
Identification of Urban Functional Zones Based on POI Density and Marginalized Graph Autoencoder

Abstract
:1. Introduction
- Statistics-based methods: These methods count the number of POIs located within each unit to calculate indicators. The units are often divided by road network data or grids and are large in size in order to ensure that they contain sufficient POIs for subsequent analysis. The indicators include the frequency density, category factor, and term frequency-inverse document frequency (TF-IDF) to quantify the socioeconomic characteristics. Chen et al. [30] calculated the POI density of each urban functional zone using the POI quadrat density method to identify single functional, mixed functional, and no-data areas within urban areas. Xie et al. [1] used the category factors of POIs as feature vectors and fused remote sensing and trajectory data to identify urban functional zones. Chen et al. [27] calculated the TF-IDF index and frequency density of POIs within units to quantify the social features of urban functional zones. However, POIs are unevenly distributed in urban areas, whereas some emerging urban districts contain sparse or no POIs. Therefore, statistical methods are insufficient for obtaining regional social attributes and judging zone types.
- Spatial-context-based methods: These methods combine the spatial contextual relationships of POIs and use machine learning methods to mine potential semantic features for functional identification. Commonly used models include Word2Vec [43] and Doc2Vec. Zhang et al. [44] proposed the GeoSemantic2vec algorithm for extracting urban functional zones from POI semantic and location information. Sun et al. [45] proposed the Block2vec model that uses the skip-gram framework to map the spatial correlations between POIs as well as mapping the study units into high-dimensional vectors to identify urban functions. Zhai et al. [28] combined POIs and a simplified Place2vec model to construct a POI-based spatial contextual relationship to detect urban functional zones at a neighborhood scale. However, in addition to the spatial adjacency between POIs, such a relationship also exists between the study units within urban areas, which is neglected in the feature extraction process.
2. Study Area and Dataset
2.1. Study Area
2.2. Data Sources and Preprocessing
2.2.1. POIs
2.2.2. Land Use Data
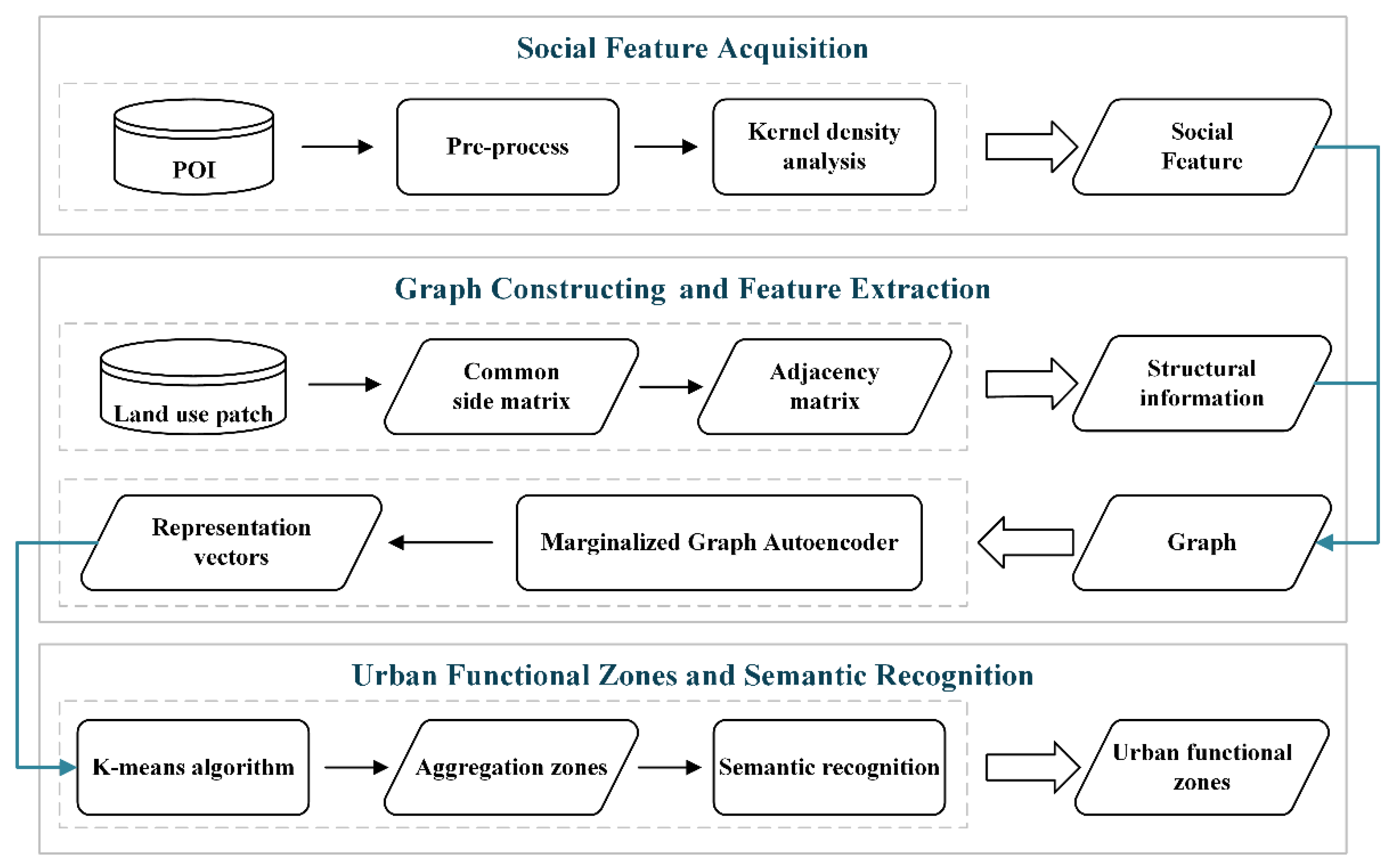
3. Methodology
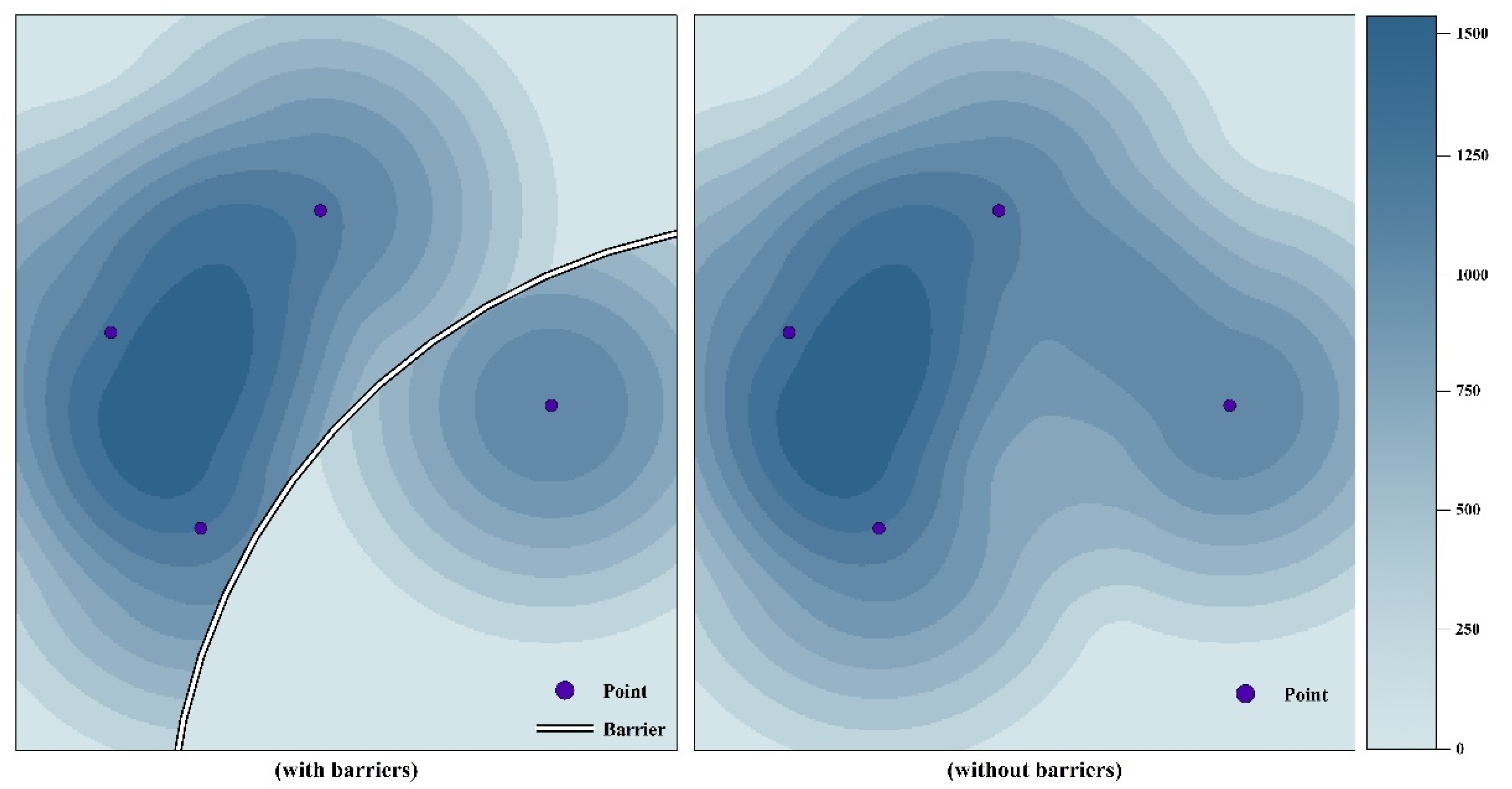
3.1. Kernel Density of POIs Considering Barrier Effects
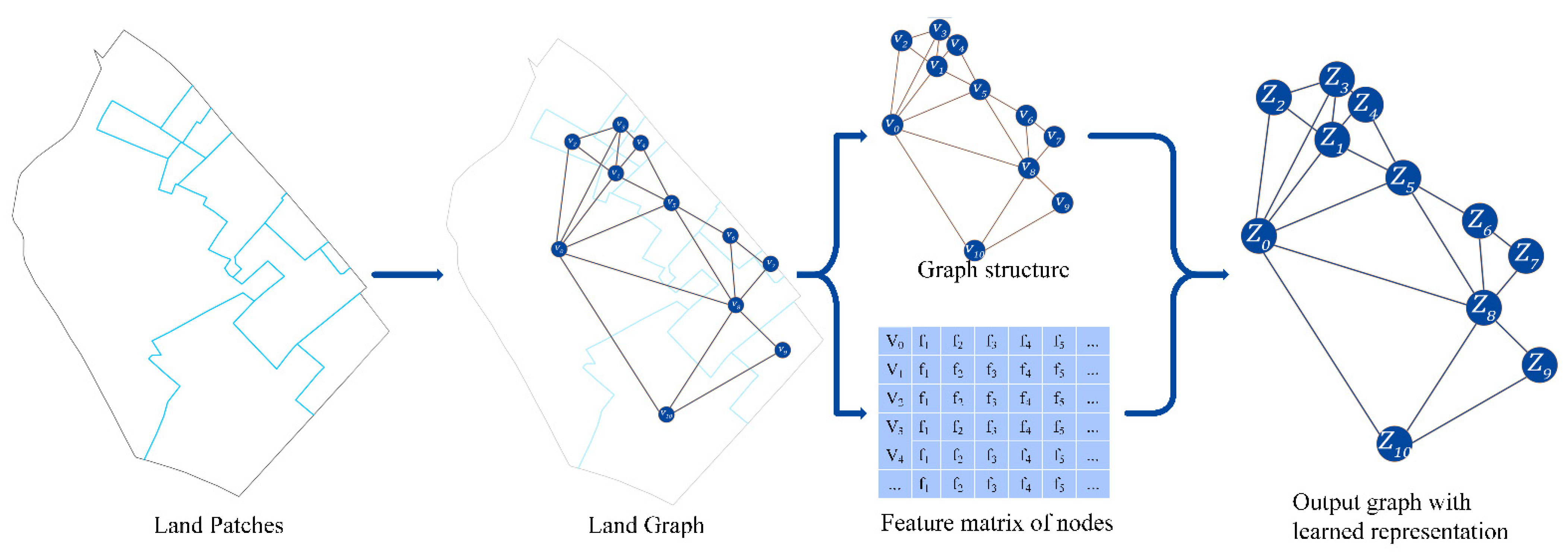
3.2. Extracting Features Using MGAE
3.3. Urban Function Clustering
3.4. Urban Functional Semantic Recognition
4. Results and Analysis
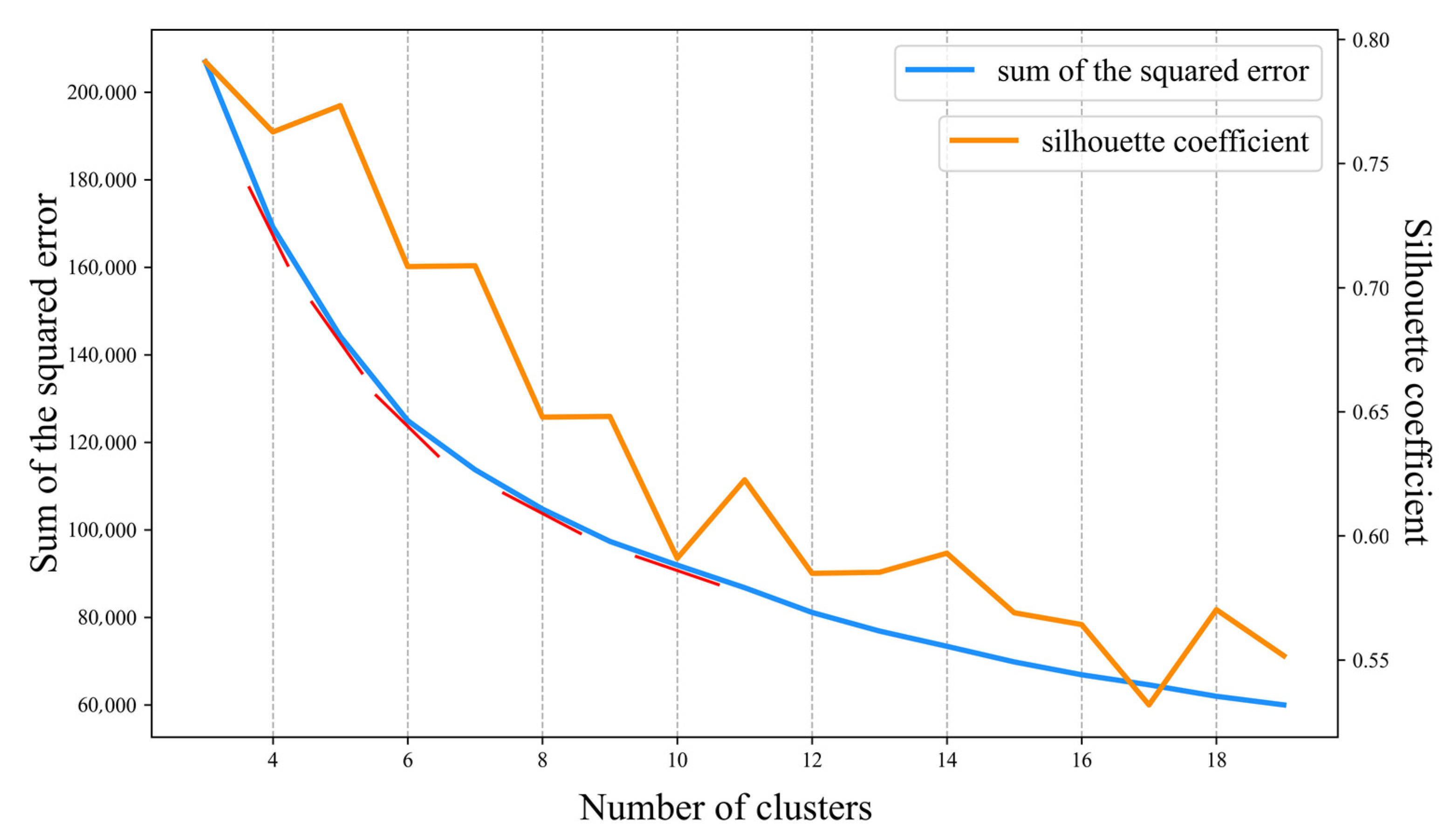
4.1. Determination of Model Parameter
4.2. Accuracy Evaluation and Performance Comparison
4.3. Urban Functional Zone Results
5. Discussion
5.1. Effect of Barriers on the Spread of POIs
5.2. Stability of the Proposed Method against POI Dilution
6. Conclusions
- Kernel density analysis is effective for enhancing sparsely and unevenly distributed POIs to identify urban functional zones by obtaining the value of POI density and spreading the influences of POIs from points of origin to their surroundings. Thus, patches that do not contain POIs can also acquire the social features of the surrounding POIs, thereby solving the problem of uneven POI distribution. Moreover, kernel density analysis with barriers performed better in terms of representing the social features of the study area.
- Combining the spatial adjacency of the analysis units and social features can improve the performance of urban functional zone identification. This method addresses the problem of ignoring the functional correlations between units and more comprehensively explores the potential social information of POIs within units. The experiments demonstrate that our model performed better than the LDA, TF-IDF, and mSDA models, and the recognition accuracy was approximately 20% better.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xie, L.; Feng, X.; Zhang, C.; Dong, Y.; Huang, J.; Liu, K. Identification of Urban Functional Areas Based on the Multimodal Deep Learning Fusion of High-Resolution Remote Sensing Images and Social Perception Data. Buildings 2022, 12, 556. [Google Scholar] [CrossRef]
- Bao, H.; Ming, D.; Guo, Y.; Zhang, K.; Zhou, K.; Du, S. DFCNN-Based Semantic Recognition of Urban Functional Zones by Integrating Remote Sensing Data and POI Data. Remote Sens. 2020, 12, 1088. [Google Scholar] [CrossRef]
- Ma, S.; Long, Y. Functional Urban Area Delineations of Cities on the Chinese Mainland Using Massive Didi Ride-Hailing Records. Cities 2020, 97, 102532. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, L.; Yan, Z.; Wu, S. A GloVe-Based POI Type Embedding Model for Extracting and Identifying Urban Functional Regions. ISPRS Int. J. Geo-Inf. 2021, 10, 372. [Google Scholar] [CrossRef]
- Tu, W.; Cao, J.; Yue, Y.; Shaw, S.-L.; Zhou, M.; Wang, Z.; Chang, X.; Xu, Y.; Li, Q. Coupling Mobile Phone and Social Media Data: A New Approach to Understanding Urban Functions and Diurnal Patterns. Int. J. Geogr. Inf. Sci. 2017, 31, 2331–2358. [Google Scholar] [CrossRef]
- Chuai, X.; Feng, J. High Resolution Carbon Emissions Simulation and Spatial Heterogeneity Analysis Based on Big Data in Nanjing City, China. Sci. Total Environ. 2019, 686, 828–837. [Google Scholar] [CrossRef]
- Zheng, Y.; Du, S.; Zhang, X.; Bai, L.; Wang, H. Estimating Carbon Emissions in Urban Functional Zones Using Multi-Source Data: A Case Study in Beijing. Build. Environ. 2022, 212, 108804. [Google Scholar] [CrossRef]
- Shi, B.; Xiang, W.; Bai, X.; Wang, Y.; Geng, G.; Zheng, J. District Level Decoupling Analysis of Energy-Related Carbon Dioxide Emissions from Economic Growth in Beijing, China. Energy Rep. 2022, 8, 2045–2051. [Google Scholar] [CrossRef]
- Dai, S.; Zuo, S.; Ren, Y. A Spatial Database of CO2 Emissions, Urban Form Fragmentation and City-Scale Effect Related Impact Factors for the Low Carbon Urban System in Jinjiang City, China. Data Brief 2020, 29, 105274. [Google Scholar] [CrossRef]
- Shi, C.; Guo, N.; Zeng, L.; Wu, F. How Climate Change Is Going to Affect Urban Livability in China. Clim. Serv. 2022, 26, 100284. [Google Scholar] [CrossRef]
- Li, T.; Zheng, X.; Zhang, C.; Wang, R.; Liu, J. Mining Spatial Correlation Patterns of the Urban Functional Areas in Urban Agglomeration: A Case Study of Four Typical Urban Agglomerations in China. Land 2022, 11, 870. [Google Scholar] [CrossRef]
- Wu, Y.; Yuan, J. Is There a Regulation in the Expansion of Urban Spatial Structure? Empirical Study from the Main Urban Area in Zhengzhou, China. Sustainability 2022, 14, 2883. [Google Scholar] [CrossRef]
- Wang, M.; He, Y.; Meng, H.; Zhang, Y.; Zhu, B.; Mango, J.; Li, X. Assessing Street Space Quality Using Street View Imagery and Function-Driven Method: The Case of Xiamen, China. ISPRS Int. J. Geo-Inf. 2022, 11, 282. [Google Scholar] [CrossRef]
- Shi, T.; Hu, X.; Guo, L.; Su, F.; Tu, W.; Hu, Z.; Liu, H.; Yang, C.; Wang, J.; Zhang, J.; et al. Digital Mapping of Zinc in Urban Topsoil Using Multisource Geospatial Data and Random Forest. Sci. Total Environ. 2021, 792, 148455. [Google Scholar] [CrossRef]
- Yu, Z.; Jing, Y.; Yang, G.; Sun, R. A New Urban Functional Zone-Based Climate Zoning System for Urban Temperature Study. Remote Sens. 2021, 13, 251. [Google Scholar] [CrossRef]
- Huang, X.; Wang, Y. Investigating the Effects of 3D Urban Morphology on the Surface Urban Heat Island Effect in Urban Functional Zones by Using High-Resolution Remote Sensing Data: A Case Study of Wuhan, Central China. ISPRS J. Photogramm. Remote Sens. 2019, 152, 119–131. [Google Scholar] [CrossRef]
- Chen, S.; Haase, D.; Qureshi, S.; Firozjaei, M.K. Integrated Land Use and Urban Function Impacts on Land Surface Temperature: Implications on Urban Heat Mitigation in Berlin with Eight-Type Spaces. Sustain. Cities Soc. 2022, 83, 103944. [Google Scholar] [CrossRef]
- Wang, H.; Li, B.; Yi, T.; Wu, J. Heterogeneous Urban Thermal Contribution of Functional Construction Land Zones: A Case Study in Shenzhen, China. Remote Sens. 2022, 14, 1851. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, Y.; Guo, G.; Zheng, Z.; Wu, Z. Characteristics of Land Surface Temperature Clusters: Case Study of the Central Urban Area of Guangzhou. Sustain. Cities Soc. 2021, 73, 103140. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, X.; Liu, Z.; Li, X. Understanding the Spatial Organization of Urban Functions Based on Co-Location Patterns Mining: A Comparative Analysis for 25 Chinese Cities. Cities 2020, 97, 102563. [Google Scholar] [CrossRef]
- Cao, R.; Tu, W.; Yang, C.; Li, Q.; Liu, J.; Zhu, J.; Zhang, Q.; Li, Q.; Qiu, G. Deep Learning-Based Remote and Social Sensing Data Fusion for Urban Region Function Recognition. ISPRS J. Photogramm. Remote Sens. 2020, 163, 82–97. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S.; Wang, Q. Hierarchical Semantic Cognition for Urban Functional Zones with VHR Satellite Images and POI Data. ISPRS J. Photogramm. Remote Sens. 2017, 132, 170–184. [Google Scholar] [CrossRef]
- Rosier, J.F.; Taubenböck, H.; Verburg, P.H.; van Vliet, J. Fusing Earth Observation and Socioeconomic Data to Increase the Transferability of Large-Scale Urban Land Use Classification. Remote Sens. Environ. 2022, 278, 113076. [Google Scholar] [CrossRef]
- Lu, W.; Tao, C.; Li, H.; Qi, J.; Li, Y. A Unified Deep Learning Framework for Urban Functional Zone Extraction Based on Multi-Source Heterogeneous Data. Remote Sens. Environ. 2022, 270, 112830. [Google Scholar] [CrossRef]
- Yang, C.; Yu, B.; Chen, Z.; Song, W.; Zhou, Y.; Li, X.; Wu, J. A Spatial-Socioeconomic Urban Development Status Curve from NPP-VIIRS Nighttime Light Data. Remote Sens. 2019, 11, 2398. [Google Scholar] [CrossRef]
- Guo, B.; Zhang, D.; Zhang, D.; Su, Y.; Wang, X.; Bian, Y. Detecting Spatiotemporal Dynamic of Regional Electric Consumption Using NPP-VIIRS Nighttime Stable Light Data–A Case Study of Xi’an, China. IEEE Access 2020, 8, 171694–171702. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, H.; Yang, H. Urban Functional Zone Recognition Integrating Multisource Geographic Data. Remote Sens. 2021, 13, 4732. [Google Scholar] [CrossRef]
- Zhai, W.; Bai, X.; Shi, Y.; Han, Y.; Peng, Z.-R.; Gu, C. Beyond Word2vec: An Approach for Urban Functional Region Extraction and Identification by Combining Place2vec and POIs. Comput. Environ. Urban Syst. 2019, 74, 1–12. [Google Scholar] [CrossRef]
- Deng, Y.; Chen, R.; Yang, J.; Li, Y.; Jiang, H.; Liao, W.; Sun, M. Identify Urban Building Functions with Multisource Data: A Case Study in Guangzhou, China. Int. J. Geogr. Inf. Sci. 2022, 36, 2060–2085. [Google Scholar] [CrossRef]
- Chen, Y.; Yang, J.; Yang, R.; Xiao, X.; Xia, J.C. Contribution of Urban Functional Zones to the Spatial Distribution of Urban Thermal Environment. Build. Environ. 2022, 216, 109000. [Google Scholar] [CrossRef]
- Crooks, A.; Pfoser, D.; Jenkins, A.; Croitoru, A.; Stefanidis, A.; Smith, D.; Karagiorgou, S.; Efentakis, A.; Lamprianidis, G. Crowdsourcing Urban Form and Function. Int. J. Geogr. Inf. Sci. 2015, 29, 720–741. [Google Scholar] [CrossRef]
- Yuan, N.J.; Zheng, Y.; Xie, X.; Wang, Y.; Zheng, K.; Xiong, H. Discovering Urban Functional Zones Using Latent Activity Trajectories. IEEE Trans. Knowl. Data Eng. 2015, 27, 712–725. [Google Scholar] [CrossRef]
- Zhang, D.; Wan, J.; He, Z.; Zhao, S.; Fan, K.; Park, S.O.; Jiang, Z. Identifying Region-Wide Functions Using Urban Taxicab Trajectories. ACM Trans. Embed. Comput. Syst. 2016, 15, 36:1–36:19. [Google Scholar] [CrossRef]
- Zhou, T.; Liu, X.; Qian, Z.; Chen, H.; Tao, F. Automatic Identification of the Social Functions of Areas of Interest (AOIs) Using the Standard Hour-Day-Spectrum Approach. ISPRS Int. J. Geo-Inf. 2019, 9, 7. [Google Scholar] [CrossRef]
- Hu, S.; Gao, S.; Wu, L.; Xu, Y.; Zhang, Z.; Cui, H.; Gong, X. Urban Function Classification at Road Segment Level Using Taxi Trajectory Data: A Graph Convolutional Neural Network Approach. Comput. Environ. Urban Syst. 2021, 87, 101619. [Google Scholar] [CrossRef]
- Qi, T.; Zhang, W.; Yuan, T. Research on the Division of Functional Zones in Downtown Beijing Under the Background of Big Data. In Proceedings of the Spatial Data and Intelligence: First International Conference, SpatialDI 2020, Shanzhen, China, 8–9 May 2020. [Google Scholar]
- Shen, Y.; Karimi, K. Urban Function Connectivity: Characterisation of Functional Urban Streets with Social Media Check-in Data. Cities 2016, 55, 9–21. [Google Scholar] [CrossRef]
- Wu, Y.; Qiao, Y.; Yang, J. Urban Functional Area Division Based on Cell Tower Classification. IEEE Access 2019, 7, 171503–171514. [Google Scholar] [CrossRef]
- Song, Z.; Wang, H.; Qin, S.; Li, X.; Yang, Y.; Wang, Y.; Meng, P. Building-Level Urban Functional Area Identification Based on Multi-Attribute Aggregated Data from Cell Phones—A Method Combining Multidimensional Time Series with a SOM Neural Network. ISPRS Int. J. Geo-Inf. 2022, 11, 72. [Google Scholar] [CrossRef]
- Li, X.; Deng, Y.; Yuan, X.; Wang, Z.; Gao, C. Data-Driven Behavioral Analysis and Applications: A Case Study in Changchun, China. Phys. Stat. Mech. Its Appl. 2022, 596, 127164. [Google Scholar] [CrossRef]
- Cai, L.; Zhang, L.; Liang, Y.; Li, J. Discovery of Urban Functional Regions Based on Node2vec. Appl. Intell. 2022, 52, 16886–16899. [Google Scholar] [CrossRef]
- Hu, S.; He, Z.; Wu, L.; Yin, L.; Xu, Y.; Cui, H. A Framework for Extracting Urban Functional Regions Based on Multiprototype Word Embeddings Using Points-of-Interest Data. Comput. Environ. Urban Syst. 2020, 80, 101442. [Google Scholar] [CrossRef]
- Yao, Y.; Li, X.; Liu, X.; Liu, P.; Liang, Z.; Zhang, J.; Mai, K. Sensing Spatial Distribution of Urban Land Use by Integrating Points-of-Interest and Google Word2Vec Model. Int. J. Geogr. Inf. Sci. 2017, 31, 825–848. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Z.; Zheng, X.; Chen, N.; Wang, Y. Extracting the Location of Flooding Events in Urban Systems and Analyzing the Semantic Risk Using Social Sensing Data. J. Hydrol. 2021, 603, 127053. [Google Scholar] [CrossRef]
- Sun, Z.; Jiao, H.; Wu, H.; Peng, Z.; Liu, L. Block2vec: An Approach for Identifying Urban Functional Regions by Integrating Sentence Embedding Model and Points of Interest. ISPRS Int. J. Geo-Inf. 2021, 10, 339. [Google Scholar] [CrossRef]
- Xu, Y.; Jin, S.; Chen, Z.; Xie, X.; Hu, S.; Xie, Z. Application of a Graph Convolutional Network with Visual and Semantic Features to Classify Urban Scenes. Int. J. Geogr. Inf. Sci. 2022, 36, 2009–2034. [Google Scholar] [CrossRef]
- Yang, J.; Zhu, J.; Sun, Y.; Zhao, J. Delimitating Urban Commercial Central Districts by Combining Kernel Density Estimation and Road Intersections: A Case Study in Nanjing City, China. ISPRS Int. J. Geo-Inf. 2019, 8, 93. [Google Scholar] [CrossRef]
- Heidenreich, N.-B.; Schindler, A.; Sperlich, S. Bandwidth Selection for Kernel Density Estimation: A Review of Fully Automatic Selectors. AStA Adv. Stat. Anal. 2013, 97, 403–433. [Google Scholar] [CrossRef]
- Li, Z.-W.; He, P. Data-Based Optimal Bandwidth for Kernel Density Estimation of Statistical Samples. Commun. Theor. Phys. 2018, 70, 728. [Google Scholar] [CrossRef]
- Wang, C.; Pan, S.; Long, G.; Zhu, X.; Jiang, J. MGAE: Marginalized graph autoencoder for graph clustering. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 889–898. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Cai, J.; Chen, Y. A Novel Unsupervised Deep Learning Method for the Generalization of Urban Form. Geo-Spat. Inf. Sci. 2022, 25, 568–587. [Google Scholar] [CrossRef]
- Verburg, P.H.; de Nijs, T.C.M.; Ritsema van Eck, J.; Visser, H.; de Jong, K. A Method to Analyse Neighbourhood Characteristics of Land Use Patterns. Comput. Environ. Urban Syst. 2004, 28, 667–690. [Google Scholar] [CrossRef]
- Chen, M.; Xu, Z.; Weinberger, K.; Sha, F. Marginalized denoising autoencoders for domain adaptation. arXiv 2012, arXiv:1206.4683. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reclassified Label | Description | Number | Proportion |
|---|---|---|---|
| Finance | ATMs; banks; pawn shops; credit unions | 1871 | 1.01% |
| Car service | Car detailing; car sales; car accessories; car inspection centers | 5092 | 2.75% |
| Corporate and factory | Plants and mines, parks; agriculture, forestry, and horticulture; office buildings, companies | 25,058 | 13.54% |
| Culture and media | Exhibition galleries; cultural palaces; radio and television | 590 | 0.32% |
| Food | Chinese restaurants; snack fast food restaurants; cake and dessert shops; foreign restaurants; bars | 22,313 | 12.06% |
| Governmental and public organizations | Government agencies | 5032 | 2.72% |
| Hotel | Star hotels; express hotels; hostels; guesthouses | 1549 | 0.84% |
| Public facility | Medical; living services | 21,692 | 11.72% |
| Residence | Interior buildings; dormitories; residential areas | 40,906 | 22.11% |
| Science and education | Training institutions; primary schools; kindergartens; secondary schools; universities | 4875 | 2.63% |
| Shopping mall | Department stores; shopping centers; home appliances; digital; stores; shopping areas | 41,452 | 22.40% |
| Sports and recreation | Sports fitness; entertainment | 5026 | 2.72% |
| Tourism attraction | Tourist attractions; water systems; natural features | 1465 | 0.79% |
| Transportation facility | Entrances/exits; subway stations; bus stops; bus lines; subway lines; transportation facilities | 8097 | 4.38% |
| Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 | Total | |
|---|---|---|---|---|---|---|
| Cluster 1 | 58 | 1 | 0 | 1 | 0 | 60 |
| Cluster 2 | 0 | 53 | 0 | 1 | 6 | 60 |
| Cluster 3 | 0 | 2 | 58 | 0 | 0 | 60 |
| Cluster 4 | 0 | 6 | 0 | 51 | 3 | 60 |
| Cluster 5 | 8 | 1 | 0 | 0 | 51 | 60 |
| Total | 66 | 63 | 58 | 53 | 60 | 300 |
| Index | Model | OA | Kappa |
|---|---|---|---|
| 1 | LDA | 62.68% | 0.52 |
| 2 | TF-IDF | 57.35% | 0.54 |
| 3 | mSDA | 34.58% | 0.26 |
| 4 | Proposed model | 90.33% | 0.88 |
| Frequency Density | |||||
|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | |
| Science and education | 1.953 | 40.677 | 439.445 | 79.841 | 19.102 |
| Corporate and factory | 42.986 | 125.100 | 639.795 | 306.240 | 92.937 |
| Food | 5.615 | 206.407 | 2101.777 | 410.648 | 70.115 |
| Hotel | 0.249 | 14.094 | 120.966 | 35.756 | 4.673 |
| Finance | 0.219 | 18.934 | 118.130 | 53.171 | 3.252 |
| Tourism attraction | 1.554 | 7.767 | 38.747 | 10.348 | 8.696 |
| Public facility | 7.822 | 187.733 | 2076.261 | 374.303 | 74.047 |
| Governmental and public organizations | 2.880 | 43.085 | 60.483 | 66.548 | 24.395 |
| Sports and recreation | 1.330 | 50.711 | 357.227 | 96.667 | 14.791 |
| Car service | 3.328 | 30.691 | 27.406 | 111.475 | 25.363 |
| Shopping mall | 13.945 | 359.059 | 4127.951 | 776.116 | 132.032 |
| Transportation facility | 2.362 | 47.689 | 238.151 | 105.754 | 21.385 |
| Residence | 17.253 | 399.193 | 639.795 | 538.780 | 200.408 |
| Culture and media | 0.199 | 4.840 | 31.186 | 10.937 | 2.586 |
| Category Factor | |||||
| C1 | C2 | C3 | C4 | C5 | |
| Science and education | 0.715 | 0.986 | 1.485 | 0.998 | 1.025 |
| Corporate and factory | 3.092 | 0.596 | 0.425 | 0.752 | 0.980 |
| Food | 0.456 | 1.109 | 1.575 | 1.139 | 0.834 |
| Hotel | 0.290 | 1.085 | 1.298 | 1.420 | 0.796 |
| Finance | 0.212 | 1.210 | 1.052 | 1.753 | 0.460 |
| Tourism attraction | 1.976 | 0.654 | 0.455 | 0.449 | 1.620 |
| Public facility | 0.651 | 1.035 | 1.596 | 1.065 | 0.904 |
| Governmental and public organizations | 1.037 | 1.027 | 0.201 | 0.819 | 1.288 |
| Sports and recreation | 0.474 | 1.197 | 1.176 | 1.177 | 0.773 |
| Car service | 1.168 | 0.713 | 0.089 | 1.336 | 1.305 |
| Shopping mall | 0.607 | 1.034 | 1.657 | 1.153 | 0.842 |
| Transportation facilities | 0.765 | 1.022 | 0.712 | 1.170 | 1.015 |
| Residence | 0.744 | 1.139 | 0.254 | 0.793 | 1.266 |
| Culture and media | 0.604 | 0.971 | 0.872 | 1.132 | 1.148 |
| Identification District | Identification Results | Map World | Remote Sensing Images |
|---|---|---|---|
| South Street |  |  |  |
| Changzhou Olympic Sports Center |  |  |  |
| Pubei Community |  |  |  |
| Xingrong High-tech Company |  |  |  |
| Percentage Dilution | OA (True Label) | Kappa (True Label) | OA (Experiment Label) | Kappa (Experiment Label) |
|---|---|---|---|---|
| 20% | 79.33% | 0.74 | 93.13% | 0.79 |
| 30% | 78.33% | 0.73 | 92.62% | 0.77 |
| 50% | 72.00% | 0.68 | 91.73% | 0.75 |
| 60% | 71.67% | 0.65 | 91.23% | 0.73 |
| 80% | 69.00% | 0.61 | 89.65% | 0.69 |
| 90% | 53.33% | 0.41 | 80.26% | 0.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, R.; Chen, Z.; Li, F.; Zhou, C. Identification of Urban Functional Zones Based on POI Density and Marginalized Graph Autoencoder. ISPRS Int. J. Geo-Inf. 2023, 12, 343. https://doi.org/10.3390/ijgi12080343
Xu R, Chen Z, Li F, Zhou C. Identification of Urban Functional Zones Based on POI Density and Marginalized Graph Autoencoder. ISPRS International Journal of Geo-Information. 2023; 12(8):343. https://doi.org/10.3390/ijgi12080343
Chicago/Turabian StyleXu, Runpeng, Zhenjie Chen, Feixue Li, and Chen Zhou. 2023. "Identification of Urban Functional Zones Based on POI Density and Marginalized Graph Autoencoder" ISPRS International Journal of Geo-Information 12, no. 8: 343. https://doi.org/10.3390/ijgi12080343
APA StyleXu, R., Chen, Z., Li, F., & Zhou, C. (2023). Identification of Urban Functional Zones Based on POI Density and Marginalized Graph Autoencoder. ISPRS International Journal of Geo-Information, 12(8), 343. https://doi.org/10.3390/ijgi12080343