1. Introduction
Uncertainty is inevitable in various geoscience-related domains, such as meteorology and computational fluid dynamics. Taking advantage of the ever-increasing computational power available, it has become common to generate ensemble data which contain a collection of outputs generated from computer simulation models [
1]. This makes it possible to intuitively analyze the uncertainty in simulations.
Vector field data, such as wind flow or ocean current data, are commonly collected or simulated in geographic space. The uncertainty in a time-varying ensemble vector field is difficult to quantify, due to the complex data structures involved—typically featuring multiple dimensions, multiple time steps, and multiple ensemble members. Understanding the uncertainty in a spatial vector field is very significant for domain experts to be able to draw reliable conclusions and make informed decisions. Visualization and visual analysis play an important role in characterizing and understanding such uncertainty [
2,
3] by transforming data and information into interactive visual representations [
4]. Using multi-view linkage techniques and interactions, domain experts can analyze uncertain behaviors and comprehensively explore the internal patterns of physical phenomena [
5,
6].
In an ensemble vector field, an ensemble pathline is a set of pathlines traced from the same spatiotemporal location in different ensemble members. Each of these pathlines—namely, each is a pathline member—means a possible motion behavior from this location. Domain experts are highly interested in the regions where the shapes of the pathline members are either similar or have large variation, which means that the motion behavior is predictable or unstable, respectively. For example, scientists need to understand the uncertainty when predicting the transport trend of a hurricane. The key to revealing this uncertainty is accurately measuring the similarity among an ensemble pathline.
The similarity measurements of ensemble pathlines can be divided into two categories: One is to compute the deformation of the Lagrangian neighborhood, by the use of such methods as principal component analysis (PCA) [
7] and finite-time Lyapunov exponent (FTLE) [
8]. The variance of the ensemble vector field is measured by analyzing the divergence of neighborhood particles after a finite time. As only the start and end locations of the pathline members are recorded during the time range, domain scientists have to trace the particles repeatedly when exploring the variances at different time scales.
The second kind of method is calculating the distance between each pair of pathline members and averaging them as the final uncertainty value. The accuracies of these methods mainly depend on the selection or definition of a distance metric. Euclidean distance [
9], dynamic time warping (DTW), and longest common subsequences (LCSS) [
10] have been applied to measure the uncertainty in ensemble vector fields. Euclidean distance [
9] is simple and efficient, computing the pointwise distance along with two pathline members directly; however, it requires the pathline members to be of equal length, which is not the general case in a vector field. As a more elastic method, dynamic time warping (DTW) [
11,
12] can match the similar shapes of two trajectories with different lengths effectively. However, DTW and Euclidean distance are both sensitive to the outliers that inevitably exist in simulations, due to the occasional failures in data generation and collection. In order to remedy this problem, longest common subsequences (LCSS) [
10] was introduced, which is the current state-of-the-art method. Its main idea is quantifying the similarity of two points on different pathline members (by 0 and 1) based on a distance threshold, following which the longest common distance between two pathline members can be computed. Thus, the influences caused by outliers can be largely decreased. Nevertheless, LCSS is not accurate enough, because it neglects the variations in the number of unmatched locations [
13] and depend on the setting of a threshold.
Due to the above shortcomings, a comprehensive measurement method which is accurate, robust to outliers, and capable of comparing pathlines with different lengths is needed. Edit distance with real penalty (ERP) [
14] and edit distance on real sequence (EDR) [
13] are two advanced measurement methods which have been commonly used for comparing mobile object trajectories. However, ERP is also sensitive to outliers. Similarly to LCSS, EDR examines the similarity of two points (by 0 and 1) based on a distance threshold. Thus, it is robust to outliers and can handle sequences with different lengths. Moreover, it can remedy the accuracy drawback of LCSS, as it computes the edit distance rather than only recording the matched positions. Based on the advantages of EDR, we propose an improved metric called AEDR (adaptive EDR) to measure the similarity among pathline members, through further computing the distance adaptively when two points are matched. AEDR can not only solve the above problems of traditional measurement methods but improve the accuracy and reduce the dependence on the threshold, in contrast to the the neighborhood-reliant measurements, such as LCSS and classical EDR. In this paper, we quantify the local uncertainty (LU) of each grid using AEDR. Moreover, we also compute the spatial neighborhood uncertainty (NU) [
15], as the neighborhood correlation structure is an essential property of the vector field. On this basis, the uncertainty correlation (CU) between a location and its neighborhood can be further evaluated using the local Moran’s I [
16].
Furthermore, using the proposed uncertainty measurements, we developed an interactive visual analysis system called UP-Vis (uncertainty pathline visualization) based on the design principle of overview-plus-detail [
17]. Globally, our system provides an overall uncertainty rendering view, presenting the specific uncertainty result of all locations and a classification view which guides the conjoint analysis of all kinds of uncertainty. When users select a location of interest from the global view, the detailed transport pattern of the ensemble pathline can be explored in the pathline view and projection view. In order to reduce visual clutter in the visualization of an ensemble pathline, we designed a glyph (called shuttlecock) to reveal the major transport trends and the corresponding divergence degrees distinctly. As for the analysis of neighborhood uncertainty, the comparison view demonstrates the difference between a location and its neighborhood.
Overall, in this paper, we propose a comprehensive framework for quantifying and analyzing the uncertainty of time-varying ensemble vector fields. Our main contributions in this work are:
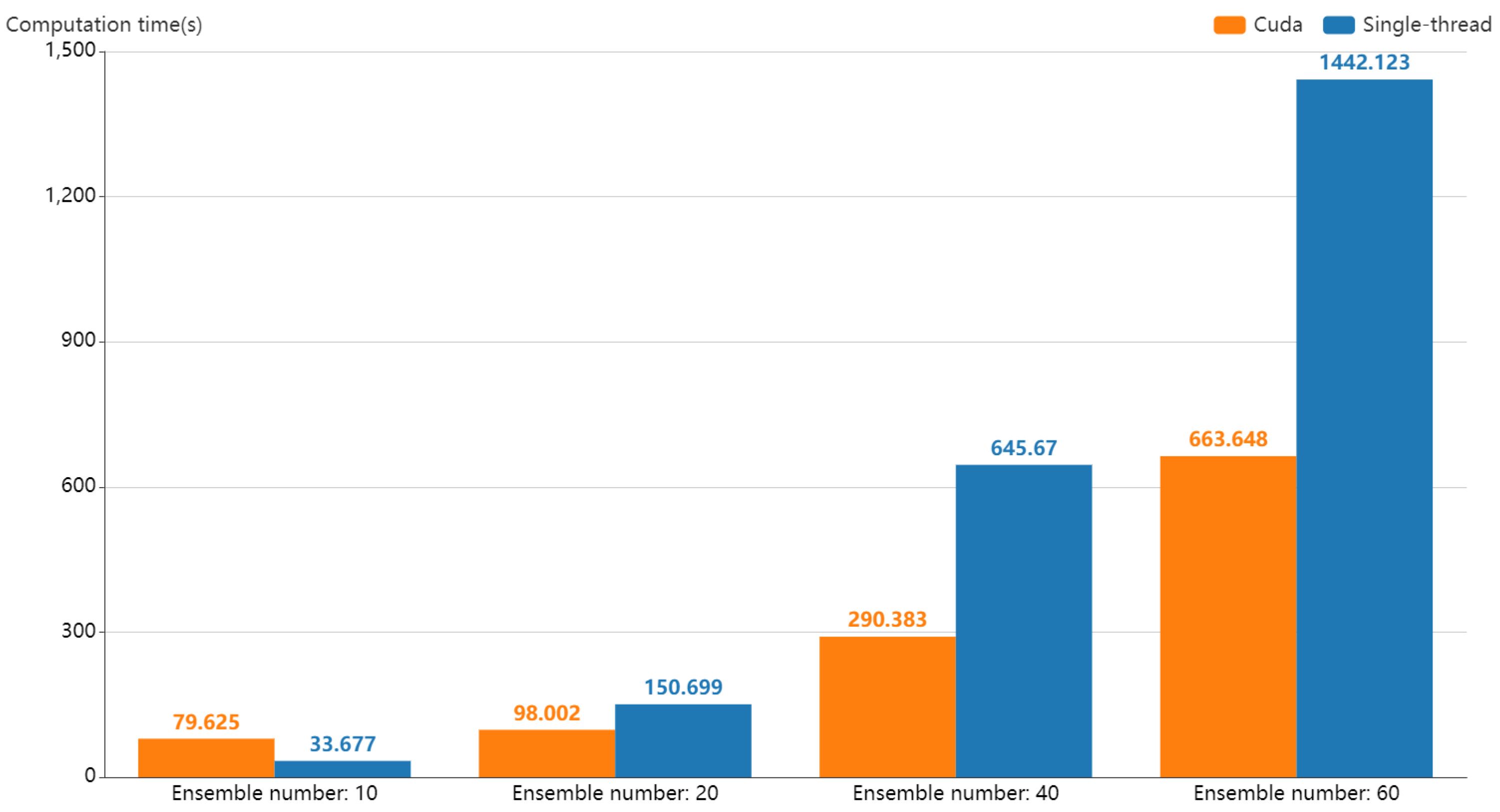
A robust and effective method for measuring the uncertainty in an ensemble vector field. We propose an improved uncertainty measurement method, AEDR, based on EDR. It was verified to be robust to outliers and more effective than the traditional measurement methods and other alternative measurement methods, including classical EDR, LCSS, ERP, DTW, and Euclidean distance. Based on AEDR, we computed the local uncertainty and neighborhood uncertainty, and the correlation between them, to satisfy the requirements of uncertainty analysis.
A comprehensive visual analysis system for exploring the uncertainty in a time-varying ensemble vector field. We designed and developed multiple co-ordinated views and an intuitive glyph based on the principle of overview-plus-detail. Using the visual analysis system, users can discover the locations of interest, inspect the transport patterns in detail, and compare the difference between a location and its neighborhood.
3. Overview
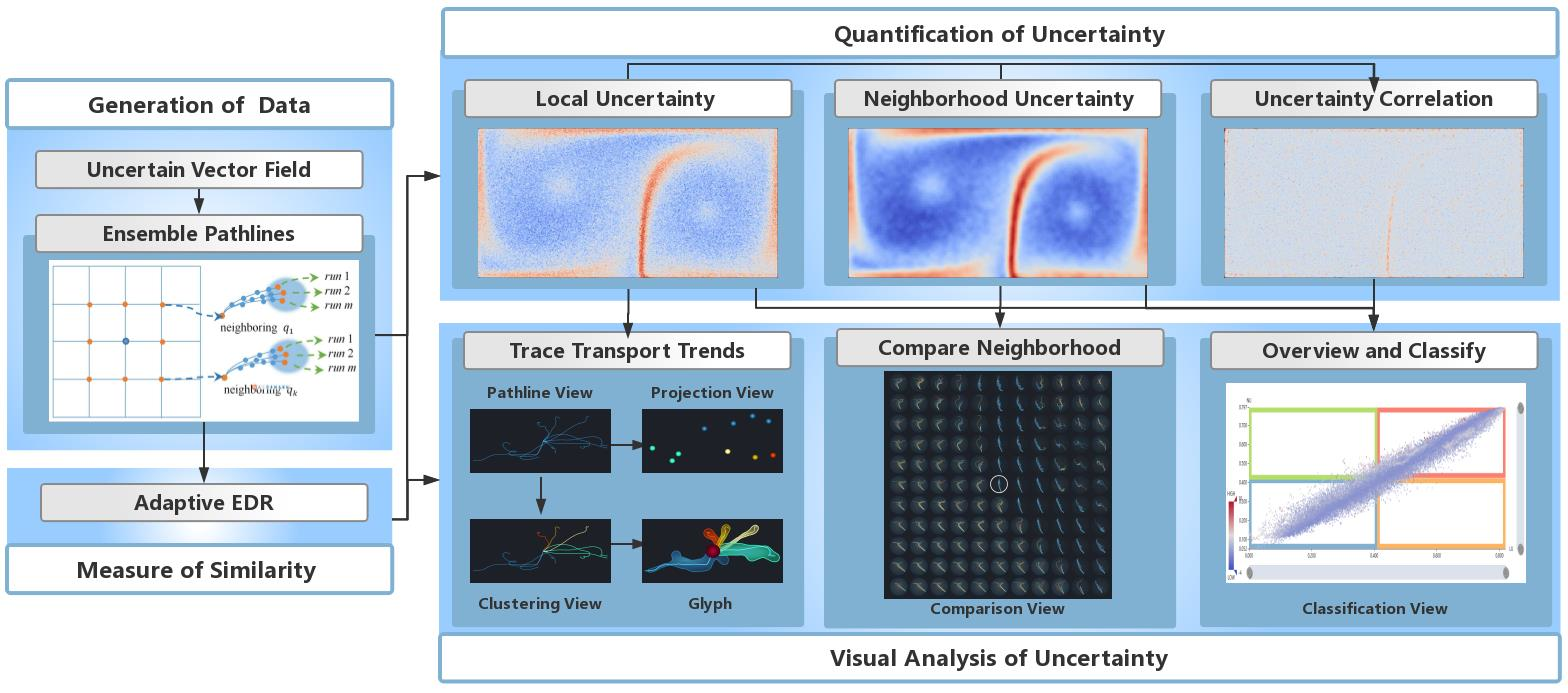
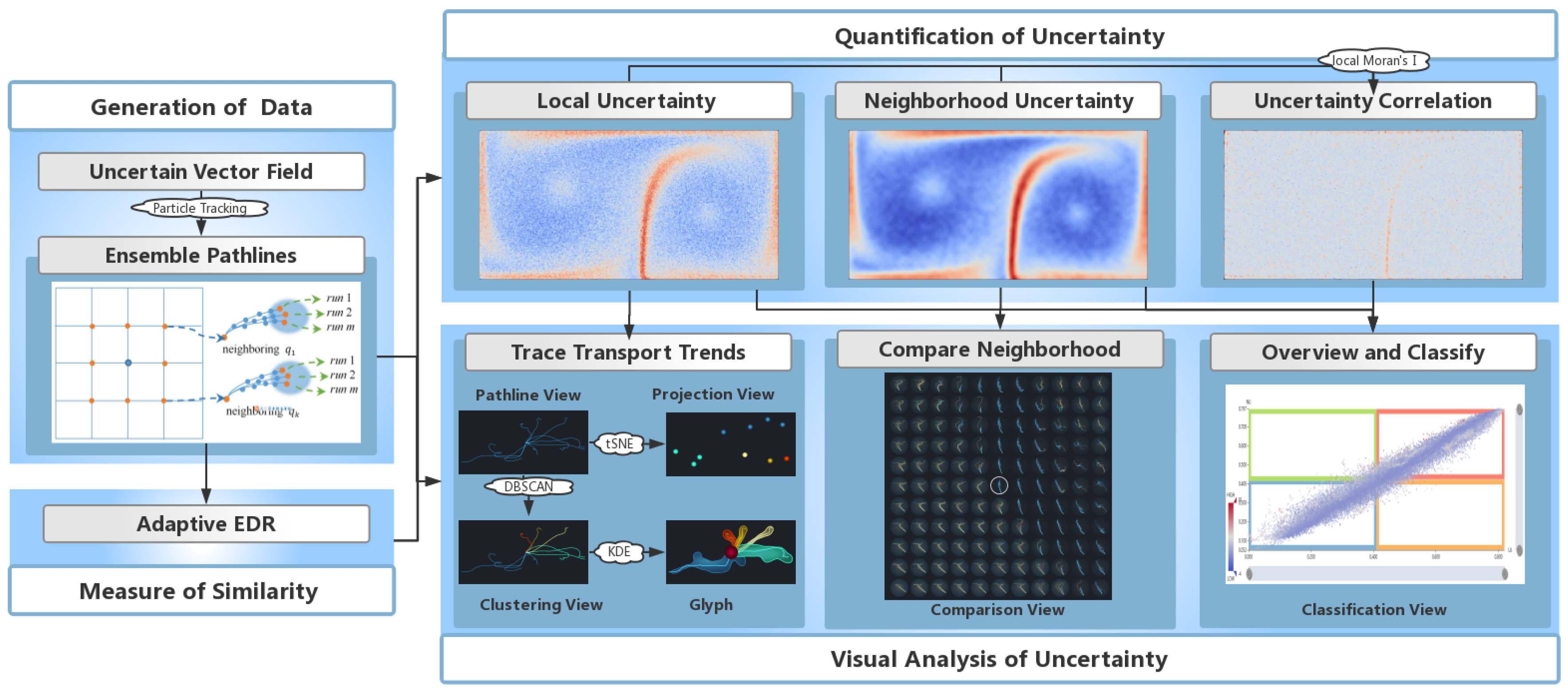
Our overall framework consists of four parts: generation of data, the measure of similarity, quantification of uncertainty, and visual analysis of uncertainty, as demonstrated in the workflow of this paper (
Figure 1). The data used in the experiements consist of a synthesized data set and a real-world weather data set. For the initial ensemble vector data, the ensemble pathline of each grid point is traced by numerical integration (Runge–Kutta method). An improved metric, AEDR, is proposed to measure the similarity between two pathline members. It is more effective and robust to outliers than traditional methods. According to the divergence degree of the corresponding ensemble pathlines, AEDR is utilized to quantify the local uncertainty (LU) and neighborhood uncertainty (NU) of each grid point. On this basis, the uncertainty correlation (CU) between the location and its neighborhood is computed, to gain more significant results.
Further, in order to assist in understanding the uncertainty, we developed a system using visual analysis techniques. Multiple linked views were designed and integrated to demonstrate the overview of the uncertainty conditions, the transport patterns of ensemble pathlines, and detailed information of the neighborhood. Based on the conjoint analysis of all types of uncertainty, the classification view gives a classification for all locations and reveals their different characteristics. Furthermore, to assist the understanding of the LU at a selected location in detail, we provide a pathline view which displays each pathline member, while the projection view shows the relationships among them. However, intricately crossed pathlines may prevent the observer from discovering transport trends. In order to solve this problem, we apply the DBSCAN clustering method based on AEDR to the pathline members and assign them to several significant trends. Then, through an intuitive glyph design, the transport trend and the divergence degree of each cluster can be present without clutter. Additionally, based on the small multiples technique, the difference between a location and its neighborhood are demonstrated in the comparison view, which facilitates the user’s understanding of the NU and CU.
4. Uncertainty Computation for Ensemble Vector Field
In this section, we introduce and evaluate the improved metric, AEDR, for computing the difference between pathlines and demonstrate the computation of LU, NU, and CU.
Given an ensemble time-varying vector field, let P denote an ensemble pathline traced from a grid point q along a period of time. It consists of m pathline members and can be written as . Each pathline member is a sequence with consecutive points. Here, is the number of the sample time steps in the pathline member and is a d-dimensional vector (where d is usually 2 or 3).
4.1. Adaptive EDR and Local Uncertainty
Edit distance (ED) [
40], which has been widely used in speech recognition, aims to measure the similarity between two strings. For two strings
A and
B,
represents the minimum number of edit operations needed to convert
A into
B, where the edit operations include inserting, deleting, and replacing. Generally, the smaller the edit distance between two strings, the more similar they are. To apply this idea to the comparison of trajectories, edit distance on real sequence (EDR) [
13] has been proposed based on ED, which can handle sequences of real values. It has been verified to be robust to outliers and more accurate than LCSS when measuring the similarity between moving object trajectories. Thus, it was determined to be a good fit for the comparison of pathlines.
For two pathline members
and
with
and
points, respectively, a distance threshold
must be set to determine whether the two points on different pathline members can be matched. Then, according to the definition in [
13], the EDR distance
between
and
can be computed by
where
and
are obtained by deleting the last point from
and
, respectively, and
can be 0 or 1. If
,
, meaning that the last point on
is matched with the last point on
; otherwise,
. However, the matching degree between the two points is ignored when they are matched by EDR, which can result in inaccurate results. Furthermore, the value of the distance threshold
will affect the result greatly, and thus, is hard to set appropriately. To illustrate the shortcomings, we take the example of two one-dimensional trajectories:
and
. If we let
, the result computed by EDR will be 0. However, the obvious differences between the trajectories should not be neglected. If
, the result will be 4. This means that a small change of the threshold may cause a large variation in the result. Thus, the traditional EDR method is not effective or accurate enough for measuring the difference between pathlines. In order to solve these problems, we compute the value of
adaptively (as shown below) when
, where the improved measurement is called adaptive EDR (AEDR).
Therefore, can be a real number in the range [0,1]. In this way, the distance between two matched points can be measured as a small value (less than 1) and the distance between two unmatched points is measured as 1. This means AER is still robust to outliers, but the dependence on the threshold is reduced.
Then, the similarity between two pathline members
and
can be calculated by
Based on the similarity between any two pathline members of a grid point
q, the uncertainty of
q can be computed by
where
m is the number of pathline members in an ensemble pathline.
4.2. Evaluation
4.2.1. Ability to Reveal Features
As the uncertainty in ensemble data does not have ground truth, different measurement methods evaluate the uncertainty according to their characteristics. According to different analysis tasks, there are many perspectives to evaluate the accuracy of uncertainty measurement.
In this paper, inspired by the work of Liu et al. [
22], we evaluate the effectiveness of AEDR through comparing its ability to reveal uncertainty features with classical EDR, DTW, ERP, and LCSS. If the measurement can present the inherent uncertainty features more clearly, it can be regarded as more effective. We used the Double-Gyre (DG) synthetic data set [
41] to carry out the evaluation experiments, which is a commonly-used synthetic data set of a 2D vector field. It is defined on the domain
, as:
where
x and
y represent the co-ordinates of the positions in the domain,
t represents the time steps, and the vector
v consists of two velocity components. The synthetic DG data set describes a time-dependent field, where the gyres expand and contract periodically in the horizontal direction. From Equations (7) and (8), it can be found that the period for
t is 10. In our experiment, we generated original data on a 401 × 201 Cartesian grid from
to
. Then, ensemble data with 20 members were formed by adding Gaussian noise
to the original synthetic data.
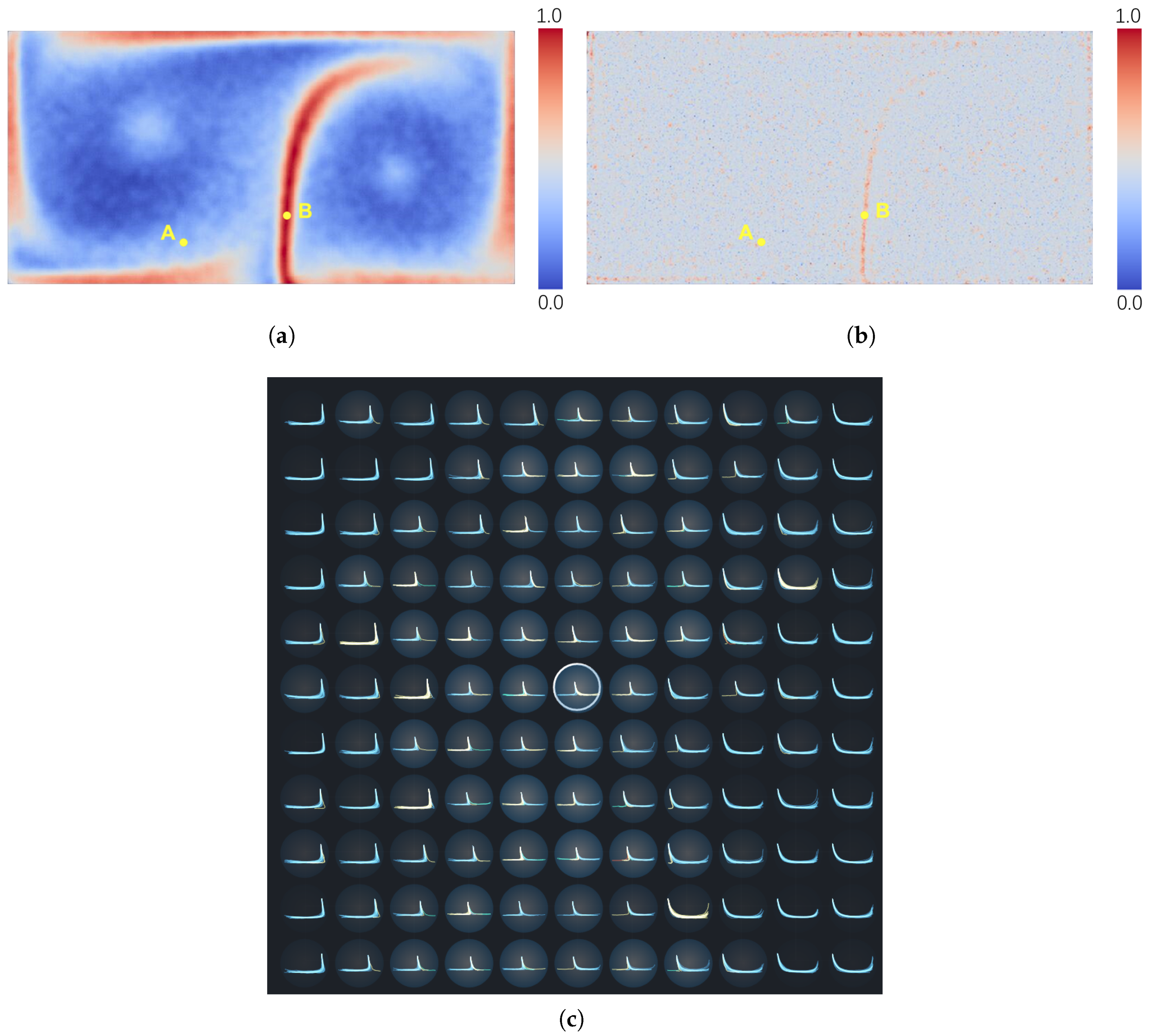
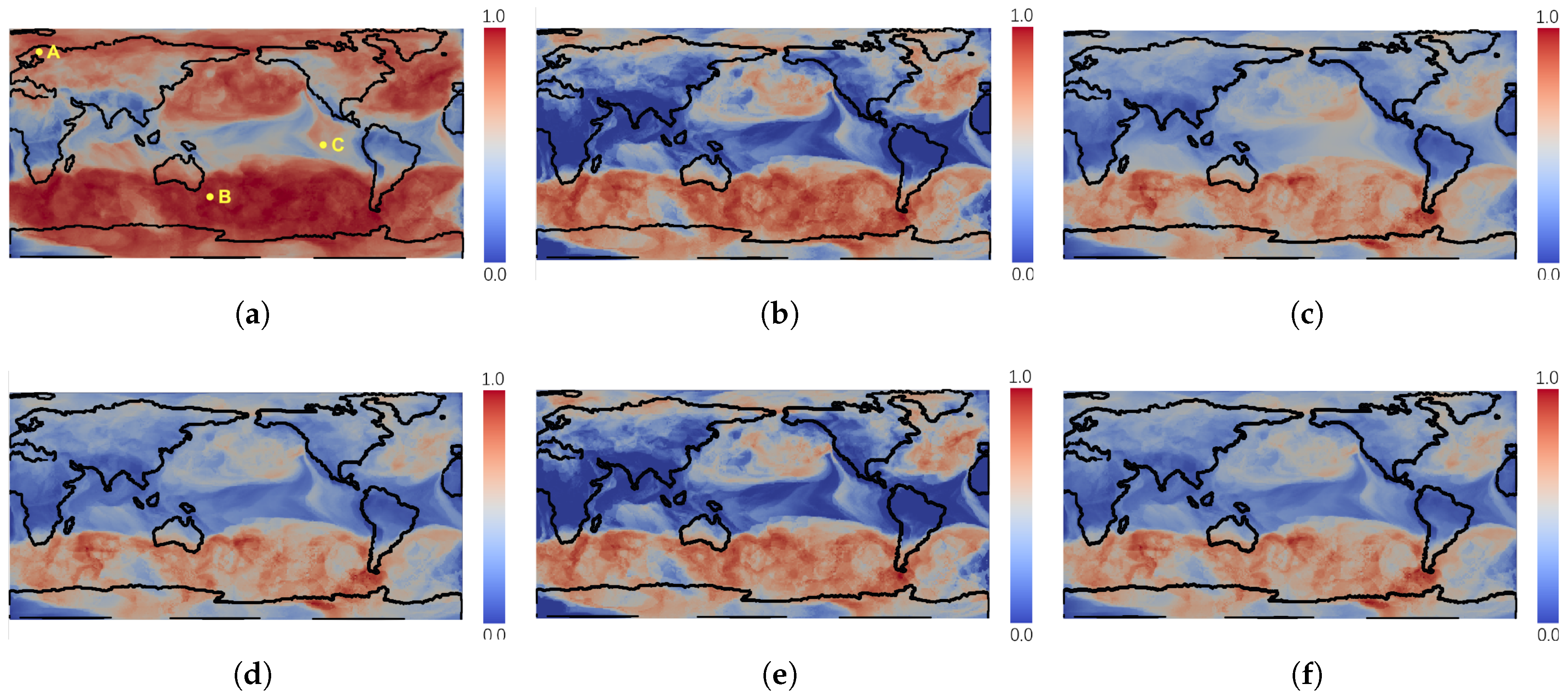
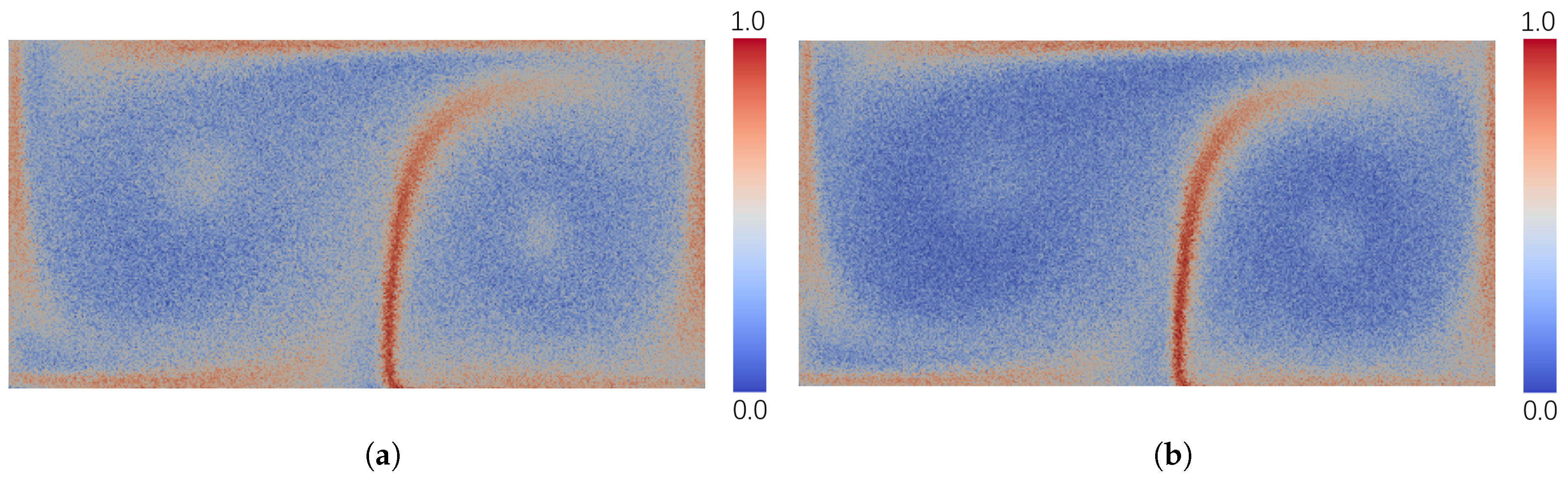
We computed the uncertainty for each grid point of the DG ensemble data using the above measurement methods.
Figure 2 displays the rendering of the computed results. To facilitate comparison, each result was normalized into the range of [0,1]. It can be observed that all rendering results revealed a distinct pattern with high uncertainty, which can be seen as the separatrix of the two gyres. This region is composed of the heteroclinic trajectories (Figure 6) which can turn in the converse direction under the effect of very little noise. Furthemore, high velocities exist at the boundaries of the gyres, causing the advected particles to diverge quickly there. Therefore, the boundaries of the gyres have relatively high uncertainty, which was presented by most of the test measurements. For the results of AEDR, classical EDR, LCSS, and Euclidean distance, this pattern can be recognized clearly, while the boundary pattern is not clear in the results of DTW and ERP.
Lower velocities and higher vorticity existed in the regions around the centers of the gyres, as compared to the outer regions. This means that the absolute variances between the pathline members traced around the center were low, compared with the outer regions. On the other hand, the pathlines traced from these regions around the gyre centers were very chaotic, from a local perspective, due to the high vorticity. This should also be regarded as high uncertainty, as the variances between the pathline members were high enough, compared with themselves. Distinctively, in the result of AEDR, the regions around the centers of gyres also presented relatively high uncertainty. However, the other measurement methods failed to capture this feature. For Euclidean distance, DTW, and ERP, this feature was ignored (
Figure 2c,d,f), because the computed uncertainty at the gyre center was too low to be rendered distinctly. As for LCSS and classical EDR, they did not consider the differences between the matched points; thus, the feature was not clear (
Figure 2b,e). AEDR could solve this problem and reveal the feature clearly (
Figure 2a), as it also computed the difference between two matched points.
4.2.2. Sensitivity to Outliers
Similar to the work of Liu et al. [
22], we evaluated the sensitivity to outliers of AEDR and the other existing approaches by performing two groups of experiments on the original DG synthetic data set. Firstly, we added Gaussian noise
to the original data to obtain a new data set
(note that
is not ensemble data).
Through computing the differences between the pathlines in DG and those in
at the same locations, the difference
for each grid point could be obtained. Then, on the basis of
, we made 1% of all the grid points outliers by adding much stronger noise or by setting the velocity component to 0. We called this data set
. Then, the differences between the pathlines in DG and
for each grid point were also computed as
. Thus, the change rate of the two different values
and
for each grid point
q was used to reveal the influence of outliers, which was computed by
A higher value of
indicates that outliers had more influence at the grid point
q. To present the sensitivity to outliers among all the grid points, we counted the numbers of grid points with change rates of more than 1%, 5%, 10%, and 15%, respectively. We compared the ability of five measurement methods (DTW, LCSS, ERP, EDR, and AEDR) to handle outliers, and the results are shown in
Table 1. It can be observed that DTW and ERP were more sensitive to outliers: under the influence of outliers, more than 16% of all points had pathline distance change rates over 1%, and more than 2% of points had change rates over 15%. The results are not surprising, as both DTW and ERP are based on Euclidean distance, which is sensitive to outliers. At the same time, the difference caused by outliers will be accumulated along with the transport process. It is not hard to see that LCSS and classical EDR were much more robust to outliers than ERP and DTW, with a lower number of points changing significantly. As for the proposed AEDR, it showed a much better ability to handle outliers. This was a result beyond our expectation, since we thought that the distance computation of the matched points would potentially be influenced by outliers. However, when the outliers cause two unmatched points to be close enough, AEDR will measure the matching degree rather than directly ignoring the distance, as is the case in LCSS and classical EDR. Thus, for this case, the result of AEDR was closer to the real condition without outliers. This can make AEDR even less sensitive to outliers than LCSS and classical EDR. This case was a general case in our evaluation experiments.
4.3. Neighborhood Uncertainty and Correlation
The neighborhood correlation structure is an essential property of a vector field. Analyzing the uncertainty of a single location together with its neighborhood can facilitate the exploration of significant features or anomalies. In view of this, we computed the uncertainty between pathline members in the neighborhood of a grid point and used it as an important indicator for the uncertainty judgment.
For a grid point
q, we sample a set of neighbor points
around
q uniformly at the initial time, as illustrated in
Figure 3b, and track the trajectories for all ensemble members in the time-series. For the neighborhood of
q, the uncertainty can be computed by
where the weight
is computed as:
where
is the distance between grid points
q and
. It is a more fuzzy result, which indicates the general condition of transport uncertainty.
Generally, the uncertainty values of nearby spatial grid points are similar. However, there usually exist anomalies in which the location and its neighborhood are dissimilar. For detecting the potential anomalies, we introduce the local Moran’s I [
16] to identify the local spatial autocorrelation, as
where
is the mean of LU over all grids. Then, we normalize
by the Z-Score [
42]. Thus, positive
indicates local positive spatial autocorrelation, which means that nearby grids have similar uncertainty values. On the contrary, negative
indicates local negative spatial autocorrelation, which means that nearby grids have dissimilar uncertainty values.
4.4. Classification Space
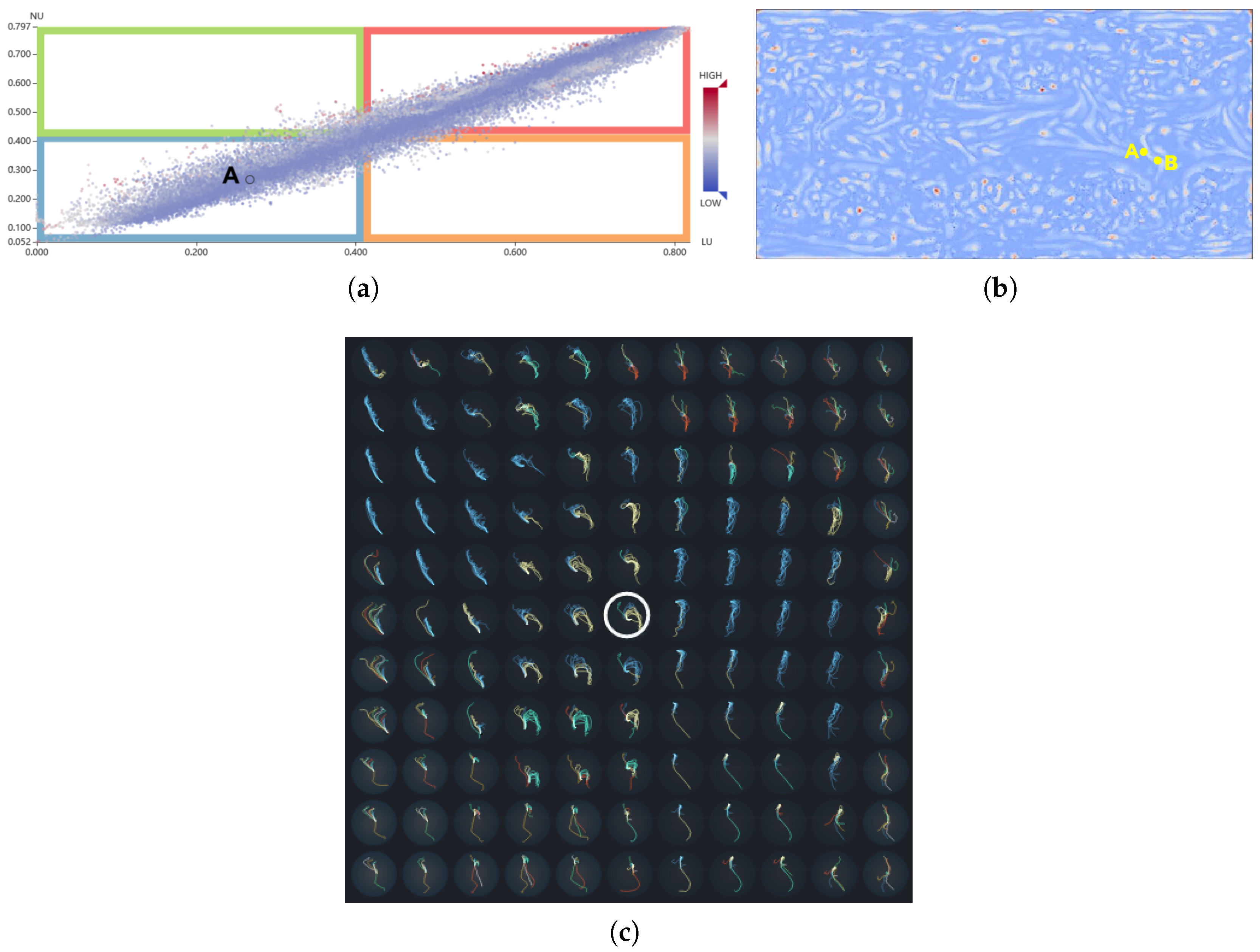
In order to comprehensively analyze the variances of a grid point, we construct a classification space where the horizontal axis represents the value of LU and the vertical axis denotes the NU value. Each grid point
q can be mapped to a 2D co-ordinate
in this space. Therefore, the variance information of all the grid points in the vector field can be visualized in a scatter plot, which helps users to clearly identify the general variances of the uncertain vector field. As exemplified in
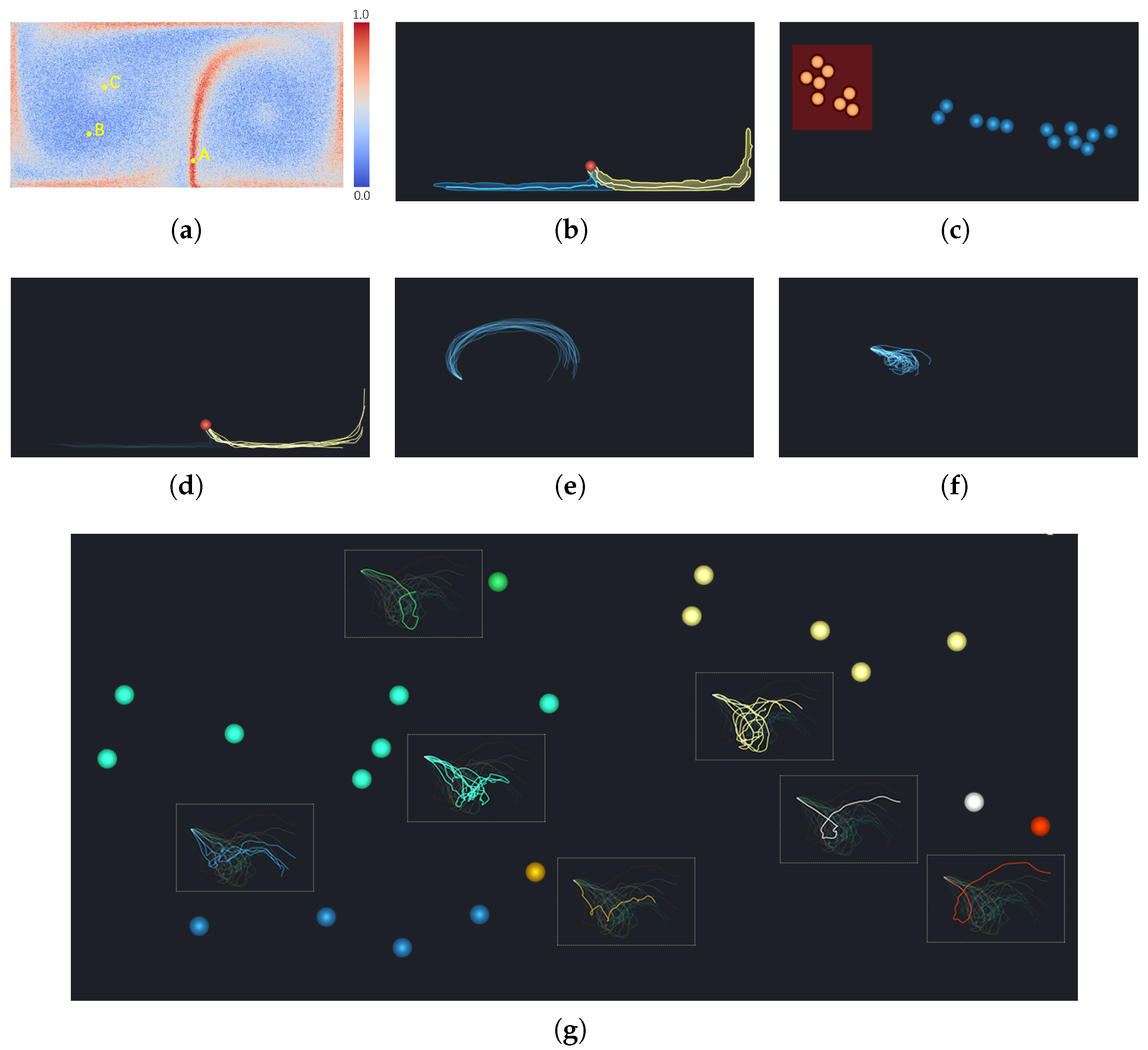
Figure 4a, the whole area is divided into four parts (a–d), as follows:
a. Low LU and low NU (blue region): The grid points mapped into this region have stable transport for different ensemble runs and the trajectories of their neighbor points are very similar. From this region, the predictable transport behaviors in an uncertain vector field can be found.
b. Low LU and high NU (green region): The transport behaviors of the grid points mapped into this region are very similar, while the trajectories of their neighboring points are dissimilar. This may be because the velocity field around these grid points is unstable, leading to the trajectories of the neighboring particles to differ.
c. High LU and low NU (orange region): It is difficult to draw a reliable conclusion as to whether the transport behaviors of the grid points mapped in this region are stable. All the trajectories of their neighboring points are very similar, but the variances of the grid points are dissimilar. The reason for this phenomenon may be that the grid points are outliers in a certain ensemble member, or that the velocity field around the grid points is stable.
d. High LU and high NU (red region): This region shows great uncertainty. It means that the variance is conspicuous, either considering the variation of themselves or their neighbors. Therefore, it can be concluded that the grid points mapped into this region have great uncertainty.
Figure 4 illustrates these four regions using the DG data set (as detailed in
Section 6.1). From the classification view (
Figure 4a), it is obvious that a majority of the grid points are located in the blue region, which presents low LU and low NU values. Other than the points in the blue region, a small number of points can be found in the green and orange regions. The reason for this can be seen in
Figure 4b, where the neighborhood particles of the points in green regions are sampled in blue and red regions, and the LU values of these regions are opposite. From
Figure 4b, we can observe that the red points are surrounded by green points, such that the points in the green region can be viewed as a transition from the unstable state to the stable state.
To further analyze the classified subspaces, we encode the point colors by the corresponding CU values. In general, when the LU and NU of a grid point have similar values, it is normal for its CU value to be high. This means that the points of the blue and red regions have darker red colors. On the contrary, when LU and NU are dissimilar, the corresponding CU is small. This means the points of the green and orange regions have darker blue colors. However, as the neighborhood can have complex conditions, some points and their neighborhoods may present non-obvious correlations or even negative correlations in the blue and red regions. For example, as marked in
Figure 4a, the point
A has a low LU and a low NU value but a low CU value. This can be explained by observing that most of the points in the neighborhood of
A have high LU values, but several neighboring points have extremely low LU values. Thus, the NU and CU of point
A are both relatively low values. In this way, some hidden anomalies can be further diagnosed.
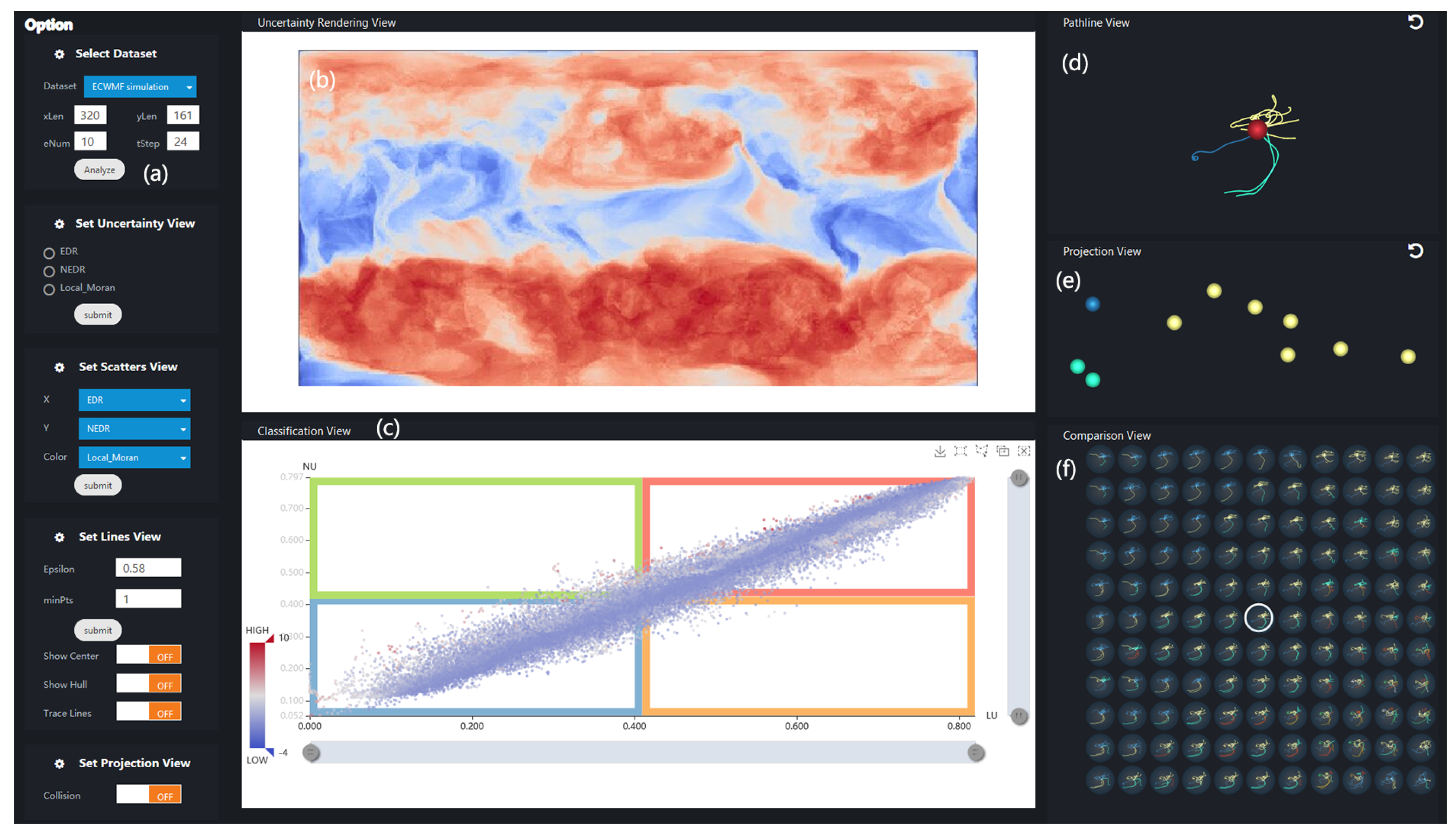
5. Visual Analysis of Uncertainty
In this section, we give insight into how all the pathline members of a grid point are transported in the time-series. We propose an interactive visual analysis system called UP-Vis (uncertainty pathline visualization), whose interfaces are shown in
Figure 5. It consists of four views: uncertainty rendering view, classification view, pathline view, and projection view. There is also a parameter panel which supports the management of data loading, parameter settings, and visualization element switching.
5.1. Extraction of Transport Pattern
Pathlines usually have different lengths, as some particles may escape from the valid boundary in the early time steps. To analyze their differences in movement, Ferstl et al. and Jarema et al. set all the pathlines to have the same length by repeating the last point of the pathline in the domain to fill the missing positions [
28,
43]. However, this method may increase the errors, due to the additional points. Using our method, the similarity between any two pathline members can be obtained even when they have different lengths. Moreover, the pathline members are clustered to recognize the major transport trends directly and are projected into 2D space to provide insight into the pathlines belonging to the same cluster.
We apply the tSNE algorithm to convert each pathline member into a scatter point in 2-dimensional space. One advantage of tSNE is that its input only requires a distance matrix between the members, which can be effectively combined with AEDR measurement. From the projection view, the relationship between pathlines can be inspected by using the distance between the scatter points. In addition, visual clutter is a common issue in scatter plots. Overlapping points can prevent users from observing the aggregated features shown in the view. A common approach is to add a new visual channel, which adds transparency to each scatter point. However, the superposition of transparency hides the number of scatter points. In this paper, we introduce a collision detection strategy which can separate the overlapping points and preserve the original layout as much as possible. Therefore, the projection view enables a visual representation that intuitively reveals the relationships between pathline members.
In order to extract the different trends of an ensemble pathline, the DBSCAN algorithm [
44] is utilized to cluster the pathline members in each ensemble pathline. DBSCAN is a density-based algorithm, which can mine arbitrary shape clusters without specifying the number of clusters in advance. Moreover, it has a strong ability to resist noise interference and can be utilized for detecting outlier pathlines. It also requires less computation, according to [
44]. DBSCAN has been widely used in the visual analysis field to extract patterns and detect abnormalities, such as movement data [
45] and streamlines [
46].
The clustering results can be changed by adjusting the parameters
and
. A large
value may lead to all pathlines being grouped into one cluster. Meanwhile, if
is too large, many pathlines will be treated as noise. Taking an ensemble pathline in weather simulation data (as described in
Section 6.2) as an example, the green pathlines shown in
Figure 6a are the original pathline members that are not clustered. When different parameters are used, the corresponding clustering results can be obtained. As shown in
Figure 6b, the pathline members were clustered into two clusters (colored by blue and yellow) when
is set as 0.8 and
is set to 1. As shown in
Figure 6c, after reducing
from 0.8 to 0.75, the pathline members were clustered into three clusters, where the pathline members marked by yellow in
Figure 6b were further divided into two clusters. Furthermore, when we increased
, from 1 to 2, the outlier pathlines were separated, as shown in
Figure 6d.
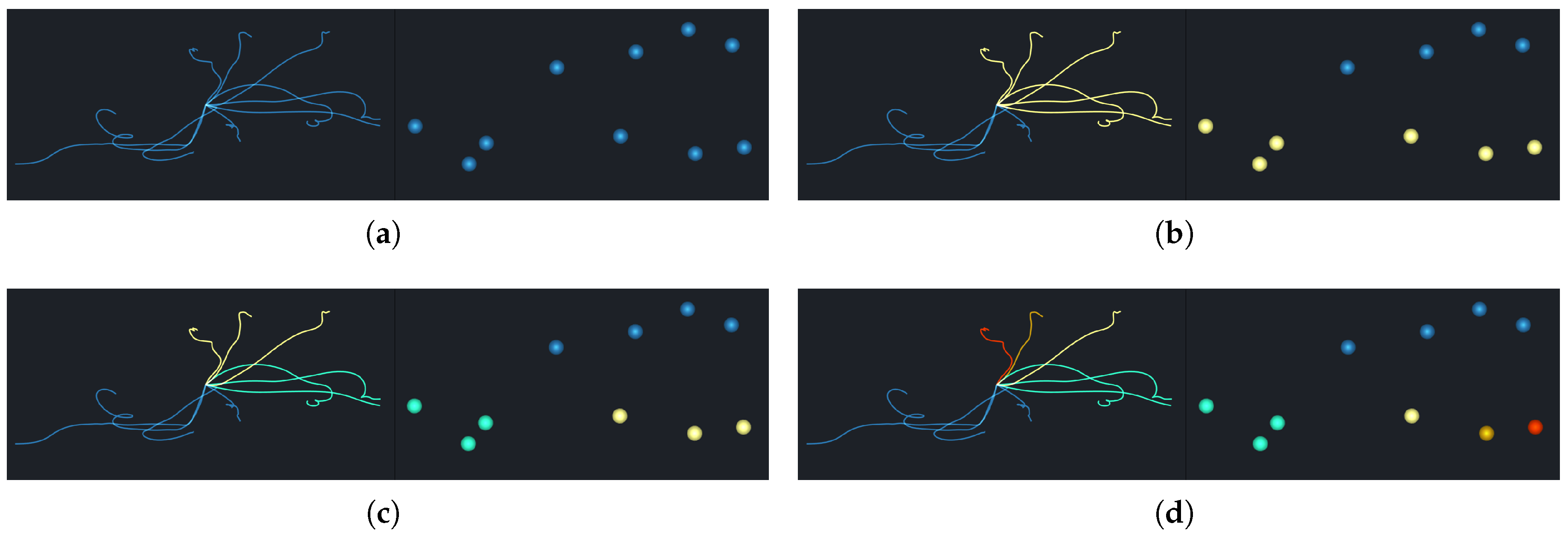
In order to globally compare the uncertainties of different grids, we set the same and for all grid points. In this way, the variance degree of pathlines could be distinguished by observing the number of clusters that were assigned. This means that the more clusters that pathlines were divided into, the greater the uncertainty of the initial grid was. Compared with other clustering algorithms, which require specification of the number of clusters, DBSCAN is more friendly and intuitive, as it does not need to compare the divergence of every cluster of different grids in order to explore the uncertainty. In addition, clustering and dimensionality reduction algorithms are uniformly integrated into our visualization system, which demonstrates the relationships between pathlines in global and local levels. Moreover, the easy-to-use brush operation can help users to explore the transport patterns and the details of pathline members.
5.2. Shuttlecock Visualization
From the pathline view described in
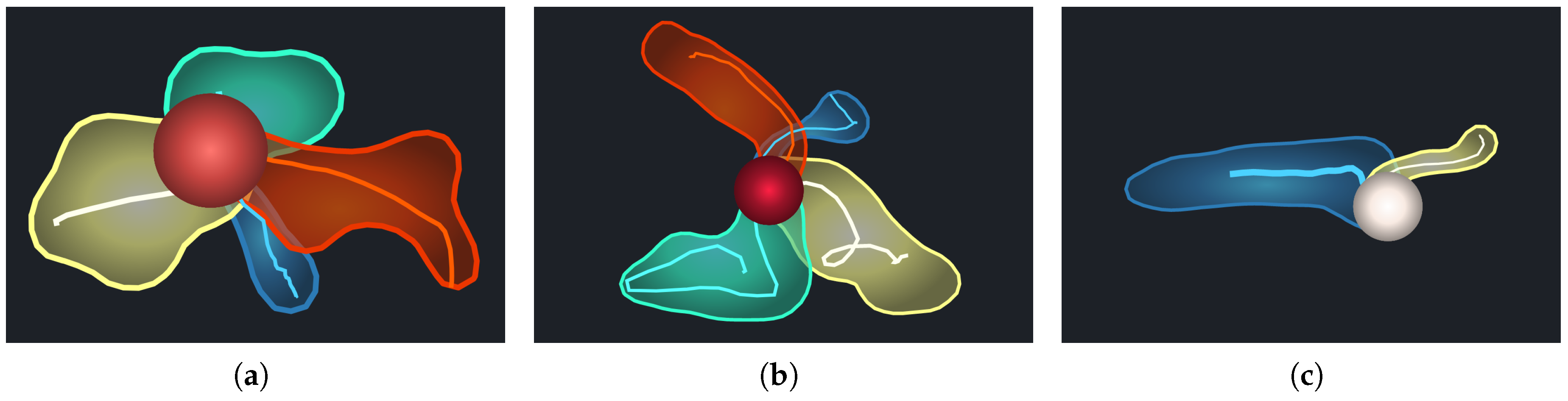
Section 5.1, we can preliminarily recognize the trends of the pathlines. However, the pathlines in real world data, with a lot of overlap and intersections, are too complicated to distinguish different patterns from. To comprehensively and intuitively display the uncertainty of a grid point in an uncertain vector field, we designed a glyph, called Shuttlecock, which consists of a circle and several “feathers.” The number of features is equal to the number of clusters. The circle represents a grid point in the uncertain vector field, and its color encodes the LU value. The color bar is coincident with the uncertainty rendering view. The deeper red the color is, the higher the LU value is.
The feathers are designed to display the major transport patterns from a grid point. Each feather is drawn as an outer contour encasing all the members of each cluster, together with the central pathline of the trend. This can intuitively describe the divergence of each pattern. In detail, for each cluster, we select equidistant sample points along each pathline and estimate the density contours for the given sample points. Then, the contour line with the lowest density is filled with a translucent color and a convex-like representation is formed. In this way, we draw the outer contour for each transport pattern. Furthermore, the pathline with the minimum AEDR distance, compared to the others in the cluster, is chosen as the central pathline. It is drawn as the stalk of the corresponding feather to approximately represent the transport trend of each cluster, where its width describes the number of pathline members in the cluster.
Thus, the shuttlecock glyph not only avoids the visual clutter caused by drawing all the pathline members but also presents the major patterns clearly, even when there are a large number of pathline members in an ensemble pathline. Through observing the different shapes of the glyph for different points, we can effectively compare the vector field uncertainty at different locations.
Figure 7 presents the glyphs of the clustering results in
Figure 6b–d. For example, the pathlines in
Figure 6b were assigned into two clusters, and
Figure 7a displays the outline and centerline of all pathlines in both of these clusters. The yellow cluster shows a more chaotic transport trend than the blue cluster. In
Figure 7b,c, the yellow cluster is further subdivided and the area of each cluster is smaller.
During the process of glyph design, we also considered several alternatives. One option was to display the track points of all timestamps inside the contour (
Figure 8a). In this way, the divergence details of the patterns can be well-preserved, but the overlap of points limits the identification of the major trends. As shown in
Figure 8b, another design was to display both the track points and the central pathlines, failing to distinguish the features when pathline clusters were close. We also tried to combine track points, central pathlines, and outer contours together (
Figure 8c); however, this design could not show the central pathlines and details clearly, due to serious visual clutter.
Compared with some commonly used uncertainty visualization designs, such as Noodles [
47], the contour boxplot [
25], and so on, our method focuses on presenting the transport patterns for a single location in detail, rather than presenting the overall uncertainty of the whole data field. In particular, Shuttlecock has been designed to help users to perceive the major trends clearly, rather than directly encode the uncertainty values in the glyph.
5.3. Comparison with Neighborhood Patterns
As discussed in
Section 4.3, we use NU to estimate the uncertainty of a location’s neighborhood and compute CU to depict the correlation between the location and its neighborhood. Different correlation patterns can be observed in the classification view (
Figure 4a). In particular, some points show a low CU, as the uncertainties of the point itself and of its neighborhood points are very different. It is useful to explore the specific differences between the grid point itself and its neighborhood, which can be solved by comparing the transport patterns of different grids in the neighborhood.
Thus, we designed a comparison view which is similar to tile stitching. It plots the pathlines of the chosen location and its neighbor locations, simultaneously, in adjacent tiles.
Figure 9 presents a case of the weather data set (as described in
Section 6.2). Each gray circular tile is affixed to a location whose opacity encodes the corresponding LU. We highlight the chosen location by adding a black border to the tile. In the interior of each tile, the pathlines traced from the location are downscaled and drawn without blurring the trend and variability. To enhance the contrast between different tiles, we cluster the pathlines in each tile with the same
and
values. Thus, users can identify and compare the transport trends at the chosen location and its neighborhood, by observing the extracted patterns marked by different colors. For example, the pathline members traced from the chosen location in
Figure 9 follow similar trends and are classified into one cluster. Similarly, some tiles in the upper part and the lower right part of the view depict the major transport trends. However, the pathlines in the other tiles diverge in different directions and show high uncertainty.
8. Conclusions and Future Work
In this paper, we have presented a novel method to analyze the uncertainty in an ensemble vector field. In order to measure the difference between pathline members effectively, we proposed a measurement method, AEDR, based on classical EDR. It is a more effective measurement method, with high robustness to outliers, support for comparison between pathline members with different lengths, and higher accuracy. On this basis, we considered the neighborhood uncertainty and computed the correlation between a location and its neighborhood. Using these measurements, we designed and developed a visual analysis system, UP-Vis, to help users to deeply and comprehensively analyze the transport patterns and the neighborhood uncertainty. We clustered the pathline members into transport trends using a novel glyph, called Shuttlecock, designed to intuitively show the trends and their diverging degrees. The classification view and comparison view can help users to understand the neighborhood correlation more deeply. Experimental results using synthetic and real data sets have demonstrated the effectiveness of our method.
In the future, we plan to explore and analyze data with multi-resolution and trace particles under different spatial scales. We also plan to use ensemble clustering to obtain more robust results for pathline clustering. Furthermore, more views for satisfying different requirements and supporting 3D analysis will be added to the visual analysis system.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}