1. Introduction
In the environment of the Internet of Things (IoT), various sensors have been mounted on objects in diverse domains, generating huge volumes of data at high speed [
1,
2]. A significant portion of sensor big data is geospatial data describing objects in relation to geographic information [
3,
4]. In general, geospatial big data refers to geographic data sets that cannot be processed using standard computing systems [
3,
4,
5].
The general consensus among researchers from various domains is that “80% of data is geographic” [
3,
6,
7,
8,
9]. The United Nations Initiative on Global Geospatial Information Management (UN-GGIM) reported that 2.5 quintillion bytes of data is created every day and a significant portion includes location components [
10]. Google generates approximately 25 PB of data daily, a large portion of which consists of spatiotemporal characteristics [
11]. The McKinsey Global Institute estimates the portion of spatial aspect data was about 1 PB in 2009 and is growing at an annual rate of 20% [
12]. Due to the exponential growth of geospatial big data, utilization of data has become a global interest, increasingly drawing the attention not only of industry and academia, but also government agencies.
To promote openness and availability of geospatial big data, the US Federal Geographic Data Committee (FGDC) has defined the concept of National Spatial Data Infrastructure (NSDI) and preserves place-based data at all levels of government, private and nonprofit sectors, and academia. The FGDC provides rich sets of geospatial data to the public to support business, government agencies, or their partners. Geospatial One-Stop (GOS) is an initiative consistent with the goals of NSDI. It establishes a web-based portal (
www.geodata.gov) for one-stop access to geospatial data and services and opens a developed portal to federal, state, and local governments, along with private citizens [
13]. The EU directive, INSPIRE (Infrastructure for Spatial Information in Europe) project, plays an equivalent role for GOS [
14,
15]. It aims to benefit all levels of public authorities in Europe by producing and sharing integrated and quality geospatial information of EU Member States. In Oceania and Asia, there are also similar initiatives such as the Australian SDI [
16] and Indian SDI [
17], respectively.
The increasing volume and diverse sources (e.g., smart phones) of collected geospatial big data have created challenges in storing, managing, and processing data. In addition to the general characteristics of big data, the unique properties of spatial data such as computationally intensive processing of the time component make dealing with geospatial big data even more complicated. To some degree, traditional distributed and parallel processing frameworks make it possible to meet performance requirements for handling large-scale data. It has been several years since developers implemented an SQL-based system and operated it in a parallel way, though it was inadequate to deal efficiently with large volumes of data. System architecture has steadily evolved and a parallel database was designed to allow multiple data instances to share a single database with improvement in performance in parallel computing environments [
18]. This is an efficient approach providing speedup and scale up for massive data, compared to traditional SQL systems.
Recently, several big data platforms have been built to facilitate developers of big data applications on a distributed and parallel computing platform. Particularly, Apache Hadoop [
19] has existed for years and proven to be a mature and very popular platform for big data analysis for various applications. Hadoop is an open source MapReduce implementation being used at major corporations such as IBM, Amazon, Facebook, and Yahoo. Hadoop, however, is ill-equipped to support geospatial big data because its core structure does not consider the unique properties of spatial data (e.g., spatial data types). Also, the efficiency of operations (e.g., spatial queries) is limited on those platforms since the Hadoop‘s internal system is uninformed about spatial data.
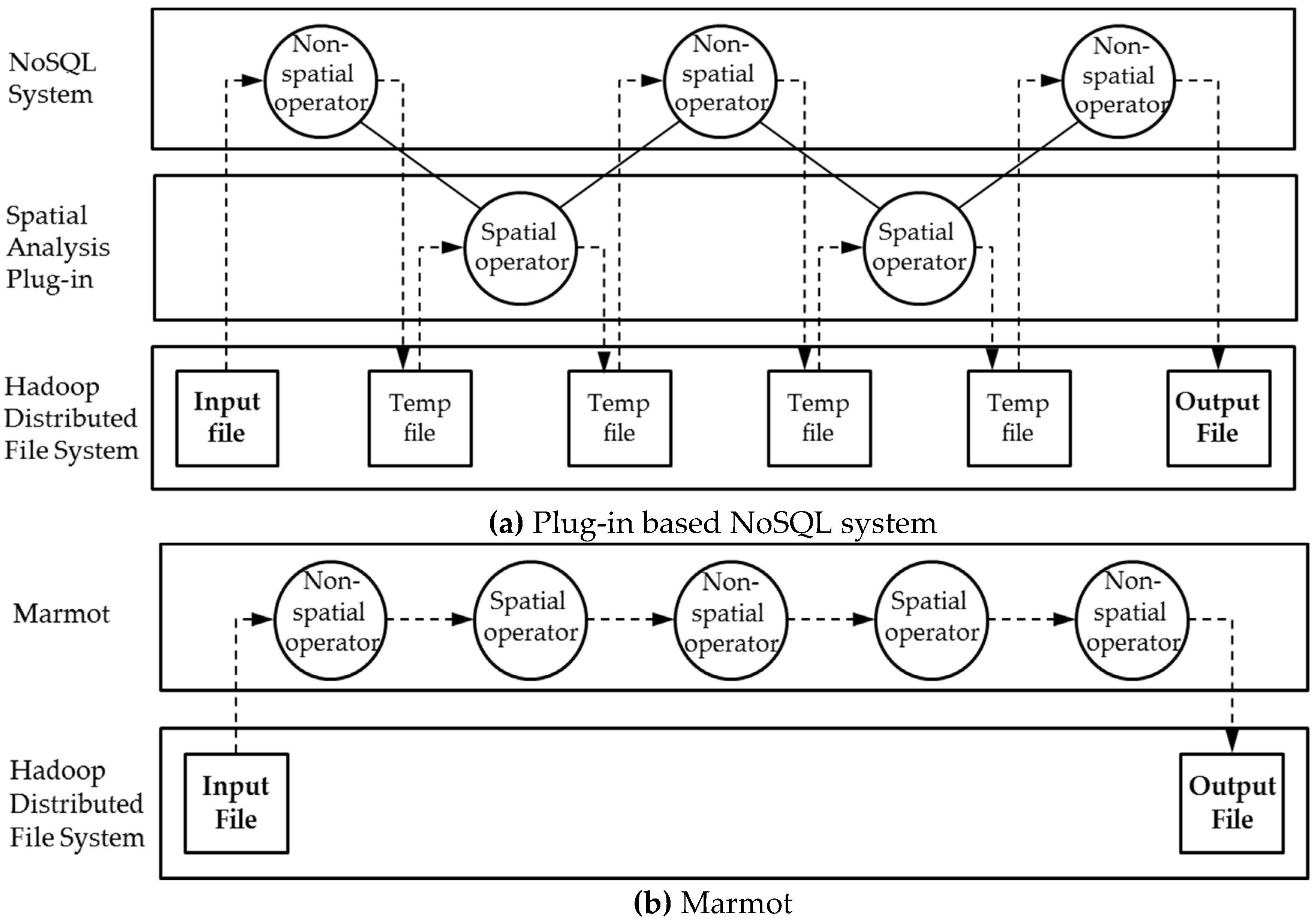
To take advantage of the Hadoop/MapReduce environment in dealing with geospatial big data, several systems supporting spatial properties on Hadoop have emerged. ESRI has released a collection of GIS tools for spatial analysis [
20] that provides access to the Hadoop system from ArcGIS products. In academia, Hadoop-GIS [
21] is designed to support multiple types of spatial queries on MapReduce via skew-aware spatial partitioning to first partition spatial objects and then process them in parallel. Similarly, GPHadoop [
22], a geoprocessing-enabled Hadoop platform, has been introduced to enable scalable geoprocessing to resolve geospatial related problems based on Hadoop and ESRI GIS tools. A main limitation of those Hadoop-based spatial systems is that they regard Hadoop as a black box and are therefore restricted by the limitations of the original Hadoop. To circumvent that issue, SpatialHadoop [
23,
24] has been designed, which injects spatial data awareness inside Hadoop making it more efficient to work with spatial data. SpatialHadoop, however, still presents a lack of integration with the core structure of Hadoop. For example, SpatialHadoop adds spatial data types or functions to the original Hadoop system as a form of plug-ins. However, compared to a solid framework, the performance of a plug-in based framework is limited by lacking seamless integration between spatial and nonspatial operations.
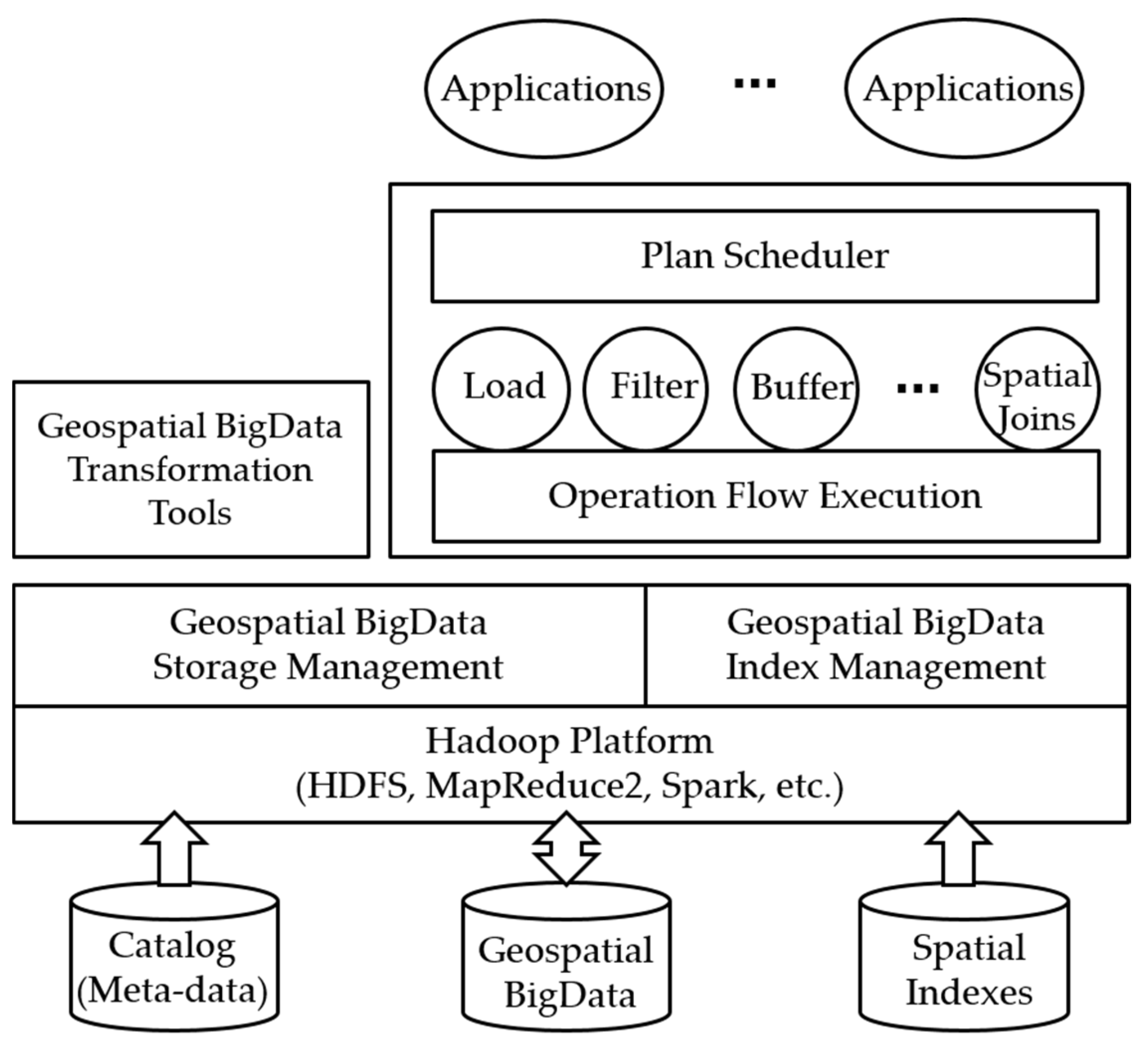
In this paper, we introduce the Marmot system, a Hadoop-based, high-performance data storage management system. It enables application developers having little working knowledge of big data technologies to implement high performance analysis tasks on geospatial big data. Compared with existing Hadoop-based spatial systems, the distinctive characteristics of Marmot can be summarized as follows.
Marmot extends Hadoop at a low level and is a stream-based system supporting seamless integration between spatial and nonspatial operations in a solid framework.
Marmot supports automatic construction of MapReduce jobs from a given spatial analysis task in ways to improve performance.
Marmot allows developers to create various spatial applications by simply combining built-in spatial or nonspatial operators.
The rest of the paper is organized as follows.
Section 2 shows our related work and
Section 3 describes a systematic overview of Marmot including integration between spatial and nonspatial operations.
Section 4 shows Marmot’s data model and
Section 5 presents the main algorithm which maps a sequence of operators for spatial analysis to MapReduce jobs and discusses implementation of Marmot. An example of a spatial application using Marmot and its performance evaluation is described in
Section 6 and
Section 7, respectively. Finally, the discussion and conclusion along with our future work are presented in
Section 8 and
Section 9.
2. Related Work
Several platforms have been developed for the processing of big data. MapReduce [
25] is a distributed and parallel programming framework and is very popular due to its simplicity, scalability, and fault-tolerance. There are two phases in the MapReduce model: Map phase and Reduce phases. The Map phase is used to receive data and generate intermediate key and value pairs; the Reduce phase is used to accept the intermediate results and combine them into a single result. Hadoop [
19] is an implementation of MapReduce as an open source form, which has been widely adopted in a majority companies as their technology stack.
Although Hadoop is known as the most representative distributed processing framework for handling big data, it cannot be used for real-time processing because the data are batched to each node for a given job. Spark [
26] is an in-memory based high performance distributed data analysis system designed to address Hadoop’s limitations. Unlike Hadoop, which is based on a batch processing engine, Spark can process data faster due to its in-memory computation policy. Although this feature provides advantages of low latency computation, there are also drawbacks such as requiring significantly more resources than Hadoop.
Most big data platforms, including Hadoop and Spark, have been designed without any specific consideration of spatial properties. A few platforms provide spatial functionalities [
20,
21,
22,
23,
24], but they generally lack spatial properties and do not support advanced geospatial operations such as geospatial joins and geostatistical operations, which are imperative for advanced geospatial analytics. SpatialHadoop [
22,
23] has been developed to enable spatial operations by extending Hadoop layers: language, storage, MapReduce, and operations. Although SpatialHadoop has been known to overcome the limitations of existing spatial big data platforms and perform better than traditional Hadoop, it is still not sufficient in supporting in-depth geospatial analysis.
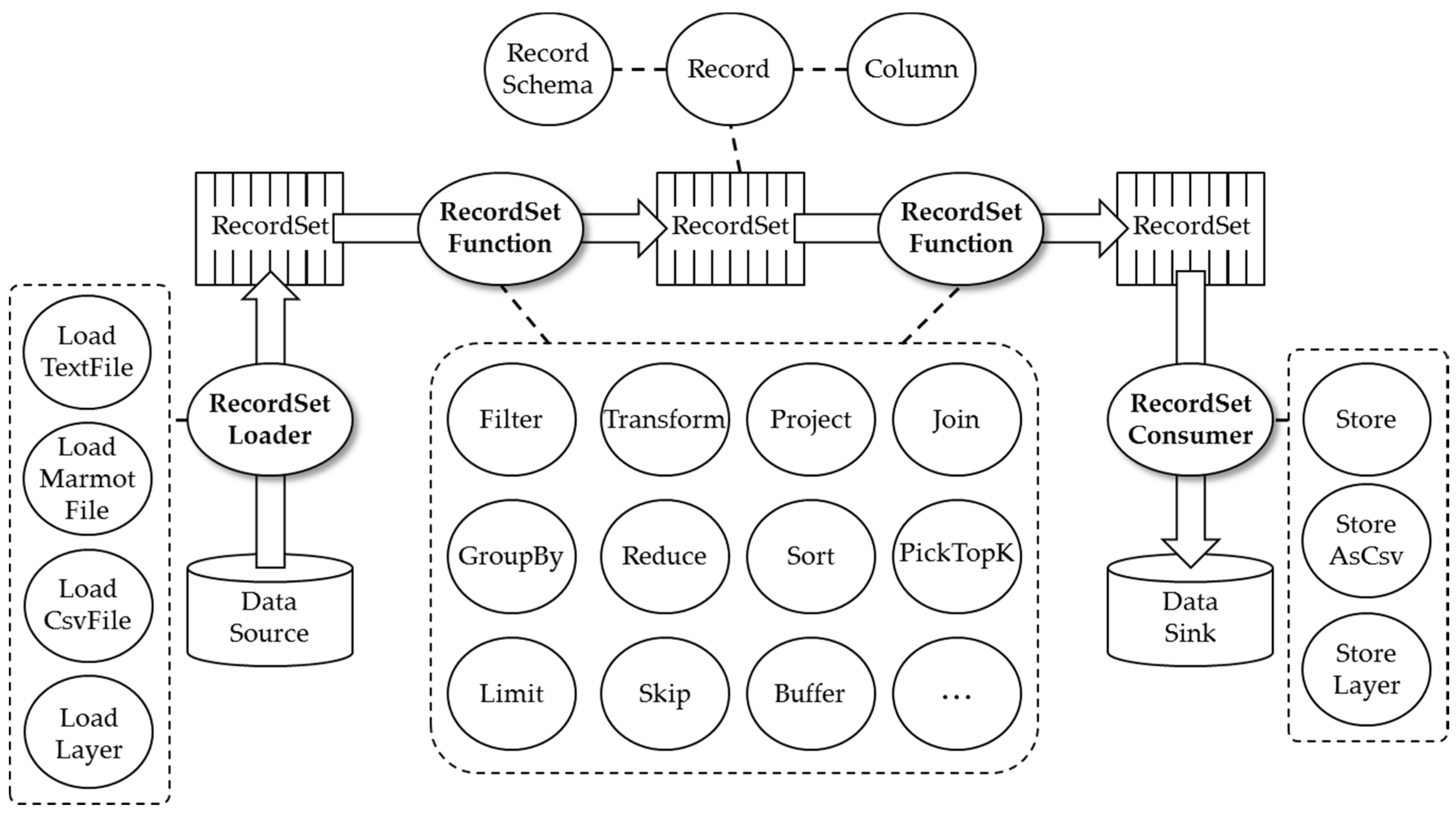
4. Marmot Data Model
The term data model refers to an abstract model that arranges the structure of data and regulates their association with each other.
Figure 3 shows the data model used in Marmot that corresponds mostly with the model in a standard relational database management system (RDBMS).
In Marmot, a Record corresponds to a record in RDBMS, the smallest unit of a data element consisting of one or more column values within a table. The definition of a Record in Marmot is shown in Definition 1.
| Definition 1. Record |
| public interface Record { |
| public RecordSchema getSchema(); |
| |
| public Object get(String colName); |
| public Object get(int idx); |
| public Object[[] getAll(); |
| |
| public void set(String colName, Object value); |
| public void set(int idx, Object value); |
| public void set(Record rec, Boolean removeOverflow); |
| |
| public Geometry getGeometry(……); |
| public String getString(……); |
| } |
A RecordSet is a set of records corresponding to a table in RDBMS which provides forward-only access to a data source. A RecordSchema represents metadata consisting of information containing the names and types of columns composing a Record. All the Records included in a specific RecordSet are compliant with the same RecordSchema. The definitions of RecordSet and RecordSchema are shown in Definition 2 and Definition 3, respectively.
| Definition 2. RecordSet |
| public interface RecordSet { |
| RecordSchema getRecordSchema(); |
| Boolean next(Record record); |
| Record nextCopy(); |
| void close(); |
| |
| Stream<Record> stream(); |
| List<Record> toList(); |
| Iterator<Record> iterator(); |
| } |
| Definition 3. RecordSchema |
| public class RecordSchema { |
| public int getColumnCount(); |
| |
| public Boolean existsColumn(String colName); |
| public Column getColumn(String colName); |
| public Column getColumnAt(int idx); |
| public Collection<Column> getColumnAll(); |
| } |
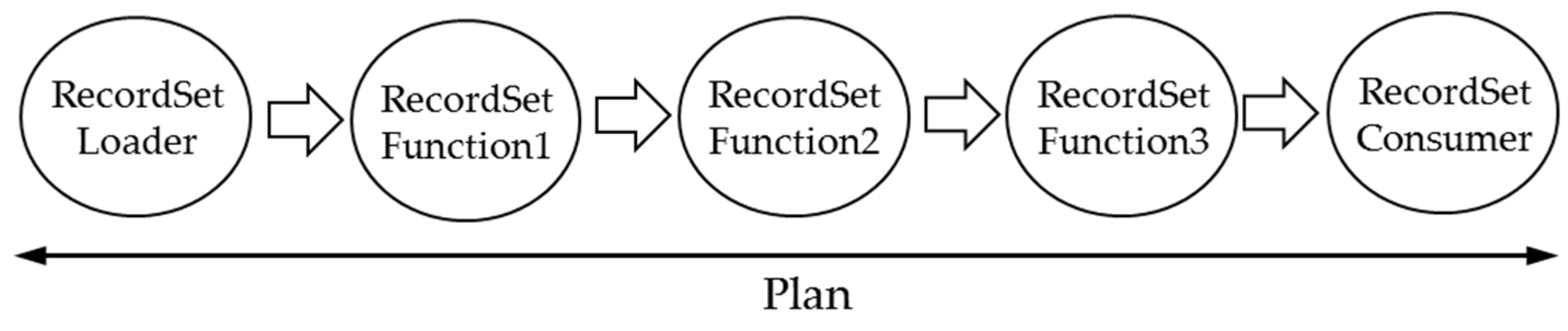
A RecordSetOperator is a processing unit using a RecordSet which corresponds to the concept of a relational operator in RDBMS. As the input and output of relational operators in RDBMS are a table, the input and output of a RecordSetOperator is a RecordSet. In Marmot, there are three types of a RecordSetOperator, as shown in
Figure 4.
A RecordSetLoader is an operator that loads input data from outside data sources and converts it to RecordSet to be handled within Marmot. For example, loadTextFile reads a text file from a given path and converts it to a RecordSet. A RecordSetConsumer stores a RecordSet created within Marmot as the final result of a given analysis to a specified outside path. A Marmot code describing RecordSetLoader and RecordSetConsumer is given in
Figure 5.
Lastly, the RecordSetFunction is an operator that takes a RecordSet as input data and outputs a new RecordSet. In Marmot, there are two types of a RecordSetFuntion: spatial operators and nonspatial operators. Spatial operators are functions taking input spatial data, analyzing various types of spatial relationships, and producing output spatial data. For example, Buffer is a spatial operator creating a new RecordSet which is the result of encompassing the area around a specific location based on a predefined distance. Project and Filter are examples of nonspatial operators, where Project produces a RecordSet composed only of specified columns; Filter generates a RecordSet consisting only of columns satisfying certain conditions.
The spatial and nonspatial operators currently supported in Marmot are shown in
Table 1. Examples of their interfaces and usages are shown in Examples 1 and 2.
| Example 1. Nonspatial operators in RecordSetFuntion |
filter(predicate_str) [Usage] filter(“age > 20”) project(column_comma_list) [Usage] project(“the_geom,id,age”) transform(File scriptFile, dropInputCols) [Usage] transform(new File(“transform_script.xml”), true) pickTopK(cmpColSpecs, topK) [Usage] pickTopK(“name,age:D”, 10) groupBy(key_cols_comma_list) [Usage] groupBy(“car_no, driver_id”)
|
| Example 2. Spatial operators in RecordSetFuntion |
• loadSpatialIndexJoin(condition, layer1, layer2, result_column1, result_colume2)[Usage] loadSpatialIndexJoin(SpatialPredicate.INTERSECTS,
“admin/cadastral/clusters”, “admin/urban_area/clusters”, “*”,
“*-{the_geom},the_geom as the_geom2”) |
6. Case Analysis: Subway Stations
To show how Marmot handles geospatial big data, this section presents an example of spatial analysis.
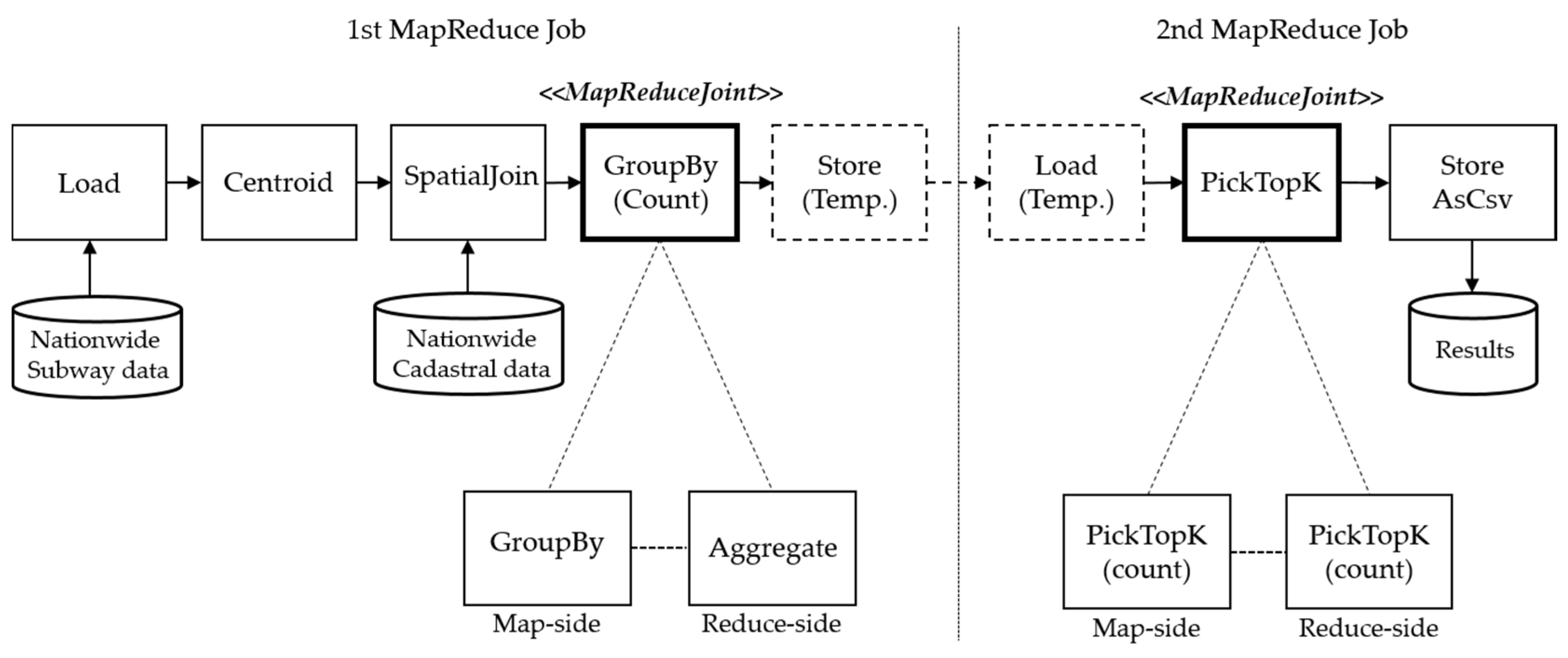
Figure 9 is a sample code of a Plan retrieving the number of subway stations per city. For this analysis, nationwide datasets of cadastral and subway stations in Korea are used.
The plan is composed of six RecordSetOperators: ‘Load’, ‘Centroid’, ‘SpatialJoin’, ‘GroupBy’, ‘PickTopK’, and ‘StoreAsCsv’. As shown in
Figure 10, using the ‘Load’ operator, Marmot reads the boundaries of each subway station and ‘Centroid’ operator computes their center coordinates. With the ‘SpatialJoin’ operator, Marmot finds a city whose boundary contains the centroid of each subway station. Then, the ‘GroupBy’ operator groups the output records based on each city and counts the number of their records. The output records should be ‘(city_id, count)’ pairs, which contain the number of subway stations for each city. Finally, the ‘PickTopK’ operator sorts the record on the basis of numbers and picks the top five cities. These five records are stored in the Hadoop Distributed File System (HDFS) by the ‘StoreAsCsv’ operator.
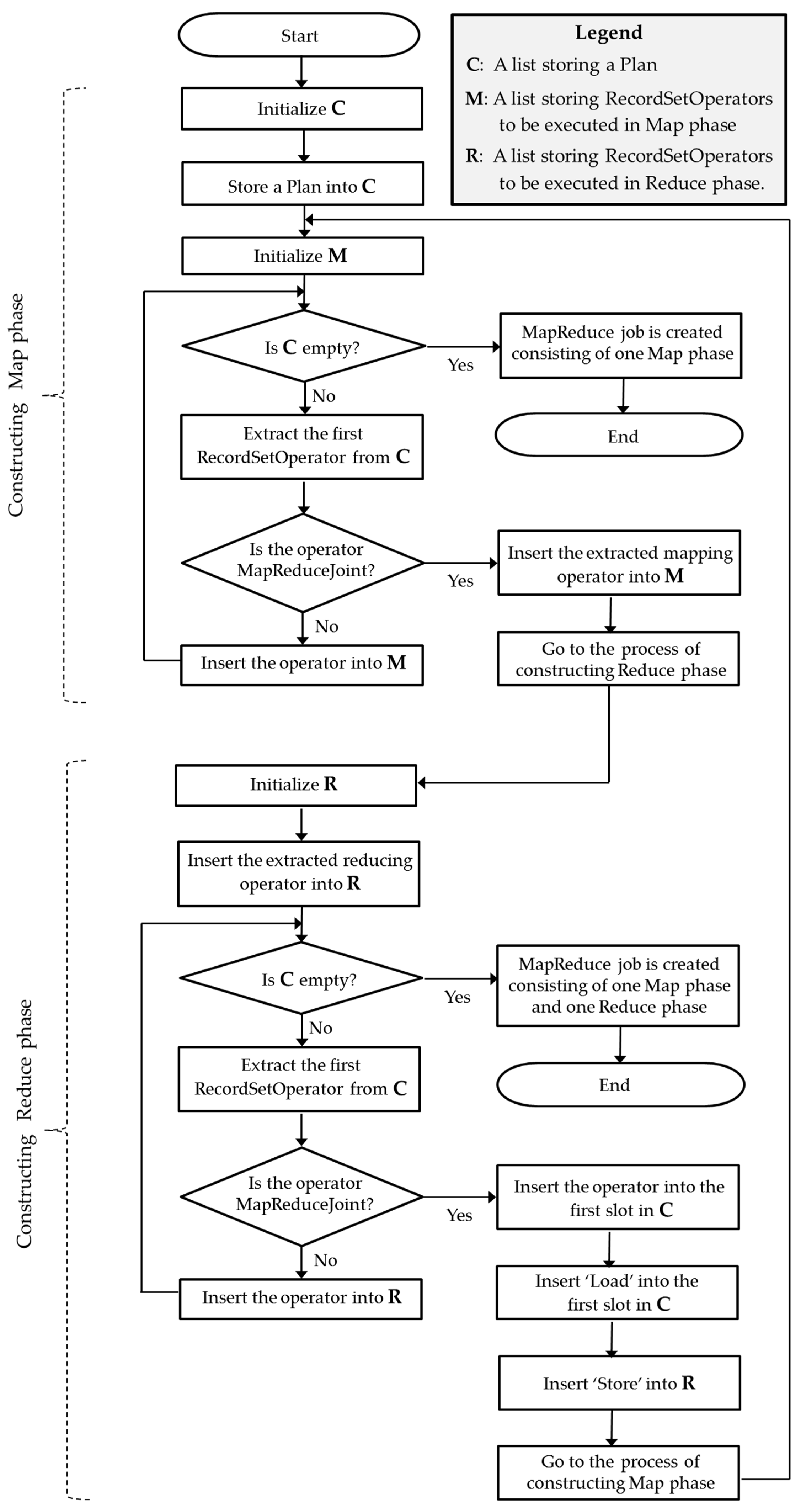
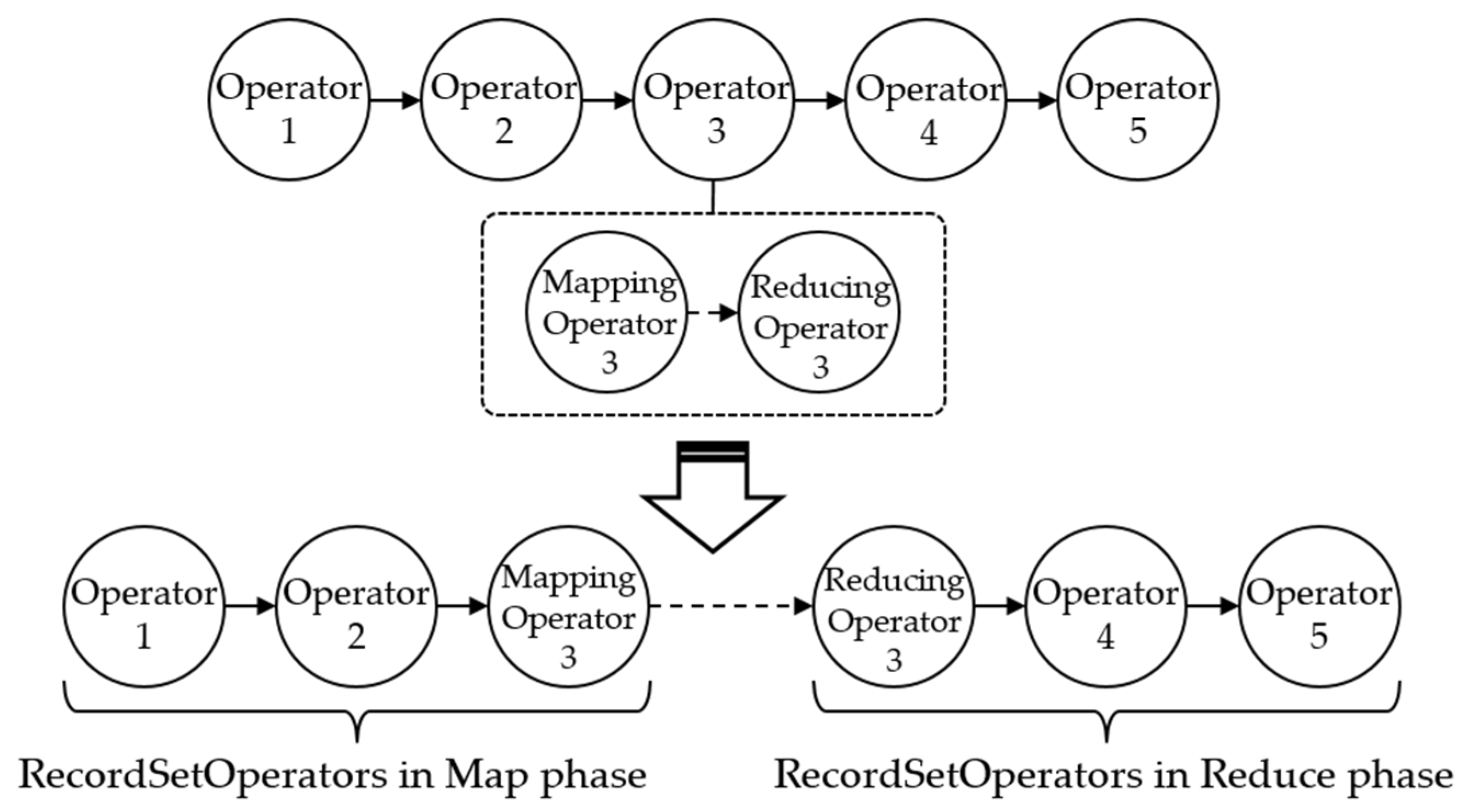
In the process of transforming the Plan to a sequence of MapReduce jobs, Marmot recognizes two ‘MapReduceJoint’ operators: ‘GroupBy’ and ‘PickTopK’. Since each ‘MapReduceJoint’ generates one MapReduce job, the plan is transformed into two separate MapReduce jobs, as depicted in
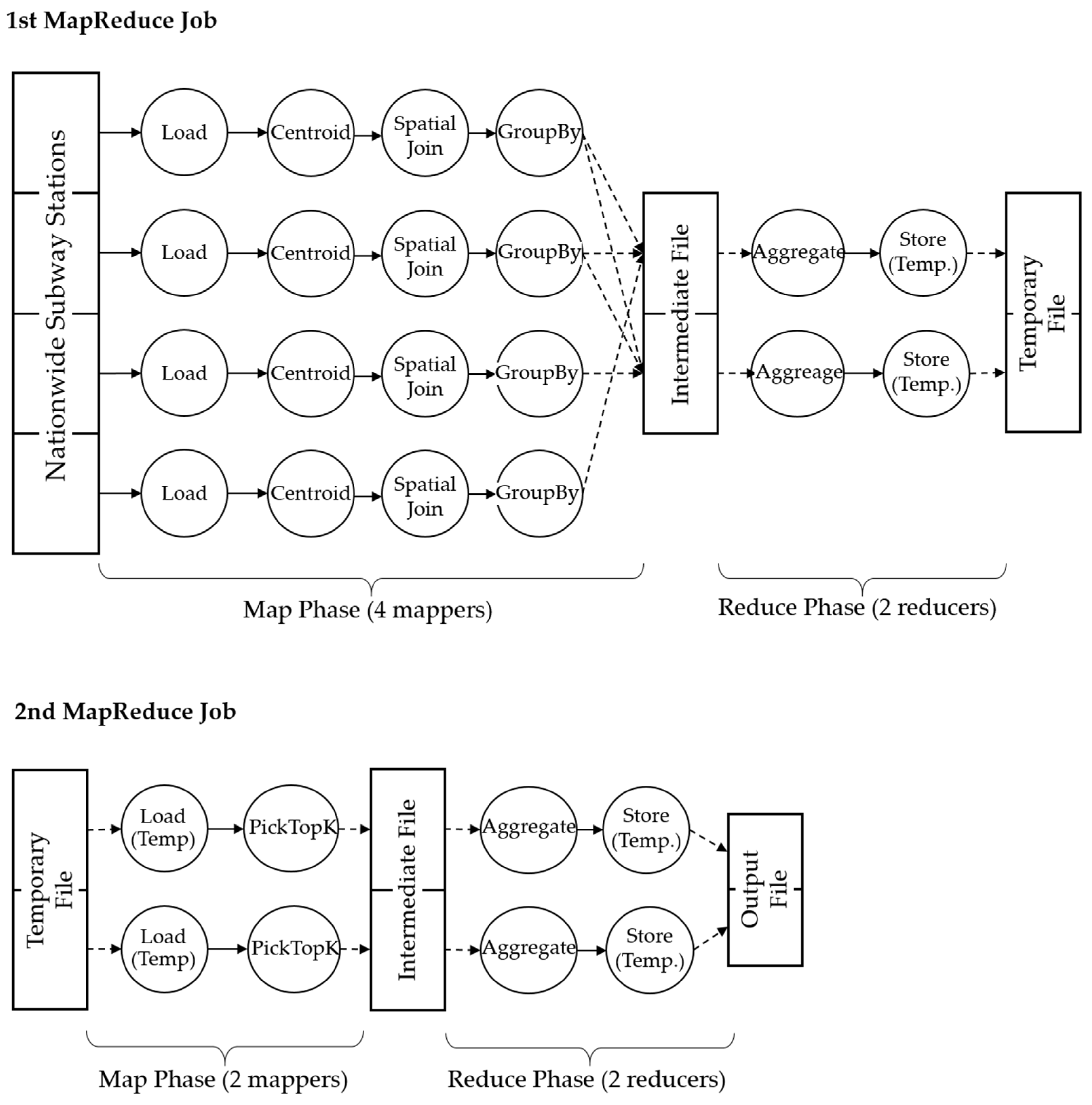
Figure 10. For the first MapReduce job, the ‘GroupBy’ operator is the breakpoint producing the first Map and Reduce tasks, and ‘PickTopK’ operator is another breakpoint to produce the second MapReduce job. The output of the first MapReduce job is stored in a temporary HDFS file—so that the second MapReduce job can continue to execute the rest of the given Plan. Marmot deletes the temporary file when the whole plan has been executed.
The sequence of RecordSetOperators assigned during Map and Reduce phases is executed in a pipeline manner by a number of mappers and reducers. The number of mappers is dynamically determined by the size of input data whereas the number of reducers is statically fixed in a Plan. During the process of a given analysis, four mappers with two reducers are used in the first MapReduce job and two mappers with two reducers are used in the second MapReduce job, as shown in
Figure 11.
7. Experiments
7.1. Test Cases
Experiments were conducted to compare the performance of Marmot to that of SpatialHadoop, one of the top MapReduce frameworks supporting spatial functionalities. Since the geospatial operators currently supported by SpatialHadoop are limited compared to Marmot, it is difficult to conduct our experiments based on complex spatial analysis tasks. Therefore, we decided to perform a comparison for each of the fundamental spatial operations supported by both SpatialHadoop and Marmot.
There are five target spatial operations in our experiments: obtaining minimum bounding rectangle (MBR) and creating spatial index, range query without index, range query with index, and spatial join with index. MBR has been most commonly used to approximate spatial objects and is one of the fundamental operations for spatial analysis. A query for obtaining MBRs is therefore included in our experiment. Spatial index also plays an important role in geospatial domain to speed up retrieving certain objects in a spatial database, making measuring the performance of creating spatial index essential for this evaluation. Range query allows one to search for spatial objects located in a specified spatial extent and is therefore a fundamental type of query in spatial databases. To see the impact of using spatial index on range query performance, we investigated two cases—with and without an index. Lastly, spatial join is one of the most important operations for combining spatial objects and serves as building blocks for processing complex spatial analysis. Even with the support of spatial index, spatial join is particularly complex and time-intensive. Thus, efficient processing of spatial join is crucial to increase query performance.
7.2. Data Description
For the experiment, we used two Tiger Files including real spatial data for Korea. One file contained a nationwide continuous cadastral map with a size of 16GB (38,744,510 polygons); the other file included major urban areas created for management of land use with a size of 0.3GB (53,087 polygons).
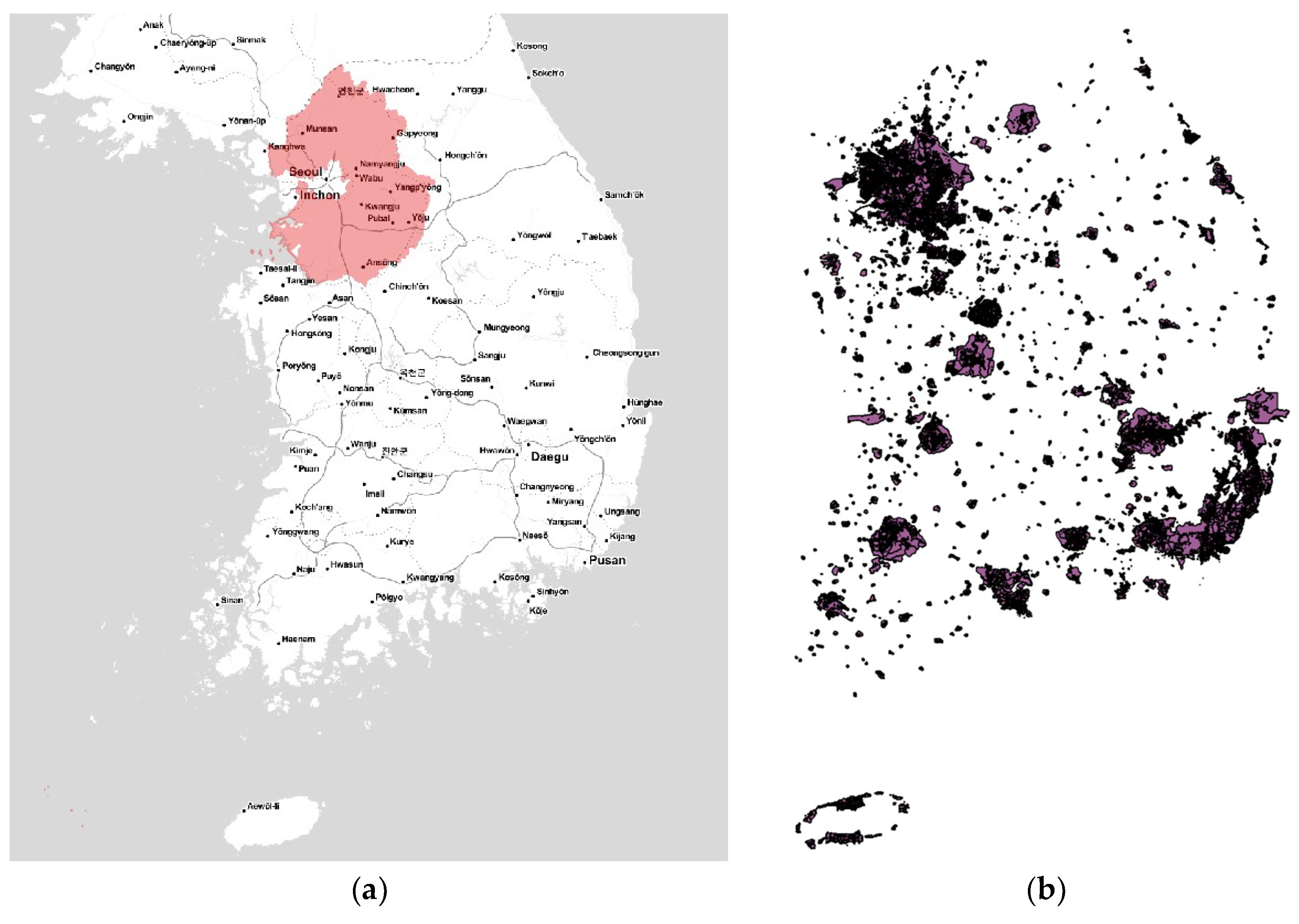
Figure 12 shows the visualization of these two Tiger Files including real spatial datasets of Korea. Particularly,
Figure 12a shows just part of the continuous cadastral map because the entire data are too large to load onto the visualization tool. To demonstrate what all the data look like, partial data with a size of 1.24GB (4,720,616 polygons) involving Seoul city and Gyeonggi Province are plotted using red on a grayscale OSM basemap as the one by Stamen.
Of the five test cases in our experiment, three cases (i.e., obtaining MBR, range query without index, and range query with index) use only the cadastral data; one case (i.e., creating spatial index) uses only the major urban data and one case (i.e., spatial join) uses both the cadastral and major urban data.
7.3. Results
Each test query was run five times and the average, after excluding the highest and lowest values, was chosen to evaluate performance. The formula to express the performance improvement rate (PIR) of Marmot is:
where SH and M are execution times required by SpatialHadoop and Marmot, respectively.
Table 4 shows the execution time of each test case and the PIR.
In designing the experiment, we included only fundamental spatial operations due to the infrastructural limits of SpatialHadoop. Although SpatialHadoop has built-in spatial analytic functions, it supports few spatial operations and lacks many useful functions such as coordinate conversation, exporting spatial data, and raster processing functions. In addition, SpatialHadoop was not designed to read Shapefiles directly, which is a very popular geospatial vector data format used in spatial domain. Instead, SpatialHadoop reads spatial data represented in well-known text (WKT) or well-known binary (WKB). Because of this, in this paper we focused on measuring only the performance of fundamental spatial operations.
In all five test cases, Marmot outperforms SpatialHadoop with a variation depending on the type of test. In the case of simple operations such as range query, the performance difference between SpatialHadoop and Marmot is small (PIR = 5% for range query without index). However, in the case of complex operations especially involving spatial index, Marmot highly outperforms SpatialHadoop (PIR = 209% for range query with index; PIR = 72% for spatial join with index). This is because those operations are strongly influenced by the performance of spatial index and Marmot greatly outperforms SpatialHadoop in these operations (PIR = 132% for creating spatial index). Lastly, in the case of creating MBR that is an essential prerequisite for creating spatial index, Marmot also has a higher performance than SpatialHadoop (PIR = 301% for creating MBR).
8. Discussion
Marmot has been developed as one component for constructing a national geospatial big data platform [
4] promoted by the Ministry of Land, Infrastructure, and Transport of the Korean government. Marmot is publicly available including GitHub [
32] and will be integrated into other components of the platform to be used for public services such as transport, real estate, or disaster prevention. Based on the long-term plans of the Korean government to promote the geospatial industry, Marmot also will be integrated with the national geospatial information open platform, V-World [
33], to provide a variety of map-based spatial analysis services. In addition, other ministries dealing with spatial data also plan to use Marmot as an infrastructure platform to provide big data based analysis services.
Compared to existing systems, Marmot is distinguished by the following. First, Marmot supports seamless integration between spatial and nonspatial operations within a solid framework, thereby improving workflow performance. Second, Marmot outperforms existing top-tier, plug-in based, spatial big data frameworks, especially for complex and time-intensive queries involving a spatial index. Third, Marmot provides a variety of spatial operators, which allow executing further complex spatial analyses. Finally, once application developers recognize a set of nonspatial and spatial operators, they can implement desired spatial analysis tasks without having to possess detailed knowledge of big data technologies.
Although Marmot shows good performance results compared to other existing research, it still needs further improvement. First, Marmot is restricted to batch processing only. Batch processing is efficient for handling huge amounts of data, but outcomes can be delayed depending on the input data size and computing power of a machine. Many recent geospatial data analytics require real-time data processing; however, Marmot does not yet support real-time processing of streamed data. Second, many machine learning algorithms read modestly sized source datasets iteratively, e.g., K-means and DBSCAN. For those applications, in-memory data processing offers the best match, but the current version of Marmot lacks this. Although Marmot utilizes memory, in part, along with disks during data processing [
34], it cannot take full advantage of in-memory computation to increase processing speed.
In the future, we first plan to investigate what additional factors create performance differences between Marmot and SpatialHadoop and conduct extensive experiments using more large-scale geospatial big data. Second, we are going to finalize implementing an Apache Spark-based geospatial big data processing system, which is currently underdeveloped. To address the aforementioned limitations of Marmot, we have selected Spark as a framework for our next system for analyzing geospatial big data since Spark supports both in-memory and real-time data processing. Finally, we will design and conduct experiments comparing performance between Marmot and the new system.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}