



A Spatial Information Extraction Method Based on Multi-Modal Social Media Data: A Case Study on Urban Inundation

 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
- In terms of data preprocessing and compared with predecessors, we use a text classification model to filter related information and remove similar blog posts within the same day. This is beneficial for cleansing the noise in social media data and standardizing the dataset as much as possible;
- For the extract of coarse-grained spatiotemporal information, we introduce a comprehensive set of stringent standardization rules for spatiotemporal data. This approach aims to facilitate the optimal structuring of potential spatiotemporal information, thereby ensuring a consistent representation across a variety of unstructured text:
- a.
- Time information → “Year–Month–Day”;
- b.
- Spatial information → “Province–City–District (or County)-Specific Geographic; Location” → Latitude and Longitude coordinates (WGS1984);
- For the extraction of fine-grained spatial information, we propose an LSGL (LoFTR-Seg Geo-Localization) method. This leverages cascading computer vision models to further improve the accuracy of spatial information extracted from coarse-grained data and, thus, enhances the utilization of image and video modal data from social media;
- The structure of this paper is as follows: Section 2 introduces our innovative multimodal social media data spatiotemporal information extraction method (MIST-SMMD); Section 3 uses the urban inundation event of the “20 July Zhengzhou Torrential Rain” as an experiment to evaluate and verify this method; Section 4 discusses and analyses the effectiveness of the method based on Section 3; and Section 5 summarizes the entire research and proposes the potential prospects for its use.
2. Methods
2.1. Technical Process
- Step One: Crawling and Preprocessing of social media data;
- Step Two: Coarse-grained extraction of spatiotemporal information;
- Step Three: Fine-grained extraction of spatial information.
2.2. Data Crawl and Pre-Process
2.2.1. Crawl Data
2.2.2. Event Classification
2.2.3. Data Cleaning
2.3. Coarse-Grained Spatiotemporal Information Extraction
2.3.1. NER
- parse_time: This function takes as input any expression relating to time (e.g., “yesterday,” “afternoon”) and returns the parsed result, mapping it onto the real-time axis (in the format of “19 May 2002 20:15:00”). This function corresponds to the “Parse Time” component in the “Time Standardization” section of Figure 2.
- parse_location: This function accepts input strings relevant to any address (e.g., “Fujian Normal University”) and provides a completed parsing result (e.g., “Fujian Province, Fuzhou City, Minhou County, Fujian Normal University”). This function corresponds to the “Parse Space” component in the “Spatial Standardization” section of Figure 2.
2.3.2. Standardization
2.4. Fine-Grained Extraction of Spatial Information
2.4.1. Feature Match
2.4.2. Feature Match
2.4.3. Evaluate
3. Experimental Setup
3.1. Research Event
3.2. Experimental Environment
3.3. Evaluation Metrics
4. Experimental Results and Analysis
4.1. Effectiveness Analysis
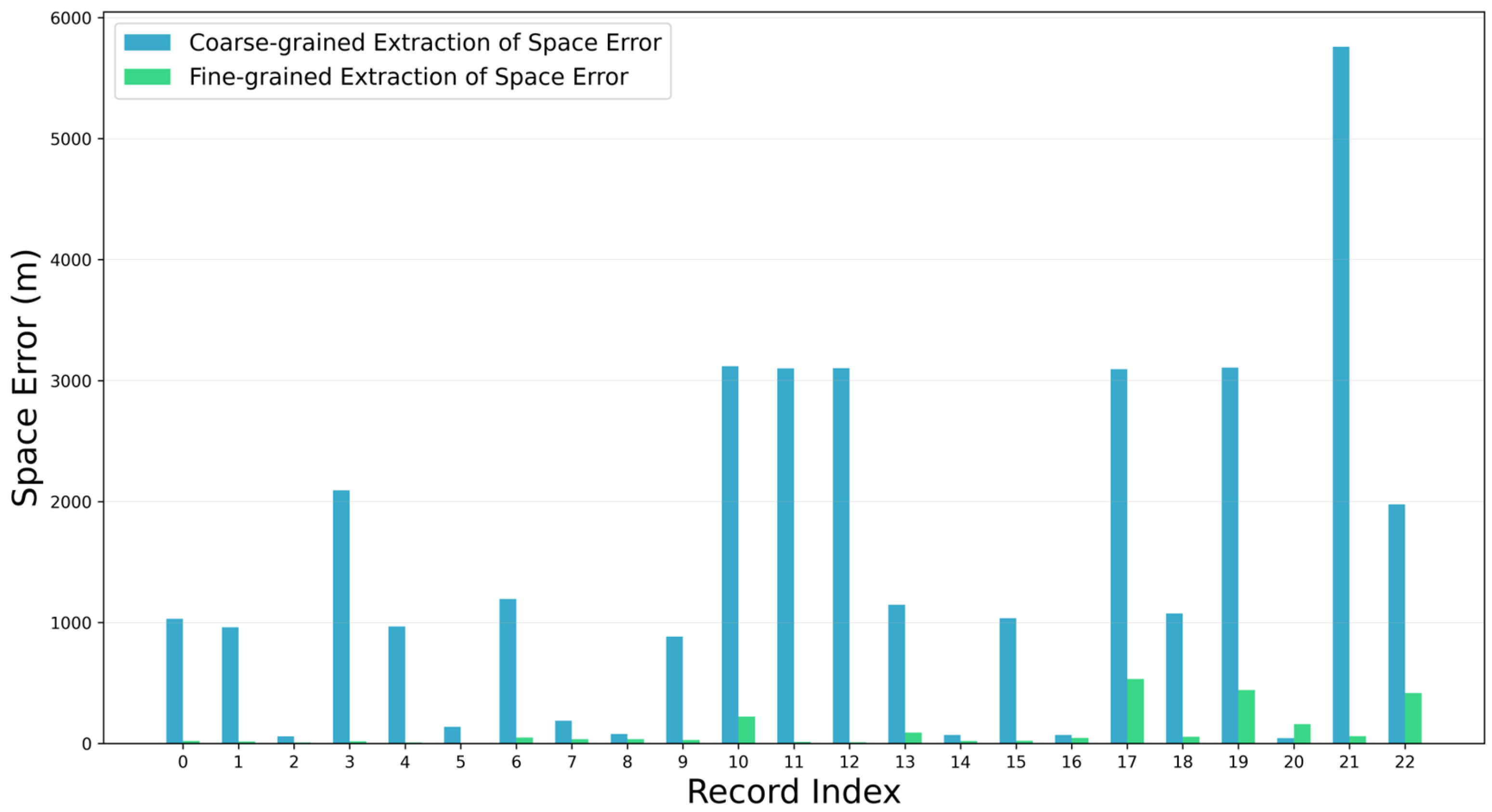
4.2. Analysis of Fine-Grained Extraction
4.3. Limitations Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Weibo Reports Fourth Quarter and Fiscal Year 2022 Unaudited Financial Results. Available online: http://ir.weibo.com/node/8856/pdf (accessed on 15 May 2023).
- Song, Y.; Huang, B.; He, Q.; Chen, B.; Wei, J.; Mahmood, R. Dynamic assessment of PM2.5 exposure and health risk using remote sensing and geo-spatial big data. Environ. Pollut. 2019, 253, 288–296. [Google Scholar] [CrossRef]
- Li, Z.; Wang, C.; Emrich, C.T.; Guo, D. A novel approach to leveraging social media for rapid flood mapping: A case study of the 2015 South Carolina floods. Cartogr. Geogr. Inf. Sci. 2018, 45, 97–110. [Google Scholar] [CrossRef]
- Zhang, Z. Spatial Analysis of Internet Sensation Based on Social Media—Taking the Jiuzhaigou Earthquake as an Example. Master’s Thesis, Nanjing University, Nanjing, China, 2019. [Google Scholar]
- Li, S.; Zhao, F.; Zhou, Y. Analysis of public opinion and disaster loss estimates from typhoons based on Microblog data. J. Tsinghua Univ. Sci. Technol. 2022, 62, 43–51. [Google Scholar]
- Wu, Q.; Qiu, Y. Effectiveness Analysis of Typhoon Disaster Reflected by Microblog Data Location Information. J. Geomat. Sci. Technol. 2019, 36, 406–411. [Google Scholar]
- Liang, C.; Lin, G.; Zhang, M. Assessing the Effectiveness of Social Media Data in Mapping the Distribution of Typhoon Disasters. J. Geogr. Inf. Sci. 2018, 20, 807–816. [Google Scholar]
- Yu, M.; Bambacus, M.; Cervone, G.; Clarke, K.; Duffy, D.; Huang, Q.; Li, J.; Li, W.; Li, Z.; Liu, Q. Spatio-temporal event detection: A review. Int. J. Digit. Earth 2020, 13, 1339–1365. [Google Scholar] [CrossRef]
- Etzioni, O.; Cafarella, M.; Downey, D.; Kok, S.; Popescu, A.-M.; Shaked, T.; Soderland, S.; Weld, D.S.; Yates, A. Web-scale information extraction in knowitall: (preliminary results). In Proceedings of the 13th International Conference on World Wide Web, New York, NY, USA, 17–20 May 2004; pp. 100–110. [Google Scholar]
- Ritter, A.; Etzioni, O.; Clark, S. Open domain event extraction from twitter. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 1104–1112. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv 2015, arXiv:1508.01991v1. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Ma, K.; Tan, Y.; Tian, M.; Xie, X.; Qiu, Q.; Li, S.; Wang, X. Extraction of temporal information from social media messages using the BERT model. Earth Sci. Inform. 2022, 15, 573–584. [Google Scholar] [CrossRef]
- Yuan, W.; Yang, L.; Yang, Q.; Sheng, Y.; Wang, Z. Extracting Spatio-Temporal Information from Chinese Archaeological Site Text. ISPRS Int. J. Geo-Inf. 2022, 11, 175. [Google Scholar] [CrossRef]
- MacEachren, A.M.; Jaiswal, A.; Robinson, A.C.; Pezanowski, S.; Savelyev, A.; Mitra, P.; Zhang, X.; Blanford, J. SensePlace2: GeoTwitter analytics support for situational awareness. In Proceedings of the VAST 2011—IEEE Conference on Visual Analytics 458 Science and Technology, Providence, RI, USA, 23–28 October 2011; pp. 181–190. [Google Scholar]
- Huang, G.S.; Zhou, Y.; Hu, X.F.; Zhao, L.Y.; Zhang, C.L. A survey of the research progress in image geo-localization. J. Geo-Inf. Sci. 2023, 25, 1336–1362. [Google Scholar]
- Ofli, F.; Alam, F.; Imran, M. Analysis of Social Media Data using Multimodal Deep Learning for Disaster Response. In Proceedings of the International Conference on Information Systems for Crisis Response and Management, Blacksburg, VA, USA, 24–27 May 2020. [Google Scholar]
- Zou, Z.; Gan, H.; Huang, Q.; Cai, T.; Cao, K. Disaster image classification by fusing multimodal social media data. ISPRS Int. J. Geo-Inf. 2021, 10, 636. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.-P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef] [PubMed]
- Shuai, X.; Hu, S.; Liu, Q. Internet media-based acquisition and processing model of earthquake disaster situation. J. Nat. Disasters 2013, 22, 178–184. [Google Scholar]
- Zhang, S.; Yang, Z.; Wang, Y. Simulation on Flood Disaster in Urban Building Complex System Based on LBM. J. Simul. 2022, 34, 2584–2594. [Google Scholar]
- Yuan, F.; Xu, Y.; Li, Q.; Mostafavi, A. Spatio-temporal graph convolutional networks for road network inundation status prediction during urban flooding. Comput. Environ. Urban Syst. 2022, 97, 101870. [Google Scholar] [CrossRef]
- Wang, E.K.; Wang, F.; Kumari, S.; Yeh, J.H.; Chen, C.M. Intelligent monitor for typhoon in IoT system of smart city. J. Supercomput. 2021, 77, 3024–3043. [Google Scholar] [CrossRef]
- Wang, Z.J.; Chen, X.Y.; Qi, Z.S.; Cui, C.F. Flood sensitivity assessment of super cities. Sci. Rep. 2023, 13, 5582. [Google Scholar] [CrossRef]
- Xing, Z.Y.; Yang, S.; Zan, X.L.; Dong, X.R.; Yao, Y.; Liu, Z.; Zhang, X.D. Flood vulnerability assessment of urban buildings based on integrating high-resolution remote sensing and street view images. Sustain. Cities Soc. 2023, 92, 104467. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Z.; Fang, D. Optimal Design of Urban Waterlogging Monitoring and Warning System in Wuhan Based on Internet of Things and GPRS Technology. Saf. Environ. Eng. 2018, 25, 37–43. [Google Scholar]
- Zeng, Z.; Xv, J.; Wang, Y. Advances in flood risk identification and dynamic modelling based on remote sensing spatial information. Adv. Water Sci. 2020, 31, 463–472. [Google Scholar]
- Wang, R.-Q.; Mao, H.; Wang, Y.; Rae, C.; Shaw, W. Hyper-resolution monitoring of urban flooding with social media and crowdsourcing data. Comput. Geosci. 2018, 111, 139–147. [Google Scholar] [CrossRef]
- Songchon, C.; Wright, G.; Beevers, L. Quality assessment of crowdsourced social media data for urban flood management. Comput. Environ. Urban Syst. 2021, 90, 101690. [Google Scholar] [CrossRef]
- BLE, SOCIAL MEDIA & FLOOD RISK AWARENESS. Available online: https://www.fema.gov/sites/default/files/documents/fema_ble-social-media-flood-risk-awareness.pdf (accessed on 15 May 2023).
- JioNLP. Available online: https://github.com/dongrixinyu/JioNLP (accessed on 15 May 2023).
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8922–8931. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Schmitt, X.; Kubler, S.; Robert, J.; Papadakis, M.; LeTraon, Y. A replicable comparison study of NER software: StanfordNLP, NLTK, OpenNLP, SpaCy, Gate. In Proceedings of the 2019 Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019; pp. 338–343. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Weibo Post 1 | Post Information | Post Information Values |
|---|---|---|
 | Created time | 19 July 2021 14:28:17 |
| IP Location | No data | |
| On 19 July, reporters discovered significant water accumulation on Jin Dai Road, Zhengzhou, approximately one kilometer from the southern Fourth Ring Road. The road lanes were severely flooded, with a nearly one-kilometer stretch of accumulated water, spanning the six lanes in both north and south directions. The deepest point of the flooding could submerge half of a vehicle’s wheel. The water was deeper on the outer lanes of the road in both directions, and when vehicles traveled at slightly higher speeds, it caused splashes exceeding twice the height of the vehicle body. Currently, this flooding situation persists, and on-site reporters did not observe any water pumping operations. Why has this particular road section experienced such severe flooding? And why has not there been any drainage operation? Journalists from Henan Traffic Radio will continue to monitor the situation. (5G On-site Reporters, Jing Yi and Lei Jing) | Is relevant | True |
| Mid 2 | 4660679711922369 |
| Label Type | Named Entity Labels | Description |
|---|---|---|
| TIME | DATE | Absolute or relative dates or periods |
| TIME | Times smaller than a day | |
| GPE | GPE | Geopolitical entity, i.e., countries, cities, and states |
| FAC | LOC | Non-GPE locations, mountain ranges, bodies of water |
| FAC | Buildings, airports, highways, bridges, etc. |
| Type | Only Text | With Text + Images (Video) | Total |
|---|---|---|---|
| Origin | 12,338 | 14,222 | 26,560 |
| Text classify | 6750 | 7886 | 14,636 |
| Data clean | 1096 | 1951 | 3047 |
| Space Error | Only Text | Text + Images | Improvement |
|---|---|---|---|
| MAESE | 1491.13 | 66.63 | 95.53% |
| RMSESE | 2068.43 | 131.88 | 93.62% |
| Space Error | Coarse-Grained Extraction | Fine-Grained Extraction | ||
|---|---|---|---|---|
| FM 1 | FM + SS 2 + QIFM 3 | FM + SS | ||
| MAESE | 1491.13 | 124.30 | 100.74 | 66.63 |
| RMSESE | 2068.43 | 227.35 | 181.16 | 131.88 |
| Classification of Result | Reason | RI * |
|---|---|---|
| Same Result | The results are all very good | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 |
| The results are all not good | 10 | |
| Improvement | Improvement after adding SS | 10, 11, 12, 13 |
| Improvement after adding SS and QIFM | 14, 15, 16 | |
| Deterioration | Deterioration after adding SS | 16, 17, 18 |
| Deterioration after adding SS and QIFM | 19, 20, 21, 22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Chen, Y.; Zhang, R.; Cui, Z.; Liu, X.; Zhang, J.; Wang, M.; Wu, Y. A Spatial Information Extraction Method Based on Multi-Modal Social Media Data: A Case Study on Urban Inundation. ISPRS Int. J. Geo-Inf. 2023, 12, 368. https://doi.org/10.3390/ijgi12090368
Wu Y, Chen Y, Zhang R, Cui Z, Liu X, Zhang J, Wang M, Wu Y. A Spatial Information Extraction Method Based on Multi-Modal Social Media Data: A Case Study on Urban Inundation. ISPRS International Journal of Geo-Information. 2023; 12(9):368. https://doi.org/10.3390/ijgi12090368
Chicago/Turabian StyleWu, Yilong, Yingjie Chen, Rongyu Zhang, Zhenfei Cui, Xinyi Liu, Jiayi Zhang, Meizhen Wang, and Yong Wu. 2023. "A Spatial Information Extraction Method Based on Multi-Modal Social Media Data: A Case Study on Urban Inundation" ISPRS International Journal of Geo-Information 12, no. 9: 368. https://doi.org/10.3390/ijgi12090368
APA StyleWu, Y., Chen, Y., Zhang, R., Cui, Z., Liu, X., Zhang, J., Wang, M., & Wu, Y. (2023). A Spatial Information Extraction Method Based on Multi-Modal Social Media Data: A Case Study on Urban Inundation. ISPRS International Journal of Geo-Information, 12(9), 368. https://doi.org/10.3390/ijgi12090368