
DeepWindows: Windows Instance Segmentation through an Improved Mask R-CNN Using Spatial Attention and Relation Modules


Abstract
:1. Introduction
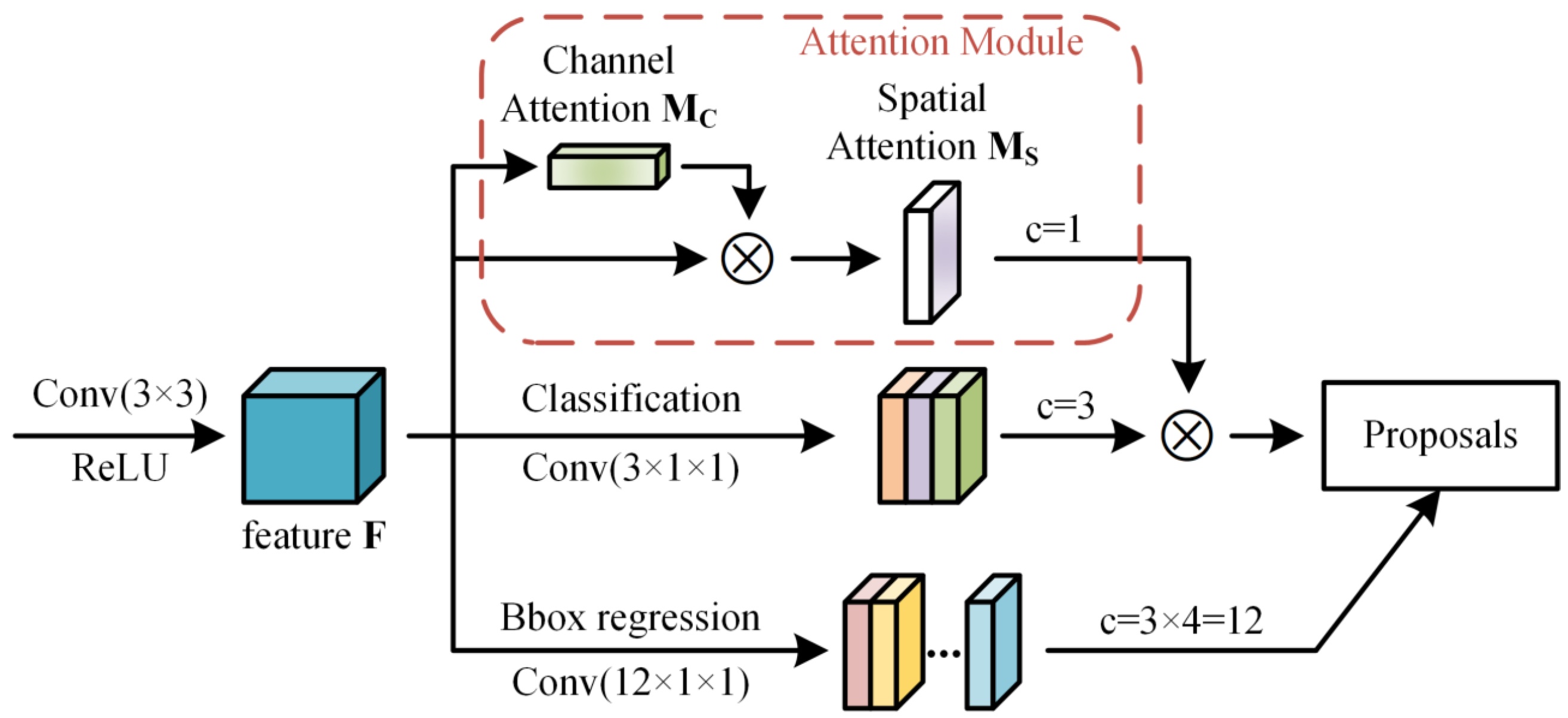
- We added a spatial attention module to the Region Proposal Network (RPN) and used channel-wise and spatial attention mechanisms to optimize the objectness scores of the RPN;
- We embedded the relation modules into the head network of Mask R-CNN, and integrated appearance and geometric features for proposal recognition;
- We standardized and concatenated different datasets and added some new images to create a new instance segmentation dataset for a window class with 1200 annotated images.
2. Related Work
3. Methodology
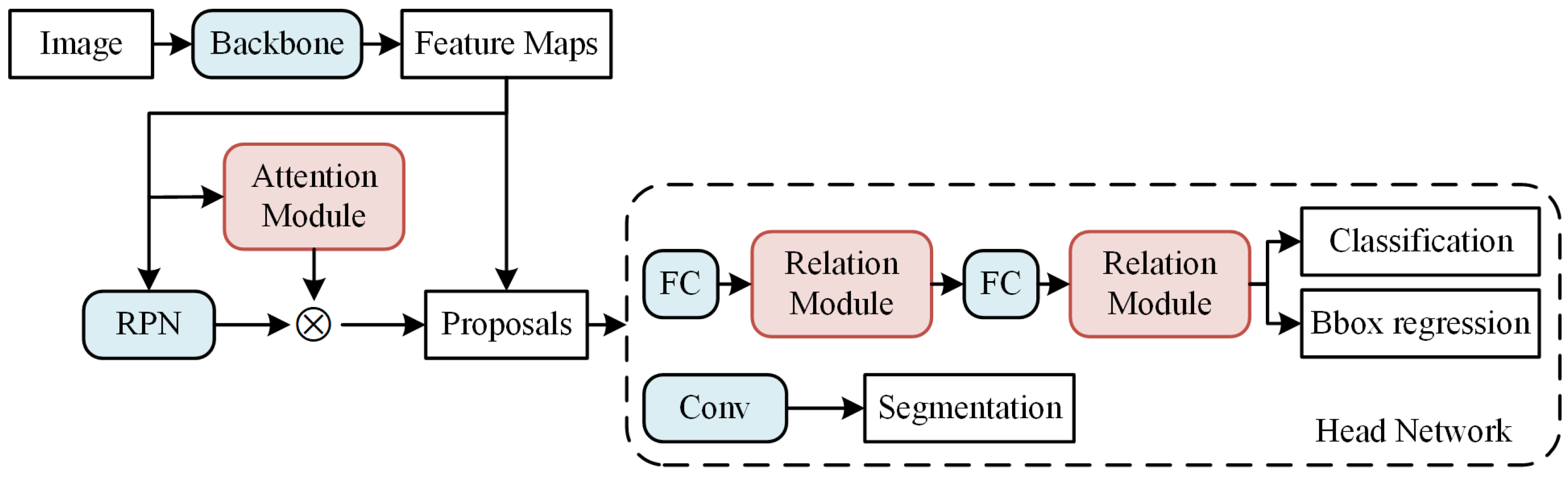
3.1. Network Architecture
3.2. RPN with Spatial Attention
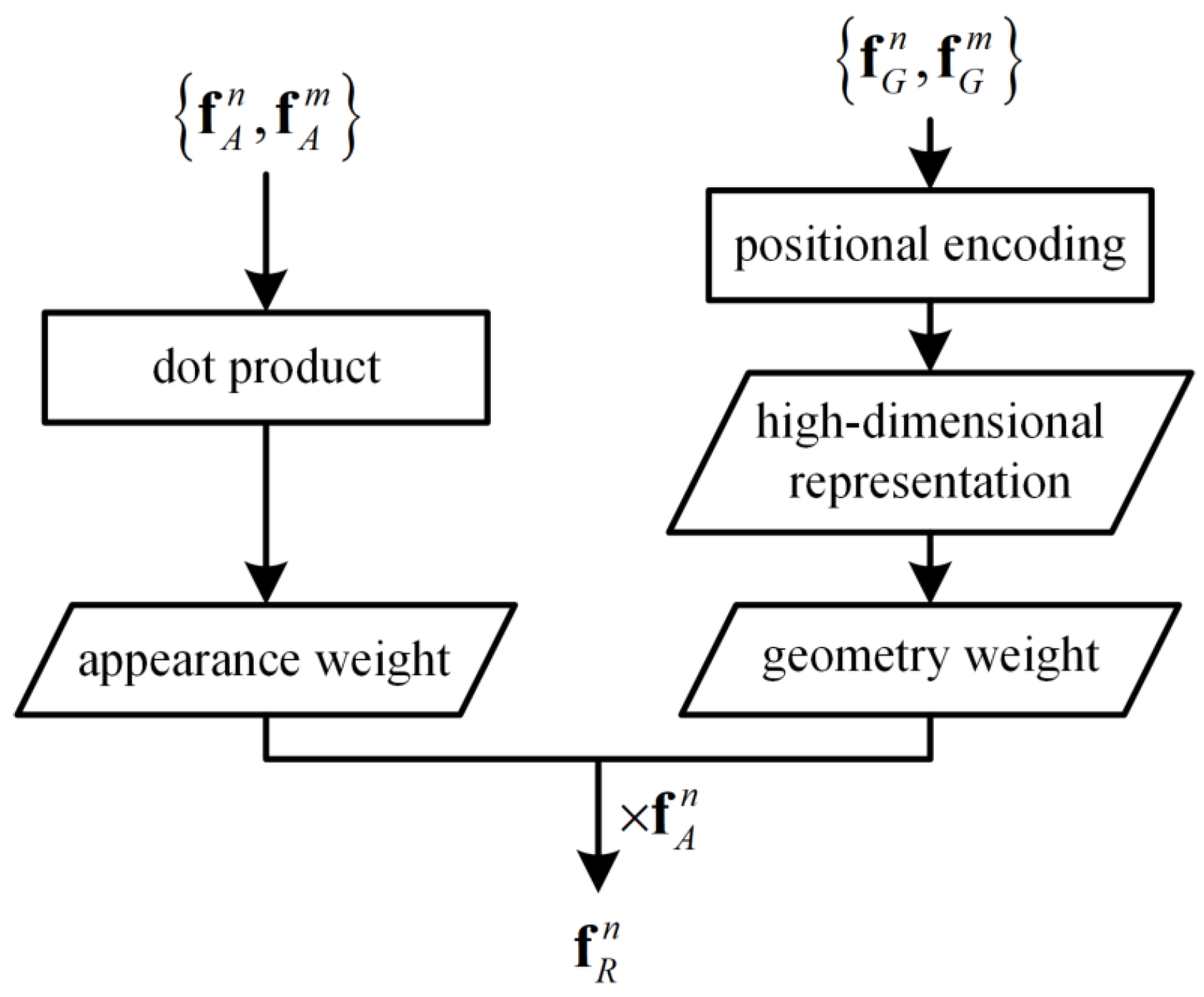
3.3. Head Network with Relation Modules
3.3.1. Relation Module
3.3.2. Relation for Instance Segmentation
4. Experiments
4.1. Our New Dataset
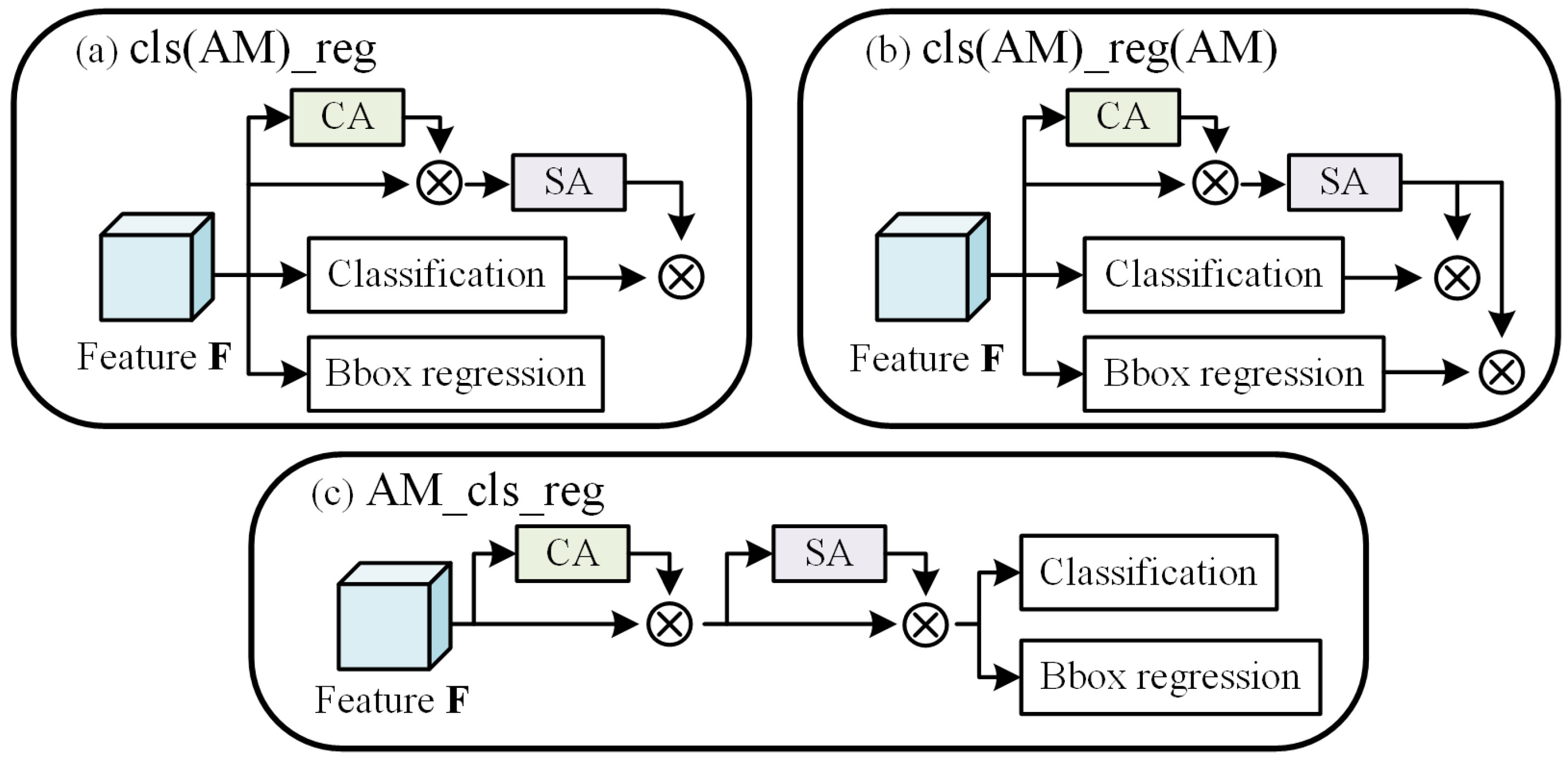
4.2. Three Variants of the RPN with Attention Modules
4.3. Comparisons of Parameters for Relation Modules
4.4. Qualitative Results
4.5. Comparisons with Other Attention-Based Methods
4.6. Comparisons with Other Window Extraction Methods
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Neuhausen, M.; Koch, C.; König, M. Image-based window detection: An overview. In Proceedings of the 23rd International Workshop of the European Group for Intelligent Computing in Engineering, Krakow, Poland, 29 June–1 July 2016. [Google Scholar]
- Gröger, G.; Plümer, L. CityGML–Interoperable semantic 3D city models. ISPRS J. Photogramm. Remote. Sens. 2012, 71, 12–33. [Google Scholar] [CrossRef]
- Kim, S.; Zadeh, P.A.; Staub-French, S.; Froese, T.; Cavka, B.T. Assessment of the impact of window size, position and orientation on building energy load using BIM. Procedia Eng. 2016, 145, 1424–1431. [Google Scholar] [CrossRef] [Green Version]
- Amirebrahimi, S.; Rajabifard, A.; Mendis, P.; Ngo, T. A framework for a microscale flood damage assessment and visualization for a building using BIM–GIS integration. Int. J. Digit. Earth 2016, 9, 363–386. [Google Scholar] [CrossRef]
- Perez, H.; Tah, J.H.M.; Mosavi, A. Deep Learning for Detecting Building Defects Using Convolutional Neural Networks. Sensors 2019, 19, 3556. [Google Scholar] [CrossRef] [Green Version]
- Taoufiq, S.; Nagy, B.; Benedek, C. HierarchyNet: Hierarchical CNN-Based Urban Building Classification. Remote Sens. 2020, 12, 3794. [Google Scholar] [CrossRef]
- Alshawa, M.; Boulaassal, H.; Landes, T.; Grussenmeyer, P. Acquisition and Automatic Extraction of Facade Elements on Large Sites from a Low Cost Laser Mobile Mapping System. In Proceedings of the ISPRS Workshop 3D Virtual Reconstruction and Visualization of Complex Architectures, Trento, Italy, 25–28 February 2009. [Google Scholar]
- Alegre, F.; Dellaert, F. A Probabilistic Approach to the Semantic Interpretation of Building Facades. In Proceedings of the International Workshop on Vision Techniques Applied to the Rehabilitation of City Centres, Lisbonne, Portugal, 25–27 October 2004. [Google Scholar]
- Müller, P.; Zeng, G.; Wonka, P.; Van Gool, L. Image-based procedural modeling of facades. ACM Trans. Graph. (TOG) 2007, 26, 85. [Google Scholar] [CrossRef]
- Ali, H.; Seifert, C.; Jindal, N.; Paletta, L.; Paar, G. Window detection in facades. In Proceedings of the 14th International Conference on Image Analysis and Processing, ICIAP 2007, Modena, Italy, 10–14 September 2007; pp. 837–842. [Google Scholar] [CrossRef] [Green Version]
- Reznik, S.; Mayer, H. Implicit shape models, self-diagnosis, and model selection for 3D façade interpretation. Photogramm. Fernerkund. Geoinf. 2008, 3, 187–196. [Google Scholar]
- Simon, L.; Teboul, O.; Koutsourakis, P.; Paragios, N. Random exploration of the procedural space for single-view 3D modeling of buildings. Int. J. Comput. Vis. 2011, 93, 253–271. [Google Scholar] [CrossRef] [Green Version]
- Cohen, A.; Schwing, A.G.; Pollefeys, M. Efficient structured parsing of facades using dynamic programming. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Jampani, V.; Gadde, R.; Gehler, P.V. Efficient facade segmentation using auto-context. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, WACV 2015, Waikoloa, HI, USA, 5–9 January 2015; pp. 1038–1045. [Google Scholar] [CrossRef]
- Mathias, M.; Martinović, A.; Van Gool, L. ATLAS: A Three-Layered Approach to Facade Parsing. Int. J. Comput. Vis. 2016, 118, 22–48. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Mosavi, A.; Ardabili, S.; Varkonyi-Koczy, A.R. List of deep learning models. In Engineering for Sustainable Future; Springer: Cham, Switzerland, 2019; pp. 202–214. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 2015, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Schmitz, M.; Mayer, H. A convolutional network for semantic facade segmentation and interpretation. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. -ISPRS Arch. 2016, 41, 709–715. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Zhang, J.; Zhu, J.; Hoi, S.C. Deepfacade: A deep learning approach to facade parsing. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 2301–2307. [Google Scholar] [CrossRef] [Green Version]
- Femiani, J.; Para, W.R.; Mitra, N.; Wonka, P. Facade Segmentation in the Wild. arXiv 2018, arXiv:1805.08634. [Google Scholar]
- Liu, H.; Xu, Y.; Zhang, J.; Zhu, J.; Li, Y.; Hoi, C.S. DeepFacade: A Deep Learning Approach to Facade Parsing with Symmetric Loss. IEEE Trans. Multimed. 2020, 22, 3153–3165. [Google Scholar] [CrossRef]
- Ma, W.; Ma, W.; Xu, S.; Zha, H. Pyramid ALKNet for Semantic Parsing of Building Facade Image. IEEE Geosci. Remote. Sens. Lett. 2020, 18, 1009–1013. [Google Scholar] [CrossRef]
- Li, C.K.; Zhang, H.X.; Liu, J.X.; Zhang, Y.Q.; Zou, S.C.; Fang, Y.T. Window Detection in Facades Using Heatmap Fusion. J. Comput. Sci. Technol. 2020, 35, 900–912. [Google Scholar] [CrossRef]
- Ma, W.; Ma, W. Deep window detection in street scenes. KSII Trans. Internet Inf. Syst. (TIIS) 2020, 14, 855–870. [Google Scholar]
- Wang, R.; Ferrie, F.P.; Macfarlane, J. A method for detecting windows from mobile lidar data. Photogramm. Eng. Remote. Sens. 2012, 78, 1129–1140. [Google Scholar] [CrossRef] [Green Version]
- Zolanvari, S.I.; Laefer, D.F. Slicing Method for curved façade and window extraction from point clouds. ISPRS J. Photogramm. Remote. Sens. 2016, 119, 334–346. [Google Scholar] [CrossRef]
- Malihi, S.; Valadan Zoej, M.J.; Hahn, M.; Mokhtarzade, M. Window Detection from UAS-Derived Photogrammetric Point Cloud Employing Density-Based Filtering and Perceptual Organization. Remote Sens. 2018, 10, 1320. [Google Scholar] [CrossRef] [Green Version]
- Xia, S.B.; Wang, R.S. Facade Separation in Ground-Based LiDAR Point Clouds Based on Edges and Windows. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1041–1052. [Google Scholar] [CrossRef]
- Sun, Y.; Li, H.; Sun, L. Window detection employing a global regularity level set from oblique unmanned aerial vehicle images and point clouds. J. Appl. Remote Sens. 2020, 14, 024513. [Google Scholar] [CrossRef]
- Leibe, B.; Leonardis, A.; Schiele, B. Combined object categorization and segmentation with an implicit shape model. In Proceedings of the Workshop on Statistical Learning in Computer Vision, ECCV 2004, Prague, Czech Republic, 11–14 May 2004; Volume 2, p. 7. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2012; Volume 2, pp. 1097–1105. [Google Scholar]
- Fathalla, R.; Vogiatzis, G. A deep learning pipeline for semantic facade segmentation. In Proceedings of the British Machine Vision Conference 2017, BMVC 2017, London, UK, 4–7 September 2017; pp. 1–13. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention Mechanisms in Computer Vision: A Survey. arXiv 2021, arXiv:2111.07624. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3588–3597. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016, pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2016; Volume 2017, pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2017; pp. 5999–6009. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 29 December 2021).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Tyleček, R.; Šára, R. Spatial pattern templates for recognition of objects with regular structure. In German Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8142 LNCS, pp. 364–374. [Google Scholar] [CrossRef] [Green Version]
- Korč, F.; Förstner, W. eTRIMS Image Database for Interpreting Images of Man-Made Scenes; Technical Report; 2009; Available online: http://www.ipb.uni-bonn.de/projects/etrims_db/ (accessed on 29 December 2021).
- Teboul, O. Ecole Centrale Paris Facades Database. Available online: http://vision.mas.ecp.fr/Personnel/teboul/data.php (accessed on 29 December 2021).
- Riemenschneider, H.; Krispel, U.; Thaller, W.; Donoser, M.; Havemann, S.; Fellner, D.; Bischof, H. Irregular lattices for complex shape grammar facade parsing. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1640–1647. [Google Scholar] [CrossRef]
- Riemenschneider, H.; Bodis-Szomoru, A.; Weissenberg, J.; Van Gool, L. Learning Where to Classify in Multi-view Semantic Segmentation. In Computer Vision—Eccv 2014, Pt V; Springer: Cham, Switzerland, 2014; Volume 8693, pp. 516–532. [Google Scholar]
- Gadde, R.; Marlet, R.; Paragios, N.; Marlet, R. Learning Grammars for Architecture-Specific Facade Parsing. Int. J. Comput. Vis. 2016, 117, 290–316. [Google Scholar] [CrossRef] [Green Version]
- Martinović, A.; Mathias, M.; Weissenberg, J.; Van Gool, L. A three-layered approach to facade parsing. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. arXiv 2020, arXiv:1910.03151. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13713–13722. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
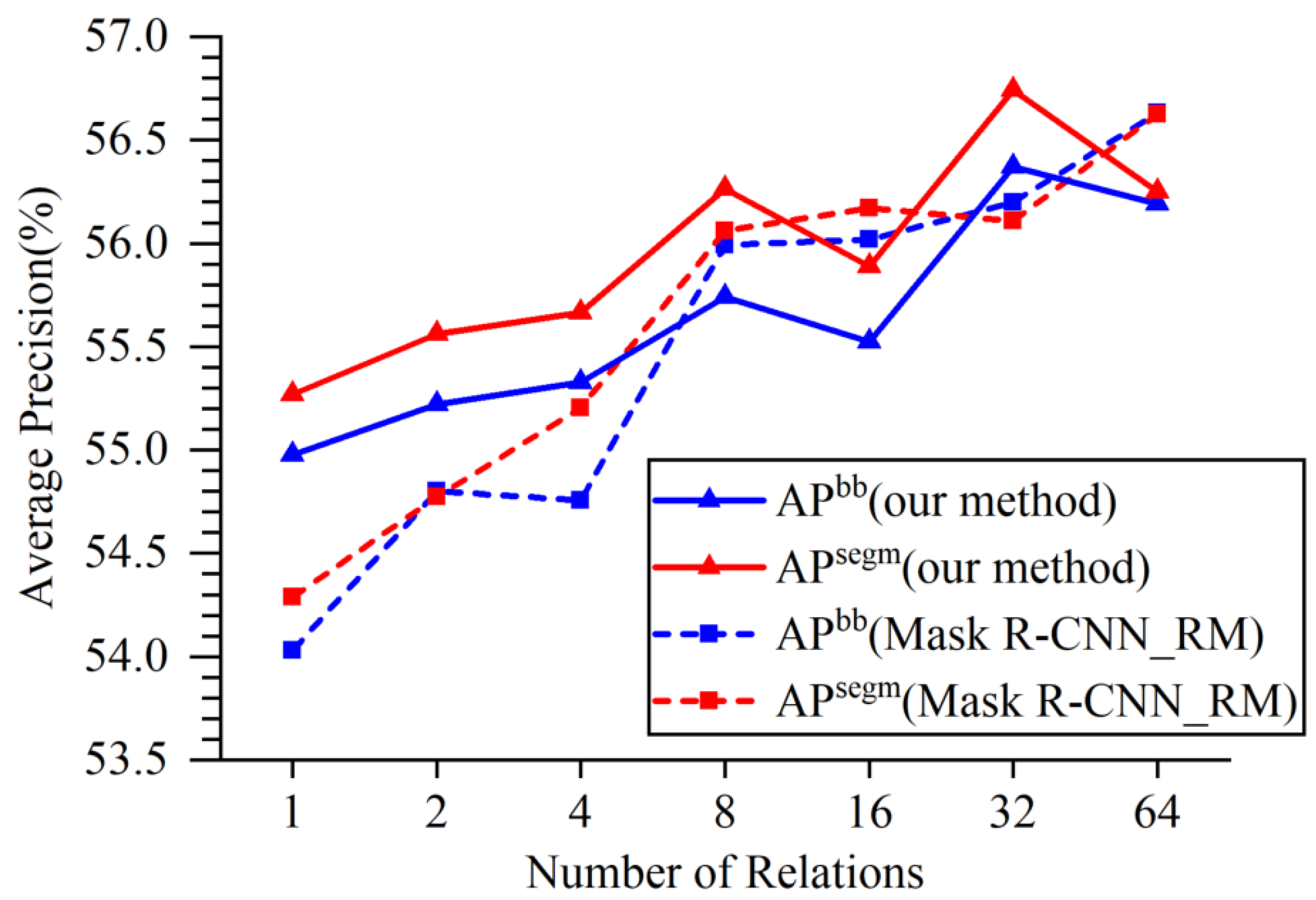{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Images | Training Set | Testing Set |
|---|---|---|---|
| CMP base | 378 | 302 | 76 |
| CMP extended | 228 | 182 | 46 |
| eTRIMS | 60 | 48 | 12 |
| ECP | 104 | 83 | 21 |
| ICG Graz50 | 50 | 40 | 10 |
| RueMonge 2014 | 219 | 175 | 44 |
| ParisArtDeco | 79 | 63 | 16 |
| TUBS | 82 | 66 | 16 |
| Merged dataset | 1200 | 959 | 241 |
| Network Architecture | AP | ||||||
|---|---|---|---|---|---|---|---|
| Mask R-CNN | 53.1 | 83.9 | 61.2 | 39.5 | 59.6 | 61.2 | |
| cls(AM)_reg | 53.8 | 84.4 | 61.0 | 40.0 | 60.4 | 59.4 | |
| cls(AM)_reg(AM) | 53.3 | 84.1 | 60.6 | 39.6 | 59.9 | 59.4 | |
| AM_cls_reg | 52.6 | 83.9 | 59.9 | 38.7 | 59.6 | 59.8 | |
| Mask R-CNN | 53.7 | 83.0 | 62.0 | 40.6 | 60.2 | 61.4 | |
| cls(AM)_reg | 54.4 | 83.6 | 62.6 | 40.9 | 60.8 | 59.6 | |
| cls(AM)_reg(AM) | 53.9 | 83.2 | 62.4 | 40.7 | 60.6 | 60.0 | |
| AM_cls_reg | 53.2 | 83.2 | 60.6 | 39.8 | 60.2 | 59.1 |
| Number of Relations | AP | ||||||
|---|---|---|---|---|---|---|---|
| 1 | bbox | 55.0 | 85.7 | 62.8 | 41.4 | 61.0 | 61.3 |
| segm | 55.3 | 84.6 | 63.5 | 41.7 | 61.3 | 61.8 | |
| 2 | bbox | 55.2 | 84.9 | 63.3 | 40.5 | 61.7 | 63.8 |
| segm | 55.6 | 84.0 | 64.8 | 40.6 | 62.1 | 62.7 | |
| 4 | bbox | 55.3 | 84.8 | 63.5 | 41.9 | 61.4 | 61.4 |
| segm | 55.7 | 83.9 | 64.9 | 42.4 | 61.8 | 61.3 | |
| 8 | bbox | 55.7 | 85.7 | 63.7 | 42.2 | 61.6 | 62.4 |
| segm | 56.3 | 84.7 | 65.4 | 43.1 | 62.1 | 62.1 | |
| 16 | bbox | 55.5 | 84.8 | 64.1 | 42.2 | 61.5 | 62.3 |
| segm | 55.9 | 84.6 | 64.7 | 42.3 | 61.8 | 62.0 | |
| 32 | bbox | 56.4 | 87.0 | 64.7 | 42.4 | 62.4 | 62.1 |
| segm | 56.7 | 86.1 | 65.5 | 42.8 | 63.1 | 62.6 | |
| 64 | bbox | 56.2 | 84.7 | 65.6 | 41.2 | 62.6 | 63.5 |
| segm | 56.2 | 84.6 | 65.9 | 41.5 | 62.6 | 62.3 |
| Number of Relations | AP | ||||||
|---|---|---|---|---|---|---|---|
| 1 | bbox | 54.0 | 84.2 | 61.9 | 40.9 | 60.6 | 60.7 |
| segm | 54.3 | 84.2 | 62.4 | 41.1 | 60.7 | 60.4 | |
| 2 | bbox | 54.8 | 85.6 | 62.5 | 41.2 | 61.0 | 62.4 |
| segm | 54.8 | 84.7 | 62.9 | 41.1 | 61.2 | 61.9 | |
| 4 | bbox | 54.8 | 85.6 | 62.3 | 41.1 | 61.3 | 62.7 |
| segm | 55.2 | 84.8 | 62.8 | 41.6 | 61.6 | 62.3 | |
| 8 | bbox | 56.0 | 85.9 | 64.3 | 42.2 | 62.1 | 63.5 |
| segm | 56.1 | 84.9 | 65.1 | 42.2 | 62.2 | 63.1 | |
| 16 | bbox | 56.0 | 85.7 | 64.6 | 42.8 | 61.8 | 62.5 |
| segm | 56.2 | 84.7 | 65.1 | 43.0 | 62.0 | 62.8 | |
| 32 | bbox | 56.2 | 85.6 | 64.5 | 42.8 | 62.2 | 64.6 |
| segm | 56.1 | 84.6 | 64.9 | 43.1 | 62.0 | 63.5 | |
| 64 | bbox | 56.6 | 86.2 | 65.7 | 41.8 | 63.0 | 64.0 |
| segm | 56.6 | 85.3 | 66.3 | 42.3 | 63.1 | 63.6 |
| Network Architecture | AP | ||||||
|---|---|---|---|---|---|---|---|
| Mask R-CNN | bbox | 53.1 | 83.9 | 61.2 | 39.5 | 59.6 | 61.2 |
| segm | 53.7 | 83.0 | 62.0 | 40.6 | 60.2 | 61.4 | |
| Mask R-CNN + CBAM | bbox | 53.2 | 85.2 | 61.5 | 39.8 | 59.7 | 61.1 |
| segm | 54.0 | 85.3 | 61.9 | 41.3 | 60.3 | 60.0 | |
| Mask R-CNN + NL | bbox | 53.6 | 84.6 | 61.7 | 40.1 | 59.9 | 62.7 |
| segm | 54.1 | 82.9 | 62.4 | 41.1 | 60.4 | 62.1 | |
| Mask R-CNN + GC | bbox | 54.4 | 85.1 | 62.8 | 40.3 | 60.9 | 63.5 |
| segm | 54.8 | 84.1 | 63.3 | 41.4 | 61.3 | 63.2 | |
| Mask R-CNN + RM | bbox | 56.0 | 85.7 | 64.6 | 42.8 | 61.8 | 62.5 |
| segm | 56.2 | 84.7 | 65.1 | 43.0 | 62.0 | 62.8 | |
| Our method | bbox | 56.4 | 87.0 | 64.7 | 42.4 | 62.4 | 62.1 |
| segm | 56.7 | 86.1 | 65.5 | 42.8 | 63.1 | 62.6 |
| eTRIMS | ECP | CMP | Graz50 | ParisArtDeco | |
|---|---|---|---|---|---|
| Schmitz et al. [22] | 86.0 | - | - | - | - |
| Liu et al. [23] | 90.9 | 93.0 | 89.0 | 87.7 | 94.2 |
| Femiani et al. [24] | 97.1 | 95.6 | - | - | - |
| Liu et al. [25] | 92.4 | 97.6 | 95.0 | 88.8 | 95.4 |
| Li et al. [27] | 84.0 | 95.0 | - | 90.0 | - |
| Our method | 96.5 | 97.2 | 96.5 | 95.2 | 96.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Malihi, S.; Li, H.; Maboudi, M. DeepWindows: Windows Instance Segmentation through an Improved Mask R-CNN Using Spatial Attention and Relation Modules. ISPRS Int. J. Geo-Inf. 2022, 11, 162. https://doi.org/10.3390/ijgi11030162
Sun Y, Malihi S, Li H, Maboudi M. DeepWindows: Windows Instance Segmentation through an Improved Mask R-CNN Using Spatial Attention and Relation Modules. ISPRS International Journal of Geo-Information. 2022; 11(3):162. https://doi.org/10.3390/ijgi11030162
Chicago/Turabian StyleSun, Yanwei, Shirin Malihi, Hao Li, and Mehdi Maboudi. 2022. "DeepWindows: Windows Instance Segmentation through an Improved Mask R-CNN Using Spatial Attention and Relation Modules" ISPRS International Journal of Geo-Information 11, no. 3: 162. https://doi.org/10.3390/ijgi11030162
APA StyleSun, Y., Malihi, S., Li, H., & Maboudi, M. (2022). DeepWindows: Windows Instance Segmentation through an Improved Mask R-CNN Using Spatial Attention and Relation Modules. ISPRS International Journal of Geo-Information, 11(3), 162. https://doi.org/10.3390/ijgi11030162