1. Introduction
Large-scale geodata is currently a topic of considerable attention in many research fields, including mobile communication [
1], public transportation [
2], medical health [
3], Earth observation [
4], and climate monitoring [
5]. To enhance the capability of analyzing massive geodata, geographic knowledge mining is turning to data-driven patterns [
6]. Distributed system and parallel computing are two feasible technologies to solve the problem of massive geodata analysis. A tremendous amount of multisource geodata is stored in a distributed spatial index system [
7], enabling people to access records efficiently. Using the advantages of the distributed system Hadoop, Aji et al. (2019) [
8] proposed a scalable high-performance spatial data warehousing system (Hadoop-GIS) that can meet the needs of managing and querying massive geodata. Furthermore, based on the MapReduce parallel computing framework and the HadoopBase database (HBase) technology, the origin–destination (OD) estimation method [
9] can efficiently manage massive bus travel data and directly reckon the origin and destinations of travel for bus passenger. In the parallel computing field, large-scale geodata could be parallelize into multiple data pieces utilizing the strategies of multiple instruction multiple data (MIMD) and single instruction multiple data (SIMD). MIMD handles multiple instructions simultaneously in opposition to SIMD. There are several environments to parallelize multiple tasks based on different strategies (SIMD, MIMD), such as a message-passing interface (MPI), a multi-core CPU, and a many-core shared-memory graphics processing unit (GPU). MPI is mainly used to standardize the communication protocol of multi-program cluster, multi-core CPU relies on the computing power of CPU core, and many-core shared-memory GPU benefits from numerous stream processors (SP). Wilkinson et al. (1999) [
10] introduce parallel programming techniques and how to solve problems at a greater computational speed than is possible with a single computer. Gong et al. (2013) [
11] proposes a parallel approach that leverages the power of multicore systems, to cope with the computational complexity of agent-based models (ABMs), and it solves the space-time complexity of a geographic system. Tang et al. (2015) [
12] and Zhang et al. (2017) [
13] explored the feasibility of using GPU to carry out the massively parallel spatial computing and accelerate the spatial point pattern analysis. Sandric et al. (2019) [
14] undertook parallelization for certain GIS features operations using their message-passing interface–GIS (MPI-GIS) system, which integrated the advantages of MPI input/output (I/O) and GPU on a cluster of nodes. Stojanovic et al. (2019) [
15] proposed an algorithm to analyze with watershed approach, called multiple flow direction (MFD), which was designed for multicore CPU or many-core GPU. Amazing progress has been achieved in the fields of computer hardware and software, which lay a solid foundation for updating geographical research tools. However, there is still a sizable problem to be solved: how existing geographic analysis tools can be transformed to accommodate the development of big geodata mining [
16]?
Spatial non-stationarity analysis is an important research field of spatial data mining. Brunsdon et al. (1996) [
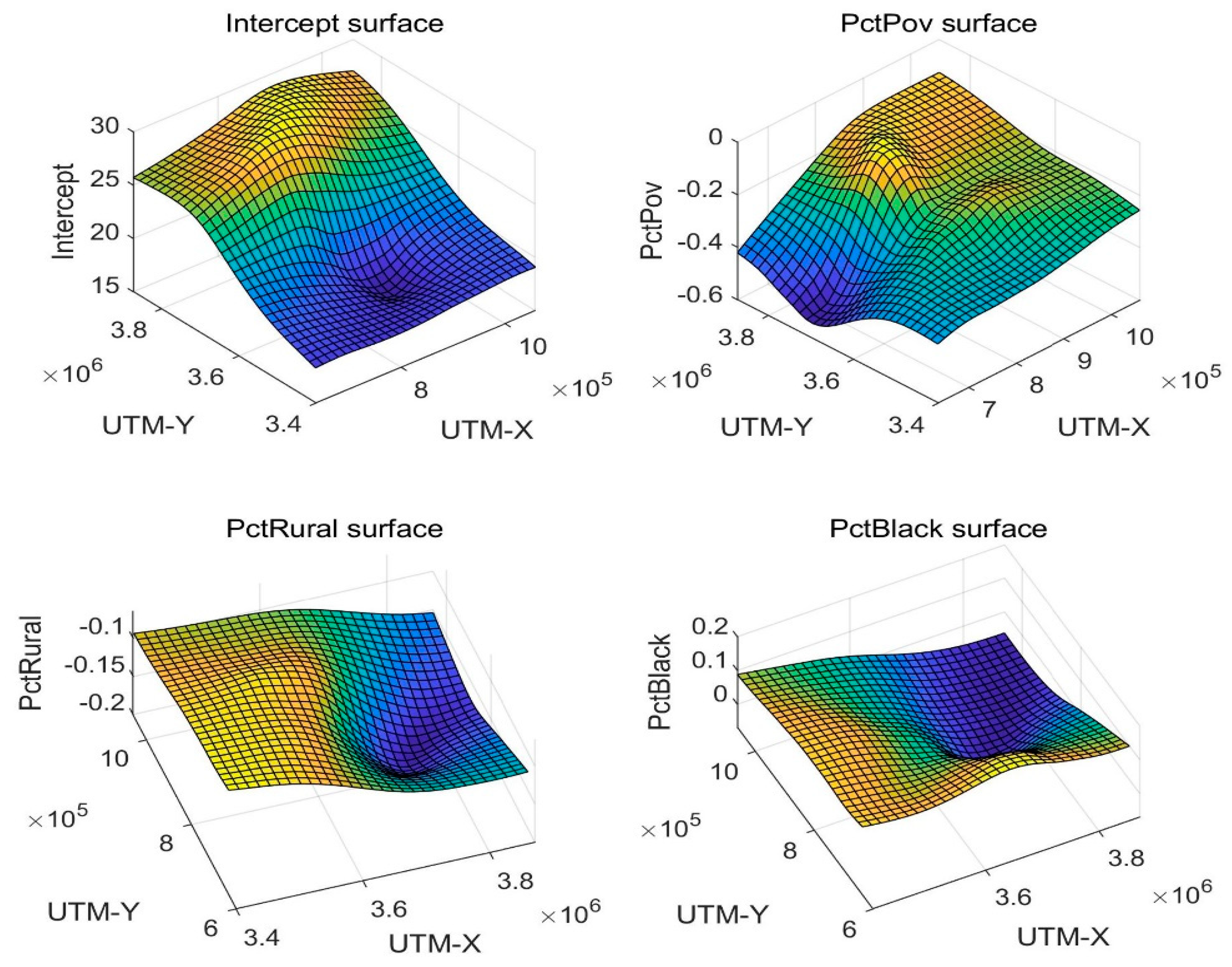
17] proposed the effective tool (GWR model) to explore spatial non-stationarity. GWR introduces the idea of local smoothness to calibrate the regression coefficients and detect spatial non-stationarity in the geographic space. The expansion of the location factor upgrades GWR from ordinary linear regression (OLR) model to a local regression model. The locally weighted least squares (LWLS) method is used to estimate the parameters point by point, where the weight refers to the distance kernel function of some point against each observation points. The results of parameter estimation from GWR are both clearly interpretable and statistically verifiable; therefore, GWR has become a major method for studying spatial heterogeneity. Zhang et al. (2020) [
18] employed GWR to identify the driving forces of wastewater discharge between provinces in China and discovered that the macro industry policy and environmental protection measures were major reasons for its spatial changes. Wu (2020) [
19] explored the influencing factors that cause spatially and temporally varying distributions of ecological footprints using GWR. Yuan et al. (2020) [
20] applied GWR to reveal the spatially varying relationships in environmental variables (Pb and Al) and suggested that GWR was more effective than conventional statistical analysis tools. Hong et al. (2020) [
21] researched the spatially heterogeneous relationship between price and pricing variables using multiscale geographically weighted regression (MGWR), in which it overcame the limitations of hedonic pricing model research for sharing economy accommodation. Wu et al. (2020) [
22] developed a geographically and temporally neural network weighted regression (GTNNWR) model that was extended from the spatiotemporal proximity neural network (STPNN), which not only exhibited a better prediction performance but also more accurately quantified the distribution of spatiotemporal heterogeneity.
Typically, parallelization of geographic analysis tools has become a comprehensive subject across computer field and geography science. The package spgwr [
23] was developed to implement GWR in the R language. Another R package (GWmodel) [
24] optimized this model with a moving window weighting technique and achieved slightly better efficiency against spgwr. The Python-based implementation (mgwr [
25]) of MGWR was developed for multiscale analysis that allowed varying relationships according to each coefficient. Li et al. (2019) [
26] (a member of the mgwr package) upgraded its mode to distributed parallelization utilized within a high-performance computing (HPC) environment and the new package (FastGWR) achieved satisfactory results. Tran et al. (2016) [
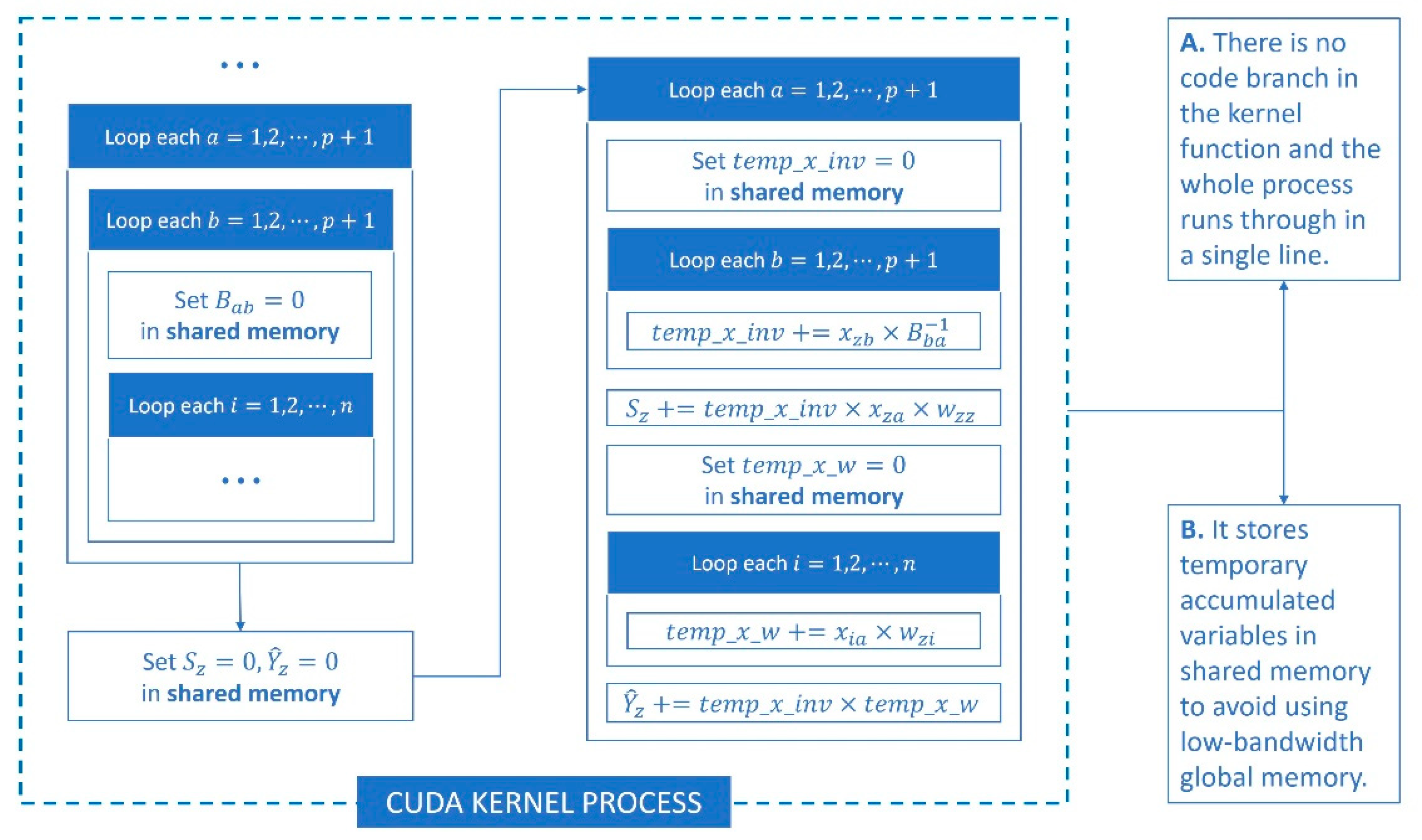
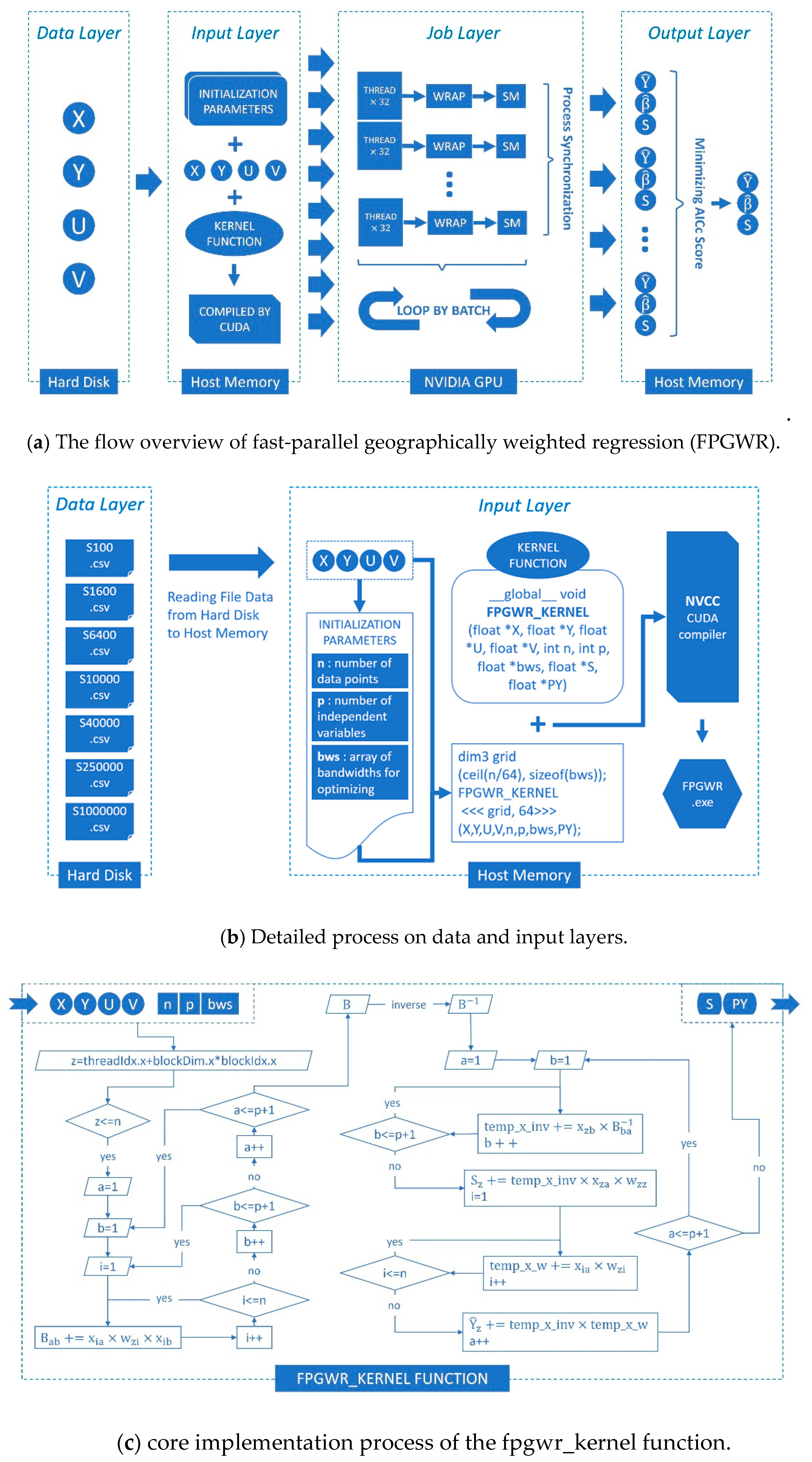
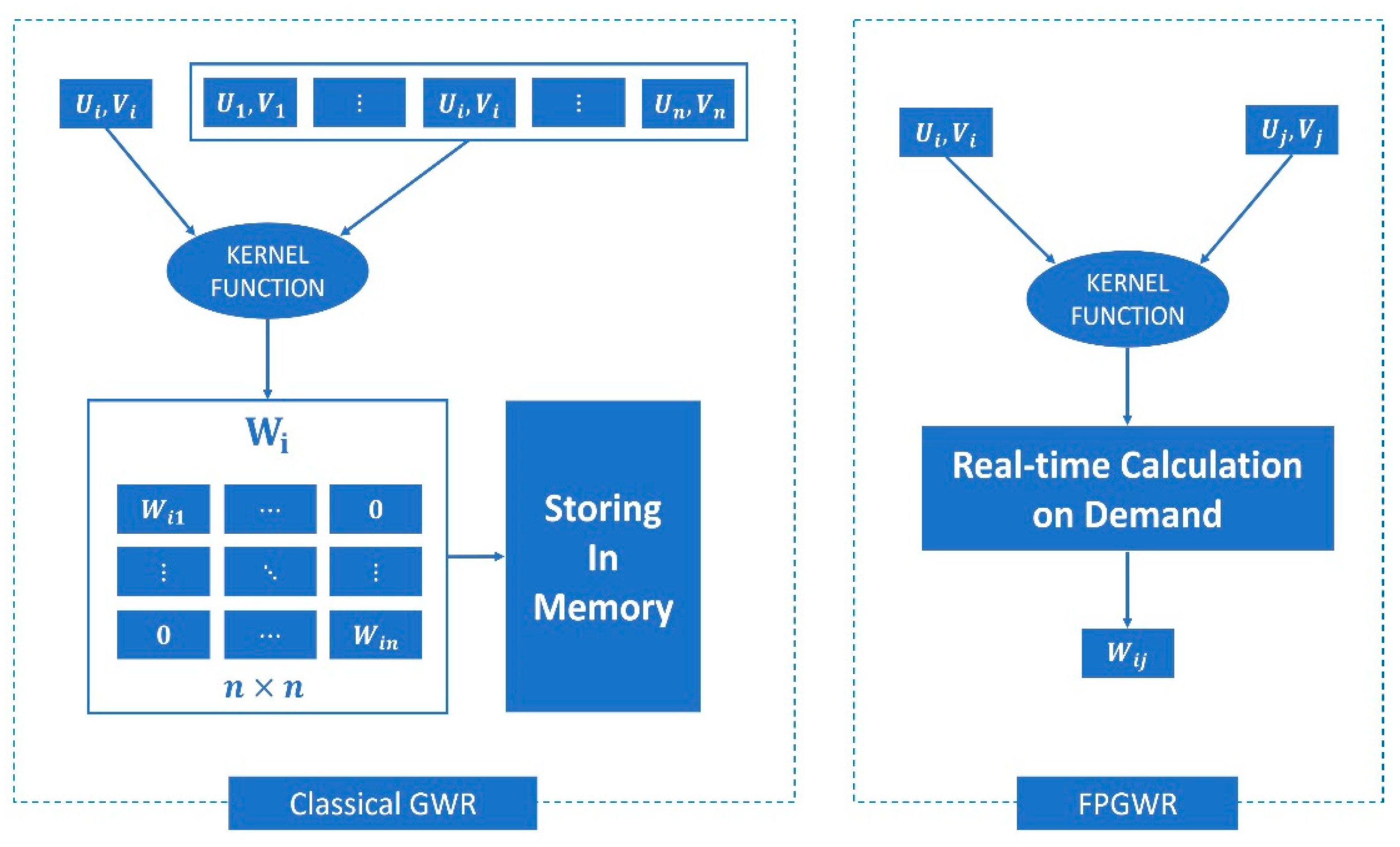
27] studied the implementation of large-scale GWR on an in-memory cluster computing framework Spark (Spark-GWR) and determined that it was a feasible solution using cluster computers to execute GWR in parallel, but great difficulty is encountered for ordinary coders in developing and testing under the cluster environment. As a representative model of local regression, GWR incorporates all of the observations (samples) into the loop of the regression sequence. The key to geographic weighting is the calculation of distance weights for each sample, where it causes costly complexity in terms of runtime and memory. At the same time, the entire process consumes a large amount of computing time because the weight calibrator participates in multilayer loops. Under the condition of large-scale geodata, GWR needs to go through two levels of large cycle iteration, the outer iteration is responsible for point by point regression, and the inner iteration is used for matrix calculation between single sample and full samples. Therefore, limited by data structure and operating mode, GWR is less effective in addressing large-scale geodata. Concurrency methods can improve the efficiency of geographic analysis tools depending on the software optimization, but the hardware parallel environment could obtain native support and achieve the best acceleration performance. Both FastGWR and Spark-GWR could divide GWR into several parallel task sets, and the two parallel programs are designed for CPU architecture that cannot be adapted to GPU architecture. FPGWR decomposes large-scale GWR into simpler parallelizable computing units utilizing atomization algorithm and processes them with numerous parallel GPU cores.
In this paper, we develop FPGWR to reduce the computational complexity in the GWR process and enable GWR’s applications in millions or even tens of millions of geodata. This technique significantly improves the efficiency in regression when utilizing the parallelization of large tasks. On the basis of the CUDA framework, atomic subtasks that are decomposed from large tasks could run on a GPU device in parallel mode. This paper contributes to the prior literature as follows. (1) FPGWR can compensate for the deficiencies of GWR in undertaking regression computation for large-scale geodata, and FPGWR with separate atomic computing units (atomization) is more efficient than GWR. (2) FPGWR is a powerful model for exploring spatial heterogeneity and incorporating high parallelism into geography analysis, which is applicable for studies in various fields, such as economic geography, social science, public health. (3) The improvement from GWR to FPGWR can provide new insights into geospatial computing from spatial and computational perspective.
5. Conclusions
GWR is a local modeling technique that has been widely used in various disciplines. However, GWR has significant computational redundancy and can handle approximately 15,000 geographical observations at most. To apply the local smoothing technique on a large-scale spatial dataset, we proposed an improved algorithm FPGWR to solve these problems. FPGWR optimizes the matrix storage mode to overcome the limitation on memory space, thereby significantly reducing the memory complexity of GWR. Furthermore, it introduces a parallel computing mode, decomposing the full-sample large cycle into an atomization process, to decrease the runtime complexity substantially.
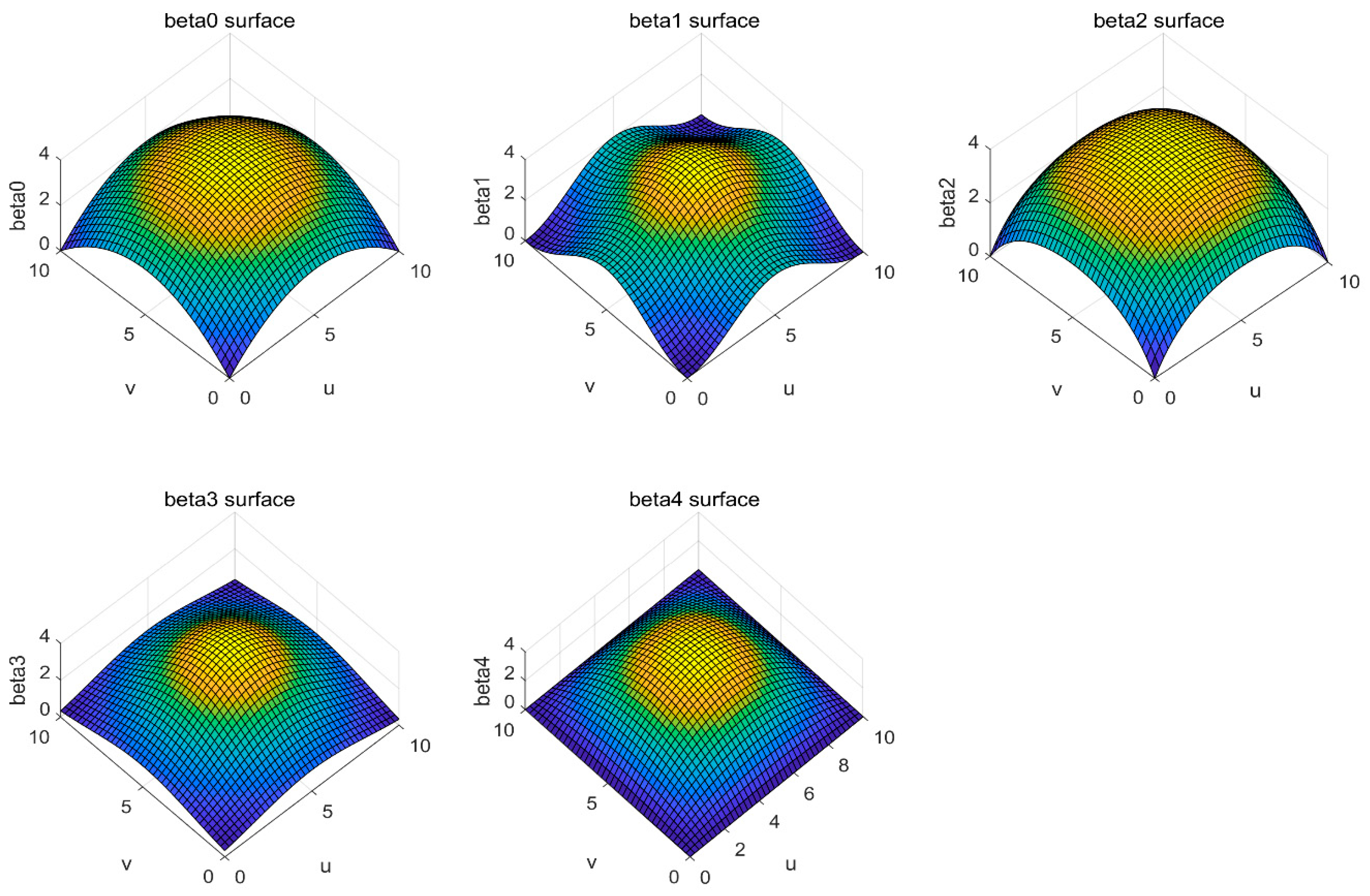
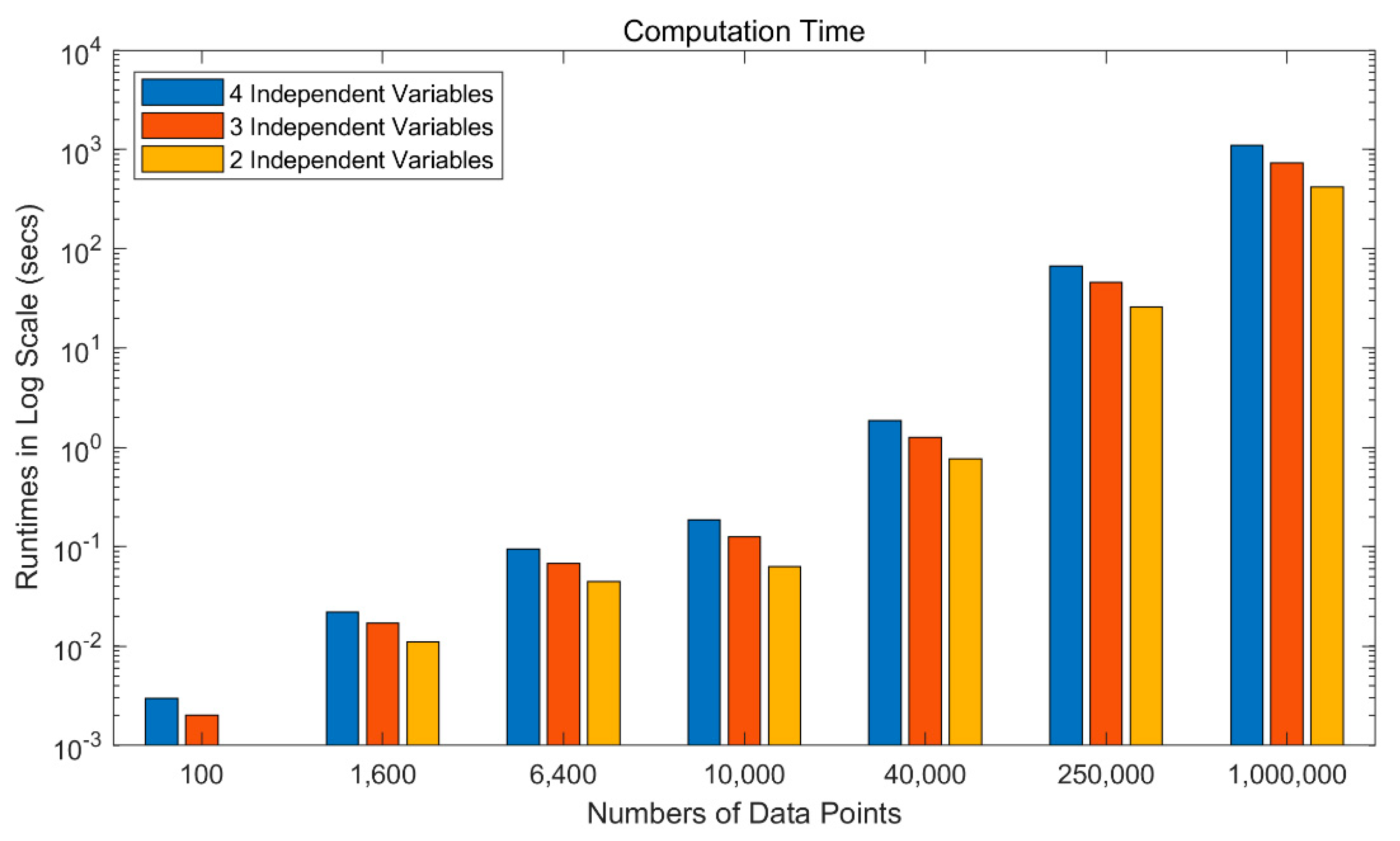
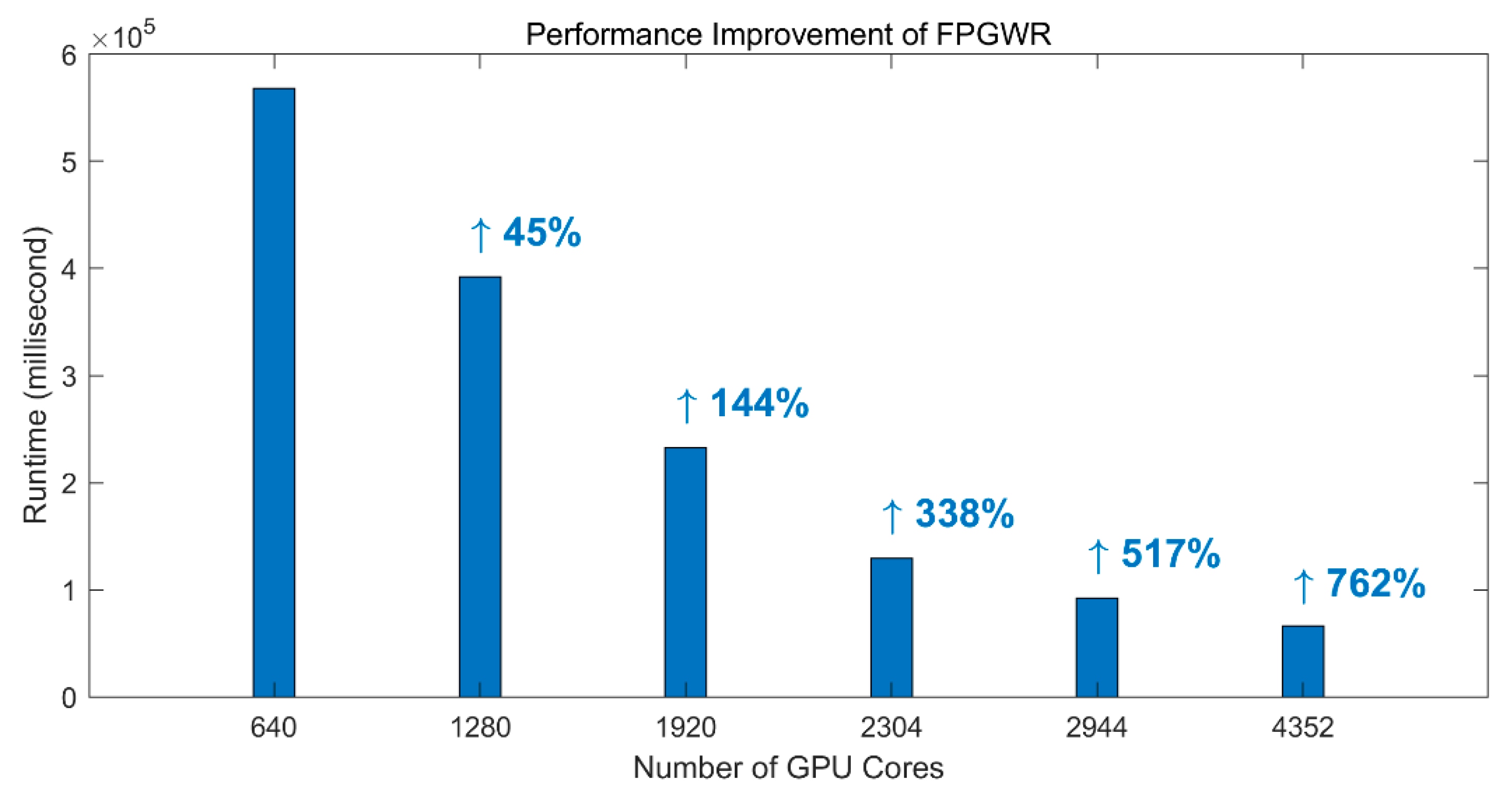
To demonstrate the practicability of FPGWR, simulation and Zillow datasets are used to conduct the experiment. The results show that the regression runtime is exponentially related to the number of observations, and thus, GWR is unable to process the regression task with large volumes of geodata. In comparison, the time taken up by FPGWR exhibits a logarithmic relationship with the number of observations; hence, FPGWR represents a significant advance in handling the massive geodata mining task.
In summary, the dilemma that limits GWR in the data scale could be considerably alleviated by FPGWR, and thus, the application domains of GWR would be potentially expanded to a large extent. Under these circumstances, increasingly large datasets from geographical or nongeographical fields could be converted to the providers of the large-scale geographic analysis services. In the future, we will investigate a key issue: how to adapt FPGWR to non-CUDA architectures, even other non-GPU HPC devices, to enhance the versatility of the extended algorithm.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}