An Unsupervised Crop Classification Method Based on Principal Components Isometric Binning


 , , and
, , and
Abstract
:1. Introduction
2. Materials
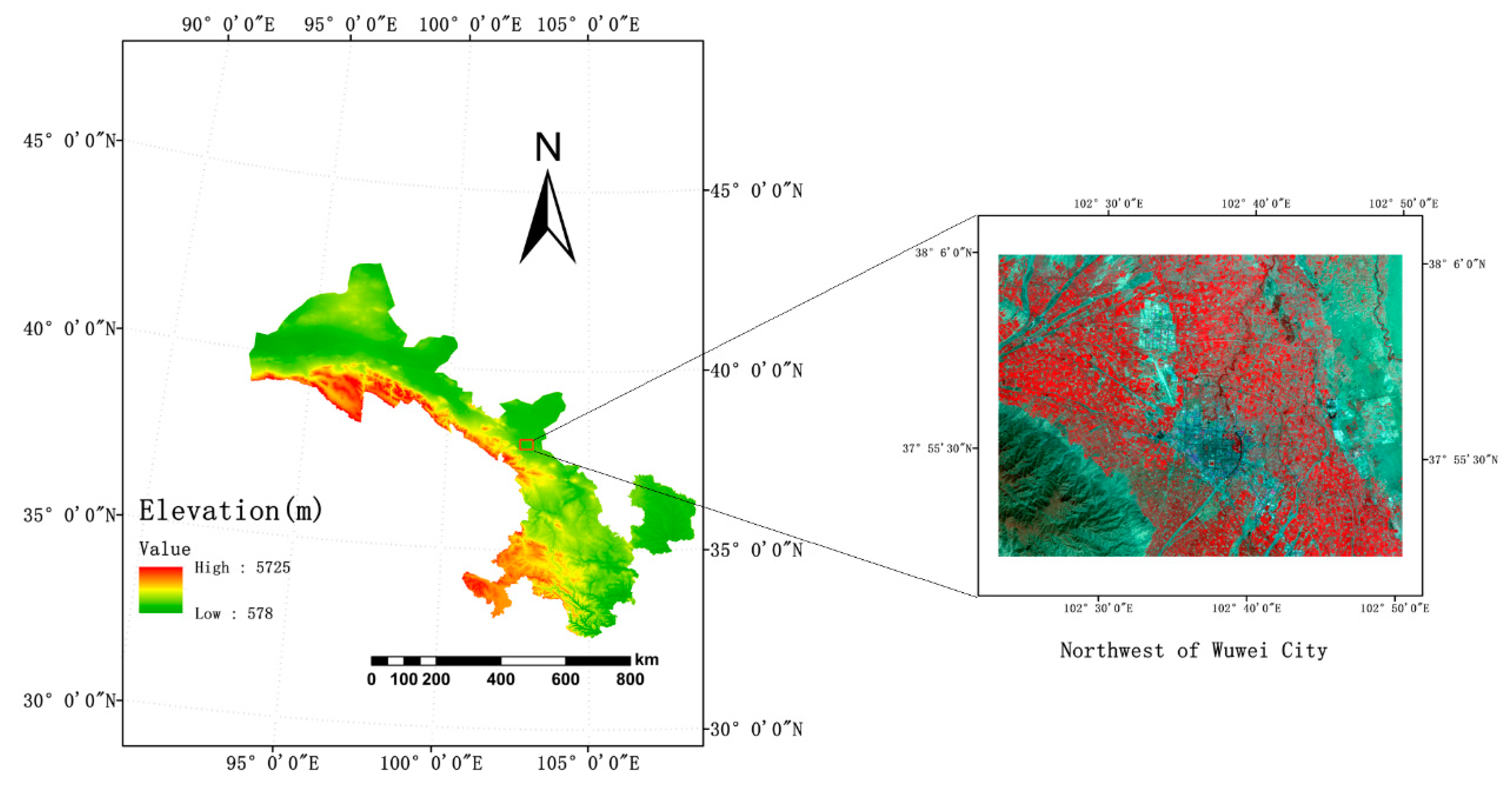
2.1. Study Area
2.2. Data Sources
2.2.1. Multitemporal GF-1 Data
2.2.2. Field Sample Data
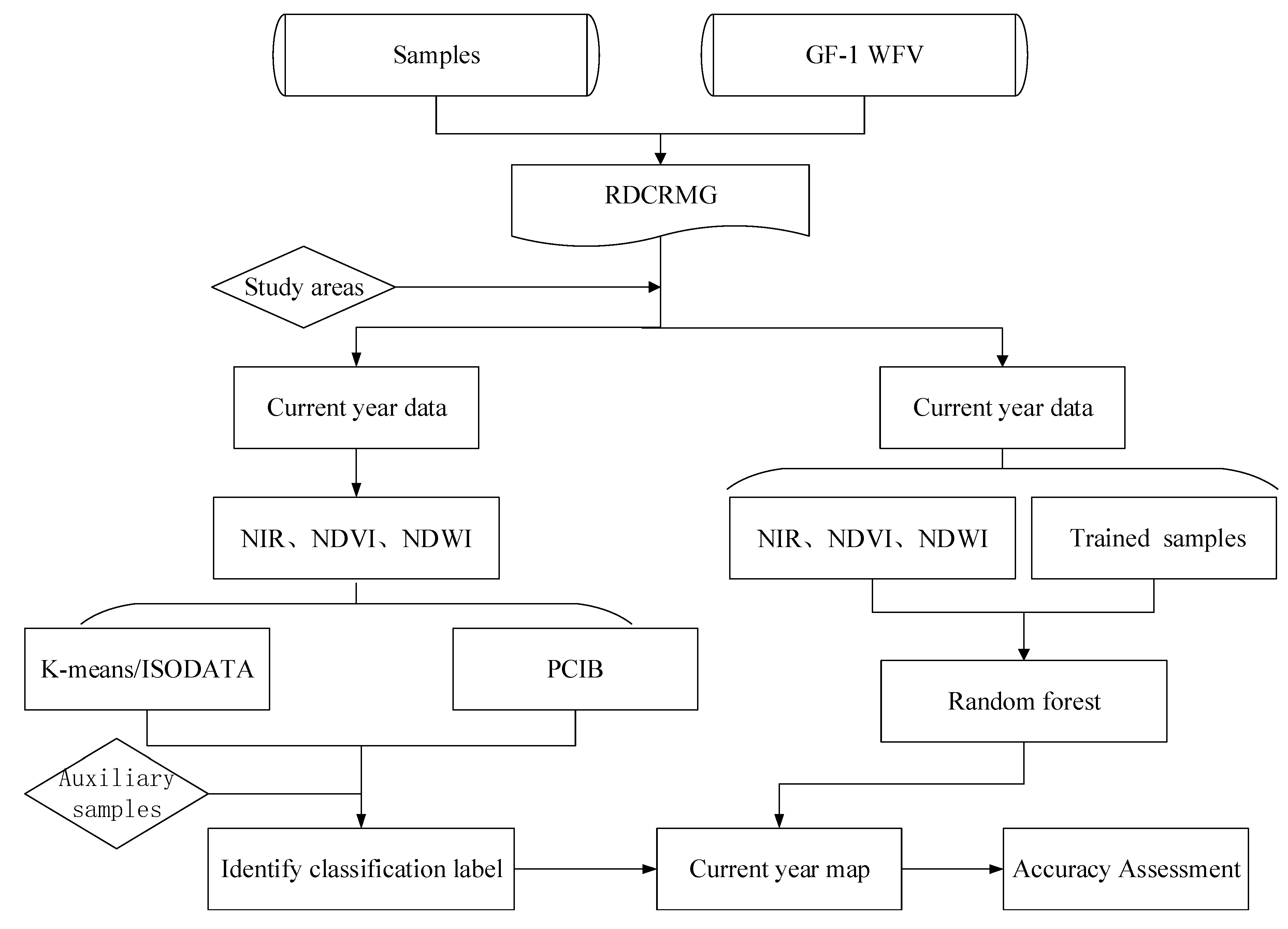
3. Methods
3.1. Data Preprocessing
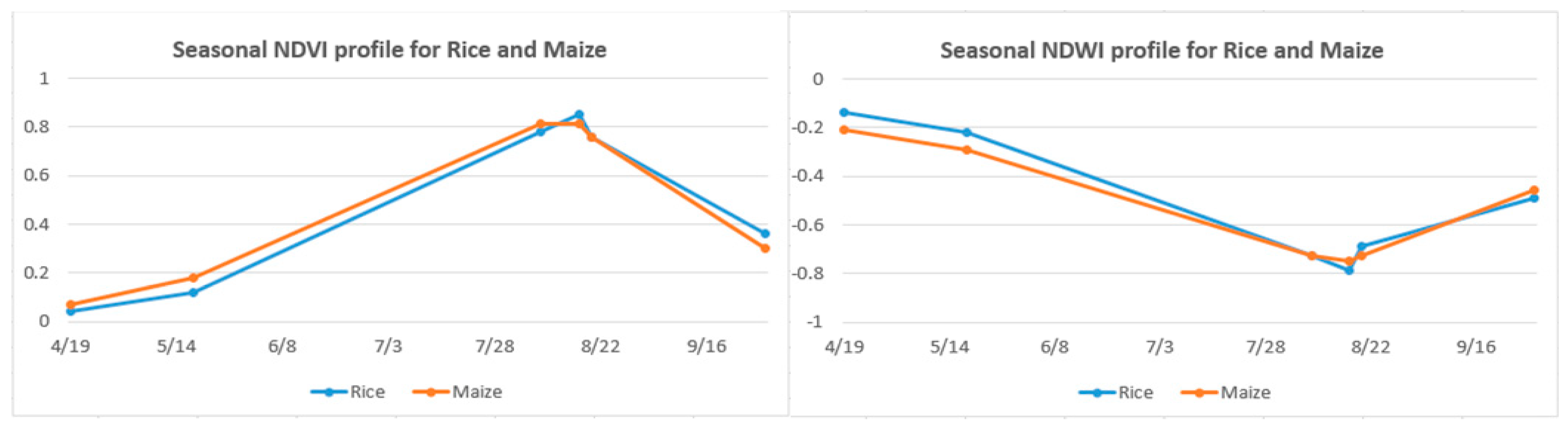
3.2. Feature Selection for Classification
3.3. Random Forest Classification
3.4. Unsupervised Classification
3.4.1. K-Means
3.4.2. ISODATA
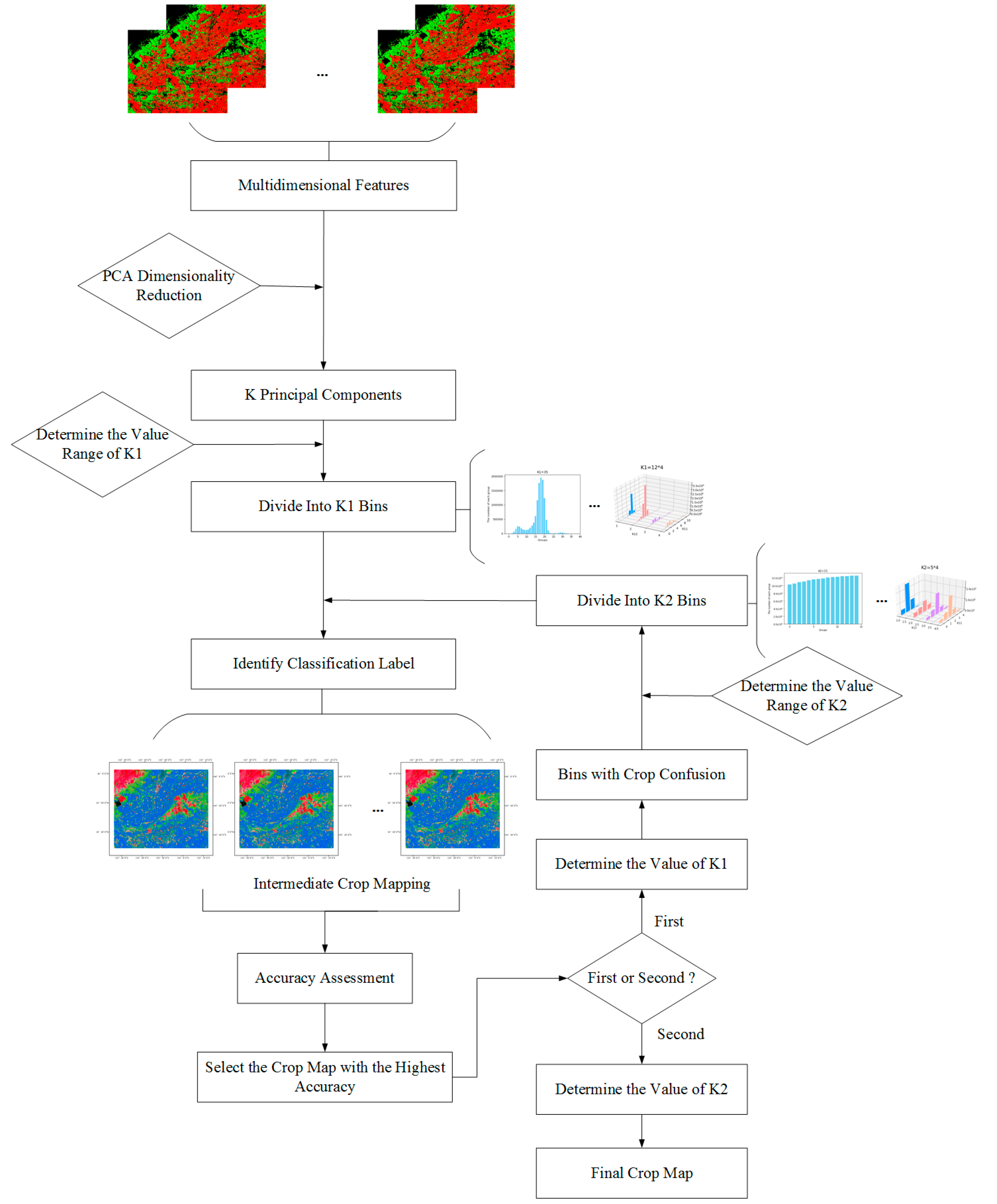
3.5. Principal Components Isometric Binning Classification
3.5.1. PCA Dimensionality Reduction
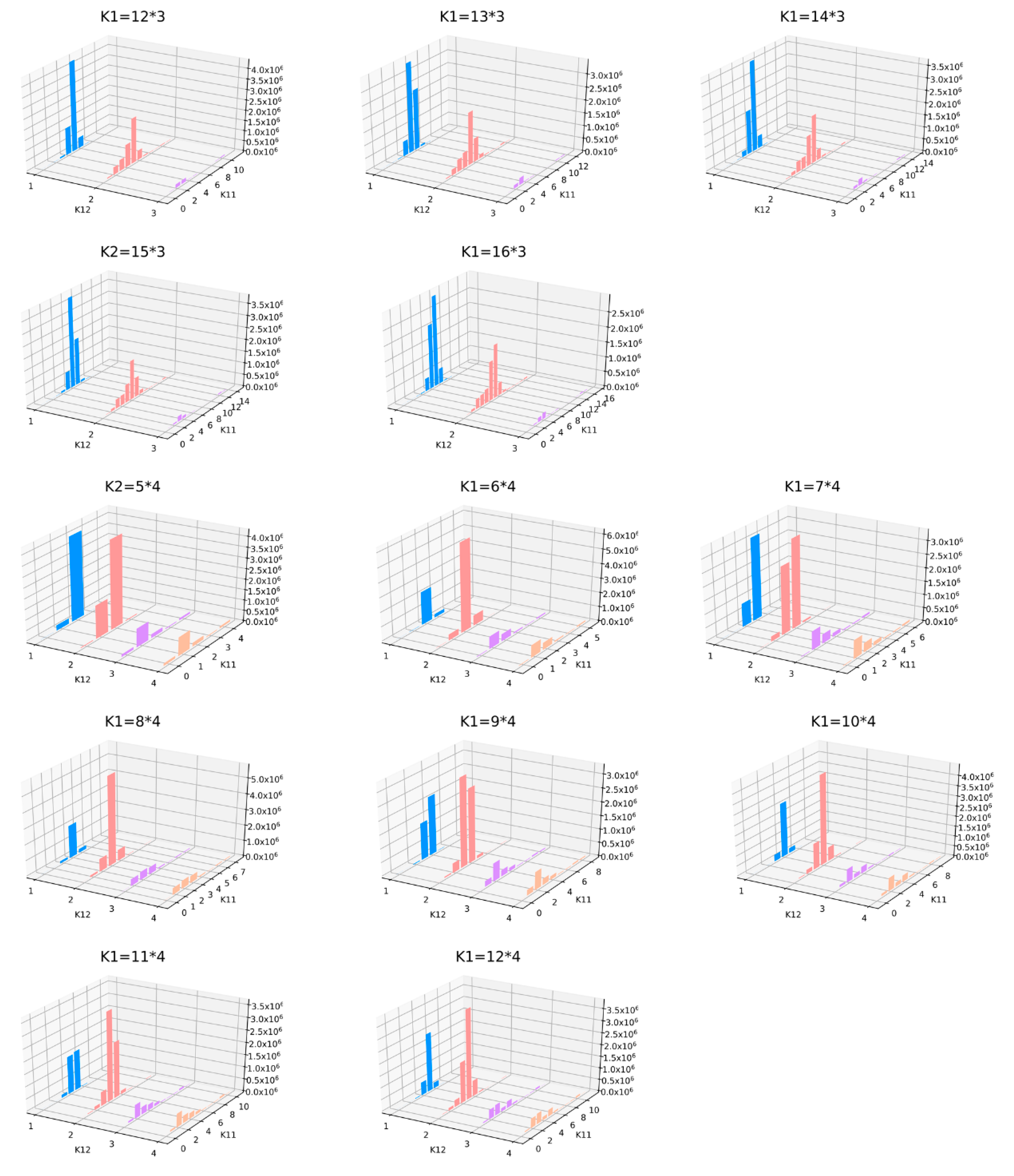
3.5.2. Principal Components Isometric Binning
- (i)
- The first principal component is divided into intervals. All pixels falling into each interval are gathered together, with bin distance , where is the maximum value of the column and is the minimum value.
- (ii)
- The second principal component is divided into intervals corresponding to the binning result of the first principal component. Each interval is then divided into sub-intervals. All pixels in each sub-interval are divided into a bin, and bin distance h = , where rj2 and are the maximum and minimum values of the column.
- (iii)
- The k-th principal component is divided into * * …* bins, that is, k1 = k11* * …* , until the end. A frequency distribution histogram is drawn to show the binning situation intuitively.
3.6. Determination of Category Labels
3.7. Accuracy Assessment
4. Results
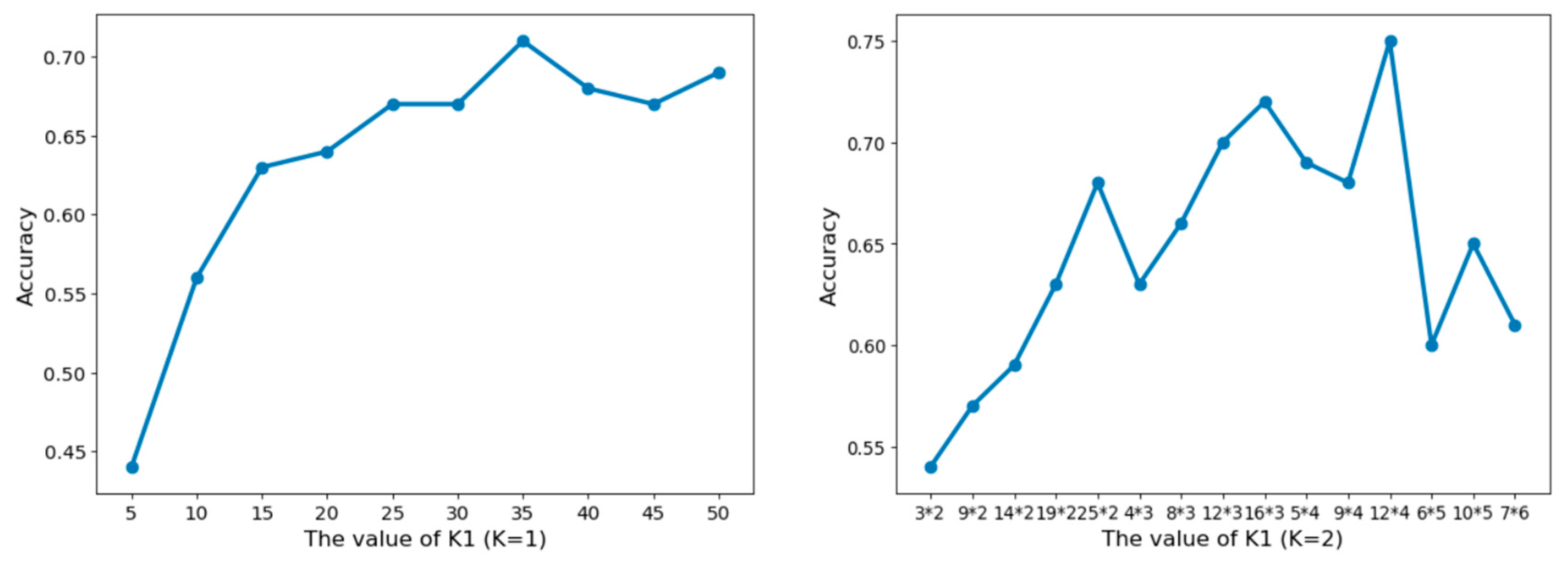
4.1. Effect of Parameter Selection
4.2. Comparison of PCIB Results
4.3. Comparison of Classification Methods
5. Discussion
5.1. Advantanges, Deficiencies and Improvenments of PCIB
5.2. Analysis of Sources of the Errors
5.3. Comparison of Computational Complexity of Three Clustering Algorithms
5.4. Additional Experiments
6. Conclusions
- (1)
- The overall accuracy of the PCIB method in the southwest of Hulin City in 2016 reaches 82%, exceeding the K-means and ISODATA algorithms. In 2017, Luobei County of Hegang City exhibited the lowest PCIB classification accuracy, with the other three methods also exhibiting low accuracies, (79%, 74% and 75% for random forest, K-means and ISODATA, respectively). Although the overall accuracy of PCIB is slightly lower than that of the random forest classifier, it meets the mapping accuracy requirements for years where large amounts of field samples are absent.
- (2)
- PCIB conducts the isometric binning of k principal components directly after the PCA dimensionality reduction. Multiple iterations per each pixel are not required, and the time complexity is linear. This consequently improves the computational efficiency compared with the Euclidean distance-based K-means and ISODATA classifiers.
- (3)
- The dependence on a large number of field samples for classification is reduced. In addition, the spatial distribution information of crops is determined in a timely and accurate manner. Our proposed method can potentially be applied to the mapping of crop classification.
Author Contributions
Funding
Conflicts of Interest
References
- Yang, B.J. Remote Sensing Monitoring of Agricultural Conditions, 1st ed.; China Agricultural Press: Beijing, China, 2005. [Google Scholar]
- Song, X.; Potapov, P.V.; Krylov, A.; King, L.; Di Bella, C.M.; Hudson, A.; Khan, A.; Adusei, B.; Stehman, S.V.; Hansen, M.C. National-scale soybean mapping and area estimation in the United States using medium resolution satellite imagery and field survey. Remote Sens. Environ. 2017, 190, 383–395. [Google Scholar] [CrossRef]
- Guo, W.; Zhao, C.Y.; Gu, X.H.; Huang, W.J.; Ma, Z.H. Remote sensing monitoring of maize planting area at town level. Trans. CSAE 2011, 27, 69–74. [Google Scholar]
- Li, Y.; Zhu, Y.; Dai, T.; Tian, Y.; Cao, W. Quantitative relationships between leaf area index and canopy reflectance spectra of wheat. Chin. J. Appl. Ecol. 2006, 17, 1443–1447. [Google Scholar]
- Wardlow, B.D.; Egbert, S.L.; Kastens, J.H. Analysis of time-series MODIS 250 m vegetation index data for crop classification in the U.S. Central Great Plains. Remote Sens. Environ. 2007, 108, 290–310. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.J.; Zhan, Y.L.; Tian, Q.J.; Gu, X.F.; Yu, T.; Wang, L. Crop classification based on GF-1/WFV NDVI time series. Trans. CSAE 2015, 31, 155–161. [Google Scholar]
- Hao, P.; Wang, L.; Zhan, Y.; Niu, Z. Using Moderate-Resolution Temporal NDVI Profiles for High-Resolution Crop Mapping in Years of Absent Ground Reference Data: A Case Study of Bole and Manas Counties in Xinjiang, China. ISPRS Int. J. Geo-Inf. 2016, 5, 67. [Google Scholar] [CrossRef] [Green Version]
- Yang, N.; Liu, D.; Feng, Q.; Xiong, Q.; Zhang, L.; Ren, T.; Zhao, Y.; Zhu, D.; Huang, J. Large-Scale Crop Mapping Based on Machine Learning and Parallel Computation with Grids. Remote Sens. 2019, 11, 1500. [Google Scholar] [CrossRef] [Green Version]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Z.; Ren, T.; Liu, D.; Ma, Z.; Tong, L.; Zhang, C.; Zhou, T.; Zhang, X.; Li, S. Identification of Seed Maize Fields with High Spatial Resolution and Multiple Spectral Remote Sensing Using Random Forest Classifier. Remote Sens. 2020, 12, 362. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Zhang, C.; Zhang, S.; Peter, M. Crop classification from full-year fully-polarimetric L-band UAVSAR time-series using the Random Forest algorithm. Int. J. Appl. Earth Obs. 2020, 87, 102032. [Google Scholar] [CrossRef]
- Mmamokoma Grace, M.; Adriaan van, N.; Zama Eric, M. Pre-harvest classification of crop types using a Sentinel-2 time-series and machine learning. Comput. Electron. Agric. 2020, 169, 105164. [Google Scholar]
- Zhong, L.H.; Hu, L.N.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Garnot, V.S.F.; Landrieu, L.; Giordano, S.; Chehata, N. Time-Space Tradeoff in Deep Learning Models for Crop Classification on Satellite Multi-Spectral Image Time Series. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 6247–6250. [Google Scholar]
- Hu, Q.; Wu, W.; Song, Q.; Lu, M. How do temporal and spectral features matter in crop classification in Heilongjiang Province, China? JIA 2017, 16, 324–336. [Google Scholar] [CrossRef]
- Gallego, J.; Craig, M.; Michaelsen, J. Best Practices for Crop Area Estimation with Remote Sensing; GEOSS: Ispra, Italy, 2008. [Google Scholar]
- Hao, P.; Wang, L.; Zhan, Y.; Wang, C.; Niu, Z.; Wu, M. Crop classification using crop knowledge of the previous-year: Case study in Southwest Kansas, USA. Eur. J. Remote Sens. 2016, 49, 1061–1077. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Liu, Z.; Liu, D.; Xiong, Q.; Yang, N. Crop Mapping Based on Historical Samples and New Training Samples Generation in Heilongjiang Province, China. Sustainability 2019, 11, 5052. [Google Scholar] [CrossRef] [Green Version]
- Lorenzo, B.; Luis, G.; Gustavo, C.; Javier, C. Mean Map Kernel Methods for Semi-supervised Cloud Classification. IEEE. Trans. Geosci. Remote Sens. 2010, 48, 207–220. [Google Scholar]
- Liu, Y.; Zhang, B.; Wang, L.M.; Wang, N. A self-trained semi-supervised SVM approach to the remote sensing land cover classification. Comput. Geosci. 2013, 59, 98–107. [Google Scholar] [CrossRef]
- Ghoggali, N.; Melgani, F. Genetic SVM Approach to Semi-supervised Multi-temporal Classification. IEEE Geosci. Remote Sens. Lett. 2008, 5, 212–216. [Google Scholar] [CrossRef]
- Bruzzone, L.; Chi, M.; Marconcini, M. A Novel Transductive SVM for Semi-supervised Classification of Remote-Sensing Images. IEEE Geosci. Remote Sens. 2006, 44, 3363–3373. [Google Scholar] [CrossRef] [Green Version]
- Hu, T.; Huang, X.; Li, J.Y.; Zhang, L.F. A novel co-training approach for urban land cover mapping with unclear Landsat time series imagery. Remote Sens. Environ. 2018, 217, 144–157. [Google Scholar] [CrossRef]
- Neeta, S.; Saroj, K. Semi-supervised classification of remote sensing images using efficient neighborhood learning method. Eng. Appl. Artif. Intell. 2020, 90, 103520. [Google Scholar]
- Ratle, F.; Camps, G.; Weston, J. Semi-supervised neural networks for efficient hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2271–2282. [Google Scholar] [CrossRef]
- Solano, Y.T.; Bovolo, F.; Bruzzone, L. A Semi-Supervised Crop-Type Classification Based on Sentinel-2 NDVI Satellite Image Time Series and Phenological Parameters. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 457–460. [Google Scholar]
- Wan, L.; Zhang, H.; Lin, G. A small-patched convolutional neural network for mangrove mapping at species level using high-resolution remote-sensing image. Ann. GIS 2019, 25, 45–55. [Google Scholar] [CrossRef]
- Gumma, M.K.; Thenkabail, P.; Teluguntla, P. Mapping Rice Fallow Areas for Short Season Grain Legumes Intensification in South Asia using MODIS 250m Time-Series Data. Int. J. Digit. Earth 2016, 9, 981–1003. [Google Scholar] [CrossRef] [Green Version]
- Xiong, J.; Prasad, S.; Murali, K. Automated cropland mapping of continental Africa using Google Earth Engine cloud computing. ISPRS J. Photogram. Remote Sens. 2017, 126, 225–244. [Google Scholar] [CrossRef] [Green Version]
- Hao, W.P.; Mei, X.R.; Cai, X.L. Crop planting extraction based on multi—Temporal remote sensing data in Northeast China. Trans. CSAE 2011, 27, 201–207. [Google Scholar]
- Cai, X.L.; Cui, Y.L. Crop planting structure extraction in irrigated areas from multi-sensor and multi—Temporal remote sensing data. Trans. CSAE 2009, 25, 124–130. [Google Scholar]
- Sherrie, W.; George, A.; David, B. Crop type mapping without field-level labels: Random forest transfer and unsupervised clustering techniques. Remote Sens. Environ. 2019, 222, 303–317. [Google Scholar]
- Iounousse, J.; Er-Raki, S.; Elmotassadeq, A. Using an unsupervised approach of Probabilistic Neural Network (PNN) for land use classification from multi-temporal satellite images. Appl. Soft Comput. 2015, 30, 1–13. [Google Scholar] [CrossRef]
- Venkata Subramanian, N.; Saravanan, N.; Bhuvaneswari, S. K-means based probabilistic neural network (KPNN) for designing physical machine—Classifier. IJITEE 2019, 9, 800–804. [Google Scholar]
- Loveland, T.R.; Reed, B.C.; Brown, J.F.; Ohlen, D.O.; Zhu, Z. Development of a global land cover characteristics database and IGBP DIS Cover from 1 km AVHRR data. Int. J. Remote Sens. 2000, 21, 1303–1330. [Google Scholar] [CrossRef]
- Zhai, Y.G.; Qu, Z.Y. Crop classification based on nonlinear dimensionality reduction using time series remote sensing images. Trans. CSAE 2018, 34, 177–183. [Google Scholar]
- Yan, L.; Roy, D.P. Improved time series land cover classification by missing-observation-adaptive nonlinear dimensionality reduction. Remote Sens. Environ. 2015, 158, 478–491. [Google Scholar] [CrossRef] [Green Version]
- Paul, S.; Kumar, D.N. Evaluation of Feature Selection and Feature Extraction Techniques on Multi-Temporal Landsat-8 Images for Crop Classification. Remote Sens. Earth Syst. Sci. 2019, 197–207. [Google Scholar] [CrossRef]
- Abedini, M.; Fauziah, A. Clustering Approach on Land Use Land Cover Classification of Landsat TM over Ulu Kinta Catchment. WAS J. 2012, 17, 809–817. [Google Scholar]
- Senthilnath, J.; Omkar, S.N.; Mani, N. Crop Stage Classification of Hyperspectral Data Using Unsupervised Techniques. IEEE J.-STARS 2013, 6, 861–866. [Google Scholar] [CrossRef]
- Dharani, M.; Sreenivasulu, G. Land use and land cover change detection by using principal component analysis and morphological operations in remote sensing applications. IJCA 2019, 1–10. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction Springer Series in Statistics; Springer: New York, NY, USA, 2009. [Google Scholar]
- Tan, P.N.; Steinbach, M.; Kumar, V. Introduction to Data Mining, 1st ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2005. [Google Scholar]
- Hu, L.Y.; Chen, Y.L.; Xu, Y. A 30 m land cover mapping of China with an efficient clustering algorithm CBEST. Sci. China Earth Sci. 2014, 57, 2293–2304. [Google Scholar] [CrossRef]
- Ye, S.; Liu, D.; Yao, X. RDCRMG: A Raster Dataset Clean & Reconstitution Multi-Grid Architecture for Remote Sensing Monitoring of Vegetation Dryness. Remote Sens. 2018, 10, 1376. [Google Scholar] [CrossRef] [Green Version]
- Xiong, Q.; Wang, Y.; Liu, D.; Ye, S.; Du, Z.; Liu, W.; Huang, J.; Su, W.; Zhu, D.; Yao, X.; et al. A Cloud Detection Approach Based on Hybrid Multispectral Features with Dynamic Thresholds for GF-1 Remote Sensing Images. Remote Sens. 2020, 12, 450. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Feng, Q.; Gong, J. Winter wheat mapping using a random forest classifier combined with multi-temporal and multi-sensor data. Int. J. Digit. Earth 2018, 11, 783–802. [Google Scholar] [CrossRef]
- Swami, A.; Jain, R. Scikit-learn: Machine Learning in Python. J. Mach. Learn Res. 2013, 12, 2825–2830. [Google Scholar]
- Kulkarni, N.M. Crop Identification Using Unsuperviesd ISODATA and K-Means from Multispectral Remote Sensing Imagery. IJERA 2017, 7, 45–49. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principle Components in Regression Analysis. Principle Component Analysis; Springer: New York, NY, USA, 1986; pp. 129–155. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Eastman, J.R.; Fulk, M. Long sequence time series evaluation using standardized principal components. Photogramm. Eng. Remote Sens. 1993, 59, 991–996. [Google Scholar]
- Hirosawa, Y.; Marsh, S.E.; Kliman, D.H. Application of standardized principal component analysis of land-cover characterization using multitemporal AVHRR data. Remote Sens. Environ. 1996, 58, 267–281. [Google Scholar] [CrossRef]
- Bellón, B.; Bégué, A.; Lo Seen, D.; De Almeida, C.A.; Simões, M. A Remote Sensing Approach for Regional-Scale Mapping of Agricultural Land-Use Systems Based on NDVI Time Series. Remote Sens. 2017, 9, 600. [Google Scholar] [CrossRef] [Green Version]
- Härdle, W.K. Nonparametric and Semiparametric Models; Springer Science & Business Media: New York, NY, USA, 2012. [Google Scholar]
- Hu, Q.W.; Shu, N. A study of a Gaussian mixture model for urban land-cover mapping based on VHR remote sensing imagery. Int. J. Remote Sens. 2016, 37, 1–13. [Google Scholar]
- Qu, Y.R.; Cai, H. Product-based neural networks for user response prediction. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016. [Google Scholar]
- Zhang, W.N.; Du, T.M. Deep Learning over Multi-Field Categorical Data; ECIR Springer: New York, NY, USA, 2016. [Google Scholar]
- Oliveira, A.L.I.; Costa, F.R.G. Novelty detection with constructive probabilistic neural networks. Neurocomputing 2008, 71, 1046–1053. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite Type | Parameter | Value (μm) | Southwest of Hulin City | Luobei County of Hegang City | ||
|---|---|---|---|---|---|---|
| Image Dates in 2016 | Image Dates in 2017 | Image Dates in 2016 | Image Dates in 2017 | |||
| GF-1 WFV | Band 1-Blue | 0.45~0.52 | 4/25, 5/18, 7/16, 9/30 | 5/2, 5/10, 6/16, 7/23 | 4/19, 5/18, 8/8, 8/17, 8/20, 9/30 | 4/3, 4/7, 5/5, 5/9, 5/10, 6/16 |
| Band 2-Green | 0.52~0.59 | |||||
| Band 3-Red | 0.63~0.69 | |||||
| Band 4-NIR | 0.77~0.89 | |||||
| Area | Year | Maize | Rice | Others | Total | No. of Auxiliary Samples | No. of Verification Samples |
|---|---|---|---|---|---|---|---|
| Southwest of Hulin City | 2016 | 165 | 103 | 54 | 322 | 71 | 109 |
| 2017 | 111 | 194 | 150 | 455 | 100 | 152 | |
| Luobei County | 2016 | 234 | 91 | 58 | 383 | 84 | 131 |
| 2017 | 137 | 99 | 170 | 406 | 90 | 136 |
| Feature Value | Formula | Application |
|---|---|---|
| Near-Infrared Reflectivity | NIR | Canopy structure |
| Normalized Difference Vegetation Index (NDVI) | NDVI = (NIR − R)/(NIR + R) | Vegetation status, canopy structure |
| Normalized Difference Water Index (NDWI) | NDWI = (G − NIR)/(G + NIR) | Canopy structure, water content |
| k1 | = 2 | = 3 | = 4 | = 5 | = 6 |
|---|---|---|---|---|---|
| k11 = 3 | k1 = 3 * 2 | \ | \ | \ | \ |
| k11 = 4 | k1 = 4 * 2 | k1 = 4 * 3 | \ | \ | \ |
| k11 = 5 | k1 = 5 * 2 | k1 = 5 * 3 | k1 = 5 * 4 | \ | \ |
| k11 = 6 | k1 = 6 * 2 | k1 = 6 * 3 | k1 = 6 * 4 | k1 = 6 * 5 | \ |
| k11 = 7 | k1 = 7 * 2 | k1 = 7 * 3 | k1 = 7 * 4 | k1 = 7 * 5 | k1 = 7 * 6 |
| k11 = 8 | k1 = 8 * 2 | k1 = 8 * 3 | k1 = 8 * 4 | k1 = 8 * 5 | k1 = 8 * 6 |
| k11 = 9 | k1 = 9 * 2 | k1 = 9 * 3 | k1 = 9 * 4 | k1 = 9 * 5 | \ |
| k11 = 10 | k1 = 10 * 2 | k1 = 10 * 3 | k1 = 10 * 4 | k1 = 10 * 5 | \ |
| k11 = 11 | k1 = 11 * 2 | k1 = 11 * 3 | k1 = 11 * 4 | \ | \ |
| k12 = 12 | k1 = 12 * 2 | k1 = 12 * 3 | k1 = 12 * 4 | \ | \ |
| k11 = 13 | k1 = 13 * 2 | k1 = 13 * 3 | \ | \ | \ |
| k11 = 14 | k1 = 14 * 2 | k1 = 14 * 3 | \ | \ | \ |
| k11 = 15 | k1 = 15 * 2 | k1 = 15 * 3 | \ | \ | \ |
| k11 = 16 | k1 = 16 * 2 | k1 = 16 * 3 | \ | \ | \ |
| k11 = 17 | k1 = 17 * 2 | \ | \ | \ | \ |
| k11 = 18 | k1 = 18 * 2 | \ | \ | \ | \ |
| k11 = 19 | k1 = 19 * 2 | \ | \ | \ | \ |
| k11 = 20 | k1 = 20 * 2 | \ | \ | \ | \ |
| k11 = 21 | k1 = 21 * 2 | \ | \ | \ | \ |
| k11 = 22 | k1 = 22 * 2 | \ | \ | \ | \ |
| k11 = 23 | k1 = 23 * 2 | \ | \ | \ | \ |
| k11 = 24 | k1 = 24 * 2 | \ | \ | \ | \ |
| k11 = 25 | k1 = 25 * 2 | \ | \ | \ | \ |
| Number | Number | Number | Number | ||||
|---|---|---|---|---|---|---|---|
| 1 | 3667 | 1 | 1554 | 7 | 979,072 | 1 | 237,690 |
| 2 | 1539 | 2 | 671,312 | ||||
| 3 | 323 | 3 | 69,849 | ||||
| 4 | 251 | 4 | 221 | ||||
| 2 | 75,943 | 1 | 1437 | 8 | 78,262 | 1 | 4197 |
| 2 | 19,095 | 2 | 52,829 | ||||
| 3 | 51,150 | 3 | 20,716 | ||||
| 4 | 4261 | 4 | 520 | ||||
| 3 | 566,651 | 1 | 1682 | 9 | 30,113 | 1 | 650 |
| 2 | 116,532 | 2 | 9634 | ||||
| 3 | 408,409 | 3 | 19,027 | ||||
| 4 | 40,028 | 4 | 802 | ||||
| 4 | 810,072 | 1 | 25,130 | 10 | 37,935 | 1 | 99 |
| 2 | 299,158 | 2 | 2001 | ||||
| 3 | 454,909 | 3 | 27,854 | ||||
| 4 | 30,875 | 4 | 7981 | ||||
| 5 | 2,454,312 | 1 | 550,465 | 11 | 96,883 | 1 | 10 |
| 2 | 1,751,244 | 2 | 491 | ||||
| 3 | 147,883 | 3 | 79,420 | ||||
| 4 | 4720 | 4 | 16,962 | ||||
| 6 | 6,562,114 | 1 | 2,466,921 | 12 | 23,726 | 1 | 7 |
| 2 | 3,799,395 | 2 | 15,165 | ||||
| 3 | 290,144 | 3 | 8274 | ||||
| 4 | 5654 | 4 | 280 |
| Overall Accuracy | Overall Accuracy | ||
|---|---|---|---|
| = 12 * 3 | 68.81% | = 5 * 4 | 68.81% |
| = 13 * 3 | 68.81% | = 6 * 4 | 64.22% |
| = 14 * 3 | 69.72% | = 7 * 4 | 69.72% |
| = 15 * 3 | 67.89% | = 8 * 4 | 68.81% |
| = 16 * 3 | 71.56% | = 9 * 4 = 10 * 4 = 11 * 4 = 12 * 4 | 67.89% 74.31% 66.01% 75.23% |
| Overall Accuracy | Overall Accuracy | ||
|---|---|---|---|
| = 4 * 3 | 79.82% | = 5 * 4 | 81.65% |
| = 5 * 3 | 78.90% | ||
| = 6 * 3 | 77.98% |
| Study Area | Year | Types | OA | Kappa | Producer Accuracy, % | User Accuracy, % | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Other | Maize | Rice | Other | Maize | Rice | |||||
| Southwest of Hulin City | 2016 | RF | 82% | 68.52% | 75% | 78% | 91% | 50% | 89% | 86% |
| K-means | 76% | 59.40% | 89% | 78% | 71% | 44% | 82% | 83% | ||
| ISODATA | 78% | 62.39% | 90% | 79% | 74% | 50% | 86% | 80% | ||
| PCIB | 82% | 69.84% | 67% | 88% | 79% | 56% | 82% | 94% | ||
| 2017 | RF | 82% | 71.74% | 76% | 68% | 94% | 70% | 76% | 94% | |
| K-means | 77% | 64.39% | 73% | 62% | 88% | 74% | 57% | 91% | ||
| ISODATA | 76% | 63.28% | 70% | 58% | 90% | 76% | 49% | 92% | ||
| PCIB | 80% | 68.27% | 73% | 71% | 88% | 82% | 54% | 92% | ||
| Luobei County | 2016 | RF | 82% | 65.24% | 68% | 83% | 88% | 65% | 90% | 71% |
| K-means | 78% | 58.60% | 55% | 81% | 88% | 60% | 86% | 68% | ||
| ISODATA | 80% | 60.01% | 82% | 79% | 87% | 45% | 94% | 68% | ||
| PCIB | 81% | 62.25% | 83% | 80% | 85% | 50% | 93% | 71% | ||
| 2017 | RF | 79% | 67.96% | 74% | 78% | 93% | 85% | 77% | 74% | |
| K-means | 74% | 60.47% | 76% | 69% | 79% | 72% | 74% | 76% | ||
| ISODATA | 75% | 61.46% | 73% | 73% | 81% | 74% | 74% | 76% | ||
| PCIB | 76% | 62.26% | 72% | 72% | 92% | 76% | 81% | 68% | ||
| Cluster Method | Number of Clusters | Maximum Iterations | Clustering Time |
|---|---|---|---|
| K-means | 3 | 20 | 0.029″ |
| ISODATA | 3 | 20 | 0.059″ |
| PCIB | 3 | / | 0.006″ |
| Satellite Type | Parameter | Value (μm) | Phase |
|---|---|---|---|
| GF-1 WFV | Band 1-Blue | 0.45~0.52 | 4/16, 4/20, 5/27, 7/17, 8/13 |
| Band 2-Green | 0.52~0.59 | ||
| Band 3-Red | 0.63~0.69 | ||
| Band 4-NIR | 0.77~0.89 |
| Area | Year | Maize | Spring Wheat | Grape | Pear | Forest | Others | Total | No. of Auxiliary Samples | No. of Verification Samples |
|---|---|---|---|---|---|---|---|---|---|---|
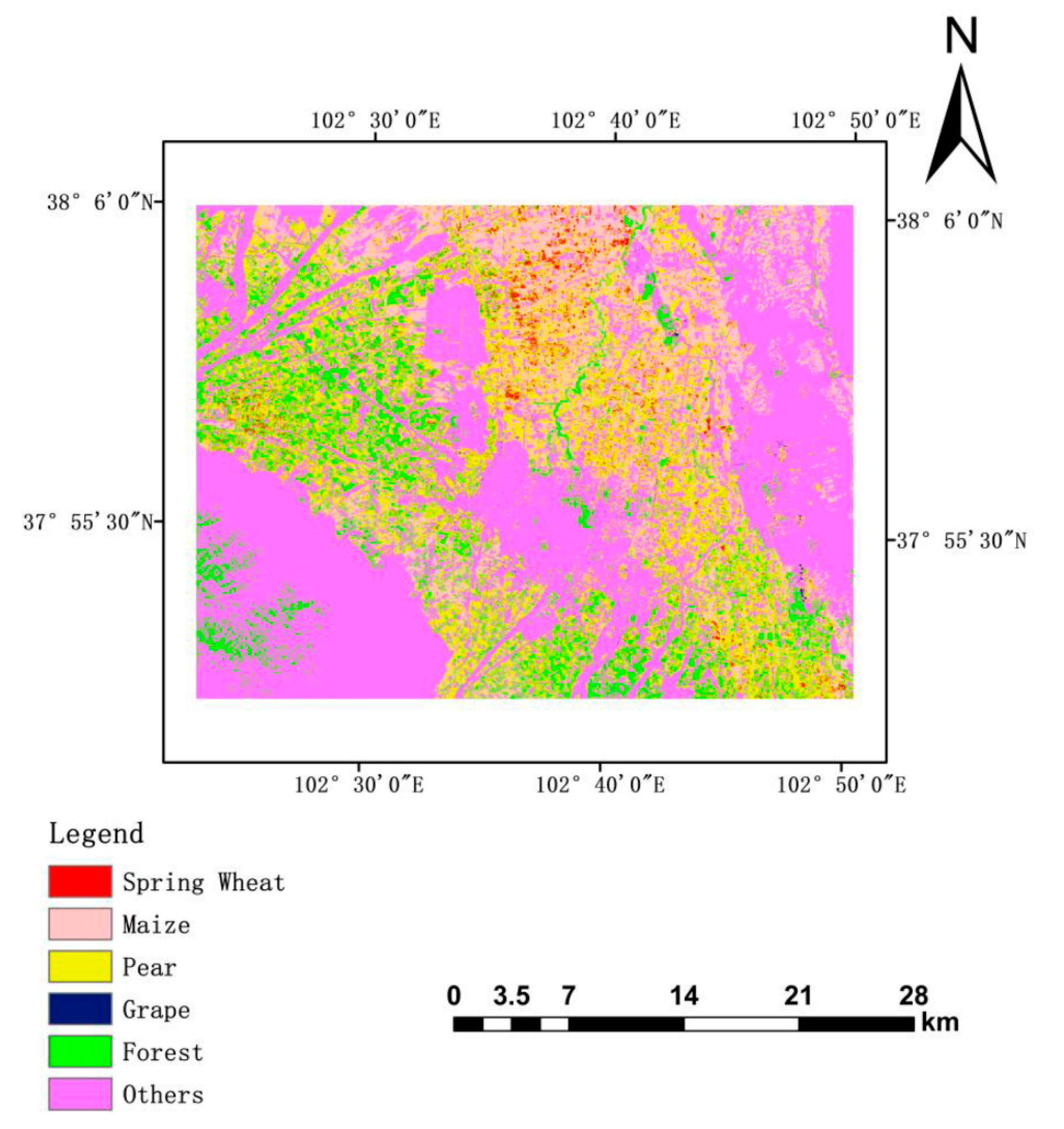
| Northwest of Wuwei City | 2018 | 73 | 25 | 36 | 65 | 36 | 82 | 317 | 106 | 71 |
| Study Area | Year | Method | OA | Kappa | Producer Accuracy % | |||||
| Others | Maize | Spring Wheat | Grape | Pear | Forests | |||||
| 93% | 81% | 100% | 100% | 76% | 100% | |||||
| Northwest of WuWei City | 2018 | PCIB | 84% | 76.5% | User Accuracy% | |||||
| Others | Maize | Spring Wheat | Grape | Pear | Forests | |||||
| 88% | 88% | 44% | 100% | 89% | 75% | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Z.; Liu, Z.; Zhao, Y.; Zhang, L.; Liu, D.; Ren, T.; Zhang, X.; Li, S. An Unsupervised Crop Classification Method Based on Principal Components Isometric Binning. ISPRS Int. J. Geo-Inf. 2020, 9, 648. https://doi.org/10.3390/ijgi9110648
Ma Z, Liu Z, Zhao Y, Zhang L, Liu D, Ren T, Zhang X, Li S. An Unsupervised Crop Classification Method Based on Principal Components Isometric Binning. ISPRS International Journal of Geo-Information. 2020; 9(11):648. https://doi.org/10.3390/ijgi9110648
Chicago/Turabian StyleMa, Zhe, Zhe Liu, Yuanyuan Zhao, Lin Zhang, Diyou Liu, Tianwei Ren, Xiaodong Zhang, and Shaoming Li. 2020. "An Unsupervised Crop Classification Method Based on Principal Components Isometric Binning" ISPRS International Journal of Geo-Information 9, no. 11: 648. https://doi.org/10.3390/ijgi9110648
APA StyleMa, Z., Liu, Z., Zhao, Y., Zhang, L., Liu, D., Ren, T., Zhang, X., & Li, S. (2020). An Unsupervised Crop Classification Method Based on Principal Components Isometric Binning. ISPRS International Journal of Geo-Information, 9(11), 648. https://doi.org/10.3390/ijgi9110648