
Centrality as a Method for the Evaluation of Semantic Resources for Disaster Risk Reduction



Abstract
:1. Introduction
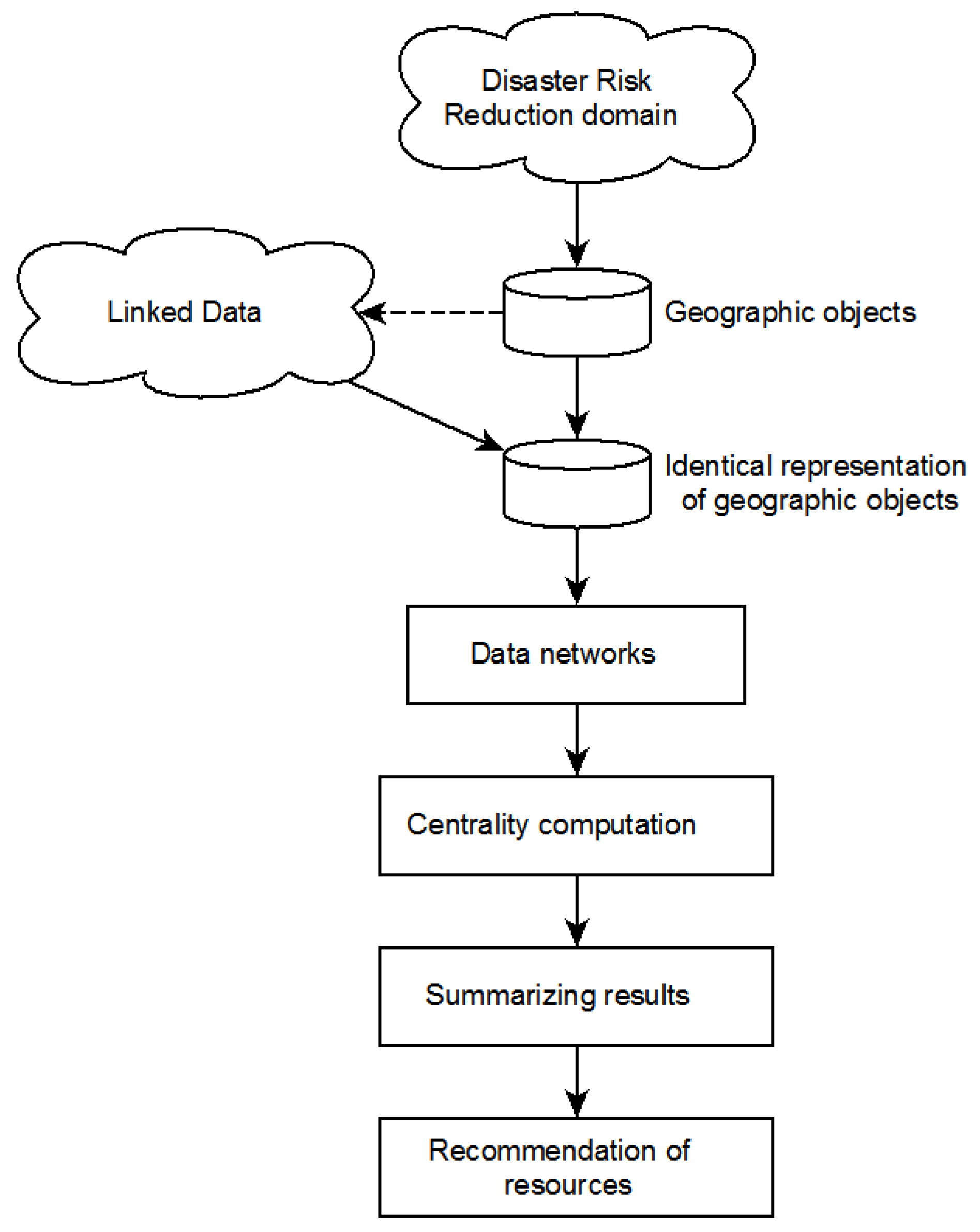
2. Materials and Methods
- Selecting sample geographic objects.
- Downloading identical representations of geographic objects from various Linked Data resources.
- Development of Data Networks representing particular concepts (see an example in Figure 2).
- Application of centrality metrics for resources evaluation.
- Summarizing information from particular Data Networks.
- Recommendation of thesauri or other semantic resources based on the results of the quantitative evaluation.
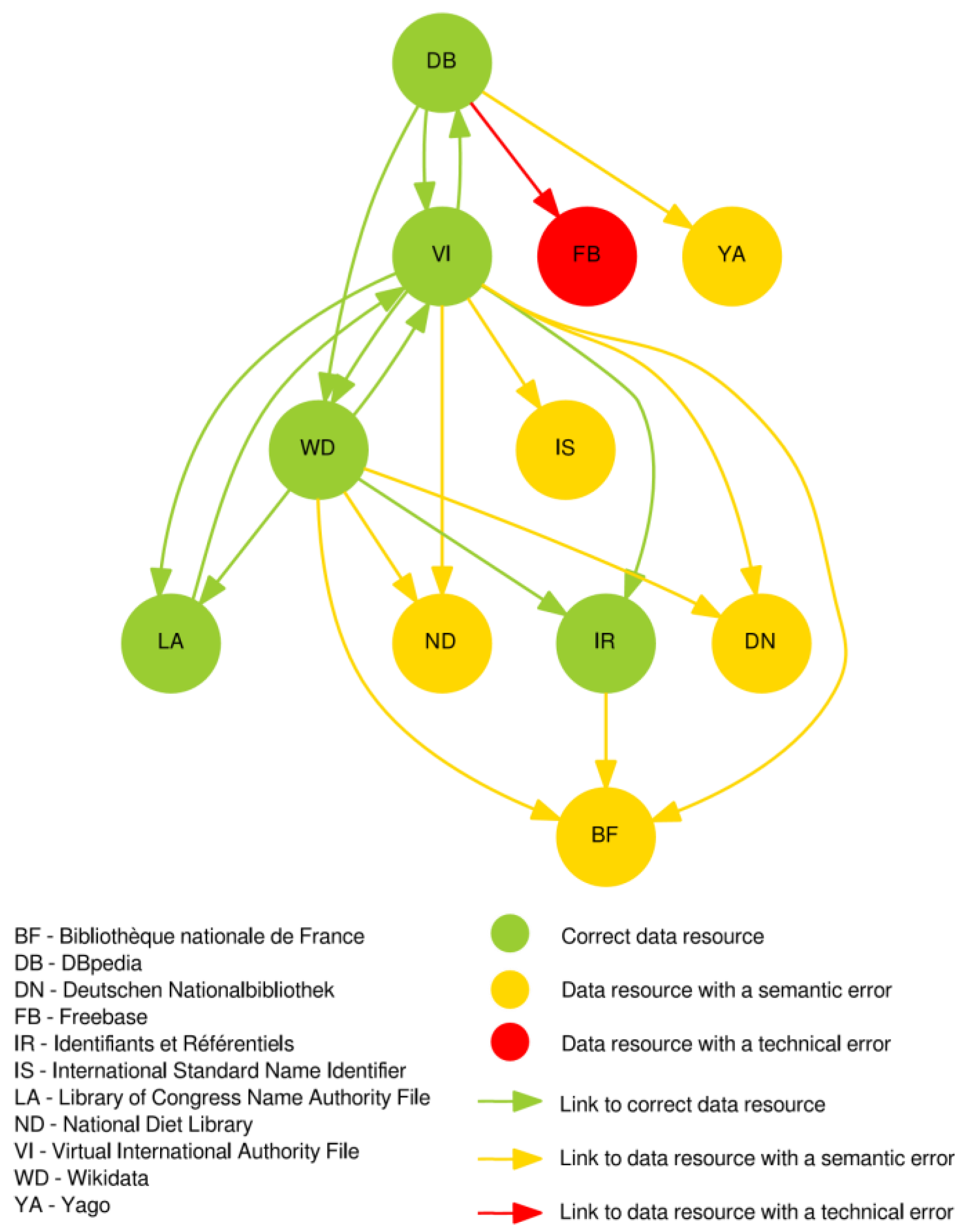
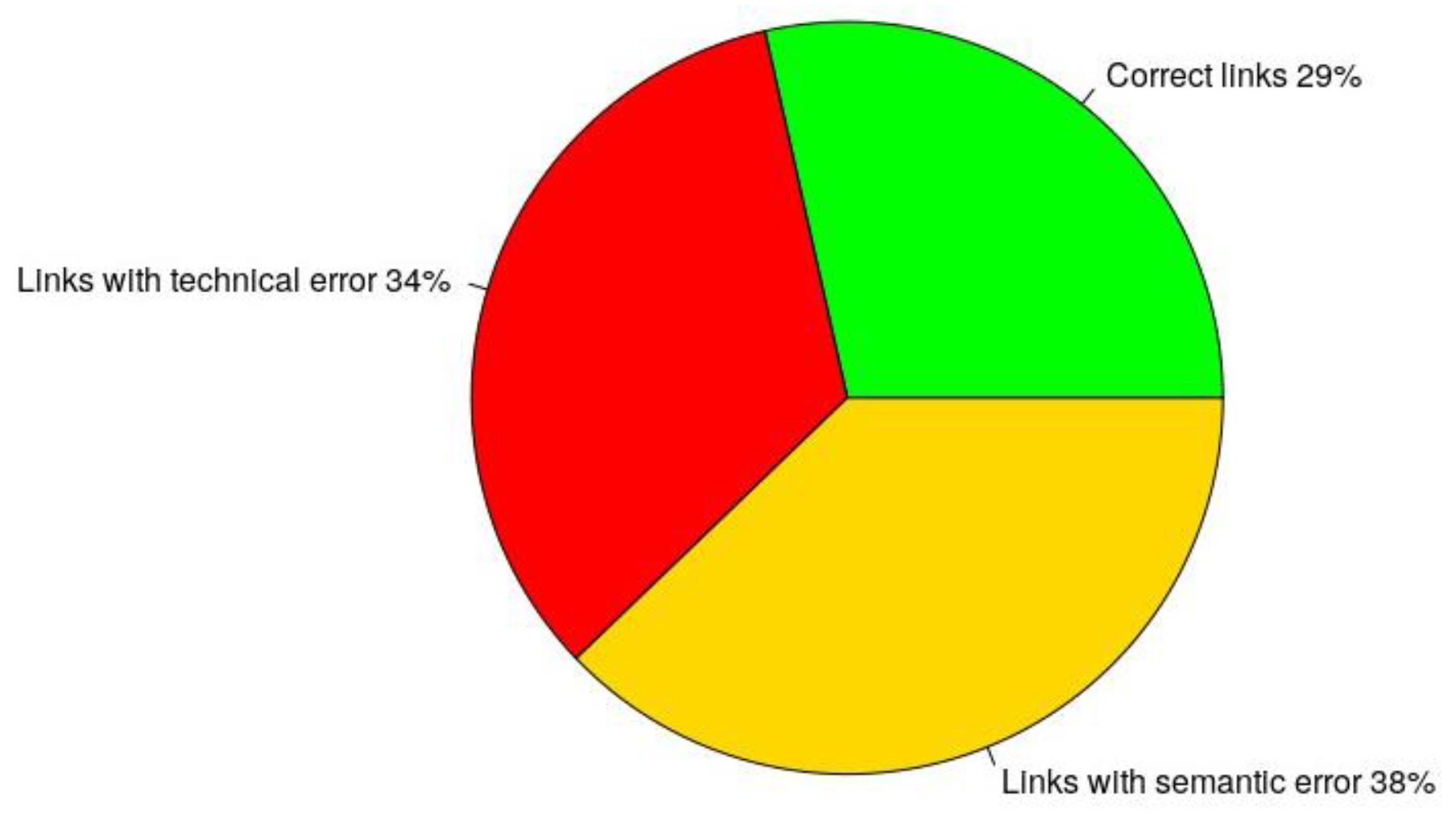
- Links leading to correct nodes (Linked Data resources);
- Links directed to data resources influenced by a semantic error (e.g., HTML view on data instead of real RDF data);
- Links targeting to data resources containing a technical error (usually not working URI, uniform resource identifier).
3. Results
- It is connected to many other resources.
- It is referenced from many other resources.
- It is close to other resources.
- It interconnects independent subgraphs of the network.
4. Discussion
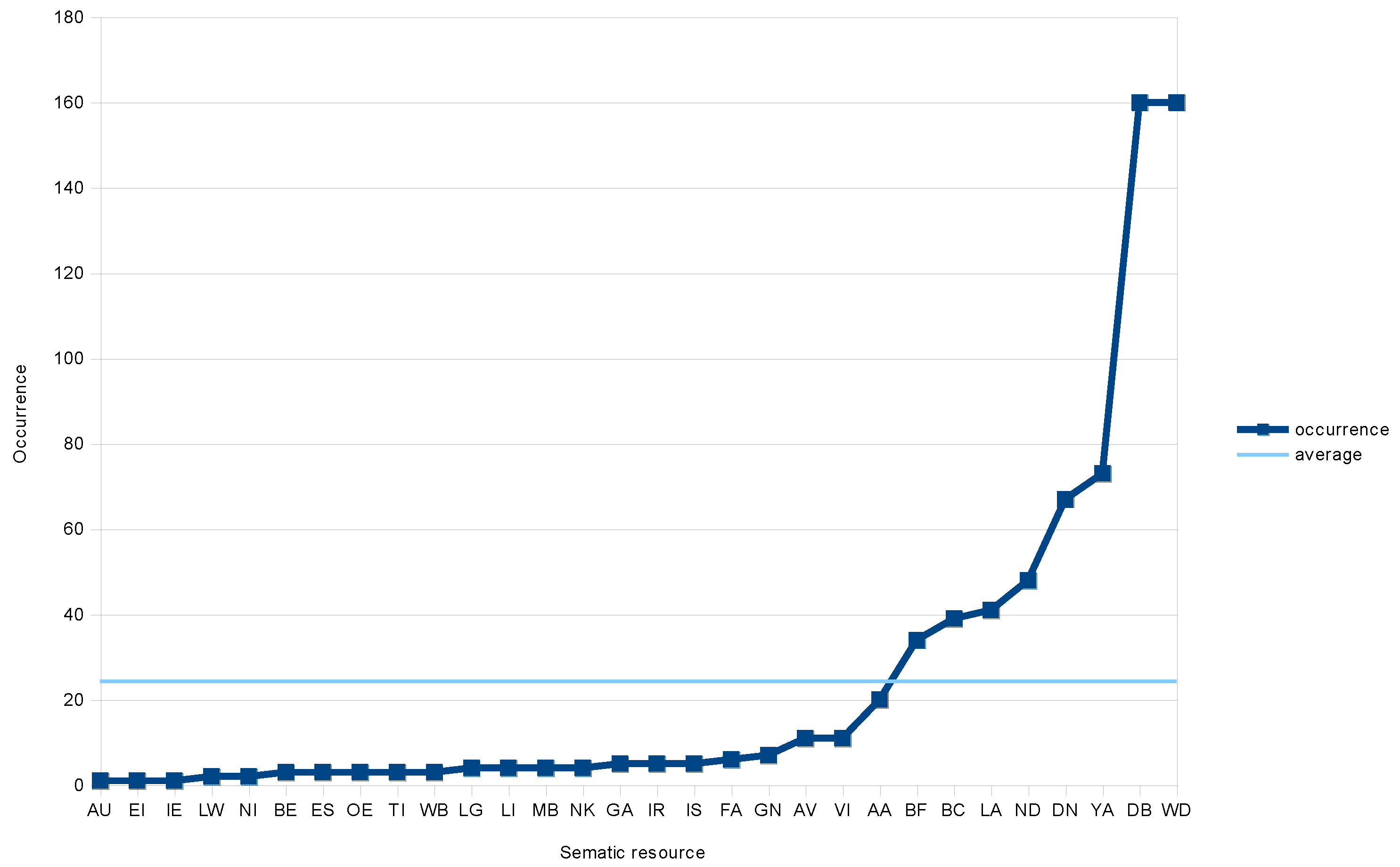
- Disaster risk reduction is a very large and multi-disciplinary field. Therefore, the portfolio of tested terms (keywords) is very heterogeneous. It contains specific terms (e.g., disaster response), general terms (e.g., accessibility, attention), geographical or personal names, and many concepts from other domains (information technologies, cartography, economics).
- Only two semantic resources contain all tested terms (Figure 4). In the case of DBpedia this fact is given by the selected system of searching of the Linked Data network (see Materials and Methods). Wikidata is the second most important resource from the view of occurrence of concepts or objects related to disaster risk reduction. This information shows that the role of Wikidata in the world of Linked Data is much more significant and it competes with DBpedia [45]. Both resources (DBpedia and Wikidata) represent the most complex semantic knowledge bases for disaster risk reduction purposes. It is evident not only from Figure 4, but also from Table 2, where Wikidata and DBpedia have the highest values in all types of centrality.
- Because all values in the Table 2 are normalized, just the simple sum can be used as the overall indicator. In addition to DBpedia and Wikidata mentioned above, there are other interesting semantic resources: Biblioteca Nazionale Centrale di Firenze, Yago, Deutschen Nationalbibliothek, Library of Congress Name Authority File and NDL (National Diet Library). Except for high centrality values (especially closeness centrality), these resources have better-than-average occurrence of tested concepts. It is also interesting to note that all of these resources (except Yago) come from the domain of libraries.
- There are important data sets missing in the set of semantic resources, such as AGROVOC, EuroVoc, GEMET (GEneral Multilingual Environmental Thesaurus), NAL (National Agricultural Library) or STW (Standard-Thesaurus Wirtschaft) Thesaurus for Economics. This is caused by the selected method of data exploitation, because none of them is connected to DBpedia or other resources related to DBpedia. This isolation of the group of the above-mentioned thesauri or ontologies is also evident from other research (e.g., [29]). The authors tested searching process starting in AGROVOC, but results were not satisfying due to the low number of tested terms contained in AGROVOC.
- Geographical concepts [10] and objects represent a specific case of disaster risk reduction terms. In addition to the above-mentioned semantic resources, they are contained in specific thesauri, ontologies, or gazetteers such as GeoNames.org, LinkedGeoData (a Linked Data version of OpenStreetMap), or FAO Geopolitical Ontology (it is not mentioned in this research).
5. Conclusions
- DBpedia and Wikidata (as the most important resources in the Linked Data space) are the most relevant resources for the studied domain as well. Wikidata plays the role of a hub (a resource interlinked to other resources) and a bridge (a component connecting not-interlinked groups of resources). These conclusions follow from the values of the outdegree and betweeness centrality. DBpedia represents an authority among Linked Data resources in the field of disaster risk reduction (derived from the indegree centrality values). Based on the closeness centrality, DBpedia is also a central node of the Linked Data space in the case of the domain processed in this article.
- There are several interesting resources (e.g., Biblioteca Nazionale Centrale di Firenze, Deutschen Nationalbibliothek, or Library of Congress Name Authority File) usually coming from library science.
- Many interesting semantic resources related to agriculture or environmental protection (e.g., AGROVOC or GEMET) contain several disaster risk reduction concepts, but they are not linked to DBpedia.
- There are several specific semantic resources for geographical objects, such as GeoNames.org or LinkedGeoData.
Acknowledgments
Author Contribution
Conflicts of Interest
References
- Zerger, A.; Smith, D.I. Impediments to using GIS for real-time disaster decision support. Comput. Environ. Urban Syst. 2003, 27, 123–141. [Google Scholar] [CrossRef]
- Schmidt-Thomé, P. The spatial effects and management of natural and technological hazards in Europe. In Final Report of the European Spatial Planning and Observation Network (ESPON) Project; Geological Survey of Finland: Espoo, Finland, 2005; pp. 1–197. [Google Scholar]
- Tran, P.; Shaw, R.; Chantry, G.; Norton, J. GIS and local knowledge in disaster management: A case study of flood risk mapping in Viet Nam. Disasters 2009, 33, 152–169. [Google Scholar] [CrossRef] [PubMed]
- Konecny, M.; Zlatanova, S.; Bandrova, T.L. Geographic Information and Cartography for Risk and Crisis Management; Springer: Heidelberg, Germany, 2010. [Google Scholar]
- Berners-Lee, T. Linked Data-Design Issues. 2006. Available online: http://www.w3.org/DesignIssues/LinkedData.Html (accessed on 3 August 2017).
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked data-the story so far. In Semantic Services, Interoperability and Web Applications; Emerging Concepts; Springer: Heidelberg, Germany, 2009; pp. 205–227. [Google Scholar]
- Heath, T.; Bizer, C. Linked data: Evolving the web into a global data space. In Synthesis Lectures on the Semantic Web: Theory and Technology; Morgan&Claypool Publishers: London, UK, 2011; pp. 1–136. [Google Scholar]
- Reznik, T.; Horakova, B.; Szturc, R. Geographic Information for Command and Control Systems Demonstration of Emergency Support System. In Intelligent Systems for Crisis Management: Geo-Information for Disaster Management (GI4DM) 2012—Lecture Notes in Geoinformation and Cartography, 1st ed.; Zlatanova, S., Dilo, A., Peters, R., Scholten, H., Eds.; Springer-Verlag: Berlin, Germany, 2013; pp. 263–275. [Google Scholar] [CrossRef]
- Reznik, T.; Horakova, B.; Szturc, R. Advanced methods of cell phone localization for crisis and emergency management applications. Int. J. Digit. Earth 2003, 8, 259–272. [Google Scholar] [CrossRef]
- Kavouras, M.; Kokla, M. Theories of Geographic Concepts: Ontological Approaches to Semantic Integration; CRC Press, Taylor & Francis Group: Boca Raton, FL, USA, 2007; pp. 1–352. [Google Scholar]
- Hart, G.; Dolbear, C. Linked Data: A Geographic Perspective; CRC Press, Taylor & Francis Group: Boca Raton, FL, USA, 2013. [Google Scholar]
- Wood, D.; Zaidman, M.; Ruth, L.; Hausenblas, M. Linked Data; Manning Publications Co.: Shelter Island, NY, USA, 2014; p. 336. [Google Scholar]
- Guéret, C.; Groth, P.; Stadler, C.; Lehmann, J. Assessing Linked Data Mappings Using Network Measures. In Extended Semantic Web Conference; Springer: Heidelberg, Germany, 2012; pp. 87–102. [Google Scholar]
- Freeman, L.C. A set of measures of centrality based on betweenness. Sociometry 1977, 40, 35–41. [Google Scholar] [CrossRef]
- Goodman, L.A. Snowball sampling. Ann.Math. Stat. 1961, 32, 148–170. [Google Scholar] [CrossRef]
- Bandrova, T.; Zlatanova, S.; Konecny, M. Three-dimensional maps for disaster management. In ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences; Copernicus GmbH: Göttingen, Germany, 2012. [Google Scholar]
- Bandrova, T.; Konecny, M. Mapping of Nature Risks and Disasters for Educational Purposes. Kartografija i Geoinformacije 2006, 5, 4–12. [Google Scholar]
- Snoeren, G.; Zlatanova, S.; Crompvoets, J.; Scholten, H. Spatial Data Infrastructure for emergency management: The view of the users; Vrije Universiteit Amsterdam: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Charvat, K.; Kubicek, P.; Talhofer, V.; Konecny, M.; Jezek, J. Spatial data infrastructure and geovisualization in emergency management. In Resilience of Cities to Terrorist and Other Threats; Springer: Heidelberg, Germany, 2008; pp. 443–473. [Google Scholar]
- Zlatanova, S. SII for Emergency Response: The 3D Challenges; ISPRS Archives–Volume XXXVII Part B4; Chen, J., Jiang, J., Nayak, S., Eds.; Copernicus GmbH: Bejing, China, 2008; pp. 1631–1637. [Google Scholar]
- Goodchild, M.F.; Glennon, J.A. Crowdsourcing geographic information for disaster response: A research frontier. Int. J. Digit. Earth 2010, 3, 231–241. [Google Scholar] [CrossRef]
- Kozel, J.; Štampach, R. Practical experience with a contextual map service. In Geographic Information and Cartography for Risk and Crisis Management; Springer: Heidelberg, Germany, 2010; pp. 305–316. [Google Scholar]
- Zlatanova, S.; Dilo, A. A Data Model for Operational and Situational Information in Emergency Response: The Dutch Case; ISPRS: Torino, Italy, 2010. [Google Scholar]
- Bell, R.; Glade, T. Multi-hazard analysis in natural risk assessments. WIT Trans. State Art Sci. Eng. 2011, 1, 1–371. [Google Scholar]
- Konecny, M.; Kubicek, P.; Stachon, Z.; Sasinka, C. The usability of selected base maps for crises management—Users’ perspectives. Appl. Geomat. 2011, 3, 189–198. [Google Scholar] [CrossRef]
- Reznik, T.; Horáková, B.; Janiurek, D. Emergency support system: Actionable real-time intelligence with fusion capabilities and cartographic displays. Adv. Mil. Technol. 2011, 6, 83–97. [Google Scholar]
- Hausenblas, M. Exploiting linked data to build web applications. IEEE Int. Comput. 2009, 13, 68–73. [Google Scholar] [CrossRef]
- Ding, L.; Shinavier, J.; Shangguan, Z.; McGuinness, D.L. SameAs networks and beyond: Analysing deployment status and implications of owl: SameAs in linked data. Proccedings of the International Semantic Web Conference, Shanghai, China, 7–11 November 2010. [Google Scholar]
- Cerba, O.; Jedlicka, K. Geomatic Concepts in Agriculture Thesauri. AGRIS On-Line Papers Econ. Inform. 2015, 7, 33. [Google Scholar]
- Cerba, O.; Jedlicka, K. Linked Forests: Semantic similarity of geographical concepts “forest”. Open Geosci. 2016, 8, 556–566. [Google Scholar] [CrossRef]
- Guéret, C.; Groth, P.; Van Harmelen, F.; Schlobach, S. Finding the achilles heel of the web of data: Using network analysis for link-recommendation. In International Semantic Web Conference; Springer: Heidelberg, Germany, 2010; pp. 289–304. [Google Scholar]
- Coursey, K.; Mihalcea, R. Topic identification using Wikipedia graph centrality. In Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics; Companion Volume: Short Papers; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009; pp. 117–120. [Google Scholar]
- Hakimov, S.; Oto, S.A.; Dogdu, E. Named entity recognition and disambiguation using linked data and graph-based centrality scoring. In Proceedings of the 4th International Workshop on Semantic Web Information Management, Scottsdale, AZ, USA, 20 May 2012. [Google Scholar]
- Zaveri, A.; Rula, A.; Maurino, A.; Pietrobon, R.; Lehmann, J.; Auer, S. Quality Assessment for Linked Data: A Survey; Semantic Web, IOS Press: Amsterdam, The Netherlands, 2016; pp. 63–93. [Google Scholar]
- Cheng, G.; Tran, T.; Qu, Y. RELIN: Relatedness and Informativeness-Based Centrality for Entity Summarization; Springer: Heidelberg, Germany, 2011; pp. 114–129. [Google Scholar]
- Sinha, R.; Mihalcea, R. Unsupervised Graph-Basedword Sense Disambiguation Using Measures of Word Semantic Similarity. In Proceedings of the IEEE International Conference Semantic Computing (ICSC), Irvine, CA, USA, 17–19 September 2007. [Google Scholar]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef]
- Haythornthwaite, C. Social network analysis: An approach and technique for the study of information exchange. Libr. Inf. Sci. Res. 1996, 18, 323–342. [Google Scholar]
- Cimenler, O.; Reeves, K.A.; Skvoretz, J. A regression analysis of researchers’ social network metrics on their citation performance in a college of engineering. J. Inf. 2014, 8, 667–682. [Google Scholar] [CrossRef]
- Freeman, L. The Development of Social Network Analysis. A Study in the Sociology of Science; BookSurge, LLC: North Charleston, SC, USA, 2004. [Google Scholar]
- Varlamis, I.; Eirinaki, M.; Louta, M. A study on social network metrics and their application in trust networks. In Proceedings of the IEEE International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2010), University of Southern Denmark, Odense, Denmark, 9–11 August 2010; pp. 168–175. [Google Scholar]
- Zimmermann, T.; Nagappan, N. Predicting defects using network analysis on dependency graphs. In Proceedings of the 2008 ACM/IEEE 30th International Conference on Software Engineering (ICSE’08), Leipzig, Germany, 10–18 May 2008. [Google Scholar]
- Borgatti, S.P.; Everett, M.G. A graph-theoretic perspective on centrality. Soc. Netw. 2006, 28, 466–484. [Google Scholar] [CrossRef]
- Thung, F.; Lo, D.; Osman, M.H.; Chaudron, M.R. Condensing class diagrams by analyzing design and network metrics using optimistic classification. In Proceedings of the 22nd International Conference on Program Comprehension; ACM: New York, NY, USA, 2014; pp. 110–121. [Google Scholar]
- Macura, J. Porovnání projektů Wikidata a DBpedia Jako Zdrojů Prostorových dat: Comparison of Wikidata and DBpedia Projects as Spatial Data Sources, 2016. Available online: https://otik.uk.zcu.cz/xmlui/handle/11025/23748?show=full (accessed on 3 August 2017).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Centrality | Properties |
|---|---|
| Indegree | It shows the normalized value of the amount of nodes of the graph being connected to the vertex for which the centrality is computed.
In the case of this article, the high value of indegree centrality means that this resource is directly referenced by other resources. |
| Outdegree | It expresses the normalized value of the amount of nodes of the graph being connected to the vertex by directed edge from the node for which the centrality is computed.
In the case of this article, the high value of indegree centrality means that this resource contains many links to other resources. |
| Closeness | This type of centrality shows how close the node is to the other vertices in the graph. In the case of Linked Data it does not play a very important role, because the data networks are not very large (tens of nodes). |
| Betweenness | It identifies weak positions of the graph–nodes (resources) representing the bridges among independent parts of data network. |
| Acronym | Outdegree | Indegree | Closeness | Betweenness |
|---|---|---|---|---|
| AA | 0.0317 | 0.0016 | 0.0242 | 0.0001 |
| AU | 0.0006 | 0 | 0.0005 | 0 |
| AV | 0.0102 | 0 | 0.0088 | 0 |
| BC | 0.0457 | 0.1081 | 0.1260 | 0.0331 |
| BE | 0.0016 | 0 | 0.0015 | 0 |
| BF | 0.0388 | 0 | 0.0271 | 0 |
| DB | 0.0598 | 0.6853 | 0.7801 | 0.0477 |
| DN | 0.1041 | 0 | 0.0752 | 0 |
| EI | 0.0003 | 0 | 0.0003 | 0 |
| ES | 0.0025 | 0 | 0.0009 | 0 |
| FA | 0.0032 | 0.0050 | 0.0116 | 0 |
| GA | 0.0022 | 0 | 0.0020 | 0 |
| GN | 0.0132 | 0.0052 | 0.0156 | 0.0011 |
| IE | 0.0007 | 0 | 0.0006 | 0 |
| IR | 0.0035 | 0.0018 | 0.0022 | 0.0001 |
| IS | 0.0028 | 0 | 0.0020 | 0 |
| LA | 0.0653 | 0.0047 | 0.0418 | 0 |
| LG | 0.0027 | 0.0042 | 0.0096 | 0 |
| LI | 0.0036 | 0 | 0.0031 | 0 |
| LW | 0.0018 | 0.0024 | 0.0052 | 0 |
| MB | 0.0015 | 0 | 0.0014 | 0 |
| ND | 0.0605 | 0 | 0.0478 | 0 |
| NI | 0.0006 | 0 | 0.0006 | 0 |
| NK | 0.0030 | 0 | 0.0027 | 0 |
| OE | 0.0009 | 0 | 0.0009 | 0 |
| TI | 0.0019 | 0.0038 | 0.0075 | 0.0004 |
| VI | 0.0162 | 0.0364 | 0.0412 | 0.0080 |
| WB | 0.0009 | 0.0038 | 0.0075 | 0 |
| WD | 0.4966 | 0.2950 | 0.4921 | 0.1425 |
| YA | 0.1808 | 0 | 0.1109 | 0 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Čerba, O.; Jedlička, K.; Čada, V.; Charvát, K. Centrality as a Method for the Evaluation of Semantic Resources for Disaster Risk Reduction. ISPRS Int. J. Geo-Inf. 2017, 6, 237. https://doi.org/10.3390/ijgi6080237
Čerba O, Jedlička K, Čada V, Charvát K. Centrality as a Method for the Evaluation of Semantic Resources for Disaster Risk Reduction. ISPRS International Journal of Geo-Information. 2017; 6(8):237. https://doi.org/10.3390/ijgi6080237
Chicago/Turabian StyleČerba, Otakar, Karel Jedlička, Václav Čada, and Karel Charvát. 2017. "Centrality as a Method for the Evaluation of Semantic Resources for Disaster Risk Reduction" ISPRS International Journal of Geo-Information 6, no. 8: 237. https://doi.org/10.3390/ijgi6080237
APA StyleČerba, O., Jedlička, K., Čada, V., & Charvát, K. (2017). Centrality as a Method for the Evaluation of Semantic Resources for Disaster Risk Reduction. ISPRS International Journal of Geo-Information, 6(8), 237. https://doi.org/10.3390/ijgi6080237