Progress and Challenges on Entity Alignment of Geographic Knowledge Bases



Abstract
:1. Introduction
- A formal and explicit coherent framework for the entity alignment of GKBs;
- A systematic classification and summarization of previous studies in terms of the algorithms of similarity metrics, similarity combination, alignment judgement, and result evaluation;
- A set of challenges for future research.
2. Definitions and Framework for Entity Alignment of GKBs
2.1. Basic Definitions
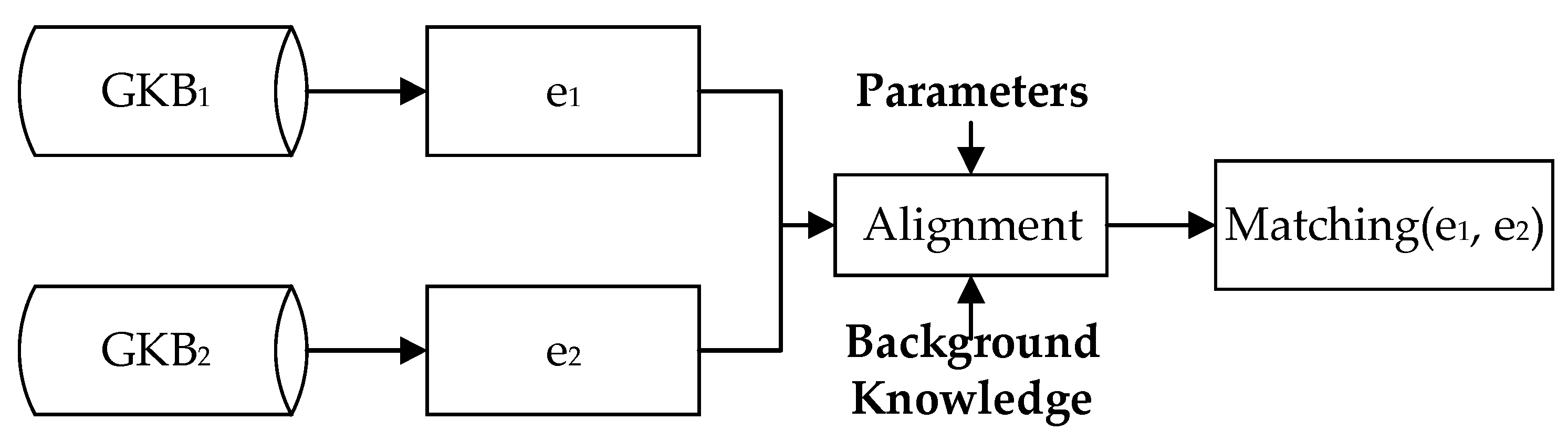
2.1.1. Problem Statement
2.1.2. Explanation for Heterogeneities in Geographic Entities
Heterogeneity in Lexicon (HL)
Heterogeneity in Structure (HS)
Heterogeneity in Spatial Position (HSp)
Heterogeneity in Category (HC)
Heterogeneity in Shape (HSh)
Heterogeneity in Data-Type of Property (HPdt)
Heterogeneity in range of property (HPr)
Heterogeneity in Property Value (HPv)
2.2. General Framework
2.2.1. Basic Ideas
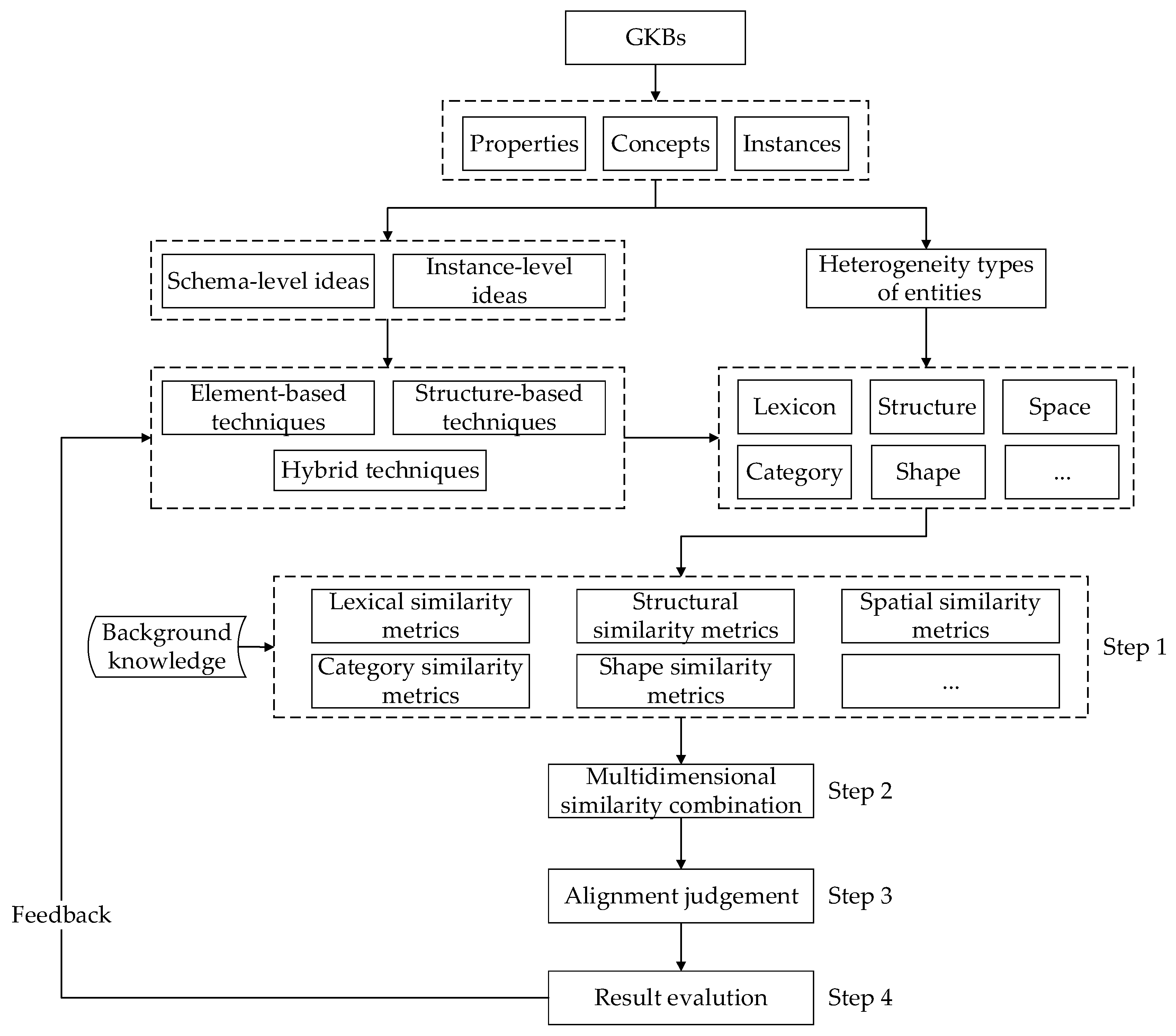
2.2.2. Standard Workflow
- Step 1.
- Similarity measurement. Determining suitable similarity metrics for each type of heterogeneities in entities.
- Step 2.
- Similarity combination. Selecting an effective method to combine multidimensional similarity scores.
- Step 3.
- Alignment judgement. Taking a decision for entity pairs to be matched based on a predefined threshold or leveraging an effective judging approach.
- Step 4.
- Result evaluation. Using suitable benchmarks and evaluation metrics to assess result quality.
3. Algorithms of Entity Alignment
3.1. Similarity Metrics
3.1.1. Lexical Similarity Metrics
3.1.2. Structural Similarity Metrics
3.1.3. Spatial Similarity Metrics
3.1.4. Category Similarity Metrics
3.1.5. Shape Similarity Metrics
3.2. Similarity Combination
3.3. Alignment Judgement
4. Evaluation of Entity Alignment
5. Challenges and Future Research
5.1. Quality Assessment of GKBs
5.2. Feature Selection and Algorithms Optimization
5.3. Alignment Techniques Integrated with Background Knowledge
5.4. Unified Infrastructure for Entity Alignment of GKBs
5.5. Entity Alignment of Large-Scale GKBs
5.6. Deep Learning-Based Entity Alignment of GKBs
5.7. Benchmark Datasets for Entity Alignment of GKBs
5.8. Applications of Entity Alignment of GKBs
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bizer, C.; Lehmann, J.; Kobilarov, G.; Auer, S.; Becker, C.; Cyganiak, R.; Hellmann, S. Dbpedia—A crystallization point for the Web of Data. Web Semant. Sci. Serv. Agents World Wide Web 2009, 7, 154–165. [Google Scholar] [CrossRef]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago—A Large Ontology from Wikipedia and WordNet. Web Semant. Sci. Serv. Agents World Wide Web 2008, 6, 203–217. [Google Scholar] [CrossRef]
- Wikidata. Available online: https://www.wikidata.org/wiki/Wikidata:Main_Page (accessed on 20 March 2018).
- Bollacker, K.; Cook, R.; Tufts, P. Freebase: A Shared Database of Structured General Human Knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22–26 July 2007; pp. 1962–1963. [Google Scholar]
- Berners, T. Publishing on the semantic web. Nature 2001, 410, 1023–1024. [Google Scholar] [CrossRef] [PubMed]
- DesignIssues: LinkedData. Available online: https://www.w3.org/DesignIssues/LinkedData.html (accessed on 20 March 2018).
- Li, L.; Liu, Y.; Zhu, H.; Ying, S.; Luo, Q.; Luo, H.; Xi, K.; Xia, H.; Shen, H. A bibliometric and visual analysis of global geo-ontology research. Comput. Geosci. 2017, 99, 1–8. [Google Scholar] [CrossRef]
- Liu, Y.; Li, L.; Shen, H.; Yang, H.; Luo, F. A Co-Citation and Cluster Analysis of Scientometrics of Geographic Information Ontology. ISPRS Int. J. Geo-Inf. 2018, 7, 120. [Google Scholar] [CrossRef]
- Couclelis, H. Ontologies of geographic information. Int. J. Geogr. Inf. Sci. 2010, 24, 1785–1809. [Google Scholar] [CrossRef]
- Bittner, T.; Donnelly, M.; Smith, B. A spatio-temporal ontology for geographic information integration. Int. J. Geogr. Inf. Sci. 2009, 23, 765–798. [Google Scholar] [CrossRef]
- Zong, N.; Nam, S.; Eom, J.H.; Ahn, J.; Joe, H.; Kim, H.G. Aligning ontologies with subsumption and equivalence relations in Linked Data. Knowl.-Based Syst. 2014, 76, 30–41. [Google Scholar] [CrossRef]
- Euzenat, J.; Shvaiko, P. Ontology Matching, 1st ed.; Springer: Heidelberg, Germany, 2007. [Google Scholar]
- Bhattacharya, I.; Getoor, L. Entity Resolution in Graphs. In Mining Graph Data, 1st ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2005; pp. 311–344. [Google Scholar]
- Whang, S.E.; Menestrina, D.; Koutrika, G.; Theobald, M.; Garcia-Molina, H. Entity resolution with iterative blocking. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, Providence, RI, USA, 29 June–2 July 2009; pp. 219–232. [Google Scholar]
- Elmagarmid, A.K.; Ipeirotis, P.G.; Verykios, V.S. Duplicate Record Detection: A Survey. IEEE Trans. Knowl. Data Eng. 2006, 19, 1–16. [Google Scholar] [CrossRef]
- Li, C.; Jin, L.; Mehrotra, S. Supporting Efficient Record Linkage for Large Data Sets Using Mapping Techniques. World Wide Web 2006, 9, 557–584. [Google Scholar] [CrossRef]
- Otero-Cerdeira, L.; Rodríguez-Martínez, F.J.; Gómez-Rodríguez, A. Ontology matching: A literature review. Expert Syst. Appl. 2015, 42, 949–971. [Google Scholar] [CrossRef]
- Shvaiko, P.; Euzenat, J. Ontology Matching: State of the Art and Future Challenges. IEEE Trans. Knowl. Data Eng. 2012, 25, 158–176. [Google Scholar] [CrossRef]
- David, J. AROMA results for OAEI 2011. In Proceedings of the 6th International Conference on Ontology Matching, Bonn, Germany, 24 October 2011; pp. 122–125. [Google Scholar]
- David, J.; Guillet, F.; Briand, H. Association Rule Ontology Matching Approach. Int. J. Semant. Web Inf. 2007, 3, 27–49. [Google Scholar] [CrossRef]
- Cruz, I.F.; Antonelli, F.P.; Stroe, C. AgreementMaker: Efficient Matching for Large Real-World Schemas and Ontologies. Proc. VLDB Endow. 2009, 2, 1586–1589. [Google Scholar] [CrossRef]
- Cruz, I.F.; Sunna, W.; Chaudhry, A. Semi-automatic Ontology Alignment for Geospatial Data Integration. In Proceedings of the Third International Conference on Geographic Information Science, Adelphi, MD, USA, 20–23 October 2004; pp. 51–66. [Google Scholar]
- Hartung, M.; Kolb, L.; Groß, A.; Rahm, E. Optimizing Similarity Computations for Ontology Matching—Experiences from GOMMA. In Proceedings of the International Conference on Data Integration in the Life Sciences, Montreal, QC, Canada, 11–12 July 2013; pp. 81–89. [Google Scholar]
- Kalfoglou, Y.; Schorlemmer, M. Ontology mapping: The state of the art. Knowl. Eng. Rev. 2005, 18, 1–31. [Google Scholar] [CrossRef]
- Hess, G.N.; Iochpe, C.; Castano, S. An Algorithm and Implementation for GeoOntologies Integration. In Proceedings of the VIII Brazilian Symposium on Geoinformatics, Campos do Jordão, São Paulo, Brazil, 19–22 November 2006; pp. 109–120. [Google Scholar]
- Sehgal, V.; Viechnicki, P.D.; Viechnicki, P.D. Entity resolution in geospatial data integration. In Proceedings of the 14th annual ACM international symposium on Advances in geographic information systems, Arlington, VA, USA, 10–11 November 2006; pp. 83–90. [Google Scholar]
- Zhao, T. The framework of a geospatial semantic web-based spatial decision support system for Digital Earth. Int. J. Digit. Earth 2010, 3, 111–134. [Google Scholar] [CrossRef]
- Li, W.; Raskin, R.; Goodchild, M. Semantic similarity measurement based on knowledge mining: An artificial neural net approach. Int. J. Geogr. Inf. Sci. 2012, 26, 1415–1435. [Google Scholar] [CrossRef]
- Yu, L.; Qiu, P.; Liu, X.; Lu, F.; Wan, B. A holistic approach to aligning geospatial data with multidimensional similarity measuring. Int. J. Digit. Earth 2017, 11, 1–18. [Google Scholar] [CrossRef]
- Volz, S. Data-driven matching of geospatial schemas. In Proceedings of the International Conference on Spatial Information Theory, Ellicottville, NY, USA, 14–18 September 2005; pp. 115–132. [Google Scholar]
- Shvaiko, P.; Euzenat, J. A Survey of Schema-based Matching Approaches; Springer: Berlin, Germany, 2005; pp. 146–171. [Google Scholar]
- Lin, F.; Sandkuhl, K. A Survey of Exploiting WordNet in Ontology Matching. In Proceedings of the Artificial Intelligence in Theory and Practice II, IFIP World Computer Congress, Milano, Italy, 7–10 September 2008; pp. 341–350. [Google Scholar]
- Sunna, W.; Cruz, I.F. Structure-Based Methods to Enhance Geospatial Ontology Alignment. In Proceedings of the International Conference on Geospatial Semantics, Mexico City, Mexico, 29–30 November 2007; pp. 82–97. [Google Scholar]
- Ballatore, A.; Wilson, D.C.; Bertolotto, M. Computing the semantic similarity of geographic terms using volunteered lexical definitions. Int. J. Geogr. Inf. Sci. 2013, 27, 2099–2118. [Google Scholar] [CrossRef]
- Ballatore, A.; Bertolotto, M.; Wilson, D.C. Grounding Linked Open Data in WordNet: The Case of the OSM Semantic Network. In Proceedings of the International Symposium on Web and Wireless Geographical Information Systems, Banff, AB, Canada, 4–5 April 2013; pp. 1–15. [Google Scholar]
- Ballatore, A.; Bertolotto, M.; Wilson, D.C. Linking geographic vocabularies through WordNet. Ann. GIS 2014, 20, 73–84. [Google Scholar] [CrossRef]
- Giunchiglia, F.; Maltese, V.; Farazi, F.; Dutta, B. GeoWordNet: A Resource for Geo-spatial Applications; Springer: Berlin/Heidelberg, Germany, 2010; pp. 121–136. [Google Scholar]
- Hu, Y. Geospatial Semantics. In Comprehensive Geographic Information Systems; Elsevier: Oxford, UK, 2017; pp. 80–94. [Google Scholar]
- Zheng, J.G.; Fu, L.; Ma, X.; Fox, P. SEM+: Tool for discovering concept mapping in Earth science related domain. Earth Sci. Inform. 2015, 8, 95–102. [Google Scholar] [CrossRef]
- Santos, R.; Murrieta-Flores, P.; Martins, B. Learning to combine multiple string similarity metrics for effective toponym matching. Int. J. Digit. Earth 2018, 11, 913–938. [Google Scholar] [CrossRef]
- Recchia, G.; Louwerse, M.M. A Comparison of String Similarity Measures for Toponym Matching. In Proceedings of the ACM Sigspatial Comp’13, Orlando, FL, USA, 5–8 November 2013; pp. 54–61. [Google Scholar]
- Levenshtein, V.I. Binary codes capable of correcting spurious insertions and deletions of ones. Probl. Inf. Transm. 1965, 1, 707–710. [Google Scholar]
- Martins, B. A Supervised Machine Learning Approach for Duplicate Detection over Gazetteer Records. In Proceedings of the International Conference on Geospatial Semantics, Brest, France, 12–13 May 2011; pp. 34–51. [Google Scholar]
- Martins, B.; Galhardas, H.; Goncalves, N. Using Random Forest classifiers to detect duplicate gazetteer records. In Proceedings of the 7th Iberian Conference on Information Systems and Technologies (CISTI 2012), Madrid, Spain, 20–23 June 2012; pp. 1–4. [Google Scholar]
- Wang, Z.; Li, J.; Zhao, Y.; Setchi, R.; Tang, J. A unified approach to matching semantic data on the Web. Knowl.-Based Syst. 2013, 39, 173–184. [Google Scholar] [CrossRef]
- Hastings, J.; Hill, L. Treatment of duplicates in the alexandria digital library gazetteer. In Proceedings of the GeoScience, Boulder, CO, USA, 25–28 September 2002. [Google Scholar]
- Auer, S.; Lehmann, J.; Hellmann, S. LinkedGeoData: Adding a Spatial Dimension to the Web of Data. In Proceedings of the International Semantic Web Conference, Chantilly, VA, USA, 25–29 October 2009; pp. 731–746. [Google Scholar]
- Stadler, C.; Lehmann, J.; Ffner, K.; Auer, S. LinkedGeoData: A core for a web of spatial open data. Semant. Web 2012, 3, 333–354. [Google Scholar] [CrossRef]
- Samal, A.; Seth, S.; Cueto, K. A feature-based approach to conflation of geospatial sources. Int. J. Geogr. Inf. Sci. 2004, 18, 459–489. [Google Scholar] [CrossRef]
- Aoe, J.I. Computer Algorithms: String Pattern Matching Strategies; John Wiley & Sons: Hoboken, NJ, USA, 1994. [Google Scholar]
- Hastings, J. Automated conflation of digital gazetteer data. Int. J. Geogr. Inf. Sci. 2008, 22, 1109–1127. [Google Scholar] [CrossRef]
- Salton, G.; Yang, C.S. The Specification of Term Values In Automatic Indexing. J. Doc. 1973, 29, 351–372. [Google Scholar] [CrossRef]
- Ballatore, A.; Bertolotto, M.; Wilson, D. A Structural-Lexical Measure of Semantic Similarity for Geo-Knowledge Graphs. ISPRS Int. J. Geo-Inf. 2015, 4, 471–492. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Santos, R.; Murrieta-Flores, P.; Calado, P.; Martins, B. Toponym matching through deep neural networks. Int. J. Geogr. Inf. Sci. 2018, 32, 324–348. [Google Scholar] [CrossRef]
- Delgado, F.; Finat, J. An evaluation of ontology matching techniques on geospatial ontologies. Int. J. Geogr. Inf. Sci. 2013, 27, 2279–2301. [Google Scholar] [CrossRef]
- Reza, K.; Ali, A.; Majid, H. A mixed approach for automated spatial ontology alignment. J. Spat. Sci. 2010, 55, 237–255. [Google Scholar] [CrossRef]
- Cruz, I.F.; Sunna, W. Structural Alignment Methods with Applications to Geospatial Ontologies. Trans. GIS. 2008, 12, 683–711. [Google Scholar] [CrossRef]
- Melnik, S.; Garcia-Molina, H.; Rahm, E. Similarity flooding: A versatile graph matching algorithm and its application to schema matching. In Proceedings of the International Conference on Data Engineering, San Jose, CA, USA, 26 February–1 March 2002; pp. 117–128. [Google Scholar]
- Kim, J.; Vasardani, M.; Winter, S. Similarity matching for integrating spatial information extracted from place descriptions. Int. J. Geogr. Inf. Sci. 2017, 31, 56–80. [Google Scholar] [CrossRef]
- Zhao, P.; Han, J.; Sun, Y. P-Rank: A comprehensive structural similarity measure over information networks. In Proceedings of the ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 553–562. [Google Scholar]
- Small, H. Co-citation in the scientific literature: A new measure of the relationship between two documents. J. Assoc. Inf. Sci. Technol. 1973, 24, 265–269. [Google Scholar] [CrossRef]
- Kessler, M.M. Bibliographic coupling between scientific papers. J. Assoc. Inf. Sci. Technol. 1963, 14, 10–25. [Google Scholar] [CrossRef]
- Ballatore, A.; Bertolotto, M.; Wilson, D.C. Geographic knowledge extraction and semantic similarity in OpenStreetMap. Knowl. Inf. Syst. 2013, 37, 61–81. [Google Scholar] [CrossRef]
- Kang, H.; Sehgal, V.; Getoor, L. GeoDDupe: A Novel Interface for Interactive Entity Resolution in Geospatial Data. In Proceedings of the International Conference Information Visualization, Zurich, Switzerland, 4–6 July 2007; pp. 489–496. [Google Scholar]
- Hess, G.N.; Iochpe, C.; Ferrara, A.; Castano, S. Towards Effective Geographic Ontology Matching. In Proceedings of the GeoSpatial Semantics, Second International Conference, Mexico City, Mexico, 29–30 November 2007; pp. 51–65. [Google Scholar]
- Safra, E.; Kanza, Y.; Sagiv, Y.; Beeri, C.; Doytsher, Y. Location-based algorithms for finding sets of corresponding objects over several geo-spatial data sets. Int. J. Geogr. Inf. Sci. 2010, 24, 69–106. [Google Scholar] [CrossRef]
- Janée, G.; Frew, J. Spatial search, ranking, and interoperability. In Proceedings of the 27th Annual International ACM SIGIR Conference, Sheffield, UK, 29 July 2004. [Google Scholar]
- Walter, V.; Fritsch, D. Matching spatial data sets: A statistical approach. Int. J. Geogr. Inf. Sci. 1999, 13, 445–473. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhu, A.X.; Song, J.; Yang, J.; Feng, M.; Sun, K.; Zhang, J.; Hou, Z.; Zhao, H. Multidimensional and quantitative interlinking approach for Linked Geospatial Data. Int. J. Digit. Earth 2017, 10, 923–943. [Google Scholar] [CrossRef]
- Bruns, H.T.; Egenhofer, M.J. Similarity of Spatial Scenes. In Proceedings of the Symposium on Spatial Data Handling, Delft, The Netherlands, 12–16 August 1996; pp. 31–42. [Google Scholar]
- Beard, K.; Sharma, V. Multidimensional ranking for data in digital spatial libraries. Int. J. Digit. Libr. 1997, 1, 153–160. [Google Scholar] [CrossRef]
- Larson, R.R.; Frontiera, P. Spatial Ranking Methods for Geographic Information Retrieval (GIR) in Digital Libraries. In Proceedings of the Research and Advanced Technology for Digital Libraries, European Conference, Bath, UK, 12–17 September 2004; pp. 45–56. [Google Scholar]
- Li, B.; Frederico, F. TDD: A Comprehensive Model for Qualitative Spatial Similarity Assessment. Spat. Cogn. Comput. 2006, 6, 31–62. [Google Scholar] [CrossRef]
- Zheng, Y.; Fen, X.; Xie, X.; Peng, S.; Fu, J. Detecting nearly duplicated records in location datasets. In Proceedings of the ACM Sigspatial International Symposium on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 137–143. [Google Scholar]
- Resnik, P. Using information content to evaluate semantic similarity in a taxonomy. In Proceedings of the 14th International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; pp. 448–453. [Google Scholar]
- Kavouras, M.; Kokla, M.; Tomai, E. Comparing categories among geographic ontologies. Comput. Geosci. 2005, 31, 145–154. [Google Scholar] [CrossRef]
- Rodriguez, M.A.; Egenhofer, M.J.; Rugg, R.D. Assessing Semantic Similarities among Geospatial Feature Class Definitions. In Interoperating Geographic Information Systems; Springer: Berlin, Germany, 1999; pp. 189–202. [Google Scholar]
- Rodriguez, M.A.; Egenhofer, M.J. Comparing geospatial entity classes: An asymmetric and context-dependent similarity measure. Int. J. Geogr. Inf. Sci. 2004, 18, 229–256. [Google Scholar] [CrossRef]
- Rodriguez, M.A.; Egenhofer, M.J. Determining semantic similarity among entity classes from different ontologies. IEEE Trans. Knowl. Data Eng. 2003, 15, 442–456. [Google Scholar] [CrossRef]
- Chen, Z.; Song, J.; Yang, Y. An Approach to Measuring Semantic Relatedness of Geographic Terminologies Using a Thesaurus and Lexical Database Sources. ISPRS Int. J. Geo-Inf. 2018, 7, 98. [Google Scholar] [CrossRef]
- Veltkamp, R.C.; Hagedoorn, M. State of the Art in Shape Matching. In Principles of Visual Information Retrieval; Springer: London, UK, 2001; pp. 87–119. [Google Scholar]
- Safra, E.; Kanza, Y.; Sagiv, Y.; Doytsher, Y. Ad hoc matching of vectorial road networks. Int. J. Geogr. Inf. Sci. 2013, 27, 114–153. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Hunter, G.J. A simple positional accuracy measure for linear features. Int. J. Geogr. Inf. Sci. 1997, 11, 299–306. [Google Scholar] [CrossRef]
- Fairbairn, D.; Albakri, M. Using Geometric Properties to Evaluate Possible Integration of Authoritative and Volunteered Geographic Information. ISPRS Int. J. Geo-Inf. 2013, 2, 349–370. [Google Scholar] [CrossRef]
- Du, H.; Alechina, N.; Jackson, M.; Hart, G. A Method for Matching Crowd-sourced and Authoritative Geospatial Data. Trans. GIS 2017, 21. [Google Scholar] [CrossRef]
- Zhu, R.; Hu, Y.; Janowicz, K.; Mckenzie, G. Spatial signatures for geographic feature types: Examining gazetteer ontologies using spatial statistics. Trans. GIS 2016, 20, 333–355. [Google Scholar] [CrossRef]
- Janowicz, K.; Schwarz, M.; Wilkes, M.; Panov, I.; Espeter, M. Algorithm, implementation and application of the SIM-DL similarity server. In Proceedings of the International Conference on Geospatial Semantics, Mexico City, Mexico, 29–30 November 2007; pp. 128–145. [Google Scholar]
- Kokla, M.; Kavouras, M. Fusion of top-level and geographical domain ontologies based on context formation and complementarity. Int. J. Geogr. Inf. Sci. 2001, 15, 679–687. [Google Scholar] [CrossRef]
- Kavouras, M.; Kokla, M. A method for the formalization and integration of geographical categorizations. Int. J. Geogr. Inf. Sci. 2002, 16, 439–453. [Google Scholar] [CrossRef]
- Peukert, E.; Maßmann, S.; König, K. Comparing Similarity Combination Methods for Schema Matching. In Proceedings of the 40th Annual Conference of the German Computer Society (GI-Jahrestagung), Leipzig, Germany, 1 October 2010; pp. 692–701. [Google Scholar]
- Tran, Q.V.; Ichise, R.; Ho, B.Q. Cluster-based similarity aggregation for ontology matching. In Proceedings of the International Conference on Ontology Matching, Bonn, Germany, 24 October 2011; pp. 142–147. [Google Scholar]
- Schwering, A. Approaches to Semantic Similarity Measurement for Geo-Spatial Data: A Survey. Trans. GIS 2008, 12, 5–29. [Google Scholar] [CrossRef]
- Jan, S.; Shah, I.; Khan, I.; Khan, F.; Usman, M. Similarity Measures and their Aggregation in Ontology Matching. Int. J. Comput. Sci. Telecommun. 2012, 3, 52–57. [Google Scholar]
- Do, H.H.; Rahm, E. COMA: A system for flexible combination of schema matching approaches. In Proceedings of the VLDB Endowment, Hong Kong, China, 20–23 August 2002; pp. 610–621. [Google Scholar]
- Hu, Y.H.; Ge, L. Learning Ranking Functions for Geographic Information Retrieval Using Genetic Programming. J. Res. Pract. Inf. Technol. 2009, 41, 39–52. [Google Scholar] [CrossRef]
- Mckenzie, G.; Janowicz, K.; Adams, B. A weighted multi-attribute method for matching user-generated Points of Interest. Cartogr. Geogr. Inf. Sci. 2014, 41, 125–137. [Google Scholar] [CrossRef]
- Li, J.; He, Z.; Zhu, Q. An entropy-based weighted concept lattice for merging multi-source geo-ontologies. Entropy 2013, 15, 2303–2318. [Google Scholar] [CrossRef]
- Chen, Z.; Song, J.; Yang, Y. Similarity Measurement of Metadata of Geospatial Data: An Artificial Neural Network Approach. ISPRS Int. J. Geo-Inf. 2018, 7, 90. [Google Scholar] [CrossRef]
- Bock, J.; Hettenhausen, J. Discrete particle swarm optimisation for ontology alignment. Inf. Sci. 2012, 192, 152–173. [Google Scholar] [CrossRef]
- Bharambe, U.; Durbha, S.S. Adaptive Pareto-based approach for geo-ontology matching. Comput. Geosci. 2018, 119, 92–108. [Google Scholar] [CrossRef]
- Daskalaki, E.; Flouris, G.; Fundulaki, I.; Saveta, T. Instance matching benchmarks in the era of Linked Data. J. Web Semant. 2016, 39, 1–14. [Google Scholar] [CrossRef]
- Keßler, C. What is the difference? A cognitive dissimilarity measure for information retrieval result sets. Knowl. Inf. Syst. 2012, 30, 319–340. [Google Scholar] [CrossRef]
- Janowicz, K.; Keßler, C.; Panov, I.; Wilkes, M.; Espeter, M.; Schwarz, M. A Study on the Cognitive Plausibility of SIM-DL Similarity Rankings for Geographic Feature Types. In Proceedings of the Agile, Washington, DC, USA, 4–8 August 2008; pp. 115–134. [Google Scholar]
- Goutte, C.; Gaussier, E. A Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation. In Proceedings of the European Conference on Information Retrieval, Santiago de Compostela, Spain, 21–23 March 2005; pp. 345–359. [Google Scholar]
- Ballatore, A.; Bertolotto, M.; Wilson, D.C. An evaluative baseline for geo-semantic relatedness and similarity. GeoInformatica 2014, 18, 747–767. [Google Scholar] [CrossRef]
- Fundulaki, I.; Ngonga-Ngomo, A.C. Instance Matching Benchmark for Spatial Data: A Challenge Proposal to OAEI. In Proceedings of the International Semantic Web Conference, Kobe, Japan, 17–21 October 2016; pp. 233–234. [Google Scholar]
- Duchateau, F.; Bellahsène, Z. Designing a Benchmark for the Assessment of XML Schema Matching Tools. Open J. Datab. 2014, 1, 3–25. [Google Scholar] [CrossRef]
- Alexe, B.; Tan, W.C.; Velegrakis, Y. STBenchmark: Towards a benchmark for mapping systems. VLDB Endow. 2008, 1, 230–244. [Google Scholar] [CrossRef]
- Euzenat, J.; Ferrara, A.; Hollink, L.; Isaac, A.; Joslyn, C.; Malaisé, V.; Meilicke, C.; Nikolov, A.; Pane, J.; Sabou, M.; et al. Results of the Ontology Alignment Evaluation Initiative 2009. In Proceedings of the 4th ISWC Workshop on Ontology Matching, Chantilly, VA, USA, 25 October 2009; pp. 73–95. [Google Scholar]
- Berjawi, B.; Duchateau, F.; Favetta, F.; Miquel, M.; Laurini, R. PABench: Designing a Taxonomy and Implementing a Benchmark for Spatial Entity Matching. In Proceedings of the Seventh International Conference on Advanced Geographic Information Systems, Applications, and Services, Lisbon, Portugal, 22–27 Feburary 2015; pp. 7–16. [Google Scholar]
- Janowicz, K.; Pehle, T.; Pehle, T.; Hart, G. Geospatial semantics and linked spatiotemporal data—Past, present, and future. Semant. Web 2012, 3, 321–332. [Google Scholar] [CrossRef]
- Stock, K.; Cialone, C. An Approach to the Management of Multiple Aligned Multilingual Ontologies for a Geospatial Earth Observation System. In Proceedings of the International Conference on GeoSpatial Sematics, Brest, France, 12–13 May 2011; pp. 52–69. [Google Scholar]
- Cruz, I.F.; Sunna, W.; Makar, N.; Bathala, S. A visual tool for ontology alignment to enable geospatial interoperability. J. Visual Lang. Comput. 2007, 18, 230–254. [Google Scholar] [CrossRef]
- Mata, F. Geographic Information Retrieval by Topological, Geographical, and Conceptual Matching. In Proceedings of the Second International Conference on GeoSpatial Semantics, Mexico City, Mexico, 29–30 November 2007; pp. 98–113. [Google Scholar]
- Vaccari, L.; Shvaiko, P.; Pane, J.; Besana, P.; Marchese, M. An evaluation of ontology matching in geo-service applications. GeoInformatica 2012, 16, 31–66. [Google Scholar] [CrossRef]
- Duckham, M.; Worboys, M. Automated Geographical Information Fusion and Ontology Alignment. In Spatial Data on the Web; Springer: Berlin, Germany, 2007; pp. 109–132. [Google Scholar]
- Lutz, M. Ontology-Based Descriptions for Semantic Discovery and Composition of Geoprocessing Services. GeoInformatica 2007, 11, 1–36. [Google Scholar] [CrossRef]
- Vaccari, L.; Shvaiko, P.; Marchese, M. A geo-service semantic integration in spatial data infrastructures. Int. J. Spat. Data Infrastruct. Res. 2009, 4, 24–51. [Google Scholar]
- Ding, R.; Chen, Z. RecNet: A deep neural network for personalized POI recommendation in location-based social networks. Int. J. Geogr. Inf. Sci. 2018, 32, 1–18. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhu, A.X.; Feng, M.; Song, J.; Zhao, H.; Yang, J.; Zhang, Q.; Sun, K.; Zhang, J.; Yao, L. A similarity-based automatic data recommendation approach for geographic models. Int. J. Geogr. Inf. Sci. 2017, 31, 1403–1424. [Google Scholar] [CrossRef]
- Senaratne, H.; Mobasheri, A.; Ali, A.L.; Capineri, C.; Haklay, M. A review of volunteered geographic information quality assessment methods. Int. J. Geogr. Inf. Sci. 2017, 31, 139–167. [Google Scholar] [CrossRef]
- Moreri, K.K.; Fairbairn, D.; James, P. Volunteered geographic information quality assessment using trust and reputation modelling in land administration systems in developing countries. Int. J. Geogr. Inf. Sci. 2018, 32, 1–29. [Google Scholar] [CrossRef]
- Barron, C.; Neis, P.; Zipf, A. A Comprehensive Framework for Intrinsic OpenStreetMap Quality Analysis. Trans. GIS 2015, 18, 877–895. [Google Scholar] [CrossRef]
- Bordogna, G.; Carrara, P.; Criscuolo, L.; Pepe, M.; Rampini, A. A linguistic decision making approach to assess the quality of volunteer geographic information for citizen science. Inf. Sci. 2014, 258, 312–327. [Google Scholar] [CrossRef]
- Marie, A.; Gal, A. Boosting Schema Matchers. In Proceedings of the OTM Confederated International Conferences On the Move to Meaningful Internet Systems, Monterrey, Mexico, 9–14 November 2008; pp. 283–300. [Google Scholar]
- Mochol, M.; Jentzsch, A.; Euzenat, J. Applying an Analytic Method for Matching Approach Selection. In Proceedings of the International Workshop on Ontology Matching, Athens, GA, USA, 5 November 2006; pp. 37–48. [Google Scholar]
- Huza, M.; Harzallah, M.; Trichet, F. OntoMas: A Tutoring System dedicated to Ontology Matching. In Enterprise Interoperability II; Springer: London, UK, 2007; pp. 377–388. [Google Scholar]
- Mochol, M.; Jentzsch, A. Towards a Rule-Based Matcher Selection. In Proceedings of the International Conference on Knowledge Engineering: Practice and Patterns, Acitrezza, Italy, 29 September–2 October 2008; pp. 109–119. [Google Scholar]
- Parent, C.; Spaccapietra, S.; Zimányi, E. Conceptual Modeling for Traditional and Spatio-Temporal Applications. In The MADS Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006; pp. 188–189. [Google Scholar]
- Shvaiko, P.; Euzenat, J. Ten Challenges for Ontology Matching. In Proceedings of the OTM Confederated International Conferences on the Move to Meaningful Internet Systems, Monterrey, Mexico, 9–14 November 2008; pp. 1164–1182. [Google Scholar]
- Lee, Y.; Sayyadian, M.; Doan, A.; Rosenthal, A.S.; Sayyadian, M.; Doan, A.; Rosenthal, A.S. eTuner: Tuning schema matching software using synthetic scenarios. VLDB J. 2008, 16, 97–122. [Google Scholar] [CrossRef]
- Duchateau, F.; Bellahsene, Z.; Coletta, R. A Flexible Approach for Planning Schema Matching Algorithms. In Proceedings of the OTM Confederated International Conferences on the Move to Meaningful Internet Systems, Monterrey, Mexico, 9–14 November 2008; pp. 249–264. [Google Scholar]
- Noy, N.F.; Musen, M.A. The PROMPT suite: Interactive tools for ontology merging and mapping. Int. J. Hum.-Comput. Stud. 2003, 59, 983–1024. [Google Scholar] [CrossRef]
- Ghazvinian, A.; Noy, N.F.; Jonquet, C.; Shah, N.; Musen, M.A. What Four Million Mappings Can Tell You about Two Hundred Ontologies. In Proceedings of the International Semantic Web Conference, Chantilly, VA, USA, 25–29 October 2009; pp. 229–242. [Google Scholar]
- Euzenat, J. Alignment infrastructure for ontology mediation and other applications. Proceedings of 1st ICSOC international workshop on Mediation in semantic web services, Amsterdam, Netherlands, 12 December 2005; pp. 81–95. [Google Scholar]
- Do, H.H.; Rahm, E. Matching large schemas: Approaches and evaluation. Inform. Syst. 2007, 32, 857–885. [Google Scholar] [CrossRef]
- Ehrig, M.; Staab, S. QOM—Quick Ontology Mapping. In Proceedings of the International Semantic Web Conference, Hiroshima, Japan, 7–11 November 2004; pp. 683–697. [Google Scholar]
- Kirsten, T.; Kolb, L.; Hartung, M.; Groß, A.; Köpcke, H.; Rahm, E. Data Partitioning for Parallel Entity Matching. Comput. Sci. 2010, 3, 1–8. [Google Scholar] [CrossRef]
- Bianco, G.D.; Galante, R.; Heuser, C.A. A fast approach for parallel deduplication on multicore processors. In Proceedings of the ACM Symposium on Applied Computing, TaiChung, Taiwan, 21–24 March 2011; pp. 1027–1032. [Google Scholar]
- Hungsik, K.; Dongwon, L. Parallel linkage. In Proceedings of the ACM, Lisbon, Portugal, 6–10 November 2007; pp. 283–292. [Google Scholar]
- Euzenat, J.; Meilicke, C.; Stuckenschmidt, H.; Shvaiko, P.; Trojahn, C. Ontology Alignment Evaluation Initiative: Six Years of Experience. In Journal on Data Semantics XV; Springer: Berlin/Heidelberg, Germany, 2011; pp. 158–192. [Google Scholar]
- Giunchiglia, F.; Yatskevich, M.; Avesani, P.; Shivaiko, P. A Large Scale Dataset for the Evaluation of Ontology Matching Systems. Knowl. Eng. Rev. 2009, 24, 137–157. [Google Scholar] [CrossRef]
- Ferrara, A.; Montanelli, S.; Noessner, J.; Stuckenschmidt, H. Benchmarking Matching Applications on the Semantic Web. In Proceedings of the Extended Semantic Web Conference on the Semanic Web: Research and Applications, Heraklion, Crete, Greece, 29 May–2 June 2011; pp. 108–122. [Google Scholar]
- Saveta, T.; Daskalaki, E.; Flouris, G.; Fundulaki, I.; Herschel, M.; Ngonga Ngomo, A.C. Pushing the Limits of Instance Matching Systems: A Semantics-Aware Benchmark for Linked Data. In Proceedings of the International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 105–106. [Google Scholar]
- Saveta, T.; Daskalaki, E.; Flouris, G.; Fundulaki, I.; Herschel, M.; Ngomo, A.C.N. LANCE: Piercing to the Heart of Instance Matching Tools. In Proceedings of the International Semantic Web Conference, Bethlehem, PA, USA, 11–15 October 2015; pp. 375–391. [Google Scholar]
- Euzenat, J.; Roşoiu, M.E.; Trojahn, C. Ontology matching benchmarks: Generation, stability, and discriminability. J. Web Semant. 2013, 21, 30–48. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Name | Number of Concepts | Number of Properties | Number of Instances | Formalized Format |
|---|---|---|---|---|
| GeoNames | 654 | 28 | 11,809,910 | OWL |
| LinkedGeoData | 1222 | 137 | 3,000,000,000 | NT |
| OSM Semantic Network | 1222 | 137 | Null | RDF |
| ADL | 210 | Null | 8,000,000 | RDF |
| Entity Type | Heterogeneities | |||||||
|---|---|---|---|---|---|---|---|---|
| HL | HS | HSp | HC | HSh | HPdt | HPr | HPv | |
| Concepts | ✓ | ✓ | ||||||
| Properties | ✓ | ✓ | ✓ | ✓ | ||||
| Instances | ✓ | ✓ | ✓ | ✓ | ✓ | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, K.; Zhu, Y.; Song, J. Progress and Challenges on Entity Alignment of Geographic Knowledge Bases. ISPRS Int. J. Geo-Inf. 2019, 8, 77. https://doi.org/10.3390/ijgi8020077
Sun K, Zhu Y, Song J. Progress and Challenges on Entity Alignment of Geographic Knowledge Bases. ISPRS International Journal of Geo-Information. 2019; 8(2):77. https://doi.org/10.3390/ijgi8020077
Chicago/Turabian StyleSun, Kai, Yunqiang Zhu, and Jia Song. 2019. "Progress and Challenges on Entity Alignment of Geographic Knowledge Bases" ISPRS International Journal of Geo-Information 8, no. 2: 77. https://doi.org/10.3390/ijgi8020077
APA StyleSun, K., Zhu, Y., & Song, J. (2019). Progress and Challenges on Entity Alignment of Geographic Knowledge Bases. ISPRS International Journal of Geo-Information, 8(2), 77. https://doi.org/10.3390/ijgi8020077