1. Introduction
Origin-destination (OD) flow is the semantic recognition and feature extraction of complex trajectory data. It clearly expresses the geographic information of the origin and destination points of real trajectory, the implicit trajectory flow direction and distance, as well as specific thematic attributes (such as population migration, logistics and freight flow, traffic flow, etc.) [
1]. However, with the popularization of GPS positioning and the increase of Internet of Things sensors, massive mobile trajectory data has also emerged. How to find the flow pattern and explore the human–earth interaction in dense OD trajectory data is an important issue in mobile trajectory data mining [
2,
3].
Some scholars use visual analysis methods such as edge bundling, OD point clustering to solve the phenomenon of overlapping and displaying confusion of edges [
1,
4,
5,
6], thus highlighting the larger flow of OD clusters. Some scholars also use spatial clustering for pattern recognition by O-point clustering, D-point clustering, OD-point clustering, and OD flow (edge) clustering for different application scenarios [
7,
8,
9,
10,
11]. In terms of research ideas and methods of OD flow clustering, most researchers regard OD flow data as a set of O and D points. According to the spatial characteristics of OD points, the point clustering algorithm is used to realize OD flow clustering through double-iteration [
12,
13,
14,
15]. These OD flow clustering algorithms are easily constrained by the spatial distribution of OD points and the setting of search radius or internal connectivity parameters. They do not have the ability to discover irregular flow clusters actively.
The existing clustering methods of geographic OD flow rely on the characteristics of geographical units and functional areas, and too closely link the inherent land use data of the origin and destination points with the dynamic geographic flow behavior. In the model driven flow clustering method, the discovered flow patterns are more classic and inferred from traditional location factors and dynamic factors, and they do not fully mine the intrinsic value of OD trajectory data. How to take full advantage of “every valuable and real data” with the idea of data-driven methods, and how to use the data representation of OD flow to mine the geographical flow pattern to verify, update, supplement, and modify the geographical unit, land-use type, and functional division, are important research contents for studying the interaction pattern of geospatial subspace and describing the geographical flow.
Facing the problems of time delay and non-dynamics caused by the dependence of inherent geographic units in geographic flow pattern mining, this paper proposes an OD flow clustering method based on vector constraints. We plan to mine the dynamic interaction mode of flow space through the data characteristics of geographic flow and provide new tools for the mining of complex and irregular flow patterns.
In this study, the spatial and geometric (behavior) attributes of OD flow are expressed by defining OD flow event point and OD flow vector, then, OD flow vector coordinates are normalized by event point spatial clustering. On this basis, OD flow clusters with similar flow patterns are found by OD flow vector clustering. Finally, taking Beijing taxi OD data as an example, this study uses the method to find taxi traffic flow communities and irregular shape clusters with the same flow pattern.
3. OD Flow Clustering Method Based on Vector Constraints
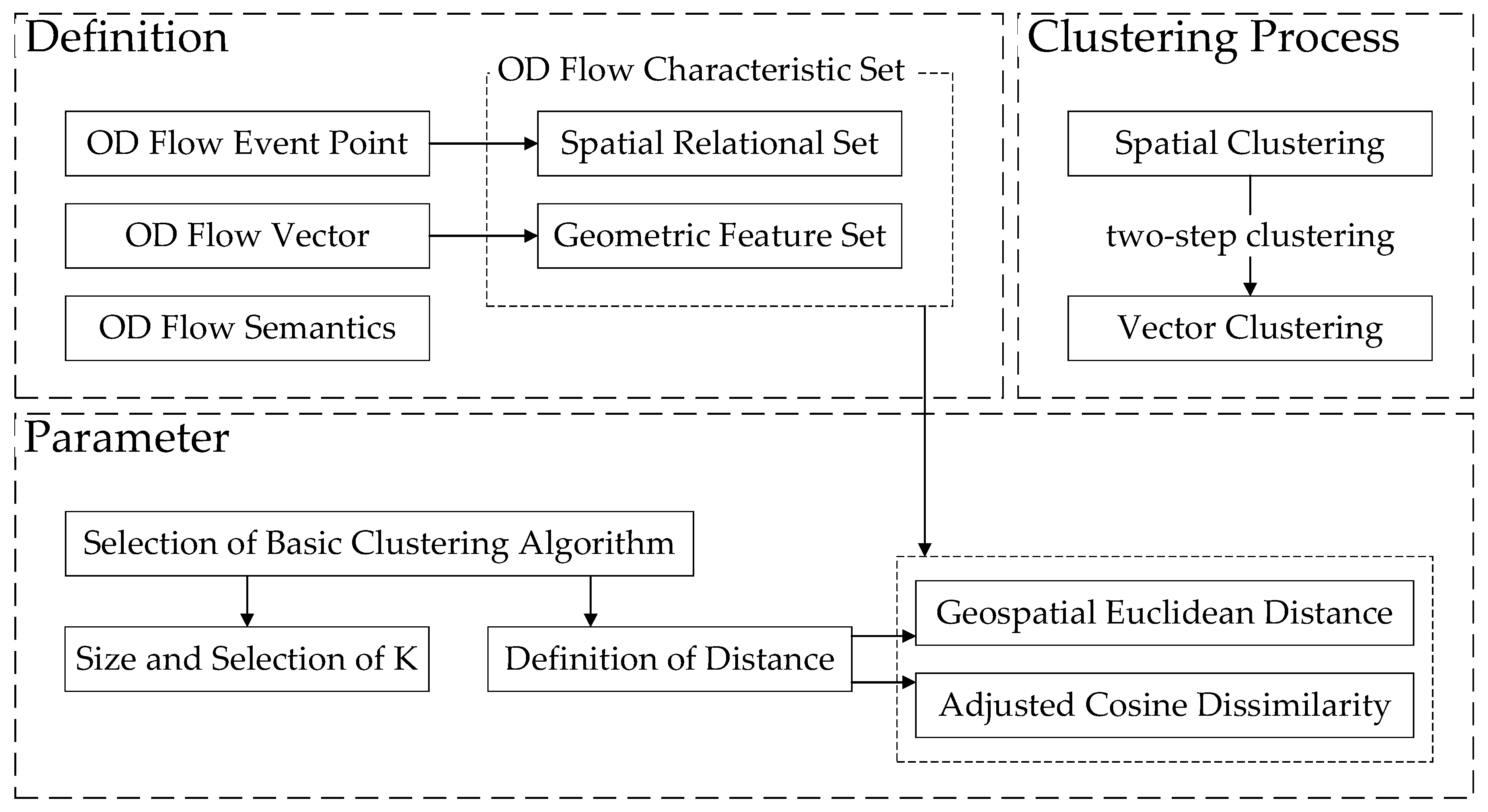
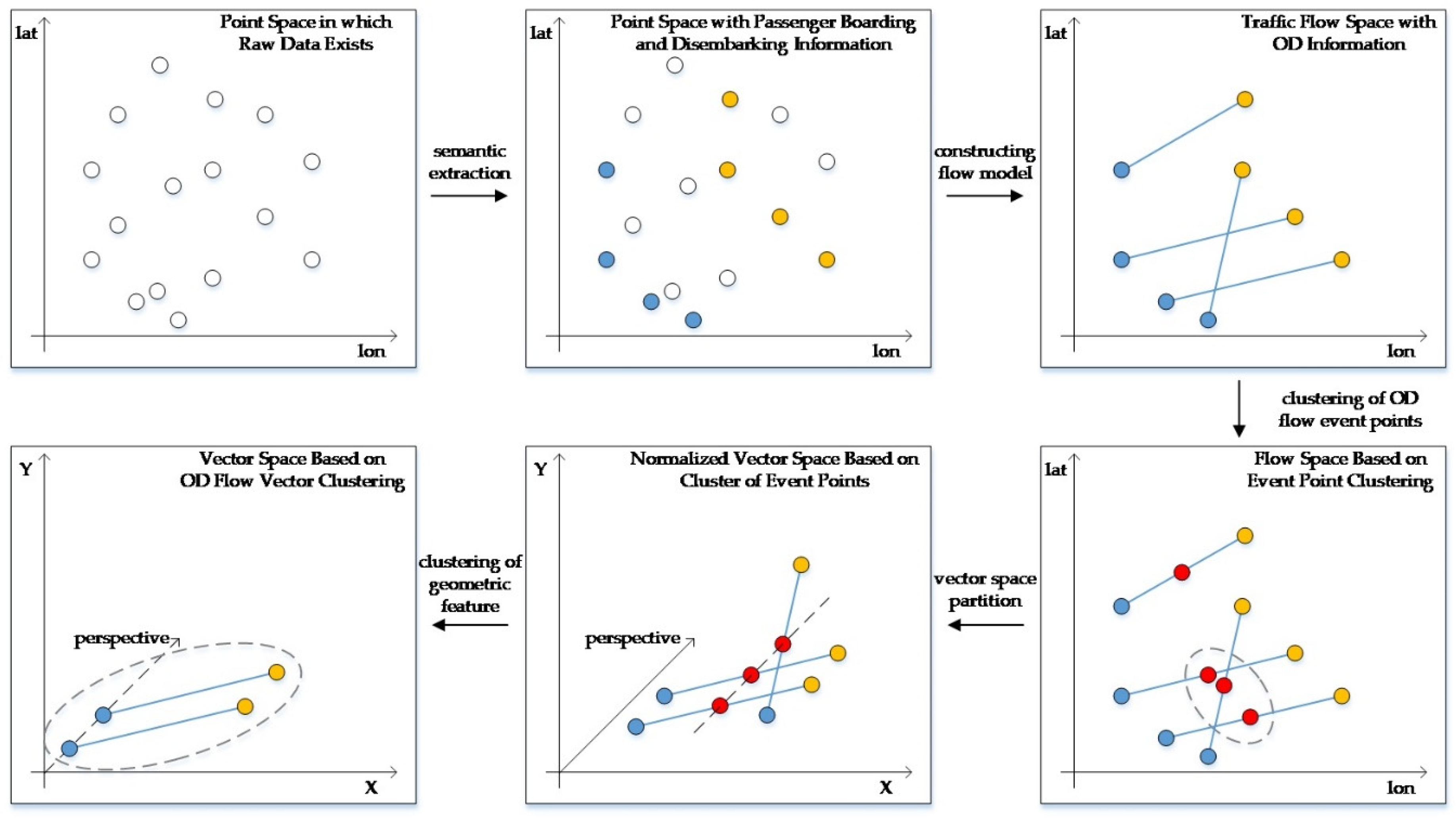
This section introduces the OD flow clustering method based on vector constraints. The method is described in the following three aspects: the definition of related concepts, model parameters (clustering number and distance function), and the details of clustering process. The components of the method are shown in
Figure 1.
3.1. Definition
3.1.1. OD Flow Event Point
where
and
are geographic coordinates of origin point (O-point), and
and
are geographic coordinates of destination point (D-point). According to Equation (1),
is the midpoint of the OD flow geometric line. Taking the taxi OD trajectory data as an example, OD flow is the taxi trajectory data which contains the semantic information of passengers boarding and disembarking positions. The generation of an OD flow represents a passenger’s travel behavior by taxi. Some scholars have proposed a spatiotemporal point process model, which regards the starting point and ending point of taxi as two different point processes [
44,
45]. If judging by the semantic information of OD flow nodes, OD flow is a point process with two different properties. If judging from the source of data collection, that is, taxi GPS data with passenger travel events (attributes), OD flow is an event with passenger semantics in the process of taxi operation, which is regarded as a point process. In this study, line can be abstracted as a point based on map generalization in small and medium scale, and further interpreted from the perspective of spatial and temporal point process. OD flow is regarded as an event of urban crowd activity and abstracted as a point process. Its spatial attributes are represented by the midpoint of geometric line of OD flow. Therefore, we define
as the event point of OD flow, which has the spatial attribute of OD flow. It should be emphasized that the original intention of using point coordinates to represent the spatial location of OD flow is to treat OD flow as a whole and as a line object and, then, use OD flow event points to represent the overall spatial location attributes of OD flow.
3.1.2. OD Flow Vector
Equation (2) shows that is the geometric vector of OD flow. Taking taxi OD trajectory data as an example, O-point is taxi GPS location when passenger boarding incident occurs, and D-point is taxi GPS location when passenger alighting incident occurs. OD flow is a directed line segment. As a semantic extraction of complex trajectory data, OD flow has no entity meaning in geographic space, but it represents passenger flow in geographic space in semantic space. Although there is no real track based on road network in OD flow, there are clear directions of crowd activity and spatial and temporal distances between OD. In this study, OD flows are considered as geometric vectors. The size and direction of OD flows are expressed by the modulus and direction of OD flows.
3.1.3. OD Flow Semantics
The semantics of OD flow can be regarded as events of urban crowd activities, which are usually inferred from the semantics of OD points [
46] (pp. 130–158). For example, from residential to office area is regarded as commuting, from residential to business circle is considered as shopping. Accordingly, the semantic information of OD flows depends heavily on the accuracy and granularity of point of interest (POI) data. In this study, the semantic information of OD points is not extracted and aggregated in advance based on urban functional areas and urban travel rules. There is no clustering trend for high-dimensional data in the whole space. Semantic space and geographic space do not necessarily have good similarity in clustering of OD flows. Therefore, it is not concerned with similar clustering of specific semantic features of OD flows in this paper. It is hoped that spatial clustering of OD flows can be used to mine the flow rules and potential patterns of OD flows.
3.1.4. OD Flow Characteristic Set
Without considering the semantic similarity, some scholars have proposed that the target features of spatial line group can be summarized as a set of spatial relations (spatial topological relations, spatial direction relations, and spatial distance relations) and a set of geometric features (line length and average length, tortuous coefficient, and line group density) [
40]. Owing to the particularity of OD line structure, it is unnecessary to pay attention to the topological relationship and tortuous coefficient of OD [
40,
43]. The direction of OD flow is not calculated by the direction angle but expressed by the geometric vector feature. The spatial distribution and distance of OD flow are replaced by the distribution density and distance of the event points of OD flow. Hence, we define the data structure of OD flow as:
3.2. Parameter
3.2.1. Selection of Basic Clustering Algorithm
In the research of spatial pattern recognition of OD flow clustering, there are three main methods to identify spatial distribution [
38]. Among them, there are two main types of improved classical clustering algorithm, hierarchical clustering algorithm for OD flow and density clustering algorithm based on origin and destination points. The advantage of the hierarchical clustering algorithm is that the structure of clustering results is tree-like, and it can be expressed by multiscale clustering. The advantage of density-based clustering algorithm is that it has the potential to mine spatial clusters of OD points with arbitrary shapes by connecting high-density spatial entities with continuous spaces into clusters. The third method focuses on extending the traditional spatial statistical method to identify OD flow clustering anomalies by defining new OD flow similarity. The limitations of existing hierarchical clustering and density clustering algorithms are as follows: First, the definition of distance and the size of value are uncertain and secondly, the constraint of discovering clusters of arbitrary shape due to the splitting of OD points in OD flows. The limitation of the modification based on spatial statistical algorithm lies in the loss of OD flow information caused by dimensionality reduction of OD flow similarity definition.
This research adopts the K-means clustering algorithm, the main reason is the definition and selection of clusters [
47,
48]. Different clustering algorithms have different definitions and mining abilities for clusters because of their different logic. The expected clustering result of this algorithm is OD flow with close spatial relationship and similar geometric shape within clusters, so it is more suitable for partition-based clustering method, which is based on central cluster definition.
3.2.2. Size and Selection of K
The selection of seed points is an important step in K-means clustering. The size of K determines the number of clusters. The selection of K affects the efficiency of iteration. In previous studies, elbow method and silhouette coefficient are classic indexes to evaluate clustering effect [
49,
50]. By traversing K, sum of squared error (SSE) and silhouette coefficients under different K values are calculated, and the elbow nodes of SSE curve and the corresponding larger silhouette coefficients are found. In previous studies, naked eye judgment was often used. In the algorithm design of this study, perceptually important points (PIP’s) is adopted to automatically identify SSE elbow points [
51], and the silhouette coefficient is used to check.
By calculating SSE, the elbow method is used to find the relationship between K value and the real clustering number.
where
is the
th cluster,
is the sample point in
, and
is the mean of all samples in
. When K is less than the real clustering number, the increase of K leads to a significant decrease in
, and when K reaches the real clustering number, the gain of clustering effect decreases rapidly with an increase of K. Therefore, the K value corresponding to the elbow inflection point of the SSE curve is the real clustering number of data.
Silhouette coefficient is a clustering evaluation method which combines cohesion and separation. For any vector
, its silhouette coefficient is:
where
is the average distance from vector
to all other points in the cluster to which it belongs, and
is the minimum distance from vector
to all points in the cluster that it does not belong. The average of all the silhouette coefficients is the total silhouette coefficients of the clustering results. The closer the silhouette coefficient approaches to 1, the better the cohesion and separation are. But the silhouette coefficient is a relative evaluation index. The silhouette coefficient fluctuates with the change of K. It is a non-convex curve. There are many local optimum solutions. Usually, the elbow method is needed to assist, and the K value corresponding to the local maximum of the silhouette coefficient is chosen as the optimal clustering number.
When determining the size of K, the elbow method is affected by subjective factors, and there are multiple local maximum values using silhouette coefficient. Therefore, the SSE perceptually important points algorithm considering silhouette coefficients (SSEPIP) is adopted to automatically extract the optimal clustering number. The process of SSEPIP is as follows.
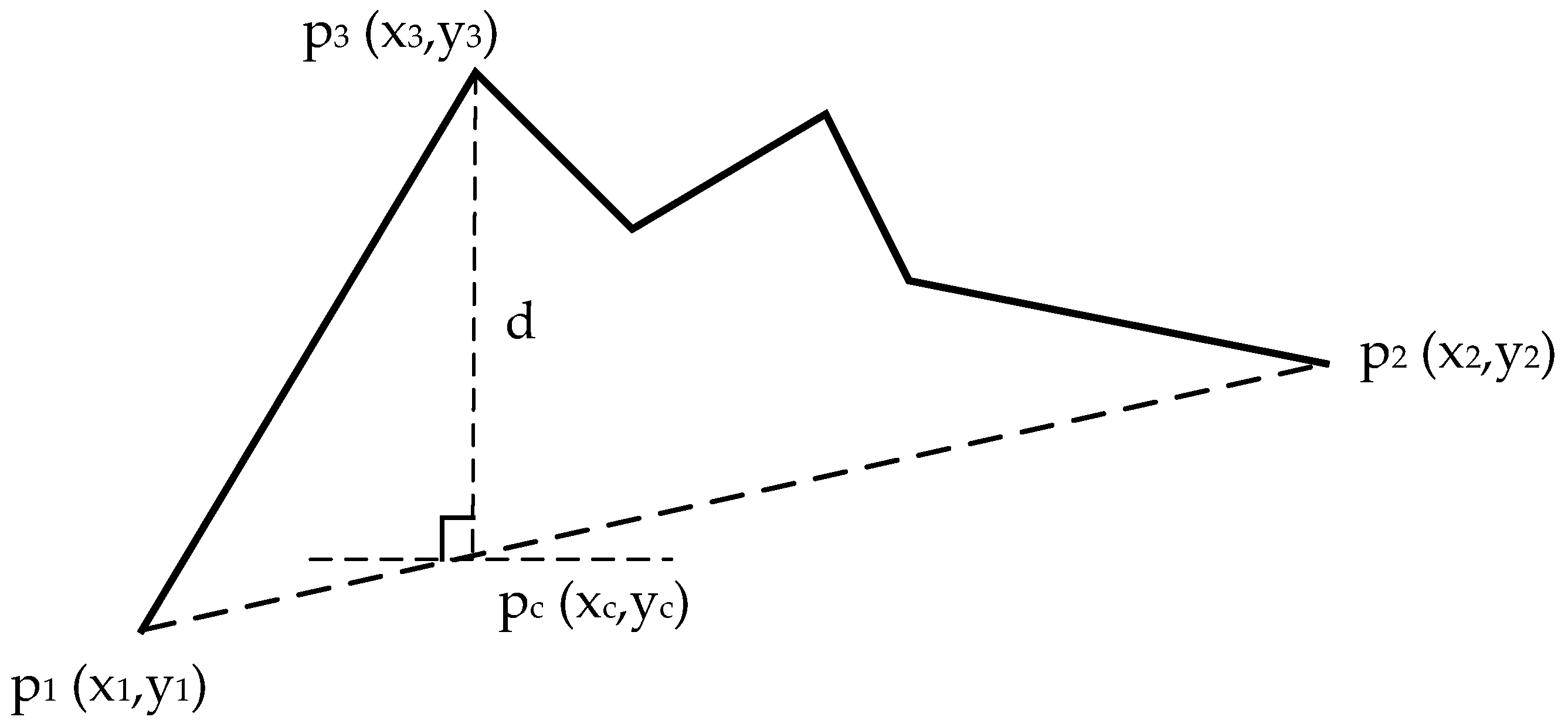
The SSE curve is defined as sequence P, where the first two PIP’s are the first and last points of P, and the next PIP is the point in P with maximum distance to the first two PIP’s. The distance is defined as the vertical distance between the test point P
3 and the straight line connecting two adjacent PIP’s (
Figure 2):
where
. PIP’s algorithm is often used for data compression, so the number of PIP’s changes with the experimental requirements. In this experiment, sequence P (SSE) is a monotone curve, and there are inflection points around the third PIP, and therefore only once PIP recognition is needed, as shown in
Figure 3.
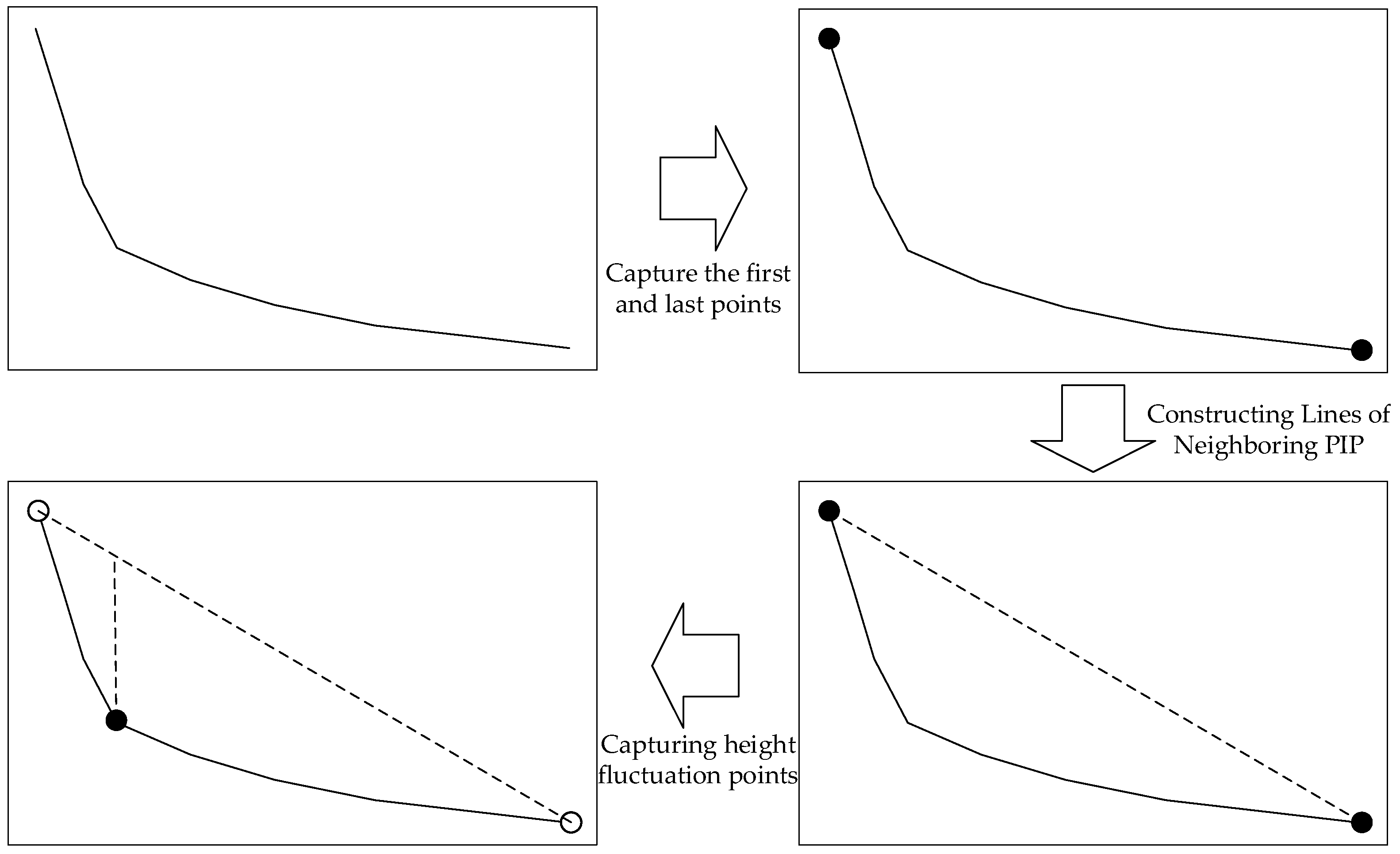
The PIP’s algorithm is generally used to compress static data, and it cannot solve the sequence with variable length stably. The third PIP oscillates slightly around the inflection point as the tail point changes, therefore, the local maximum point of silhouette coefficient is used as the constraint condition to help select the best K value. In order to better illustrate the recognition process, the SSE sequence and the silhouette coefficient sequence are standardized.
Figure 4 shows the stepwise results of using silhouette coefficient to assist in identifying SSE inflection points. The black line represents SSE sequence and the blue line represents silhouette coefficient sequence.
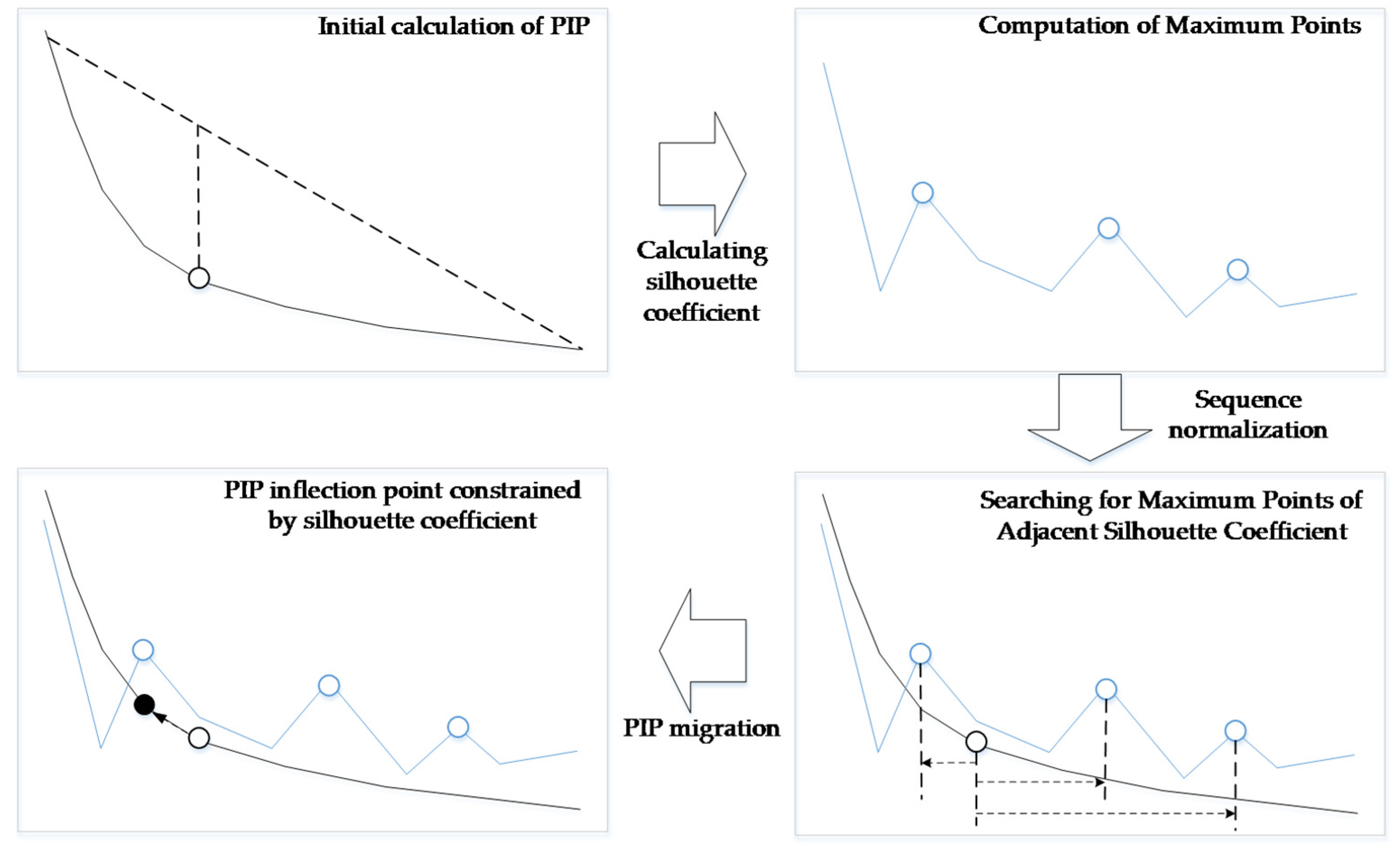
In the traversal process of K value, each new position needs to be selected. In order to optimize the efficiency of clustering algorithm in each cycle, we evaluate the average silhouette coefficients of each spatial cluster and generate new seed points in the range of the spatial cluster with the smallest silhouette coefficients for the next round of calculation. The specific process is shown in
Figure 5.
3.2.3. Definition of Distance
In the research of spatial statistics methods of OD flow, some scholars obtained the distance of OD flow by weighted summation of O-point distance and D-point distance [
52]. Some scholars obtained the distance of OD flow by weighted summation of vector coordinates and attribute variables of OD flow [
53]. In this study, we take OD flow as a whole object, and try to construct the corresponding distance function through the spatial and geometric attributes of OD flow. However, in high-dimensional data analysis, data from different dimensions cannot be directly compared and calculated. When constructing distance function, weight allocation has strong subjectivity. In this study, two-step clustering based on spatial dimension similarity and geometric feature similarity is carried out, while Euclidean distance and adjusted cosine similarity are used as spatial distance function and geometric feature distance function.
The spatial characteristic distance of OD flow is defined as the geospatial Euclidean distance of OD flow event points.
The geometric characteristic distance of OD flow is defined as the adjusted cosine dissimilarity.
R is the intra-cluster mean in a given dimension. The adjusted cosine similarity normalizes different dimensions according to the difference of vector angles, indirectly considers the influence factors of vector modulus, and synthetically measures the similarity of vector size and direction [
54]. Because the range of the similarity is [−1,1], the distance function is the dissimilarity calculated by the difference.
3.3. Clustering Process
Compared with traditional clustering, the difficulty of line clustering and even high-dimensional clustering is how to deal with high-dimensional information. From a differential point of view, a straight line is constructed from innumerable points, so the process point model is suitable for describing flow space data. Vector is the best descriptive features of line shape. The size and direction of vectors describe the length and angle of line, thus expressing the distance and direction of flow. But vector features cannot describe spatial dimension information. Therefore, we use event points to express the spatial information of the flow. Any high-dimensional object can be mapped into a point object in two-dimensional space. In this study, the spatial characteristics of the OD flow event points are used to reflect the spatial properties of the flow. In this way, we express any flow object through the event points and vectors of the flow, and cluster from the spatial dimension and the geometric dimension in two steps.
The clustering logic is shown in
Figure 6.
Figure 6 shows the process of transforming OD flow data from point space to flow space, and then to vector space in clustering algorithm logic. The white dots represent the original taxi GPS data, the blue dots represent the passenger boarding position, the yellow dots represent the passenger getting off position, and the red dots represent the OD flow event point. The proposed algorithm can be divided into the following two steps: The first step is to constrain the vector coordinate system by spatial clustering of OD flow event points, and the second step is to constrain the OD flow vector characteristics by clustering the similarity of geometric vectors. The original OD data exists in discrete GPS trajectory point space. In previous studies, paired OD point set data was obtained by semantic extraction. In this paper, we construct OD flow dataset by calculating OD flow event points and OD flow vector of OD point pairs and transform OD point set space into OD flow space. In OD flow space, we describe the expression of OD flow data as two dimensions, i.e., spatial dimension and geometric feature dimension, and define that the elements in OD flow cluster should satisfy both spatial dimension similarity and geometric feature dimension similarity. In this way, the OD flow clustering process is realized by the two-step clustering method. The first is the process of “space division”. In small-scale or multiscale analysis, the geospatial location attributes of OD flow are expressed by OD flow event points. Therefore, the OD flow is divided into several spatial clusters in the flow space by using the OD flow event point clustering. The size and direction of OD flow are different in each spatial cluster, while the spatial location relationship between OD flows is relatively close. Then, it is the “vector clustering” process. In this process, only considering the geometric characteristics of OD flows in each spatial cluster, adjusted cosine similarity is calculated by OD flow vectors and clustered. The implicit premise is that OD flows in each spatial cluster are translated before geometric feature clustering, ignoring the spatial location differences of OD clusters in the same spatial cluster, and then the OD flow vector coordinate system is unified. Therefore, after “space partitioning”, each spatial cluster in OD flow space is transformed into an independent vector space, and all vector clustering processes run in parallel.
In this study, the spatial distance and morphological distance are not integrated into a composite flow distance function. The reason is that the fusion of spatial distance and morphological distance is very complex, and the two features depend on each other and influence each other. Some studies tried to use weighted distance function to express the flow distance, but the problem of multiscale expression and global normalization cannot be well solved [
52,
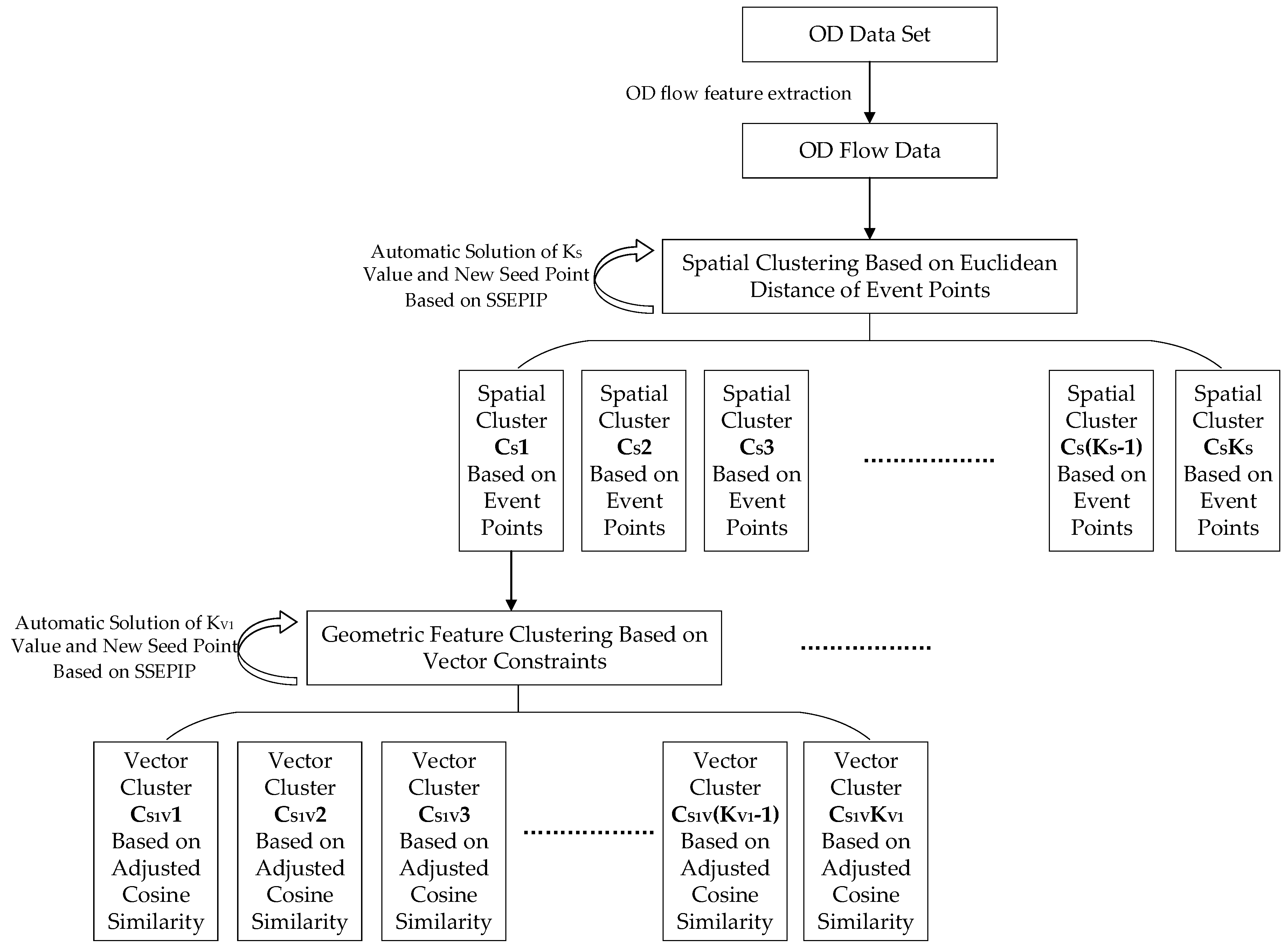
53]. From the global point of view, the scale differences caused by different lengths, angles, and spatial locations cannot be well solved. From the local point of view, the density distribution of different dimensions has a significant impact on clustering results, so the global optimal solution cannot be obtained. Therefore, this study attempts to solve the global distribution through dimension segmentation, first through spatial clustering, in order to obtain a cluster set with close spatial relations within the cluster and assume that each spatial cluster exists in a separate and unified vector space coordinate system. Then, clustering is carried out by the geometric feature distance in the spatial cluster to solve the problem of uneven local feature density, and representative vector clusters in different spatial clusters are obtained respectively. The specific steps are as follows:
Step 1 At present, most OD flow data storage forms are O-point coordinates (XO, YO), D-point coordinates (XD, YD), and thematic attributes. Therefore, it is necessary to extract OD flow event points and calculate flow vectors to obtain OD flow feature set.
Step 2 K-means clustering based on the spatial distance of event points. The KS value increases from 2 to the optimal number of spatial clusters solved by SSEPIP.
Step 3 For each spatial cluster (N in number), K-means clustering is carried out based on the geometric feature distance of OD flow vectors. The KVN value increases from 2 to the optimal number of vector clusters solved by SSEPIP.
Step 4 By calculating the average of OD flow event points and OD flow vectors in clusters, we can get representative flows of clusters, and visualize them (expressing the direction of OD flows by moving points).
The origin-destination flow clustering vector constraints (ODFCVC) method is suitable for distributed computing environment, especially for the third step of the algorithm, each spatial cluster performs the geometric feature clustering operation independently.
The flow chart of clustering method is shown in
Figure 7.
is the N-th spatial cluster based on OD flow event points, . is the optimal solution of global spatial cluster K value. is the M-th vector cluster contained in the N-th spatial cluster, . is the optimal solution of vector cluster K value based on the adjusted cosine similarity in the N-th spatial cluster.
Assuming that the distance matrix is a symmetric matrix. A
matrix with a diagonal of 0 is constructed by clustering O and D points for n OD flows in previous flow clustering methods. However, in the ODFCVC method, the distance matrix size is:
When constructing the distance of composite flow, the full dimension feature matrix generates unnecessary redundancy, because when the difference between one dimension is too large, there is no need to consider the similarity of the other dimensions. Therefore, through the gradual clustering of different dimensions, first, we cluster on the spatial feature dimension, grouping OD flows based on spatial clusters and unification of vector coordinate systems. Then, we cluster on geometric feature dimension, and extract representative vector features through adjusted cosine similarity in each spatial cluster. This method also improves the normalization error and local feature loss caused by solidifying vector features into four or eight directions in previous studies [
55,
56].
4. Experiments and Analysis
Section 4 introduces an example of traffic flow pattern mining using the ODFCVC method. This section contains three experiments. The first experiment is to analyze the OD data of taxis in Beijing by using the ODFCVC method. The second and third experiments are to analyze the spatial cluster and vector cluster generated by clustering.
4.1. Taxi OD Flow Clustering Based on ODFCVC
Taxi OD flow is a kind of trajectory with the location information of taxi passengers getting on and off by semantics extraction from taxi trajectory data generated by GPS positioning. Compared with the complex real trajectory, OD flow does not depend entirely on the real road network data and can directly reflect the characteristics of urban residents’ travel. It is an important data source for mining the spatial and temporal activities of urban population [
46] (pp. 60–61). The data we used in the experiment are some taxi GPS trajectory data (more than 12 150 pieces) from 6 a.m. to 9 a.m. on 11 January 2008 in Beijing. The data format is the raw taxi GPS trajectory data structure, including the taxi encryption number, GPS feedback time, real-time longitude and latitude, riding status, riding events, speed, direction angle, and other fields [
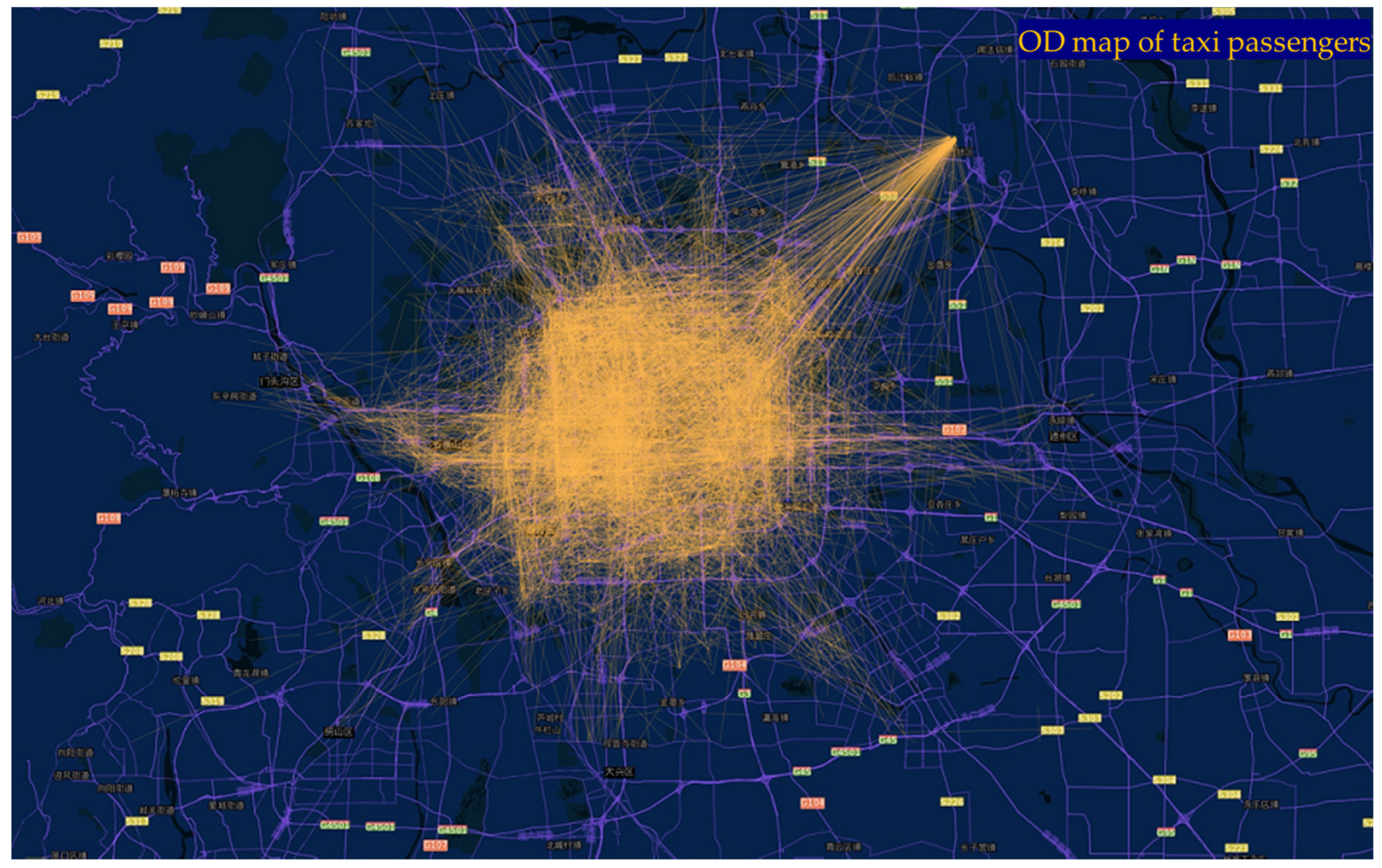
46] (pp. 76–79). In order to facilitate the visualization of clustering results, we use JavaScript + HTML + CSS front-end web development technology to carry out all the experiments and use JavaScript language to write clustering and visualization methods. The visualization of taxi OD flow without clustering analysis is shown in
Figure 8.
Through the automatic determination and test of the optimal K value, the K value of the spatial cluster based on OD flow event points is 4, and the K value of the vector cluster contained in each spatial cluster is 4, 4, 5, and 4, respectively.
In order to verify the significance of the number k of clustering results solved by SSEPIP, we use the stability of clustering as the evaluation criteria [
57]. The method of draw a random subsample of the original data set without replacement is used to generate perturbed versions (p1, p2, p3) of the dataset, and the sampling rate is 0.8. The distance function uses the minimal matching distance. The experimental results of clustering stability in the process of “space division” and “vector clustering” are shown in
Table 1. The stability index shows the effectiveness of SSEPIP to solve the optimal clustering number automatically.
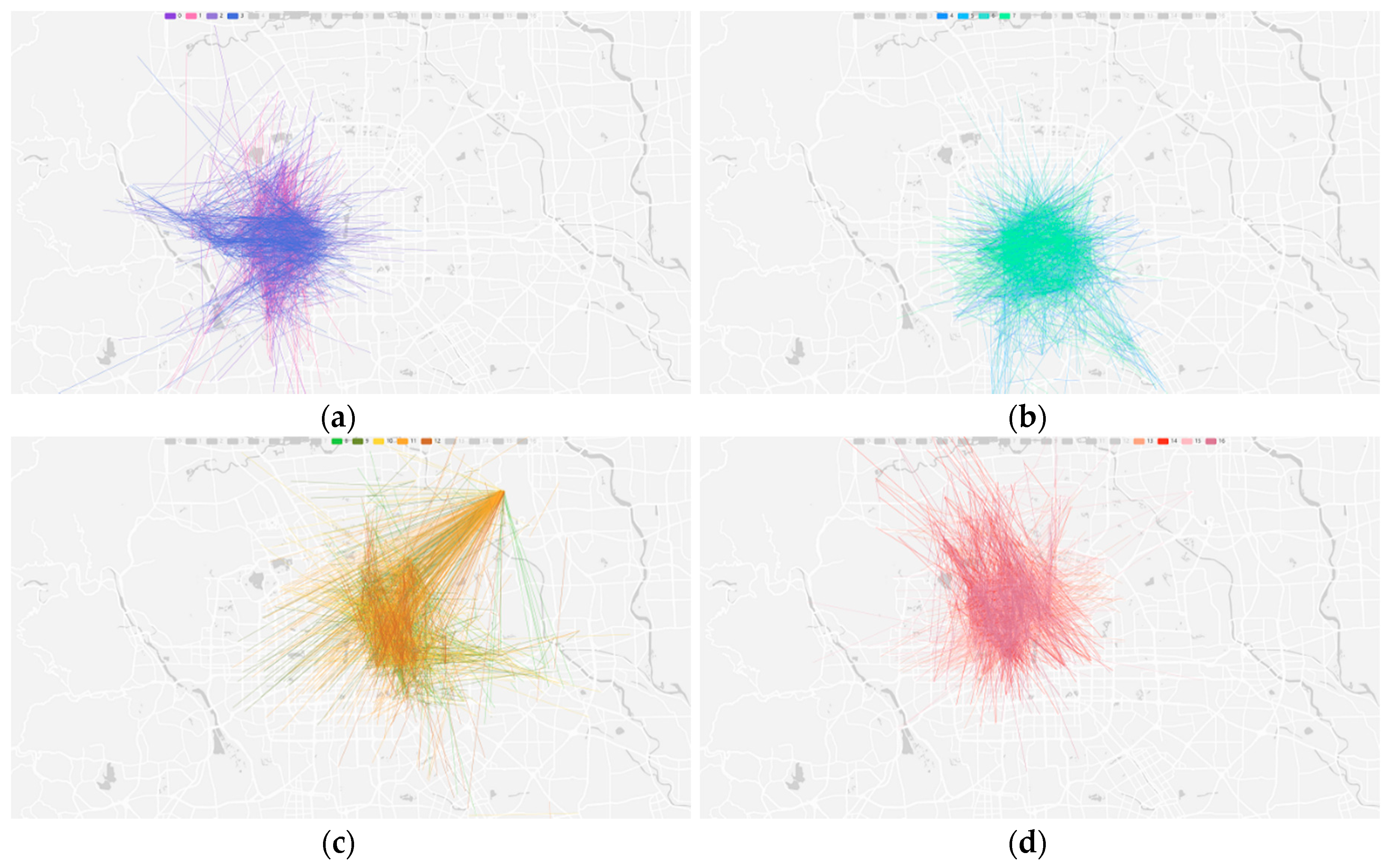
The OD flow spatial cluster generated in the clustering process is shown in
Figure 9, and the final clustering result is shown in
Figure 10. In order to observe the overall flow trend of 17 clusters, we calculate the OD flow event point mean and OD flow vector mean of all kinds of clusters as representative visualization descriptive indicators. The visualization results are shown in the nested view in
Figure 10.
4.2. Spatial Cluster Analysis of Taxi OD Flow Clustering
Figure 9 is the visualization result of OD flow event point spatial clustering based on spatial partition index extraction after the ODFCVC method. By comparing with
Figure 10, we see that the cluster product of the first step clustering “spatial partition” is the OD flow vector coordinate system constraint, and the OD flow cluster is obviously divided into four spatial clusters, each of which constrains different vector clusters. This compound flow model is mainly influenced by the calculation of OD flow event points. OD flow is not a real trajectory, and there is no midpoint of the trajectory. By defining the OD flow event point, the midpoint of the OD flow is regarded as the spatial abstraction of the OD flow. Therefore, the midpoint of OD flow has certain physical significance in clustering analysis and pattern recognition.
The original intention of spatial clustering based on OD flow event points is, on the one hand, to satisfy the similarity conditions in OD flow clusters in spatial dimension, and on the other hand, to simplify the amount of data when calculating geometric similarity and enhance the expression of local feature difference. However, whether OD flow spatial cluster has physical significance is worth our in-depth consideration. Therefore, we use community discovery algorithm in network analysis to realize OD flow communities based on different geographical units and try to understand the physical significance of taxi OD flow spatial cluster through comparative analysis.
We find communities in the graph constructed by OD flow using Clauset–Newman–Moore (CNM) greedy modularity maximization [
58,
59]. The corresponding process is shown in
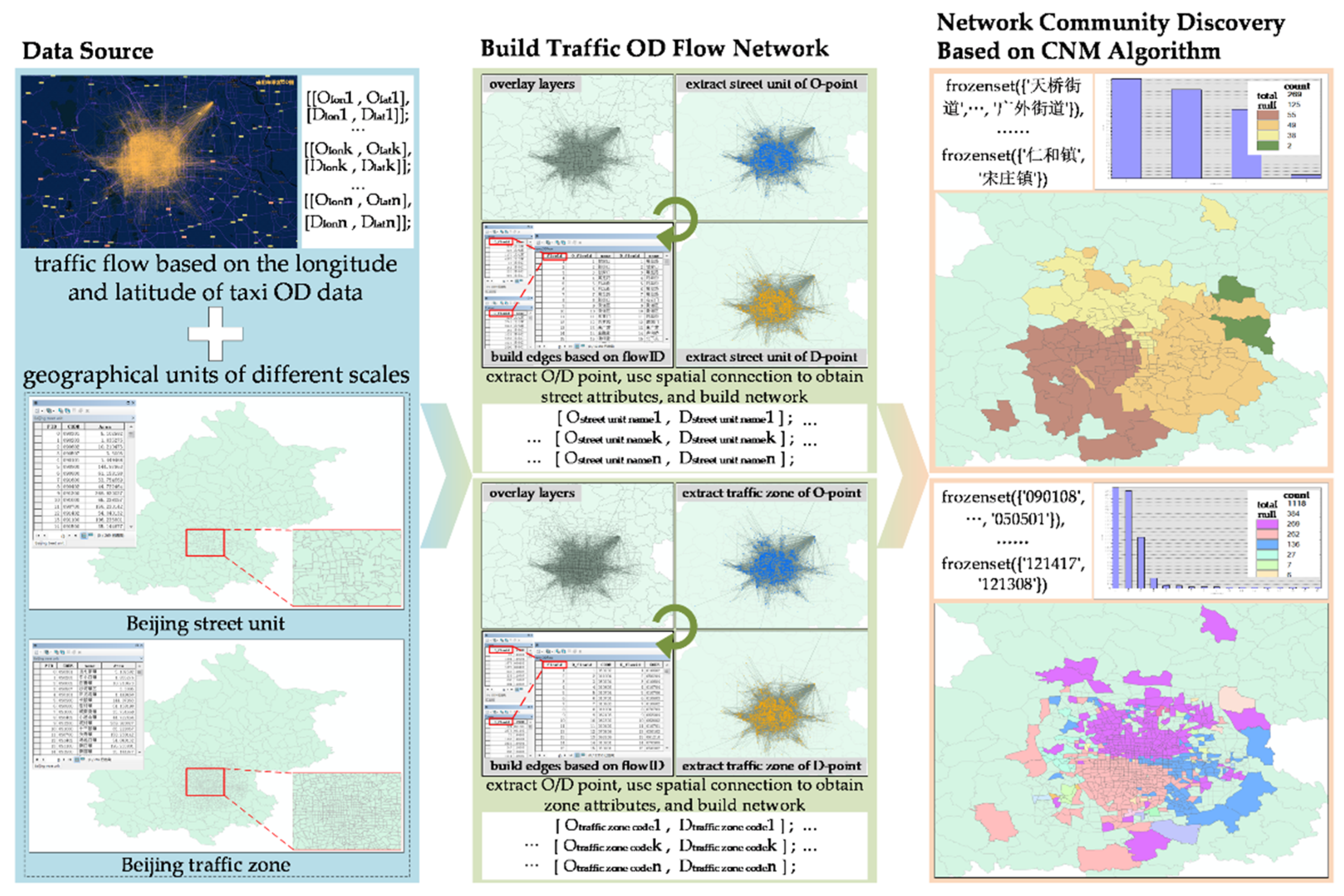
Figure 11. The network analysis function is realized by NetworkX software package, and the community visualization is realized by ArcMap. The taxi OD flow network is constructed by taking Beijing traffic zone and Beijing street unit as nodes [
60]. Through overlay analysis of different geographic units and OD flow, the OD interactive graph of taxi trip based on geographic units is obtained. Then, we use the most classical module-based community discovery algorithm CNM to get the OD flow community without geographical space constraints, and visually display on a map.
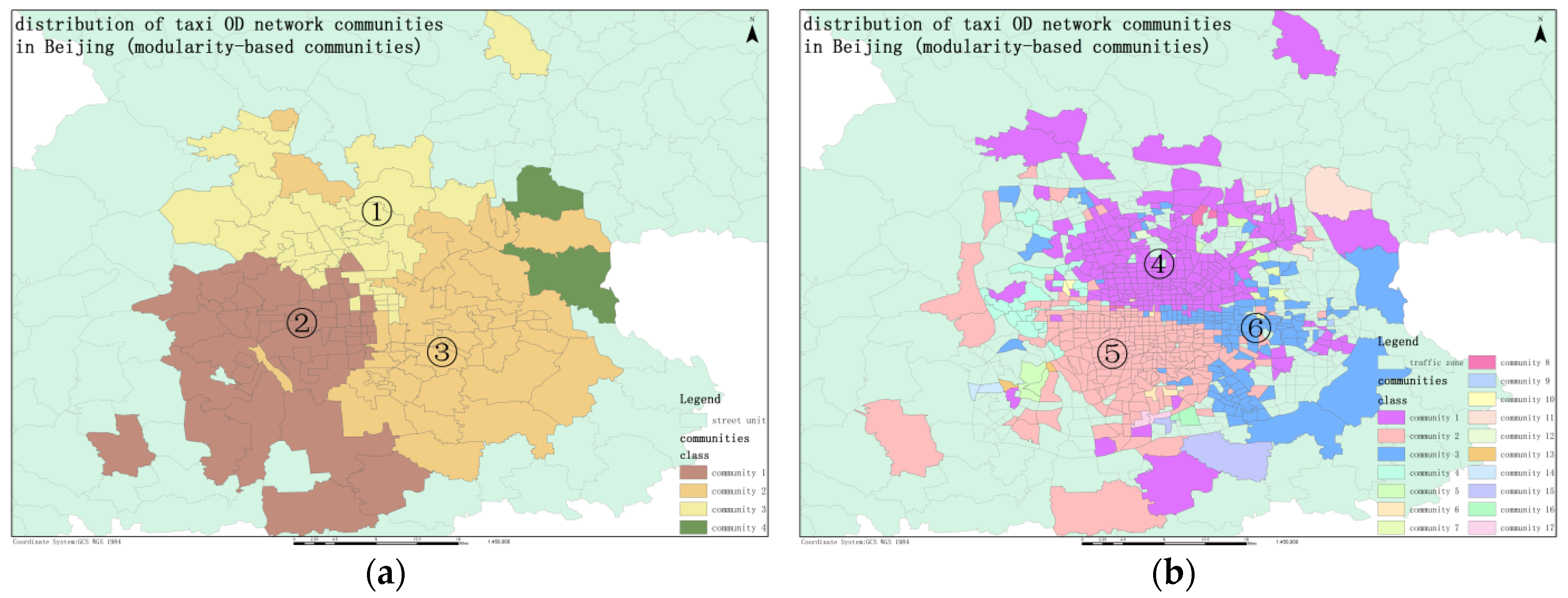
Figure 12 shows the community distribution of taxi OD flow network with traffic zone and block (street unit) as nodes, respectively. We annotate the six main communities (the number of nodes in the community is more than 10% of the total nodes), which is represented by ①–⑥.
By comparing
Figure 9 and
Figure 12, we analyze the relationship and difference between the OD flow spatial cluster extracted by the ODFCVC method and the OD flow network community obtained by classic network community algorithm. First of all, comparing the network communities mined by the CNM algorithm on different granularity of geographical units, there are some similarities and differences between them.
In terms of similarities, there are three main traffic flow communities, covering the central area of Beijing. The communities are located in the north, southwest, and southeast of the central urban area of Beijing. Each community has a certain degree of geographical spatial connectivity. In terms of differences, due to the more detailed division of traffic zones, the community formed is also more fragmented, and there are geographical gaps within the community. There are community boundary contradictions in the west, northeast, and south of Beijing central area.
Then, compared with
Figure 9 and
Figure 12, it can be found that the spatial partition results based on the first step clustering of the ODFCVC method have strong similarity with the network community mining, and some interesting phenomena are found. The number of spatial clusters obtained by clustering is 4. Because the clustering results are based on the K-means algorithm, the spatial clusters have global characteristics and ignore local anomalies, therefore, the spatial clusters obtained by Euclidean distance clustering of OD flow event points have internal continuity. Spatial cluster (a) corresponds to the north of network community ②, spatial cluster (b) corresponds to the east of network community ⑤ and the south of community ② and ③, spatial cluster (c) corresponds to the intersection of network community ⑥ and community ③ and community ④, and spatial cluster (d) corresponds to network community ①. It can be seen that the OD flow spatial cluster obtained by clustering has certain practical significance. In the south of Beijing, where the network community is controversial, the new spatial cluster (b) obtained by the ODFCVC method is beneficial to explain and unify the network community obtained by different geographical units.
Using the OD flow midpoint as the event point is easier to find the flow clustered mode. The physical significance of taxi OD flow cluster is due to the attraction of urban functional areas and the social interaction of transportation hubs, resulting in traffic flow cluster with obvious spatial division. Because the formation of traffic flow community is dependent on the urban traffic hub, we compare the cluster result with the spatial distribution of Beijing traffic hub [
61] and find that the two have obvious spatial correlation (Transport Center (a) includes Beijing West Railway Station and Liuliqiao Passenger Transport Hub. Transport Center (b) includes Beijing South Railway Station, Songjiazhuang Transport Hub, and Nanyuan Airport. Transport Center (c) includes Beijing Railway Station, Sihui Public Transport Hub, and Beijing Capital International Airport. Transport Center (d) includes Xiyuan Transport Hub). Through the spontaneous behavior of urban people’s travel activities, urban traffic centers can be identified without the influence of functional areas of origin-destination points. It can also be found that the transport hub not only serves as a passenger flow distribution center, but also attracts the traffic interaction around it. Therefore, the ODFCVC method can better identify OD flow communities and discover OD flow clusters with potential spatial connections.
4.3. Vector Cluster Analysis of Taxi OD Flow Clustering
On the basis of the recognition of OD flow event point spatial cluster, this clustering method can find representative geometric feature clusters with arbitrary shape. In previous studies, the similarity of OD points is often constrained by defining regular search space, or additional geographic unit partition, or uniformly continuous density space, so as to obtain rule clusters with similar geometry, or irregular clusters with similar semantic features or uniform density of OD points. The morphological structure of these clusters depends on the parameter definitions of hierarchical and density-based clustering algorithms. However, due to the solidification of search radius, intra-cluster connectivity, and other parameters, existing aggregation algorithms cannot deal very well with the global density of non-uniform line sets.
Traditional methods pay more attention to “geographic attraction” to “flow behavior” [
46] (pp. 111–114), but the ODFCVC method is the opposite. For taxi OD trajectory analysis, the spatial location and thematic attributes of OD points are static geoproblems, and the spatiotemporal trajectory generated by taxi activities is a problem of urban dynamics. In the past, people’s dynamic spatiotemporal modeling and analysis focus more on the rigorous causal inference. Because the characteristics of OD point’s functional area meet the law of urban activity, it will produce corresponding travel behavior. Therefore, when travel behavior has similar OD points, this kind of travel behavior is the same mode. This kind of analysis method which first has “geographic attraction” and then “flow behavior” has a great dependence on the accuracy of OD data, and is limited by the factors of urban functional areas and POI data updating, does not have the premise of initiative discovery of new patterns. In the data-driven way, the proposed method tries to find the geographic similarity attracting such behavior by analyzing the flow behavior and excavate the urban subspace interaction under the new urban science paradigm.
The whole process of the algorithm does not need any preset parameters. It only needs to calculate the optimal K value of the spatial cluster and the geometric cluster, respectively, by the silhouette coefficient, the sum of squares of errors, and other indicators. The first step of spatial clustering and adjusted cosine similarity solves the feature loss caused by global data normalization as far as possible. Moreover, because of the geometric constraints, the method does not use the conventional two-point constraints and is only affected by the K value of geometric cluster based on spatial cluster optimization and adjusted cosine similarity, therefore, OD flows find clusters with irregular distribution. Therefore, the ODFCVC method recognizes not only clusters of similar patterns with regular shapes, but also clusters with convergence and divergence patterns. As shown in
Figure 10c, the origin points of convergence pattern and destination points of evacuation pattern affected by traffic center do not have the characteristics of point similarity in traditional clustering method, that is, they do not have uniform connectivity density or similar spatial distance. However, using the ODFCVC method, we find the main traffic flow divergence and convergence modes based on the influence of Capital International Airport.
Since the ODFCVC method can find the convergence and divergence mode of the flow clusters, we also try to explain it by the point set density distribution in vector space.
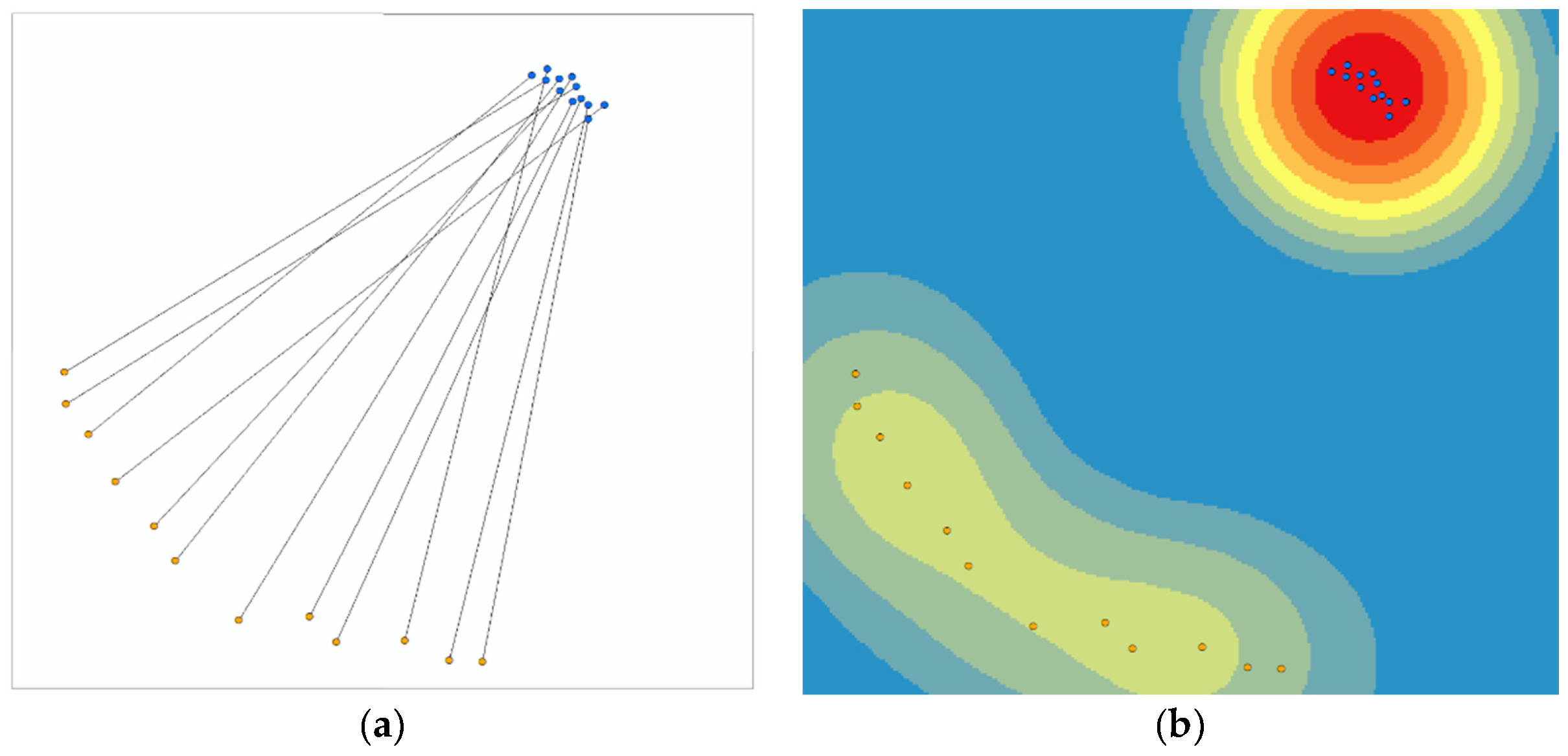
Figure 13 and
Figure 14 show the distribution of kernel density of OD point data in geographic space and vector space. The kernel density analysis and result visualization are realized by ArcMap.
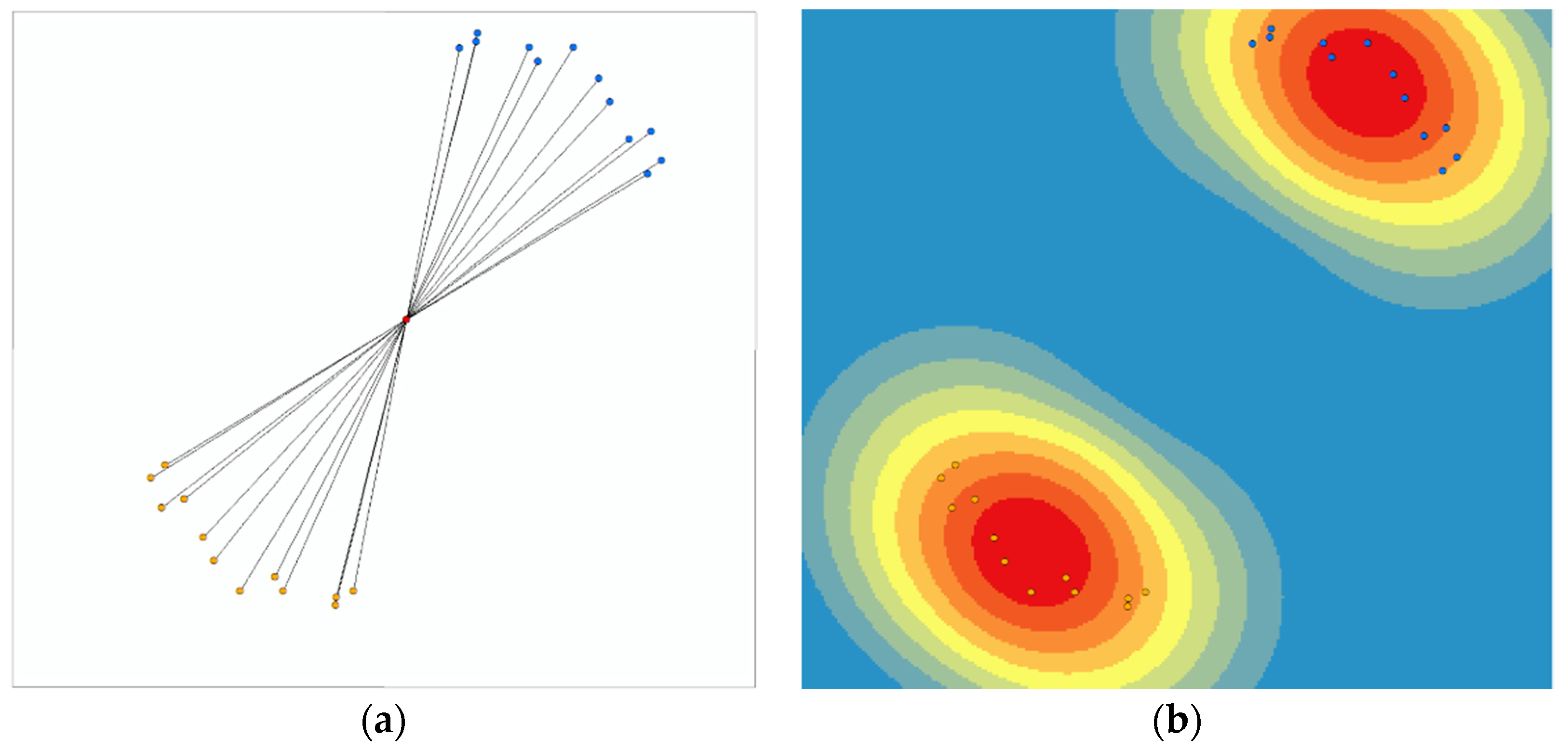
Density consistency is an important criterion for evaluating clustering results. In density-based clustering, OD flows with OD points in the same density space tend to be regarded as the same pattern. In geographical space, the O-point of divergence mode traffic flow and the D-point of convergence mode traffic flow are in high-density space, while the D-point of divergence mode traffic flow and the O-point of convergence mode traffic flow are in low-density space.
Figure 13b shows the heterogeneity of the density distribution of OD points in geospatial space. Therefore, it is difficult to find these patterns automatically by using the traditional clustering methods of density and simple connectivity index.
In the algorithm flow proposed in this paper, OD flow is mapped to vector space, and the relative geographic location of OD points changes with the aggregation of OD flow event points. Because only the direction and size of vector are considered in the vector coordinate system, we can set the OD flow event point as the intersection point and move the relative position of OD flow vector. It can be found that the density distribution of OD points is relatively homogeneous.
Figure 14b shows the homogeneity of the density distribution of OD points in vector space.
5. Conclusions and Discussion
In this paper, a two-step clustering method for OD data is proposed. The pattern characteristics of OD flow are represented by OD flow event points and OD flow vector, and OD data is mapped from massive point set space to independent vector feature space. This method simplifies the complexity of OD flow similarity calculation and pays more attention to the overall spatial distribution and movement trend of OD flow. Compared with the previous studies, the proposed method breaks away from the line clustering idea based on two-point clustering, pays more attention to the overall (high-dimensional) similarity of OD flows, optimizes the dimension of feature matrix in the clustering process, and achieves the automatic optimal clustering number calculation without any parameters. The ODFCVC method can mine arbitrary shape OD flow clusters with representative characteristics and find OD flow communities, which is conducive to optimizing traffic zone planning and analyzing OD flow dynamics problems.
The ODFCVC method can be combined with the existing research [
15,
38]. On the one hand, it can be compared with the results of previous algorithms to evaluate the dynamic functional area attributes of geographical units. On the other hand, it can be combined with density-based algorithm and partition-based algorithm to strengthen the recognition ability of density domain intensity and construct multiscale clustering results while maintaining the flow characteristics.
Through the experiment of Beijing Taxi OD data, the method mines out the important traffic centers and traffic flow communities affected by traffic hubs in Beijing without relying on geographical units, which makes up for the shortage of traditional traffic engineering and urban planning by using transport capacity, passenger flow, construction scale, spatial accessibility, and other indicators to evaluate the importance of traffic hubs. In addition, this method breaks through the limitations of the “parallel line” experience mode in the previous pattern mining, and finds the cluster mode (OD points are similar respectively), divergence mode (O points are similar), and convergence mode (D points are similar) of traffic flow at the same time, which is more suitable for the real traffic flow.
Through the kernel density analysis of OD points in geographic space and vector space, we found that the ODFCVC method can map the OD flow of irregular shape pattern to the vector space with homogeneous OD point density by using the method of geometric constraints, which meets the conditions of traditional OD flow density clustering. Therefore, the method based on density clustering can also be applied to pattern mining of OD flow in vector space.
The original intention of traffic flow pattern and OD flow pattern mining is not simply from data to pattern, different measurement functions and different indicators can produce a variety of flow patterns. However, how to use the patterns found by clustering algorithm reasonably and apply them to traffic planning, urban planning, and other fields is the value of research. Previous clustering algorithms rely heavily on the idea that “OD points are similar, so OD flows are similar”, and deeply study different measurement indexes such as spatial similarity, thematic similarity, and land use type similarity of OD points [
8,
39]. The ODFCVC method does not rely on the similarity index of OD points, and can excavate representative flow patterns. It excavates the internal connection between OD points of nongeographic spatial similarity in the same pattern, and update and iterate from “observing the flow of human activities” to “observing the points of land use types”. It also provides new means for the research of urban land use renewal, urban dynamic function area mining, urban internal space interaction, multiscale traffic district planning, and so on.
Information extraction is an important obstacle to traffic information services and applications. The division of traffic zones (communities) is an important component of traffic surveys, travel demand forecasting, trip generation, and trip distribution [
62]. The traditional traffic zone division method cannot reflect the latest or real-time traffic patterns and the consistent characteristics within a traffic zone and ignores the mobility and community characteristics of traffic behavior [
62,
63]. Our research applies the ODFCVC method to traffic OD flow, which can identify traffic flow communities with frequent internal interactions and regional interaction behaviors with typical travel patterns. It provides a new means for dividing traffic zones and revealing the spatial structure characteristics.
The method also has strong expansibility. First, the similarity function, that is, different distance functions can be replaced according to the research requirements when measuring the similarity of spatial relations and geometric features of flows. Secondly, the basic clustering algorithm, that is, as long as the logic of multistep clustering based on dimension deconstruction is concerned, each step can be replaced by a clustering algorithm that relies on different clustering centers to meet the needs of researchers. Thirdly, the research object and analysis dimension, that is, for OD flow data, this paper only analyses the spatial dimension and dynamic feature dimension but does not consider the influence of time dimension. It can expand multidimensional data analysis by step clustering. For any high-dimensional geometric form such as area data and volume data, the geometric center and high-dimensional geometric vectors can be used to express spatial and morphological features. Finally, the computing environment, that is, because the whole operation process of the method presents a tree-like diffusion pattern, clustering analysis of each dimension can be computed distributed on the basis of the results of the previous clustering step.
However, the method still has some shortcomings in multilevel structure expression and similarity judgment. The ODFCVC method considers the complexity of OD flow clustering from the perspective of spatial location and geometric vectors, but there is no multiscale partition and pattern mining for any single dimension space, which is mainly due to the limitations of K-means algorithm. In the aspect of similarity threshold, we adopt the traditional silhouette coefficient and SSE to automatically obtain the optimal K value. However, these parameters are the optimal solution of spatial clustering for the whole sample and the optimal solution of vector space geometric feature clustering for the spatial cluster, which lack a certain prior constraint for similarity. Therefore, in future research, considering that the dataset is affected by the change of the field of view and scale, we plan to optimize the ODFCVC method to have the ability of multiscale analysis, and therefore mine multiscale compound flow patterns and complex flow patterns.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}