Urban Scene Vectorized Modeling Based on Contour Deformation


Abstract
:
1. Introduction
- -
- An effective bilateral smoothing and RANSAC based dominant direction detection method.
- -
- An efficient deformation energy optimization defined on the contour triangulation to align the boundary to the target directions.
- -
- A novel deformation based building modeling method, which enables us to generate compact LOD0 and LOD1 models from orthophoto and DSM.
2. Proposed Method
2.1. Overview
- -
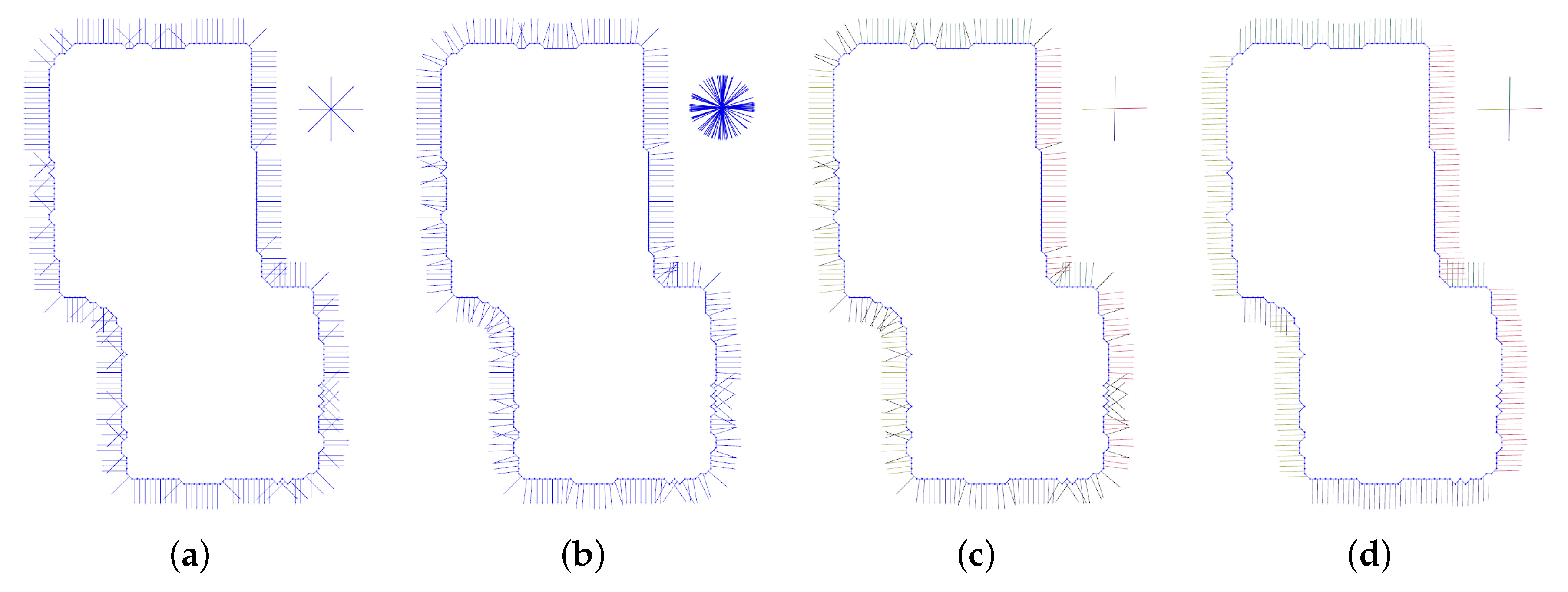
- Firstly, dominant directions of the building contour are detected through the RANSAC on the bilaterally smoothed normals, Figure 2b.
- -
- Then each edge of the contour is assigned with one of the dominant directions as the alignment target through an MRF formulation, Figure 2c.
- -
- With the target direction and the deformation energy defined on the contour triangle mesh, we align the boundary edges to the target direction, Figure 2d.
- -
- Finally, compact LOD0 and LOD1 models are generated by connecting the corner vertexes and extruding them to their averaged heights in DSM, Figure 2e,f.
2.2. Dominant Directions Detection
2.3. Align Direction
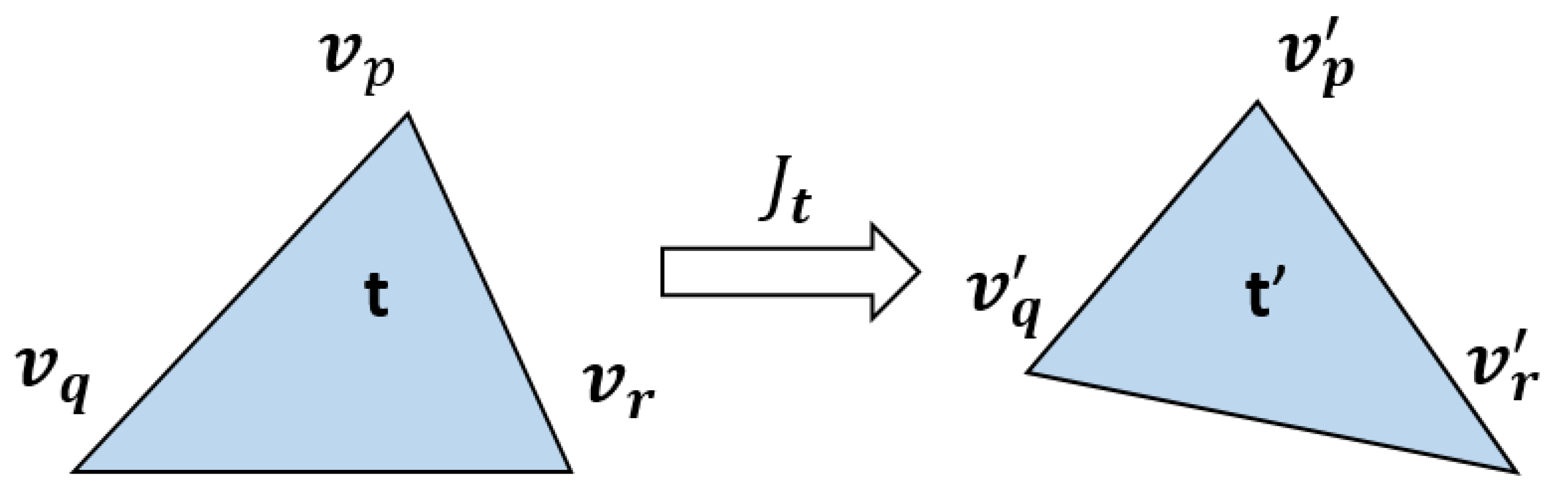
2.4. Deformation Formulation
2.5. Model Generation
3. Results and Discussion
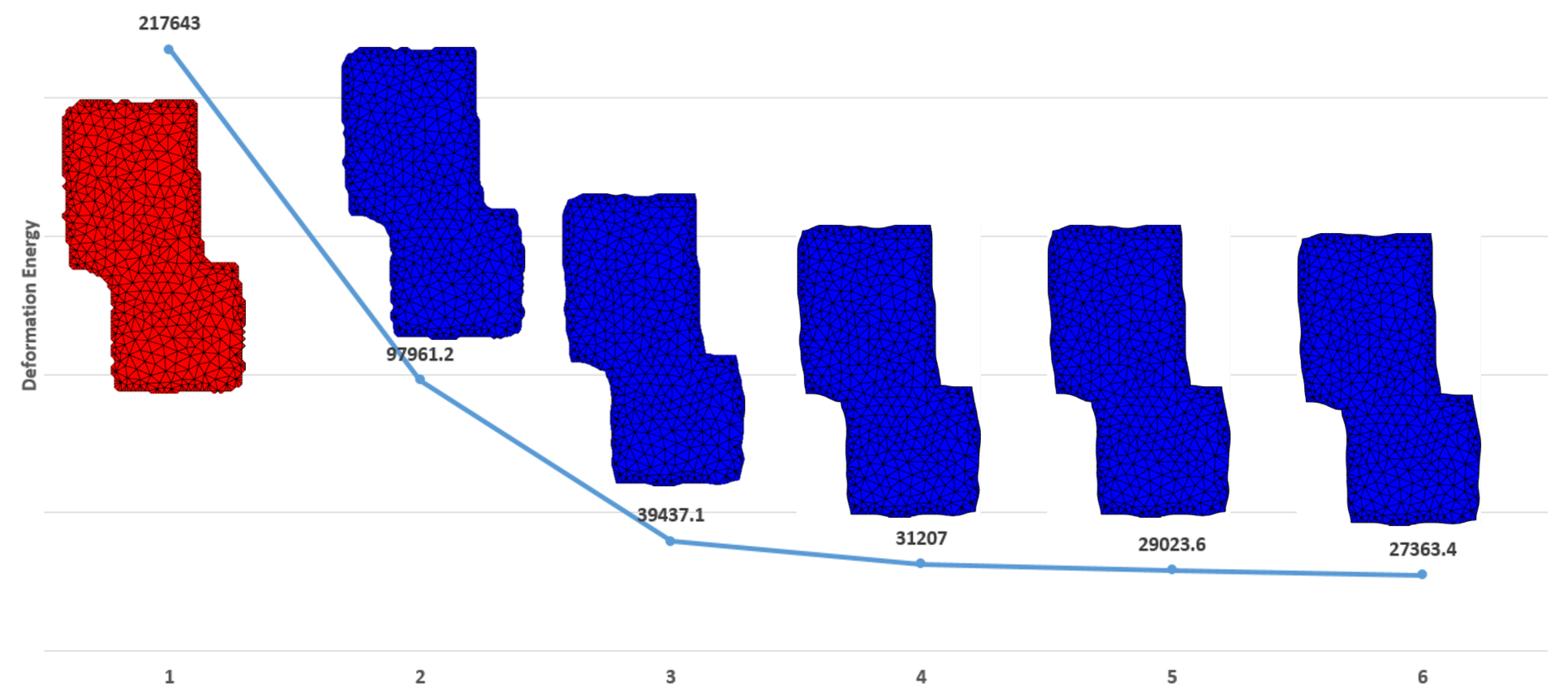
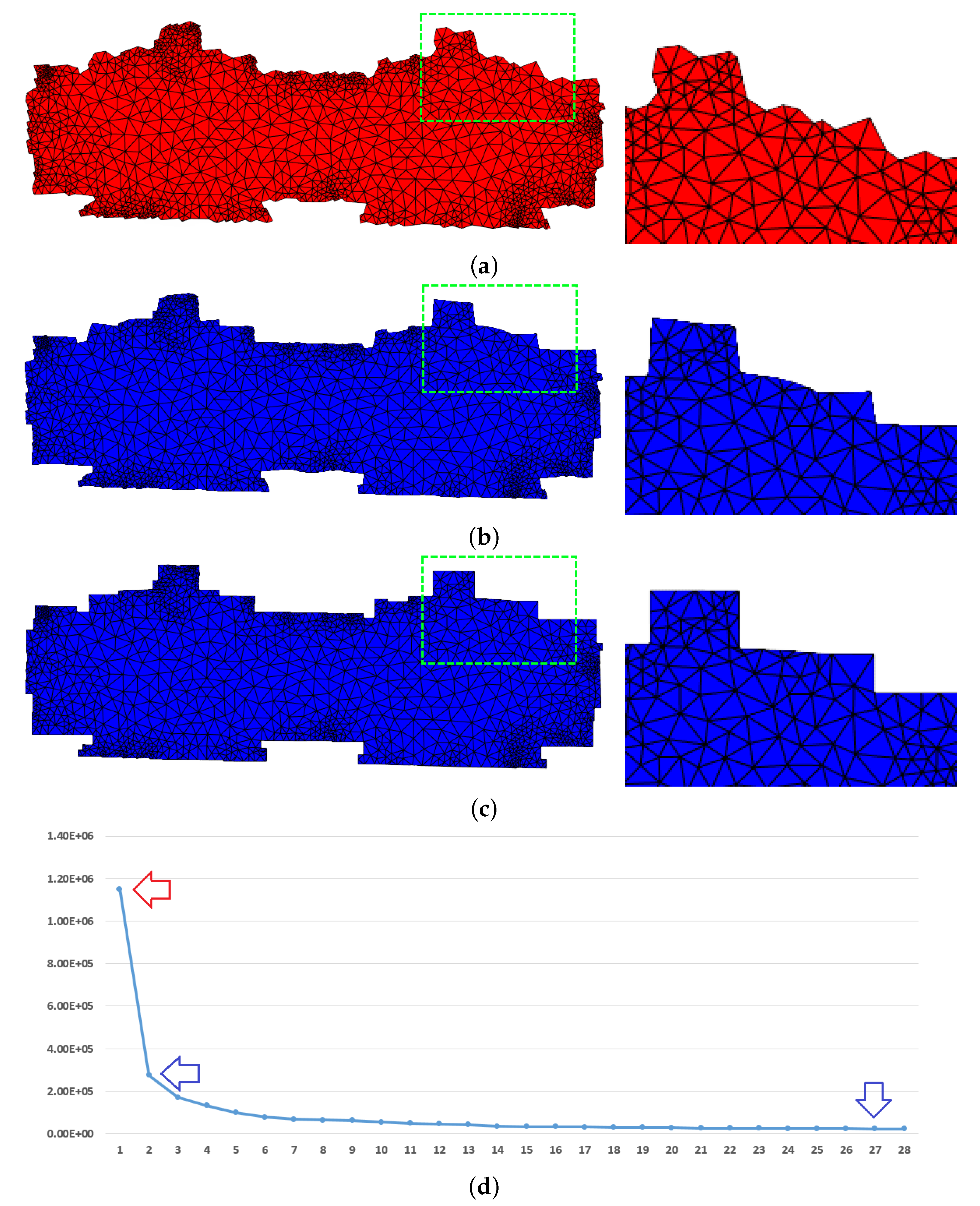
3.1. Effect of Alignment Deformation
3.2. Quality Comparison
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
References
- Musialski, P.; Wonka, P.; Aliaga, D.G.; Wimmer, M.; Gool, L.V.; Purgathofer, W. A Survey of Urban Reconstruction. Comput. Graph. Forum. 2013, 32, 146–177. [Google Scholar] [CrossRef]
- Rouhani, M.; Lafarge, F.; Alliez, P. Semantic segmentation of 3D textured meshes for urban scene analysis. ISPRS J. Photogramm. Remote Sens. 2017, 123, 124–139. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- ISPRS. ISPRS 2D Semantic Labeling Contest. Available online: http://www2.isprs.org/commissions/comm3/wg4/semantic-labeling.html (accessed on 12 December 2019).
- Ramer, U.; Douglas, D.; Peucker, T. Ramer–Douglas–Peucker Algorithm. Comput. Graph. Image Process 1972, 1, 244–256. [Google Scholar] [CrossRef]
- Poullis, C. A Framework for Automatic Modeling from Point Cloud Data. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2563–2575. [Google Scholar] [CrossRef] [PubMed]
- Furukawa, Y.; Ponce, J. Accurate Camera Calibration from Multi-View Stereo and Bundle Adjustment. Int. J. Comput. Vis. 2009, 84, 257–268. [Google Scholar] [CrossRef]
- Furukawa, Y.; Curless, B.; Seitz, S.M.; Szeliski, R. Towards Internet-scale multi-view stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1434–1441. [Google Scholar]
- Agarwal, S.; Furukawa, Y.; Snavely, N.; Simon, I.; Curless, B.; Seitz, S.M.; Szeliski, R. Building Rome in a Day. Commun. ACM 2011, 54, 105–112. [Google Scholar] [CrossRef]
- Cui, H.; Shen, S.; Gao, W.; Hu, Z. Efficient Large-Scale Structure from Motion by Fusing Auxiliary Imaging Information. IEEE Trans. Image Process. 2015, 22, 3561–3573. [Google Scholar]
- Langguth, F.; Sunkavalli, K.; Hadap, S.; Goesele, M. Shading-aware multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 469–485. [Google Scholar]
- Cui, H.; Gao, X.; Shen, S.; Hu, Z. HSfM: Hybrid Structure-from-Motion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2393–2402. [Google Scholar]
- Hofer, M.; Maurer, M.; Bischof, H. Efficient 3D scene abstraction using line segments. Comput. Vis. Image Underst. 2017, 157, 167–178. [Google Scholar] [CrossRef]
- Bódis-Szomorú, A.; Riemenschneider, H.; Gool, L.V. Efficient edge-aware surface mesh reconstruction for urban scenes. Comput. Vis. Image Underst. 2017, 157, 3–24. [Google Scholar] [CrossRef]
- Verdie, Y.; Lafarge, F.; Alliez, P. LOD Generation for Urban Scenes. ACM Trans. Graph. 2015, 34, 30:1–30:14. [Google Scholar] [CrossRef] [Green Version]
- Nan, L.; Wonka, P. PolyFit: Polygonal Surface Reconstruction from Point Clouds. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2372–2380. [Google Scholar]
- Kelly, T.; Femiani, J.; Wonka, P.; Mitra, N.J. BigSUR: Large-scale Structured Urban Reconstruction. ACM Trans. Graph. 2017, 36, 204:1–204:16. [Google Scholar] [CrossRef]
- Nguatem, W.; Mayer, H. Modeling Urban Scenes from Pointclouds. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3857–3866. [Google Scholar]
- Zhu, L.; Shen, S.; Gao, X.; Hu, Z. Large Scale Urban Scene Modeling from MVS Meshes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 614–629. [Google Scholar]
- Zeng, H.; Wu, J.; Furukawa, Y. Neural procedural reconstruction for residential buildings. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 737–753. [Google Scholar]
- Li, M.; Rottensteiner, F.; Heipke, C. Modelling of buildings from aerial LiDAR point clouds using TINs and label maps. ISPRS J. Photogramm. Remote Sens. 2019, 154, 127–138. [Google Scholar] [CrossRef]
- Li, M.; Wonka, P.; Nan, L. Manhattan-World Urban Reconstruction from Point Clouds. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 54–69. [Google Scholar]
- Li, M.; Nan, L.; Smith, N.; Wonka, P. Reconstructing building mass models from UAV images. Comput. Graph. 2016, 54, 84–93. [Google Scholar] [CrossRef] [Green Version]
- Zhu, L.; Shen, S.; Hu, L.; Hu, Z. Variational Building Modeling from Urban MVS meshes. In Proceedings of the IEEE International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 318–326. [Google Scholar]
- CityGML. CityGML. Available online: http://www.opengeospatial.org/standards/citygml (accessed on 4 April 2019).
- Joo, K.; Oh, T.H.; Kweon, I.S.; Bazin, J.C. Globally Optimal Inlier Set Maximization for Atlanta World Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed]
- Schnabel, R.; Wahl, R.; Klein, R. Efficient RANSAC for Point-Cloud Shape Detection. Comput. Graph. Forum 2007, 26, 214–226. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef] [Green Version]
- Boykov, Y.; Kolmogorov, V. An experimental comparison of min-cut/max- flow algorithms for energy minimization in vision. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1124–1137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- The CGAL Project. The Computational Geometry Algorithms Library. Available online: https://www.cgal.org (accessed on 8 November 2019).
- Fu, X.M.; Liu, Y.; Guo, B. Computing locally injective mappings by advanced MIPS. ACM Trans. Graph. (TOG) 2015, 34, 71. [Google Scholar] [CrossRef]
- Pix4D. Pix4D. Available online: https://pix4d.com/ (accessed on 18 November 2019).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ground Truth | Ours LOD0 | RDP [7] | Poullis et al. [8] | Zhu et al. [21] |
|---|---|---|---|---|
 |  |  |  |  |
| IoU | 0.96 | 0.94 | 0.95 | 0.87 |
 |  |  |  |  |
| IoU | 0.94 | 0.92 | 0.93 | 0.78 |
| Region | B | C | D |
|---|---|---|---|
| Contour |  |  |  |
| LOD0 |  |  |  |
| LOD1 |  |  |  |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, L.; Shen, S.; Gao, X.; Hu, Z. Urban Scene Vectorized Modeling Based on Contour Deformation. ISPRS Int. J. Geo-Inf. 2020, 9, 162. https://doi.org/10.3390/ijgi9030162
Zhu L, Shen S, Gao X, Hu Z. Urban Scene Vectorized Modeling Based on Contour Deformation. ISPRS International Journal of Geo-Information. 2020; 9(3):162. https://doi.org/10.3390/ijgi9030162
Chicago/Turabian StyleZhu, Lingjie, Shuhan Shen, Xiang Gao, and Zhanyi Hu. 2020. "Urban Scene Vectorized Modeling Based on Contour Deformation" ISPRS International Journal of Geo-Information 9, no. 3: 162. https://doi.org/10.3390/ijgi9030162
APA StyleZhu, L., Shen, S., Gao, X., & Hu, Z. (2020). Urban Scene Vectorized Modeling Based on Contour Deformation. ISPRS International Journal of Geo-Information, 9(3), 162. https://doi.org/10.3390/ijgi9030162