



Semantic Segmentation and Roof Reconstruction of Urban Buildings Based on LiDAR Point Clouds

Abstract
:1. Introduction
- Propose a semantic segmentation network based on enhanced local feature aggregation. The network enhances the point-by-point local features from both structural information and semantic information to realize effective semantic segmentation of building point clouds.
- Propose a roof surface point cloud automatic identification method to extract the roof point cloud plane.
- Propose a building topology reconstruction method based on roof vertical plane inference to realize the topology reconstruction of buildings.
2. Related Work
3. Methodology
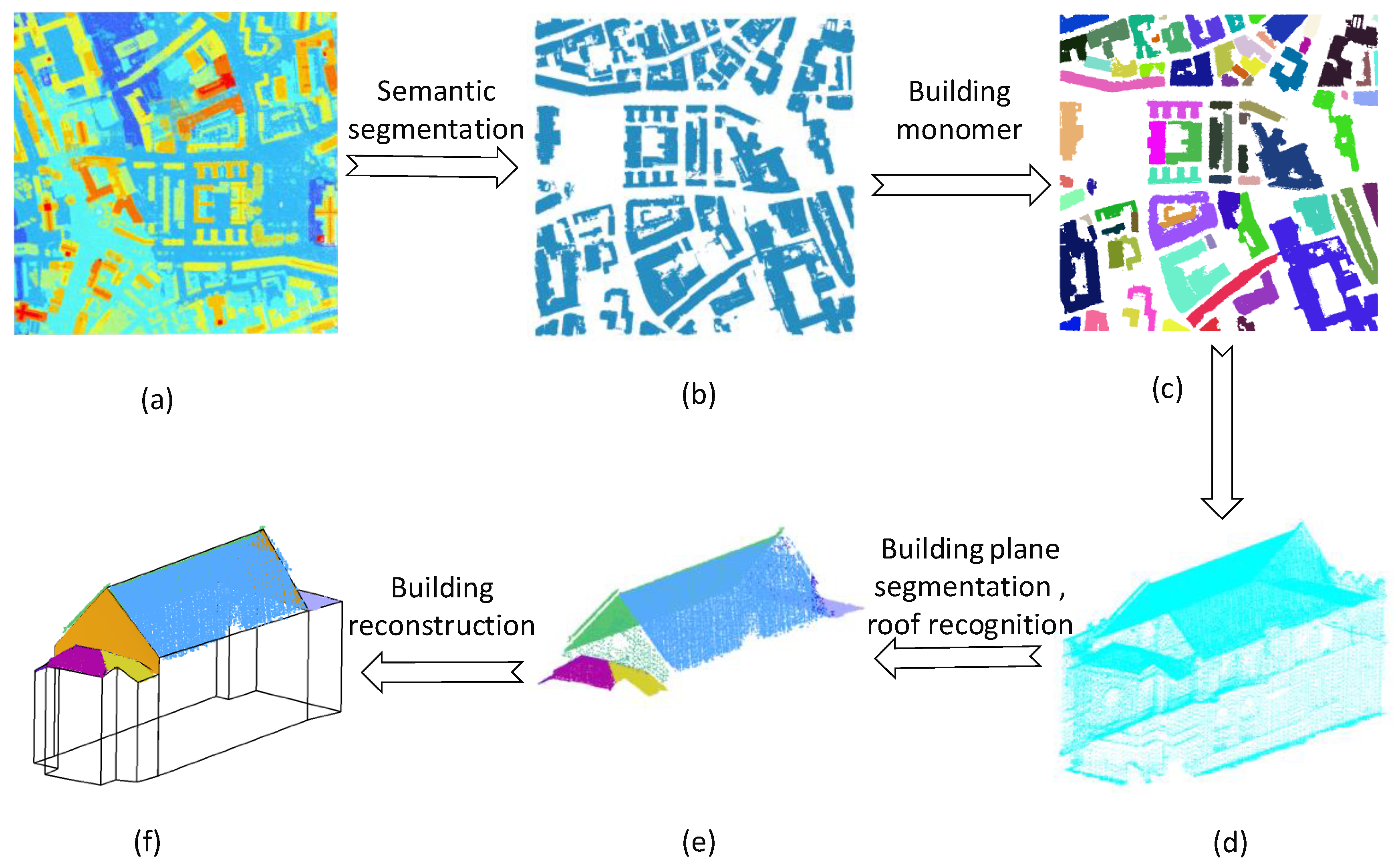
3.1. Overview
3.2. Semantic Segmentation of Building Point Clouds Based on Enhanced Local Feature Aggregation
- (1)
- Local feature coding.
- (2)
- Mixed Pooling.
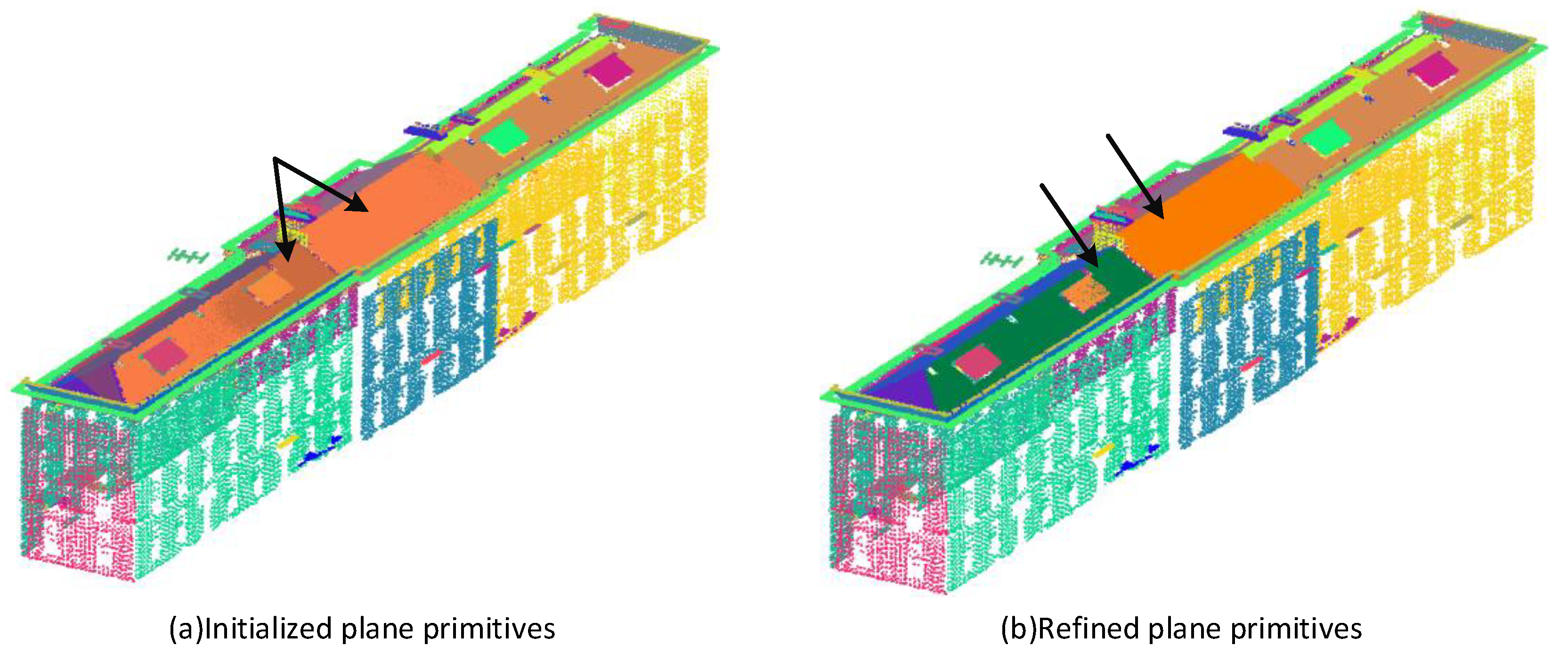
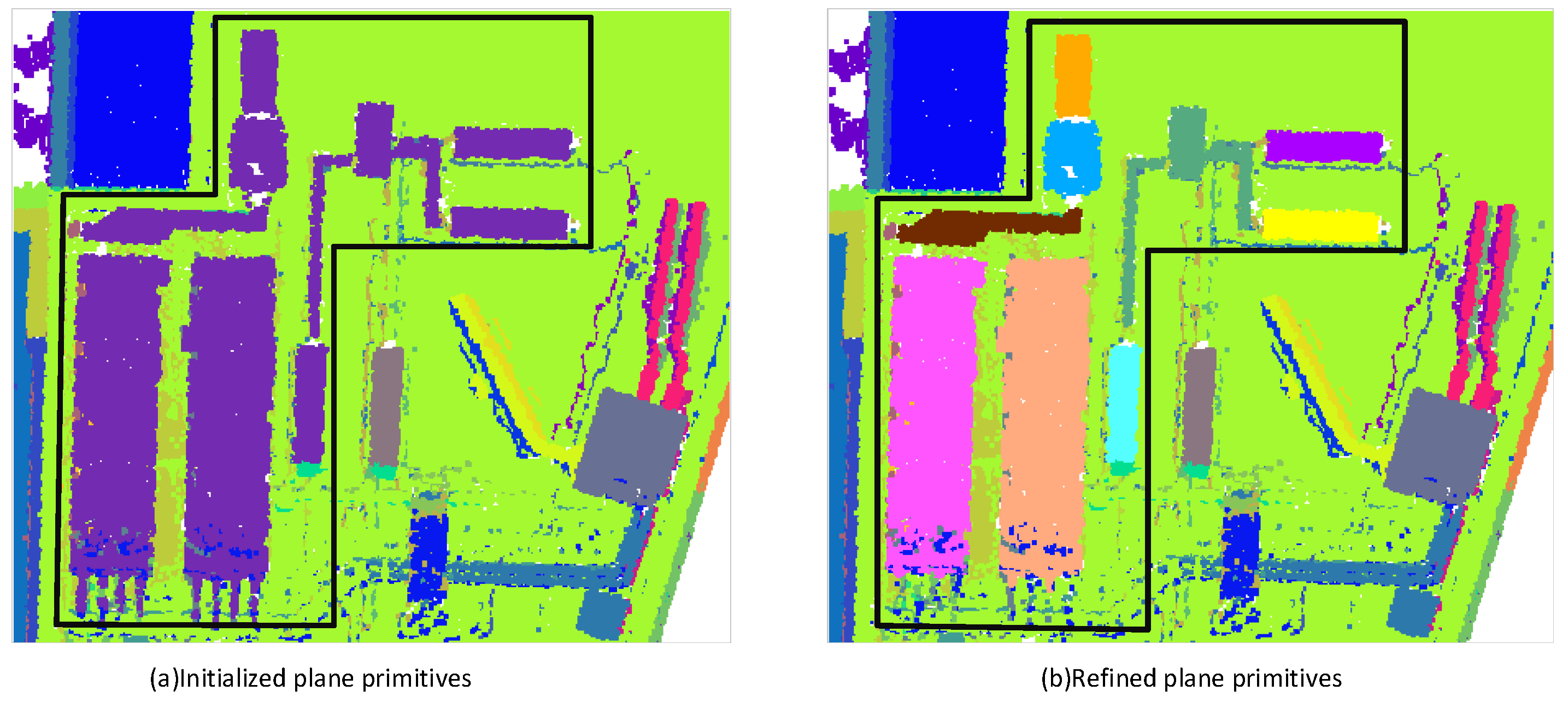
3.3. Building Point Cloud Plane Segmentation and Roof Plane Identification
3.4. Structured Reconstruction of Buildings Based on Roof Vertical Plane Inference
3.4.1. Roof Vertical Plane Inference
3.4.2. Roof Plane Topology Map Construction
3.4.3. Roof Polygon Reconstruction
3.4.4. Structured Model Reconstruction of Buildings
4. Experimentation and Analysis
4.1. Building Point Cloud Semantic Segmentation and Monolithization
4.1.1. Semantic Segmentation Dataset
4.1.2. Semantic Segmentation Data Preprocessing
4.1.3. Network Setup
4.1.4. Semantic Segmentation Accuracy Evaluation Metrics
4.1.5. Building Semantic Segmentation Results
4.1.6. Building Monomer Results

4.2. Accuracy Analysis of Structured Building Models
4.2.1. Building Reconstruction Data
4.2.2. Precision Evaluation Metrics
4.2.3. Building Plane Segmentation and Roof Identification Results
4.2.4. Reconstruction Models and Comparative Analysis
4.2.5. Evaluation and Analysis of Regional Reconstruction Model Accuracy
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Biljecki, F.; Stoter, J.; Ledoux, H.; Zlatanova, S.; Çöltekin, A. Applications of 3D city models: State of the art review. ISPRS Int. J. Geo-Inf. 2015, 4, 2842–2889. [Google Scholar] [CrossRef]
- Chen, R. The development of 3D city model and its applications in urban planning. In Proceedings of the 2011 19th International Conference on Geoinformatics, Shanghai, China, 24–26 June 2011; pp. 1–5. [Google Scholar]
- Jovanović, D.; Milovanov, S.; Ruskovski, I.; Govedarica, M.; Sladić, D.; Radulović, A.; Pajić, V. Building virtual 3D city model for smart cities applications: A case study on campus area of the university of novi sad. ISPRS Int. J. Geo-Inf. 2020, 9, 476. [Google Scholar] [CrossRef]
- Costantino, D.; Vozza, G.; Alfio, V.S.; Pepe, M. Strategies for 3D Modelling of Buildings from Airborne Laser Scanner and Photogrammetric Data Based on Free-Form and Model-Driven Methods: The Case Study of the Old Town Centre of Bordeaux (France). Appl. Sci. 2021, 11, 10993. [Google Scholar] [CrossRef]
- Li, Z.; Shan, J.; Sensing, R. RANSAC-based multi primitive building reconstruction from 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2022, 185, 247–260. [Google Scholar] [CrossRef]
- Xiong, B.; Elberink, S.O.; Vosselman, G.; Sensing, R. A graph edit dictionary for correcting errors in roof topology graphs reconstructed from point clouds. ISPRS J. Photogramm. Remote Sens. 2014, 93, 227–242. [Google Scholar] [CrossRef]
- Xiong, B.; Jancosek, M.; Elberink, S.O.; Vosselman, G.; Sensing, R. Flexible building primitives for 3D building modeling. ISPRS J. Photogramm. Remote Sens. 2015, 101, 275–290. [Google Scholar] [CrossRef]
- Huang, W.; Jiang, S.; Jiang, W.J.S. A model-driven method for pylon reconstruction from oblique UAV images. Sensors 2020, 20, 824. [Google Scholar] [CrossRef] [PubMed]
- Chen, D.; Wang, R.; Peethambaran, J.; Sensing, R. Topologically aware building rooftop reconstruction from airborne laser scanning point clouds. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7032–7052. [Google Scholar] [CrossRef]
- Li, H.; Xiong, S.; Men, C.; Liu, Y. Roof reconstruction of aerial point cloud based on BPPM plane segmentation and energy optimization. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 5828–5848. [Google Scholar] [CrossRef]
- Li, L.; Song, N.; Sun, F.; Liu, X.; Wang, R.; Yao, J.; Cao, S.; Sensing, R. Point2Roof: End-to-end 3D building roof modeling from airborne LiDAR point clouds. ISPRS J. Photogramm. Remote Sens. 2022, 193, 17–28. [Google Scholar] [CrossRef]
- Sampath, A.; Shan, J.; Sensing, R. Segmentation and reconstruction of polyhedral building roofs from aerial lidar point clouds. IEEE Trans. Geosci. Remote Sens. 2009, 48, 1554–1567. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, H.; Cheng, L.; Li, M.; Wang, Y.; Xia, N.; Chen, Y.; Tang, Y. Three-dimensional reconstruction of building roofs from airborne LiDAR data based on a layer connection and smoothness strategy. Remote Sens. 2016, 8, 415. [Google Scholar] [CrossRef]
- Huang, J.; Stoter, J.; Peters, R.; Nan, L. City3D: Large-scale building reconstruction from airborne LiDAR point clouds. Remote Sens. 2022, 14, 2254. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, Y.; Ling, X.; Wan, Y.; Liu, L.; Li, Q. TopoLAP: Topology recovery for building reconstruction by deducing the relationships between linear and planar primitives. Remote Sens. 2019, 11, 1372. [Google Scholar] [CrossRef]
- Nan, L.; Wonka, P. Polyfit: Polygonal surface reconstruction from point clouds. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2353–2361. [Google Scholar]
- Yang, S.; Cai, G.; Du, J.; Chen, P.; Su, J.; Wu, Y.; Wang, Z.; Li, J.; Sensing, R. Connectivity-aware Graph: A planar topology for 3D building surface reconstruction. ISPRS J. Photogramm. Remote Sens. 2022, 191, 302–314. [Google Scholar] [CrossRef]
- Cheng, R.; Razani, R.; Taghavi, E.; Li, E.; Liu, B. 2-s3net: Attentive feature fusion with adaptive feature selection for sparse semantic segmentation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 12547–12556. [Google Scholar]
- Hou, Y.; Zhu, X.; Ma, Y.; Loy, C.C.; Li, Y. Point-to-voxel knowledge distillation for lidar semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8479–8488. [Google Scholar]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching efficient 3d architectures with sparse point-voxel convolution. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 685–702. [Google Scholar]
- Xu, J.; Zhang, R.; Dou, J.; Zhu, Y.; Sun, J.; Pu, S. Rpvnet: A deep and efficient range-point-voxel fusion network for lidar point cloud segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16024–16033. [Google Scholar]
- Yan, X.; Gao, J.; Zheng, C.; Zheng, C.; Zhang, R.; Cui, S.; Li, Z. 2dpass: 2d priors assisted semantic segmentation on lidar point clouds. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 677–695. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 4–19 June 2020; pp. 11108–11117. [Google Scholar]
- Schnabel, R.; Wahl, R.; Klein, R. Efficient RANSAC for point-cloud shape detection. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2007; pp. 214–226. [Google Scholar]
- El-Sayed, E.; Abdel-Kader, R.F.; Nashaat, H.; Marei, M. Plane detection in 3D point cloud using octree-balanced density down-sampling and iterative adaptive plane extraction. IET Image Process. 2018, 12, 1595–1605. [Google Scholar] [CrossRef]
- Rabbani, T.; Van Den Heuvel, F.; Vosselmann, G. Segmentation of point clouds using smoothness constraint. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2006, 36, 248–253. [Google Scholar]
- Wu, H.; Zhang, X.; Shi, W.; Song, S.; Cardenas-Tristan, A.; Li, K.; Sensing, R. An accurate and robust region-growing algorithm for plane segmentation of TLS point clouds using a multiscale tensor voting method. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4160–4168. [Google Scholar] [CrossRef]
- Zhu, X.; Liu, X.; Zhang, Y.; Wan, Y.; Duan, Y.; Sensing, R. Robust 3-D plane segmentation from airborne point clouds based on quasi-a-contrario theory. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7133–7147. [Google Scholar] [CrossRef]
- Albers, B.; Kada, M.; Wichmann, A. Automatic extraction and regularization of building outlines from airborne LiDAR point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 555–560. [Google Scholar] [CrossRef]
- Gilani, S.A.N.; Awrangjeb, M.; Lu, G. Segmentation of airborne point cloud data for automatic building roof extraction. GIScience Remote Sens. 2018, 55, 63–89. [Google Scholar] [CrossRef]
- Li, L.; Yan, H. Building contour regularization method based on ground LIDAR point cloud data. In Proceedings of the 2021 IEEE 4th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 18–20 June 2021; pp. 1937–1941. [Google Scholar]
- Zhang, X.-Q.; Wang, H.; Shan, Y.-H.; Leng, L. Building Contour Extraction Based on LiDAR Point Cloud. In Proceedings of the ITM Web of Conferences, Wuhan, China, 24–26 March 2017; p. 10004. [Google Scholar]
- Edelsbrunner, H.; Kirkpatrick, D.; Seidel, R. On the shape of a set of points in the plane. IEEE Trans. Inf. Theory 1983, 29, 551–559. [Google Scholar] [CrossRef]
- Widyaningrum, E.; Peters, R.Y.; Lindenbergh, R. Building outline extraction from ALS point clouds using medial axis transform descriptors. Pattern Recognit. Lett. 2020, 106, 107447. [Google Scholar] [CrossRef]
- Kustra, J. Computing refined skeletal features from medial point clouds. Pattern Recognit. Lett. 2016, 76, 13–21. [Google Scholar] [CrossRef]
- Chen, D.; Zhang, L.; Mathiopoulos, P.T.; Huang, X. A methodology for automated segmentation and reconstruction of urban 3-D buildings from ALS point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4199–4217. [Google Scholar] [CrossRef]
- Verma, V.; Kumar, R.; Hsu, S. 3D building detection and modeling from aerial LIDAR data. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 2213–2220. [Google Scholar]
- Wang, R.; Huang, S. Building3D: A Urban-Scale Dataset and Benchmarks for Learning Roof Structures from Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Xu, B. Deep learning guided building reconstruction from satellite imagery-derived point clouds. arXiv 2020, arXiv:2005.09223. [Google Scholar]
- Yu, D.; Ji, S.; Liu, J. Automatic 3D building reconstruction from multi-view aerial images with deep learning. ISPRS J. Photogramm. Remote Sens. 2021, 171, 155–170. [Google Scholar] [CrossRef]
- Yastikli, N.; Cetin, Z. Classification of raw LiDAR point cloud using point-based methods with spatial features for 3D building reconstruction. Arab. J. Geosci. 2021, 14, 146. [Google Scholar] [CrossRef]
- Sahebdivani, S.; Arefi, H.; Maboudi, M. Deep learning based classification of color point cloud for 3D reconstruction of interior elements of buildings. In Proceedings of the 2020 International Conference on Machine Vision and Image Processing (MVIP), Qom, Iran, 18–20 February 2020; pp. 1–6. [Google Scholar]
- Zhang, L.; Li, Z.; Li, A.; Liu, F.J.I.J.o.P.; Sensing, R. Large-scale urban point cloud labeling and reconstruction. ISPRS J. Photogramm. Remote Sens. 2018, 138, 86–100. [Google Scholar] [CrossRef]
- Zhou, Q.-Y.; Neumann, U. 2.5 d dual contouring: A robust approach to creating building models from aerial lidar point clouds. In Proceedings of the Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Proceedings, Part III 11. pp. 115–128. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Kazhdan, M.; Bolitho, M.; Hoppe, H. Poisson surface reconstruction. In Proceedings of the Fourth Eurographics Symposium on Geometry Processing, Sardinia, Italy, 26–28 June 2006. [Google Scholar]
- Peterson, L. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Trans. Database Syst. 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G.J.R.s. An easy-to-use airborne LiDAR data filtering method based on cloth simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Noto, M.; Sato, H. A method for the shortest path search by extended Dijkstra algorithm. In Proceedings of the SMC 2000 Conference Proceedings: 2000 IEEE International Conference on Systems, Man and Cybernetics: “Cybernetics Evolving to Systems, Humans, Organizations, and their Complex Interactions”, Nashville, TN, USA, 8–11 October 2010. [Google Scholar]
- Phan, A.V.; Le Nguyen, M.; Nguyen, Y.L.H.; Bui, L.T.J.N.N. Dgcnn: A convolutional neural network over large-scale labeled graphs. Neural Netw. 2018, 108, 533–543. [Google Scholar] [CrossRef]
- Boulch, A. ConvPoint: Continuous convolutions for point cloud processing. Comput. Graph. 2020, 88, 24–34. [Google Scholar] [CrossRef]
- Qiu, S.; Anwar, S.; Barnes, N. Semantic segmentation for real point cloud scenes via bilateral augmentation and adaptive fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1757–1767. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OA | Precision | mIoU | Building | Grass | Sidewalk | Street | Bush | Tree | Undefined | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| DGCNN [51] | 74.12 | 42.8 | 53.34 | 41.66 | 75.63 | 30.56 | 15.64 | 32.45 | 0.37 | 92.48 | 44.52 |
| ConvPoint [52] | 75.46 | 50.5 | 60.12 | 49.50 | 78.15 | 38.52 | 38.71 | 44.83 | 0.80 | 93.83 | 51.63 |
| RandLA-Net [23] | 77.74 | 52.0 | 62.48 | 51.01 | 80.63 | 43.68 | 37.06 | 46.05 | 1.52 | 91.64 | 56.48 |
| Qiu [53] | 78.94 | 55.8 | 64.76 | 54.34 | 85.44 | 45.12 | 44.12 | 52.12 | 3.25 | 92.45 | 57.63 |
| Ours | 79.02 | 55.9 | 63.02 | 54.49 | 89.74 | 44.02 | 42.54 | 51.75 | 3.63 | 92.78 | 57.01 |
| Model | Params(M) | mIoU | Car | Bicycle | Motorcycle | Truck | Other Vehicle | Person | Bicyclist | Motorcyclist | Road | Parking | Sidewalk | Other Ground | Building | Fence | Vegetation | Trunk | Terrain | Pole | Traffic Sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet | 3.0 | 14.6 | 46.3 | 1.3 | 0.3 | 0.1 | 0.8 | 0.2 | 0.2 | 0.0 | 61.6 | 15.8 | 35.7 | 1.4 | 41.4 | 12.9 | 31.0 | 4.6 | 17.6 | 2.4 | 3.7 |
| SPG | 0.3 | 17.4 | 49.3 | 0.2 | 0.2 | 0.1 | 0.8 | 0.3 | 2.7 | 0.1 | 45.0 | 0.6 | 28.5 | 0.6 | 64.3 | 20.8 | 48.9 | 27.2 | 24.6 | 15.9 | 0.8 |
| PointNet++ | 6.0 | 20.1 | 53.7 | 1.9 | 0.2 | 0.9 | 0.2 | 0.9 | 1.0 | 0.1 | 72.0 | 18.7 | 41.8 | 5.6 | 62.3 | 16.9 | 46.5 | 0.9 | 30.0 | 6.0 | 8.9 |
| TangentConv | 0.4 | 40.9 | 90.8 | 2.7 | 16.5 | 15.2 | 12.1 | 23.0 | 28.4 | 8.1 | 83.9 | 33.4 | 63.9 | 15.4 | 83.4 | 49.0 | 79.5 | 49.3 | 58.1 | 35.8 | 28.5 |
| RandLA-Net | 1.2 | 53.9 | 94.2 | 26.0 | 25.8 | 40.1 | 38.9 | 49.2 | 48.2 | 7.2 | 90.7 | 60.3 | 73.7 | 20.4 | 86.9 | 56.3 | 81.4 | 61.3 | 66.8 | 49.2 | 47.7 |
| SPVNAS | 12.5 | 67.0 | 97.2 | 50.6 | 50.4 | 56.6 | 58.0 | 67.4 | 67.1 | 50.3 | 90.2 | 67.6 | 75.4 | 21.8 | 91.6 | 66.9 | 86.1 | 73.4 | 71.0 | 64.3 | 67.3 |
| AF2-S3Net | - | 69.7 | 94.5 | 65.4 | 86.8 | 39.2 | 41.1 | 80.7 | 80.4 | 74.3 | 91.3 | 68.8 | 72.5 | 53.5 | 87.9 | 63.2 | 70.2 | 68.5 | 53.7 | 61.5 | 71.0 |
| RPVNet | 24.8 | 70.3 | 97.6 | 68.4 | 68.7 | 44.2 | 61.1 | 75.9 | 74.4 | 73.4 | 93.4 | 70.3 | 80.7 | 33.3 | 93.5 | 72.1 | 86.5 | 75.1 | 71.7 | 64.8 | 61.4 |
| PVKD | - | 71.2 | 97.0 | 67.9 | 69.3 | 53.5 | 60.2 | 75.1 | 73.5 | 50.5 | 91.8 | 70.9 | 77.5 | 41.0 | 92.4 | 69.4 | 86.5 | 73.8 | 71.9 | 64.9 | 65.8 |
| 2DPASS | _ | 72.9 | 97.0 | 63.6 | 63.4 | 61.1 | 61.5 | 77.9 | 81.3 | 74.1 | 89.7 | 67.4 | 74.7 | 40.0 | 93.5 | 72.9 | 86.2 | 73.9 | 71.0 | 65.0 | 70.4 |
| Ours | 1.5 | 58.0 | 94.7 | 50.4 | 40.8 | 36.1 | 37.0 | 52.1 | 54.3 | 10.4 | 91.4 | 59.8 | 75.4 | 21.4 | 94.1 | 55.4 | 83.4 | 61.8 | 68.3 | 52.1 | 58.8 |
| Collection of Building Planes | Based on Plane Normal Vectors | Based on Plane Normal Vectors and Heights | Based on CSF Algorithm | |
|---|---|---|---|---|
| B1 |  |  angle > . |  angle > and height > 8 m. |  cloth resolution = 0.5, classification threshold = 0.5. |
| B2 |  |  angle > . |  angle > and height > 10 m. |  cloth resolution = 0.5, classification threshold = 0.5. |
| B3 |  |  angle > . |  angle > and height > 20 m. |  cloth resolution = 0.5, classification threshold = 0.5. |
| Building Reconstruction Steps | Corresponding Methods | Parameter Setting |
|---|---|---|
| Step1: building plane segmentation | RANSAC plane segmentation | Distance threshold from point to plane 0.1 m, minimum number of points 10, iteration number 500. |
| Step2: building plane optimization | DBSCAN plane optimization | Search radius 0.15 m, minimum number of points 3. |
| Step3: roof plane identification | CSF algorithm to recognize roof planes | cloth resolution 0.3 m, classification threshold 0.5 m. |
| Step4: roof plane initial boundary vertex acquisition | Alpha shape extracts contour points and RANSAC fits straight lines. | Alpha parameter 0.3, distance threshold for straight line fitting is 0.3 m. |
| Step5: roof vertical plane reasoning | Fit the plane according to the structural characteristics of the building | None |
| Step6: roof plane adjacency judgment | Set the distance threshold to judge the adjacency between the planes | The distance threshold is generally set to 3–5 times the average point cloud spacing. |
| Step7: roof topology reconstruction | Intersect planes to find intersection points, intersect straight lines. | None |
| Step8: building model reconstruction | Stretch the outer contour of the roof to the ground | None |
| Max | Mean | RMS | |
|---|---|---|---|
| P2M (m) | 0.67 | 0.31 | 0.42 |
| M2P (m) | 0.39 | 0.25 | 0.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, X.; Guo, B.; Li, C.; Sun, N.; Wang, Y.; Yao, Y. Semantic Segmentation and Roof Reconstruction of Urban Buildings Based on LiDAR Point Clouds. ISPRS Int. J. Geo-Inf. 2024, 13, 19. https://doi.org/10.3390/ijgi13010019
Sun X, Guo B, Li C, Sun N, Wang Y, Yao Y. Semantic Segmentation and Roof Reconstruction of Urban Buildings Based on LiDAR Point Clouds. ISPRS International Journal of Geo-Information. 2024; 13(1):19. https://doi.org/10.3390/ijgi13010019
Chicago/Turabian StyleSun, Xiaokai, Baoyun Guo, Cailin Li, Na Sun, Yue Wang, and Yukai Yao. 2024. "Semantic Segmentation and Roof Reconstruction of Urban Buildings Based on LiDAR Point Clouds" ISPRS International Journal of Geo-Information 13, no. 1: 19. https://doi.org/10.3390/ijgi13010019
APA StyleSun, X., Guo, B., Li, C., Sun, N., Wang, Y., & Yao, Y. (2024). Semantic Segmentation and Roof Reconstruction of Urban Buildings Based on LiDAR Point Clouds. ISPRS International Journal of Geo-Information, 13(1), 19. https://doi.org/10.3390/ijgi13010019