3.3.1. Machine Translation
In the experiment of place name translation, 29,686 words were counted, and their occurrence frequency was 13,102 times. In addition, 72,565 pairs of words were counted, and their occurrence frequency was 116,217 times. The probability distribution of words, word pairs and point mutual information is calculated, as shown in
Figure 8.
In the figure, the word frequency (red) and word pair frequency (green) correspond to the lower coordinate axis, with a value range of approximately (8.6*10−6, 0.025), and the point mutual information (blue) corresponds to the upper coordinate axis, with a value range of approximately (−4, 12).
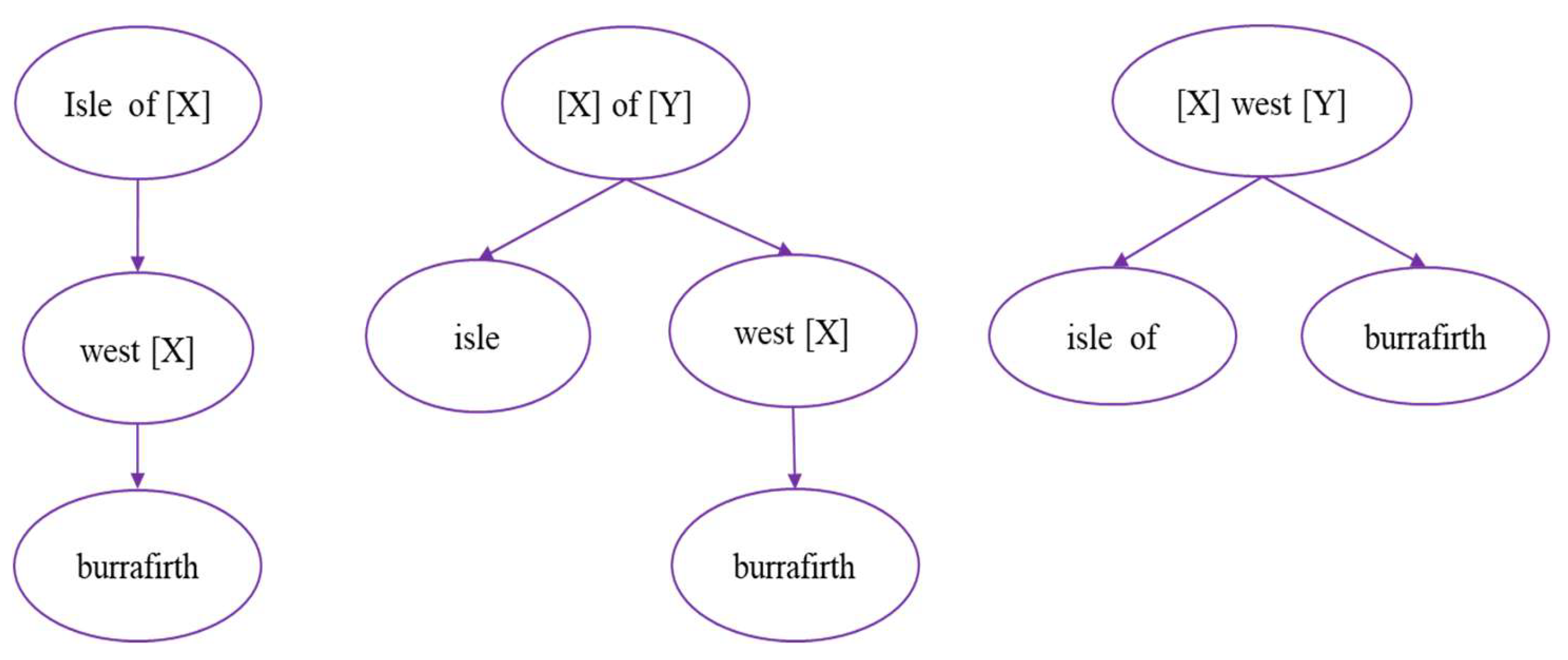
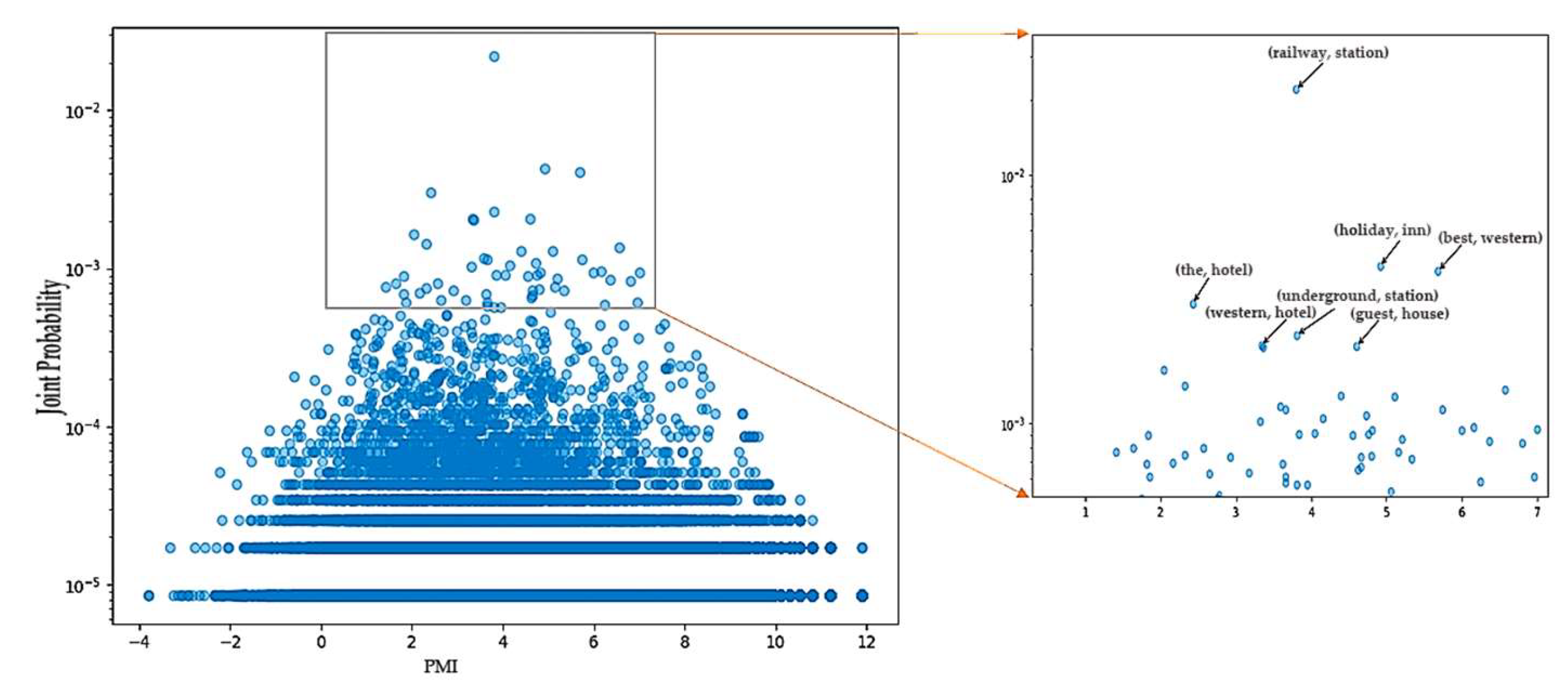
Figure 9 is the corresponding scatterplot of word-pair frequency and pointwise mutual information. The bottom parallel line represents the lower frequency distribution of word pairs. The right small plot shows the word pair with a higher pointwise mutual information value. From top to bottom, from left to right, the order is railway (railway, station), (the, hotel), (holiday, inn), (best, western), (western, hotel), (underground, station) and (guest, house).
The thresholds of the joint distribution (word-pair frequency) and point mutual information are reasonably set according to
Figure 8 and
Figure 9. Because the word pairs with a lower value of the joint distribution may also obtain a higher point mutual information value, the word pairs with a frequency of 1, 2, 3, and 4 are discarded in order to achieve a high-quality template, and the threshold of the joint distribution is set to 5*10
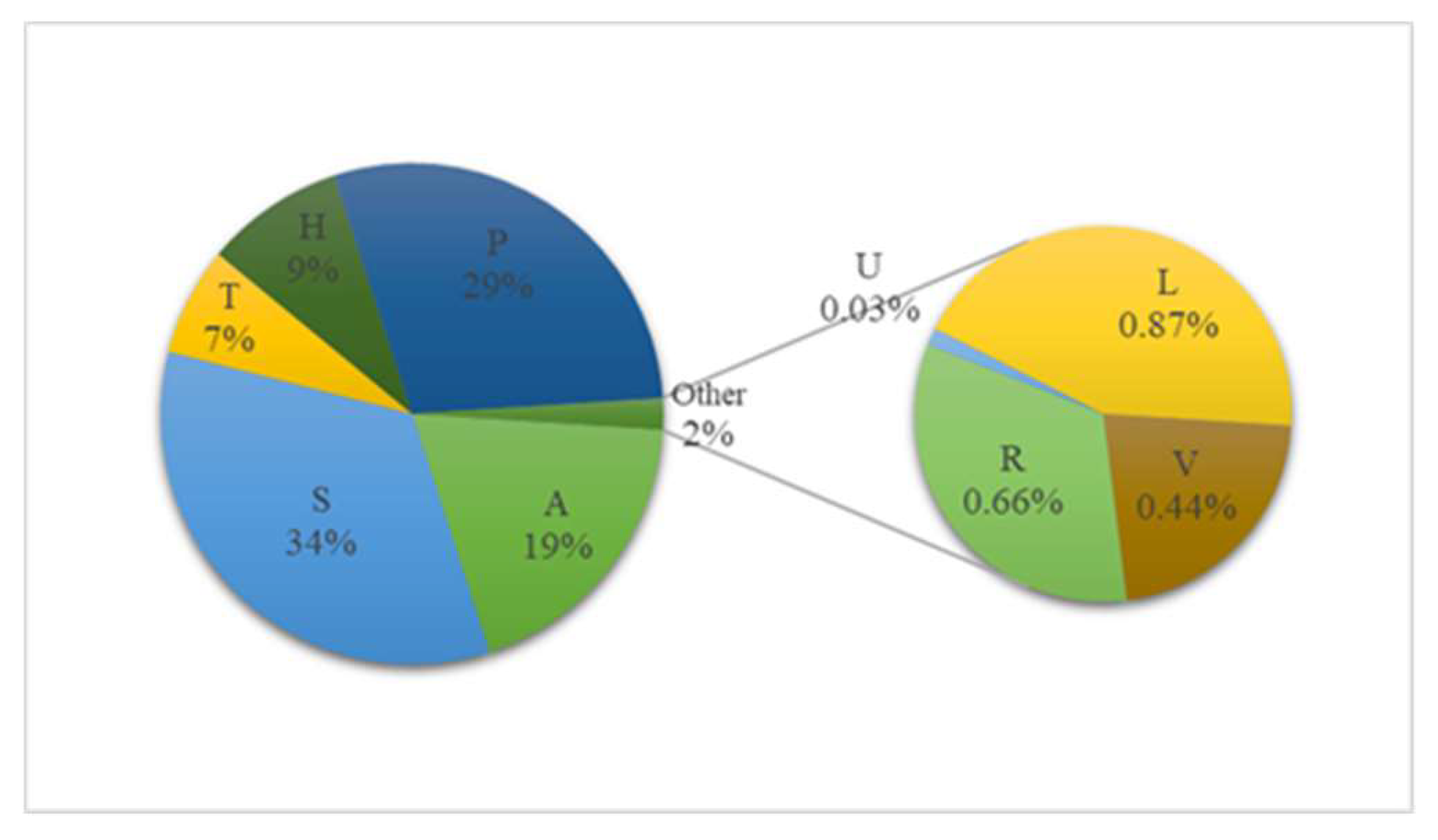
−5. The point mutual information threshold is set to 3.1, and the first 80% of the word pairs are selected. Similarly, according to the probability accumulation map, the extraction threshold of the template is set to 3, and a total of 876 geographical name templates are obtained, of which 279 belong to the commonly used building facilities (S), which has the highest proportion. Partial templates are shown in
Table 4.
In the process of geographical name translation, 4219 place names with the number of words of 3 or more were structurally decomposed, and the average depth of the established trees was 1.8, while the average number of decomposed templates was 2.7. Given that determining whether the template matched by randomly selecting the data of 100 geographical names is reasonably evaluated manually, the acceptable rate is 91%.
Six thousand results of place name translations in this experiment have been randomly selected and sent to a professional translation company for proofreading, with an 84.5% acceptability rate. Meanwhile, 500 geographical names are randomly translated by Baidu Translation and Google Translation, and after manual review, the acceptability rates of translation results are 74.4% and 52.6%, respectively.
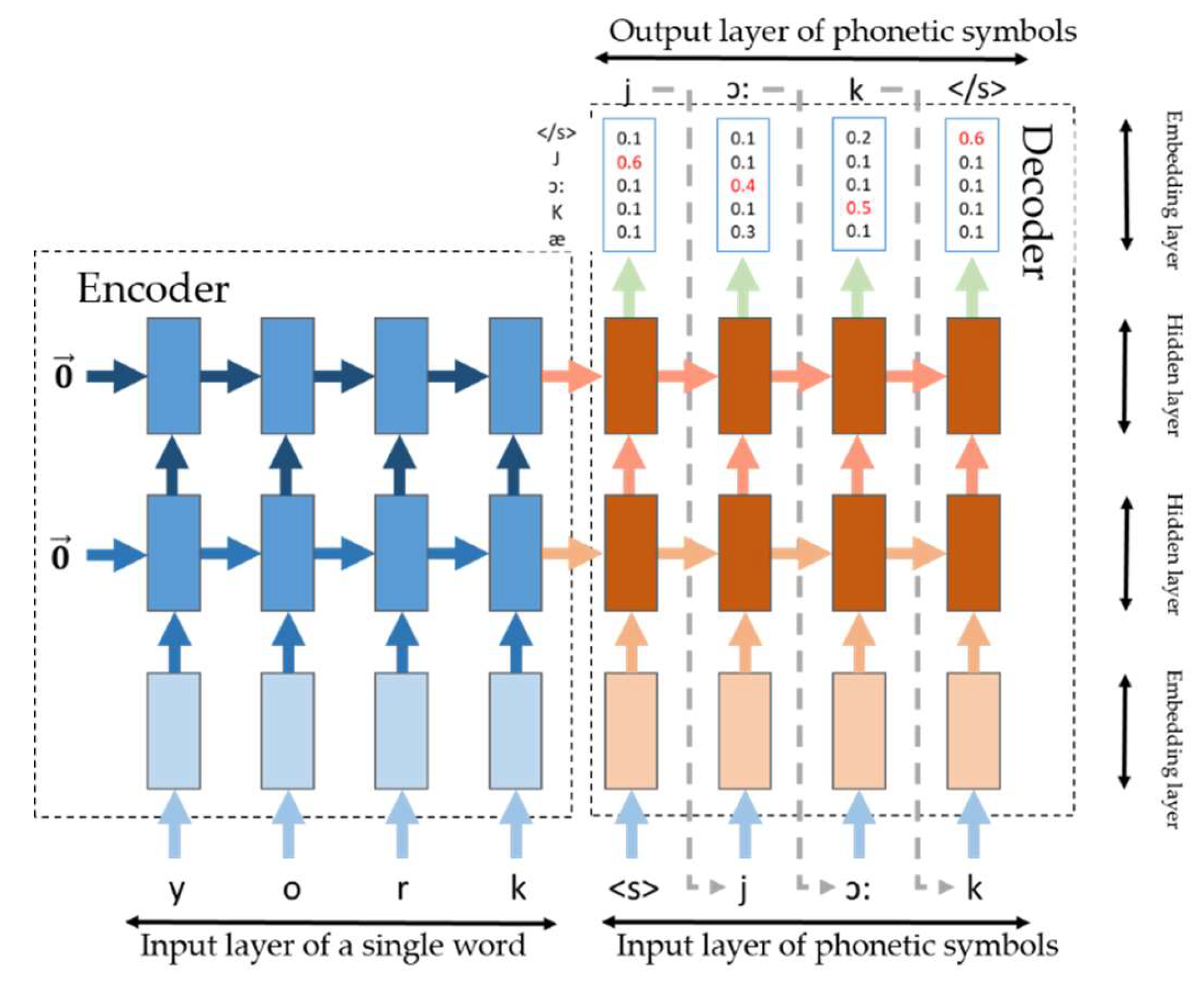
The corpus data of the “word-phonetic symbol” used for training comes from the open source English dictionary, with a total of 97,857, and is divided into a training set, verification set and test set according to the ratio of 70:20:10. The training environment of the phonetic symbol generation model is as follows: GPU: GTX970M, CPU: i7-6700HQ, and OS: Windows 10, version 1803. Since the network structure of the phonetic symbol generation model will significantly affect the quality of the results, this paper uses the 10-fold cross-validation method to train different neural network structures. The following are the hyperparameter settings and evaluation indicators of several major network structures. To ensure the quality of the generated phonetic symbols, this paper uses the general accuracy rate, BLEU and ROUGE to evaluate the model. The comparison results are shown in
Table 5.
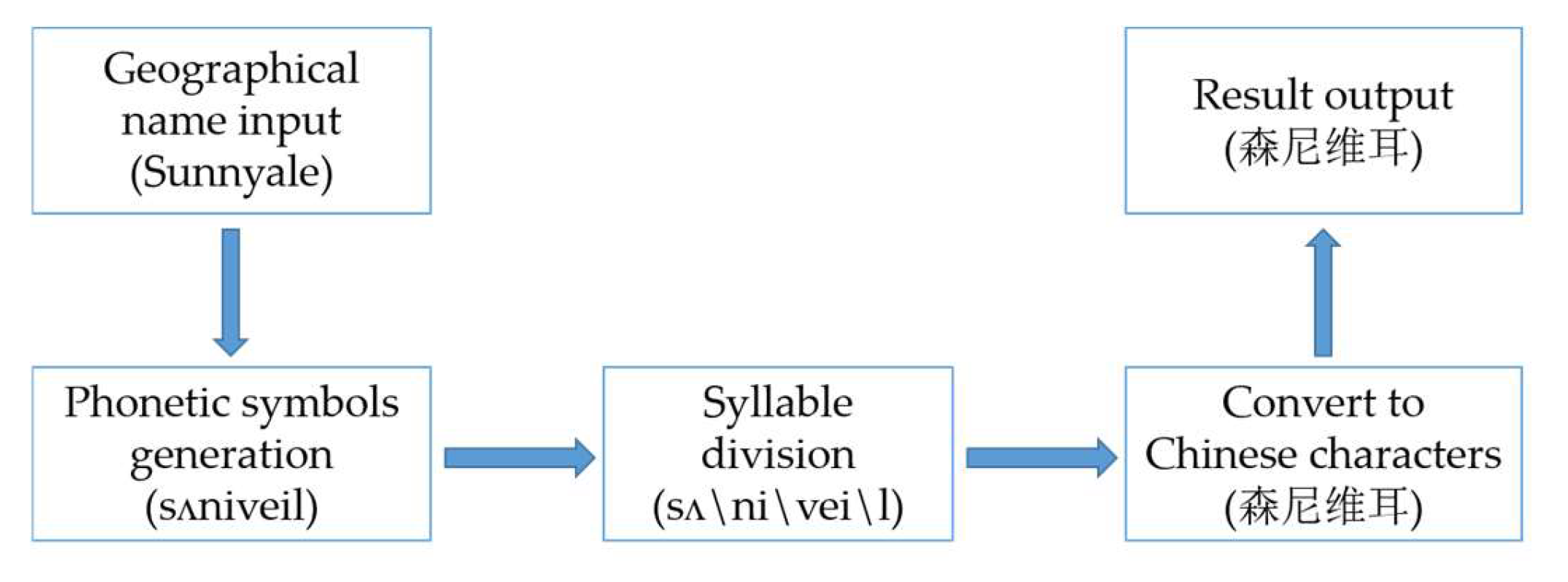
Finally, we choose Structure 1 as the final model structure, and obtain corresponding translation results for 500 words in the standard special name database through phonetic symbol generation, syllable division, and conversion to Chinese characters. The accuracy obtained by comparison is approximately 92.7%.
The minimum entropy algorithm original corpus is from the phonetic symbols in the English dictionary, and 300 of them are selected for artificial syllable division as the test set. In the experiment, the average entropy of the original phonetic corpus decreased from 3.28 bits to 3.02 bits, and the probability distribution function of the final syllable set was obtained. The syllables obtained by experiments were compared with the syllables of 300 reserved special names that were manually divided. The accuracy rate is 93.3%.
3.3.2. Automatic Evaluation of Translation Results
This paper automatically evaluates the accuracy of translation results of all English geographical names. The main parameters (partial) are shown in
Table 6.
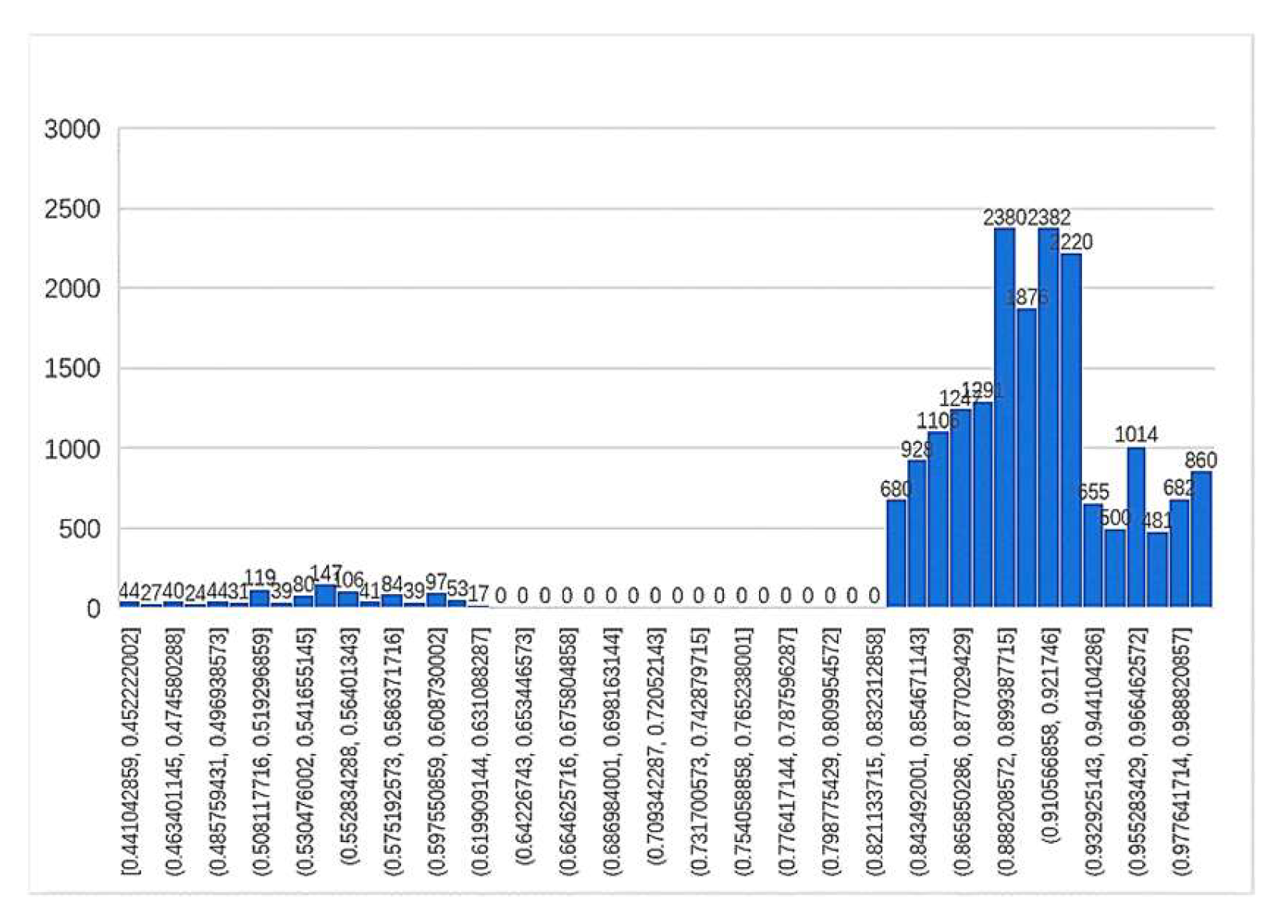
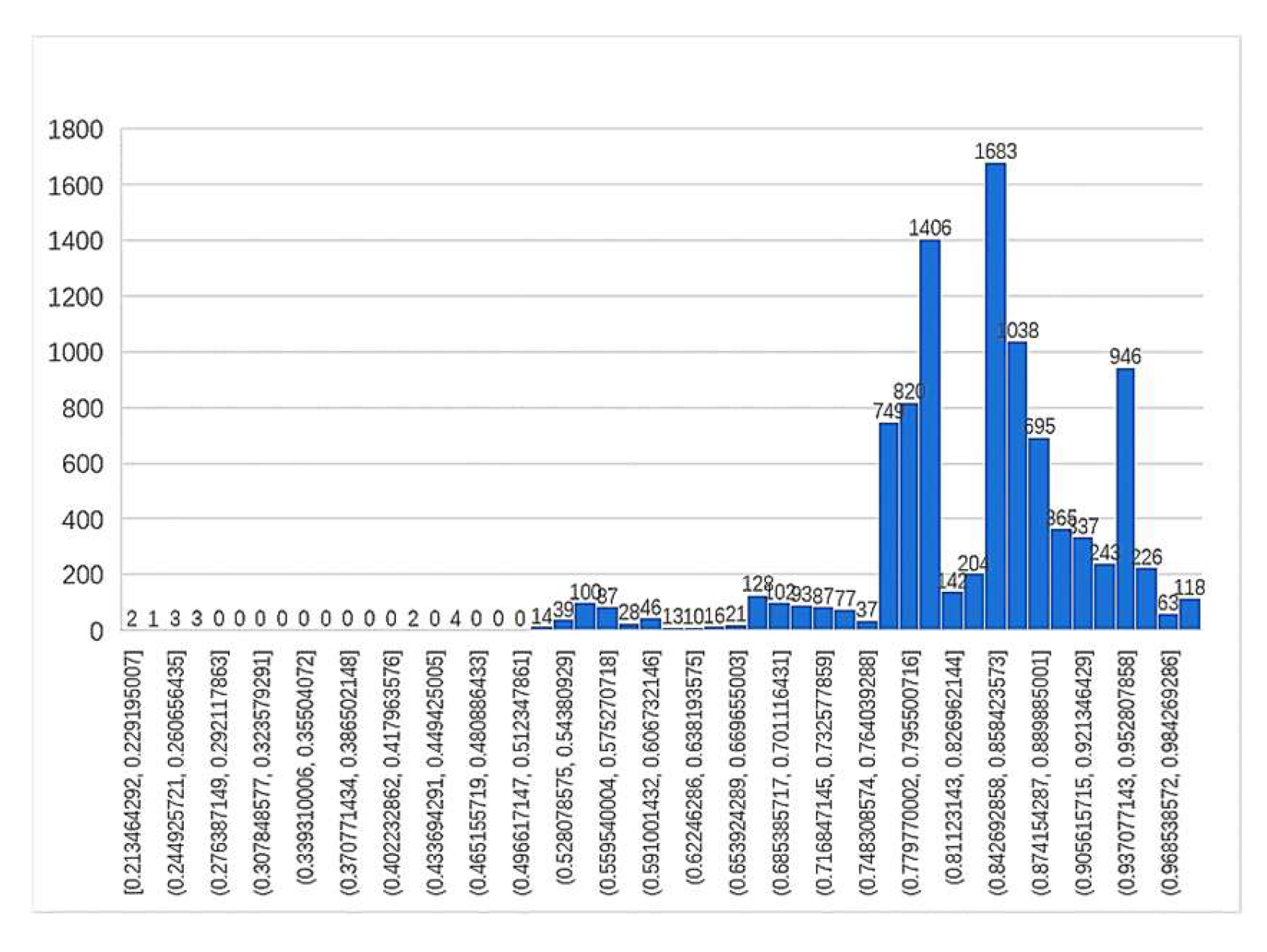
The lexical structure of geographical names of different lengths differs in complexity and will contribute differently to the evaluation indicators. To make the machine evaluation more accurate, the evaluation index values of the three groups of place name data, including two-word, three-word and multi-word names, were normalized, and the thresholds were set after analysis to determine the reliability interval. The distribution histogram of evaluation indicators for each group is shown in the
Figure 10,
Figure 11 and
Figure 12.
According to the histogram of the two-word geographical name evaluation index, it was found that the index declined before 0.83; therefore, the threshold value of this group was set at 0.83, and the unreliable rate of the translation results was 1034/19334 = 5.34%. In the histogram of the three-word geographical name evaluation index, although there was a brief decline between 0.764 and 0.84, there was still a peak after 0.764; therefore, the threshold was set at 0.764, and the unreliability rate of the translation result was 912/9948 = 9.17%. In multi-word geographical names, the distribution in this group was similar to the right-deviation distribution of a skewed distribution. Because the skewed distribution is not suitable for statistical analysis, this paper converts it to a normal distribution by the Box–Cox variation (
λ = 1.39), whose expected value and standard deviation are (
μ,
δ) = (0.623,0.112). Finally, the
μ-2δ is selected as 0.399, and the threshold is 0.654 after reduction. The unreliability rate of the translation result is 909/6983 = 13.02%. The translation results of unreliable geographical names are shown in
Table 7.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}