A Multiresolution Vector Data Compression Algorithm Based on Space Division

Abstract
:1. Introduction
2. Methodology
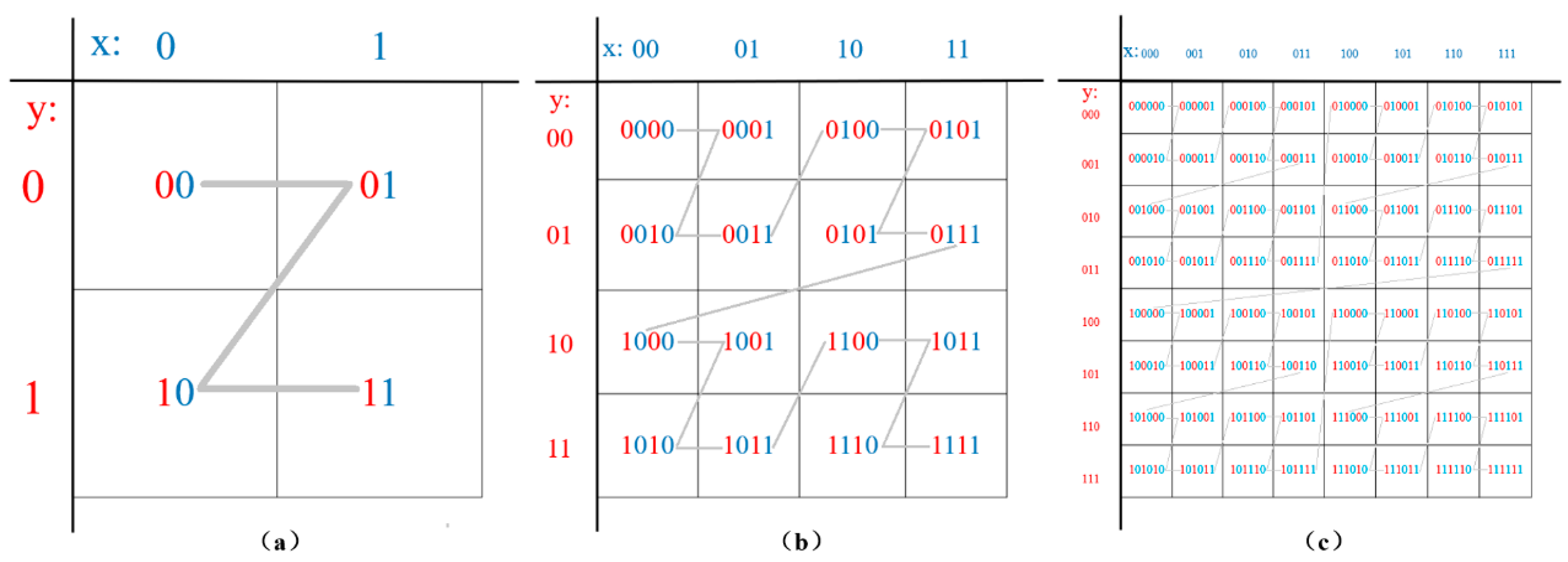
2.1. A Hybrid Implementation of Morton Encoding and Geohash Encoding
2.2. Grid Filter
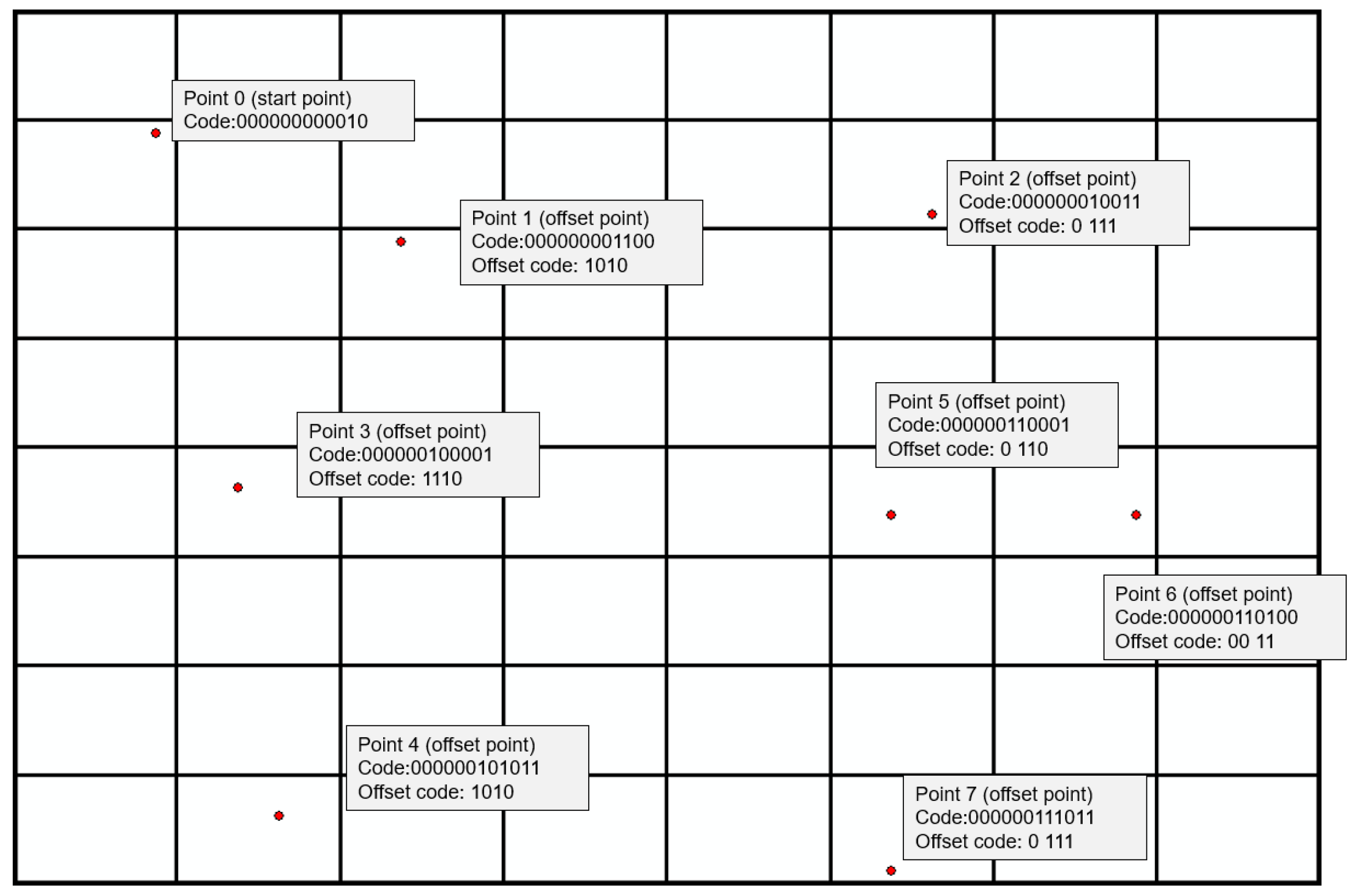
2.3. Binary Offset Storage
- (1)
- Sort points according to their corresponding binary codes.
- (2)
- Take the first point as origin, and all following points are presented in binary form using the number of grid cells (steps in the Morton order) that deviates from its preceding point.
- (3)
- Length of offset binary code will be greater than 1 and less than the length of the original binary code, and the maximum length of all offset binary code lengths will be taken as the storage length.
- (4)
- For records with insufficient offset bits, supplementary bits are added and filled with “0” to ensure uniform storage length.
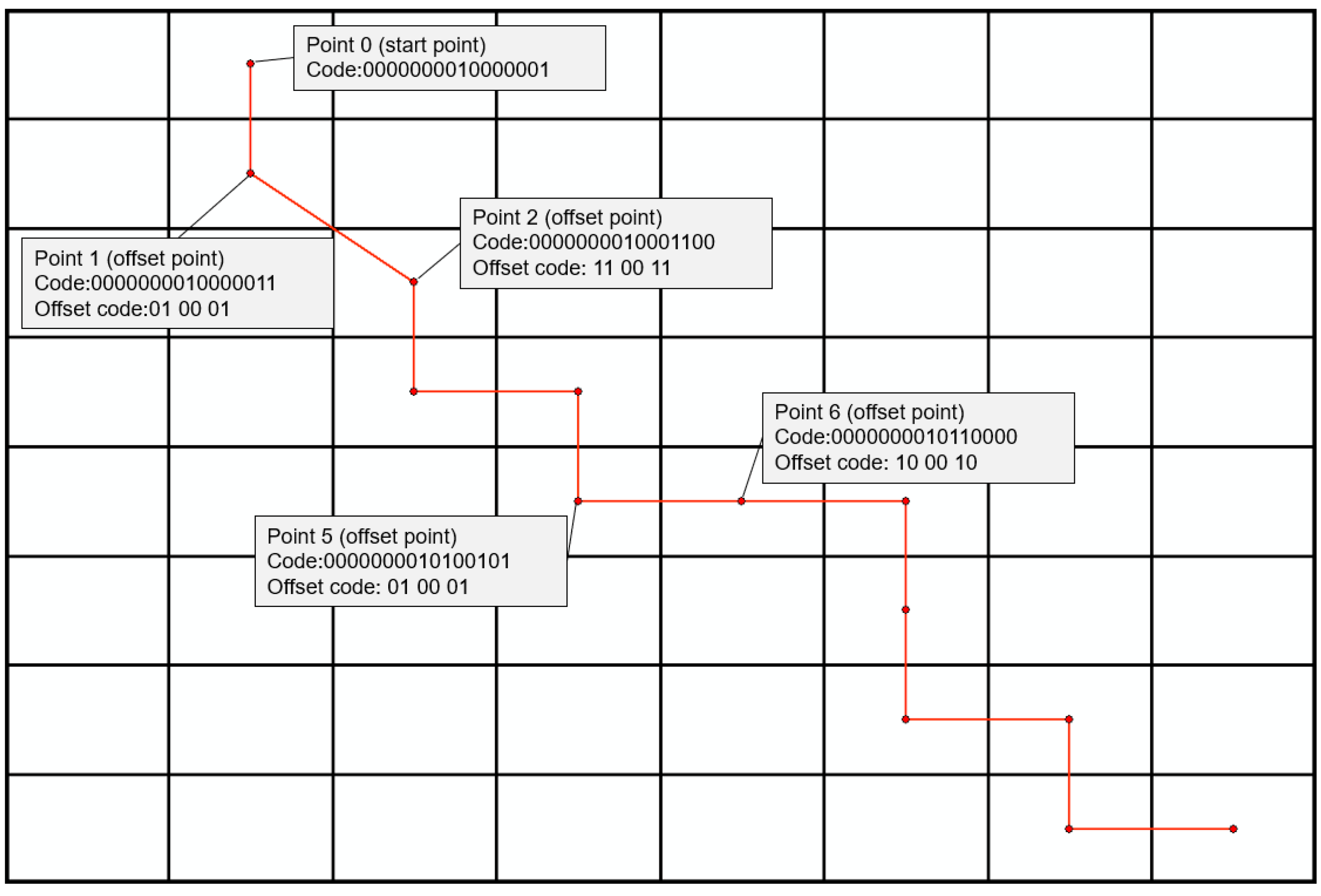
- (1)
- Record the number of nodes and starting point coordinates of each vector object, then calculate offset in the unit of the vector object.
- (2)
- Set up direction bit, calculate the offset direction of each coordinate point to its preceding point, Use “0” or “1” to represent left or right in horizontal direction, downward or upward in vertical direction, respectively.
- (3)
- Calculate offset, record offsets of rows and columns along latitude and longitude directions, convert them into binary codes and store them alternately as the final offset.
- (4)
- Determine offset binary code length as the maximum length of all offset binary code lengths.
- (5)
- For records with insufficient offset bits, set up supplementary bits, fill with “0” to ensure uniform storage length.
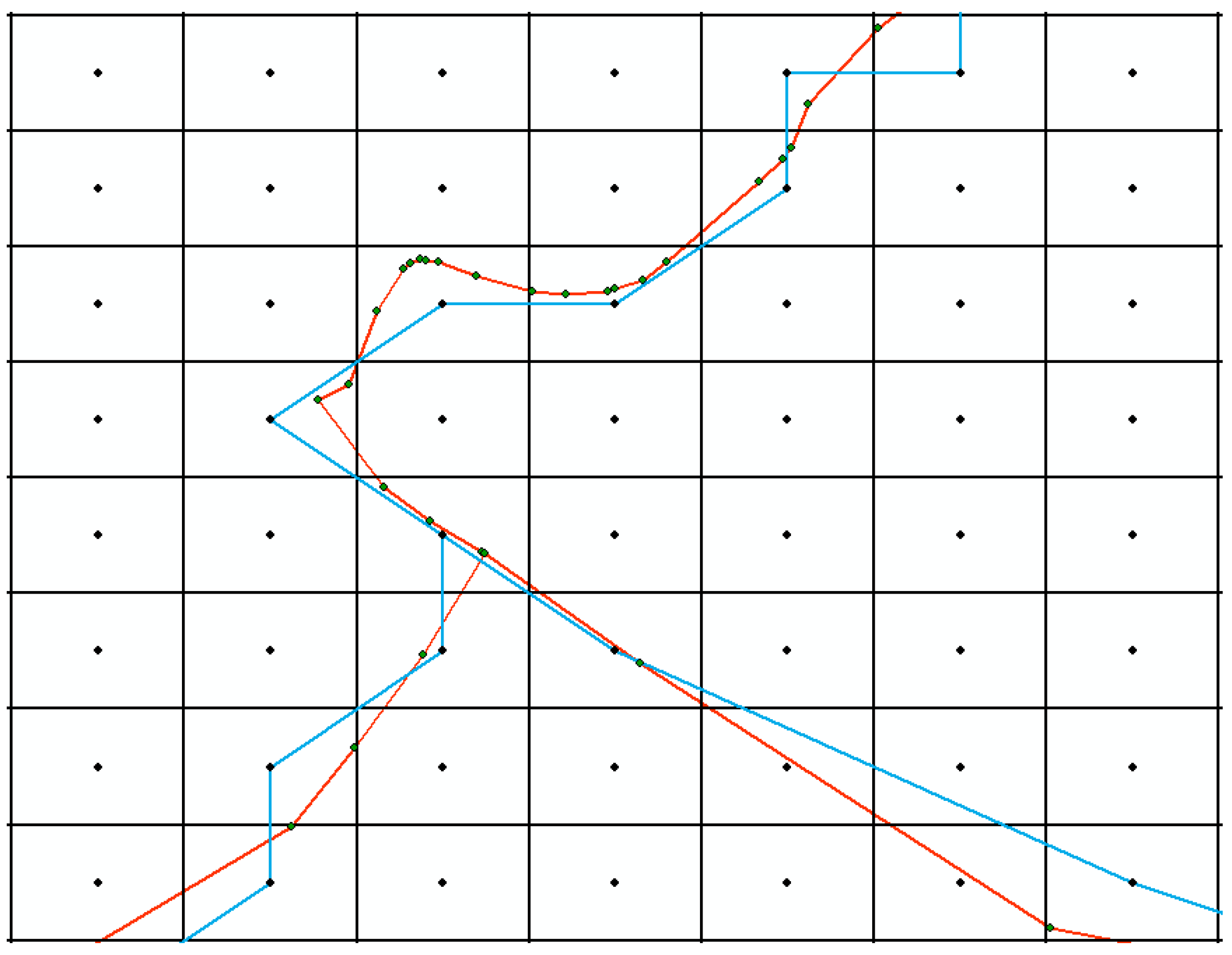
2.4. Error Evaluation
3. Data and Experiment Results
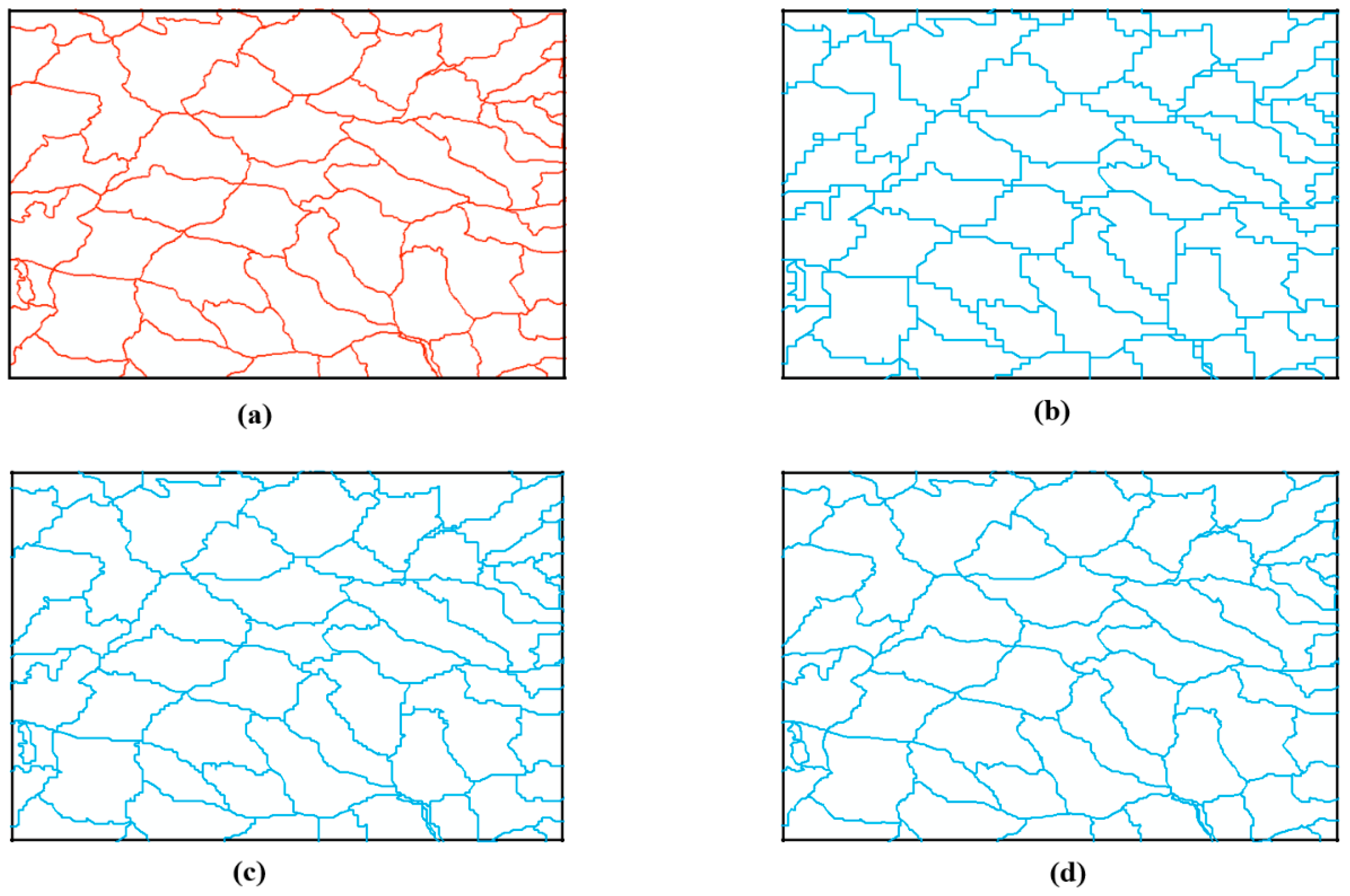
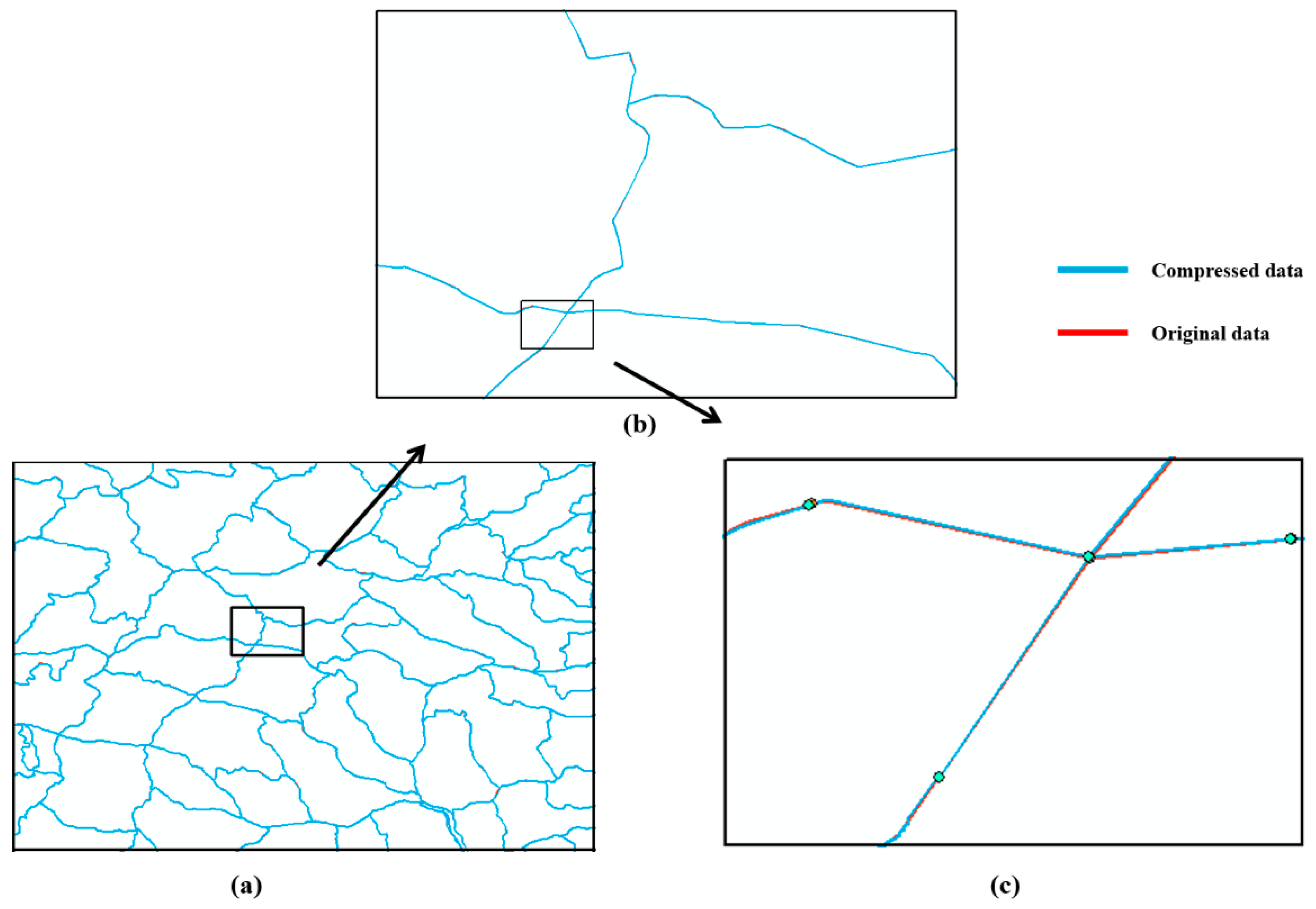
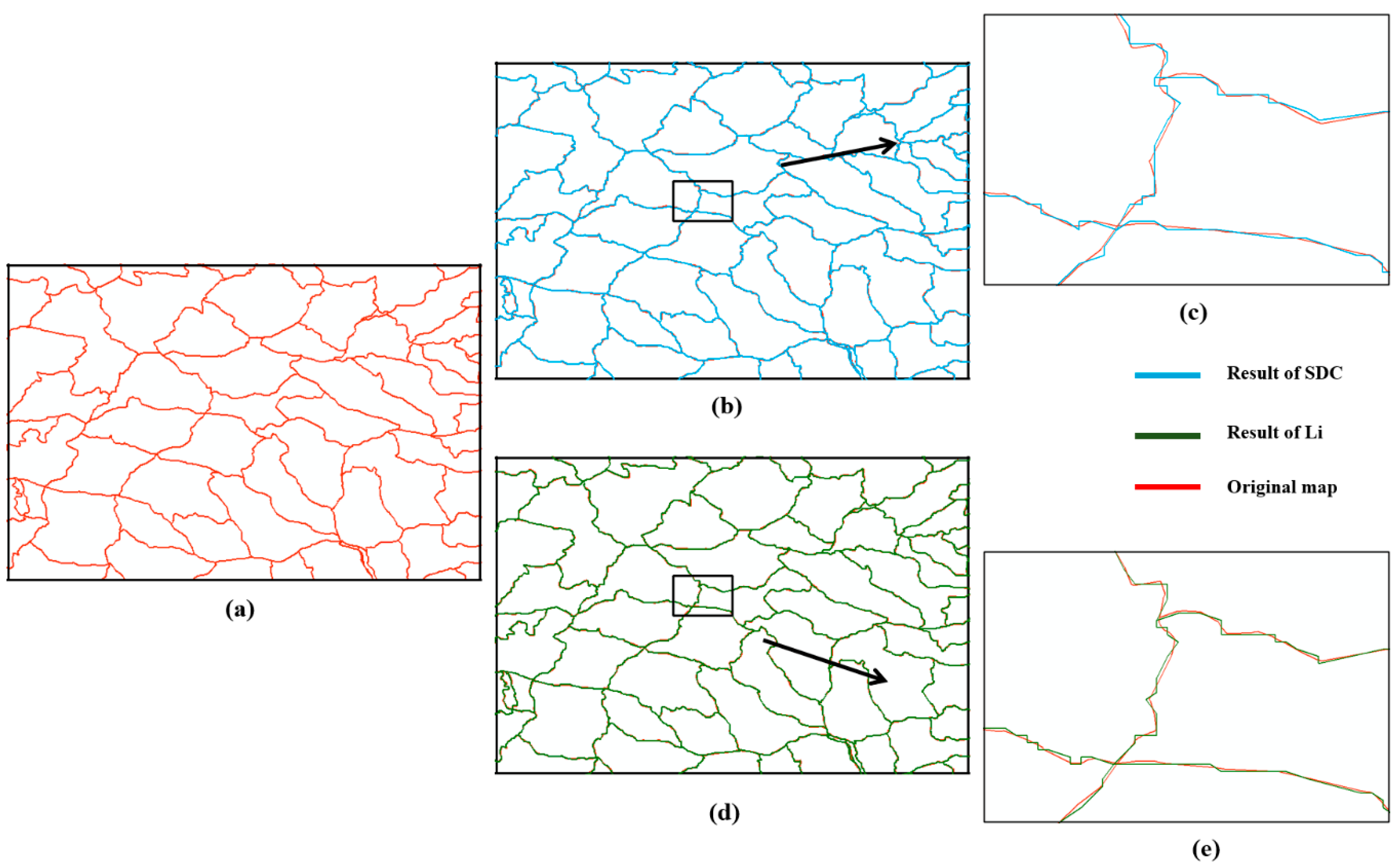
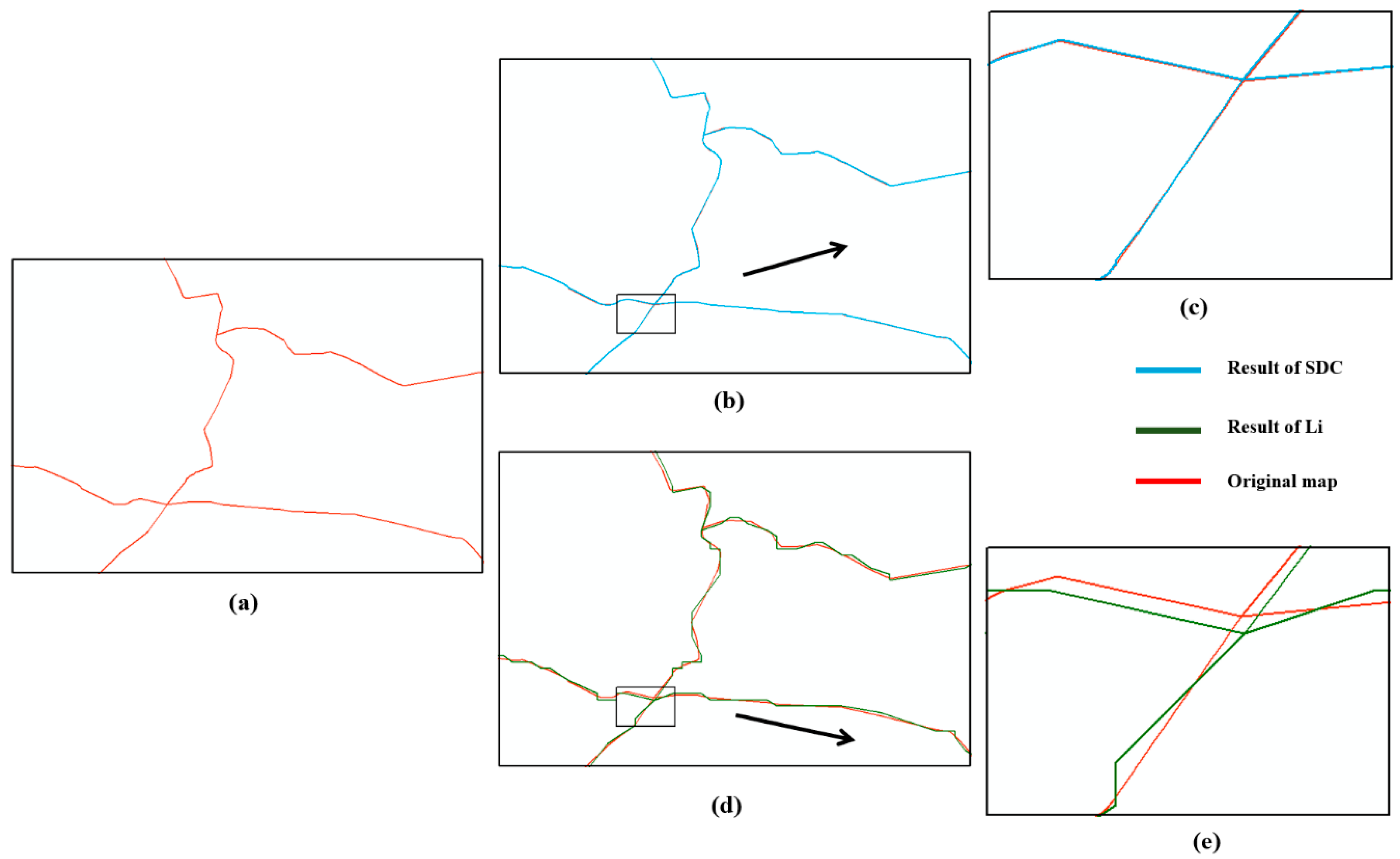
3.1. Visual Comparison
3.2. Data Rate Saving and Comparison
4. Conclusions and Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tao, W. Interdisciplinary urban GIS for smart cities: Advancements and opportunities. Geo-Spat. Inf. Sci. 2013, 16, 25–34. [Google Scholar] [CrossRef]
- Jo, J.; Lee, K.-W. High-performance geospatial big data processing system based on mapreduce. ISPRS Int. J. Geo-Inf. 2018, 7, 399. [Google Scholar] [CrossRef] [Green Version]
- Coluccia, G.; Lastri, C.; Guzzi, D.; Magli, E.; Nardino, V.; Palombi, L.; Pippi, I.; Raimondi, V.; Ravazzi, C.; Garoi, F.; et al. Optical compressive imaging technologies for space big data. IEEE Trans. Big Data 2019, 6, 430–442. [Google Scholar] [CrossRef]
- Li, C.; Wu, Z.; Wu, P.; Zhao, Z. An adaptive construction method of hierarchical spatio-temporal index for vector data under peer-to-peer networks. ISPRS Int. J. Geo-Inf. 2019, 8, 512. [Google Scholar] [CrossRef] [Green Version]
- Feng, B.; Zhu, Q.; Liu, M.; Li, Y.; Zhang, J.; Fu, X.; Zhou, Y.; Li, M.; He, H.; Yang, W. An efficient graph-based spatio-temporal indexing method for task-oriented multi-modal scene data organization. ISPRS Int. J. Geo-Inf. 2018, 7, 371. [Google Scholar] [CrossRef] [Green Version]
- Huang, W.; Yang, J.; Chen, Y.; Zhang, Y.; Zhang, R. Method of vector data compression based on sector screening. Geomat. Inf. Sci. Wuhan Univ. 2016, 41, 487–491. [Google Scholar] [CrossRef]
- Sim, M.S.; Kwak, J.H.; Lee, C.H. Fast shape matching algorithm based on the improved douglas-peucker algorithm. KIPS Trans. Softw. Data Eng. 2016, 5, 497–502. [Google Scholar] [CrossRef]
- Lee, S.; Hwang, W.; Jung, J.; Kwon, K. Vector map data compression using polyline feature. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2014, 97, 1595–1604. [Google Scholar] [CrossRef]
- Chand, A.; Vijender, N. Positive blending hermite rational cubic spline fractal interpolation surfaces. Calcolo 2015, 52, 1–24. [Google Scholar] [CrossRef]
- Visvalingam, M.; Whelan, J.C. Implications of weighting metrics for line generalization with Visvalingam’s Algorithm. Cartogr. J. 2016, 53, 1–15. [Google Scholar] [CrossRef]
- Visvalingam, M. The visvalingam algorithm: Metrics, measures and heuristics. Cartogr. J. 2016, 53, 1–11. [Google Scholar] [CrossRef]
- Zhu, F.; Miao, L.; Liu, W. Research on vessel trajectory multi-dimensional compression algorithm based on Douglas-Peucker theory. Appl. Mech. Mater. 2014, 694, 59–62. [Google Scholar] [CrossRef]
- Wang, Z.; Müller, J.-C. Line generalization based on analysis of shape characteristics. Cartogr. Geogr. Inf. Syst. 1998, 25, 3–15. [Google Scholar] [CrossRef]
- Ai, T.; Ke, S.; Yang, M.; Li, J. Envelope generation and simplification of polylines using Delaunay Triangulation. Int. J. Geogr. Inf. Sci. 2017, 31, 297–319. [Google Scholar] [CrossRef]
- Yan, Z.P.; Wang, H.J.; He, Q.Q. A statistical analysis of papers and author group in geomatics and information science of Wuhan University. Adv. Mater. Res. 2014, 998, 1536–1540. [Google Scholar] [CrossRef]
- Xue, S.; Wang, G.; Guo, J.; Yu, W.; Xu, X. Vector map data compression of frequency domain with consideration of maximum absolute error. Geomat. Inf. Sci. Wuhan Univ. 2018, 43, 1438–1444. [Google Scholar]
- Yu, X.; Zhang, J.; Zhang, L. Spatial vector data compression method based on integer wavelet transform. Earth Sci. J. China Univ. Geosci. 2011, 36, 381–385. [Google Scholar]
- Bjørke, J.; Nilsen, S. Efficient representation of digital terrain models: Compression and spatial de-correlation techniques. Comput. Geosci. 2002, 28, 433–445. [Google Scholar] [CrossRef]
- Li, Q.; Yang, C.; Chen, A. Research on geographical relational database model in webGIS. J. Image Graph. 2000, 2, 33–37. [Google Scholar]
- Li, Q.; Liu, X.; Cao, D. Research in webGIS vector spatial data compression methods. J. Image Graph. 2001, 12, 81–85. [Google Scholar]
- Kasban, H.; Hashima, S. Adaptive radiographic image compression technique using hierarchical vector quantization and Huffman encoding. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 2855–2867. [Google Scholar] [CrossRef]
- Ozsoy, A. An efficient parallelization of longest prefix match and application on data compression. Int. J. High Perform. Comput. Appl. 2015, 30, 276–289. [Google Scholar] [CrossRef]
- Isenburg, M.; Lindstrom, P.; Snoeyink, J. Lossless compression of floating-point geometry. Comput. Aided Des. 2004, 1, 495–501. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, J. Fast translating algorithm between QTM code and longitude/latitude coordination. Acta Geod. Cartogr. Sin. 2003, 32, 272–277. [Google Scholar]
- Sahr, K.; White, D.; Kimerling, A.J. Geodesic discrete global grid systems. Cartogr. Geogr. Inf. Sci. 2020, 30, 121–134. [Google Scholar] [CrossRef] [Green Version]
- Google. 2020. Available online: https://github.com/google/s2geometry (accessed on 20 September 2020).
- Uber. 2020. Available online: https://eng.uber.com/h3/ (accessed on 20 September 2020).
- Geohash. 2020. Available online: https://en.wikipedia.org/wiki/Geohash (accessed on 20 September 2020).
- Zhou, C.; Lu, H.; Xiang, Y.; Wu, J.; Wang, F. GeohashTile: Vector geographic data display method based on geohash. ISPRS Int. J. Geo-Inf. 2020, 9, 418. [Google Scholar] [CrossRef]
- Yi, X.; Xu, Z.; Guo, C.; Liu, D. Spatial index structure based on patricia tree. Comput. Eng. 2015, 41, 69–74. [Google Scholar]
- Tang, L.; Da, F.-P.; Huang, Y. Compression algorithm of scattered point cloud based on octree coding. In Proceedings of the 2016 2nd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 14–17 October 2016; Volume 2, pp. 85–89. [Google Scholar]
- Gong, X.; Ci, L.; Yao, K. Split-merge algorithm of image based on Morton code. Comput. Eng. Des. 2007, 22, 5440–5443. [Google Scholar]
- Yang, B.; Purves, R.; Weibel, R. Variable-resolution compression of vector data. GeoInformatica 2008, 12, 357–376. [Google Scholar] [CrossRef] [Green Version]
- Samet, H. Applications of Spatial Data Structures; Addision-Wesley: New York, NY, USA, 1990. [Google Scholar]
- Li, Z.; Openshaw, S. Algorithms for automated line generalization1 based on a natural principle of objective generalization. Int. J. Geogr. Inf. Sci. 1992, 6, 373–389. [Google Scholar] [CrossRef]
- OpenStreetMap. Available online: https://www.openstreetmap.org/#map=10/27.1295/31.1133 (accessed on 20 January 2020).
- LZMA. Available online: http://en.wikipedia.org/wiki/Lempel-Ziv-Markov_chain_algorithm (accessed on 25 November 2020).
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef] [Green Version]
- Ai, T. Constraints of progressive transmission of spatial data on the web. Geo-Spat. Inf. Sci. 2010, 13, 85–92. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | Bit Length | Binary Code |
|---|---|---|
| 1 | 2 | 01 |
| 2 | 4 | 0110 |
| 3 | 6 | 011010 |
| 4 | 8 | 01101000 |
| 5 | 10 | 0110100001 |
| 6 | 12 | 011010000100 |
| 7 | 14 | 01101000010001 |
| 8 | 16 | 0110100001000111 |
| 9 | 18 | 011010000100011101 |
| Starting Point | Offset Point 1 | Offset Point 2 | ||
|---|---|---|---|---|
| 000000000010 | Supplementary bits | Offset bits | Supplementary bits | Offset bits |
| 1010 | 0 | 111 | ||
| Number | Starting Point | Offset Point 1 | Offset Point 2 | ||||
|---|---|---|---|---|---|---|---|
| 13 | 0000000010000001 | Direction bits | Supplementary bits | Offset bits | Direction bits | Supplementary bits | Offset bits |
| 01 | 00 | 01 | 11 | 00 | 11 | ||
| n | Bit Length | Number of Rows/Columns | Longitude Resolution (m) | Latitude Resolution (m) | Max_Error (m) | Distance (m) | Magnification |
|---|---|---|---|---|---|---|---|
| 10 | 20 | 1024 | 652.262641 | 585.449125 | 438.2343 | 250 | 0.57 |
| 11 | 22 | 2048 | 326.131321 | 292.724562 | 219.11715 | 250 | 1.14 |
| 12 | 24 | 4096 | 163.06566 | 146.362281 | 109.55857 | 250 | 2.28 |
| 13 | 26 | 8192 | 81.53283 | 73.181141 | 54.779288 | 250 | 4.56 |
| 14 | 28 | 16,384 | 40.766415 | 36.59057 | 27.389644 | 250 | 9.13 |
| 15 | 30 | 32,863 | 20.324284 | 18.242397 | 13.655233 | 250 | 18.31 |
| 16 | 32 | 65,536 | 10.191604 | 9.147643 | 6.8474112 | 250 | 36.51 |
| 17 | 34 | 131,072 | 5.095802 | 4.573821 | 3.4237054 | 250 | 73.02 |
| 18 | 36 | 262,144 | 2.547901 | 2.286911 | 1.7118529 | 250 | 146.04 |
| 19 | 38 | 524,288 | 1.27395 | 1.143455 | 0.855926 | 250 | 292.08 |
| 20 | 40 | 1,048,576 | 0.636975 | 0.571728 | 0.4279632 | 250 | 584.16 |
| n | Bit Length | RESP.shp | gis_osm_natural_free_1.shp | ||
| Compressed File Size (BYTE) | Data RateSaving | Compressed File Size (KB) | Data Rate Saving | ||
| 5 | 10 | 600 | 98.67% | 17 | 99.89% |
| 6 | 12 | 801 | 98.22% | 30 | 99.81% |
| 7 | 14 | 1206 | 97.32% | 46 | 99.71% |
| 8 | 16 | 1603 | 96.44% | 72 | 99.54% |
| 9 | 18 | 2007 | 95.54% | 122 | 99.23% |
| 10 | 20 | 2409 | 94.64% | 199 | 98.74% |
| 11 | 22 | 2808 | 93.76% | 316 | 97.99% |
| 12 | 24 | 3207 | 92.87% | 473 | 97.00% |
| 13 | 26 | 3613 | 91.97% | 674 | 95.72% |
| 14 | 28 | 4012 | 91.08% | 928 | 94.11% |
| 15 | 30 | 4411 | 90.19% | 1 248 | 92.08% |
| n | Bit Length | LRDL.shp | gis_osm_roads_free_1.shp | ||
| Compressed File Size (KB) | Data Rate Saving | Compressed File Size (MB) | Data Rate Saving | ||
| 5 | 10 | 17 | 99.60% | 4.4 | 98.67% |
| 6 | 12 | 20 | 99.52% | 4.8 | 98.55% |
| 7 | 14 | 28 | 99.31% | 5.1 | 98.46% |
| 8 | 16 | 39 | 99.06% | 5.5 | 98.34% |
| 9 | 18 | 65 | 98.41% | 6.2 | 98.13% |
| 10 | 20 | 109 | 97.33% | 7.1 | 97.85% |
| 11 | 22 | 174 | 95.72% | 8.3 | 97.49% |
| 12 | 24 | 263 | 93.55% | 11 | 96.68% |
| 13 | 26 | 372 | 90.88% | 15.7 | 95.26% |
| 14 | 28 | 491 | 87.95% | 23.1 | 93.02% |
| 15 | 30 | 598 | 85.33% | 32.5 | 90.18% |
| LZMA | LZX | ||||
|---|---|---|---|---|---|
| Data | Original File Size (KB) | Compressed File Size (KB) | Data Rate Saving | Compressed File Size (KB) | Data Rate Saving |
| RESP.shp | 44 | 22 | 50.00% | 25 | 43.18% |
| gis_osm_natural_free_1.shp | 15,752 | 3 906 | 75.20% | 5 372 | 65.90% |
| LRDL.shp | 4075 | 2 248 | 44.83% | 2 610 | 35.95% |
| gis_osm_roads_free_1.shp | 339,477 | 100 850 | 70.29% | 122 226 | 64.00% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, D.; Wang, T.; Li, X.; Ni, Y.; Li, Y.; Jin, Z. A Multiresolution Vector Data Compression Algorithm Based on Space Division. ISPRS Int. J. Geo-Inf. 2020, 9, 721. https://doi.org/10.3390/ijgi9120721
Liu D, Wang T, Li X, Ni Y, Li Y, Jin Z. A Multiresolution Vector Data Compression Algorithm Based on Space Division. ISPRS International Journal of Geo-Information. 2020; 9(12):721. https://doi.org/10.3390/ijgi9120721
Chicago/Turabian StyleLiu, Dongge, Tao Wang, Xiaojuan Li, Yeqing Ni, Yanping Li, and Zhao Jin. 2020. "A Multiresolution Vector Data Compression Algorithm Based on Space Division" ISPRS International Journal of Geo-Information 9, no. 12: 721. https://doi.org/10.3390/ijgi9120721
APA StyleLiu, D., Wang, T., Li, X., Ni, Y., Li, Y., & Jin, Z. (2020). A Multiresolution Vector Data Compression Algorithm Based on Space Division. ISPRS International Journal of Geo-Information, 9(12), 721. https://doi.org/10.3390/ijgi9120721