On the Risk Assessment of Terrorist Attacks Coupled with Multi-Source Factors

 ,
, 

Abstract
:1. Introduction and Related Works
1.1. Introduction
1.2. Related Works
2. Method
2.1. Data Processing
- (1)
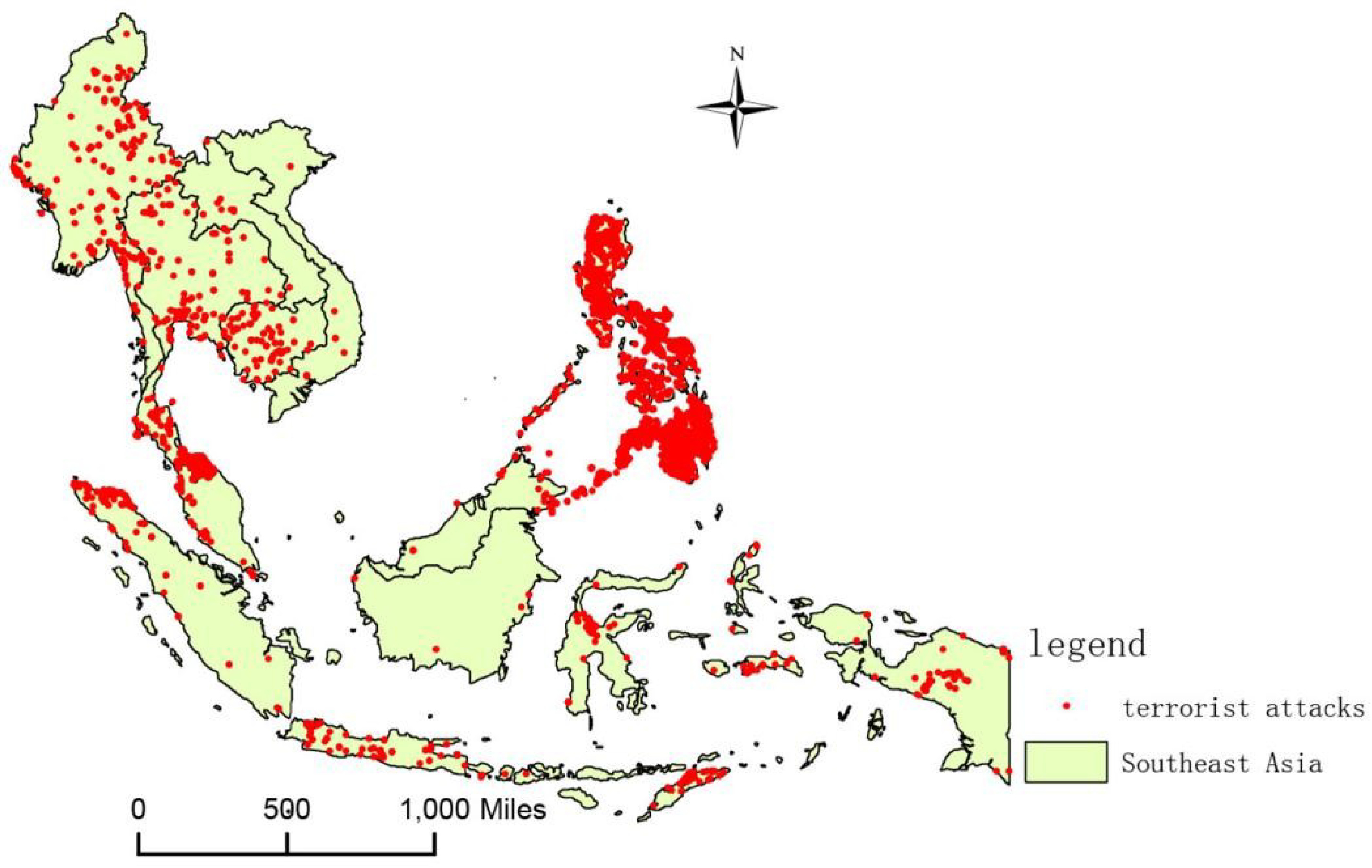
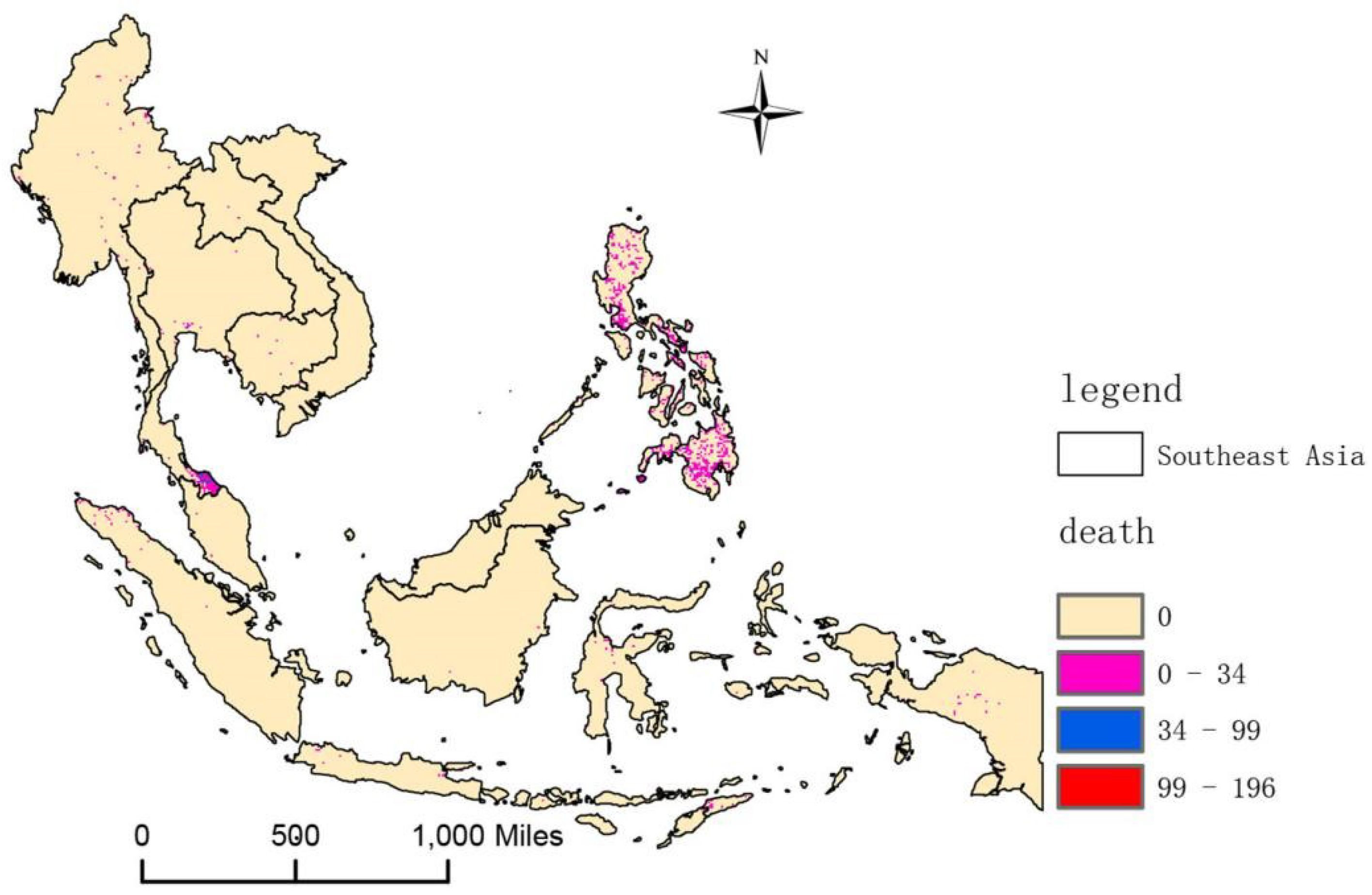
- Based on GTD, the location of terrorist attacks in Southeast Asia, as well as the numbers of casualties, can be obtained, and the information on the terrorist attacks is converted into raster data, selecting a grid with a 0.1° × 0.1° resolution. The grid serves as a spatial unit to facilitate the statistical determination of the number of terrorist incidents and the total number of casualties.
- (2)
- The raster data of five factors can be obtained by G-Econ 4.0 (a dataset of world economic activity): the distance from the main sailing lake (km), the distance from the main sailing river (km), the distance from the ice-free sea, the average precipitation (mm/a), and the average temperature (°C); subsequently, ArcMap 10.3 is used to sample the above raster data in a 0.1° × 0.1° grid.
- (3)
- Ethnic diversity is based on the GeoEPR (National Relations Dataset); the main drug area is based on the World Drug Report and the national administrative border; nighttime lighting is based on the Earth Observation Organization; population density; and topography is based on NASA’s Earth Observatory. We use ArcMap 10.3 to sample the above data in a 0.1° × 0.1° grid.
- (4)
- With respect to points of interest (POIs), we use the Google Places API to get POI data of Southeast Asia, and then use ArcMap 10.3 to sample it in a 0.1° × 0.1° grid.
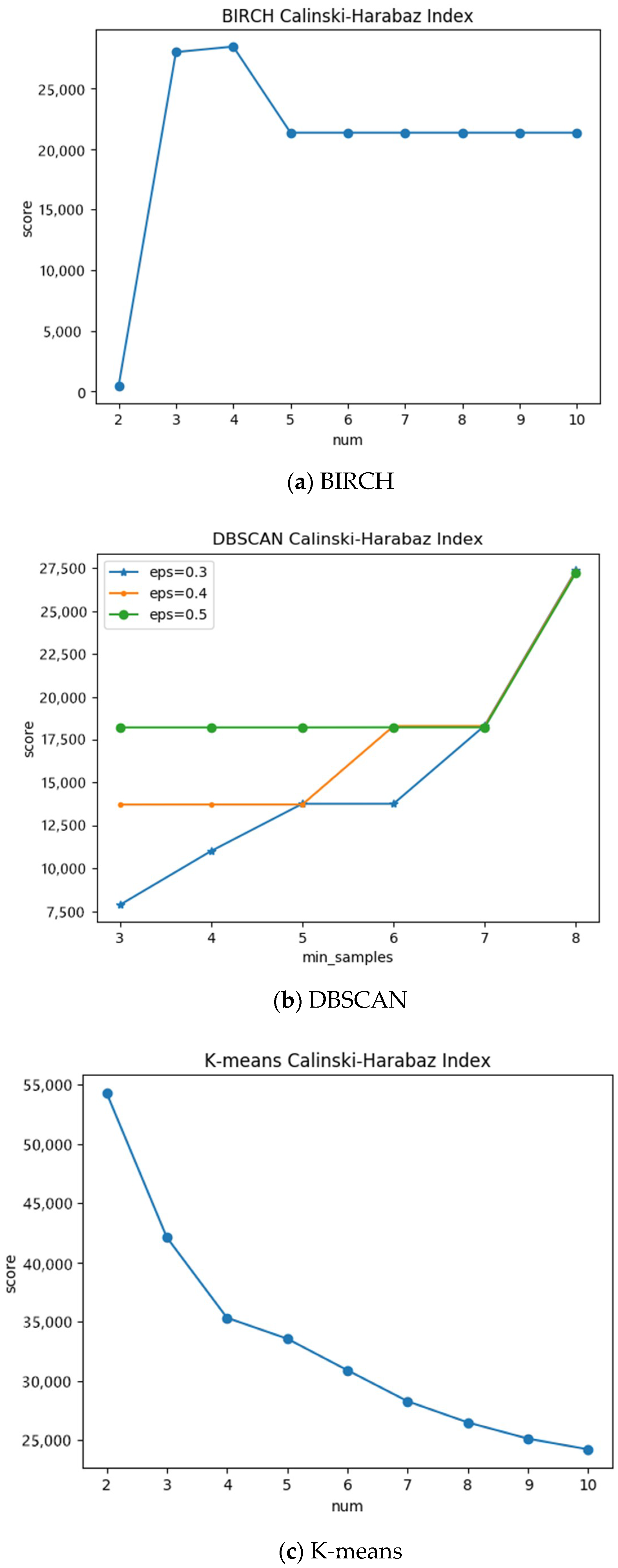
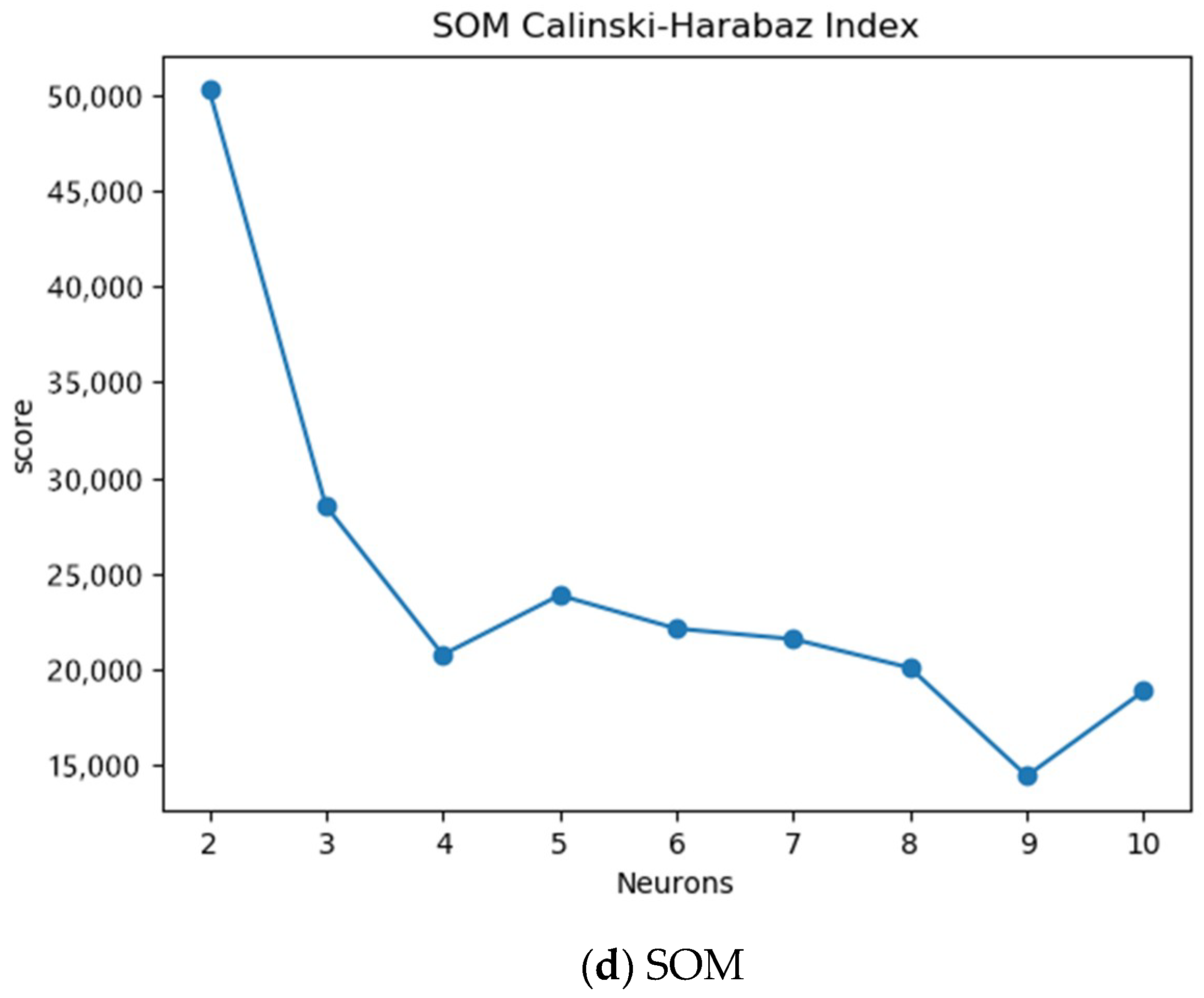
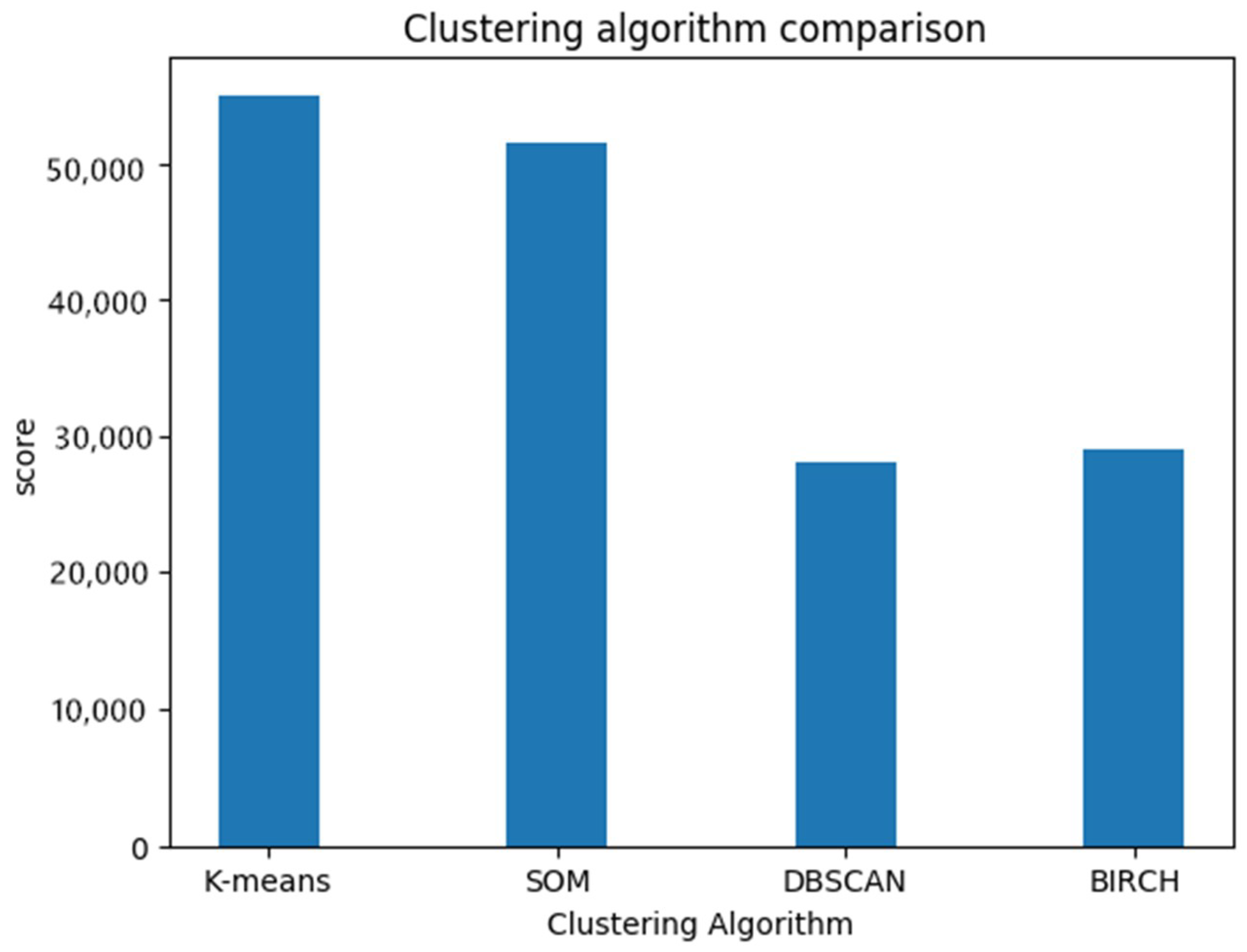
2.2. Algorithm
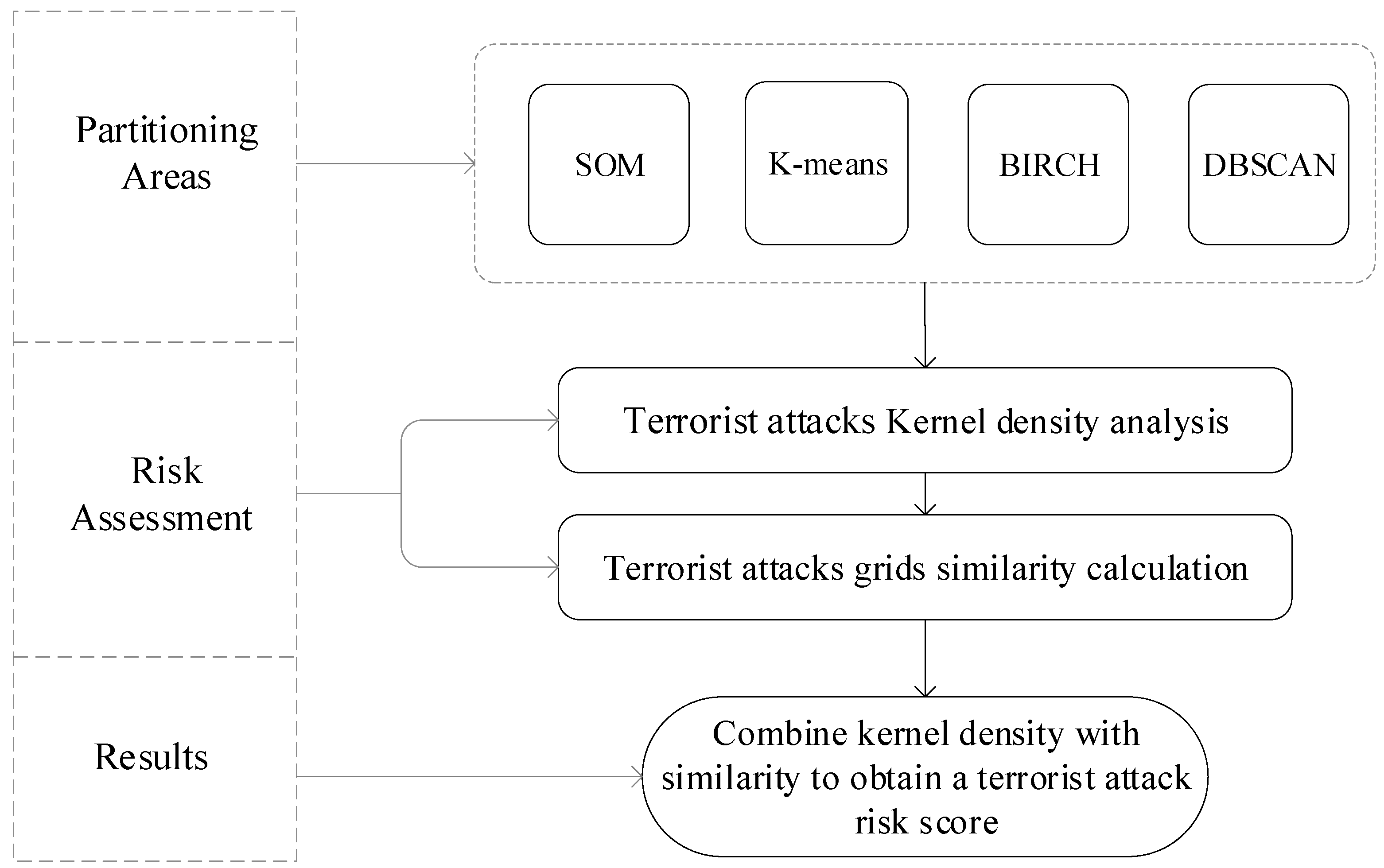
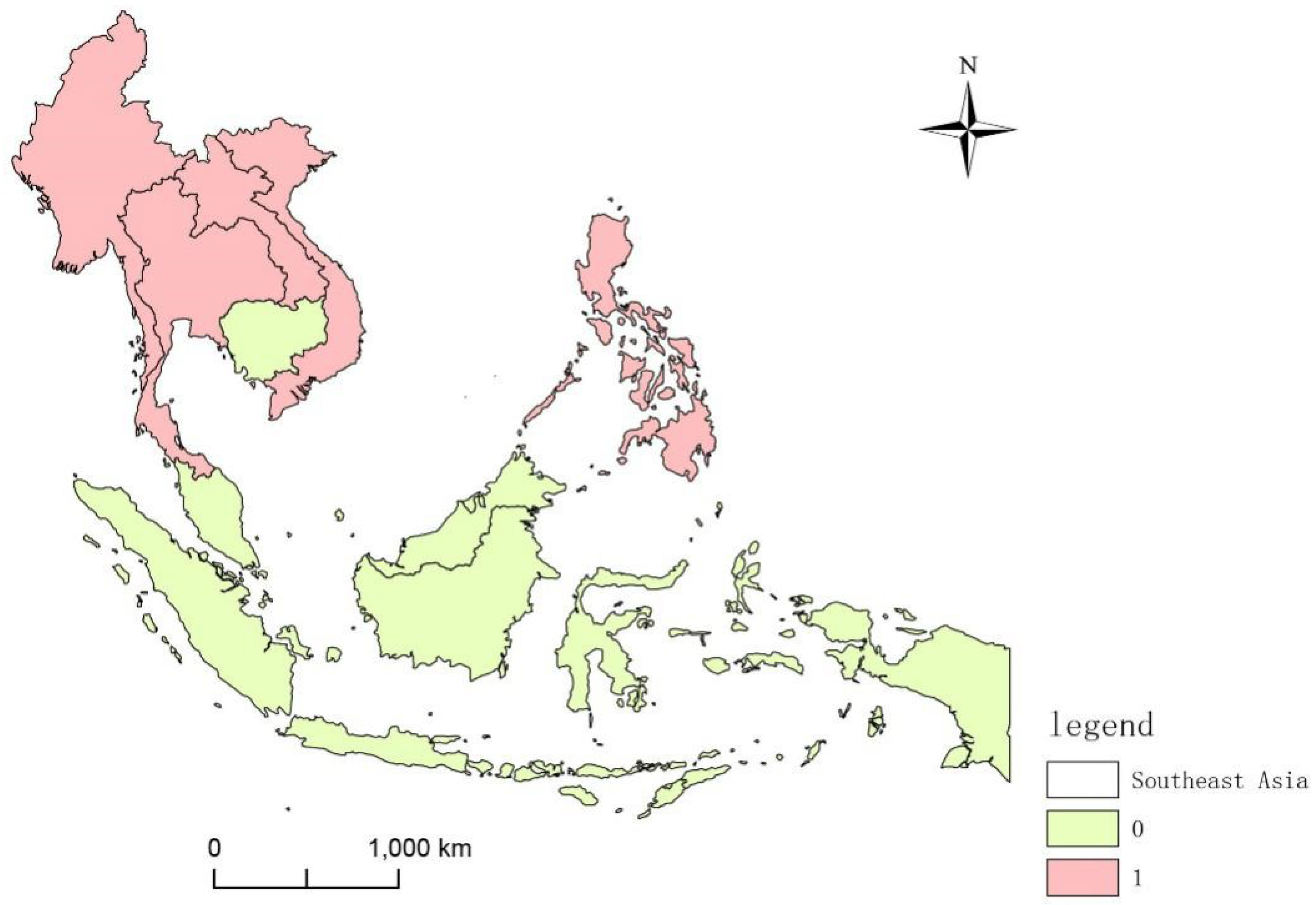
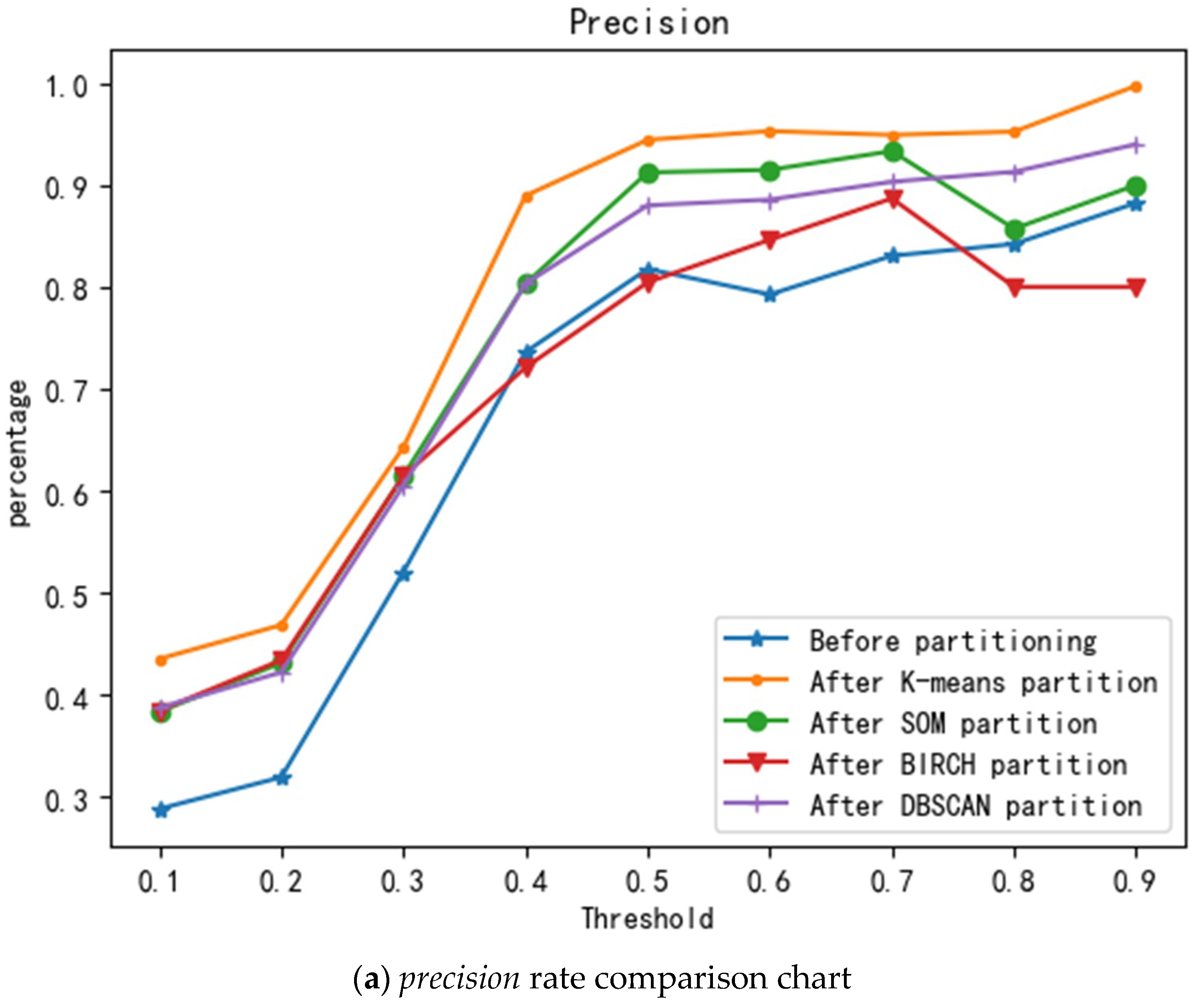
2.2.1. Partitioning Areas
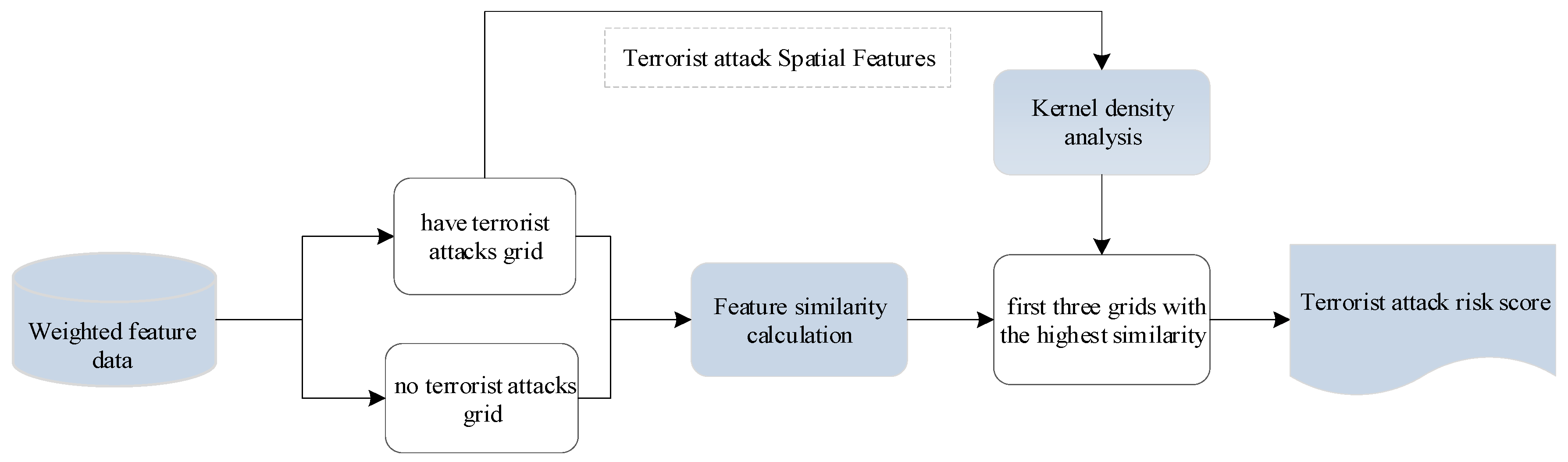
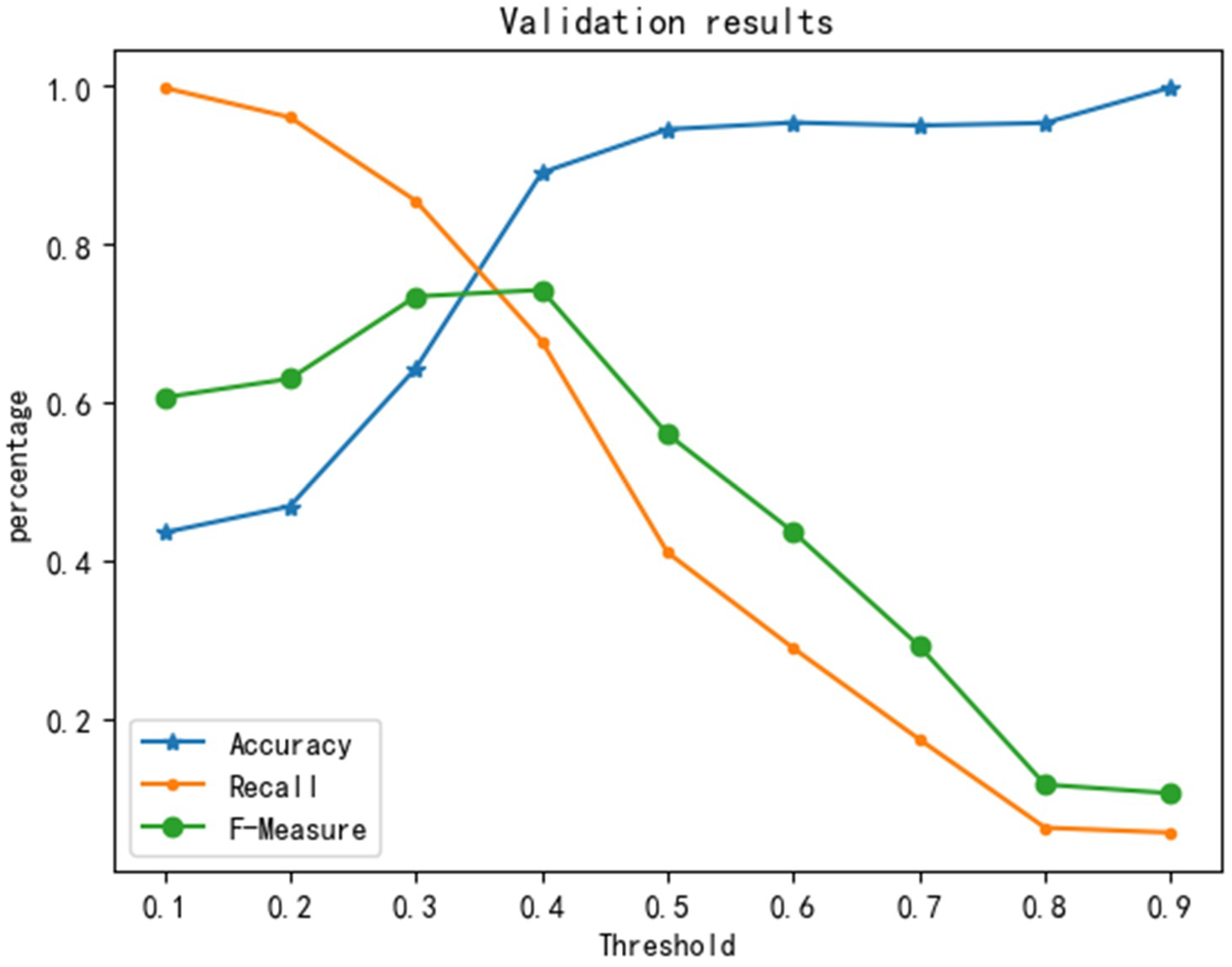
2.2.2. Risk Assessment
3. Results and Analysis
3.1. Regional Division Results
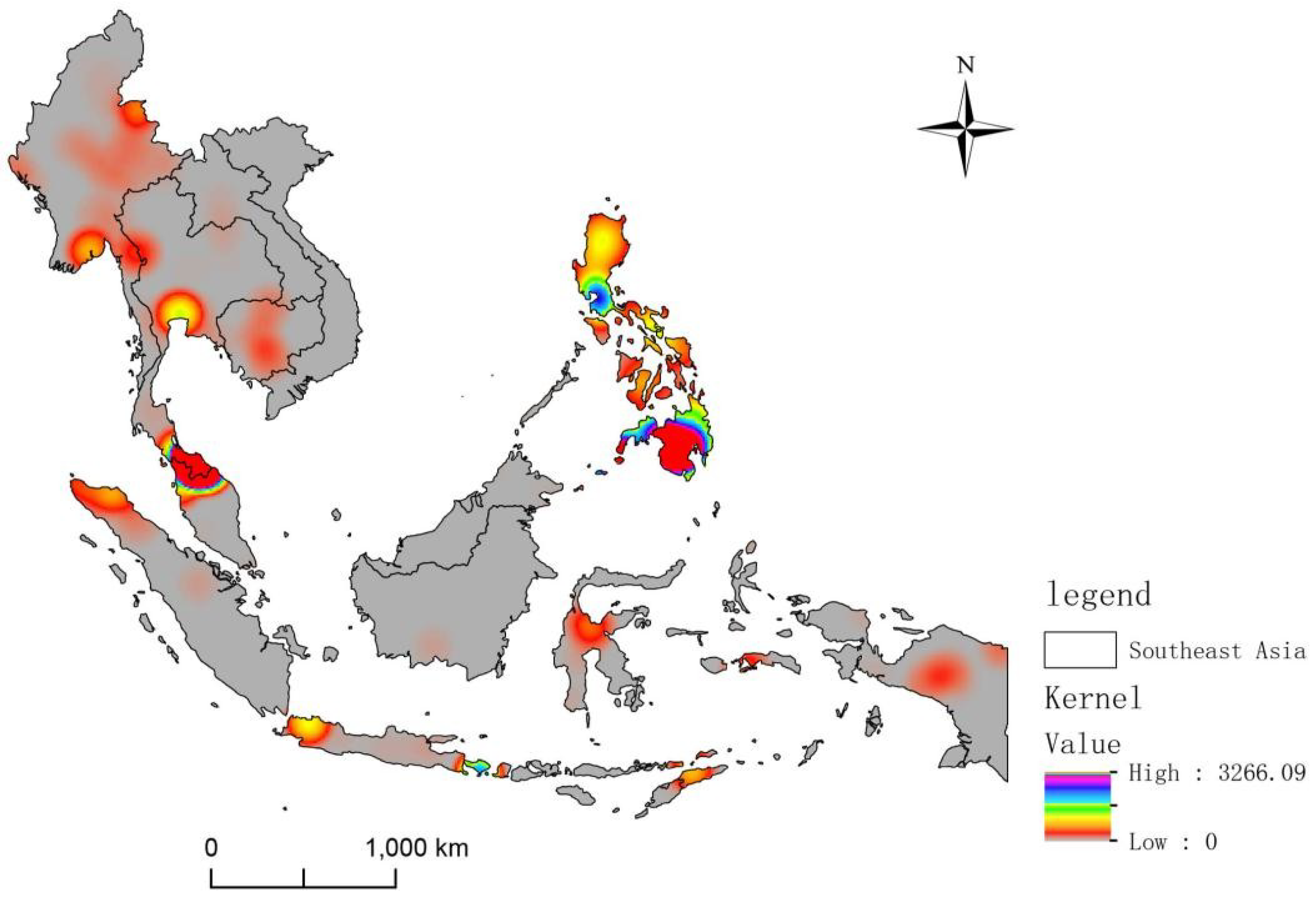
3.2. Spatial Characteristics
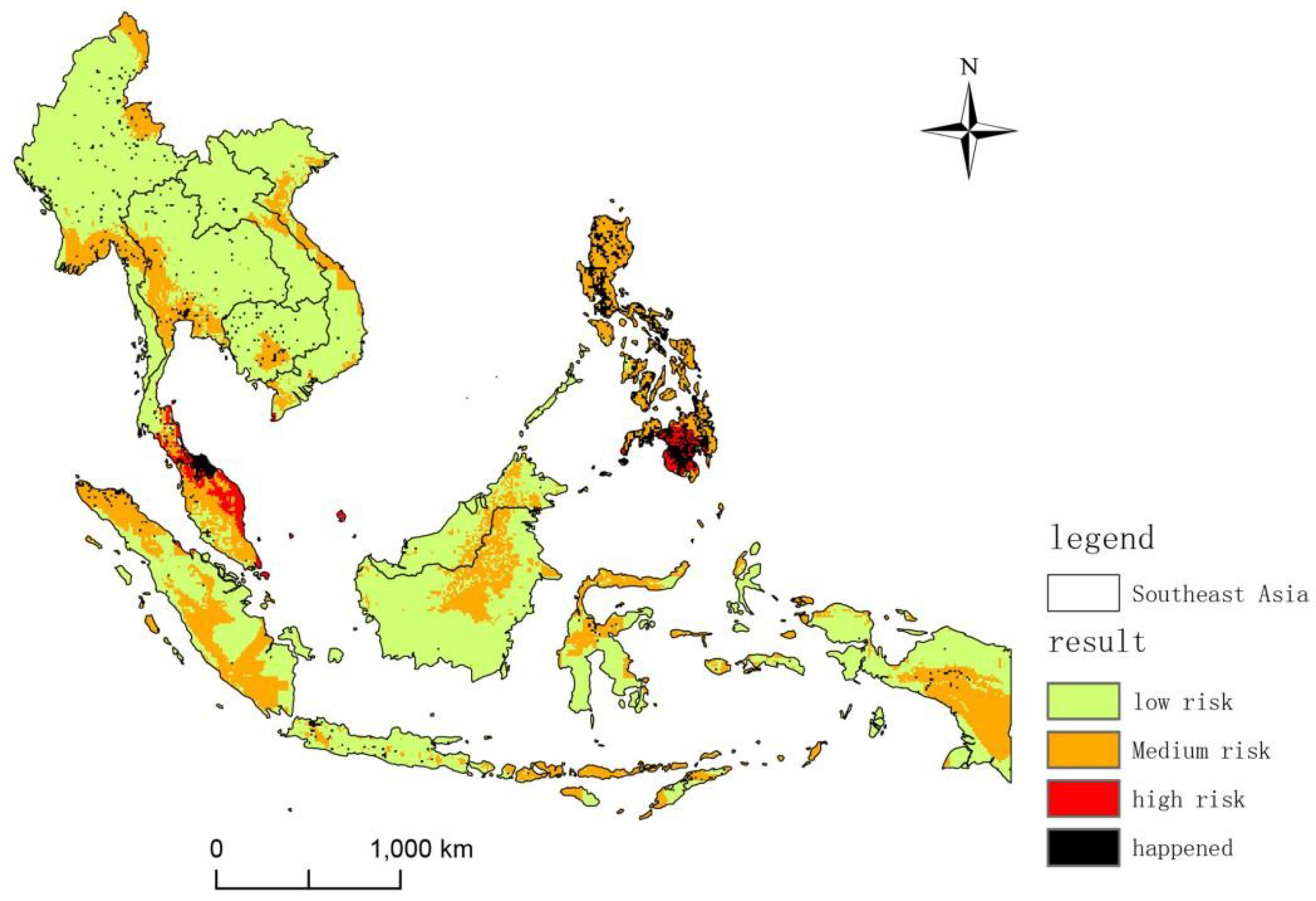
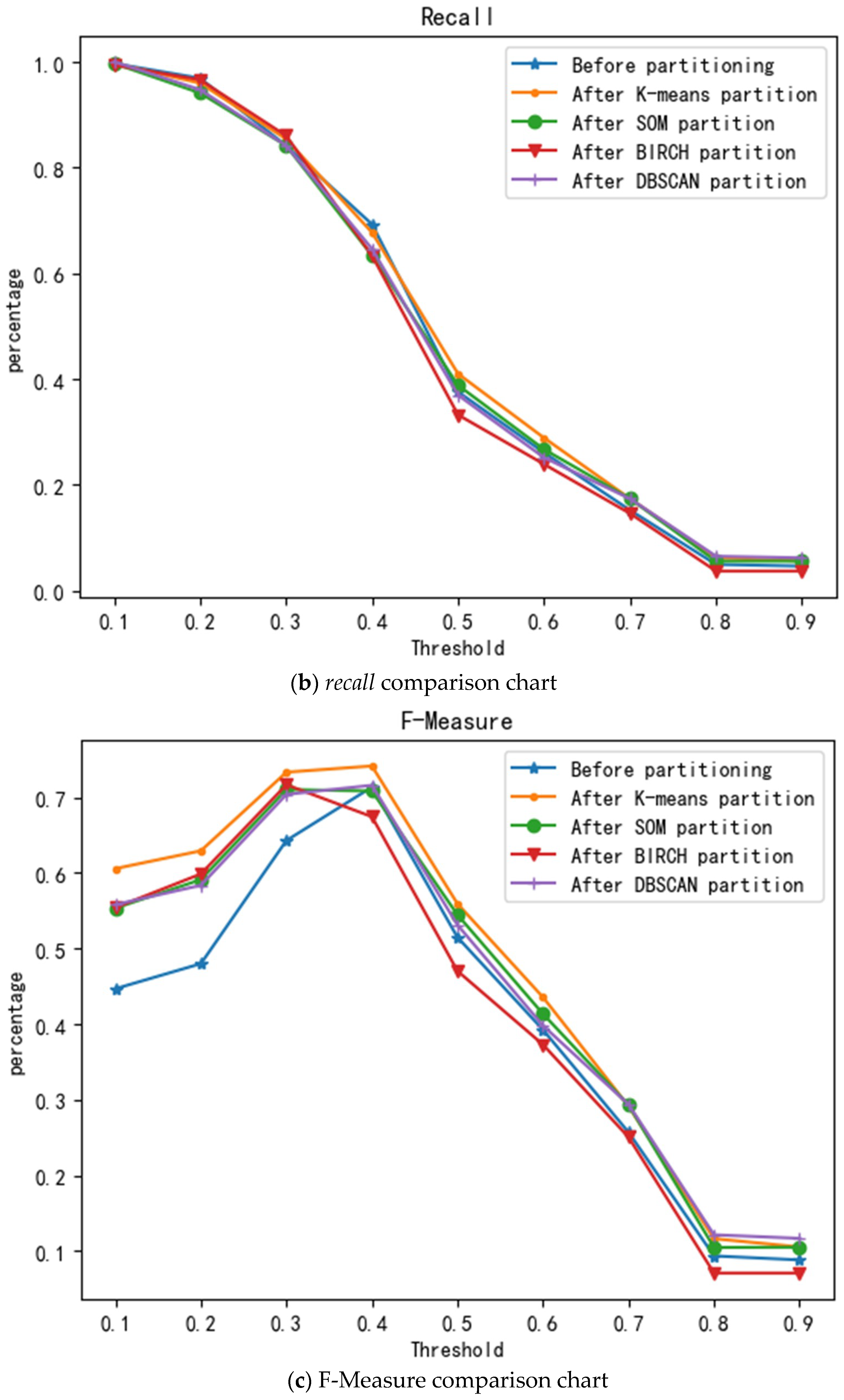
3.3. Assessment Results
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Beck, U. The Terrorist Threat World Risk Society Revisited. Theory Cult. Soc. 2002, 19, 39–55. [Google Scholar] [CrossRef]
- Piazza, J.A. Types of Minority Discrimination and Terrorism. Confl. Manag. Peace Sci. 2012, 29, 521–546. [Google Scholar] [CrossRef]
- Perliger, A.; Pedahzur, A. Counter Cultures, Group Dynamics and Religious Terrorism. Polit. Stud. 2016, 64, 297–314. [Google Scholar] [CrossRef]
- Findley, M.G.; Young, J.K. Terrorism, Democracy, and Credible Commitments. Int. Stud. Q. 2011, 55, 357–378. [Google Scholar] [CrossRef]
- Hsiang, S.M.; Burke, M.; Miguel, E. Quantifying the influence of climate on human conflict. Science 2013, 341, 1212. [Google Scholar] [CrossRef] [PubMed]
- Scheffran, J.; Brzoska, M.; Kominek, J.; Link, P.M.; Schilling, J. Climate Change and Violent Conflict. Science 2012, 336, 869–871. [Google Scholar] [CrossRef] [PubMed]
- Horowitz, M.C.; Perkoski, E.; Potter, P.B.K. Tactical Diversity in Militant Violence. Int. Organ. 2018, 72, 139–171. [Google Scholar] [CrossRef]
- Enders, W.; Sandler, T.; Gaibulloev, K. Domestic versus transnational terrorism: Data, decomposition, and dynamics. J. Peace Res. 2011, 48, 319–337. [Google Scholar] [CrossRef]
- Aradau, C.; van Munster, R. The Time/Space of Preparedness Anticipating the “Next Terrorist Attack”. Space Cult. 2012, 15, 98–109. [Google Scholar] [CrossRef]
- LaFree, G.; Dugan, L.; Xie, M.; Singh, P. Spatial and Temporal Patterns of Terrorist Attacks by ETA 1970 to 2007. J. Quant. Criminol. 2012, 28, 7–29. [Google Scholar] [CrossRef]
- Hastings, J.V. Geography, globalization, and terrorism: The plots of Jemaah Islamiyah. Secur. Stud. 2008, 17, 505–530. [Google Scholar] [CrossRef]
- Waheed, A.; Ahmad, M.M. Socioeconomic impacts of terrorism on affected families in Lahore, Pakistan. J. Aggress. Maltreatment Trauma 2012, 21, 202–222. [Google Scholar] [CrossRef]
- Stewart, M.A. Civil War as State-Making: Strategic Governance in Civil War. Int. Organ. 2018, 72, 205–226. [Google Scholar] [CrossRef]
- Findley, M.G.; Young, J.K. Terrorism and Civil War: A Spatial and Temporal Approach to a Conceptual Problem. Perspect. Polit. 2012, 10, 285–305. [Google Scholar] [CrossRef]
- Sivasamy, R.; Njoku, O.A. Mixed average-based fuzzy time series models for forecasting future civilian fatalities by terrorist attacks in south Asia. Int. J. Phys. Math. Sci. 2014, 4, 20–25. [Google Scholar]
- Minu, K.K.; Lineesh, M.C.; John, C.J. Wavelet Neural Networks for Nonlinear Time Series Analysis. Nonlinear Anal.-Real World Appl. 2010, 4, 2485–2495. [Google Scholar]
- Faryal, G.; Wasi Haider, B.; Usman, Q. Terrorist Group Prediction Using Data Classification. In Proceedings of the International Conference on Artificial Intelligence and Pattern Recognition, Kuala Lumpur, Malaysia, 17–19 November 2014. [Google Scholar]
- Dong, Q.L. Machine Learning and Conflict Prediction:A Cross-Disciplinary Approach. World Econ. Polit. 2017, 7, 100–118. (In Chinese) [Google Scholar]
- Blair, R.A.; Blattman, C.; Hartman, A. Predicting Local Violence: Evidence from a Panel Survey in Liberia. J. Peace Res. 2017, 54, 298–312. [Google Scholar] [CrossRef]
- Ivan, S.S. Has the Global War on Terror Changed the Terrorist Threat? A Time-Series Intervention Analysis. Stud. Confl. Terror. 2009, 32, 743–761. [Google Scholar]
- Raghavan, V.; Galstyan, A.; Tartakovsky, A.G. Hidden Markov Models for the Activity Profile of the terrorist Groups. Ann. Appl. Stat. 2013, 7, 2402–2430. [Google Scholar] [CrossRef]
- Adam, S.; Gerald, S.; Anna, N.; Aaron, C. Forecasting the Risk of Extreme Massacres in Syria. Eur. Rev. Int. Stud. 2014, 1, 50–68. [Google Scholar] [Green Version]
- Feng, D.G.; Zhang, Y.; Zhang, Y.Q. An Overview of Information Security Risk Assessment. J Commun. 2004, 25, 10–18. (In Chinese) [Google Scholar]
- Sun, J.G.; Liu, J.; Zhao, L.Y. Research on Clustering Algorithm. J. Softw. 2008, 19, 48–61. (In Chinese) [Google Scholar] [CrossRef]
- Garcia-Escudero, L.A.; Gordaliza, A.; Matran, C. A central limit theorem for multivariate generalized trimmed k-means. Ann. Stat. 1999, 27, 1061–1079. [Google Scholar]
- Madan, S.; Dana, K.J. Modified balanced iterative reducing and clustering using hierarchies (m-BIRCH) for visual clustering. Pattern Anal. Appl. 2016, 19, 1023–1040. [Google Scholar] [CrossRef]
- Birant, D.; Kut, A. ST-DBSCAN: An algorithm to discover spatial-temporal distributions of physical seawater characteristics and a case study in Turkish seas. J. Mar. Sci. Technol. 2007, 60, 208–221. [Google Scholar]
- Teuvo, K. Self-organized formation of topologically correct factor maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar]
- Wang, Y.M.; Liu, Y.Q.; Li, L.; Infield, D.; Han, S. Short-Term Wind Power Forecasting Based on Clustering Pre-Calculated CFD Method. Energies 2018, 11, 854. [Google Scholar] [CrossRef]
- Sun, G.L.; Song, Z.C.; Liu, J.L.; Zhu, S.X.; He, Y.J. Factor Selection Method Based on Maximum Information Coefficient and Approximate Markov Blanket. Acta Autom Sin. 2017, 43, 795–805. (In Chinese) [Google Scholar]
- Duong, T. Bandwidth selectors for multivariate kernel density estimation. Bull. Aust. Math. Soc. 2005, 71, 351–352. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Author | Content |
|---|---|---|
| Research from the national scale | Blair R A | Using the 2008 data and neural networks to successfully predict the Liberian conflict in 2010 with accuracy between 0.65 and 0.74 |
| Dong Q | Machine learning based on BP neural network predicts terrorist attacks in India from 2010 to 2016 | |
| Research from time series | Ivan Sascha Sheehan | A time-series approach to investigate the relationship between global strategic armed forces-related incidents and transnational terrorism |
| R. Sivasamy | Using the MABM to fit the civilian casualty data caused by terrorist attacks in South Asia and Predict the Civilian Casualties in 2014 | |
| K. K. Minu | Applying WNN to Terrorist Attack Time-Series of Nonstationary Nonlinear Time-Series | |
| Research from the terrorist attacks | Gohar F | Proposed a new framework for classification and forecasting to predict terrorist organizations |
| Raghavan V | Hidden Markov Models are used to establish a model for the terrorist organization’s activity and detect the sudden situation of the organization. | |
| Scharpf A | Using a power-law distribution based on observations to calculate the likelihood of a single event |
| Type of Data | Source | Publisher | |
|---|---|---|---|
| Latitude | Global Terrorism Database (GTD), 1970–2016 | START, University of Maryland (https://www.start.umd.edu/gtd/) | |
| Longitude | |||
| Distance to major navigable lake | G-Econ 4.0, 2011 | Yale University (http://gecon.yale.edu/) | |
| Distance to major navigable river | |||
| Distance to ice—free Ocean | |||
| Average precipitation | |||
| Average temperature | |||
| Ethnic diversity | GeoEPR, the Ethnic Power Relations dataset, 2014 | Center for Comparative and International Studies (CIS), International Conflict Research (http://www.icr.ethz.ch/data/index) | |
| Major drug regions | World drug report, 2016 | Division for Policy Analysis and Public Affairs, United Nations Office on Drugs and Crime (http://www.unvienna.org/unov/en/unodc.html) | |
| Nighttime lights | Nighttime Lights of the World, 2013 | The Earth Observation Group, NOAA (http://ngdc.noaa.gov/eog/index.html) | |
| Population density | Population density of the World, 2015 | NASA’s Earth Observatory (http://neo.sci.gsfc.nasa.gov/) | |
| Topography | Digital elevation model (DEM), 2011 | ||
| POI | Transportation site | Google Places API, 2018 | Google (https://developers.google.cn/places/web-service/intro) |
| Religious places | |||
| Political places | |||
| Catering outlets | |||
| Accommodation outlets | |||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Jin, M.; Fu, J.; Hao, M.; Yu, C.; Xie, X. On the Risk Assessment of Terrorist Attacks Coupled with Multi-Source Factors. ISPRS Int. J. Geo-Inf. 2018, 7, 354. https://doi.org/10.3390/ijgi7090354
Zhang X, Jin M, Fu J, Hao M, Yu C, Xie X. On the Risk Assessment of Terrorist Attacks Coupled with Multi-Source Factors. ISPRS International Journal of Geo-Information. 2018; 7(9):354. https://doi.org/10.3390/ijgi7090354
Chicago/Turabian StyleZhang, Xun, Min Jin, Jingying Fu, Mengmeng Hao, Chongchong Yu, and Xiaolan Xie. 2018. "On the Risk Assessment of Terrorist Attacks Coupled with Multi-Source Factors" ISPRS International Journal of Geo-Information 7, no. 9: 354. https://doi.org/10.3390/ijgi7090354
APA StyleZhang, X., Jin, M., Fu, J., Hao, M., Yu, C., & Xie, X. (2018). On the Risk Assessment of Terrorist Attacks Coupled with Multi-Source Factors. ISPRS International Journal of Geo-Information, 7(9), 354. https://doi.org/10.3390/ijgi7090354