Anomalous Urban Mobility Pattern Detection Based on GPS Trajectories and POI Data


Abstract
:1. Introduction
- Functional regions are effectively identified based on POI data. DBSCAN, a density-based clustering algorithm, is applied to identify functional regions. The weighted TF-IDF technique, considering the significance of feature POIs, is proposed to calculate the function values of functional regions.
- Mobility vectors, extracted from OD trips, are proposed to record the information of human movement; the mean shift algorithm is used to aggregate the movements into different urban mobility patterns. Anomalous urban mobility patterns can be detected and differentiated from normal urban mobility patterns in urban areas. Additionally, this method can effectively detect anomalous mobility patterns at different temporal scales.
- A case study is conducted using taxi GPS trajectory and POI data in the city of Wuhan, China. The results show that the proposed method can effectively identify functional regions and interesting mobility patterns.
2. Related Work
2.1. Functional Region Discovery
2.2. Urban Mobility Pattern Detection
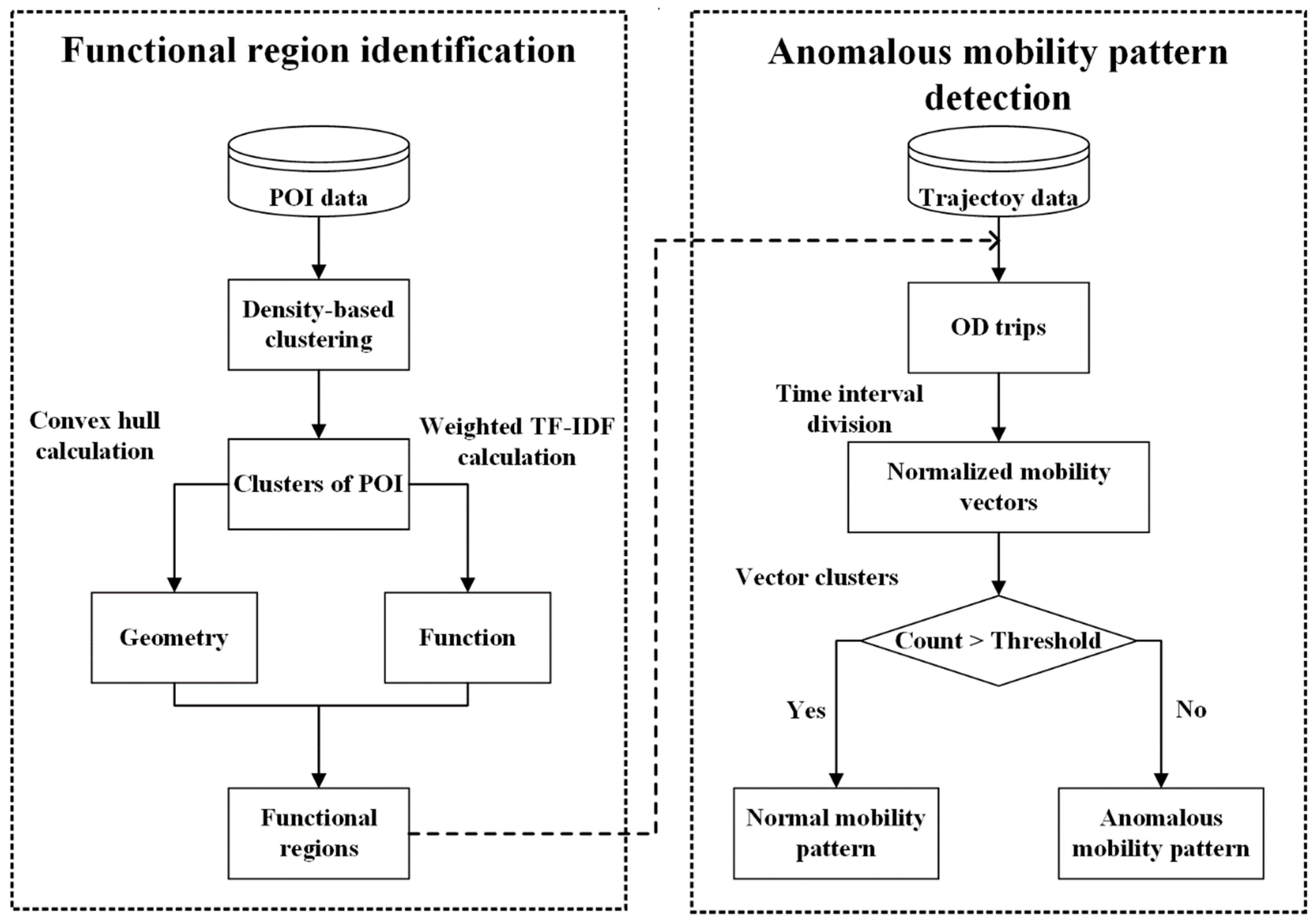
3. Anomalous Urban Mobility Pattern Detection
3.1. Preliminaries
3.2. Framework of Anomalous Urban Mobility Pattern Detection
3.3. Functional Region Identification
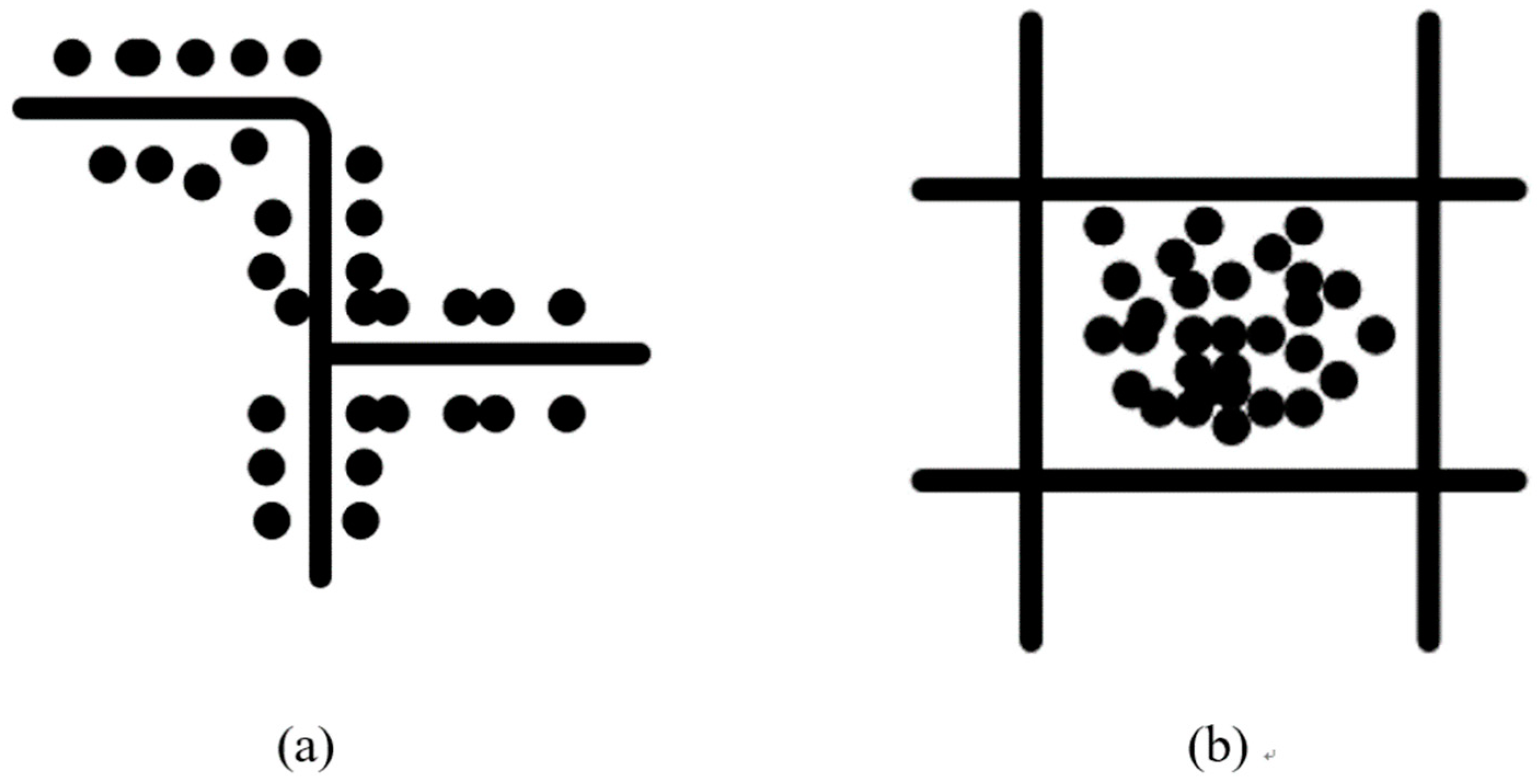
3.3.1. DBSCAN Algorithm for POI Clustering
3.3.2. Weighted TF-IDF for Function Value Calculation
3.4. Anomalous Mobility Pattern Detection
| Algorithm 1: Mean shift clustering algorithm for mobility vectors. | |
| Input: the set of mobility vectors , the bandwidth , the stop threshold | |
| Output: the clustering result of | |
| 1: | //store the final value of each mobility vector after the mean shift procedure |
| 2: | |
| 3: | Foreachin |
| 4: | |
| 5: | While do |
| 6: | //Search all vectors within the radius |
| 7: | |
| 8: | //Calculate the mean vector of neighbors |
| 9: | If Then |
| 10: | |
| 11: | |
| 12: | Break |
| 13: | End If |
| 14: | End While |
| 15: | End Foreach |
| 16: | // Extract the cluster centers from the set |
| 17: | Foreachin |
| 18: | |
| 19: | End Foreach |
4. Case Study
4.1. Dataset
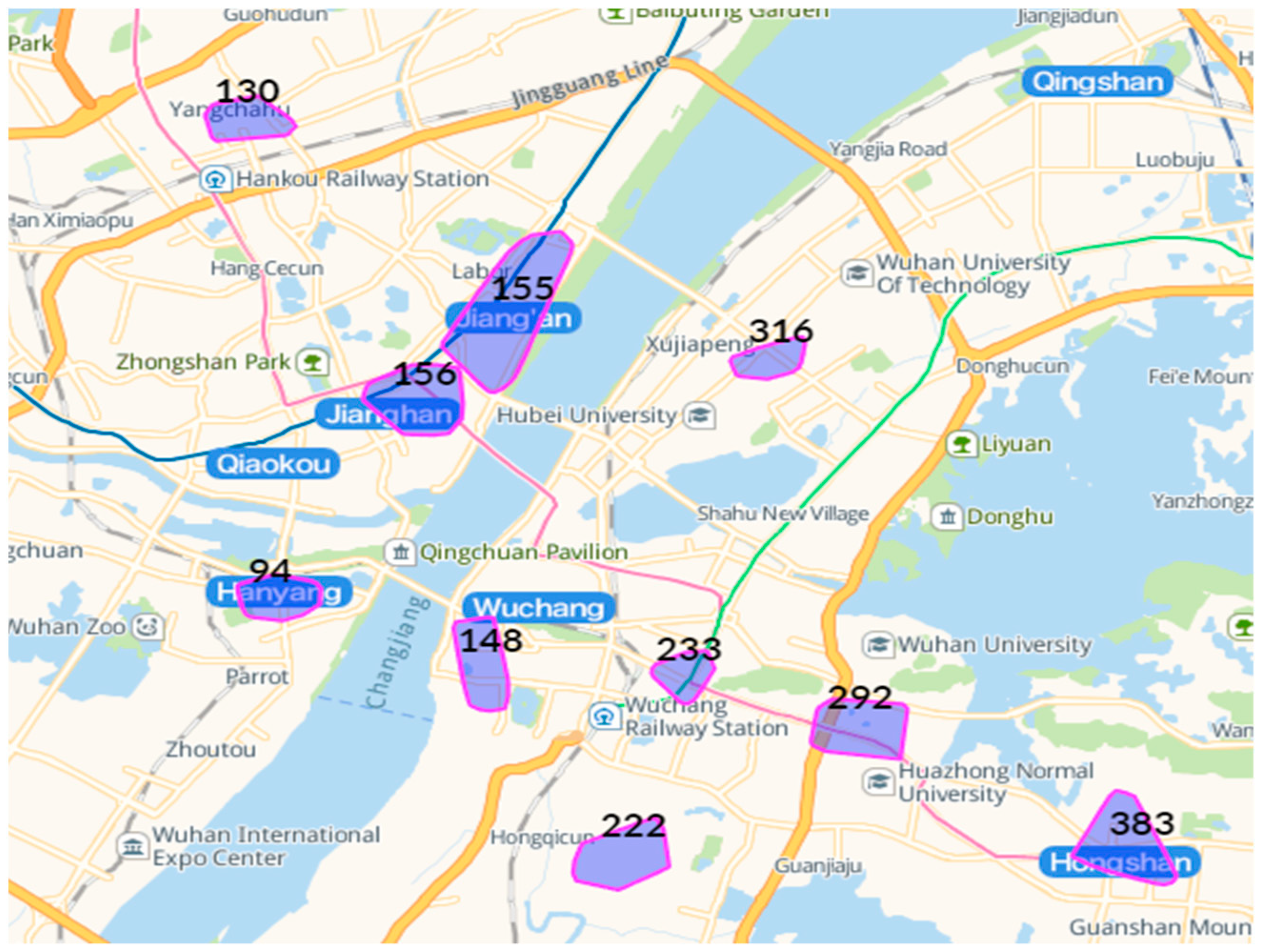
4.2. Functional Region Identification
4.2.1. Functional Region Identification Based on DBSCAN and WTF-IDF
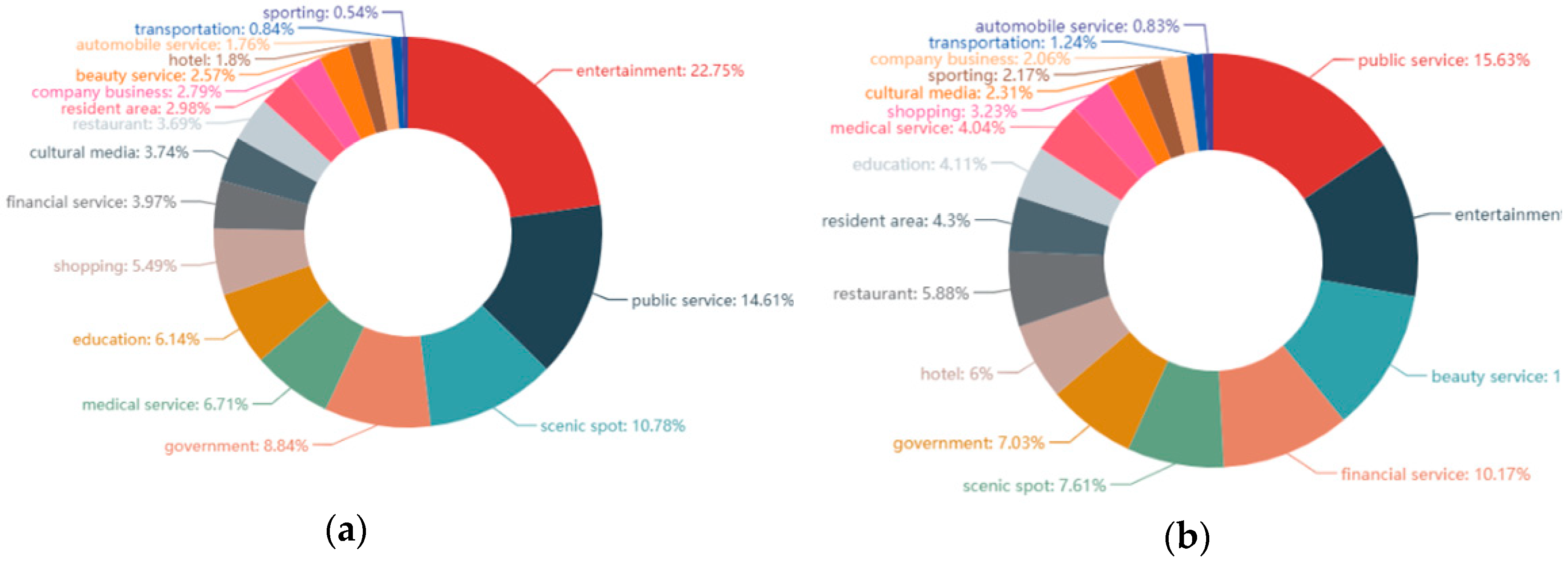
4.2.2. Performance Comparison between WTF-IDF and TF-IDF
4.3. Anomalous Urban Mobility Pattern Detection
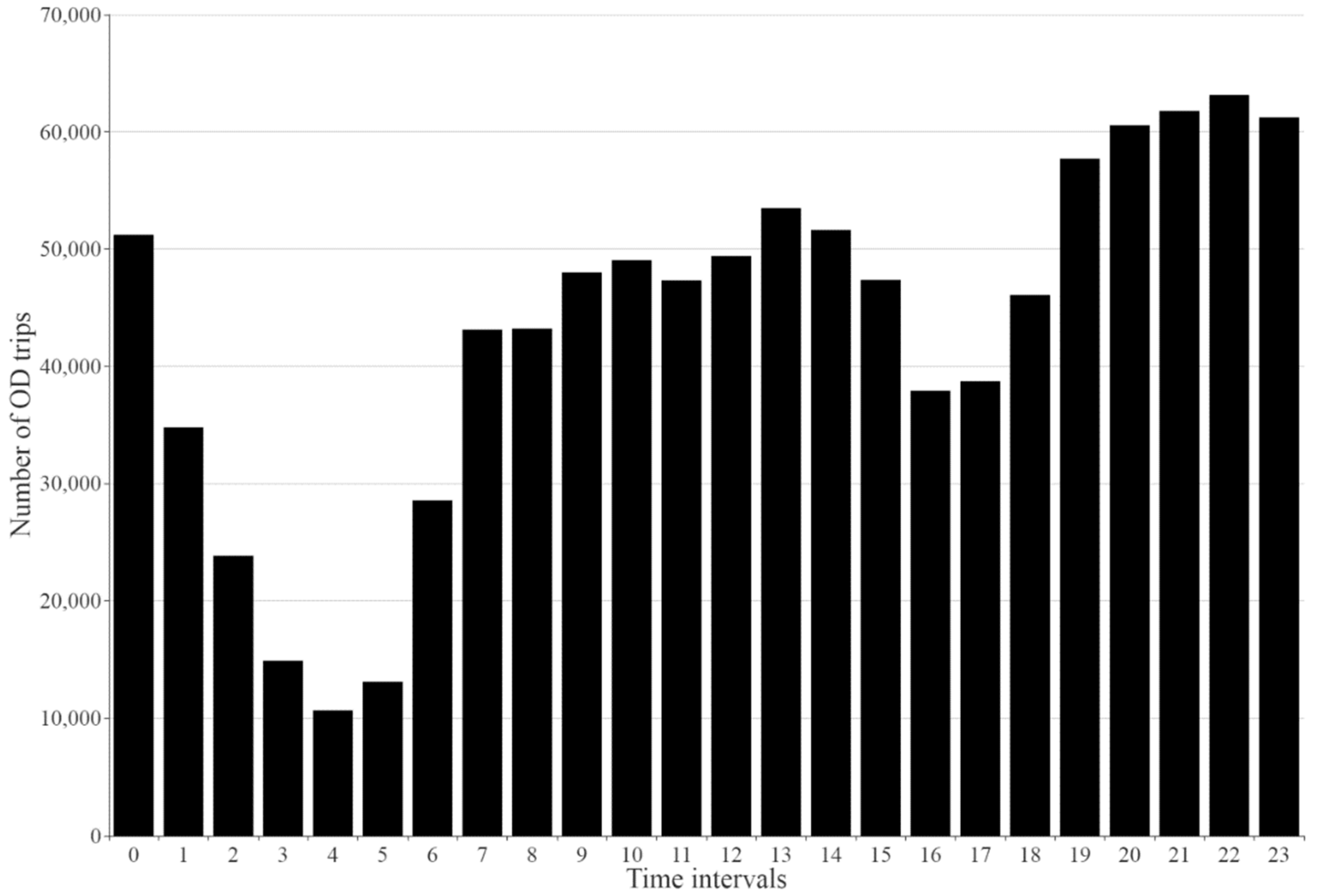
4.3.1. Distribution of OD Trips
4.3.2. Anomalous Urban Mobility Pattern at the Scale of Day
4.3.3. Anomalous Urban Mobility Pattern at the Scale of Hour
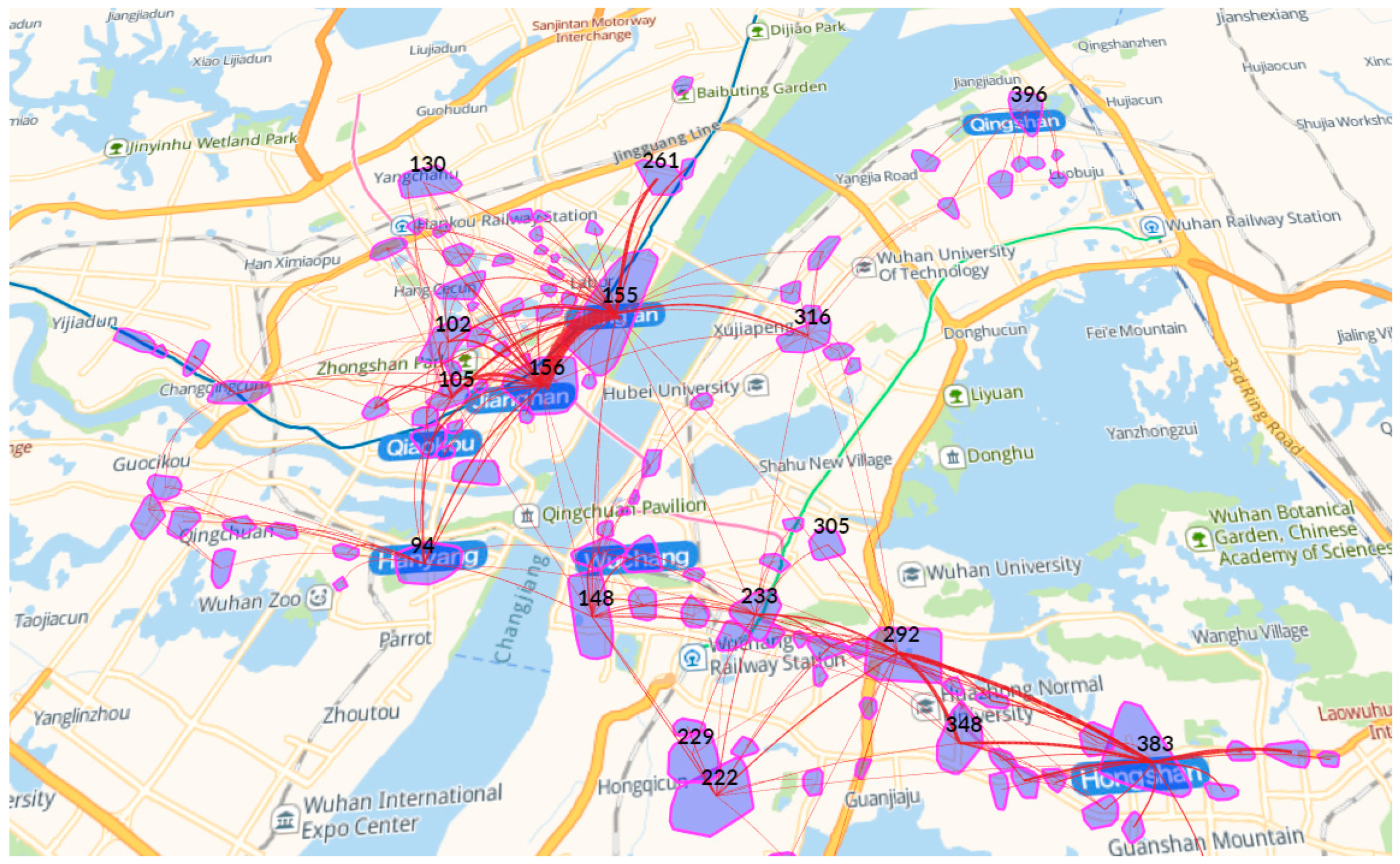
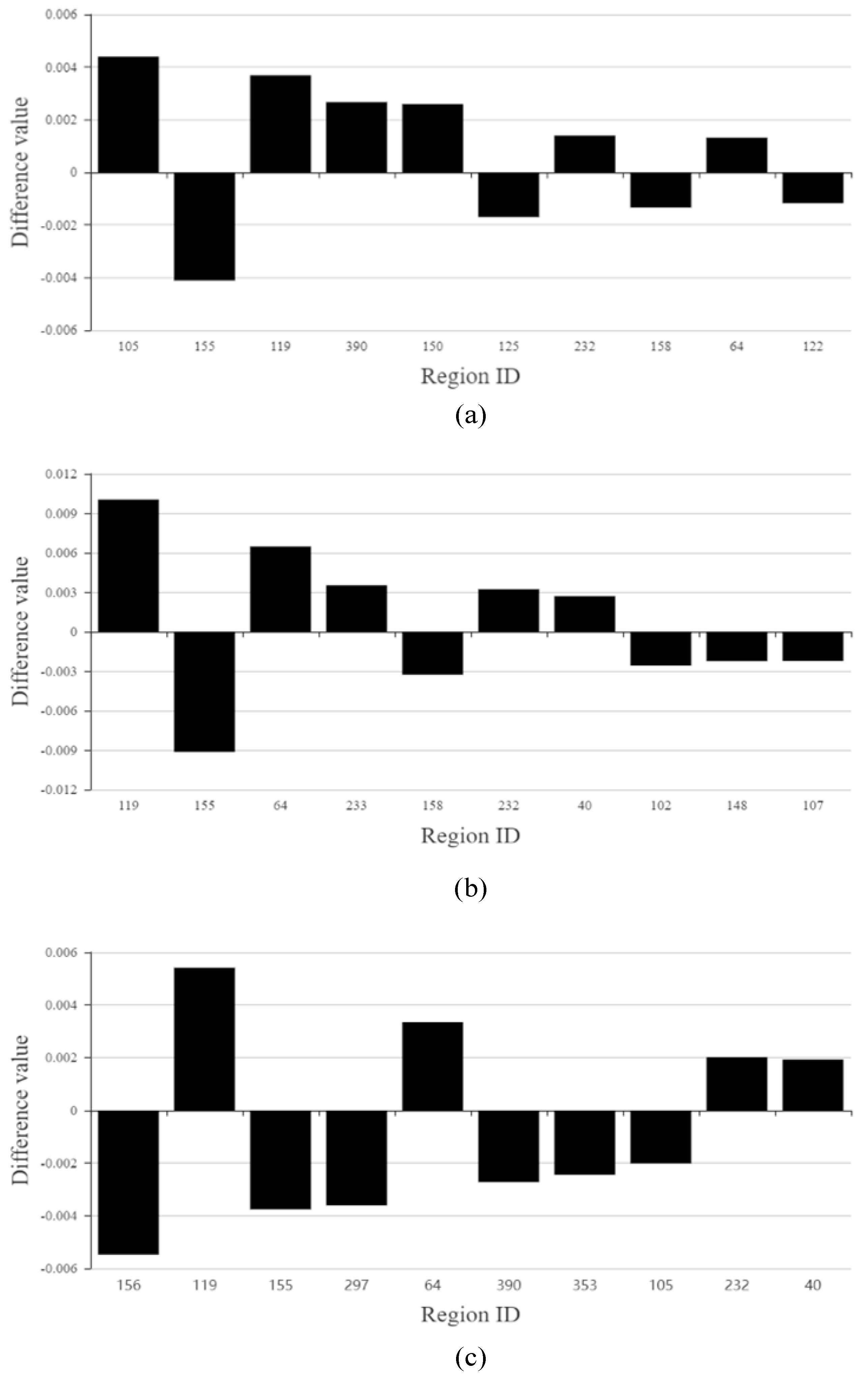
4.3.4. Anomalous Urban Mobility Pattern Based on a Grid
5. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Liu, Y.; Wang, F.; Xiao, Y.; Gao, S. Urban land uses and traffic “source-sink areas”: Evidence from GPS-enabled taxi data in Shanghai. Landsc. Urban Plan. 2012, 106, 73–87. [Google Scholar] [CrossRef]
- D’Andrea, E.; Marcelloni, F. Detection of traffic congestion and incidents from GPS trace analysis. Expert Syst. Appl. 2017, 73, 43–56. [Google Scholar] [CrossRef]
- Wang, Y.; Gu, Y.; Dou, M.; Qiao, M. Using Spatial Semantics and Interactions to Identify Urban Functional Regions. ISPRS Int. J. Geo-Inf. 2018, 7, 130. [Google Scholar] [CrossRef]
- Liu, X.; Ban, Y. Uncovering Spatio-Temporal Cluster Patterns Using Massive Floating Car Data. ISPRS Int. J. Geo-Inf. 2013, 2, 371–384. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Heppenstall, A.; Turner, A.; Comber, A. Who, Where, Why and When? Using Smart Card and Social Media Data to Understand Urban Mobility. ISPRS Int. J. Geo-Inf. 2019, 8, 271. [Google Scholar] [CrossRef]
- Wang, H.; Huang, H.; Ni, X. Revealing Spatial-Temporal Characteristics and Patterns of Urban Travel: A Large-Scale Analysis and Visualization Study with Taxi GPS Data. ISPRS Int. J. Geo-Inf. 2019, 8, 257. [Google Scholar] [CrossRef]
- Cui, G.; Luo, J.; Wang, X. Personalized travel route recommendation using collaborative filtering based on GPS trajectories. Int. J. Digit. Earth 2018, 11, 284–307. [Google Scholar] [CrossRef]
- Qu, B.; Yang, W.; Cui, G.; Wang, X. Profitable Taxi Travel Route Recommendation Based on Big Taxi Trajectory Data. IEEE Trans. Intell. Transp. Syst. 2019. [Google Scholar] [CrossRef]
- Yue, Y.; Zhuang, Y.; Yeh, A.G.O.; Xie, J.Y.; Ma, C.L.; Li, Q.Q. Measurements of POI-based mixed use and their relationships with neighbourhood vibrancy. Int. J. Geogr. Inf. Sci. 2017, 31, 658–675. [Google Scholar] [CrossRef]
- Wang, P.; Fu, Y.; Liu, G.; Hu, W.; Aggarwal, C. Human mobility synchronization and trip purpose detection with mixture of hawkes processes. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2017), Halifax, NS, Canada, 13–17 August 2017; pp. 495–503. [Google Scholar]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using human mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2012), Beijing, China, 12–16 August 2012; pp. 186–194. [Google Scholar]
- Yuan, N.J.; Zheng, Y.; Xie, X.; Wang, Y.; Zheng, K.; Xiong, H. Discovering Urban Functional Zones Using Latent Activity Trajectories. IEEE Trans. Knowl. Data Eng. 2018, 27, 712–725. [Google Scholar] [CrossRef]
- Qi, G.; Li, X.; Li, S.; Pan, G.; Wang, Z.; Zhang, D. Measuring social functions of city regions from large-scale taxi behaviors. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), Seattle, WA, USA, 21–25 March 2011; pp. 384–388. [Google Scholar]
- Shi, L.; Gangopadhyay, A.; Janeja, V.P. STenSr: Spatio-temporal tensor streams for anomaly detection and pattern discovery. Knowl. Inf. Syst. 2015, 43, 333–353. [Google Scholar] [CrossRef]
- Fanaee-T, H.; Gama, J. Event detection from traffic tensors: A hybrid model. Neurocomputing 2016, 203, 22–33. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Zhu, Q.; Guo, S.; Jin, Z.; Lin, Y.R.; Cao, N. Anomaly detection in spatiotemporal data via regularized non-negative tensor analysis. Data Min. Knowl. Discov. 2018, 32, 1056–1073. [Google Scholar] [CrossRef] [Green Version]
- Gao, S.; Janowicz, K.; Couclelis, H. Extracting urban functional regions from points of interest and human activities on location-based social networks. Trans. GIS 2017, 21, 446–467. [Google Scholar] [CrossRef]
- Cao, J.; Tu, W.; Li, Q.; Zhou, M.; Cao, R. Exploring the distribution and dynamics of functional regions using mobile phone data and social media data. In Proceedings of the 14th International Conference on Computers in Urban Planning and Urban Management, Boston, MA, USA, 10 July 2015. [Google Scholar]
- Kaltenbrunner, A.; Meza, R.; Grivolla, J.; Codina, J.; Banchs, R. Urban cycles and mobility patterns: Exploring and predicting trends in a bicycle-based public transport system. Pervasive Mob. Comput. 2010, 6, 455–466. [Google Scholar] [CrossRef]
- Peng, C.; Jin, X.; Wong, K.C.; Shi, M.; Liò, P. Collective human mobility pattern from taxi trips in urban area. PLoS ONE 2012, 7, e34487. [Google Scholar]
- Zhang, W.; Li, S.; Pan, G. Mining the semantics of origin-destination flows using taxi traces. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing-UbiComp ’12, Pittsburgh, PA, USA, 5–8 September 2012; p. 943. [Google Scholar]
- Kuang, W.; An, S.; Jiang, H. Detecting traffic anomalies in urban areas using taxi GPS data. Math. Probl. Eng. 2015. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. Kdd 1996, 96, 226–231. [Google Scholar]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef] [Green Version]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 5, 603–619. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. JMLR 2011, 12, 2825–2830. [Google Scholar]
- Baidu Map API. Available online: http://lbsyun.baidu.com/index.php?title=jspopular (accessed on 20 September 2017).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Name | Function Type | Category Type | Location |
|---|---|---|---|---|
| 1 | Fu Meng market | Shopping | Super market | 113.712° E, 30.405° N |
| 2 | Wuhan University | Education | University | 114.359° E, 30.540° N |
| 3 | ICBC | Financial services | Bank | 113.775° E, 30.238° N |
| 4 | Cheng Gong hospital | Medical services | Hospital | 113.717° E, 30.406° N |
| 5 | ICBC ATM | Financial services | ATM | 113.849° E, 30.264° N |
| .ε, MinPts | Number of Functional Regions | Number of POIs in Functional Region | ||
|---|---|---|---|---|
| Min. | Avg. | Max. | ||
| 42, 16 | 2118 | 16 | 56 | 1543 |
| 68, 32 | 880 | 32 | 136 | 3629 |
| 109, 64 | 434 | 64 | 281 | 5169 |
| 224, 128 | 141 | 128 | 1201 | 33,184 |
| Region ID | Top Three Leading Functions | Function Label | |||
|---|---|---|---|---|---|
| TF-IDF | WTF-IDF | ||||
| 56 | Entertainment | 0.23 | Transportation | 0.38 | Transportation Automobile service |
| Transportation | 0.21 | Automobile service | 0.18 | ||
| Shopping | 0.20 | Entertainment | 0.17 | ||
| 279 | Government | 0.19 | Cultural media | 0.26 | Cultural media Government |
| Cultural media | 0.15 | Public services | 0.17 | ||
| Public services | 0.15 | Government | 0.15 | ||
| 5 | Shopping | 0.38 | Entertainment | 0.28 | Entertainment Shopping |
| Restaurant | 0.21 | Shopping | 0.27 | ||
| Entertainment | 0.20 | Tourism | 0.19 | ||
| 192 | Public services | 0.21 | Medical services | 0.27 | Medical services Resident area |
| Medical services | 0.17 | Public services | 0.24 | ||
| Entertainment | 0.16 | Entertainment | 0.17 | ||
| 227 | Resident area | 0.28 | Public services | 0.23 | Resident area Entertainment |
| Entertainment | 0.19 | Resident area | 0.22 | ||
| Public services | 0.16 | Entertainment | 0.21 | ||
| Region ID | Number of POIs | Center | |
|---|---|---|---|
| Latitude | Longitude | ||
| 56 | 114 | 30.773° E | 114.205° N |
| 279 | 65 | 30.365° E | 114.329° N |
| 5 | 71 | 30.567° E | 114.053° N |
| 192 | 65 | 30.604° E | 114.287° N |
| 227 | 67 | 30.503° E | 114.323° N |
| Origin | Destination | ||||
|---|---|---|---|---|---|
| Region ID | Frequency | Leading Function | Region ID | Frequency | Leading Function |
| 155 | 90,023 | Entertainment | 155 | 86,778 | Entertainment |
| 156 | 48,965 | Public service | 156 | 57,343 | Public service |
| 383 | 32,052 | Entertainment | 292 | 32,537 | Education |
| 292 | 30,286 | Education | 383 | 32,287 | Entertainment |
| 105 | 26,932 | Entertainment | 105 | 25,213 | Entertainment |
| 94 | 19,875 | Public service | 233 | 21,720 | Public service |
| 233 | 19,161 | Public service | 148 | 20,793 | Public service |
| 148 | 18,689 | Public service | 102 | 18,267 | Entertainment |
| 102 | 18,208 | Entertainment | 94 | 17,853 | Public service |
| 316 | 16,151 | Entertainment | 348 | 15,916 | Entertainment |
| Anomalous Urban Mobility Patterns Based on Grid | Anomalous Urban Mobility Patterns Based on DBSCAN Clustering | ||
|---|---|---|---|
| October 2–October 6 | September 20, October 2–October 5 | ||
| October 1 | October 1 | ||
| September 18, September 30 | September 18, September 19, September 30 | ||
| October 7, October 8 | |||
| September 19 | |||
| September 20 | |||
| Anomalous Pattern | Region IDs | ||
|---|---|---|---|
| 10774 | 11796 | 11925 | |
| 10774 | 11796 | 11925 | |
| 10774 | 11796 | 11925 | |
| 10774 | 10629 | 8432 | |
| 11796 | 11925 | 10629 | |
| 11796 | 11147 | 10629 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Cui, G.; Zhong, M.; Wang, X. Anomalous Urban Mobility Pattern Detection Based on GPS Trajectories and POI Data. ISPRS Int. J. Geo-Inf. 2019, 8, 308. https://doi.org/10.3390/ijgi8070308
Xu Z, Cui G, Zhong M, Wang X. Anomalous Urban Mobility Pattern Detection Based on GPS Trajectories and POI Data. ISPRS International Journal of Geo-Information. 2019; 8(7):308. https://doi.org/10.3390/ijgi8070308
Chicago/Turabian StyleXu, Zhenzhou, Ge Cui, Ming Zhong, and Xin Wang. 2019. "Anomalous Urban Mobility Pattern Detection Based on GPS Trajectories and POI Data" ISPRS International Journal of Geo-Information 8, no. 7: 308. https://doi.org/10.3390/ijgi8070308
APA StyleXu, Z., Cui, G., Zhong, M., & Wang, X. (2019). Anomalous Urban Mobility Pattern Detection Based on GPS Trajectories and POI Data. ISPRS International Journal of Geo-Information, 8(7), 308. https://doi.org/10.3390/ijgi8070308