
Limiting the Collection of Ground Truth Data for Land Use and Land Cover Maps with Machine Learning Algorithms

 , ,
, ,  and
and
Abstract
:1. Introduction
2. Materials and Methods
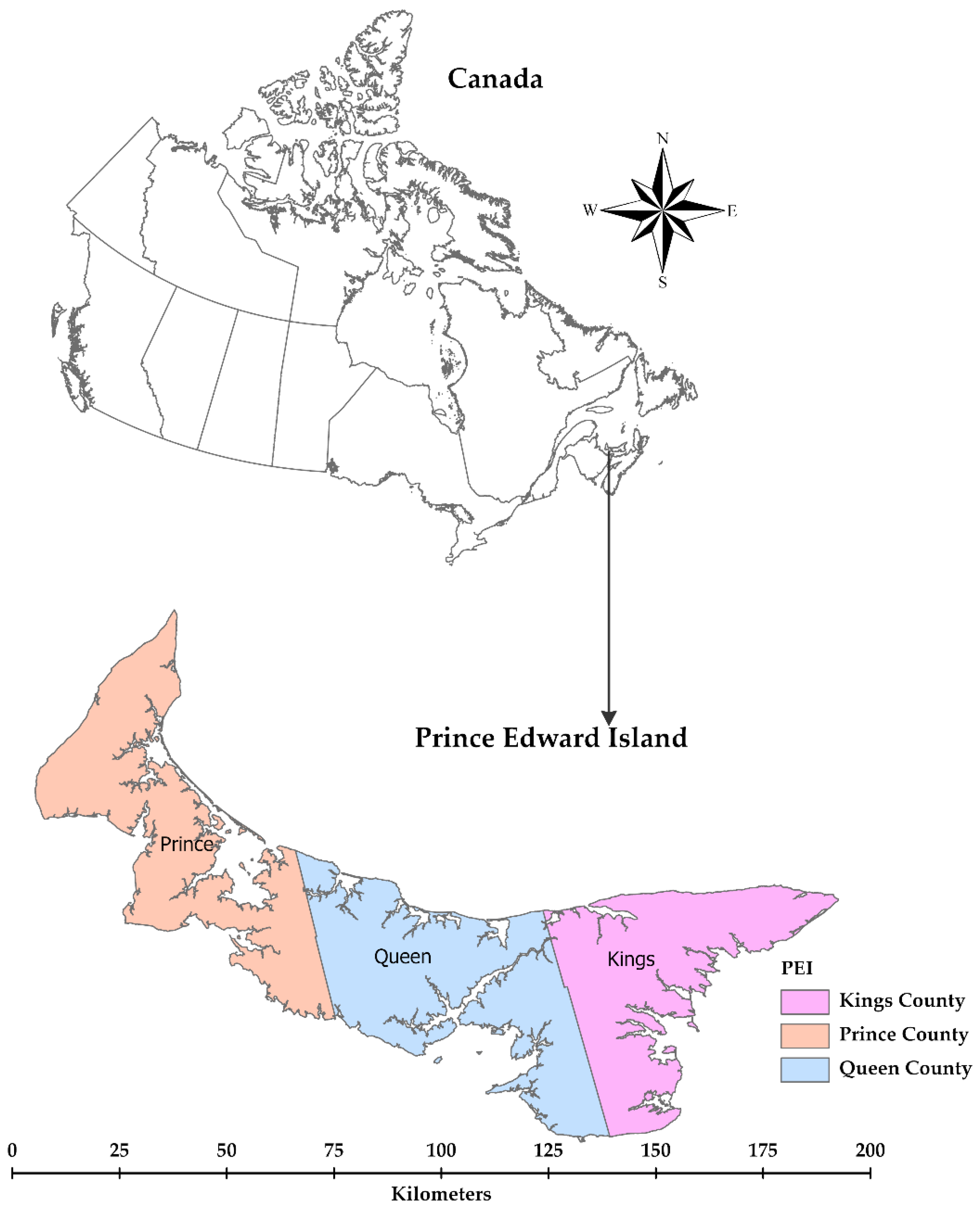
2.1. The Study Area
2.2. Data Acquisition
2.3. Data Preparation
2.4. Remote Sensing Indices and LULC Classes
2.5. Machine Learning Algorithm
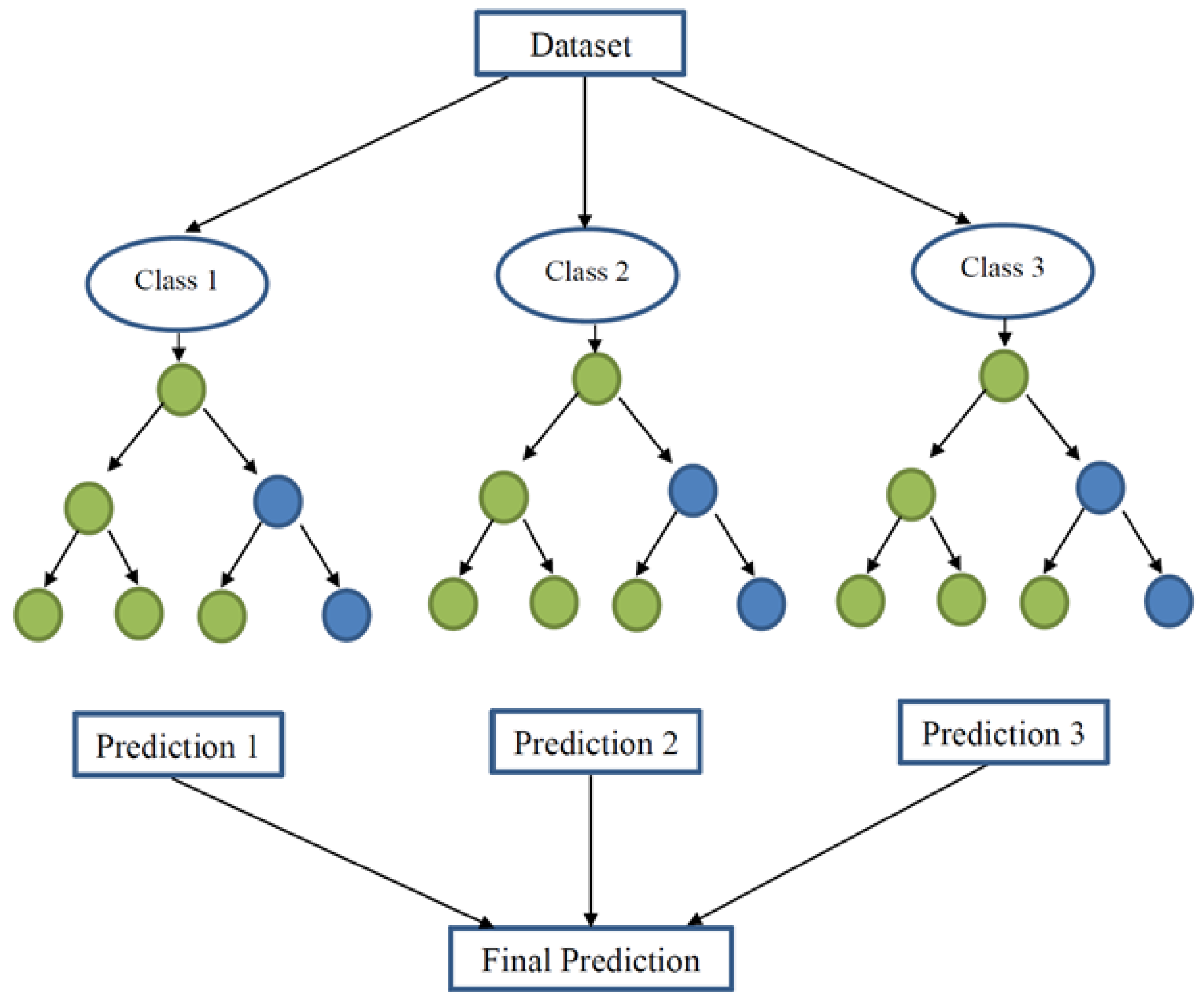
2.5.1. Random Forest Classifier
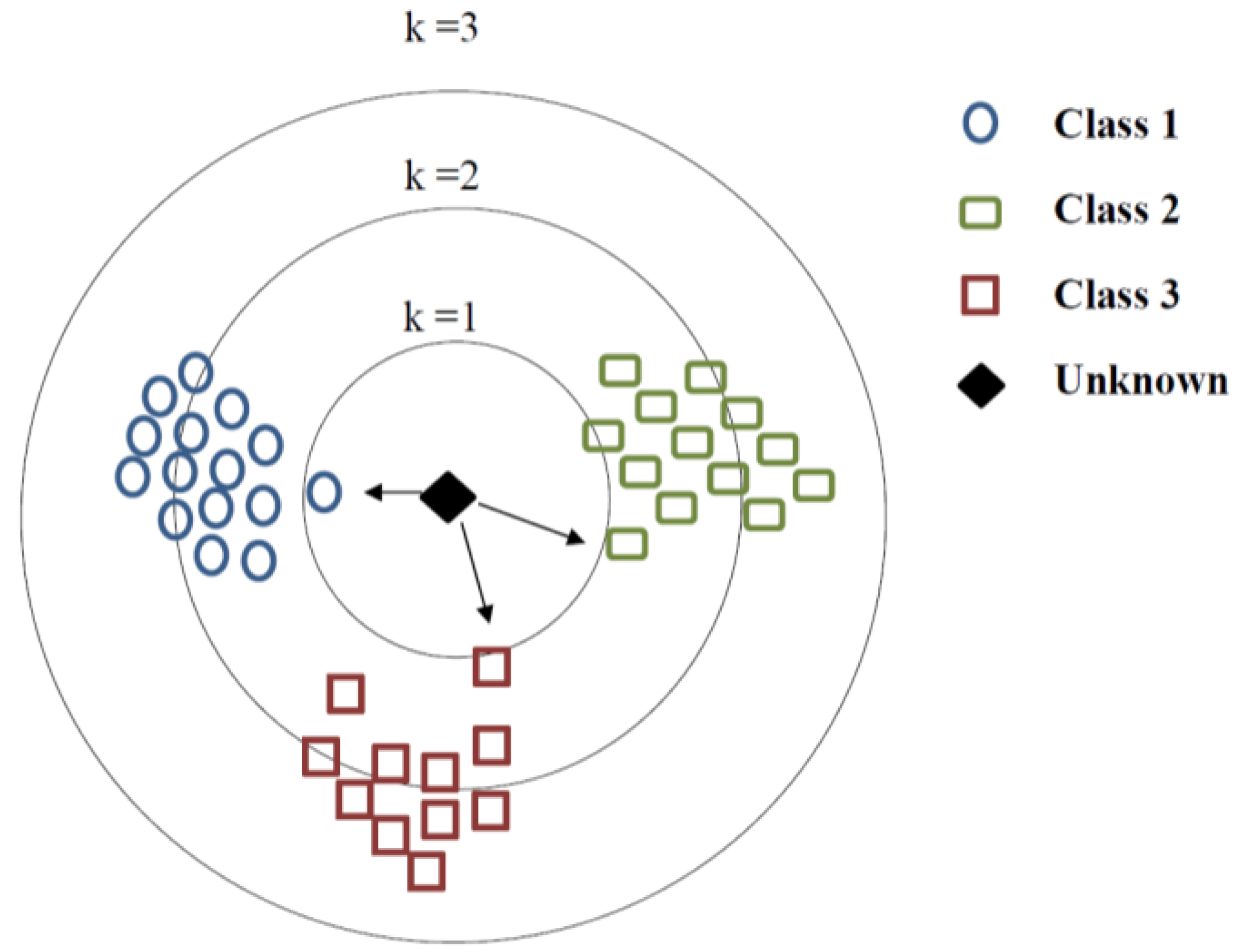
2.5.2. K-Nearest Neighbour
2.5.3. K Dimensional-Tree
2.6. Ground Truth Data for Validation and Model Evaluation Criteria
3. Results
3.1. Land Use and Land Cover Mapping Results
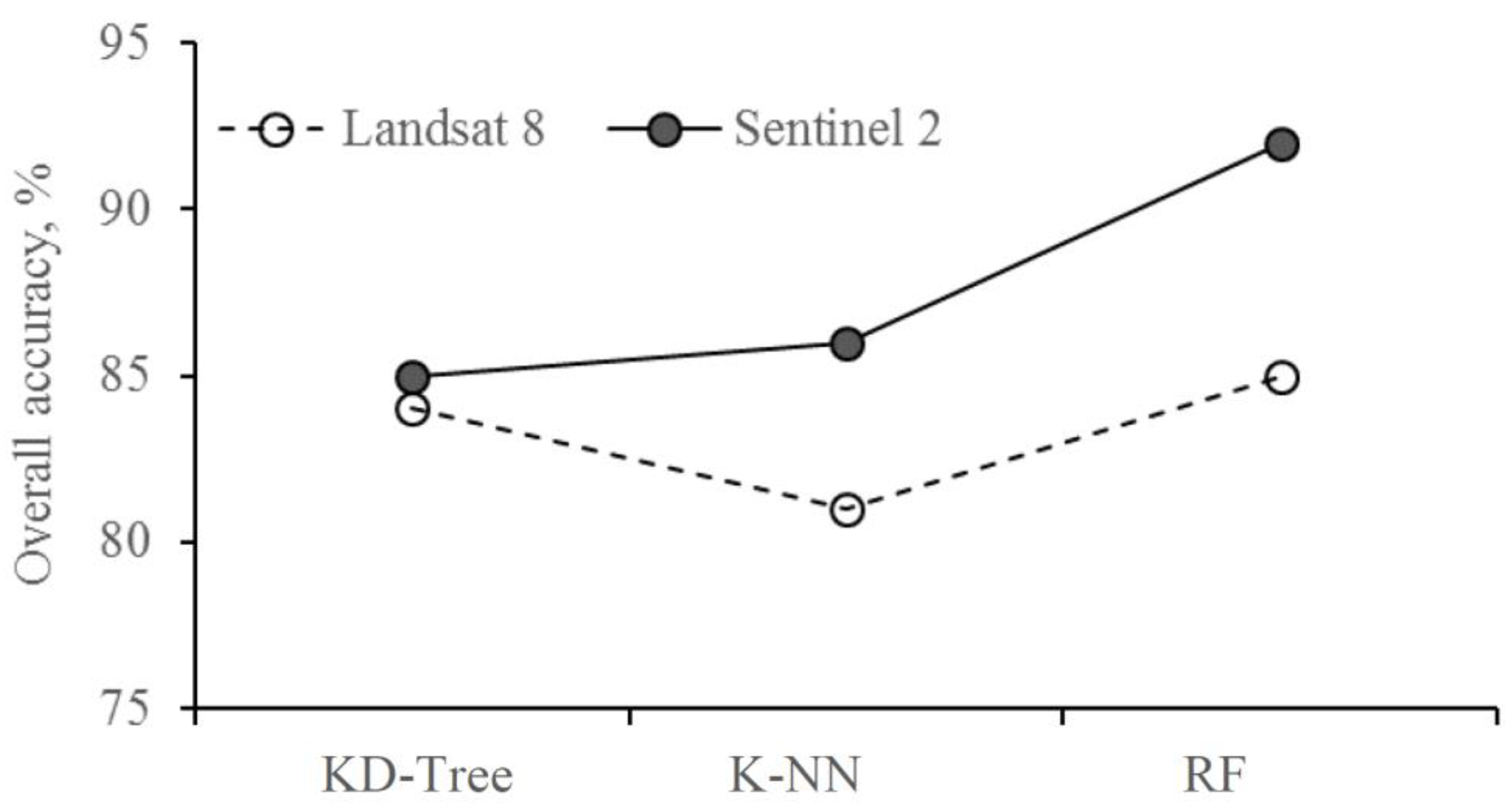
3.2. Satellite Accuracy Comparison
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nguyen, H.T.T.; Doan, T.M.; Radeloff, V. Applying Random Forest Classification to Map Land Use/Land Cover Using Landsat 8 OLI. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 363–367. [Google Scholar] [CrossRef] [Green Version]
- Burkhard, B.; Kroll, F.; Nedkov, S.; Müller, F. Mapping Ecosystem Service Supply, Demand and Budgets. Ecol. Indic. 2012, 21, 17–29. [Google Scholar] [CrossRef]
- Phiri, D.; Morgenroth, J. Developments in Landsat Land Cover Classification Methods: A Review. Remote Sens. 2017, 9, 967. [Google Scholar] [CrossRef] [Green Version]
- Abdi, A.M. Land Cover and Land Use Classification Performance of Machine Learning Algorithms in a Boreal Landscape Using Sentinel-2 Data. GISci. Remote Sens. 2020, 57, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Showqi, I.; Rashid, I.; Romshoo, S.A. Land Use Land Cover Dynamics as a Function of Changing Demography and Hydrology. GeoJournal 2014, 79, 297–307. [Google Scholar] [CrossRef]
- United Nations Department of Economic and Social Affairs—Population Division. Global Population Growth and Sustainable Development; United Nations Department of Economic and Social Affairs—Population Division: New York, NY, USA, 2021; ISBN 9789211483505. [Google Scholar]
- Li, P.; Moon, W.M. Land Cover Classification Using MODIS–ASTER Airborne Simulator (MASTER) Data and NDVI: A Case Study of the Kochang Area, Korea. Can. J. Remote Sens. 2004, 30, 123–136. [Google Scholar] [CrossRef]
- Vajda, S.; Santosh, K.C. A Fast K-Nearest Neighbor Classifier Using Unsupervised Clustering. In Proceedings of the Communications in Computer and Information Science, Istanbul, Turkey, 17–18 December 2017; Volume 709, pp. 185–193. [Google Scholar]
- Mohan, M.; Pathan, S.K.; Narendrareddy, K.; Kandya, A.; Pandey, S. Dynamics of Urbanization and Its Impact on Land-Use/Land-Cover: A Case Study of Megacity Delhi. J. Environ. Prot. 2011, 2, 1274–1283. [Google Scholar] [CrossRef] [Green Version]
- Serra, P.; More, G.; Pons, X. Thematic Accuracy Consequences in Cadastre Land-Cover Enrichment from a Pixel and from a Polygon Perspective. Photogramm. Eng. Remote Sens. 2009, 75, 1441–1449. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Wang, C.; Zhong, C.; Zhang, Z.; Liu, Q. Mapping Typical Urban LULC from Landsat Imagery without Training Samples or Self-Defined Parameters. Remote Sens. 2017, 9, 700. [Google Scholar] [CrossRef] [Green Version]
- Fisette, T.; Davidson, A.; Daneshfar, B.; Rollin, P.; Aly, Z.; Campbell, L. Annual Space-Based Crop Inventory for Canada: 2009–2014. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 5095–5098. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A.; Sanchez-Hernandez, C.; Boyd, D.S. Training Set Size Requirements for the Classification of a Specific Class. Remote Sens. Environ. 2006, 104, 1–14. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A Survey of Image Classification Methods and Techniques for Improving Classification Performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Piper, J. Variability and Bias in Experimentally Measured Classifier Error Rates. Pattern Recognit. Lett. 1992, 13, 685–692. [Google Scholar] [CrossRef]
- Heydari, S.S.; Mountrakis, G. Effect of Classifier Selection, Reference Sample Size, Reference Class Distribution and Scene Heterogeneity in per-Pixel Classification Accuracy Using 26 Landsat Sites. Remote Sens. Environ. 2018, 204, 648–658. [Google Scholar] [CrossRef]
- Huang, C.; Davis, L.S.; Townshend, J.R.G. An Assessment of Support Vector Machines for Land Cover Classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Ramezan, C.A.; Warner, T.A.; Maxwell, A.E.; Price, B.S. Effects of Training Set Size on Supervised Machine-Learning Land-Cover Classification of Large-Area High-Resolution Remotely Sensed Data. Remote Sens. 2021, 13, 368. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of Machine-Learning Classification in Remote Sensing: An Applied Review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Jamali, A. Evaluation and Comparison of Eight Machine Learning Models in Land Use/Land Cover Mapping Using Landsat 8 OLI: A Case Study of the Northern Region of Iran. SN Appl. Sci. 2019, 1, 1448. [Google Scholar] [CrossRef] [Green Version]
- Vishwanath, N.; Ramesh, B.; Sreenivasa Rao, P. Unsupervised Classification of Remote Sensing Images Using K-Means Algorithm. Int. J. Latest Trends Eng. Technol. 2016, 7, 548–552. [Google Scholar] [CrossRef]
- Shivakumar, B.R.; Rajashekararadhya, S.V. Investigation on Land Cover Mapping Capability of Maximum Likelihood Classifier: A Case Study on North Canara, India. Procedia Comput. Sci. 2018, 143, 579–586. [Google Scholar] [CrossRef]
- Mather, P.; Tso, B. Classification Methods for Remotely Sensed Data; CRC Press: Boca Raton, FL, USA, 2016; ISBN 9780429192029. [Google Scholar]
- Abbas, Z.; Jaber, H.S. Accuracy Assessment of Supervised Classification Methods for Extraction Land Use Maps Using Remote Sensing and GIS Techniques. IOP Conf. Ser. Mater. Sci. Eng. 2020, 745, 012166. [Google Scholar] [CrossRef]
- Desai, C.; Umrikar, B. Image classification tool for land use land cover analysis: A comparative study of maximum likelihood and minimum distance method. Int. J. Geol. Earth Environ. Sci. 2012, 2, 189–196. [Google Scholar]
- Nguyen, H.A.T.; Sophea, T.; Gheewala, S.H.; Rattanakom, R.; Areerob, T.; Prueksakorn, K. Integrating Remote Sensing and Machine Learning into Environmental Monitoring and Assessment of Land Use Change. Sustain. Prod. Consum. 2021, 27, 1239–1254. [Google Scholar] [CrossRef]
- Jia, K.; Wei, X.; Gu, X.; Yao, Y.; Xie, X.; Li, B. Land Cover Classification Using Landsat 8 Operational Land Imager Data in Beijing, China. Geocarto Int. 2014, 29, 941–951. [Google Scholar] [CrossRef]
- Thanh Noi, P.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2017, 18, 18. [Google Scholar] [CrossRef] [Green Version]
- Ali, M.Z.; Qazi, W.; Aslam, N. A Comparative Study of ALOS-2 PALSAR and Landsat-8 Imagery for Land Cover Classification Using Maximum Likelihood Classifier. Egypt. J. Remote Sens. Space Sci. 2018, 21, 29–35. [Google Scholar] [CrossRef]
- Clerici, N.; Valbuena Calderón, C.A.; Posada, J.M. Fusion of Sentinel-1a and Sentinel-2A Data for Land Cover Mapping: A Case Study in the Lower Magdalena Region, Colombia. J. Maps 2017, 13, 718–726. [Google Scholar] [CrossRef] [Green Version]
- Government of Prince Edward Island. Prince Edward Island Population Report 2020; Government of Prince Edward Island: Charlottetown, PE, Canada, 2020.
- Department of Environment, E. and C.A. Our Changing Climate. Available online: https://www.princeedwardisland.ca/en/information/environment-energy-and-climate-action/our-changing-climate (accessed on 27 July 2021).
- Asokan, A.; Anitha, J.; Ciobanu, M.; Gabor, A.; Naaji, A.; Hemanth, D.J. Image Processing Techniques for Analysis of Satellite Images for Historical Maps Classification-An Overview. Appl. Sci. 2020, 10, 4207. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Roy, D.P.; Wulder, M.A.; Loveland, T.R.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Helder, D.; Irons, J.R.; Johnson, D.M.; Kennedy, R.; et al. Landsat-8: Science and Product Vision for Terrestrial Global Change Research. Remote Sens. Environ. 2014, 145, 154–172. [Google Scholar] [CrossRef] [Green Version]
- Richardson, A.J.; Everitt, J.H. Using Spectral Vegetation Indices to Estimate Rangeland Productivity. Geocarto Int. 1992, 7, 63–69. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and Photographic Infrared Linear Combinations for Monitoring Vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef] [Green Version]
- Zha, Y.; Gao, J.; Ni, S. Use of Normalized Difference Built-up Index in Automatically Mapping Urban Areas from TM Imagery. Int. J. Remote Sens. 2003, 24, 583–594. [Google Scholar] [CrossRef]
- Li, H.; Wang, C.; Zhong, C.; Su, A.; Xiong, C.; Wang, J.; Liu, J. Mapping Urban Bare Land Automatically from Landsat Imagery with a Simple Index. Remote Sens. 2017, 9, 249. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and Regression by RandomForest. R News 2002, 2, 18–22. [Google Scholar]
- Fix, E. Discriminatory Analysis: Nonparametric Discrimination, Consistency Properties; International Statistical Institute: Voorburg, The Netherlands, 1951. [Google Scholar]
- Cover, T.M.; Hart, P.E. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Karegowda, A.G.; Jayaram, M.A.; Manjunath, A.S. Cascading K-Means Clustering and K-Nearest Neighbor Classifier for Categorization of Diabetic Patients. Int. J. Eng. Adv. Technol. 2012, 1, 147–151. [Google Scholar]
- Narasimhulu, Y.; Suthar, A.; Pasunuri, R.; China Venkaiah, V. Ckd-Tree: An Improved Kd-Tree Construction Algorithm. CEUR Workshop Proc. 2021, 2786, 211–218. [Google Scholar]
- Dolatshah, M.; Hadian, A.; Minaei-Bidgoli, B. Ball*-Tree: Efficient Spatial Indexing for Constrained Nearest-Neighbor Search in Metric Spaces. arXiv 2015, arXiv:1511.00628. [Google Scholar]
- Story, M.; Congalton, R.G. Remote Sensing Brief Accuracy Assessment: A User’s Perspective. Photogramm. Eng. Remote Sens. 1986, 52, 397–399. [Google Scholar]
- McHugh, M.L. Lessons in Biostatistics Interrater Reliability: The Kappa Statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Chen, D.; Stow, D.A.; Gong, P. Examining the Effect of Spatial Resolution and Texture Window Size on Classification Accuracy: An Urban Environment Case. Int. J. Remote Sens. 2004, 25, 2177–2192. [Google Scholar] [CrossRef]
- Rao, P.; Zhou, W.; Bhattarai, N.; Srivastava, A.K.; Singh, B.; Poonia, S.; Lobell, D.B.; Jain, M. Using Sentinel-1, Sentinel-2, and Planet Imagery to Map Crop Type of Smallholder Farms. Remote Sens. 2021, 13, 1870. [Google Scholar] [CrossRef]
- Nguyen, H.T.T.; Doan, T.M.; Tomppo, E.; McRoberts, R.E. Land Use/Land Cover Mapping Using Multitemporal Sentinel-2 Imagery and Four Classification Methods-A Case Study from Dak Nong, Vietnam. Remote Sens. 2020, 12, 1367. [Google Scholar] [CrossRef]
- Lowe, B.; Kulkarni, A. Multispectral Image Analysis Using Random Forest. Int. J. Soft Comput. 2015, 6, 1–14. [Google Scholar] [CrossRef]
- Franco-Lopez, H.; Ek, A.R.; Bauer, M.E. Estimation and Mapping of Forest Stand Density, Volume, and Cover Type Using the k-Nearest Neighbors Method. Remote Sens. Environ. 2001, 77, 251–274. [Google Scholar] [CrossRef]
- Salovaara, K.J.; Thessler, S.; Malik, R.N.; Tuomisto, H. Classification of Amazonian Primary Rain Forest Vegetation Using Landsat ETM+ Satellite Imagery. Remote Sens. Environ. 2005, 97, 39–51. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good Practices for Estimating Area and Assessing Accuracy of Land Change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Chaves, M.E.D.; Picoli, M.C.A.; Sanches, I.D. Recent Applications of Landsat 8/OLI and Sentinel-2/MSI for Land Use and Land Cover Mapping: A Systematic Review. Remote Sens. 2020, 12, 3062. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
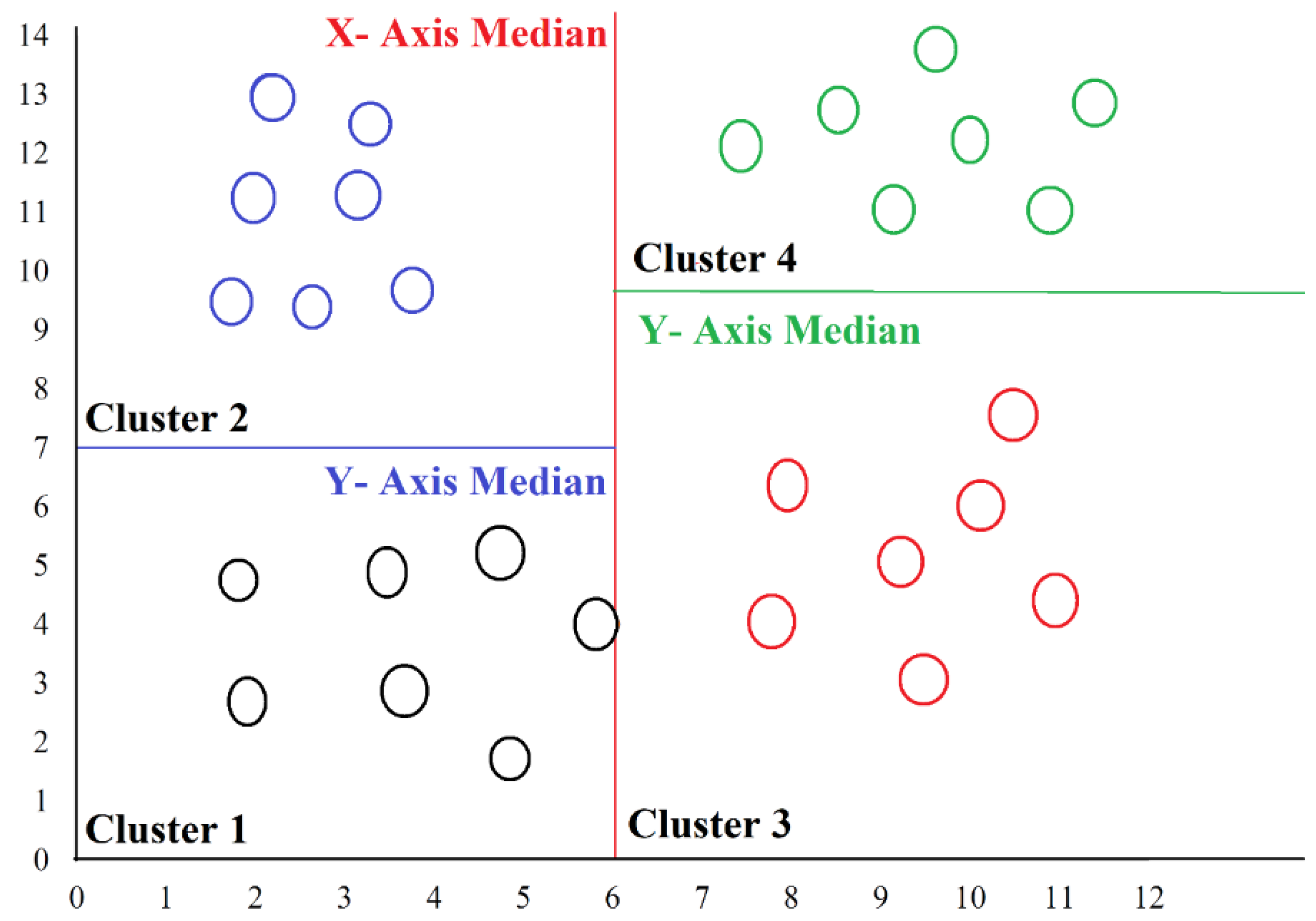{kind=link}
{kind=link}
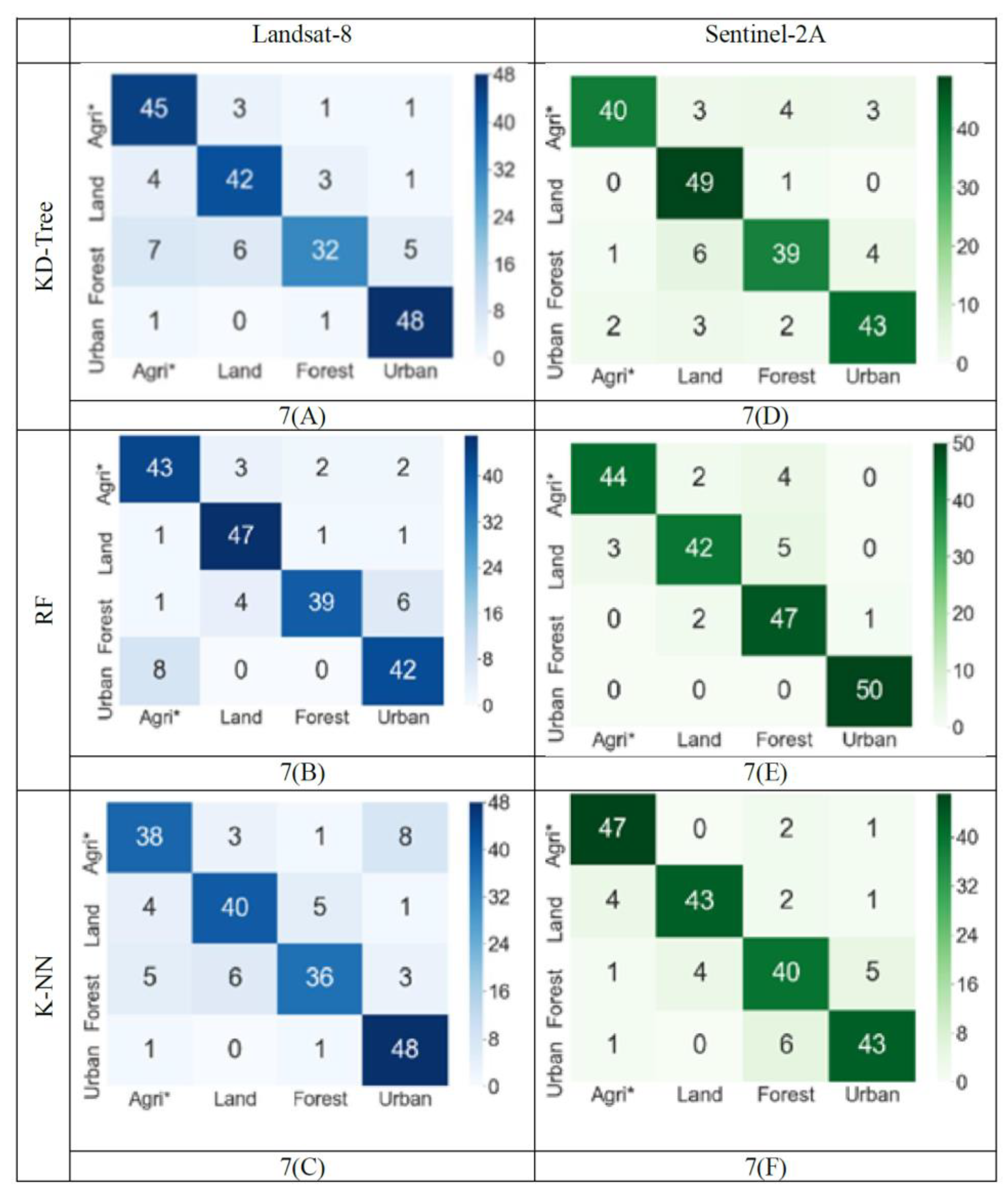{kind=link}
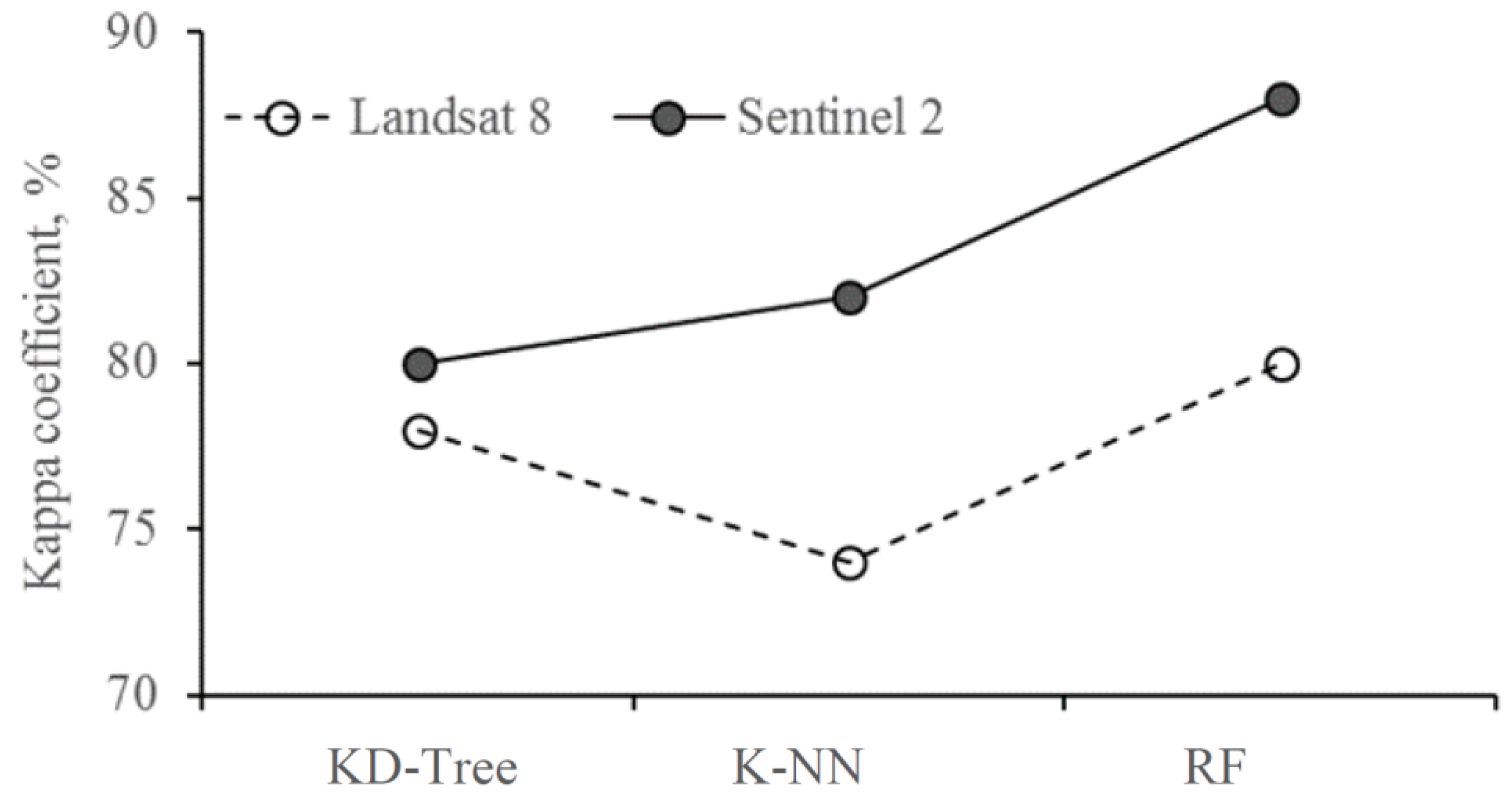{kind=link}
{kind=link}
| Satellites | Number of Bands | Resolution (m) | Acquisition Date (Day/Month/Year) | Path-Row/Tile (Number) | Cloud Cover (%) |
|---|---|---|---|---|---|
| Sentinel-2A | 13 | 10–60 | 26 July 2019 | T20TLS | ≤10 |
| 16 July 2019 | T20TMT | ≤10 | |||
| 20 July 2019 | T20TNS | ≤10 | |||
| 28 July 2019 | T20TMS | ≤10 | |||
| Landsat-8 | 11 | 15–100 | 26 July 2019 | 008-028 | ≤10 |
| 26 July 2019 | 007-028 | ≤10 | |||
| 7 July 2019 | 007-027 | ≤10 |
| Type | Index | Formulas | References |
|---|---|---|---|
| Vegetation Index | DVI | [36] | |
| NDVI | [37] | ||
| Urban index | NDBI | [38] | |
| UI | [39] | ||
| Barren land index | NBLI | [39] |
| LULC Class | Description |
|---|---|
| Agriculture | Cultivated land, crop fields, vegetable fields |
| Urban | Residential, commercial, industrial, mixed urban, other urban |
| Barren Land | Exposed soil, construction site, fallow land |
| Forest | Deciduous forest and mix forest, shrubs, and other |
| Classifier | Classes | User Accuracy (%) | Producer Accuracy (%) | User Accuracy (%) | Producer Accuracy (%) |
|---|---|---|---|---|---|
| Sentinel-2A | Landsat-8 | ||||
| KD-Tree | Agriculture | 80 | 93 | 90 | 79 |
| Barren Land | 98 | 80 | 84 | 82 | |
| Forest | 78 | 85 | 64 | 86 | |
| Urban | 86 | 86 | 96 | 87 | |
| RF | Agriculture | 88 | 94 | 86 | 81 |
| Barren Land | 84 | 91 | 94 | 87 | |
| Forest | 94 | 84 | 78 | 92 | |
| Urban | 100 | 98 | 84 | 82 | |
| K-NN | Agriculture | 94 | 89 | 76 | 79 |
| Barren Land | 86 | 91 | 80 | 82 | |
| Forest | 80 | 80 | 72 | 84 | |
| Urban | 86 | 86 | 96 | 80 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, U.; Esau, T.J.; Farooque, A.A.; Zaman, Q.U.; Abbas, F.; Bilodeau, M.F. Limiting the Collection of Ground Truth Data for Land Use and Land Cover Maps with Machine Learning Algorithms. ISPRS Int. J. Geo-Inf. 2022, 11, 333. https://doi.org/10.3390/ijgi11060333
Ali U, Esau TJ, Farooque AA, Zaman QU, Abbas F, Bilodeau MF. Limiting the Collection of Ground Truth Data for Land Use and Land Cover Maps with Machine Learning Algorithms. ISPRS International Journal of Geo-Information. 2022; 11(6):333. https://doi.org/10.3390/ijgi11060333
Chicago/Turabian StyleAli, Usman, Travis J. Esau, Aitazaz A. Farooque, Qamar U. Zaman, Farhat Abbas, and Mathieu F. Bilodeau. 2022. "Limiting the Collection of Ground Truth Data for Land Use and Land Cover Maps with Machine Learning Algorithms" ISPRS International Journal of Geo-Information 11, no. 6: 333. https://doi.org/10.3390/ijgi11060333
APA StyleAli, U., Esau, T. J., Farooque, A. A., Zaman, Q. U., Abbas, F., & Bilodeau, M. F. (2022). Limiting the Collection of Ground Truth Data for Land Use and Land Cover Maps with Machine Learning Algorithms. ISPRS International Journal of Geo-Information, 11(6), 333. https://doi.org/10.3390/ijgi11060333