An Intersection-First Approach for Road Network Generation from Crowd-Sourced Vehicle Trajectories

Abstract
:1. Introduction
- (1)
- In grid space, we extracted the intersections by identifying the number of eight neighborhoods, per pixel, in the single-pixel “center-lines” and considered different resolutions, which can keep as many intersections as possible in our extraction method and also make the extraction results more accurate in the subsequent fusion processing.
- (2)
- In vector space, the clustering method to rapidly search for and find density peaks (CFDP) [31] was used to extract road intersections for the first time. Moreover, our method, which considers the distribution density of trajectory data and the traffic flow characteristic of roads, is available for both low-frequency and high-frequency trajectories, thereby solving the problem faced by other methods, such as heading and speed only being available for high-frequency trajectories.
- (3)
- An intersection fusion mechanism that integrates the advantages of cluster computing and image recognition was developed to overcome sampling sparseness and uneven distribution of the vehicle trajectory data. At the same time, this fusion mechanism can recognize true intersections and undetermined intersections, thereby guaranteeing the integrity of the extraction results and reducing the blindness of eliminating false intersections.
- (4)
- Making full use of the direct dependency between intersections and center-lines of the road can further adjust road information and repair fractured segments, thereby guaranteeing the precision of road segments around intersections. We also constructed an Intersection–Link model and used the road segment between intersections as the unit to identify single/double directional information and the turning relationships of the road network, to guarantee the precise geometry and correct topology of the road networks.
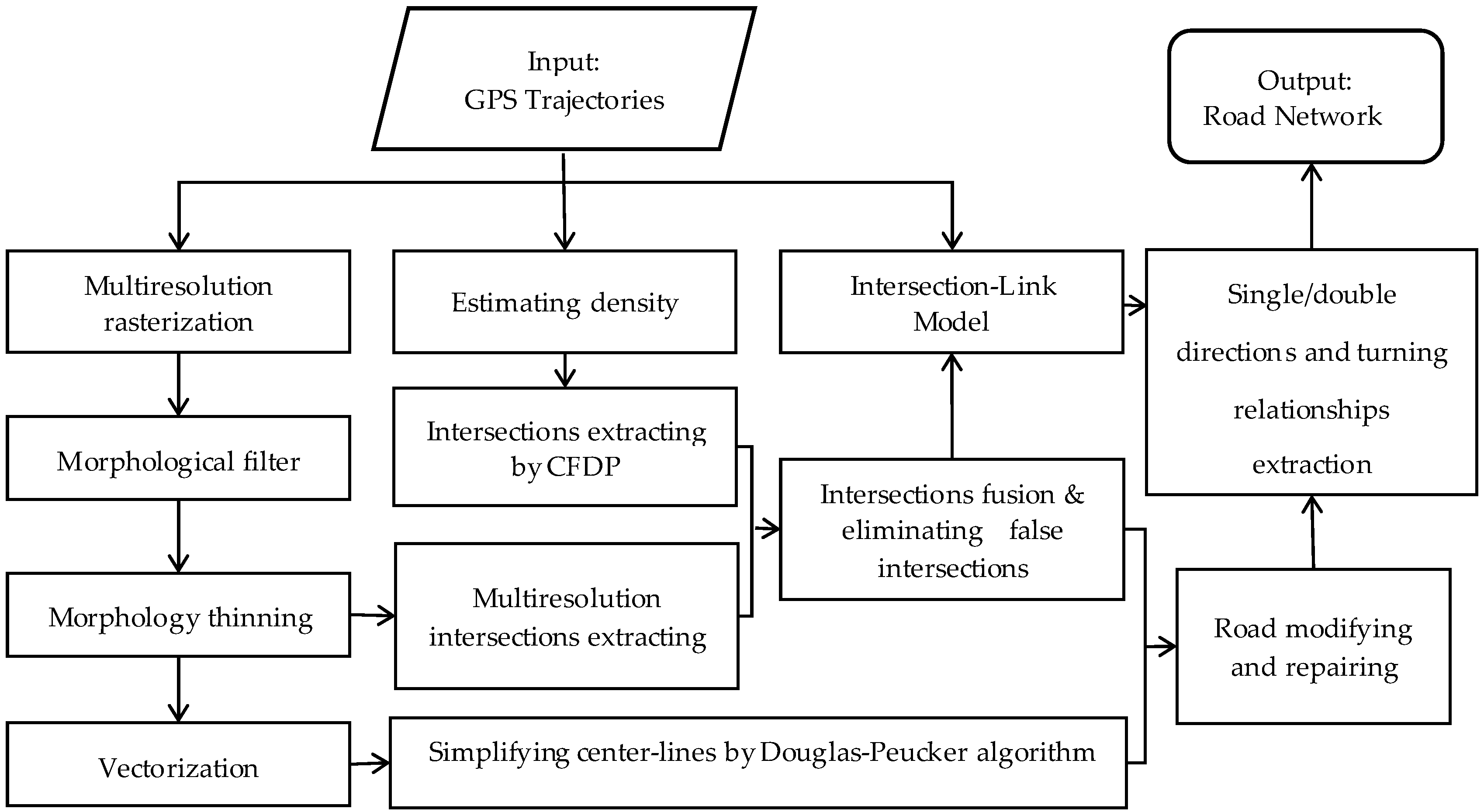
2. Road Network Generation Framework
- (1)
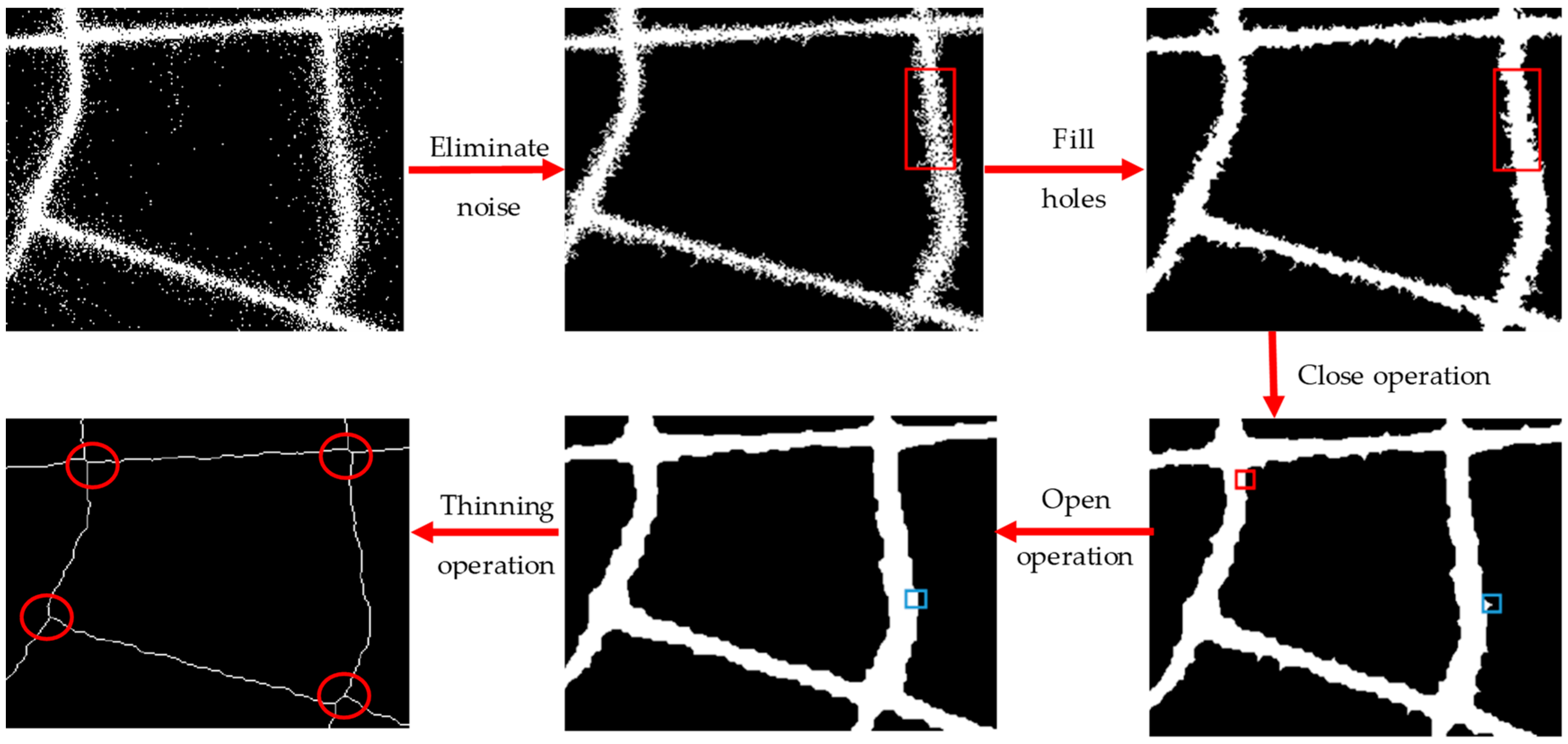
- In the grid space, road intersections were extracted by identifying the number of pixels in each pixel’s eight neighborhoods from different resolution single-pixel “center-lines” to extract as many road intersections as possible. Before this, corresponding mathematical morphology processing, such as rasterization, open operation, close operation, filling holes, smoothing surfaces, and morphology thinning, needed to be done.
- (2)
- In the vector space, we considered the distribution density of the trajectory and extracted the road intersections via the clustering method of CFDP. In this critical part, in order to eliminate the trajectory points with large deviations caused by drift, Kernel Density Estimation (KDE) was first used to smooth the trajectory data.
- (3)
- In the aspect of integrated intersection extraction, a corresponding fusion mechanism was constructed. The true intersections and undetermined intersections were distinguished according to the fusion of the clustering results of the CFDP algorithm and the mathematical morphological extraction results from different resolution raster images. Finally, Principal Component Analysis (PCA) was used to analyze the undetermined intersections and detect the pseudo intersections so as to ensure the accuracy of eliminating the false intersections.
- (4)
- In terms of road network generation, a road improvement method was proposed to guarantee the precise geometry and correct topology of the road networks based on the above intersection extraction results. At the same time, we also designed the Intersection–Link model to identify the single/double direction information and turning relationships of the road network.
3. Integrated Intersection Extraction
3.1. Extracting Intersections under a Raster Space Using the Morphology Method
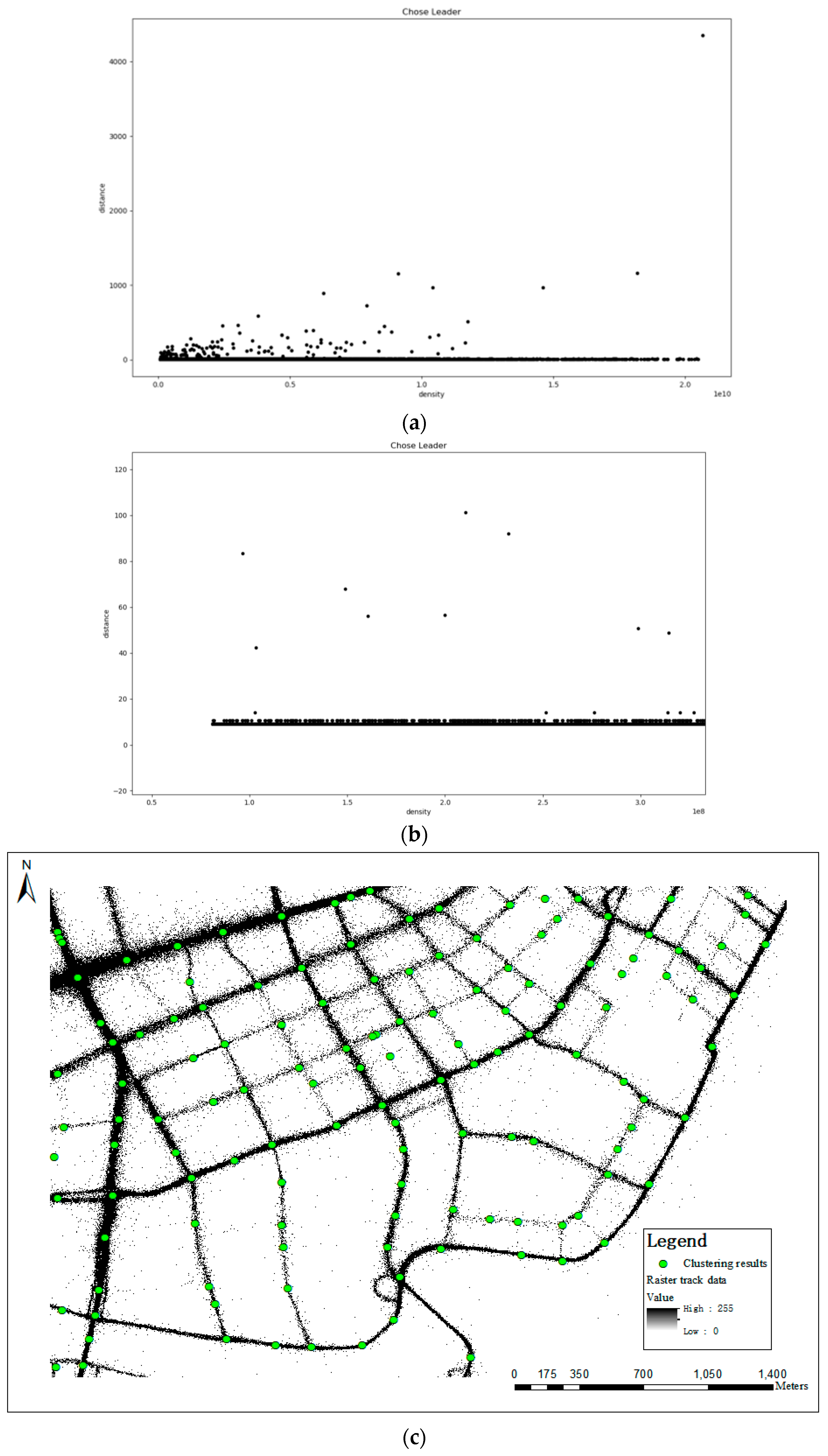
3.2. Extracting Intersections Under a Vector Space Based on CFDP
3.2.1. Estimating Density
3.2.2. Extracting Intersections
3.3. Fusion and Eliminating Pseudo Intersections
3.3.1. Fusion of the Intersection Extraction Results
3.3.2. Elimination of False Intersections from Undetermined Results
4. Road Network Generation
4.1. The Road Improvement
4.2. Identifying Single/Double Directions and Turning Relationships
4.2.1. Intersection–Link Model Construction
4.2.2. Removing the Pseudo-Intersection–Link Relationship
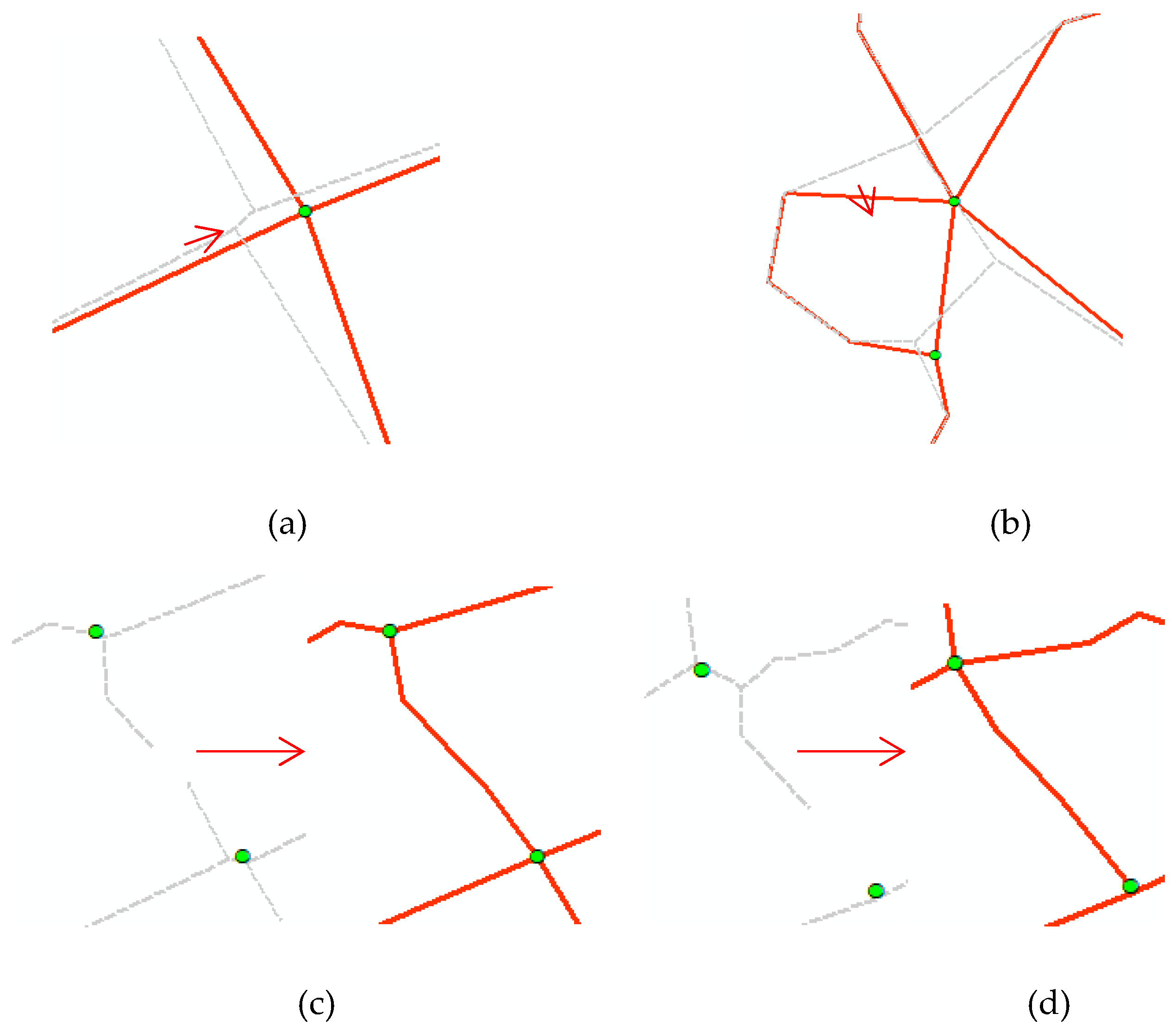
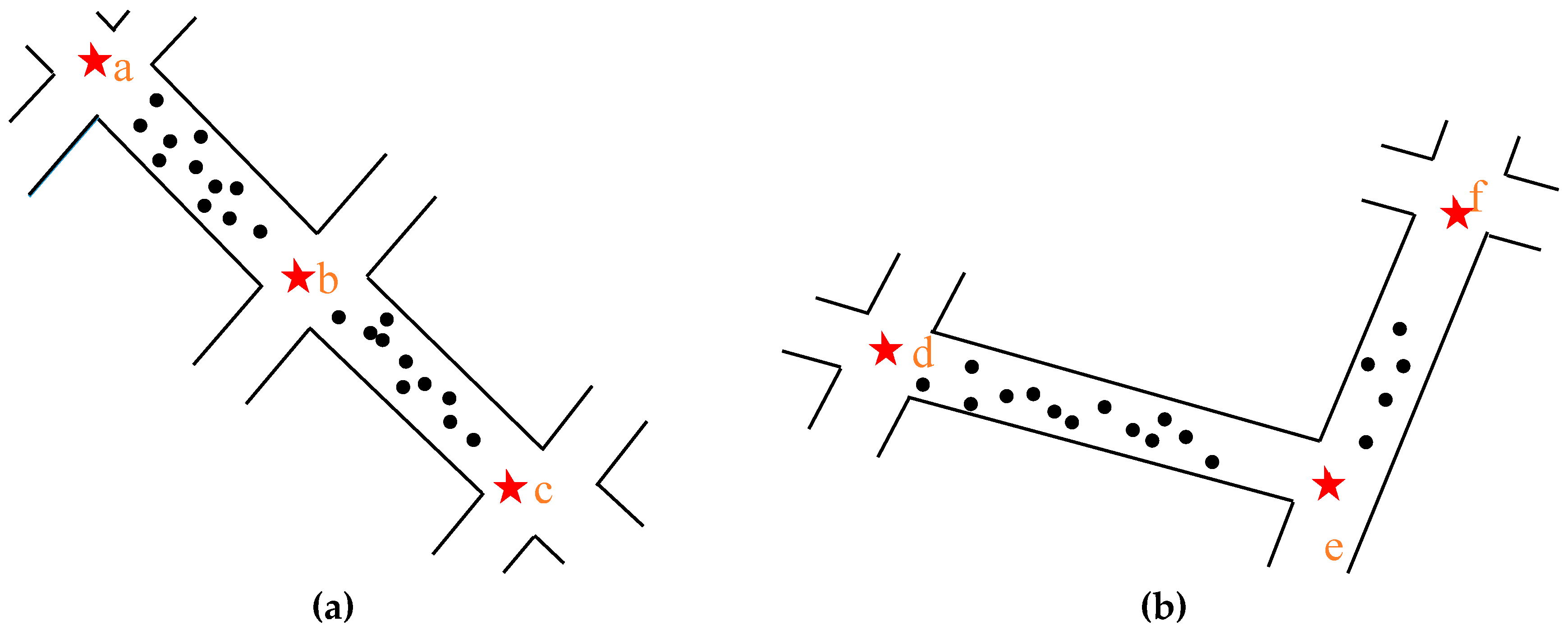
- We use the straight line connecting the two road intersections as the diameter to establish the circular buffer zone. If there are too many other intersections in the buffer, the two intersections are too far apart. If so, delete the Intersection–Link relationship of the two intersections.
- The Intersection–Link relationships are formed between two of the three road intersections (such as a, b, and c), which are located in the same straight line. The lengths of ab, ac, and bc were calculated accordingly to eliminate the Intersection–Link relationship of the longest pair of intersections, as shown in Figure 13a.
- Most sections of urban roads are straight lines, while some sections have small radians. Based on this observation, the maximum distance d from the intersection line (let the length be L) in the normal track points is calculated. If d/L is greater than the threshold, then delete the Intersection–Link relationship. This strategy can eliminate the situation seen in Figure 13b.
4.2.3. Determining the Characteristics of a Road Network
5. Experiments and Analysis
5.1. Study Area and Data Sets
5.2. Experimental Results of the Proposed Method
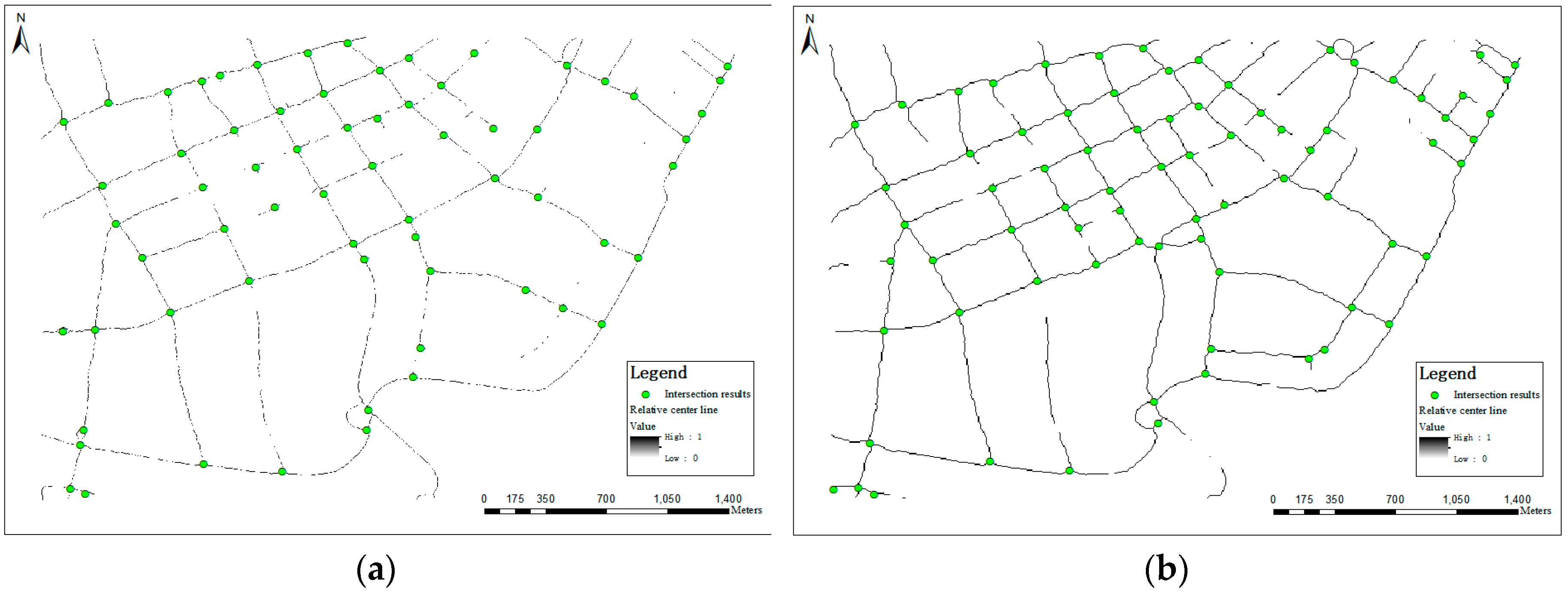
5.2.1. Intersection Detecting Results
5.2.2. Road Network Detection Results
5.2.3. Single/Double Direction Information and Turning Relationship Detection Results
5.3. Results Evaluation and Analysis
5.3.1. Visual Inspection
5.3.2. Quantitative Comparisons
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chiang, Y.Y.; Knoblock, C.A. Automatic extraction of road intersection position, connectivity, and orientations from raster maps. In Proceedings of the 16th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Irvine, CA, USA, 5–7 November 2008. [Google Scholar]
- Fu, G. Road Extraction Method Using Multi-Source Remote Sensing Data; Tsinghua University: Beijing, China, 2014. [Google Scholar]
- Li, R.; Si, Y.; Ma, D.; Qu, Y. Extraction method of high-resolution image of road intersections based on semantic rules. J. Surv. Mapp. Sci. Technol. 2017, 34, 168–174. [Google Scholar]
- Hu, X.; Li, Y.; Shan, J.; Zhang, J.; Zhang, Y. Road Centerline Extraction in Complex Urban Scenes from LiDAR Data Based on Multiple Features. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7448–7456. [Google Scholar]
- Oloo, F. Mapping Rural Road Networks from Global Positioning System (GPS) Trajectories of Motorcycle Taxis in Sigomre Area, Siaya County, Kenya. ISPRS Int. J. Geo-Inf. 2018, 7, 309. [Google Scholar] [CrossRef]
- Ekpenyong, F.; Palmerbrown, D.; Brimicombe, A. Extracting road information from recorded GPS data using snap-drift neural network. Neurocomputing 2009, 73, 24–36. [Google Scholar] [CrossRef]
- Mobasheri, A.; Huang, H.; Degrossi, L.; Zipf, A. Enrichment of OpenStreetMap Data Completeness with Sidewalk Geometries Using Data Mining Techniques. Sensors 2018, 18, 509. [Google Scholar] [CrossRef]
- Amin, M. A Rule-Based Spatial Reasoning Approach for OpenStreetMap Data Quality Enrichment; Case Study of Routing and Navigation. Sensors 2017, 17, 2498. [Google Scholar] [Green Version]
- Wei, Y.; Tinghua, A.; Wei, L. A Method for Extracting Road Boundary Information from Crowdsourcing Vehicle GPS Trajectories. Sensors 2018, 18, 1261. [Google Scholar] [Green Version]
- John, S.; Hahmann, S.; Rousell, A.; Löwner, M.O.; Zipf, A. Deriving incline values for street networks from voluntarily collected GPS traces. Cartogr. Geogr. Inf. Sci. 2017, 44, 152–169. [Google Scholar] [CrossRef]
- Li, J.; Qin, Q.; You, L.; Xie, C. Parking lot extraction method based on floating car data. Geomat. Inf. Sci. Wuhan Univ. 2013, 38, 599–603. [Google Scholar]
- Tang, L.; Kan, Z.; Zhang, X.; Yang, X.; Huang, F.; Li, Q. Travel time estimation at intersections based on low-frequency spatial-temporal GPS trajectory big data. Cartogr. Geogr. Inf. Sci. 2016, 43, 417–426. [Google Scholar] [CrossRef]
- Winden, K.V.; Biljecki, F.; Spek, S.V.D. Automatic Update of Road Attributes by Mining GPS Tracks. Trans. GIS 2016, 20, 664–683. [Google Scholar] [CrossRef]
- Cao, L.; Krumm, J. From GPS traces to a routable road map. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 4–6 November 2009. [Google Scholar]
- Ahmed, M.; Wenk, C. Constructing street networks from GPS trajectories. In Proceedings of the 20th Annual European Symposium on Algorithms, Ljubljana, Slovenia, 10–12 September 2012. [Google Scholar]
- Tang, L.L.; Liu, Z.; Yang, X. Spatial-temporal trajectory fusion and road network generation method in line with cognitive rules. Acta Surv. Mapp. 2015, 44, 1271–1276. [Google Scholar]
- Edelkamp, S.; Schrödl, S. Route Planning and Map Inference with Global Positioning Traces. In Computer Science in Perspective, Essays Dedicated to Thomas Ottmann; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Bruntrup, R.; Edelkamp, S.; Jabbar, S.; Scholz, B. Incremental map generation with GPS traces. In Proceedings of the 9th IEEE International Conference on Intelligent Transportation Systems, Las Vegas, NV, USA, 6–8 June 2005. [Google Scholar]
- Liao, L.C.; Jiang, X.H.; Zou, F.M.; Li, L.M.; Lai, H.T. Directed density method for trajectory data clustering of floating vehicles. J. Earth Inf. Sci. 2015, 17, 1152–1161. [Google Scholar]
- Davies, J.J.; Beresford, A.R.; Hopper, A. Scalable, Distributed, Real-Time Map Generation. IEEE Pervasive Comput. 2006, 5, 47–54. [Google Scholar] [CrossRef]
- Biagioni, J.; Eriksson, J. Map inference in the face of noise and disparity. In Proceedings of the International Conference on Advances in Geographic Information Systems, Redondo Beach, Los Angeles County, CA, USA, 6–9 November 2012. [Google Scholar]
- Mariescu-Istodor, R.; Fränti, P. CellNet: Inferring Road Networks from GPS Trajectories. ACM Trans. Spat. Algorithms Syst. 2018, 4, 8. [Google Scholar] [CrossRef]
- Xie, X.; Liao, W.; Aghajan, H.; Veelaert, P.; Philips, W. Detecting road intersections from GPS traces using longest common subsequence algorithm. ISPRS Int. J. Geo-Inf. 2017, 6, 1. [Google Scholar] [CrossRef]
- Karagiorgou, S.; Pfoser, D.; Skoutas, D. Segmentation-based road network construction. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013. [Google Scholar]
- Xie, X.; Bingyungwong, K.; Aghajan, H.; Veelaert, P.; Philips, W. Inferring directed road networks from GPS traces by track alignment. ISPRS Int. J. Geo-Inf. 2015, 4, 2446–2471. [Google Scholar] [CrossRef]
- Tang, L.; Niu, L.; Yang, X.; Zhang, X.; Li, Q.; Xiao, S. Recognition and Structural Extraction of Urban Road Intersection Using Large Trajectory Data. Acta Geod. Cartogr. Sin. 2017, 46, 770–779. [Google Scholar]
- Wang, J.; Wang, C.; Song, X.; Raghavan, V. Automatic intersection and traffic rule detection by mining motor-vehicle GPS trajectories. Comput. Environ. Urban Syst. 2017, 64, 19–29. [Google Scholar] [CrossRef]
- Wang, J.; Rui, X.; Song, X.; Tan, X.; Wang, C.; Raghavan, V. A novel approach for generating routable road maps from vehicle GPS traces. Int. J. Geogr. Inf. Sci. 2014, 29, 69–91. [Google Scholar] [CrossRef]
- Deng, M.; Huang, J.; Zhang, Y.; Liu, H.; Tang, L.; Tang, J.; Yang, X. Generating urban road intersection models from low-frequency GPS trajectory data. Int. J. Geogr. Inf. Sci. 2018, 32, 2337–2361. [Google Scholar] [CrossRef]
- Fathi, A.; Krumm, J. Detecting road intersections from GPS traces. In Proceedings of the 6th International Conference on Geographic Information Science, Zurich, Switzerland, 14–17 September 2010; pp. 56–69. [Google Scholar]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492. [Google Scholar] [CrossRef] [PubMed]
- Douglas, D.H.; Peucker, T.K. Algorithms for the Reduction of the Number of Points Required to Represent a Digitized Line or Its Caricature. Cartogr. Int. J. Geogr. Inf. Geovis. 1973, 10, 112–122. [Google Scholar] [CrossRef]
- Ahmed, M.; Karagiorgou, S.; Pfoser, D.; Wenk, C. A comparison and evaluation of map construction algorithms using vehicle tracking data. GeoInformatica 2015, 19, 601–632. [Google Scholar] [CrossRef]
- Mapconstruction. Available online: https://pfoser.github.io/mapconstruction/ (accessed on 22 July 2018).
- Tang, L.; Yang, X.; Kan, Z.; Wang, X.; Li, Q.; Shaw, S. Traffic Lane Numbers Detection Based on the Naive Bayesian Classification. China J. Highw. Transp. 2016, 29, 116–123. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| High-resolution Results | Low-resolution Results | CFDP Clustering Results | Judging Results |
|---|---|---|---|
| √ | √ | √ | True |
| √ | √ | True | |
| √ | √ | True | |
| √ | √ | True | |
| √ | False | ||
| √ | False | ||
| √ | Undetermined |
| Datasets | S | K | D | R1 | R2 | Δ | |||
|---|---|---|---|---|---|---|---|---|---|
| 2.5 Resolution | 5 Resolution | ||||||||
| Close Operation | Open Operation | Open Operation | Open Operation | ||||||
| Wuhan | 10 | 4 | 4 | 3 | 0.25 | 20 | 80 | 100 | 0.96 |
| Chicago | 4 | 3 | 3 | 3 | 1 | 75 | 80 | 100 | 0.9 |
| Paths | Whether One Can Pass | Paths | Whether One Can Pass | The Single/Double Direction Decision |
|---|---|---|---|---|
| 65–69 | Yes | 69–65 | No | Single |
| 62–69 | No | 69–62 | Yes | Single |
| 72–69 | No | 69–72 | Yes | Single |
| 75–69 | Yes | 69–75 | NO | Single |
| Paths | Paths | Whether One Can Pass | Whether One Can Pass in Reality |
|---|---|---|---|
| 65–69 | 69–62 | Yes | Yes |
| 65–69 | 69–72 | Yes | Yes |
| 65–69 | 69–75 | NO | NO |
| 62–69 | 69–65 | NO | NO |
| 62–69 | 69–72 | NO | NO |
| 62–69 | 69–75 | NO | NO |
| 72–69 | 69–62 | NO | NO |
| 72–69 | 69–65 | NO | NO |
| 72–69 | 69–75 | NO | NO |
| 75–69 | 69–62 | Yes | Yes |
| 75–69 | 69–65 | NO | NO |
| 75–69 | 69–72 | Yes | Yes |
| dataset | Methods | Precision | Recall | F-value |
|---|---|---|---|---|
| Chicago | Proposed | 50/51 = 98.04% | 50/71 = 70.42% | 81.97% |
| Ahmed | 40/52 = 76.92% | 40/71 = 56.34% | 65.04% | |
| Davies | 19/19 = 100% | 19/71 = 26.76% | 42.22% | |
| Wuhan | Proposed | 109/117 = 93.16% | 109/123 = 88.62% | 90.84% |
| Ahmed | 37/50 = 74% | 37/123 = 30.08% | 42.77% | |
| Davies | 69/81 = 85.19% | 69/123 = 56.10% | 67.65% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Xiang, L.; Li, S.; Wang, D. An Intersection-First Approach for Road Network Generation from Crowd-Sourced Vehicle Trajectories. ISPRS Int. J. Geo-Inf. 2019, 8, 473. https://doi.org/10.3390/ijgi8110473
Zhang C, Xiang L, Li S, Wang D. An Intersection-First Approach for Road Network Generation from Crowd-Sourced Vehicle Trajectories. ISPRS International Journal of Geo-Information. 2019; 8(11):473. https://doi.org/10.3390/ijgi8110473
Chicago/Turabian StyleZhang, Caili, Longgang Xiang, Siyu Li, and Dehao Wang. 2019. "An Intersection-First Approach for Road Network Generation from Crowd-Sourced Vehicle Trajectories" ISPRS International Journal of Geo-Information 8, no. 11: 473. https://doi.org/10.3390/ijgi8110473
APA StyleZhang, C., Xiang, L., Li, S., & Wang, D. (2019). An Intersection-First Approach for Road Network Generation from Crowd-Sourced Vehicle Trajectories. ISPRS International Journal of Geo-Information, 8(11), 473. https://doi.org/10.3390/ijgi8110473