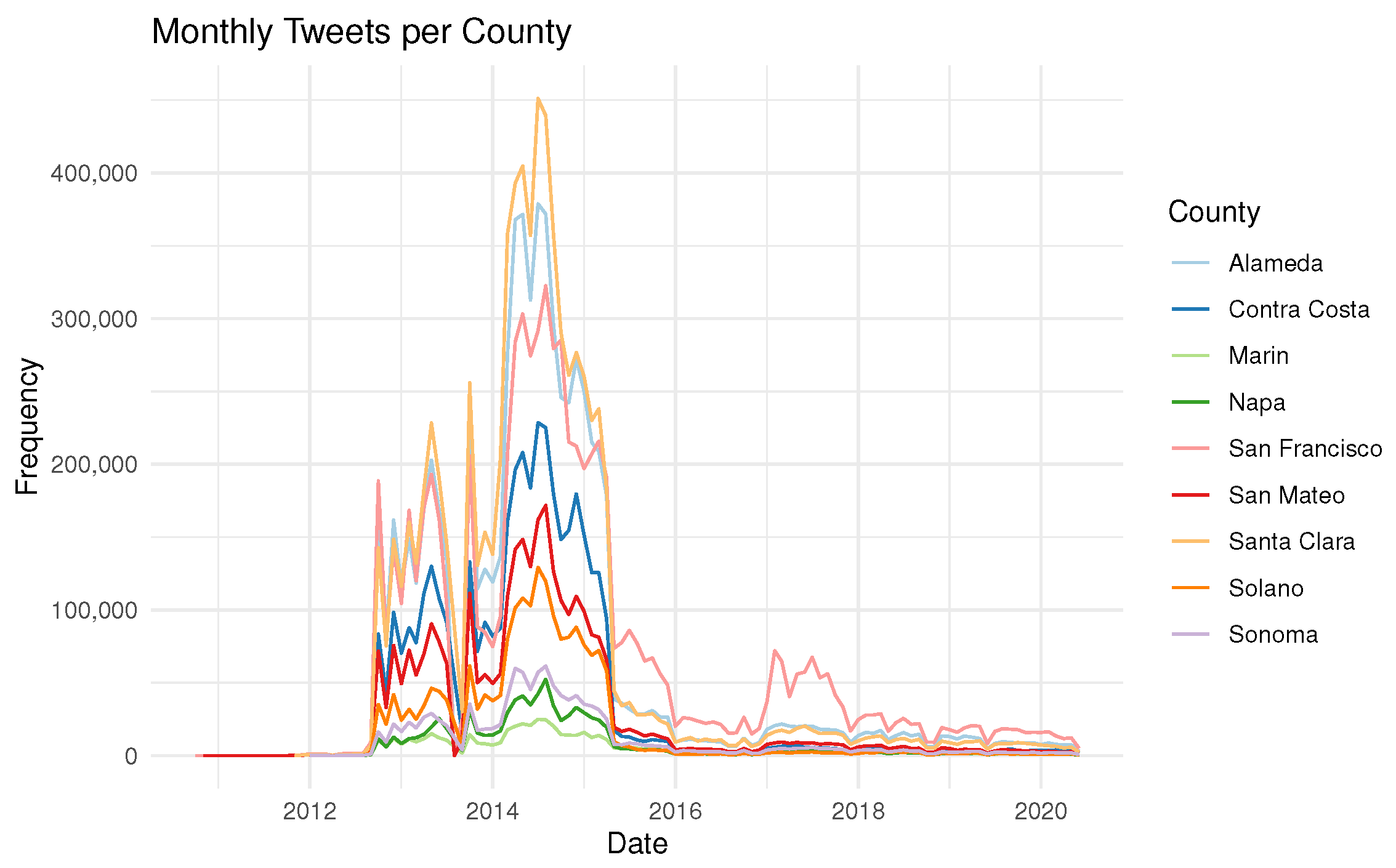
Twitter usage is skewed by demographic and geographic context. The population of some regions and the movements of their members will be represented more strongly than others. There might, for example, be residential areas with few active Twitter users, but a large working population. Or there might be places with few permanent residents that attract large numbers of visitors like sports venues or shopping centers. It is important to incorporate knowledge of such places when interpreting the results of a study like ours. Another factor that influences the availability of georeferenced Twitter data is time. There can be multiple reasons for changes in data availability over time, for example changes in user numbers, data sharing policies by Twitter or differences in user activity over time. To ensure that the results of the study still hold despite these changes, it is important to validate temporal subsets of the data to ensure their integrity.
While LODES is limited to home-to-work mobility, Twitter flows represent other travel purposes as well. Ideally, the difference between the two datasets should be based on non-commuting mobility only. In reality, however, there is some overlap between commuting and non-commuting trips during rush hours and there is also a not insignificant number of commute trips outside of traditional rush hours, which make it hard to separate the movement populations.
From the perspective of statistical error analysis, it is possible to scale the Twitter origin land-use class distributions to resemble the distributions from LODES and adjust the Twitter destination land-use classes accordingly. This would skew the distribution of Twitter flows towards that of LODES at the cost of introducing an additional error term. Another issue regarding the use of LODES data as reference for Twitter flows is the temporal lag between the two data sources. The LODES data used in this study are from 2019 and therefore more recent than most of the Twitter data. Discerning the effects of this lag on results is problematic, because the amount of Twitter data, user demographics and data availability may also vary over time. Results with high temporal lags must therefore be interpreted carefully and, where possible, substantiated with additional data.
LODES data do not contain information about temporal trip characteristics like the time of day or weekday. Having this additional information would be beneficial for the quality of time-sensitive analysis and for specifying assumptions about the commuting process.
Movement data of a person may reveal intimate insights into their life. Following the geo-privacy by design guidelines by [
51,
52], we apply the principle of data economy throughout the entire workflow and only disclose results where the spatial and temporal aggregation prevents the identification of individuals. It is therefore crucial, that researchers utilizing similar methods and data sources uphold the principles of information privacy and ideally, develop methods that obscure personal information in GSND adequately without compromising study outcomes.
6.3. Discussion of Results and Relevance for Urban Planning
Our comparison of the two differently sourced flow data employed methods designed to highlight different aspects of the data. Focusing on flow magnitudes, we found spatial scale to be the most influential factor. At small scales such as the county level, we are able to model the proportion of flows well, whereas on larger scales, we observe significant differences between Twitter and LODES flows. Given the observed differences between three spatial scales, we recommend investigating even more scale levels to learn more about this aspect of the data. Alternatively, one could abandon the use of administrative boundaries altogether and use regularly spaced grid cells to explore the impact of spatial scales.
The transition to a road network analysis with its comparison of street segment loads allowed us to compare different flow populations with much higher granularity. We found that during rush hours, the data sources deviate significantly, which suggests that Twitter flows capture regular trips with purposes other than commuting. The graph-based analysis also shows that Twitter trips are generally much shorter than LODES commutes, which lends support to trip purposes other than direct travel to work as well, even if many of them fall into rush hour times. This interpretation is also supported by the analysis of land use class connections, which again show significant differences between LODES and Twitter. One assumption that is built into the model based on the street network is that the mode of transport is by car, which is implemented via the graph weighting scheme. This skews the results towards car-specific infrastructure like highways, which has to be considered when interpreting them. As one would expect from trips to work, LODES data contain fewer connections between residential areas when compared to Twitter flows. Finally, the proportions of the remaining land use classes point again to differences in trip purpose.
Potential Use in Urban Planning
Transportation planning and policy requires long-range planning that uses demographic forecasting and travel demand modeling to direct infrastructure investments. The existing data sources like the decennial census and its derivative data products such as LODES are well suited to support these analyses. In recent years, the prevalence of volunteered geographic information and similar data sources made available by commercial providers like SeeClickFix [
56], Waze [
57], or, in the case of this study, Twitter, have helped planners and managers undertake just-in-time planning, making adjustments in response to public requests for intervention. We argue that GSND from Twitter can be used to support planning in the three to five-year time frame, to undertake modest capital improvements and other planning and policy interventions that are likely to benefit the public because the data are reliable and immediately usable to planners. Given that Twitter data availability varies significantly over time and the volume declined toward the end of the study period, alternative, more stable data sources of comparable data structure would be beneficial when using these methods in urban planning.
Given that only 16.6% of vehicle trips on U.S. streets are work-related [
8], the remaining 83.4% of trips are not addressed by the LODES data. As we could show in our large-scale, region-based comparisons, Twitter-derived trips differ in their spatiotemporal characteristics from work- related ones, which raises questions about the validity of transportation models purely based on LODES data. There is an obvious need for data that complements LODES and captures the remaining flows at a comparable spatial scale. We suggest that the methods presented in this article are a step toward the development of such a dataset. Another important finding, however, is the high correlation between Twitter and LODES flows on the street segment level. Given that the general-purpose Twitter flows and commuter-based LODES flows are similar on this scale, we can conclude that LODES flows do not only represent commuter travel, but are also appropriate for general-purpose transportation modeling.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}