Spatial-Temporal Event Detection from Geo-Tagged Tweets


Abstract
:1. Introduction
2. Related work
3. Methodology
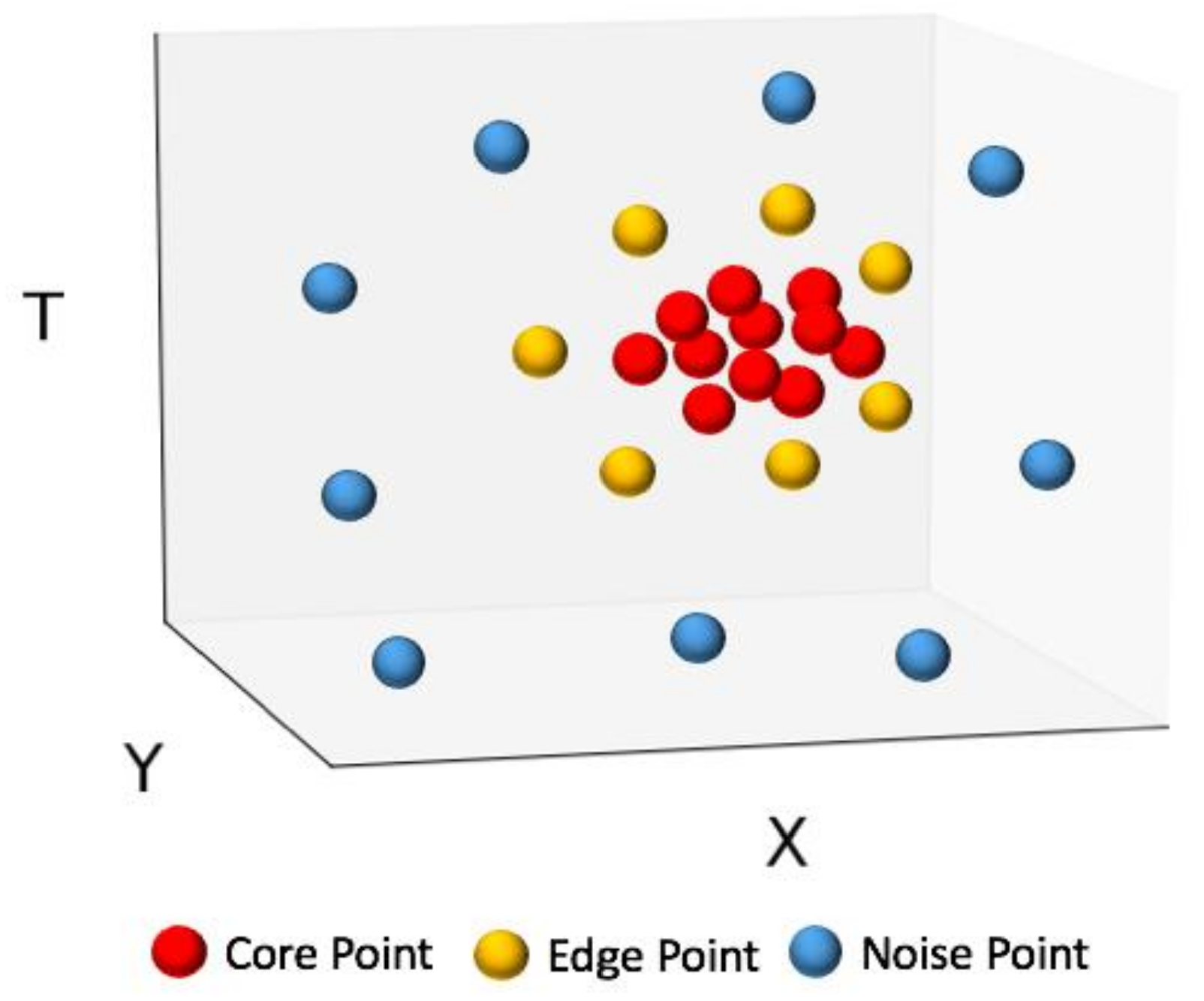
3.1. DBSCAN and ST-DBSCAN
- (1)
- A point p is a core point if at least minPts points are within a distance d (d-neighborhood) of it. These points are considered to be directly reachable from p. No points are directly reachable from a non-core point.
- (2)
- A point q is reachable from p if there is point chain: a path p1, …, pn with p1 = p and pn = q, where each pi+1 is directly reachable from pi.
- (3)
- All points that are not reachable from any other point are outliers.
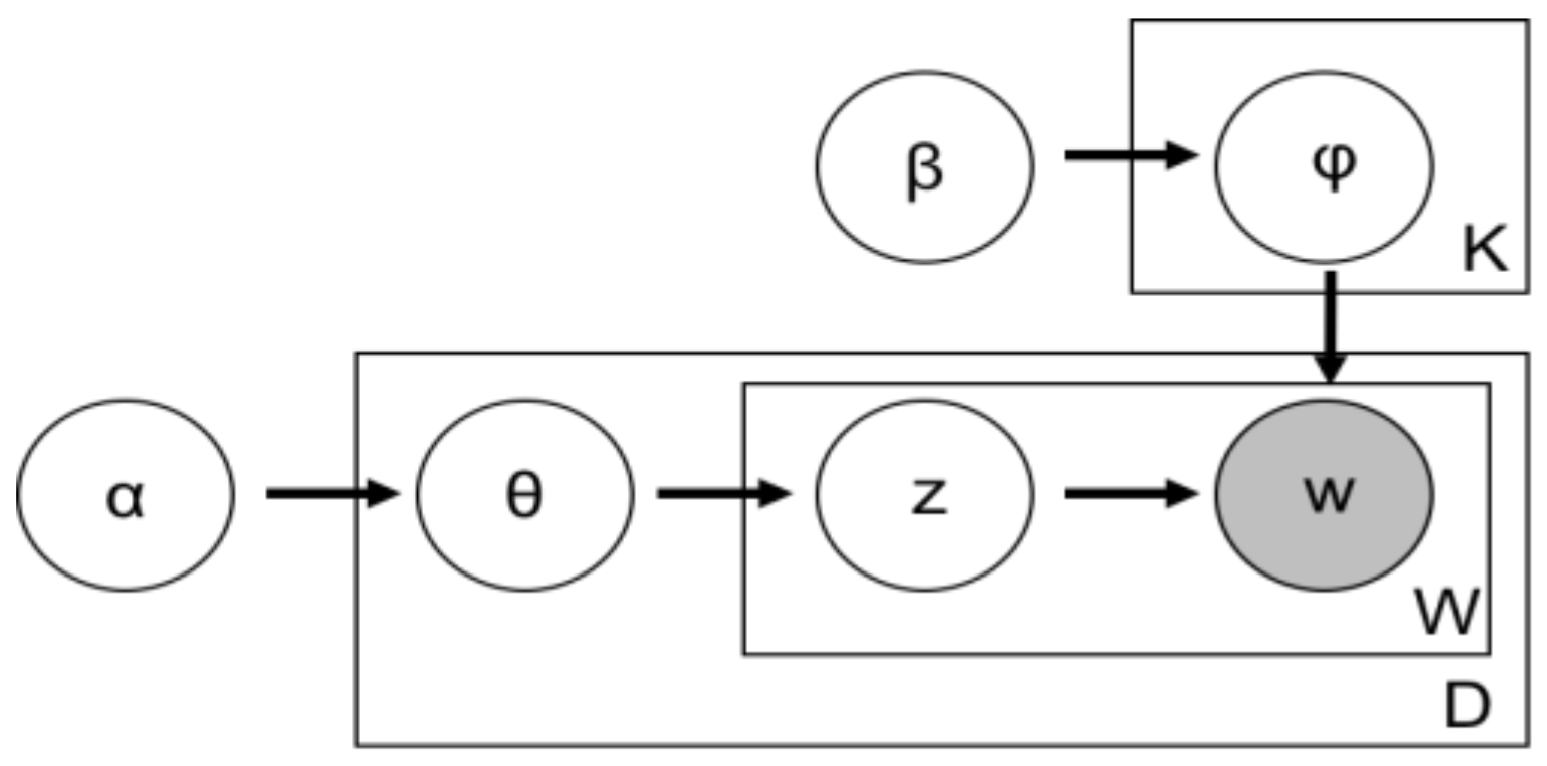
3.2. Latent Dirichlet Allocation (LDA)
- α is the parameter of the Dirichlet prior on the document—topic distributions of all tweets
- β is the parameter of the Dirichlet prior on the topic—word distribution of all tweets
- θj is the topic distribution for tweet j
- ϕk is the word distribution for topic k
- zij is the topic for the i-th word in tweet j
- wij is the specific word among all tweets
3.3. Workflow for Event Detection
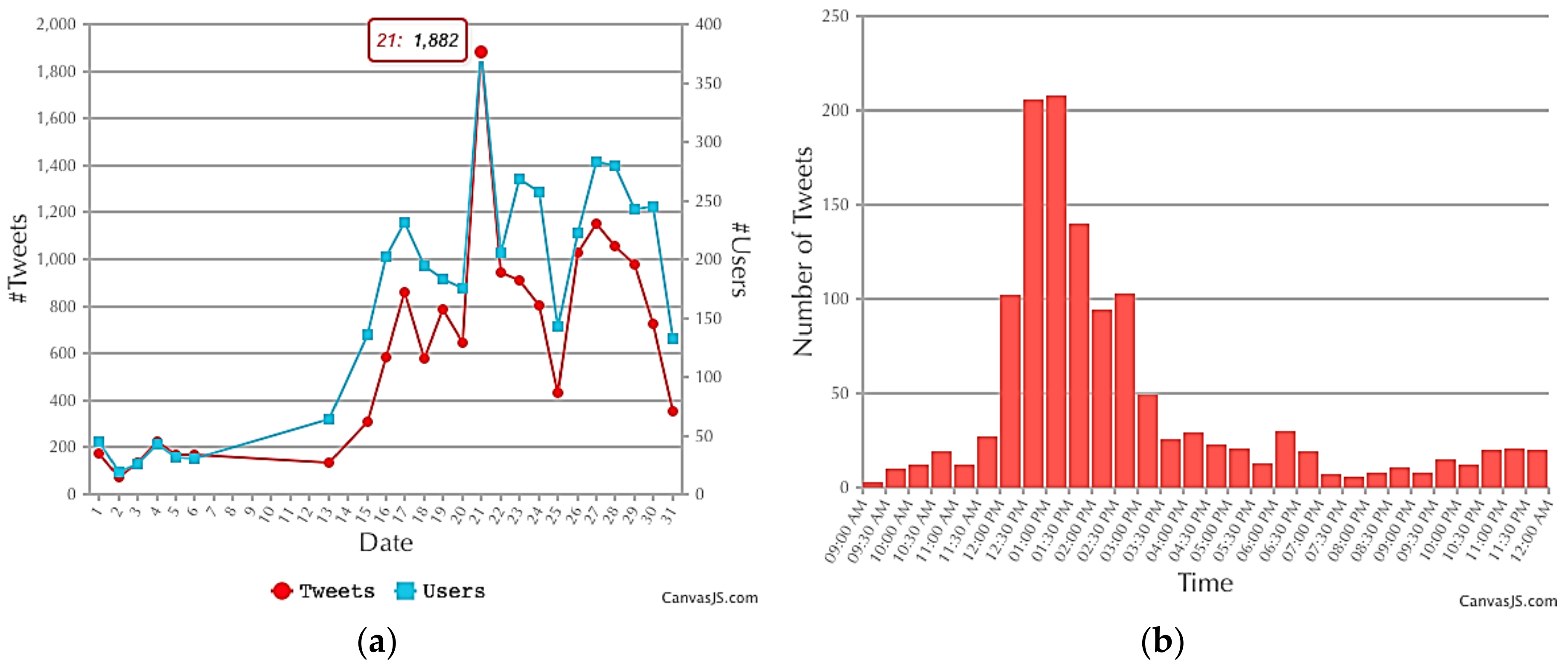
- Group tweets by day and generate charts showing the number of tweets and users by the day of the month.
- Apply ST-DBSCAN to cluster the tweets of every day. For every cluster, generate its spatial, temporal and textual patterns.
- Apply LDA to identify potential topics in the cluster and analyze the structure of every tweet. For example, if the probability construction of a sentence is 60% for Topic 1, 40% for Topic 2, then this sentence is labeled as a sentence of Topic 1.
4. Tests and Results
- (1)
- Public Streams: streams of public data flowing through Twitter can be pushed.
- (2)
- User Streams: streams of a single user, which contain almost all of the data corresponding to the user, can be accessed.
- (3)
- Site Stream: streams of the multi-users version of user streams are accessible.
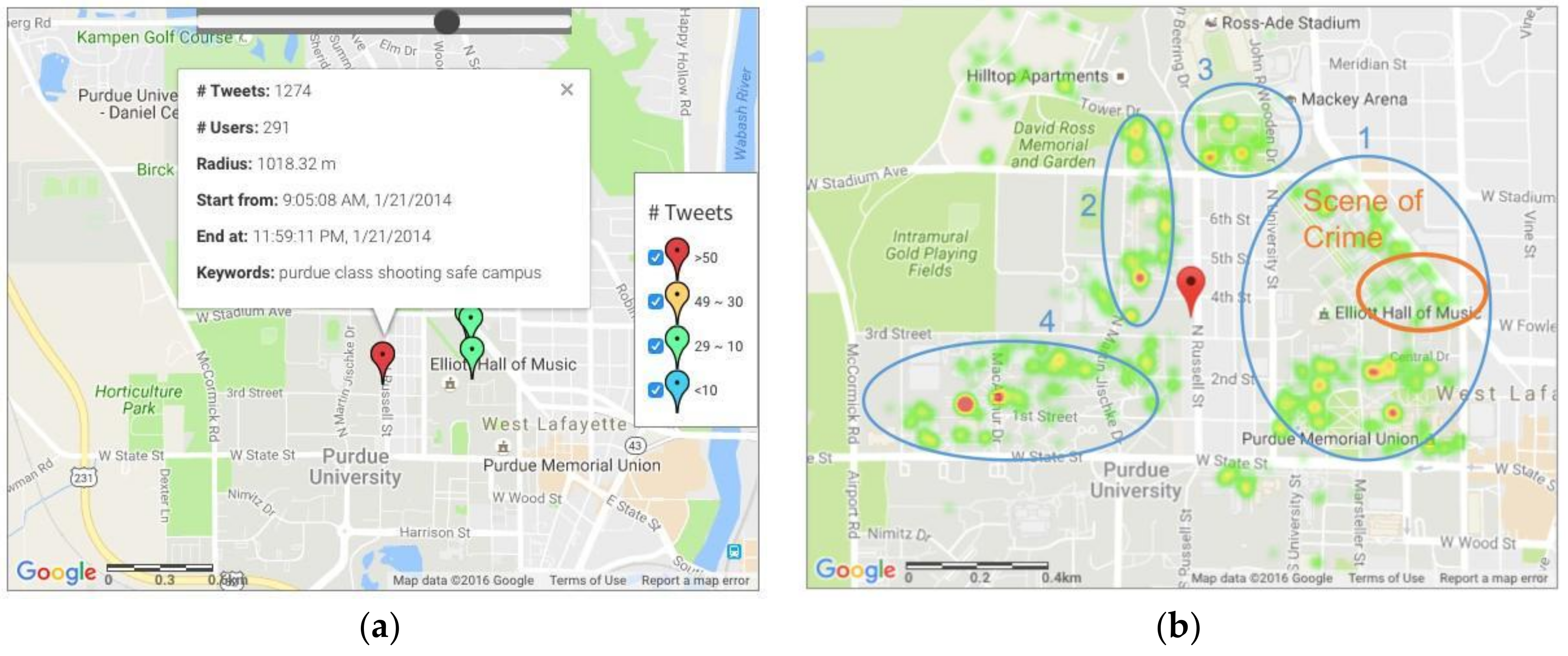
4.1. Detection of Known Events
4.1.1. Gunshot in West Lafayette, IN
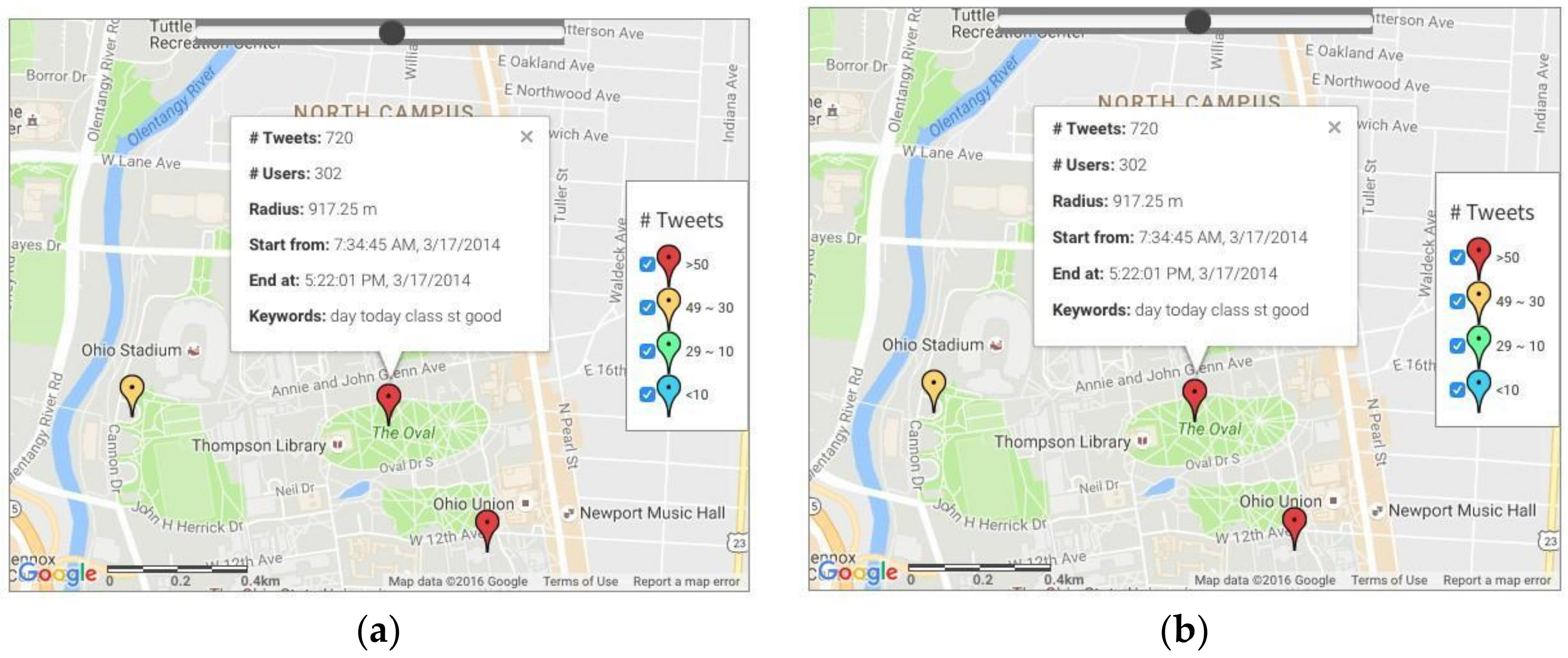
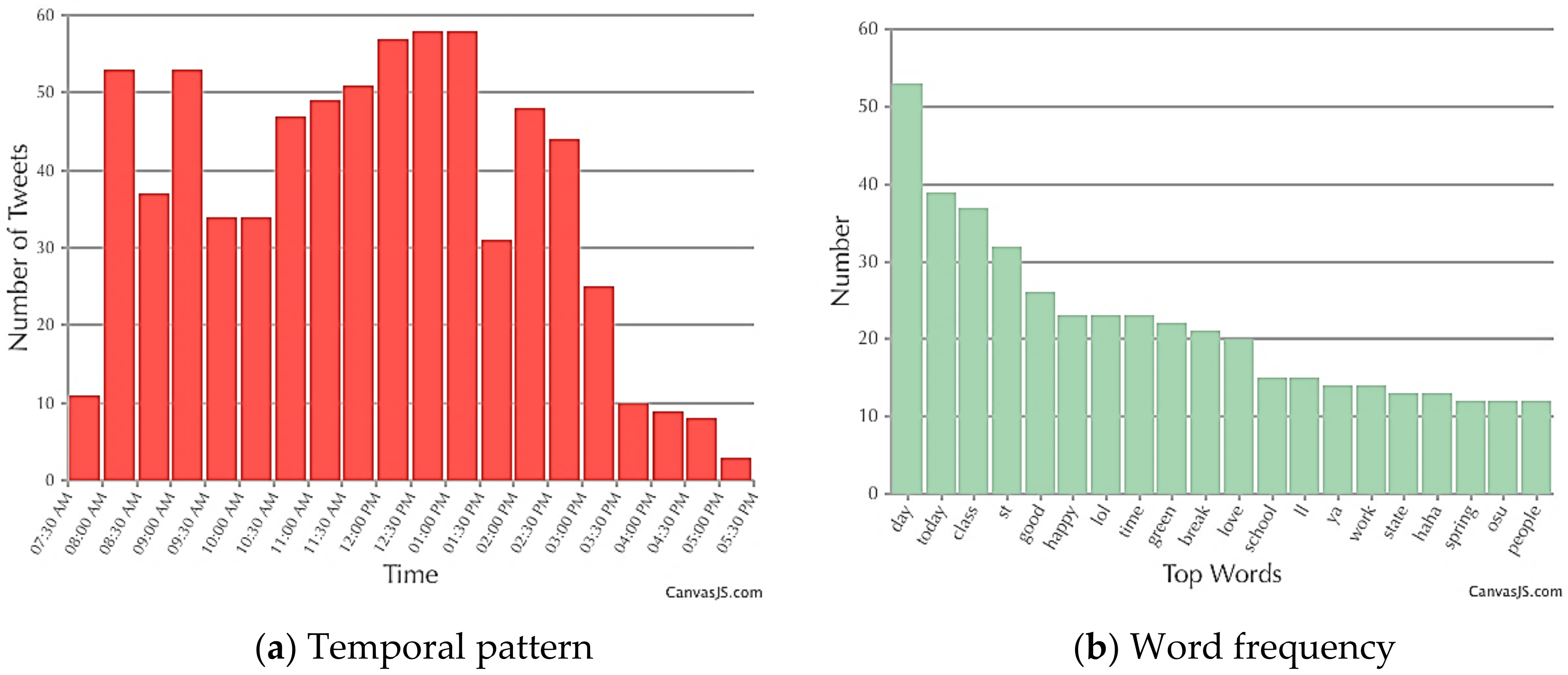
4.1.2. Saint Patrick’s Day in Columbus, OH
4.2. Detection of Unknown Events
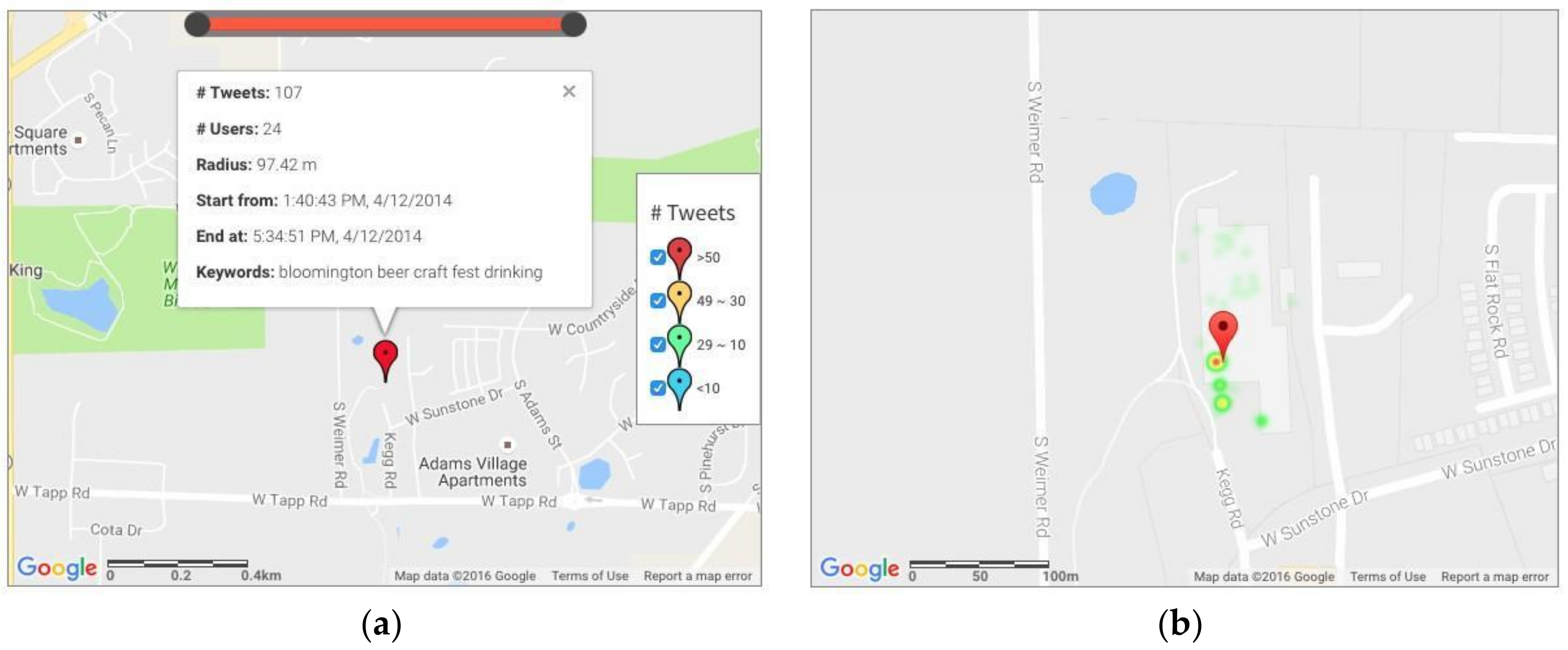
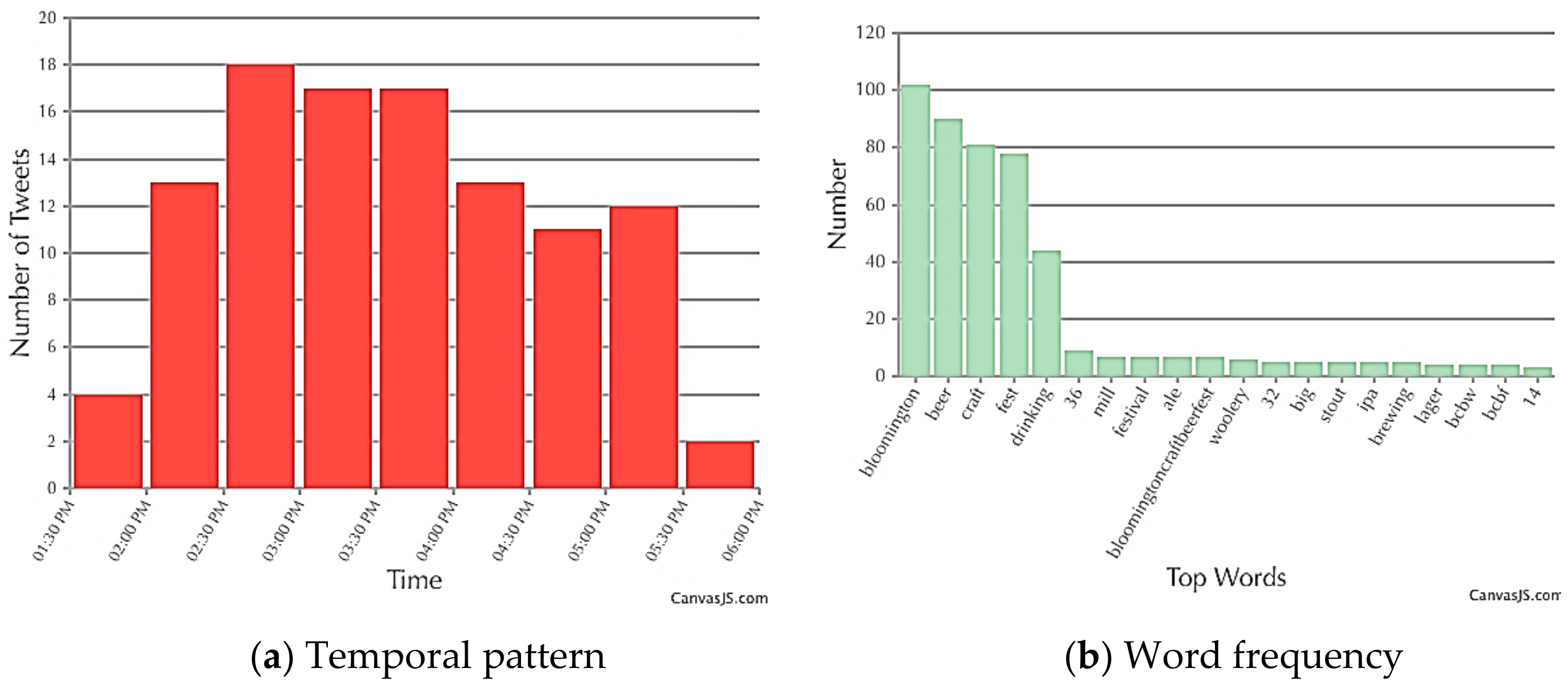
4.2.1. Beer Festival in Bloomington
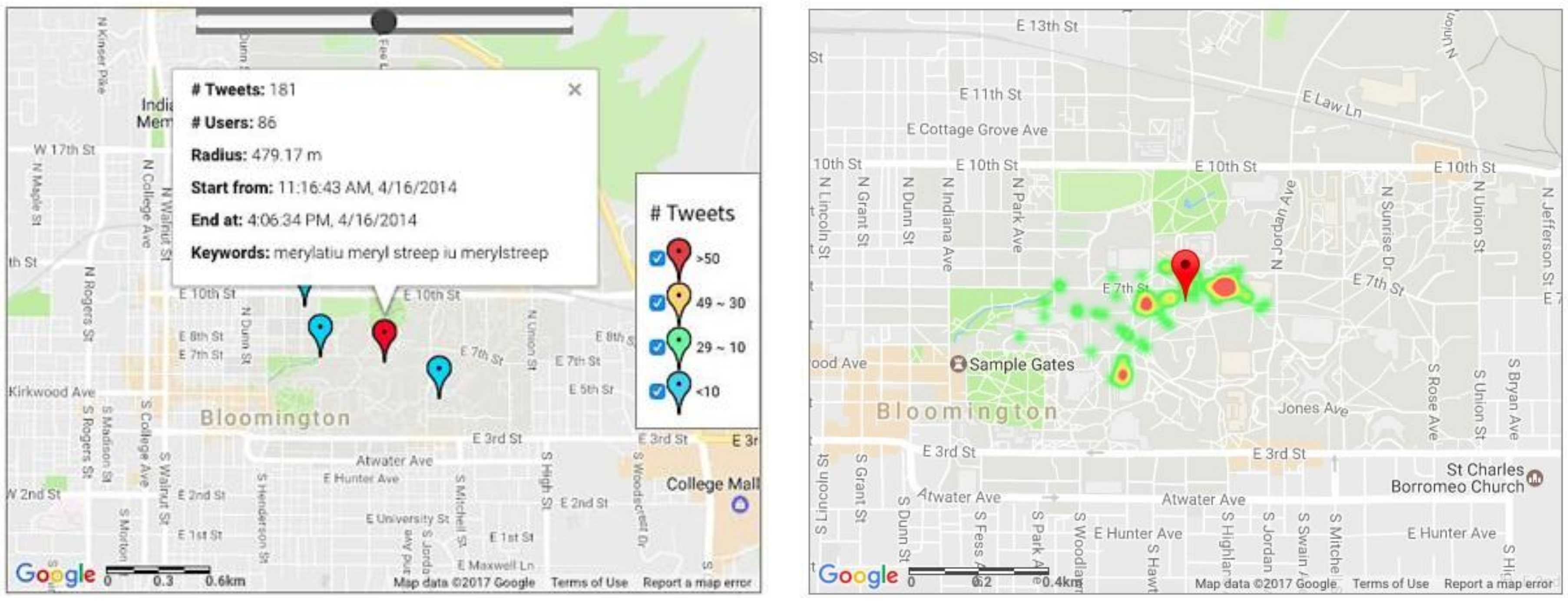
4.2.2. Meryl Streep’s Visit to Indiana University
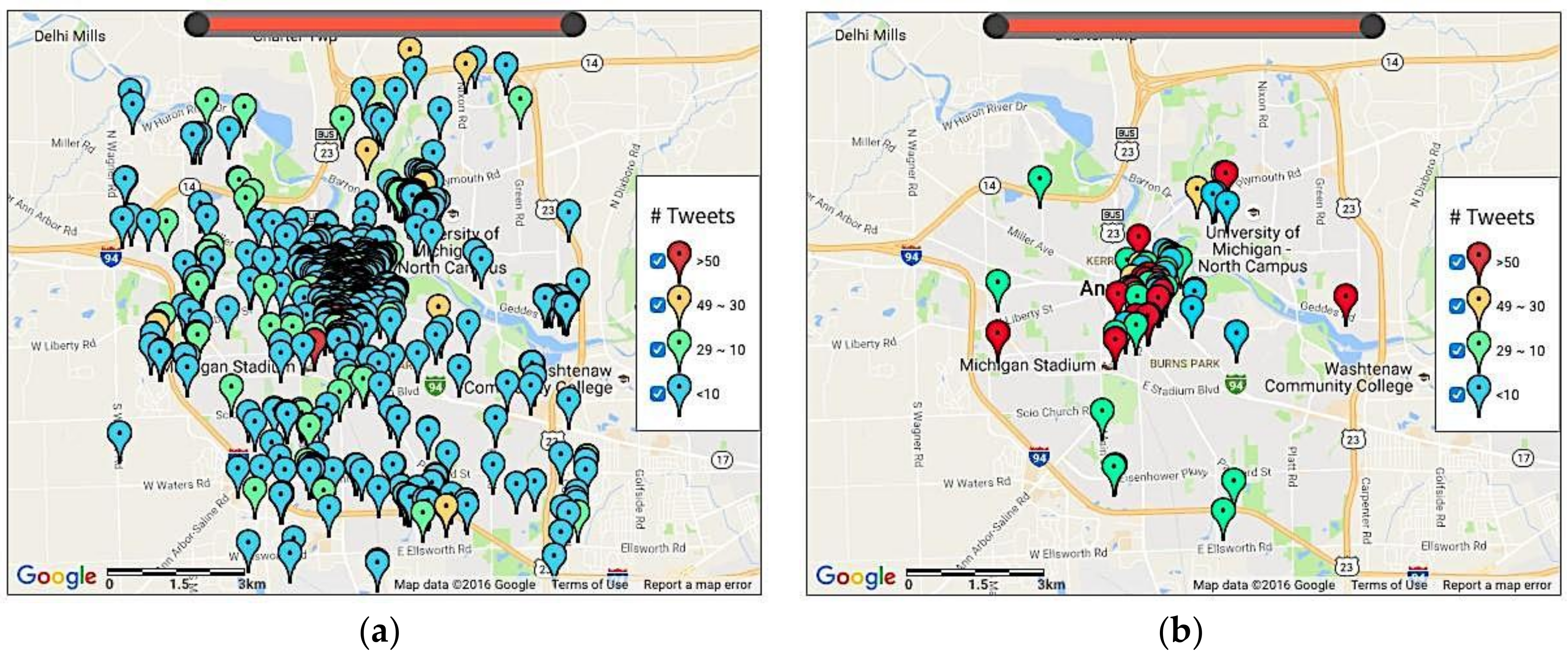
4.3. Detection of Recurring Events
5. Discussion
5.1. Parameter Selections
5.2. Event Details Revealed and Understood
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Milstein, S.; Lorica, B.; Magoulas, R.; Hochmuth, G.; Chowdhury, A.; O’Reilly, T. Twitter and the micro-messaging revolution. In Communication, Connections, and Immediacy–140 Characters at a Time; O’Reilly Media, Inc.: Champaign, IL, USA, 2008. [Google Scholar]
- Kwak, H.; Lee, C.; Park, H.; Moon, S. What is Twitter, a social network or a news media? In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; ACM: New York, NY, USA, 2010; pp. 591–600. [Google Scholar]
- Statista—The Statistics Portal. Number of monthly active international Twitter users from 1st quarter 2010 to 4th quarter 2017 (in millions) 2018. Available online: https://www.statista.com/statistics/274565/monthly-active-international-twitter-users/ (accessed on 12 February 2018).
- Kwan, M.-P. Algorithmic geographies: big data, algorithmic uncertainty, and the production of geographic knowledge. Ann. Assoc. Am. Geogr. 2016, 106, 274–282. [Google Scholar]
- Miller, G. Social scientists wade into the tweet stream. Science 2011, 333, 1814–1815. [Google Scholar] [CrossRef] [PubMed]
- Morales, A.J.; Vavilala, V.; Benito, R.M.; Bar-Yam, Y. Global patterns of synchronization in human communications. J. R. Soc. Interface 2017. [Google Scholar] [CrossRef] [PubMed]
- Leetaru, K.; Wang, S.; Cao, G.; Padmanabhan, A.; Shook, E. Mapping the global Twitter heartbeat: The geography of Twitter. First Monday 2013, 18, 4–5. [Google Scholar] [CrossRef]
- Grandjean, M. A social network analysis of Twitter: Mapping the digital humanities community. Cogent Arts Humanit. 2016, 3, 1171458. [Google Scholar] [CrossRef]
- Hahmann, S.; Purves, R.S.; Burghardt, D. Twitter location (sometimes) matters: Exploring the relationship between georeferenced tweet content and nearby feature classes. J. Spat. Inf. Sci. 2014, 9, 1–36. [Google Scholar] [CrossRef]
- Sloan, L.; Morgan, J. Who tweets with their location? Understanding the relationship between demographic characteristics and the use of geoservices and geotagging on Twitter. PLoS ONE 2015, 10, e0142209. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Li, Q.; Shan, J. Discover patterns and mobility of twitter users—A study of four U.S. college cities. ISPRS Int. J. Geo-Inf. 2017, 6, 42. [Google Scholar] [CrossRef]
- Jurgens, D.; McCorriston, J.; Ruths, D. Geolocation prediction in Twitter using social networks: A critical analysis and review of current practice. In Proceedings of the 9th International Conference on Web and Social Media (ICWSM-15), Oxford, UK, 26–29 May 2015. [Google Scholar]
- Patel, N.; Stevens, F.R.; Huang, Z.J.; Gaughan, A.E.; Elyazar, I.; Tatem, A.J. Improving large area population mapping using geotweet densities. Trans. GIS 2017, 21, 317–331. [Google Scholar] [CrossRef] [PubMed]
- Montasser, O.; Kifer, D.V. Predicting demographics of high-resolution geographies with geotagged tweets. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17), San Francisco, CA, USA, 4–10 February 2017. [Google Scholar]
- De Bruijn, J.A.; de Moel, H.; Jongman, B.; Wagemaker, J.; Aerts, J.C.J.H. TAGGS: Grouping tweets to improve global geoparsing for disaster response. J. Geovisualization Spat. Anal. 2018, 2, 2. [Google Scholar] [CrossRef]
- Nguyen, O.C.; McCullough, M.; Meng, H.-W.; Paul, D.; Li, D.P.; Kath, S.; Loomis, G.; Nsoesie, E.O.; Wen, M.; Smith, K.R.; et al. Geotagged U.S. tweets as predictors of county-level health outcomes, 2015–2016. Am. J. Public Health 2017, 107, 1776–1782. [Google Scholar] [CrossRef] [PubMed]
- Chaniotakis, E.; Antoniou, C.; Aifadopoulou, G.; Dimitriou, L. Inferring activities from social media data. Transp. Res. Record: J. Transp. Res. Board 2017, 2666, 29–37. [Google Scholar] [CrossRef]
- Hong, I.; Jung, J.-K. What is so “hot” in heatmap? Qualitative code cluster analysis with foursquare venue. Cartographica 2017, 52, 332–348. [Google Scholar] [CrossRef]
- Yang, Y.; Pierce, T.; Carbonell, J. A study of retrospective and on-line event detection. In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998; ACM: New York, NY, USA, 1998; pp. 28–36. [Google Scholar]
- Crampton, J.W.; Graham, M.; Poorthuis, A.; Shelton, T.; Stephens, M.; Wilson, M.W.; Zook, M. Beyond the geotag: situating ‘big data’ and leveraging the potential of the geoweb. Cartogr. Geogr. Inf. Sci. 2013, 40, 130–139. [Google Scholar] [CrossRef]
- Phuvipadawat, S.; Murata, T. Breaking news detection and tracking in Twitter. In Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Toronto, ON, Canada, 31 August–3 September 2010; Volume 3, pp. 120–123. [Google Scholar]
- Lee, R.; Sumiya, K. Measuring geographical regularities of crowd behaviors for Twitter-based geo-social event detection. In Proceedings of the 2nd ACM SIGSPATIAL International Workshop on Location-based Social Networks, San Jose, CA, USA, 3–5 November 2010; ACM: New York, NY, USA, 2010; pp. 1–10. [Google Scholar]
- Weng, J.; Lee, B.-S. Event detection in Twitter. ICWSM 2011, 11, 401–408. [Google Scholar]
- Pennacchiotti, M.; Popescu, A.-M. A machine learning approach to Twitter user classification. ICWSM 2011, 11, 281–288. [Google Scholar]
- Benson, E.; Haghighi, A.; Barzilay, R. Event discovery in social media feeds. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 389–398. [Google Scholar]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on the World Wide Web, Raleigh, NC, USA, 26–30 April 2010; ACM: New York, NY, USA, 2010; pp. 851–860. [Google Scholar]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Tweet analysis for real- time event detection and earthquake reporting system development. IEEE Trans. Knowl. Data Eng. 2013, 25, 919–931. [Google Scholar] [CrossRef]
- Walther, M.; Kaisser, M. Geo-spatial event detection in the twitter stream. In Proceedings of the European Conference on Information Retrieval, Moscow, Russia, 24–27 March 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 356–367. [Google Scholar]
- Huang, Q.; Wong, W. Modeling and visualizing regular human mobility patterns with uncertainty: An example using Twitter data. Ann. Assoc. Am. Geogr. 2015, 105, 1179–1197. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Oakland, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–38. [Google Scholar]
- Sander, J.; Ester, M.; Kriegel, H.-P.; Xu, X.-W. Density-based clustering in spatial databases: The algorithm DBSCAN and its applications. Data Mining Knowl. Discov. 1998, 2, 169–194. [Google Scholar] [CrossRef]
- Ankerst, M.; Breunig, M.; Kriegel, H.-P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. In ACM Sigmod Record; ACM: New York, NY, USA, 1999; Volume 28, pp. 49–60. [Google Scholar]
- Kailing, K.; Kriegel, H.-P.; Kröger, P. Density-connected subspace clustering for high-dimensional data. In Proceedings of the 2004 SIAM International Conference on Data Mining (SDM04), Philadelphia, PA, USA, 22 March 2004; SIAM: Philadelpha, PA, USA; Volume 4. [Google Scholar]
- Kulldorff, M. A spatial scan statistics. Commun. Stat.-Theory Methods 1997, 26, 1481–1496. [Google Scholar] [CrossRef]
- Wikipedia. Topic Model. 27 September 2016. Available online: https://en.wikipedia.org/wiki/Topic_model (accessed on 18 October 2016).
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391. [Google Scholar] [CrossRef]
- Hofmann, T. Probabilistic latent semantic indexing. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; ACM: New York, NY, USA, 1999; pp. 50–57. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Beli, D.M.; Griffiths, T.L.; Jordan, M.I.; Tenenbaum, J.B. Hierarchical topic models and the nested Chinese restaurant process. In Advances in Neural Information Processing Systems; MIP Press: Cambridge, MA, USA, 2004; pp. 17–24. [Google Scholar]
- Teh, Y.W. A hierarchical Bayesian language model based on Pitman-Yor processes. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 20 July 2006; Association for Computational Linguistics: Stroudsburg, PA, USA, 2006; pp. 985–992. [Google Scholar]
- Birant, D.; Kut, A. ST-DBSCAN: An algorithm for clustering spatial–temporal data. Data Knowledge Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X.W. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD, Portland, Oregon, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. A Brief Survey of Text Mining: Classification, Clustering and Extraction Techniques. arXiv, 1707; arXiv:1707.02919v2. [Google Scholar]
- Jelodar, J.; Wang, Y.; Yuan, C.; Feng, X. Latent Dirichlet Allocation (LDA) and Topic modeling: models, applications. A Survey. arXiv, 1711; arXiv:1711.04305v1. [Google Scholar]
- Krestel, R.; Fankhauser, P.; Nejdl, W. Latent Dirichlet allocation for tag recommendation. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 23–25 October 2009; ACM: New York, NY, USA, 2009; pp. 61–68. [Google Scholar]
- Porteous, I.; Newman, D.; Ihler, A.; Asuncion, A.; Smyth, P.; Welling, M. Fast collapsed Gibbs sampling for latent Dirichlet allocation. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; ACM: New York, NY, USA, 2008; pp. 569–577. [Google Scholar]
- Twitter. The Streaming APIs Overview. 2014. Available online: https://dev.twitter.com/streaming/overview (accessed on 18 October 2016).
- Purdue University. Victim, Suspect Identified in Purdue Campus Shooting. 2014. Available online: https://www.purdue.edu/newsroom/releases/2014/Q1/purdue-police-confirm-1-fatality,-1-in-custody-following-campus-shooting.html (accessed on 18 October 2016).
- Wikipedia. Saint Patrick’s Day. 11 October 2016. Available online: https://en.wikipedia.org/wiki/Saint_Patrick%27s_Day (accessed on 18 October 2016).
- Bloom Magazine. Bloomington Craft Beer Festival. 2014. Available online: http://www.magbloom.com/events/bloomington-craft-beer-festival/ (accessed on 21 November 2016).
- Indiana University Bloomington. Meryl Streep Will Receive an Honorary Doctoral Degree. 2014. Available online: http://archive.news.indiana.edu/releases/iu/2014/02/meryl-streep-honorary-doctorate.shtml (accessed on 22 February 2017).
- FBschedules.com. 2015 Michigan Wolverines Football Schedule. 2015. Available online: http://www.fbschedules.com/ncaa-15/big-ten/2015-michigan-wolverines-football-schedule.php (accessed on 21 November 2016).
- Wallach, H.M.; Murray, I.; Salakhutdinov, R.; Mimno, D. Evaluation methods for topic models. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; ACM: New York, NY, USA, 2009; pp. 1105–1112. [Google Scholar]
- Chang, J.; Gerrish, S.; Wang, C.; Boyd-Graber, J.L.; Blei, D.M. Reading tea leaves: How humans interpret topic models. In Advances in Neural Information Processing Systems; MIP Press: Cambridge, MA, USA, 2009; pp. 288–296. [Google Scholar]
- Malik, M.M.; Lamba, H.; Nakos, C.; Pfeffer, J. Population bias in geotagged tweets. In Standards and Practices in Large-Scale Social Media Research: Papers from the 2015 ICWSM Workshop; AAAI Press: Palo Alto, CA, USA, 2015; pp. 18–27. [Google Scholar]
- Tasse, D.; Liu, Z.; Sciuto, A.; Hong, J.I. State of the Geotags: Motivations and Recent Changes. In Proceedings of the Eleventh International AAAI Conference on Web and Social Media (ICWSM 2017), Montreal, QC, Canada, 15–18 May 2017. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Purdue | Class | Shooting | Safe | Campus | Stay | People | Building | Today | lol |
| 165 | 101 | 96 | 96 | 83 | 55 | 48 | 48 | 45 | 45 |
| Good | Day | School | Love | Normal | Lock-down | EE | PrayforPurdue | Classes | Shot |
| 39 | 38 | 35 | 34 | 33 | 30 | 30 | 30 | 29 | 28 |
| Word, % | T1 | T2 | T3 | T4 | T5 | T6 |
|---|---|---|---|---|---|---|
| W1 | class, 6.1 | time, 2.1 | purdue, 2.9 | safe, 8.5 | building, 4.3 | good, 3.8 |
| W2 | purdue, 4.1 | lol, 1.9 | school, 2.6 | purdue, 6.9 | shooting, 3.4 | lol, 3.2 |
| W3 | campus, 3.8 | nigga, 1.5 | people, 2.2 | stay, 4.8 | class, 3.0 | shit, 2.3 |
| W4 | normal, 3.1 | gonna, 1.4 | tonight, 1.9 | campus, 3.1 | ee, 2.4 | crazy, 1.9 |
| W5 | classes, 2.7 | great, 1.2 | boilerstrong, 1.8 | shooting, 2.8 | police, 2.1 | yea, 1.9 |
| W6 | shooting, 2.4 | love, 1.0 | today, 1.8 | prayforpurdue,2.2 | lockdown, 1.7 | man, 1.8 |
| W7 | resume, 2.2 | text, 0.9 | love, 1.8 | hope, 2.0 | shooter, 1.3 | news, 1.7 |
| W8 | shot, 2.2 | stop, 0.9 | happened, 1.5 | happen, 1.9 | physics, 1.1 | people, 1.7 |
| W9 | operations, 1.9 | dining, 0.9 | call, 1.4 | friends, 1.9 | lecture, 1.1 | girl, 1.6 |
| W10 | day, 1.7 | back, 0.8 | day, 1.3 | prayers, 1.6 | door, 1.1 | damn, 1.5 |
| #Tweets | 177 | 167 | 184 | 219 | 203 | 266 |
| Topics | Shooting at Purdue campus | School life | Feelings towards shooting | Actions towards shooting | Actions towards shooting | Feelings towards shooting |
| Word, % | T1 | T2 | T3 | T4 | T5 | T6 |
|---|---|---|---|---|---|---|
| W1 | love, 1.7 | back, 4.4 | good, 4.7 | green, 4.0 | day, 8.7 | class, 2.2 |
| W2 | professor, 1.3 | break, 3.9 | lol, 3.7 | today, 3.5 | st, 5.5 | time, 1.7 |
| W3 | columbus, 1.3 | school, 2.6 | miss, 2.8 | state, 2.2 | happy, 4.0 | year, 1.4 |
| W4 | found, 1.2 | time, 2.3 | ya, 2.6 | ohio, 2.2 | class, 2.7 | feel, 1.3 |
| W5 | live, 1.0 | spring, 2.2 | love, 1.5 | osu, 1.8 | today, 2.2 | haha, 1.2 |
| W6 | place, 1.0 | work, 2.1 | hope, 1.3 | wearing, 1.7 | birthday, 1.9 | win, 1.1 |
| W7 | thing, 0.9 | week, 1.8 | food, 1.1 | university, 1.5 | irish, 1.8 | wanna, 1.1 |
| W8 | omg, 0.9 | wait, 1.3 | pretty, 1.0 | campus, 1.3 | patty’s, 1.4 | bracket, 0.9 |
| W 9 | class, 0.9 | hate, 1.3 | make, 1.0 | college, 1.2 | patrick’s, 1.4 | perfect, 0.9 |
| W10 | study, 0.8 | people, 1.2 | shit, 0.9 | eyes, 1.1 | girl, 1.1 | made, 0.8 |
| #Tweets | 146 | 108 | 99 | 102 | 108 | 115 |
| Topics | School life | School life | School life | Wearing green at Ohio State Campus | Feelings towards Saint Patrick’s Day | School life |
| Word, % | T1 | T2 |
|---|---|---|
| W1 | bloomington, 17.7 | bloomingtoncraftbeerfest, 3.8 |
| W2 | beer, 14.2 | mill, 3.8 |
| W3 | craft, 14.0 | woolery, 3.2 |
| W4 | fest, 13.7 | bcbf, 2.7 |
| W5 | drinking, 7.6 | bcbw, 2.7 |
| W6 | 36, 1.6 | stout, 2.5 |
| W7 | ale, 1.2 | lager, 1.9 |
| W8 | festival, 1.0 | beer, 1.9 |
| W9 | 32, 0.9 | stone, 1.5 |
| W10 | brewing, 0.8 | rock, 1.1 |
| #Tweets | 83 | 25 |
| Topics | Drinking Beer in Bloomington Fest | Tweets with hashtag ‘bloomingtoncraftbeerfest’ |
| Word, % | T1 | T2 | T3 | T4 | T5 | T6 |
|---|---|---|---|---|---|---|
| W1 | merylatiu, 4.2 | lol, 4.7 | merylatiu,12.8 | amp, 2.3 | meryl, 16.7 | merylatiu,12.4 |
| W2 | react, 1.2 | class, 4.3 | young, 2.6 | campus,2.2 | streep, 12.0 | witch, 4.5 |
| W3 | miranda, 1.2 | time, 3.2 | weight, 1.9 | found, 2.0 | merylstreep,4.0 | woods, 3.2 |
| W4 | thatsall, 1.2 | love, 2.8 | women, 1.9 | things, 2.0 | indiana, 3.2 | play, 3.2 |
| W5 | priestly, 1.2 | thing, 2.5 | min, 1.8 | interested,2.0 | honorary, 3.2 | favorite, 3.1 |
| W6 | pants, 1.2 | week, 2.0 | excited, 1.6 | fed, 2.0 | merylatiu, 2.9 | turned, 1.9 |
| W7 | day, 1.2 | great, 1.8 | advice, 1.6 | appetites, 2.0 | iu, 2.8 | roles, 1.9 |
| W8 | candystriped,1.2 | numbers,1.2 | make, 1.4 | guy, 1.6 | university,2.7 | made, 1.9 |
| W9 | iu’s, 1.2 | bad, 1.1 | work, 1.4 | omnivore, 1.4 | auditorium,2.3 | decide, 1.9 |
| W10 | back, 1.2 | 10, 1.0 | 50, 1.3 | finally, 1.4 | degree, 1.7 | article, 1.9 |
| #Tweets | 29 | 25 | 27 | 28 | 45 | 18 |
| Topic | Meryl Streep at IU | School life | Hashtag merylatiu related to young women | School life | Meryl Streep received honor | Hashtag merylatiu and witch woods |
| Michigan | Stadium | Big | House | Blue | Goblue | University | game | wolverines |
| 206/230 | 144/164 | 143/136 | 136/128 | 125/106 | 100/65 | 32/65 | 22/28 | 18/13 |
| day | Ann | arbor | football | northwestern | great | hail | today | wildcats |
| 17/18 | 12/17 | 12/16 | 15/12 | 22/ | 19/ | 16/ | 14/ | 14/ |
| shutout | hailtothevictors | beatstate | state | gogreen | spartans | today | mi | green |
| 13/ | 10/ | /26 | /23 | /17 | /16 | /14 | /12 | /11 |
| Word, % | T1 | T2 | T3 | T4 | ||||
|---|---|---|---|---|---|---|---|---|
| Date | 10 Oct. | 17 Oct. | 10 Oct. | 17 Oct. | 10 Oct. | 17 Oct. | 10 Oct. | 17 Oct. |
| W1 | big 15.9 | big 17.4 | michigan 16.6 | michigan 18.0 | big 7.5 | michigan 12.4 | michigan 6.7 | day 6.0 |
| W2 | house 15.7 | house 17.3 | stadium 11.3 | stadium 9.8 | goblue 6.0 | university 10.0 | game 5.8 | game 5.4 |
| W3 | blue 15.1 | michigan 14.0 | university 7.6 | university 6.5 | house 5.5 | stadium 9.8 | great 5.6 | great 2.4 |
| W4 | michigan 14.2 | blue 13.8 | goblue 6.0 | state 5.2 | shutout 3.4 | goblue 8.4 | day 5.3 | big 2.2 |
| W5 | stadium 12.6 | stadium 11.6 | northwestern 4.0 | spartans 3.6 | homecoming 2.8 | beatstate 4.8 | goblue 4.9 | msu 2.1 |
| W6 | goblue 5.2 | goblue 4.3 | hail 3.6 | gogreen 3.3 | 380 2.0 | team 2.3 | football, 4.7 | today 2.1 |
| W7 | Hailto thevictors 1.2 | beatstate 1.2 | wolverines 3.5 | ann 3.1 | northwestern 1.8 | good 1.5 | bighouse 3.0 | friends 1.8 |
| W8 | team 0.7 | posted 0.9 | wildcats 3.4 | wolverines 3.0 | uofm 1.5 | football 1.3 | wolverine 2.3 | sweetest 1.7 |
| W9 | latergram 0.4 | green 0.8 | arbor 2.9 | arbor 3.0 | umich 1.5 | today 1.3 | beautiful 1.9 | happy 1.7 |
| W10 | hailyes 0.4 | tailgating 0.6 | ann 2.9 | game 2.4 | michigan 1.4 | hail 1.3 | today 1.8 | fun 1.6 |
| #Tweet | 112 | 115 | 51 | 56 | 34 | 48 | 34 | 37 |
| Topics | Big house game, go blue | University of Michigan vs its opponents | Homecoming game, go blue | Michigan great day, go blue | Great game with MSU | |||
| #Topics | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| Perplexity | 43.1 | 39.7 | 40.3 | 39.4 | 35.5 | 36.8 | 36.3 | 36.0 | 36.8 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Li, Y.; Shan, J. Spatial-Temporal Event Detection from Geo-Tagged Tweets. ISPRS Int. J. Geo-Inf. 2018, 7, 150. https://doi.org/10.3390/ijgi7040150
Huang Y, Li Y, Shan J. Spatial-Temporal Event Detection from Geo-Tagged Tweets. ISPRS International Journal of Geo-Information. 2018; 7(4):150. https://doi.org/10.3390/ijgi7040150
Chicago/Turabian StyleHuang, Yuqian, Yue Li, and Jie Shan. 2018. "Spatial-Temporal Event Detection from Geo-Tagged Tweets" ISPRS International Journal of Geo-Information 7, no. 4: 150. https://doi.org/10.3390/ijgi7040150
APA StyleHuang, Y., Li, Y., & Shan, J. (2018). Spatial-Temporal Event Detection from Geo-Tagged Tweets. ISPRS International Journal of Geo-Information, 7(4), 150. https://doi.org/10.3390/ijgi7040150