
Review of Forty Years of Technological Changes in Geomatics toward the Big Data Paradigm


Abstract
:1. Introduction
2. Four Decades of Geomatics Revisited through the Vs of Big Data
2.1. Volume: Storage and Numerical Processing Requirements
2.1.1. Data, Spatial Data, Storage, Access and Analysis: A Retrospective
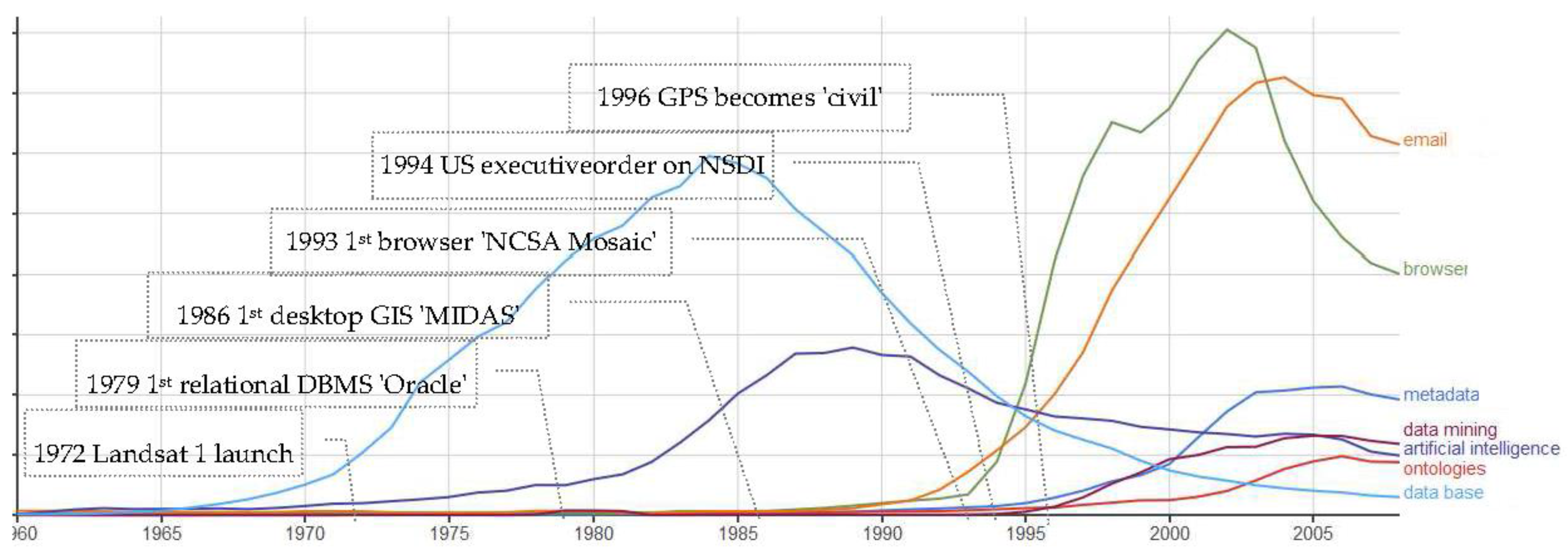
- Precursor tools for reasoning and image processing: data analysis 1958, pattern recognition 1958, artificial intelligence 1961, principal component analysis 1960, correspondence analysis 1975, image processing 1965, image understanding 1970, and machine learning 1981;
- Data and corporate knowledge: databases 1965–1970, data warehouse 1988–1992, metadata 1991, OLAP 1994, data mining 1995, business intelligence 1996, and analytics 2004;
- Spatial information data, devices, and tools: satellite imagery or remote sensing 1970, Landsat 1972, GPS 1975, and spatial data quality 1990; and
- Internet tools: Internet 1990, email 1992, browser 1992, web and website 1994 (Note: “web” and Internet, are not shown—out of scale versus the other terms—”browser” is a good proxy).Alas, while still accessible, Ngram stopped including books in 2008 so the terms “cloud computing” and “Big Data”, are too “young”, and absent in Ngram.
- Big Data’s birth year is around 2010, while spatial data traces back to 1970, before the Landsat data;
- Database and AI tools are at their apogee between 1975 and 1985, extensively used for processing the phenomenal amount of data harvested by satellites: a Petabyte over the decade, at a time when central memory of big computers was limited to a few Megabytes;
- 1995 emerges as a tipping point, with the widespread use of the Internet tools, and with data mining, analytics, ontologies taking over databases and AI, whose buzz is somewhat fading. This tipping point marks an important paradigm shift, following Thomas Kuhn’s “Structure of scientific revolutions”. It does not mark a discovery (e.g., the transistor in 1947) or a technological success (e.g., Landsat launch in 1972) but a collective consciousness (Term used by social theorists like Durkheim, Althusser, and Jung to explicate how patterns of commonality emerge among large groups of autonomous individuals.) that all the technologies related to computation (algorithms, personal devices, network, etc.), and to information (data collections, surveys, literature, news, etc.) should merge together.
2.1.2. Geospatial Data = Huge Data before Big Data
2.2. Variety and Velocity: Data Structure before Unstructured Data
2.2.1. From Ancillary Data, to Metadata
- Earth observation: The program “CORINE” (“Coordination of Information on the Environment”: program initiated in 1985 by the European Commission.), which monitors the change in land use in Europe, by updating data from the classes extracted from satellite images, uses metadata extensively [3].
- Automated cartography: How do you make explicit the topology in data vector representation? Topology is implicit, in a correct geometry, but the burden of re-computing it every time is much too heavy. Therefore, in the 1990s, several NGIs were working on what eventually became the ISO 19101: GI Reference model (the underlying concept is the polygon-arc-node model, with all topology relationships), as in Table 1, which says that parcels “2” and “3” are adjacent, and their union forms a single hole into parcel “1.” Themes and rules can be added: metadata are mandatory for deciphering all that information.
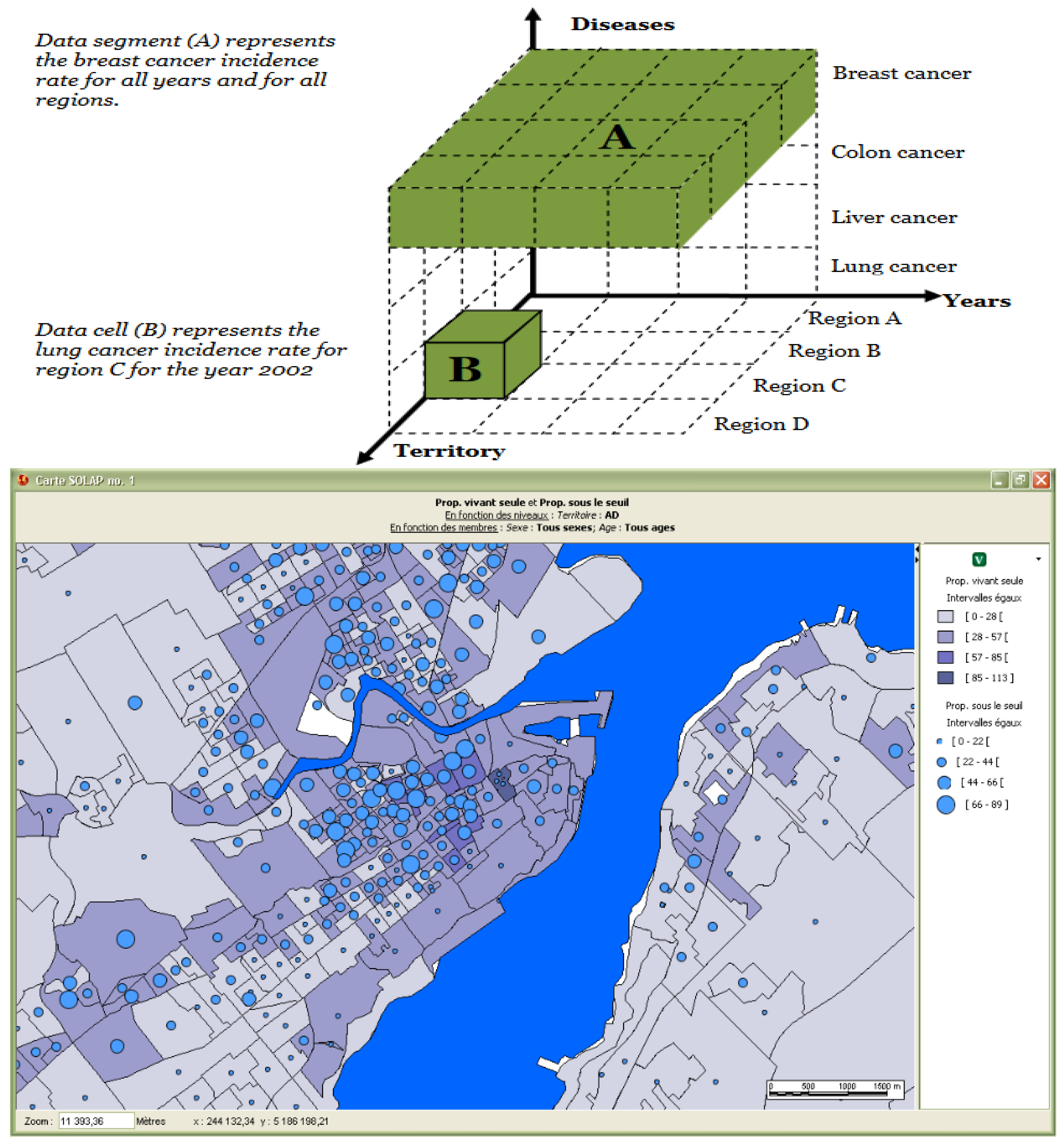
2.2.2. From Data Columns to Data Cubes
2.2.3. Streaming, Parallelism, and Pre-Processing in Geomatics
2.3. Value, Validity, Veracity and Variability: Turning Data into Knowledge
2.3.1. Value, Added by Data Processing: From Data Analysis to Data Mining
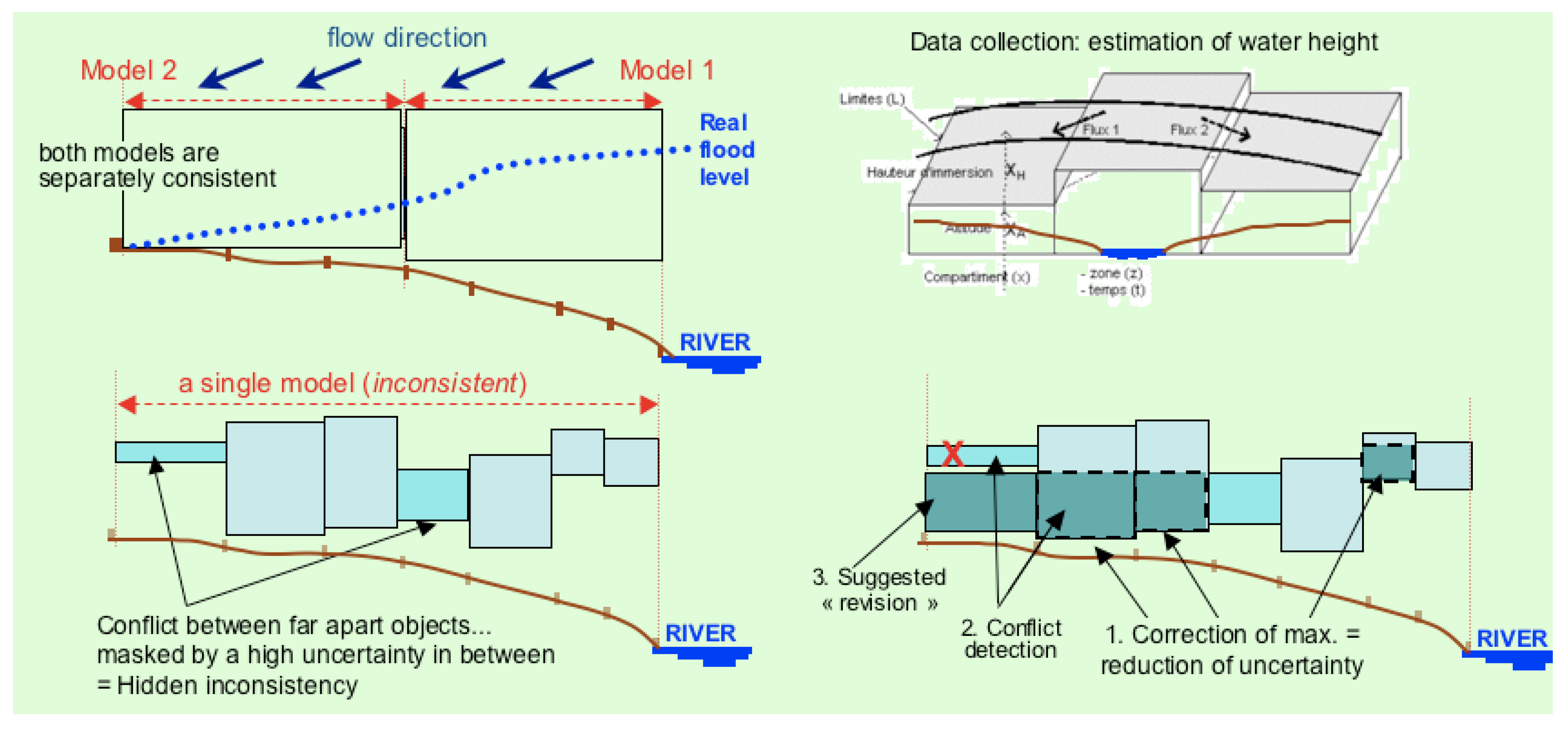
2.3.2. Veracity, Data Uncertainty: From Precision to Quality Indicators
2.3.3. Validity, Data Consistency: Rational Knowledge from Uncertain Knowledge
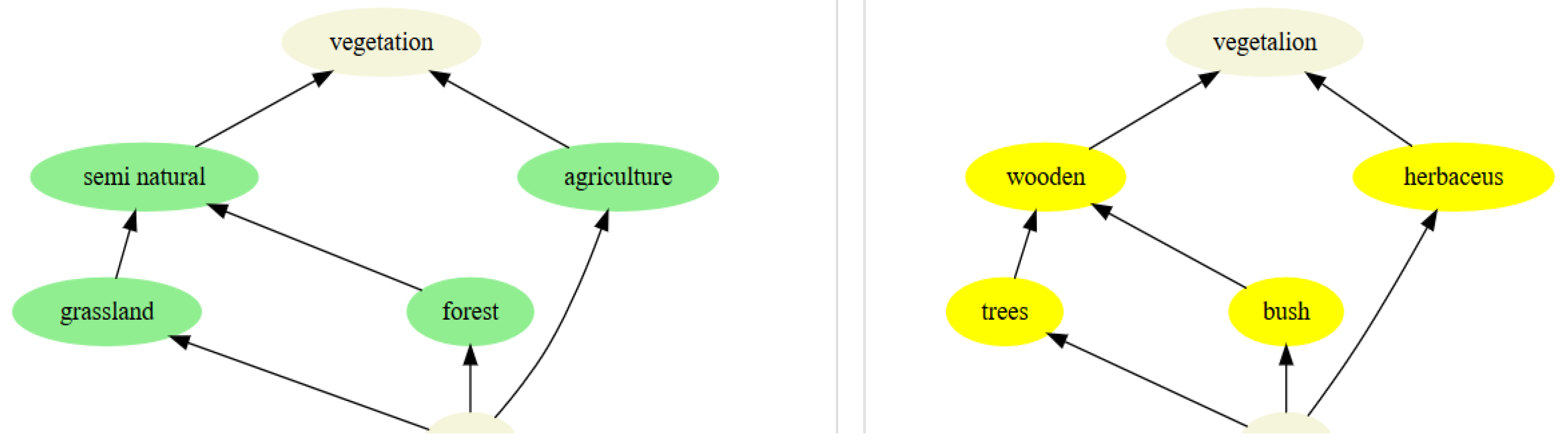
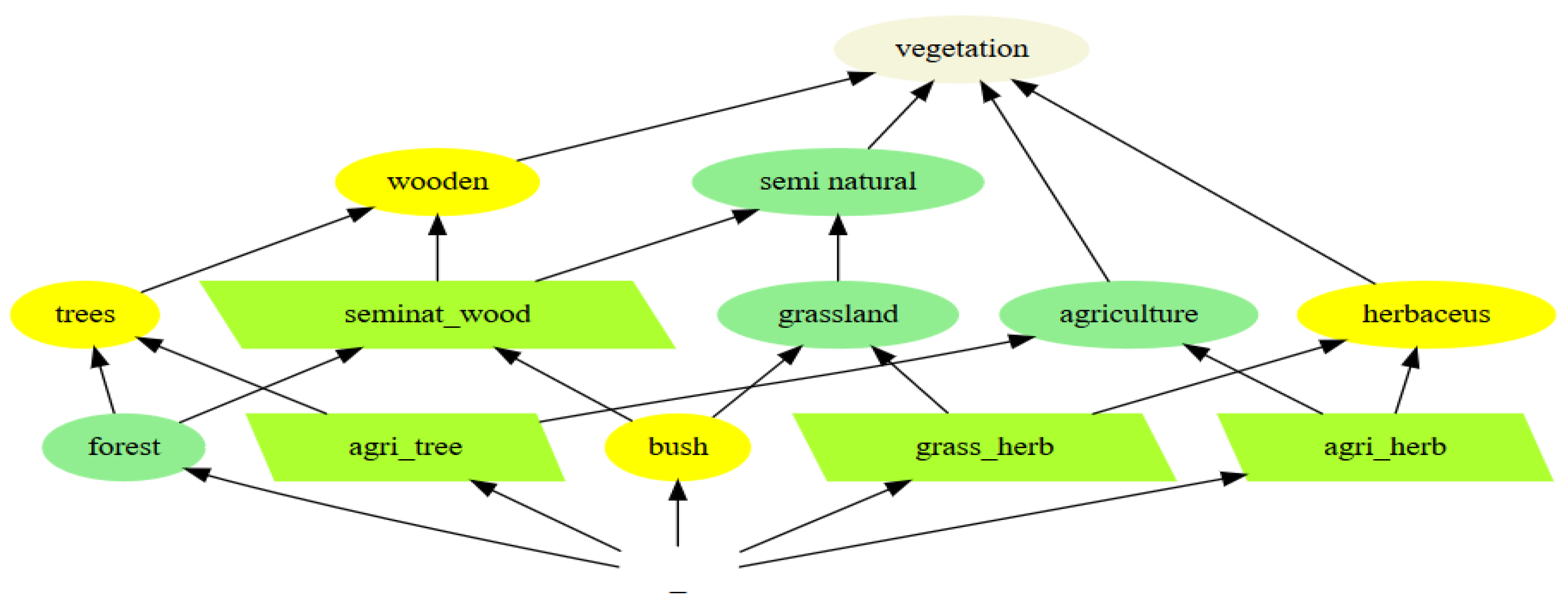
2.4. Ontologies and Variability: Data Are Acts, Not Facts
- Using the same set of parcels as the unique key, a new relation is built, as the union of the two original relations: it is a functional relation.
- A Galois lattice is derived: new nodes emerge, and the new partial order is derived directly from the observations, not from the two original partial orders.
- The new nodes must be interpreted in terms of a mixture of the two original taxonomies: it points out that some original classes are more problematic, e.g., a meadow parcel of the real world could have been classified as herbaceous in Taxonomy 2 (yellow), but either grassland, then semi-natural, or agriculture, in Taxonomy 1 (green).
- Indices of quality can be attached to the original classifications, weighed by the cumulated areas of the related parcels, or by any context data, to quantify the uncertainty attached to every new node.
3. Discussion
3.1. Volume
3.2. Velocity
3.3. Variety (and Visualization)
3.4. Value, Veracity, Validity, and Variability
3.5. Conclusions
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| BDaaS | Big Data as a Service |
| DBMS | Data Base Management System (RDBMS: Relational DBMS) |
| GIS | Geographic Information System |
| ISO | International Standards Organization |
| LAI | Leaf Area Index (vegetation monitoring) |
| NGO | National Geographic Organization |
| OECD | Organisation for Economic Co-operation and Development |
| OLAP | On-Line Analytical Process (SOLAP: Spatial OLAP) |
| PCA | Principal Component Analysis |
| UNESCO | United Nations Educational, Scientific, Cultural Organization |
References
- Michel, J.B.; Shen, Y.K.; Aiden, A.P.; Veres, A.; Gray, M.K.; Pickett, J.P.; Hoiberg, D.; Clancy, D.; Norvig, P.; Orwant, J. Quantitative analysis of culture using millions of digitized books. Science 2011, 331, 176–182. [Google Scholar] [CrossRef] [PubMed]
- Thomson-Reuters. Available online: http://blog.thomsonreuters.com/index.php/Big%20Data-graphic-of-the-day (accessed on 24 August 2016).
- Kimball, R.; Ross, M. The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling, 2nd ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2002. [Google Scholar]
- Dempsey, C. Where is the Phrase “80% of Data is Geographic”. Available online: https://www.gislounge.com/80-percent-data-is-geographic/ (accessed on 24 August 2016).
- European Environment Agency. CORINE Land Cover—Part1: Methodology. Available online: http://www.eea.europa.eu/publications/COR0-part1 (accessed on 24 August 2016).
- Bédard, Y.; Lam, S.; Proulx, M.-J.; Caron, P.-Y.; Létourneau, F. Data warehousing for spatial data: Research issues. In Proceedings of the International Symposium: Geomatics in the Era of Radarsat (GER’97), Ottawa, ON, Canada, 25–30 May 1997.
- Stefanovic, N. Design and Implementation of On-Line Analytical Processing (OLAP) of Spatial Data. Ph.D. Thesis, School of Computing Science, Simon Fraser University, Vancouver, BC, Canada, January 1997. [Google Scholar]
- Rivest, S.; Bédard, Y.; Proulx, M.J.; Nadeau, M.; Hubert, F.; Pastor, J. SOLAP: Merging business intelligence with geospatial technology for interactive spatio-temporal exploration and analysis of data. ISPRS J. Photogramm. Remote Sens. 2005, 60, 17–33. [Google Scholar] [CrossRef]
- Bernier, E.; Gosselin, P.; Badard, T.; Bédard, Y. Easier surveillance of climate-related health vulnerabilities through a Web-based spatial OLAP application. Int. J. Health Geograph. Apr. 2009, 8, 18. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Stefanovic, N.; Koperski, K. Selective materialization: An efficient method for spatial data cube construction. In Research and Development in Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 1998; pp. 144–158. [Google Scholar]
- Qiu, J.; Gao, H.; Ding, S.X. Recent advances on fuzzy-model-based nonlinear networked control systems: A survey. IEEE Trans. Ind. Electron. 2016, 63, 1207–1217. [Google Scholar] [CrossRef]
- Tukey, J.W. Exploratory Data Analysis; Addison-Wesley: Reading, MA, USA, 1977. [Google Scholar]
- Jeansoulin, R.; Fontaine, Y.; Frei, W. Multitemporal segmentation by means of fuzzy sets. In Proceedings of the 7th LARS Symposium on Machine Processing of Remotely Sensed Data, with Special Emphasis on Range, Forest, and Wetlands Assessment, Purdue University, West Lafayette, IN, USA, 23–26 June 1981; pp. 336–340.
- Diday, E. The dynamic clusters method in nonhierarchical clustering. Int. J. Comput. Inf. Sci. 1973, 2, 61–88. [Google Scholar] [CrossRef]
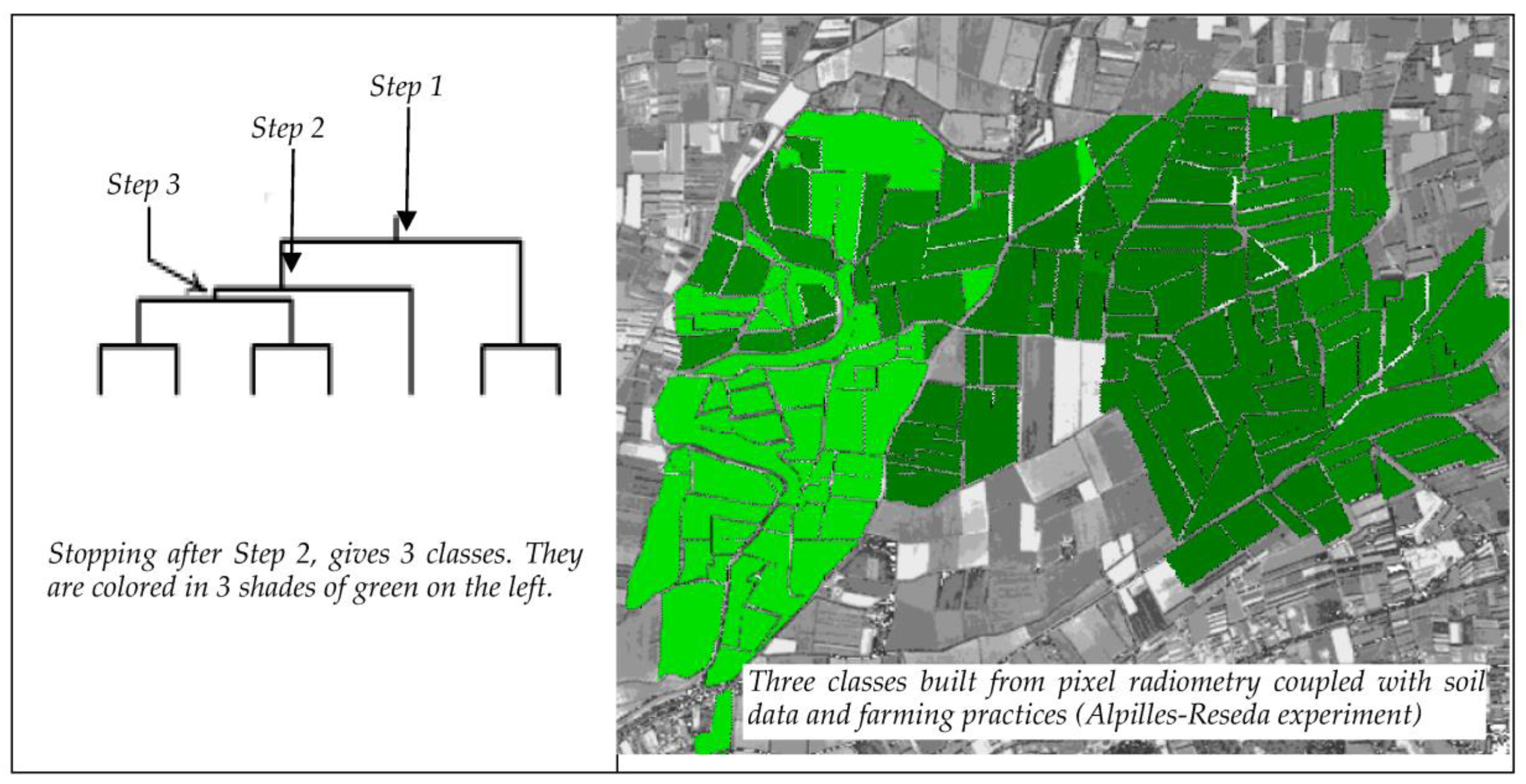
- Olioso, A.; Prevot, L.; Baret, F.; Vlevers, J.G.P.W. Spatial aspects in the Alpilles-ReSeDA project. In Proceedings of the Workshop Scaling and Modelling in Forestry: Applications in Remote Sensing and GIS, Montréal, QC, Canada, 19–21 March 1998.
- Jonckheere, I.; Fleck, S.; Nackaerts, K.; Muys, B.; Coppin, P.; Weiss, M.; Baret, F. Review of methods for in situ leaf area index determination. Agric. For. Meteorol. 2004, 121, 19–35. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: New York, NY, USA, 1990. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Cortes, C.; Vapnik, V.N. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Jeansoulin, R.; Wilson, N. Quality of geographic information: Ontological approach and artificial intelligence tools in the Revigis project. In Proceedings of the 8th EC-GI& GIS Workshop, Dublin, Ireland, 3–5 July 2002.
- Ferrucci, D.; Brown, E.; Chu-Carroll, J.; Fan, J.; Gondek, D.; Kalyanpur, A.A.; Lally, A.; Murdock, J.W.; Nyberg, E.; Prager, J. Building Watson: An overview of the DeepQA project. AI Mag. 2010, 31, 59–79. [Google Scholar]
- Randell, D.A.; Cui, Z.; Cohn, A.G. A spatial logic based on regions and connection. In Proceedings of the 3rd International Conference on Principles of Knowledge Representation and Reasoning, San Mateo, CA, USA, October 1992; pp. 165–176.
- Euzenat, J.; Bessière, C.; Jeansoulin, R.; Revault, J.; Schwer, S. Dossier Raisonnement spatial et temporel. Bull. de l’Assoc. Fr. de l’Intell. Artif. 1997, 29, 2–13. [Google Scholar]
- Cavarroc, M.-A.; Benferhat, S.; Jeansoulin, R. Modeling land use changes using Bayesian networks. In Proceedings of the 22nd IASTED International Conference on Artificial Intelligence and Applications, Innsbruck, Austria, 16 February 2004.
- Gruber, T.; Olsen, G. An ontology for engineering mathematics. In Proceedings of the Fourth International Conference on Principles of Knowledge Representation and Reasoning, Bonn, Germany, 24–27 May 1994; pp. 258–269.
- Halevy, A. Why Your Data Won’t Mix? ACM Queue: New York, NY, USA, 2005. [Google Scholar]
- Comber, A.J.; Fisher, P.; Wadsworth, R. Ignore the ontological aspects of land cover at your peril: A plea for expanded metadata. In Proceedings of the Remote Sensing & Photogrammetry Society Conference, Aberdeen, UK, 6 September 2004.
- Lund, H.G. Definitions of Forest, Deforestation, Afforestation, and Reforestation; Forest Information Services: Gainesville, VA, USA, 2007. [Google Scholar]
- Quine, W.V. On What There is; Harvard University Press: Cambridge, TN, USA, 1948. [Google Scholar]
- Ganter, B.; Wille, R. Formal Concept Analysis: Mathematical Foundations; Springer: Berlin, Germany, 1999. [Google Scholar]
- Smith, G.M.; Brown, N.J.; Thomson, A.G. CORINE Land Cover 2000: Semi-Automated Updating of CORINE Land Cover in the UK; Centre for Ecology and Hydrology, UK Natural Environment Research Council: Monks Wood, UK, 2005. [Google Scholar]
- Pham, T.T.; Phan-Luong, V.; Jeansoulin, R. Data quality based fusion: Application to the land cover. In Proceedings of the 7th International Conference on Information Fusion (FUSION’04), Stockholm, Sweden, 28 June–1 July 2004.
- Jeansoulin, R.; Curé, O.; Ahmed, A.; Gademer, A.; Rudant, J.-P. Geographical information is an act, not a Fact. In Proceedings of the 12th AGILE International Conference on Geographic Information Science, Leibniz University, Hannover, Germany, 2–5 June 2009.
- Vasseur, B.; Jeansoulin, R.; Devillers, R.; Frank, A. External quality evaluation of geographical applications: An ontological approach. In Fundamentals of Spatial Data Quality; Devillers, R., Jeansoulin, R., Eds.; ISTE Publishing: London, UK, 2006; pp. 255–270. [Google Scholar]
- Teich, D.A. SQL -vs- NoSQL: Database Design Debate Isn’t Even a Real Fight. February 2016. Available online: http://searchdatamanagement.techtarget.com/tip/SQL-vs-NoSQL-database-design-debate-isnt-even-a-real-fight (accessed on 24 August 2016).
- Grimes, S. Big Data: Avoid ‘Wanna V’ Confusion. Available online: http://www.informationweek.com/big-data/big-data-analytics/big-data-avoid-wanna-v-confusion/d/d-id/1111077 (accessed on 24 August 2016).
- Hopkins, B. Forrester Principal Analyst, in TechTarget Interview, by Mark Brunelli. Available online: http://searchdatamanagement.techtarget.com/news/2240036228/Will-your-organization-benefit-from-big-data-processing-technology (accessed on 24 August 2016).
- Lazer, D.; Kennedy, R. What We Can Learn From the Epic Failure of Google Flu Trends. Available online: http://www.wired.com/2015/10/can-learn-epic-failure-google-flu-trends/ (accessed on 24 August 2016).
- Kuhn, T.S. Structure of Scientific Revolutions; University of Chicago Press: Chicago, IL, USA, 1962. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Coordinates (or Vertices) | Contains | is in | Touches | Has Hole(s) | Theme, etc. |
|---|---|---|---|---|---|---|
| 1 | x,y; x,y; x,y;x,y; | #2;#3 | - | - | 1 | - |
| 2 | x,y; x,y; x,y; x,y | - | #1 | #3 | 0 | - |
| 3 | x,y; x,y; x,y | - | #1 | #2 | 0 | - |
| Data Quality Element (Sub-Element) | Description |
|---|---|
| Completeness (omission, commission, logical consistency) | Presence of features, their attributes and relationships(absence or excess of data, adherence to rules of the data structure) |
| Conceptual consistency | Adherence to rules of the conceptual schema, to value domains, etc. |
| Topological consistency | Correctness of explicit topology, closeness to respective position of features |
| Positional accuracy | Accuracy in absolute point positioning, gridded data positioning |
| Temporal consistency | Accuracy of temporal attributes and their relationships |
| Thematic accuracy | Accuracy of quantitative attributes, class correctness |
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeansoulin, R. Review of Forty Years of Technological Changes in Geomatics toward the Big Data Paradigm. ISPRS Int. J. Geo-Inf. 2016, 5, 155. https://doi.org/10.3390/ijgi5090155
Jeansoulin R. Review of Forty Years of Technological Changes in Geomatics toward the Big Data Paradigm. ISPRS International Journal of Geo-Information. 2016; 5(9):155. https://doi.org/10.3390/ijgi5090155
Chicago/Turabian StyleJeansoulin, Robert. 2016. "Review of Forty Years of Technological Changes in Geomatics toward the Big Data Paradigm" ISPRS International Journal of Geo-Information 5, no. 9: 155. https://doi.org/10.3390/ijgi5090155
APA StyleJeansoulin, R. (2016). Review of Forty Years of Technological Changes in Geomatics toward the Big Data Paradigm. ISPRS International Journal of Geo-Information, 5(9), 155. https://doi.org/10.3390/ijgi5090155