

Analysis of the Aggregation Characteristics and Influencing Elements of Urban Catering Points in Small Scale: Methods and Results
Abstract
:1. Introduction
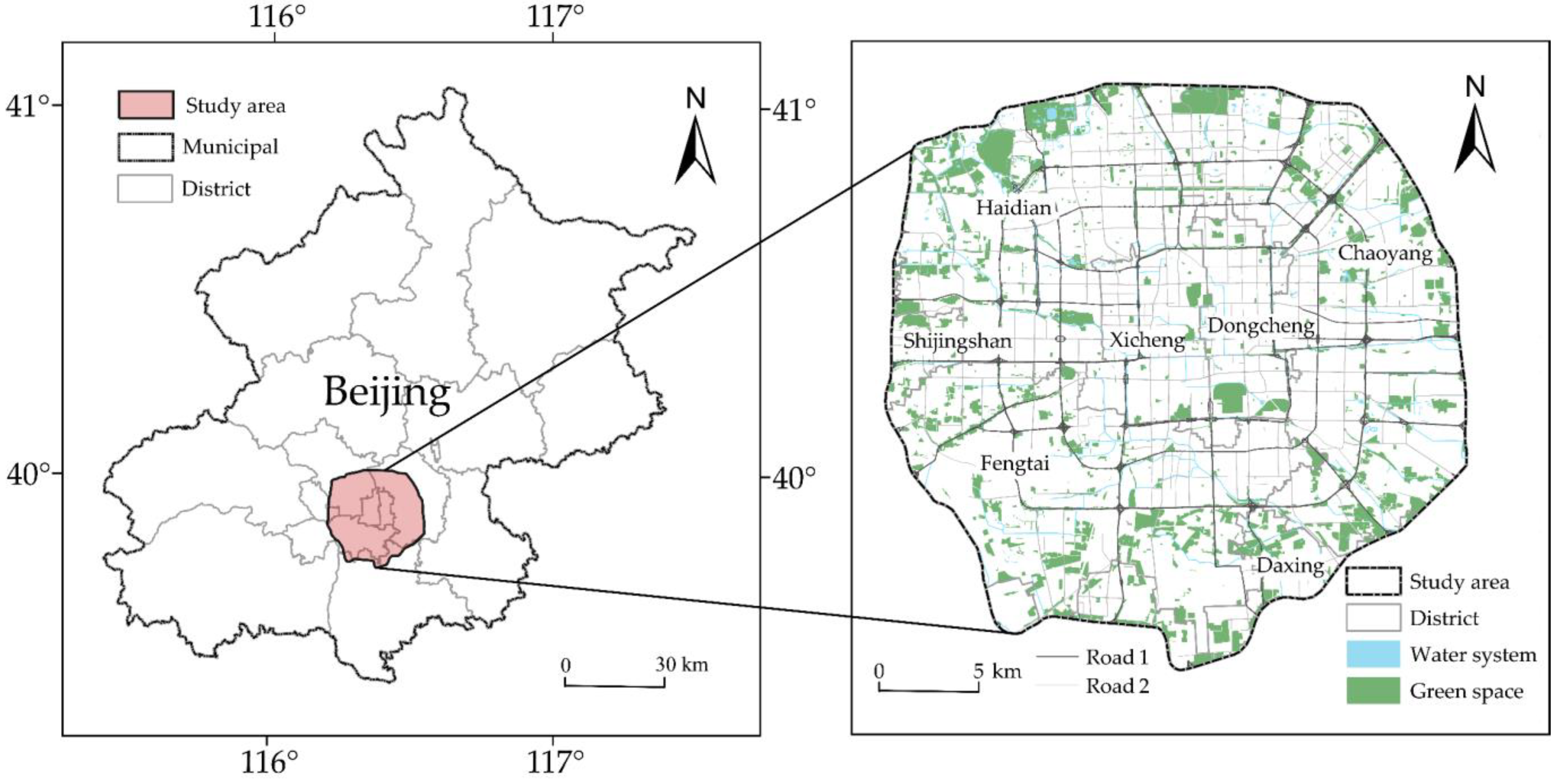
2. Study Area and Data Sources
- (1)
- [cp], with a total of 92,668 catering points.
- (2)
- [SC], with 210 shopping centers, which are comprehensive commercial complexes that house a large number of retail stores, dining establishments, entertainment facilities, and service amenities;
- (3)
- [SP], including 365 shopping plazas, 298 chain supermarkets, amounting to 663 points in total, which are generally smaller in scale and have a relatively focused commercial format, primarily focusing on retail and providing purchasing and sales services for goods;
- (4)
- [BS], including 6792 business office buildings, which are specifically designed and designated for housing offices and conducting business activities;
- (5)
- [RE], including 15,617 residential entry points, which are the designated locations through which individuals enter or exit residential areas or properties.
3. Overall Characteristics of the Density Distribution of Catering Points
- (1)
- Divide the study area into square grid cells with a side length of τ. The number of catering points in each grid cell is counted to obtain a set of grid cells containing more than 0 catering points, represented as , where n is the total sample size. The number of catering points contained in is denoted as , which represents the sample value of .
- (2)
- Group the samples into a reduced number of “bins” using the data binning method, where each “bin” represents a specific interval of sample values. Set the number of bins as . For comparability purposes, the same number of bins is used across all scales (corresponding to different τ, with different sample maximum and minimum values and bin widths). All samples are binned, and a value of , which is the central value of bin . Since the planar area of all grids is the same, represents the number of catering points instead of density. The number of samples falling into bin is . Using the method of frequency instead of probability, the probability distribution function is defined as:
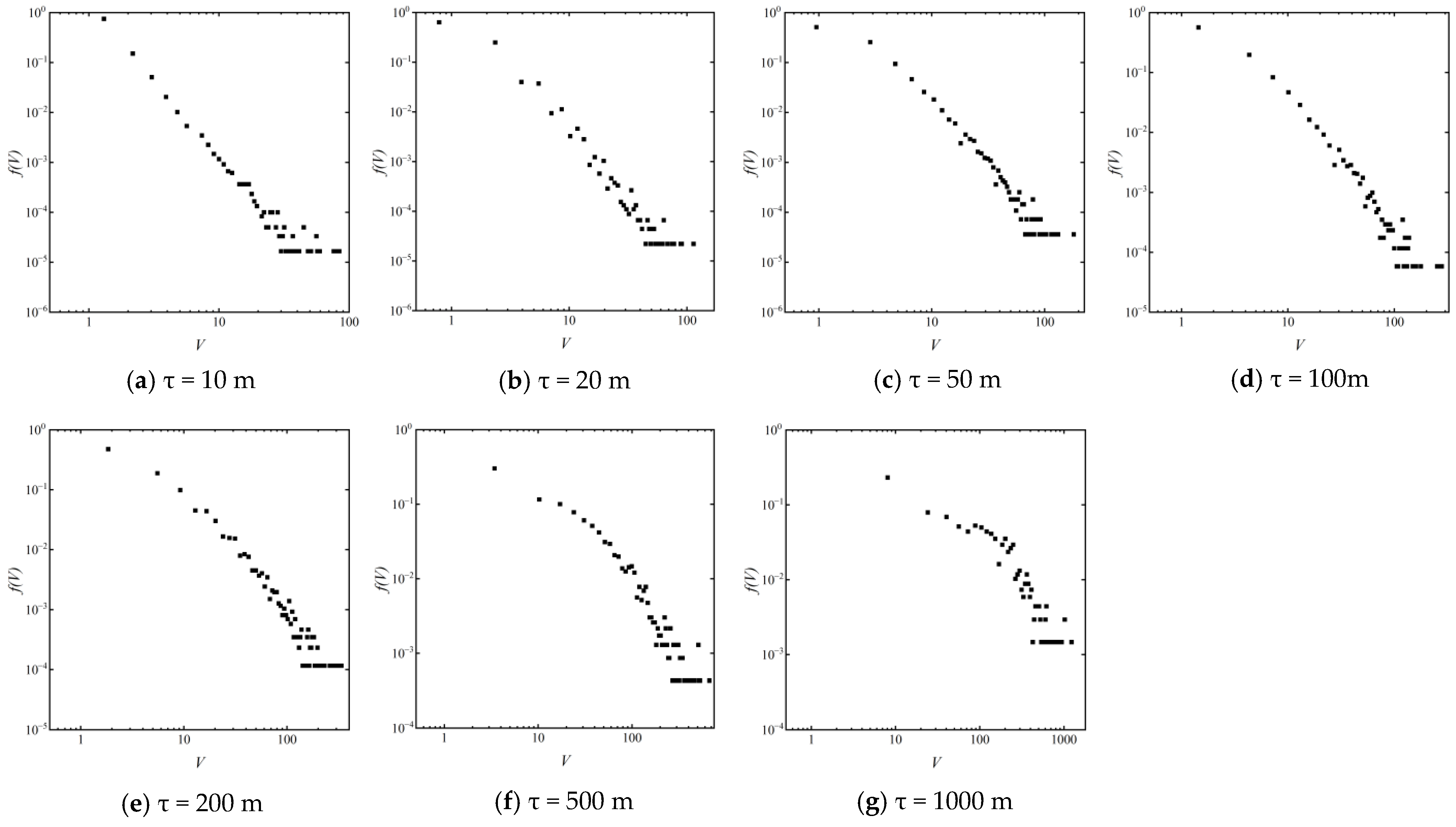
3.1. Power-Law Distribution Characteristics of Planar Density
3.2. Information Entropy of Density Distribution
3.3. Mechanism of Preferential Attachment
4. Aggregation Effect Analysis of Agglomeration Kernel Elements and Catering Points
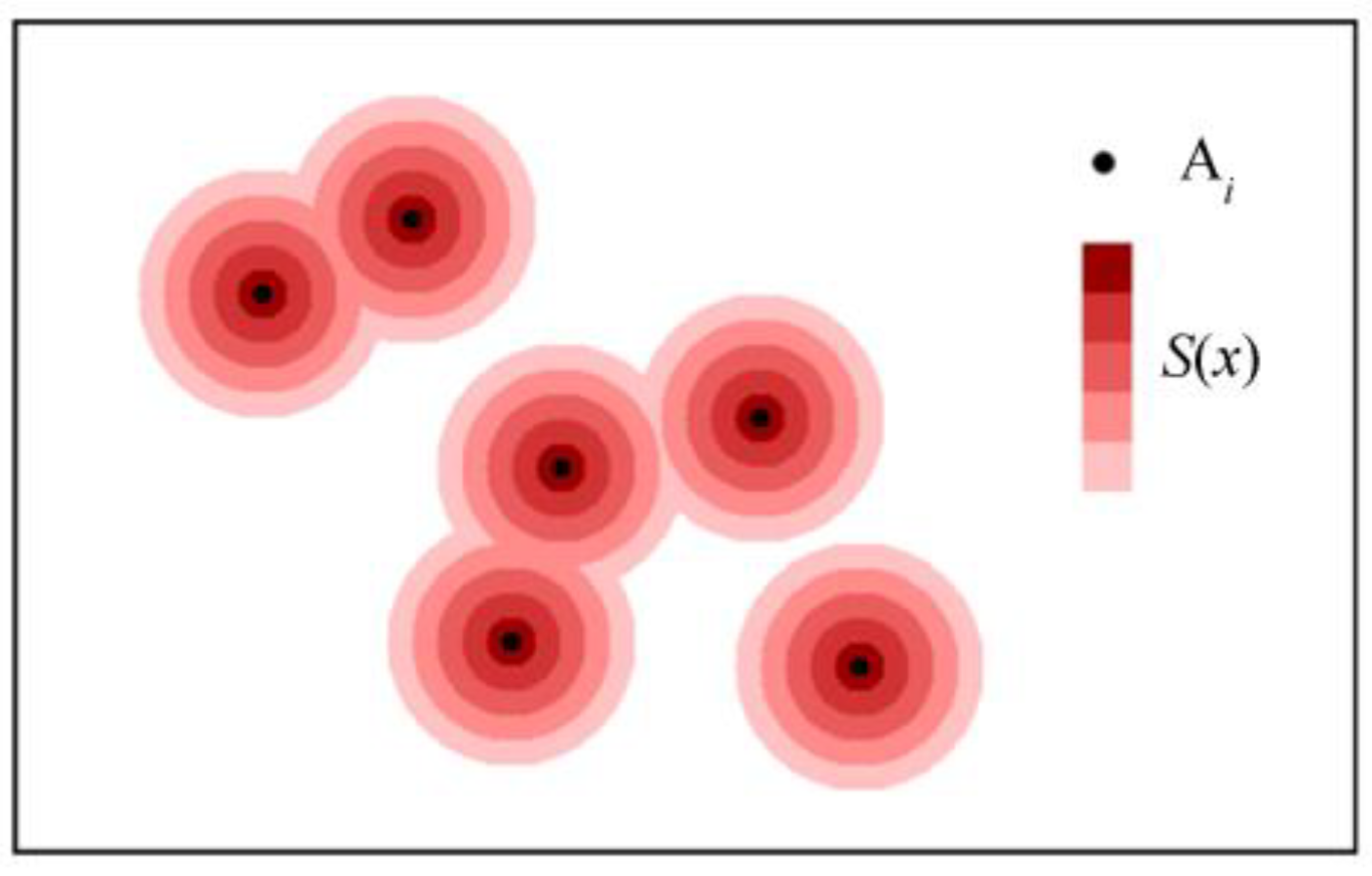
4.1. Basic Spatial Process Function
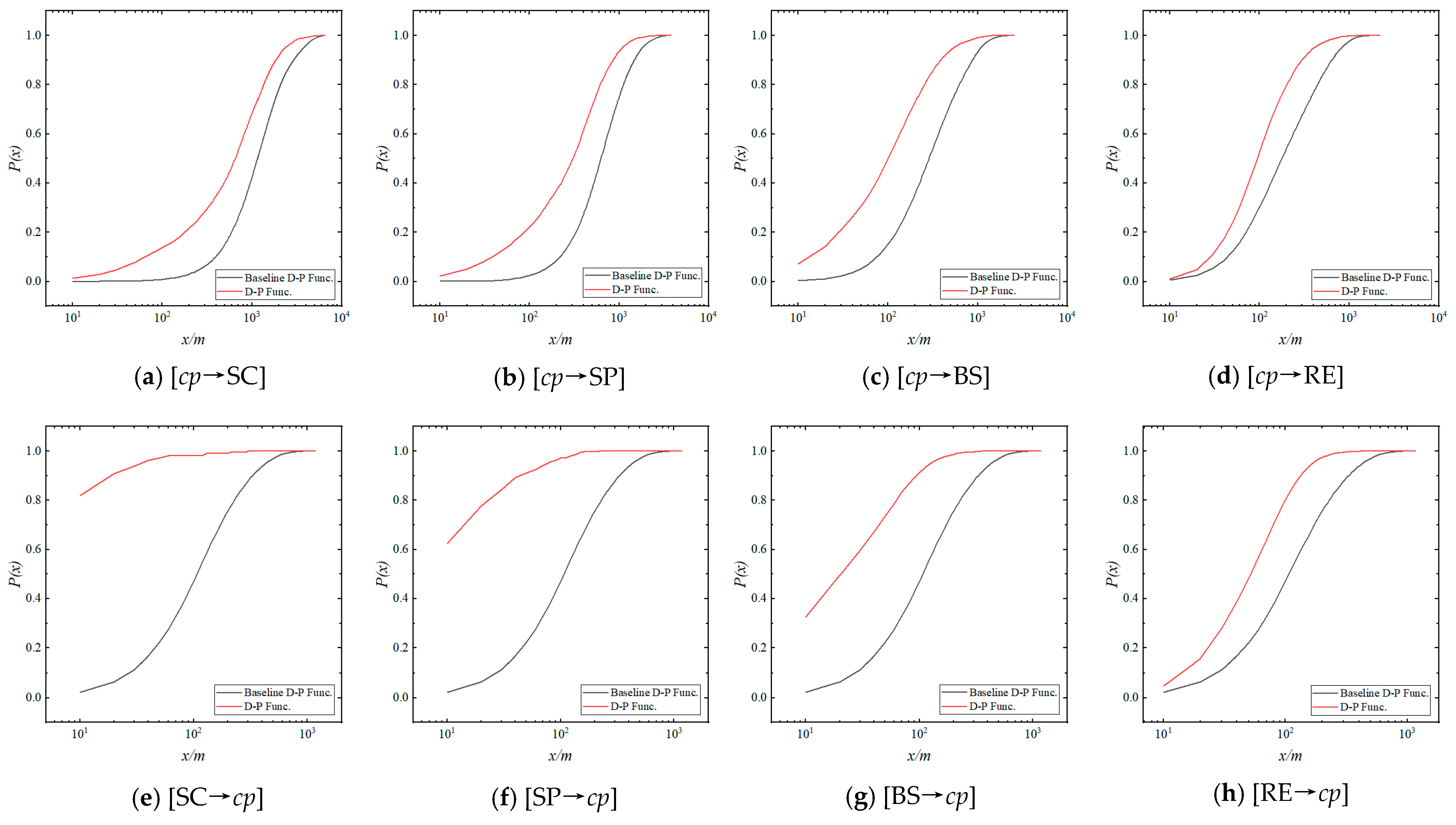
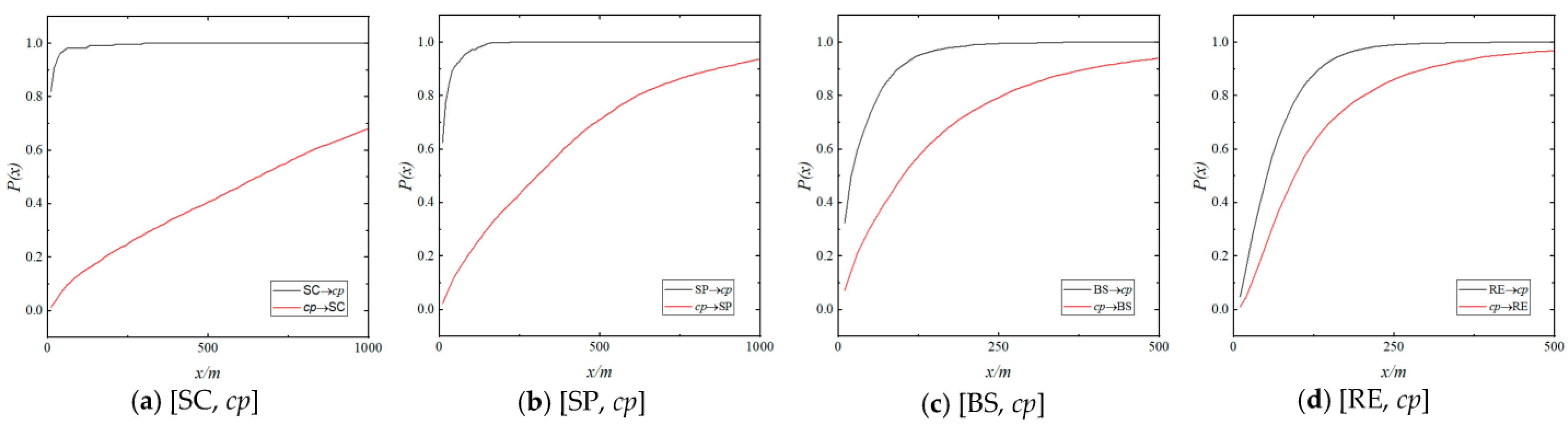
4.2. Distance–Proportion Function
4.3. Baseline Distribution and Baseline D-P function
4.4. Symmetry Analysis of Aggregation Effect
5. Agglomeration Effect Analysis of Agglomeration Kernel Elements to Catering Points
5.1. Basic Characteristic Parameters
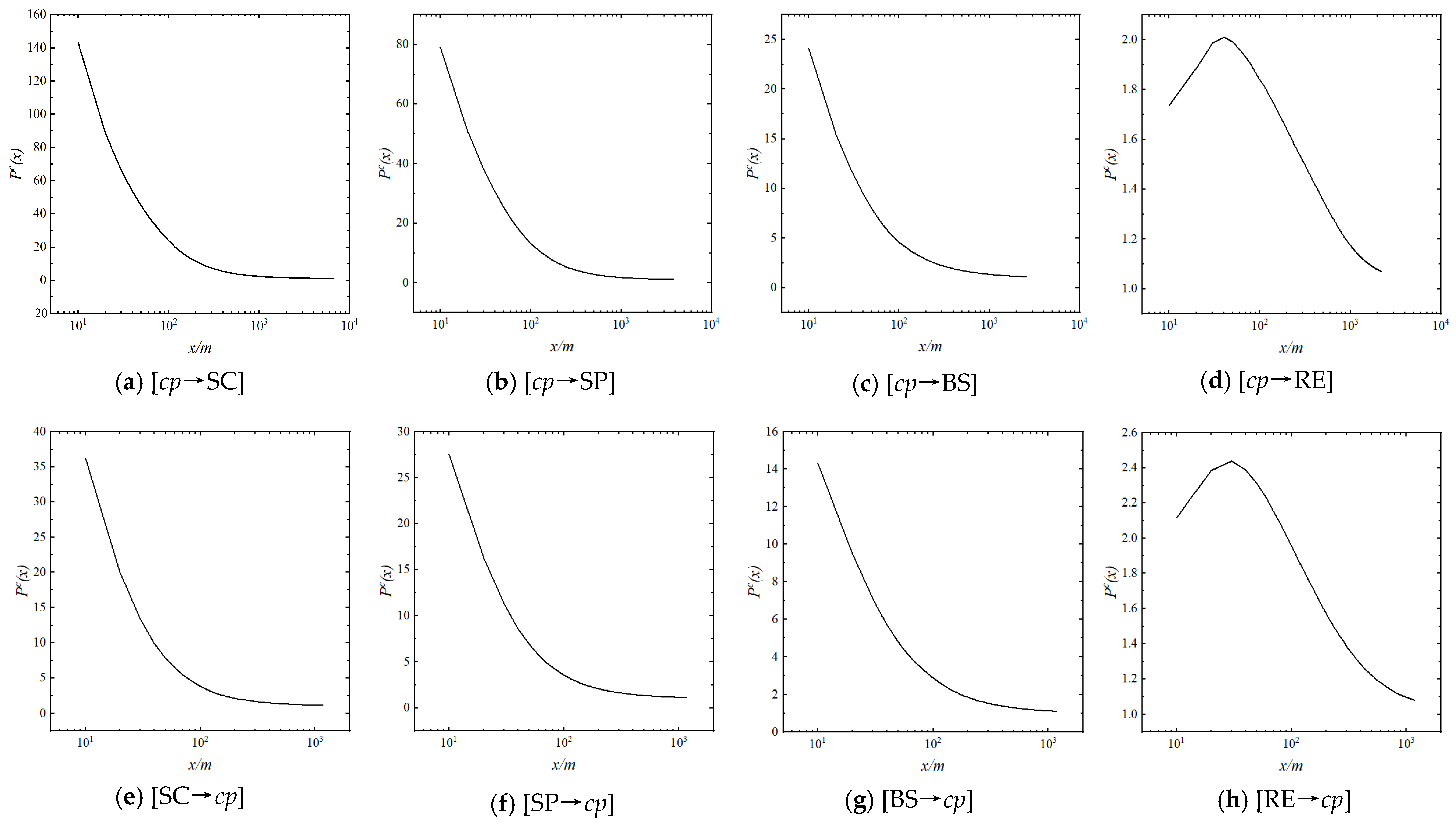
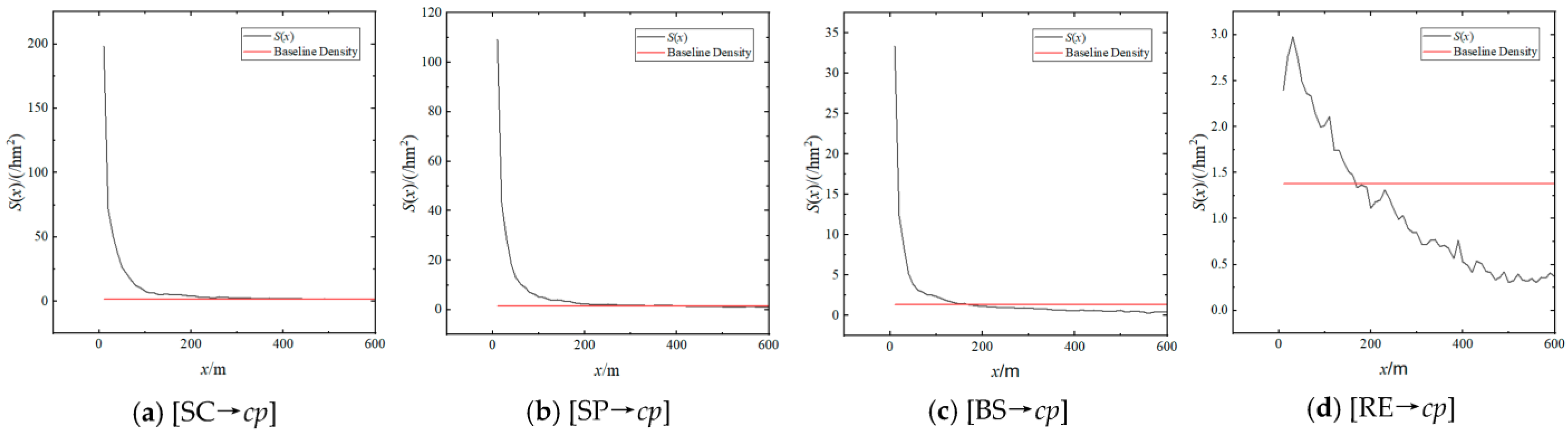
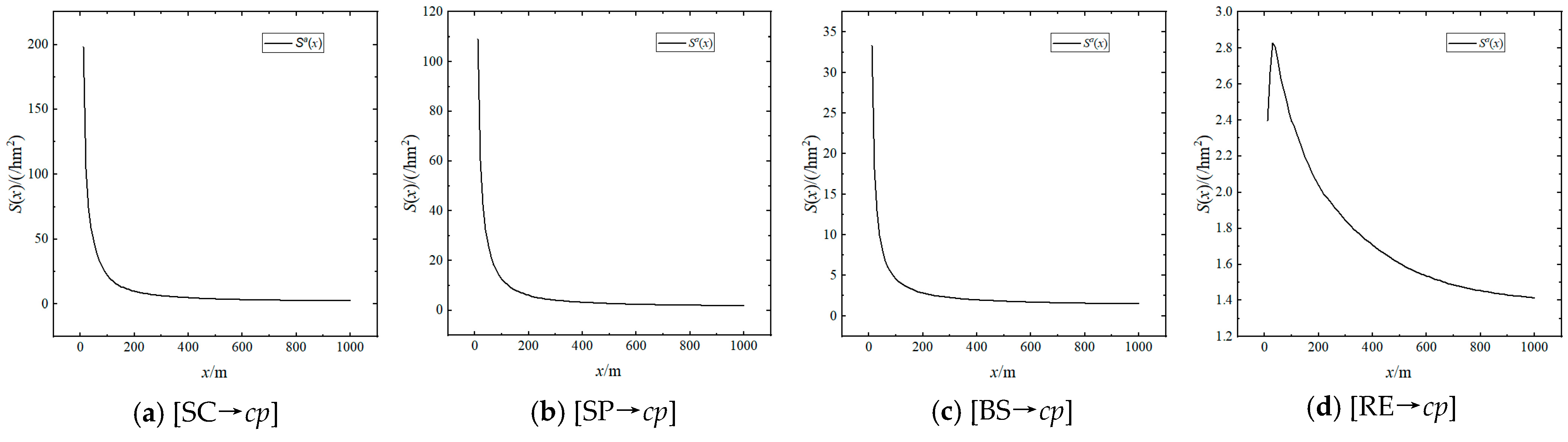
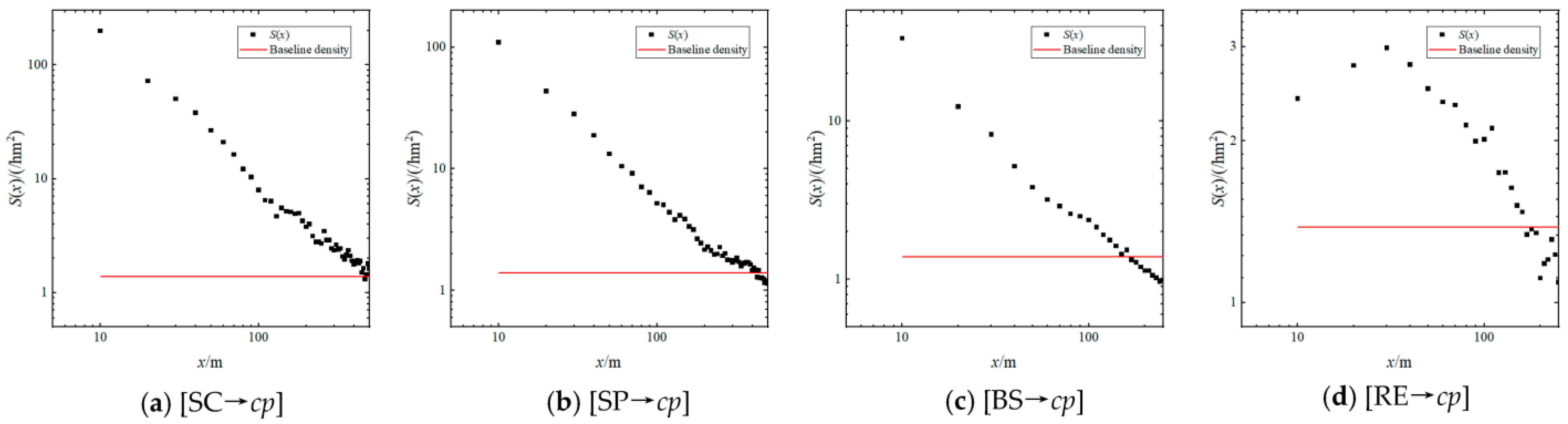
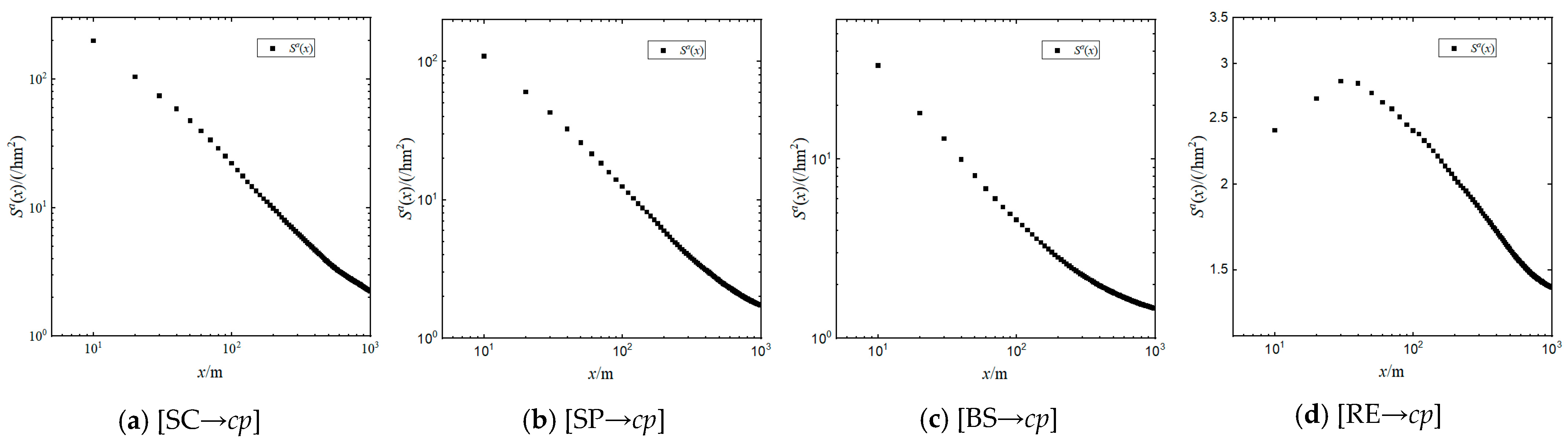
5.2. Distance–Density Function
5.3. Distance–Density Correlation
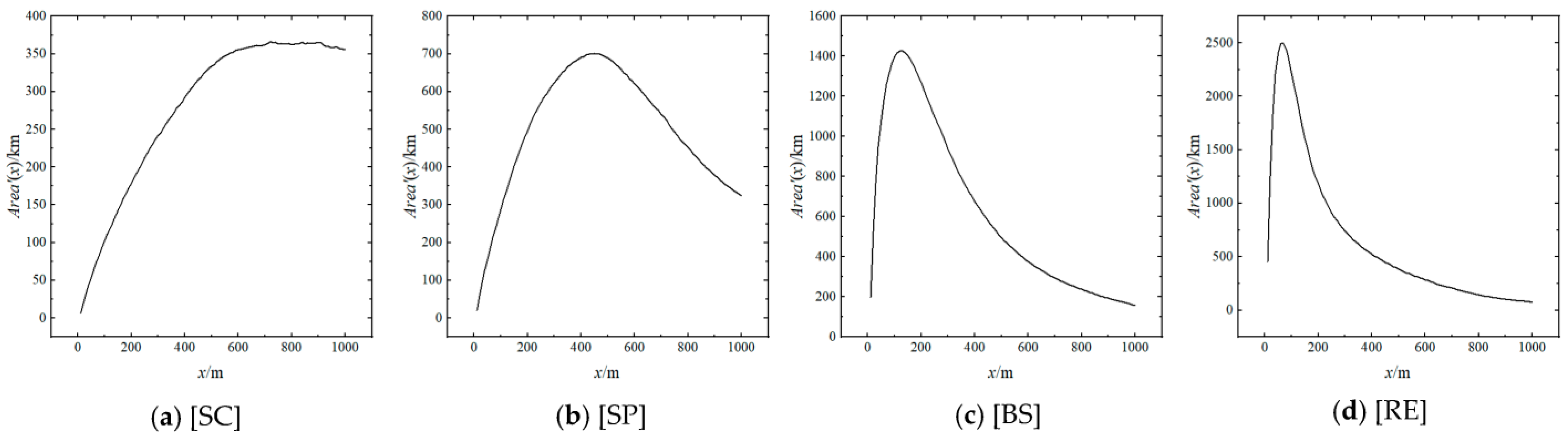
5.4. Effective Distance of Agglomeration Effect
5.5. Explanation of The Power-Law Distribution Characteristic of Catering Points Density
6. Conclusions
- (1)
- The spatial density distribution of catering points in the study area presents power-law distribution characteristics at scales ranging from 10 to 1000 m, with a more pronounced characteristic at smaller scales. This data-driven finding interprets the mechanism of preferential attachment in the competition for catering point site selection.
- (2)
- Using the spatial process analysis method, an aggregation effect analysis model based on the distance–proportion function and an agglomeration effect analysis model based on the distance–density function were established. An empirical analysis between the candidate points sets and the catering points set was conducted, which demonstrated the validity of the model.
- (3)
- The aggregation effect analysis revealed that the candidate agglomeration kernel elements exhibited a global-scale aggregation effect on catering points, indicating their categorical impact on the aggregation characteristics of catering points.
- (4)
- The agglomeration effect analysis revealed that the candidate agglomeration kernel elements exhibit an agglomeration effect on catering points. Two important conclusions were drawn: firstly, there is a power-law decay relationship between the density and distance of catering points, revealing the mechanism of preferential attachment in the competition for catering point site selection. Secondly, it identified the effective distance of agglomeration effect by different agglomeration kernel elements.
- (5)
- Based on the conclusions derived from the agglomeration effect analysis, mathematical methods were utilized to explain the power-law distribution characteristics of density of catering points. The study formed an organic connection between micro-level effect analysis and macro-level characteristic analysis.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hotelling, H. Stability in Competition. Econ. J. 1929, 39, 41–57. [Google Scholar] [CrossRef]
- Oppewal, H.; Holyoake, B. Bundling and retail agglomeration effects on shopping behavior. J. Retail. Consum. Serv. 2004, 11, 61–74. [Google Scholar] [CrossRef]
- James, P.; Bound, D. Urban morphology types and open space distribution in urban core areas. Urban Ecosyst. 2009, 12, 417–424. [Google Scholar] [CrossRef]
- Yang, Z.; Sliuzas, R.; Cai, J.; Ottens, H.F. Exploring spatial evolution of economic clusters: A case study of Beijing. Int. J. Appl. Earth Obs. Geoinf. 2012, 19, 252–265. [Google Scholar] [CrossRef]
- Lan, T.; Yu, M.; Xu, Z.; Wu, Y. Temporal and spatial variation characteristics of catering facilities based on POI data: A case study within 5th ring road in Beijing. Procedia Comput. Sci. 2018, 131, 1260–1268. [Google Scholar] [CrossRef]
- Li, Y.; Liu, H.; Wang, L.-E. Spatial distribution pattern of the catering industry in a tourist city: Taking Lhasa city as a case. J. Resour. Ecol. 2020, 11, 191–205. [Google Scholar]
- Prayag, G.; Landré, M.; Ryan, C. Restaurant location in Hamilton, New Zealand: Clustering patterns from 1996 to 2008. Int. J. Contemp. Hosp. Manag. 2012, 24, 430–450. [Google Scholar] [CrossRef]
- Wang, T.; Wang, Y.; Zhao, X.; Fu, X. Spatial distribution pattern of the customer count and satisfaction of commercial facilities based on social network review data in Beijing, China. Comput. Environ. Urban Syst. 2018, 71, 88–97. [Google Scholar] [CrossRef]
- Wang, W.; Wang, S.; Chen, H.; Liu, L.; Fu, T.; Yang, Y. Analysis of the characteristics and spatial pattern of the catering industry in the four central cities of the Yangtze River Delta. ISPRS Int. J. Geo-Inf. 2022, 11, 321. [Google Scholar] [CrossRef]
- Zheng, D.; Li, C. Research on Spatial Pattern and Its Industrial Distribution of Commercial Space in Mianyang Based on POI Data. J. Data Anal. Inf. Process. 2020, 8, 20. [Google Scholar] [CrossRef] [Green Version]
- Fang, Y.; Mao, J.; Liu, Q.; Huang, J. Exploratory space data analysis of spatial patterns of large-scale retail commercial facilities: The case of Gulou District, Nanjing, China. Front. Archit. Res. 2021, 10, 17–32. [Google Scholar] [CrossRef]
- Reigadinha, T.; Godinho, P.; Dias, J. Portuguese food retailers–Exploring three classic theories of retail location. J. Retail. Consum. Serv. 2017, 34, 102–116. [Google Scholar] [CrossRef] [Green Version]
- Zheng, T. Relationship between Urban Retail Commercial Space Distribution and the Road Network & Population Distribution: Comparison of Mobility and Non-Current Factors. IOSR J. Bus. Manag. 2019, 21, 42–48. [Google Scholar]
- Porta, S.; Strano, E.; Iacoviello, V.; Messora, R.; Latora, V.; Cardillo, A.; Wang, F.; Scellato, S. Street centrality and densities of retail and services in Bologna, Italy. Environ. Plan. B Plan. Des. 2009, 36, 450–465. [Google Scholar] [CrossRef] [Green Version]
- Saraiva, M.; Pinho, P. Spatial modelling of commercial spaces in medium-sized cities. GeoJournal 2017, 82, 433–454. [Google Scholar] [CrossRef]
- Wang, F.; Niu, F.-Q. Urban commercial spatial structure optimization in the metropolitan area of Beijing: A microscopic perspective. Sustainability 2019, 11, 1103. [Google Scholar] [CrossRef] [Green Version]
- Barabási, A.-L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scale | Sample Size | Minimum | Maximum | Number of Bins | Information Entropy |
|---|---|---|---|---|---|
| 10 m | 60,271 | 1 | 84 | 100 | 1.301 |
| 20 m | 45,561 | 1 | 114 | 100 | 1.577 |
| 50 m | 27,755 | 1 | 181 | 100 | 2.166 |
| 100 m | 17,206 | 1 | 278 | 100 | 2.168 |
| 200 m | 8687 | 1 | 338 | 100 | 2.711 |
| 500 m | 2322 | 1 | 672 | 100 | 3.799 |
| 1000 m | 682 | 1 | 1228 | 100 | 4.345 |
| Pc(x) | ||||
|---|---|---|---|---|
| 100 m | 200 m | 500 m | dmax | |
| [cp→SC] | 23.908 | 11.379 | 4.302 | 1.116 |
| [cp→SP] | 13.343 | 6.702 | 2.804 | 1.120 |
| [cp→BS] | 4.628 | 2.859 | 1.731 | 1.106 |
| [cp→RE] | 1.841 | 1.639 | 1.356 | 1.069 |
| [SC→cp] | 3.844 | 2.166 | 1.372 | 1.134 |
| [SP→cp] | 3.561 | 2.091 | 1.354 | 1.128 |
| [BS→cp] | 2.878 | 1.875 | 1.299 | 1.108 |
| [RE→cp] | 1.957 | 1.574 | 1.222 | 1.081 |
| Ps(x) | |||
|---|---|---|---|
| 100 m | 200 m | 500 m | |
| [SC, cp] | 0.159 | 0.239 | 0.396 |
| [SP, cp] | 0.260 | 0.381 | 0.604 |
| [BS, cp] | 0.610 | 0.724 | 0.865 |
| [RE, cp] | 0.712 | 0.815 | 0.917 |
| Cp (x) | Cr (x) | |||||
|---|---|---|---|---|---|---|
| 100 m | 200 m | 500 m | 100 m | 200 m | 500 m | |
| [SC→cp] | 0.138 | 0.217 | 0.406 | 61.757 | 96.332 | 178.329 |
| [SP→cp] | 0.222 | 0.371 | 0.712 | 31.710 | 51.730 | 99.089 |
| [BS→cp] | 0.499 | 0.729 | 0.941 | 7.427 | 10.031 | 12.789 |
| [RE→cp] | 0.522 | 0.796 | 0.969 | 3.873 | 4.853 | 5.758 |
| S(x)(/hm2) | Sa(x)(/hm2) | Cutoff- Distance(m) | |||||
|---|---|---|---|---|---|---|---|
| 100 m | 200 m | 500 m | 100 m | 200 m | 500 m | ||
| [SC→cp] | 7.965 | 3.769 | 1.630 | 22.116 | 9.856 | 3.727 | 800 |
| [SP→cp] | 5.172 | 2.152 | 1.131 | 12.468 | 5.973 | 2.618 | 450 |
| [BS→cp] | 2.365 | 1.133 | 0.615 | 4.580 | 2.827 | 1.801 | 170 |
| [RE→cp] | 2.012 | 1.109 | 0.307 | 2.394 | 2.038 | 1.606 | 150 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Yao, J. Analysis of the Aggregation Characteristics and Influencing Elements of Urban Catering Points in Small Scale: Methods and Results. ISPRS Int. J. Geo-Inf. 2023, 12, 275. https://doi.org/10.3390/ijgi12070275
Liu Y, Yao J. Analysis of the Aggregation Characteristics and Influencing Elements of Urban Catering Points in Small Scale: Methods and Results. ISPRS International Journal of Geo-Information. 2023; 12(7):275. https://doi.org/10.3390/ijgi12070275
Chicago/Turabian StyleLiu, Yuefeng, and Jiayi Yao. 2023. "Analysis of the Aggregation Characteristics and Influencing Elements of Urban Catering Points in Small Scale: Methods and Results" ISPRS International Journal of Geo-Information 12, no. 7: 275. https://doi.org/10.3390/ijgi12070275
APA StyleLiu, Y., & Yao, J. (2023). Analysis of the Aggregation Characteristics and Influencing Elements of Urban Catering Points in Small Scale: Methods and Results. ISPRS International Journal of Geo-Information, 12(7), 275. https://doi.org/10.3390/ijgi12070275