
A System for Aligning Geographical Entities from Large Heterogeneous Sources


Abstract
:1. Introduction
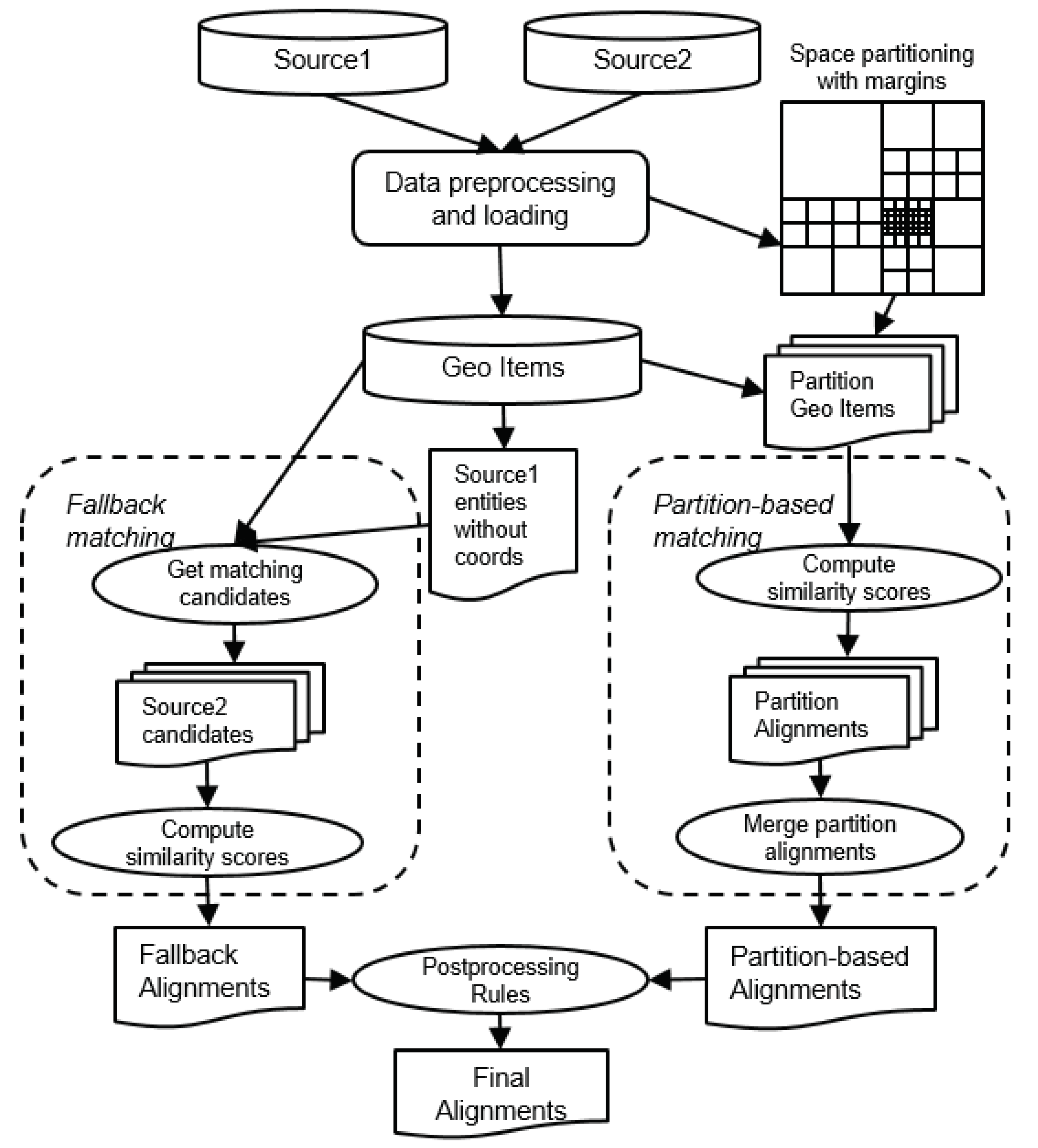
- We designed a new alignment system GeographicaL Entities AligNment (GLEAN), which leverages the main attributes of geographical entities: label, category (or type), address and coordinates. GLEAN first computes individual similarity measures for each of the attributes, then combines them into a final similarity measure for the checked entities’ pair. This alignment similarity is then compared to a threshold to make a decision on the matching.
- We combined the use of local context relevance of tokens with multilingual sentence encoders to compute the label component similarity.
- We used unsupervised-type embedding and type demotion approaches for type component scoring.
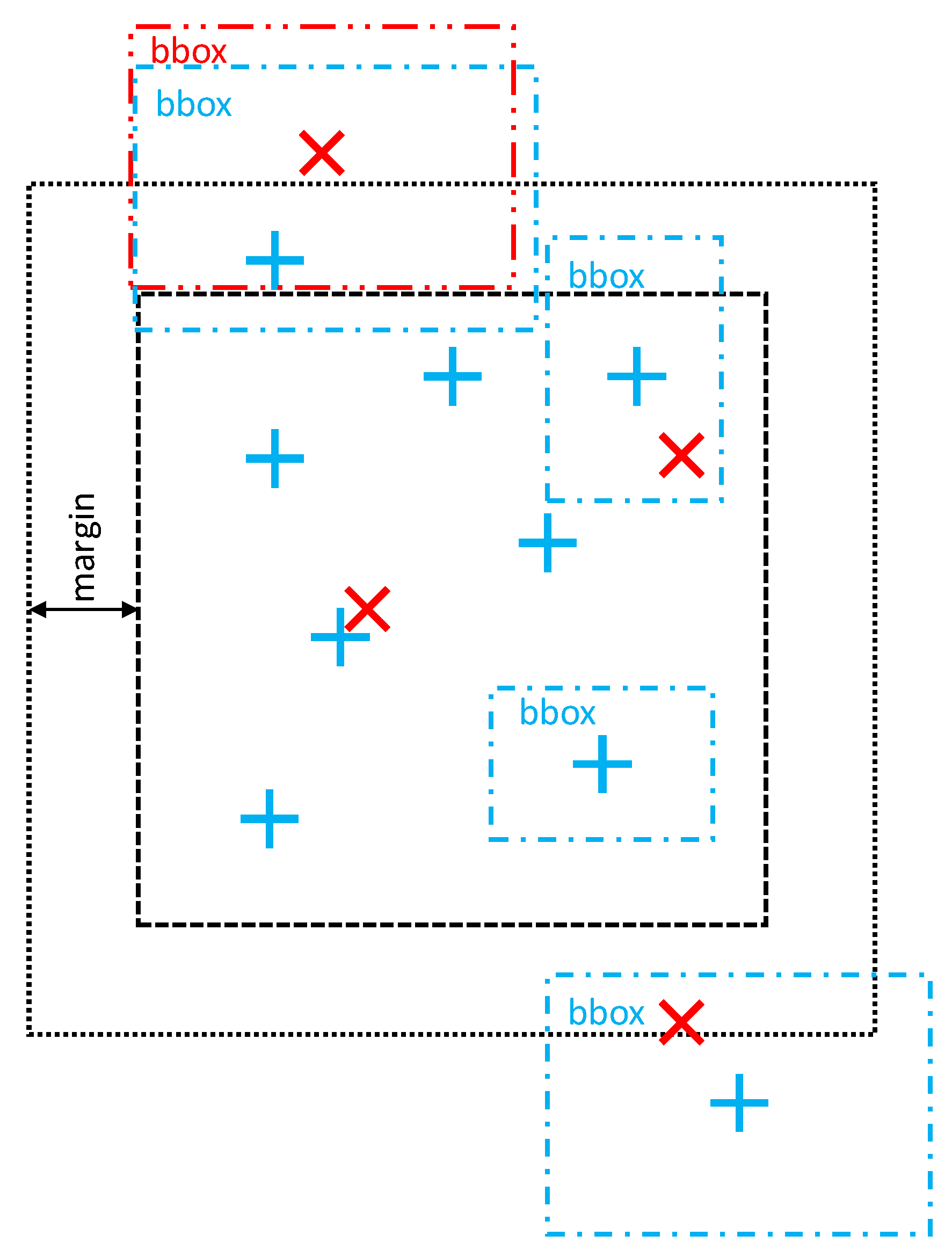
- We applied a scalable adaptable-margin partitioning in large-scale geographical entities datasets in order to improve the scalability of our alignment system.
- We evaluated the impact of our contributions in the alignment similarity score and the scalability of our offline matching approach.
2. Related Work
3. Problem Statement
- and may have different structures (i.e., the labels may be written in different ways, potentially containing more general parts, and the parts may be ordered differently). and may also be available in different languages (sometimes, there are no overlapping languages).
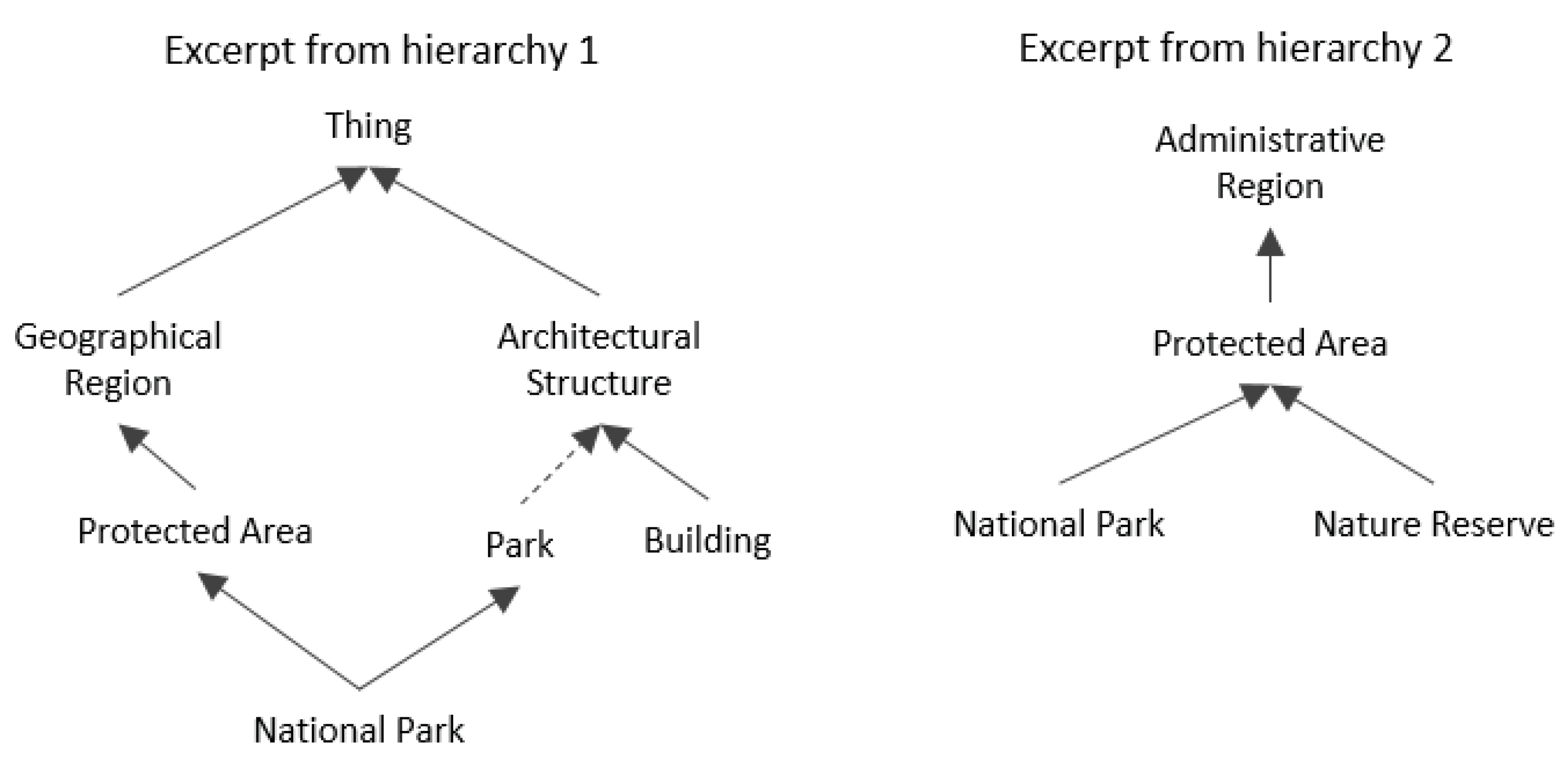
- and may have different degrees of granularity, hierarchical structures and types’ names.
- and may have different formats and come with different levels of incompleteness. Additionally, they may contain more/less relevant information.
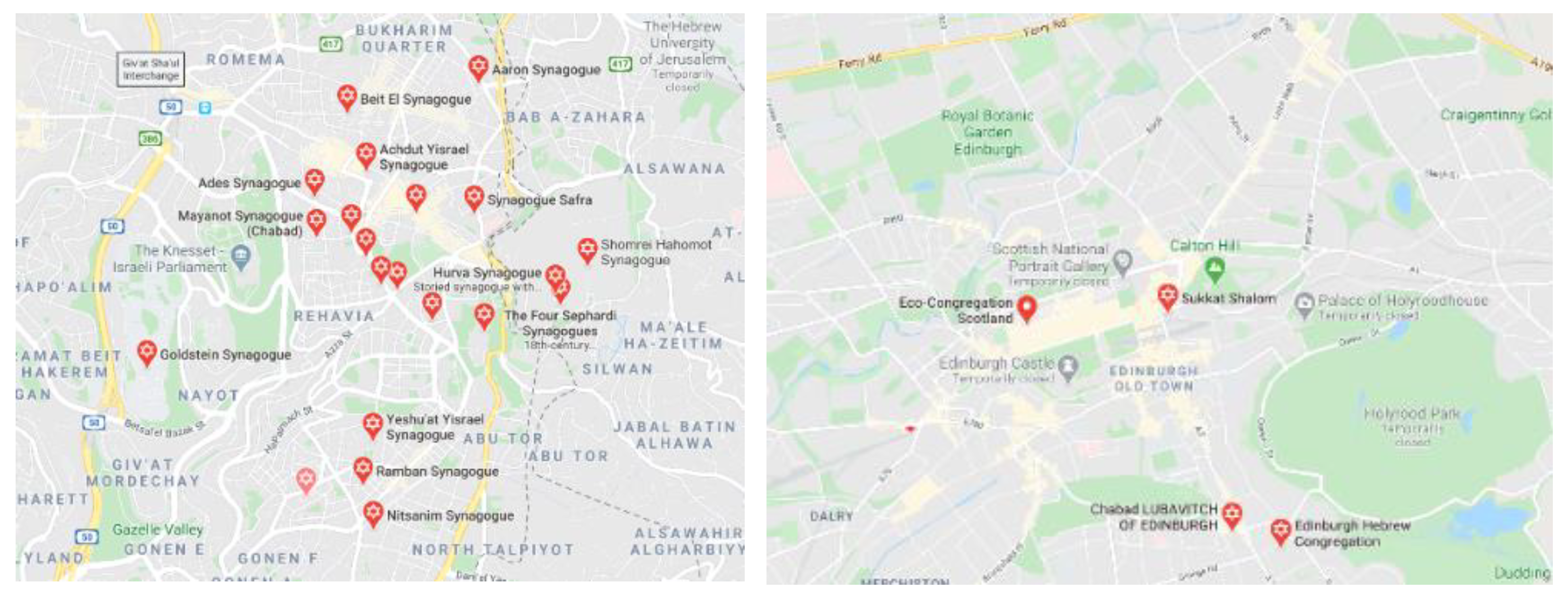
- and may be some distance away from each other, and one of them might also not be available. Few of the entities that have / available include bounding box information.
4. Components of GLEAN
4.1. Local Context Token Relevance
4.2. Alignment Scores
4.2.1. Label Component
4.2.1.1. Label Preprocessing
4.2.1.2. Label Parts Ordering
- Original label: “Edinburgh, Candlemaker Row, Greyfriars Church, George Buchanan’s Monument
- Reordered label: “George Buchanan’s Monument, Greyfriars Church, Candlemaker Row, Edinburgh
4.2.1.3. Multilingual Sentence Encoders
4.2.1.4. Local IDF Weighted Similarity
4.2.2. Type Component
4.2.2.1. Type Embeddings
4.2.2.2. Type Demotion
4.2.3. Address Component
4.2.4. Geographical Distance Component
4.3. Postprocessing Rules
5. Architecture of GeographicaL Entities AligNment (GLEAN) System
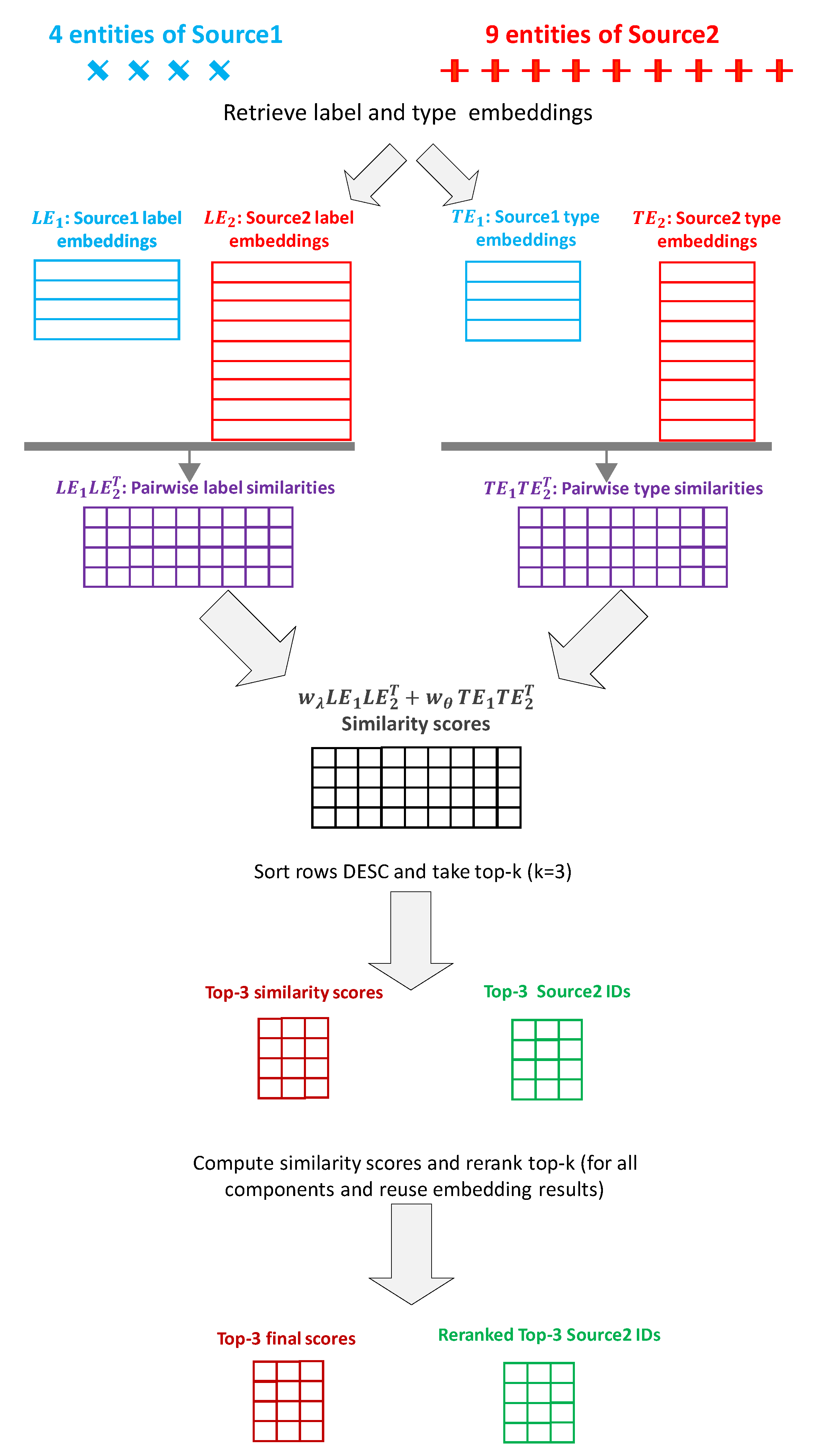
5.1. Partition-Based Matching
5.2. Fallback Matching
5.3. Discussion of the Online Alignment Scenario
6. Experiments
6.1. Datasets
6.2. Results and Discussions
6.2.1. Ablation Study
- GLEAN: complete system with no ablated parts.
- LIDFJ: the local-IDF Jaccard similarity is removed with label score relying exclusively on multilingual sentence encoder.
- MLSE: the multilingual sentence encoder is removed with only LIDFJ being used as label score.
- TypeComp: the entire type score component is removed (both embedding and demotion components). This means the resulting alignment completely ignores the types.
- TypeDem: the type demotion is removed with type scores relying on embeddings exclusively.
- TypeGD: the type-based geographical distance score is removed with component scores no longer being type dependent.
6.2.2. Examples of GLEAN’s Alignment
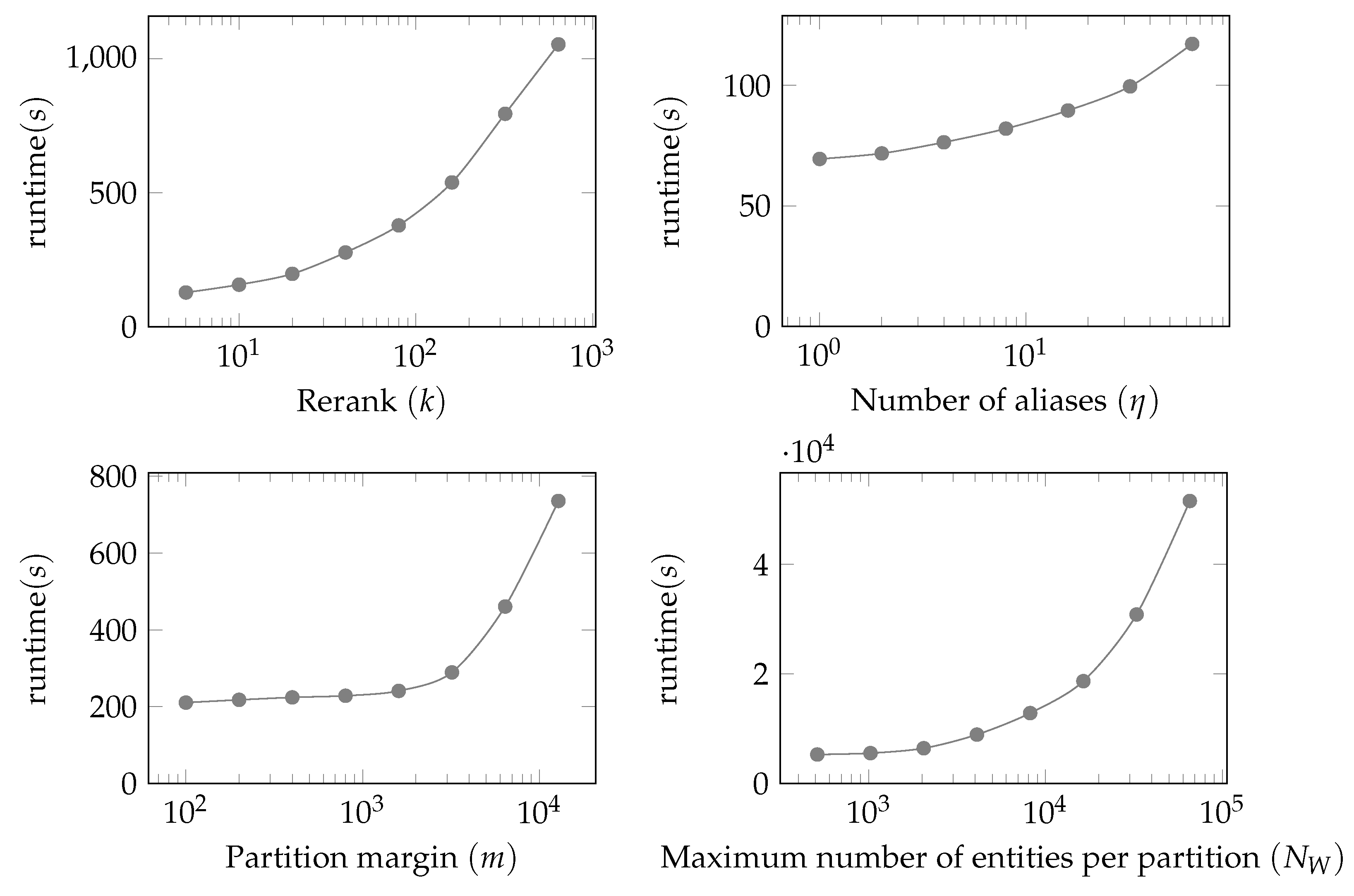
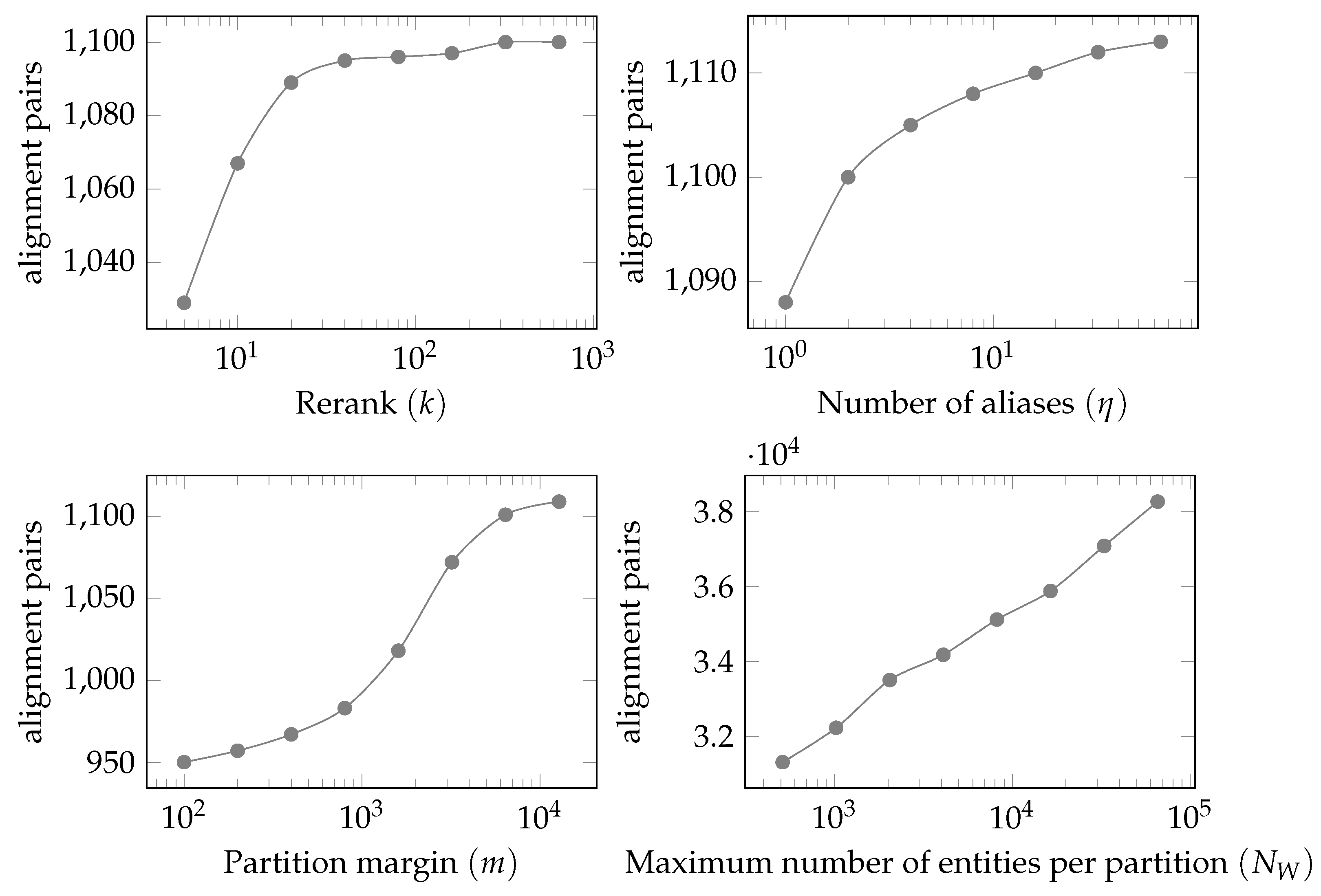
6.2.3. Scalability of GLEAN
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goodchild, M. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef] [Green Version]
- Wiemann, S.; Bernard, L. Spatial data fusion in Spatial Data Infrastructures using Linked Data. Int. J. Geogr. Inf. Sci. 2016, 30, 613–636. [Google Scholar] [CrossRef]
- Scheffler, T.; Schirru, R.; Lehmann, P. Matching Points of Interest from Different Social Networking Sites. In Proceedings of the 35th Annual German Conference on Advances in Artificial Intelligence, Saarbrücken, Germany, 24–27 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 245–248. [Google Scholar] [CrossRef]
- Beeri, C.; Doytsher, Y.; Kanza, Y.; Safra, E.; Sagiv, Y. Finding Corresponding Objects When Integrating Several Geo-Spatial Datasets. In Proceedings of the 13th Annual ACM International Workshop on Geographic Information Systems, New York, NY, USA, 3–6 November 2005; pp. 87–96. [Google Scholar] [CrossRef]
- Samal, A.; Seth, S.C.; Cueto, K. A feature-based approach to conflation of geospatial sources. Int. J. Geogr. Inf. Sci. 2004, 18, 459–489. [Google Scholar] [CrossRef]
- Deng, Y.; Luo, A.; Liu, J.; Wang, Y. Point of Interest Matching between Different Geospatial Datasets. ISPRS Int. J. Geo-Inf. 2019, 8, 435. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Vasardani, M.; Winter, S. Similarity matching for integrating spatial information extracted from place descriptions. Int. J. Geogr. Inf. Sci. 2017, 31, 56–80. [Google Scholar] [CrossRef]
- Li, X.; Morie, P.; Roth, D. Semantic Integration in Text: From Ambiguous Names to Identifiable Entities. AI Mag. 2005, 26, 45–58. [Google Scholar] [CrossRef]
- Safra, E.; Kanza, Y.; Sagiv, Y.; Doytsher, Y. Integrating Data from Maps on the World-Wide Web. In Proceedings of the Web and Wireless Geographical Information Systems, 6th International Symposium, W2GIS 2006, Hong Kong, China, 4–5 December 2006; Carswell, J.D., Tezuka, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4295, pp. 180–191. [Google Scholar] [CrossRef] [Green Version]
- McKenzie, G.; Janowicz, K.; Adams, B. Weighted Multi-Attribute Matching of User-Generated Points of Interest. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, New York, NY, USA, 5–8 November 2013; pp. 440–443. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Chu, Y.; Hu, H.; Feng, J.; Zhu, X. Top-k Spatio-textual Similarity Search. In Proceedings of the Web-Age Information Management—15th International Conference, WAIM 2014, Macau, China, 16–18 June 2014; Li, F., Li, G., Hwang, S., Yao, B., Zhang, Z., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8485, pp. 602–614. [Google Scholar] [CrossRef]
- Novack, T.; Peters, R.; Zipf, A. Graph-Based Matching of Points-of-Interest from Collaborative Geo-Datasets. ISPRS Int. J. Geo-Inf. 2018, 7, 117. [Google Scholar] [CrossRef] [Green Version]
- Purvis, B.; Mao, Y.; Robinson, D. Entropy and its Application to Urban Systems. Entropy 2019, 21, 56. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Low, R.; Tekler, Z.D.; Cheah, L. An End-to-End Point of Interest (POI) Conflation Framework. ISPRS Int. J. Geo-Inf. 2021, 10, 779. [Google Scholar] [CrossRef]
- Alexakis, M.; Athanasiou, S.; Kouvaras, Y.; Patroumpas, K.; Skoutas, D. SLIPO: Scalable Data Integration for Points of Interest. In Proceedings of the 2nd ACM SIGSPATIAL International Workshop on Geospatial Data Access and Processing APIs, Seattle, WA, USA, 3 November 2020. [Google Scholar] [CrossRef]
- Giannopoulos, G.; Skoutas, D.; Maroulis, T.; Karagiannakis, N.; Athanasiou, S. FAGI: A Framework for Fusing Geospatial RDF Data. In Proceedings of the Move to Meaningful Internet Systems: OTM 2014 Conferences, Amantea, Italy, 27–31 October 2014; Meersman, R., Panetto, H., Dillon, T., Missikoff, M., Liu, L., Pastor, O., Cuzzocrea, A., Sellis, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 553–561. [Google Scholar]
- Yu, F.; West, G.; Arnold, L.; McMeekin, D.; Moncrieff, S. Automatic geospatial data conflation using semantic web technologies. In Proceedings of the Australasian Computer Science Week Multiconference, Canberra, Australia, 1–6 February 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1–10. [Google Scholar] [CrossRef]
- Nahari, M.K.; Ghadiri, N.; Baraani-Dastjerdi, A.; Sack, J. A novel similarity measure for spatial entity resolution based on data granularity model: Managing inconsistencies in place descriptions. Appl. Intell. 2021, 51, 6104–6123. [Google Scholar] [CrossRef]
- Cousseau, V.; Barbosa, L. Linking place records using multi-view encoders. Neural Comput. Appl. 2021, 33, 12103–12119. [Google Scholar] [CrossRef]
- Jiang, X.; de Souza, E.N.; Pesaranghader, A.; Hu, B.; Silver, D.L.; Matwin, S. TrajectoryNet: An Embedded GPS Trajectory Representation for Point-Based Classification Using Recurrent Neural Networks. In Proceedings of the 27th Annual International Conference on Computer Science and Software Engineering, Markham, ON, Canada, 6–8 November 2017; IBM Corp.: Foster City, CA, USA, 2017; pp. 192–200. [Google Scholar]
- Sehgal, V.; Getoor, L.; Viechnicki, P.D. Entity Resolution in Geospatial Data Integration. In Proceedings of the 14th Annual ACM International Symposium on Advances in Geographic Information Systems, Arlington, VA, USA, 10–11 November 2016; Association for Computing Machinery: New York, NY, USA, 2006; pp. 83–90. [Google Scholar] [CrossRef]
- Li, C.; Liu, L.; Dai, Z.; Liu, X. Different Sourcing Point of Interest Matching Method Considering Multiple Constraints. ISPRS Int. J. Geo-Inf. 2020, 9, 214. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Cer, D.; Ahmad, A.; Guo, M.; Law, J.; Constant, N.; Ábrego, G.H.; Yuan, S.; Tar, C.; Sung, Y.; et al. Multilingual Universal Sentence Encoder for Semantic Retrieval. arXiv 2019, arXiv:1907.04307. [Google Scholar]
- Chidambaram, M.; Yang, Y.; Cer, D.; Yuan, S.; Sung, Y.; Strope, B.; Kurzweil, R. Learning Cross-Lingual Sentence Representations via a Multi-task Dual-Encoder Model. arXiv 2018, arXiv:1810.12836. [Google Scholar]
- Feng, F.; Yang, Y.; Cer, D.; Arivazhagan, N.; Wang, W. Language-agnostic BERT Sentence Embedding. arXiv 2020, arXiv:2007.01852. [Google Scholar]
- Yang, B.; Yih, S.W.t.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the International Conference on Learning Representations (ICLR) 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | HuaweiPD | Wikidata |
|---|---|---|
| Entities | 105.5 M | 8.1 M |
| Coordinates | 105.5 M | 7.7 M |
| BoundingBoxes | 1.1 M | 8.8 K |
| Labels/Aliases | 114.6 M | 37.1 M |
| Languages | 237 | 441 |
| Types | 744 | 2.4 M |
| SubClassOf | 731 | 2.9 M |
| Ablated | F1-Score | Precision | Recall | Accuracy |
|---|---|---|---|---|
| GLEAN | 0.913 | 0.973 | 0.860 | 0.953 |
| LIDFJ | 0.888 | 0.984 | 0.810 | 0.940 |
| MLSE | 0.792 | 0.973 | 0.668 | 0.897 |
| TypeComp | 0.886 | 0.936 | 0.842 | 0.943 |
| TypeDem | 0.820 | 0.894 | 0.757 | 0.907 |
| TypeGD | 0.857 | 0.949 | 0.781 | 0.928 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Melo, A.; Er-Rahmadi, B.; Pan, J.Z. A System for Aligning Geographical Entities from Large Heterogeneous Sources. ISPRS Int. J. Geo-Inf. 2022, 11, 96. https://doi.org/10.3390/ijgi11020096
Melo A, Er-Rahmadi B, Pan JZ. A System for Aligning Geographical Entities from Large Heterogeneous Sources. ISPRS International Journal of Geo-Information. 2022; 11(2):96. https://doi.org/10.3390/ijgi11020096
Chicago/Turabian StyleMelo, André, Btissam Er-Rahmadi, and Jeff Z. Pan. 2022. "A System for Aligning Geographical Entities from Large Heterogeneous Sources" ISPRS International Journal of Geo-Information 11, no. 2: 96. https://doi.org/10.3390/ijgi11020096
APA StyleMelo, A., Er-Rahmadi, B., & Pan, J. Z. (2022). A System for Aligning Geographical Entities from Large Heterogeneous Sources. ISPRS International Journal of Geo-Information, 11(2), 96. https://doi.org/10.3390/ijgi11020096