1. Introduction
In the past, forestry research typically relied on two-dimensional representations (images) of forested areas [
1,
2,
3]. The advent of Light Detection and Ranging (LiDAR) and the development of navigational systems such as Global Navigational Satellite System (GNSS) or Inertial Measurement Unit (IMU) enabled scientists to analyse the forest in a tri-dimensional space, using data formats such as point clouds or surface models [
4]. Mounting a LiDAR sensor on an aerial platform (a method commonly referred to as Airborne Laser Scanning—ALS) allows efficient collection of high-precision data for relatively large areas. The result of LiDAR data collection is a data structure called point cloud, which can be used to obtain information related to the horizontal and vertical structure of the forest [
5], from the top of the canopy to the ground level; in other words, laser scanning offers a new perception on forest structure and processes, at a local or regional level [
6].
From a LiDAR point cloud, certain forest parameters can be determined, such as: aboveground forest biomass [
7,
8,
9], Leaf Area Index (LAI) [
10,
11,
12,
13,
14] or canopy density [
15,
16]. Furthermore, LiDAR data can be used for tree inventories [
17,
18,
19,
20], monitoring vegetation health [
21,
22,
23,
24] or generating Canopy Height Models (CHMs) [
16,
25].
The main advantage of LiDAR, with regard to forestry, is the fact that laser pulses can penetrate the canopy cover, with some of the pulses reaching the ground level. Therefore, geomorphological data is collected even if the ground is covered by forest vegetation, allowing the generation of a detailed and accurate ground surface model.
In general, a data structure that models the elevation over an area is called a Digital Elevation Model (DEM). In short, a DEM is simply a surface that represents the elevation of a certain area in reference to a common vertical datum. When this type of model is used for a representation of the bare-earth surface, it can also be termed as Digital Terrain Model (DTM). In this paper, we opted for the term DTM, in order to emphasize the fact that the models we analyse, while generally speaking classify as DEMs, are meant specifically to represent the surface of the bare-earth.
To obtain such a representation of the ground surface, a LiDAR point cloud must initially be filtered—a process which involves the separation of ground-level points from the original point cloud [
26]. This filtered point cloud, containing only points which are at (or close to) the ground level, can afterwards serve for the interpolation of a continuous surface that models the variation of ground elevation.
A ground model obtained from ALS data can be used in forestry for various purposes, such as: (1) the development of forest road networks [
27], (2) the identification of existing forest roads [
28,
29], (3) the optimisation of forest skid trails [
30] and (4) finding optimal harvesting solutions [
31,
32,
33]. Furthermore, a DTM is generally an intermediate product when estimating various forest parameters from LiDAR data [
18,
34,
35,
36,
37]; the accuracy of the DTM will therefore influence the quality of subsequent estimations [
38].
In the case of dense forest cover, the penetration rate of laser pulses is hindered, resulting in a lower density of ground-level observations [
39]. Furthermore, ground points will not have a uniform spatial distribution, with most of them concentrating inside gaps in the canopy cover. In these conditions, proper processing of the LiDAR point cloud (ground filtering followed by DTM interpolation) is an important step to ensure a high-quality model of the ground surface is obtained. DTM accuracy will depend on: (1) the measurement accuracy and precision of the laser system, (2) the accuracy of point cloud filtering and (3) the method of interpolation. [
40] carried out a classification of the error component affecting DTM accuracy in the case of LiDAR data, establishing that the interpolation error is the second-most important factor affecting DTM accuracy (after the measurement system error).
Numerous interpolation algorithms have been developed in the last decades, stimulating research into their relative accuracy [
41]. Previous research has not established a definitive consensus regarding the performance of interpolation methods. For example, Inverse Distance Weighted (IDW), possibly the most widely used method, is found to have a relatively low accuracy in some studies [
38,
41,
42,
43,
44], while in others it provides the most accurate ground surface [
45,
46]. However, when comparing previous research, one has to take into account the source of altimetry data. The accuracy of interpolation can be assessed using synthetic [
41,
47] or real data. The main sources of elevation data are: digital stereo-matching [
42], topographical maps with isolines [
46] and ground surveys carried out using topographical equipment [
43,
44], GNSS receivers [
48] or LiDAR sensors [
38,
45,
49].
Regarding the influence of external factors on DTM quality, the consensus is relatively better. Among the main factors that are usually taken into account when analysing DTM quality, the following are typically found to have some degree of influence on accuracy: morphological complexity of the ground surface [
41,
42,
43,
45,
49], density of input data [
42,
43,
50,
51], model resolution [
38,
46] and the presence or characteristics of vegetation [
44,
45,
49].
In this paper, we propose a quantitative analysis of the relative performance of nine interpolation algorithms, with the aim of testing the accuracy of DTM generation from LiDAR point cloud data in difficult conditions (mountainous terrain with a high degree of surface roughness and covered by dense forest vegetation). To compare algorithm performance, we used the cross-validation method, which involves the random separation of observations into two datasets: one used for prediction and the other for validation. This method provides a pseudo-external dataset, in situations where using an independent dataset for validation is not feasible. Any systematic error (e.g., the measurement error of the LiDAR system) will evidently not be taken into account, but the method can still provide an estimation of the relative accuracy of interpolation methods. External factors that were taken into account for the analysis of DTM accuracy are: model resolution, ground slope, ground point density and canopy cover density.
In addition, recognizing that free DEMs with worldwide coverage such as Advanced Spaceborne Thermal Emission Reflection Radiometer (ASTER) [
52] or Shuttle Radar Topography Mission (SRTM) [
53] are common products in forestry practice and research (especially at regional scales), we established the following as a secondary objective: a comparison between the most accurate model obtained from the interpolation of LiDAR data and the ASTER/SRTM datasets available for our test site. These models are global in coverage and operate at a different scale in terms of space (their resolution of 1-arcsecond corresponds to a cell-size of about 21 × 30 m at the latitude of our test area) and level of precision, so they are not suitable as validation data for ALS data or the interpolation methods that were tested. Therefore, results pertaining to this secondary objective are presented in
Appendix A.
2. Materials and Methods
2.1. Test Site
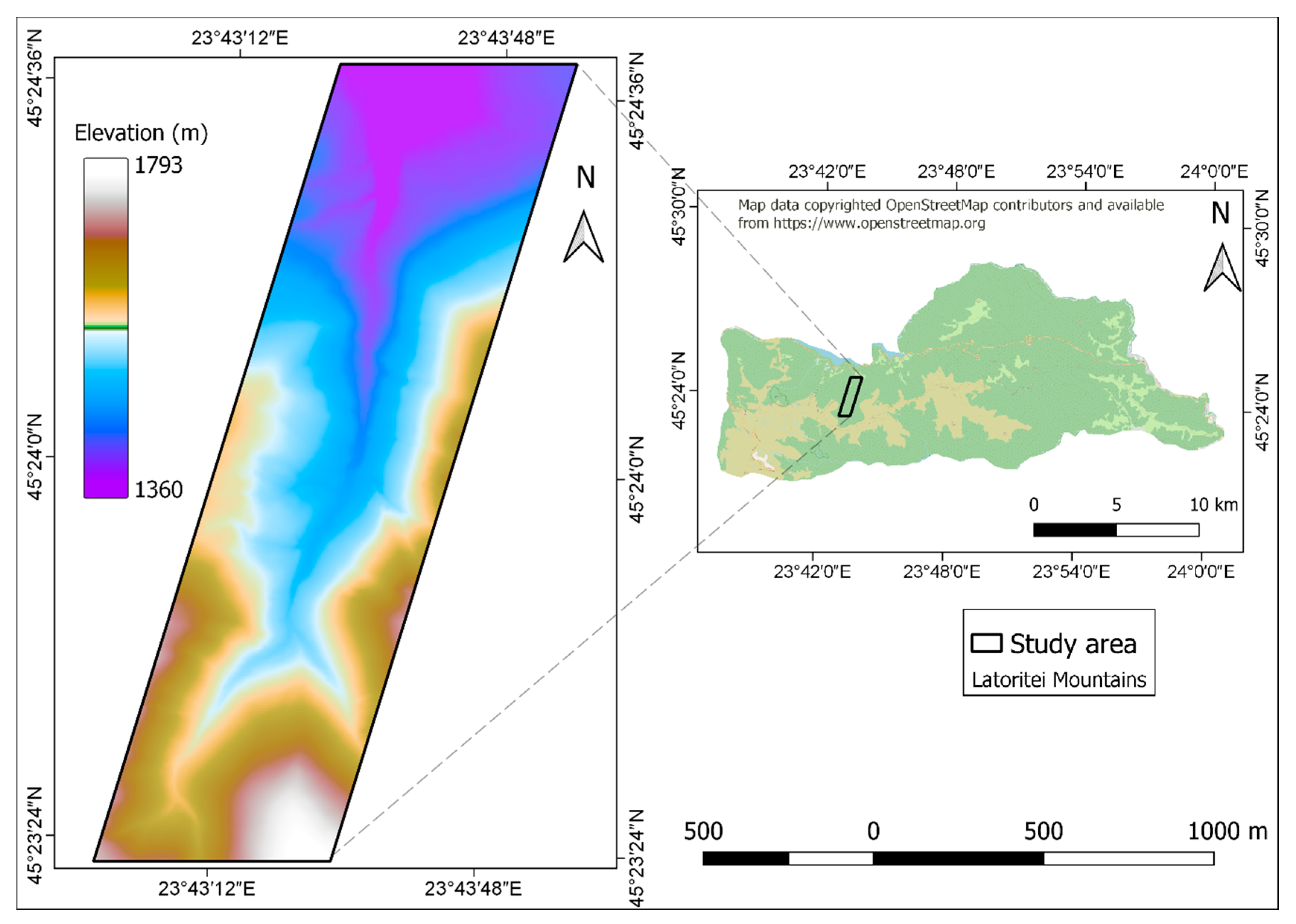
The analysis was carried out in a test site with an area of 1.6 km
2, located in the Latoriței Mountains of Romania, along the Bora River valley (
Figure 1). Most of the area is covered with forest vegetation, mainly spruce (90 percent) and pine (10 percent). The majority of tree stands have an age of 90–95 years, with younger stands (55–75 years) also being present to a smaller extent. The most recent forest management plan indicates a high canopy density, with an average value of 0.8. The area is characterised by steep, mountainous relief, with ground slope having an average value of 26 degrees.
2.2. LiDAR Data
LiDAR data was collected by ALS using a full-wave
Riegl LMS-Q560 mounted on a Diamond Aircraft Industries airplane (the
DA42 MPP). Parameters of the laser sensor and flight technical data are presented in
Table 1.
The resulting point cloud has an average density of 5.2 points m−2, which was achieved by scanning the same area two or three times. LiDAR data was delivered in the Universal Transversal Mercator (UTM) projection (zone 35N), with matched scan strips but unclassified point data.
As previously discussed, the initial point cloud contains both ground-level returns (or ground points) and returns caused by various above-ground objects, such as forest vegetation [
54]. To accurately model the ground surface, above-ground laser returns have to be eliminated from the initial point cloud, in a process commonly called ground filtering [
26]. To achieve this, we used a combined method: initially, we applied an automatic ground filter using the
lasground algorithm included in the LasTools software package (rapidlasso GmbH). The filtered point cloud was then visually checked, in order to manually correct any noticeable filtering errors. Therefore, the filtered dataset should theoretically contain only points located at (or close to) the ground level. This final point cloud has an average density of 0.9 points m
−2, corresponding to an average point spacing of 1.06 m.
2.3. Validation Data and Accuracy Assessment
To estimate the accuracy of interpolation, a validation dataset has to be used for comparison. To achieve this, we used the technique called cross-validation [
55,
56], which involves the separation of the initial dataset into two separate sets: one used for prediction and the other for validation. In some papers, this method is referred to as true validation [
42,
57]. In choosing the proportion between the subsets two aspects have to be considered [
38]: (1) the validation data should contain enough observations to ensure the statistical significance of the results and (2) the integrity of the prediction set should be kept intact. There are no widely accepted guidelines for establishing the percentage of initial observations to be used for validation. As an example, we find that [
42] uses 4 percent of input data for validation, while [
38] uses 3 percent of data for the same purpose, [
45] uses 0.1 percent of input data (but also carries out external validation using independent data) and [
47] uses 10 percent of initial data to test a newly-developed method of DTM interpolation from LiDAR data.
Taking previous research into account and the specifics of our data, we established the following proportions: 95 percent of the initial ground points are used for prediction (1.06 mil. points) while the remaining 5 percent (n = 52,358) are used for validation. The validation dataset has an average density of 1 point per 31.9 m2 and an average distance between pairs of closest points of 2.48 m2 (SD = 1.58 m). It is reasonable to assume that this would ensure a sufficient reliability of the accuracy analysis.
In other words, we randomly select 95 percent of observations to represent the input data for DTM interpolation, with the remaining 5 percent used for estimating the accuracy of the resulting models.
The accuracy of a DTM is estimated by calculating the residual (or vertical error) for each validation point [
58]:
where
E(i) is the vertical error (or residual value) for validation point
i,
ZDTM(i) is the elevation value of the raster cell in which point
i is located and
ZALS(i) is the measured elevation for point
i.
To clarify, ZDTM(i) is the elevation value estimated via interpolation for the centre of the DTM cell in which i is located, not for its exact location. Therefore, an extra error component is added, because of the distance between validation points and the cell centres of the raster model. This effect is evidently exacerbated in rougher terrain (where elevation has a higher local variance) and for lower modelling resolutions (larger cell sizes). Based on the residual values, accuracy estimates such as mean signed/unsigned error, standard deviation and Root Mean Square Error (RMSE) were calculated.
To get a clearer picture of the overall DTM accuracy, absolute (unsigned) vertical errors were calculated and classified. Error classification is by necessity subjective, as there is no accepted standard in the field of forestry for this aspect. In our case, we took into account the accuracy that is usually strived for in practice. For example, we considered absolute elevation errors of less than 0.20 m to be very low. In the end, we defined the following classification for absolute residual values: very low (less than 0.20 m), low (between 0.21 and 0.50 m), significant (between 0.51 and 1.00 m) and extreme (over 1.00 m).
We emphasize that the lack of independent data for external validation means that any of the reported accuracy estimates should be taken as a measure of the relative performance of interpolation methods, not as absolute indicators of the accuracy of elevation estimates. As previously stated, the main purpose of this paper is to compare the relative performance of different interpolation methods, not to estimate absolute geodetical errors, nor to model the error budget.
2.4. Interpolation Algorithms
In a general sense, an interpolation algorithm involves the definition of a prediction function, which can be used to estimate the values for unsampled points, based on the known values of neighbouring points.
Most methods of interpolation use weighted averages of known data points to predict values for unsampled points, with the difference being the method by which these weights are calculated. Therefore, for many of these algorithms the general formula for prediction can be written as follows [
59]:
where
denotes the estimated value for point
,
z(
xi) is the measured value for point
,
is the weight asociated with observation
z(xi) and
n is the total number of reference points used for the estimation of
.
Nine interpolation algorithms were tested:
Inverse Distance Weighted (IDW) is one of the most widely used algorithms for surface modelling. The weight attributed to a reference point is based on its distance from the unsampled point for which the estimation is made, with reference points further away having a lower weight [
60]. IDW is an intuitive method of interpolation, in that it assumes that there is a degree of spatial autocorrelation of measured values; in other words, closer points are likely to have similar values.
Nearest Neighbour (NeN) is a simple approach: each unsampled point will be given the value of its closest measured point. This is achieved by constructing Thiessen polygons for all reference points. The Thiessen polygon of a point is the area of influence associated with that point; all unsampled points inside a polygon are closer to its centre than to any other reference point. Therefore, all unsampled points inside a Thiessen polygon will be assigned the value of the reference point in the centre of that polygon.
Natural Neighbour (NN) is similar to Nearest Neighbour, but more complex [
61]. The first step is the generation of a network of Thiessen polygons. Unsampled points for which the prediction is made are then overlaid with the network and a new set of Thiessen polygons are generated for them. Each new polygon will overlap with one or more of the original polygons. The centre points of those polygons are called the “natural neighbours” of the unsampled point used to generate the Thiessen polygon. The weight each reference value has in the interpolation of an unsampled point is based on the degree of overlap between initial Thiessen polygons and the polygon associated with the unsampled point.
Delauney Triangulation (DT) involves the generation of a Triangular Irregular Network (TIN) from the input point data. The general principle of a Delauney triangulation network is that no known point is inside the circumcirle of any of the generated triangles [
62]. By following this approach, a Delauney network will maximise the minimum angle of all triangles and ensure that triangle edges are relatively short. Each unsampled point is located inside a triangle of the network and its predicted value is calculated via a simple linear or polynomial interpolation using the known values for that triangle’s vertices.
Spline-based interpolators are a class of global, non-convex interpolation algorithms, which involve the fitting of a flexible surface (commonly called spline) through a set of measured observations. The interpolation function will pass through (or close to) all measured values. These algorithms work on the assumption that each measured value has an inherent measurement error, which can be reduced by generating a smooth surface of minimal tension [
43]. This local smoothing is achieved by generating a spline surface of minimal tension. The main difference between these algorithms is the mathematical form of the function used for surface generation. For this paper, we tested four spline-based algorithms:
Multilevel B-Spline (BS), which uses a hierarchy of coarse-to-fine control lattices to generate a sequence of B-Spline functions, the sum of which is the final interpolation function [
63].
Cubic Spline (CS), which is based on the construction of a bivariate cubic spline function [
64].
Thin-Plate Spline (TPS), which uses the namesake function to generate surfaces. Thin-plate Spline is the 2D generalization of the cubic spline function [
65].
Thin-Plate Spline by TIN (TPSTIN) is a variant of TPS that involves the construction of a TIN (Triangular Irregular Network) prior to interpolation. A TIN is a 3D mesh composed of triangles of varying area, using the set of measured points as vertices. Instead of a global Thin-plate Spline function, TPSTIN involves the generation of a separate function for each triangle of the network.
Ordinary Kriging (OK) is a geostatistical interpolation procedure that aims to quantify the degree of spatial auto-correlation of measured values. This is done by generating a semi-variogram, which depicts the overall shape, magnitude and spatial scale for the variation of the measured variable [
66]. Over this graph a model is then fitted, which is used to assign weights to observations. These weights used for interpolation are therefore a function of the spatial co-variance of the observations [
46].
A summary of the interpolation methods, their main characteristics and the abbreviations used going further are presented in
Table 2. Most algorithms are deterministic, with the exception of Ordinary Kriging, which is geostatistical. Furthermore, prediction methods vary in terms of: scale of analysis (some estimate values on a global scale, rather than local), smoothing of predictions at sampled locations (exact vs. approximate methods) or shape (convex algorithms will always predict values inside the range of known values and predictions for non-convex algorithms can potentially fall outside the range of sampled values).
2.5. Factors Considered for DTM Accuracy
The variation of DTM accuracy was analysed by taking into account the following factors:
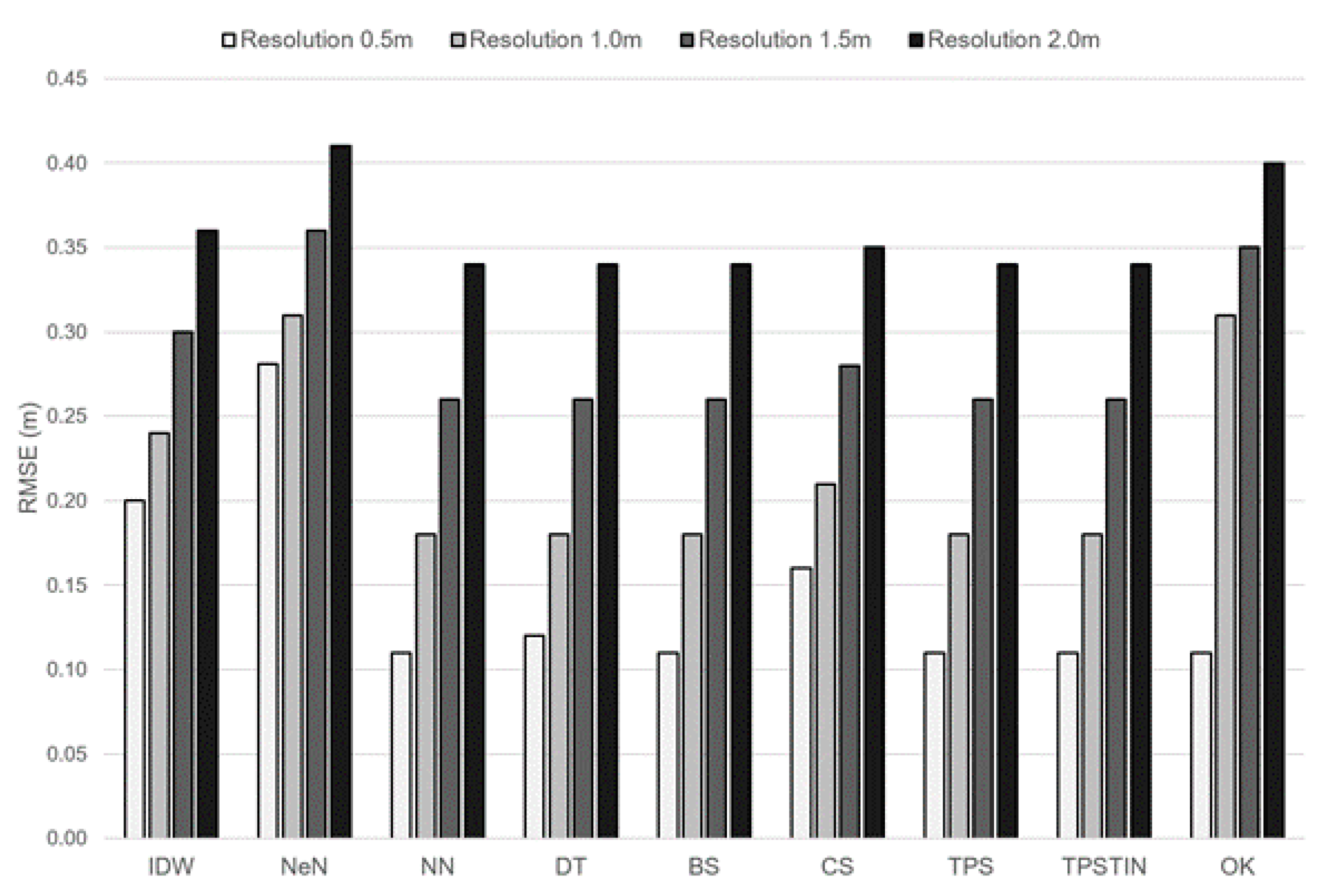
Spatial resolution, which is the main characteristic of a raster data structure (such as a DTM); four model resolutions were tested: 0.5 m, 1.0 m, 1.5 m and 2.0 m.
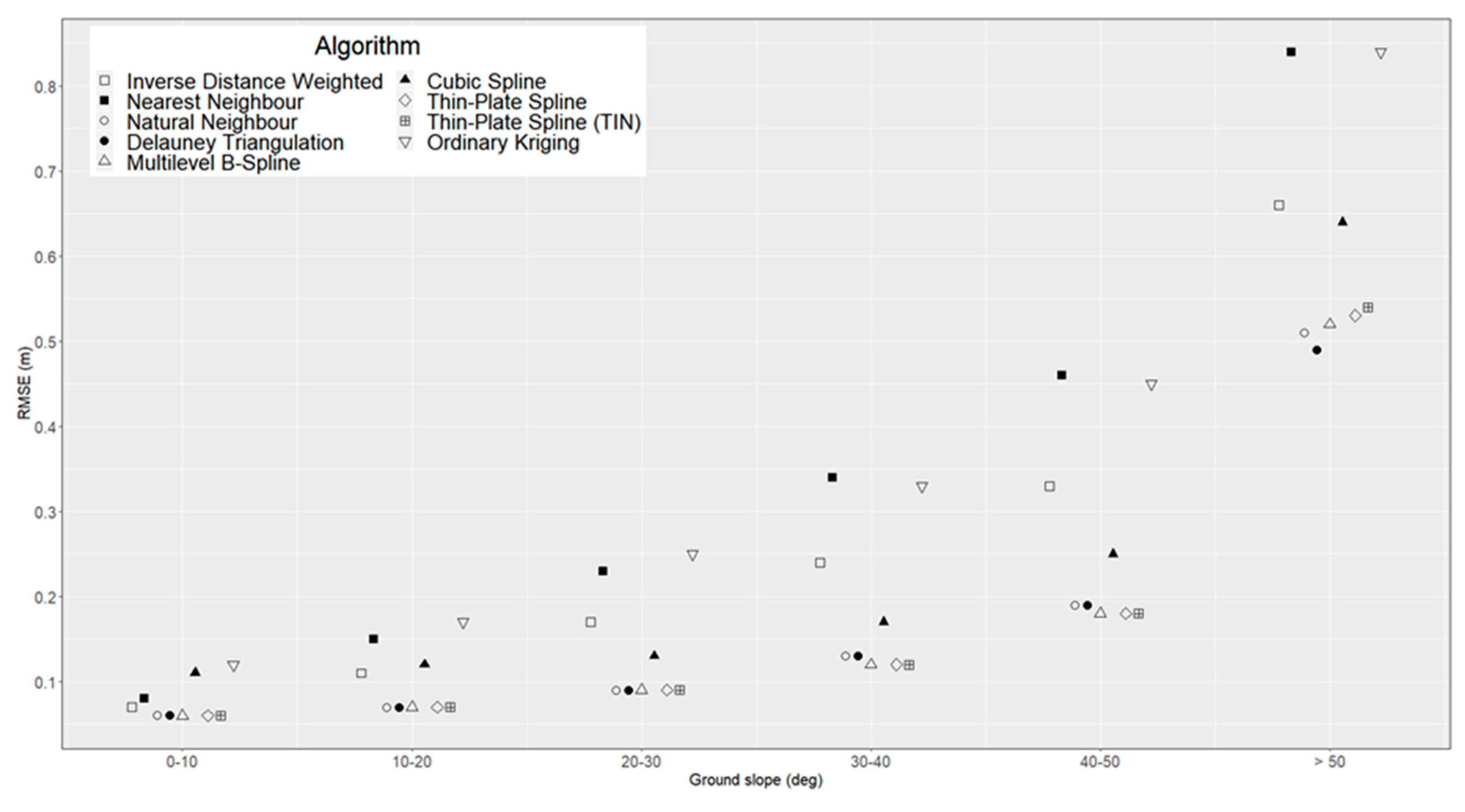
Ground slope, which was determined using a reference DTM, generated from the complete dataset (both prediction and validation points) by Natural Neighbour interpolation at a 0.5 m resolution. Ground slope values were then classified as follows: 0–10, 11–20, 21–30, 31–40, 41–50 and >50 degrees.
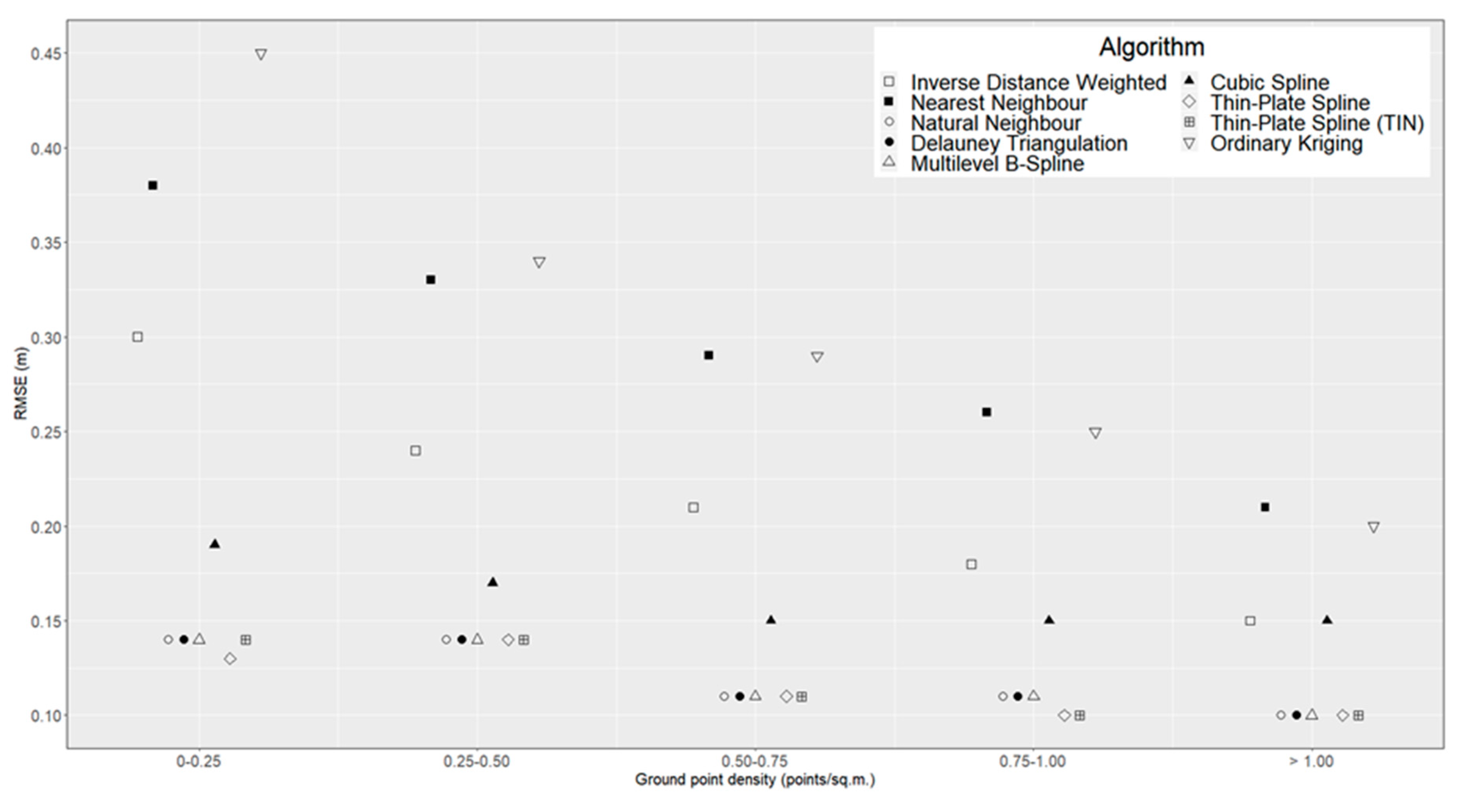
Point density, which was determined in a raster structure at a 1.0 m resolution. To reduce the noise level of the density model, a mean filter with a 5 × 5 kernel size was applied. Point density values were classified as follows: 0–0.25, 0.26–0.50, 0.51–0.75, 0.75–1.00 and >1.00 points m−2.
Canopy density was determined in a raster structure, using the initial LiDAR point cloud and the formula proposed by [
68], implemented in the FUSION LiDAR processing software:
where
δi is the canopy density for cell
i of the model,
n is the number of LiDAR returns inside cell
i that are above a user-established height threshold and
N is the total number of returns inside cell
i. Height threshold was set to 3 m, assuming that LiDAR returns below this height are likely objects such as understory vegetation, fallen tree trunks, boulders etc.
To ensure that the estimated canopy density is meaningful, the model resolution has to be larger than a typical tree crown diameter. We took into account the fact that, at the time of LiDAR data collection, most tree stands in our test area were close to harvesting age, in which case Romanian forestry guidelines recommend an average distance between trees of 6–8 m [
69]. Therefore, we set a value of 15 m for the resolution of the canopy density raster model, in the assumption that most, if not all, tree crowns should have a canopy diameter below this.
Estimated canopy density values were classified as follows: 0–10, 11–40, 41–60, 61–80 and 81–100 percent.
4. Discussion
Results indicate that, for the most part, tested interpolation algorithms have a relatively similar performance, in terms of overall DTM accuracy. Mean signed errors are very close to zero in all cases, indicating the lack of a prediction bias. It is worth pointing out that some previous studies find a positive bias of elevation prediction, in the case of dense forest vegetation. For example, [
70] reports a mean DTM error of 0.31 m for unlogged coniferous tree stands, while [
45] report a mean DTM error of 0.23 m for uncut aspen tree stands. The effect (or lack thereof) of forest composition and/or harvesting practices on the bias of ground elevation estimates from ALS data is worth further investigation.
Accuracy estimation for different model resolutions shows that, regardless of interpolation algorithm, lower DTM resolutions are associated with higher RMSE values (
Figure 3). This is in accordance with previous research [
38,
44,
46], but it is worth pointing out that at lower resolutions the distance between raster cell centres (the points for which prediction is made during the interpolation) and validation points will likely increase.
With regard to ground slope, previous research indicates that it should have an impact on the accuracy of the ground surface representation [
44,
45,
49,
71]. This is indeed the case here, as we find that RMSE values for all algorithms increase with ground slope. However, not all algorithms are equally affected. This is especially observed in the case of very steep terrain (ground slope of over 40 degrees), where some of the algorithms have a comparatively poorer performance (
Figure 4). This is confirmed by r correlation coefficient values, which highlight a very significant correlation between mean RMSE values and ground slope categories (
p-value < 0.01) for these algorithms (
Table 5). On the other hand, for most spline-based methods (which achieve a better overall performance) we find that the correlation between RMSE and ground slope is insignificant (
p-value > 0.05). There is no clear provable explanation for this behaviour, but our assumption is that it has to do with what we called the ‘shape’ of algorithms (
Table 2). As previously discussed, some algorithms (called convex) will always predict values inside the range of known values, while non-convex algorithms can predict values outside this range. In very rugged terrain (high slope values) it is unlikely that sampled points will cover the whole range of real elevation values. In other words, local maxima and minima will generally fall outside the sampled interval of elevation values, therefore will not be properly modelled by convex algorithms. On the other hand, non-convex algorithms (generally spline-based) are better suited to predict local maxima and minima even when those values fall outside the range of observations. This assumption is warranted by the fact that three out of the five convex algorithms that were tested have a degrading relative performance when ground slope increases (these being NeN, IDW and OK). This is in line with previous research: [
42] tested IDW and three spline-based interpolation methods and noted that IDW has a lower performance in rugged test plots because of its inability to properly model local maxima/minima; [
43] tested four interpolation methods in a hilly area and reported that IDW produced a higher rate of error clustering near the top of the hill (local maxima) when compared to non-convex methods like TPS or Multi-Quadratic.
On the other hand, at least one of the algorithms that we tested (DT) follows the opposite trend: even if DT is convex, this method actually has the best accuracy at the highest slope class (relative to the other algorithms). Further research is necessary to establish if this is something that has to do with DT’s approach to interpolation or random behaviour.
The next external factor that was considered is the ground point density (
Figure 5). While the reduction of point density has a noticeable effect on RMSE for NeN, IDW and OK algorithms, the other interpolation methods that were tested have a lower variation of RMSE across point density classes. A higher variance of RMSE values between interpolation methods for lower point densities is also reported by [
72]. For most algorithms, we find a significant negative correlation between mean RMSE values and point density categories (
Table 5), with the sole exception of TPS (r = -.87,
p-value > 0.05).
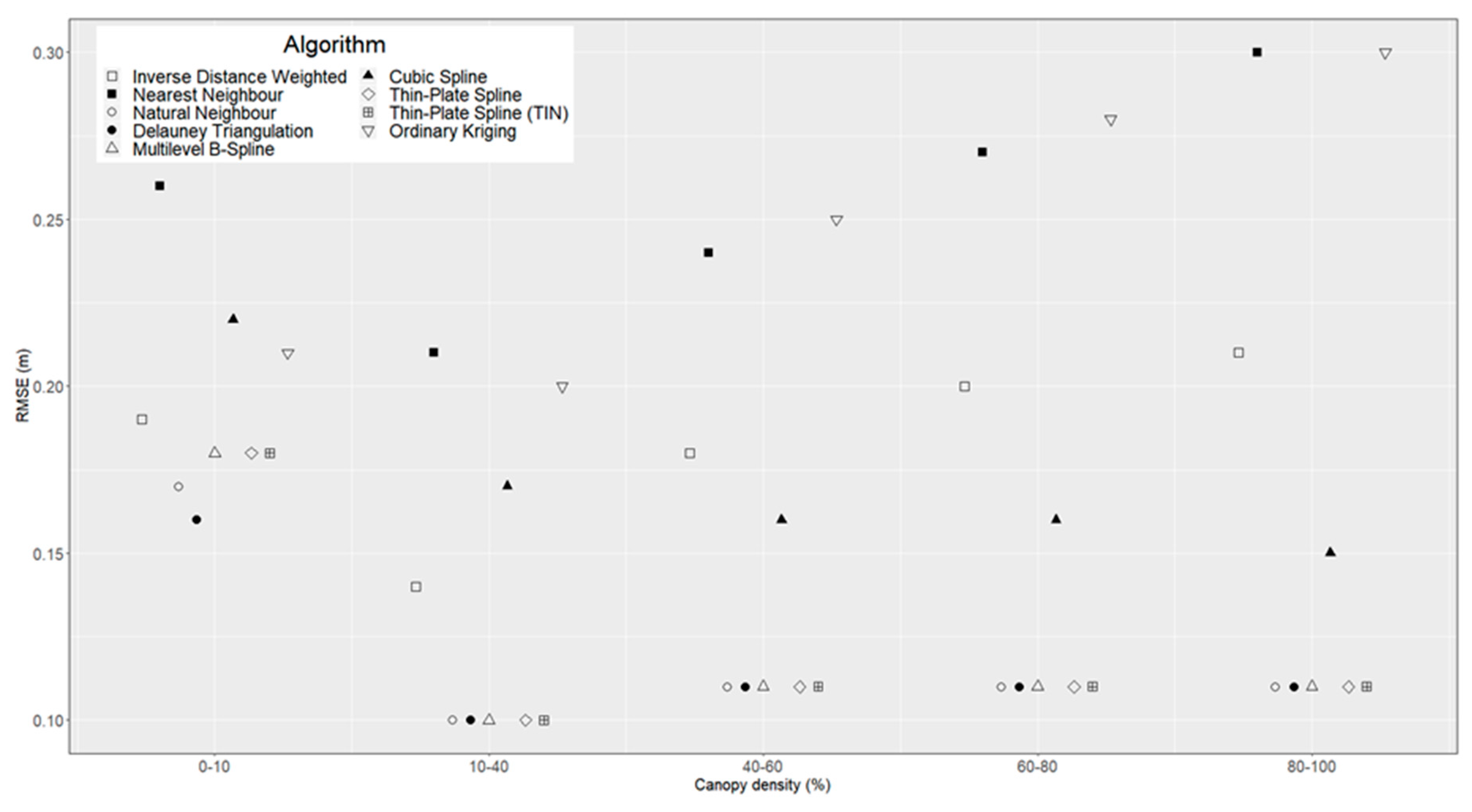
With regard to canopy density, we find that algorithms do not follow the same trend (
Figure 6). Some of the methods that were tested (NN, DT, BS and spline-based methods except CS) have near-constant mean RMSE values across canopy density categories, while others have lower accuracy in dense canopy cover (NeN, IDW and OK). In addition, OK is the only algorithm for which we find a significant positive correlation between canopy density and RMSE (r = 0.95,
p-value < 0.05).
It is worth pointing out that the distribution of validation points across canopy density categories is strongly skewed to the right: while only 4 percent of the validation points are assigned to the first canopy density category (0–10 percent canopy cover), the last category (80–100 percent canopy cover) includes 58 percent of the validation points. Therefore, mean RMSE values calculated for the lower canopy density classes have a relatively large 0.95 confidence interval.
There is no significant body of research that focuses on the effect that vegetation conditions have on the accuracy of ground-surface modelling from ALS data, especially for the specific case of forest eco-systems. Furthermore, vegetation conditions can be looked at from different perspectives: while in our study we only considered the density of the canopy cover, other researchers looked at DTM accuracy for different vegetation classes [
45] or for varying understory vegetation heights [
49]. As a result of this, it is difficult to put the results presented in
Figure 6 into perspective.
Leaving aside the lowest canopy density class (0–10 percent) due to its unreliability (a higher 0.95 confidence interval due to a low number of validation points), it is apparent that, generally speaking, canopy density has a similar effect as ground point density (
Figure 5), except inversed (since an increase of canopy cover density should cause a decrease of ground point density). Therefore, if we look at this two factor in conjunction, we can see that: (1) several algorithms are not affected by changes in ground point/canopy density—NN, DT, BS, TPS, TPS
TIN; (2) some algorithms have a decreased performance at higher canopy density/lower ground point density—NeN, OK, IDW and (3) the rest of the algorithms seem to have random changes in terms of accuracy between classes of canopy density/ground point density.
In other words, results would indicate that canopy density acts as a proxy of ground point density, in terms of its influence on the accuracy of ground-surface modelling in dense forest environments. This is contrary to our initial assumption, which was that canopy density (while evidently linked to a certain extent with ground point density) would exhibit a different influence on DTM interpolation. This assumption was made by considering the theoretical effect that canopy density would have on the spatial distribution of ALS ground points. While in open terrain the variation of ground point density (for example by changing the altitude of the LiDAR sensor platform) would be evenly spread (point density is generally homogenous), increased canopy density would not only cause a general lowering of ground point density, but also an increase in the clustering of these points (with most of observations grouped under gaps in the canopy cover).
However, results show that this expected clustering of ground points in areas of higher canopy density is either not significant, or it does not have a noticeable influence on the interpolation of the ground surface model. Further research needs to be carried out before we can state that the effect of canopy density on DTM accuracy is fully explained by changes in terms of ground point density. This additional research should be ideally carried out in areas with different forest compositions and with a distribution of canopy densities closer to the normal (as stated, canopy density values for our test site are skewed to the right).
To sum up, results indicate that for our test conditions (mountainous areas with dense canopy cover), the relatively lower accuracy of some interpolation methods (namely Nearest Neighbour, Inverse Distance Weighted and Ordinary Kriging) is likely attributed to areas of steep slope and/or lower point densities caused by the presence of dense forest cover.
5. Conclusions
An accuracy assessment of DTM interpolation from LiDAR point cloud data in difficult terrain conditions (mountainous relief with dense forest cover) was carried out. In lack of independent data at a sufficient density and accuracy, we had to carry out the performance analysis of interpolation algorithms using cross-validation, which involves separating a certain proportion of the initial dataset (in our case 5 percent) to use as validation. The limitation of this approach is that any systematic errors (which affect the initial dataset in its entirety) are not taken into account, so none of the reported accuracy estimates are to be taken as global estimates of modelling accuracy. In other words, the results that were presented can only be considered as indicators of the relative performance of the tested interpolation methods in a densely-forested area, which was indeed our main purpose.
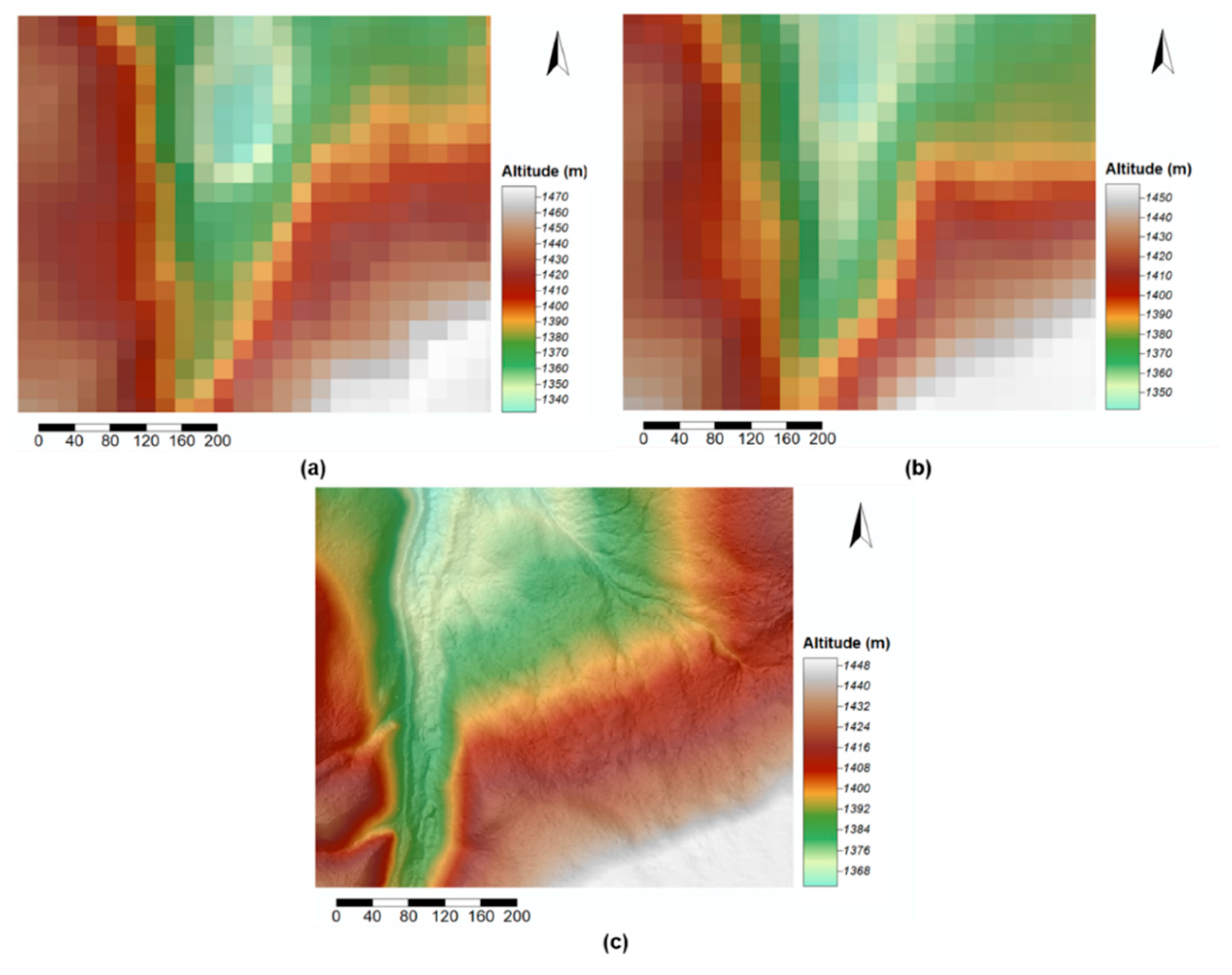
Nine interpolation methods were tested and results show that, as far as general DTM accuracy is concerned, algorithm performance is relatively similar. Therefore, we propose that a visual analysis of interpolated DTMs is warranted, alongside the quantitative one. In addition, such an analysis has the advantage that it can easily inform the end user about the quality of the ground surface model [
73]. Significant visual artefacts are present for Inverse Distance Weighted, Nearest Neighbour and Ordinary Kriging. On the other hand, surfaces generated by spline-based methods are generally artefact-free; as they apply a degree of smoothing to the generated surface, DTMs obtained using these methods are more appealing (in terms of visualisation). This is not to say that visual analysis is as important as the quantitative one, since a better-looking model does not necessarily mean a more accurate prediction.
With regard to TPS and its variant TPSTIN, results do not highlight any significant difference between their respective DTMs. Therefore, the significantly longer processing time of TPSTIN (relative to TPS) is not justified.
The best overall accuracy is achieved by spline-based methods and the Natural Neighbour algorithm. These methods have a similar response to the variations of ground slope, ground point density and, to a lesser extent, canopy cover density. However, it is worth mentioning that spline-based algorithms generally involve a time-consuming process of parameter optimisation, while Natural Neighbour does not require any user input.
Overall, results indicate that ALS point clouds are a viable source for accurate ground surface modelling even in less than ideal conditions, such as steep slopes covered with dense forest vegetation. However, issues concerning model resolution, interpolation method and parameter optimisation need to be taken into account.
While the effect of model resolution, ground slope and the ground point density of the ALS point cloud have been established for our test area, the influence of canopy density on different interpolation algorithms is not entirely clear and warrants further research.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





