Are the Poor Digitally Left Behind? Indications of Urban Divides Based on Remote Sensing and Twitter Data

 , ,
, , 
Abstract
:1. Introduction
2. Background and Rationale
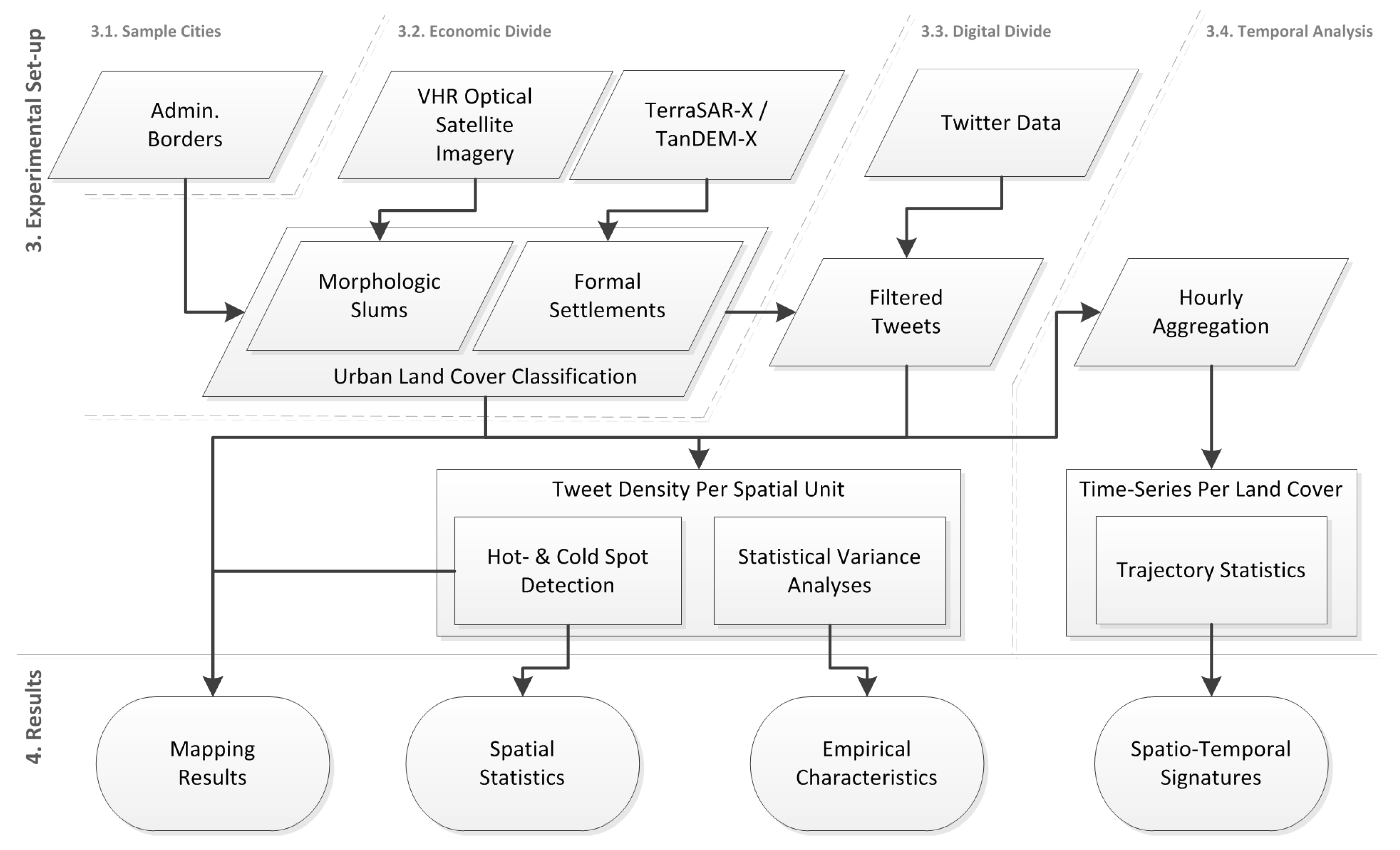
3. Experimental Set-Up: Materials and Methods
3.1. Selection of Experimental Cities
- We select cities which feature a significant share of urban poor documented in literature or official census data.
- We select cities containing building morphologies characteristic for slums, which are in line with the conceptual ontology presented by [20] and the related empirical basis demonstrated by [15]. This physical appearance differs to formal settlements and can be classified by VHR optical remote sensing data.
- We select cities at different cultural areas and continents across the globe.
3.2. Mapping the Economic Divide
3.2.1. Remote Sensing Data
- Optical sensors, such as QuickBird or WorldView, provide geometric resolutions of 1m and better and thus, the urban morphology is represented by individual buildings. We apply these data for the delimitation of morphologic slums. Figure 2a illustrates the complex urban environment by contrasting geometric, planned, formal building structures with non-regular, unplanned, non-formal building structures of morphological slums.
- We use radar data from the TerraSAR-X and TanDEM-X missions at Stripmap mode providing geometric resolutions of 3 m. For urban landscapes spatial complexity of varying objects within small areas is characteristic. In radar data this is represented in highly textured image regions of strong directional, non-Gaussian backscatter due to double bounce effects. This information is used along with the intensity information to delineate ‘settlements’ from ‘non-settlements’ using an unsupervised image analysis technique, for technical details we refer to [43]. The accuracies of the settlement classification in dense urban areas (as in our case studies) have been measured beyond 90% [44].
3.2.2. Mapping Morphologic Slums versus Formal Settlements
3.3. Mapping the Digital Divide
3.3.1. Twitter Data
3.3.2. Filtering and Processing of Twitter Data
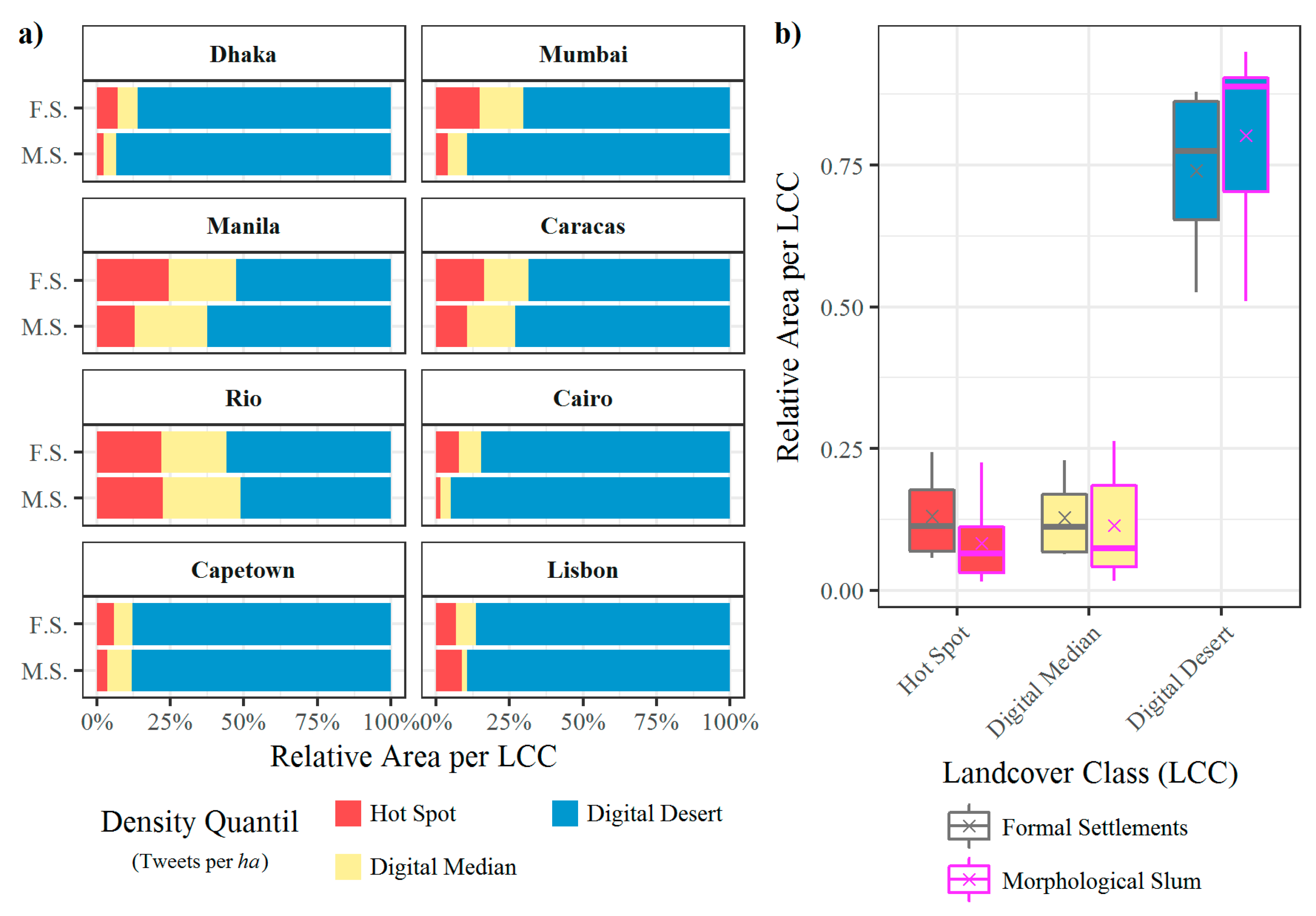
3.3.3. Statistical Spatial Variations of Tweet Densities between Morphological Slums and Formal Settlements
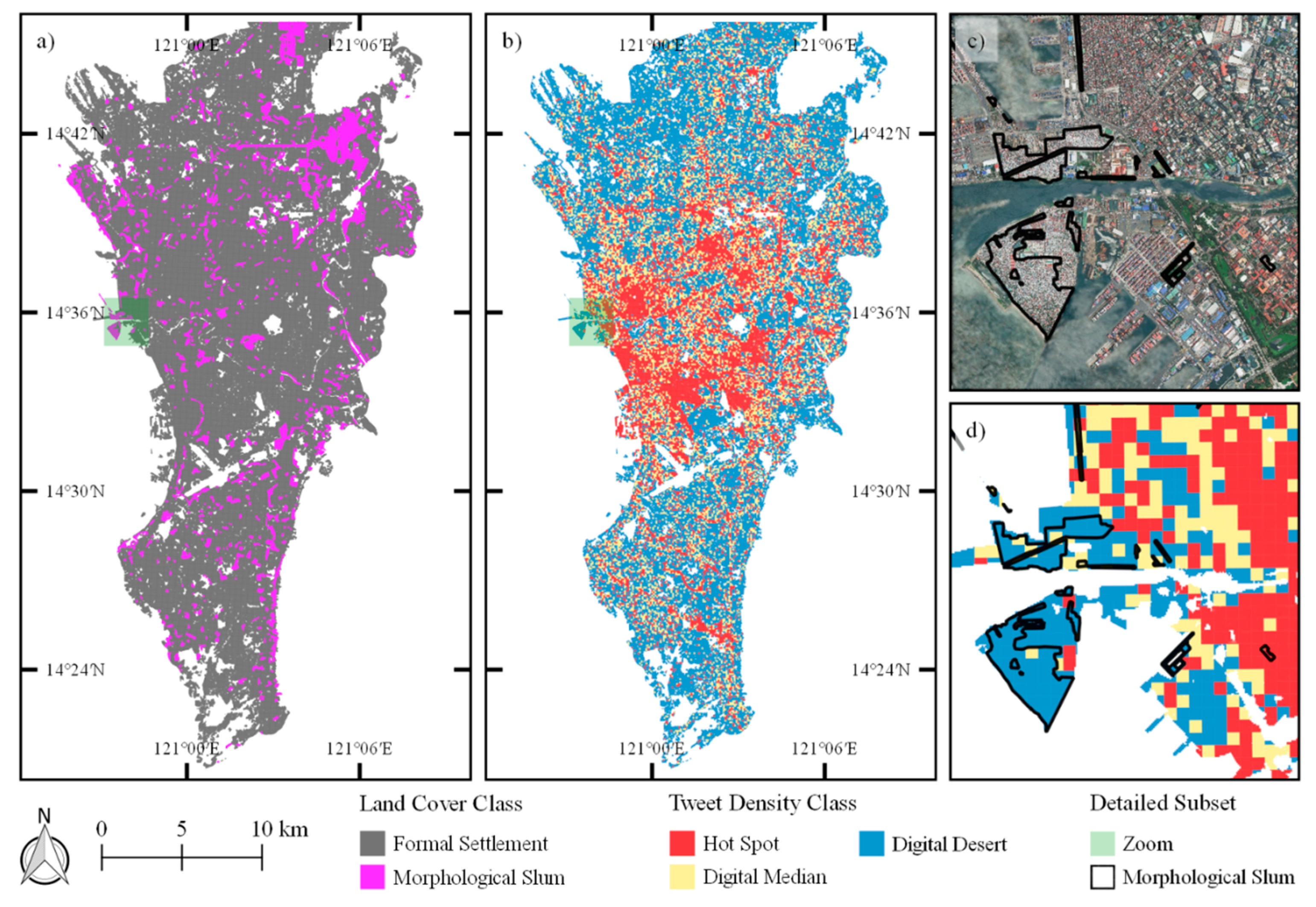
3.3.4. Detection of Digital Hot and Cold Spots
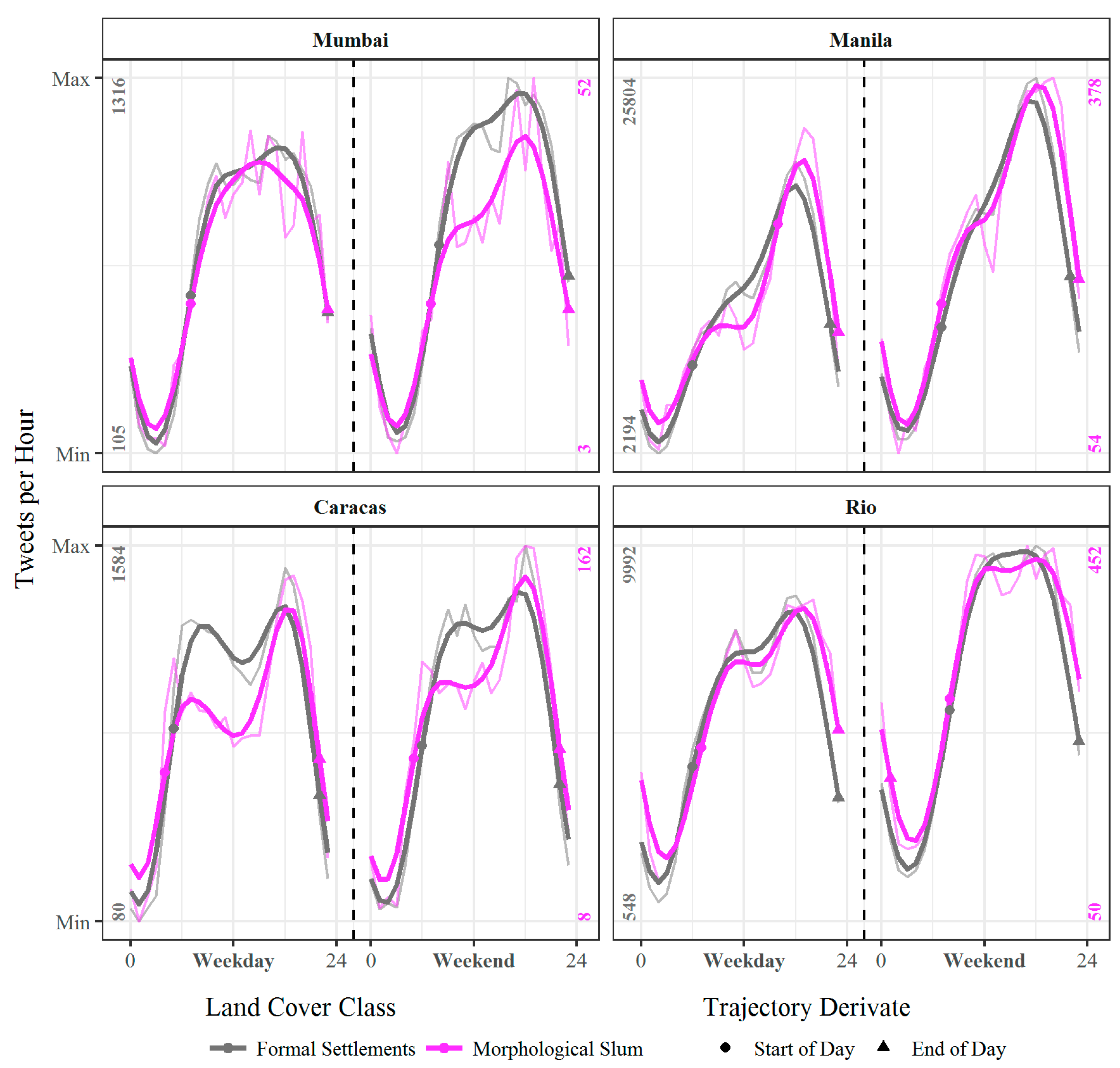
3.4. Temporal Analysis
4. Results
4.1. Data and Mapping Results
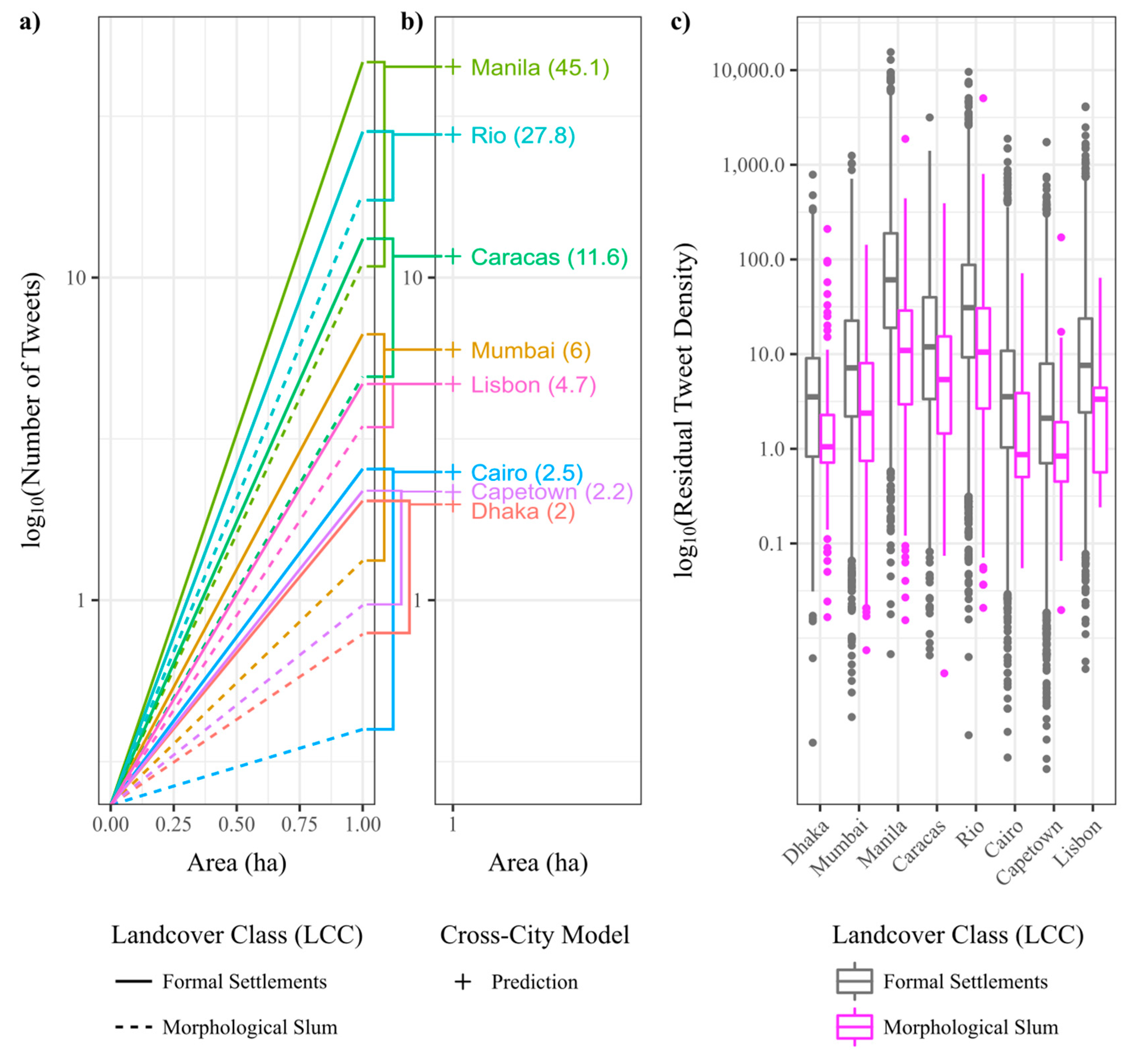
- In general, we classify 274,184 hectare of cumulated settlement areas for all our sample cities. We find that only 5.54% of the settlement areas are occupied by ‘morphologic slums’. However, for the area share of morphologic slums of the total settlement area we observe a strong variation across cities from 18.90% in Caracas to only 0.11% in Lisbon (Table 1).
- The preprocessed twitter data set contains 3.73 million geolocated tweets cumulated for all sample cities. We find that twitter activity varies significantly across cities, with Manila featuring more than 2 million tweets vs. Dhaka with only about 30,000 tweets within the time period of monitoring. Beyond, we also find that a relatively small share of tweets of 2.7% is localized in morphologic slum areas. However, we also observe strong variations of shares of tweets in morphologic slums across cities from 8.74% in Caracas to only 0.07% in Lisbon (Table 1).
4.2. Variance Analysis of Tweet Densities Across Cities and Within Cities (between Morphological Slums and Formal Settlements)
4.3. Spatial Statistics of Digital Hot Spots and Cold Spots
4.4. Temporal Signatures of Twitter Activities
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hollis, L. Cities Are Good for You: The Genius of the Metropolis, 1st ed.; Bloomsbury Press: New York, NY, USA, 2013; ISBN 978-1-62040-206-1. [Google Scholar]
- UN-Habitat. Planning Sustainable Cities: Global Report on Human Settlements 2009; Routledge: London, UK, 2009; ISBN 1-134-90071-6. [Google Scholar]
- UN-Habitat. Urbanization and Development Emerging Futures: World Cities Report; United Nations Publication: New York, NY, USA, 2016. [Google Scholar]
- Milanovic, B. Die Ungleiche Welt: Migration, das Eine Prozent und Die Zukunft der Mittelschicht; Suhrkamp: Berlin, Germany, 2016. [Google Scholar]
- International Organization for Migration. World Migration Report 2015: Migrants and Cities: New Partnerships to Manage Mobility; International Organization for Migration (IOM): Geneva, Switzerland, 2015; ISBN 978-92-9068-709-2. [Google Scholar]
- Tacoli, C.; McGranahan, G.; Satterthwaite, D. Urbanisation, Rural-Urban Migration and Urban Poverty; International Institute for Environment and Development: London, UK, 2015; ISBN 978-1-78431-137-7. [Google Scholar]
- Taubenböck, H.; Wurm, M. Ich weiß, dass ich nichts weiß—Bevölkerungsschätzung in der Megacity Mumbai. In Globale Urbanisierung; Springer: Berlin, Germany, 2015; pp. 171–178. [Google Scholar]
- Crampton, J.W.; Graham, M.; Poorthuis, A.; Shelton, T.; Stephens, M.; Wilson, M.W.; Zook, M. Beyond the geotag: Situating ‘big data’ and leveraging the potential of the geoweb. Cartogr. Geogr. Inf. Sci. 2013, 40, 130–139. [Google Scholar] [CrossRef]
- OECD. Poverty Rate (Indicator). 2018. Available online: https://doi.org/10.1787/0fe1315d-en (accessed on 24 July 2018).
- Sliuzas, R.; Mboup, G.; de Sherbinin, A. Report of the Expert Group Meeting on Slum Identification and Mapping; CIESIN, UN-Habitat, ITC: Enschede, The Netherlands, 2008; Volume 36. [Google Scholar]
- Bibi, S. Measuring Poverty in a Multidimensional Perspective: A Review of Literature. PEP Working Paper No. 2005-07. Available online: https://ssrn.com/abstract=850487 (accessed on 1 November 2005).
- Harvey, D. Rebellische Städte: Vom Recht auf Stadt zur Urbanen Revolution; Suhrkamp: Berlin, Germany, 2013; ISBN 978-3-518-12657-8. [Google Scholar]
- Barber, B.R. If Mayors Ruled the World: Dysfunctional Nations, Rising Cities; Yale University Press: New Haven, CT, USA, 2014; ISBN 978-0-300-20932-7. [Google Scholar]
- Glaeser, E.L.; Kahn, M.E.; Rappaport, J. Why do the poor live in cities? The role of public transportation. J. Urban. Econ. 2008, 63, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Taubenböck, H.; Kraff, N.J.; Wurm, M. The morphology of the Arrival City—A global categorization based on literature surveys and remotely sensed data. Appl. Geogr. 2018, 92, 150–167. [Google Scholar] [CrossRef]
- Perlman, J.E. Marginality from Myth to Reality—The Favelas of Rio de Janeiro 1968–2005. 2005. Available online: http://advantronsample2.com/Marginality_from_Myth_to_Reality.pdf (accessed on 5 June 2018).
- Mitra, S.; Mulligan, J.; Schilling, J.; Harper, J.; Vivekananda, J.; Krause, L. Developing risk or resilience? Effects of slum upgrading on the social contract and social cohesion in Kibera, Nairobi. Environ. Urban. 2017, 29, 103–122. [Google Scholar] [CrossRef]
- Wratten, E. Conceptualizing urban poverty. Environ. Urban. 1995, 7, 11–38. [Google Scholar] [CrossRef] [Green Version]
- Kuffer, M.; Pfeffer, K.; Sliuzas, R. Slums from Space—15 Years of Slum Mapping Using Remote Sensing. Remote Sens. 2016, 8, 455. [Google Scholar] [CrossRef]
- Kohli, D.; Sliuzas, R.; Kerle, N.; Stein, A. An ontology of slums for image-based classification. Comput. Environ. Urban Syst. 2012, 36, 154–163. [Google Scholar] [CrossRef]
- Owen, K.K.; Wong, D.W. An approach to differentiate informal settlements using spectral, texture, geomorphology and road accessibility metrics. Appl. Geogr. 2013, 38, 107–118. [Google Scholar] [CrossRef]
- Engstrom, R.; Sandborn, A.; Qin, Y.; Burgdorfer, J.; Stow, D.; Weeks, J.; Graesser, J. Mapping slums using spatial features in Accra, Ghana. In Proceedings of the Urban Remote Sensing Event, 2015 Joint, Lausanne, Switzerland, 30 March–1 April 2015; pp. 1–4. [Google Scholar]
- Wurm, M.; Taubenböck, H.; Weigand, M.; Schmitt, A. Slum mapping in polarimetric SAR data using spatial features. Remote Sens. Environ. 2017, 194, 190–204. [Google Scholar] [CrossRef]
- Sandborn, A.; Engstrom, R.N. Determining the Relationship between Census Data and Spatial Features Derived From High-Resolution Imagery in Accra, Ghana. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1970–1977. [Google Scholar] [CrossRef]
- Wurm, M.; Taubenböck, H. Detecting social groups from space—Assessment of remote sensing-based mapped morphological slums using income data. Remote Sens. Lett. 2018, 9, 41–50. [Google Scholar] [CrossRef]
- Norris, P. Digital Divide: Civic Engagement, Information Poverty, and the Internet Worldwide; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Hersberger, J.A. Are the economically poor information poor? Does the digital divide affect the homeless and access to information? Can. J. Inf. Libr. Sci. 2003, 27, 44–63. [Google Scholar]
- Blank, G. The Digital Divide among Twitter Users and Its Implications for Social Research. Soc. Sci. Comput. Rev. 2017, 35, 679–697. [Google Scholar] [CrossRef]
- Leetaru, K.; Wang, S.; Cao, G.; Padmanabhan, A.; Shook, E. Mapping the global Twitter heartbeat: The geography of Twitter. First Monday 2013, 18, 5–6. [Google Scholar] [CrossRef]
- Li, L.; Goodchild, M.F.; Xu, B. Spatial, temporal, and socioeconomic patterns in the use of Twitter and Flickr. Cartogr. Geogr. Inf. Sci. 2013, 40, 61–77. [Google Scholar] [CrossRef]
- Nemer, D. Online Favela: The Use of Social Media by the Marginalized in Brazil. Inf. Technol. Dev. 2015, 22, 364–379. [Google Scholar] [CrossRef]
- Wyche, S.P.; Forte, A.; Yardi Schoenebeck, S. Hustling online: Understanding consolidated facebook use in an informal settlement in Nairobi. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 2823–2832. [Google Scholar]
- Klotz, M.; Wurm, M.; Zhu, X.X.; Taubenböck, H. Digital deserts on the ground and from space—An experimental spatial analysis combining social network and earth observation data in megacity Mumbai. In Proceedings of the Joint Urban Remote Sensing Event, Dubai, UAE, 6–8 March 2017; pp. 1–4. [Google Scholar]
- Frias-Martinez, V.; Soto, V.; Hohwald, H.; Frias-Martinez, E. Characterizing Urban Landscapes Using Geolocated Tweets. In Proceedings of the 2012 International Conference on Privacy, Security, Risk and Trust and 2012 International Confernece on Social Computing, Amsterdam, The Netherlands, 3–5 September 2012; pp. 239–248. [Google Scholar]
- Domínguez, D.R.; Díaz Redondo, R.P.; Vilas, A.F.; Khalifa, M.B. Sensing the city with Instagram: Clustering geolocated data for outlier detection. Expert Syst. Appl. 2017, 78, 319–333. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, X.; Gao, S.; Gong, L.; Kang, C.; Zhi, Y.; Chi, G.; Shi, L. Social Sensing: A New Approach to Understanding Our Socioeconomic Environments. Ann. Assoc. Am. Geogr. 2015, 105, 512–530. [Google Scholar] [CrossRef]
- Cranshaw, J.; Schwartz, R.; Hong, J.I.; Sadeh, N. The Livehoods Project: Utilizing Social Media to Understand the Dynamics of a City. In Proceedings of the Sixth International AAAI Conference on Weblogs and Social Media, Dublin, Ireland, 4–7 June 2012; pp. 58–65. [Google Scholar]
- Goodchild, M.F. The quality of big (geo)data. Dialogues Hum. Geogr. 2013, 3, 280–284. [Google Scholar] [CrossRef]
- Morstatter, F.; Pfeffer, J.; Liu, H.; Carley, K.M. Is the Sample Good Enough? Comparing Data from Twitter’s Streaming API with Twitter’s Firehose. In Proceedings of the Seventh International Conference on Weblogs and Social Media, Cambridge, MA, USA, 8–11 July 2013. [Google Scholar]
- Mislove, A.; Lehmann, S.; Ahn, Y.-Y.; Onnela, J.-P.; Rosenquist, J.N. Understanding the Demographics of Twitter Users. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; p. 11. [Google Scholar]
- Anselin, L.; Williams, S. Digital neighborhoods. J. Urban. Int. Res. Placemak. Urban. Sustain. 2016, 9, 305–328. [Google Scholar] [CrossRef]
- GADM. Database of Global Administrative Areas; GADM: Montreal, QC, Cannada, 2018. [Google Scholar]
- Esch, T.; Taubenböck, H.; Roth, A.; Heldens, W.; Felbier, A.; Thiel, M.; Schmidt, M.; Müller, A.; Dech, S. TanDEM-X mission—New perspectives for the inventory and monitoring of global settlement patterns. J. Appl. Remote Sens. 2012, 6, 061702. [Google Scholar] [CrossRef]
- Klotz, M.; Kemper, T.; Geiß, C.; Esch, T.; Taubenböck, H. How good is the map? A multi-scale cross-comparison framework for global settlement layers: Evidence from Central Europe. Remote Sens. Environ. 2016, 178, 191–212. [Google Scholar] [CrossRef] [Green Version]
- Graesser, J.; Cheriyadat, A.; Vatsavai, R.R.; Chandola, V.; Long, J.; Bright, E. Image Based Characterization of Formal and Informal Neighborhoods in an Urban Landscape. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1164–1176. [Google Scholar] [CrossRef]
- Twitter Inc. Annual Report; Twitter Inc.: San Francisco, CA, USA, 2017. [Google Scholar]
- Chambers, J.; Freeny, A.; Heiberger, R. Analysis of variance; designed experiments. Stat. Model. S 1992, 5, 145–193. [Google Scholar]
- Filippa, G.; Cremonese, E.; Migliavacca, M.; Galvagno, M.; Forkel, M.; Wingate, L.; Tomelleri, E.; Morra di Cella, U.; Richardson, A.D. Phenopix: A R package for image-based vegetation phenology. Agric. For. Meteorol. 2016, 220, 141–150. [Google Scholar] [CrossRef] [Green Version]
- Engstrom, R.; Hersh, J.; Newhouse, D. Poverty from Space: Using High-Resolution Satellite Imagery for Estimating Economic Well-Being; Policy Research Working Papers; World Bank Group: Washington, DC, USA, 2017. [Google Scholar]
- Zandbergen, P.A. Accuracy of iPhone Locations: A Comparison of Assisted GPS, WiFi and Cellular Positioning. Trans. GIS 2009, 13, 5–25. [Google Scholar] [CrossRef]
- Davis, M. Planet. der Slums; Assoziation A: Berlin, Germany, 2007; ISBN 978-3-935936-56-9. [Google Scholar]
- Fuchs, M. Slum als Projekt: Dharavi und die Falle der Marginalisierung. In Mumbai–Delhi–Kolkata. Annäherungen an die Megastädte Indiens; Draupadi: Heidelberg, Germany, 2006; pp. 47–63. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| City | Settlement Area Based on Remote Sensing Data | Number of Recorded Tweets and Shares of Tweets | Number of Twitter Users | |||
|---|---|---|---|---|---|---|
| Total (ha) | Morphologic Slum (%) | Total (n) | Morphologic Slum (%) | Total (n) | Morphologic Slum (%) | |
| Dhaka | 20,817 | 6.79% | 28,395 | 3.11% | 17,773 | 3.1% |
| Mumbai | 23,940 | 14.21% | 133,161 | 3.5% | 79,540 | 2.99% |
| Manila | 47,552 | 6.09% | 2,038,719 | 1.61% | 1,265,235 | 1.36% |
| Caracas | 16,333 | 18.9% | 233,876 | 8.74% | 108,346 | 7.81% |
| Rio | 36,191 | 6.66% | 999,525 | 4.55% | 583,973 | 4.15% |
| Cairo | 52,482 | 2.53% | 122,192 | 0.43% | 71,325 | 0.3% |
| Capetown | 40,673 | 1.49% | 87,779 | 0.64% | 50,962 | 0.47% |
| Lisbon | 36,196 | 0.11% | 150,861 | 0.07% | 98,136 | 0.04% |
| Weekday | Weekend | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SOD | EOD | LOD | RMSE | SOD | EOD | LOD | RMSE | ||
| Mumbai | Formal Settlement. | 7.08 | 23.06 | 15.98 | 0.039 | 8.09 | 23.06 | 14.97 | 0.042 |
| Morphological slum | 7.08 | 23.06 | 15.98 | 0.073 | 7.08 | 23.06 | 15.98 | 0.080 | |
| Manila | Formal Settlement. | 6.07 | 22.04 | 15.98 | 0.032 | 7.08 | 22.04 | 14.97 | 0.033 |
| Morphological slum | 16.04 | 23.06 | 7.01 | 0.044 | 7.08 | 23.06 | 15.98 | 0.056 | |
| Caracas | Formal Settlement. | 5.06 | 22.04 | 16.99 | 0.052 | 6.07 | 22.04 | 15.98 | 0.048 |
| Morphological slum | 4.04 | 22.04 | 18.00 | 0.058 | 5.06 | 22.04 | 16.99 | 0.057 | |
| Rio | Formal Settlement. | 6.07 | 23.06 | 16.99 | 0.035 | 8.09 | 23.06 | 14.97 | 0.028 |
| Morphological slum | 7.08 | 23.06 | 15.98 | 0.038 | 8.09 | 1.08 | 16.99 | 0.043 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taubenböck, H.; Staab, J.; Zhu, X.X.; Geiß, C.; Dech, S.; Wurm, M. Are the Poor Digitally Left Behind? Indications of Urban Divides Based on Remote Sensing and Twitter Data. ISPRS Int. J. Geo-Inf. 2018, 7, 304. https://doi.org/10.3390/ijgi7080304
Taubenböck H, Staab J, Zhu XX, Geiß C, Dech S, Wurm M. Are the Poor Digitally Left Behind? Indications of Urban Divides Based on Remote Sensing and Twitter Data. ISPRS International Journal of Geo-Information. 2018; 7(8):304. https://doi.org/10.3390/ijgi7080304
Chicago/Turabian StyleTaubenböck, Hannes, Jeroen Staab, Xiao Xiang Zhu, Christian Geiß, Stefan Dech, and Michael Wurm. 2018. "Are the Poor Digitally Left Behind? Indications of Urban Divides Based on Remote Sensing and Twitter Data" ISPRS International Journal of Geo-Information 7, no. 8: 304. https://doi.org/10.3390/ijgi7080304
APA StyleTaubenböck, H., Staab, J., Zhu, X. X., Geiß, C., Dech, S., & Wurm, M. (2018). Are the Poor Digitally Left Behind? Indications of Urban Divides Based on Remote Sensing and Twitter Data. ISPRS International Journal of Geo-Information, 7(8), 304. https://doi.org/10.3390/ijgi7080304