

Enhancing Adversarial Learning-Based Change Detection in Imbalanced Datasets Using Artificial Image Generation and Attention Mechanism


Abstract
:1. Introduction
- Firstly, we propose a data augmentation strategy designed to effectively generate new CD samples featuring diverse changes in numerous buildings. By employing building label creation and artificial image generation, we enhance the existing CD dataset, ultimately mitigating the risk of class imbalance challenges commonly encountered during the training of DL models for remote sensing building change detection.
- Secondly, we present an innovative adversarial training framework called Adv-CDNet, which utilizes a modified Pix2Pix model and integrates a channel attention mechanism. This model can directly map bi-temporal images to a CM while extracting more discriminative features, in the imbalanced dataset, for the CD task.
- Thirdly, we assess the performance of our high-resolution image generation framework on datasets with severe class imbalance. Experimentation involves two distinct publicly available Remote Sensing (RS) building Change Detection (CD) datasets. Comprehensive comparisons between our Adv-CDNet and other state-of-the-art methods show its effectiveness over alternative approaches. Furthermore, the empirical findings from the evaluations of the incorporation of our data augmentation technique demonstrate significant improvement in the performance of our proposed model.
2. Related Works
2.1. Deep-Learning-Based Methods for Remote Sensing Change Detection
2.2. Class Imbalance Challenge in Change Detection
3. Materials and Methods
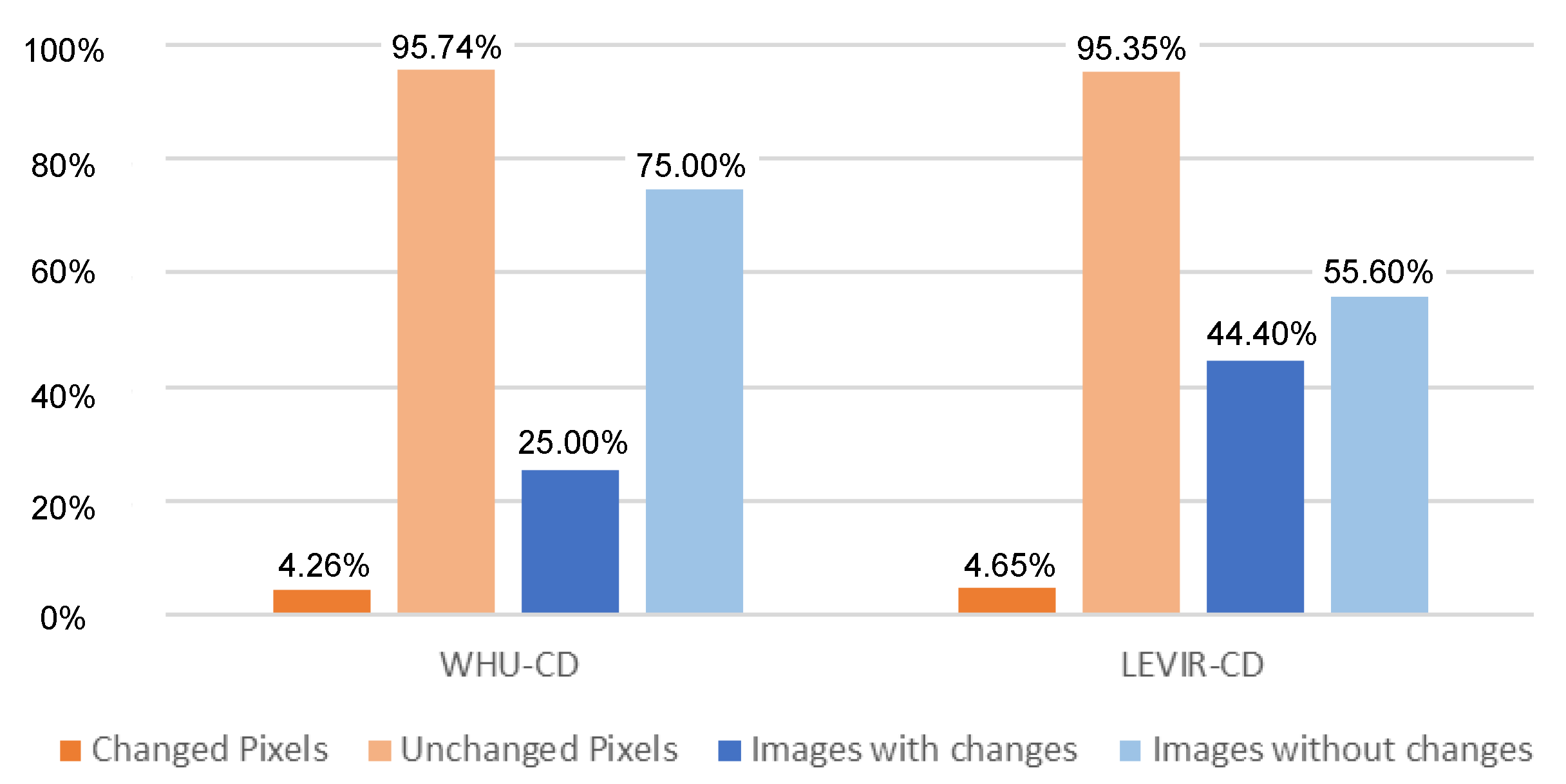
3.1. Dataset Preparation
3.1.1. Change Detection Dataset
3.1.2. Data Preparation for Remote Sensing Image Generation
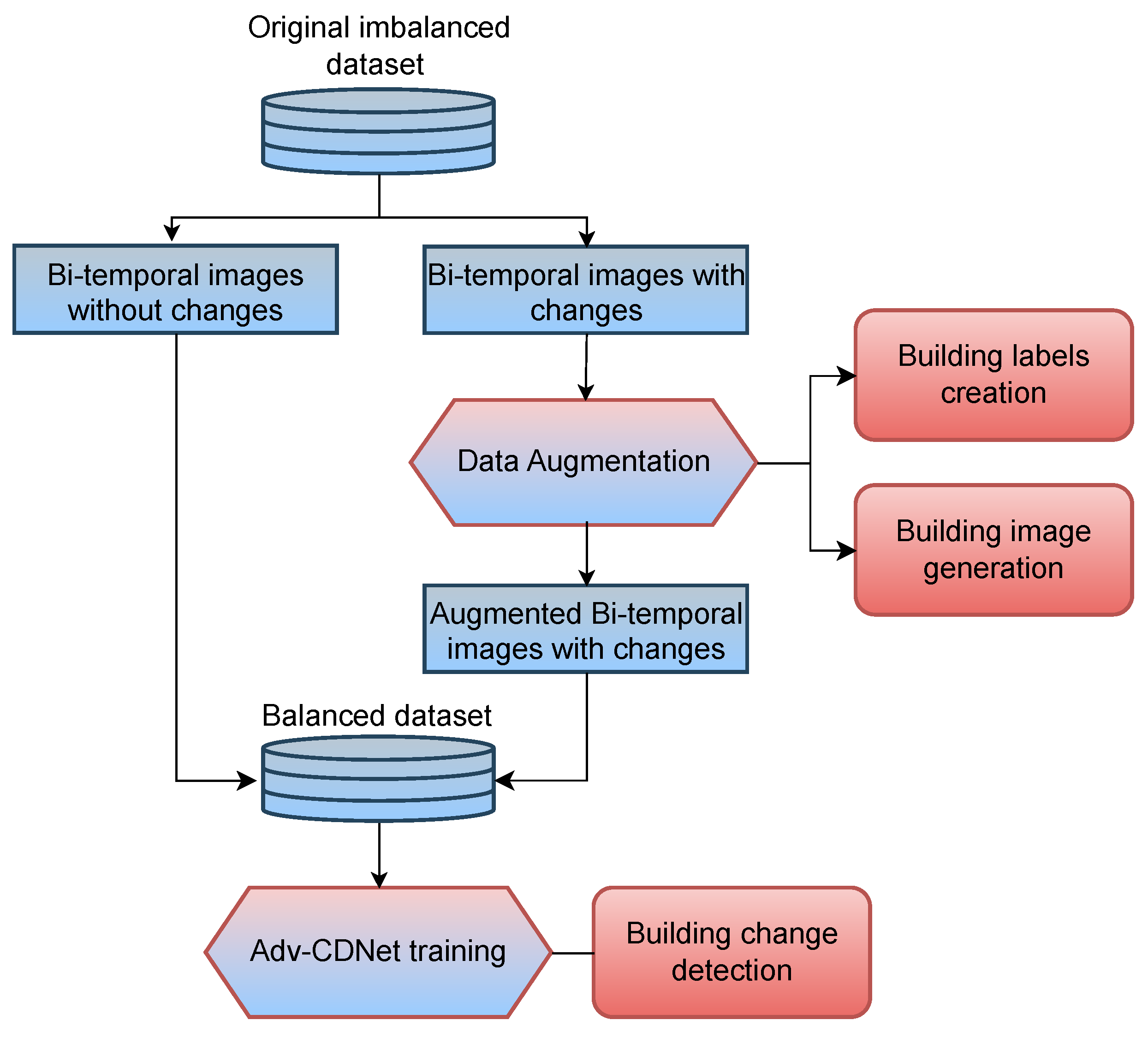
3.2. Data Augmentation Strategy
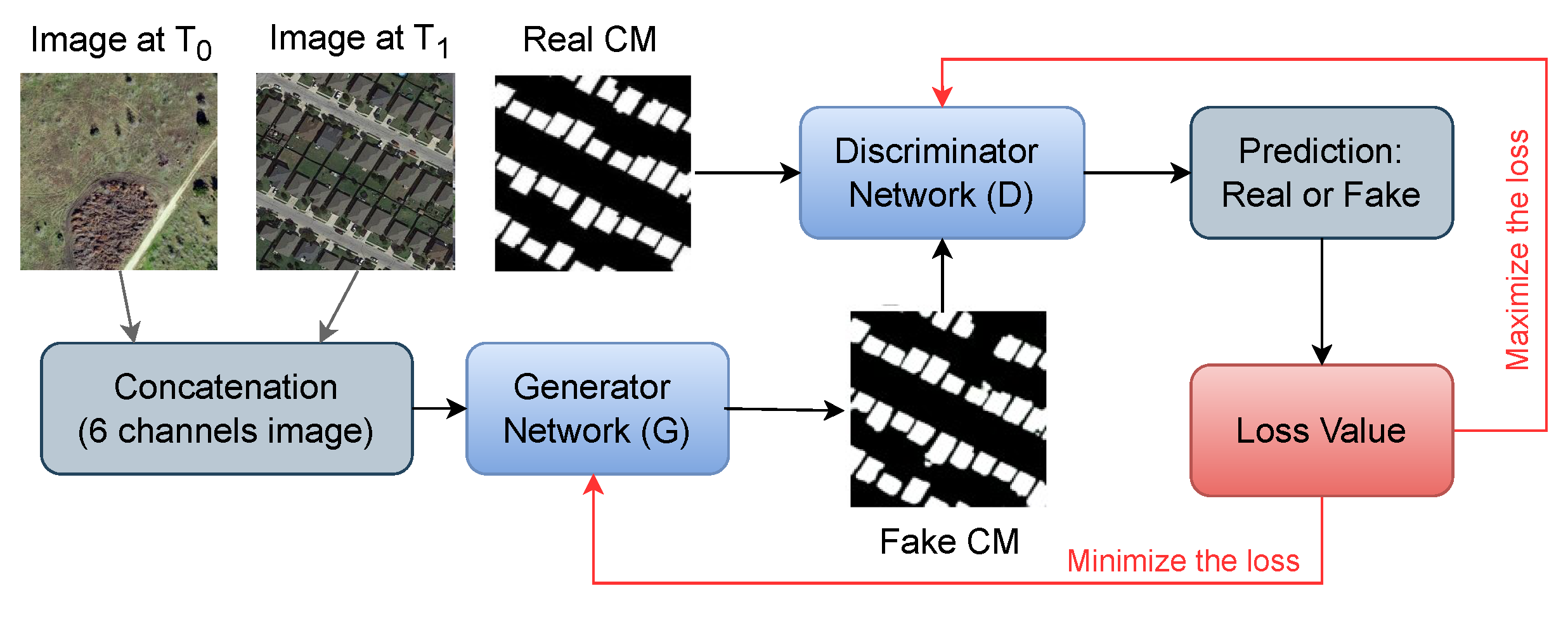
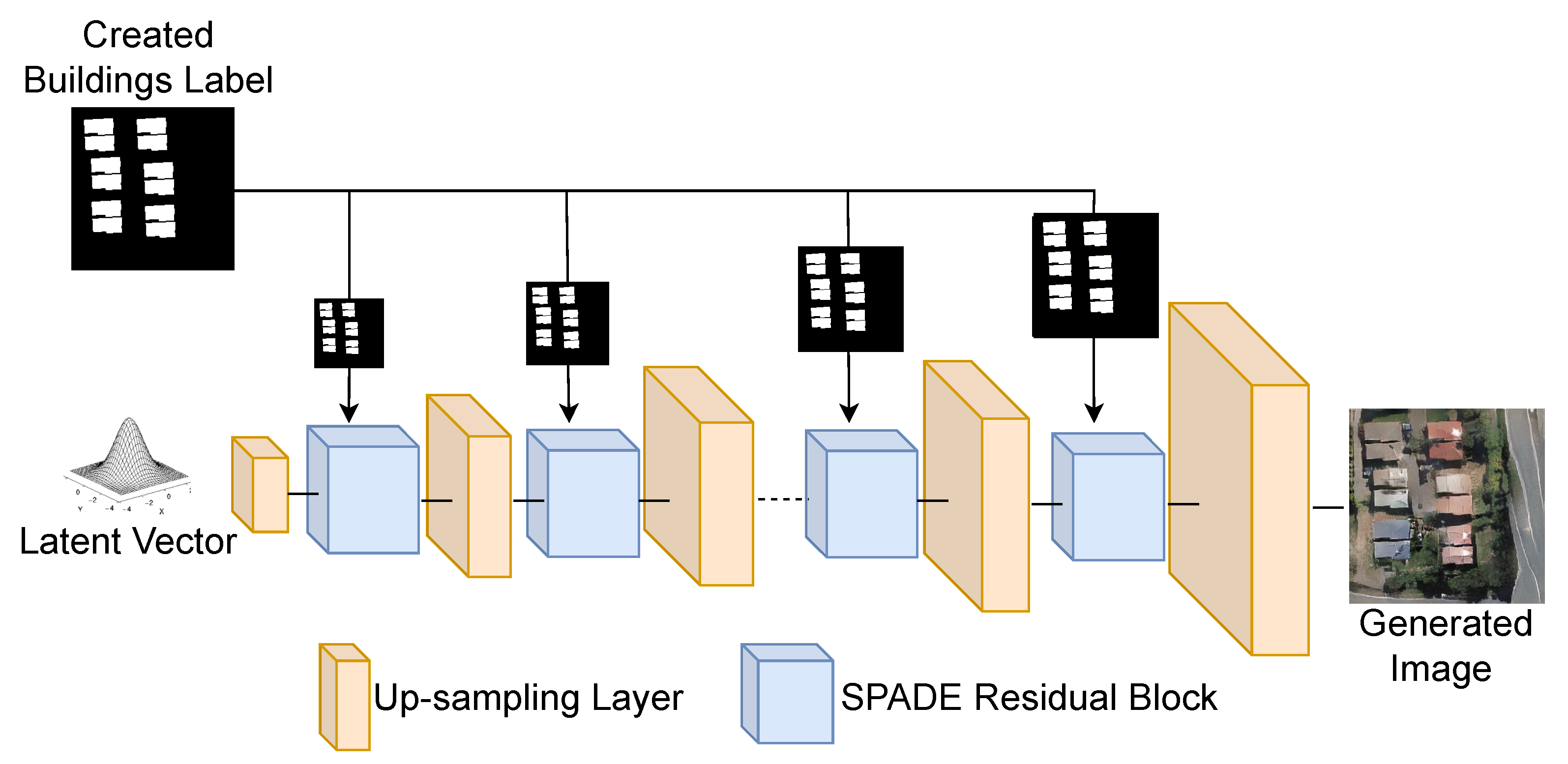
3.2.1. Building Change Detection Image Generator Model
3.2.2. Building Label Creation for Change Detection
| Algorithm 1: Building Change Samples Generation |
 |
3.2.3. New Sample Generation for the Change Detection Dataset
3.3. Building Change Detection Model
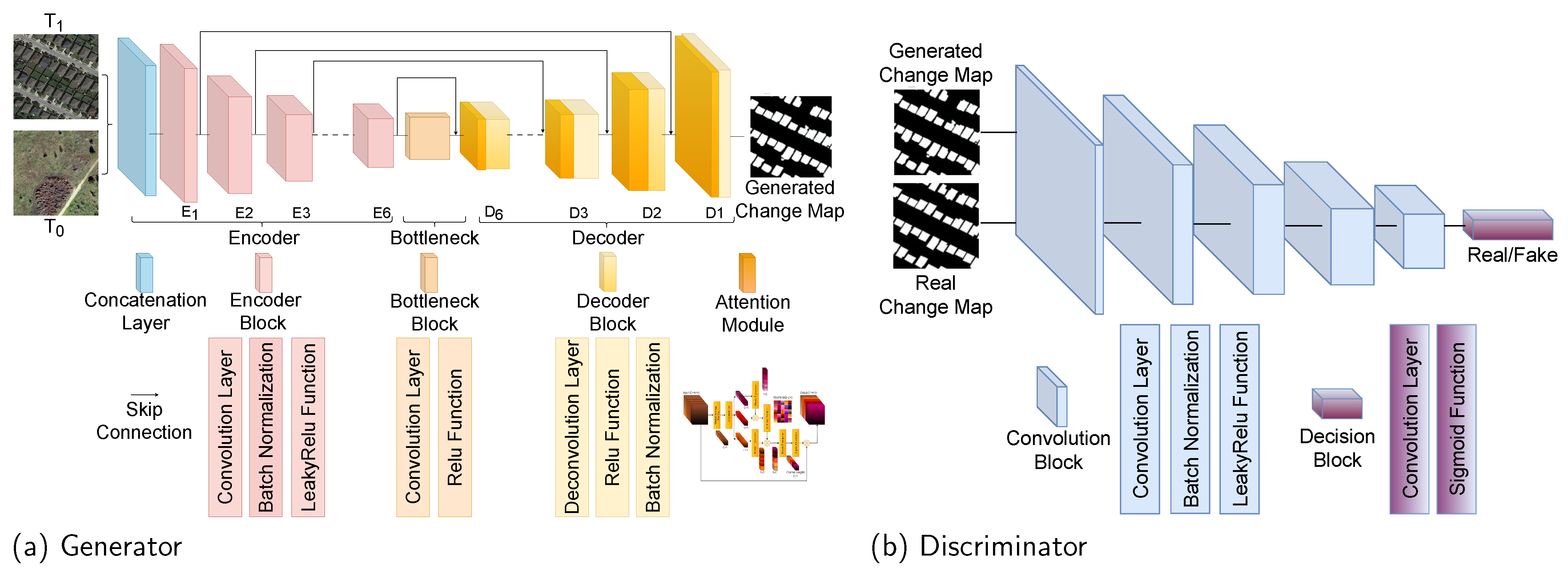
3.3.1. Adversarial Change Detection Network (Adv-CDNet)
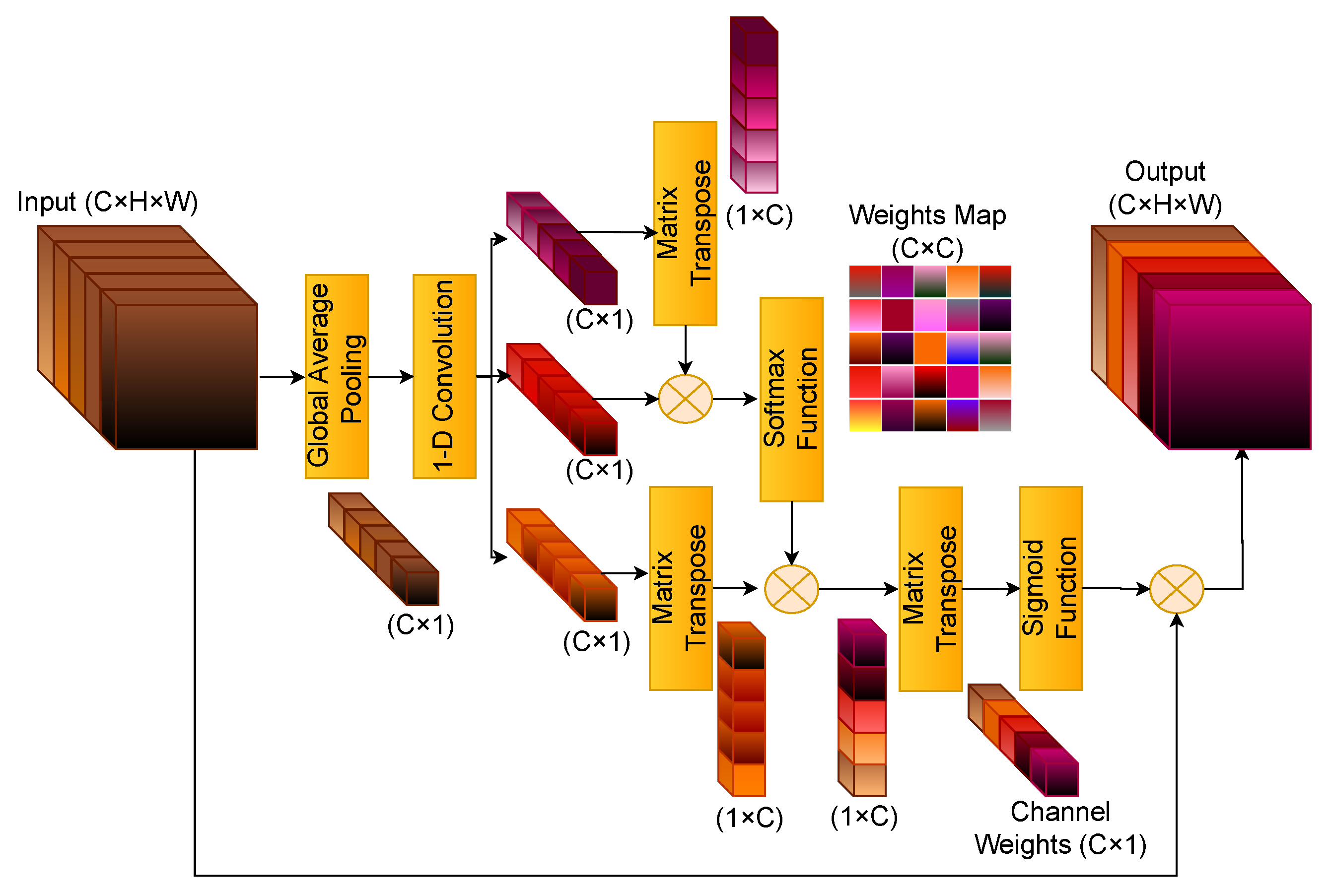
3.3.2. Channel Attention Module
4. Experiments and Results
4.1. Experimental Setup
4.2. Evaluation
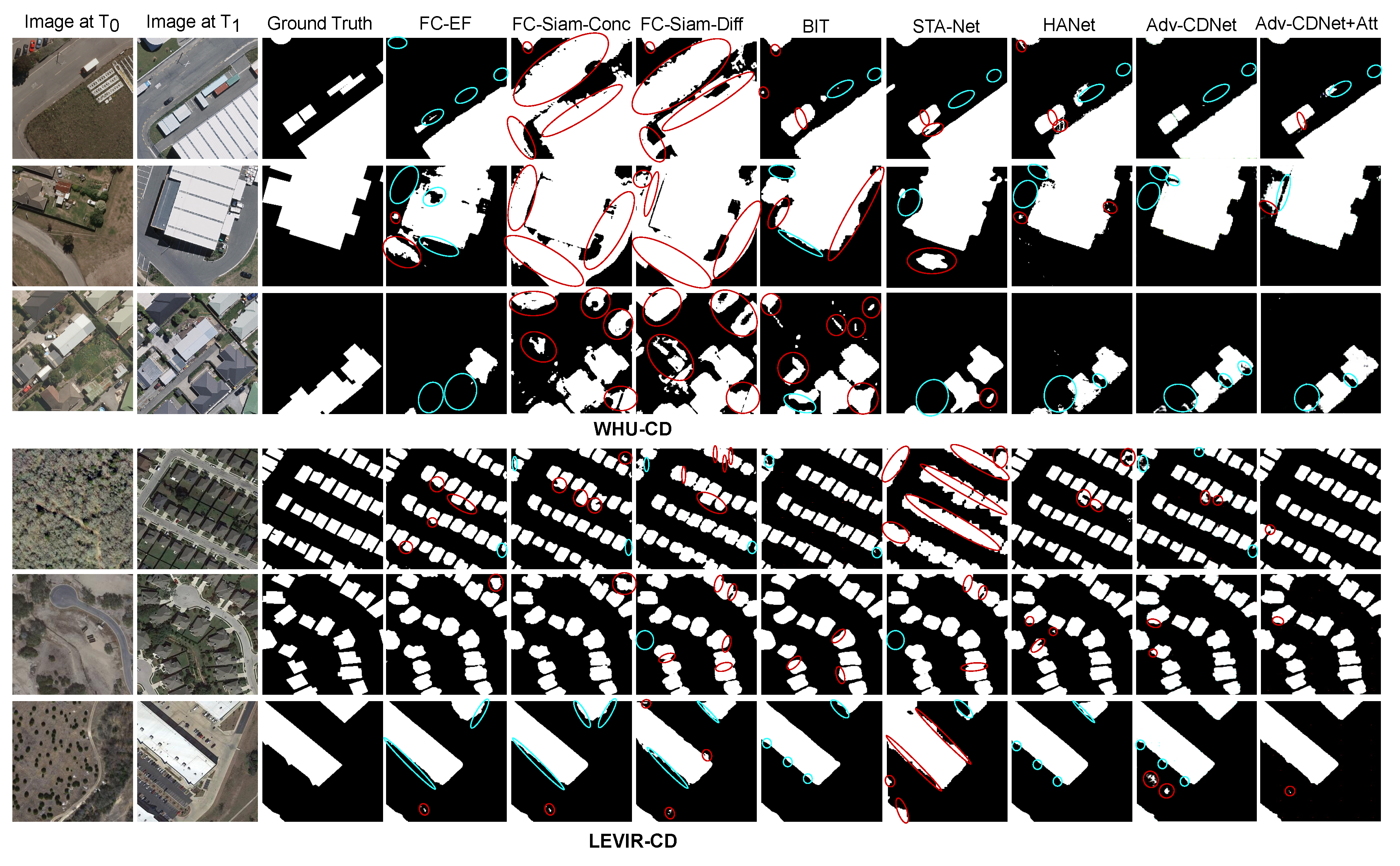
4.3. Comparison with the State-of-the-Art Change Detection Methods
- Fully Convolutional Early Fusion (FC-EF) [43]: This method employs image-level fusion based on the U-Net architecture. The bi-temporal images are concatenated into a single input for the U-Net model, facilitating holistic feature extraction.
- Fully Convolutional Siamese Concatenation (FC-Siam-Conc) [43]: In contrast to FC-EF, FC-Siam-Conc adopts feature-level fusion. It leverages two encoders with shared weights to extract features from bi-temporal images, concatenating them to the decoder at the same level.
- Fully Convolutional Siamese Difference (FC-Siam-Diff) [43]: This method shares similarities with FC-Siam-Conc, differing primarily in the formation of skip connections. Instead of simple concatenation, FC-Siam-Diff transports the absolute value of the difference between bi-temporal features to the decoder.
- Bitemporal Image Transformer (BIT) [44]: This network captures contextual information within the spatial–temporal domain. By leveraging transformer, BIT effectively models contexts between different temporal images, enhancing its ability to analyze and interpret complex spatial–temporal relationships.
- Spatial–Temporal Attention Neural Network (STANet) [9]: STANet represents a metric-based Siamese FCN approach, enhanced with a spatial–temporal attention module to extract more discriminative features.
- Hierarchical Attention Network (HANet) [26]: This model is a discriminative Siamese network, featuring a hierarchical attention network (HAN) with a lightweight and efficient self-attention mechanism, which is designed to integrate multiscale features and refine detailed features.
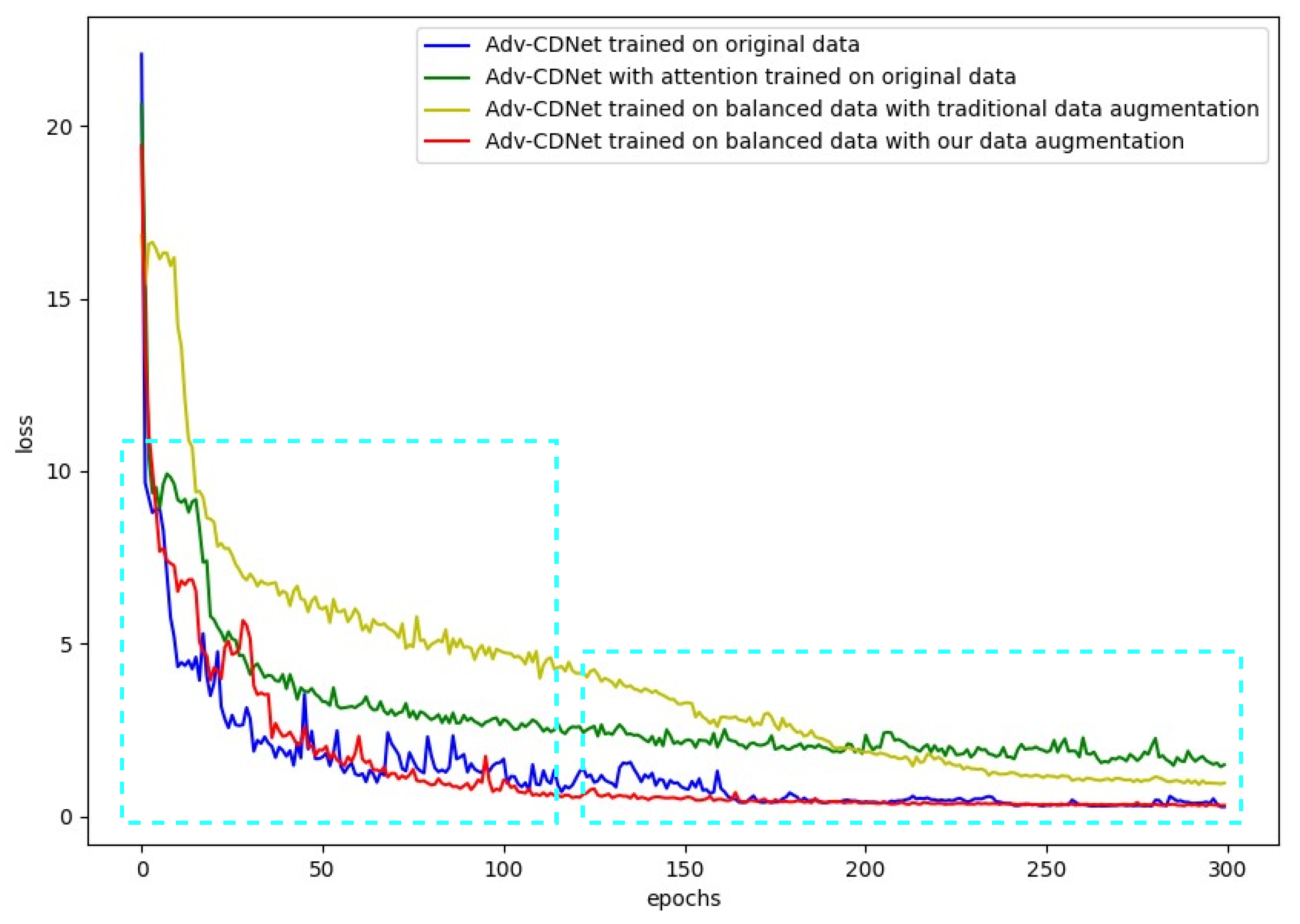
4.4. Data Augmentation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Adv-CDNet | Adversarial Change Detection Network |
| c-GAN | conditional Generative Adversarial Network |
| CD | Change Detection |
| CM | Change Map |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| GAN | Generative Adversarial Network |
| LEVIR-CD | LEVIR Building Change Detection Dataset |
| RS | Remote Sensing |
| RSCD | Remote Sensing Change Detection |
| VHR | Very High-Resolution |
| WHU-CD | WHU Building Change Detection Dataset |
References
- Singh, A. Digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef]
- Borana, S.; Yadav, S. Urban land-use susceptibility and sustainability—Case study. In Water, Land, and Forest Susceptibility and Sustainability, Volume 2; Elsevier: Amsterdam, The Netherlands, 2023; pp. 261–286. [Google Scholar] [CrossRef]
- Oubara, A.; Wu, F.; Amamra, A.; Yang, G. Survey on Remote Sensing Data Augmentation: Advances, Challenges, and Future Perspectives. In Advances in Computing Systems and Applications, Proceedings of the 5th Conference on Computing Systems and Applications, Algiers, Algeria, 17–18 May 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 95–104. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change detection based on artificial intelligence: State-of-the-art and challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual attentive fully convolutional Siamese networks for change detection in high-resolution satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1194–1206. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar] [CrossRef]
- Niu, X.; Gong, M.; Zhan, T.; Yang, Y. A conditional adversarial network for change detection in heterogeneous images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 45–49. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Lv, N.; Ma, H.; Chen, C.; Pei, Q.; Zhou, Y.; Xiao, F.; Li, J. Remote sensing data augmentation through adversarial training. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9318–9333. [Google Scholar] [CrossRef]
- Xiao, Q.; Liu, B.; Li, Z.; Ni, W.; Yang, Z.; Li, L. Progressive data augmentation method for remote sensing ship image classification based on imaging simulation system and neural style transfer. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9176–9186. [Google Scholar] [CrossRef]
- Singh, A.; Bruzzone, L. SIGAN: Spectral Index Generative Adversarial Network for Data Augmentation in Multispectral Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6003305. [Google Scholar] [CrossRef]
- Liu, W.; Luo, B.; Liu, J. Synthetic Data Augmentation Using Multiscale Attention CycleGAN for Aircraft Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4009205. [Google Scholar] [CrossRef]
- Xu, X.; Zhao, B.; Tong, X.; Xie, H.; Feng, Y.; Wang, C.; Xiao, C.; Ke, X.; Du, J. A Data Augmentation Strategy Combining a Modified pix2pix Model and the Copy-Paste Operator for Solid Waste Detection With Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8484–8491. [Google Scholar] [CrossRef]
- Seo, M.; Lee, H.; Jeon, Y.; Seo, J. Self-Pair: Synthesizing Changes from Single Source for Object Change Detection in Remote Sensing Imagery. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 6374–6383. [Google Scholar] [CrossRef]
- Chen, H.; Li, W.; Shi, Z. Adversarial Instance Augmentation for Building Change Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5603216. [Google Scholar] [CrossRef]
- Li, Y.; Chen, H.; Dong, S.; Zhuang, Y.; Li, L. Multi-Temporal SamplePair Generation for Building Change Detection Promotion in Optical Remote Sensing Domain Based on Generative Adversarial Network. Remote Sens. 2023, 15, 2470. [Google Scholar] [CrossRef]
- Feng, Y.; Jiang, J.; Xu, H.; Zheng, J. Change detection on remote sensing images using dual-branch multilevel intertemporal network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4401015. [Google Scholar] [CrossRef]
- Li, Z.; Tang, C.; Liu, X.; Zhang, W.; Dou, J.; Wang, L.; Zomaya, A.Y. Lightweight Remote Sensing Change Detection With Progressive Feature Aggregation and Supervised Attention. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5602812. [Google Scholar] [CrossRef]
- Samadi, F.; Akbarizadeh, G.; Kaabi, H. Change detection in SAR images using deep belief network: A new training approach based on morphological images. IET Image Process. 2019, 13, 2255–2264. [Google Scholar] [CrossRef]
- Ye, Y.; Wang, M.; Zhou, L.; Lei, G.; Fan, J.; Qin, Y. Adjacent-Level Feature Cross-Fusion With 3-D CNN for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5618214. [Google Scholar] [CrossRef]
- He, C.; Zhao, Y.; Dong, J.; Xiang, Y. Use of GAN to Help Networks to Detect Urban Change Accurately. Remote Sens. 2022, 14, 5448. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE international conference on image processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar] [CrossRef]
- Han, C.; Wu, C.; Guo, H.; Hu, M.; Chen, H. HANet: A hierarchical attention network for change detection with bi-temporal very-high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3867–3878. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5604816. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Y.; Luo, L.; Wang, N. CSA-CDGAN: Channel self-attention-based generative adversarial network for change detection of remote sensing images. Neural Comput. Appl. 2022, 34, 21999–22013. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, G.; Zhang, Y.; Wang, B.; Li, H.; Fan, L. MCHA-Net: A multi-end composite higher-order attention network guided with hierarchical supervised signal for high-resolution remote sensing image change detection. ISPRS J. Photogramm. Remote Sens. 2023, 202, 40–68. [Google Scholar] [CrossRef]
- Zhang, J.; Pan, B.; Zhang, Y.; Liu, Z.; Zheng, X. Building Change Detection in Remote Sensing Images Based on Dual Multi-Scale Attention. Remote Sens. 2022, 14, 5405. [Google Scholar] [CrossRef]
- Ren, H.; Xia, M.; Weng, L.; Hu, K.; Lin, H. Dual-Attention-Guided Multiscale Feature Aggregation Network for Remote Sensing Image Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4899–4916. [Google Scholar] [CrossRef]
- Cao, Z.; Wu, M.; Yan, R.; Zhang, F.; Wan, X. Detection of small changed regions in remote sensing imagery using convolutional neural network. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Beijing, China, 18–20 November 2020; Volume 502, p. 012017. [Google Scholar] [CrossRef]
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building change detection for remote sensing images using a dual-task constrained deep siamese convolutional network model. IEEE Geosci. Remote Sens. Lett. 2020, 18, 811–815. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. In Proceedings of the 2016 International Conference on Learning Representations (ICLR 2016), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning (ICML’17), Sydney, NSW, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gauthier, J. Conditional Generative Adversarial Nets for Convolutional Face Generation. 2014. Available online: https://www.semanticscholar.org/paper/Conditional-generative-adversarial-nets-for-face-Gauthier/5cd47e5d004d75fe773a252bde35b56d5d56ce06 (accessed on 6 March 2017).
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2337–2346. [Google Scholar] [CrossRef]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar] [CrossRef]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. In Proceedings of the Sixth International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar] [CrossRef]
- Guo, Q.; Zhang, J.; Zhu, S.; Zhong, C.; Zhang, Y. Deep multiscale Siamese network with parallel convolutional structure and self-attention for change detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5406512. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection with Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607514. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | FLOPs | Param | WHU-CD | LEVIR-CD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (G) | (M) | OA | IoU | Pre | Re | F1 | OA | IoU | Pre | Re | F1 | |
| FC-EF | 2.29 | 1.35 | 95.30 | 46.12 | 58.47 | 68.58 | 63.12 | 97.81 | 64.79 | 78.16 | 79.12 | 78.63 |
| FC-Siam-Conc | 2.29 | 1.54 | 87.00 | 40.51 | 54.00 | 78.23 | 63.89 | 98.33 | 70.64 | 87.25 | 78.77 | 82.79 |
| FC-Siam-Diff | 2.29 | 1.35 | 96.77 | 49.91 | 60.24 | 51.53 | 55.54 | 97.91 | 63.11 | 85.99 | 70.35 | 77.39 |
| Adv-CDNet | 13.41 | 6.14 | 98.20 | 50.43 | 77.74 | 56.22 | 65.26 | 98.62 | 74.85 | 90.95 | 80.88 | 85.62 |
| BIT | 4.35 | 3.55 | 96.96 | 57.49 | 79.58 | 65.49 | 71.85 | 97.81 | 75.65 | 88.84 | 83.05 | 85.85 |
| STA-Net | 13.88 | 16.92 | 93.18 | 56.63 | 61.83 | 82.57 | 70.71 | 95.92 | 75.01 | 77.79 | 95.56 | 84.10 |
| HANet | 14.07 | 3.03 | 97.35 | 58.34 | 82.14 | 62.96 | 71.28 | 98.63 | 75.85 | 87.45 | 85.12 | 86.27 |
| Adv-CDNet + Attention | 13.41 | 6.80 | 98.53 | 59.83 | 84.21 | 63.02 | 72.10 | 98.67 | 76.10 | 90.54 | 82.92 | 86.56 |
| Methods | WHU-CD | LEVIR-CD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| OA | IoU | Pre | Re | F1 | OA | IoU | Pre | Re | F1 | |
| Adv-CDNet | ||||||||||
| without data augmentation | 98.20 | 50.43 | 77.74 | 56.22 | 65.26 | 98.62 | 74.85 | 90.95 | 80.88 | 85.62 |
| Adv-CDNet | ||||||||||
| with traditional augmentation | 98.23 | 53.36 | 84.05 | 59.37 | 69.58 | 98.11 | 74.91 | 89.98 | 81.63 | 85.60 |
| Adv-CDNet | ||||||||||
| with our augmentation | 98.61 | 71.87 | 85.55 | 78.29 | 81.76 | 98.64 | 75.24 | 90.24 | 82.75 | 86.33 |
| Methods | WHU-CD | LEVIR-CD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| OA | IoU | Pre | Re | F1 | OA | IoU | Pre | Re | F1 | |
| BIT | 96.96 | 57.49 | 79.58 | 65.49 | 71.85 | 97.81 | 75.65 | 88.84 | 83.05 | 85.85 |
| BIT with DA | 98.42 | 70.20 | 82.35 | 78.76 | 80.52 | 98.22 | 76.35 | 89.94 | 83.33 | 86.50 |
| STA-Net | 93.18 | 56.63 | 61.83 | 82.57 | 70.71 | 95.92 | 75.01 | 77.79 | 95.56 | 84.10 |
| STA-Net with DA | 96.11 | 69.92 | 75.98 | 85.20 | 80.33 | 96.56 | 76.11 | 78.53 | 95.41 | 86.15 |
| HANet | 97.35 | 58.34 | 82.14 | 62.96 | 71.28 | 98.63 | 75.85 | 87.45 | 85.12 | 86.27 |
| HANet with DA | 98.63 | 71.72 | 83.65 | 80.86 | 82.23 | 98.65 | 76.37 | 90.54 | 82.92 | 86.56 |
| Adv-CDNet + Attention | 98.53 | 59.83 | 84.21 | 63.02 | 72.10 | 98.67 | 76.10 | 90.54 | 82.92 | 86.56 |
| Adv-CDNet + Attention with DA | 98.99 | 72.95 | 86.94 | 79.89 | 83.27 | 98.70 | 76.74 | 91.12 | 82.71 | 86.71 |
| Dataset | Changed / Unchanged Maps | Method | OA | IoU | Pre | Re | F1 |
|---|---|---|---|---|---|---|---|
| WHU-CD | 25%/75% (original data) | Adv-CDNet | 98.20 | 50.43 | 77.74 | 56.22 | 65.26 |
| Adv-CDNet + Attention | 98.53 | 59.83 | 84.21 | 63.02 | 72.10 | ||
| 50%/50% | Adv-CDNet | 98.61 | 71.87 | 85.55 | 78.29 | 81.76 | |
| Adv-CDNet + Attention | 98.99 | 72.95 | 86.94 | 79.89 | 83.27 | ||
| 75%/25% | Adv-CDNet | 99.35 | 90.53 | 91.21 | 99.19 | 95.03 | |
| Adv-CDNet + Attention | 99.17 | 88.03 | 90.3 | 97.22 | 93.63 | ||
| 100%/0% | Adv-CDNet | 98.84 | 84.14 | 85.21 | 98.53 | 91.34 | |
| Adv-CDNet + Attention | 98.95 | 85.49 | 86.18 | 99.07 | 92.17 | ||
| LEVIR-CD | 44.4%/55.6% (original data) | Adv-CDNet | 98.62 | 74.85 | 90.95 | 80.88 | 85.62 |
| Adv-CDNet + Attention | 98.67 | 76.10 | 90.54 | 82.92 | 86.56 | ||
| 50%/50% | Adv-CDNet | 98.64 | 75.24 | 90.24 | 82.75 | 86.33 | |
| Adv-CDNet + Attention | 98.70 | 76.74 | 91.12 | 82.71 | 86.71 | ||
| 75%/25% | Adv-CDNet | 98.59 | 74.56 | 89.95 | 81.33 | 85.42 | |
| Adv-CDNet + Attention | 98.48 | 73.62 | 86.24 | 83.41 | 84.80 | ||
| 100%/0% | Adv-CDNet | 98.02 | 67.44 | 80.33 | 80.78 | 80.56 | |
| Adv-CDNet + Attention | 98.08 | 68.53 | 80.38 | 82.30 | 81.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oubara, A.; Wu, F.; Maleki, R.; Ma, B.; Amamra, A.; Yang, G. Enhancing Adversarial Learning-Based Change Detection in Imbalanced Datasets Using Artificial Image Generation and Attention Mechanism. ISPRS Int. J. Geo-Inf. 2024, 13, 125. https://doi.org/10.3390/ijgi13040125
Oubara A, Wu F, Maleki R, Ma B, Amamra A, Yang G. Enhancing Adversarial Learning-Based Change Detection in Imbalanced Datasets Using Artificial Image Generation and Attention Mechanism. ISPRS International Journal of Geo-Information. 2024; 13(4):125. https://doi.org/10.3390/ijgi13040125
Chicago/Turabian StyleOubara, Amel, Falin Wu, Reza Maleki, Boyi Ma, Abdenour Amamra, and Gongliu Yang. 2024. "Enhancing Adversarial Learning-Based Change Detection in Imbalanced Datasets Using Artificial Image Generation and Attention Mechanism" ISPRS International Journal of Geo-Information 13, no. 4: 125. https://doi.org/10.3390/ijgi13040125
APA StyleOubara, A., Wu, F., Maleki, R., Ma, B., Amamra, A., & Yang, G. (2024). Enhancing Adversarial Learning-Based Change Detection in Imbalanced Datasets Using Artificial Image Generation and Attention Mechanism. ISPRS International Journal of Geo-Information, 13(4), 125. https://doi.org/10.3390/ijgi13040125