Taxonomy-Oriented Domain Analysis of GIS: A Case Study for Paleontological Software Systems


Abstract
:1. Introduction
- Domain analysisInformation source analysis (ISA): This activity analyzes sources of information that can support the domain analysis in order to obtain a first set of requirements.Subdomain analysis and conceptualization (SAC): The information recovered in the previous process is used to analyze and organize the features or services that the subdomain should offer together with the general features derived from the upper domains. Also, in this process the subdomain must be conceptualized by different software artifacts (such as class models and process models) when it is possible.Reusable component analysis (RCA): This process identifies the set of reusable components that could be used to implement the features defined in the last process. It returns a preliminary reference architecture.
- Organizational analysisReuse and boundary analysis (RBA): This activity defines the organizational boundary, commonality, and variability features. Thus, by considering the features specified in the subdomain analysis and conceptualization process and the information from domain experts, the scope of the product line must be defined.Platform analysis and design (PAD): This activity builds the reference architecture based on the features defined in the previous activities and processes. The preliminary structure of reusable components defined in the reusable component analysis process is reorganized and refined. Here, each component with its common and variable parts (when necessary) is fully designed.
2. Related Work
3. Background
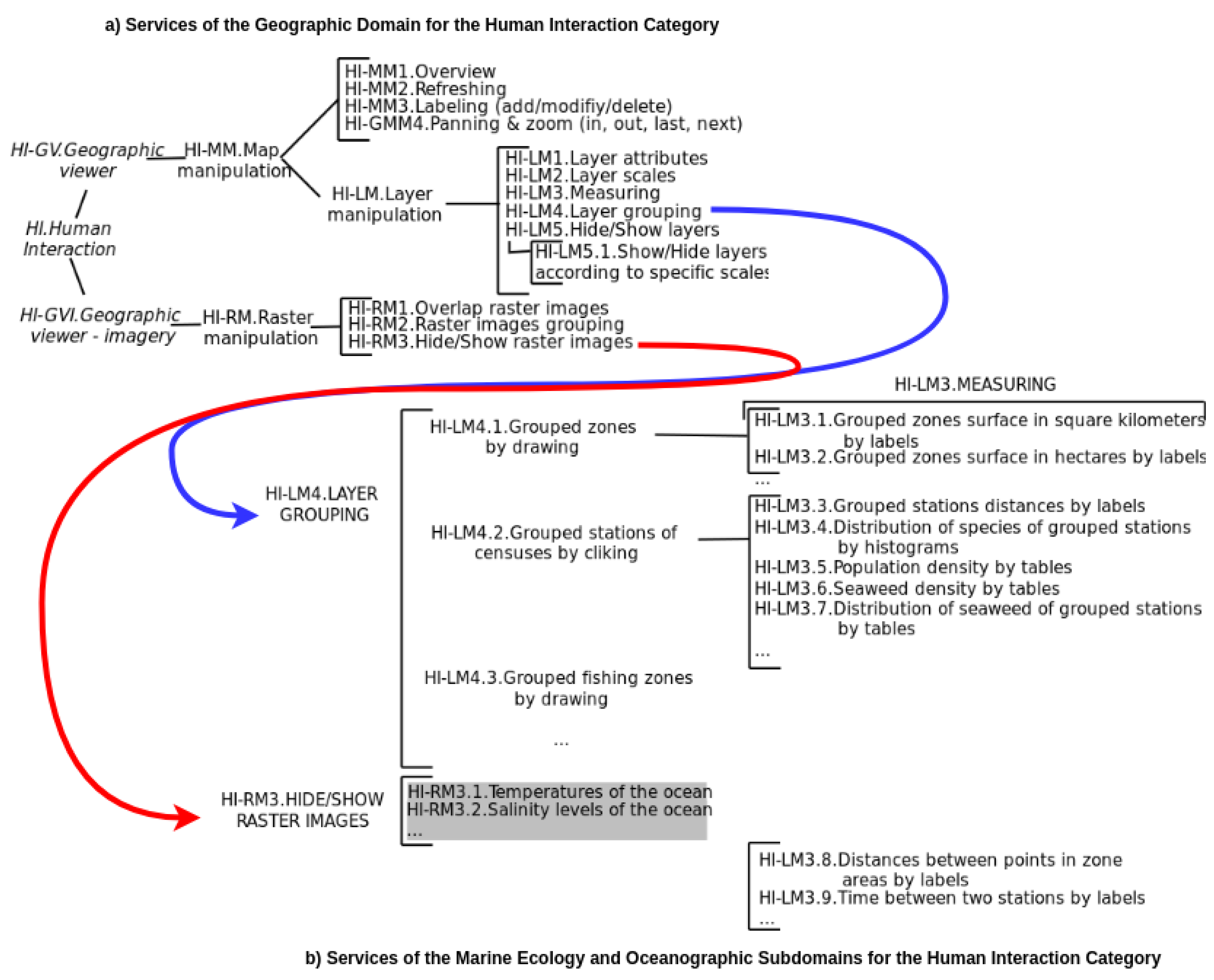
3.1. Standards for GIS: Taxonomy for Geographic Services
- (HI) Human interaction services for management of user interfaces, graphics, and multimedia; and for presentation of compound documents.
- (MMS) Model/information management services for management of the development, manipulation, and storage of metadata, conceptual schemas, and datasets.
- (WTS) Workflow/Task services for support of specific tasks or work-related activities conducted by humans.
- (PS) Processing services for large-scale computations involving substantial amount of data. It contains four subcategories based on the General Feature Model (ISO 19109 std—Rules for Application Schema 19109, ISO/IEC, 2005.):
- -
- (PS-S) Geographic processing services—spatial
- -
- (PS-T) Geographic processing services—thematic
- -
- (PS-Te) Geographic processing services—temporal
- -
- (PS-M) Geographic processing services—metadata
- -
- (CS) Communication services for encoding and transfer of data across communications networks.
3.2. A Taxonomy for the Marine Ecology Subdomain
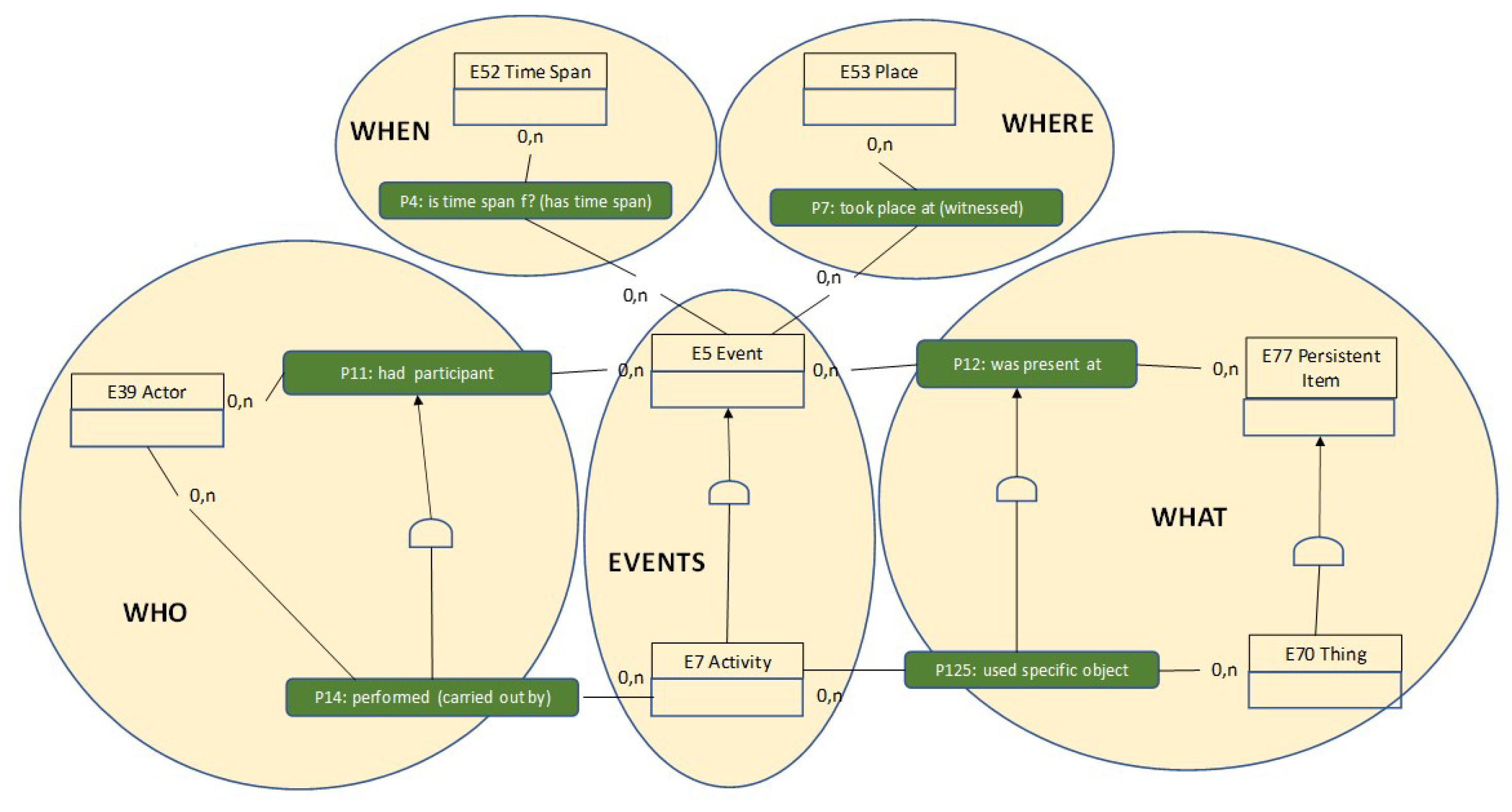
3.3. Contextual Information: The Paleontology Subdomain
4. Our Domain Analysis Approach in a Nutshell
- Information source analysis (ISA): During this activity we use the information provided by standards, existing information (in digital and/or paper format) and domain experts. This analysis obtains a first set of requirements (described on Section 5.2).
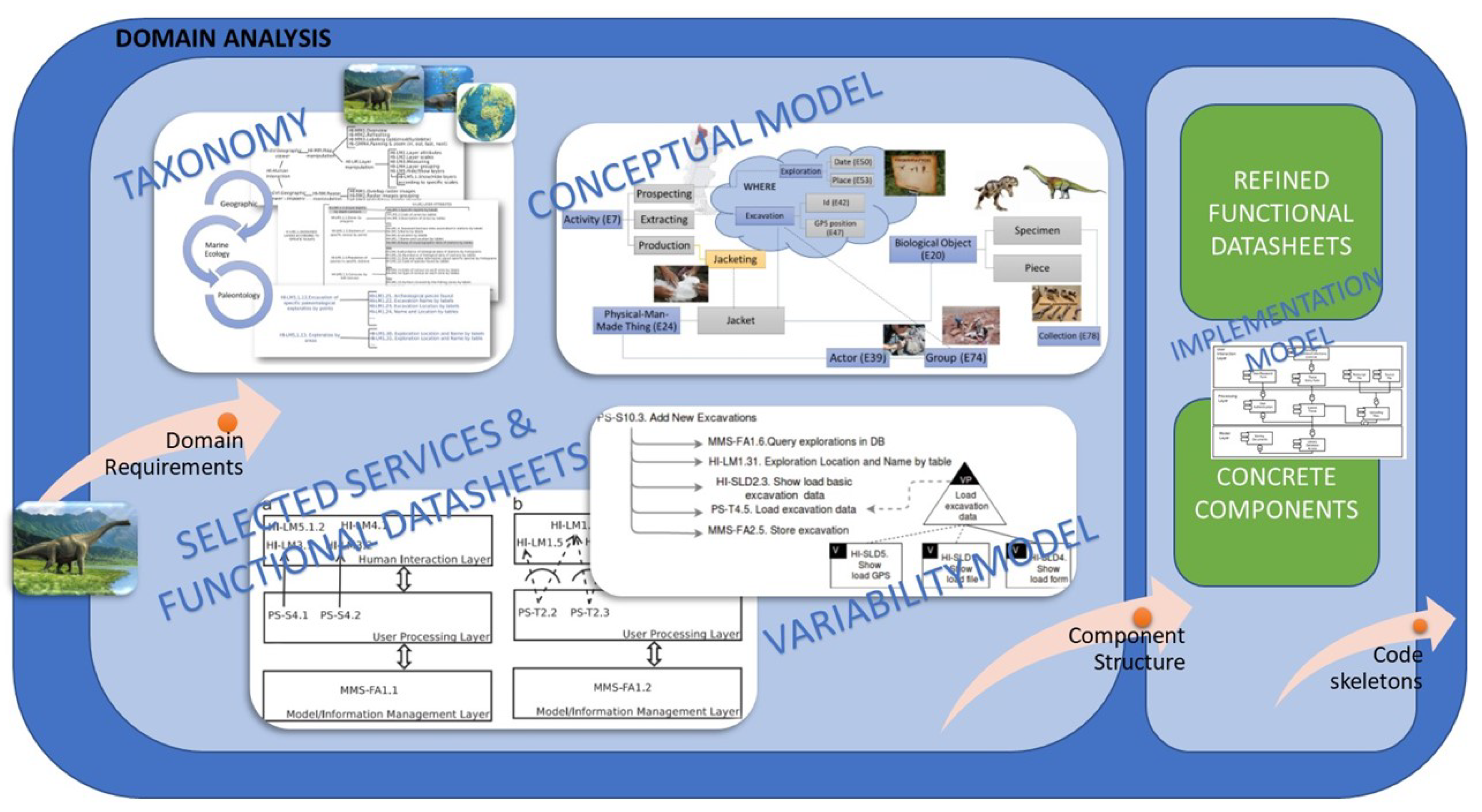
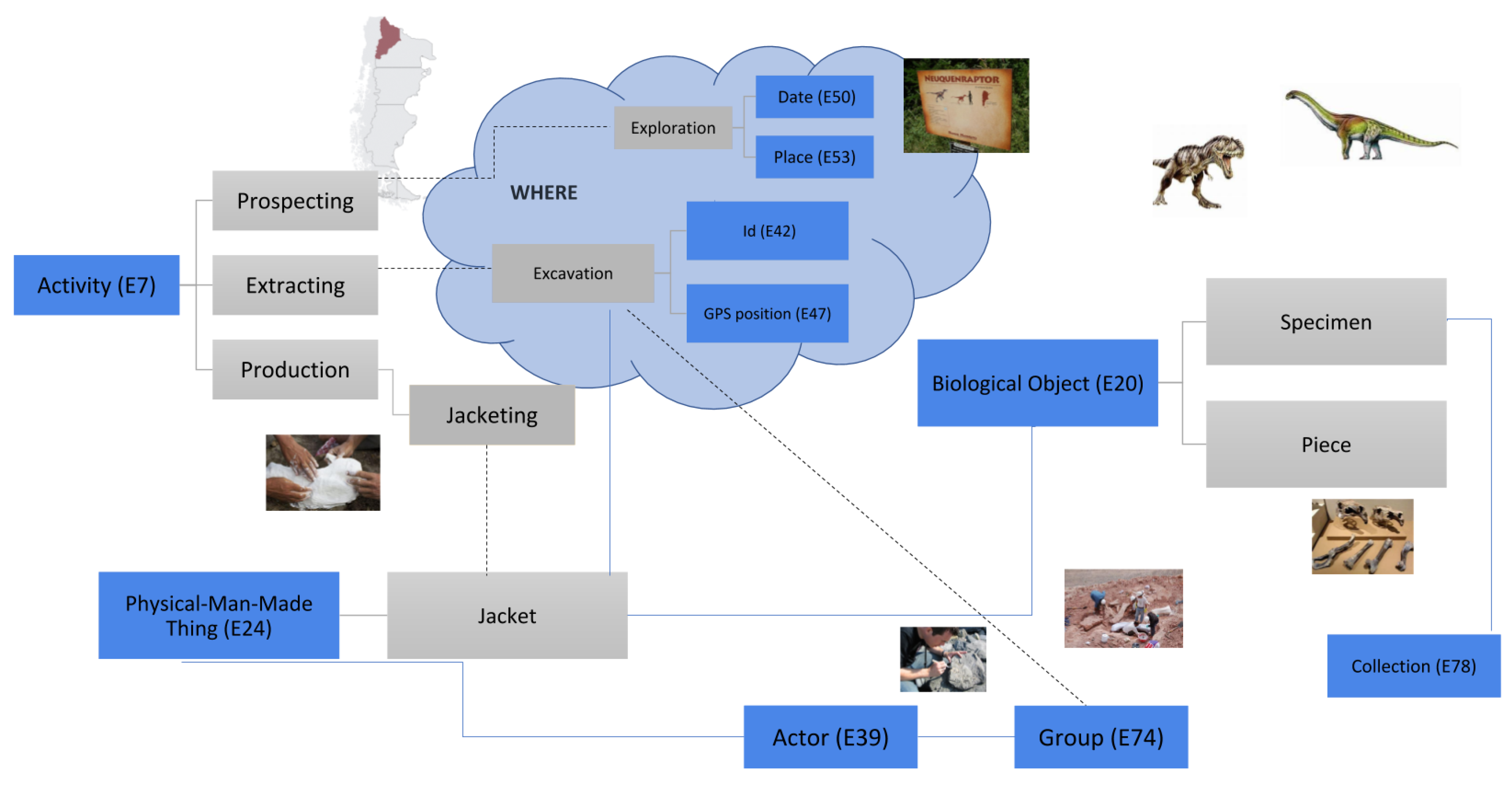
- Subdomain analysis and conceptualization (SAC): The output of the previous activity is refined in order to generate artifacts (e.g., services) that characterize the subdomain. To do this, two semantic resources are analyzed—the domain taxonomies (Figure 2) and the contextual information. After analyzing requirements information and determining the existence of the relevant domain standards, a domain modeler build the conceptual model (described in Section 5.1) based on domain entities and properties—whether the concepts are standardized from pre-existing standards or the conceptual models are committed to experts. This element is shown in Figure 4 as “Conceptual Model” and was introduced in Section 3.3 for the paleontology subdomain. Similarly, modelers build the domain taxonomy by reusing pre-existing taxonomies (Section 3.1) through refinement, reuse, extension or a combination of these options. For example, what can be similar between (a) finding schools of fish and showing their location on a map and (b) identifying fossil distributions that are being explored in a geographic area? The answer comes from reuse: we can reuse geographic location services in both cases, but display them differently by specializing services corresponding to the human interface; or process information by grouping data differently for each of the cases. This element is shown in Figure 4 as “Taxonomy” and was briefly introduced in Section 3.1 and Section 3.2 for the geographic and marine ecology domains. The taxonomy for the paleontology subdomain is further elaborated in Section 5.2.
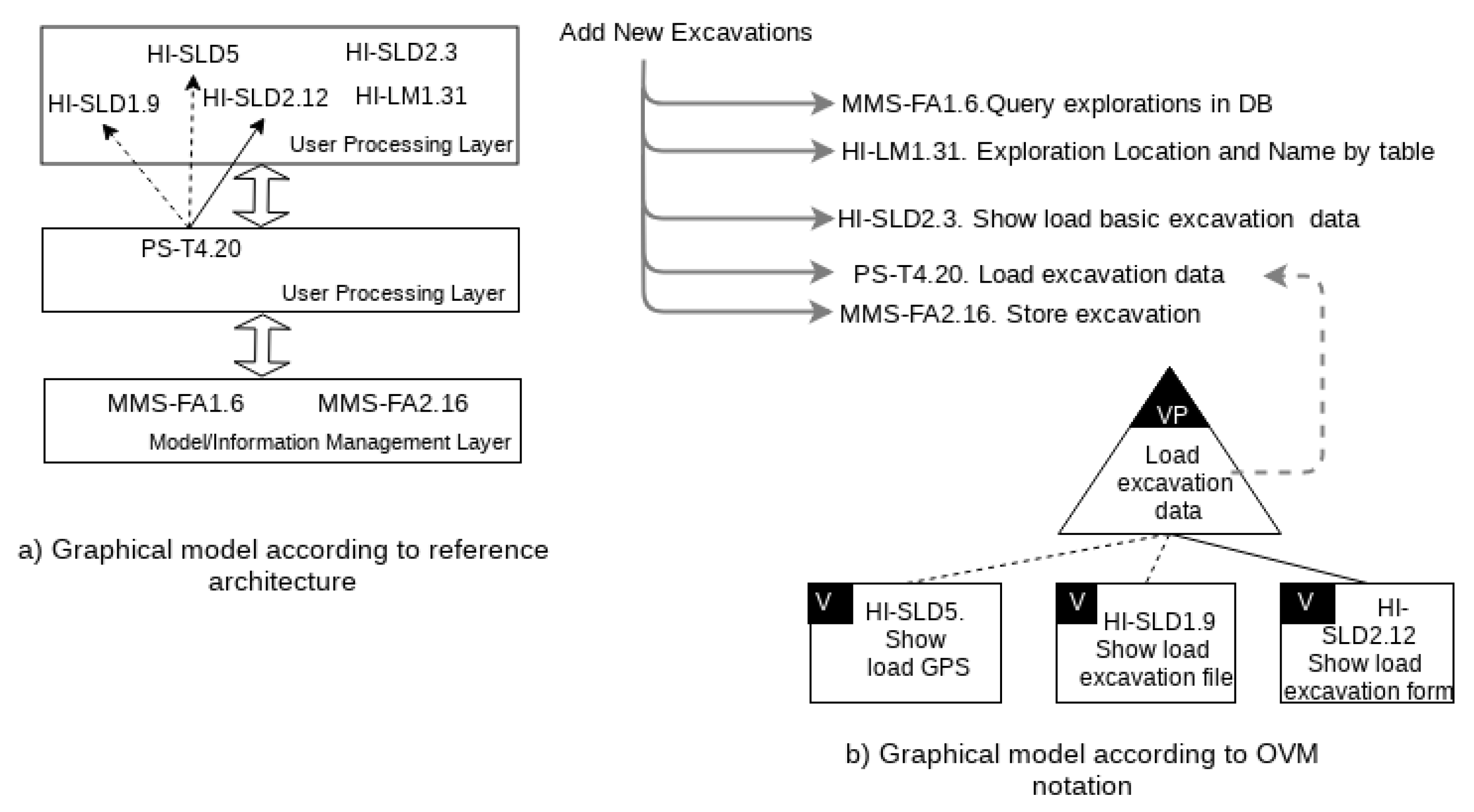
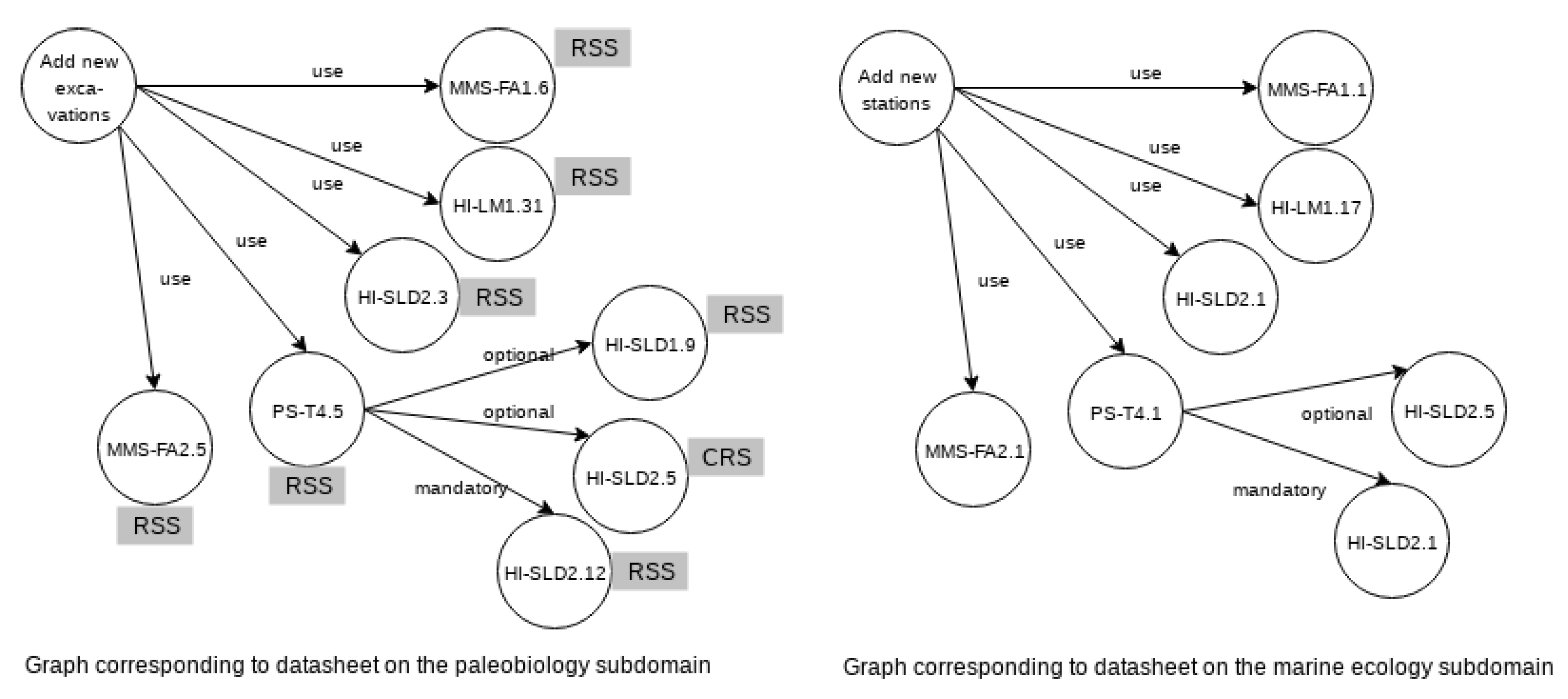
- Reusable component analysis (RCA): In this activity we build a reference architecture that is used for designing functionality in the way of functional datasheets, which are created after analyzing the interactions of selected taxonomy services (referred as “Selected Services” in Figure 4). Each functional datasheet (Table 1) includes five items:
- Id: an identification,
- Name: a textual description of the main function,
- Domain: the domain in which it is included, or it was firstly created,
- Services: a list of services (from the taxonomy) used to represent the functionality, and
- Variability Models: a set of graphical artifacts showing the service interactions (as common and variant services). For the last item, any graphical diagram could be used. However, in our work we use a graphical notation based on variability annotation of collaboration diagrams (of UML). The required variability, according to the functionality to be represented, is attached to the diagrams by using the OVM notation [3]. In Table 1 we can see an example of the variability model item for the Add New Excavations datasheet in which two graphical models are provided.
- Organizational Analysis: As part of the organization analysis activities, the refined artifacts are used to determine the structure of the software that implements the platform architecture (“Implementation Model” in Figure 4). It models the way in which each refined functional datasheet (based on the taxonomy refinement) is implemented as software components. This platform is then used in the configuration of the products to create the architecture of a specific application. The final output consists of a set of code skeletons ready “for reuse”.
5. A taxonomy to Assist Domain Analysis in SPLs for the Paleontology Subdomain
5.1. Mapping Conceptual Models
5.1.1. Domain Requirements
5.1.2. Standard Information
5.1.3. Information about Other Domains
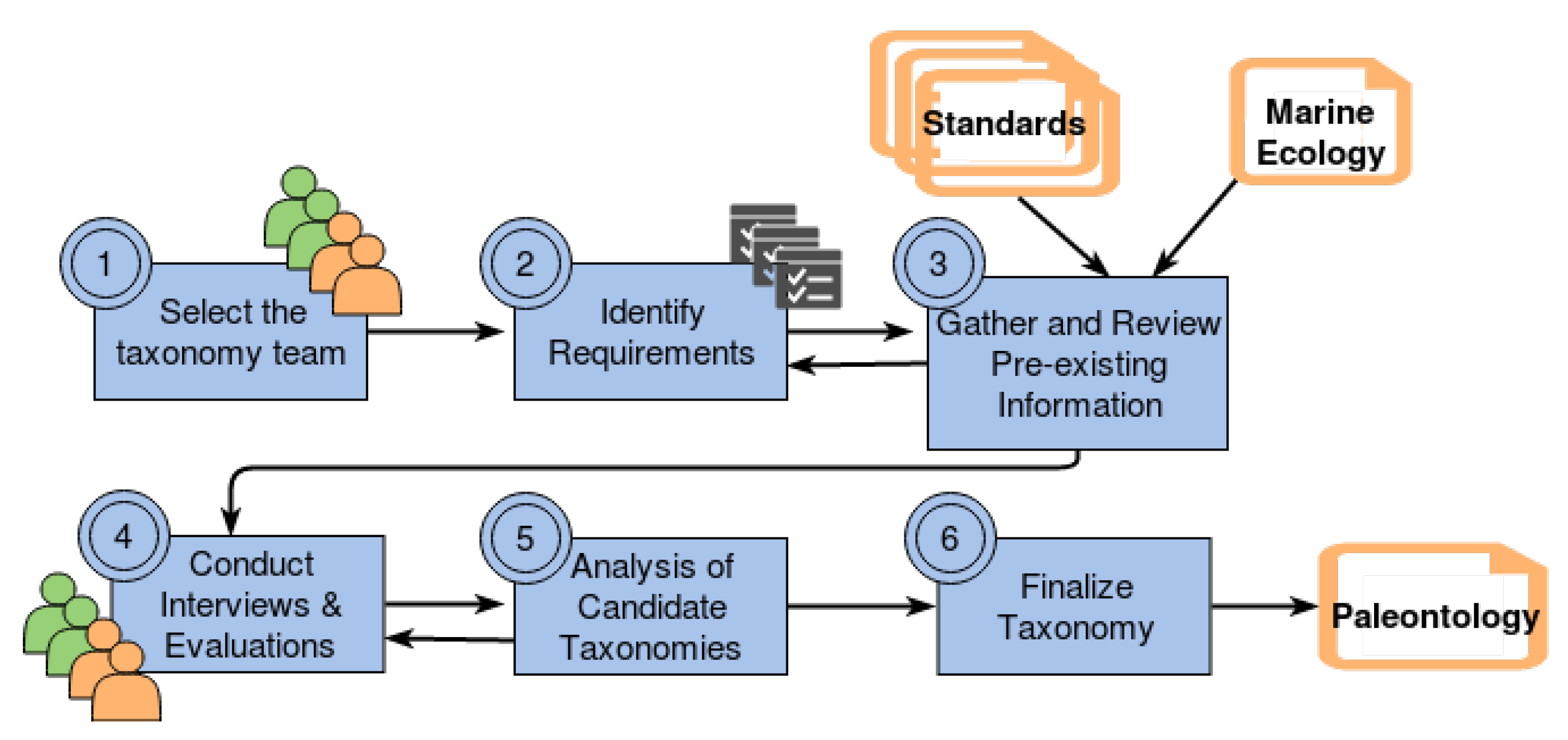
5.2. Creating the Taxonomy in the Paleontology Subdomain
- Planning: during this step, we defined the interviews’ goals identifying possible sub-goals and an execution order
- Media and language selection: here, we selected different interactions, such as the use of visual tools, prototypes, similar cases, etc.
- Cognitive approach: whether we followed an analytic or experimental approach, where cases were run to clarify a point. In some cases, we all together just analyzed material supplied by paleontologists; while other cases required demonstrations on the field (such as jacketing).
- Social approach: we followed an expert-driven strategy taking into account paleontologists’ descriptions during the interviews. These descriptions were committed after an iterative process for agreement. In case cooperation was needed to reach such agreement, we followed a participatory strategy through workshops for knowledge refinement.
- Conversation techniques: these were selected according to the interviews’ goals defined during Planning. For instance, workshops helped us to reach consensus and committed knowledge, as well as validation interviews; meanwhile “brown-paper” sessions were used to identify relevant and aware knowledge. In our case, interviews were progressively structured to incorporate domain knowledge, and identify common and variable features as reusable/required services.
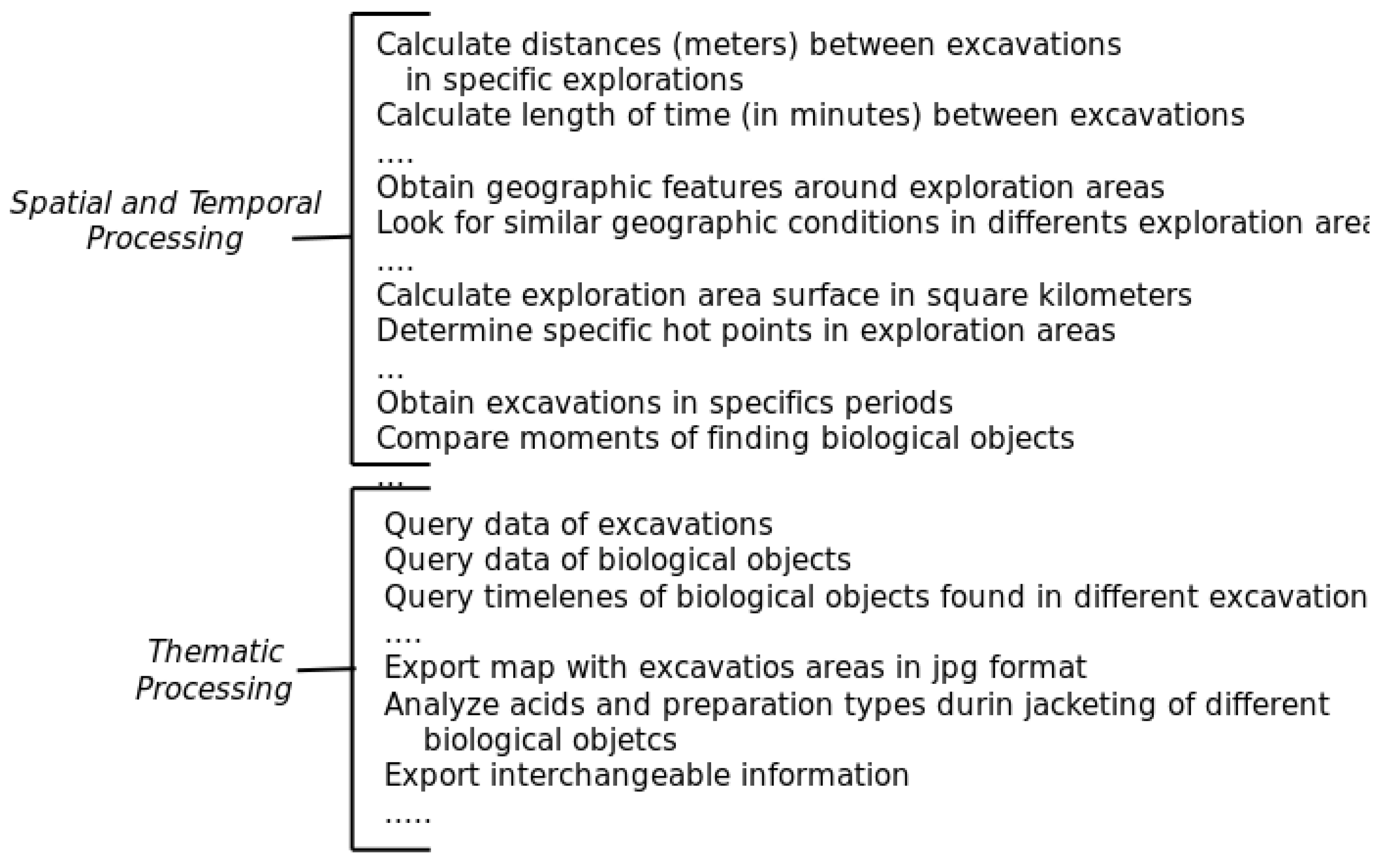
5.3. Guides for Composing Services during SPL Design And Product Implementation
6. Reuse Analysis
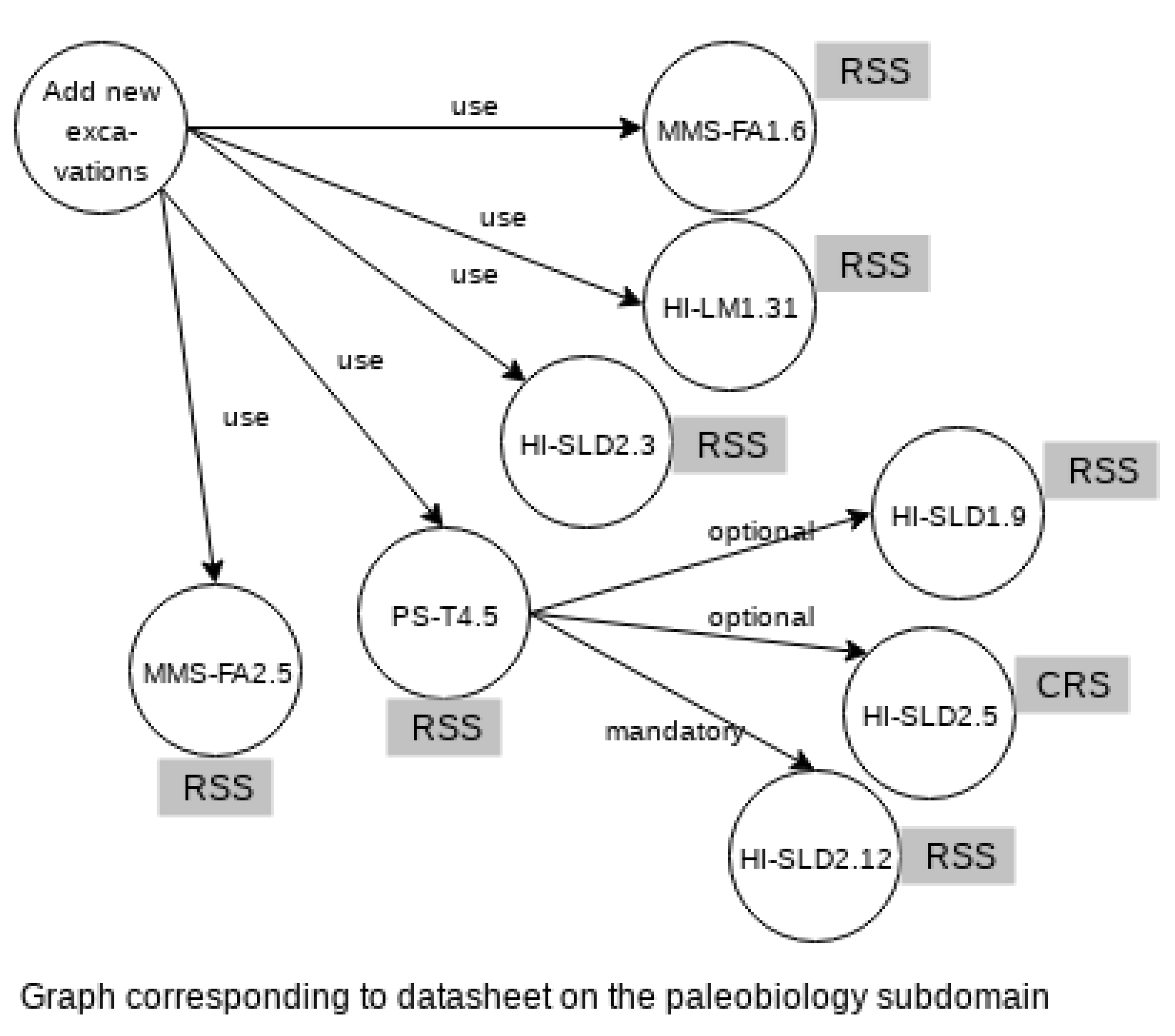
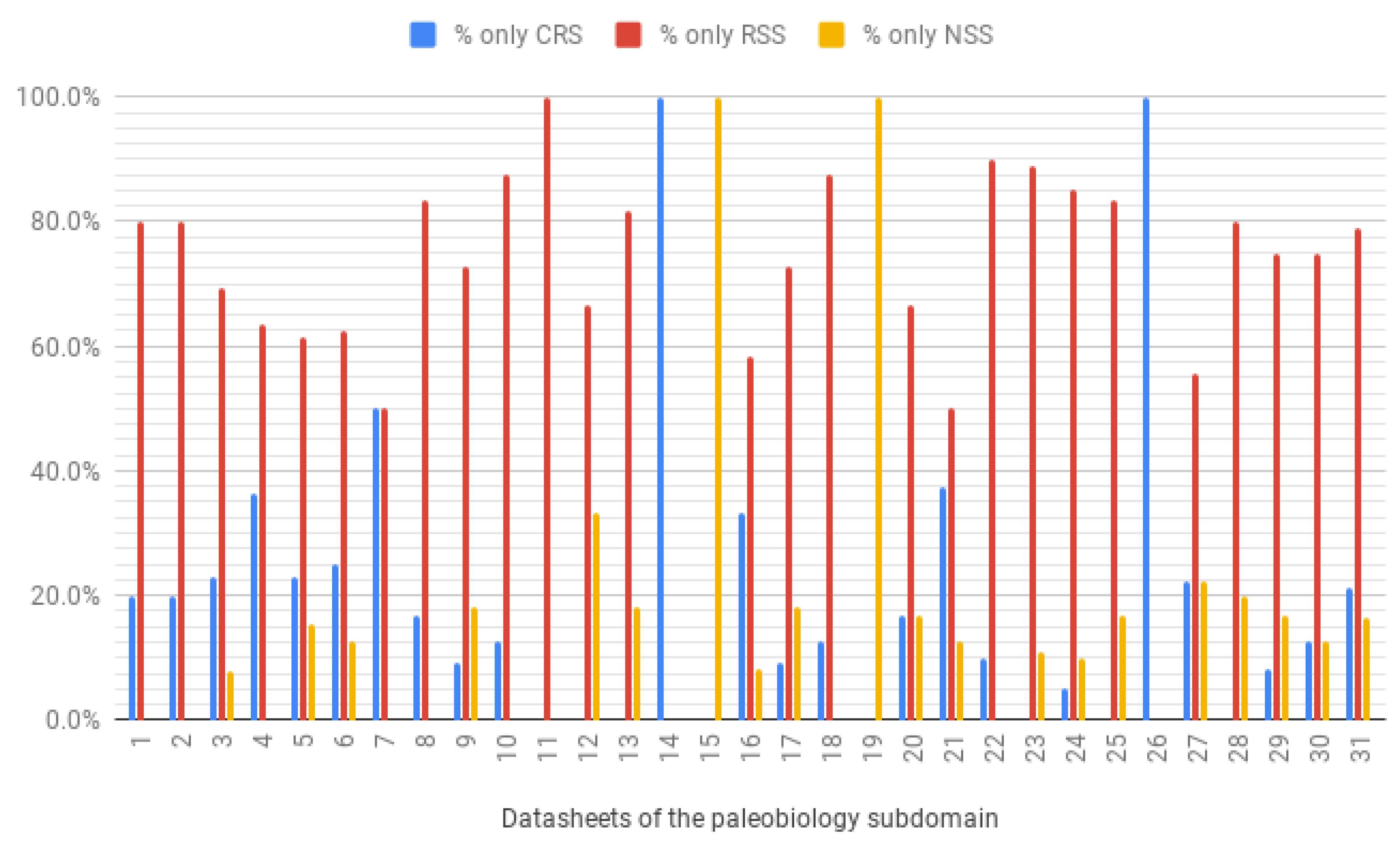
- Completely Reusables Services (CRS) are those services of the geographical domain or some subdomain, which are reused without modification by the functionalities of the paleobiology SPL. Examples of these services are those that are black and red in Figure 11 and Figure 12, and that are related to this subdomain. These services do not need any type of adaptation to be reused.
- New Services for Specialization (NSS) are new services generated only to this subdomain, and consequently they are not related to services of the other domains. Examples of NSS services are those defined as specializations of the ISO 21127, which were not used by the marine ecology subdomain. Some examples of these services are defined in Table 2, such as label the jacket outside the plastic bag or package. In this case, the services need to be designed and implemented from scratch.
- We transformed 30 datasheets of the paleobiology subdomain and 60 datasheets from the marine biology subdomain into a graph structure according to Definition 1.
- We labeled each service of the 30 graphs of the paleobiology subdomain into the three types of services (CRS, RSS, and NSS services).
- We calculated the cost model of Equation (1) by considering hypothetical costs of deletion/substitution according to the type of service involved: 1 for CRS services, 2 for RSS services, and 3 for NSS services. Although the costs are not real, values intent to show that costs are higher when we have less reuse (In this preliminary analysis we do not consider arcs representing variability dependencies and restrictions). A special case is when we have to insert new nodes, that is, when a graph of the marine ecology domain has nodes that are not present in the graph of the paleobiology domain. These nodes represent services belonging only to the marine ecology subdomain, in this case we assigned the same cost as a NSS service.
7. Conclusions and Future Work
- The use of previous information available enables software engineers to organize and improve the task of specifying requirements for the paleobiology subdomain: The fact that we had a lot of information available and ready to be used, represented a solid base to define new services and functionalities in the paleobiology subdomain. On one hand, we had a service taxonomy already defined for the geographic and a marine ecology subdomain, which gave us the possibility of organizing the information gathered by domain experts in an already known and applied structure. On the other hand, the use of standards on cultural heritage worked as a controlled vocabulary for all stakeholders providing a common language (which resulted in better communication).
- The definition of services by considering different domains/subdomains was the starting point to improve reuse during SPL development: As we have described throughout and analyzed in Section 6, the service taxonomy and its use in the different subdomains gave us a reasonable and measurable level of reuse of the services on specific functionalities of the product line. The level of reuse identified improved implementing and testing activities during SPL development, because services and functionalities reused were already developed.
- Future software product lines over some other subdomain of the geographic domain can be done by applying the same taxonomy and process: The process of adding new services to the taxonomy belonging to a new subdomain to be included, can be done by applying the same steps proposed in Section 5. These guides, already applied here and in [5], can be also reused as well as all the service taxonomy.
- The reuse analysis gave us an overall view about the real suitability of our development to take advantage of reuse artifacts in a domain: Our analysis provided the general basis to understand the way reuse is reached; and a way to measure it according to the mapping of services (in a taxonomy) and functionalities. However, we must continue working on this analysis by considering real costs of adaptations, extensions and re-implementations of new or reused functionalities.
- New SPL developments might be supported by the same methodology and focused on improving reuse of services and functionalities: The reuse analysis performed in Section 6, in addition to provide a preliminary panorama of the reuse reached, will be useful for building a supporting tool, which helps find the most similar services and functionalities among all lines previously defined. That is what you need when a new SPL is built for another subdomain within the taxonomy.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CIDOC | International Committee for Documentation |
| CRM | Conceptual Reference Model |
| CRMsci | Scientific Observation Model |
| CRS | Completely Reusables Services |
| CS | Communication services |
| EOSE | Extended Open Systems Environment |
| GIS | Geographic Information Systems |
| NSMUnco | Natural Science Museum at University of Comahue |
| GPS | Global Positioning System |
| HI | Human interaction services |
| ISO | International Organization for Standardization |
| LIDO | Lightweight Information Describing Object |
| MMS | Model/information management services |
| MPL | Multiple Product Lines |
| NSS | New Services for Specialization |
| OGC | Open Geospatial Consortium |
| PS | Processing services |
| PS-M | Geographic processing services—metadata |
| PS-S | Geographic processing services—spatial |
| PS-T | Geographic processing services—thematic |
| PS-Te | Geographic processing services—temporal |
| RSS | Reusable Services for Specialization |
| SPL | Software Product Line |
| SPLE | Software Product Line Engineering |
| WTS | Workflow/Task services |
Appendix A. Standards Related to Paleontology Subdomain
- ISO 19107 (Spatial Schema International standard 19107, ISO/IEC 2003.): From this standard we analyzed the ways spatial data can be stored together with the set of operations applied to them. For example, each excavation is represented as a GM_Point from this standard.
- ISO 19108 (Temporal schema International standard 19108, ISO/IEC 2002.): Similar to the previous standard but applied to temporal data. Here it is important to store time periods the dinosaurs lived in (TM_Period), specific moments in which fossils had been found (TM_Instant), etc.
- ISO 19109: This standard is the basis of the conceptual schema (Figure 6), which is focused on geographic and thematic classes for representing geographical and non-geographical features respectively.
- ISO 19119: This standard is the core of the taxonomy structure and reference architecture. As we explained in Section 3.1 (Figure 2), we followed a three layer-based architecture by assigning services included within each of these layers.
- ISO 21127 (Information and documentation—A reference ontology for the interchange of cultural heritage information—ISO 21127:2014): We analyzed the reference ontology defined in the cultural heritage information, in which any action about a biological or physical object is represented as an activity (such as Acquisition or Curation). At the same time, this ontology uses geographical information for representing periods, places, etc.
- CIDOC-CRM: As we described in Section 3.3, this standard was analyzed for applying its four perspectives when the services and functionalities were defined. It was applied as a support to the reference ontology analyzed in the ISO 21127.
- LIDO (LIDO—Lightweight Information Describing Objects Version 1.0—http://network.icom.museum/cidoc/working-groups/lido/what-is-lido/): As it is an XML schema for describing museum objects, we analyzed metadata defined here for aligning our information representation.
- SPECTRUM (https://collectionstrust.org.uk/): It is a UK standard for collection management. It specifies how to manage collections and what to do with artifacts during their lifecycle in a collection. Activities defined in CIDOC and ISO 21127 were analyzed with respect to this standard.
- Argentinian Laws: Here provincial and national laws were analyzed in order to adapt processes to the current legislation. For example the Law 25743 (Ley de Protección del Patrimonio Arqueológico y Paleontológico—http://servicios.infoleg.gob.ar/infolegInternet/anexos/85000-89999/86356/norma.htm) defines the way in which the cultural heritage must be acquired, moved, and preserved by specific organizations (such as museums) and the state. These mechanisms support processes defined by international standards by adding specific national information to be considered. As in Argentina the largest number of museums are state-owned, the Argentinian laws are related to specific aspects about how to register the paleontological pieces found, how to ask for exploration and excavation permissions, time ranges in which administrative and legal procedures should be carry out, and penalties in the case of non-compliance. In general, these Argentinian laws do not contradict international standards and some of them refer to some of these standards respect to the way of cataloguing pieces, type of codification, etc. (Decreto 1022/2004—http://servicios.infoleg.gob.ar/infolegInternet/verNorma.do;jsessionid=E7D998DB288023C0F191221C9DA2C53C?id=97432).
References
- Clements, P.C.; Northrop, L. Software Product Lines: Practices and Patterns; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2001. [Google Scholar]
- van der Linden, F.; Schmid, K.; Rommes, E. Software Product Lines in Action: The Best Industrial Practice in Product Line Engineering; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Pohl, K.; Böckle, G.; Linden, F.J.v.d. Software Product Line Engineering: Foundations, Principles and Techniques; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Buccella, A.; Cechich, A.; Arias, M.; Pol’la, M.; del Socorro Doldan, M.; Morsan, E. Towards systematic software reuse of GIS: Insights from a case study. Comput. Geosci. 2013, 54, 9–20. [Google Scholar] [CrossRef]
- Buccella, A.; Cechich, A.; Pol’la, M.; Arias, M.; Doldan, S.; Morsan, E. Marine Ecology Service Reuse through Taxonomy-Oriented SPL Development. Comput. Geosci. 2014, 73, 108–121. [Google Scholar] [CrossRef]
- Bosch, J. Design and Use of Software Architectures: Adopting and Evolving a Product-line Approach; ACM Press Books; Addison-Wesley: Boston, MA, USA, 2000. [Google Scholar]
- Naoumidou, N.; Chatzidaki, M.; Alexopoulou, A. “ARIADNE” conservation documentation system: Conceptual design and projection on the CIDOC CRM. framework and limits. In Proceedings of the Annual Conference of CIDOC, Athens, Greece, 15–18 September 2008. [Google Scholar]
- Felicetti, A.; Scarselli, T.; Mancinelli, M.L.; Niccolucci, F. Mapping ICCD Archaeological Data to CIDOC-CRM: the RA Schema. In Proceedings of the Workshop Practical Experiences with CIDOC CRM and its Extensions, Co-Located with the 17th International Conference on Theory and Practice of Digital Libraries (CEUR Workshop Proceedings CEUR-WS.org), Valletta, Malta, 26 September 2013; Volume 1117. [Google Scholar]
- Carlisle, P.K.; Avramides, I.; Dalgity, A.; Myers, D. The Arches Heritage Inventory and Management System: A Standards-Based Approach to the Management of Cultural Heritage Information; Technical Report; World Monuments Fund: Los Angeles, CA, USA, 2014. [Google Scholar]
- Myers, D.; Dalgity, A.; Avramides, I. The Arches heritage inventory and management system: A platform for the heritage field. J. Cult. Herit. Manag. Sustain. Dev. 2016, 6, 213–224. [Google Scholar] [CrossRef]
- Hiebel, G.; Hanke, K.; Hayek, I. Methodology for CIDOC CRM based data integration with spatial data. In Proceedings of the 38th Annual Conference on Computer Applications and Quantitative Methods in Archaeology, Granada, Spain, 6–9 April 2010. [Google Scholar]
- Hiebel, G.; Doerr, M.; Hanke, K.; Masur, A. How to Put Archaeological Geometric Data into Context? Representing Mining History Research with CIDOC CRM and Extensions. Int. J. Herit. Digit. Era 2014, 3, 557–577. [Google Scholar] [CrossRef] [Green Version]
- Cohen, S. Ontology and taxonomy of services in a service-oriented architecture. Archit. J. 2007, 11, 30–35. [Google Scholar]
- Nickerson, R.C.; Varshney, U.; Muntermann, J.; Isaac, H. Taxonomy development in information systems: Developing a taxonomy of mobile applications. In Proceedings of the 17th European Conference on Information Systems (ECIS 2009), Verona, Italy, 8–10 June 2009; pp. 1138–1149. [Google Scholar]
- Hunink, I.; Rene, E.; Jansen, S.; Brinkkemper, S. Industry taxonomy engineering: The case of the European software ecosystem. In Proceedings of the Fourth European Conference on Software Architecture: Companion Volumem, Copenhagen, Denmark, 23–26 August 2010; ACM: New York, NY, USA, 2010; pp. 111–118. [Google Scholar]
- ESPRIT/ESSI Project no 21580. Guidelines for Best Practice in User Interface for GIS, Section 6 List of key GIS Operations. 1998. Available online: https://es.scribd.com/document/169790630/Guideline-for-best-practice (accessed on 31 May 2019).
- Albrecht, J. Universal GIS Operations for Environmental Modeling. In Proceedings of the Third International Conference/Workshop on Integration GIS and Environmental Modeling, Sante Fe, NM, USA, 21–25 January 1996. [Google Scholar]
- Sklar, F.; Constanza, R. The Development of Dynamic Spatial Models for Landscape Ecology: A review and prognosis. In Quantitative Methods in Landscape Ecology; Turner, M., Gardner, R., Eds.; Springer: New York, NY, USA, 1991; pp. 239–288. [Google Scholar]
- Braun, G.; Pol’la, M.; Cecchi, L.; Buccella, A.; Fillottrani, P.; Cechich, A. A DL semantics for reasoning over OVM-based variability models. In Proceedings of the 30th International Workshop on Description Logics (DL 2017), Montpellier, France, 18–21 July 2017. [Google Scholar]
- Pol’la, M.; Buccella, A.; Arias, M.; Cechich, A. SeVaTax: Service taxonomy selection & validation process for SPL development. In Proceedings of the 34th International Conference of the Chilean Computer Science Society (SCCC), Santiago, Chile, 9–13 November 2015; pp. 1–6. [Google Scholar]
- Buccella, A.; Pol’la, M.; Cechich, A.; Arias, M. A Variability Representation Approach Based on Domain Service Taxonomies and Their Dependencies. In Proceedings of the 33rd International Conference of the Chilean Computer Science Society (SCCC), Talca, Chile, 8–14 November 2014; pp. 116–119. [Google Scholar]
- Arias, M.; Buccella, A.; Cechich, A. Smooth transition from abstract to concrete spl components: A client-server implementation for the geographic domain. In Proceedings of the 1st Symposium of the Argentine Chapter of Geosciences and Remote Sensing Society, Ciudad Autónoma de Buenos Aires, Argentina, 16 June 2016. [Google Scholar]
- Pesce, F.; Caballero, S.; Buccella, A.; Cechich, A. Reusing a Geographic Software Product Line Platform: A Case Study in the Paleontological Sub-domain. In Computer Science–CACIC 2017; Springer: Berlin, Germany, 2018; pp. 145–154. [Google Scholar]
- Choksy, C.E.B. 8 Steps to develop a taxonomy. Inf. Manag. J. 2006, 40, 30–41. [Google Scholar]
- Lankhorst, C.M.L. Enterprise Architecture at Work: Modelling, Communication, and Analysis, 1st ed.; Springer: Berlin, Germany, 2005. [Google Scholar]
- Arias, M.; DeRenzis, A.; Buccella, A.; Flores, A.; Cechich, A. Classification-based Mining of Reusable Components on Software Product Lines. IEEE Latin Am. Trans. 2016, 14, 870–876. [Google Scholar] [CrossRef]
- Arias, M.; Buccella, A.; Cechich, A. Búsqueda de Funcionalidades basada en Expansión de Consultas para LPS. In Proceedings of the CACIC’16: XXII Congreso Argentino de Ciencias de la Computación, San Luis, Argentina, 3–7 October 2016. [Google Scholar]
- Mijač, M.; Stapic, Z. Reusability Metrics of Software Components: Survey. In Proceedings of the 26th Central European Conference on Information and Intelligent Systems, Varaždin, Hrvatska, 23–25 September 2015; pp. 221–231. [Google Scholar]
- Gacek, C. Detecting Architectural Mismatches During System Composition; Technical Report; University of Southern California: Los Angeles, CA, USA, 1997. [Google Scholar]
- Schoknecht, A.; Thaler, T.; Fettke, P.; Oberweis, A.; Laue, R. Similarity of Business Process Models: A State-of-the-Art Analysis. ACM Comput. Surv. 2017, 50, 52:1–52:33. [Google Scholar] [CrossRef]
- Becker, M.; Laue, R. Analysing Differences between Business Process Similarity Measures. In Business Process Management Workshops; Daniel, F., Barkaoui, K., Dustdar, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 39–49. [Google Scholar]
- Dijkman, R.; Dumas, M.; van Dongen, B.; Käärik, R.; Mendling, J. Similarity of Business Process Models: Metrics and Evaluation. Inf. Syst. 2011, 36, 498–516. [Google Scholar] [CrossRef]
- Dijkman, R.; Dumas, M.; García-Bañuelos, L. Graph Matching Algorithms for Business Process Model Similarity Search. In Business Process Management; Dayal, U., Eder, J., Koehler, J., Reijers, H.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 48–63. [Google Scholar] [Green Version]
- Bunke, H.; Shearer, K. A graph distance metric based on the maximal common subgraph. Pattern Recogn. Lett. 1998, 19, 255–259. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Id | FD2 |
| Name | Add New Excavations |
| Domain | Palentology subdomain |
| Services | MMS-FA1.6, HI-LM1.31, PS-T4.20, HI-SLD2.3, … |
| Variability Models |  |
| Activities | Services |
|---|---|
| Recording explorations | assign an exploration code |
| request for the permission for prospecting | |
| define the excavation area | |
| select the director of the exploration | |
| define the dates in which the exploration will be open | |
| define the excavation activities | |
| … | |
| Recording excavations | assign an excavation code |
| specify an excavation name | |
| register the excavation GPS point | |
| attach to an exploration registry | |
| define the exploration team | |
| define the responsible for exploration | |
| record the fossils found | |
| … | |
| Recording jacketing | assign an excavation code |
| assign the preparation type | |
| record the acids applied | |
| attach to an excavation registry | |
| record the biological objects involved | |
| record the tools for Excavation | |
| label the jacket outside the plastic bag or package | |
| … |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buccella, A.; Cechich, A.; Porfiri, J.; Diniz Dos Santos, D. Taxonomy-Oriented Domain Analysis of GIS: A Case Study for Paleontological Software Systems. ISPRS Int. J. Geo-Inf. 2019, 8, 270. https://doi.org/10.3390/ijgi8060270
Buccella A, Cechich A, Porfiri J, Diniz Dos Santos D. Taxonomy-Oriented Domain Analysis of GIS: A Case Study for Paleontological Software Systems. ISPRS International Journal of Geo-Information. 2019; 8(6):270. https://doi.org/10.3390/ijgi8060270
Chicago/Turabian StyleBuccella, Agustina, Alejandra Cechich, Juan Porfiri, and Domenica Diniz Dos Santos. 2019. "Taxonomy-Oriented Domain Analysis of GIS: A Case Study for Paleontological Software Systems" ISPRS International Journal of Geo-Information 8, no. 6: 270. https://doi.org/10.3390/ijgi8060270
APA StyleBuccella, A., Cechich, A., Porfiri, J., & Diniz Dos Santos, D. (2019). Taxonomy-Oriented Domain Analysis of GIS: A Case Study for Paleontological Software Systems. ISPRS International Journal of Geo-Information, 8(6), 270. https://doi.org/10.3390/ijgi8060270