1. Introduction
In order to develop a reasonable and desirable policy for improving the city structure and the city resource allocation to support the city sustainable development, urban planners and policy makers must improve their understanding of land use distribution that influence people’s real-time activity pattern. Understanding the land use distribution is very important, since the different categories of land use attract different proportional people who have different activity purposes and thus influence the city resource allocation such as public transportation. In addition, the information of land use distribution can assist urban planners in learning about the urban structure at a fine scale and how planners can efficiently improve that. Therefore, the technology of spatially fine-grained land use classification is needed for urban sustainable development. As in modern cities, there are increasing numbers of building complexes, and conventional land use classification approaches such as remote sensing are not well applicable to identifying the specific functions of building complexes. For instance, a building complex sometimes includes restaurants, offices, or hotels located in different rooms or floors. Conventional remote sensing approaches cannot well identify the specific functions of large or tall buildings such as complexes. Although aerial remote sensing technologies can better classify building functions than satellite remote sensing technologies, they are highly costly and time-consuming. A less costly but novel approach is needed to classify land use at a finer level (e.g., building-level) in an urban environment.
In the past, human activity patterns were investigated in traditional household surveys. However, this way is time-consuming and high-cost. With the development of social networks and location-based services, the number of social media applications such as Foursquare, Facebook, Twitter, Weibo, etc., continue to increase. Therefore, the location-based information gained from those applications has been frequently used in many fields and has thus produced a lot of social benefits. Those data make a significant contribution to city center recognition [
1], recommendation systems [
2,
3,
4,
5], and human activity patterns [
6,
7,
8]. Owing to the different activities of residents in different points-of-interest (POIs), the information can be used to indicate the function or the activity category of certain POI. In a word, within different POIs, people may demonstrate different movements (e.g., in residential POI, people may check-in when they get up or leave home in the morning and then come back home or watch TV in the evening, whereas, in shopping center POI, people may check-in more when they undertake shopping or entertainment activities in the evening or weekend). This may allow us to investigate and refine the internal human activity structure of certain big functional areas, where a number of similar POIs are highly mixed in, by location-based social network (LBSN) data.
With the maturity of remote sensing technology, the ability of remote sensing technology to capture the physical features of ground objects has increasingly improved. Therefore, the remote sensing technology has been regarded as a common or even vital approach to classifying land use. Theoretically, classifying land use is mainly based on the technology of remote sensing, which can recognize land use by spectral and textual characteristics [
9,
10,
11]. However, since the traditional methods consider only physical factors, social factors have not been considered by these methods, which might significantly impact the accuracy of classifying land use [
12]. Therefore, to bring together physical characteristics and social functions of lands, some studies attempted to combine remote sensing images with emerging geospatial big data produced by humans in everyday life in land use classifications {e.g., applying mobile phone data as a supplement for remote sensing images to land use classification [
12], classifying land use by the use of taxi trip data and remote sensing data to improve the accuracy of classification [
13], integrating social media data and remote sensing data to classify land use [
14], collected volunteered geographic information (VGI) data such as OpenStreetMap to model the land use patterns [
15], and even combining Landsat images with POIs to map the urban land use [
16]}. However, the number of mixed-use lands is increasingly growing nowadays, and these lands sometimes are too mixed to be well investigated by conventional approaches such as remote sensing (e.g., commercial land consists of different functional areas such as eating, hotel, entertainment, etc.). In this case, conventional parcel- or area-level land use classifications cannot satisfy the demand of modern urban planning [
17]. To address this issue, classifying land use or functional areas at a finer spatial scale is needed to enhance urban planning. In other words, refining functional area classification can provide greater assistance to urban planning [
17]. For instance, Long and Liu used POI data to precisely measure land use mix to reduce the mismatch between urban land use plans and actual land use [
17]. It can be demonstrated that the POI-based approach can better measure the land use mix than the traditionally parcel-based approach. Furthermore, previous studies have proposed social sensing approaches instead of remote sensing approaches to classify functional areas or land use parcels according to human mobility and activity patterns [
12]. However, those studies have a limited spatial granularity, as land use types predicted based on mobile phone record data are at the parcel or the area level, whilst a more fine-grained land use data, such as POI-level or building-level data, are definitely more useful in urban planning [
17]. To abridge this research gap, we attempted to classify land use at a finer scale according to human mobility and activity patterns reflected by LBSN data. Our proposed social sensing approach has some advantages over other existing social sensing approaches, including low cost and fine granularity.
In our study, we only utilized a small part of POI and check-in data for POI-level land use classification. In other words, we finished finer precision work with fewer kinds of data. Specifically, we firstly investigated spatial and temporal patterns of human mobility and activity behavior using check-in data from a popular Chinese LBSN named Sina Weibo and subsequently applied those patterns to predicting the category of POI to refine urban land use classification in Guangzhou, China. Our proposed approach can be potentially applied to classify building functions according to visitors’ human and mobility behavior and buildings’ locational characteristics.
The remainder of this paper is organized as follows:
Section 2 introduces the data sources and the study area.
Section 3 presents the methodology used in this paper.
Section 4 presents the empirical results and discussion. Finally, this paper presents the conclusion and future works.
4. Result and Discussion
For our experimental data gained from Weibo, we firstly selected check-in data according to the rule proposed in
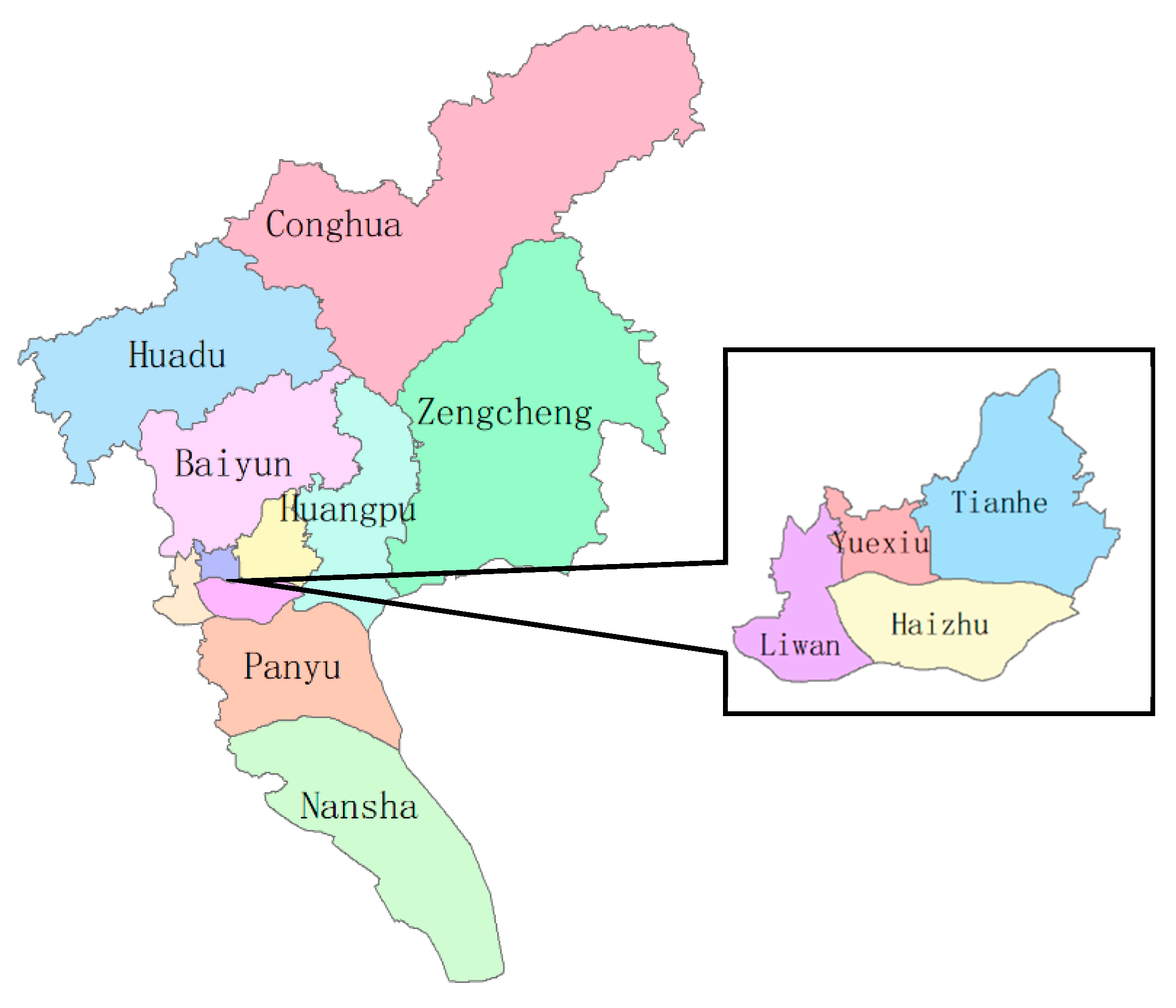
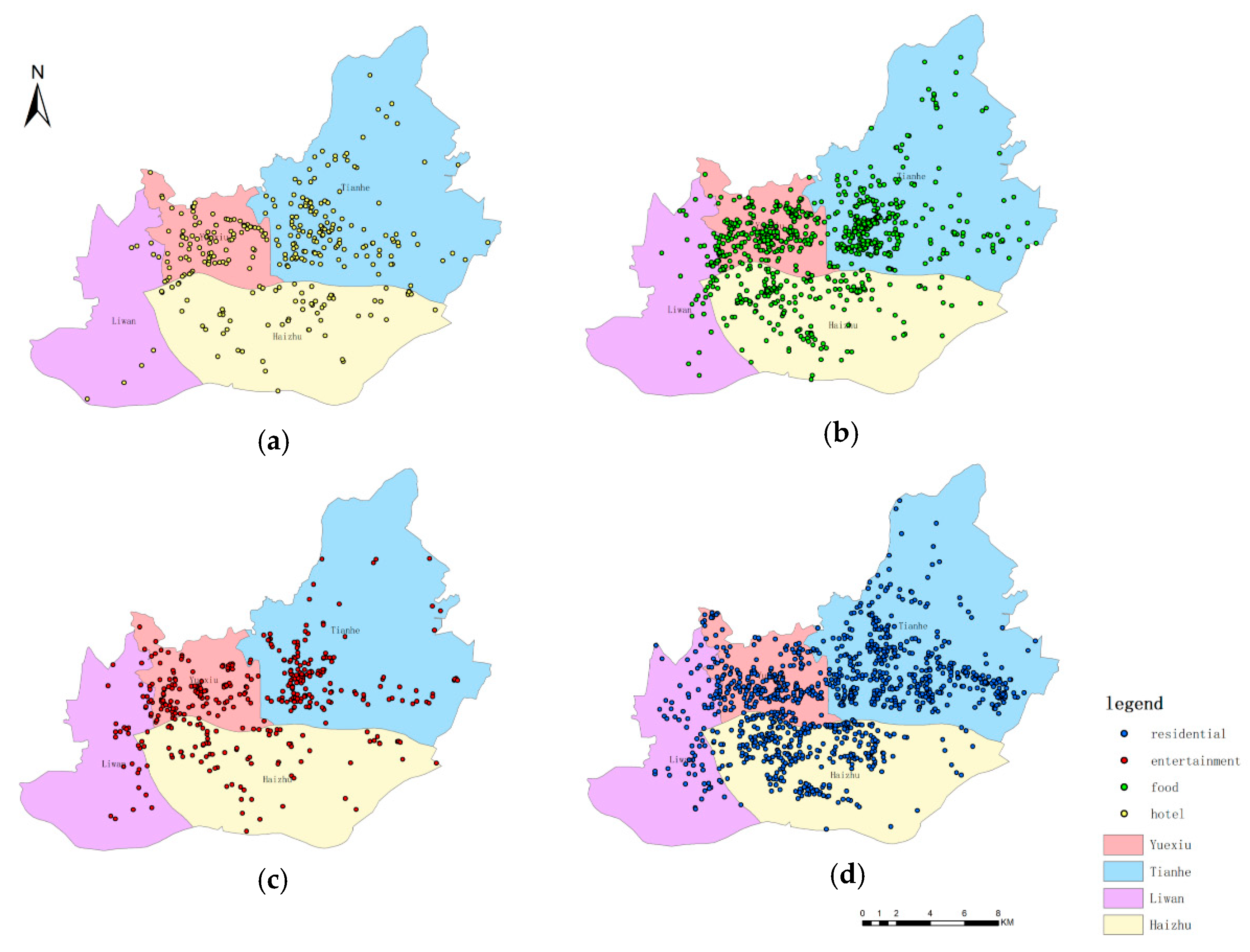
Section 2.2. Subsequently, we mapped four POI categories in four main urban districts of Guangzhou (Liwan, Haizhu, Yuexiu, Tianhe) by using the no-further-process dataset, wherein the POI set only represents POI of storing check-in records, the result of visualization shown as
Figure 7. The majority of POIs, as the exhibition of the
Figure 7, are located at the districts of Tianhe, Yuexiu, and Haizhu, where one can witness the modernization and the prosperity of Guangzhou. Moreover, the POIs of food and residential present a relatively homogeneous distribution in the three regions, while the POIs of hotel and entertainment exhibit a relative clustering distribution in the regions of Tianhe and Yuexiu. The
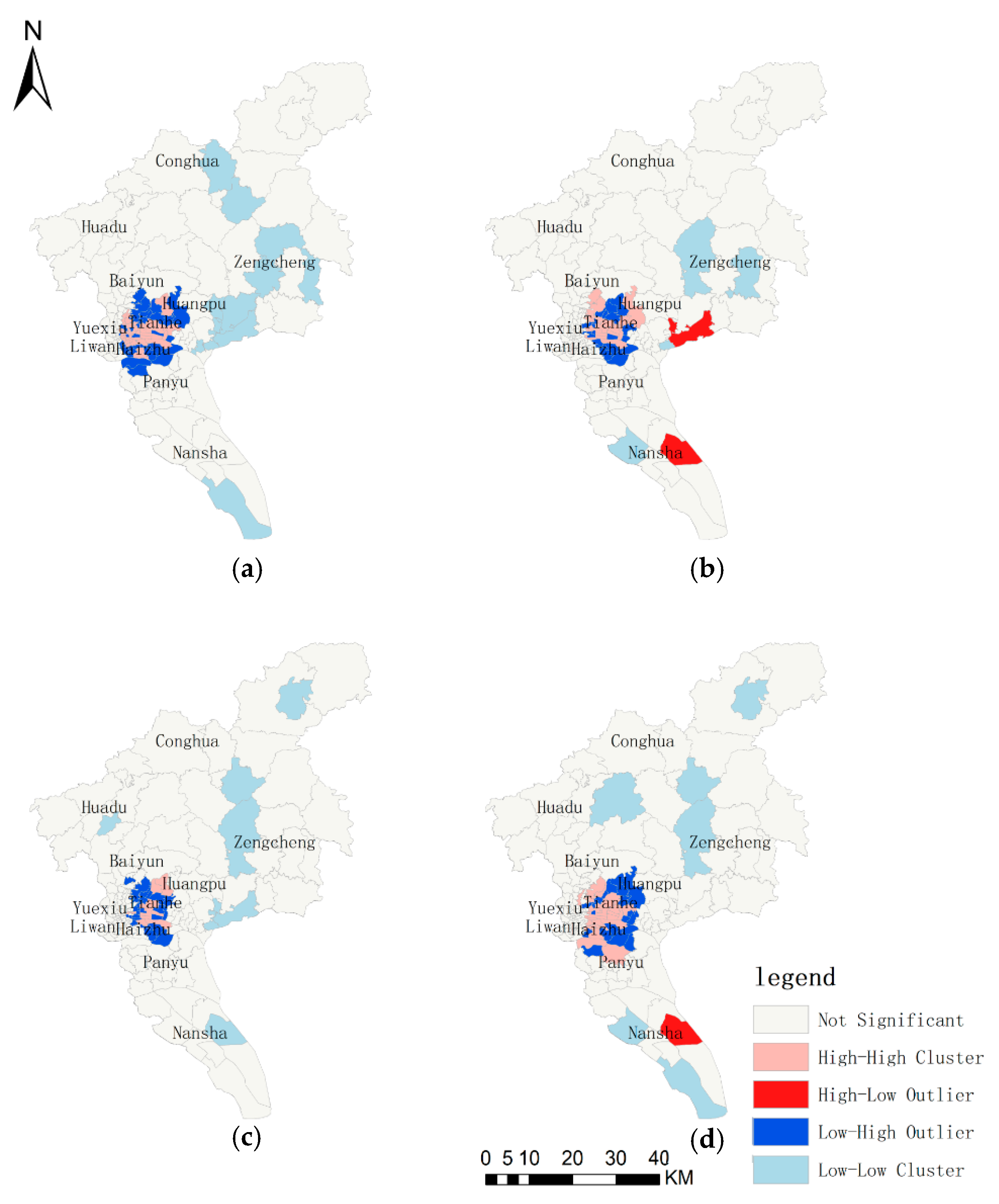
Figure 7 shows a high-level mix of four POI categories, especially in the districts of Tianhe and Yuexiu. It is worth mentioning that Tianhe and Yuexiu are the new town and the old town of the city, respectively, and they are also the most populous districts where a high-level land use mix exists. As the locations of four POI categories were likely to exhibit different spatial patterns, we further examined whether check-in counts of four POI categories were likely to exhibit different spatial patterns as well. Therefore, we utilized local Moran’s
I to recognize the check-in quantity’s clustering features of different POI categories across city of Guangzhou after the map of Guangzhou was separated by the borders of towns and communities, shown as
Figure 8. As the
Figure 8 exhibits, the distribution maps of four POI categories were generally similar, but slight differences still existed in the local area; these differences may offer the possibility to recognize different types of POI in high mix areas. Moreover, the high-high cluster distribution of four types mainly existed in main urban districts, which means that the majority of users prefer to check in and be active at this area, and the significantly high mix of various human activities exists here. The situation of the high-level mix not only means it is necessary to refine land use types but also means it is hard for us to seek obvious boundaries to separate the four POI categories if only based on the display of
Figure 7 and
Figure 8. Therefore, at the level of space distribution, we speculated that the human activity types in the four kinds of POI cannot be recognized.
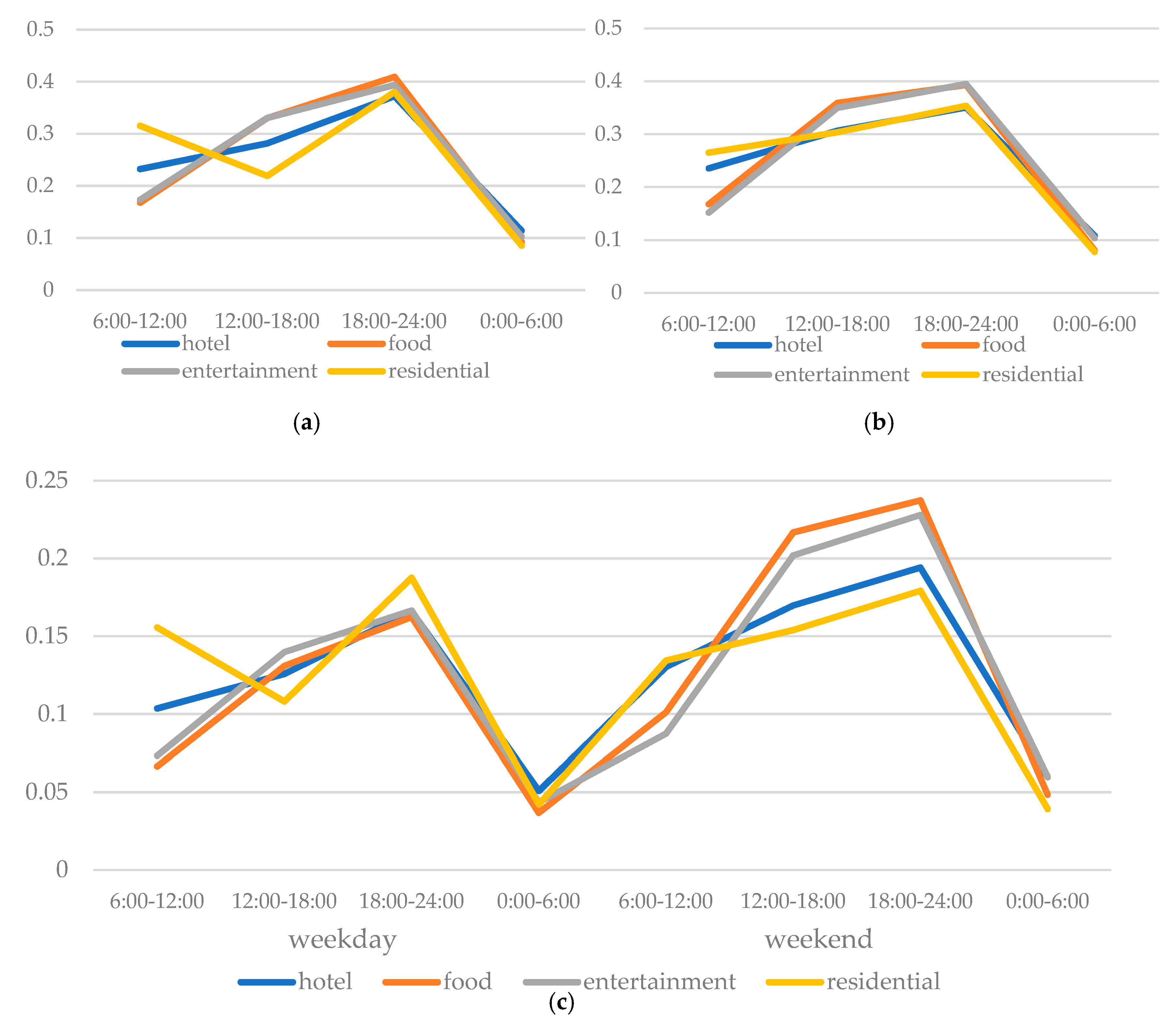
Beside the difference in the spatial distribution of POIs, the discrepancy in the check-in behavior patterns of users (e.g., number of check-ins, temporal patterns of check-in behavior, etc.) also can potentially assist in categories recognition. More specifically, in this study, we attempted to incorporate the temporal features of human check-in behavior into the POI category classification. In general, human activities are likely to be regular in daily life (e.g., people enjoy food in midday or evening, relax themselves at entertainment venues in non-working times, and stay at home in the evening or before going to work). Therefore, we firstly divided the check-in dataset into four time periods (6:00–12:00, 12:00–18:00, 18:00–24:00, 0:00–6:00) and two day types (weekday, weekend). We plotted the distribution of check-ins among the four time periods in weekday and in weekends, respectively shown as
Figure 9a,b. The line charts (
Figure 9a,b) indicate that people prefer to check in at home during the weekday mornings (before going to work) and evenings (after finishing work) and go to enjoy food and entertainment during weekday afternoons or nights, while, during the weekend, human mobility and activity patterns exhibit a relatively disordered state (each POI category reflects a similar active curve). It can be validated by the phenomenon that people generally have a regular daily schedule for work and entertainment on weekdays, while, due to more free time and space to schedule their personalized life, people tend to have a less regular daily schedule on weekends. Subsequently, we plotted the distribution of check-ins among eight time periods after one week was separated into weekday and weekend. More specifically, weekday check-ins and weekend check-ins were both averaged, as there are more weekdays than weekend days in total (e.g., the number of total weekday check-ins was divided by five, and the number of total weekend check-ins was divided by two; subsequently, two results were summed as total data in
Figure 9c), illuminated as
Figure 9c. In addition to the information reflected by
Figure 9a,b, the broken line graph illustrates that the check-ins of POIs of hotel and residential hardly increase, while a significant growth takes place in the check-in number of POIs of food and entertainment. The discussions above indicate that temporal features of human check-in behavior pattern can benefit the recognition of POI categories. Therefore, the consideration of temporal features in check-in behavior were considered in the POI category prediction.
Beside the spatial and the temporal features, the quality of samples is also significantly essential for modeling. In order to explore the feasibility of the proposed rule for filtering samples in
Section 2.2, the comparison between three rules (proposed rule, no further process, same threshold) mentioned in
Section 2.2 were performed in the following. We utilized the RF to model the POI types pattern in this comparison, and the prediction accuracy of the three rules (proposed rule, no further process, same threshold) for the modeling sample selected were 76.75%, 45.77%, and 57.24%, respectively. Prediction accuracies indicates that the proposed rule for filtering samples performs with higher effectiveness than the other two rules. Therefore, we could speculate that the no further process rule may have caused the poor accuracy due to the potential existence of fake check-ins, while the same threshold rule increased the accuracy, since the rule filtered part of fake check-ins and less representative POI check-in data. Therefore, we selected the dataset filtered by the proposed rule in the following process.
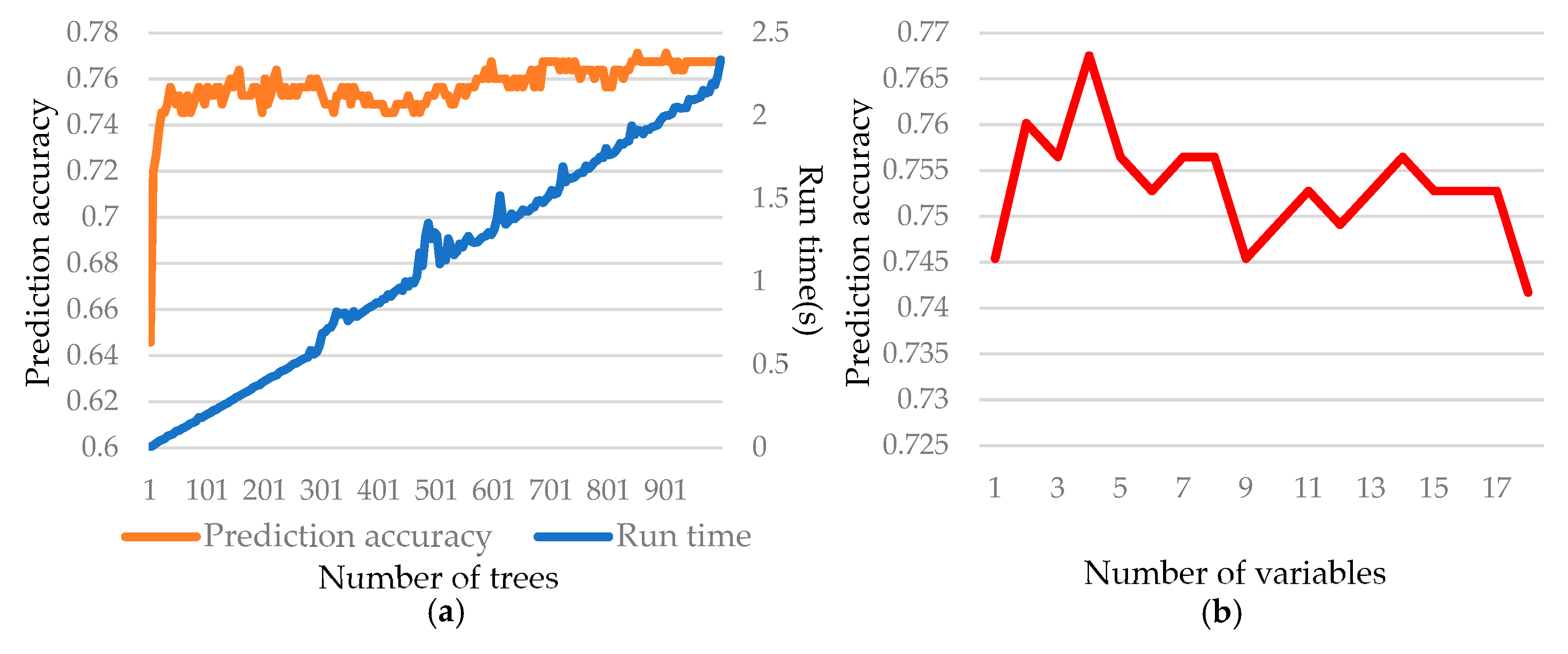
In general, the parameters of the model are a crucial part of optimizing model performances, and an optimal model is beneficial to the prediction precision as well as the efficiency. Therefore, in order to optimize the model, it is critical to examine the effect of model parameters on the performance of the model. In this process, according to Thanh Noi and Kappas [
21], the max number of decision trees and splitting variables were selected as main parameters to explore the optimal RF model in this study. We firstly separated the dataset into training and predicted samples for training and testing prediction accuracy, respectively. Secondly, we constructed a model under the number of decision trees during the range from one to 1000 in increments of five. Generally, a bigger quantity of decision trees causes higher prediction accuracy, while the limitation of that is the time consumed. Therefore, we wanted to make a balance between time consumed and prediction accuracy. As the exhibition of
Figure 10a we observed that the building trees beyond approximately 280 did not result in considerable additional performance increase but caused a slight decrease of prediction accuracy; finally, the relatively stable prediction accuracy happened at the tree beyond approximately 700. Therefore, we selected the forest size of 700 as a reasonable trade-off between time consumed and prediction accuracy. Subsequently, we built the model under the quantity of splitting variables from one to 18 (total number of selected features was 19). We could speculate that the performance of RF would be the best when the max number of splitting variables was four, as the illustration of
Figure 10b. We thus choose four as the max number of splitting variables in our model. Through the experiment, we found that the other parameters of RF did not have a significant positive influence for the prediction accuracy in the study. Therefore, we do not discuss the influence of other parameters in detail herein.
Using the check-in dataset, we also explored the influences of explanatory variables for predicting POI categories. The importance of explanatory variables was calculated based on the Gini impurity index mentioned in
Section 3. The process of calculation is as follows:
- (1)
Calculating the Gini under node of m and the Gini after splitting from m, the importance of this explanatory variable in node of m is the difference between that;
- (2)
Calculating the importance of this explanatory variable under all nodes of the tree by step (1), the importance of this explanatory variable under this tree is the sum of that;
- (3)
Calculating the importance of this independent variable under all trees of this RF model by step (2), the importance of this explanatory variable under this RF model is the sum of that.
Through these three steps, we calculated and ranked the importance of all features in our model, shown as
Table 3. It was obvious that each variable had a different influence on the prediction of POI categories. The variables of V1 and V2 as well as V3 played critical roles in predicting POI categories. It is presumably because, in large public venues such as entertainment, the numbers of users and check-ins are significantly larger than venues such as residential and hotel. According to that, the information of these variables can reasonably classify a large part of POIs. Meanwhile, the variables of V7 and V12 offered less effect to POI category prediction issues. We speculate that the period of 0:00–6:00 produced check-in data too small in size to generate obvious statistical results and to have a positive impact.
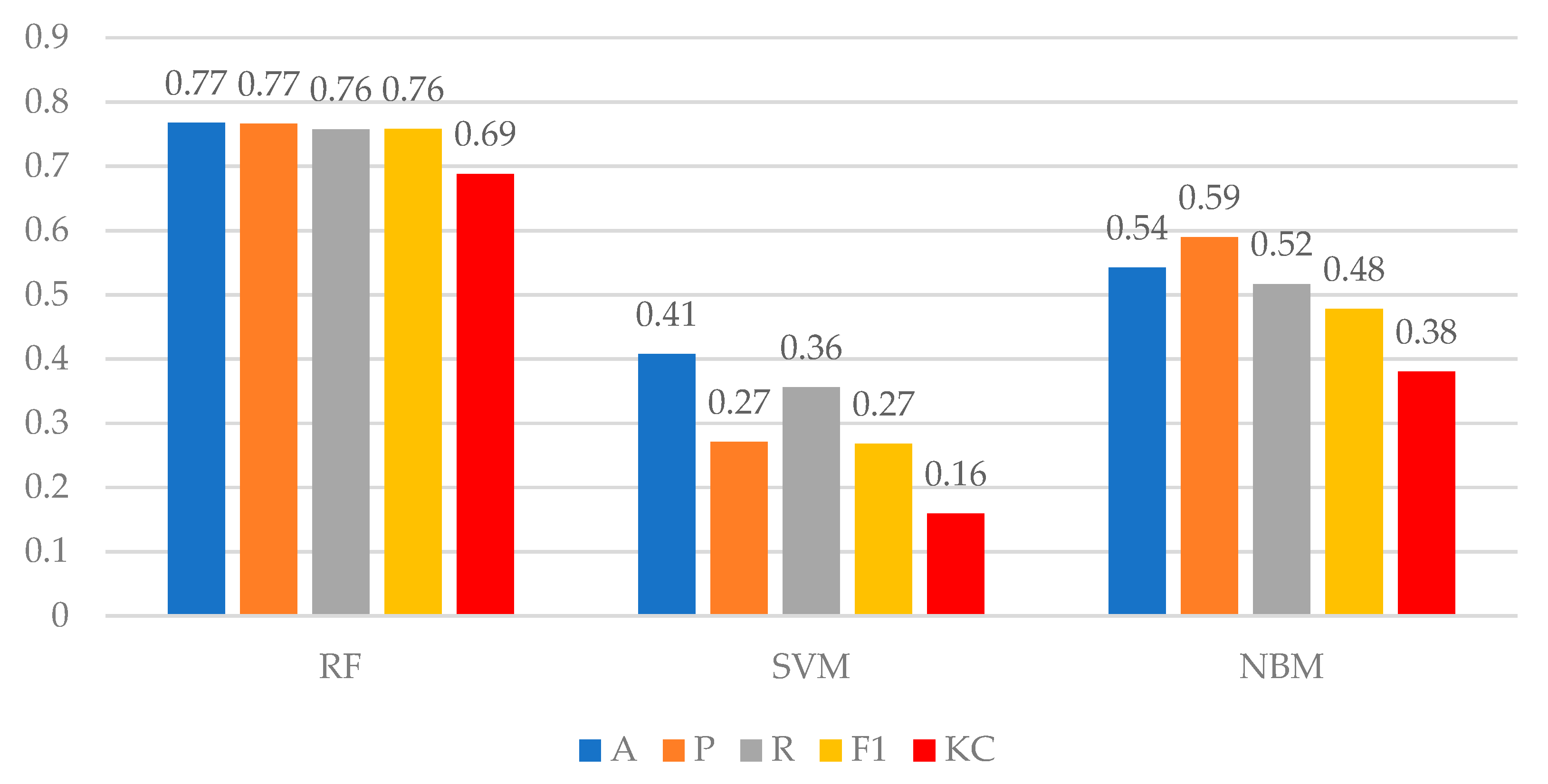
To determine whether the proposed model can achieve a relatively high accuracy in predicting POI categories, we made a comparison between random forest (RF), support vector machine (SVM), and naïve Bayes model (NBM). The principles of these models are exhibited in
Section 3. In the same rule for filtering check-in data and splitting training datasets and test datasets, we fitted these models by using the same training dataset. Subsequently, we utilized these fitting models to predict POI categories. The prediction results of RF, SVM, and NBM were 76.75%, 40.76%, and 54.24% respectively, which can also be viewed as the accuracy of the three models. In the perspective of accuracy, the RF showed a better prediction performance than SVM and NBM in our study. However, accuracy alone cannot fully demonstrate the performance of these models; we therefore utilized five common classification evaluation indicators, accuracy (A), precision (P), recall (R), F1-score (F1), and kappa coefficient (KC), to show capability of the three models. We calculated these indicators by the equations as follows:
where
denotes the number of correctly predicted in i-th categories; N represents the total number of samples in the testing dataset;
denotes the number of predictions in i-th categories;
denotes the total number of the testing samples in i-th categories;
can be calculated by the way accuracy was calculated (and one can say that
is accuracy); and
can be calculated by
.
The comparison of the five common classification evaluation indicators between three models is shown as
Figure 11 after calculating with the above equations. Moreover, the indicators of P, R, and F1, shown as the
Figure 11, were further calculated under the rule of macro average. In other words, the macro average was the arithmetic mean of all categories. It is obvious that the RF showed a significantly better prediction performance than SVM and NBM in terms of five evaluation indicators. We speculated that the best performer would be RF, and the next best performer would be NBM, followed by SVM in this study. Therefore, we selected the RF as our optimal model in our research. To obtain an overall prediction accuracy, we subsequently utilized the RF to obtain the overall accuracy of 72.21% by 10 predictions in different training and test samples.
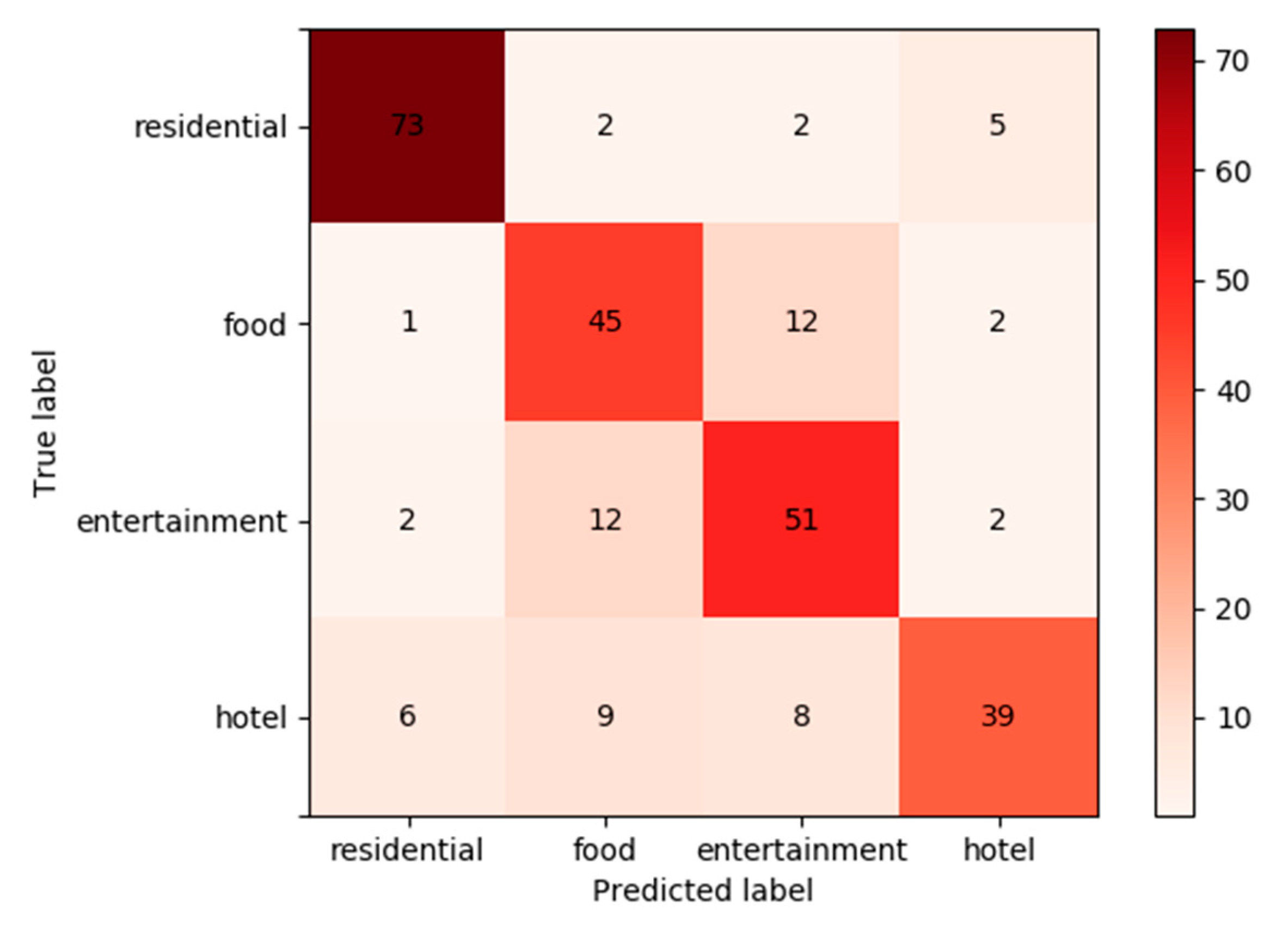
In order to further analyze the prediction results and acquire improvement implications for future works, we output the confusion matrix generated from the RF-based prediction, shown as the
Figure 12. It is obvious that residential had a higher R of 89.02%, while food, entertainment, and hotels only had Rs of 75%, 76.12%, and 62.9%, respectively. It is shown that some POIs of hotels were wrongly predicted to residential, food, and entertainment. According to that, we speculate that the reason is hotels are not only similar to residential in users’ check-in behavior patterns but are also similar to food and entertainment in both POIs’ locational characteristics and users’ check-in behavior patterns, because some large hotels own canteens and facilities such as swimming pools and gyms. Therefore, this caused the similarity in spatial and temporal features of check-ins. Moreover, some POIs of food and entertainment were confused with each other. It is presumably because, in the process of initial classification, we classified large shopping centers as entertainment, while there might be a few canteens in a large shopping center. In the future, we can explore other explanatory variables to clearly distinguish these POI categories to improve the model accuracy.
Through the experiment, we can see that the overall accuracy calculated by 10 times prediction achieved 72.21%, and the current highest prediction accuracy could achieve 76.75%. It means that we could precisely predict nearly three-quarters of POI-level land use categories in the study area, Guangzhou. Although the accuracy of a previous study that utilized deep learning exceeded our method [
22], our method can gain fine-scale results and obtain needed data with less cost. Our approach has some advantages over other social sensing approaches, including low cost and fine granularity. The urban planner can directly utilize our model to learn about the city structure in a finer scale if they need to understand the urban structure in detail and thus change city policy or structures to meet the demand of urban development. They only need to prepare the variables required by the method, and the method is even flexible enough to replace the check-in data with data such as Global Navigation Satellite System (GNSS)-trajectory or real-time recording locations in their study areas. The other finding during processing (e.g., the different check-in patterns on weekdays and weekends, the different check-in behavior during different periods of the day, and the spatial distribution of check-in) can assist in optimizing the resource allocation to match the spatiotemporal feature of a city. Moreover, this method may provide the opportunity to attain the finer level land use classification in certain districts lacking POI data. However, the deficiency of supervised classification such as RF is the demand of operator intervention [
23], which slows the efficiency of processing data in the method. Therefore, in the future, we can develop a model to improve the efficiency of processing data before classification. Moreover, the approach proposed in this study is likely to have potential applicability in classifying building-level land use (i.e., functions of buildings) according to human mobility and activity behavior and buildings’ locational characteristics. Human mobility and activity behavior can be measured by social media data (e.g., check-ins, posts, and images), GNSS trajectories, and mobile phone records. Buildings’ locations can be acquired via some open mapping projects such as OpenStreetMap. Our approach paves a new potential way to identify functions of buildings by using other social sensing data such as GNSS trajectories and mobile phone records and OpenStreetMap’s building data.
5. Conclusions
In the current study, we proposed a random forest method to analyze and predict the categories of POI to refine land use types by using Weibo check-in data in Guangzhou, China. In this random forest method, we proposed a rule considering the features of POI types to filter check-in data for obtaining the relatively representative check-in data of POI. This rule shows a better effect than the rule given few considerations about the features of POI categories. Subsequently, we explored spatial and temporal features of check-in data. The spatial distribution feature found from
Section 4 (check-in data are significantly concentrated in main urban areas) reveals the existence of high-level land use mix and the necessity of refining land use types. More detailed information of functional areas rather than land use types is essential to the urban planners for better designing spatial structures and resource allocation of a city. The temporal distribution feature in all times of day during weekdays and weekends illustrates that different POI categories determine different functions and activity types, while different activity types own the special temporal features, through which we can recognize the different POI types. Apart from spatial and temporal distributions of check-ins, we also examined the impacts of model parameters on model performances so we could select a relatively optimal trade-off parameter to achieve a better prediction result. Furthermore, we made a comparison between random forest (RF), support vector machines (SVM), and naïve Bayes model (NBM), and the results illustrate that RF achieved a higher prediction accuracy in this study. In our experiment, our proposed RF achieved the highest accuracy of 76.75% and overall accuracy of 72.21%. This demonstrates that we can identify functional areas at a finer scale by recognizing POI categories in the highly mixed-use areas to achieve the purpose of refining land use types.
Our work fills part of gaps from parcel-level land use classification to finer resolution land use classification, which allows city decision makers to observe the city pattern at a finer land use structure. It provides another way to research the highly mixed prosperous central city districts and complicated urban village. Moreover, the approach proposed in this study can be potentially applied to identifying functions of buildings according to visitors’ mobility and activity behavior and buildings’ locational characteristics.
However, there are some limitations in this study, and we therefore need to consider how to address them and further improve the method in the future. First of all, the relatively low predicted precision of hotel POIs caused our model to achieve a relatively poor performance. Therefore, a better feature should be found to improve the predicted precision of hotel POIs to refine this RF model in the future. Furthermore, our model only works in the four POI categories mentioned above. This is a limitation in highly mixed-use cities, thus the extensibility of our model should be refined in a later work. In other words, the applicability of model can be extended to the classification of more POI categories. Moreover, combining RF with other deep learning models may be a feasible way to improve this methodology. Owing to the lack of the dataset belonging to another city, we cannot verify our model’s ability utilized in other cities. Apart from that, other types of data, such as real-time population distribution data, can be integrated in the future work to enhance the performance of this model. Finally, we would attempt to identify functions of buildings by using other social sensing data such as GNSS trajectories and mobile phone records and OpenStreetMap’s building data in the near future once social sensing data are available.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}