Crime Prediction with Historical Crime and Movement Data of Potential Offenders Using a Spatio-Temporal Cokriging Method



Abstract
:1. Introduction
2. Related Work
2.1. Crime Prediction Methods
2.2. Role of Offenders in Criminal Activities
3. Study Area and Data
3.1. Study Area
3.2. Data
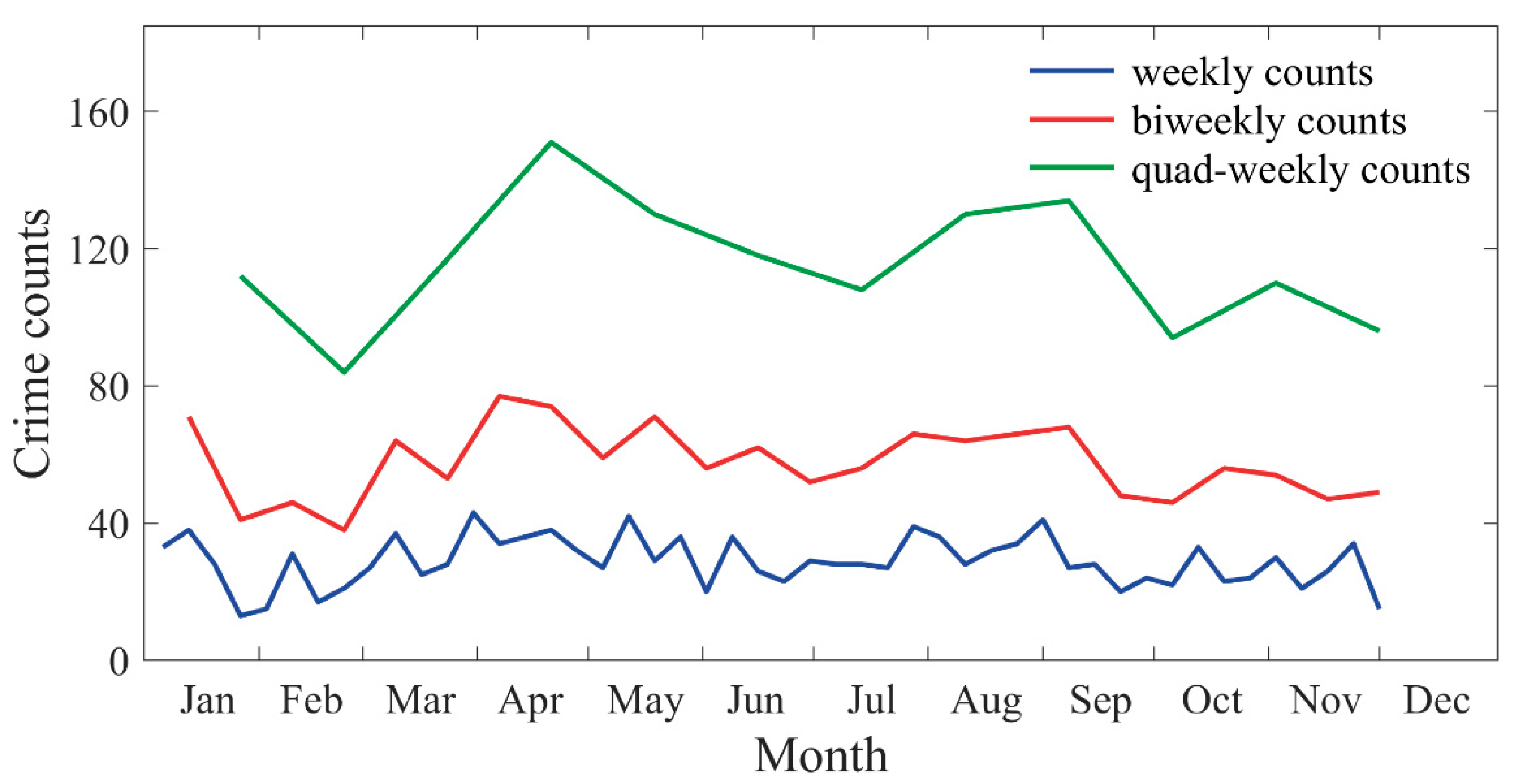
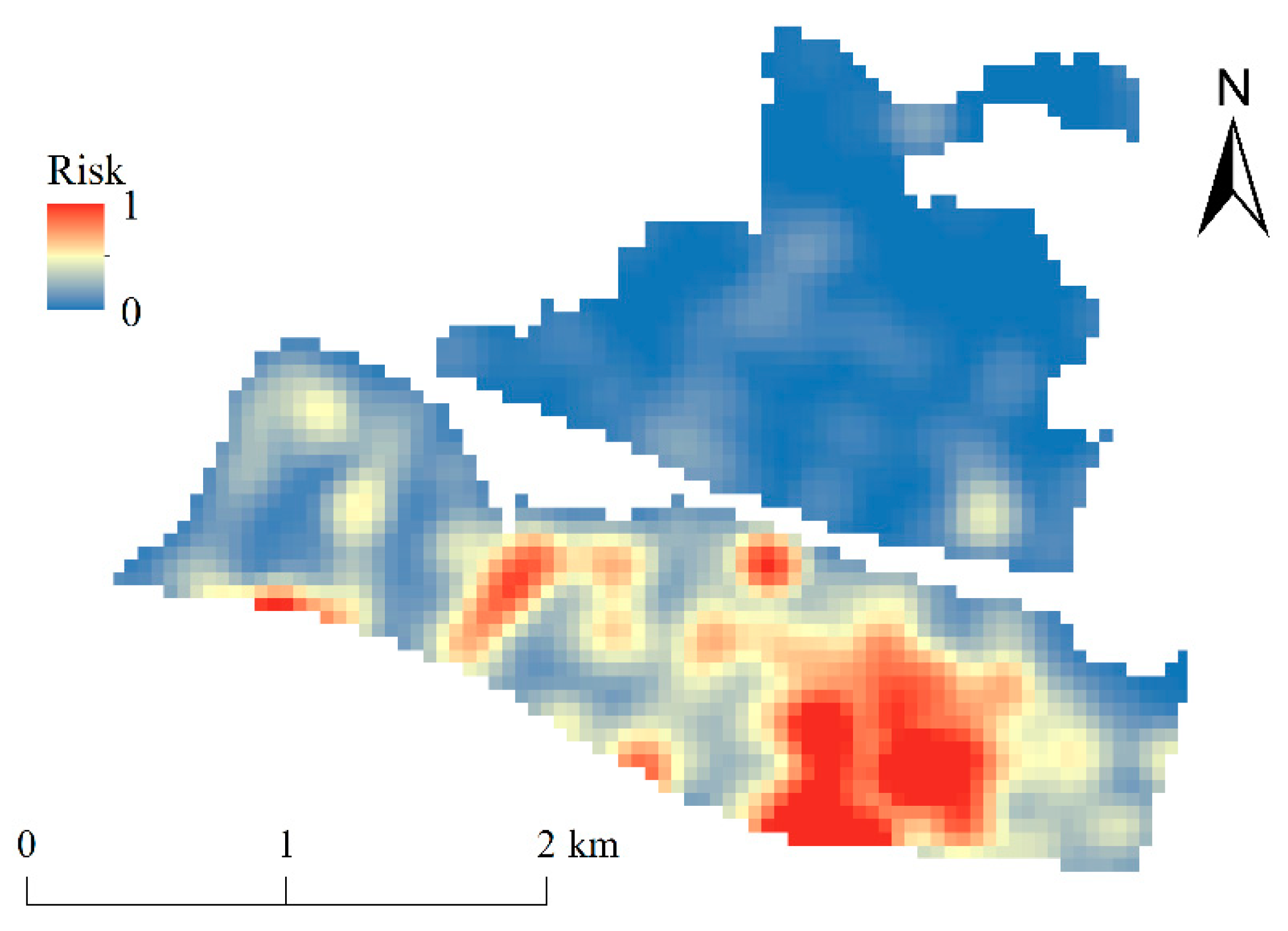
3.2.1. Historical Crime Risk (Primary Variable)
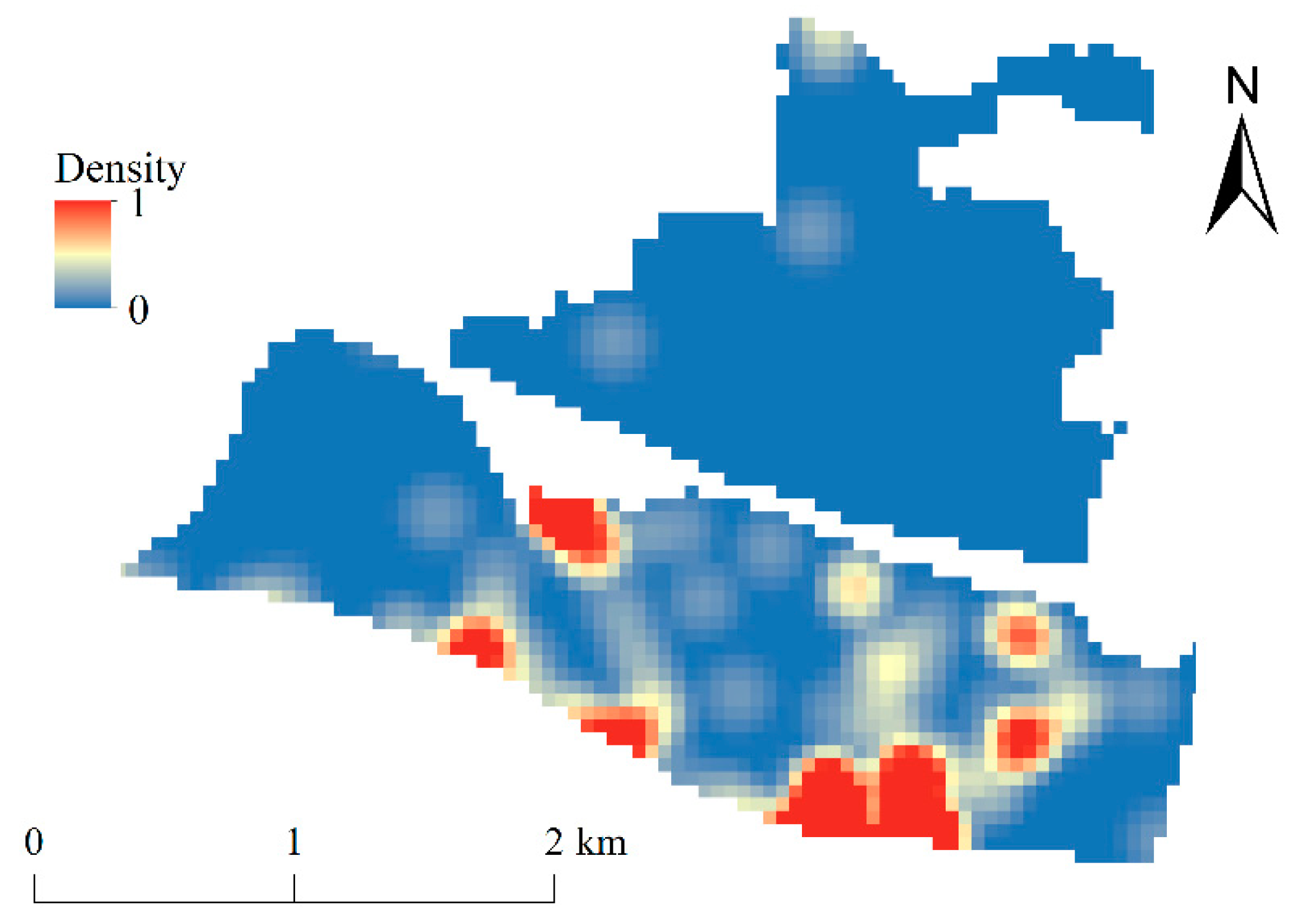
3.2.2. Potential Offenders (Covariate)
3.2.3. Correlation between the Primary Variable and the Covariate
4. Research Method: ST-Cokriging
4.1. Mathematical Principles
4.2. Accuracy Evaluation
5. Results
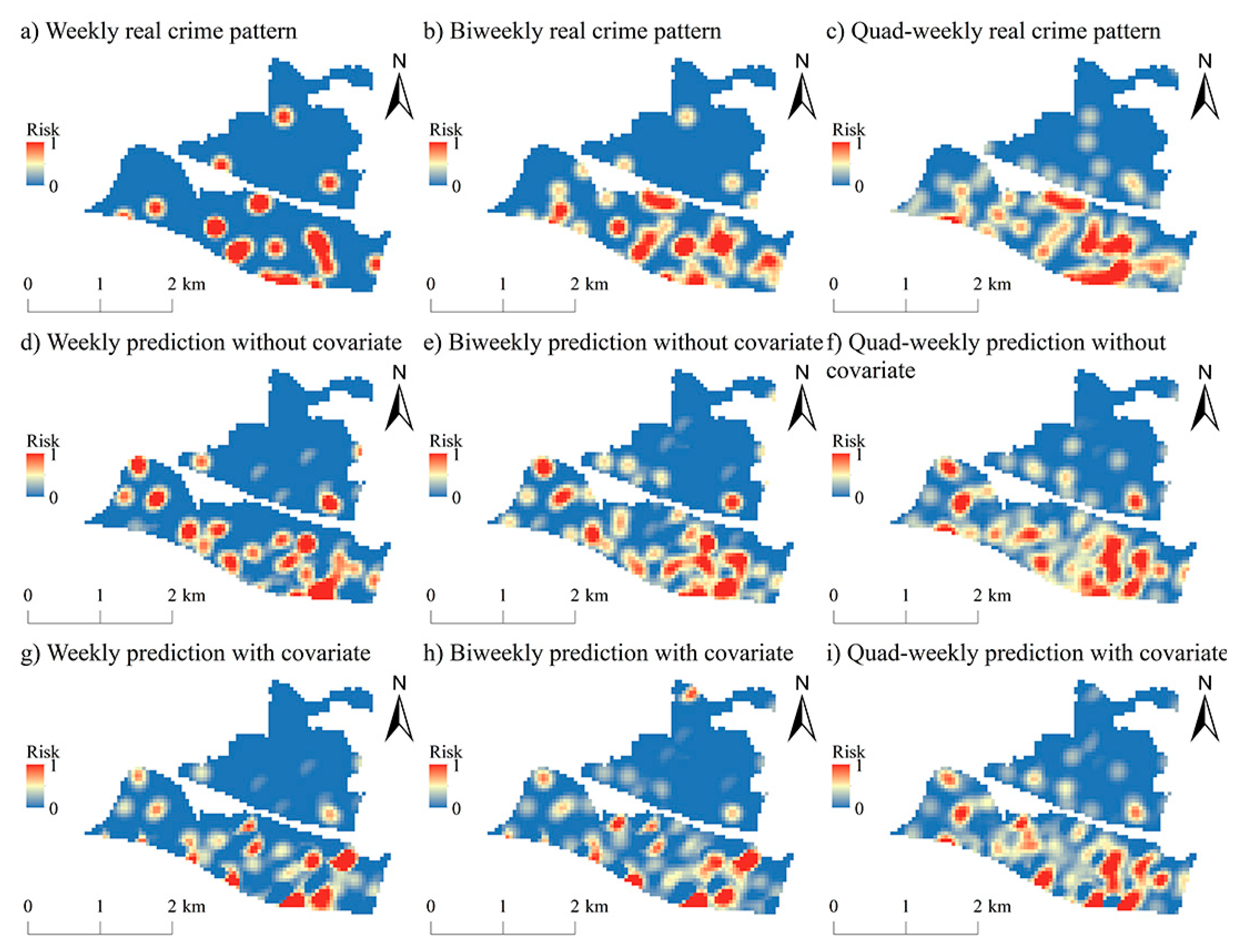
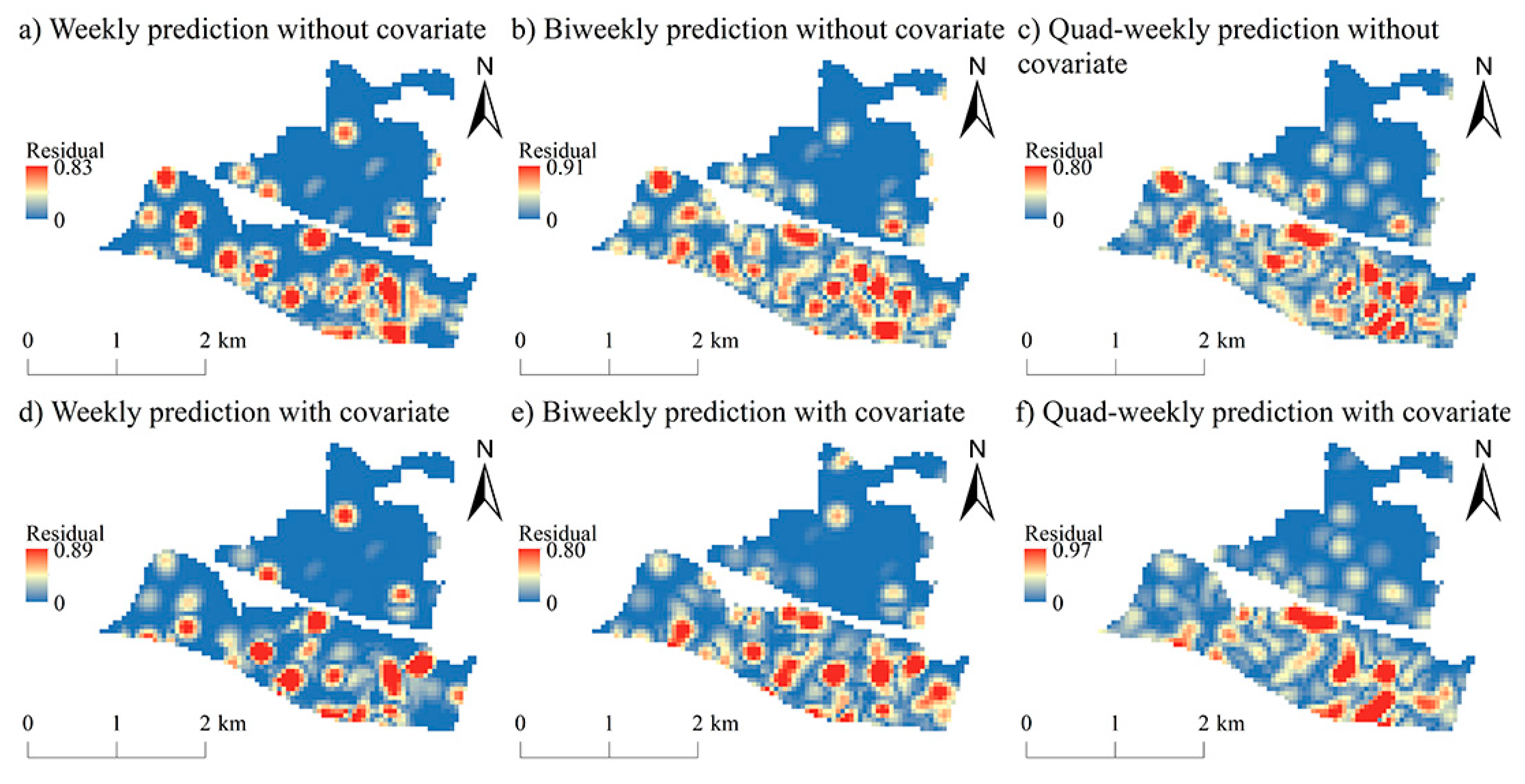
5.1. Predictive Hot Spots
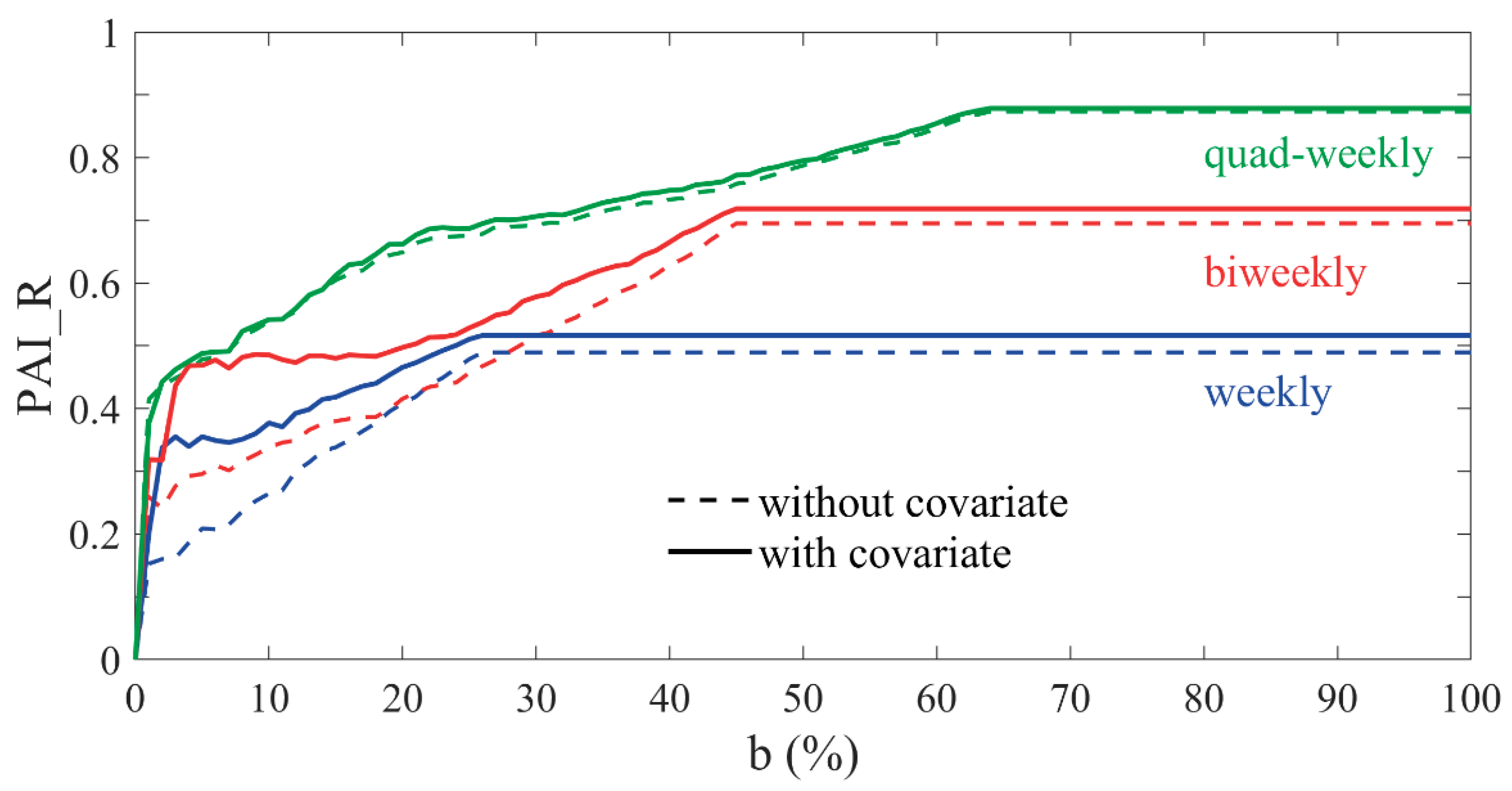
5.2. Prediction Accuracy
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Note
References
- Brantingham, P.L.; Brantingham, P.J. Nodes, Paths and Edges: Considerations on the Complexity of Crime and the Physical Environment. J. Environ. Psychol. 1993, 13, 3–28. [Google Scholar] [CrossRef]
- Kinney, J.B.; Brantingham, P.L.; Wuschke, K.; Kirk, M.G.; Brantingham, P.J. Crime attractors, generators, and detractors: Land use and urban crime opportunities. Built Environ. 2008, 34, 62–74. [Google Scholar] [CrossRef]
- Shaw, C.R.; McKay, H.D. Juvenile Delinquency and Urban Areas; University of Chicago Press: Chicago, IL, USA, 1942. [Google Scholar]
- Bogomolov, A.; Lepri, B.; Staiano, J.; Oliver, N.; Pianesi, F.; Pentland, A. Once upon a crime: Towards crime prediction from demographics and mobile data. In Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014. [Google Scholar]
- Castelli, M.; Sormani, R.; Trujillo, L.; Popovic, A. Predicting per capita violent crimes in urban areas: An artificial intelligence approach. J. Ambient. Intell. Humaniz. Comput. 2017, 8, 29–36. [Google Scholar] [CrossRef]
- Mohler, G.; Short, M.B.; Brantingham, P.J.; Schoenberg, F.P.; Tita, G.E. Self-Exciting point process modeling of crime. J. Am. Stat. Assoc. 2011, 106, 100–108. [Google Scholar] [CrossRef]
- Saltos, G.; Cocea, M. An exploration of crime prediction using data mining on open data. Int. J. Inf. Technol. Decis. Mak. 2017, 16, 1155–1181. [Google Scholar] [CrossRef]
- Wang, X.; Gerber, M.S.; Brown, D.E. Automatic crime prediction using events extracted from twitter posts. In Proceedings of the International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction, Hyattsville, MD, USA, 3–5 April 2012. [Google Scholar]
- Chainey, S.; Tompson, L.; Uhlig, S. The utility of hot spot mapping for predicting spatial patterns of crime. Secur. J. 2008, 21, 4–28. [Google Scholar] [CrossRef]
- Eck, J.E.; Chainey, S.; Cameron, J.G.; Leitner, M.; Wilson, R.E. Mapping Crime: Understanding Hot Spots; National Institute of Justice: Washington, DC, USA, 2005.
- Toole, J.L.; Eagle, N.; Plotkin, J.B. Spatiotemporal correlations in criminal offense records. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–18. [Google Scholar] [CrossRef]
- Kang, H.W.; Kang, H.B. Prediction of crime occurrence from multi-modal data using deep learning. PLoS ONE 2017, 12, e0176244. [Google Scholar] [CrossRef]
- Ackerman, W.V. Socioeconomic correlates of increasing crime rates in smaller communities. Prof. Geogr. 2010, 50, 372–387. [Google Scholar] [CrossRef]
- Andresen, M.A. A spatial analysis of crime in Vancouver, British Columbia: A synthesis of social disorganization and routine activity theory. Can. Geographer. 2006, 50, 487–502. [Google Scholar] [CrossRef]
- Bowers, K. Risky facilities: Crime radiators or crime absorbers? A comparison of internal and external levels of theft. J. Quant. Criminol. 2014, 30, 389–414. [Google Scholar] [CrossRef]
- Groff, E.R.; Lockwood, B. Criminogenic facilities and crime across street segments in Philadelphia: Uncovering evidence about the spatial extent of facility influence. J. Res. Crime Delinq. 2014, 51, 277–314. [Google Scholar] [CrossRef]
- Curtis, J.W. Integrating sketch maps with gis to explore fear of crime in the urban environment: A review of the past and prospects for the future. Am. Cartographer. 2012, 39, 175–186. [Google Scholar] [CrossRef]
- Jií, P.; Ivan, I.; Lucie, M. Comparing Residents’ Fear of Crime with Recorded Crime Data-Case Study of Ostrava, Czech Republic. ISPRS Int. Geo-Inf. 2019, 8, 401. [Google Scholar]
- Prieto, C.R.; Bishop, S.R. Fear of crime: The impact of different distributions of victimisation. Palgrave Commun. 2018, 4, 1–8. [Google Scholar]
- Cohen, L.E.; Felson, M. Social change and crime rate trends: A routine activity approach. Am. Sociol. Rev. 1979, 44, 588–608. [Google Scholar] [CrossRef]
- Bernasco, W.; Kooistra, T. Effects of residential history on commercial robbers’ crime location choices. Eur. J. Criminol. 2010, 7, 251–265. [Google Scholar] [CrossRef] [Green Version]
- Johnson, S.D.; Bowers, K.J. Permeability and burglary risk: Are cul-de-sacs safer? J. Quant. Criminol. 2010, 26, 89–111. [Google Scholar] [CrossRef]
- Lammers, M.; Menting, B.; Ruiter, S.; Bernasco, W. Biting once, twice: The influence of prior on subsequent crime location choice. Criminology 2015, 53, 309–329. [Google Scholar] [CrossRef]
- Menting, B.; Lammers, M.; Ruiter, S.; Bernasco, W. Family matters: Effects of family members’ residential areas on crime location choice. Criminology 2016, 54, 413–433. [Google Scholar] [CrossRef]
- Ackerman, A.R.; Sacks, M. Can general strain theory be used to explain recidivism among registered sex offenders? J. Crim. Justice 2012, 40, 187–193. [Google Scholar] [CrossRef]
- Yang, B.; Liu, L.; Lan, M.; Wang, Z.; Zhou, H.; Yu, H. A spatio-temporal Cokriging method for crime prediction using historical crime data and transitional zones identified from nightlight imagery. Int. J. Geogr. Inf. Sci. 2020, 34, 1740–1764. [Google Scholar] [CrossRef]
- Short, M.B.; D’Orsogna, M.R.; Pasour, V.B.; Tita, G.E.; Brantingham, P.J.; Bertozzi, A.L.; Chayes, L.B. A statistical model of criminal behavior. Math. Models Methods Appl. Sci. 2008, 18, 1249–1267. [Google Scholar] [CrossRef]
- Couckuyt, I.; Koziel, S.; Dhaene, T. Surrogate modeling of microwave structures using kriging, co-kriging, and space mapping. Int. J. Numer. Model Electron. Netw. Device Fields 2013, 26, 64–73. [Google Scholar] [CrossRef]
- Kanankege, K.S.T.; Alkhamis, M.A.; Phelps, N.B.D.; Perez, A.M. A probability co-kriging model to account for reporting bias and recognize areas at high risk for zebra mussels and Eurasian watermilfoil invasions in Minnesota. Front. Vet. Sci. 2017, 4, 231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liang, X.; Schilling, K.E.; Zhang, Y.; Jones, C.S. Co-Kriging estimation of Nitrate-Nitrogen loads in an agricultural river. Water Resour. Manag. 2016, 30, 1771–1784. [Google Scholar] [CrossRef]
- Eom, J.K.; Park, M.S.; Heo, T.; Huntsinger, L.F. Improving the prediction of annual average daily traffic for nonfreeway facilities by applying a spatial statistical method. Transp. Res. Record. 2006, 1968, 20–29. [Google Scholar] [CrossRef]
- Zou, H.; Yue, Y.; Li, Q.; Yeh, A.G. An improved distance metric for the interpolation of link-based traffic data using kriging: A case study of a large-scale urban road network. Int. J. Geogr. Inf. Sci. 2012, 26, 667–699. [Google Scholar] [CrossRef]
- Snepvangers, J.J.; Heuvelink, G.B.; Huisman, J.A. Soil water content interpolation using spatio-temporal kriging with external drift. Geoderma 2003, 112, 253–271. [Google Scholar] [CrossRef]
- Sideris, I.V.; Gabella, M.; Erdin, R.; Germann, U. Real-time radar-rain-gauge merging using spatio-temporal co-kriging with external drift in the alpine terrain of Switzerland. Q. J. R. Meteorol. Soc. 2014, 140, 1097–1111. [Google Scholar] [CrossRef]
- Bae, B.; Kim, H.; Lim, H.; Liu, Y.; Han, L.D.; Freeze, P.B. Missing data imputation for traffic flow speed using spatio-temporal cokriging. Transp. Res. Part C Emerg. Technol. 2018, 88, 124–139. [Google Scholar] [CrossRef]
- Lan, M.; Liu, L.; Hernandez, A.; Liu, W.; Zhou, H.; Wang, Z. The Spillover Effect of Geotagged Tweets as a Measure of Ambient Population for Theft Crime. Sustainability 2019, 11, 6748. [Google Scholar] [CrossRef] [Green Version]
- Gerber, M.S. Predicting crime using Twitter and kernel density estimation. Decis. Support Syst. 2014, 61, 115–125. [Google Scholar] [CrossRef]
- Chen, X.; Cho, Y.; Jang, S.Y. Crime prediction using Twitter sentiment and weather. In Proceedings of the 2015 Systems and Information Engineering Design Symposium, Charlottesville, VA, USA, 24 April 2015. [Google Scholar]
- Agnew, R. Foundation for a general strain theory of crime and delinquency. Criminology 1992, 30, 47–87. [Google Scholar] [CrossRef]
- Fisher, B.S.; Wilkes, A.R. A tale of two ivory towers. A comparative analysis of victimization rates and risks between university students in the United States and England. Br. J. Criminol. 2003, 43, 526–545. [Google Scholar] [CrossRef]
- Rountree, P.W.; Land, K.C. The generalizability of multilevel models of burglary victimization: A cross-city comparison. Soc. Sci. Res. 2000, 29, 284–305. [Google Scholar] [CrossRef]
- Tseloni, A.; Wittebrood, K.; Farrell, G.; Pease, K. Burglary victimization in England and wales, the United States and the Netherlands: A cross-national comparative test of routine activities and lifestyle theories. Br. J. Criminol. 2004, 44, 66–91. [Google Scholar] [CrossRef]
- Clarke, R.V.; Eck, J. Become a Problem-Solving Crime Analyst; Willan Publishing: Uffculme, UK, 2003. [Google Scholar]
- Beauregard, E.; Rossmo, D.K.; Proulx, J. A descriptive model of the hunting process of serial sex offenders: A rational choice perspective. J. Fam. Violence 2007, 22, 449–463. [Google Scholar] [CrossRef]
- Mogavero, M.C.; Hsu, K. Sex offender mobility: An application of crime pattern theory among child sex offenders. Sex. Abus. J. Res. Treat. 2018, 30, 908–931. [Google Scholar] [CrossRef]
- Santtila, P.; Hakkanen, H.; Canter, D.V.; Elfgren, T. Classifying homicide offenders and predicting their characteristics from crime scene behavior. Scand. J. Psychol. 2003, 44, 107–118. [Google Scholar] [CrossRef]
- Mccuish, E.C.; Cale, J.; Corrado, R.R. A prospective study of offending patterns of youth homicide offenders into adulthood. Youth Violence Juv. Justice 2018, 16, 18–36. [Google Scholar] [CrossRef]
- Ratcliffe, J.H. A temporal constraint theory to explain opportunity-based spatial offending patterns. J. Res. Crime Delinq. 2006, 43, 261–291. [Google Scholar] [CrossRef]
- Bernasco, W.; Nieuwbeerta, P. How do residential burglars select target areas? A new approach to the analysis of criminal location choice. Br. J. Criminol. 2005, 45, 296–315. [Google Scholar] [CrossRef] [Green Version]
- Townsley, M.; Sidebottom, A. All offenders are equal, but some are more equal than others: Variation in journeys to crime between offenders. Criminology 2010, 48, 897–917. [Google Scholar] [CrossRef]
- Bernasco, W. A sentimental journey to crime: Effects of residential history on crime location choice. Criminology 2010, 48, 389–416. [Google Scholar] [CrossRef]
- Rossmo, D.K.; Lu, Y.; Fang, T.B. Spatial-temporal crime paths. In Patterns, Prevention and Geometry of Crime; Andresen, M.A., Kinney, J.B., Eds.; Routledge: New York, NY, USA, 2012; pp. 16–42. [Google Scholar]
- Walsh, W.F. Compstat: An analysis of an emerging police managerial paradigm. Polic. Int J Police Strateg. Manag. 2001, 24, 347–362. [Google Scholar] [CrossRef]
- Rosenfeld, R.; Fornango, R. The impact of economic conditions on robbery and property crime: The role of consumer sentiment. Criminology 2007, 45, 735–769. [Google Scholar] [CrossRef]
- Liu, L.; Feng, J.; Ren, F.; Xiao, L. Examining the relationship between neighborhood environment and residential locations of juvenile and adult migrant burglars in China. Cities 2018, 82, 10–18. [Google Scholar] [CrossRef]
- Blakeslee, D.S.; Fishman, R. Weather shocks, agriculture, and crime: Evidence from India. J. Hum. Resour. 2018, 53, 750–782. [Google Scholar] [CrossRef]
- Horrocks, J.; Menclova, A.K. The effects of weather on crime. N. Z. Econ. Pap. 2011, 45, 231–254. [Google Scholar] [CrossRef]
- Linning, S.J.; Andresen, M.A.; Brantingham, P.J. Crime seasonality: Examining the temporal fluctuations of property crime in cities with varying climates. Int. J. Offender Ther. Comp. Criminol. 2016, 61, 1866–1891. [Google Scholar] [CrossRef] [PubMed]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman and Hall: London, UK, 1987. [Google Scholar]
- Wilcox, P.; Eck, J.E. Criminology of the unpopular: Implications for policy aimed at payday lending facilities. Criminol. Public Policy 2011, 10, 473–482. [Google Scholar] [CrossRef]
- Banse, R.; Koppehelegossel, J.; Kistemaker, L.M.; Werner, V.A.; Schmidt, A. Pro-criminal attitudes, intervention, and recidivism. Aggress. Violent Behav. 2013, 18, 673–685. [Google Scholar] [CrossRef] [Green Version]
- Braverman, D.W.; Doernberg, S.N.; Runge, C.P.; Howard, D.S. OxRec model for assessing risk of recidivism: Ethics. Lancet Psychiatry 2016, 3, 808–809. [Google Scholar] [CrossRef] [Green Version]
- Fazel, S.; Chang, Z.; Fanshawe, T.R.; Langstrom, N.; Lichtenstein, P.; Larsson, H.; Mallett, S. Prediction of violent reoffending on release from prison: Derivation and external validation of a scalable tool. Lancet Psychiatry 2016, 3, 535–543. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Lan, M.; Eck, J.E.; Kang, E.L. Assessing the effects of bus stop relocation on street robbery. Comput. Environ. Urban 2020, 80, 101455. [Google Scholar] [CrossRef]
- Gauthier, T.D. Detecting trends on using Spearman’s rank correlation co-efficient. Enviorn. Forensic 2001, 2, 359–362. [Google Scholar] [CrossRef]
- Selinger, C.P.; Ochieng, A.O.; George, V.; Leong, R.W. The accuracy of adherence self-report scales in patients on thiopurines for inflammatory bowel disease: A comparison with drug metabolite levels and medication possession ratios. Inflamm. Bowel Dis. 2019, 25, 919–924. [Google Scholar] [CrossRef]
- Krige, D.G. A Statistical Approach to Some Mine Valuations and Allied Problems at the Witwatersrand. Master’s Thesis, The University of Witwatersrand, Johannesburg, South Africa, 1951. [Google Scholar]
- Atkinson, P.M.; Pardoiguzquiza, E.; Chicaolmo, M. Downscaling Cokriging for super-resolution mapping of continua in remotely sensed images. IEEE Trans. Geosci. Remote Sens. 2008, 46, 573–580. [Google Scholar] [CrossRef]
- Chilès, J.; Delfiner, P. Geostatistics: Modeling Spatial Uncertainty; Wiley: New York, NY, USA, 1999. [Google Scholar]
- Cressie, N.A.C. Statistics for Spatial Data; Wiley: New York, NY, USA, 1993. [Google Scholar]
- Joel, M.C.; Leslie, W.K.; Miller, J. Risk terrain modeling: Brokering criminological theory and GIS methods for crime forecasting. Justice Q. 2011, 28, 360–381. [Google Scholar]
- Melo, S.N.; Pereira, D.V.; Andresen, M.A.; Matias, L.F. Spatial/temporal variations of crime: A routine activity theory perspective. Int. J. Offender Ther. Comp. Criminol. 2018, 62, 1967–1991. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z. Crime Research in Three Big Economy Regions in Contemporary China; China People’s Public Security University Press: Beijing, China, 2006. [Google Scholar]
- Song, G.; Bernasco, W.; Liu, L.; Xiao, L.; Zhou, S.; Liao, W. Crime feeds on legal activities: Daily mobility flows help to explain thieves’ target location choices. J. Quant. Criminol. 2019, 35, 831–854. [Google Scholar] [CrossRef] [Green Version]
- Bernasco, W. Adolescent offenders’ current whereabouts predict locations of their future crimes. PLoS ONE 2019, 14, e0210733. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Historical Crime Distribution | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Potential Offenders’ Distribution | Periods (in the year 2017) | 09.11 | 09.18 | 09.25 | 10.02 | 10.09 | 10.16 | 10.23 | 10.30 |
| The same period (weekly) | 0.096 ** | 0.220 ** | 0.059 ** | 0.200 ** | 0.256 ** | 0.029 ** | 0.097 ** | 0.200 ** | |
| The following period (weekly) | 0.311 ** | 0.283 ** | 0.005 ** | 0.197 ** | 0.134 ** | 0.085 ** | 0.291 ** | 0.161 ** | |
| The same period (biweekly) | 0.326 ** | 0.156 ** | 0.355 ** | 0.298 ** | |||||
| The following period (biweekly) | 0.261 ** | 0.228 ** | 0.147 ** | 0.133 ** | |||||
| The same period (quad-weekly) | 0.287 ** | 0.470 ** | |||||||
| The following period (quad-weekly) | 0.365 ** | 0.374 ** | |||||||
| Predictive Periods | Without Covariate | With Covariate | ||
|---|---|---|---|---|
| PCC | RMSE | PCC | RMSE | |
| 6 November 2017 to 12 November 2017 (for weekly basis) | 0.216 ** | 0.179 | 0.300 ** | 0.145 |
| 6 November 2017 to 19 November 2017 (for biweekly basis) | 0.254 ** | 0.187 | 0.309 ** | 0.152 |
| 6 November 2017 to 3 December 2017 (for quad-weekly basis) | 0.509 ** | 0.185 | 0.449 ** | 0.171 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, H.; Liu, L.; Yang, B.; Lan, M. Crime Prediction with Historical Crime and Movement Data of Potential Offenders Using a Spatio-Temporal Cokriging Method. ISPRS Int. J. Geo-Inf. 2020, 9, 732. https://doi.org/10.3390/ijgi9120732
Yu H, Liu L, Yang B, Lan M. Crime Prediction with Historical Crime and Movement Data of Potential Offenders Using a Spatio-Temporal Cokriging Method. ISPRS International Journal of Geo-Information. 2020; 9(12):732. https://doi.org/10.3390/ijgi9120732
Chicago/Turabian StyleYu, Hongjie, Lin Liu, Bo Yang, and Minxuan Lan. 2020. "Crime Prediction with Historical Crime and Movement Data of Potential Offenders Using a Spatio-Temporal Cokriging Method" ISPRS International Journal of Geo-Information 9, no. 12: 732. https://doi.org/10.3390/ijgi9120732
APA StyleYu, H., Liu, L., Yang, B., & Lan, M. (2020). Crime Prediction with Historical Crime and Movement Data of Potential Offenders Using a Spatio-Temporal Cokriging Method. ISPRS International Journal of Geo-Information, 9(12), 732. https://doi.org/10.3390/ijgi9120732