Detecting Anomalous Trajectories and Behavior Patterns Using Hierarchical Clustering from Taxi GPS Data



Abstract
:1. Introduction
2. Related Works about Trajectory Clustering for Anomalous Trajectory Detection
3. Trajectory Clustering Method that Integrates Edit Distance and Hierarchical Clustering
3.1. Improved Edit Distance for GPS Trajectory Data
3.1.1. Edit Distance Operation Cost
3.1.2. Normalization
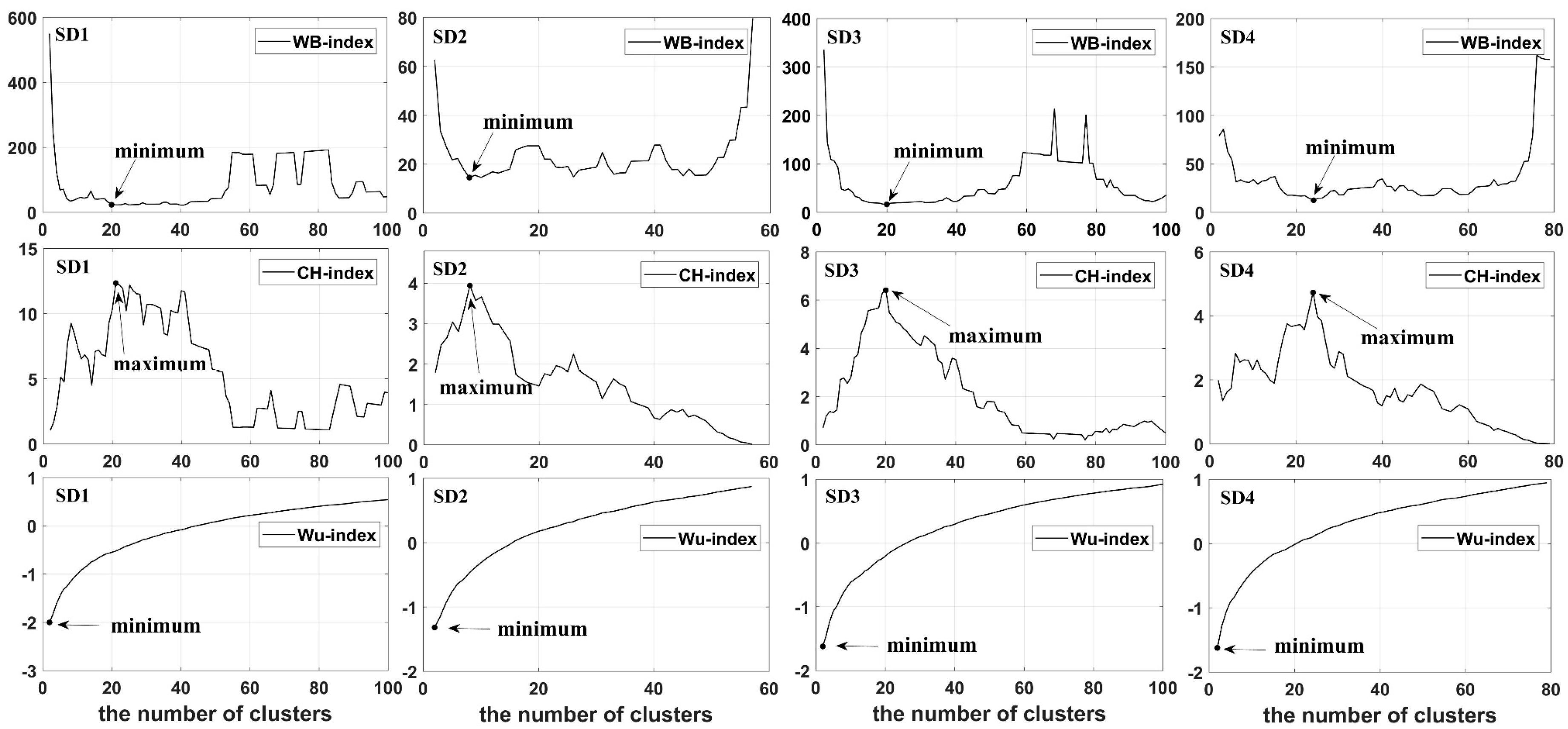
3.2. Determining the Number of Clusters in Hierarchical Clustering
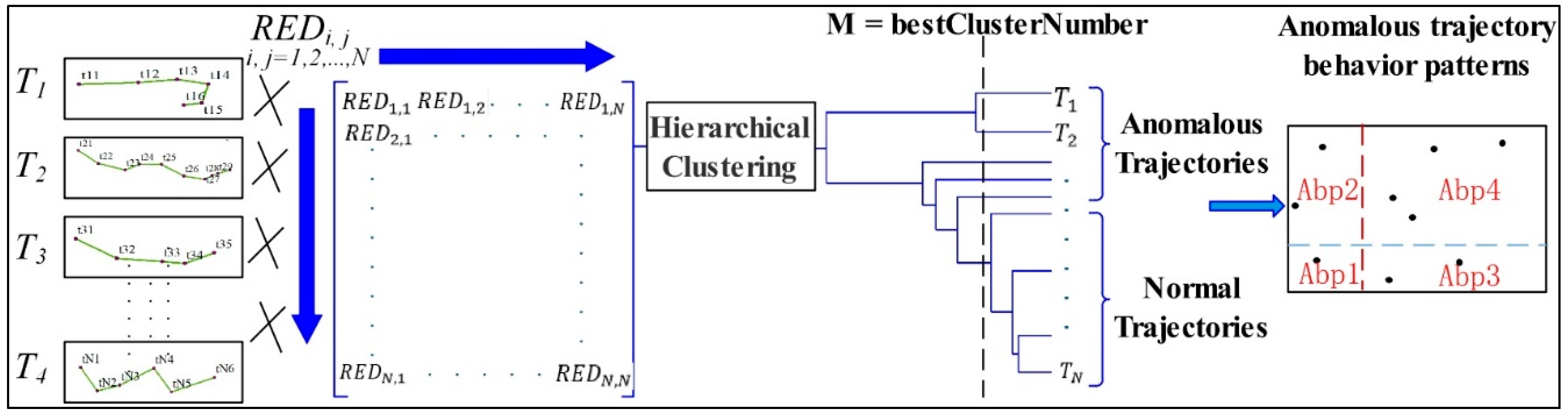
3.3. Anomalous Trajectories and Behavior Pattern Detection
3.3.1. Definition of Anomalous Trajectories
3.3.2. Algorithm Flowchart of Anomalous Trajectory Detection
| Algorithm 1: Trajectory clustering for anomalous trajectory detection |
| Input: a trajectory dataset = []; : the optimal number of clusters. Output: the trajectory clusters C = [, ,……, ] and with anomalous attributes label Step1: Similarity measurement of trajectories based on improved edit distance algorithm begin (, N): the number of points of ; : the normalization value of the edit distance between and ; : the edit distance matrix of and ; ED: the distance matrix of . for i = 0 to N − 1 for j = 0 to i pick a pair of trajectories and compute the value of the first row and first column of the for i = 2 to + 1 for j = 2 to + 1 min([i][j]+insert, [i][j]+delete, [i][j]+replace) by formulas (2)–(4) ED[i][j] = return the edit distance matrix of trajectory dataset ED[i][j] Step 2: Clustering trajectories into groups by using hierarchical clustering each trajectory forms an initial cluster = [(i = 1, 2, …, N)], x is the optimal clustering number repeat find the pair of clusters of minimum dissimilarity: = add = to C and delete from C N = N – 1 until N = x end return the result of hierarchical clustering C = [,,……,] Step 3: Label anomalous trajectories based on clustering results repeat find include the number of trajectories only one and label anomalous trajectories end return a trajectory dataset = [] with anomalous attributes label |
3.3.3. Discovering Anomalous Behavior Patterns Based on Statistical Indicators
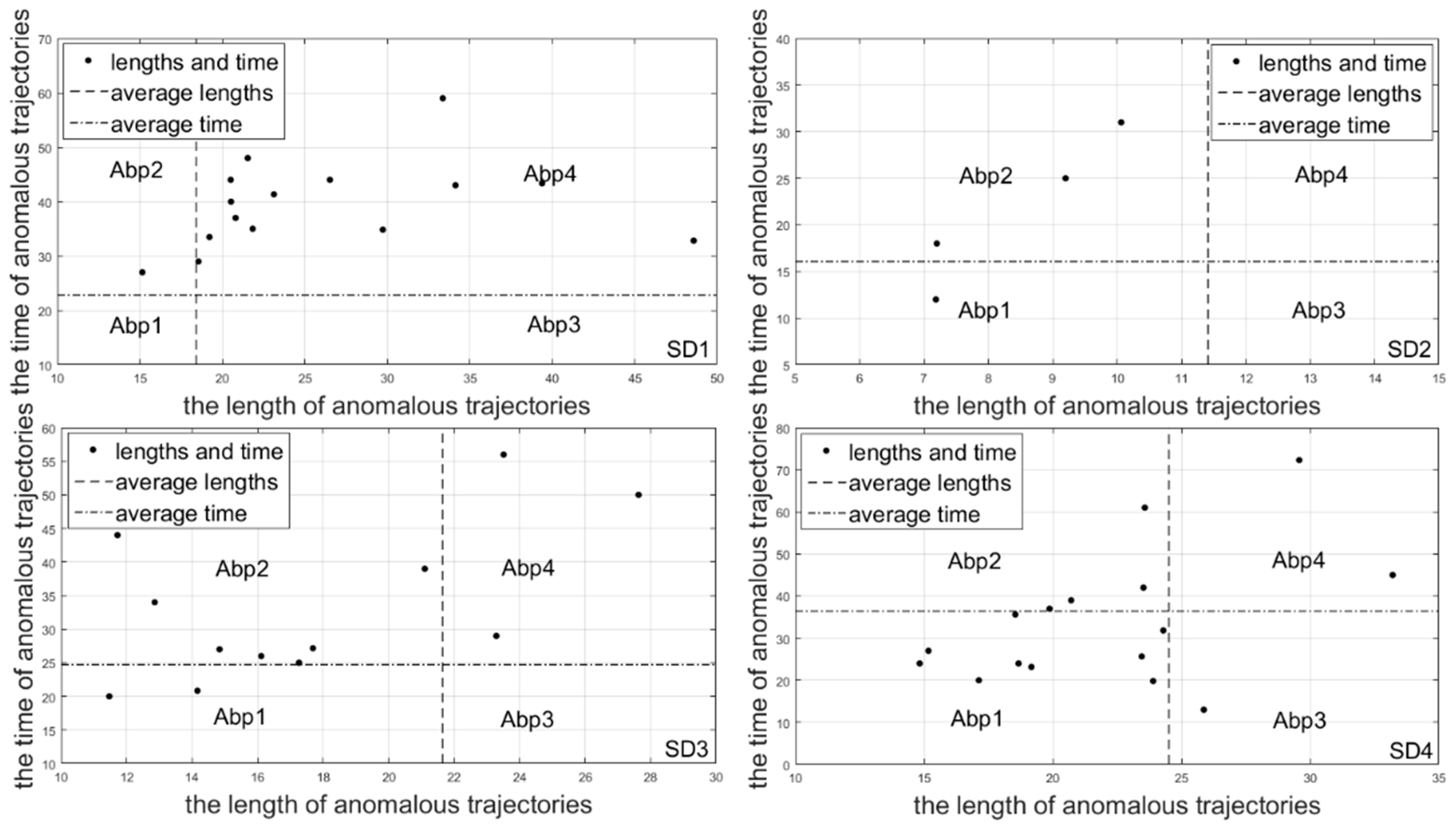
- Anomalous behavior pattern 1(Abp1): ,
- Anomalous behavior pattern 2(Abp2): ,
- Anomalous behavior pattern 3(Abp3): , and
- Anomalous behavior pattern 4(Abp4): .
4. Experiment of the Proposed Approach
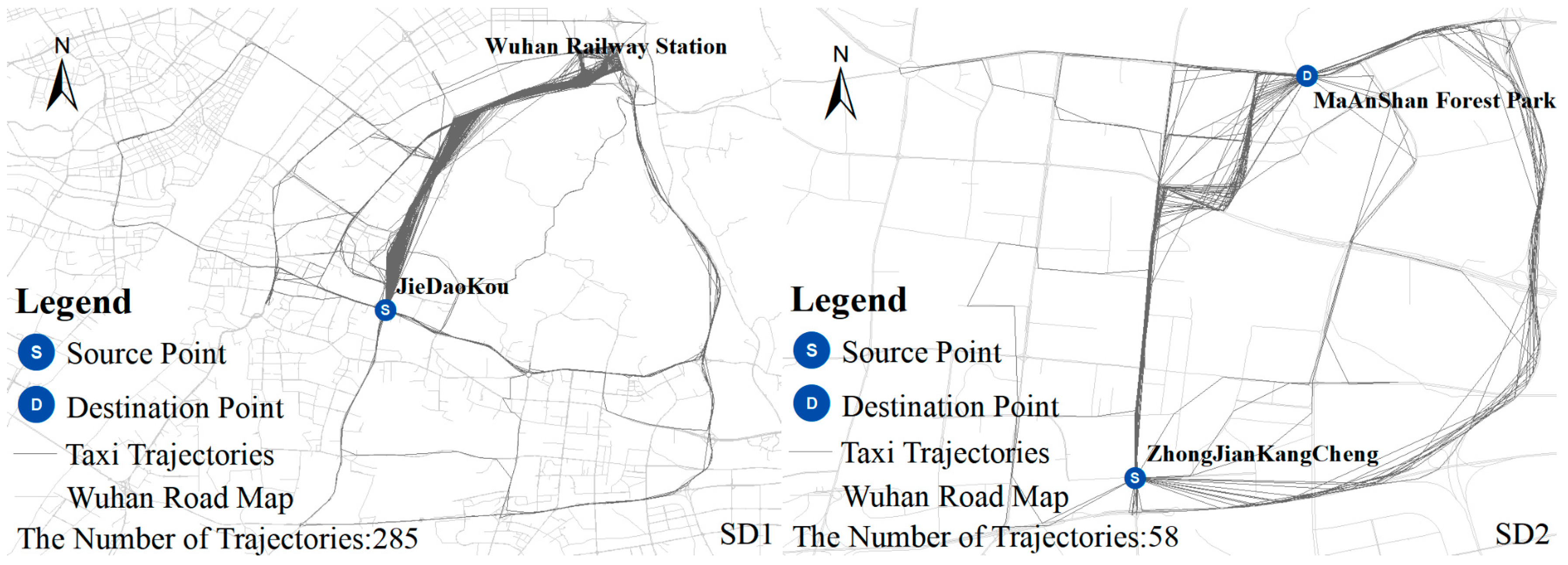
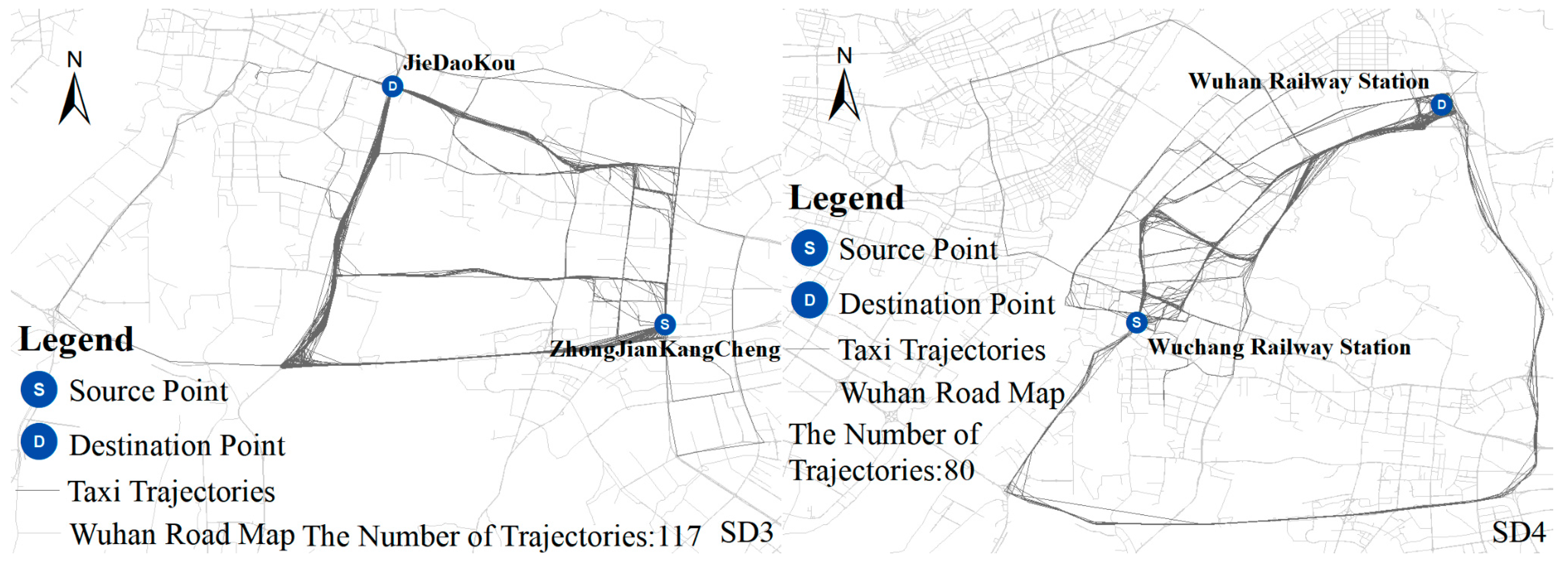
4.1. Taxi Trajectory Data Pre-Processing
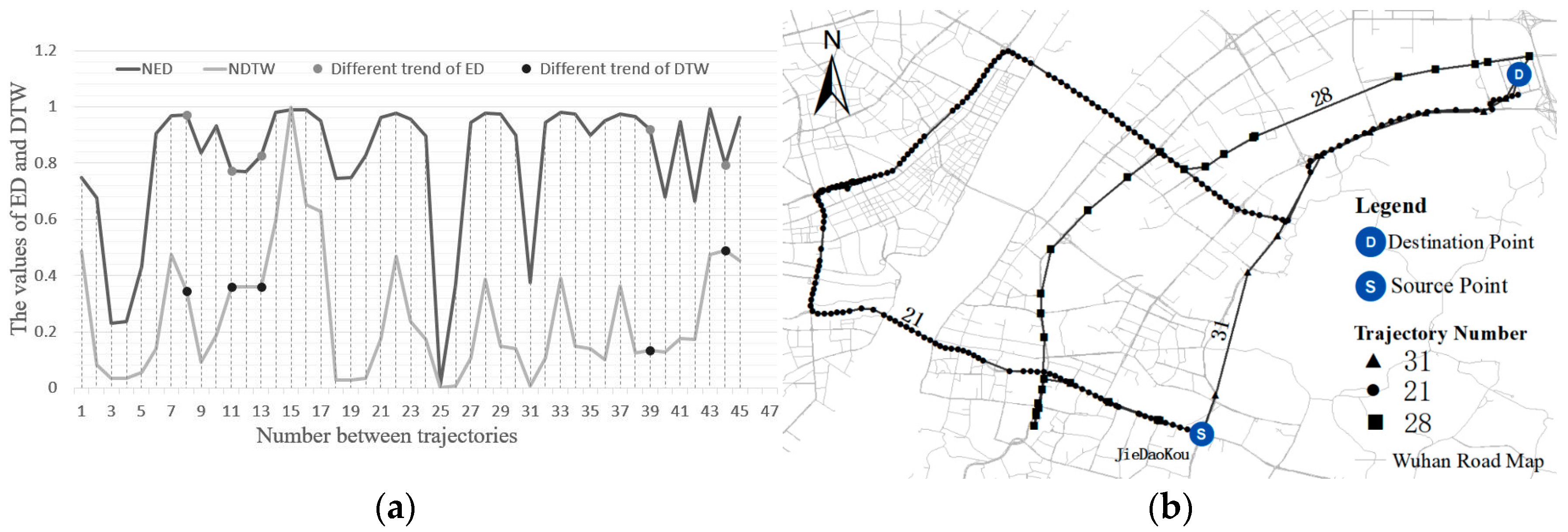
4.2. Distance Measurement of Taxi Trajectory Data
4.3. Comparison of Indices for Automatic Trajectory Clustering
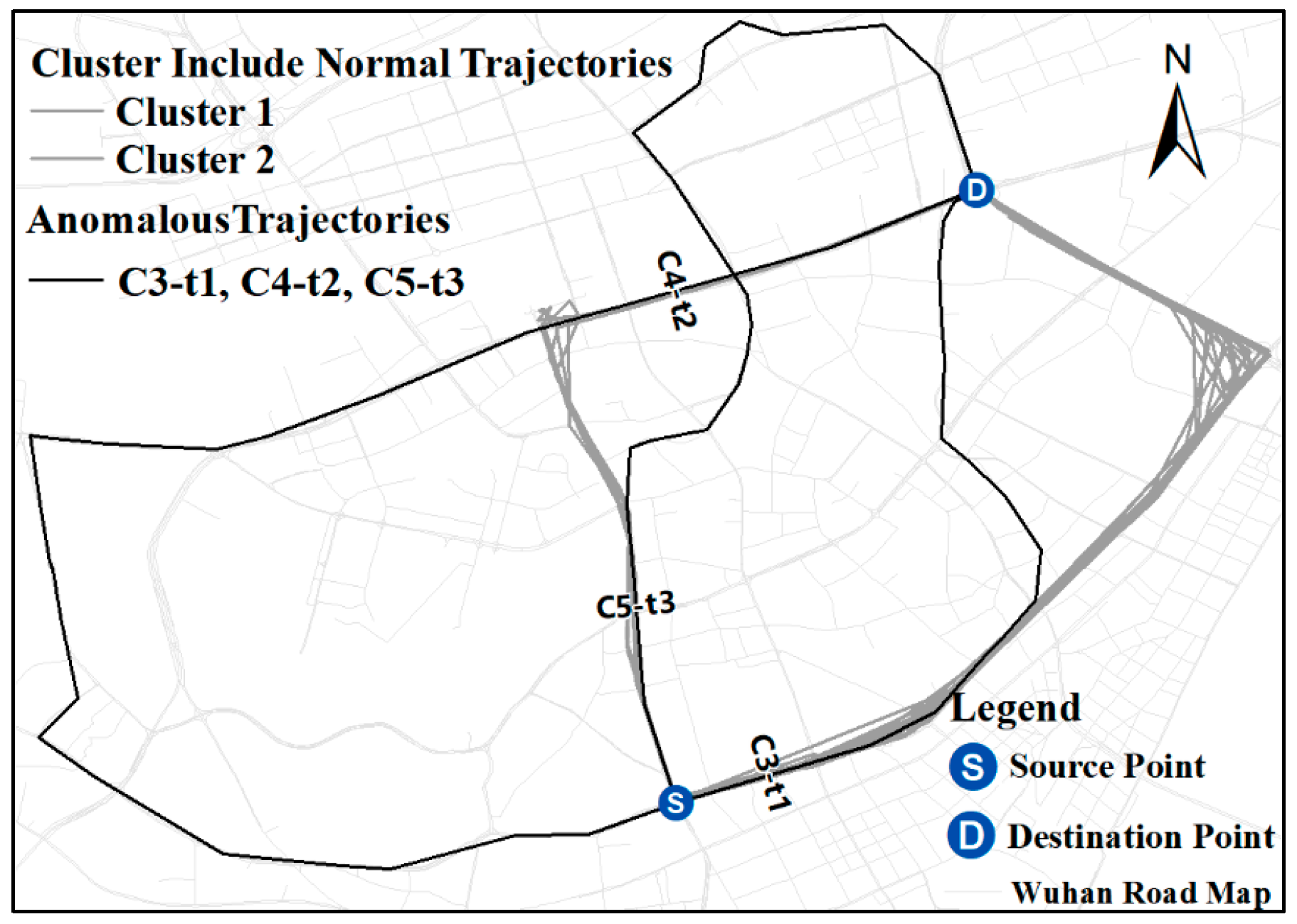
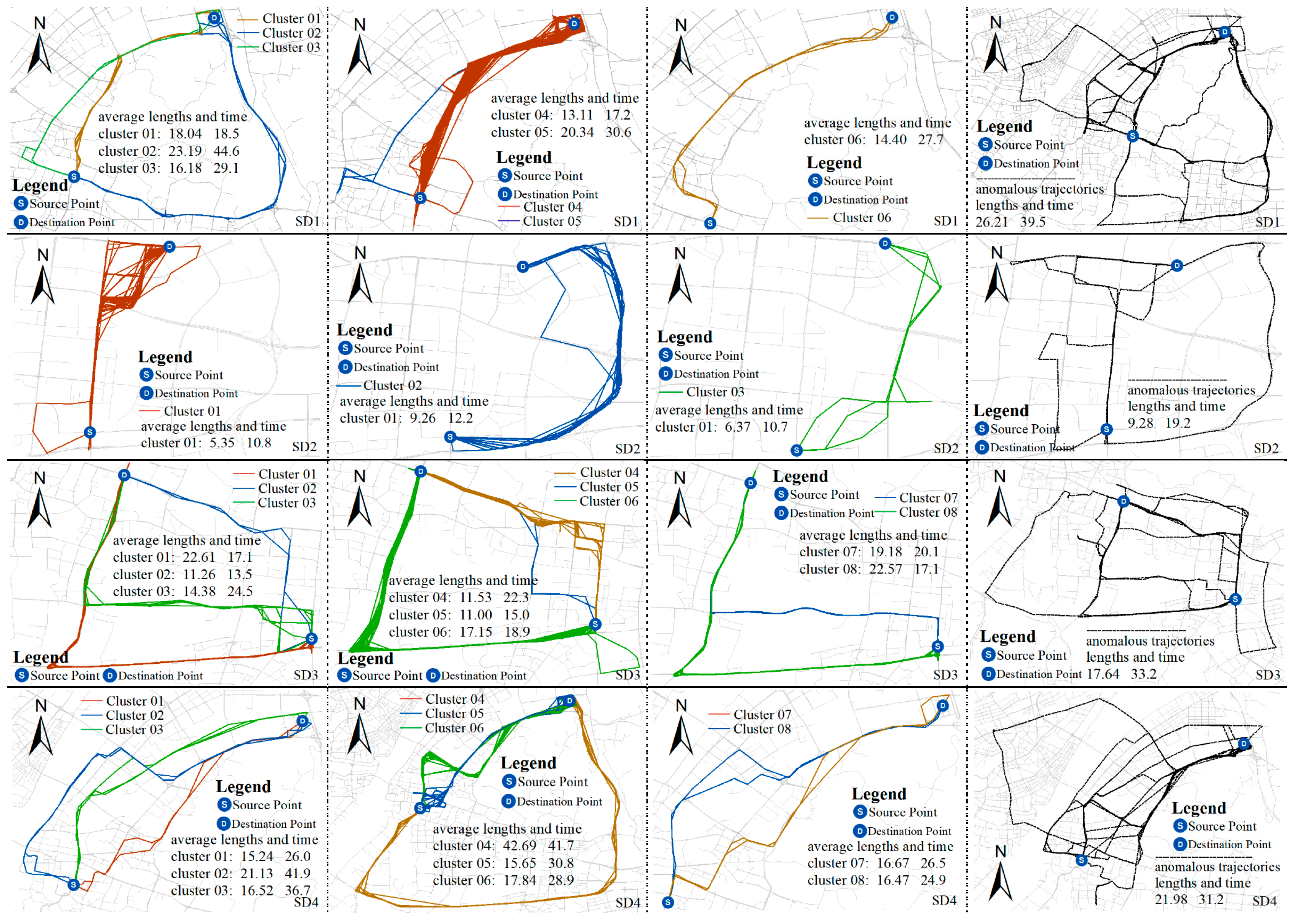
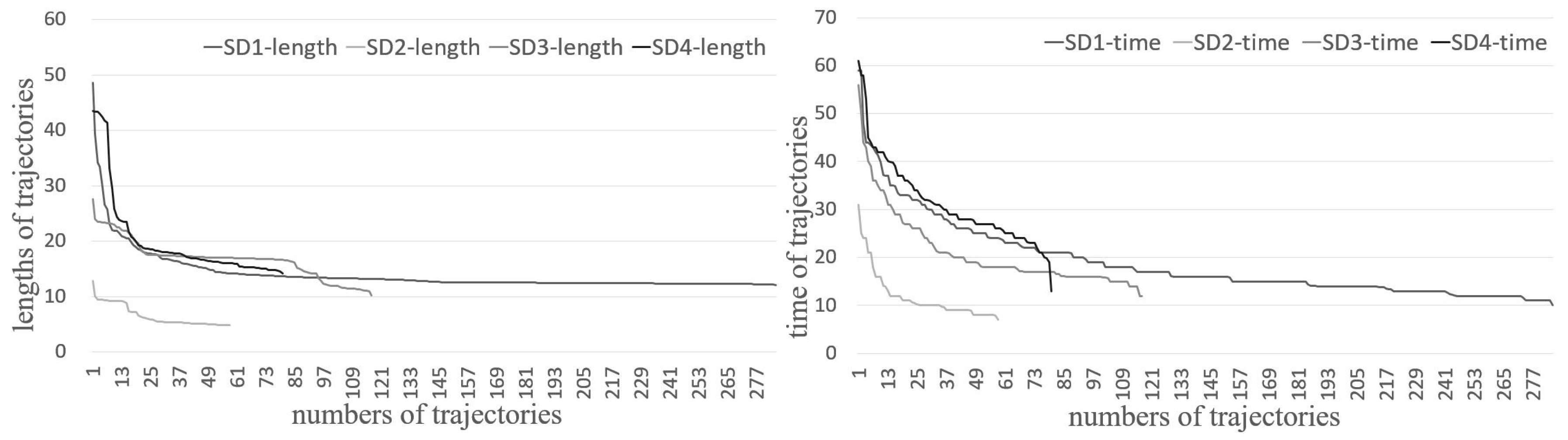
4.4. Anomalous Trajectory Detection by Trajectory Clustering
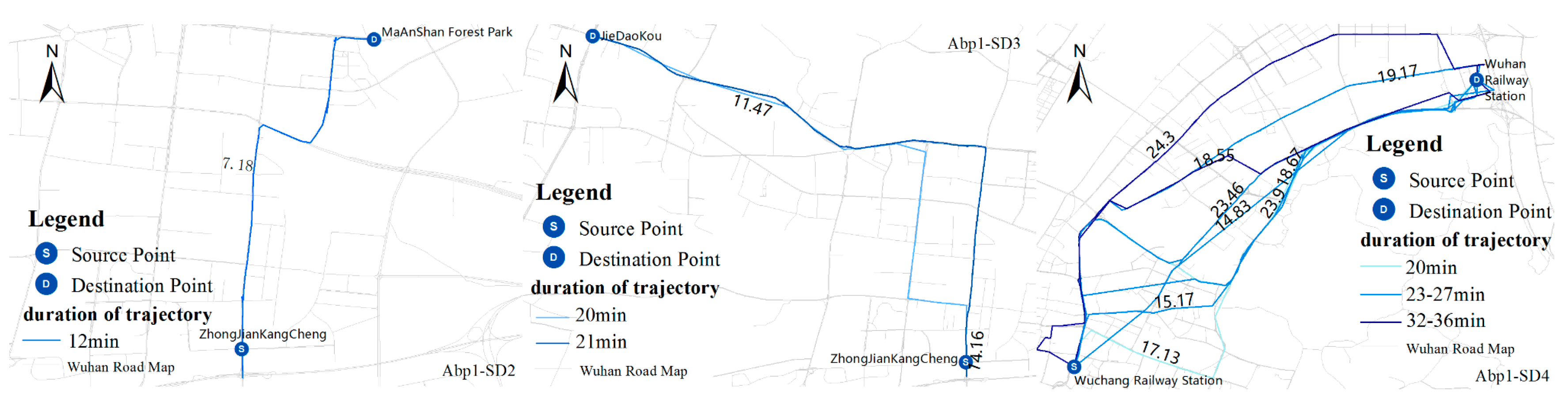
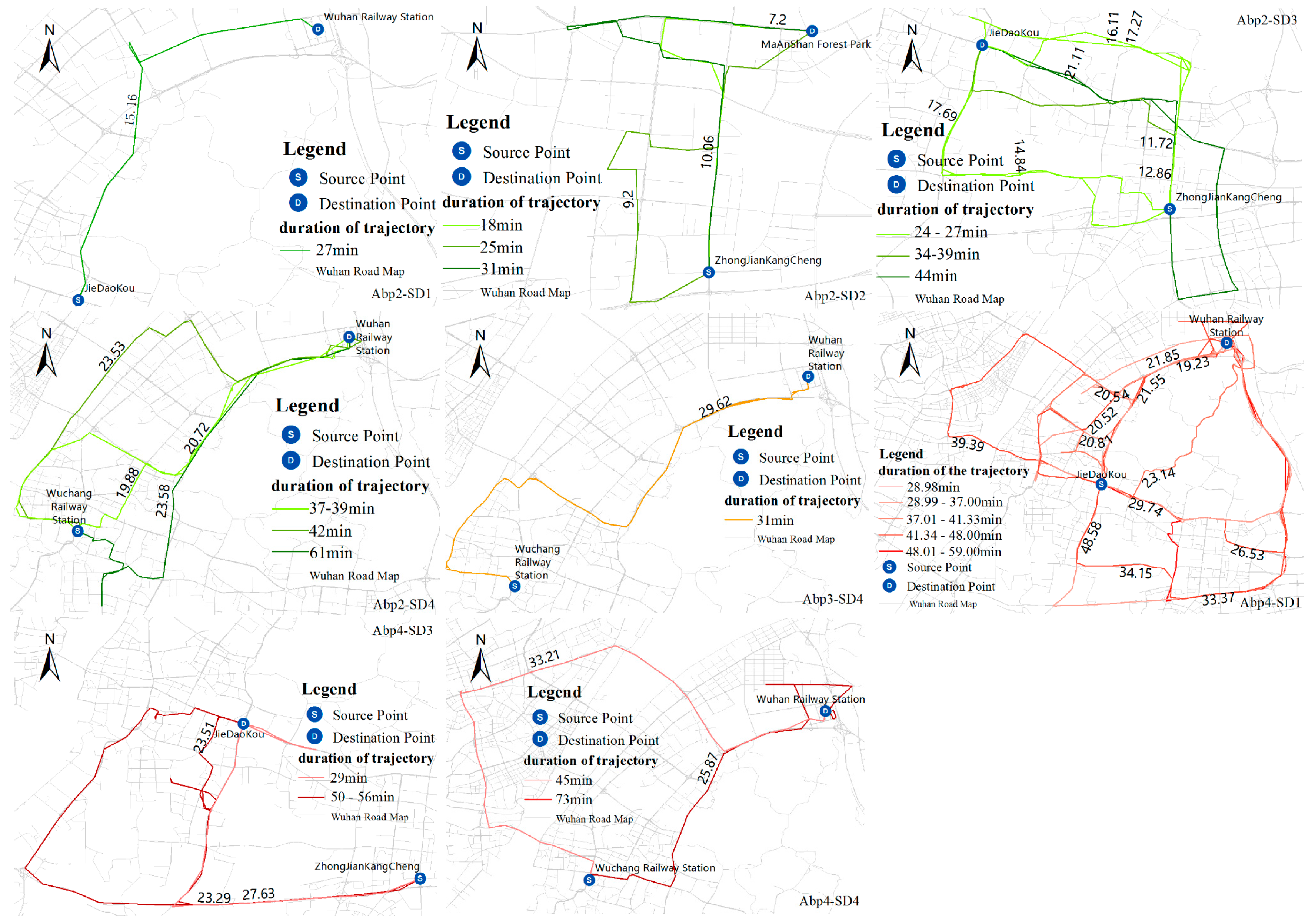
4.5. Anomalous Trajectory Behavior Pattern Analysis
5. Discussion
6. Conclusions and Future Research
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zhang, S.; Wang, Z. Correction: Inferring Passenger Denial Behavior of Taxi Drivers from Large-Scale Taxi Traces. PLoS ONE 2017, 12, e0171876. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Ban, Y. Uncovering Spatio-Temporal Cluster Patterns Using Massive Floating Car Data. ISPRS Int. J. Geo-Inf. 2013, 2, 371–384. [Google Scholar] [CrossRef]
- Yin, P.; Ye, M.; Lee, W.C.; Li, Z. Mining GPS Data for Trajectory Recommendation. In Advances in Knowledge Discovery and Data Mining; Springer International Publishing: Cham, Switzerland, 2014; pp. 50–61. [Google Scholar]
- Matsubara, Y.; Li, L.; Papalexakis, E.; Lo, D.; Sakurai, Y.; Faloutsos, C. F-Trail: Finding Patterns in Taxi Trajectories. In Advances in Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2013; pp. 86–98. [Google Scholar]
- Liu, S.; Ni, L.M.; Krishnan, R. Fraud Detection from Taxis’ Driving Behaviors. IEEE Trans. Veh. Technol. 2014, 63, 464–472. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, Y.; Yuan, J.; Xie, X. Urban computing with taxicabs. In International Conference on Ubiquitous Computing; ACM: New York, NY, USA, 2011; pp. 89–98. [Google Scholar]
- Li, Z.; Filev, D.P.; Kolmanovsky, I.; Atkins, E.; Lu, J. A New Clustering Algorithm for Processing GPS-Based Road Anomaly Reports with a Mahalanobis Distance. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1980–1988. [Google Scholar] [CrossRef]
- Chen, Q.; Qiu, Q.; Li, H.; Wu, Q. A neuromorphic architecture for anomaly detection in autonomous large-area traffic monitoring. In Proceedings of the IEEE International Conference on Computer-Aided Design, San Jose, CA, USA, 18–21 November 2013; pp. 202–205. [Google Scholar]
- Wang, Z.; Lu, M.; Yuan, X.; Zhang, J.; Van De Wetering, H. Visual Traffic Jam Analysis Based on Trajectory Data. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2159–2168. [Google Scholar] [CrossRef] [PubMed]
- Yuan, J.; Zheng, Y.; Zhang, C.; Xie, W.; Xie, X.; Sun, G.; Huang, Y. T-drive: Driving directions based on taxi trajectories. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; ACM: New York, NY, USA, 2010; pp. 99–108. [Google Scholar]
- Ge, Y.; Xiong, H.; Liu, C.; Zhou, Z.H. A Taxi Driving Fraud Detection System. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011; pp. 181–190. [Google Scholar]
- Zhang, D.; Li, N.; Zhou, Z.H.; Chen, C.; Sun, L.; Li, S. iBAT: Detecting anomalous taxi trajectories from GPS traces. In Proceedings of the 13th international conference on Ubiquitous computing, Beijing, China, 17–21 September 2011; ACM: New York, NY, USA, 2011; pp. 99–108. [Google Scholar]
- Kim, J.; Mahmassani, H.S. Spatial and Temporal Characterization of Travel Patterns in a Traffic Network Using Vehicle Trajectories. Transp. Res. Part C Emerg. Technol. 2015, 9, 164–184. [Google Scholar]
- Huang, H. Anomalous behavior detection in single-trajectory data. Int. J. Geogr. Inf. Sci. 2015, 29, 2075–2094. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; ACM: New York, NY, USA, 2010; pp. 851–860. [Google Scholar]
- Kumar, D.; Bezdek, J.C.; Rajasegarar, S.; Leckie, C.; Palaniswami, M. A visual-numeric approach to clustering and anomaly detection for trajectory data. Vis. Comput. Int. J. Comput. Graph. 2017, 33, 1–17. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 75–79. [Google Scholar] [CrossRef]
- Hwang, J.R.; Kang, H.Y.; Li, K.J. Spatio-Temporal Similarity Analysis between Trajectories on Road Networks. In Perspectives in Conceptual Modeling; Springer: Berlin/Heidelberg, Germany, 2005; pp. 280–289. [Google Scholar]
- Lee, J.G.; Han, J.; Li, X. Trajectory Outlier Detection: A Partition-and-Detect Framework. In Proceedings of the 2008 IEEE 24th International Conference on Data Engineering, Cancun, Mexico, 7–12 April 2008; pp. 140–149. [Google Scholar]
- Guan, B.; Liu, L.; Chen, J. Using Relative Distance and Hausdorff Distance to Mine Trajectory Clusters. Telkomnika Indones. J. Electr. Eng. 2013, 11, 115–122. [Google Scholar] [CrossRef]
- Won, J.I.; Kim, S.W.; Baek, J.H.; Lee, J. Trajectory clustering in road network environment. In Proceedings of the CIDM IEEE Symposium on Computational Intelligence and Data Mining, Nashville, TN, USA, 30 March–2 April 2009; pp. 299–305. [Google Scholar]
- Sha, W.; Xiao, Y.; Wang, H.; Li, Y.; Wang, X. Searching for spatio-temporal similar trajectories on road networks using Network Voronoi Diagram. Commun. Comput. Inf. Sci. 2015, 482, 361–371. [Google Scholar]
- Lee, J.G.; Han, J.; Whang, K.Y. Trajectory clustering: A partition-and-group framework. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; ACM: New York, NY, USA, 2007; pp. 593–604. [Google Scholar]
- Abraham, S.; Lal, P.S. Spatio-temporal similarity of network-constrained moving object trajectories using sequence alignment of travel locations. Transp. Res. Part C Emerg. Technol. 2012, 23, 109–123. [Google Scholar] [CrossRef]
- Chen, L.; Ng, R. On The Marriage of Lp-norms and Edit Distance. In Proceedings of the Thirtieth International Conference on Very Large Data Bases, Toronto, ON, Canada, 31 August–3 September 2004; pp. 792–803. [Google Scholar]
- Chen, L.; Özsu, M.T.; Oria, V. Robust and fast similarity search for moving object trajectories. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; pp. 491–502. [Google Scholar]
- Dodge, S.; Laube, P.; Weibel, R. Movement similarity assessment using symbolic representation of trajectories. Int. J. Geogr. Inf. Sci. 2012, 26, 1563–1588. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y.; Raubal, M. Measuring similarity of mobile phone user trajectories–a Spatio-temporal Edit Distance method. Int. J. Geogr. Inf. Sci. 2014, 28, 496–520. [Google Scholar] [CrossRef]
- Bermingham, L.; Lee, I. A general methodology for n-dimensional trajectory clustering. Expert Syst. Appl. 2015, 42, 7573–7581. [Google Scholar] [CrossRef]
- Fu, Z.; Hu, W.; Tan, T. Similarity based vehicle trajectory clustering and anomaly detection. In Proceedings of the 2005 IEEE International Conference on Image Processing, Genova, Italy, 14 September 2005. [Google Scholar]
- Roh, G.P.; Hwang, S.W. NNCluster: An efficient clustering algorithm for road network trajectories. In Proceedings of the 15th International Conference on Database Systems for Advanced Applications, Tsukuba, Japan, 1–4 April 2010; Springer: Berlin/Heidelberg, Germany, 2010; Volume Part II, pp. 47–61. [Google Scholar]
- Amorim, R.C. Feature Relevance in Ward’s Hierarchical Clustering Using the Lp Norm; Springer: New York, NY, USA, 2015. [Google Scholar]
- Ketchen, D.J.; Shook, C.L. The Application of Cluster Analysis in Strategic Management Research: An Analysis and Critique. Strateg. Manag. J. 1996, 17, 441–458. [Google Scholar] [CrossRef]
- Salvador, S.; Chan, P. Determining the Number of Clusters/Segments in Hierarchical Clustering/Segmentation Algorithms. In Proceedings of the IEEE International Conference on Tools with Artificial Intelligence, Boca Raton, FL, USA, 15–17 November 2004; pp. 576–584. [Google Scholar]
- Zhao, Q.; Fränti, P. WB-index: A sum-of-squares based index for cluster validity. Data Knowl. Eng. 2014, 92, 77–89. [Google Scholar] [CrossRef]
- Xu, L. Bayesian Ying–Yang machine, clustering and number of clusters. Pattern Recognit. Lett. 1997, 18, 1167–1178. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar]
- Zhao, P.; Qin, K.; Ye, X.; Wang, Y.; Chen, Y. A trajectory clustering approach based on decision graph and data field for detecting hotspots. Int. J. Geogr. Inf. Syst. 2016, 31, 1101–1127. [Google Scholar] [CrossRef]
- Wu, L.; Hu, S.; Yin, L.; Wang, Y.; Chen, Z.; Guo, M.; Xie, Z. Optimizing Cruising Routes for Taxi Drivers Using a Spatio-Temporal Trajectory Model. ISPRS Int. J. Geo-Inf. 2017, 6, 373. [Google Scholar] [CrossRef]
- Buza, K.A. Fusion Methods for Time-Series Classification; Peter Lang: Bern, Switzerland, 2011. [Google Scholar]
- Marussy, K.; Buza, K. SUCCESS: A New Approach for Semi-supervised Classification of Time-Series. In Artificial Intelligence and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2013; pp. 437–447. [Google Scholar]
- Mariescu-Istodor, R.; Fränti, P. Grid-Based Method for GPS Route Analysis for Retrieval. ACM Trans. Spat. Algorithms Syst. 2017, 3, 1–28. [Google Scholar] [CrossRef]
- Murtagh, F. Clustering in Massive Data Sets. In Handbook of Massive Data Sets; Abello, J., Pardalos, P.M., Resende, M.G.C., Eds.; Springer: Boston, MA, USA; pp. 501–543.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vehicle ID | Time | Longitude | Latitude | Direction | Acc | State |
|---|---|---|---|---|---|---|
| 1681 | 00:00:00 | 114.**** | 30.**** | 142 | On | empty |
| 7864 | 00:00:50 | 114.**** | 30.**** | 0 | On | heave |
| ... | ... | ... | ... | ... | ... | ... |
| 1681 | 00:00:50 | 114.**** | 30.**** | 20 | On | heave |
| 7864 | 00:00:60 | 114.**** | 30.**** | 40 | On | heave |
| Group Name | First Group (SD1) | Second Group (SD2) | Third Group (SD3) | Fourth Group (SD4) |
|---|---|---|---|---|
| Source (S) | JieDaoKou | ZhongJian KangCheng | ZhongJian KangCheng | Wuchang Railway Station |
| Destination (D) | Wuhan Railway Station | MaAnShan Forest Park | JieDaoKou | WuHan Railway Station |
| Number | Trajectory ID Pairs | IED | NIED | DTW | NDTW |
|---|---|---|---|---|---|
| 07 | 1, 180 | 63.6384 | 0.9681 | 1538.5648 | 0.4743 |
| 08 | 1, 188 | 38.1715 | 0.9723 | 1115.1115 | 0.3437 |
| 10 | 21, 28 | 61.0285 | 0.9325 | 612.7917 | 0.1888 |
| 11 | 21, 31 | 43.2647 | 0.7715 | 1166.6670 | 0.3596 |
| 12 | 21, 68 | 43.1681 | 0.7700 | 1168.2111 | 0.3601 |
| 13 | 21, 82 | 49.4162 | 0.82741 | 1165.6056 | 0.3593 |
| 38 | 21, 126 | 40.5420 | 0.9645 | 401.3309 | 0.1235 |
| 39 | 21, 120 | 40.0110 | 0.9209 | 438.9380 | 0.1351 |
| 43 | 82, 188 | 75.7054 | 0.9913 | 1540.9585 | 0.4750 |
| 44 | 82, 209 | 61.7448 | 0.7938 | 1587.8943 | 0.4895 |
| ID | t1 | 2 | 3 | 4 | t2 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| S | 0 | 4 | 4 | 4 | 1 | 4 | 4 | 4 | 4 | 4 | 3 | 4 | 4 | 4 | 3 | 4 |
| C1 | 3 | 2 | 2 | 2 | 0 | 2 | 3 | 2 | 3 | 3 | 4 | 3 | 2 | 2 | 1 | 3 |
| A | 4 | 2 | 2 | 2 | 0 | 2 | 4 | 2 | 4 | 4 | 3 | 4 | 2 | 2 | 3 | 4 |
| W | 3 | 2 | 2 | 2 | 0 | 2 | 1 | 2 | 1 | 1 | 4 | 1 | 2 | 2 | 4 | 1 |
| C2 | 0 | 2 | 2 | 2 | 1 | 2 | 3 | 2 | 3 | 3 | 4 | 3 | 2 | 2 | 4 | 3 |
| ID | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | t3 | 27 | 28 | 29 | 30 | 31 | |
| S | 4 | 4 | 4 | 4 | 3 | 4 | 4 | 3 | 4 | 2 | 4 | 4 | 3 | 4 | 4 | |
| C1 | 3 | 3 | 2 | 3 | 4 | 2 | 3 | 4 | 2 | 4 | 2 | 2 | 1 | 2 | 3 | |
| A | 4 | 4 | 2 | 4 | 3 | 2 | 4 | 3 | 2 | 1 | 2 | 2 | 3 | 2 | 4 | |
| W | 1 | 3 | 2 | 1 | 4 | 2 | 3 | 4 | 2 | 4 | 2 | 2 | 4 | 2 | 1 | |
| C2 | 3 | 3 | 2 | 3 | 4 | 2 | 3 | 4 | 2 | 4 | 2 | 2 | 4 | 2 | 3 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Qin, K.; Chen, Y.; Zhao, P. Detecting Anomalous Trajectories and Behavior Patterns Using Hierarchical Clustering from Taxi GPS Data. ISPRS Int. J. Geo-Inf. 2018, 7, 25. https://doi.org/10.3390/ijgi7010025
Wang Y, Qin K, Chen Y, Zhao P. Detecting Anomalous Trajectories and Behavior Patterns Using Hierarchical Clustering from Taxi GPS Data. ISPRS International Journal of Geo-Information. 2018; 7(1):25. https://doi.org/10.3390/ijgi7010025
Chicago/Turabian StyleWang, Yulong, Kun Qin, Yixiang Chen, and Pengxiang Zhao. 2018. "Detecting Anomalous Trajectories and Behavior Patterns Using Hierarchical Clustering from Taxi GPS Data" ISPRS International Journal of Geo-Information 7, no. 1: 25. https://doi.org/10.3390/ijgi7010025
APA StyleWang, Y., Qin, K., Chen, Y., & Zhao, P. (2018). Detecting Anomalous Trajectories and Behavior Patterns Using Hierarchical Clustering from Taxi GPS Data. ISPRS International Journal of Geo-Information, 7(1), 25. https://doi.org/10.3390/ijgi7010025