Combining Object-Based Image Analysis with Topographic Data for Landform Mapping: A Case Study in the Semi-Arid Chaco Ecosystem, Argentina

 , and
, and
Abstract
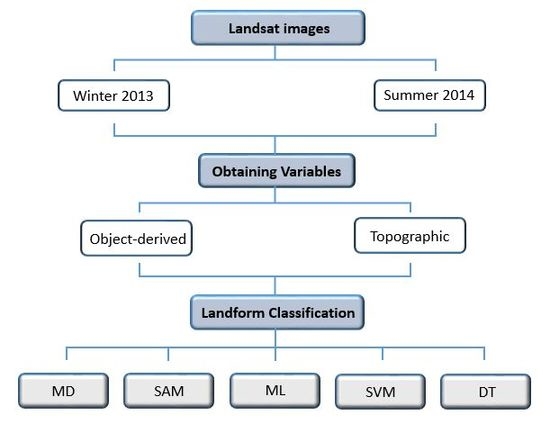
:
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Satellite Data and Preprocessing
2.3. Ground-Truth Landform Distribution
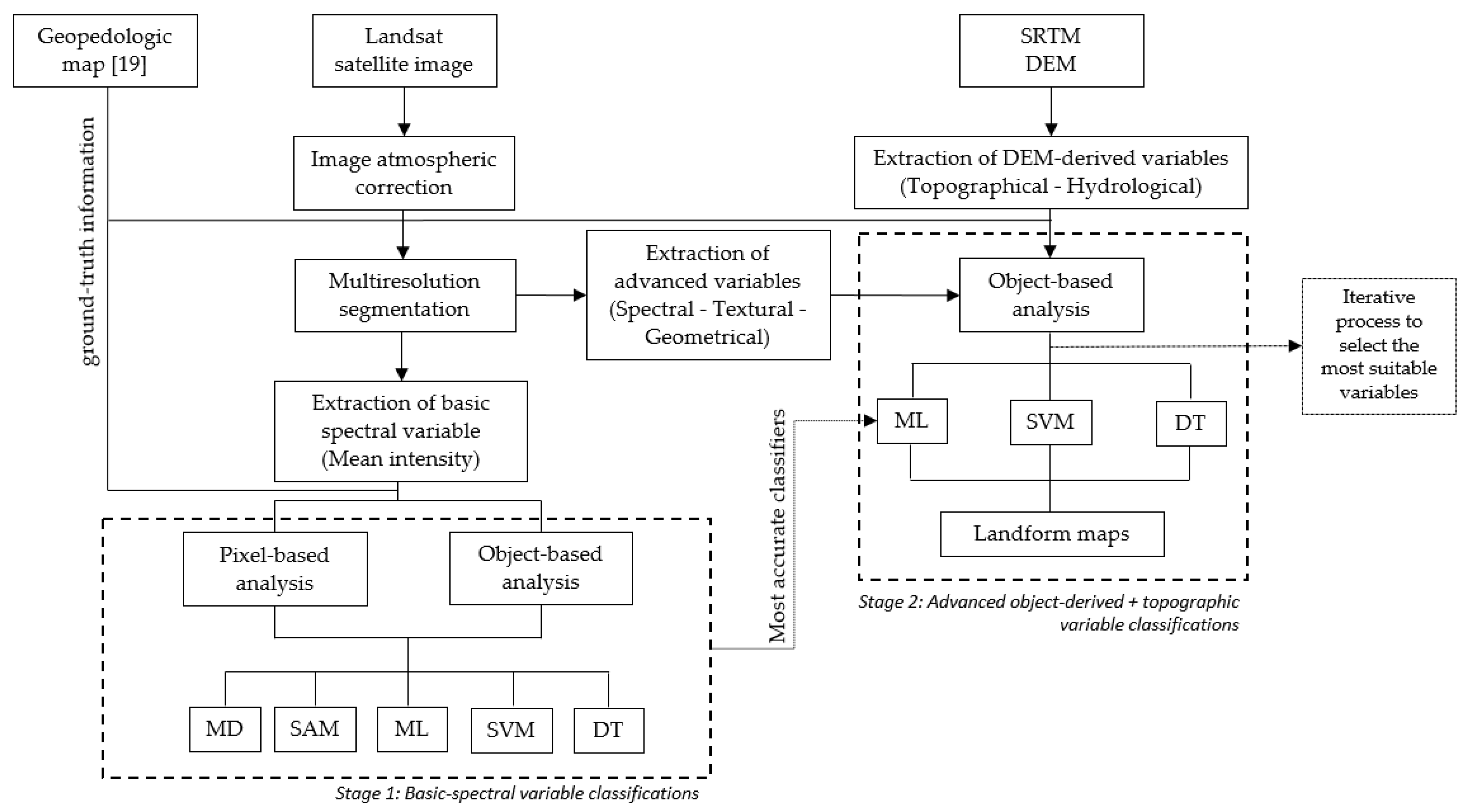
3. Methods
3.1. Stage 1: Basic-Spectral Variable Classifications
3.1.1. Segmentation
3.1.2. Basic-Spectral Landform Classification and Accuracy Assessments
3.2. Stage 2: Advanced Object-Derived + Topographic Variable Classifications
3.2.1. Object-Derived Variables
3.2.2. Topographic variables
3.2.3. Advanced Landform Classification and Accuracy Assessments
3.2.4. Evaluation of the Importance of the Variables in the Prediction
4. Results
4.1. Stage 1: Basic-Spectral Variable Classifications
4.2. Stage 2: Advanced Object-Derived + Topographic Variable Classifications
4.3. Evaluation of the Importance of the Variables in the Prediction
5. Discussion
5.1. Stage 1: Basic-Spectral Variable Classifications
5.2. Stage 2: Advanced Object-Derived + Topographic Variable Classifications
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Morello, J.; Pengue, W.; Rodríguez, A. tapa de uso de los recursos naturales y desmantelamiento de la biota del Chaco. In La Situación Ambiental Argentina 2005; Brown, A., Martinez Ortiz, U., Acerbi, M., Corcuera, J., Eds.; Fundación Vida Silvestre Argentina: Buenos Aires, Argentina, 2006; pp. 83–90. [Google Scholar]
- Angueira, C. Evaluación de Tierra, Esquema FAO: Lavalle-Tapso-Frias; INTA: Santiago del Estero, Argentina, 1994. [Google Scholar]
- Hudson, B.D. The soil survey as paradigm-based science. Soil Sci. Soc. Am. J. 1992, 56, 836–841. [Google Scholar] [CrossRef]
- Jafari, A.; Finke, P.A.; Vande Wauw, J.; Ayoubi, S.; Khademi, H. Spatial prediction of USDA-great soil groups in the arid zarand region, Iran: Comparing logistic regression approaches to predict diagnostic horizons and soil types. Eur. J. Soil Sci. 2012, 63, 284–298. [Google Scholar] [CrossRef]
- Hartemink, A.E.; Hempel, J.; Lagacherie, P.; McBratney, A.B.; McKenzie, N.J. GlobalSoilMap.net—A New Digital Soil Map of the World. In Digital Soil Mapping. Bridging Research, Environmental Application, and Operation; Boettinger, J.L., Howell, D.W., Moore, A.C., Hartemink, A.E., Kienast-Brown, S., Eds.; Springer: Dordrecht, The Netherlands, 2010; pp. 423–428. [Google Scholar]
- McBratney, A.B.; Mendonça Santos, M.L.; Minasny, B. On digital soil mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- Ballantine, J.A.C.; Okin, G.S.; Prentiss, D.E.; Roberts, D.A. Mapping North African landforms using continental scale unmixing of MODIS imagery. Remote Sens. Environ. 2005, 97, 470–483. [Google Scholar] [CrossRef]
- McKenzie, N.J.; Ryan, P.J. Spatial prediction of soil properties using environmental correlation. Geoderma 1999, 89, 67–94. [Google Scholar] [CrossRef]
- Dobos, E.; Michelli, E.; Baumgardner, M.F.; Biehl, L.; Helt, T. Use of combined digital elevation model and satellite radiometric data for regional soil mapping. Geoderma 2000, 97, 376–391. [Google Scholar] [CrossRef]
- Kalambukattu, J.G.; Kumar, S.; Arya Raj, R. Digital soil mapping in a Himalayan watershed using remote sensing and terrain parameters employing artificial neural network model. Environ. Earth Sci. 2018, 77, 203. [Google Scholar] [CrossRef]
- Mahmoudabadi, E.; Karimi, A.; Haghnia, G.H.; Sepehr, A. Digital soil mapping using remote sensing indices, terrain attributes, and vegetation features in the rangelands of northeastern Iran. Environ. Monit. Assess. 2017, 189, 500. [Google Scholar] [CrossRef] [PubMed]
- Van Niekerk, A. A comparison of land unit delineation techniques for land evaluation in the Western Cape, South Africa. Land Use Policy 2010, 27, 937–945. [Google Scholar] [CrossRef] [Green Version]
- Drǎguţ, L.; Eisank, C. Automated object-based classification of topography from SRTM data. Geomorphology 2012, 141–142, 21–33. [Google Scholar] [CrossRef] [PubMed]
- Castillejo-González, I.L.; López-Granados, F.; García-Ferrer, A.; Peña-Barragán, J.M.; Jurado-Expósito, M.; de la Orden, M.S.; González-Audicana, M. Object- and pixel-based analysis for mapping crops and their agro-environmental associated measures using QuickBird imagery. Comput. Electron. Agric. 2009, 68, 207–215. [Google Scholar] [CrossRef]
- Peña-Barragán, J.M.; Ngugi, M.K.; Plant, R.E.; Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar] [CrossRef] [Green Version]
- Arroyo, L.A.; Johansen, K.; Armston, J.; Phinn, S. Integration of LiDAR and QuickBird imagery for mapping riparian biophysical parameters and land cover types in Australian tropical savannas. For. Ecol. Manag. 2010, 259, 598–606. [Google Scholar] [CrossRef]
- Machala, M.; Zejdová, L. Forest mapping through object-based image analysis of multispectral and LiDAR aerial data. Eur. J. Remote Sens. 2015, 47, 117–131. [Google Scholar] [CrossRef]
- Du, S.; Zhang, F.; Zhang, X. Semantic classification of urban buildings combining VHR image and GIS data: An improved random forest approach. ISPRS J. Photogramm. Remote Sens. 2015, 105, 107–119. [Google Scholar] [CrossRef]
- Sebari, I.; He, D. Automatic fuzzy object-based analysis of VHSR images for urban objects extraction. ISPRS J. Photogramm. Remote Sens. 2013, 79, 171–184. [Google Scholar] [CrossRef]
- Van Asselen, S.; Seijmonsbergen, A.C. Expert-driven semi-automated geomorphological mapping for a mountainous area using a laser DTM. Geomorphology 2006, 78, 309–320. [Google Scholar] [CrossRef]
- Schneevoigt, N.J.; van der Linden, S.; Thamm, H.; Schrott, L. Detecting alpine landforms from remotely sensed imagery: A pilot study in the Bavarian Alps. Geomorphology 2008, 93, 104–119. [Google Scholar] [CrossRef]
- Vamshi, G.T.; Martha, T.R.; Vinod Kumar, K. An object-based classification method for automatic detection of lunar impact craters from topographic data. Adv. Space Res. 2016, 57, 1978–1988. [Google Scholar] [CrossRef]
- Martha, T.R.; Mohan Vamsee, A.; Tripathi, V.; Vinod Kumar, K. Detection of coastal landforms in a deltaic area using a multi-scale object-based classification method. Curr. Sci. 2018, 114, 1338–1345. [Google Scholar] [CrossRef]
- Mulder, V.L.; de Bruin, S.; Schaepman, M.E.; Mayr, T.R. The use of remote sensing in soil and terrain mapping—A review. Geoderma 2011, 162, 1–19. [Google Scholar] [CrossRef]
- Angueira, C.; Cruzate, G.; Zamora, E.M.; Olmedo, G.F.; Sayago, J.M.; Castillejo González, I. Soil mapping based on landscape classification in the semiarid Chaco, Argentina. In Geopedology: An Integration of Geomorphology and Pedology for Soil and Landscape Studies; Zink, J.A., Metternicht, G., Bocco, G., Del Valle, H.F., Eds.; Sringer: Basel, Switzerland, 2015; pp. 285–303. [Google Scholar]
- Baatz, M.; Schäpe, A. Multiresolution segmentation: An optimization approach for high quality multi-scale image segmentation. In Proceedings of the 12th Symposium for Applied Geographic Information Processing (Angewandte Geographische Informationsverarbeitung XII), Salzburg, Austria, 5–7 July 2000; AGIT: Salzburg, Austria, 2000. [Google Scholar]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification. Technical Report; National Taiwan University: Taiwan, China, 2003. [Google Scholar]
- Quinlan, R. C4-5: Programs for Machine Learning; Morgan Kaufmann: San Mateo, CA, USA, 1993. [Google Scholar]
- Iwahashi, J.; Pike, R.J. Automated classifications of topography from DEMs by an unsupervised nested-means algorithm and a three-part geometric signature. Geomorphology 2007, 86, 409–440. [Google Scholar] [CrossRef]
- Manzo, C.; Valentini, E.; Taramelli, A.; Filipponi, F.; Disperati, L. Spectral characterization of coastal sediments using field spectral libraries, airborne hyperspectral images and topographic LiDAR data (FHyL). Int. J. Appl. Earth Obs. Geoinf. 2015, 36, 54–68. [Google Scholar] [CrossRef]
- Friedl, M.A.; Brodley, C.E. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–408. [Google Scholar] [CrossRef]
- Rogan, J.; Franklin, J.; Stow, D.; Miller, J.; Woodcock, C.; Roberts, D. Mapping land-cover modifications over large areas: A comparison of machine learning algorithms. Remote Sens. Environ. 2008, 112, 2272–2283. [Google Scholar] [CrossRef]
- Drummond, C.; Holte, R.C. C4.5, class imbalance, and cost sensitivity: Why under-sampling beats over-sampling. In Proceedings of the 20th International Conference on Machine Learning Workshop on Learning from Imbalanced Datasets II (ICML 2013), Washington, DC, USA, 21 August 2003; Citeseer: Washington, DC, USA, 2013; pp. 1–8. [Google Scholar]
- Duro, D.C.; Franklin, S.E.; Dubé, M.G. A comparison of pixel-based and object-based image analysis with selected machine learning algorithms for the classification of agricultural landscapes using SPOT-5 HRG imagery. Remote Sens. Environ. 2012, 118, 259–272. [Google Scholar] [CrossRef]
- Poursanidis, D.; Chrysoulaki, N.; Mitraka, Z. Landsat 8 vs. Landsat 5: A comparison based on urban and peri-urban land cover mapping. Int. J. Appl. Earth Obs. Geoinf. 2015, 35, 259–269. [Google Scholar] [CrossRef]
- Gilbertson, J.K.; van Niekerk, A. Value of dimensionality reduction for crop differentiation with multi-temporal imagery and machine learning. Comput. Electron. Agric. 2017, 142, 50–58. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef] [Green Version]
- Myburgh, G.; Van Niekerk, A. Impact of training set size on object-based land cover classification: A comparison of three classifiers. Int. J. Appl. Geospatial Res. 2014, 5, 49–67. [Google Scholar] [CrossRef]
- Brown de Colstoun, E.C.; Story, M.H.; Thompson, C.; Commisso, K.; Smith, T.G.; Irons, J.I. National Park vegetation mapping using multitemporal Landsat 7 data and a decision tree classifier. Remote Sens. Environ. 2003, 85, 316–327. [Google Scholar] [CrossRef]
- Richards, J.A.; Jia, X. Remote Sensing Digital Image Analysis: An Introduction; Springer: New York, NY, USA, 2006. [Google Scholar]
- Rogan, J.; Franklin, J.; Roberts, D.A. A comparison of methods for monitoring multitemporal vegetation change using thematic mapper imagery. Remote Sens. Environ. 2002, 80, 143–156. [Google Scholar] [CrossRef]
- Aksoy, E.; Ozsoy, G.; Sabri Dirim, M. Soil mapping approach in GIS using Landsat satellite imagery and DEM data. Afr. J. Agric. Res. 2009, 4, 1295–1302. [Google Scholar]
- Hansen, M.K.; Brown, D.J.; Dennison, P.E.; Graves, S.A.; Bricklemyer, R.S. Inductively mapping expert-derived soil-landscape units within Dambo wetland catenae using multispectral and topographic data. Geoderma 2009, 150, 72–84. [Google Scholar] [CrossRef]
- Zhu, A. Measuring uncertainty in class assignment for natural resource maps under fuzzy logic. Photogramm. Eng. Remote Sens. 1997, 63, 1195–1202. [Google Scholar]
- Anders, N.S.; Seijmonsbergen, A.C.; Bouten, W. Segmentation optimization and stratified object-based analysis for semi-automated geomorphological mapping. Remote Sens. Environ. 2011, 115, 2976–2985. [Google Scholar] [CrossRef]
- Taramelli, A. Detecting landforms using quantitative radar roughness characterization and spectral mixing analysis. Stud. Comput. Intell. 2011, 348, 225–249. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
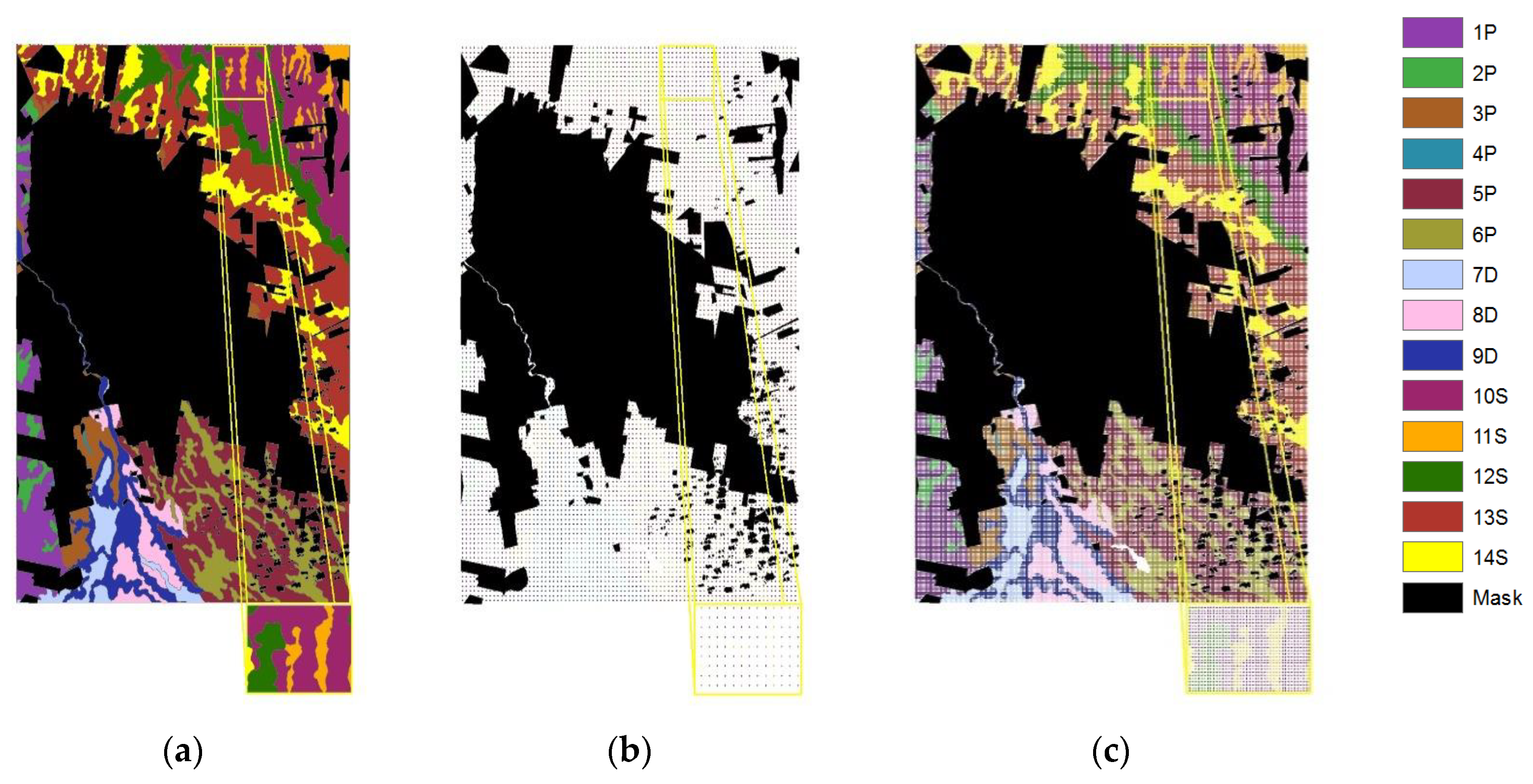
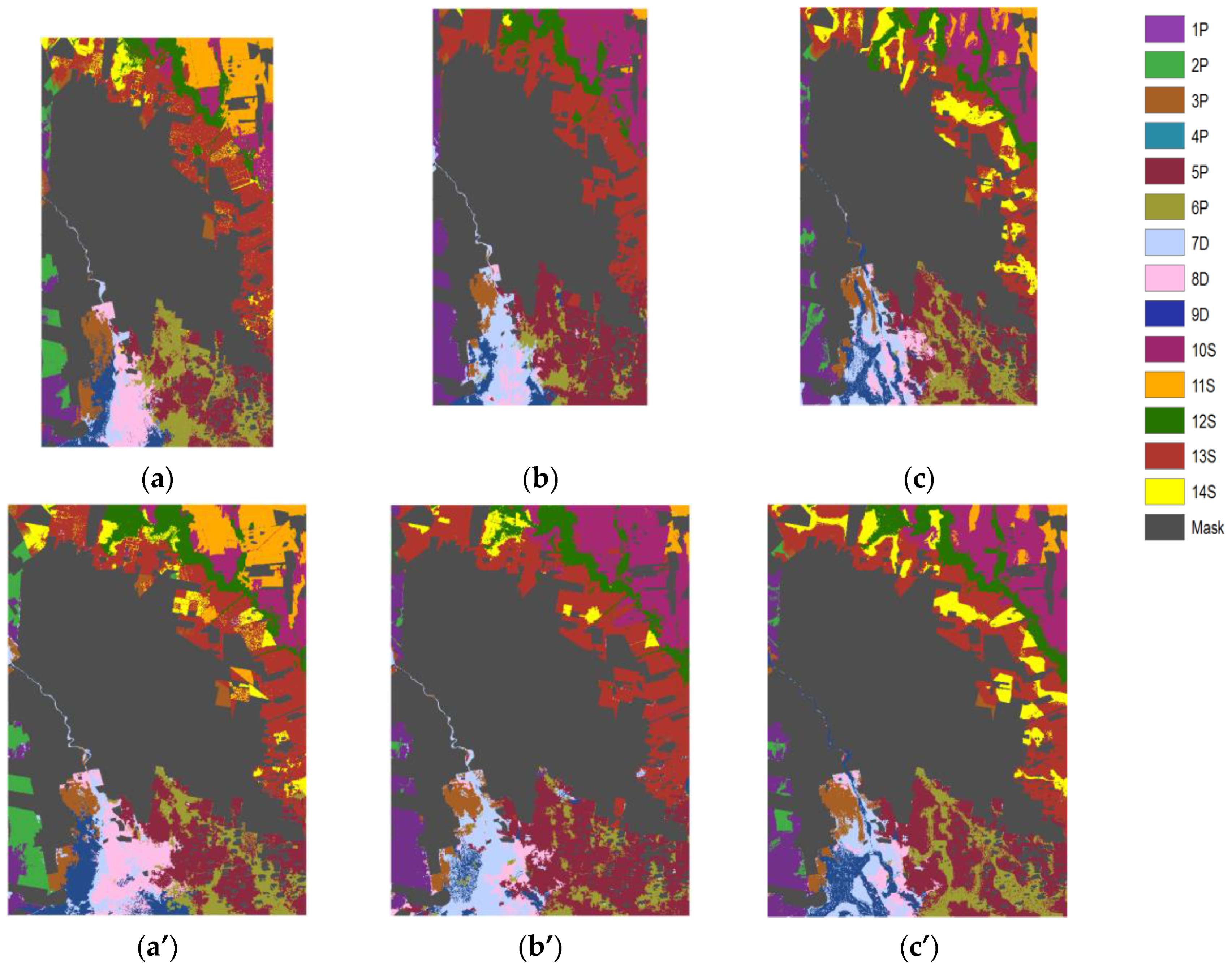
| Landscape | Molding | Facies | Landform | Code |
|---|---|---|---|---|
| Fluvio-eolian Chaco plain (Sali-Dulce River) | Proximal megafan | Eolian | Loess cover | 1P |
| Blowout depression | 2P | |||
| Distal megafan | Alluvial | Interfluvial plain | 3P | |
| Infilled channel | 4P | |||
| Old alluvial overland flow | Alluvial | Overflowed depression | 5P | |
| Alluvial overflow levee | 6P | |||
| Valley (Dulce River) | Middle terrace (mt) | Alluvial | Levee and overflows (mt) | 7D |
| Low terrace (lt) | Levee and overflows (lt) | 8D | ||
| Active floodplain | River | 9D | ||
| Alluvial migratory plain (Salado River) | Active fluvial valley | Alluvial | Alluvial overflow plain | 10S |
| Levee | 11S | |||
| Active floodplain | Alluvial | Alluvial overflow swamp | 12S | |
| Fluvio-eolian terrace remnant | Eolian over alluvial | Alluvial flat | 13S | |
| Alluvial channel | 14S |
| Type | Variable | Name | Brief Description |
|---|---|---|---|
| Spectrality | Mean | Mean | Mean of the intensity values of all pixels forming an image object |
| Standard deviation | St_Dev | Standard Deviation of the intensity values of all pixels forming an image object | |
| Skewness | Skew | Asymmetry of the distribution of all pixels forming an image object | |
| Brightness | Bright | Sum of brightness weight in all layers of an image object multiply by the mean intensity of the same object | |
| Max difference | Max_Diff | Ration between the maximum difference of mean intensity of an image object in the different layers and the brightness of the same image object | |
| Texture | Correlation | GLCM_C | Linear dependency of gray levels of neighboring pixels on the gray level co-occurrence matrix (GLCM) |
| Entropy | GLCM_E | Distribution of the pixel values on the gray level co-occurrence matrix (GLCM) | |
| Homogeneity | GLCM_H | Amount of local variation in the image based on the gray level co-occurrence matrix (GLCM) | |
| Mean | GLCM_M | Average expressed by the frequency of occurrence of a pixel combination with a certain neighbor pixel value | |
| Geometry | Area | Area | Number of pixels forming an image object |
| Length | Length | Multiplication between the number of pixels and the length-to-width ratio of an image object | |
| Width | Width | Ration between the number of pixels and the length-to-width ratio of an image object | |
| Asymmetry | Asymm | Relative length of an image object compared to a regular ellipse polygon | |
| Border index | Border_I | Ratio between the border lengths of the image object and the smallest enclosing rectangle | |
| Compactness | Compact | Ratio between the length x width of the object and its area | |
| Density | Density | Ratio between the area of an image object and its approximated radius | |
| Elliptic fit | Ellip_Fit | Comparison between the area of an imagen and an ellipse with the same area as the selected image object | |
| Main direction | Main_Dir | Direction of the eigenvector belonging to the larger of the two eigenvalues | |
| Radius of largest enclosed ellipse | R_Largest | Ratio of the radius of the largest enclosed ellipse to the radius of the original ellipse | |
| Radius of smallest enclosing ellipse | R_Smallest | Ratio of the radius of the smallest enclosing ellipse to the radius of the original ellipse | |
| Rectangular fit | Rect_Fit | Comparison between the area of the image object outside a rectangle with the same area as the image object, and the area inside the rectangle | |
| Roundness | Round | Difference of the enclosing ellipse and the enclosed ellipse | |
| Shape index | Shape_I | Comparison between the border length feature of the image object and four times the square root of its area |
| Type | Variable | Name | Brief Description |
|---|---|---|---|
| Topography | Elevation | Elev | Terrain altitude on a reference system |
| Slope | Slope | Steepness of the terrain relative to the horizontal plane | |
| Aspect | Aspect | Compass the direction that a terrain slope faces | |
| Plan Curvature | Plan_Cuv | Curvature of the hypothetical contour line that passes through a specific cell | |
| Profile Curvature | Prof_Curv | Curvature of the surface in the direction of the steepest slope | |
| Hydrology | Altitude about channel network | Alt_Ch | Vertical distance to a channel network base level |
| Catchment area | Catch_Area | Area of land draining into a stream or a water course | |
| Channel network base level | Ch_Net | Base level of a channel network | |
| Convergence index | Conv_I | Structure of the relief as a set of convergent areas (channels) and divergent areas (ridges) | |
| LS Factor | LS_Factor | Combination of slope length factor (L) and slope steepness factor (S) to compute the effect of slope length and slope steepness on erosion. | |
| Wetness index | Wet_I | Value in a flow accumulation raster for the corresponding DEM |
| MD 1 | SAM | ML | SVM | DT | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| OA 2 | K | OA | K | OA | K | OA | K | OA | K | |
| Winter-13 Image | ||||||||||
| PBIA 3 | 31.7 | 0.25 | 23.0 | 0.16 | 32.1 | 0.25 | 42.6 | 0.33 | 38.3 | 0.30 |
| OBIA | 43.7 | 0.37 | 28.8 | 0.22 | 49.2 | 0.43 | 55.1 | 0.48 | 67.2 | 0.63 |
| Summer-14 Image | ||||||||||
| PBIA | 28.7 | 0.22 | 19.4 | 0.13 | 29.5 | 0.23 | 36.8 | 0.25 | 36.5 | 0.28 |
| OBIA | 40.7 | 0.34 | 22.5 | 0.16 | 46.1 | 0.40 | 46.2 | 0.37 | 71.5 | 0.68 |
| Variables | Winter-13 Image | Summer-14 Image | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ML 1 | SVM | DT | ML | SVM | DT | |||||||
| OA 2 | K | OA | K | OA | K | OA | K | OA | K | OA | K | |
| S 3 | 52.9 | 0.47 | 59.0 | 0.53 | 67.5 | 0.63 | 57.2 | 0.52 | 52.9 | 0.46 | 72.1 | 0.68 |
| S + To | 56.3 | 0.51 | 62.8 | 0.57 | 71.5 | 0.68 | 59.6 | 0.55 | 59.7 | 0.54 | 74.2 | 0.71 |
| S + To + Tx | - | - | 63.6 | 0.58 | - | - | 59.9 | 0.55 | 63.8 | 0.59 | 74.7 | 0.71 |
| S + To + Tx + G | 58.7 | 0.54 | 64.5 | 0.59 | 72.0 | 0.68 | 60.8 | 0.56 | 64.8 | 0.60 | 74.7 | 0.71 |
| All | 13.7 | 0.11 | 64.4 | 0.59 | 67.8 | 0.64 | 24.1 | 0.20 | 65.4 | 0.61 | 70.7 | 0.67 |
| Method 1 | Imagery | Individual Landform Uses | Statistics 2 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1P | 2P | 3P | 5P | 6P | 7D | 8D | 9D | 10S | 11S | 12S | 13S | 14S | σ | |||
| ML | Winter-13 | 59.8 | 86.1 | 75.0 | 59.3 | 66.8 | 69.9 | 73.3 | 22.6 | 31.9 | 97.9 | 57.5 | 82.2 | 23.6 | 62.0 | 23.5 |
| Summer-14 | 32.1 | 95.5 | 65.7 | 71.1 | 54.1 | 82.2 | 77.1 | 31.2 | 39.8 | 92.7 | 74.1 | 79.5 | 32.6 | 63.7 | 23.2 | |
| SVM | Winter-13 | 96.0 | 0.2 | 45.6 | 83.6 | 27.2 | 52.2 | 30.2 | 68.1 | 90.7 | 14.8 | 64.7 | 90.1 | 2.4 | 51.2 | 34.1 |
| Summer-14 | 89.5 | 10.5 | 53.4 | 83.4 | 31.1 | 33.7 | 30.5 | 68.3 | 88.1 | 29.9 | 68.4 | 84.8 | 17.5 | 53.0 | 28.8 | |
| DT | Winter-13 | 75.5 | 91.2 | 72.5 | 88.3 | 33.8 | 62.7 | 66.0 | 64.6 | 78.8 | 61.1 | 78.4 | 84.1 | 48.4 | 69.6 | 16.1 |
| Summer-14 | 90.4 | 54.6 | 70.3 | 84.3 | 51.4 | 63.6 | 62.1 | 64.1 | 92.4 | 29.7 | 77.0 | 88.7 | 49.0 | 67.5 | 18.8 | |
| Statistics | 73.9 | 56.4 | 63.8 | 78.3 | 44.1 | 60.7 | 56.5 | 53.2 | 70.3 | 54.4 | 70.0 | 84.9 | 28.9 | |||
| σ | 24.3 | 42.2 | 11.7 | 11.0 | 15.7 | 16.5 | 21.0 | 20.6 | 27.2 | 35.2 | 8.0 | 4.0 | 18.2 | |||
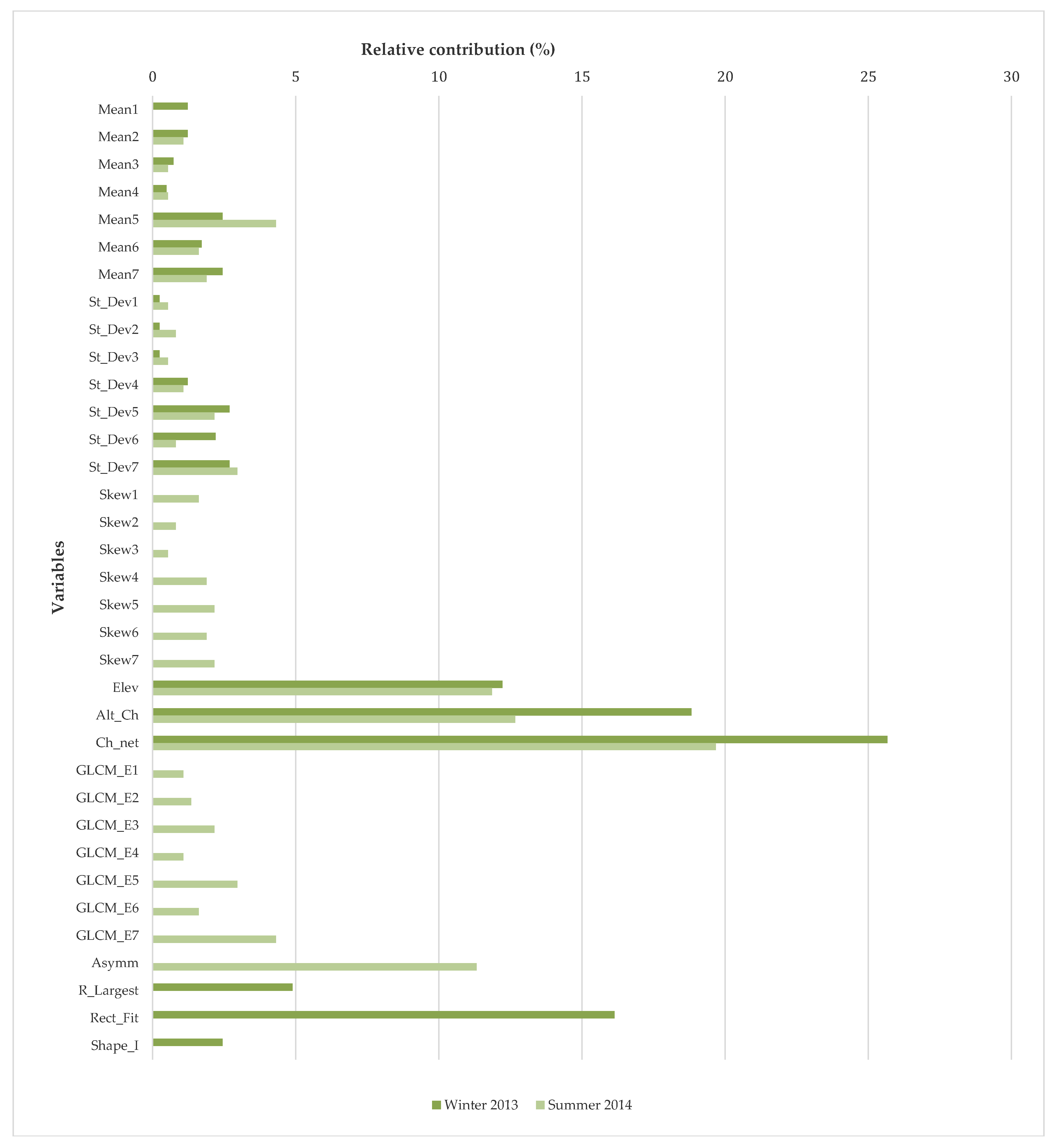
| Type | Variable | Winter-13 Image | Summer-14 Image | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ML | SVM | DT | Utility (%) | ML | SVM | DT | Utility (%) | Utility (%) | ||
| Spectral | Mean | *1 | * | * | 100 | * | * | * | 100 | 100 |
| St_Dev | * | * | * | 100 | * | * | * | 100 | 100 | |
| Skew | * | 33.3 | * | * | * | 100 | 66.7 | |||
| Bright | 0 | * | 33.3 | 16.7 | ||||||
| Max_Diff | * | * | 66.7 | * | * | 66.7 | 66.7 | |||
| Utility (%) | 60.0 | 80.0 | 40.0 | 100 | 80.0 | 60.0 | ||||
| Topographical | Elev | * | * | * | 100 | * | * | * | 100 | 100 |
| Slope | * | 33.3 | * | 33.3 | 33.3 | |||||
| Aspect | * | 33.3 | * | 33.3 | 33.3 | |||||
| Plan_Cur | 0 | 0 | 0 | |||||||
| Prof_Cur | 0 | 0 | 0 | |||||||
| Alt_Ch | * | * | * | 100 | * | * | * | 100 | 100 | |
| Catch_Area | 0 | 0 | 0 | |||||||
| Ch_Net | * | * | * | 100 | * | * | 66.7 | 83.4 | ||
| Conv_I | * | 33.3 | * | * | 66.7 | 50.0 | ||||
| LS_Factor | 0 | 0 | 0 | |||||||
| Wet_I | 0 | 0 | 0 | |||||||
| Utility (%) | 54.5 | 27.3 | 27.3 | 36.4 | 45.5 | 27.3 | ||||
| Textural | GLCM_C | 0 | * | 33.3 | 16,7 | |||||
| GLCM_E | 0 | * | * | 66.6 | 33.3 | |||||
| GLCM_H | * | 33.3 | * | * | 66.6 | 50.0 | ||||
| GLCM_M | * | 33.3 | * | 33.3 | 33.3 | |||||
| Utility (%) | 0.0 | 50.0 | 0.0 | 25.0 | 100 | 25.0 | ||||
| Geometrical | Area | 0 | 0 | 0 | ||||||
| Length | * | * | 66.7 | * | * | 66.7 | 66.7 | |||
| Width | 0 | * | 33.3 | 16.7 | ||||||
| Asymm | * | * | 66.7 | * | * | 66.7 | 66.7 | |||
| Border_I | * | 33.3 | 0 | 16.7 | ||||||
| Compact | 0 | 0 | 0 | |||||||
| Density | 0 | 0 | 0 | |||||||
| Ellip_Fit | 0 | 0 | 0 | |||||||
| Main_Dir | 0 | 0 | 0 | |||||||
| R_Largest | * | * | * | 100 | * | 33.3 | 66.7 | |||
| R_Smallest | 0 | 0 | 0 | |||||||
| Rect_Fit | * | * | * | 100 | * | 33.3 | 66.7 | |||
| Round | 0 | 0 | 0 | |||||||
| Shape_I | * | * | 66.7 | 0 | 33.3 | |||||
| Utility (%) | 36.4 | 42.9 | 21.4 | 14.3 | 28.6 | 7.1 | ||||
| No. of variables used | 13 | 15 | 8 | 12 | 17 | 8 | ||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Castillejo-González, I.L.; Angueira, C.; García-Ferrer, A.; Sánchez de la Orden, M. Combining Object-Based Image Analysis with Topographic Data for Landform Mapping: A Case Study in the Semi-Arid Chaco Ecosystem, Argentina. ISPRS Int. J. Geo-Inf. 2019, 8, 132. https://doi.org/10.3390/ijgi8030132
Castillejo-González IL, Angueira C, García-Ferrer A, Sánchez de la Orden M. Combining Object-Based Image Analysis with Topographic Data for Landform Mapping: A Case Study in the Semi-Arid Chaco Ecosystem, Argentina. ISPRS International Journal of Geo-Information. 2019; 8(3):132. https://doi.org/10.3390/ijgi8030132
Chicago/Turabian StyleCastillejo-González, Isabel Luisa, Cristina Angueira, Alfonso García-Ferrer, and Manuel Sánchez de la Orden. 2019. "Combining Object-Based Image Analysis with Topographic Data for Landform Mapping: A Case Study in the Semi-Arid Chaco Ecosystem, Argentina" ISPRS International Journal of Geo-Information 8, no. 3: 132. https://doi.org/10.3390/ijgi8030132
APA StyleCastillejo-González, I. L., Angueira, C., García-Ferrer, A., & Sánchez de la Orden, M. (2019). Combining Object-Based Image Analysis with Topographic Data for Landform Mapping: A Case Study in the Semi-Arid Chaco Ecosystem, Argentina. ISPRS International Journal of Geo-Information, 8(3), 132. https://doi.org/10.3390/ijgi8030132