



Search Engine for Open Geospatial Consortium Web Services Improving Discoverability through Natural Language Processing-Based Processing and Ranking
 , ,
, ,
Abstract
:1. Introduction
2. Background
2.1. OGC Web Services
2.2. Geospatial Search Engine
2.3. Ranking Methods
2.4. Semantic Augmentation
2.5. Data Visualization
3. Methods
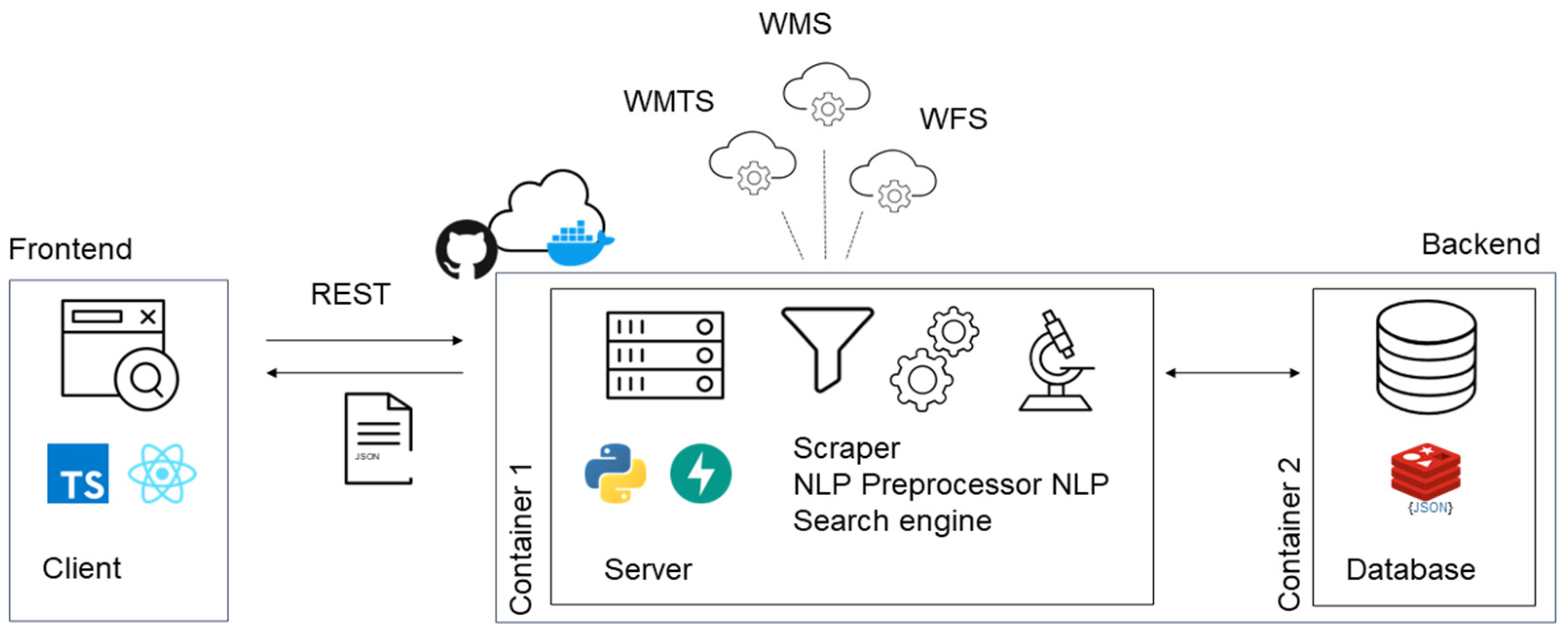
3.1. Architecture
3.2. Scraper
3.3. Semantic Augmentation and Preprocessing
3.4. High-Performance Database
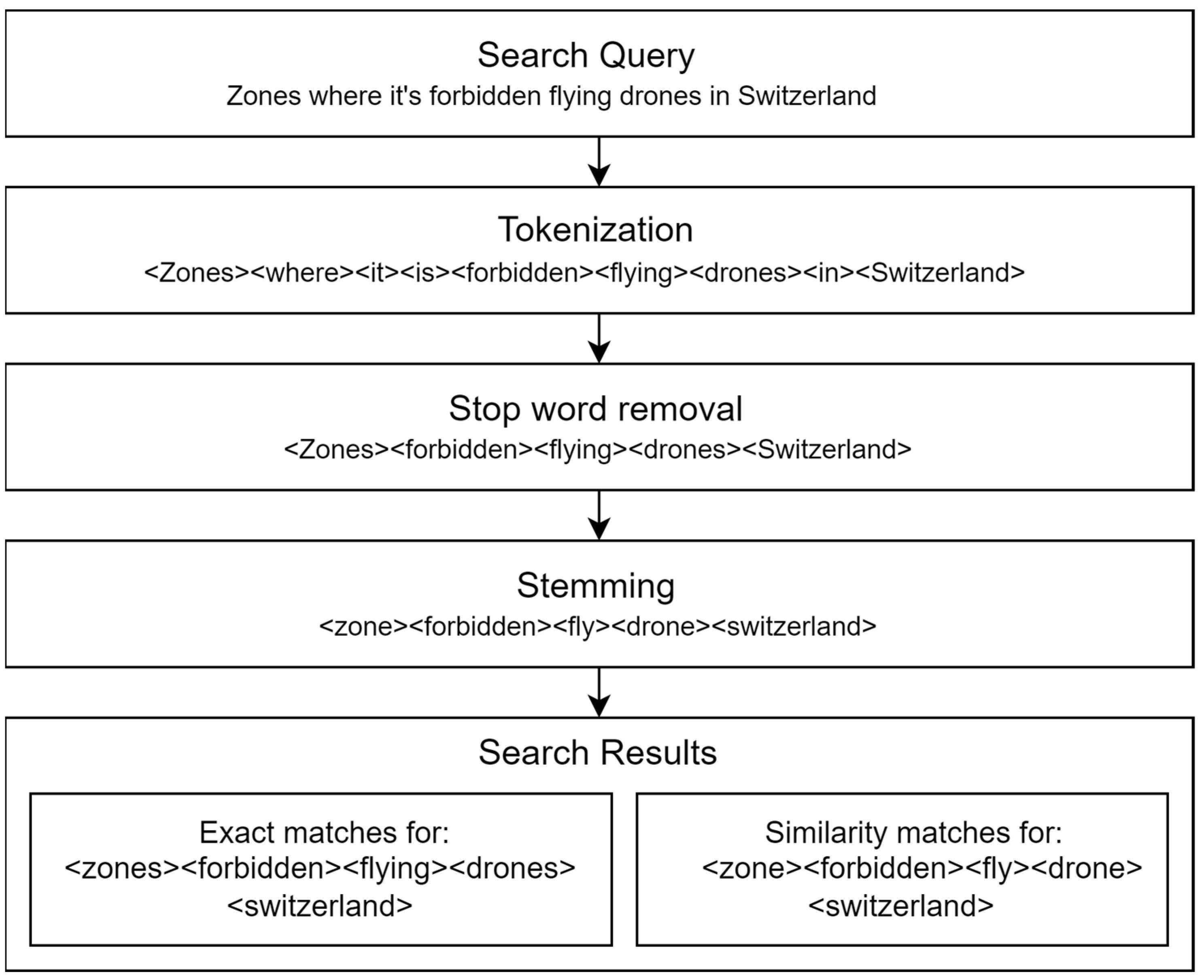
3.5. Query Expansion
3.6. Results Ranking
4. Results
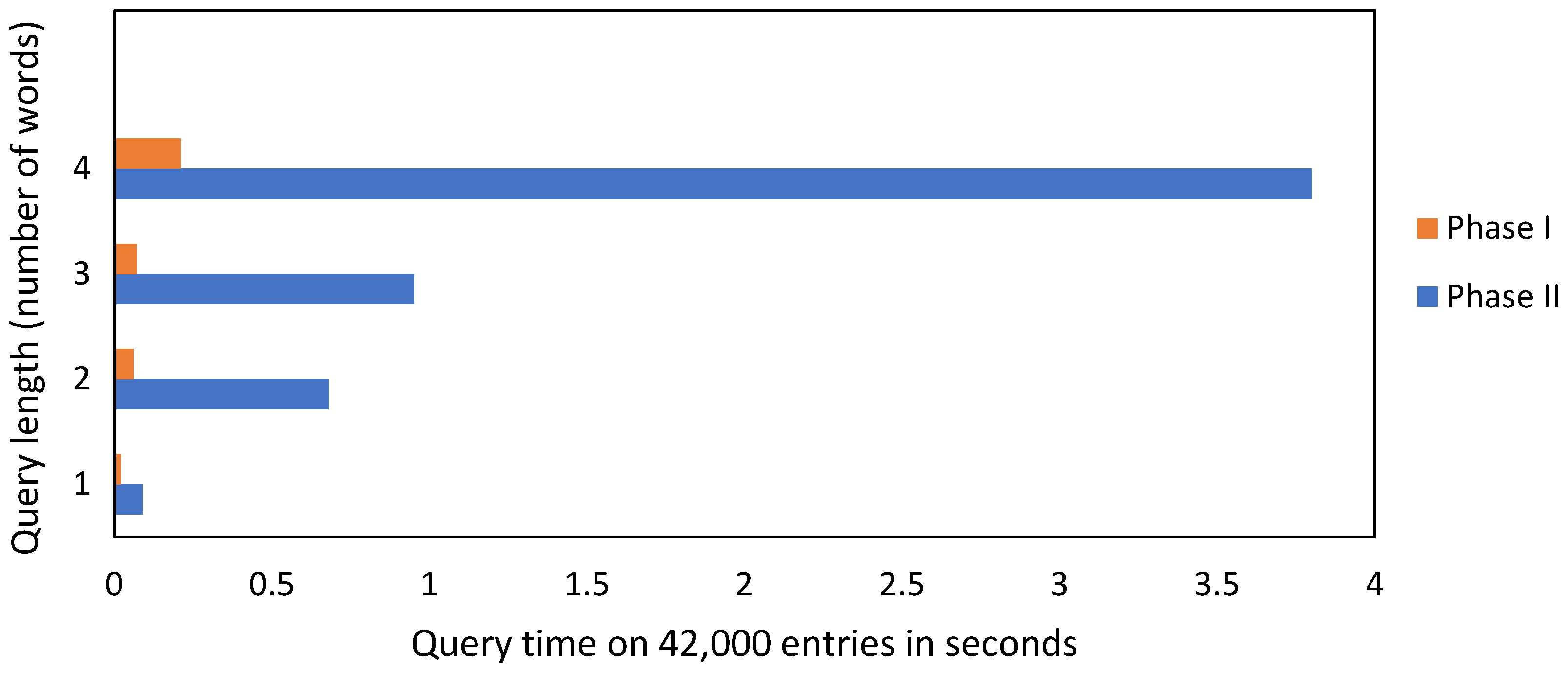
4.1. System Response Times
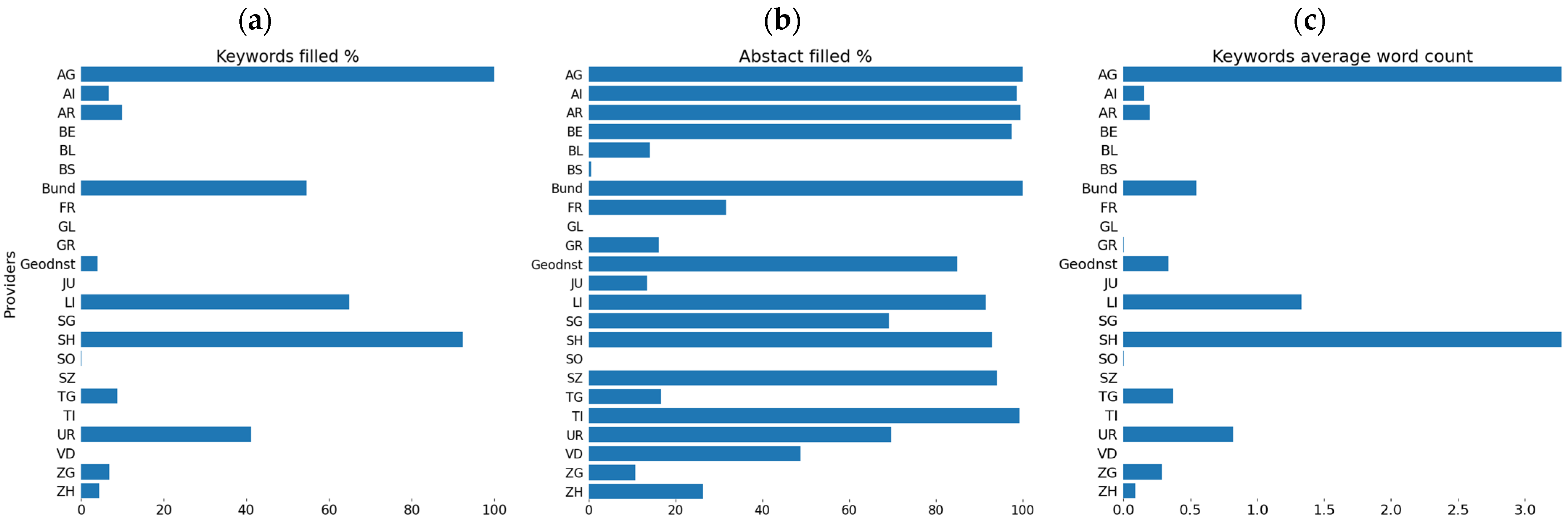
4.2. OWS Dataset Discoverability
4.3. Search Results’ Ranking
4.4. GeoHarvester PoC Prototype
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ma, J.; Co, J.E.; Quintanilla, A. A Semantic Index Structure for Integrating OGC Services in a Spatial Search Engine. In Proceedings of the 2010 IEEE Conference on Open Systems (ICOS 2010), Kuala Lumpur, Malaysia, 5–7 December 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 103–108. [Google Scholar]
- De la Beaujardiere, J. OpenGIS® Web Map Server Implementation Specification 2006. Available online: https://portal.ogc.org/files/?artifact_id=14416 (accessed on 11 November 2023).
- Maso, J.; Pomakis, K.; Julià, N. OpenGIS® Web Map Tile Service Implementation Standard 2010. Available online: https://portal.ogc.org/files/?artifact_id=35326 (accessed on 11 November 2023).
- Vretanos, P.A. Web Feature Service Implementation Specification 2005. Available online: https://portal.ogc.org/files/?artifact_id=8339 (accessed on 11 November 2023).
- Yue, P.; Di, L.; Zhao, P.; Yang, W.; Yu, G.; Wei, Y. Semantic Augmentations for Geospatial Catalogue Service. In Proceedings of the 2006 IEEE International Symposium on Geoscience and Remote Sensing, Denver, CO, USA, 31 July–4 August 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 3486–3489. [Google Scholar]
- Oesch, D. Resultate Der GeoUnconference—Thema 16—Service-Verzeichnis 2022. Available online: https://github.com/GeoUnconference/discussions/discussions/38 (accessed on 29 November 2023).
- Bone, C.; Ager, A.; Bunzel, K.; Tierney, L. A Geospatial Search Engine for Discovering Multi-Format Geospatial Data across the Web. Int. J. Digit. Earth 2016, 9, 47–62. [Google Scholar] [CrossRef]
- Huang, C.-Y.; Chang, H. GeoWeb Crawler: An Extensible and Scalable Web Crawling Framework for Discovering Geospatial Web Resources. ISPRS Int. J. Geo-Inf. 2016, 5, 136. [Google Scholar] [CrossRef]
- Miao, L.; Guo, J.; Cheng, W.; Zhou, Y. A Novel Model to Support OGC Web Services Semantic Search Using OWL-S. In Proceedings of the 2016 24th International Conference on Geoinformatics, Galway, Ireland, 14–20 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–4. [Google Scholar]
- Saquicela, V.; Vilches-Blázquez, L.M.; Freire, R.; Corcho, O. Annotating OGC Web Feature Services Automatically for Generating Geospatial Knowledge Graphs. Trans. GIS 2022, 26, 505–541. [Google Scholar] [CrossRef]
- Miao, L.; Liu, C.; Fan, L.; Kwan, M.-P. An OGC Web Service Geospatial Data Semantic Similarity Model for Improving Geospatial Service Discovery. Open Geosci. 2021, 13, 245–261. [Google Scholar] [CrossRef]
- Halilali, M.S.; Gouardères, E.; Gaio, M.; Devin, F. Geospatial Web Services Discovery through Semantic Annotation of WPS. ISPRS Int. J. Geo-Inf. 2022, 11, 254. [Google Scholar] [CrossRef]
- Shen, S.; Liu, W.; Wu, H.; Chen, Y. A Multi-Level Comprehensive Evaluation Method for Quality of WMS Based on Fuzzy Mathematics. In Proceedings of the 2009 17th International Conference on Geoinformatics, Fairfax, VA, USA, 12–14 August 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1–5. [Google Scholar]
- Woodruff, A.G.; Plaunt, C. GIPSY: Automated Geographic Indexing of Text Documents. J. Am. Soc. Inf. Sci. 1994, 45, 645–655. [Google Scholar] [CrossRef]
- Amitay, E.; Har’El, N.; Sivan, R.; Soffer, A. Web-a-Where: Geotagging Web Content. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, 25 July 2004; ACM: New York, NY, USA, 2004; pp. 273–280. [Google Scholar]
- Purves, R.S.; Clough, P.; Jones, C.B.; Arampatzis, A.; Bucher, B.; Finch, D.; Fu, G.; Joho, H.; Syed, A.K.; Vaid, S.; et al. The Design and Implementation of SPIRIT: A Spatially Aware Search Engine for Information Retrieval on the Internet. Int. J. Geogr. Inf. Sci. 2007, 21, 717–745. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; ISBN 978-0-521-86571-5. [Google Scholar]
- Frontiera, P.; Larson, R.; Radke, J. A Comparison of Geometric Approaches to Assessing Spatial Similarity for GIR. Int. J. Geogr. Inf. Sci. 2008, 22, 337–360. [Google Scholar] [CrossRef]
- Andrade, L.; Silva, M. Relevance Ranking for Geographic IR. In Proceedings of the 3rd ACM Workshop on Geographic Information Retrieval, Seattle, WA, USA, 10 August 2006. [Google Scholar]
- Rose, S.; Engel, D.; Cramer, N.; Cowley, W. Automatic Keyword Extraction from Individual Documents. In Text Mining; Berry, M.W., Kogan, J., Eds.; Wiley: Hoboken, NJ, USA, 2010; pp. 1–20. ISBN 978-0-470-74982-1. [Google Scholar]
- Robertson, S.; Walker, S.; Jones, S.; Hancock-Beaulieu, M.; Gatford, M. Okapi at TREC-3; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 1994. [Google Scholar]
- Kendall, M.G. A New Measure of Rank Correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Larson, R.R. Ranking Approaches for GIR. SIGSPATIAL Spec. 2011, 3, 37–41. [Google Scholar] [CrossRef]
- Chen, L.; Cong, G.; Jensen, C.S.; Wu, D. Spatial Keyword Query Processing: An Experimental Evaluation. Proc. VLDB Endow. 2013, 6, 217–228. [Google Scholar] [CrossRef]
- Ji, X.; Sungu-Eryilmaz, Y.; Momeni, E.; Rawassizadeh, R. Speeding Up Question Answering Task of Language Models via Inverted Index. arXiv 2022. [Google Scholar] [CrossRef]
- Park, D.; Ahn, C.W. Self-Supervised Contextual Data Augmentation for Natural Language Processing. Symmetry 2019, 11, 1393. [Google Scholar] [CrossRef]
- Jehangir, B.; Radhakrishnan, S.; Agarwal, R. A Survey on Named Entity Recognition—Datasets, Tools, and Methodologies. Nat. Lang. Process. J. 2023, 3, 100017. [Google Scholar] [CrossRef]
- Shneiderman, B.; Byrd, D.; Croft, W.B. Sorting out Searching: A User-Interface Framework for Text Searches. Commun. ACM 1998, 41, 95–98. [Google Scholar] [CrossRef]
- Purves, R.S.; Clough, P.; Jones, C.B.; Hall, M.H.; Murdock, V. Geographic Information Retrieval: Progress and Challenges in Spatial Search of Text. FNT Inf. Retr. 2018, 12, 164–318. [Google Scholar] [CrossRef]
- Sarhan, S. Smart Voice Search Engine. J. Comput. Appl. 2014, 90, 40–44. [Google Scholar] [CrossRef]
- Roy, N.; Maxwell, D.; Hauff, C. Users and Contemporary SERPs: A (Re-)Investigation Examining User Interactions and Experiences. arXiv 2022. [Google Scholar] [CrossRef]
- Oesch, D. Geoservice Harvester POC Open Geo Services Reported by the Swiss Gov Agencies and Third Parties 2023. Available online: https://github.com/davidoesch/geoservice_harvester_poc (accessed on 15 August 2023).
- Honnibal, M.; Boyd, A.; Van Landeghem, S.; Montani, I. spaCy: Industrial-Strength Natural Language Processing in Python. 2020. Available online: https://zenodo.org/doi/10.5281/zenodo.1212303 (accessed on 15 August 2023).
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Bosco, C.; Lombardo, V.; Vassallo, D.; Lesmo, L. Building a Treebank for Italian: A Data-Driven Annotation Schema. In Proceedings of the Second International Conference on Language Resources and Evaluation (LREC’00), Athens, Greece, 31 May–2 June 2000; Gavrilidou, M., Carayannis, G., Markantonatou, S., Piperidis, S., Stainhauer, G., Eds.; European Language Resources Association (ELRA): Paris, France, 2000. [Google Scholar]
- Weischedel, R.; Palmer, M.; Marcus, M.; Hovy, E.; Pradhan, S.; Ramshaw, L.; Xue, N.; Taylor, A.; Kaufman, J.; Franchini, M.; et al. OntoNotes Release 5.0; 2806280 KB; Linguistic Data Consortium: Philadelphia, PA, USA, 2013. [Google Scholar]
- Brants, S.; Dipper, S.; Eisenberg, P.; Hansen-Schirra, S.; König, E.; Lezius, W.; Rohrer, C.; Smith, G.; Uszkoreit, H. TIGER: Linguistic Interpretation of a German Corpus. Res. Lang. Comput. 2004, 2, 597–620. [Google Scholar] [CrossRef]
- Candito, M.; Seddah, D. Le Corpus Sequoia: Annotation Syntaxique et Exploitation Pour l’adaptation d’analyseur Par Pont Lexical. In Proceedings of the TALN 2012—19e Conférence sur le Traitement Automatique des Langues Naturelles, Grenoble, France, 4–8 June 2012. [Google Scholar]
- Shuyo, N. Language Detection Library for Java 2010. Available online: http://code.google.com/p/language-detection/ (accessed on 10 November 2023).
- Chen, S.; Tang, X.; Wang, H.; Zhao, H.; Guo, M. Towards Scalable and Reliable In-Memory Storage System: A Case Study with Redis. In Proceedings of the 2016 IEEE Trustcom/BigDataSE/ISPA, Tianjin, China, 23–26 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1660–1667. [Google Scholar]
- Card, S.K.; Robertson, G.G.; Mackinlay, J.D. The Information Visualizer, an Information Workspace. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems Reaching through Technology—CHI’ 91, New Orleans, LA, USA, 27 April–2 May 1991; ACM Press: New York, NY, USA, 1991; pp. 181–186. [Google Scholar]
- Porter, M.F. An Algorithm for Suffix Stripping. Program 1980, 14, 130–137. [Google Scholar] [CrossRef]
- Chen, J.; Jiménez-Ruiz, E.; Horrocks, I.; Antonyrajah, D.; Hadian, A.; Lee, J. Augmenting Ontology Alignment by Semantic Embedding and Distant Supervision. In The Semantic Web; Verborgh, R., Hose, K., Paulheim, H., Champin, P.-A., Maleshkova, M., Corcho, O., Ristoski, P., Alam, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12731, pp. 392–408. ISBN 978-3-030-77384-7. [Google Scholar]
- Federal Statistical Office Permanent Resident Population by Category of Citizenship and Sex by Canton and City, 1999–2022. 2022. Available online: https://www.bfs.admin.ch/asset/en/26565157 (accessed on 12 November 2023).
- Elnagar, S.; Yoon, V.; Thomas, M.A. An Automatic Ontology Generation Framework with An Organizational Perspective. In Proceedings of the Hawaii International Conference on System Sciences 2020, Honolulu, HI, USA, 7–10 January 2020; ScholarSpace: Kathmandu, Nepal, 2020. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
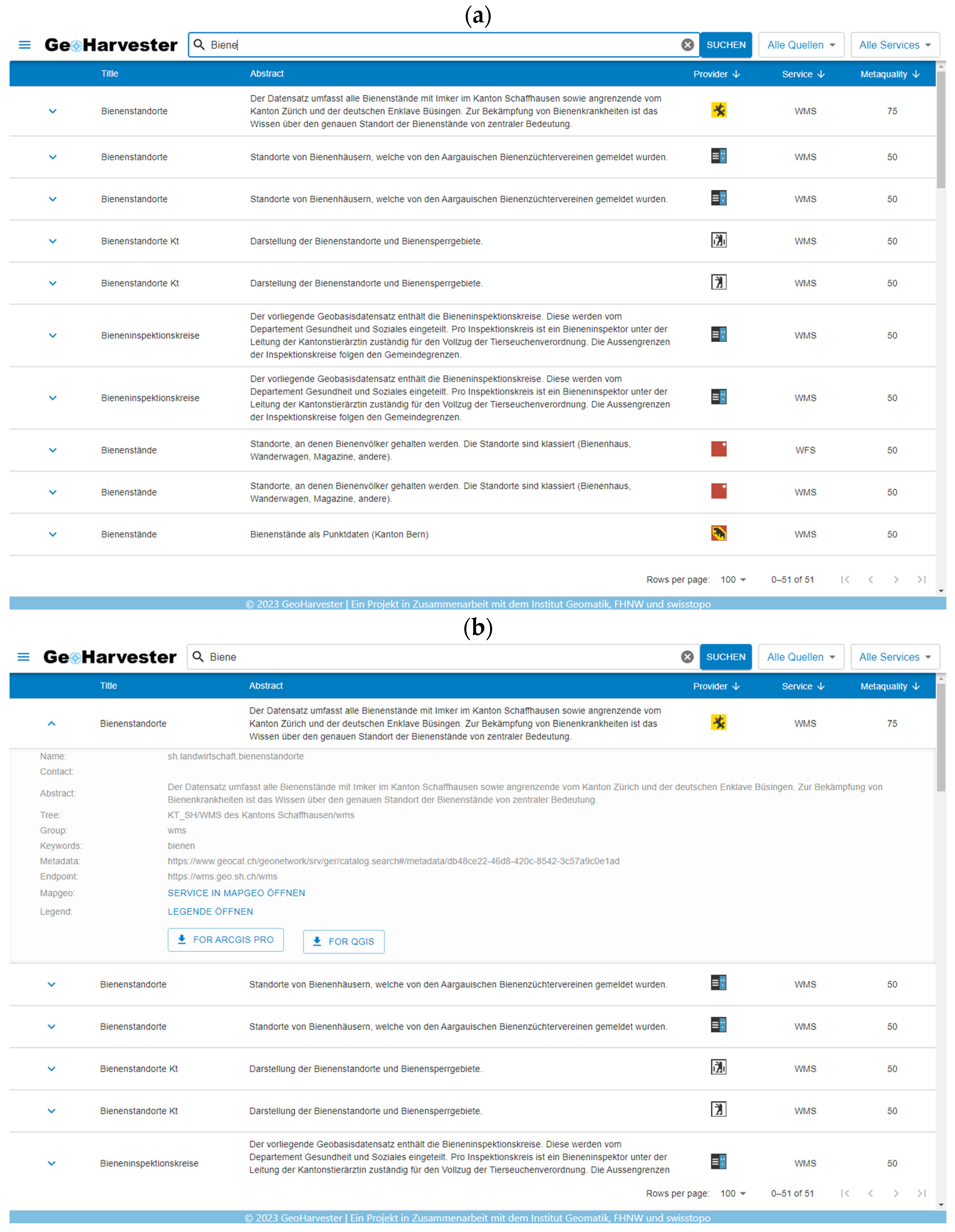{kind=link}
| Field Name | Description | Format | Mandatory |
|---|---|---|---|
| Provider | Manger of the data | Text | ✔ |
| Title | Short title | Text | ✔ |
| Name | Name or identifier of the layer | Text | ✔ |
| Tree | Layer tree | Tree structure | ✔ |
| Group | Category of the data | Text | |
| Abstract | A brief summary | Text | |
| Keywords | Relevant keywords | List of string | |
| Legend | Link to legend | URL | |
| Contact | Contact information | Text | |
| Service Link | GetCapabilities link | URL | ✔ |
| Publication date | Publication Date | Date | |
| Service type | OGC Service type | WMS/WMTS/WFS | ✔ |
| Zoom level | Max zoom level | Int | ✔ |
| Center | Lat/Lon in WGS84 | Tuple of float | ✔ |
| Bounding box | Extent of data layer WSEN | List of float | ✔ |
| Field Name | Derived from Original Columns | Format |
|---|---|---|
| NLP keywords | Abstract | List of string |
| NLP summary | Abstract | Text |
| Metadata quality | Abstract, Keywords | Integer |
| Municipality | OWS Datasets Discovered | Municipality | OWS Datasets Discovered | Municipality | OWS Datasets Discovered | |||
|---|---|---|---|---|---|---|---|---|
| Without Extracted Information | With Extracted Information | Without Extracted Information | With Extracted Information | Without Extracted Information | With Extracted Information | |||
| Lausanne | 0 | 116 | Meyrin | 0 | 0 | Schlieren | 0 | 0 |
| Winterthur | 10 | 11 | Carouge | 0 | 0 | Adliswil | 0 | 0 |
| Biel | 34 | 52 | Kreuzlingen | 0 | 0 | Volketswil | 0 | 0 |
| Thun | 12 | 16 | Wädenswil | 0 | 0 | Thalwil | 0 | 0 |
| Bellinzona | 162 | 162 | Riehen | 158 | 158 | Olten | 0 | 3 |
| Uster | 4 | 8 | Allschwil | 0 | 0 | Pully | 0 | 0 |
| Vernier | 0 | 0 | Renens | 6 | 6 | Regensdorf | 0 | 0 |
| Chur | 0 | 1 | Wettingen | 0 | 3 | Ostermundigen | 0 | 0 |
| Sion | 0 | 0 | Nyon | 0 | 2 | Littau | 0 | 0 |
| Yverdon | 0 | 0 | Bülach | 0 | 0 | Pratteln | 0 | 0 |
| Emmen | 6 | 10 | Vevey | 0 | 0 | Freienbach | 84 | 84 |
| Dübendorf | 0 | 0 | Opfikon | 0 | 0 | Wallisellen | 0 | 0 |
| Rapperswil | 0 | 0 | Reinach | 0 | 1 | Wohlen | 0 | 1 |
| Dietikon | 0 | 2 | Baden | 4 | 7 | Morges | 0 | 0 |
| Wetzikon | 0 | 0 | Onex | 0 | 0 | Steffisburg | 0 | 0 |
| User Query | NLP-Refined Query * Search Topic Term in Bold | KTD Score Columns Used for Ranking | Document Store | ||||
|---|---|---|---|---|---|---|---|
| Title | Keywords | Title + Keywords | Title + Keywords + NLP Extraction | Potential Exact Matches | Potential Thematic Matches * | ||
| Eignung der Solarenergie in der Schweiz | <eignung><solarenergie> <schweiz> | 0.89 | 0 | 0.92 | 1 | 4 | 21 |
| Eignung der Solarenergie in Kanton Aargau | <eignung><solarenergie> <kanton aargau> | 0.82 | 0 | 0.8 | 0.88 | 2 | 21 |
| Rohstoffe in der Schweiz | <rohstoff><schweiz> | 0.1 | 0 | 0.27 | 0.84 | 8 | 20 |
| Rohstoffe in Kanton Schaffhausen | <rohstoff><kanton schaffhausen> | 0 | 0 | 0 | 0.87 | 1 | 20 |
| Wildtierkorridore in der Schweiz | <wildtierkorridor><schweiz> | 0.2 | 0 | 0.08 | 0.68 | 4 | 43 |
| Wildtierkorridore in Kanton Solothurn | <wildtierkorridor> <kanton solothurn> | 0.18 | 0 | 0.18 | 0.84 | 1 | 43 |
| Radwege in der Schweiz | <radweg><schweiz> | 0.74 | 0 | 0.1 | 0.6 | 4 | 74 |
| Velowege in der Schweiz | <veloweg><schweiz> | 0.66 | 0 | 0.14 | 0.98 | 4 | 74 |
| Radwege in Zürich | <radweg><zürich> | 0.8 | 0.11 | 0.8 | 1 | 1 | 74 |
| Radwege in Kanton Schwyz | <radweg><kanton schwyz> | 0.53 | 0 | 0.53 | 1 | 2 | 74 |
| Bewilligungen von der Wasserbauabteilung in Zürich | <bewilligung> <wasserbauabteilung><zürich> | 0.93 | 0.71 | 0.93 | 0.96 | 1 | 10 |
| Bezirke der Kanton Zürich | <bezirk><kanton zürich> | 0.76 | 0.16 | 0.75 | 0.96 | 3 | 19 |
| Römische Pfosten Augusta Rauirica | <römisch><pfosten> <augusta raurica> | 1 | 0.89 | 1 | 1 | 1 | 37 |
| Berufsinformationszentren in Kanton Bern | <berufsinformationszentre> <kanton bern> | 0.87 | 0 | 0.87 | 1 | 4 | 10 |
| Fotopunkte der Amphibienzugstelle | <fotopunkt> <amphibienzugstelle> | 0.72 | 0.66 | 0.72 | 0.88 | 11 | 21 |
| Einschränkungen für Drohne in der Schweiz | <einschränkung> <drohne><schweiz> | 0.91 | 0.44 | 0.93 | 0.94 | 3 | 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferrari, E.; Striewski, F.; Tiefenbacher, F.; Bereuter, P.; Oesch, D.; Di Donato, P. Search Engine for Open Geospatial Consortium Web Services Improving Discoverability through Natural Language Processing-Based Processing and Ranking. ISPRS Int. J. Geo-Inf. 2024, 13, 128. https://doi.org/10.3390/ijgi13040128
Ferrari E, Striewski F, Tiefenbacher F, Bereuter P, Oesch D, Di Donato P. Search Engine for Open Geospatial Consortium Web Services Improving Discoverability through Natural Language Processing-Based Processing and Ranking. ISPRS International Journal of Geo-Information. 2024; 13(4):128. https://doi.org/10.3390/ijgi13040128
Chicago/Turabian StyleFerrari, Elia, Friedrich Striewski, Fiona Tiefenbacher, Pia Bereuter, David Oesch, and Pasquale Di Donato. 2024. "Search Engine for Open Geospatial Consortium Web Services Improving Discoverability through Natural Language Processing-Based Processing and Ranking" ISPRS International Journal of Geo-Information 13, no. 4: 128. https://doi.org/10.3390/ijgi13040128
APA StyleFerrari, E., Striewski, F., Tiefenbacher, F., Bereuter, P., Oesch, D., & Di Donato, P. (2024). Search Engine for Open Geospatial Consortium Web Services Improving Discoverability through Natural Language Processing-Based Processing and Ranking. ISPRS International Journal of Geo-Information, 13(4), 128. https://doi.org/10.3390/ijgi13040128