Identification of Salt Deposits on Seismic Images Using Deep Learning Method for Semantic Segmentation


Abstract
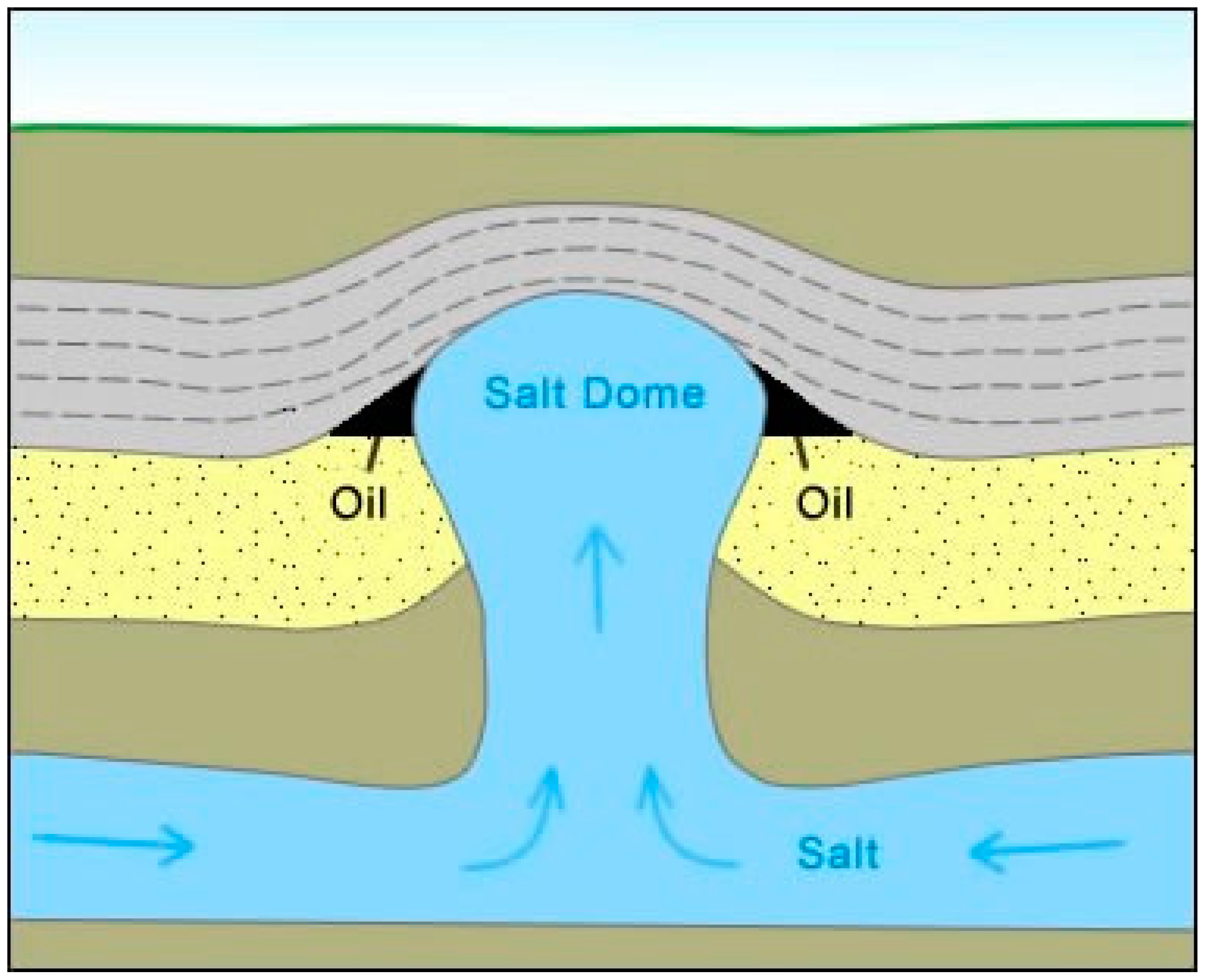
:1. Introduction
2. Related Work
3. Method Description
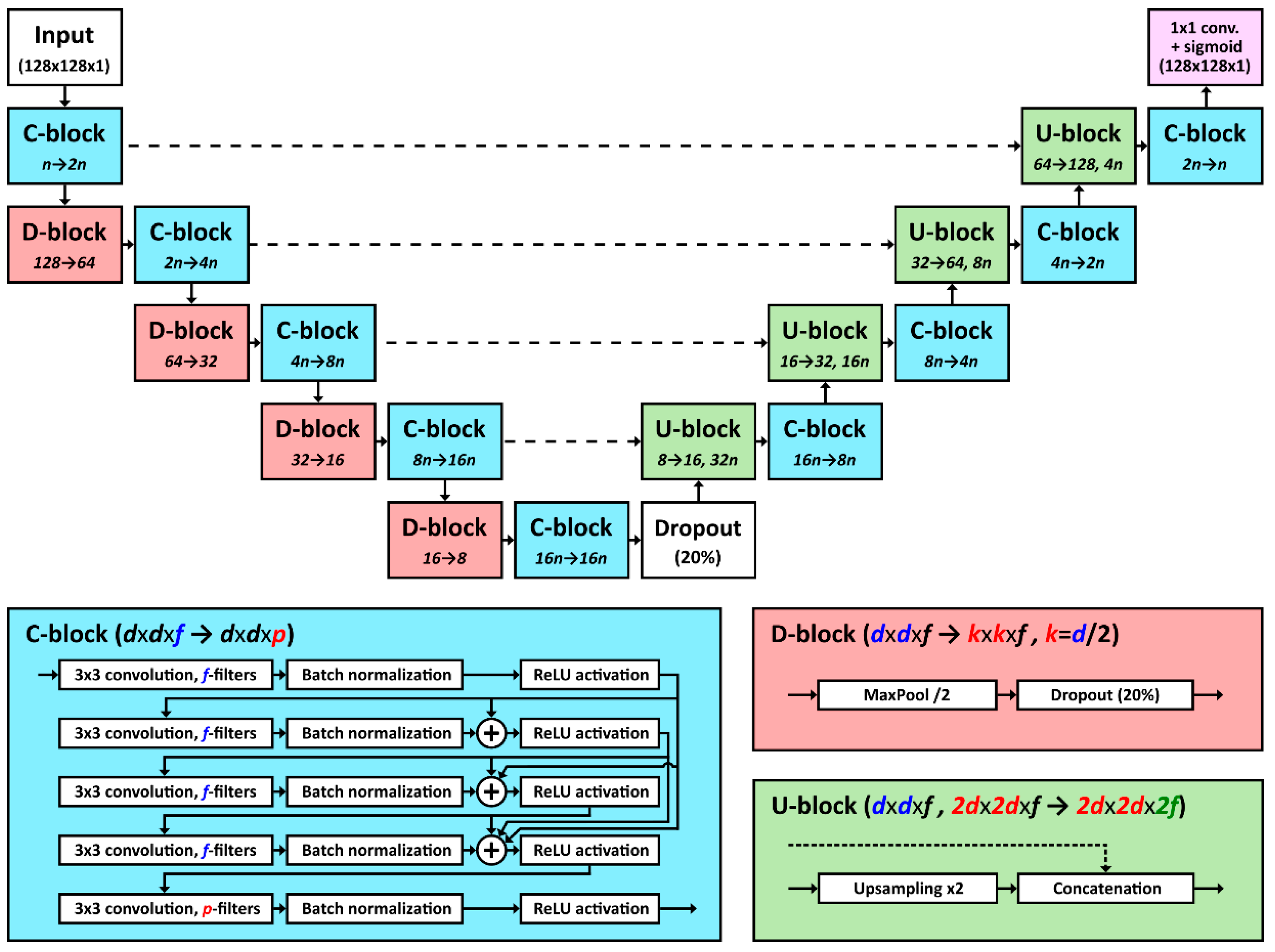
3.1. Network Architecture
3.2. Implementation and Training
4. Results and Discussion
4.1. Competition Results
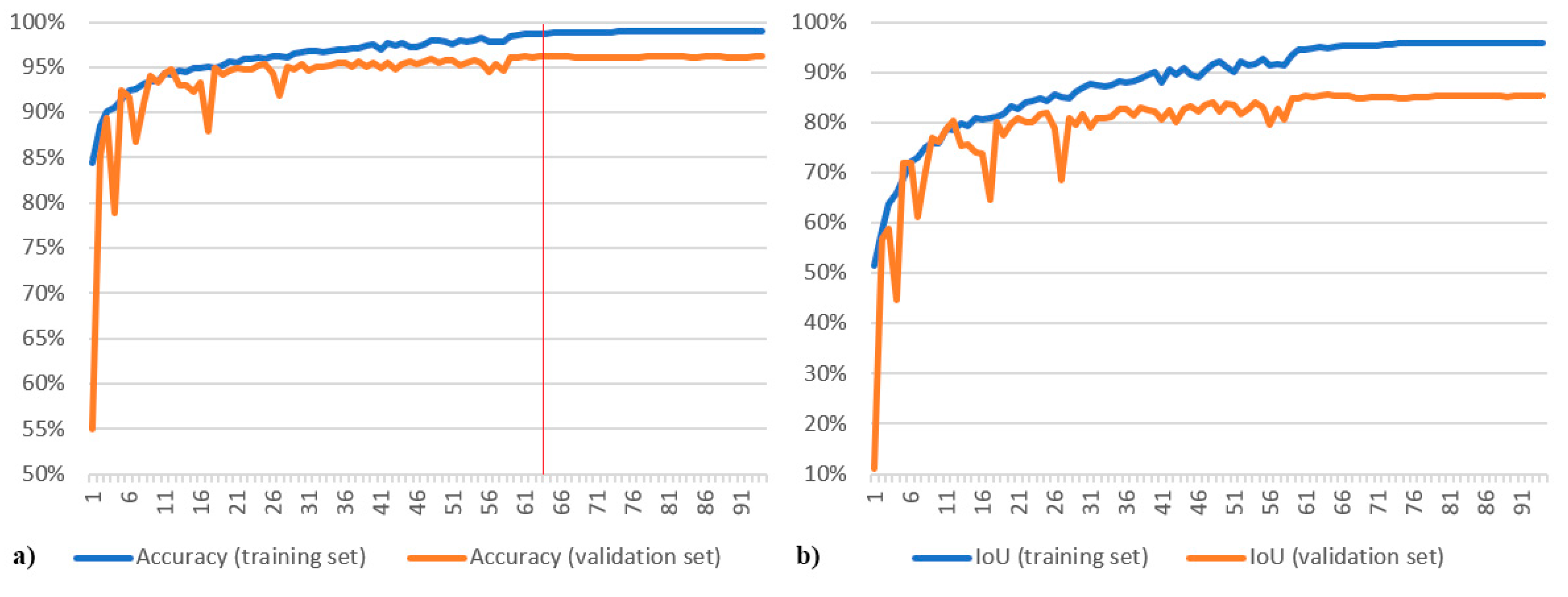
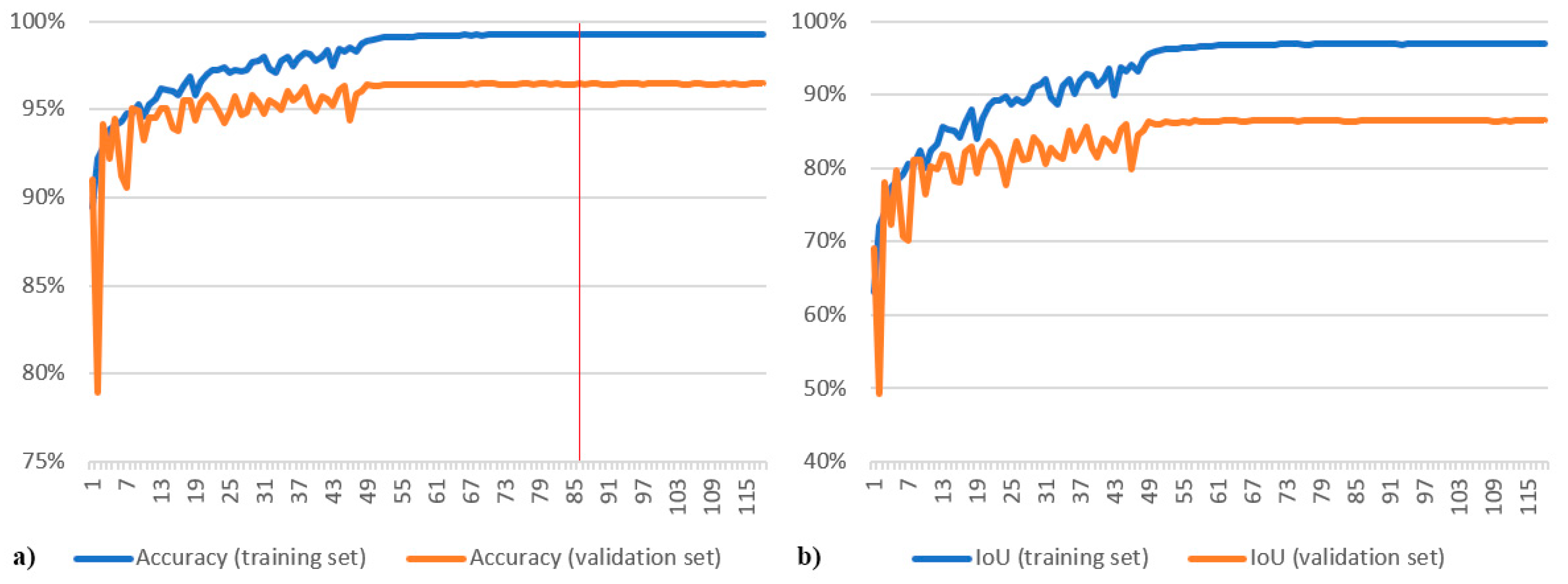
4.2. Post-Competition Analyses
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chevron.com: Seismic Imagining. Available online: https://www.chevron.com/stories/seismic-imaging (accessed on 17 November 2019).
- Kaggle.com: TGS Salt Identification Challenge, Segment Salt Deposits Beneath the Earth’s Surface. Available online: https://www.kaggle.com/c/tgs-salt-identification-challenge (accessed on 17 November 2019).
- LeCun, Y.; Boser, B.; Denker, J.; Henderson, D.; Howard, R.; Hubbard, W.; Jackel, L. Handwritten digit recognition with a back-propagation network. In Advances in Neural Information Processing Systems 2; The MIT Press: Cambridge, MA, USA, 1990; pp. 396–404. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, Spain, 3–8 December 2012; Volume 2, pp. 1097–1105. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); LNCS; Springer: Cham, Switzerland, 2014; Volume 8689, pp. 818–833. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; ICLR: London, UK, 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; CVPR: Washington, WA, USA, 2015; pp. 3431–3440. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; CVPR: Washington, WA, USA, 2015; pp. 447–456. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1520–1528. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Kirillov, A.; He, K.; Girshick, R.; Dollár, P. A Unified Architecture for Instance and Semantic Segmentation. Available online: http://presentations.cocodataset.org/COCO17-Stuff-FAIR.pdf (accessed on 19 November 2019).
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing, VCIP 2017, St. Petersburg, FL, USA, 10–13 December 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2881–2890. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 2261–2269. [Google Scholar]
- Pitas, I.; Kotropoulos, C. A texture-based approach to the segmentation of seismic images. Pattern Recognit. 1992, 25, 929–945. [Google Scholar] [CrossRef]
- Hegazy, T.; AlRegib, G. Texture attributes for detecting salt bodies in seismic data. In Proceedings of the Society of Exploration Geophysicists International Exposition and 84th Annual Meeting SEG 2014, Denver, CO, USA, 26–31 October 2014; Society of Exploration Geophysicists: Tulsa, OK, USA, 2014; pp. 405–408. [Google Scholar]
- Shafiq, M.A.; Wang, Z.; Amin, A.; Hegazy, T.; Deriche, M.; AlRegib, G. Detection of salt-dome boundary surfaces in migrated seismic volumes using gradient of textures. In SEG Technical Program Expanded Abstracts; Society of Exploration Geophysicists: Tulsa, OK, USA, 2015; Volume 34, pp. 1811–1815. [Google Scholar]
- Halpert, A.; Clapp, R.G. Salt Body Segmentation with Dip and Frequency Attributes, Stanford Exploration Project, Report SEP134. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.483.6634&rep=rep1&type=pdf#page=119 (accessed on 19 November 2019).
- Shafiq, M.A.; Alshawi, T.; Long, Z.; Alregib, G. SalSi: A new seismic attribute for salt dome detection. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing—Proceedings, Shanghai, China, 20–25 March 2016; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2016; pp. 1876–1880. [Google Scholar]
- Asjad, A.; Mohamed, D. A new approach for salt dome detection using a 3D multidirectional edge detector. Appl. Geophys. 2015, 12, 334–342. [Google Scholar] [CrossRef]
- Wu, X. Methods to compute salt likelihoods and extract salt boundaries from 3D seismic images. Geophysics 2016, 81, IM119–IM126. [Google Scholar] [CrossRef]
- Di, H.; Shafiq, M.; AlRegib, G. Multi-attribute k -means clustering for salt-boundary delineation from three-dimensional seismic data. Geophys. J. Int. 2018, 215, 1999–2007. [Google Scholar] [CrossRef] [Green Version]
- Wrona, T.; Pan, I.; Gawthorpe, R.L.; Fossen, H. Seismic facies analysis using machine learning. Geophysics 2018, 83, O83–O95. [Google Scholar] [CrossRef]
- Schuegraf, P.; Bittner, K. Automatic Building Footprint Extraction from Multi-Resolution Remote Sensing Images Using a Hybrid FCN. ISPRS Int. J. Geo-Inf. 2019, 8, 191. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Luo, J.; Huang, B.; Hu, X.; Sun, Y.; Yang, Y.; Xu, N.; Zhou, N. DE-Net: Deep Encoding Network for Building Extraction from High-Resolution Remote Sensing Imagery. Remote Sens. 2019, 11, 2380. [Google Scholar] [CrossRef] [Green Version]
- Alidoost, F.; Arefi, H.; Tombari, F. 2D Image-To-3D Model: Knowledge-Based 3D Building Reconstruction (3DBR) Using Single Aerial Images and Convolutional Neural Networks (CNNs). Remote Sens. 2019, 11, 2219. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.; Du, C.; Chen, H.; Xu, Y.; Guo, N.; Jing, N. Road Extraction from Very High Resolution Images Using Weakly labeled OpenStreetMap Centerline. ISPRS Int. J. Geo-Inf. 2019, 8, 478. [Google Scholar] [CrossRef] [Green Version]
- Li, L. Deep Residual Autoencoder with Multiscaling for Semantic Segmentation of Land-Use Images. Remote Sens. 2019, 11, 2142. [Google Scholar] [CrossRef] [Green Version]
- Dramsch, J.S.; Lüthje, M. Deep learning seismic facies on state-of-the-art CNN architectures. In Proceedings of the 2018 SEG International Exposition and Annual Meeting, SEG 2018, Anaheim, CA, USA, 14–19 October 2018; Society of Exploration Geophysicists: Tulsa, OK, USA, 2019; pp. 2036–2040. [Google Scholar]
- Di, H.; Wang, Z.; AlRegib, G. Real-time seismic image interpretation via deconvolutional neural network. In Proceedings of the 2018 SEG International Exposition and Annual Meeting, SEG 2018, Anaheim, CA, USA, 14–19 October 2018; Society of Exploration Geophysicists: Tulsa, OK, USA, 2019; pp. 2051–2055. [Google Scholar]
- Di, H.; Wang, Z.; AlRegib, G. Deep Convolutional Neural Networks for Seismic Salt-Body Delineation. In Proceedings of the AAPG Annual Convention and Exhibition 2018, Utah, UT, USA, 20–23 May 2018. [Google Scholar]
- Waldeland, A.U.; Jensen, A.C.; Gelius, L.-J.; Solberg, A.H.S. Convolutional neural networks for automated seismic interpretation. Lead. Edge 2018, 37, 529–537. [Google Scholar] [CrossRef]
- Zeng, Y.; Jiang, K.; Chen, J. Automatic seismic salt interpretation with deep convolutional neural networks. In Proceedings of the ACM International Conference Proceeding Series, Cambridge, UK, 23–26 March 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 16–20. [Google Scholar]
- Shi, Y.; Wu, X.; Fomel, S. SaltSeg: Automatic 3D salt segmentation using a deep convolutional neural network. Interpretation 2019, 7, SE113–SE122. [Google Scholar] [CrossRef]
- Wu, X.; Liang, L.; Shi, Y.; Fomel, S. FaultSeg3D: Using synthetic data sets to train an end-to-end convolutional neural network for 3D seismic fault segmentation. Geophysics 2019, 84, IM35–IM45. [Google Scholar] [CrossRef]
- Babakhin, Y.; Sanakoyeu, A.; Kitamura, H. Semi-Supervised Segmentation of Salt Bodies in Seismic Images using an Ensemble of Convolutional Neural Networks. In Pattern Recognition; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K.; San Diego, U. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1492–1500. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel ‘squeeze & excitation’ in fully convolutional networks. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2018; Volume 11070 LNCS, pp. 421–429. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. In Proceedings of the British Machine Vision Conference 2018, BMVC 2018, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Keras: The Python Deep Learning Library. Available online: https://keras.io (accessed on 16 October 2019).
- TensorFlow: An End-to-end Open Source Machine Learning Platform. Available online: https://www.tensorflow.org/ (accessed on 16 October 2019).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yakubovskiy, P. Segmentation Models, Github Library. Available online: https://github.com/qubvel/segmentation_models (accessed on 19 November 2019).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ensemble Size | Number of Filters in the First Layer (n)/Number of Networks | Public Score | Private Score |
|---|---|---|---|
| 5 | 16/5 | 0.82519 | 0.84525 |
| 5 | 24/5 | 0.82859 | 0.84771 |
| 5 | 32/5 | 0.83181 | 0.85087 |
| 10 | 24/5, 32/5 | 0.83314 | 0.85202 |
| 25 | 16/15, 24/5, 32/5 | 0.83328 | 0.85241 |
| The result of the winning solution [41] | 0.88832 | 0.89646 | |
| The result of the first submitted solution | 0.74828 | 0.76996 |
| Segmentation Model | Number of Convolutional Layers/Filters | Public Score | Private Score |
|---|---|---|---|
| Original model (n = 32) | 46/9761 | 0.83181 | 0.85087 |
| Original model w/o dropout | 46/9761 | 0.83108 | 0.85219 |
| U-Net (n = 32) | 48/10561 | 0.82446 | 0.84404 |
| FPN | 51/11137 | 0.83623 | 0.85145 |
| LinkNet | 53/9617 | 0.82591 | 0.84565 |
| PSPNet | 23/4225 | 0.83137 | 0.81138 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Milosavljević, A. Identification of Salt Deposits on Seismic Images Using Deep Learning Method for Semantic Segmentation. ISPRS Int. J. Geo-Inf. 2020, 9, 24. https://doi.org/10.3390/ijgi9010024
Milosavljević A. Identification of Salt Deposits on Seismic Images Using Deep Learning Method for Semantic Segmentation. ISPRS International Journal of Geo-Information. 2020; 9(1):24. https://doi.org/10.3390/ijgi9010024
Chicago/Turabian StyleMilosavljević, Aleksandar. 2020. "Identification of Salt Deposits on Seismic Images Using Deep Learning Method for Semantic Segmentation" ISPRS International Journal of Geo-Information 9, no. 1: 24. https://doi.org/10.3390/ijgi9010024
APA StyleMilosavljević, A. (2020). Identification of Salt Deposits on Seismic Images Using Deep Learning Method for Semantic Segmentation. ISPRS International Journal of Geo-Information, 9(1), 24. https://doi.org/10.3390/ijgi9010024