

Quantifying Urban Linguistic Diversity Related to Rainfall and Flood across China with Social Media Data
 , , , ,
, , , ,  and
and
Abstract
:1. Introduction
2. Data
3. Method
3.1. Preprocessing Rainfall and Flood Microblogs
3.2. Constructing Daily Count Vectors for Precipitation and Microblogs
3.3. Extracting Precipitation-Related Keywords
3.4. Spatial Analysis of Rainfall and Flood Related Keywords
4. Results
4.1. Rainfall and Flood Related Keyword Library
4.2. Semantic Feature Variations of Keywords
4.3. Spatial Feature Variations of Keywords
5. Discussion
5.1. Potential Influencing Factors of the Public Choice of Specific Terms
5.2. Potential Influencing Factors of the Richness of Urban Language Expressions
5.3. Leveraging Language Diversity for Urban Resilience
5.4. Limitations and Future Directions
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tomasello, M. Origins of Human Communication; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Baldwin, D.A. Understanding the link between joint attention and language. In Joint Attentio; Psychology Press: London, UK, 2014; pp. 131–158. [Google Scholar]
- Fu, C.; McKenzie, G.; Frias-Martinez, V.; Stewart, K. Identifying spatiotemporal urban activities through linguistic signatures. Comput. Environ. Urban Syst. 2018, 72, 25–37. [Google Scholar] [CrossRef]
- O’Brien, S.; Federici, F.; Cadwell, P.; Marlowe, J.; Gerber, B. Language translation during disaster: A comparative analysis of five national approaches. Int. J. Disaster Risk Reduct. 2018, 31, 627–636. [Google Scholar] [CrossRef]
- Lyons, J. Language and Linguistics; Cambridge University Press: Cambridge, UK, 1981. [Google Scholar]
- Bühler, K. Theory of Language. The Representational Function of Language; John Benjamin Publishing Company: Amsterdam, The Netherlands, 1990. [Google Scholar]
- Huang, Y.; Guo, D.; Kasakoff, A.; Grieve, J. Understanding US regional linguistic variation with Twitter data analysis. Comput. Environ. Urban Syst. 2016, 59, 244–255. [Google Scholar] [CrossRef]
- Uekusa, S. The paradox of social capital: A case of immigrants, refugees and linguistic minorities in the Canterbury and Tohoku disasters. Int. J. Disaster Risk Reduct. 2020, 48, 101625. [Google Scholar] [CrossRef]
- Evans, N.; Levinson, S.C. The myth of language universals: Language diversity and its importance for cognitive science. Behav. Brain Sci. 2009, 32, 429–448. [Google Scholar] [CrossRef] [PubMed]
- Renfrew, C. World linguistic diversity. Sci. Am. 1994, 270, 116–123. [Google Scholar] [CrossRef]
- Väisänen, T.; Järv, O.; Toivonen, T.; Hiippala, T. Mapping urban linguistic diversity with social media and population register data. Comput. Environ. Urban Syst. 2022, 97, 101857. [Google Scholar] [CrossRef]
- Crawford, T.; Villeneuve, M.; Yen, I.; Hinitt, J.; Millington, M.; Dignam, M.; Gardiner, E. Disability inclusive disaster risk reduction with culturally and linguistically diverse (CALD) communities in the Hawkesbury-Nepean region: A co-production approach. Int. J. Disaster Risk Reduct. 2021, 63, 102430. [Google Scholar] [CrossRef]
- Vaux, B. American dialects. Let’s Go USA 2004. [Google Scholar]
- Nestle, M. Soda Politics: Taking on Big Soda (and Winning); Oxford University Press: New York, NY, USA, 2015. [Google Scholar]
- Hauerwas, L.B.; Gomez-Barreto, I.M.; Fernández, R.S. Transformative Innovation in teacher education: Research toward a critical global didactica. Teach. Teach. Educ. 2023, 123, 103974. [Google Scholar] [CrossRef]
- Bonnett, A. Multiracism: Rethinking Racism in Global Context; John Wiley & Sons: Hoboken, NJ, USA, 2021. [Google Scholar]
- Rashid, A. Language Policy and Planning in Multilingual Pakistan. Pak. J. Linguist. 2023, 5, 40–52. [Google Scholar]
- El Ayadi, N. Linguistic sound walks: Setting out ways to explore the relationship between linguistic soundscapes and experiences of social diversity. Soc. Cult. Geogr. 2022, 23, 227–249. [Google Scholar] [CrossRef]
- Bromham, L.; Dinnage, R.; Skirgård, H.; Ritchie, A.; Cardillo, M.; Meakins, F.; Greenhill, S.; Hua, X. Global predictors of language endangerment and the future of linguistic diversity. Nat. Ecol. Evol. 2022, 6, 163–173. [Google Scholar] [CrossRef]
- Liu, Q.; Colak, F.Z.; Agirdag, O. Celebrating culture and neglecting language: Representation of ethnic minorities in Chinese primary school textbooks (1976–2021). J. Curric. Stud. 2022, 54, 687–711. [Google Scholar] [CrossRef]
- Gorenflo, L.J.; Romaine, S.; Mittermeier, R.A.; Walker-Painemilla, K. Co-occurrence of linguistic and biological diversity in biodiversity hotspots and high biodiversity wilderness areas. Proc. Natl. Acad. Sci. USA 2012, 109, 8032–8037. [Google Scholar] [CrossRef]
- Bernal, G.; Jiménez-Chafey, M.I.; Domenech Rodríguez, M.M. Cultural adaptation of treatments: A resource for considering culture in evidence-based practice. Prof. Psychol. Res. Pract. 2009, 40, 361. [Google Scholar] [CrossRef]
- Leeman, J.; Modan, G. Commodified language in Chinatown: A contextualized approach to linguistic landscape 1. J. Socioling. 2009, 13, 332–362. [Google Scholar] [CrossRef]
- Peng, S.; Wang, G.; Xie, D. Social influence analysis in social networking big data: Opportunities and challenges. IEEE Netw. 2016, 31, 11–17. [Google Scholar] [CrossRef]
- Duan, Y.; Edwards, J.S.; Dwivedi, Y.K. Artificial intelligence for decision making in the era of Big Data–evolution, challenges and research agenda. Int. J. Inf. Manag. 2019, 48, 63–71. [Google Scholar] [CrossRef]
- Jimenez-Marquez, J.L.; Gonzalez-Carrasco, I.; Lopez-Cuadrado, J.L.; Ruiz-Mezcua, B. Towards a big data framework for analyzing social media content. Int. J. Inf. Manag. 2019, 44, 1–12. [Google Scholar] [CrossRef]
- Wang, N.; Du, Y.; Liang, F.; Yi, J.; Wang, H. Spatiotemporal Changes of Urban Rainstorm-Related Micro-Blogging Activities in Response to Rainstorms: A Case Study in Beijing, China. Appl. Sci. 2019, 9, 4629. [Google Scholar] [CrossRef]
- Son, J.; Lee, J.; Oh, O.; Lee, H.K.; Woo, J. Using a Heuristic-Systematic Model to assess the Twitter user profile’s impact on disaster tweet credibility. Int. J. Inf. Manag. 2020, 54, 102176. [Google Scholar] [CrossRef]
- Huang, Q.; Xiao, Y. Geographic situational awareness: Mining tweets for disaster preparedness, emergency response, impact, and recovery. ISPRS Int. J. Geo-Inf. 2015, 4, 1549–1568. [Google Scholar] [CrossRef]
- Yan, Y.; Eckle, M.; Kuo, C.-L.; Herfort, B.; Fan, H.; Zipf, A. Monitoring and assessing post-disaster tourism recovery using geotagged social media data. ISPRS Int. J. Geo-Inf. 2017, 6, 144. [Google Scholar] [CrossRef]
- Blodgett, S.L.; Green, L.; O’Connor, B. Demographic dialectal variation in social media: A case study of African-American English. arXiv 2016, arXiv:1608.08868. [Google Scholar]
- Sadat, F.; Kazemi, F.; Farzindar, A. Automatic identification of arabic dialects in social media. In Proceedings of the First International Workshop on Social Media Retrieval and Analysis, Gold Coast, QD, Australia, 11 July 2014; pp. 35–40. [Google Scholar]
- Tse, Y.K.; Zhang, M.; Doherty, B.; Chappell, P.; Garnett, P. Insight from the horsemeat scandal: Exploring the consumers’ opinion of tweets toward Tesco. Ind. Manag. Data Syst. 2016, 116, 1178–1200. [Google Scholar] [CrossRef]
- MacPhee, D.; Handsfield, L.J.; Paugh, P. Conflict or conversation? Media portrayals of the science of reading. Read. Res. Q. 2021, 56, S145–S155. [Google Scholar] [CrossRef]
- Wang, X.; Yao, H. In government microblogs we trust: Doing trust work in Chinese government microblogs during COVID-19. Discourse Commun. 2022, 16, 716–734. [Google Scholar] [CrossRef]
- Qian, J.; Du, Y.; Yi, J.; Liang, F.; Huang, S.; Wang, X.; Wang, N.; Tu, W.; Pei, T.; Ma, T. Regional geographical and climatic environments affect urban rainstorm perception sensitivity across China. Sustain. Cities Soc. 2022, 87, 104213. [Google Scholar] [CrossRef]
- Kruspe, A.; Kersten, J.; Klan, F. Detection of actionable tweets in crisis events. Nat. Hazards Earth Syst. Sci. 2021, 21, 1825–1845. [Google Scholar] [CrossRef]
- Borden, J.; Zhang, X.A.; Hwang, J. Improving automated crisis detection via an improved understanding of crisis language: Linguistic categories in social media crises. J. Contingencies Crisis Manag. 2020, 28, 281–290. [Google Scholar] [CrossRef]
- De Bruijn, J.A.; De Moel, H.; Jongman, B.; De Ruiter, M.C.; Wagemaker, J.; Aerts, J.C. A global database of historic and real-time flood events based on social media. Sci. Data 2019, 6, 311. [Google Scholar] [CrossRef]
- Rachunok, B.; Bennett, J.; Flage, R.; Nateghi, R. A path forward for leveraging social media to improve the study of community resilience. Int. J. Disaster Risk Reduct. 2021, 59, 102236. [Google Scholar] [CrossRef]
- Li, L.; Ma, Z.; Cao, T. Leveraging social media data to study the community resilience of New York City to 2019 power outage. Int. J. Disaster Risk Reduct. 2020, 51, 101776. [Google Scholar] [CrossRef]
- Huang, S.; Du, Y.; Yi, J.; Liang, F.; Qian, J.; Wang, N.; Tu, W. Understanding Human Activities in Response to Typhoon Hato from Multi-Source Geospatial Big Data: A Case Study in Guangdong, China. Remote Sens. 2022, 14, 1269. [Google Scholar] [CrossRef]
- Qian, J.; Du, Y.; Yi, J.; Liang, F.; Wang, N.; Ma, T.; Pei, T. Quantifying unequal urban resilience to rains across China from location-aware big data. Nat. Hazards Earth Syst. Sci. Discuss. 2023, 23, 317–328. [Google Scholar] [CrossRef]
- Li, W.; Wang, S.; Chen, X.; Tian, Y.; Gu, Z.; Lopez-Carr, A.; Schroeder, A.; Currier, K.; Schildhauer, M.; Zhu, R. Geographvis: A knowledge graph and geovisualization empowered cyberinfrastructure to support disaster response and humanitarian aid. ISPRS Int. J. Geo-Inf. 2023, 12, 112. [Google Scholar] [CrossRef]
- Zade, H.; Shah, K.; Rangarajan, V.; Kshirsagar, P.; Imran, M.; Starbird, K. From situational awareness to actionability: Towards improving the utility of social media data for crisis response. Proc. ACM Hum.-Comput. Interact. 2018, 2, 195. [Google Scholar] [CrossRef]
- Verma, S.; Vieweg, S.; Corvey, W.; Palen, L.; Martin, J.; Palmer, M.; Schram, A.; Anderson, K. Natural language processing to the rescue? Extracting “situational awareness” tweets during mass emergency. In Proceedings of the International AAAI Conference on Web and Social Media, Bacelona, Spain, 17–21 July 2011; pp. 385–392. [Google Scholar]
- Moore, F.C.; Obradovich, N. Using remarkability to define coastal flooding thresholds. Nat. Commun. 2020, 11, 530. [Google Scholar] [CrossRef] [PubMed]
- Songchon, C.; Wright, G.; Beevers, L. Quality assessment of crowdsourced social media data for urban flood management. Comput. Environ. Urban Syst. 2021, 90, 101690. [Google Scholar] [CrossRef]
- Wang, B.; Loo, B.P.; Zhen, F.; Xi, G. Urban resilience from the lens of social media data: Responses to urban flooding in Nanjing, China. Cities 2020, 106, 102884. [Google Scholar] [CrossRef]
- Said, N.; Ahmad, K.; Gul, A.; Ahmad, N.; Al-Fuqaha, A. Floods detection in twitter text and images. arXiv 2020, arXiv:2011.14943. [Google Scholar]
- Del Gratta, R.; Goggi, S.; Pardelli, G.; Calzolari, N. The LRE Map: What does it tell us about the last decade of our field? Lang. Resour. Eval. 2021, 55, 259–283. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, X.; Cao, J.; Li, H.; Zhang, Q. Barriers and requirements to climate change adaptation of mountainous rural communities in developing countries: The case of the eastern Qinghai-Tibetan Plateau of China. Land Use Policy 2020, 95, 104354. [Google Scholar] [CrossRef]
- Wisner, B. Climate change and cultural diversity. Int. Soc. Sci. J. 2010, 61, 131–140. [Google Scholar] [CrossRef]
- Wohl, E.E. Inland Flood Hazards: Human, Riparian, and Aquatic Communities; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Muñoz, D.; Moftakhari, H.; Moradkhani, H. Compound effects of flood drivers and wetland elevation correction on coastal flood hazard assessment. Water Resour. Res. 2020, 56, e2020WR027544. [Google Scholar] [CrossRef]
- Burke, M.; Hsiang, S.M.; Miguel, E. Global non-linear effect of temperature on economic production. Nature 2015, 527, 235–239. [Google Scholar] [CrossRef] [PubMed]
- Feng, Y.; Xiao, Q.; Brenner, C.; Peche, A.; Yang, J.; Feuerhake, U.; Sester, M. Determination of building flood risk maps from LiDAR mobile mapping data. Comput. Environ. Urban Syst. 2022, 93, 101759. [Google Scholar] [CrossRef]
- Kwak, Y.-j. Nationwide flood monitoring for disaster risk reduction using multiple satellite data. ISPRS Int. J. Geo-Inf. 2017, 6, 203. [Google Scholar] [CrossRef]
- DeFrancis, J. The Chinese Language: Fact and Fantasy; University of Hawaii Press: Honolulu, HI, USA, 1986. [Google Scholar]
- Levizzani, V.; Kidd, C.; Kirschbaum, D.B.; Kummerow, C.D.; Nakamura, K.; Turk, F.J. Satellite Precipitation Measurement; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Liu, Z.; Du, Y.; Yi, J.; Liang, F.; Ma, T.; Pei, T. Quantitative association between nighttime lights and geo-tagged human activity dynamics during typhoon Mangkhut. Remote Sens. 2019, 11, 2091. [Google Scholar] [CrossRef]
- Yi, J.; Du, Y.; Liang, F.; Pei, T.; Ma, T.; Zhou, C. Anomalies of dwellers’ collective geotagged behaviors in response to rainstorms: A case study of eight cities in China using smartphone location data. Nat. Hazards Earth Syst. Sci. 2019, 19, 2169–2182. [Google Scholar] [CrossRef]
- Gembris, D.; Taylor, J.G.; Schor, S.; Frings, W.; Suter, D.; Posse, S. Functional magnetic resonance imaging in real time (FIRE): Sliding-window correlation analysis and reference-vector optimization. Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 2000, 43, 259–268. [Google Scholar] [CrossRef]
- Kelejian, H.H.; Prucha, I.R. On the asymptotic distribution of the Moran I test statistic with applications. J. Econom. 2001, 104, 219–257. [Google Scholar] [CrossRef]
- Weigel, R.; Krauss, J.K. Center median-parafascicular complex and pain control. Stereotact. Funct. Neurosurg. 2004, 82, 115–126. [Google Scholar] [CrossRef]
- Florax, R.J.; Rey, S. The impacts of misspecified spatial interaction in linear regression models. In New Directions in Spatial Econometrics; Springer: Berlin/Heidelberg, Germany, 1995; pp. 111–135. [Google Scholar]
- Anselin, L.; Rey, S.J. Open source software for spatial data science. Geogr. Anal. 2022, 54, 429–438. [Google Scholar] [CrossRef]
- Oxford, R.; Nyikos, M. Variables affecting choice of language learning strategies by university students. Mod. Lang. J. 1989, 73, 291–300. [Google Scholar] [CrossRef]
- Warschauer, M.; Said, G.R.E.; Zohry, A.G. Language choice online: Globalization and identity in Egypt. J. Comput.-Mediat. Commun. 2002, 7, JCMC744. [Google Scholar] [CrossRef]
- Pennycook, A.; Otsuji, E. Metrolingualism: Language in the City; Routledge: Oxfordshire, UK, 2015. [Google Scholar]
- Maican, M.-A.; Cocoradă, E. Online foreign language learning in higher education and its correlates during the COVID-19 pandemic. Sustainability 2021, 13, 781. [Google Scholar] [CrossRef]
- Gnach, A.; Weber, W.; Engebretsen, M.; Perrin, D. Digital Communication and Media Linguistics; Cambridge University Press: Cambridge, UK, 2022. [Google Scholar]
- Pomeroy, J. Cities of Opportunities: Connecting Culture and Innovation; Routledge: Oxfordshire, UK, 2020. [Google Scholar]
- Yuan, F.; Li, M.; Liu, R.; Zhai, W.; Qi, B. Social media for enhanced understanding of disaster resilience during Hurricane Florence. Int. J. Inf. Manag. 2021, 57, 102289. [Google Scholar] [CrossRef]
- Wang, X.; Xing, Y.; Wei, Y.; Zheng, Q.; Xing, G. Public opinion information dissemination in mobile social networks–taking Sina Weibo as an example. Inf. Discov. Deliv. 2020, 48, 213–224. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Website | Resolution | Data Time |
|---|---|---|---|
| https://open.weibo.com (accessed on 22 May 2021) | Points/s | 2017 | |
| GPM | https://gpm.nasa.gov/data/imerg (accessed on 11 February 2022) | 0.1°/30 min | 2017 |
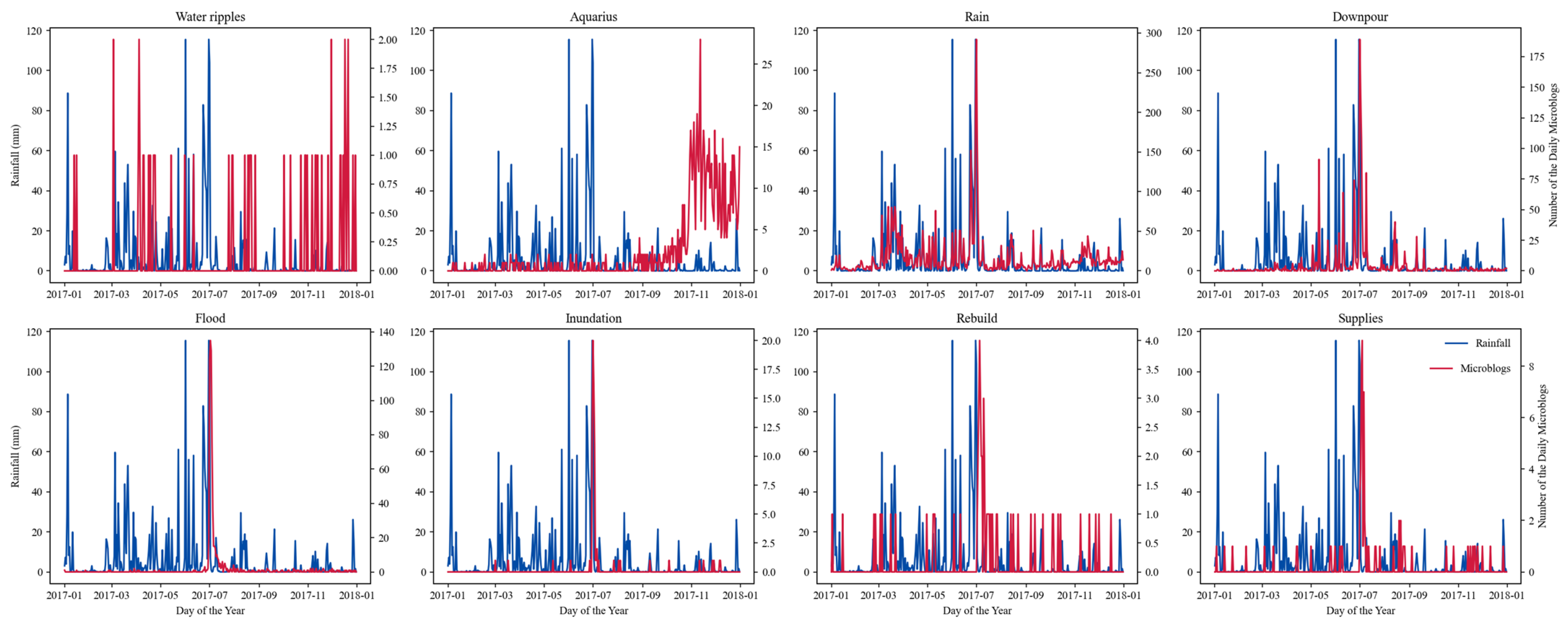
| Keyword | Number of Microblogs | Pearson r |
|---|---|---|
| Water ripples | 52 | −0.06 |
| Aquarius | 896 | −0.14 ** |
| Rain | 6014 | 0.68 *** |
| Downpour | 1705 | 0.47 *** |
| Flood | 726 | 0.18 *** |
| Inundation | 81 | 0.36 *** |
| Rebuild | 59 | −0.03 |
| Supplies | 75 | 0.01 |
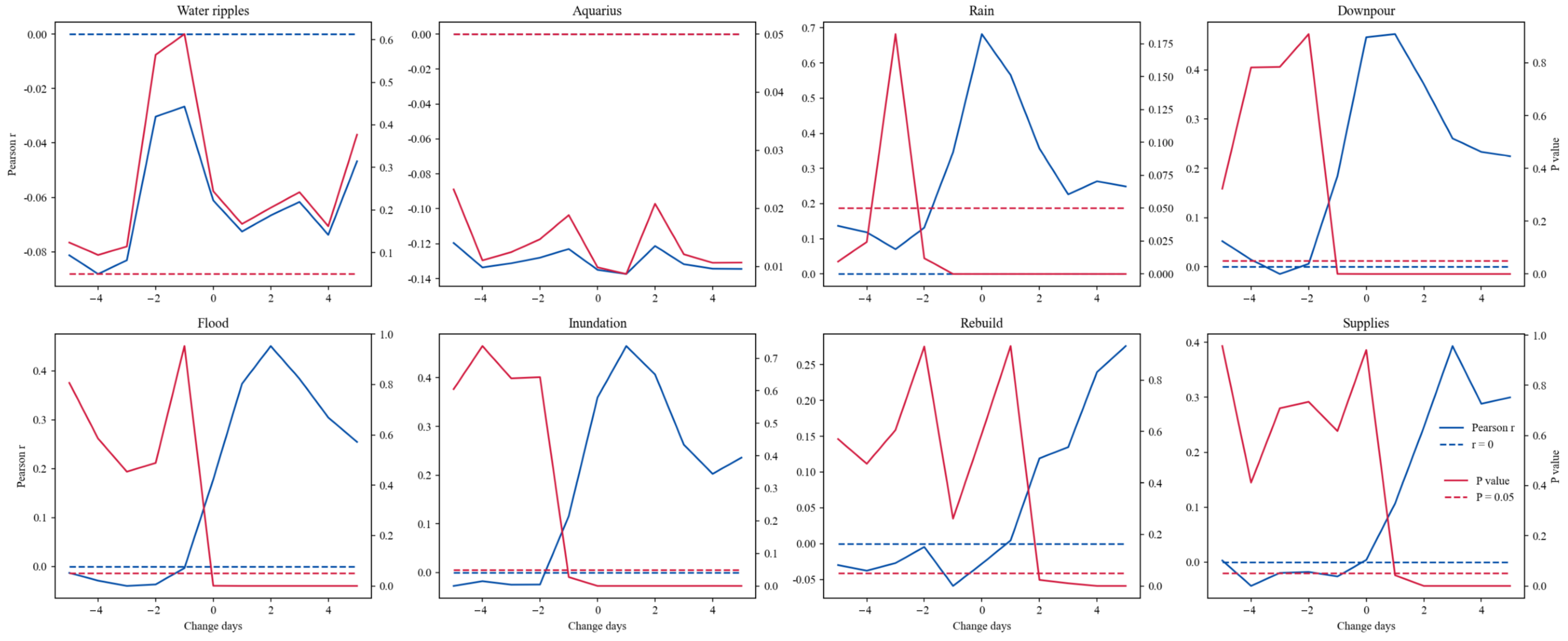
| Keyword | Number of Microblogs | True or False | MCC | OL (Days) |
|---|---|---|---|---|
| Water ripples | 52 | False | ||
| Aquarius | 896 | False | ||
| Rain | 6014 | True | 0.68 | 0 |
| Downpour | 1705 | True | 0.47 | 1 |
| Flood | 726 | True | 0.45 | 2 |
| Inundation | 81 | True | 0.47 | 1 |
| Rebuild | 59 | True | 0.28 | 5 |
| Supplies | 75 | True | 0.40 | 3 |
| Category | Top5_POS | Proportion | Count | Entropy |
|---|---|---|---|---|
| Rainfall | n | 0.69 | 109 | 1.48 |
| i | 0.1 | 16 | ||
| v | 0.09 | 14 | ||
| l | 0.07 | 11 | ||
| t | 0.04 | 7 | ||
| Flood | v | 0.45 | 69 | 2.19 |
| n | 0.31 | 47 | ||
| l | 0.07 | 11 | ||
| vn | 0.05 | 7 | ||
| i | 0.03 | 5 | ||
| Other | n | 0.37 | 104 | 2.95 |
| v | 0.26 | 73 | ||
| l | 0.05 | 14 | ||
| nr | 0.05 | 14 | ||
| a | 0.04 | 12 |
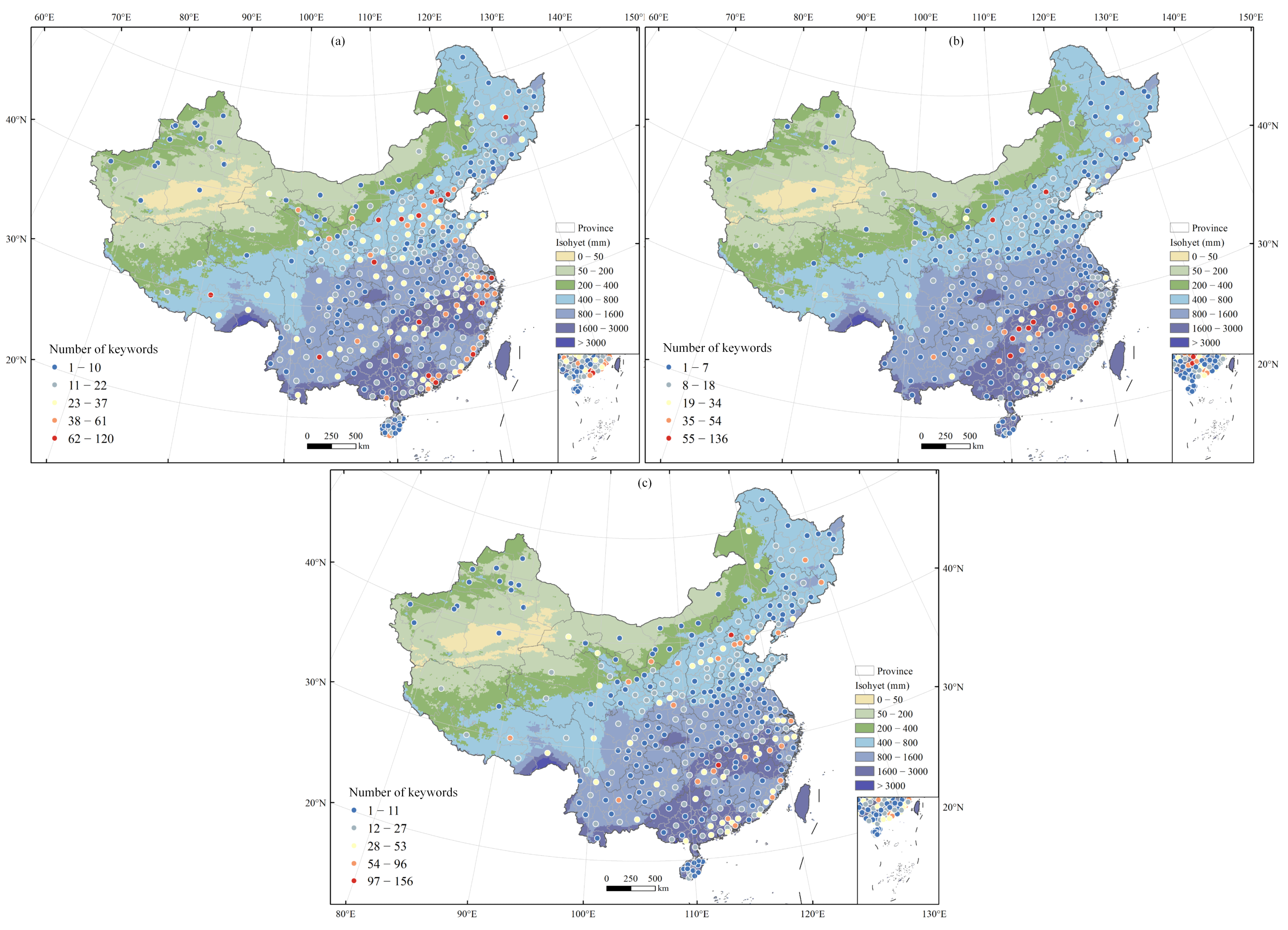
| Category | Moran I | Z-Score |
|---|---|---|
| Rainfall | 0.18 | 9.97 |
| Flood | 0.12 | 7.78 |
| Other | 0.09 | 5.68 |
| Level 1 | Level 2 | Level 3 | Level 4 | Keywords |
|---|---|---|---|---|
| Natural level | Rainfall characteristics | Singular rainfall features | Rainfall intensity | Light rain; Moderate rain; Heavy rain; Floods |
| Multi-dimensional rainfall | Rainfall duration | Continuous rain; Prolonged rain | ||
| Rainfall timing | After the rain; Rainy night | |||
| Weather conditions | Temperature | Autumn rain | ||
| Humidity | Plum rain | |||
| Social level | Education level | Torrential rain pours down | ||
| Dialect habits | Accumulated water; The water has risen; Soaked; Where did all this water come from? | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, J.; Du, Y.; Liang, F.; Yi, J.; Wang, N.; Tu, W.; Huang, S.; Pei, T.; Ma, T. Quantifying Urban Linguistic Diversity Related to Rainfall and Flood across China with Social Media Data. ISPRS Int. J. Geo-Inf. 2024, 13, 92. https://doi.org/10.3390/ijgi13030092
Qian J, Du Y, Liang F, Yi J, Wang N, Tu W, Huang S, Pei T, Ma T. Quantifying Urban Linguistic Diversity Related to Rainfall and Flood across China with Social Media Data. ISPRS International Journal of Geo-Information. 2024; 13(3):92. https://doi.org/10.3390/ijgi13030092
Chicago/Turabian StyleQian, Jiale, Yunyan Du, Fuyuan Liang, Jiawei Yi, Nan Wang, Wenna Tu, Sheng Huang, Tao Pei, and Ting Ma. 2024. "Quantifying Urban Linguistic Diversity Related to Rainfall and Flood across China with Social Media Data" ISPRS International Journal of Geo-Information 13, no. 3: 92. https://doi.org/10.3390/ijgi13030092
APA StyleQian, J., Du, Y., Liang, F., Yi, J., Wang, N., Tu, W., Huang, S., Pei, T., & Ma, T. (2024). Quantifying Urban Linguistic Diversity Related to Rainfall and Flood across China with Social Media Data. ISPRS International Journal of Geo-Information, 13(3), 92. https://doi.org/10.3390/ijgi13030092