
A Novel Dynamic Physical Storage Model for Vehicle Navigation Maps

Abstract
:1. Introduction
2. Methodology
2.1. The Structure of the CNDF Model
2.1.1. Multi-Scale Grid Index
2.1.2. Logical Structure of the CNDF Model
2.1.3. Physical Structure of the CNDF Model
2.2. Route Computing Models of the CNDF Model
2.2.1. The Reach-Based Hierarchical Network
2.2.2. The Reach-Based Hierarchical Shortest-Path Algorithm
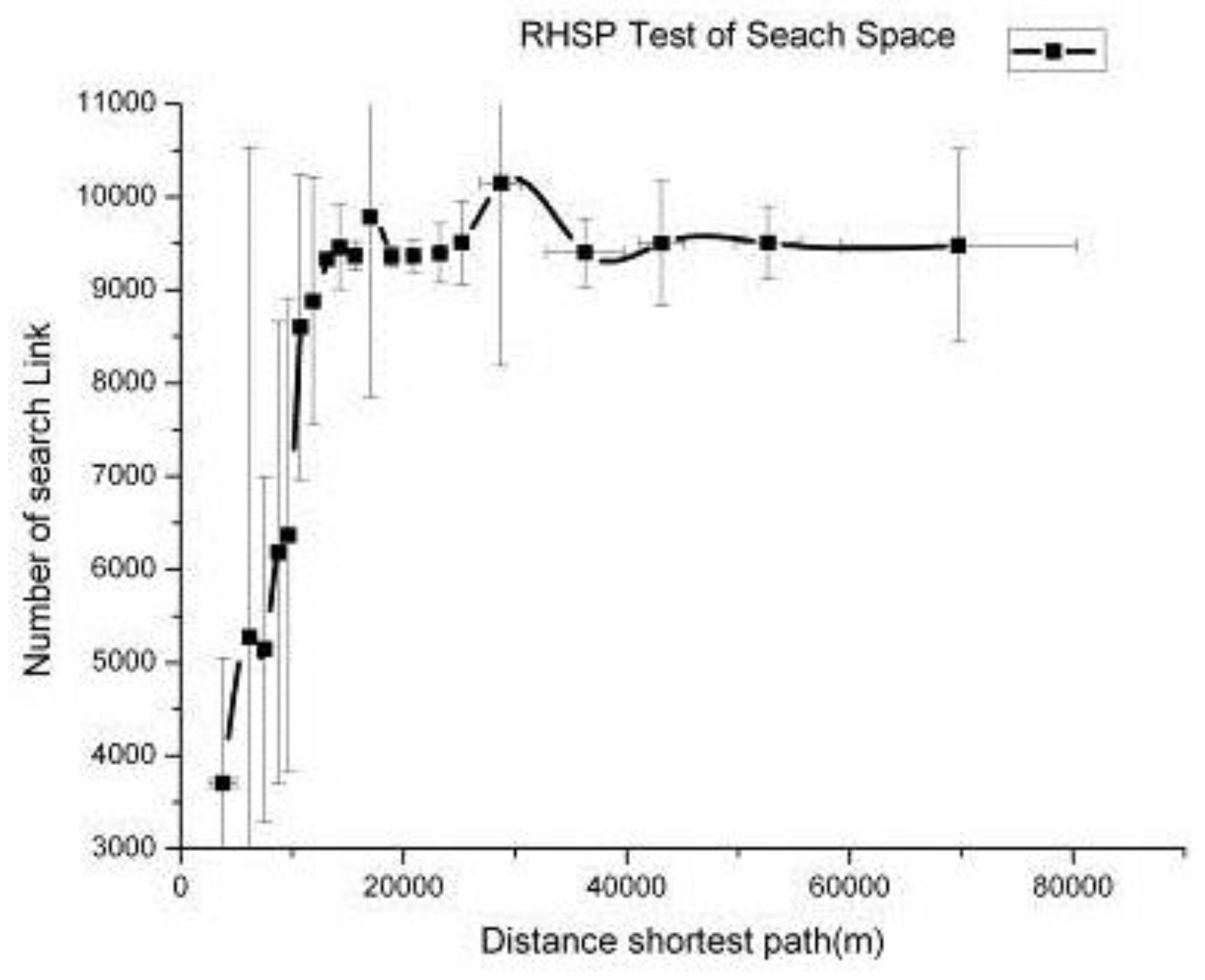
2.2.3. The Scope Evaluation of Readjustment
2.3. Data Update Mechanism of the CNDF Model
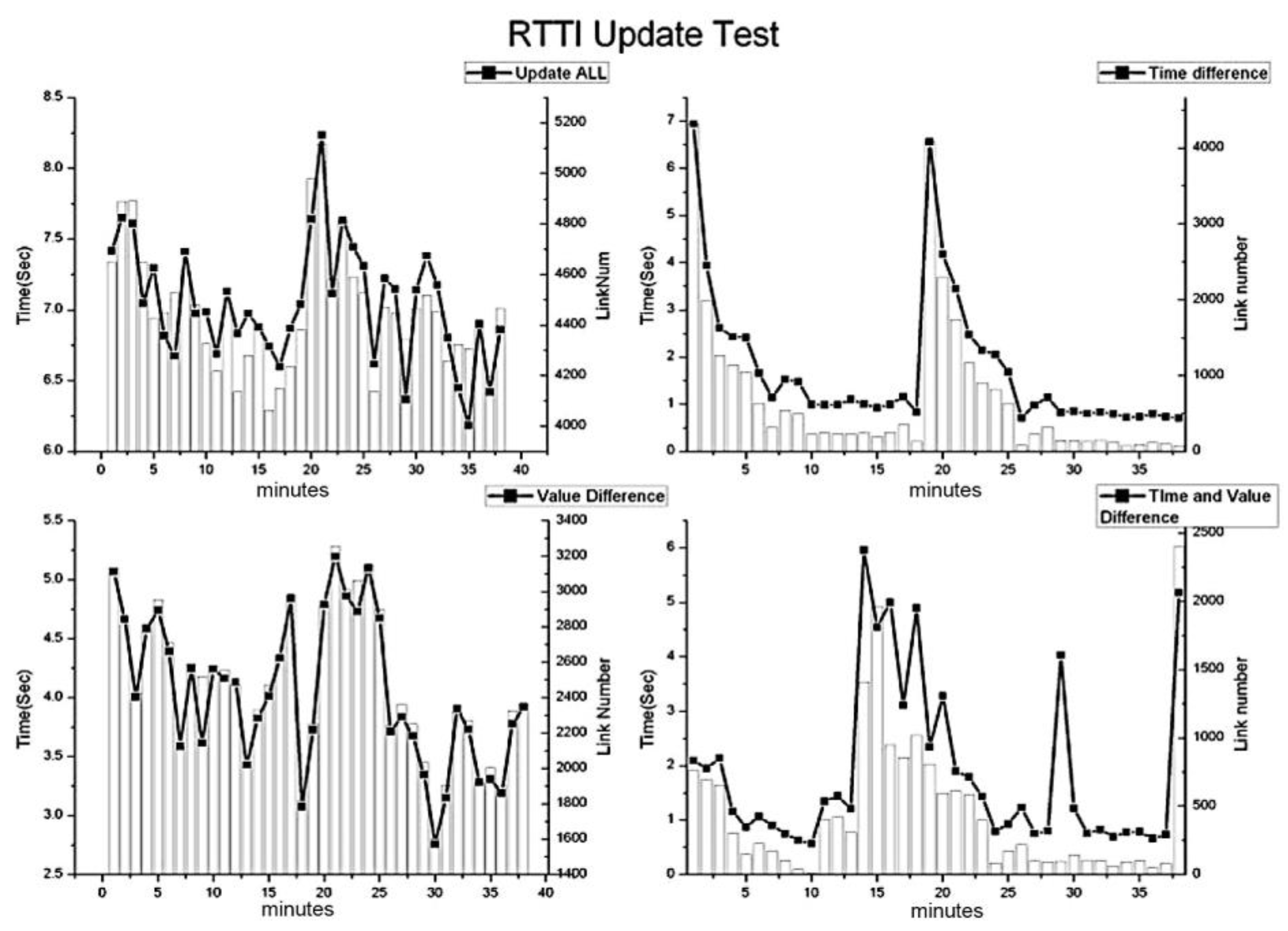
2.3.1. The Update Mechanism for Navigation Data
2.3.2. The Maintenance Process for Navigation Data
3. Experiment and Results
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix
The Linear Link Coding (LLC) Algorithm

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FUNCTION Coding |
|---|
| /*RD is the set of detailed road link DRD*/ |
| /*Travel is an abstract link that contains a list of detailed road links*/ |
| FUNCTION Coding (RD) |
| (1)LM = 0; //Init the code variable |
| (2)FOR i = MAX_LEVEL TO 1//Code link from top to bottom |
| (3) FOR EACH DRD IN RD |
| (4) Travel = {DRD}; //if the level of DRD is less than i or equal to i but has been coded to jump to the next |
| (5) IF Level (DRD) < i OR Level (DRD) == i AND HasCode (DRD) THEN |
| CONTINUE; |
| (6) TraceForward (DRD, i, Travel); //Search next DRD along until meet road crossing |
| (7) TraceBackward (DRD, i, Travel); //Search prevision DRD conversely until meet road crossing |
| (8) IF HasCode (DRD) THEN//DRD has been coded in higher level |
| (9) k = GetLink(UpTravel, Head(Travel), i + 1); //Get the upper level link containing first DRD |
| Travel.FP = Mid(UpTravel, k).FP; //Assign high link start node post to DRD |
| k = GetLink(UpTravel, Tail(Travel), i + 1); //Get the upper level link containing last DRD |
| Travel.TP = Mid(UpTravel, k).TP; //Assign high link end node post to DRD |
| (10) ELSE//Assign a new coding |
| (11) Travel.FP = LM |
| (12) FOR EACH e IN Travel//Assign code to the sub-DRD |
| (13) e.FP = LM; |
| (14) LM += Int(m(e)/k + 1); |
| (15) e.TP = LM; |
| NEXT s |
| (16) Travel.TP = LM; |
| END IF |
| NEXT DRD |
| NEXT i |
References
- NAVTECH PSF Specification for SDAL Format Version 1.7. Available online: http://www.janczinsky.cz/dwn/SDAL_spec.pdf (accessed on 5 November 2015).
- KIWI Format Specification Version 1.2.2 (JIS D0810). Available online: http://www.jsa.or.jp/default_english/default_english.html (accessed on 5 November 2015).
- Requirements and Logical Data Model for Physical Storage Format (PSF) and Application Program Interface (API) and Logical Data Organization for PSF used in Intelligent Transport Systems (ITS) Database Technology. Available online: http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=39447 (accessed 5 November 2015).
- Xu, Y.; Recker, W. Modeling dynamic vehicle navigation in a self-organizing, peer-to-peer, distributed traffic information system. J. Intell. Transp. Sys. Technol. Plan. Oper. 2006, 10, 185–204. [Google Scholar]
- Paz, A.; Veeramisti, N.; Khanal, I.; Baker, J.; Fuente-Mella, H. Development of a comprehensive database system for safety analyst. Sci. World J. 2015, 2015, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Simandl, J.K.; Graettinger, A.J.; Smith, R.K.; Barnett, T.E. GIS based non-signalized intersection data inventory tool to improve traffic safety. In Proceedings of the Transportation Research Board 94th Annual Meeting, Washington, DC, USA, 11–15 January 2015.
- Alvanaki, F.; Goncalves, R.; Ivanova, M.; Kyzirakos, K. GIS navigation boosted by column stores. Proc. VLDB Endow. 2015, 8, 1956–1959. [Google Scholar] [CrossRef]
- Park, E.; Kim, H.; Ohm, J.Y. Understanding driver adoption of car navigation systems using the extended technology acceptance model. Behav. Info. Technol. 2015, 34, 741–751. [Google Scholar] [CrossRef]
- Feng, J.; Watanabe, T. Index Techniques. In Index and Query Methods in Road Networks; Feng, J., Watanabe, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 11–39. [Google Scholar]
- Wu, H.; Liu, Z.; Zhang, S. Spatial-Temporal dynamic segmentation model. In Proceedings of the 10th International Conference of Chinese Transportation Professionals, Beijing, China, 4–8 August 2010.
- Wagner, D.; Willhalm, T. Speed-Up techniques for shortest-path computations. In STACS 2007: 24th Annual Symposium on Theoretical Aspects of Computer Science; Thomas, P., Well, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 23–36. [Google Scholar]
- Chen, C.; Jia, Y.; Shu, M.; Wang, Y. Hierarchical adaptive path-tracking control for autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1–13. [Google Scholar]
- Li, Q.; Zeng, Z.; Zhang, T.; Li, J.; Wu, Z. Path-finding through flexible hierarchical road networks: An experiential approach using taxi trajectory data. Int. J. Appl. Earth Obs. Geoinform. 2011, 13, 110–119. [Google Scholar] [CrossRef]
- Weng, M.; Jiang, S.; Qu, R. Hierarchical spatial reasoning and case of way-finding. Geo-spatial Inf. Sci. 2008, 11, 269–272. [Google Scholar] [CrossRef]
- Schubert, E.; Zimek, A.; Kriegel, H.P. Geodetic distance queries on r-trees for indexing geographic data. Lect. Notes Comput. Sci. 2013, 8098, 146–164. [Google Scholar]
- Delling, D.; Sanders, P.; Schultes, D.; Wagner, D. Engineering route planning algorithms. In Algorithmics of Large and Complex Networks: Design, Analysis, and Simulation; Lerner, J., Wagner, D., Zweig, K.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 117–139. [Google Scholar]









| PSF Name | Owner | Information |
|---|---|---|
| Car IN | Siemensvdo | http://www.siemensvdo.com |
| KIWI | KIWI forum | http://www.jsa.or.jp |
| SDAL | NAVTEQ | http://www.navteq.com |
| Siemens AF | Siemensvdo | http://www.siemensvdo.com |
| TRAVELPILOT | blaupunkt | http://www.blaupunkt.com |
| PSI | BMW | http://www.psf-initiative.com |
| FUNCTION RHSP |
|---|
| /*SS[level][node] is the set of start nodes of each level*/ |
| /*TT[level][node] is the set of end nodes of each level*/ |
| /*HEAP is sorted by m(s, v), implemented according tot he binary heap or Fibonacci heap*/ |
| /*RB[level] is the bound array of each level{b0, b1, b2, .., bn};*/ |
| /*RHTopo is the reach-based hierarchical network*/ |
| FUNCTION RHSP(s ,t ,RHTopo, RB[]) |
| (1)COST = 0; LEVEL = 0; |
| (2)Union(SS[0], s); Union(TT[0], t); Insert(HEAP, s, COST);//Init start set, end set and heap |
| (3)WHILE ((u = ExtraMin(HEAP, COST) ! = NULL)//Search higher level Node |
| (4) IF Within (SS[0], u) THEN RETURN COST;//target is found. |
| (5) IF Reach(u) < RB[LEVEL] THEN CONTINUE;//Filter lower lev-el node last loop left |
| (6) IF COST>RB[LEVEL+1] AND LEVEL+1 ≤ MAXLEVEL THEN |
| //Search upper-level nodes around target node, whose distance to t within bi at end side |
| (7) ENDUP = QuerybyPoint(RHTopo, point(x(t), y(t)), RB[LEVEL+1])); |
| (8) Union(TT[LEVEL +1], ENDUP); //Record the targets of upper level |
| (9) LEVEL++;//Begin higher level search |
| (10) CONTINUE; |
| END IF |
| (11) IF Reach(u) > RB [LEVEL] THEN Union(SS[LEVEL+1], u);//Save higher level node |
| (12) FOR EACH v IN Adjoin(RHTopo, u);//Get each node adjoin to u for spread |
| (13) IF OnPath (HEAP, v) THEN CONTINUE; |
| (14) IF UnFound (HEAP, v) THEN Insert(HEAP, v, COST + m(u, v)); |
| (15) ELSE IF COST+ m(u, v) < m(HEAP, s, v) THEN Update(HEAP, v, COST + m(u, v)); |
| NEXT v |
| NEXT |
| (16) FOR LEVEL= MAXLEVEL -1 TO 0//Search lower level node iteratively until target t is found |
| (17) FOR EACH u IN TT[LEVEL]//Get target nodes of higher level as start node of lower level |
| (18) IF !OnPath(HEAP, u) THEN CONTINUE;//filter the candidate targets not on path |
| (19) Insert(HEAP, u, m(HEAP, s, u));//Re-insert to heap with path cost m(s, u, P) |
| NEXT u |
| (20) WHILE ((u = ExtraMin(HEAP, COST) != NULL)//Search Lower level Node |
| (21) IF Within (SS[0], u) THEN RETURN COST;//target is found. |
| //control the search space is not over bi+1 |
| (22) IF Distance( (x(t), y(t), x(v), y(v) ) > RB[LEVEL+1] THEN CONTINUE; |
| (23) FOR EACH v IN Adjoin(RHTopo, u);//Get each node adjoin to u |
| (24) IF OnPath (HEAP, v) THEN CONTINUE; |
| (25) IF UnFound (HEAP, v) THEN Insert(HEAP, v, COST + m(u, v)); |
| (26) ELSE IF COST+ m(u, v) < m(HEAP, s, v) THEN |
| Update(HEAP, v, COST + m(u, v)); |
| NEXT v |
| NEXT u |
| NEXT LEVEL |
| (27)RETURN -1; //Not found target |
| level | Links of Natural Hierarchy | Links of Reach Hierarchy |
|---|---|---|
| 0 | 451,601 | 329,999 |
| 1 | 53,576 | 141,908 |
| 2 | 10,701 | 50,103 |
| 3 | 12,132 | 6000 |
| Item | Parameter |
|---|---|
| CPU | ARM 500 MHz |
| SDRAM | 64MB (32Bit) |
| NOR Flash | 64MB (32Bit) |
| Storage | 1GB SD Card (Class 6) |
| compiler | GCC 3.4.3 |
| Operation system | Linux 2.6 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Zhong, E.; Li, K.; Song, G.; Cai, W. A Novel Dynamic Physical Storage Model for Vehicle Navigation Maps. ISPRS Int. J. Geo-Inf. 2016, 5, 53. https://doi.org/10.3390/ijgi5040053
Wang S, Zhong E, Li K, Song G, Cai W. A Novel Dynamic Physical Storage Model for Vehicle Navigation Maps. ISPRS International Journal of Geo-Information. 2016; 5(4):53. https://doi.org/10.3390/ijgi5040053
Chicago/Turabian StyleWang, Shaohua, Ershun Zhong, Kai Li, Guanfu Song, and Wenwen Cai. 2016. "A Novel Dynamic Physical Storage Model for Vehicle Navigation Maps" ISPRS International Journal of Geo-Information 5, no. 4: 53. https://doi.org/10.3390/ijgi5040053
APA StyleWang, S., Zhong, E., Li, K., Song, G., & Cai, W. (2016). A Novel Dynamic Physical Storage Model for Vehicle Navigation Maps. ISPRS International Journal of Geo-Information, 5(4), 53. https://doi.org/10.3390/ijgi5040053