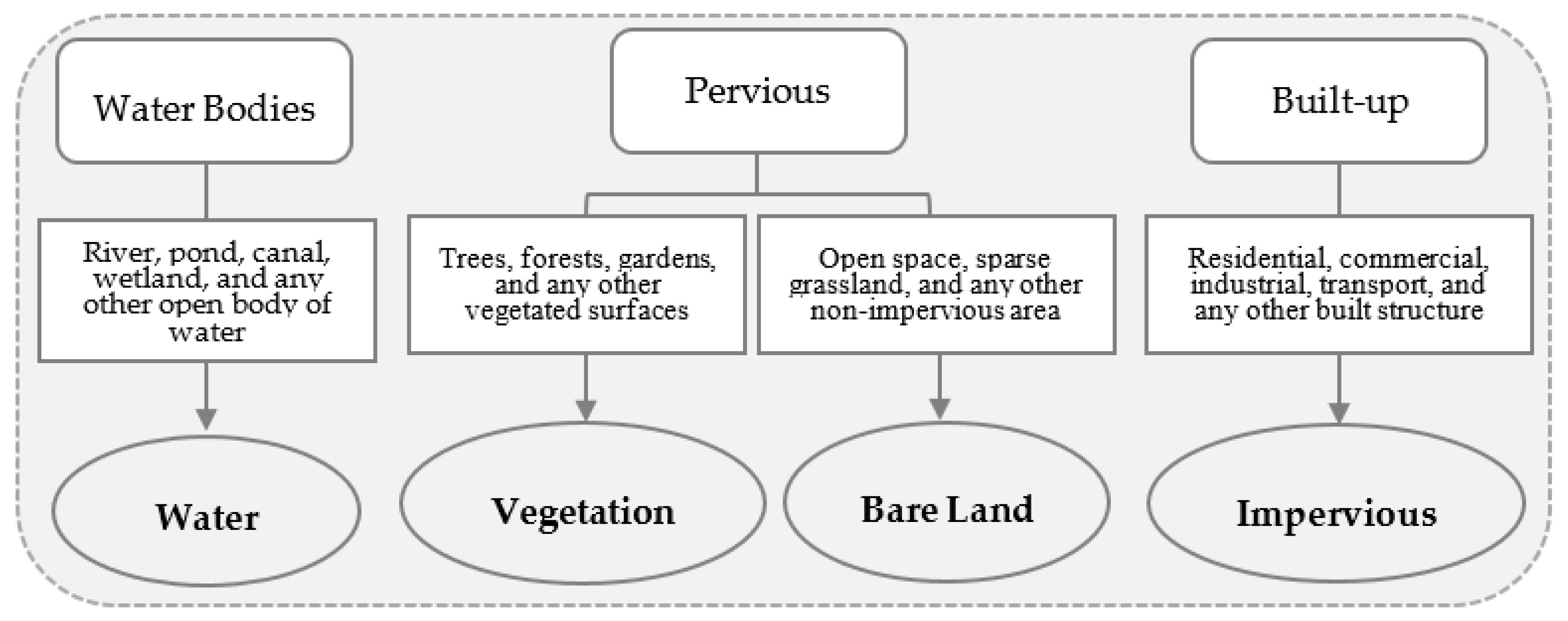
1. Introduction
Land cover analysis is a fundamental procedure in the study of the geographic environment [
1,
2]. Urban sprawl largely affects land covers and the terrestrial ecosystems [
3,
4]. The changes in land cover result in changes in ecosystems [
5]. Information on land cover is essential for monitoring and managing the ecosystem, and is also important for regional and local level planning and for managing urban sprawl [
6,
7]. Traditional land cover surveys are labor intensive and time-consuming [
8]. It is highly desirable to develop reliable and more automated methods for land cover mapping. Satellite imagery provides efficient data for monitoring land cover changes at local and global scales [
2,
6]. However, in urban areas, land cover mapping is challenging due to the large spatial and temporal variations caused by the diversified activities in these areas [
9].
Over the past decades, remote sensing has been widely used to map urban land covers. The land cover maps derived from image classification is important for monitoring multi-temporal changes and analyzing socio-ecological issues [
10]. Various image classification approaches [
11,
12,
13,
14,
15,
16] have been developed to classify urban land covers. The classification approaches have been commonly grouped as parametric and non-parametric classifiers. Image classification based on either pixels or objects have also been widely used in the past [
17]. Although various land cover classification approaches are available [
12,
13,
14,
15,
16], the selection of the best classifier is difficult because each of the methods has its own strengths and limitations. Use of spectral indices has proved to be an effective alternative means of mapping land covers. Because spectral indices demonstrate the relative abundance of features of interest [
18]. Moreover, the spectral index values primarily characterize a particular land cover.
Various spectral indices have been developed and used to detect different land cover types [
6,
19]. For example, the normalized difference vegetation index (NDVI), developed by Rouse et al. [
20], extracts vegetation and biomass information. The soil-adjusted vegetation index (SAVI) proposed by Huete [
21] separates vegetation and water in urban areas. The normalized difference water index (NDWI) developed by McFeeters [
22] delineates open water features in remote sensing images. The modified normalized difference water index (MNDWI) [
23] enhances accurate water detection. The normalized difference built-up index (NDBI), developed by Zha et al. [
24] is widely used to map built-up urban areas. The built-up index (BUI) [
25] and the indexed-based built-up index (IBI) [
26] delineate urban built-up features. The tasseled cap (TC) indices have been used to enhance the information on biophysical coastal zones, water, soil, and vegetation [
27].
In addition to the individual indices, different combinations of indices or modified indices have been developed and used to map land covers [
6,
28,
29,
30]. Although there are various methods for mapping land cover types, the existing approaches face limitations to classify urban land covers. First, separating impervious and bare land is still a challenge [
6,
31]. Second, although several indices can detect vegetation and water, no single index can detect them both. Third, the existing water indices do not accurately separate water from shadows. In urban areas, detecting surface water is a challenge because of the existence of dark building shadows [
32]. However, no previous studies have considered shadows when detecting urban water in relatively low-resolution images. In this study, we propose three novel indices: the modified normalized difference bare-land index (MNDBI), tasseled cap water and vegetation index (TCWVI), and shadow index (ShDI). Together, they address the above-mentioned limitations of existing methods. Approaches for optimizing the thresholds of the proposed indices are also developed. Based on the new indices, an automatic approach for urban land cover classification is implemented.
In the next section, the paper continues with a brief literature review on land cover classification.
Section 3 describes the study areas and data sources, and presents the principles of the formulation of the three novel spectral indices in detail. An approach of threshold optimization for the spectral indices is elaborated in this section.
Section 4 details the experimental validation and results.
Section 5 discusses the findings, and finally, concluding remarks are presented in
Section 6.
2. Literature Review
Various image classification approaches; e.g., parametric and non-parametric classification methods have been used to map land covers [
11,
12,
18,
33,
34,
35,
36,
37,
38,
39]. Among these works, the traditional parametric maximum likelihood classifier (MLC) has been widely used. This approach has proved to be an optimal classifier for normally distributed training data [
11]. Non-parametric algorithms, e.g., support vector machines (SVMs), neural networks (NNs), decision tree (DT) and random forest (RF), have been developed to enhance the classification accuracy. SVM employs optimization algorithms to generate boundaries and provides good classification results with limited spectral-mixed training data. However, the selection of required parameters of the SVM algorithm significantly influence the classification accuracy [
40,
41], thus requires an optimum parameter search [
13]. NN classifier involves a repeated feedforward and back-propagation process and performs well for land cover classification. However, the training phase requires many input parameters that are difficult to set, and the efficiency is low during the training phase [
42]. DT is a non-parametric classifier that does not require any a priori statistical assumptions regarding the distribution of data. However, the performance of this classifier is affected by the decision threshold [
43,
44]; therefore, it is important to assign appropriate thresholds. RF is an ensemble classifier that breaks down the classification process into a series of trees [
11]. The land cover classification methods can also be based on either pixels or objects [
17]. Pixel-based methods are favorable to moderate and low-resolution images, but they may fail to accurately differentiate adjacent classes that have a high spectral similarity [
45]. In contrast, object-oriented classification uses a minimum unit of information and minimizes the salt-and-pepper effect [
15], and this technique has been proved to be suitable for high-resolution images [
17,
46].
Spectral index has also been widely used as an effective alternative means of mapping land covers. Over the last decades, various spectral index based automatic and semi-automatic classification methods have been exploited for mapping land covers [
6,
33,
47]. For example, Li et al. [
6] applied a combination of the NDVI, vegetation and water masking index (VWMI), bright impervious surface binary (BISB), and normalized difference bare land index (NDBLI) to classify urban land covers using Landsat-8 Operational Land Imager (OLI) images. In this approach, the spectral indices were used to select training data, and then a machine learning classifier support vector machine (SVM) was applied to detect land covers. He et al. [
33] applied a semiautomatic segmentation approach to map urban built-up areas by enhancing the normalized difference built-up index. Chen et al. [
47] developed an integrated automated approach to map land covers using iterated training samples and markov random fields (MRFs) model. They applied iterations to refine the unchanged area as training samples and the MRF model to reduce salt-and-pepper effects. Different combinations of indices have also been used to map land covers. For example, Doustfatemeh and Baleghi [
1] used Landsat 7 Enhanced Thematic Mapper Plus (ETM+) to extract urban areas. In the first step, they used Otsu optimal thresholding [
48] to extract features using the NDVI, NDWI, and SVI, and then extracted urban points (UPs) using a symmetric gradient calculation based on structural features. When the results were combined, 90–95% overall accuracy was achieved at three study sites. Patel and Mukherjee [
28] extracted impervious features by inputting the SAVI, MNDWI, NDBI, BUI, and IBI indices into a backpropagation neural network. However, this approach detected only impervious features; all of the other land cover types were grouped into a single class. Bhatt et al. [
29] used the NDVI, MNDWI, and modified SAVI indices and applied object-oriented classification to Landsat-5 (TM) and Landsat-8 (OLI) images. It is notable that the object-based classification is appropriate for high-resolution imagery; this approach achieved an overall accuracy of 90.1%. Eslami and Mohammadzadeh [
30] introduced two novel vegetation indices, subdividing vegetation index (SVI) and minus/subdividing vegetation index (MSVI), to extract vegetation. Then, they extracted 24 textural features using the gray level co-occurrence matrix (GLCM) and applied the maximum noise fraction (MNF) to map urban land cover using hyperspectral thermal infrared data.
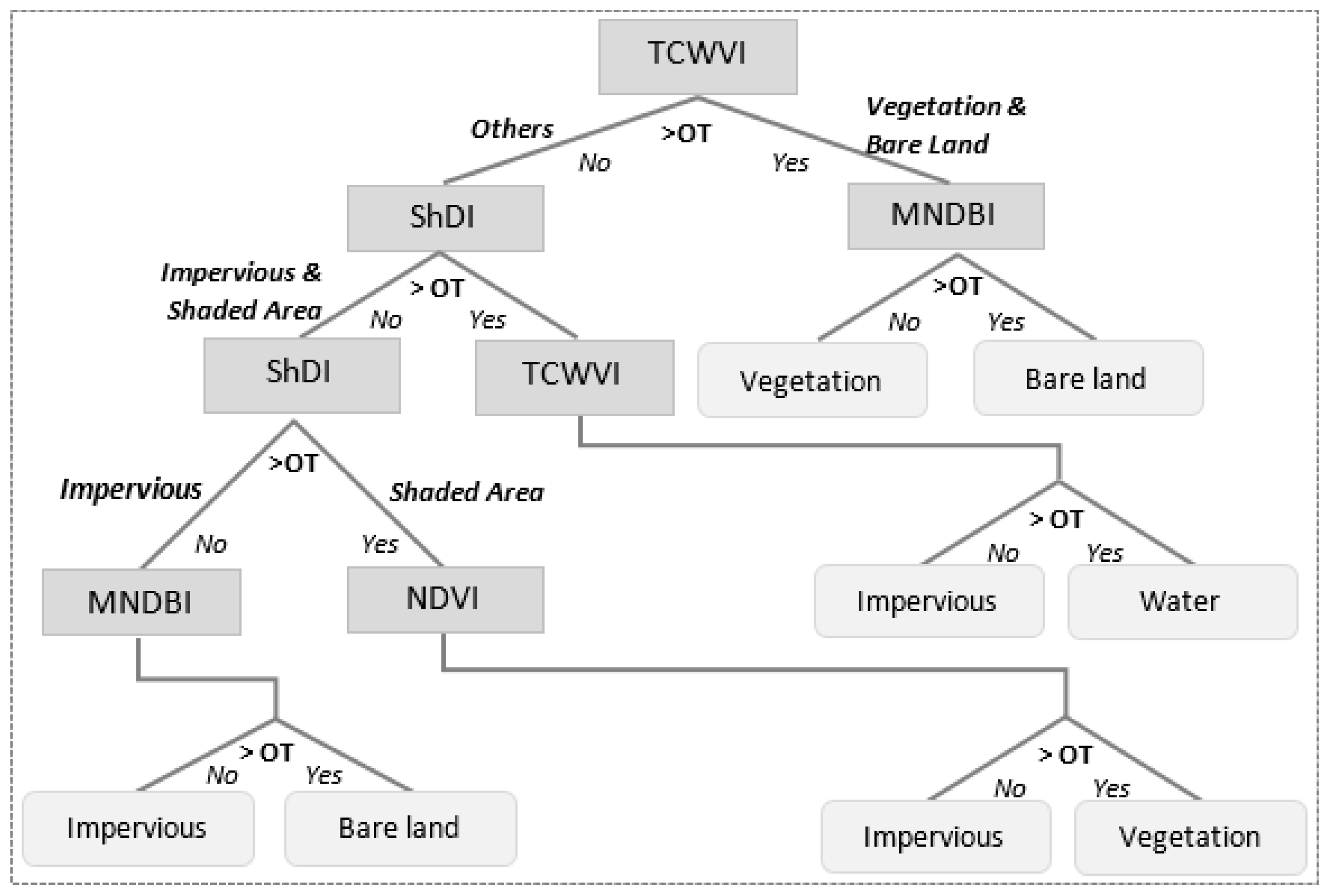
The existing land cover classification approaches have their merits but they also face limitations as described previously, especially in the complex urban environment. Precise land cover mapping in a heterogeneous urban environment is still a challenge and it is an ongoing subject of research. This study proposes three novel spectral indices, MNDBI, TCWVI, and ShDI, and a threshold optimization approach to enhance urban land cover mapping. This paper highlights the following contributions:
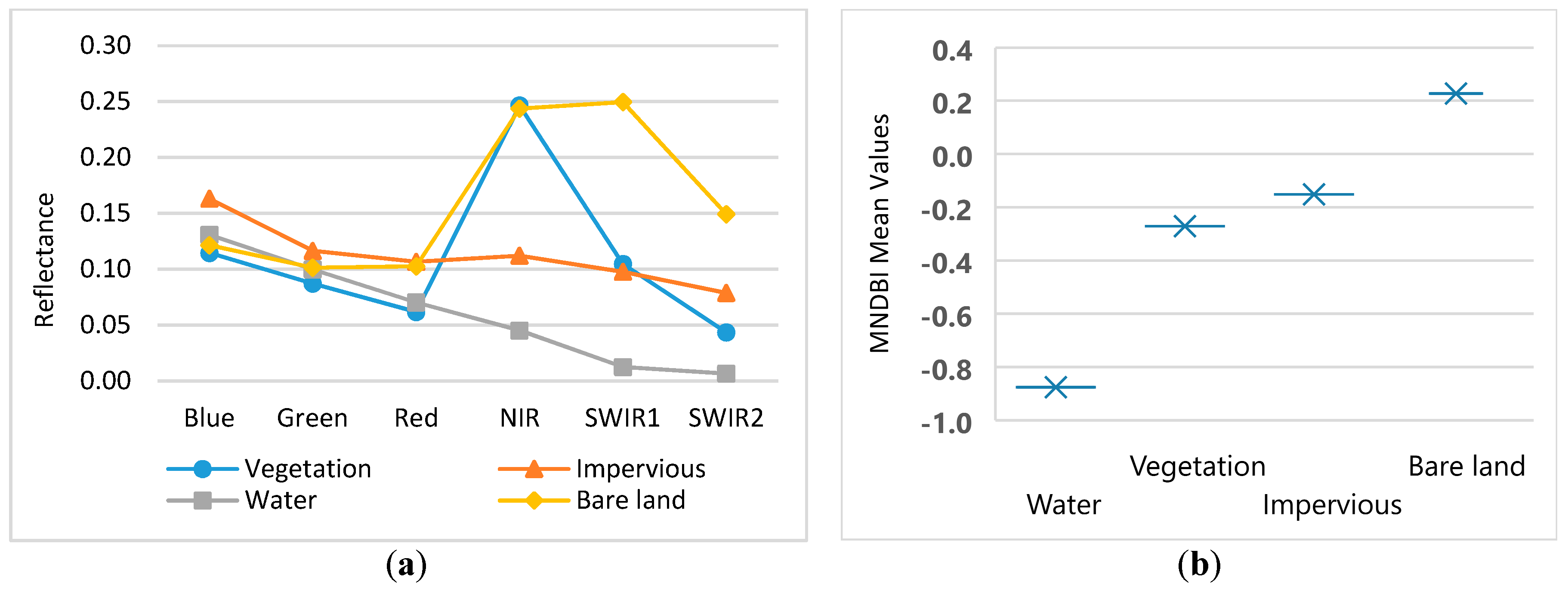
1. The proposed MNDBI is effective to separate impervious and bare land by using the spectral bands blue and shortwave infrared 2 (SWIR2).
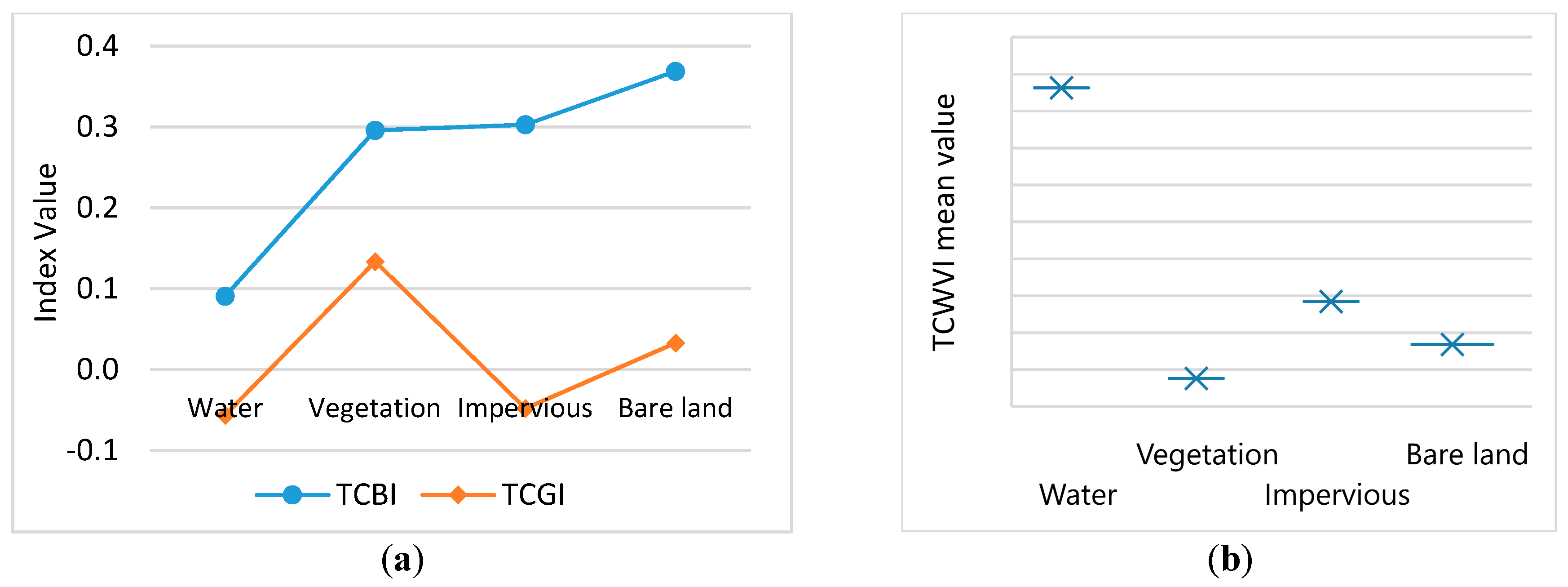
2. The proposed TCWVI can facilitate simultaneous detection of vegetation and water using the tasseled cap brightness index (TCBI) and the tasseled cap greenness index (TCGI).
3. The proposed ShDI uses the spectral bands near infrared (NIR), SWIR2, blue and red for delineating shadows in low-resolution images in order to improve the accuracy of water extraction in urban areas.
4. The proposed threshold optimization approach for the spectral indices is able to maximize spectral separability between adjacent land covers for enhanced land cover classification.
4. Experimental Validation
This section describes the evaluation of the proposed indices, threshold optimization, and the final classification results. In the first stage, the performances of the proposed indices are evaluated. To evaluate the performance of the MNDBI, two other indices, the NDBI and NDBLI, are used in a comparative analysis. Next, impervious and bare lands are segregated using optimized thresholds for the MNDBI, NDBI, and NDBLI. As a further test, a sensitivity analysis is carried out. The performance of the TCWVI is compared to the performance of the MNDWI and NDVI. First, the accuracy of the TCWVI’s detection of water is assessed by comparing it with the MNDWI. Second, a comparative analysis of the TCWVI and NDVI is performed to assess the accuracy of the TCWVI in detecting vegetation. Finally, quantitative accuracy assessment measures are used to evaluate the indices sensitivity. The performance of the ShDI is also evaluated by comparing the results of the two study sites.
In the second stage, the threshold optimization procedure is evaluated. First, mean and optimized thresholds are used to detect land covers; then sensitivity analysis is performed for both study sites. The most frequently used accuracy assessment measures, overall accuracy (OA) and kappa coefficient, are computed to assess the sensitivity of the threshold optimization. In the final stage, the results of the automated classification are evaluated. A comparative analysis is performed using the SVM algorithm because a number of studies used this robust classifier for comparison with other land cover classification methods [
36,
37,
38,
39]. In this study, the SVM algorithm is implemented using the radial basis function (RBF) kernel. The optimized parameters C, P and γ are set to 312, 0 and 0.5, respectively, for the Hong Kong dataset, and to 100, 0 and 0.5, respectively, for the Dhaka dataset. For evaluation, the accuracy assessment measures are computed. Several studies [
6,
12,
18] have conducted accuracy assessments using random sample pixels. In contrast, Goodchild et al. [
61] suggested using a minimum of 50 random point samples for each class to assess accuracy. However, it is important to select an appropriate number of samples to accurately assess post classification [
12]. To determine the number of required samples, the Multinominal Distribution Equation (6) offered by Congalton [
62] is used.
where
n is the number of required pixels,
B = (α/k)*100, α is the confidence interval, k is the number of classes,
is the ratio of area of the
ith class, and
is the desired precision.
In the Hong Kong dataset, a minimum of 53 reference pixels are required to accurately assess bare land and a maximum of 615 are required to assess vegetation. For the Dhaka dataset, a minimum of 114 pixels is required for bare land and a maximum of 618 for vegetation. In this study, we use more than the minimum requirement. To improve the accuracy of our assessment, 4000 ground truth data are collected from high-resolution images of Hong Kong and 4100 from images of Dhaka. In this study, land covers are classified using images with a resolution of 30 m/pixel, afterward, ground truth data is collected from high-resolution images (6 m/pixel) for validation purpose. A classified pixel of 30 m is equivalent to a patch of 25 pixels on the high-resolution image. Thus, careful consideration is given so that the selected ground truth data adequately form a patch of 25 pixels of the high-resolution image.
4.1. Performance Evaluation of the Proposed Indices
The following section presents the performance of the proposed indices in addressing the previously mentioned limitations of urban land cover classification. In this study, to test the transferability and robustness a similar evaluation approach is implemented in both study sites. However, to be concise, the results of the Hong Kong study site are provided in detail. In contrast, the evaluation results of the Dhaka study site are summarized in brief.
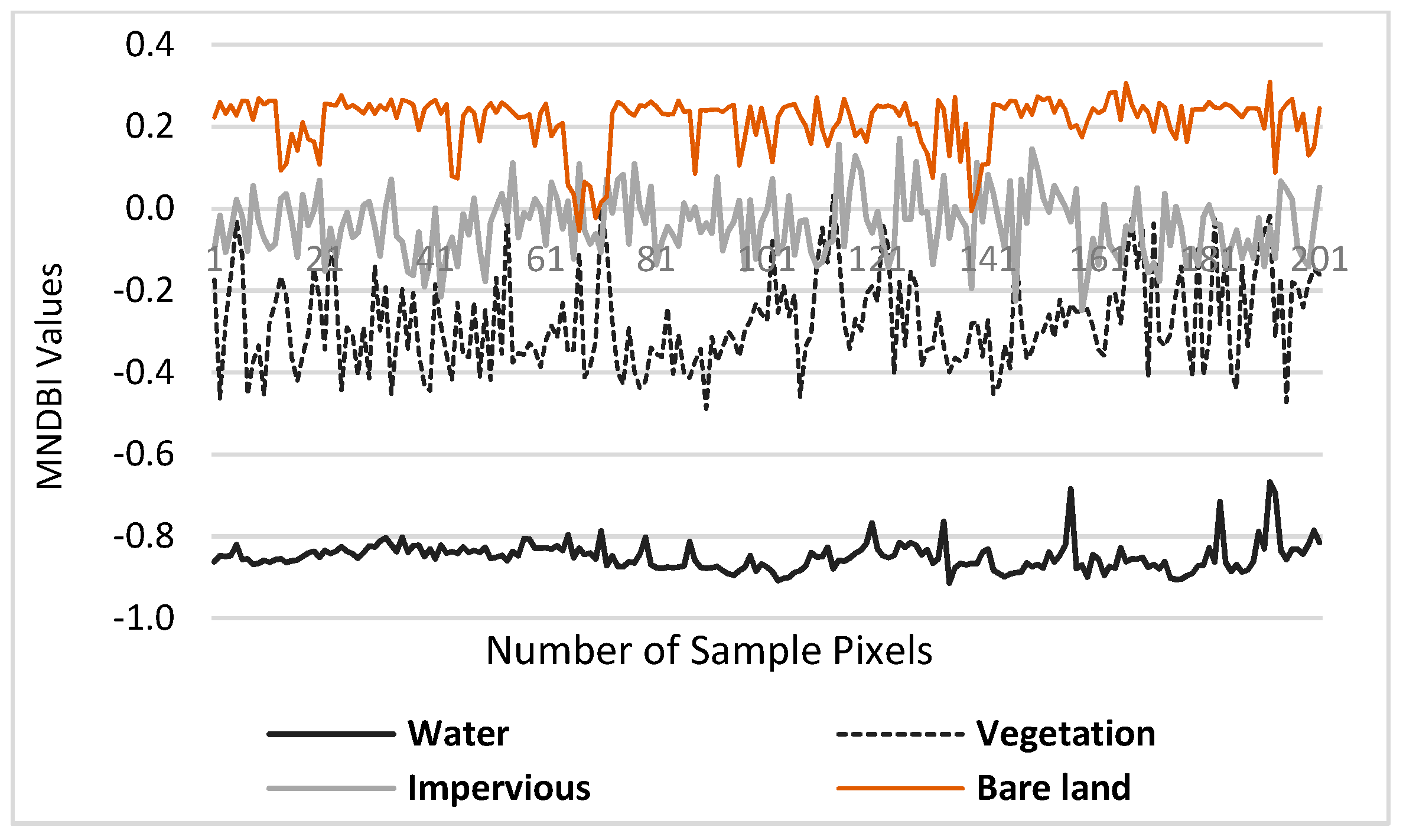
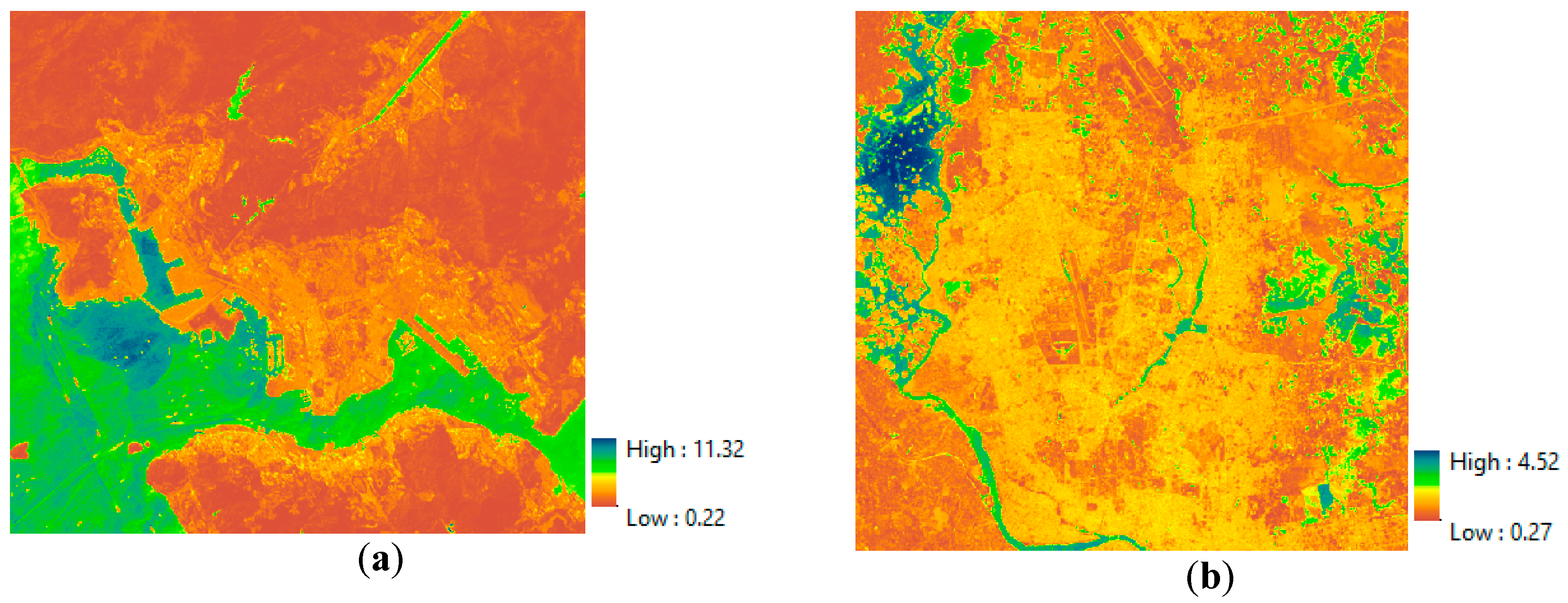
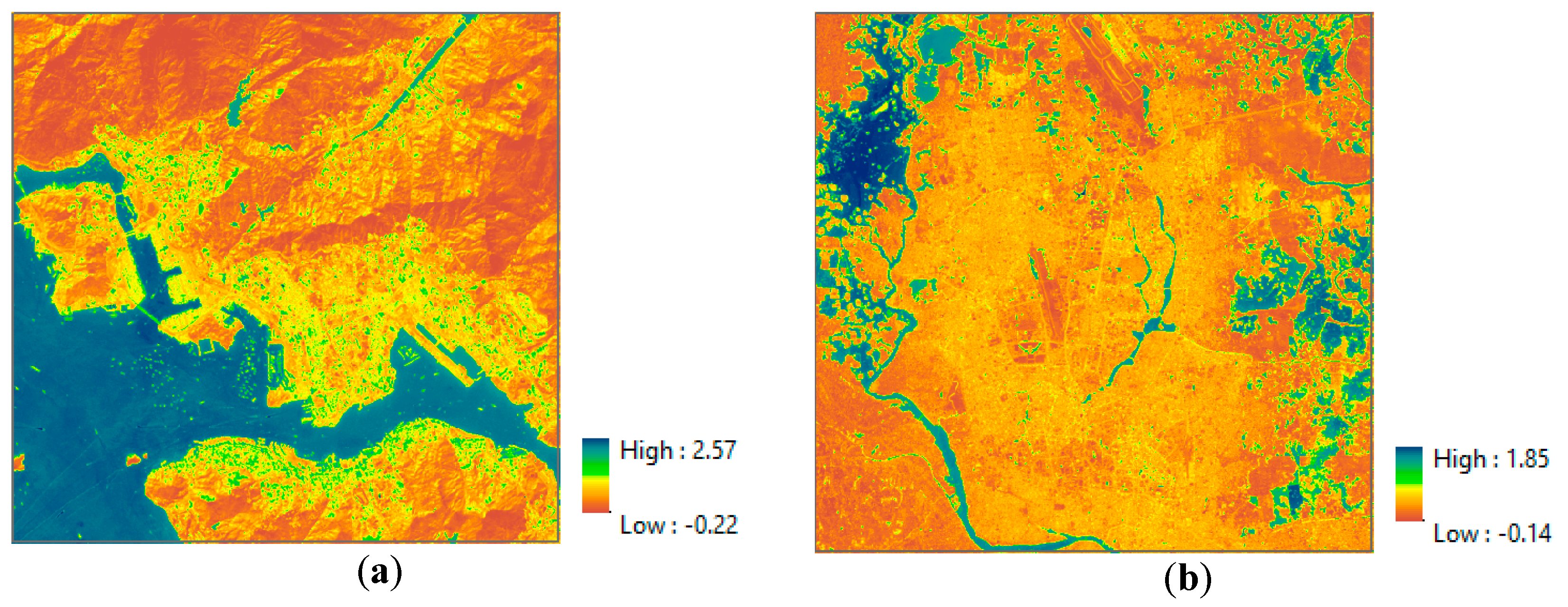
4.1.1. Evaluation of the MNDBI
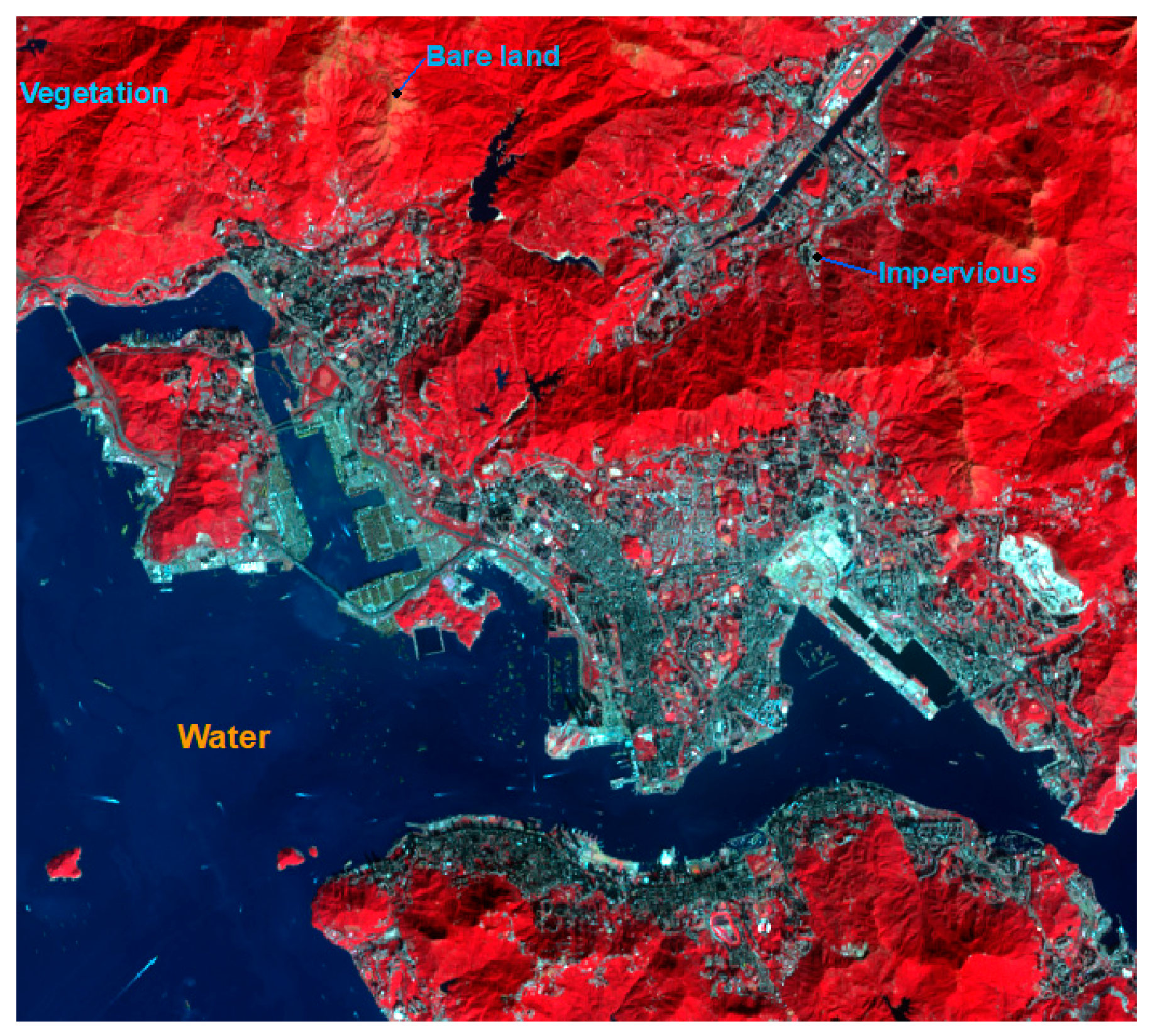
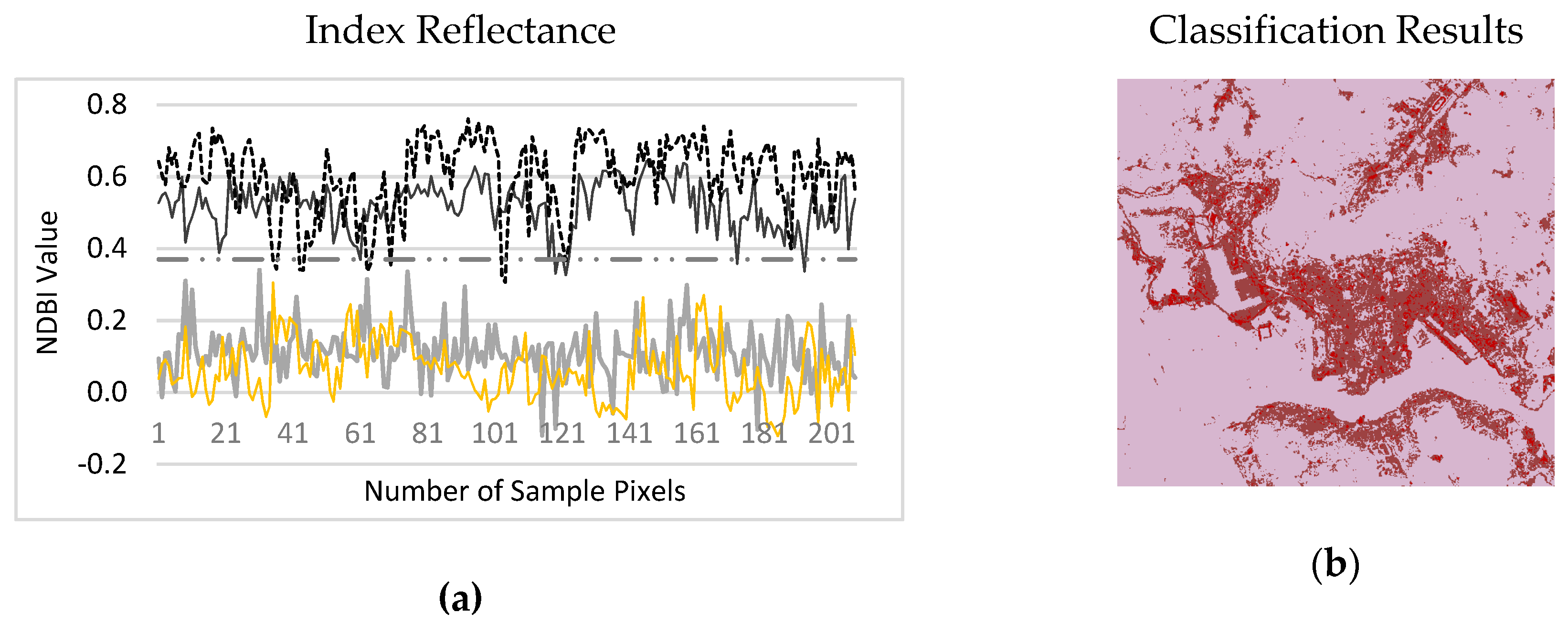
Figure 10 shows the delineated MNDBI maps for the Hong Kong and Dhaka datasets. The highest values indicate bare land and the lowest values indicate water. The intermediate values indicate impervious areas and vegetation.
Figure 11 presents the evaluation results of the MNDBI for the Hong Kong dataset. As illustrated in
Figure 11a, the impervious and bare land are integrated and the spectral mean difference is not significant; thus, the NDBI is not good enough to separate impervious and bare land. However, the NDBI clearly separates natural features such as vegetation and water from other types of land cover.
Figure 11c indicates that, to some extent, the NDBLI can separate bare land from impervious areas but complete separation is still a challenge. As large numbers of areas of impervious and bare land have similar reflectance values, there is a high degree of misclassification of these types, as shown in
Figure 11d. However,
Figure 11e illustrates that the MNDBI has the highest positive values for bare land and the spectral mean difference between bare land and adjacent impervious areas are significant. Thus, the MNDBI is better at separating impervious and bare land, as shown in
Figure 11f.
As a further comparison, the Dhaka dataset is used to evaluate the performance of the MNDBI. The accuracy of the results is summarized in
Table 4. The sensitivity analysis results indicate that the MNDBI has a better performance than the other indices. Specifically, the highest accuracy is observed for the MNDBI and the lowest for the NDBLI. The investigation confirms that the results are consistent and similar to those for the Hong Kong dataset. In summary, the proposed MNDBI is better than the other indices in separating impervious and bare land.
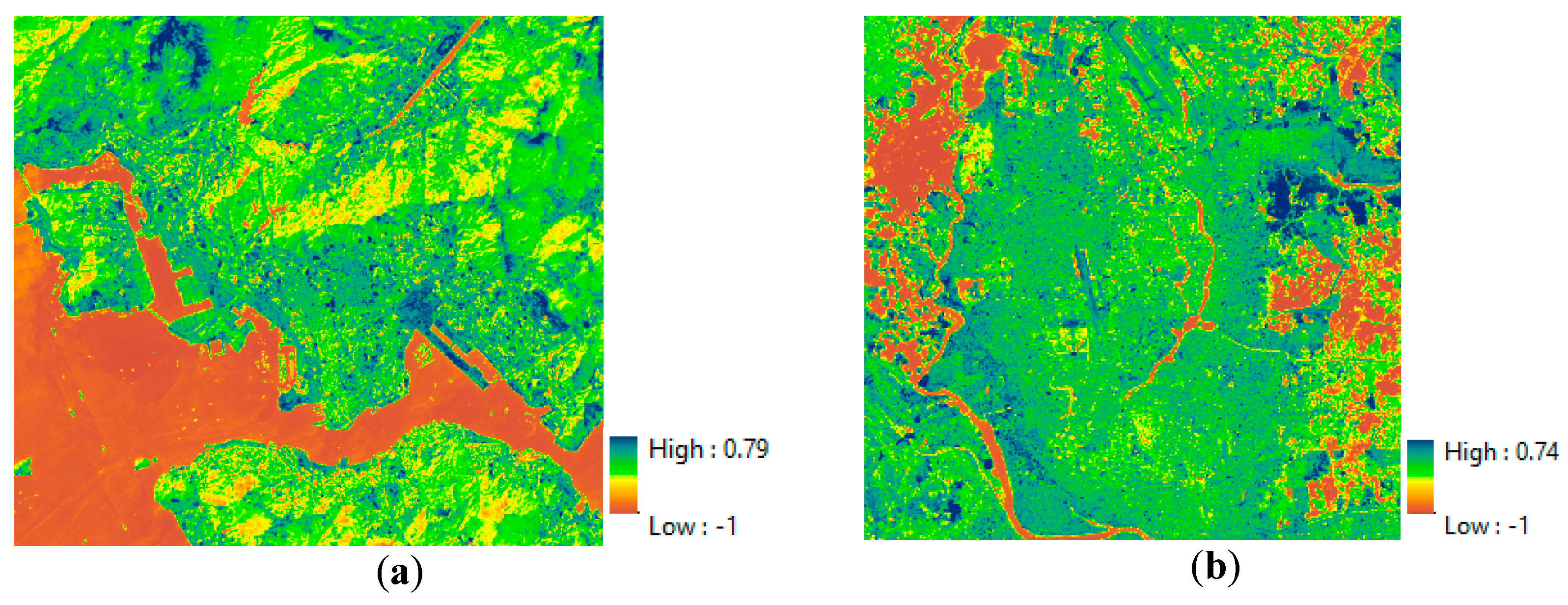
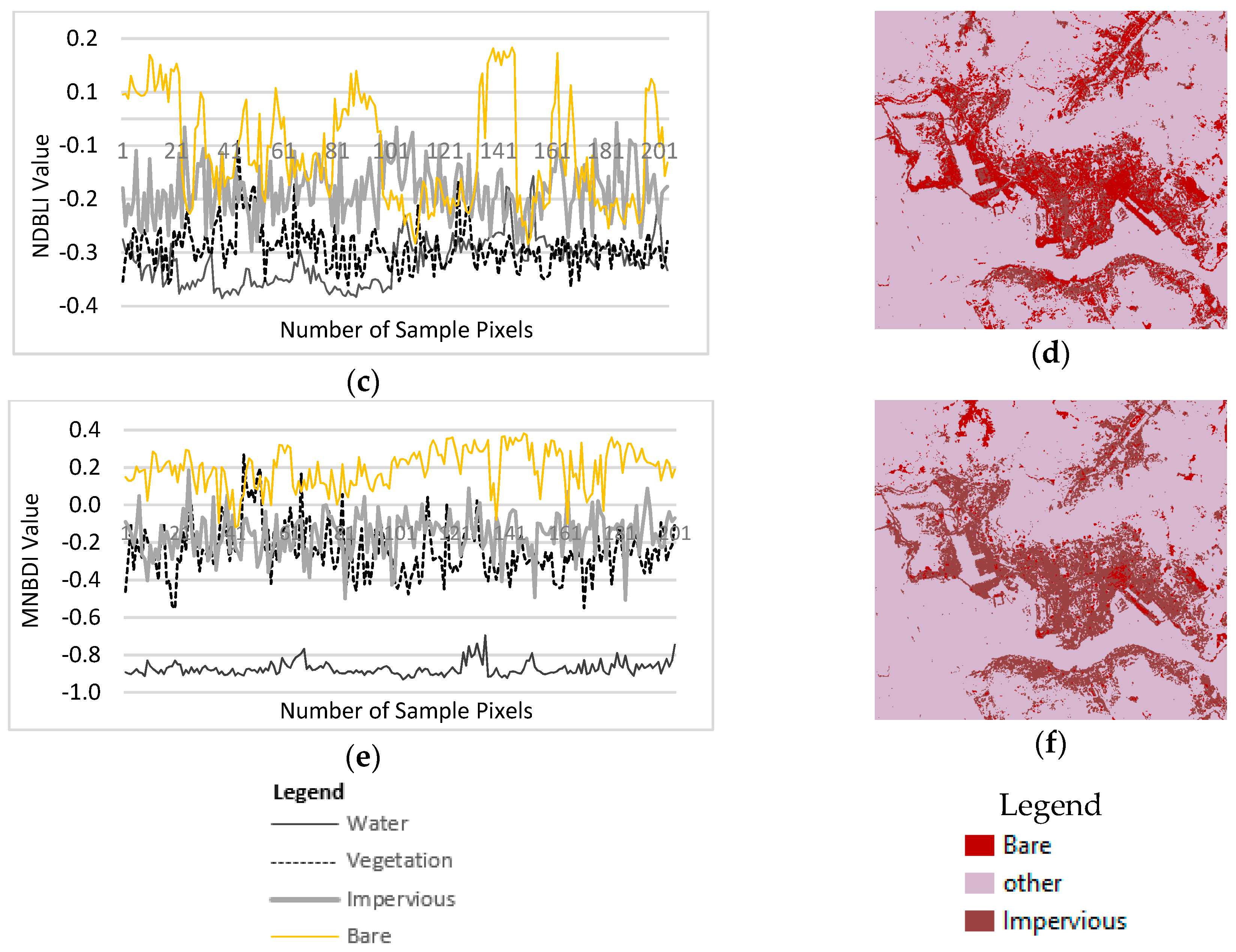
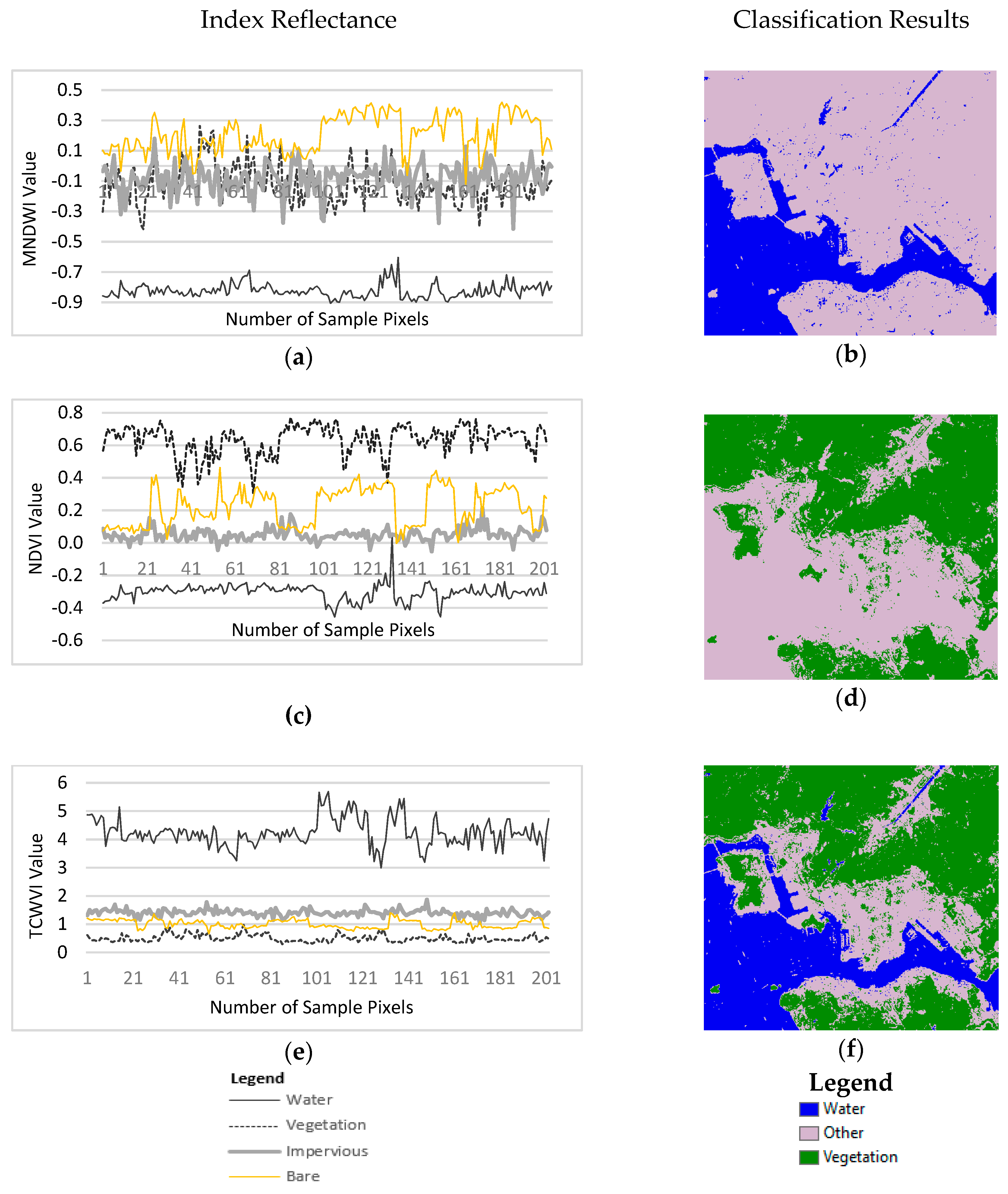
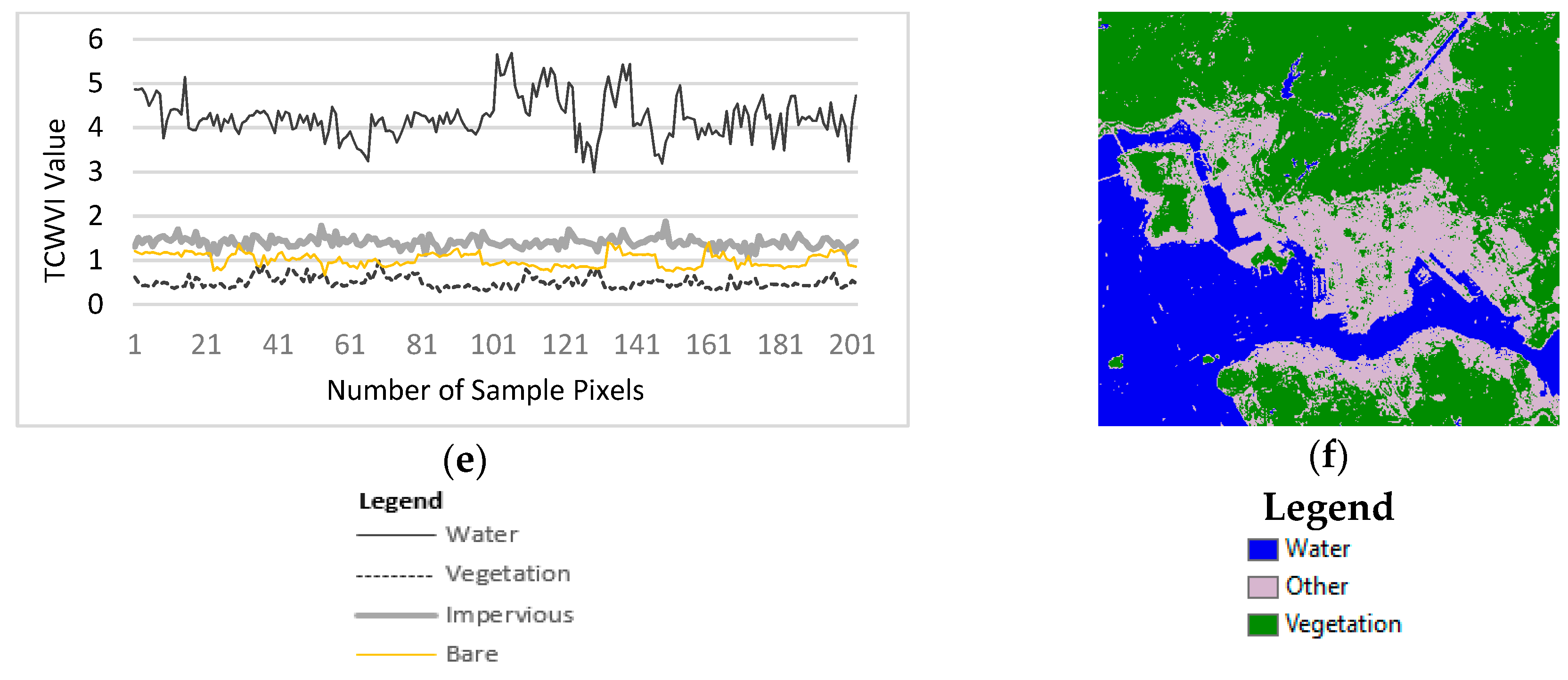
4.1.2. Evaluation of the TCWVI
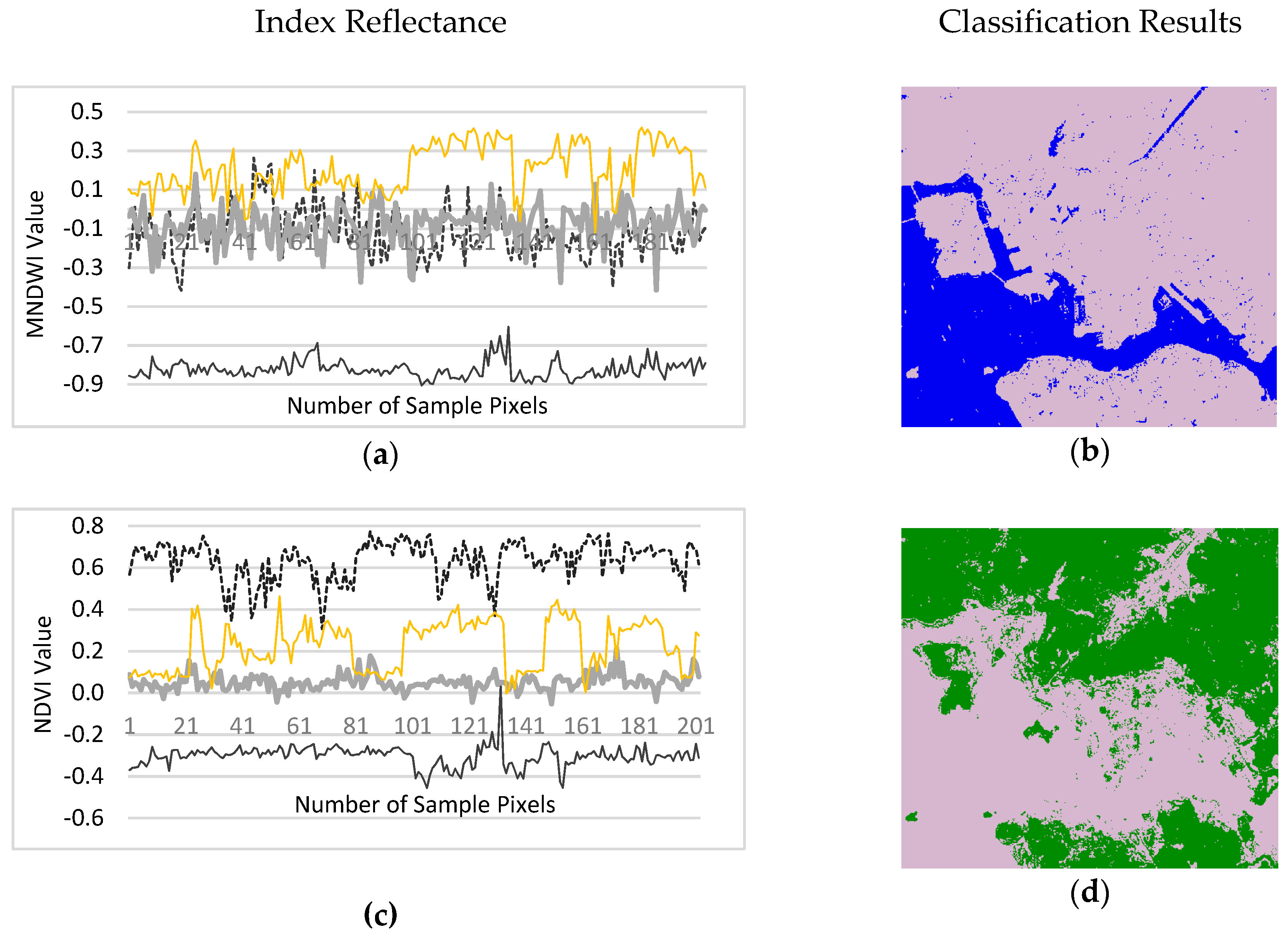
Figure 12 shows the delineated TCWVI maps based on the Hong Kong and Dhaka datasets. These maps show a clear separation between water and vegetation, with the highest values indicating water and the lowest vegetation. The intermediate values indicate areas of impervious and bare land.
The results of the evaluation of the TCWVI for the Hong Kong dataset are presented in
Figure 13. As illustrated in
Figure 13a, in the MNDWI map water has the lowest negative values and bare land has the highest positive values. There is also a significant mean difference between water and adjacent land cover types. The separability analysis shows that the MNDWI is a good indicator of water, but a salt and pepper effect is observed when thresholds are used to extract water, as shown in
Figure 13b. As illustrated in
Figure 13c, the scatter plot of the NDVI results indicates that vegetation has the highest positive values, bare land has the second highest values, and these two are adjacent land cover types. Water has the lowest values. The extracted vegetation using the optimized threshold of the NDVI is shown in
Figure 13d. The spectral separability of the TCWVI produces results that are opposite those of the NDVI. In this case, the highest values are observed for water, with a significant mean difference between water and adjacent land cover types, and the lowest values are observed for vegetation, as shown in
Figure 13e. In the proposed framework, vegetation and water are extracted together using the TCWVI, as shown in
Figure 13f. The comparative analysis demonstrates a good agreement between the NDVI and TCWVI for detecting vegetation, and a good agreement between the MNDWI and TCWVI for detecting water.
As a further comparison, the Dhaka dataset is used to evaluate the performance of the TCWVI. The results of the sensitivity analysis, shown in
Table 5, indicate an acceptable performance of the TCWVI for both study sites. In summary, the results demonstrate that the proposed TCWVI can simultaneously detect water and vegetation with a satisfactory degree of accuracy. Moreover, the TCWVI improves the detection of water, as it minimizes the salt and pepper effect. The results also demonstrate that the TCWVI reduces dependency on two indices and enhances the extraction of vegetation and water using a single index.
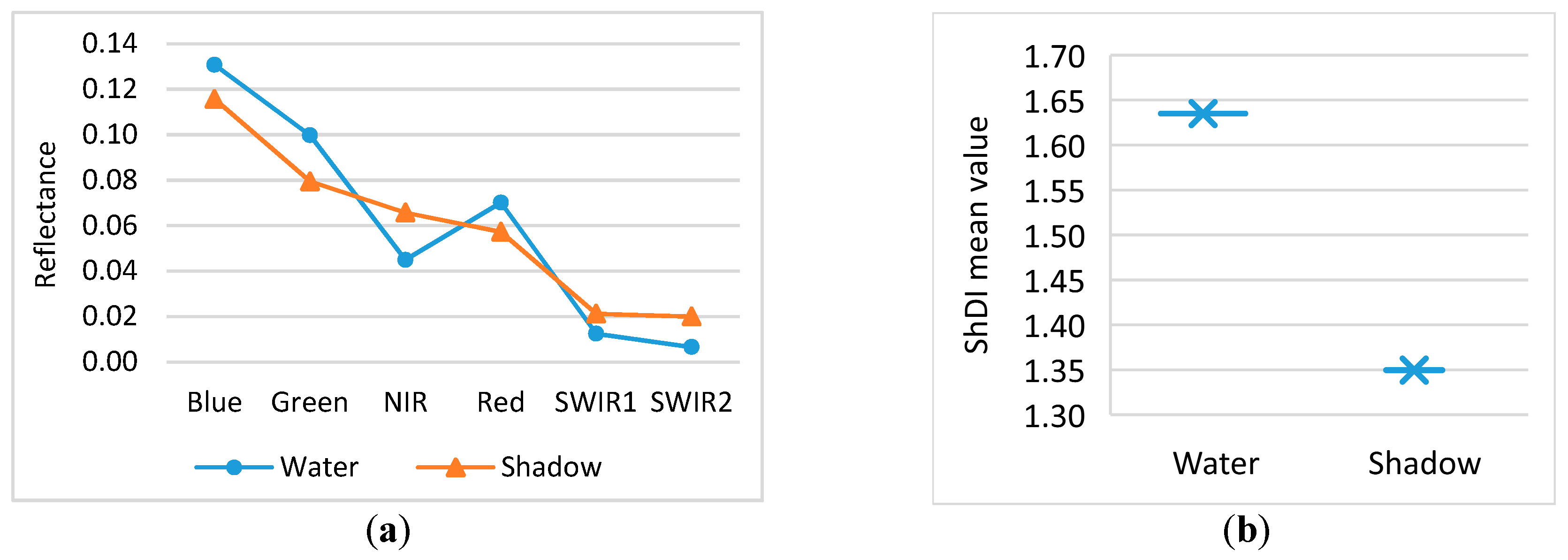
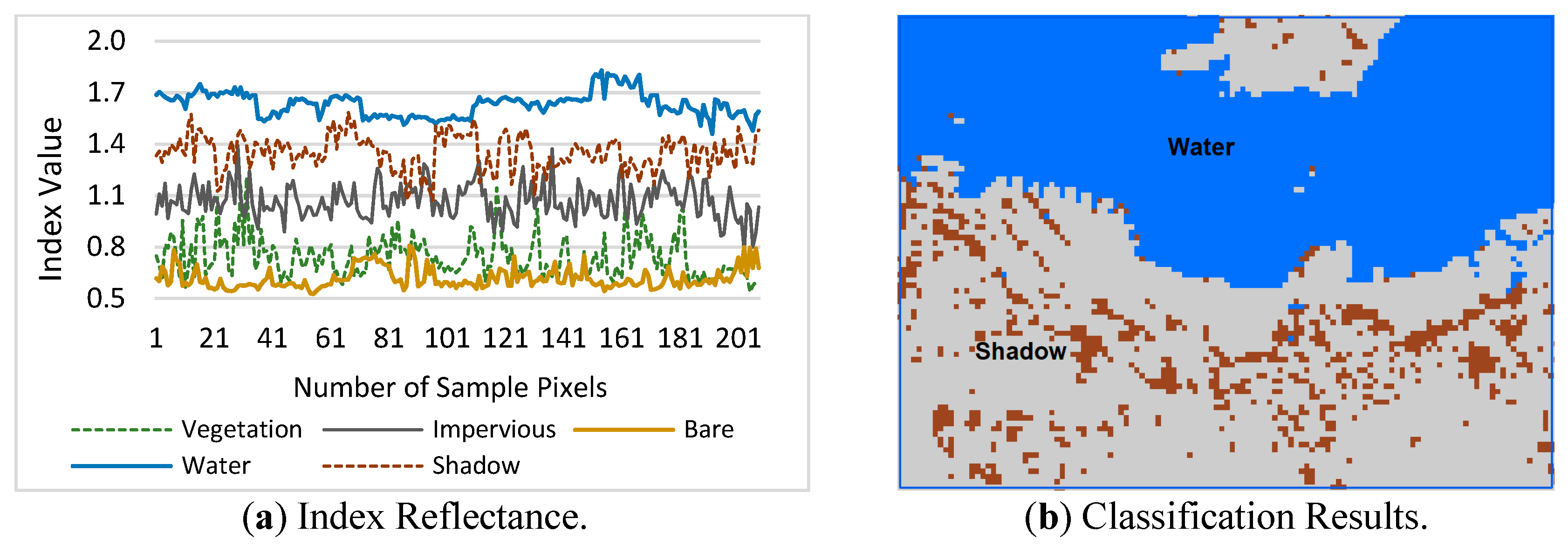
4.1.3. Evaluation of the ShDI
Figure 14 shows the delineated ShDI maps for the Hong Kong and Dhaka datasets. In the Hong Kong dataset, the highest values indicate water, the second highest shadow, and the lowest vegetation (
Figure 14a). In the Dhaka dataset, the highest values indicate water, the second highest impervious land, and the lowest vegetation (
Figure 14b).
Figure 15 presents the results of the evaluation of the ShDI. Landsat-8 false-color images of Hong Kong indicate the existence of shadows, as shown in
Figure 6a. Therefore, although water is extracted, as shown in
Figure 13b, the salt-and-pepper effect is observed. As illustrated in
Figure 15a, for the ShDI, water has the highest reflectance values, the second highest is shadow, and vegetation has the lowest values. The classification results illustrated in
Figure 15b show that the ShDI can separate water from shadows. A similar pattern is observed at the second study site, but as shadow is not detected in Dhaka, water has the highest values and vegetation has the lowest values.
4.2. Sensitivity of Threshold Optimization
Table 6 shows the impact of the mean and optimized threshold values for the TCWVI on the detection of water and vegetation. The water detection results demonstrate that the optimized threshold provides higher accuracy than the mean threshold. The result also indicates that the optimized threshold improves the detection of vegetation. Similar findings are observed in the separation of impervious and bare land. In this section, we have illustrated the sensitivity of the TCWVI. A similar approach to assess the sensitivity of other indices demonstrates that the optimized threshold produces the most consistent performance and the highest accuracy in detecting land covers of both study sites.
4.3. Results of the Land Cover Classification and Comparative Analysis
In this section, the results of the proposed method for classifying urban land cover based on three new indices are compared to the results of a popular classifier, the SVM algorithm. The proposed method is automated and uses the optimized thresholds of the new indices. In contrast, the SVM algorithm is implemented after optimization the parameters C, P and γ.
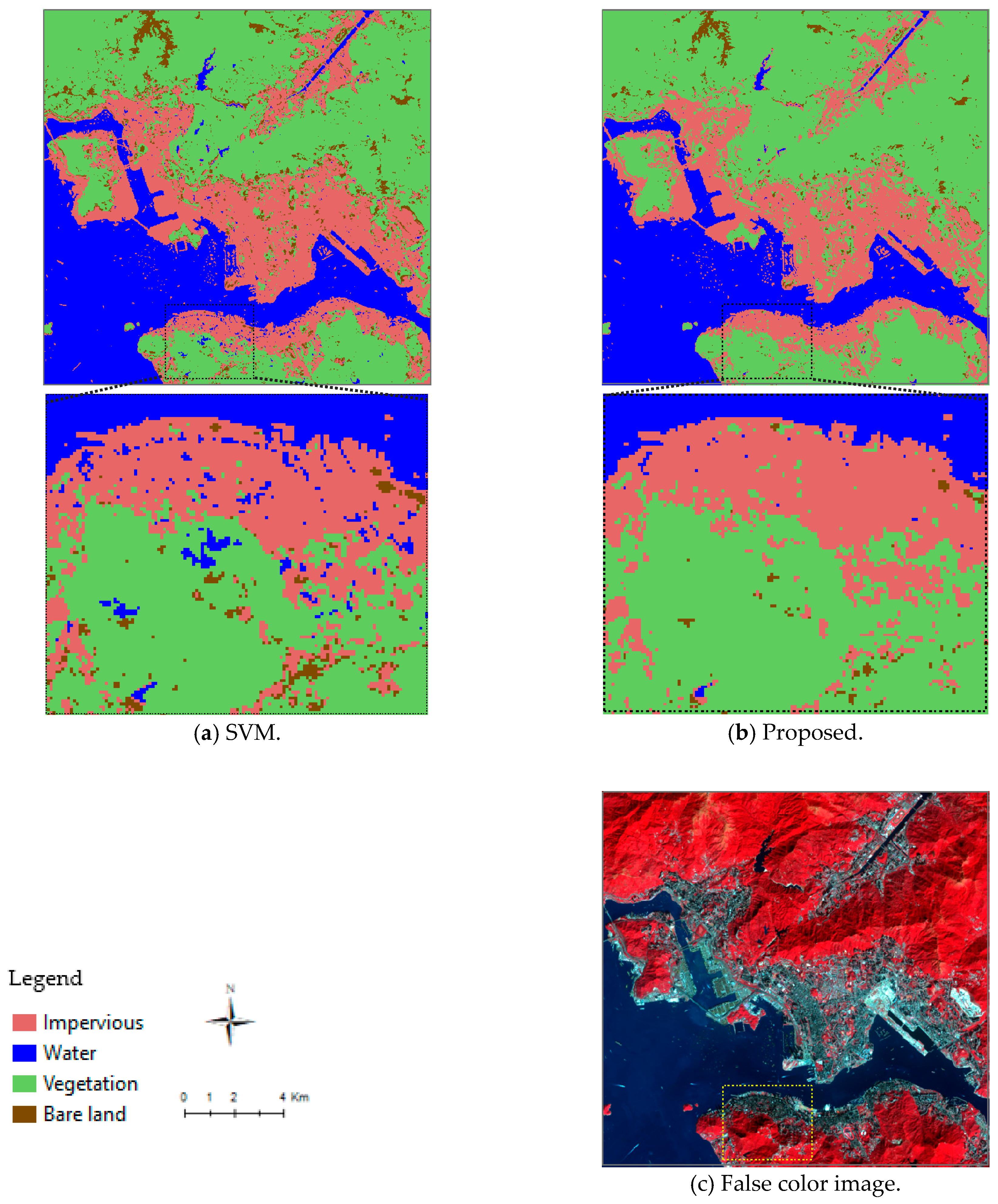
Figure 16 presents a visual comparison of the classifications obtained by the proposed approach and the SVM algorithm for the Hong Kong dataset. The results of the SVM algorithm have an over-detection of water and bare land, reducing the accuracy of the detection of these land cover types compared to the proposed approach. As illustrated in
Table 7, the classified data of the SVM algorithm substantially deviate from the user and producer accuracy for all land cover types. In contrast, the proposed approach has a better overall performance with slight deviations. Its overall accuracy, 96.1% with a kappa coefficient of 0.95, also demonstrates that the proposed approach performs better than the SVM algorithm. The assessment indicates that the approach is most accurate for classifying water and least accurate for classifying bare land. Although the accuracy in classifying bare land is relatively low compared to other land covers, the proposed approach improves the separation of impervious and bare land. Overall, the approach has an accuracy of 94% in the detection of impervious areas.
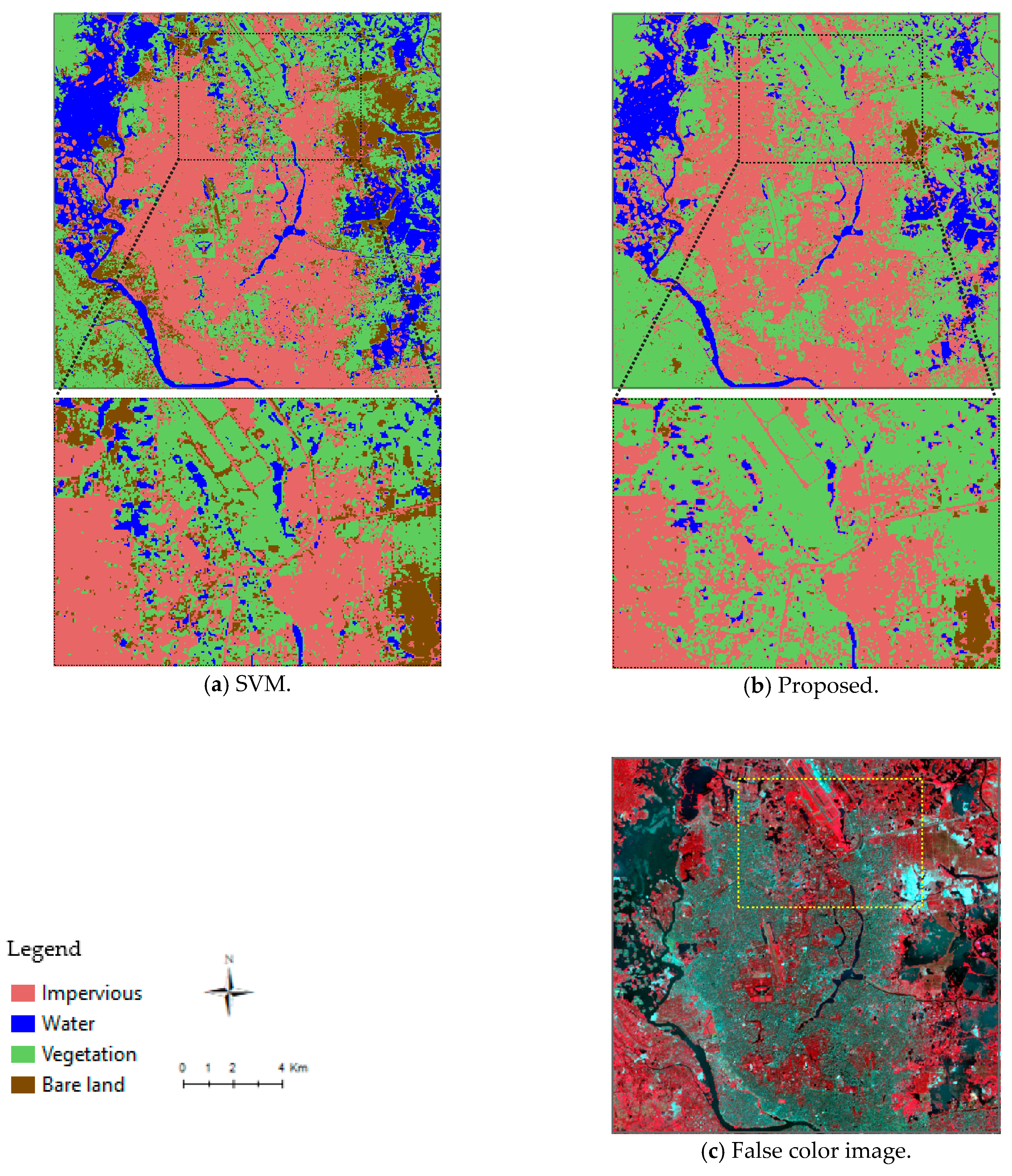
A comparison of the results of the proposed approach and the SVM algorithm for the Dhaka dataset is presented in
Figure 17. The results are very similar to those for Hong Kong. The accuracy assessment for the Dhaka dataset, shown in
Table 8, indicates that the proposed approach has a better performance than the SVM algorithm. The overall classification accuracy, 94.1% with a kappa coefficient of 0.92, is higher than the classification accuracy of the SVM algorithm. In the Dhaka example, the best performance is in the classification of water and the worst in the classification of bare land. Impervious areas are detected with an accuracy of nearly 94%. Overall, our proposed approach can detect land covers with a level of accuracy that is better than that of the SVM algorithm. However, the proposed approach is slightly more accurate for Hong Kong than for Dhaka.
5. Discussion
Various factors, e.g., atmospheric transmission, cloud, wind, image acquisition time, and vegetation types, can affect spectral band reflectance. Moreover, the characteristics of the physical properties and the variation in atmospheric correction altogether can affect the threshold values of the indices. Thus, careful consideration should be given to choosing spectral thresholds to detect land cover types in different cities. For example, the bare land in Dhaka is sand and soil, the geology of Hong Kong is dominated by rocks. As the physical properties of bare land in these two study sites are dissimilar, the range of band reflectance and index values using the proposed MNDBI varies between the two study sites. Moreover, as the vegetative covers are also variable, the band reflectance and threshold of the TCWVI and NDVI also vary between the two study sites. Similarly, the thresholds for other land cover types are variable, thus it is important to identify the local spectral values to each land cover type prior to applying this approach of classification. The proposed approach is a pixel-based solution; thus, its performance with high-resolution images must be assessed. In this study, we have used only Landsat-8 OLI images. A future study is required to fully evaluate the applicability of this approach to other higher resolution dataset; e.g., the Sentinel 2 data.
The results indicate high accuracy in Hong Kong compared to the Dhaka case study. In terms of development, Hong Kong is compact and has a less fragmented pattern of land cover, whereas Dhaka is very dense, but characterized by fragmented urban sprawl. The extent of fragmentation is reflected in the complicated and diverse pattern of land cover types in Dhaka. Dhaka also encompasses several small bodies of water, such as ponds and canals, which are surrounded by vegetation that reduces visibility. The use of low-resolution image is impotent to properly detect narrow water bodies and results in misclassification. An example of such misclassification is illustrated in
Figure 18. It is noticeable that a narrow strip of water body is classified as vegetation 18c. In this illustration, the existence of water is verified using the Google Earth image and the high-resolution SPOT-6 image. The verifications confirm that the strip covers a body of water having an average width of 10 m (Google Earth) and 6 m (SPOT 6), respectively. However, the resolution of Landsat data is 30 m/pixel. Thus, such narrow water bodies are not properly detected in the low-resolution Landsat images. These underlying factors contribute to the relatively lower accuracy in the detection of water and vegetation, and the overall lower accuracy in the Dhaka case study compared to the Hong Kong case study.
Statistical accuracy assessment is important to the thematic maps derived from remote sensing data, thus the Kappa coefficient is often used. This study uses similar accuracy assessment measures. However, the Kappa coefficient does not deal with the pairwise comparison, and agreement and disagreement between categories [
63]. Moreover, the Kappa index compares accuracy to a baseline of randomness. However, randomness is not a reasonable alternative for mapping [
64]. The use of the Bradley–Terry (BT) model determines the agreement within a category and disagreement in relation to another category [
63]. In addition, the quantity disagreement and allocation disagreement of two simple measures are useful compared to Kappa indices [
64]. In this study, we have estimated only the kappa coefficient, however, other accuracy assessment measures will be considered in our future works to facilitate a pairwise comparison, and agreement and disagreement between categories.
6. Conclusions
The main purpose of this study is to improve automatic land cover mapping in urban areas. To achieve this task, we propose three novel indices and a new approach to threshold optimization. As band reflectance and index values vary over different physical properties and land covers, spectral separability analysis is needed to effectively determine the optimized threshold for separating land cover types. The evaluation of the proposed indices and the process of threshold optimization indicates that they perform satisfactorily at both study sites. Specifically, we achieve better results separating impervious and bare land with the MNDBI than with other indices. The MNDBI also has the lowest negative values for water, and the mean difference with other land covers are significant at both study sites. Thus, future studies could evaluate the ability of the MNDBI to detect water. The TCWVI can simultaneously detect vegetation and water with acceptable accuracy. Moreover, the shadow index developed in this study improves water detection by maximizing the reflectance between water and shadow. The experimental analysis demonstrates that the proposed approach performs better than the SVM algorithm. The new approach is a reliable automatic classification method that provides between 94% and 96% accuracy.
Although this method enhances land cover classification and improves the separation between impervious and bare land, complete separation is still a challenge. In addition, thresholds are optimized using training data, thus further study is required to develop an automatic approach of threshold optimization and make the proposed approach more functional in the near future. The overall results indicate that the proposed method is promising and reliable to enhance land cover classification in urban areas. The proposed land cover classification approach is of significance to facilitate the monitoring of terrestrial ecosystems, water resources, and urban sprawl.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
