Quantifying Efficiency of Sliding-Window Based Aggregation Technique by Using Predictive Modeling on Landform Attributes Derived from DEM and NDVI




Abstract
:1. Introduction
1.1. GIS Attributes
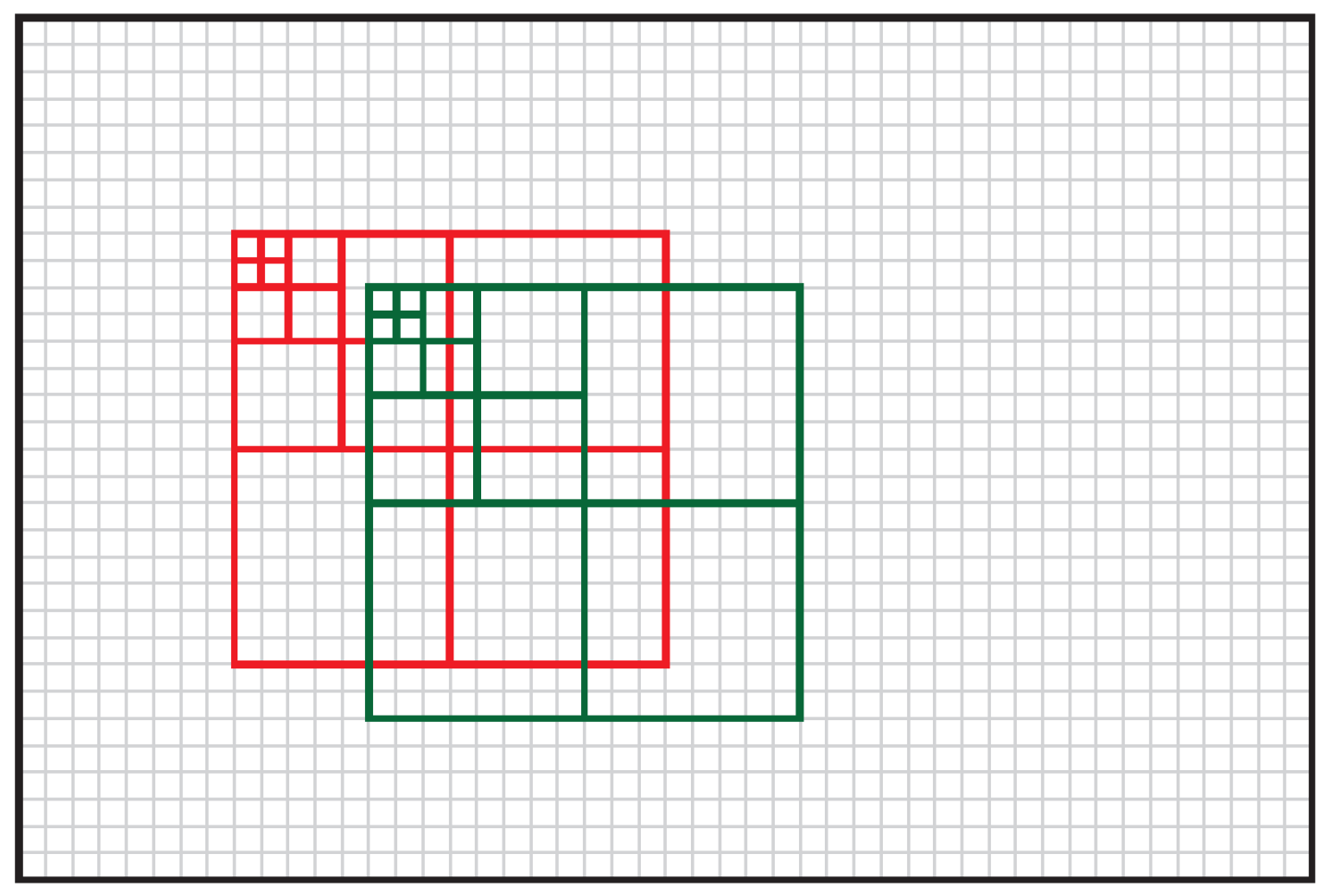
1.2. Sliding Window Analysis
2. Materials and Methods
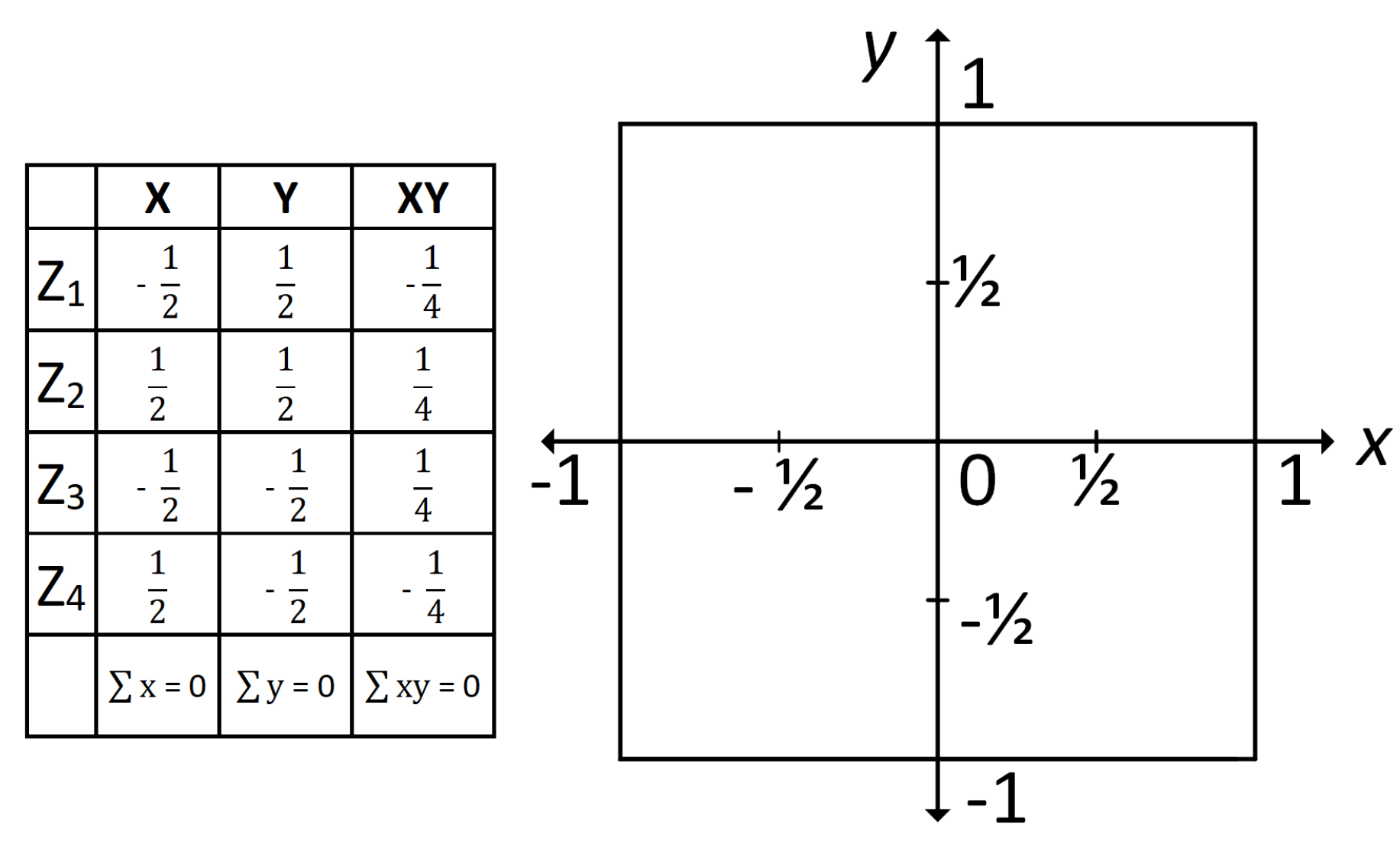
2.1. Topographic Variables
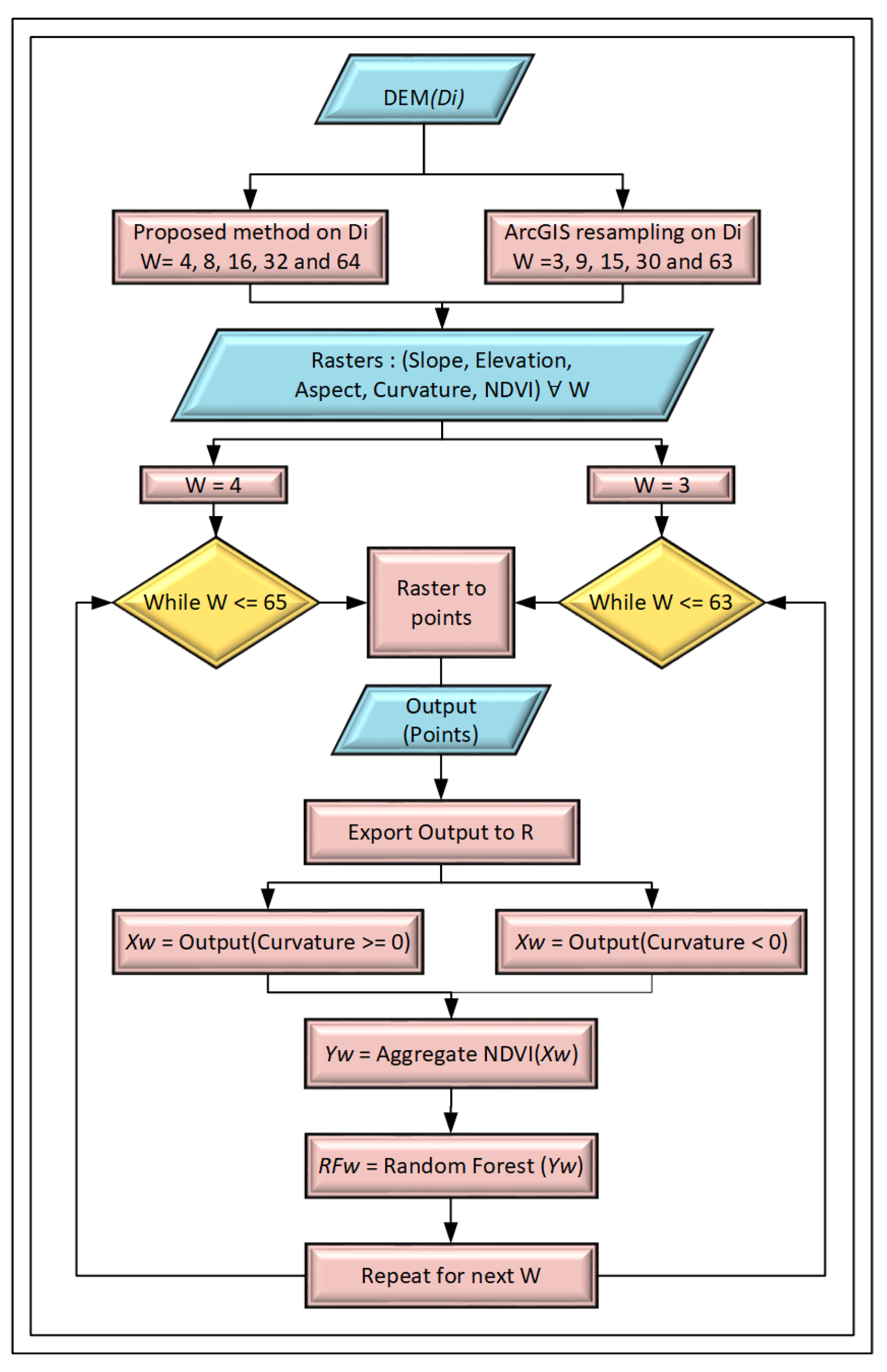
2.2. Algorithm
2.3. Study Area
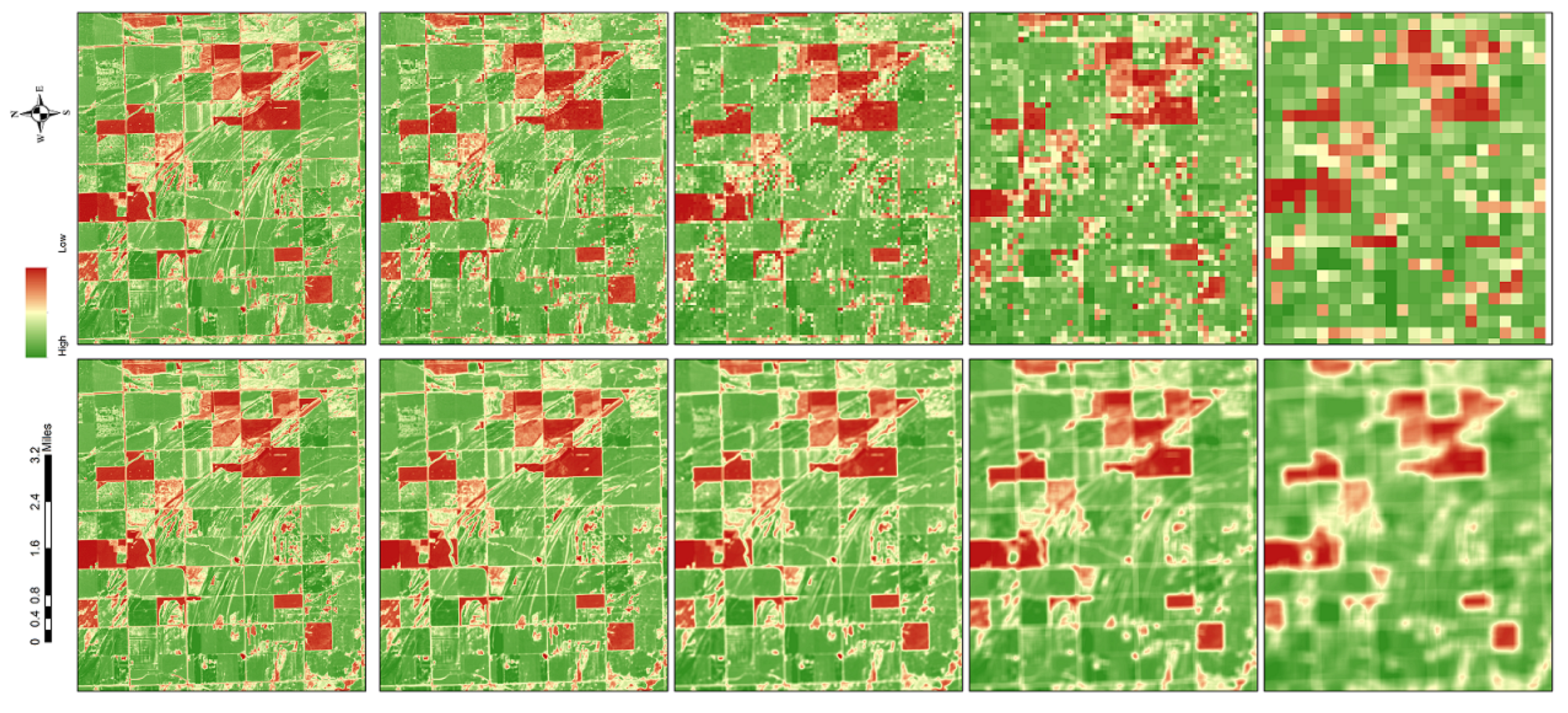
2.4. Multiscalar Data Generation Technique
3. Results
3.1. Random Forest Based Predictive Modeling
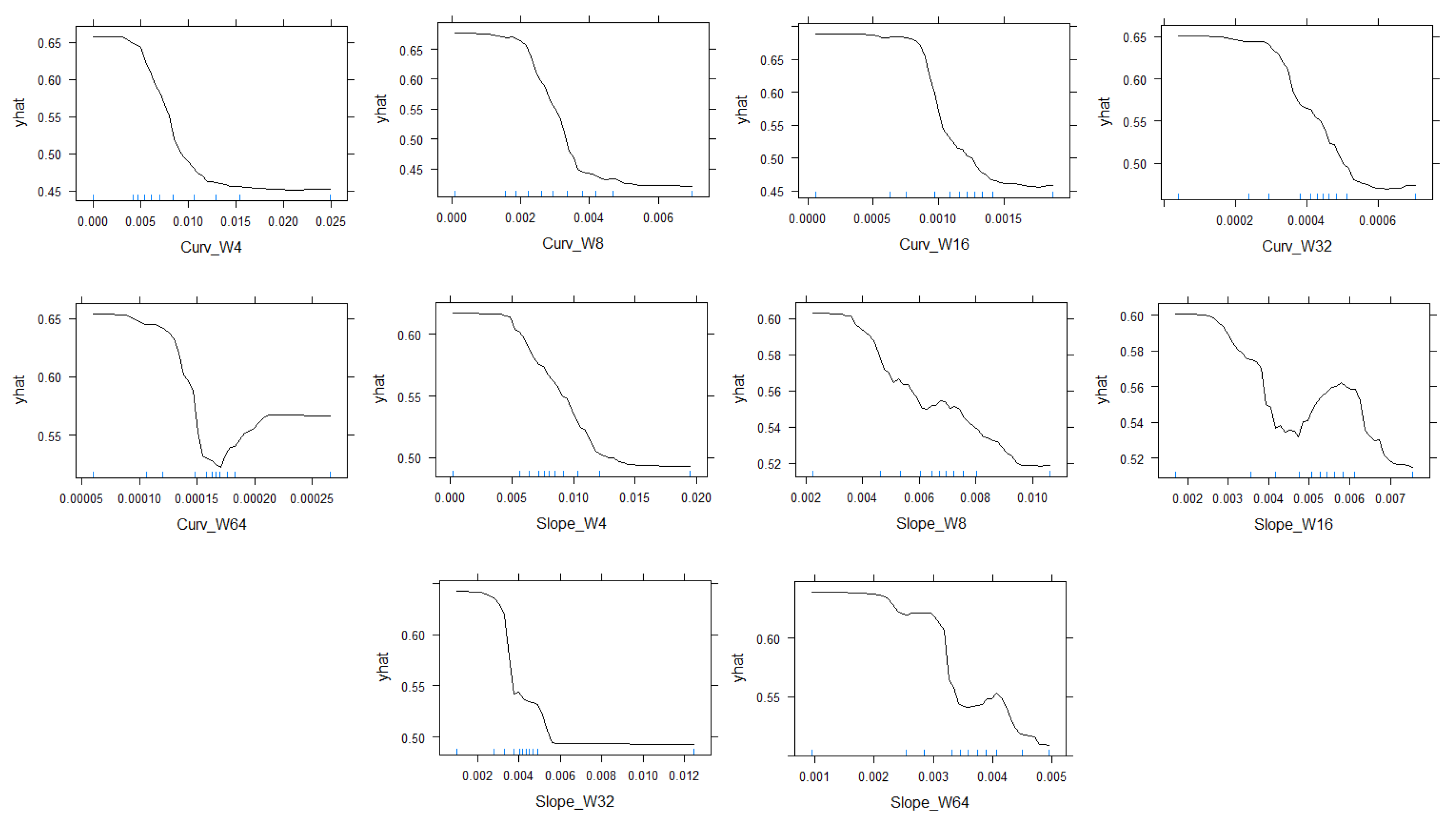
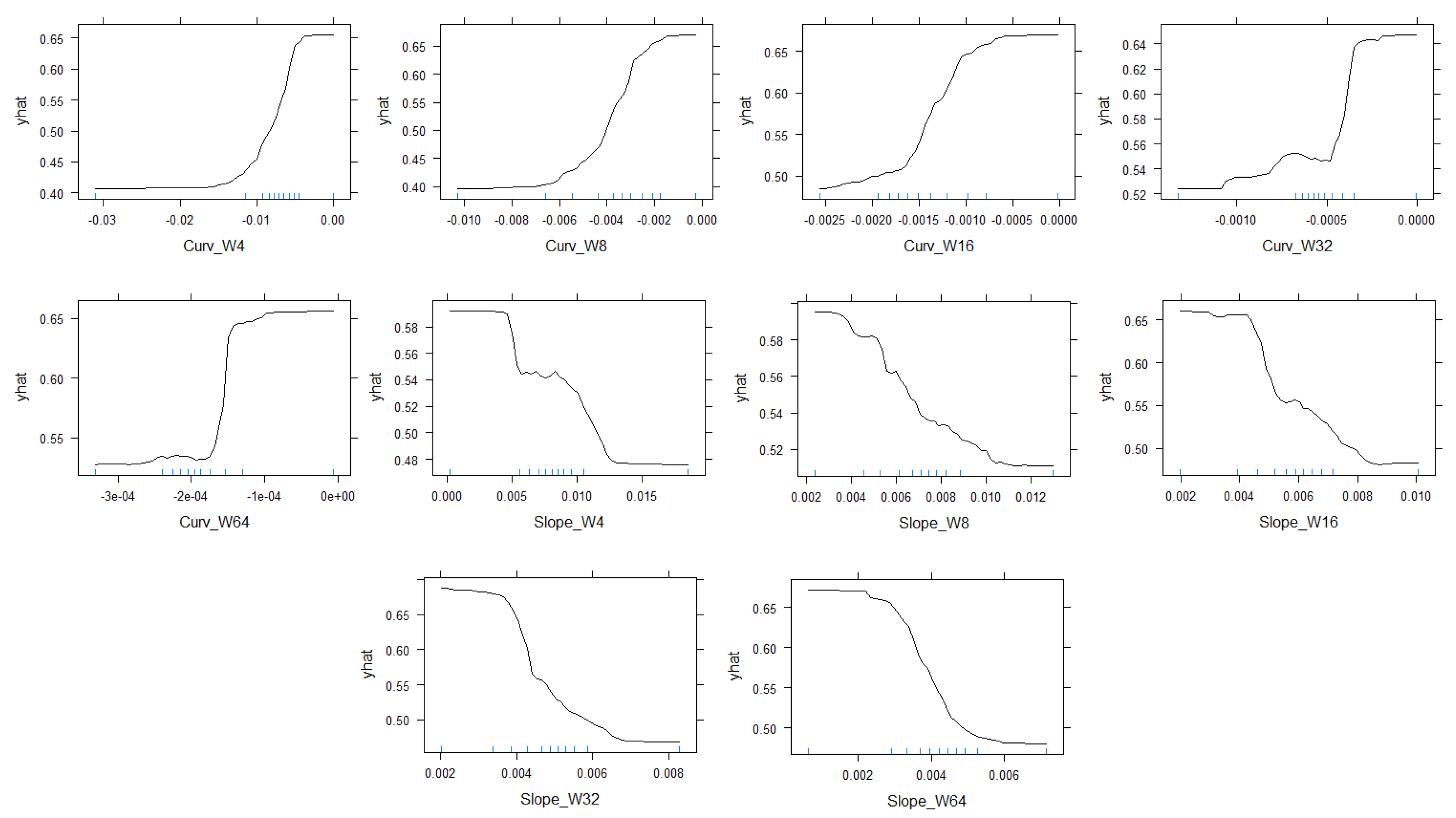
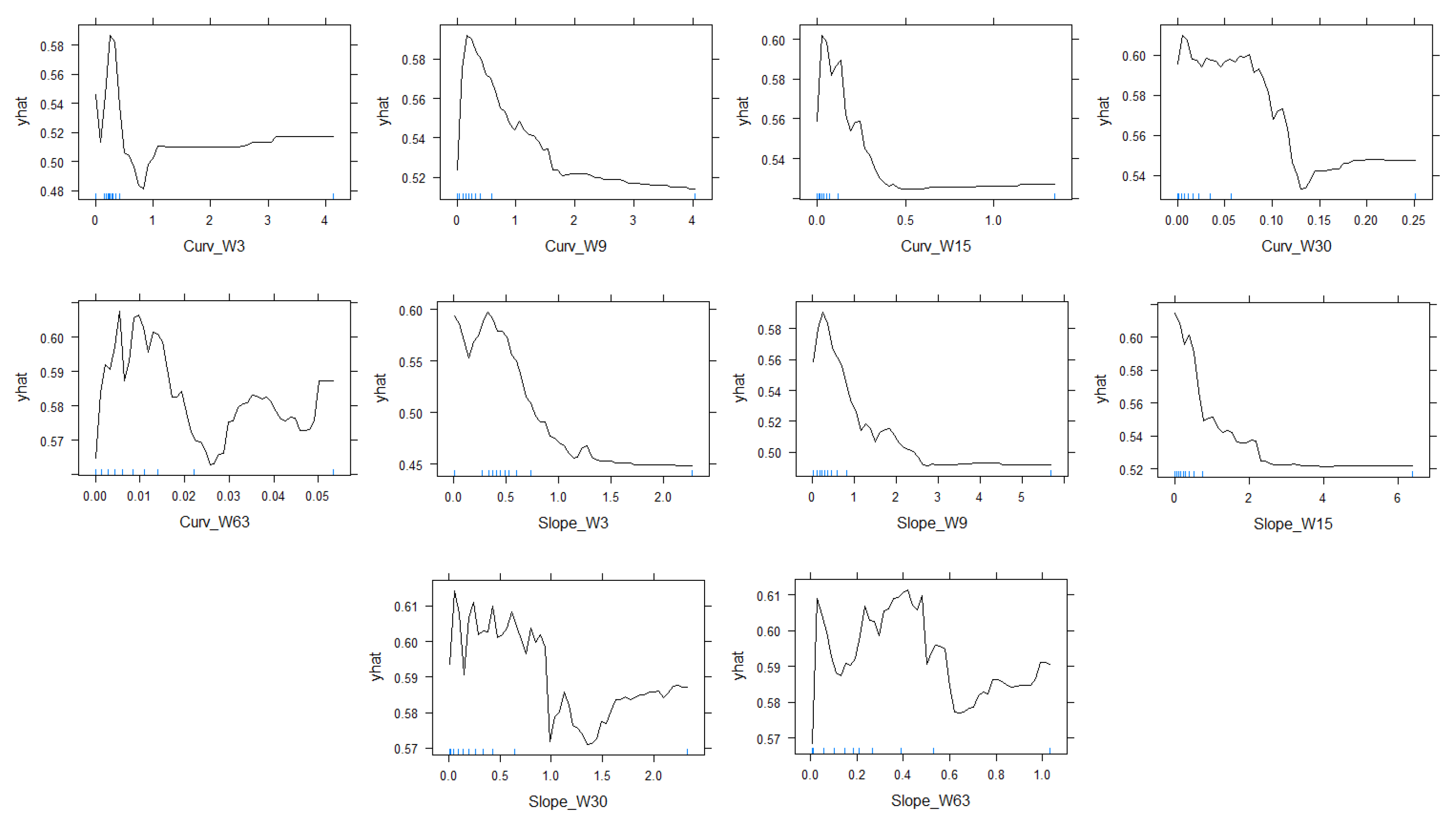
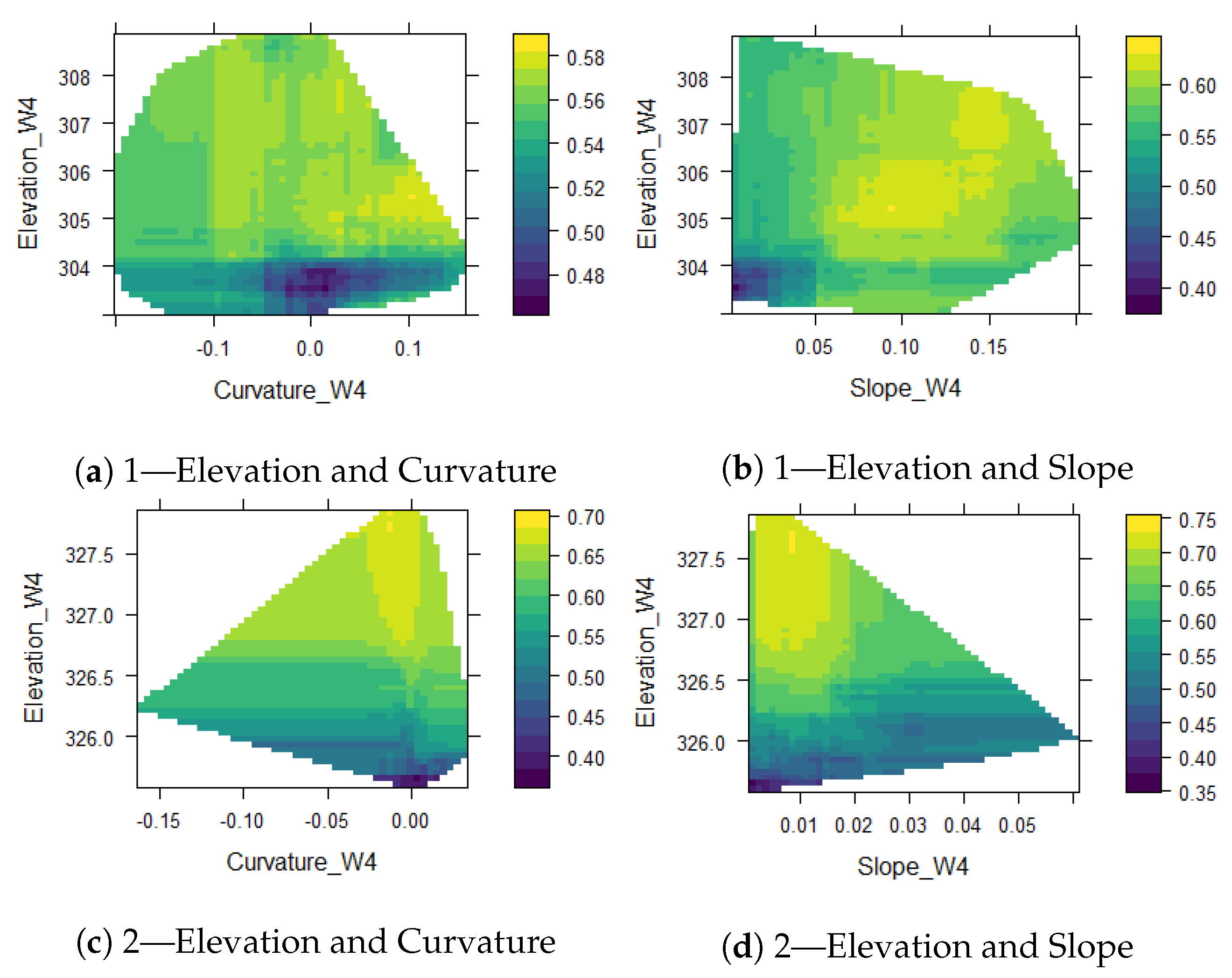
3.2. Partial Dependence Plots
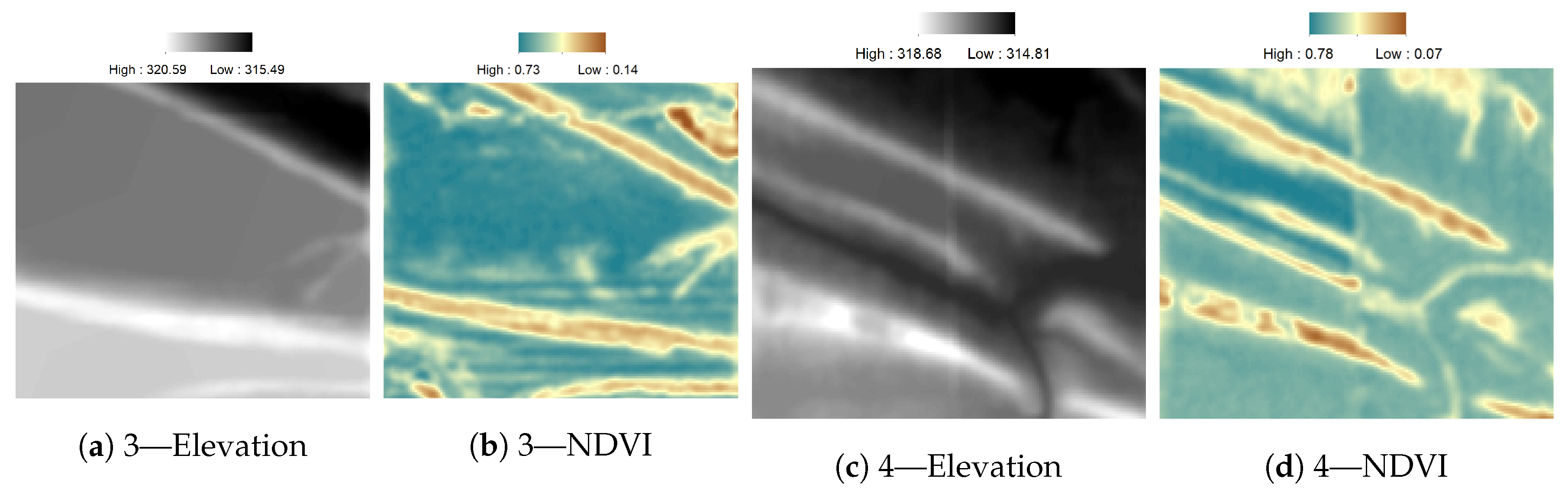
3.3. NDVI Pattern in Areas of Depression
3.4. NDVI Pattern in Highlands
3.5. Error Analysis
4. Discussion
4.1. Random Forest Based Predictive Modeling
4.1.1. Proposed Method
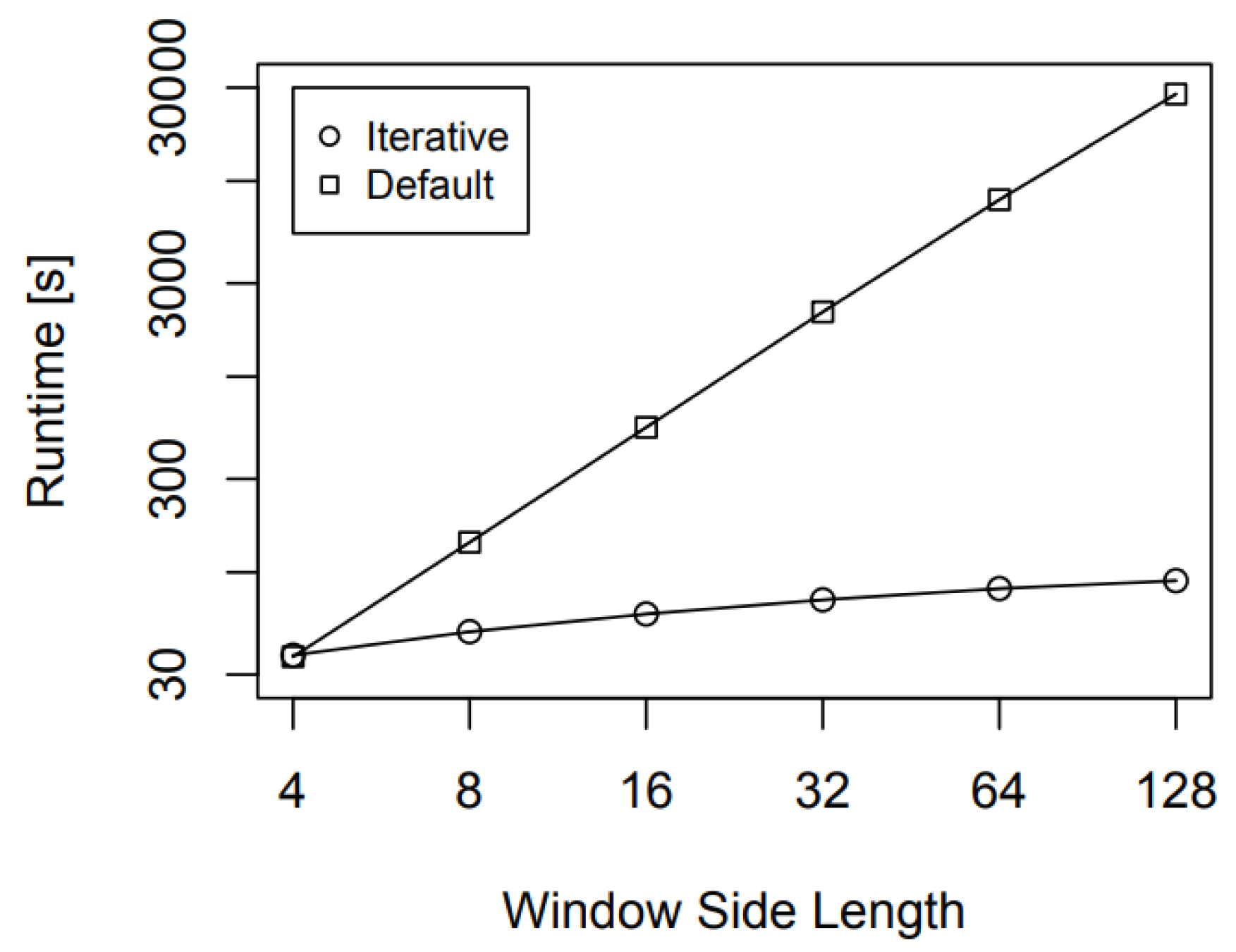
4.1.2. Traditional Resampling Method
4.2. Partial Dependence Plots
4.3. NDVI Pattern in Areas of Depression
4.4. NDVI Pattern in Highlands
4.5. Error Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| NDVI | Normalized Difference Vegetation Index |
| SOM | Self-Organizing Maps |
| RMSE | Root Mean Square Error |
| DEM | Digital Elevation Model |
| GIS | Geographical Information Systems |
| PDP | Partial Dependence Plot |
Appendix A. Algorithm for Sliding Window Aggregation
| Algorithm 1: Aggregation algorithm |
 |
References
- Hutchinson, M.; Gallant, J. Digital elevation models. In Terrain Analysis: Principles and Applications; John Wiley & Sons: New York, NY, USA, 2000; pp. 29–50. [Google Scholar]
- Hickey, R. Slope angle and slope length solutions for GIS. Cartography 2000, 29, 1–8. [Google Scholar] [CrossRef]
- Chang, K.T.; Tsai, B.W. The effect of DEM resolution on slope and aspect mapping. Cartogr. Geogr. Inf. Syst. 1991, 18, 69–77. [Google Scholar] [CrossRef]
- Tweed, S.O.; Leblanc, M.; Webb, J.A.; Lubczynski, M.W. Remote sensing and GIS for mapping groundwater recharge and discharge areas in salinity prone catchments, southeastern Australia. Hydrogeol. J. 2007, 15, 75–96. [Google Scholar] [CrossRef]
- Pradhan, S. Crop area estimation using GIS, remote sensing and area frame sampling. Int. J. Appl. Earth Obs. Geoinf. 2001, 3, 86–92. [Google Scholar] [CrossRef]
- Zhang, H.; Xi, L.; Ma, X.; Lu, Z.; Ji, Y.; Ren, Y. Research and development of the information management system of agricultural science and technology to farmer based on GIS. In Proceedings of the International Conference on Computer and Computing Technologies in Agriculture, Wuyishan, China, 18–20 August 2007; Springer: Berlin, Germany, 2007; pp. 141–150. [Google Scholar]
- Matsushita, B.; Yang, W.; Chen, J.; Onda, Y.; Qiu, G. Sensitivity of the enhanced vegetation index (EVI) and normalized difference vegetation index (NDVI) to topographic effects: A case study in high-density cypress forest. Sensors 2007, 7, 2636–2651. [Google Scholar] [CrossRef] [PubMed]
- Jin, X.; Zhang, Y.; Schaepman, M.; Clevers, J.; Su, Z. Impact of elevation and aspect on the spatial distribution of vegetation in the Qilian mountain area with remote sensing data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2008, 37, 1385–1390. [Google Scholar]
- Nadal-Romero, E.; Petrlic, K.; Verachtert, E.; Bochet, E.; Poesen, J. Effects of slope angle and aspect on plant cover and species richness in a humid Mediterranean badland. Earth Surf. Process. Landf. 2014, 39, 1705–1716. [Google Scholar] [CrossRef] [Green Version]
- Friedl, M.A.; Brodley, C.E. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Friedl, M.A.; Brodley, C.E.; Strahler, A.H. Maximizing land cover classification accuracies produced by decision trees at continental to global scales. IEEE Trans. Geosci. Remote Sens. 1999, 37, 969–977. [Google Scholar] [CrossRef]
- Liu, K.; Li, X.; Shi, X.; Wang, S. Monitoring mangrove forest changes using remote sensing and GIS data with decision-tree learning. Wetlands 2008, 28, 336. [Google Scholar] [CrossRef]
- Denton, A.M.; Ahsan, M.; Franzen, D.; Nowatzki, J. Multi-scalar analysis of geospatial agricultural data for sustainability. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 2139–2146. [Google Scholar]
- Denton, A.M.; Gomes, R.; Franzen, D. Scaling up window-based slope computations for geographic information systems. In Proceedings of the 2018 IEEE International Conference on Electro Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018. [Google Scholar]
- Ramsey, R.D.; Wright, D.L., Jr.; McGinty, C. Evaluating the use of Landsat 30m Enhanced Thematic Mapper to monitor vegetation cover in shrub-steppe environments. Geocarto Int. 2004, 19, 39–47. [Google Scholar] [CrossRef]
- Rozario, P.F.; Oduor, P.; Kotchman, L.; Kangas, M. Quantifying spatiotemporal change in landuse and land cover and accessing water quality: A case study of Missouri watershed james sub-region, north Dakota. J. Geogr. Inf. Syst. 2016, 8, 663–682. [Google Scholar] [CrossRef]
- Rozario, P.F.; Oduor, P.; Kotchman, L.; Kangas, M. Transition modeling of land-use dynamics in the Pipestem Creek, North Dakota, USA. J. Geosci. Environ. Prot. 2017, 5, 182. [Google Scholar] [CrossRef]
- Andersen, H.E.; McGaughey, R.J.; Reutebuch, S.E. Estimating forest canopy fuel parameters using LIDAR data. Remote Sens. Environ. 2005, 94, 441–449. [Google Scholar] [CrossRef]
- Sharma, M.; Paige, G.B.; Miller, S.N. DEM development from ground-based LiDAR data: A method to remove non-surface objects. Remote Sens. 2010, 2, 2629–2642. [Google Scholar] [CrossRef]
- Callow, J.N.; Van Niel, K.P.; Boggs, G.S. How does modifying a DEM to reflect known hydrology affect subsequent terrain analysis? J. Hydrol. 2007, 332, 30–39. [Google Scholar] [CrossRef]
- Chang, M. Forest Hydrology: An Introduction to Water and Forests; CRC press: Boca Raton, FL, USA, 2006. [Google Scholar]
- Renard, K.G.; Foster, G.R.; Weesies, G.; McCool, D.; Yoder, D.C. Predicting Soil Erosion by Water: A Guide to Conservation Planning with the Revised Universal Soil Loss Equation (RUSLE); United States Department of Agriculture: Washington, DC, USA, 1997; Volume 703.
- Srinivasan, R.; Engel, B. Effect of slope prediction methods on slope and erosion estimates. Appl. Eng. Agric. 1991, 7, 779–783. [Google Scholar] [CrossRef]
- Warren, S.D.; Hohmann, M.G.; Auerswald, K.; Mitasova, H. An evaluation of methods to determine slope using digital elevation data. Catena 2004, 58, 215–233. [Google Scholar] [CrossRef] [Green Version]
- Longley, P.A.; Goodchild, M.F.; Maguire, D.J.; Rhind, D.W. Geographic Information Science and Systems; John Wiley & Sons: New York, NY, USA, 2015. [Google Scholar]
- De Smith, M.J.; Goodchild, M.F.; Longley, P. Geospatial Analysis: A Comprehensive Guide to Principles, Techniques and Software Tools; Troubador Publishing Ltd.: Leicester, UK, 2007. [Google Scholar]
- Zevenbergen, L.W.; Thorne, C.R. Quantitative analysis of land surface topography. Earth Surf. Process. Landf. 1987, 12, 47–56. [Google Scholar] [CrossRef]
- Wilson, J.P.; Gallant, J.C. Terrain Analysis: Principles and Applications; John Wiley & Sons: New York, NY, USA, 2000. [Google Scholar]
- Evans, I.S. General geomorphometry, derivatives of altitude, and descriptive statistics. In Spatial Analysis in Geomorphology; CRC Press: Boca Raton, FL, USA, 1972; pp. 17–90. [Google Scholar]
- Chen, D.; Stow, D.; Gong, P. Examining the effect of spatial resolution and texture window size on classification accuracy: An urban environment case. Int. J. Remote Sens. 2004, 25, 2177–2192. [Google Scholar] [CrossRef]
- Albani, M.; Klinkenberg, B.; Andison, D.; Kimmins, J. The choice of window size in approximating topographic surfaces from digital elevation models. Int. J. Geogr. Inf. Sci. 2004, 18, 577–593. [Google Scholar] [CrossRef]
- Wood, J. The Geomorphological Characterisation of Digital Elevation Models. Ph.D. Thesis, University of Leicester, Leicester, UK, 1996. [Google Scholar]
- Neteler, M.; Mitasova, H. Open Source GIS: A Grass GIS Approach; Springer Science & Business Media: New York, NY, USA, 2013; Volume 689. [Google Scholar]
- International Water Institute. Red River Basin Decision Information Network. Available online: https://iwinst.org/ (accessed on 20 May 2017).
- RapidEye, A. Satellite imagery product specifications. In Satellite Imagery Product Specifications: Version; RapidEye AG: Brandenburg An der Havel, Germany, 2011. [Google Scholar]
- Planet Imagery and Archive RapidEye. Available online: https://www.planet.com/products/planet-imagery/#re-imagery-product (accessed on 25 May 2017).
- ESRI. ArcGIS Desktop: Release 10; Environmental Systems Research Institute: Redlands, CA, USA, 2011. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2013. [Google Scholar]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Lerman, R.I.; Yitzhaki, S. A note on the calculation and interpretation of the Gini index. Econ. Lett. 1984, 15, 363–368. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Greenwell, B.M. pdp: An R Package for Constructing Partial Dependence Plots. R J. 2017, 9, 421–436. [Google Scholar] [CrossRef]
- Alganci, U.; Besol, B.; Sertel, E. Accuracy Assessment of Different Digital Surface Models. ISPRS Int. J. Geo-Inf. 2018, 7, 114. [Google Scholar] [CrossRef]
- Rozario, P.; Madurapperuma, B.; Wang, Y. Remote Sensing Approach to Detect Burn Severity Risk Zones in Palo Verde National Park, Costa Rica. Remote Sens. 2018, 10, 1427. [Google Scholar] [CrossRef]
- Rozario, P.F.; Oduor, P.G.; Kotchman, L.; Kangas, M. Uncertainty Analysis of Spatial Autocorrelation of Land-Use and Land-Cover Data within Pipestem Creek in North Dakota. J. Geosci. Environ. Prot. 2017, 5, 71. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Kienzle, S. The effect of DEM raster resolution on first order, second order and compound terrain derivatives. Trans. GIS 2004, 8, 83–111. [Google Scholar] [CrossRef]
- Vannucci, M.; Colla, V. Meaningful discretization of continuous features for association rules mining by means of a SOM. In Proceedings of the 12th European Symposium on Artificial Neural Networks (ESANN), Bruges, Belgium, 28–30 April 2004; pp. 489–494. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Positive Curvature Results | ||||||||||||
| # of | Proposed Method | ArcGIS Method | ||||||||||
| Trees | Win | OOB | GINI Impurity Decrease | Win | OOB | GINI Impurity Decrease | ||||||
| Size | Acc % | Curv | Slope | Aspect | Elev | Size | Acc % | Curv | Slope | Aspect | Elev | |
| 500 | 4 | 94.67 | 34.75 | 29.34 | 6.6 | 17.05 | 3 | 31.96 | 16.04 | 17.86 | 13.63 | 23.09 |
| 8 | 92.74 | 40.23 | 20.51 | 9.06 | 14.14 | 9 | 19.11 | 11.79 | 12.5 | 11.23 | 14.79 | |
| 16 | 84.09 | 32.34 | 18.61 | 14.45 | 15.4 | 15 | 14.28 | 6.34 | 6.67 | 6.18 | 7.71 | |
| 32 | 82.64 | 26.25 | 23.13 | 15.29 | 13.41 | 30 | 5.56 | 2.01 | 2.06 | 2.09 | 2.57 | |
| 64 | 92.09 | 2 | 1.96 | 1.04 | 1.51 | 63 | −0.36 | 0.49 | 0.49 | 0.46 | 0.51 | |
| Negative Curvature Results | ||||||||||||
| 500 | 4 | 84.04 | 37.97 | 23.84 | 8.26 | 16.24 | 3 | 51.89 | 19.82 | 19.87 | 10.38 | 23.2 |
| 8 | 95.31 | 42.74 | 26.16 | 5.19 | 10.32 | 9 | 21.26 | 14.15 | 12.57 | 11.57 | 16.64 | |
| 16 | 84.46 | 30.74 | 24.13 | 8.12 | 17.85 | 15 | 10.5 | 7.64 | 7.44 | 7.76 | 9.32 | |
| 32 | 88.65 | 18.12 | 26.26 | 9.81 | 23.67 | 30 | 6.44 | 2.55 | 2.56 | 2.53 | 3.16 | |
| 64 | 94.5 | 19.33 | 23.72 | 6.97 | 14.67 | 63 | −10.58 | 0.6 | 0.59 | 0.58 | 0.57 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gomes, R.; Denton, A.; Franzen, D. Quantifying Efficiency of Sliding-Window Based Aggregation Technique by Using Predictive Modeling on Landform Attributes Derived from DEM and NDVI. ISPRS Int. J. Geo-Inf. 2019, 8, 196. https://doi.org/10.3390/ijgi8040196
Gomes R, Denton A, Franzen D. Quantifying Efficiency of Sliding-Window Based Aggregation Technique by Using Predictive Modeling on Landform Attributes Derived from DEM and NDVI. ISPRS International Journal of Geo-Information. 2019; 8(4):196. https://doi.org/10.3390/ijgi8040196
Chicago/Turabian StyleGomes, Rahul, Anne Denton, and David Franzen. 2019. "Quantifying Efficiency of Sliding-Window Based Aggregation Technique by Using Predictive Modeling on Landform Attributes Derived from DEM and NDVI" ISPRS International Journal of Geo-Information 8, no. 4: 196. https://doi.org/10.3390/ijgi8040196
APA StyleGomes, R., Denton, A., & Franzen, D. (2019). Quantifying Efficiency of Sliding-Window Based Aggregation Technique by Using Predictive Modeling on Landform Attributes Derived from DEM and NDVI. ISPRS International Journal of Geo-Information, 8(4), 196. https://doi.org/10.3390/ijgi8040196