A Smart Web-Based Geospatial Data Discovery System with Oceanographic Data as an Example

 ,
,  , , ,
, , ,
Abstract
:1. Introduction
- (1)
- Lack of semantic context. Keyword-based search is widely adopted in operational geospatial data portals. Since keyword search uses string matching without considering the semantic context, precision, and recall, the two important measurements for search relevance are hard to be guaranteed [8]. For example, when querying “sea surface temperature” using a keyword search, the query is interpreted as a Boolean query “sea AND surface AND temperature.” The search results likely contain the terms “sea”, “surface” and “temperature” within their textual content but may not result in documents containing its common abbreviation “sst”.
- (2)
- Only single attribute based ranking. There are typically hundreds or even thousands of datasets related to the given query. Current search engines in most geospatial data portals tend to induce end users to focus on one single data attribute (e.g., spatial resolution) [9]. PO.DAAC provides several features to rank the search results, including all-time popularity, monthly popularity, grid spatial resolution, etc. This approach largely fails to take account of users’ multidimensional preferences for geospatial data, which often results in less than optimal user experience [10].
- (3)
- Lack of data relevancy. There exist hidden relationships among data hosted by a search engine. For example, after a user clicks on a data, he or she should be informed of the latest version of the clicked data which often has a better accuracy. In addition, Earth system scientists often need to interconnect their research using multiple physical parameters because important discoveries and the overall progress of science often transcend the domain of a single discipline [11].
2. Related Work
3. System Framework
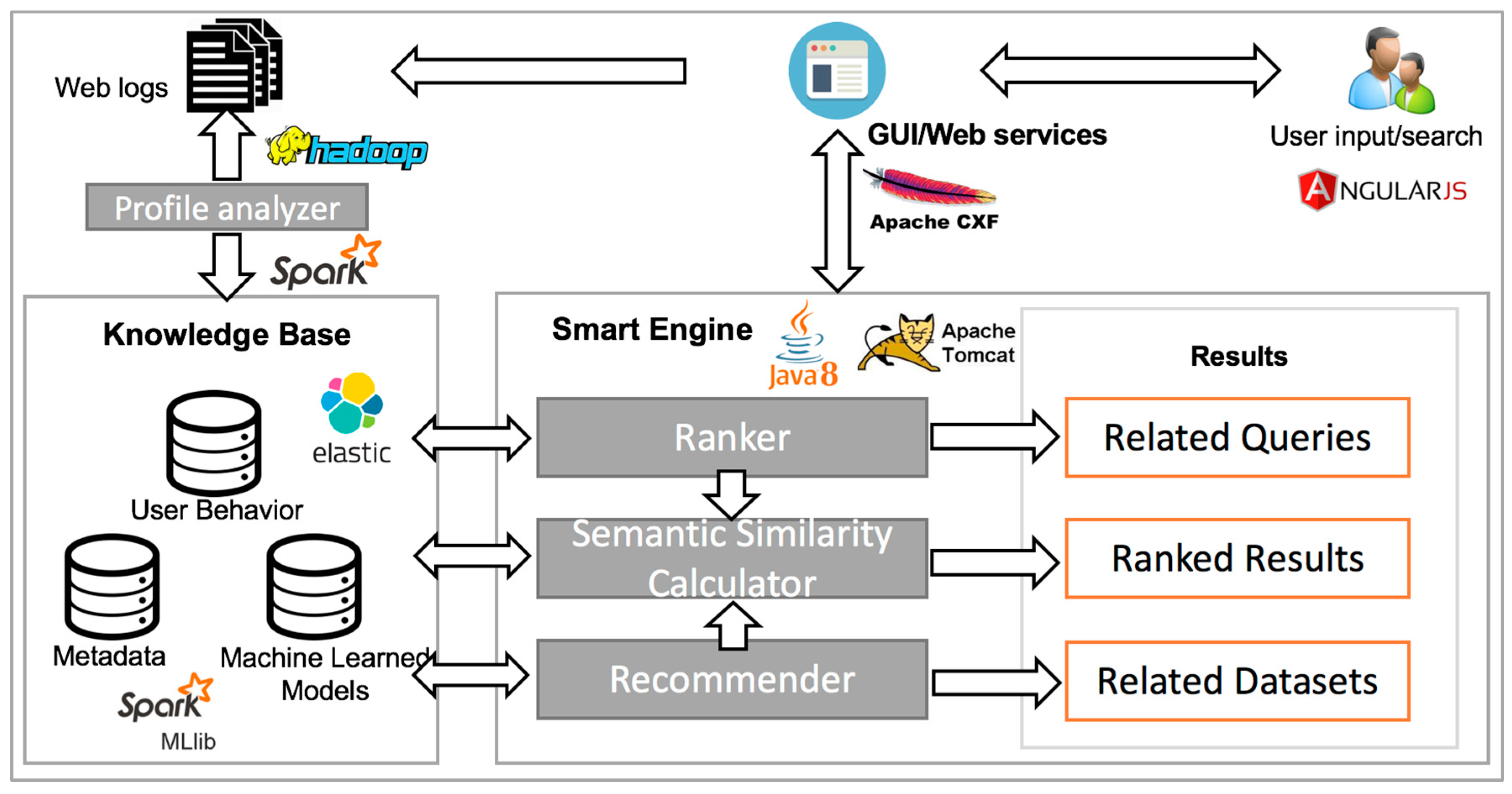
3.1. Architecture
3.2. System Components
3.2.1. System Web GUI
3.2.2. Knowledge Base
3.2.3. Smart Engine
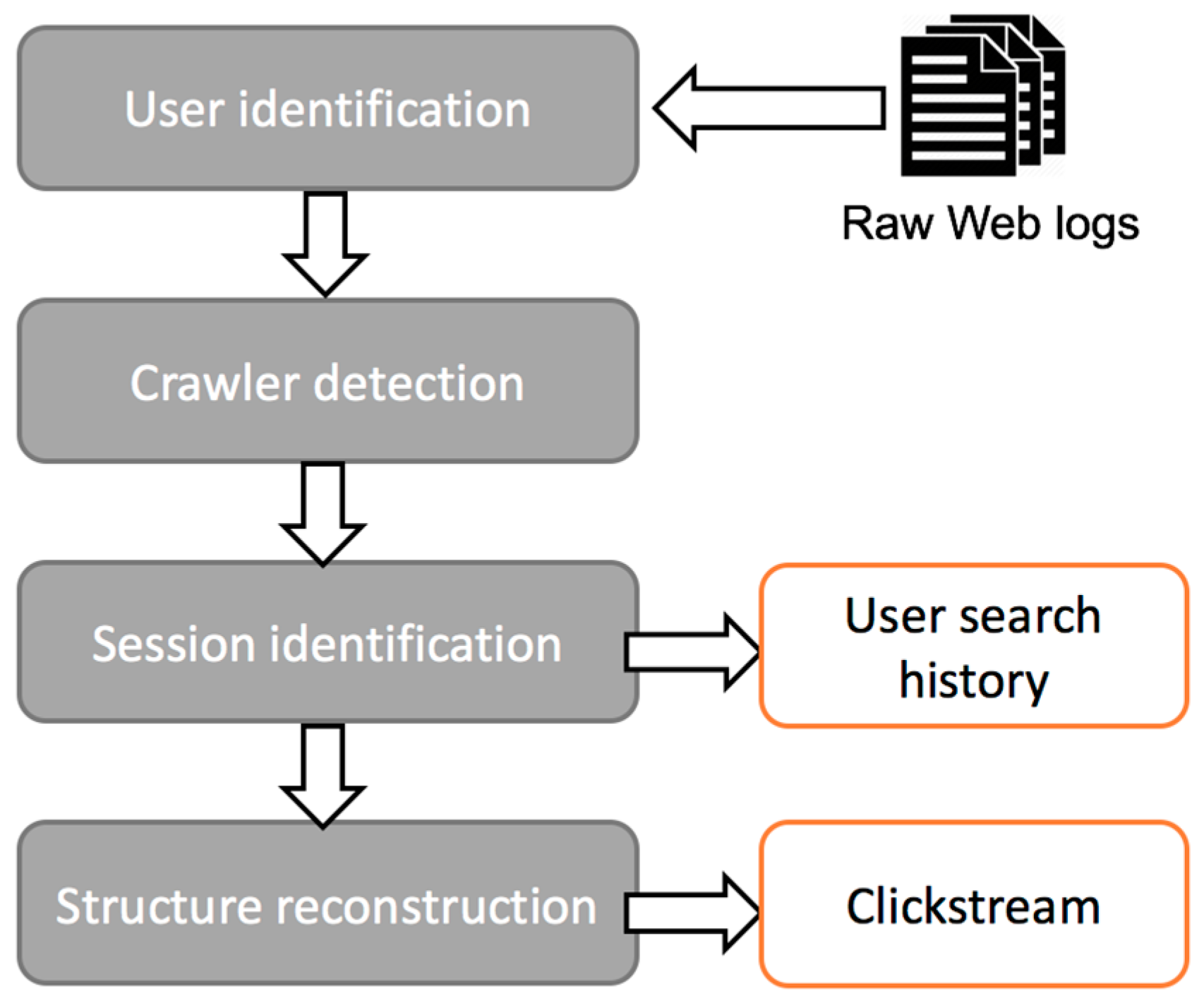
3.2.4. Profile Analyzer
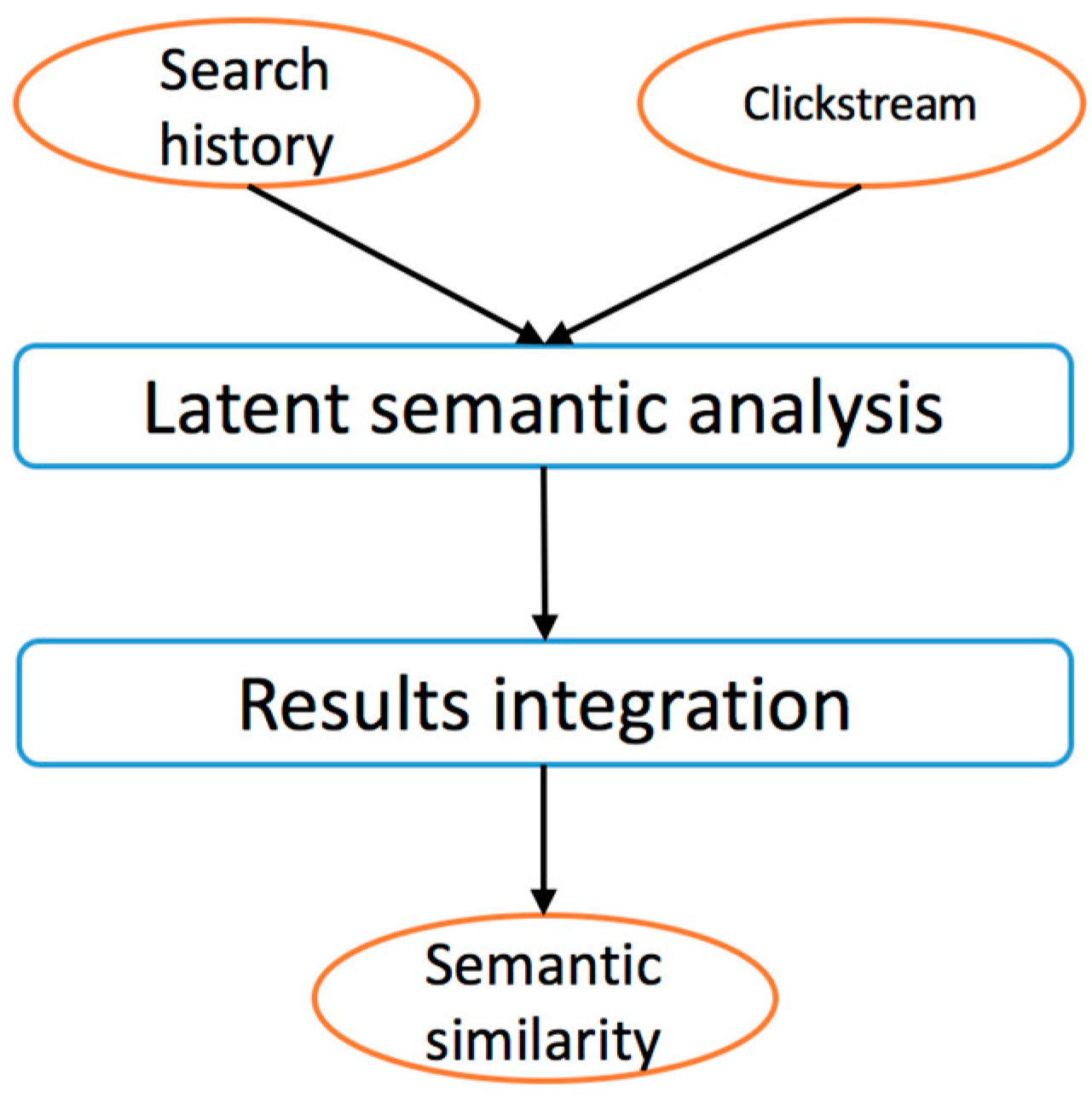
3.2.5. Semantic Similarity Calculator
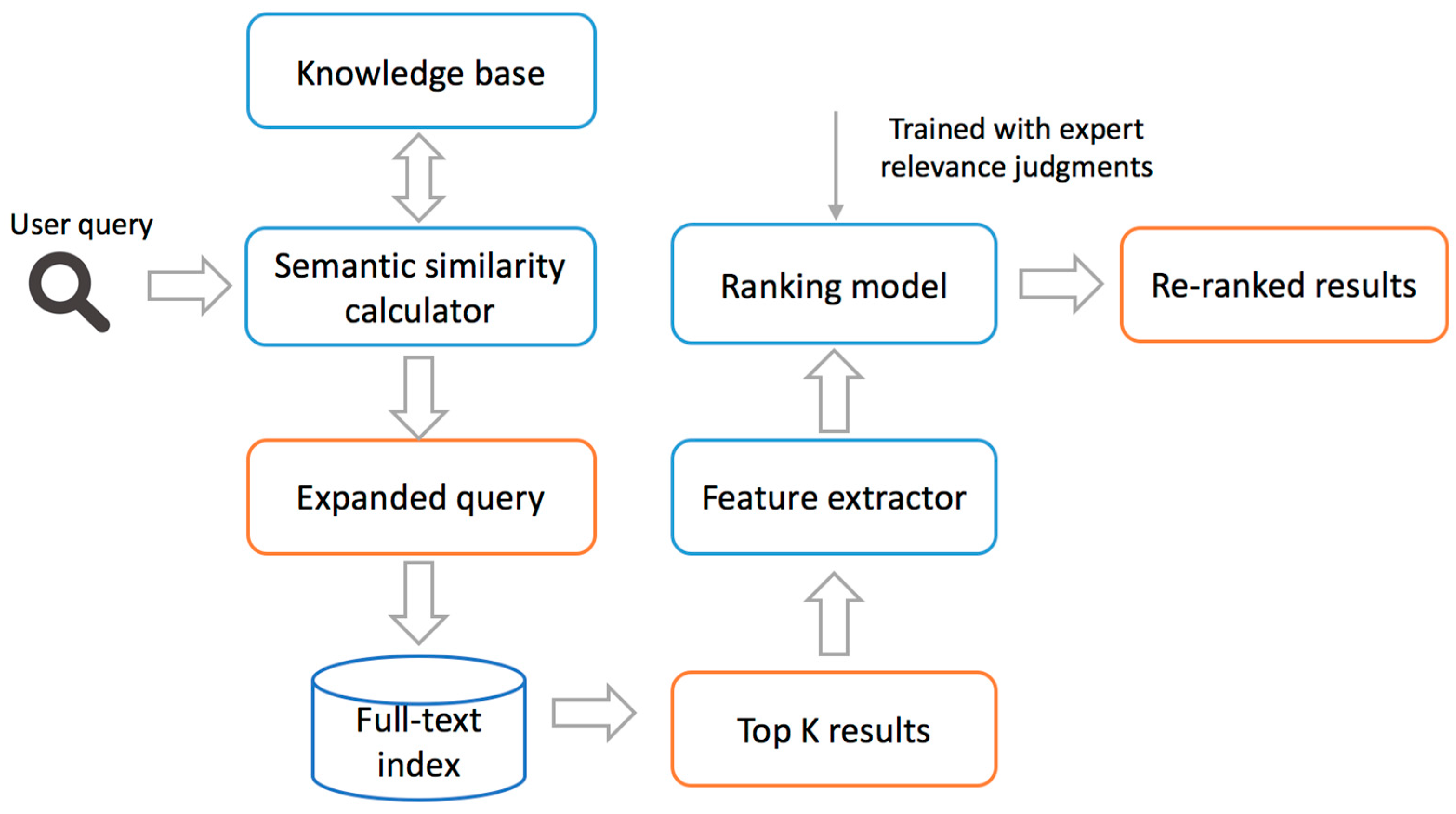
3.2.6. Ranker
3.2.7. Recommender
3.3. Implementation
3.3.1. Data
3.3.2. System Implementation
3.4. User Scenario
3.5. Use Cases
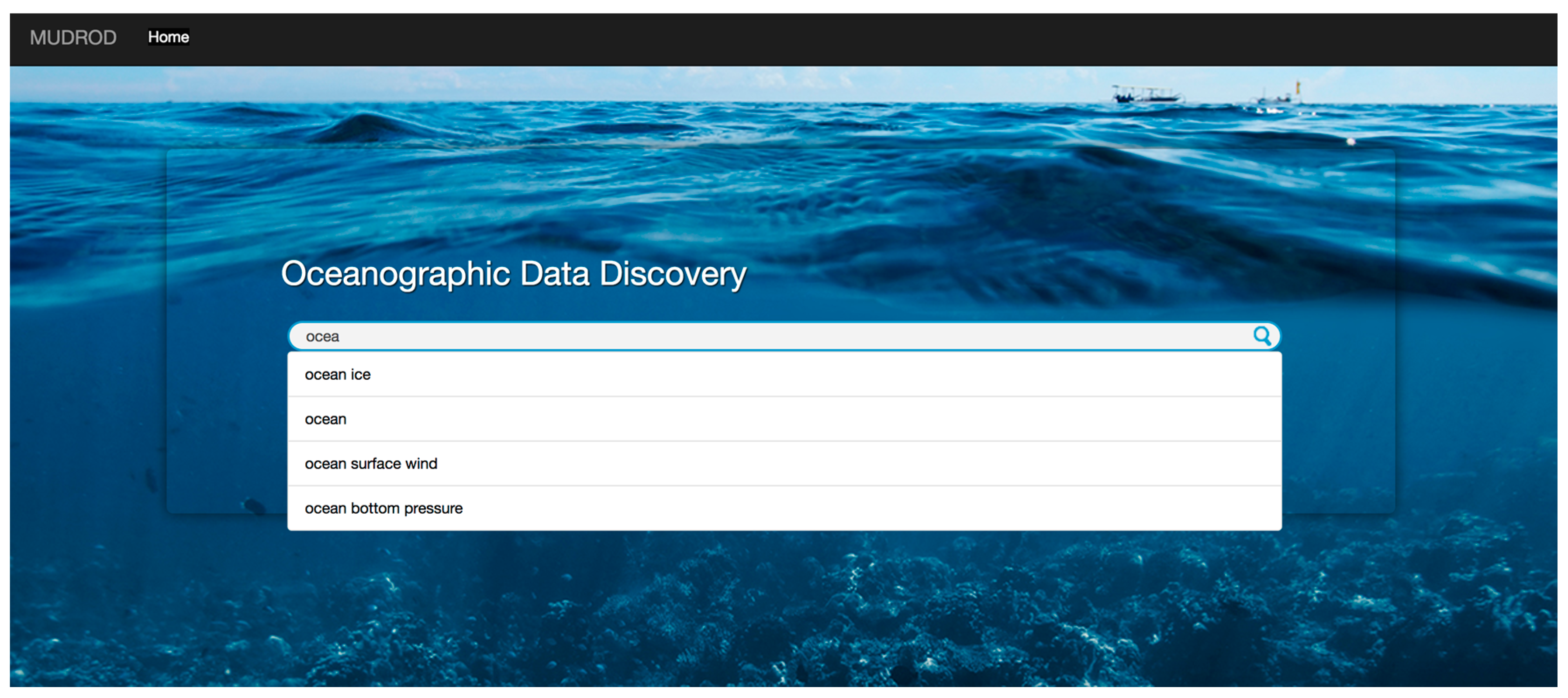
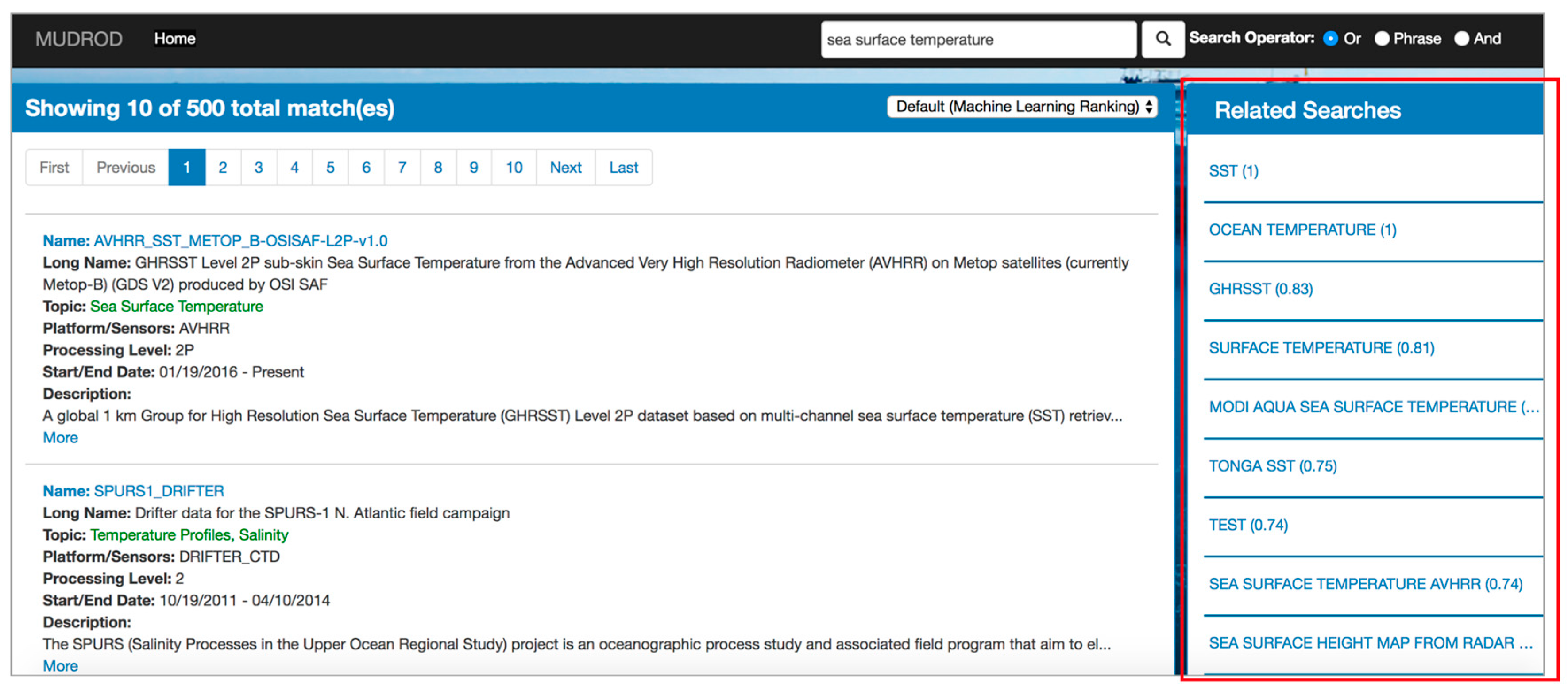
3.5.1. Query Suggestion
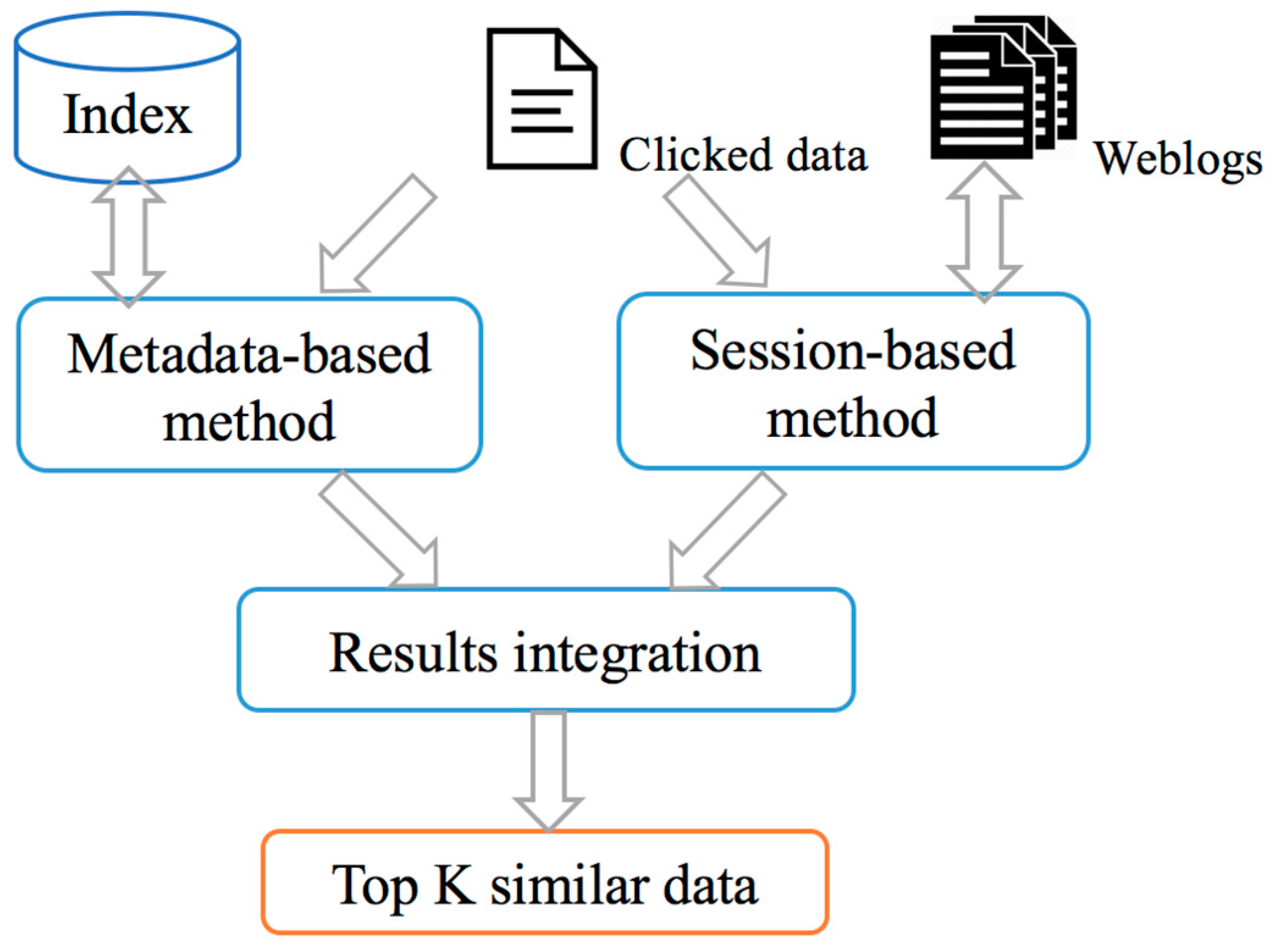
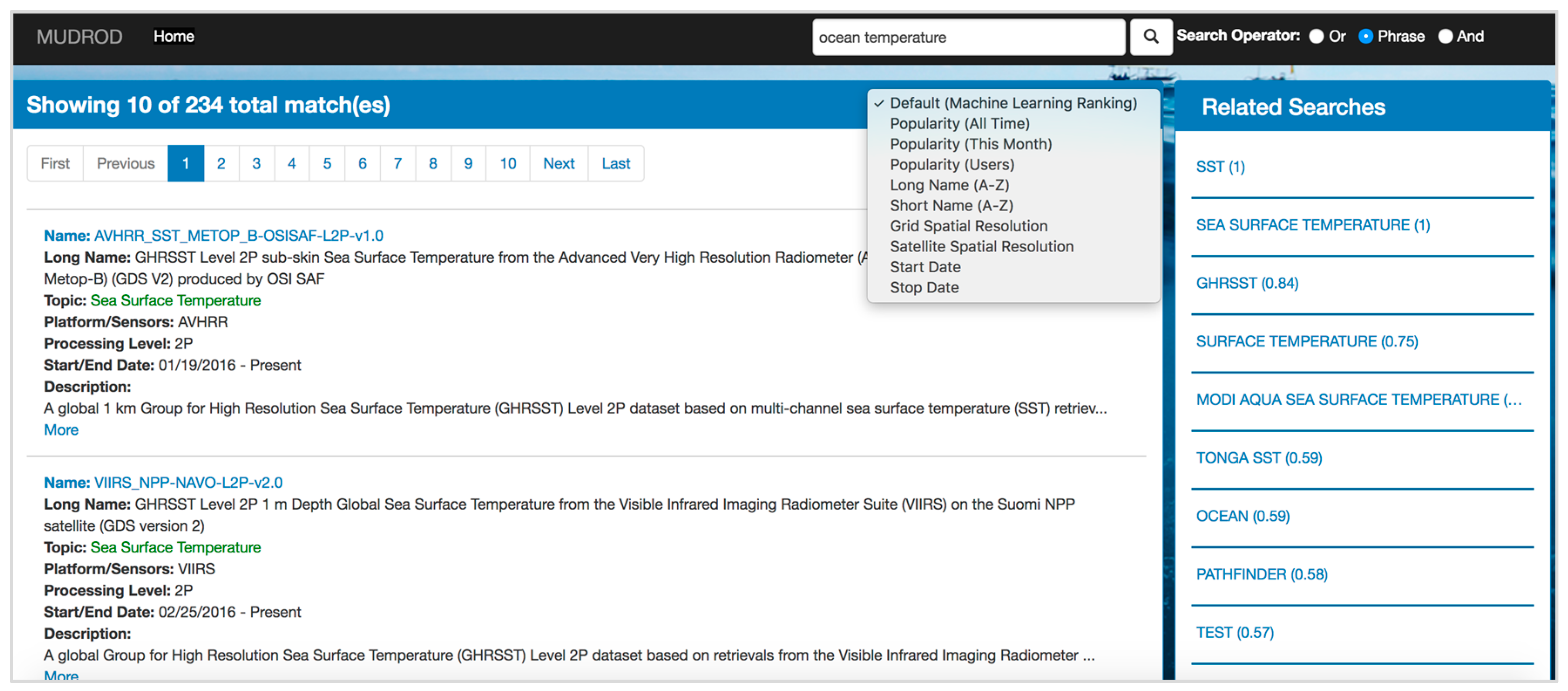
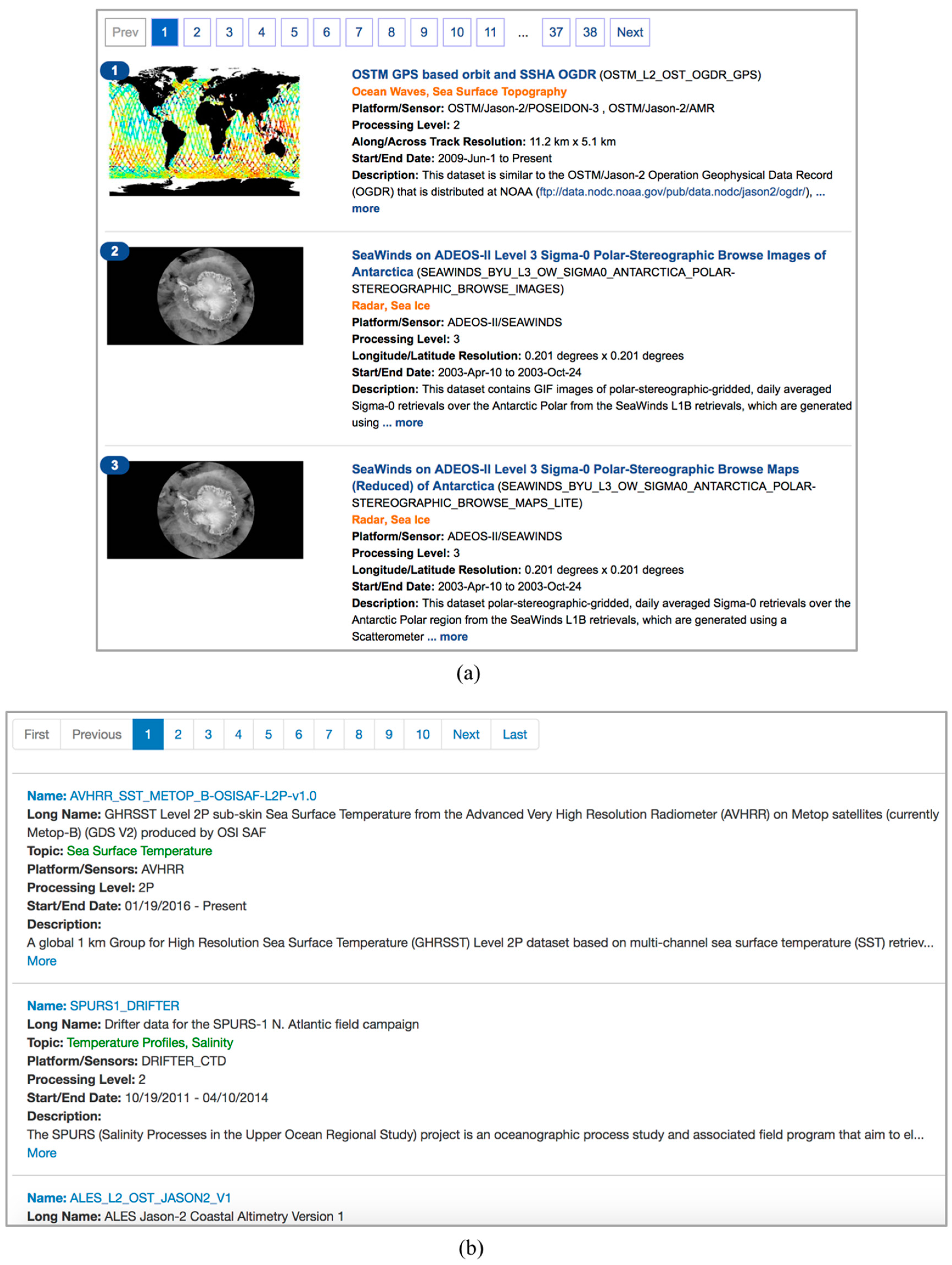
3.5.2. Search Ranking
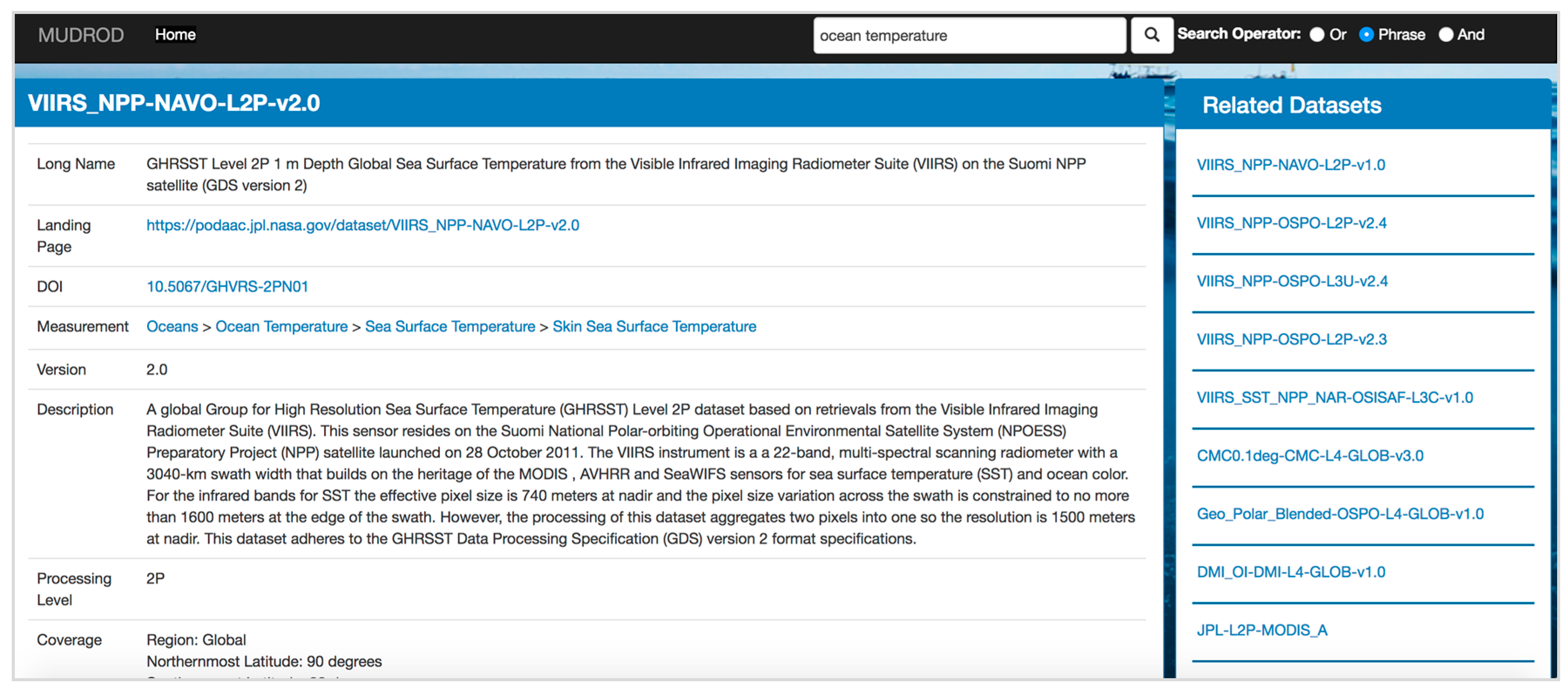
3.5.3. Recommendation
4. Conclusions and Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hartmann, D.L. Global Physical Climatology; Elsevier: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Fan, Y.; Ginis, I.; Hara, T. The effect of wind–wave–current interaction on air–sea momentum fluxes and ocean response in tropical cyclones. J. Phys. Oceanogr. 2009, 39, 1019–1034. [Google Scholar] [CrossRef]
- Devarakonda, R.; Palanisamy, G.; Wilson, B.E.; Green, J.M. Mercury: Reusable metadata management, data discovery and access system. Earth Sci. Inf. 2010, 3, 87–94. [Google Scholar] [CrossRef]
- NASA. NASA Strategic Plan. 2011. Available online: https://www.nasa.gov/pdf/516579main_NASA2011StrategicPlan.pdf (accessed on 7 April 2017).
- Yang, C.; Yu, M.; Hu, F.; Jiang, Y.; Li, Y. Utilizing Cloud Computing to address big geospatial data challenges. Comput. Environ. Urban Syst. 2017, 61, 120–128. [Google Scholar] [CrossRef]
- Overpeck, J.T.; Meehl, G.A.; Bony, S.; Easterling, D.R. Climate data challenges in the 21st century. Science 2011, 331, 700–702. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Goodchild, M.F.; Raskin, R. Towards geospatial semantic search: Exploiting latent semantic relations in geospatial data. Int. J. Digit. Earth 2014, 7, 17–37. [Google Scholar] [CrossRef]
- Jiang, Y.; Xia, J.; Liu, K. Polar CI Portal: A Cloud based polar resource discovery engine. In Cloud Computing in Ocean and Atmospheric Sciences; Vance, T.C., Merati, N., Yang, C., Yuan, M., Eds.; Academic Press: Amsterdam, The Netherlands, 2016; pp. 163–185. [Google Scholar]
- Jiang, Y.; Li, Y.; Yang, C.; Hu, F.; Armstrong, E.M.; Huang, T.; Moroni, D.; McGibbney, L.J.; Finch, C.J. Towards intelligent geospatial data discovery: A machine learning framework for search ranking. Int. J. Digit. Earth 2017, 1–16. [Google Scholar] [CrossRef]
- Ghose, A.; Ipeirotis, P.G.; Li, B. Designing ranking systems for hotels on travel search engines by mining user-generated and crowdsourced content. Mark. Sci. 2012, 31, 493–520. [Google Scholar] [CrossRef]
- NRC. New Research Opportunities in The earth Sciences; National Academies Press: Washington, DC, USA, 2012. [Google Scholar]
- AlJadda, K.; Korayem, M.; Grainger, T.; Russell, C. Crowdsourced query augmentation through semantic discovery of domain-specific jargon. In Proceedings of the 2014 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 27–30 October 2014; pp. 808–815. [Google Scholar]
- Semantic Web for Earth and Environmental Terminology (SWEET). Available online: https://www.researchgate.net/publication/250346856_Semantic_Web_for_Earth_and_Environmental_Terminology_SWEET (accessed on 10 May 2017).
- Gunay, A.; Akcay, O.; Altan, M.O. Building a semantic based public transportation geoportal compliant with the INSPIRE transport network data theme. Earth Sci. Inf. 2014, 7, 25–37. [Google Scholar] [CrossRef]
- Dumais, S.T. Latent semantic analysis. Annu. Rev. Inf. Sci. Technol. 2004, 38, 188–230. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. Adv. Neural Inf. Process. Syst. 2002, 1, 601–608. [Google Scholar]
- Hu, Y.; Janowicz, K.; Prasad, S.; Gao, S. Metadata topic harmonization and semantic search for linked-data driven geoportals: A case study using ArcGIS Online. Trans. GIS 2015, 19, 398–416. [Google Scholar] [CrossRef]
- Gormley, C.; Tong, Z. Elasticsearch: The Definitive Guide: A Distributed Real-Time Search and Analytics Engine; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [Google Scholar]
- Martins, B.; Calado, P. Learning to rank for geographic information retrieval. In Proceedings of the 6th Workshop on Geographic Information Retrieval, Zurich, Switzerland, 18–19 February 2010; p. 21. [Google Scholar]
- Shaw, B.; Shea, J.; Sinha, S.; Hogue, A. Learning to rank for spatiotemporal search. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013; pp. 717–726. [Google Scholar]
- Linked Data-The Story So Far. Available online: https://eprints.soton.ac.uk/271285/ (accessed on 10 May 2017).
- Krisnadhi, A.; Hu, Y.; Janowicz, K.; Hitzler, P.; Arko, R.; Carbotte, S.; Chandler, C.; Cheatham, M.; Fils, D.; Finin, T. The GeoLink modular oceanography ontology. In Proceedings of the 14th International Semantic Web Conference, Bethlehem, PA, USA, 11–15 October 2015; pp. 301–309. [Google Scholar]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Vockner, B.; Richter, A.; Mittlböck, M. From geoportals to geographic knowledge portals. ISPRS Int. J. Geo-Inf. 2014, 2, 256–275. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, Y.; Yang, C.; Armstrong, E.M.; Huang, T.; Moroni, D. Reconstructing sessions from data discovery and access logs to build a semantic knowledge base for improving data discovery. ISPRS Int. J. Geo-Inf. 2017, 5, 54. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, Y.; Yang, C.; Liu, K.; Armstrong, E.; Huang, T.; Moroni, D.; Finch, C. A comprehensive methodology for discovering semantic relationships among geospatial vocabularies using oceanographic data discovery as an example. Int. J. Geogr. Inf. Sci. 2017, 31, 2310–2328. [Google Scholar] [CrossRef]
- McPhaden, M.J. Genesis and evolution of the 1997-98 El Niño. Science 1999, 283, 950–954. [Google Scholar] [CrossRef] [PubMed]
- UCAR. SST Data Sets: Overview & Comparison Table. 2014. Available online: https://climatedataguide.ucar.edu/climate-data/sst-data-sets-overview-comparison-table (accessed on 10 May 2017).
- Martin, M.; Dash, P.; Ignatov, A.; Banzon, V.; Beggs, H.; Brasnett, B.; Cayula, J.-F.; Cummings, J.; Donlon, C.; Gentemann, C. Group for High Resolution Sea Surface temperature (GHRSST) analysis fields inter-comparisons. Part 1: A GHRSST multi-product ensemble (GMPE). Deep Sea Res. Part II 2012, 77, 21–30. [Google Scholar] [CrossRef]
- Li, Y.; Jiang, Y.; Hu, F.; Yang, C.; Huang, T.; Moroni, D.; Fench, C. Leveraging cloud computing to speedup user access log mining. In Proceedings of the OCEANS 2016 MTS/IEEE Monterey, Monterey, CA, USA, 19–23 Septembe 2016; pp. 1–6. [Google Scholar]
- Jin, B.; Song, W.; Zhao, K.; Wei, X.; Hu, F.; Jiang, Y. A high performance, spatiotemporal statistical analysis system based on a Spatiotemporal Cloud Platform. ISPRS Int. J. Geo-Inf. 2017, 6, 165. [Google Scholar] [CrossRef]
- Mining and Utilizing Dataset Relevancy from Oceanographic Dataset (MUDROD) Metadata, Usage Metrics, and User Feedback to Improve Data Discovery and Access. Available online: http://adsabs.harvard.edu/abs/2015AGUFMIN51B1809J (accessed on 10 May 2017).
- Ranjan, R. Streaming big data processing in datacenter clouds. IEEE Cloud Comput. 2014, 1, 78–83. [Google Scholar] [CrossRef]
- Agichtein, E.; Brill, E.; Dumais, S. Improving web search ranking by incorporating user behavior information. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 6–11 August 2006; pp. 19–26. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Family | Example Source(s) | Number of Datasets | Parameter(s) | Discipline(s) |
|---|---|---|---|---|
| Ocean Wind | QuikSCAT, ASCAT, OSCAT | 94 | OSWV | PO, Met, ASI, Climate, OB |
| Ocean Radar | QuikSCAT, ASCAT, OSCAT | 50 | OSWV | PO, Met, ASI, Climate, OB |
| Ocean Temperature | AVHRR, MODIS, AMSR-E, TMI | 205 | SST | PO, Met, ASI, Climate, OB |
| Ocean Circulation | Multi-Sensor | 5 | OSC | PO, ASI, Climate, OB |
| Ocean Salinity | Aquarius | 147 | SSS, OSW, OST | PO, ASI, Climate |
| Ocean Topography | T/P, Jason -1, -2, Envisat | 29 | OST | PO, Met, ASI, Climate, OB |
| Gravity | Grace | 70 | G | PO, Climate |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Li, Y.; Yang, C.; Hu, F.; Armstrong, E.M.; Huang, T.; Moroni, D.; McGibbney, L.J.; Greguska, F.; Finch, C.J. A Smart Web-Based Geospatial Data Discovery System with Oceanographic Data as an Example. ISPRS Int. J. Geo-Inf. 2018, 7, 62. https://doi.org/10.3390/ijgi7020062
Jiang Y, Li Y, Yang C, Hu F, Armstrong EM, Huang T, Moroni D, McGibbney LJ, Greguska F, Finch CJ. A Smart Web-Based Geospatial Data Discovery System with Oceanographic Data as an Example. ISPRS International Journal of Geo-Information. 2018; 7(2):62. https://doi.org/10.3390/ijgi7020062
Chicago/Turabian StyleJiang, Yongyao, Yun Li, Chaowei Yang, Fei Hu, Edward M. Armstrong, Thomas Huang, David Moroni, Lewis J. McGibbney, Frank Greguska, and Christopher J. Finch. 2018. "A Smart Web-Based Geospatial Data Discovery System with Oceanographic Data as an Example" ISPRS International Journal of Geo-Information 7, no. 2: 62. https://doi.org/10.3390/ijgi7020062
APA StyleJiang, Y., Li, Y., Yang, C., Hu, F., Armstrong, E. M., Huang, T., Moroni, D., McGibbney, L. J., Greguska, F., & Finch, C. J. (2018). A Smart Web-Based Geospatial Data Discovery System with Oceanographic Data as an Example. ISPRS International Journal of Geo-Information, 7(2), 62. https://doi.org/10.3390/ijgi7020062