An Effective Privacy Architecture to Preserve User Trajectories in Reward-Based LBS Applications †




Abstract
:1. Introduction
2. Background and Related Work
2.1. Inference and Linking Attacks
2.2. Anonymization Techniques
2.3. Adversary and Background Knowledge
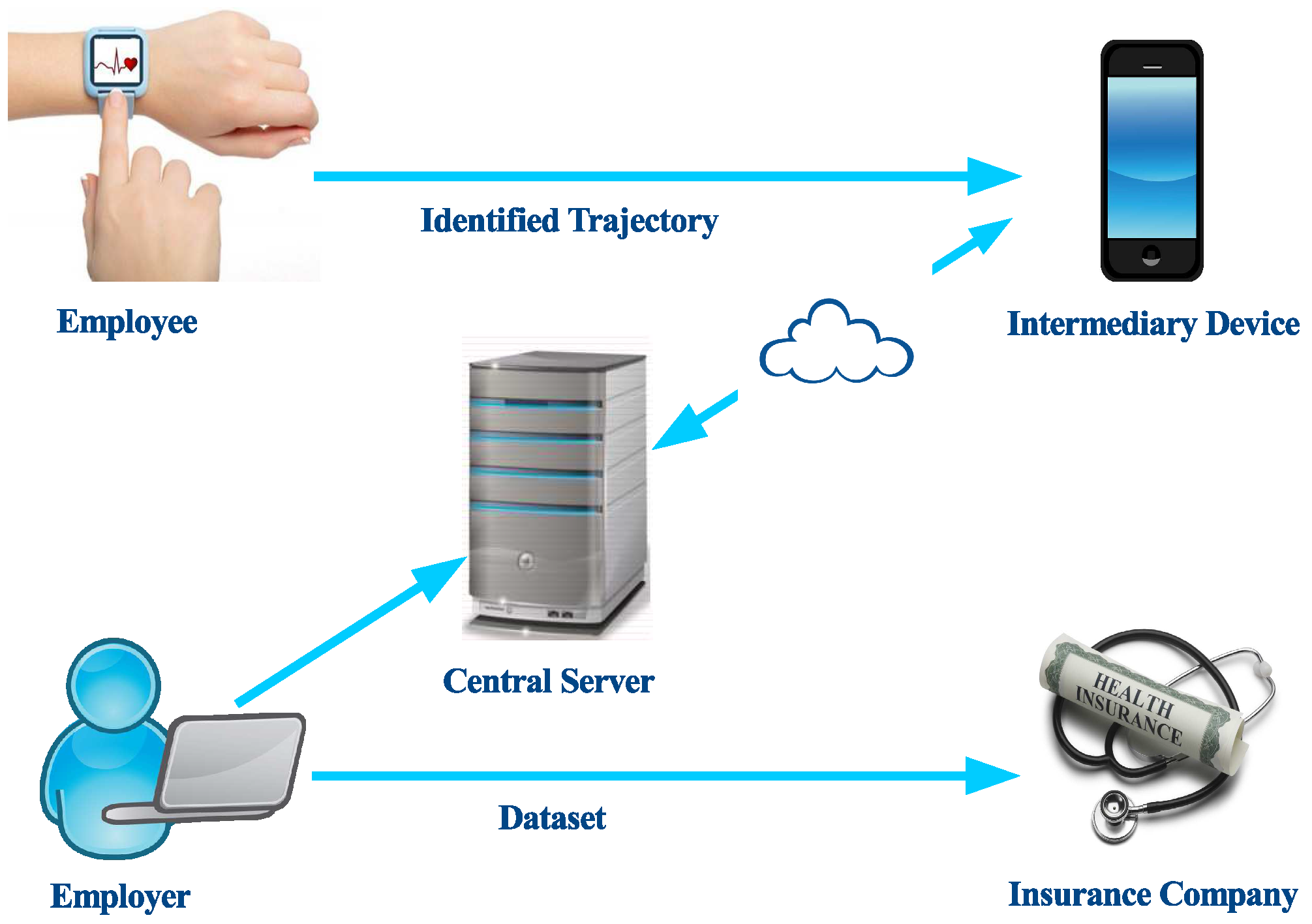
3. A Client-Server-Based Privacy Methodology
3.1. Client-Server Privacy Architecture
3.2. Anonymization
3.3. Anonymization Algorithms
3.3.1. Generation of Global Location Set
| Algorithm 1 Generation of a global location set. |
| Input: A bounding box B in the OpenStreetMap [34] with four parameters where and are longitude coordinates and and are latitude coordinates; Output: Generate the possible visited locations {all possible visited locations} in the bounding box B;
|
3.3.2. Anonymized Location Trajectory
| Algorithm 2 Anonymized location trajectory. |
| Input: Identified trajectory L, global location set . Output: Anonymized location trajectory in the global location set .
|
3.4. Discussion on the Anonymization Technique
4. Experimental Evaluation
4.1. Data Set
4.2. Privacy Breach
4.3. Location Trajectory Anonymization
4.4. Data Utility
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Mattke, S.; Liu, H.; Caloyeras, J.P.; Huang, C.Y.; Van Busum, K.R.; Khodyakov, D.; Shier, V. Workplace Wellness Programs Study; Rand Corporation: Santa Monica, CA, USA, 2013. [Google Scholar]
- Raij, A.; Ghosh, A.; Kumar, S.; Srivastava, M. Privacy risks emerging from the adoption of innocuous wearable sensors in the mobile environment. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 11–20. [Google Scholar]
- Choi, H.; Chakraborty, S.; Charbiwala, Z.M.; Srivastava, M.B. Sensorsafe: a framework for privacy-preserving management of personal sensory information. In Secure Data Management; Springer: Berlin, Germany, 2011; pp. 85–100. [Google Scholar]
- Issa, H.; Shafaee, A.; Agne, S.; Baumann, S.; Dengel, A. User-sentiment based evaluation for market fitness trackers-evaluation of fitbit one, jawbone up and nike+ fuelband based on amazon.com customer reviews. In Proceedings of the 1st International Conference on Information and Communication Technologies for Ageing Well and e-Health, ICT4AgeingWell 2015, Lisbon, Portugal, 20–22 May 2015; SCITEPRESS: Setúbal, Portugal, 2015; pp. 171–179. [Google Scholar]
- Plarre, K.; Raij, A.; Hossain, S.M.; Ali, A.A.; Nakajima, M.; al’Absi, E.; Ertin, T.; Kamarck, T.; Kumar, S.; Scott, M.; et al. Continuous inference of psychological stress from sensory measurements collected in the natural environment. In Proceedings of the 2011 10th International Conference on Information Processing in Sensor Networks (IPSN), Chicago, IL, USA, 12–14 April 2011; pp. 97–108. [Google Scholar]
- Reddy, S.; Burke, J.; Estrin, D.; Hansen, M.; Srivastava, M. Determining transportation mode on mobile phones. In Proceedings of the 12th IEEE International Symposium on Wearable Computers, ISWC 2008, Pittsburgh, PA, USA, 28 September–1 October 2008; pp. 25–28. [Google Scholar]
- Kotz, D.; Avancha, S.; Baxi, A. A privacy framework for mobile health and home-care systems. In Proceedings of the First ACM Workshop on Security and Privacy in Medical and Home-Care Systems, Chicago, IL, USA, 13 November 2009; pp. 1–12. [Google Scholar]
- Krumm, J. Inference attacks on location tracks. In Pervasive Computing; Springer: Berlin, Germany, 2007; pp. 127–143. [Google Scholar]
- Aïvodji, U.M.; Gambs, S.; Huguet, M.-J.; Killijian, M.-O. Meeting points in ridesharing: A privacy-preserving approach. Transp. Res. Part C Emerg. Technol. 2016, 72, 239–253. [Google Scholar] [CrossRef]
- Hasan, A.S.M.T.; Jiang, Q.; Li, C.; Chen, L. An effective model for anonymizing personal location trajectory. In Proceedings of the 6th International Conference on Communication and Network Security, Singapore, 26–29 Novemerbr 2016; pp. 35–39. [Google Scholar]
- Hasan, A.S.M.T.; Jiang, Q.; Li, C. An effective grouping method for privacy-preserving bike sharing data publishing. Future Internet 2017, 9, 65. [Google Scholar] [CrossRef]
- Citi Bike Daily Ridership and Membership Data. Available online: https://www.citibikenyc.com/system-data (accessed on 3 April 2017).
- Fan, L.; Xiong, L.; Sunderam, V. Fast: Differentially private real-time aggregate monitor with filtering and adaptive sampling. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 1065–1068. [Google Scholar]
- Cao, Y.; Yoshikawa, M. Differentially private real-time data release over infinite trajectory streams. In Proceedings of the 2015 16th IEEE International Conference on Mobile Data Management (MDM), Pittsburgh, PA, USA, 15–18 June 2015; Volume 2, pp. 68–73. [Google Scholar]
- Armstrong, M.P.; Rushton, G.; Zimmerman, D.L. Geographically masking health data to preserve confidentiality. Stat. Med. 1999, 18, 497–525. [Google Scholar] [CrossRef]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzz. Knowl. Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. L-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 3. [Google Scholar] [CrossRef]
- Gambs, S.; Killijian, M.-O.; del Prado Cortez, M.N. Show me how you move and i will tell you who you are. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Security and Privacy in GIS and LBS, San Jose, CA, USA, 2 November 2010; pp. 34–41. [Google Scholar]
- Zhang, Z.; Sun, Y.; Xie, X.; Pan, H. An efficient method on trajectory privacy preservation. In Big Data Computing and Communications; Springer: Berlin, Germany, 2015; pp. 231–240. [Google Scholar]
- Langheinrich, M. Privacy by design principles of privacy aware ubiquitous Systems. In International Conference on Ubiquitous Computing; Springer: Berlin, Germany, 2001; pp. 273–291. [Google Scholar]
- Kwan, M.-P.; Casas, I.; Schmitz, B. Protection of geoprivacy and accuracy of spatial information: How effective are geographical masks? Cartogr. Int. J. Geogr. Inform. Geovisual. 2004, 39, 15–28. [Google Scholar] [CrossRef]
- Hansell, S. Aol removes search data on vast group of web users. N. Y. Times 2006, 8, C4. [Google Scholar]
- Narayanan, A.; Shmatikov, V. De-anonymizing social networks. In Proceedings of the 2009 30th IEEE Symposium on Security and Privacy, Oakland, CA, USA, 17–20 May 2009; pp. 173–187. [Google Scholar]
- Krumm, J. A survey of computational location privacy. Pers. Ubiquitous Comput. 2009, 13, 391–399. [Google Scholar] [CrossRef]
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.-L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.-L. Limits of predictability in human mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef] [PubMed]
- Gkoulalas-Divanis, A.; Verykios, V. A free terrain model for trajectory k–Anonymity. In Database and Expert Systems Applications; Springer: Berlin, Germany, 2008; pp. 49–56. [Google Scholar]
- Hasan, A.S.M.T.; Jiang, Q.; Luo, J.; Li, C.; Chen, L. An effective value swapping method for privacy preserving data publishing. Secur. Commun. Netw. 2016, 9, 3219–3228. [Google Scholar] [CrossRef]
- Pfitzmann, A.; Hansen, M. Anonymity, Unlinkability, Unobservability, Pseudonymity, and Identity Management-a Consolidated Proposal for Terminology; version v0.25, December 2005, Citeseer. Available online: https://www.freehaven.net/anonbib/cache/terminology.pdf (accessed on 6 April 2017).
- Gruteser, M.; Grunwald, D. Anonymous usage of location-based services through spatial and temporal cloaking. In Proceedings of the 1st International Conference on Mobile Systems, Applications and Services, San Francisco, CA, USA, 5–8 May 2003; pp. 31–42. [Google Scholar]
- Domingo-Ferrer, J.; Sramka, M.; Trujillo-Rasúa, R. Privacy-preserving publication of trajectories using microaggregation. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Security and Privacy in GIS and LBS, San Jose, CA, USA, 2 November 2010; pp. 26–33. [Google Scholar]
- Samarati, P.; Sweeney, L. Generalizing data to provide anonymity when disclosing information. In Proceedings of the seventeenth ACM SIGACT-SIGMOD-SIGART symposium on Principles of database systems, Seattle, DC, USA, 1–3 June 1998; Volume 98, p. 188. [Google Scholar]
- Liu, S.; Qu, Q.; Chen, L.; Ni, L.M. SMC: A practical schema for privacy-preserved data sharing over distributed data streams. IEEE Trans. Big Data 2015, 1, 68–81. [Google Scholar] [CrossRef]
- OpenStreetMap Contributors. Available online: https://www.openstreetmap.org (accessed on 3 March 2017).
- Greenfeld, J.S. Matching gps observations to locations on a digital map. In Proceedings of the Transportation Research Board 81st Annual Meeting, Washington, DC, USA, 13–17 January 2002. [Google Scholar]
- Zheng, Y.; Zhang, L.; Xie, X.; Ma, W.-Y. Mining interesting locations and travel sequences from gps trajectories. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 May 2009; pp. 791–800. [Google Scholar]
- Zheng, Y.; Li, Q.; Chen, Y.; Xie, X.; Ma, W.-Y. Understanding mobility based on gps data. In Proceedings of the 10th International Conference On Ubiquitous Computing, Seoul, Korea, 21–24 September 2008; pp. 312–321. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2015. [Google Scholar]
- Eugster, M.J.A.; Schlesinger, T. osmar: OpenStreetMap and R Journal, 2010. Accepted for Publication on 14 August 2012. Available online: http://osmar.r-forge.r-project.org/RJpreprint.pdf (accessed on 4 January 2017).
- Wickham, H.; Francois, R. dplyr: A Grammar of Data Manipulation, 2015, r Package Version 0.4.3. Available online: https://CRAN.R-project.org/package=dplyr (accessed on 4 January 2017).
- QGIS Development Team, QGIS Geographic Information System, Open Source Geospatial Foundation, 2009. Available online: http://qgis.osgeo.org (accessed on 3 March 2017).
- Gonzalez, H.; Halevy, A.Y.; Jensen, C.S.; Langen, A.; Madhavan, J.; Shapley, R.; Shen, W.; Goldberg-Kidon, J. Google fusion tables: web-centered data management and collaboration. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, Indianapolis, IN, USA, 6–10 June 2010; pp. 1061–1066. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, Oregon, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Peixoto, D.A.; Xie, L. Mining Trajectory Data. 2013. Available online: https://www.researchgate.net/profile/Douglas_Peixoto/publication/275381558_Mining_Trajectory_Data/links/553b4e320cf245bdd76468c5.pdf (accessed on 28 December 2017).
- Zheng, Y. Trajectory data mining: An overview. ACM Trans. Intell. Syst. Technol. 2015, 6, 29. [Google Scholar] [CrossRef]
- Li, Q.; Zheng, Y.; Xie, X.; Chen, Y.; Liu, W.; Ma, W.-Y. Mining user similarity based on location history. In Proceedings of the 16th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Irvine, CA, USA, 5–7 November 2008; p. 34. [Google Scholar]
- Zhang, Q.; Koudas, N.; Srivastava, D.; Yu, T. Aggregate query answering on anonymized tables. In Proceedings of the IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 116–125. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Anonymization | Methodology | Privacy Breach | Data Utility |
|---|---|---|---|
| Pseudonymization [29] | Substitutes the identity of the individual with arbitrary values. | High | High |
| Generalization [32] | Generalizes the trajectory data. | Medium | Low |
| Suppression [16] | Suppresses the trajectory data by a suppressed value, namely (*). | Low | Low |
| Perturbation [15,21,33] | Appends random noise to the trajectory data, and does not consider the surroundings. | Low | Medium |
| Anonymization Technique | Average Relative Distortion |
|---|---|
| Bounded Perturbation | 0.206357345 |
| Perturbation | 0.48617868 |
| Anonymization Technique | Average Relative Distortion in the Morning | Average Relative Distortion in the Evening |
|---|---|---|
| Bounded Perturbation | 0.240973419 | 0.280139043 |
| Perturbation | 0.561570944 | 0.52706014 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hasan, A.S.M.T.; Qu, Q.; Li, C.; Chen, L.; Jiang, Q. An Effective Privacy Architecture to Preserve User Trajectories in Reward-Based LBS Applications. ISPRS Int. J. Geo-Inf. 2018, 7, 53. https://doi.org/10.3390/ijgi7020053
Hasan ASMT, Qu Q, Li C, Chen L, Jiang Q. An Effective Privacy Architecture to Preserve User Trajectories in Reward-Based LBS Applications. ISPRS International Journal of Geo-Information. 2018; 7(2):53. https://doi.org/10.3390/ijgi7020053
Chicago/Turabian StyleHasan, A S M Touhidul, Qiang Qu, Chengming Li, Lifei Chen, and Qingshan Jiang. 2018. "An Effective Privacy Architecture to Preserve User Trajectories in Reward-Based LBS Applications" ISPRS International Journal of Geo-Information 7, no. 2: 53. https://doi.org/10.3390/ijgi7020053
APA StyleHasan, A. S. M. T., Qu, Q., Li, C., Chen, L., & Jiang, Q. (2018). An Effective Privacy Architecture to Preserve User Trajectories in Reward-Based LBS Applications. ISPRS International Journal of Geo-Information, 7(2), 53. https://doi.org/10.3390/ijgi7020053