Spatial Footprints of Human Perceptual Experience in Geo-Social Media


Abstract
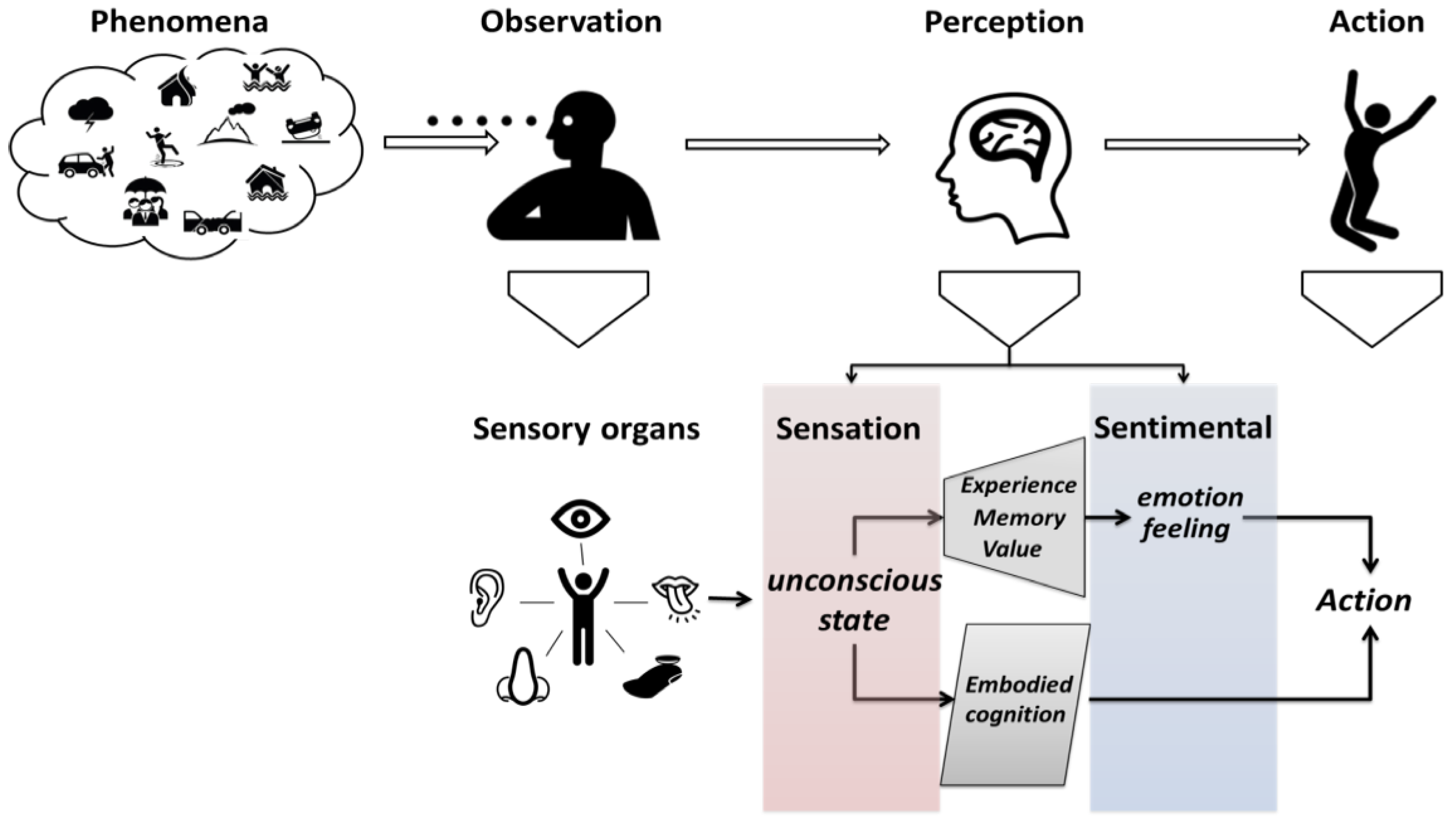
:1. Introduction
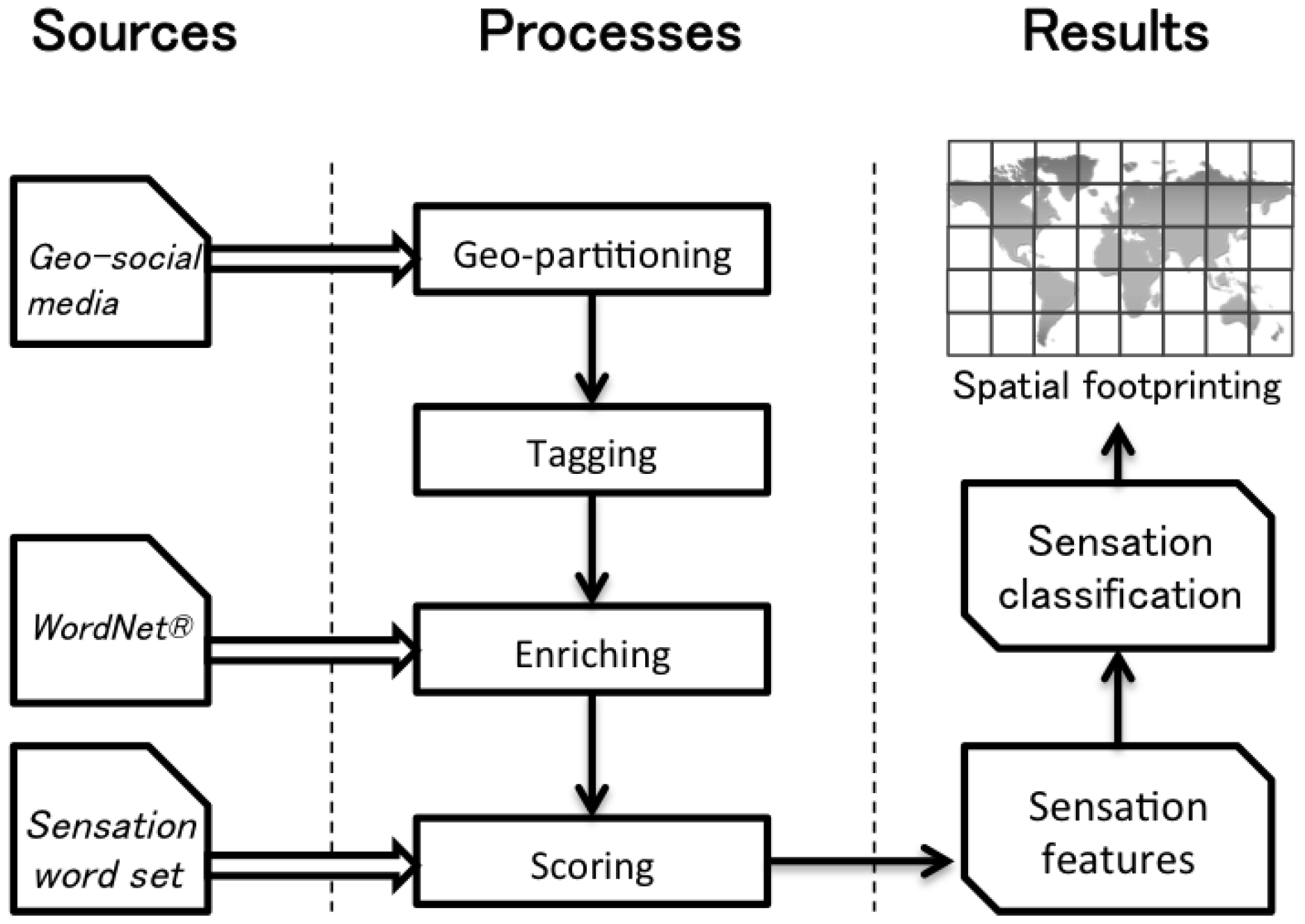
- Sensation feature analysis: The sensation measurements assigned to sight, hearing, touch, smell, and taste in sentences were addressed with sensation word sets and WordNet [29]. Based on the five senses, unstructured text was turned into structure data for sensation classification. This classification contributed to the construction of a sensation corpus for studying social perceptual experiences by lowering costs and complexity.
- Geo-spatial footprint analysis: The natural language of social media was considered as a kind of sensor data, and we tried to exploit this data to discover a geo-spatial knowledge. For this purpose, a domain area was divided into several sub-areas to identify sensation patterns from geo-spatial footprints on social media. Additionally, strong trends in sensation features were identified for each area and their patterns were compared.
- Comprehensive evaluation: To evaluate the proposed classification approach, available alternatives (random forest, support vector machine (SVM), multilayer perceptron (MLP), convolutional neural network (CNN), and recurrent convolutional neural network (RCNN)) were performed with the proposed sensation features and general word-based features. These results identified the best-performing combinations for classification.
2. Related Work
3. Methodology
3.1. Lexicon Resources
3.2. Sensation Feature Extraction
3.2.1. Geo-Partitioning
3.2.2. Tagging
3.2.3. Enriching
3.2.4. Scoring
- Definition 1. Sensation Intensity
3.3. Sensation Classification
- Definition 2. Normalized Sensation Intensity
4. Experiments and Evaluations
4.1. Dataset
4.2. Classification Results
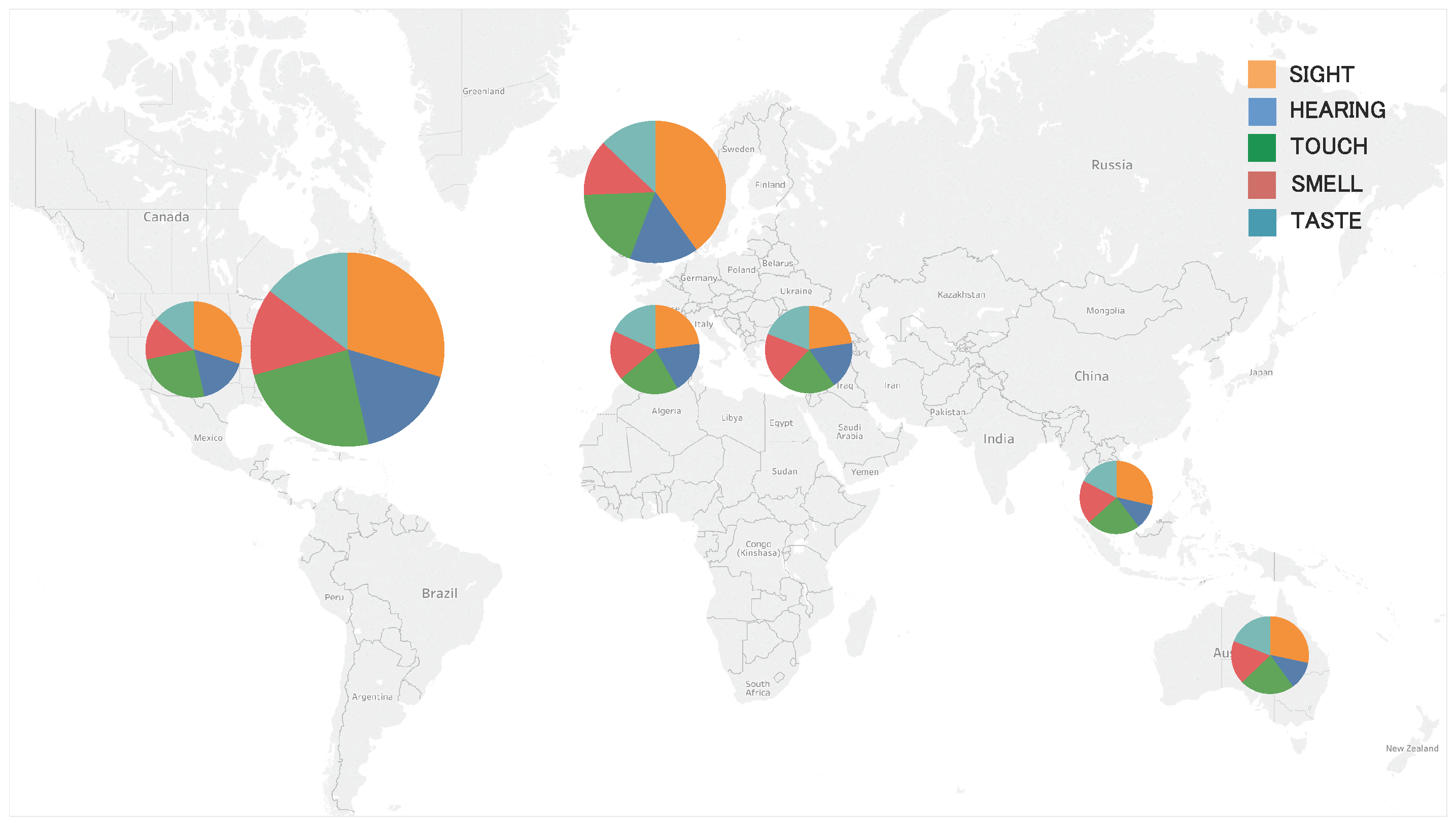
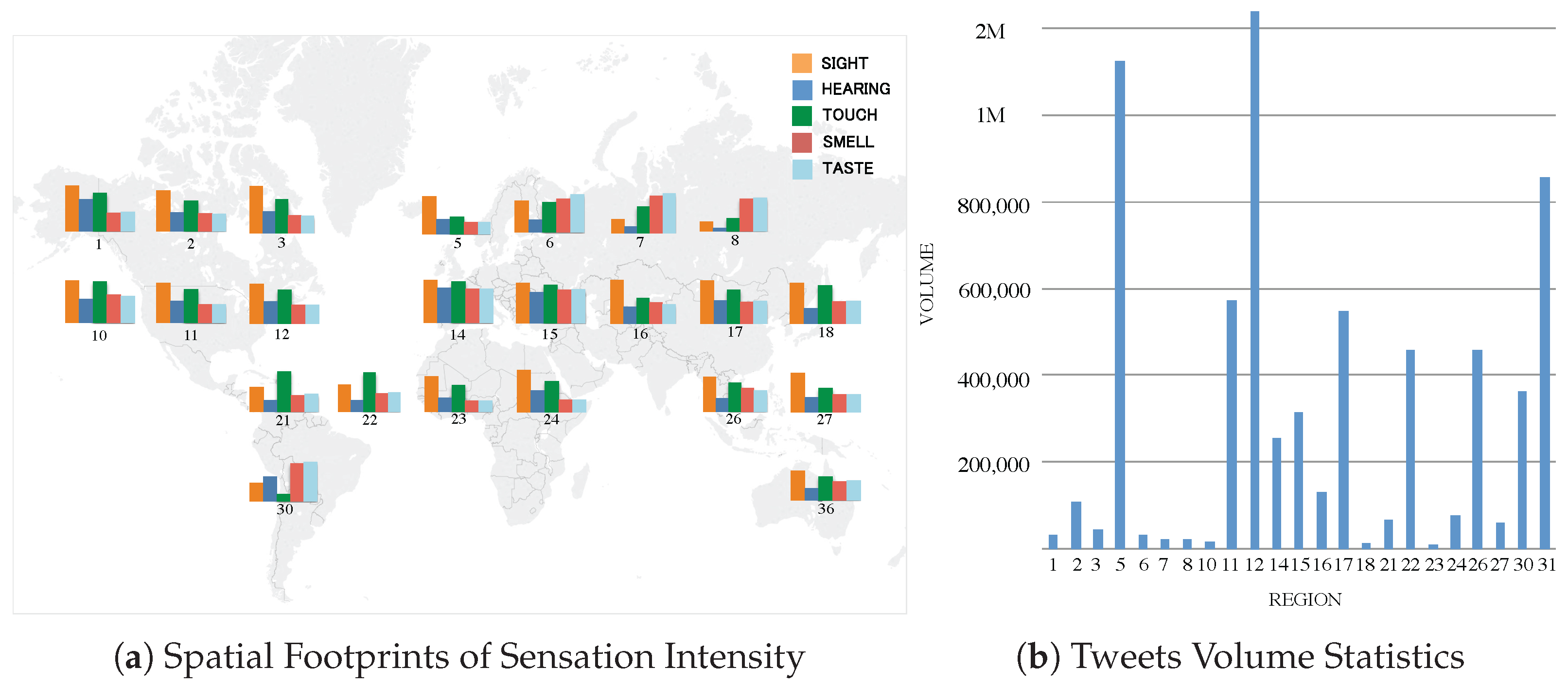
4.3. Geo-Spatial Analysis of Sensation Intensity
- Sight: My eyes are on black haired girls with blue and green eyes.
- Hearing: Music really loud from the next door.
- Touch: It’s such a cold morning.
- Smell: The room smelt odour like rotten eggs and spoiled tomatoes.
- Taste: This root beer is definitely sweet but doesn’t contain alcohol.
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kietzmann, J.H.; Hermkens, K.; McCarthy, I.P.; Silvestre, B.S. Social media? Get serious! Understanding the functional building blocks of social media. Bus. Horiz. 2011, 54, 241–251. [Google Scholar] [CrossRef]
- Hanna, R.; Rohm, A.; Crittenden, V.L. We’re all connected: The power of the social media ecosystem. Bus. Horiz. 2011, 54, 265–273. [Google Scholar] [CrossRef]
- Constantinides, E. Social Media/Web 2.0 as Marketing Parameter: An Introduction. In Proceedings of the 8th International Congress Marketing Trends, Paris, France, 16–17 January 2009; pp. 15–17. [Google Scholar]
- Neti, S. Social media and its role in marketing. Int. J. Enterp. Comput. Bus. Syst. 2011, 1, 1–15. [Google Scholar]
- Chen, H.; Chiang, R.H.L.; Storey, V.C. Business Intelligence and Analytics: From Big Data to Big Impact. MIS Q. 2012, 36, 1165–1188. [Google Scholar]
- Zeng, D.; Chen, H.; Lusch, R.; Li, S.H. Social Media Analytics and Intelligence. IEEE Intell. Syst. 2010, 25, 13–16. [Google Scholar] [CrossRef]
- Mangold, W.G.; Faulds, D.J. Social media: The new hybrid element of the promotion mix. Bus. Horiz. 2009, 52, 357–365. [Google Scholar] [CrossRef]
- Minelli, M.; Chambers, M.; Dhiraj, A. Big Data, Big Analytics: Emerging Business Intelligence and Analytic Trends for Today’s Businesses; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2013. [Google Scholar] [CrossRef]
- He, W.; Zha, S.; Li, L. Social media competitive analysis and text mining: A case study in the pizza industry. Int. J. Inf. Manag. 2013, 33, 464–472. [Google Scholar] [CrossRef]
- Malthouse, E.C.; Haenlein, M.; Skiera, B.; Wege, E.; Zhang, M. Managing Customer Relationships in the Social Media Era: Introducing the Social CRM House. J. Interact. Mark. 2013, 27, 270–280. [Google Scholar] [CrossRef]
- Dey, L.; Haque, S.M.; Khurdiya, A.; Shroff, G. Acquiring Competitive Intelligence from Social Media. In Proceedings of the 2011 Joint Workshop on Multilingual OCR and Analytics for Noisy Unstructured Text Data, Beijing, China, 17 September 2011; ACM: New York, NY, USA, 2011; pp. 3:1–3:9. [Google Scholar] [CrossRef]
- Governatori, G.; Iannella, R. A modelling and reasoning framework for social networks policies. Enterp. Inf. Syst. 2011, 5, 145–167. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Pak, A.; Paroubek, P. Twitter as a Corpus for Sentiment Analysis and Opinion Mining. In Proceedings of the International Conference on Language Resources and Evaluation, LREC 2010, Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Hutto, C.J.; Gilbert, E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text; ICWSM; Adar, E., Resnick, P., Choudhury, M.D., Hogan, B., Oh, A.H., Eds.; The AAAI Press: Palo Alto, CA, USA, 2014; Available online: http://www.aaai.org/ocs/index.php/ICWSM/ICWSM14/paper/view/8109 (accessed on 29 November 2017).
- Cambria, E.; Schuller, B.; Xia, Y.; Havasi, C. New Avenues in Opinion Mining and Sentiment Analysis. IEEE Intell. Syst. 2013, 28, 15–21. [Google Scholar] [CrossRef]
- Damian, R.I.; Sherman, J.W. A process-dissociation examination of the cognitive processes underlying unconscious thought. J. Exp. Soc. Psychol. 2013, 49, 228–237. [Google Scholar] [CrossRef]
- Huizenga, H.M.; Wetzels, R.; van Ravenzwaaij, D.; Wagenmakers, E.J. Four empirical tests of Unconscious Thought Theory. Organ. Behav. Hum. Decis. Process. 2012, 117, 332–340. [Google Scholar] [CrossRef]
- Dijksterhuis, A.; Nordgren, L.F. A Theory of Unconscious Thought. Perspect. Psychol. Sci. 2006, 1, 95–109. [Google Scholar] [CrossRef] [PubMed]
- Simonson, I. In Defense of Consciousness: The Role of Conscious and Unconscious Inputs in Consumer Choice. J. Consum. Psychol. 2005, 15, 211–217. [Google Scholar] [CrossRef]
- Lindstrom, M. Broad sensory branding. J. Prod. Brand Manag. 2005, 14, 84–87. [Google Scholar] [CrossRef]
- Hultén, B. Sensory marketing: The multi-sensory brand—Experience concept. Eur. Bus. Rev. 2011, 23, 256–273. [Google Scholar] [CrossRef]
- Krishna, A. Sensory Marketing: Research on the Sensuality of Products; Taylor & Francis: Abingdon, UK, 2011. [Google Scholar]
- Krishna, A. An integrative review of sensory marketing: Engaging the senses to affect perception, judgment and behavior. J. Consum. Psychol. 2012, 22, 332–351. [Google Scholar] [CrossRef]
- Schmitt, B. Experiential Marketing: How to Get Customers to Sense, Feel, Think, Act, Relate; Free Press: New York, NY, USA, 2000. [Google Scholar]
- Huang, X.I.; Zhang, M.; Hui, M.K.; Wyer, R.S. Warmth and conformity: The effects of ambient temperature on product preferences and financial decisions. J. Consum. Psychol. 2014, 24, 241–250. [Google Scholar] [CrossRef]
- Pastra, K.; Balta, E.; Dimitrakis, P.; Karakatsiotis, G. Embodied Language Processing: A New Generation of Language Technology. Available online: https://www.aaai.org/ocs/index.php/WS/AAAIW11/paper/viewFile/4003/4293 (accessed on 24 November 2017).
- Lee, J.; Kim, K.S.; Kwon, Y.; Ogawa, H. Understanding Human Perceptual Experience in Unstructured Data on the Web. In Proceedings of the International Conference on Web Intelligence, WI ’17, Leipzig, Germany, 23–26 August 2017; ACM: New York, NY, USA, 2017; pp. 491–498. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: A Lexical Database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Adedoyin-Olowe, M.; Gaber, M.M.; Stahl, F.T. A Survey of Data Mining Techniques for Social Media Analysis. J. Data Min. Digit. Hum. 2014, arXiv:1312.46172014. [Google Scholar]
- Liu, B.; Zhang, L. A Survey of Opinion Mining and Sentiment Analysis. In Mining Text Data; Springer: Boston, MA, USA, 2012; pp. 415–463. [Google Scholar]
- Turney, P.D. Thumbs up or Thumbs down: Semantic Orientation Applied to Unsupervised Classification of Reviews. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, ACL ’02, Philadelphia, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 417–424. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up: Sentiment Classification Using Machine Learning Techniques. In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing—Volume 10, EMNLP ’02, Philadelphia, PA, USA, 6–7 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 79–86. [Google Scholar] [CrossRef]
- Cheng, A.J.; Chen, Y.Y.; Huang, Y.T.; Hsu, W.H.; Liao, H.Y.M. Personalized Travel Recommendation by Mining People Attributes from Community-contributed Photos. In Proceedings of the 19th ACM International Conference on Multimedia, MM ’11, Scottsdale, AZ, USA, 28 November–1 December 2011; ACM: New York, NY, USA, 2011; pp. 83–92. [Google Scholar] [CrossRef]
- Guy, I.; Zwerdling, N.; Ronen, I.; Carmel, D.; Uziel, E. Social Media Recommendation Based on People and Tags. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’10, Geneva, Switzerland, 19–23 July 2010; ACM: New York, NY, USA, 2010; pp. 194–201. [Google Scholar] [CrossRef]
- Hermida, A.; Fletcher, F.; Korell, D.; Logan, D. Share, like, recommend. J. Stud. 2012, 13, 815–824. [Google Scholar] [CrossRef]
- Bollen, J.; Mao, H.; Zeng, X. Twitter mood predicts the stock market. J. Comput. Sci. 2010, 2, 1–8. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Shirai, K.; Velcin, J. Sentiment analysis on social media for stock movement prediction. Expert Syst. Appl. 2015, 42, 9603–9611. [Google Scholar] [CrossRef]
- Si, J.; Mukherjee, A.; Liu, B.; Li, Q.; Li, H.; Deng, X. Exploiting Topic based Twitter Sentiment for Stock Prediction. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (ACL 2013), Sofia, Bulgaria, 4–9 August 2013; Volume 2: Short Papers. pp. 24–29. Available online: http://aclweb.org/anthology/P/P13/P13-2005.pdf (accessed on 23 November 2017).
- Watts, D.; George, K.M.; Kumar, T.A.; Arora, Z. Tweet sentiment as proxy for political campaign momentum. In Proceedings of the 2016 IEEE International Conference on Big Data (BigData 2016), Washington, DC, USA, 5–8 December 2016; pp. 2475–2484. [Google Scholar] [CrossRef]
- Shirky, C. The Political Power of Social Media: Technology, the Public Sphere, and Political Change. Foreign Aff. 2011, 90, 28–41. [Google Scholar]
- Ratkiewicz, J.; Conover, M.; Meiss, M.; Goncalves, B.; Flammini, A.; Menczer, F. Detecting and Tracking Political Abuse in Social Media. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- De Vries, L.; Gensler, S.; Leeflang, P.S. Popularity of Brand Posts on Brand Fan Pages: An Investigation of the Effects of Social Media Marketing. J. Interact. Mark. 2012, 26, 83–91. [Google Scholar] [CrossRef]
- Hollebeek, L.D.; Glynn, M.S.; Brodie, R.J. Consumer Brand Engagement in Social Media: Conceptualization, Scale Development and Validation. J. Interact. Mark. 2014, 28, 149–165. [Google Scholar] [CrossRef] [Green Version]
- Jussila, J.J.; Kärkkäinen, H.; Aramo-Immonen, H. Social Media Utilization in Business-to-business Relationships of Technology Industry Firms. Comput. Hum. Behav. 2014, 30, 606–613. [Google Scholar] [CrossRef]
- Baird, C.H.; Parasnis, G. From social media to social customer relationship management. Strategy Leadersh. 2011, 39, 30–37. [Google Scholar] [CrossRef]
- Tan, S.; Wang, Y.; Cheng, X. Combining Learn-based and Lexicon-based Techniques for Sentiment Detection without Using Labeled Examples. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’08, Singapore, 20–24 July 2008; ACM: New York, NY, USA, 2008; pp. 743–744. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Tang, D.; Qin, B.; Liu, T. Document Modeling with Gated Recurrent Neural Network for Sentiment Classification. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 1422–1432. Available online: http://aclweb.org/anthology/D15-1167 (accessed on 23 November 2017).
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1746–1751. [Google Scholar]
- Poria, S.; Cambria, E.; Gelbukh, A. Deep Convolutional Neural Network Textual Features and Multiple Kernel Learning for Utterance-Level Multimodal Sentiment Analysis. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 2539–2544. Available online: http://aclweb.org/anthology/D15-1303 (accessed on 23 November 2017).
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent Convolutional Neural Networks for Text Classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI’15, Austin, TX, USA, 25–30 January 2015; AAAI Press: Palo Alto, CA, USA, 2015; pp. 2267–2273. [Google Scholar]
- Navigli, R. Word Sense Disambiguation: A Survey. ACM Comput. Surv. 2009, 41, 10:1–10:69. [Google Scholar] [CrossRef]
- Shutova, E. Automatic Metaphor Interpretation as a Paraphrasing Task. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, HLT ’10, Los Angeles, CA, USA, 1–6 June 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 1029–1037. [Google Scholar]
- Yarowsky, D. Unsupervised Word Sense Disambiguation Rivaling Supervised Methods. In Proceedings of the 33rd Annual Meeting on Association for Computational Linguistics, ACL ’95, Cambridge, MA, USA, 26–30 June 1995; Association for Computational Linguistics: Stroudsburg, PA, USA, 1995; pp. 189–196. [Google Scholar]
- Banerjee, S.; Pedersen, T. An Adapted Lesk Algorithm for Word Sense Disambiguation Using WordNet. Computational Linguistics and Intelligent Text Processing; Gelbukh, A., Ed.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 136–145. [Google Scholar]
- Palanisamy, P.; Yadav, V.; Elchuri, H. Serendio: Simple and Practical Lexicon Based Approach to Sentiment Analysis. In Proceedings of the Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013), Atlanta, GA, USA, 14–15 June 2013; Association for Computational Linguistics: Atlanta, GA, USA, 2013; pp. 543–548. Available online: http://www.aclweb.org/anthology/S13-2091 (accessed on 13 November 2017).
- Melville, P.; Gryc, W.; Lawrence, R.D. Sentiment Analysis of Blogs by Combining Lexical Knowledge with Text Classification. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’09, Paris, France, 28 June–1 July 2009; ACM: New York, NY, USA, 2009; pp. 1275–1284. [Google Scholar] [CrossRef]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-based Methods for Sentiment Analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Baccianella, S.; Esuli, A.; Sebastiani, F. SentiWordNet 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining; LREC; Calzolari, N., Choukri, K., Maegaard, B., Mariani, J., Odijk, J., Piperidis, S., Rosner, M., Tapias, D., Eds.; European Language Resources Association: Paris, France, 2010; Available online: http://nmis.isti.cnr.it/sebastiani/Publications/LREC10.pdf (accessed on 13 November 2017).
- Agerri, R.; García-Serrano, A. Q-WordNet: Extracting Polarity from WordNet Senses. In Proceedings of the International Conference on Language Resources and Evaluation, LREC 2010, Valletta, Malta, 17–23 May 2010; Available online: http://www.lrec-conf.org/proceedings/lrec2010/pdf/695_Paper.pdf (accessed on 13 November 2017).
- Strapparava, C.; Valitutti, A. WordNet-Affect: An Affective Extension of WordNet. In Proceedings of the 4th International Conference on Language Resources and Evaluation, ELRA, Lisbon, Portugal, 26–28 May 2004; pp. 1083–1086. Available online: http://www.lrec-conf.org/proceedings/lrec2004/369.pdf (accessed on 3 October 2017).
- Kounios, J.; Fleck, J.I.; Green, D.L.; Payne, L.; Stevenson, J.L.; Bowden, E.M.; Jung-Beeman, M. The origins of insight in resting-state brain activity. Neuropsychologia 2008, 46, 281–291. [Google Scholar] [CrossRef] [PubMed]
- Spence, C.; Shankar, M.U. The Influence of Auditory Cues on The Perception of, and Responses to, Food and Drink. J. Sens. Stud. 2010, 25, 406–430. [Google Scholar] [CrossRef]
- Gimpel, K.; Schneider, N.; O’Connor, B.; Das, D.; Mills, D.; Eisenstein, J.; Heilman, M.; Yogatama, D.; Flanigan, J.; Smith, N.A. Part-of-speech Tagging for Twitter: Annotation, Features, and Experiments. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: Short Papers—Volume 2, HLT ’11, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 42–47. Available online: http://dl.acm.org/citation.cfm?id=2002736.2002747 (accessed on 2 November 2017).
- Lesk, M. Automatic Sense Disambiguation Using Machine Readable Dictionaries: How to Tell a Pine Cone from an Ice Cream Cone. In Proceedings of the 5th Annual International Conference on Systems Documentation, SIGDOC ’86, Toronto, ON, Canada, 1 June 1986; ACM: New York, NY, USA, 1986; pp. 24–26. [Google Scholar] [CrossRef]
- Luhn, H.P. A Statistical Approach to Mechanized Encoding and Searching of Literary Information. IBM J. Res. Dev. 1957, 1, 309–317. [Google Scholar] [CrossRef]
- Yu, H.; Han, J.; Chang, K.C.C. PEBL: Positive Example Based Learning for Web Page Classification Using SVM. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’02, Edmonton, AB, Canada, 23–25 July 2002; ACM: New York, NY, USA, 2002; pp. 239–248. [Google Scholar] [CrossRef]
- John, G.H.; Langley, P. Estimating Continuous Distributions in Bayesian Classifiers. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, UAI’95, Montreal, QC, Canada, 18–20 August 1995; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1995; pp. 338–345. [Google Scholar]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993. [Google Scholar]
- Ho, T.K. Random Decision Forests. In Proceedings of the Third International Conference on Document Analysis and Recognition (ICDAR ’95), Montreal, QC, Canada, 14–16 August 1995; IEEE Computer Society: Washington, DC, USA, 1995; Volume 1, pp. 278–282. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27:1–27:27. [Google Scholar] [CrossRef]
- Hilton, K. Psychology the science of sensory marketing. Harv. Bus. Rev. 2015, 3, 28–31. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Part-of-Speech | Selected Semantic Relation |
|---|---|
| Noun, Verb | {direct hypernym, sister term} |
| Adjective | {see also, similar term} |
| Adverb | {synonyms} |
| Features | Classifier | F1 Measure | Accuracy | |
|---|---|---|---|---|
| Random Forest | 60.7 | 61.24 | ||
| Word | SVM | 64.4 | 65.68 | |
| feature | MLP | 68.2 | 69.88 | |
| CNN | 79.1 | 79.33 | ||
| RCNN | 80.1 | 80.39 | ||
| Naive Bayes | 61.2 | 62.42 | ||
| Sensation | Weight | C4.5 | 68.9 | 68.97 |
| feature | (4) | Random Forest | 78.4 | 78.56 |
| SVM | 80.1 | 80.24 | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Ogawa, H.; Kwon, Y.; Kim, K.-S. Spatial Footprints of Human Perceptual Experience in Geo-Social Media. ISPRS Int. J. Geo-Inf. 2018, 7, 71. https://doi.org/10.3390/ijgi7020071
Lee J, Ogawa H, Kwon Y, Kim K-S. Spatial Footprints of Human Perceptual Experience in Geo-Social Media. ISPRS International Journal of Geo-Information. 2018; 7(2):71. https://doi.org/10.3390/ijgi7020071
Chicago/Turabian StyleLee, Jun, Hirotaka Ogawa, YongJin Kwon, and Kyoung-Sook Kim. 2018. "Spatial Footprints of Human Perceptual Experience in Geo-Social Media" ISPRS International Journal of Geo-Information 7, no. 2: 71. https://doi.org/10.3390/ijgi7020071
APA StyleLee, J., Ogawa, H., Kwon, Y., & Kim, K. -S. (2018). Spatial Footprints of Human Perceptual Experience in Geo-Social Media. ISPRS International Journal of Geo-Information, 7(2), 71. https://doi.org/10.3390/ijgi7020071