1. Introduction
Social media services are ubiquitous and often faster than conventional media in terms of information distribution. This advantage is made use of in numerous situations, for example in disaster management [
1]. Modern disaster management concepts, such as
Virtual Operation Support Teams (VOSTs), even depend on this kind of information source. For them to be able to accomplish their tasks, social media data are being gathered and stored, before being analyzed and evaluated.
Analyzing and evaluating social media data by counting appearances of posts that contain certain information is a common practice. For example, the topic of their payload content, but also their attached location data, date and time, or even information about the user are valuable criteria to search for. The result then is a list of posts matching these search criteria that can be used as a basis for diagrams or overview maps highlighting trends or hot spot areas.
A common approach to gather the data is to query public interfaces provided by social media services for either a real-time data stream or a historical list of posts, and store the resulting data in local databases to be processed by analytics applications in order to investigate their characteristics. This approach is called
exploratory data analysis, but can also be interpreted as
data retention (see
Section 2.2), a practice which is problematic in numerous ways. Recent incidents of contact tracing data misuse [
2] stand exemplarily for side-effects of gathering large sets of personal data. Once a set of data has been gathered for whatever reason, it is subject to being misused by third parties. Especially in disaster management, personal data must be taken good care of. People being affected by disasters are vulnerable. They are potentially dependent on receiving or sharing reliable information or seeking help through social media services. It is even possible that using social media services is their only opportunity. This makes retention of this kind of data problematic in terms of their original creators’ informational self-determination: once data are collected and stored by a third party, their original creator can neither update nor delete it and, thus, has lost control over it. Moreover, having access to such datasets enables to extract a list of users who have obviously been at a certain place. This can be crucial in relevant situations with special privacy interest for users, for example in refugee movements, demonstrations, or riots.
This raises the question of the necessity to store large amounts of personal data from the social media services. A progressive and privacy-aware approach to answer this question is to not store collateral data, meaning that kind of data that are not necessary for the accomplishment of the task that the data are being gathered for. In our research, we aim to provide methods and technology to process social media data following this approach. We propose to actively prevent the gathering of collateral data and, thus, better protect privacy of social media data creators.
To achieve this, we introduce a method to store social media data in a structure, that is build on top of a data storage algorithm called HyperLogLog (HLL). We show how to use the technology on real-time streaming social media data with a usage scenario in disaster management. This is especially significant, because the usefulness of such data is very ephemeral. Once a disaster is overcome, most of the data have lost their relevance. This increases the urgency to pay attention to what data need to be gathered in the first place.
Our concept is developed with generic application on any social media services or networks in mind. For the presentation in this paper, we focus on data taken from the well-known social media service Twitter. We reference Twitter posts as our example social media data, which we accessed through the Twitter API with academic research access level [
3]. Readers should be aware tough, that Twitter is only used exemplarily as a data source and should not be considered an obligatory foundation for this work. The herein presented concepts apply to data sourced from any social media platform, including decentralized networks such as the fediverse [
4].
In
Section 2, we explain the fundamentals on disaster management in general, the concept of VOSTs, why data retention is a serious threat and the fundamental functionality of HLL. Following up in
Section 3, we describe our proposed concept to store social media data, without accidentally storing collateral data, by utilizing HLL to mitigate the data retention threat. We also describe a potential scenario in disaster management, wherein the concept is applied. In
Section 4, we will give a short insight in the proof-of-concept implementation. Afterwards, we discuss the pros and cons of our proposed method in
Section 5, concluding with an outlook of further research.
3. Concept
Based on pre-described fundamentals (see
Section 2), our previous work on HLL [
46,
47] and findings resulting from our case study [
45], we present a concept to store and process data from a real-time stream of social media posts in a way that protects from the side-effects of data retention.
In addition to its unknown extent, the particular characteristic of real-time streaming data is its ephemerality. Data come in and can be processed, but the next moment they are gone and cannot be reconsidered, unless they are stored locally. However, according to our research goals, the storage of collateral data should be prevented.
In this section, we first outline the term collateral data, as well as the purpose of geohash locations in the concept. We then introduce the utility of the HLL technology to only store necessary data. Finally, we classify the concept using an operational scenario.
3.1. Collateral Data
When utilizing some analytics software to monitor the occurrence of pre-defined terms, conventional analytics tools would store the social media data in a database, to be able to run further analytics and visualizations over it. Typically, relational or non-relational database management systems are used ([
18] p. 163). This procedure brings the side-effect of storing
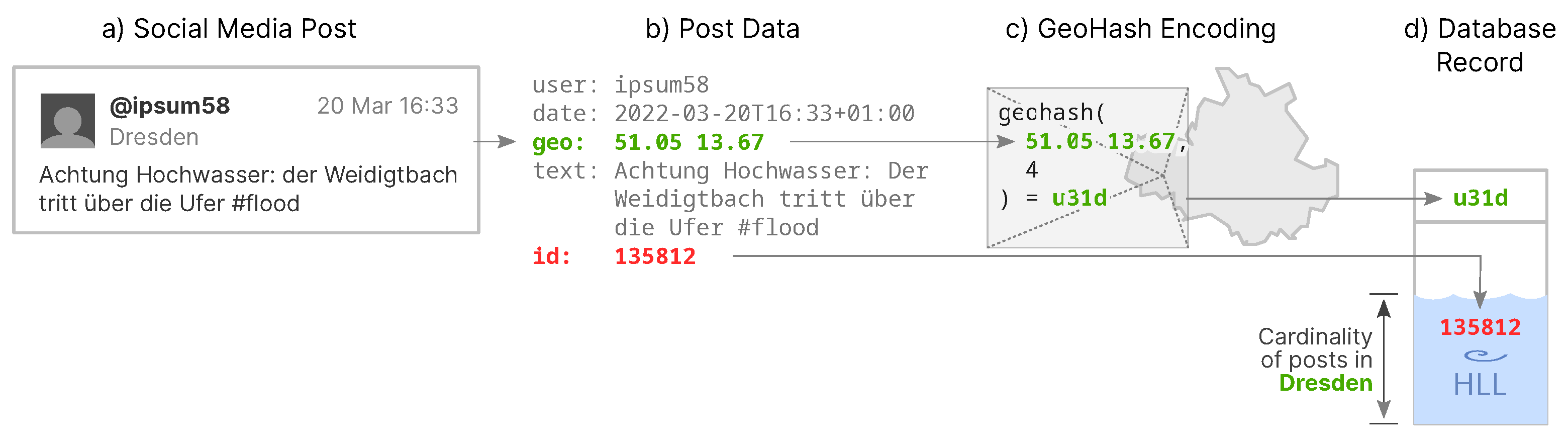
collateral data, which are data that are not required to fulfil the task of computing the post cardinality. An example of a data item for the occurrence of a well-known social media post matching a search criteria is shown in
Figure 1b. In addition to the location of the post, it also includes information about the author, the date and time, as well as the entire content of the post. These data can be used for example to identify the original creator of the post, and, thus, for other purposes than originally intended, which we identify as data retention (see
Section 2.2).
To determine the cardinality of posts containing the term
flood in a certain area, most of the data shown in
Figure 1b are not required. We know that the present post matches our pre-defined term, because we had created a search rule for it (see
Section 4) and, therefore, all posts we receive will match the search term. The actual content of each post is not necessary to store, consequentially. Furthermore, we neither require the time of creation nor the author for each individual post to state the cardinality of all the posts.
In order to state the cardinality of posts, we do need to assign the posts some ID as the unique identifier of each post. In our proof-of-concept implementation (see
Section 4), such an ID, is already provided by the Twitter API (red color in
Figure 1). We also need the location data of each post (green color in
Figure 1) in order to determine the location of the potential flood incident. For any location-based social media data analysis, e.g., a VOST to be able to localize potential disaster situations, the need for some sort of geo-referencing data is essential. Our concept introduces a method to store these data in a way that it is only useful to determine the post cardinality, the number of posts with occurrences of said pre-defined terms.
3.2. Geohash Locations
The concept is about determining the cardinality of posts for a certain area. To sort individual posts into areas, the geo-location of a post is generalized by converting the original location data to a
geohash (see
Section 2.3). Posts come with geo-location information of multiple quality levels (see
Section 4), each still representing a point value (latitude, longitude). The concept requires the geodata to be converted to an area, so that multiple posts can be associated with it. If each post had its own location point value, there would be an individual database entry for every post (see
Section 3.3), unless multiple posts had been sent from the exact same place. Therefore, a suitable precision value must be defined for the geocode along with the search term in our concept. If the precision is too low and, thus, the area too large, there will be too many posts and potential incidents are more difficult to locate. If the precision is too high and, thus, the area too small, there will not be enough posts in an area to be able to determine anomalies in their occurrence. In
Figure 1c, the precision value is
4, so the resulting geohash has a length of four characters.
3.3. HyperLogLog Storage
We declare the spatial information (represented by a geohash) as the key characteristic of a social media post. It is stored into the database in clear text, serving as the index of the database record (see
Figure 1d). The identifier (ID) of the post is in turn stored in a HyperLogLog (HLL) set in relation to its geohash. Post IDs that arrive later in the stream and match the same geohash will be added to this HLL set, which increases its cardinality by one for each new post. The resulting HLL data structure represents all posts matching a certain term from a certain area, from which it is impossible to derive the post IDs back from it.
Figure 1d depicts this procedure, showing the post ID “plunge” into the HLL set (represented by a basin or sink).
Utilizing HLL, we do
not store the post IDs itself, but only calculate hashes from them and store them in an array of counters that represents the set of post IDs.
Figure 2 shows an exemplary database table structure with geohashes and post IDs. The geohash values each represent an area, and the corresponding HLL sets represent the IDs of posts that occurred in that area. Having a database with geohashes and their corresponding HLL set, as shown in
Figure 2, it is possible to compute the cardinality of the HLL set and, thus, determine the number of posts in each area.
The result of a set’s cardinality computation could as well be achieved by just incrementing an integer per seen post ID and storing the sum instead of an HLL set. The significance about using the HLL algorithm instead, is that it provides the opportunity to do
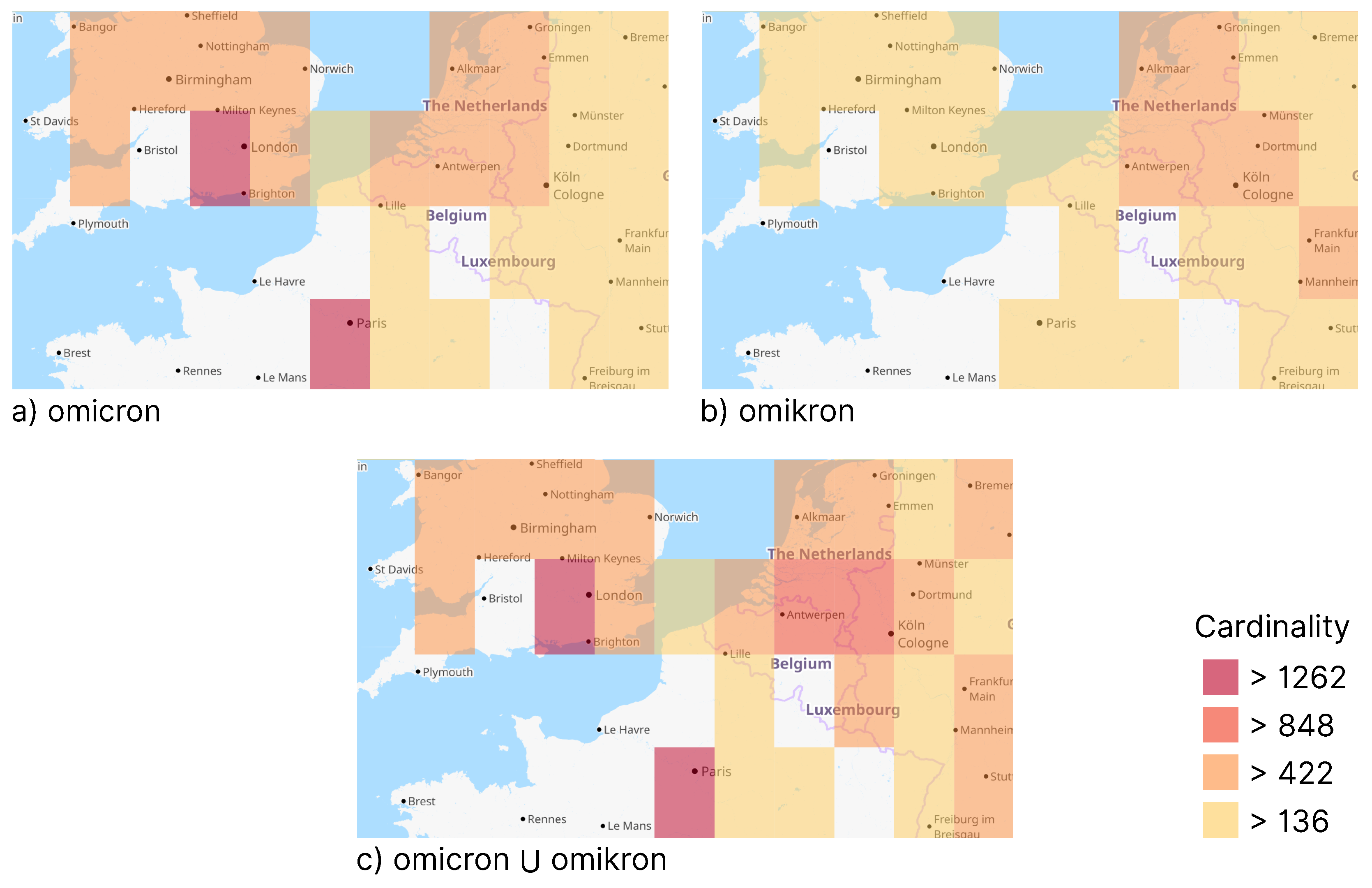
set operations, such as unions and intersections, on the HLL sets. Both operations allow quantitative evaluations of relationships between HLL sets and can useful for combinations of multiple individual sets. Additionally, sets of multiple terms can be combined. The result can, e.g., support VOSTs in specifying a disaster scenario (see
Section 3.4). An intersection of
fire and
forest sets could lead more precisely to disaster incidents than both terms on their own. It still makes sense to monitor the terms individually in the first place, because, for example, a combination of
fire and
accident can lead and different incidents than a combination of
forest and
accident.
Furthermore, different terms could have the same meaning, for example
flood,
high tide,
wave, and
tsunami could all refer to the same situation. So a union of HLL sets on posts over these terms can increase the accuracy of a disaster detection (see
Section 3.4). Likewise, terms in different languages could also be monitored in combination. This may, e.g., enable VOSTs to monitor larger, multiple languages involving areas, such as border triangles, or including smaller countries, such as Benelux or the Baltics.
Figure 3 emphasizes that the combination of different terms can lead to more accurate visualizations and, therefore, more rational assessments of the situation.
3.4. Scenario
In this subsection, we present our concept in an exemplary disaster management scenario, in which a VOST passively monitors a real-time social media data stream (see
Section 2.1). A software system does the monitoring in a day-to-day routine and notifies about peaks or anomalies in order to detect potential disasters. The VOST would define a set of terms, which indicate potential disasters and, therefore, should be monitored for occurrence within posts. There is an expected noise floor, namely an average occurrence of these terms during normal times. For example, every hour there are between 50 and 500 posts in a certain area containing the term
flood. The number of posts will normally increase by a value in this range per hour. In our concept, we call the number of posts their
cardinality.
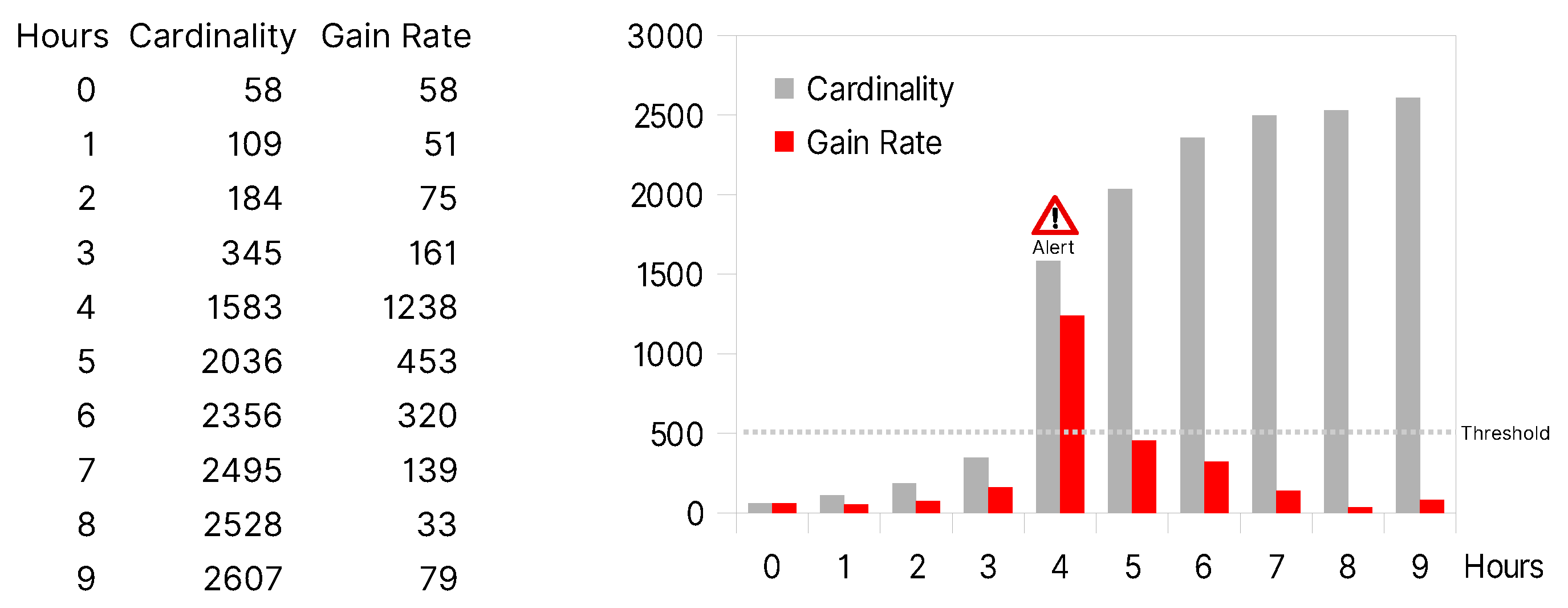
During a disaster, the occurrence of posts, including certain terms, and thus their cardinality may increase by a recognizably higher amount than the average, for example by 1238. For our concept, we propose the utility of a monitoring tool that checks the cardinality in a defined time range, for example every hour. Visualizing the
gain rate of the post cardinality will result in a peak in the graph (see
Figure 4). If the peak exceeds a pre-defined threshold, it will trigger an alert. It may indicate a potential disaster situation and a need for attention by the VOST.
Figure 4 shows an exemplary graph of the post cardinality gain over time and its corresponding gain rate. It includes a pre-defined threshold of posts per time range set to 500. At position 4, a large cardinality gain by 1238 posts occurs, which exceeds the threshold. It triggers an alert for the VOST with the corresponding monitored term and the threshold, for example “term
flood has exceeded 500 posts per hour”.
Once the VOST is alerted for a peak in the cardinality gain for some pre-defined terms, they may start their investigation on that matter. This usually includes browsing social media services through their search functions in order to receive live occurrences of posts relevant to the context [
11]. This stage marks the end of our concept scenario.
4. Implementation
We created a proof-of-concept implementation for this concept called
VGIsink [
49]. It is designed as an HTTP-based RESTful API [
50] to ensure standard-compliant access for any client application. While the proposed concept is dedicated to work generically with data from any social media platform, the VGIsink implementation is restricted to compatibility with Twitter.
Setting up a working example requires to gain access to the Twitter API in order to curate a custom real-time stream of posts. The
filtered stream feature provided through the Twitter API [
51] allows to define
rules with terms to be monitored to curate such a custom stream. Adding the
has:geo operator to each term ensures that the stream is limited to posts that contain geo-information. Furthermore, the geohash precision value must be defined for each rule, in order to set the size of the areas in which post cardinalities should be computed. This is out of scope of the Twitter API and, thus, we made it part of VGIsink.
Within our implementation, we adopted the term
rule from the Twitter API to define an individual target to monitor. A rule is defined by a
term and a
precision value. For each rule, a table is created in the application database, following the structure described in
Figure 2. Every arriving post in the real-time stream is defined by its geo-information. It can be either a specific coordinate with a latitude and a longitude value or a bounding box describing a more generic place. In case of a specific coordinate, it will be transferred to the corresponding geohash according to the defined precision value. A bounding box will be transferred into a list of all geohashes, whose center is inside the bounding box. We assume relevance of a post for the entire place, so the cardinality will increment for each geohash in that list. The geohash will be stored in clear text as the table record’s primary key. The ID of the post will be added to an HLL set in the table record corresponding to the geohash. The VGIsink implementation utilizes the PostgreSQL HLL implementation [
52].
Reading the resulting data means querying a certain VGIsink rule. A query to such a rule returns a JSON-formed list of areas and their corresponding cardinality. Each area is converted from the geohash to a Postgis geometry [
53] and then returned as a standard GeoJSON [
54] compliant coordinate, as shown in Listing 1. The cardinality is calculated using the according PostgreSQL HLL function.
A list of areas with their corresponding cardinality can be visualized for example in a mapping application.
Figure 3 shows an example implementation using Leaflet [
55]. It features a number of rectangular areas, each representing a geohash. The color of a rectangle represents its cardinality, where lighter means lower and darker means higher values.
Listing 1. Example of a list of GeoJSON objects with the corresponding cardinality.
[ "type": "Polygon", "cardinality": 108, "coordinates": [ [ [ 5.625, 49.21875 ], [ 5.625, 50.625 ], [ 7.03125, 50.625 ], [ 7.03125, 49.21875 ], [ 5.625, 49.21875 ] ] ] ]
5. Discussion
The rationale behind the concept presented in this paper is to provide a concept to utilize the HLL technology in order to prevent unnecessary data retention. In the following we evaluate the concept, discuss its scope and go into a number of potential alternative approaches.
The conventional way to store social media data prior to analytic processes is to just store the raw data without any further preparation. This, of course, leads to data retention as the major point of criticism (see
Section 2.2). With DP we already named a potential alternative strategy to store data in a privacy-aware way in
Section 2.4, though we have also declared it unsuitable in the scenario of storing social media data for its characteristics of enlarging the already large amount of data even further. In addition, defining the distribution of randomness is not possible, if the scope of the data is unknown, which is true for a stream of data whose end is indefinite.
A trivial alternative would be to only store the number of posts matching a certain rule as an integer in the database. This would not only reduce the data footprint immensely and prevent the possibility to make statements about individual items within the set. However, it only allows basic arithmetic functions and takes away the opportunity to do set operations, such as unions and intersections, over multiple datasets. We do not claim that using HLL to solve the problem is the only alternative. The low storage footprint and the fast processing speed make it a very suitable method to process social media data with their usual characteristics of being really extensive.
While we introduced the concept using only minimal examples in
Section 3 and
Section 4, it is actually intended to operate on a much larger number of terms and rules, respectively. It could be hundreds or even thousands of them, the number of rules is potentially unlimited. It is possible to consider only posts for one HLL set, that contain two or more specific terms, or if a combination of events from different facets occur, e.g., a term occurs during a pre-defined time range. Search terms are also not limited to nouns as introduced, but they can include verbs, adjectives, or any other kind of words. As described in
Section 3.3, the combination of terms may sharpen their semantics and enables a more precise dataset. Preselecting relevant terms could be automated by a suitable topic modeling technique [
56], to find terms with similar meanings automatically. Nevertheless, choosing the right terms to redeem good results needs the experience of professionals, which members of VOSTs are expected to bring along. If new topics arise on social media, new terms appear along, e.g.,
covid, new rules must be created for each.
A considerable extension to this concept might feature automatic adjustments of the geohash precision value, e.g., once a certain cardinality is exceeded. A higher precision value would split the area into smaller pieces and, therefore, reduce the size of each area. Resulting HLL sets can then be unified or intersected with other sets on their own. This argumentation is only theoretical, and no experiments have been performed on this approach. The concept relies on the experience of VOSTs to determine a sane value.
The most important limitation of the concept is the lack of ability to perform exploratory or otherwise selective qualitative analysis. It is not intended by design to be able to investigate for clues within a dataset, that have not been planned to discover. For further investigation on individual incidents that this concept can detect, VOSTs derive to other tools or applications provided by social media platforms themselves anyway [
45].
With respect to common facets [
57], this concept only considers spatial information in terms of collected data. In combination with other data spatial information is deemed privacy-relevant [
58]. However, as shown in
Figure 2, spatial information in the form of the geohash is the only data stored in clear text. The social facet, information about the user, is not stored as per definition of the concept. Temporal information can only be retrieved, if cardinalities are queried periodically and stored, e.g., in a time series database, such as Prometheus [
59] or InfluxDB [
60].
The ID of a post stored in an HLL set along with the corresponding geohash represents the entire social media data item. It can not be retrieved from the HLL set per definition of the HLL algorithm. However, if the ID of a post is known, it is possible to evaluate, whether it is included in an HLL set. An attacker only needs to calculate the cardinality of the set, then add the post ID to the set and then calculate the cardinality again. If it has not changed, then the post ID has been in the set before. This shows that HLL itself cannot preserve privacy, if the attacker has further information [
40]. It does not impair the concept though, because the described situation is not considered an attack vector. Attempts to discover single items in an HLL set of social media post IDs is regarded unnecessary effort. Since the data are publicly available from the social media services, attackers can also obtain them from there directly. An exception to this may be a case in which a social media post has been deleted online, while its post ID is still known to the attacker. However, this will only prove that the post has existed. This is trivial, if the attacker is already in possession of the ID. No other content from the post can be recovered from the HLL set. Adversarial perturbations of the input stream to alter the cardinality estimation of an HLL set through the exploitation of security flaws (see
Section 2.4) are also of purely theoretical use. This concept aims to prevent data retention and attacks to the entirety of a dataset. For example, it prevents revealing all the user names, that have posted in a certain area. This can be crucial in relevant situations of disaster management. Exemplary situations with special privacy interest for users include refugee movements, demonstrations, and riots, among others.
Edge cases involve situations, in which, for example, there is only one post within a certain area. It is obvious to unveil its identity, if the cardinality of a geohash is 1 and the attacker can look up the social media service for posts within that area, assuming it has not been deleted by the time. This can be mitigated in advance by defining a smaller geohash precision value and, thus, choosing a larger area, accepting a lower accuracy of the overall dataset. Furthermore, applying filter lists on specific sensitive context factors can mitigate privacy invasions [
61].
In future research, this concept can gain its effectivity in combination with other techniques. Since social media data include more and more images and videos today, pattern recognition can help detect relevant posts for disaster situations [
62]. This can contribute to more precise post cardinalities and, therefore, help VOSTs to improve the groundwork for their analysis. More advanced example implementations with other than the spatial facet being the key for HLL sets could demonstrate the full potential of this technology.
6. Conclusions
In this paper, we have introduced a method to prevent collateral data when storing real-time social media data streams for analytic purposes. Our method proposes the usage of HyperLogLog (HLL), a cardinality estimation algorithm. While this technology has been applied in many contexts for the purpose of performance improvements, we newly introduced it as a method to prevent unnecessary data retention and thus protect privacy.
We embedded the method in a disaster management scenario, in which virtual operation support teams define certain terms to be monitored for occurrence and get alerted at a certain threshold. This scenario shows the usefulness of our method exemplarily for any data analysis scenario, wherein results are based only on statistical values and there is no necessity to refer to individual items in the dataset.
However, the HLL algorithm does not protect from proving existence of individual items in the set, if external knowledge is applied. The concept prevents from gaining access to previously unknown individual items. Limitations further apply for exploratory data analysis on the stored data, since the only information stored is the occurrence of a post in a certain area. This limitation is intentional for the sake of preventing unnecessary data retention of social media data and the risk of abuse, loss, or public exposure of data that were unnecessary to gather in the first place.




{kind=link}
{kind=link}
{kind=link}
{kind=link}



