

Similarity Measurement and Retrieval of Three-Dimensional Voxel Model Based on Symbolic Operator

Abstract
:1. Introduction
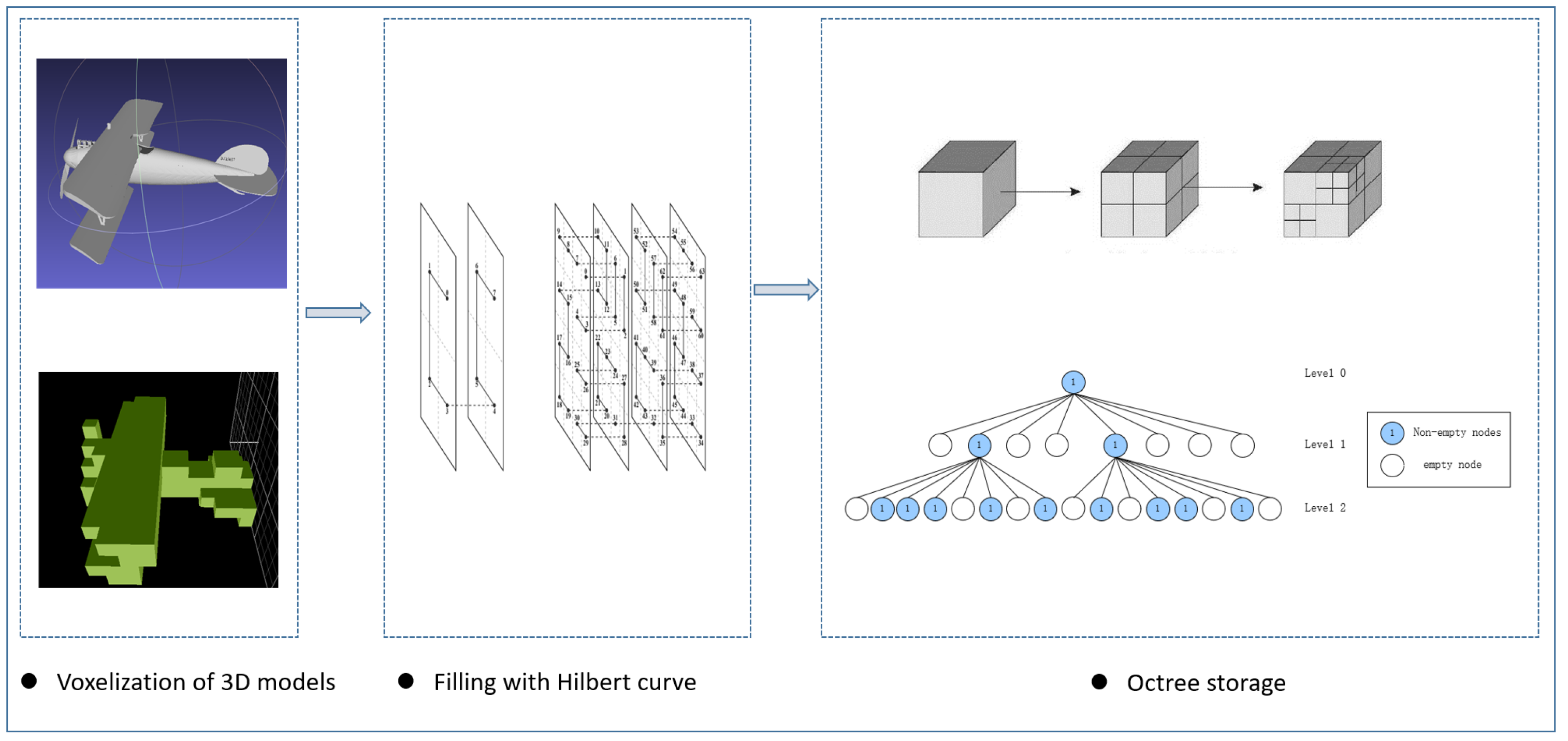
- Based on space-filling curves and octree structures, this study focuses on voxelization and feature extraction methods for three-dimensional models. A feature extraction method for three-dimensional voxel models based on the Hilbert curve is proposed, enabling the mapping of three-dimensional models to voxel models and further to sequential data. This approach achieves feature extraction and sequential representation for three-dimensional voxel models.
- We propose a method for representing the features of three-dimensional voxel models based on symbolic operators and their similarity measurement. Symbolic operators are mappings from a function space to a symbolic space. To mitigate the curse of dimensionality, the sequential data obtained from the three-dimensional voxel model are mapped to a hexadecimal symbolic space, yielding the feature description of the three-dimensional model (VSO, representation of 3D voxel model based on symbolic operators). Based on this representation, a similarity measurement method is proposed.
2. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Extraction | Algorithm | |
|---|---|---|
| Manual design-based | Based on statistical data | GD [28] |
| D2 [29] | ||
| Based on geometric shape | LFD [19] | |
| SPH [30] | ||
| ICP [31] | ||
| Based on topological structure | Reeb [32] | |
| Based on local feature | FPFH [33] | |
| SHOT [34] | ||
| Learning-based | Based on voxelization | VoxelNet [35] |
| Based on multiple viewpoints | 3D ShapeNet [36] | |
| MVCNN [37] | ||
| Based on raw point cloud | PointNet [38] |
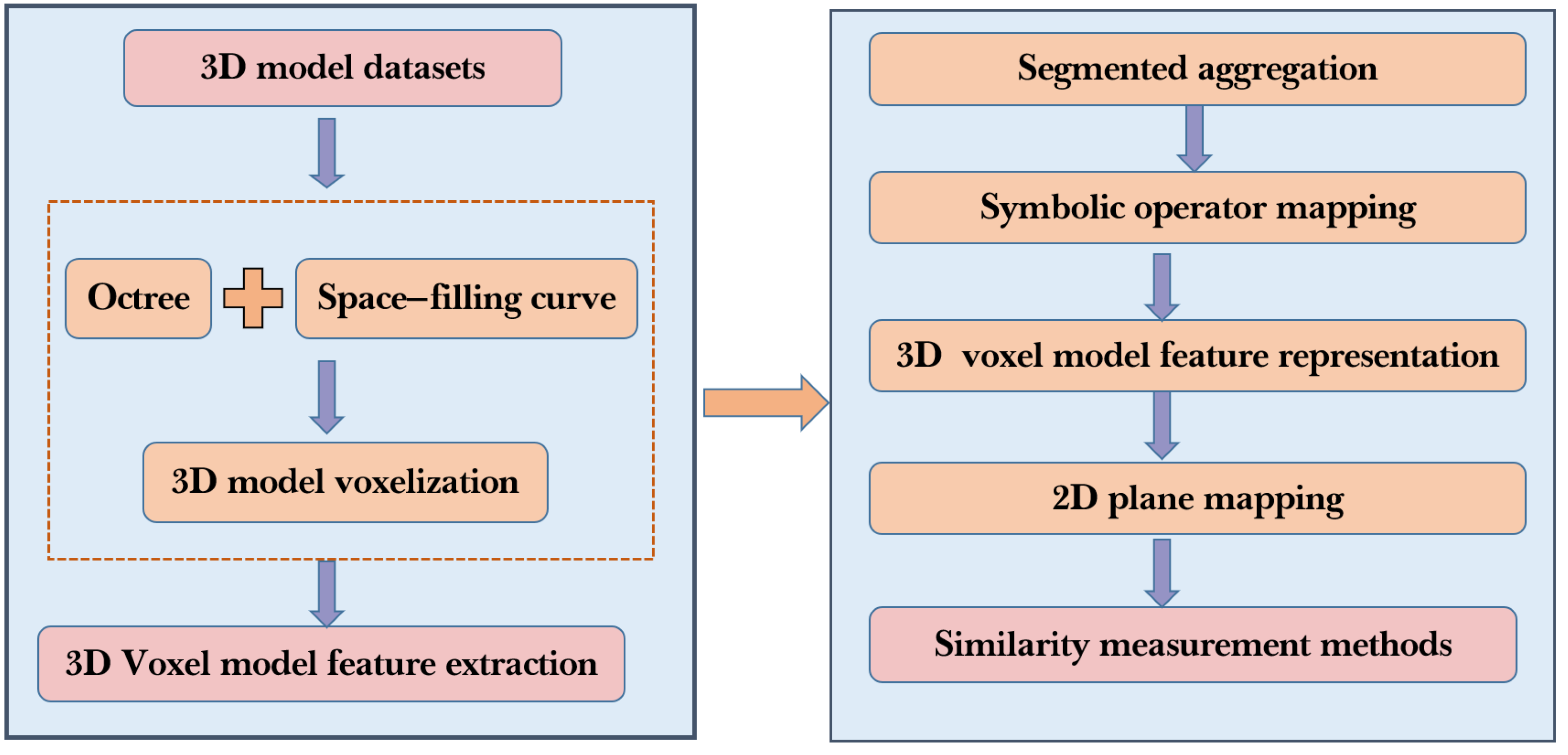
3. Architecture of 3D Model Retrieval Based on VSO
3.1. Voxelization of Models Based on the Hilbert Curve
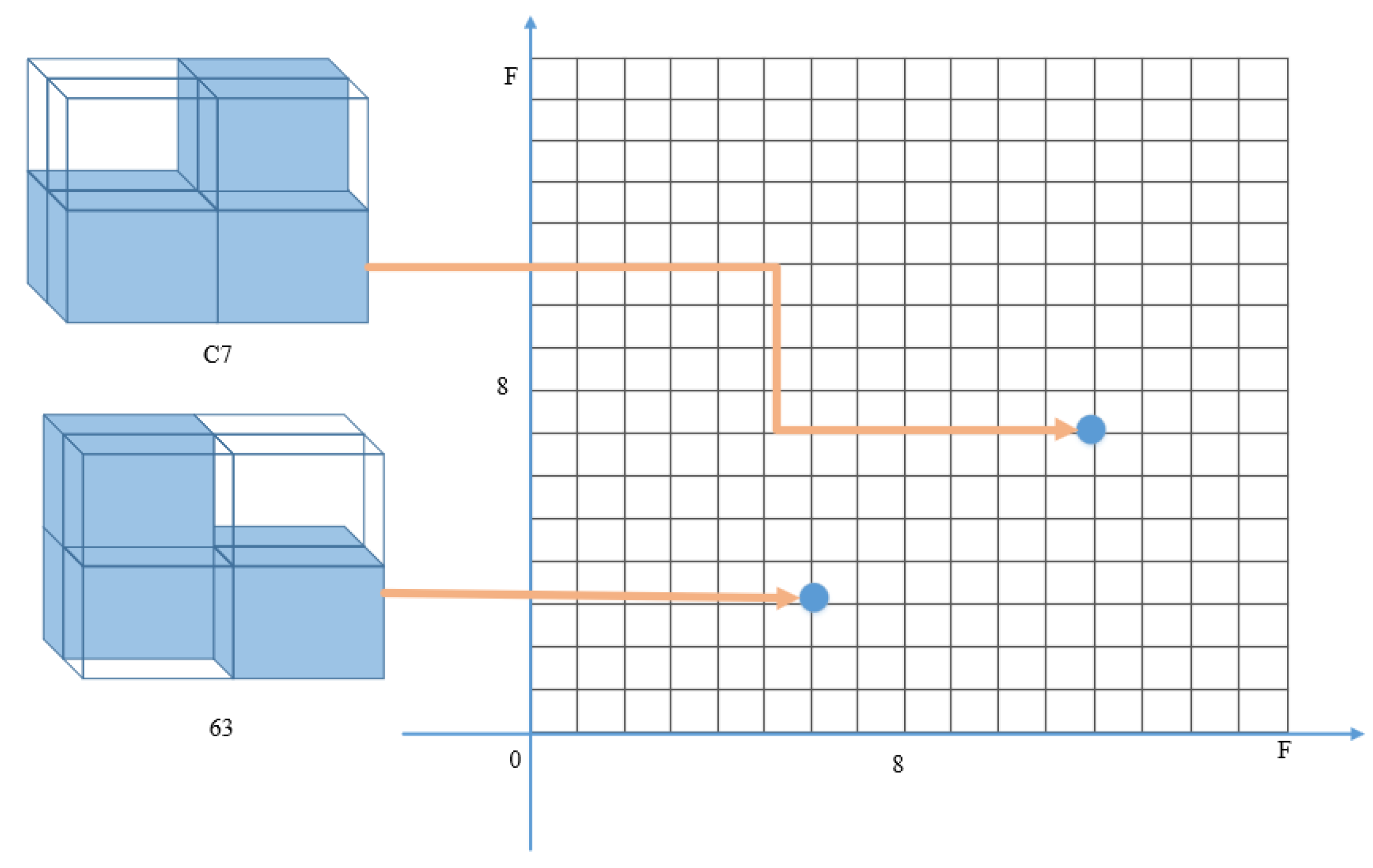
3.2. Three-Dimensional Voxel Model Feature Representation Based on Symbolic Operators
3.3. Similarity Measurement Method Based on VSO
3.4. Summary
4. Experimental Validation
4.1. Experimental Data
4.2. Evaluation Metrics
- Accuracy:
- Confusion Matrix:
4.3. Experimental Methods
- Three-dimensional model voxelization particle size analysis experiment:
- Three-dimensional model similarity measurement method and feature dimension analysis experiment:
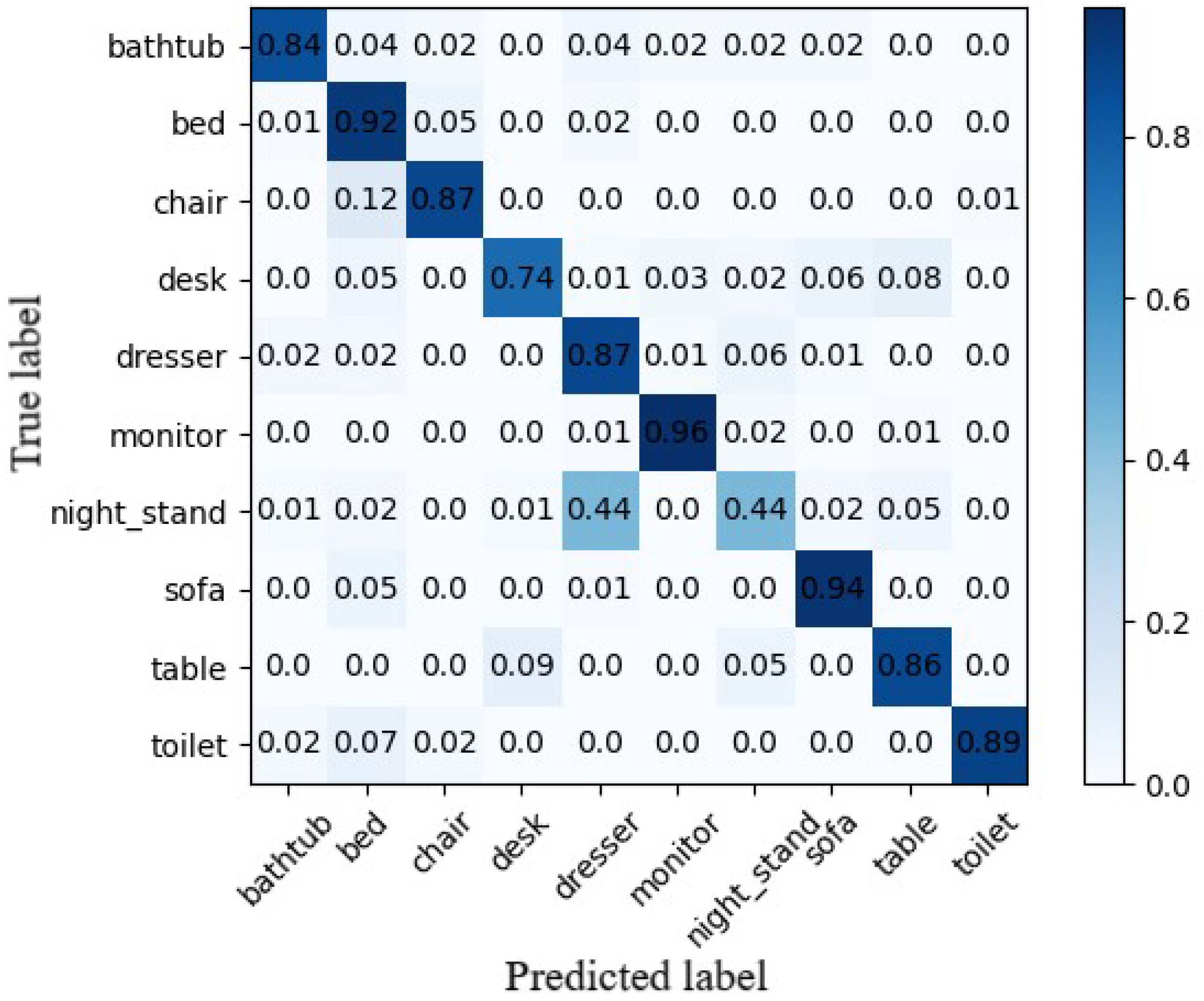
4.4. Analysis of Experimental Results
- Three-dimensional model voxelization particle size analysis experiment:
- Three-dimensional model similarity measurement method and feature dimension analysis experiment:
5. Discussion
6. Conclusions and Future Works
- Feature extraction of 3D voxel models is based on voxel representation, preserving the complete voxel data of 3D models. However, many 3D models have complex structures composed of numerous edges and faces. When the voxel granularity increases, the time cost of voxelization also increases. Therefore, improving the efficiency of voxelization for 3D models is an important area for future research.
- The VSO representation and similarity measurement methods for 3D voxel models currently focus mainly on shape and structural information. However, real-world 3D models also include rich attribute information such as color, texture, and density. Incorporating other attribute information in addition to shape and structural information is expected to enhance the accuracy of 3D model classification and retrieval and broaden the application scope. Therefore, exploring how to fully utilize various attribute information of models and designing similarity measurement methods applicable to multi-attribute features are worthwhile directions for further research.
- In the field of geographic information, there are many three-dimensional geographic spatial objects, such as underground geological bodies like rock masses and ore bodies, as well as landform features like mountains and valleys. Utilizing the method proposed in this paper to voxelize these three-dimensional geographic spatial objects and exploring how to use them for feature representation and similarity measurement is one of our future research directions. This research can facilitate the understanding, analysis, and management of the Earth’s surface and subsurface spaces, providing more possibilities for the application of geographic information systems.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dobroś, K.; Hajto-Bryk, J.; Zarzecka, J. Application of 3D-printed teeth models in teaching dentistry students: A scoping review. Eur. J. Dent. Educ. 2023, 27, 126–134. [Google Scholar] [CrossRef]
- Xu, X.; Rioux, T.P.; Castellani, M.P. Three dimensional models of human thermoregulation: A review. J. Therm. Biol. 2023, 112, 103491. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Zang, Y.; Xiong, Z.; Bian, X.; Wen, C.; Lu, X.; Wang, C.; Junior, J.M.; Goncalves, W.N.; Li, J. 3D building model generation from MLS point cloud and 3D mesh using multi-source data fusion. Int. J. Appl. Earth Obs. Geoinf. 2023, 116, 103171. [Google Scholar] [CrossRef]
- Li, P. Production of Film and Television Animation Based on Three-Dimensional Models Based on Deep Image Sequences. In Proceedings of the Machine Learning, Image Processing, Network Security and Data Sciences: 4th International Conference, MIND 2022, Virtual Event, 19–20 January 2023; Proceedings, Part II. Springer: Cham, Switzerland, 2023; pp. 131–138. [Google Scholar]
- Zhang, C.; Chen, T. Efficient feature extraction for 2D/3D objects in mesh representation. In Proceedings of the 2001 International Conference on Image Processing (Cat. No. 01CH37205), Thessaloniki, Greece, 7–10 October 2001; Volume 3, pp. 935–938. [Google Scholar] [CrossRef]
- Serafin, J.; Olson, E.; Grisetti, G. Fast and robust 3D feature extraction from sparse point clouds. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 4105–4112. [Google Scholar] [CrossRef]
- Lu, K.; Wang, Q.; Xue, J.; Pan, W. 3D model retrieval and classification by semi-supervised learning with content-based similarity. Inf. Sci. 2014, 281, 703–713. [Google Scholar] [CrossRef]
- Fu, T. A review on time series data mining. Eng. Appl. Artif. Intell. 2011, 24, 164–181. [Google Scholar] [CrossRef]
- Wattenberg, M. A note on space-filling visualizations and space-filling curves. In Proceedings of the IEEE Symposium on Information Visualization, INFOVIS 2005, Minneapolis, MN, USA, 23–25 October 2005; pp. 181–186. [Google Scholar]
- Wang, P.S.; Liu, Y.; Guo, Y.X.; Sun, C.Y.; Tong, X. O-cnn: Octree-based convolutional neural networks for 3d shape analysis. ACM Trans. Graph. (TOG) 2017, 36, 1–11. [Google Scholar] [CrossRef]
- Jjumba, A.; Dragićević, S. Towards a voxel-based geographic automata for the simulation of geospatial processes. ISPRS J. Photogramm. Remote Sens. 2016, 117, 206–216. [Google Scholar] [CrossRef]
- Piris, G.; Herms, I.; Griera, A.; Colomer, M.; Arnó, G.; Gomez-Rivas, E. 3DHIP-calculator—A new tool to stochastically assess deep geothermal potential using the heat-in-place method from voxel-based 3D geological models. Energies 2021, 14, 7338. [Google Scholar] [CrossRef]
- Fisher-Gewirtzman, D.; Shashkov, A.; Doytsher, Y. Voxel based volumetric visibility analysis of urban environments. Surv. Rev. 2013, 45, 451–461. [Google Scholar] [CrossRef]
- Khan, M.S.; Kim, I.S.; Seo, J. A boundary and voxel-based 3D geological data management system leveraging BIM and GIS. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103277. [Google Scholar] [CrossRef]
- Min, P.; Kazhdan, M.; Funkhouser, T. A comparison of text and shape matching for retrieval of online 3D models. In Proceedings of the Research and Advanced Technology for Digital Libraries: 8th European Conference, ECDL 2004, Bath, UK, 12–17 September 2004; Proceedings 8. Springer: Berlin/Heidelberg, Germany, 2004; pp. 209–220. [Google Scholar]
- Kassimi, M.A.; Elbeqqali, O. Semantic based 3D model retrieval. In Proceedings of the 2012 International Conference on Multimedia Computing and Systems, Tangiers, Morocco, 10–12 May 2012; pp. 195–199. [Google Scholar]
- Tangelder, J.W.H.; Veltkamp, R.C. A survey of content based 3D shape retrieval methods. Multimed. Tools Appl. 2008, 39, 441–471. [Google Scholar] [CrossRef]
- Pei, Y.; Gu, K. Overview of content and semantic based 3D model retrieval. J. Comput. Appl. 2020, 40, 1863–1872. [Google Scholar]
- Chen, D.Y.; Tian, X.P.; Shen, Y.T.; Ouhyoung, M. On visual similarity based 3D model retrieval. In Proceedings of the Computer Graphics Forum; Blackwell Publishing, Inc.: Oxford, UK, 2003; Volume 22, pp. 223–232. [Google Scholar]
- Regli, W.C.; Cicirello, V.A. Managing digital libraries for computer-aided design. Comput.-Aided Des. 2000, 32, 119–132. [Google Scholar] [CrossRef]
- Zaharia, T.; Preteux, F.J. 3D-shape-based retrieval within the MPEG-7 framework. Nonlinear image processing and pattern analysis xii. SPIE 2001, 4304, 133–145. [Google Scholar]
- Biasotti, S.; Marini, S.; Mortara, M.; Patane, G.; Spagnuolo, M.; Falcidieno, B. 3D shape matching through topological structures. In Proceedings of the Discrete Geometry for Computer Imagery: 11th International Conference, DGCI 2003, Naples, Italy, 19–21 November 2003; Proceedings 11. Springer: Berlin/Heidelberg, Germany, 2003; pp. 194–203. [Google Scholar]
- Kim, H.; Cha, M.; Mun, D. Shape distribution-based retrieval of 3D CAD models at different levels of detail. Multimedia Tools and Applications 2017, 76, 15867–15884. [Google Scholar] [CrossRef]
- Li, B.; Godil, A.; Johan, H. Hybrid shape descriptor and meta similarity generation for non-rigid and partial 3D model retrieval. Multimed. Tools Appl. 2014, 72, 1531–1560. [Google Scholar] [CrossRef]
- Van De Weijer, J.; Schmid, C. Coloring local feature extraction. In Proceedings of the Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Proceedings, Part II 9. Springer: Berlin/Heidelberg, Germany, 2006; pp. 334–348. [Google Scholar]
- Imrie, F.; Bradley, A.R.; van der Schaar, M.; Deane, C.M. Deep generative models for 3D linker design. J. Chem. Inf. Model. 2020, 60, 1983–1995. [Google Scholar] [CrossRef]
- Gezawa, A.S.; Zhang, Y.; Wang, Q.; Yunqi, L. A review on deep learning approaches for 3d data representations in retrieval and classifications. IEEE Access 2020, 8, 57566–57593. [Google Scholar] [CrossRef]
- Lian, Z.; Godil, A.; Bustos, B.; Daoudi, M.; Hermans, J.; Kawamura, S.; Kurita, Y.; Lavoua, G.; Suetens, P.D. Shape retrieval on non-rigid 3D watertight meshes. In Proceedings of the Eurographics Workshop on 3d Object Retrieval (3DOR), Lluandudno, UK, 10 April 2011. [Google Scholar]
- Cheng, H.C.; Lo, C.H.; Chu, C.H.; Kim, Y.S. Shape similarity measurement for 3D mechanical part using D2 shape distribution and negative feature decomposition. Comput. Ind. 2011, 62, 269–280. [Google Scholar] [CrossRef]
- Kazhdan, M.; Funkhouser, T.; Rusinkiewicz, S. Rotation invariant spherical harmonic representation of 3d shape descriptors. In Proceedings of the Symposium on Geometry Processing, Aachen, Germany, 23–25 June 2003; Volume 6, pp. 156–164. [Google Scholar]
- Zhang, J.; Yao, Y.; Deng, B. Fast and robust iterative closest point. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3450–3466. [Google Scholar] [CrossRef]
- Hilaga, M.; Shinagawa, Y.; Kohmura, T.; Kunii, T.L. Topology matching for fully automatic similarity estimation of 3D shapes. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 12–17 August 2001; pp. 203–212. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Marton, Z.C.; Beetz, M. Aligning point cloud views using persistent feature histograms. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3384–3391. [Google Scholar]
- Salti, S.; Tombari, F.; Di Stefano, L. SHOT: Unique signatures of histograms for surface and texture description. Comput. Vis. Image Underst. 2014, 125, 251–264. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Garcia-Garcia, A.; Gomez-Donoso, F.; Garcia-Rodriguez, J.; Orts-Escolano, S.; Cazorla, M.; Azorin-Lopez, J. Pointnet: A 3d convolutional neural network for real-time object class recognition. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1578–1584. [Google Scholar]
- Sun, D.; Qu, L. Survey on Feature Representation and Similarity Measurement of Time Series. J. Front. Comput. Sci. Technol. 2021, 15, 195–205. [Google Scholar]
- Agrawal, R.; Faloutsos, C.; Swami, A. Efficient similarity search in sequence databases. In Proceedings of the International Conference on Foundations of Data Organization & Algorithms; Springer: Berlin/Heidelberg, Germany, 1993; pp. 69–84. [Google Scholar]
- Chan, K.P.; Fu, A.W.C. Efficient time series matching by wavelets. In Proceedings of the15th International Conference on Data Engineering; IEEE Computer Society: Los Alamitos, CA, USA, 1999; pp. 126–133. [Google Scholar]
- Keogh, E.; Chakrabarti, K.; Pazzani, M.; Mehrotra, S. Dimensionality Reduction for Fast Similarity Search in Large Time Series Databases. Knowl. Inf. Syst. 2001, 3, 263–286. [Google Scholar] [CrossRef]
- Lin, J.; Keogh, E.; Wei, L.; Lonardi, S. Experiencing SAX: A novel symbolic representation of time series. Data Min. Knowl. Discov. 2007, 15, 107–144. [Google Scholar] [CrossRef]
- Korn, F.; Jagaciish, H.V.; Faloutsos, C. Efficiently supporting ad hoc queries in large datasets of time sequences. In Proceedings of the ACM SIG MOD International Conference on Management of Data, Tucson, AZ, USA, 13–15 May 1997; ACM: New York, NY, USA, 1997; pp. 289–300. [Google Scholar]
- Mor, B.; Garhwal, S.; Kumar, A. A systematic review of hidden Markov models and their applications. Arch. Comput. Methods Eng. 2021, 28, 1429–1448. [Google Scholar] [CrossRef]
- Fokianos, K.; Fried, R.; Kharin, Y.; Voloshko, V. Statistical analysis of multivariate discrete-valued time series. J. Multivar. Anal. 2022, 188, 104805. [Google Scholar] [CrossRef]
- Chen, H.Y.; Liu, C.H.; Sun, B. Survey on similarity measurement of time series data mining. Control Decis. 2017, 32, 1–11. [Google Scholar]
- Bai, S.; Qi, H.D.; Xiu, N. Constrained best Euclidean distance embedding on a sphere: A matrix optimization approach. SIAM J. Optim. 2015, 25, 439–467. [Google Scholar] [CrossRef]
- Hsu, C.J.; Huang, K.S.; Yang, C.B.; Guo, Y.P. Flexible dynamic time warping for time series classification. Procedia Comput. Sci. 2015, 51, 2838–2842. [Google Scholar] [CrossRef]
- Wang, S.; Wen, Y.; Zhao, H. Study on the similarity query based on LCSS over data stream window. In Proceedings of the IEEE 2015 IEEE 12th International Conference on e-Business Engineering, Beijing, China, 23–25 October 2015; pp. 68–73. [Google Scholar]
- Jagadish, H.V. Analysis of the Hilbert curve for representing two-dimensional space. Inf. Process. Lett. 1997, 62, 17–22. [Google Scholar] [CrossRef]
- Kilimci, P.; Kalipsiz, O. Indexing of spatiotemporal Data: A comparison between sweep and z-order space filling curves. In Proceedings of the IEEE International Conference on Information Society (i-Society 2011), London, UK, 27–29 June 2011; pp. 450–456. [Google Scholar]
- Mokbel, M.F.; Aref, W.G.; Kamel, I. Analysis of multi-dimensional space-filling curves. GeoInformatica 2003, 7, 179–209. [Google Scholar] [CrossRef]
- Levchenko, O.; Kolev, B.; Yagoubi, D.E.; Akbarinia, R.; Masseglia, F.; Palpanas, T.; Shasha, D.; Valduriez, P. BestNeighbor: Efficient evaluation of kNN queries on large time series databases. Knowl. Inf. Syst. 2021, 63, 349–378. [Google Scholar] [CrossRef]













| Type | Feature Representation Methods | Time Complexity |
|---|---|---|
| Non-data-adaptive methods | DFT | O(nlog(n)) |
| DWT | O(n) | |
| PAA | Fastest O(n) | |
| Data-adaptive methods | SAX | O(n) |
| SVD | O(Mn2) | |
| Model-based methods | HMM | |
| MCs |
| Predicted Value | |||
|---|---|---|---|
| Positive | Negative | ||
| Ground truth | Positive | TP | FN |
| Negative | FP | TN | |
| Original 3D model | Voxel model, G = 32 |
 |  |
| Voxel model, G = 16 | Voxel model, G = 8 |
 |  |
| Voxelized Granularity | Classification Accuracy | Average Calculation Time (ms) |
|---|---|---|
| 22, 4 × 4 × 4 | 75.3% | 0.208 |
| 23, 8 × 8 × 8 | 80.0% | 3.398 |
| 24, 16 × 16 × 16 | 84.0% | 10.392 |
| 25, 32 × 32 × 32 | 85.9% | 118.163 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Liu, X.; Zhang, C. Similarity Measurement and Retrieval of Three-Dimensional Voxel Model Based on Symbolic Operator. ISPRS Int. J. Geo-Inf. 2024, 13, 89. https://doi.org/10.3390/ijgi13030089
He Z, Liu X, Zhang C. Similarity Measurement and Retrieval of Three-Dimensional Voxel Model Based on Symbolic Operator. ISPRS International Journal of Geo-Information. 2024; 13(3):89. https://doi.org/10.3390/ijgi13030089
Chicago/Turabian StyleHe, Zhenwen, Xianzhen Liu, and Chunfeng Zhang. 2024. "Similarity Measurement and Retrieval of Three-Dimensional Voxel Model Based on Symbolic Operator" ISPRS International Journal of Geo-Information 13, no. 3: 89. https://doi.org/10.3390/ijgi13030089
APA StyleHe, Z., Liu, X., & Zhang, C. (2024). Similarity Measurement and Retrieval of Three-Dimensional Voxel Model Based on Symbolic Operator. ISPRS International Journal of Geo-Information, 13(3), 89. https://doi.org/10.3390/ijgi13030089