An Improved Parallelized Multi-Objective Optimization Method for Complex Geographical Spatial Sampling: AMOSA-II


Abstract
:1. Introduction
2. Literature Review
3. Methodology
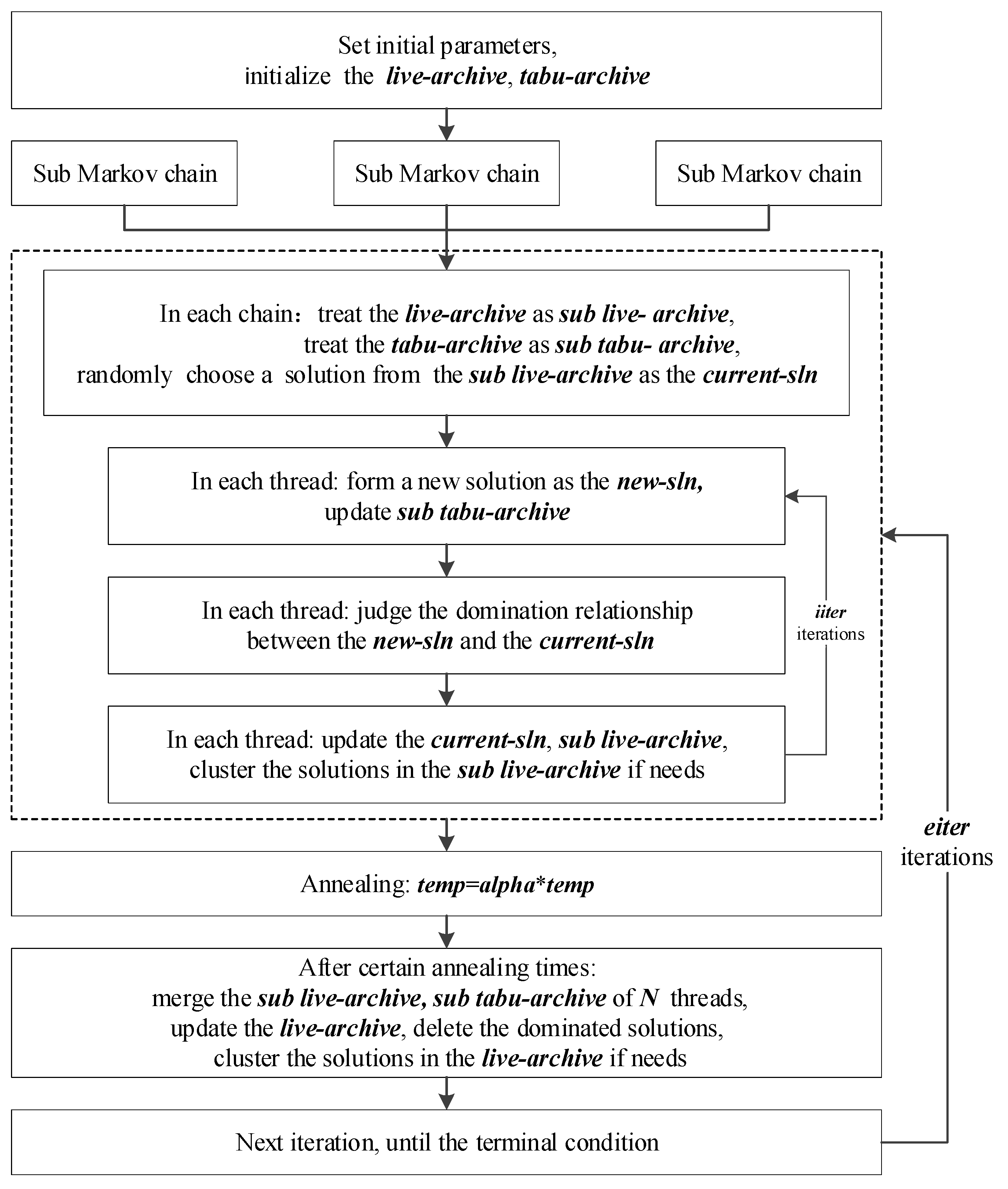
3.1. The Framework of AMOSA-II
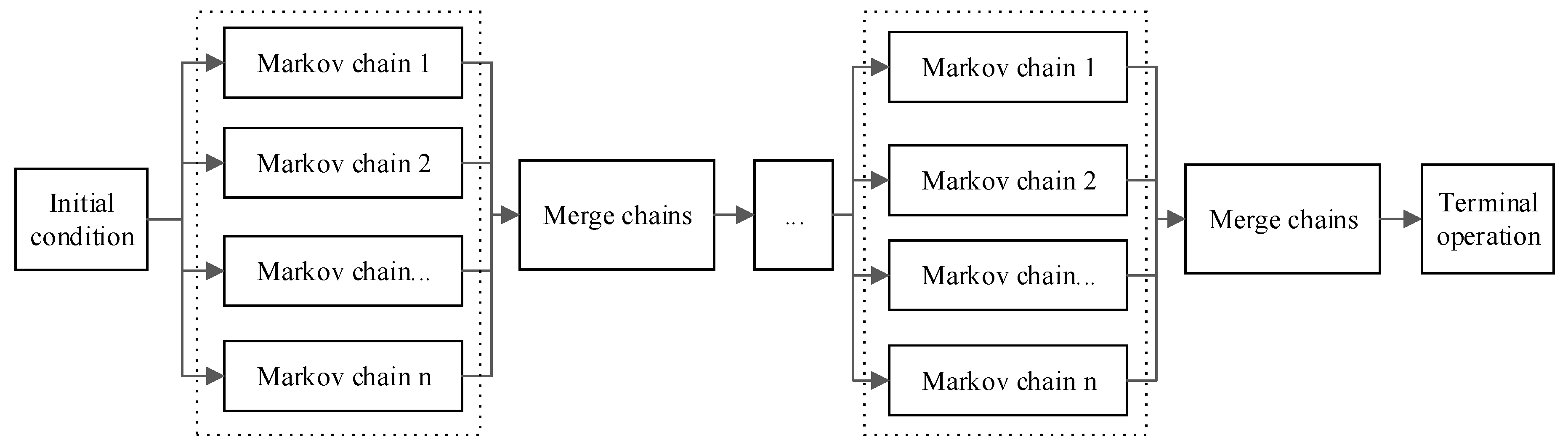
3.2. Multiple Markov Chains
3.3. Parallelization based on Multiple Markov Chains
3.4. The Tabu-Archive Constraint
3.5. Complexity Analysis
3.6. Performance Indices
4. Performance Test on Traditional Test Problems
4.1. Experiment Case
4.2. Experiment Design
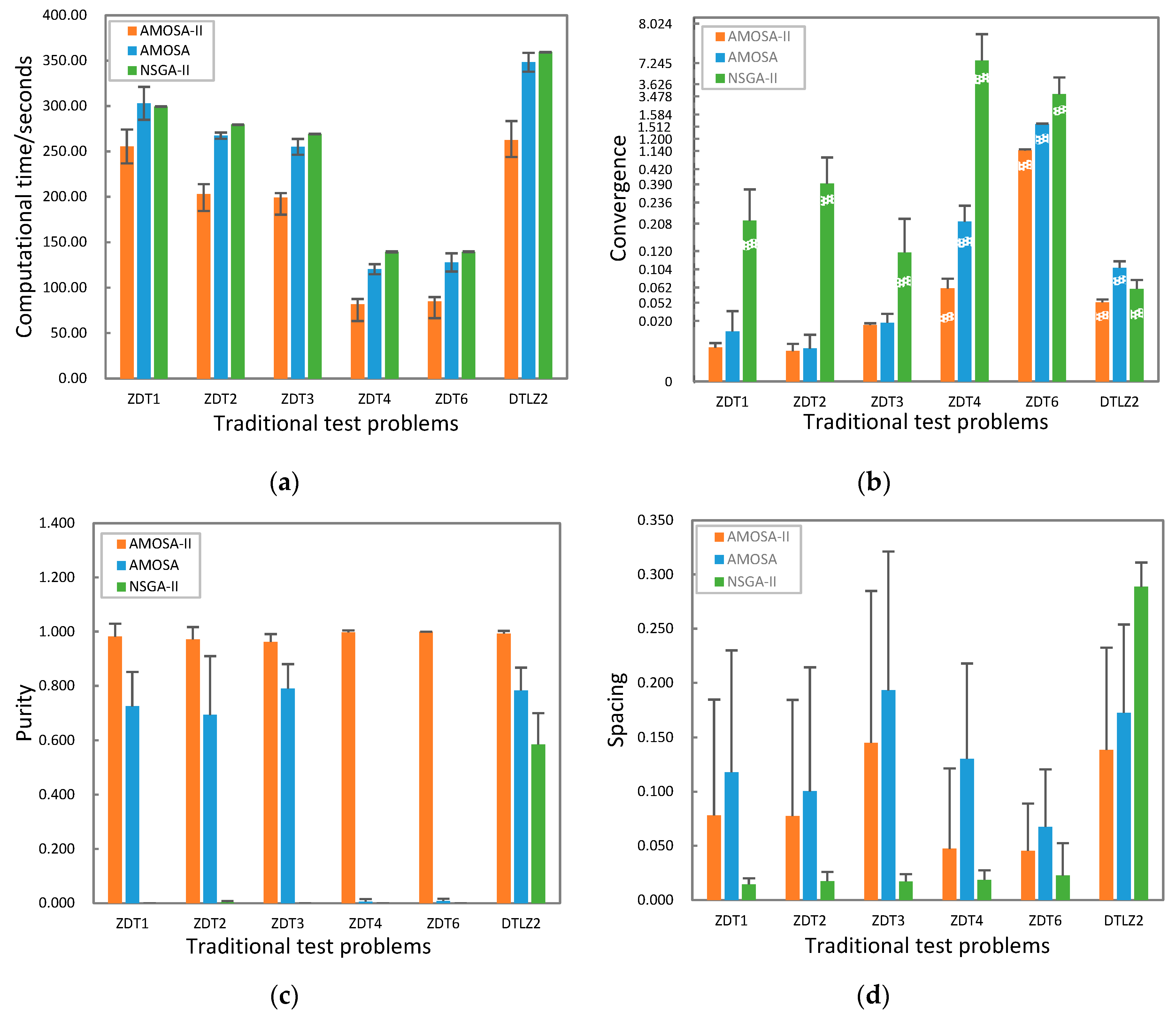
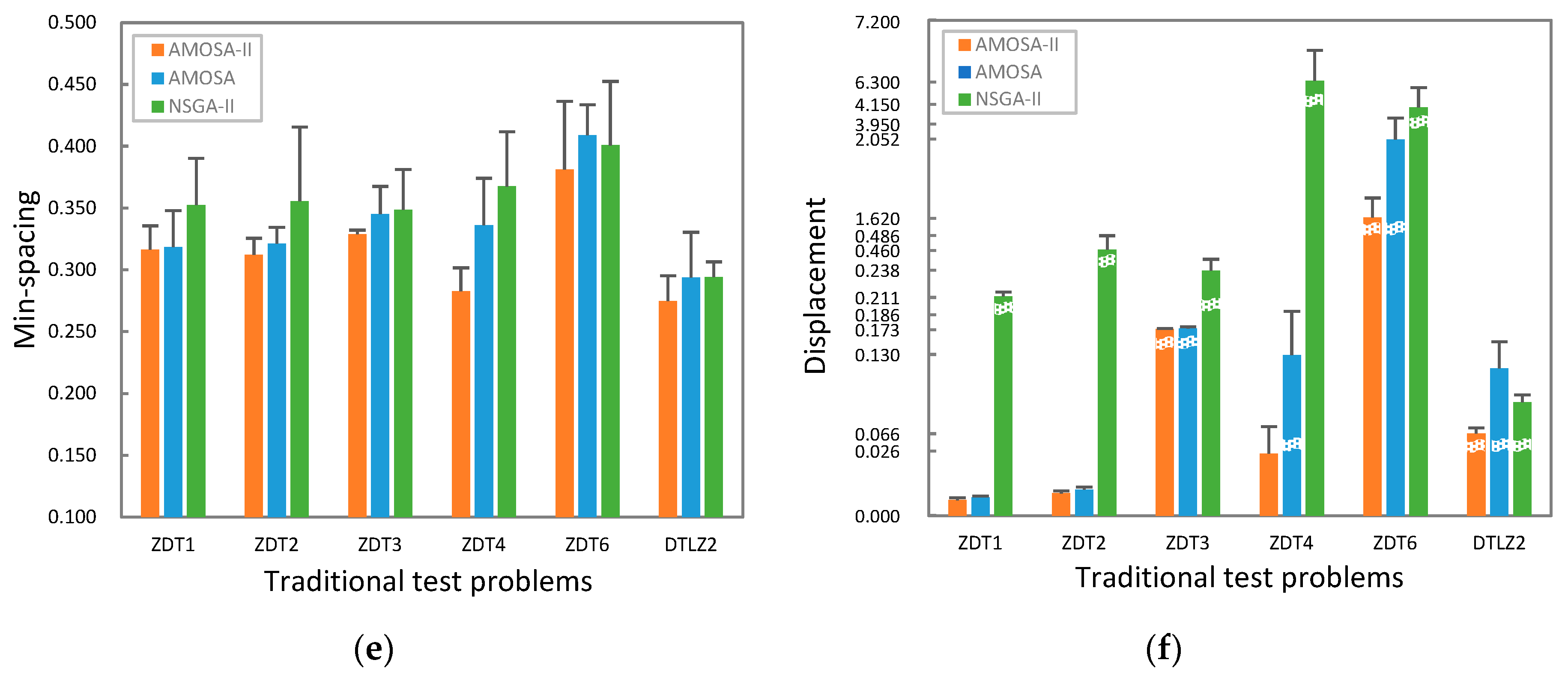
4.3. Results
5. Performance Analysis in Spatial Sampling
5.1. Experiment Case
5.2. Experiment Design
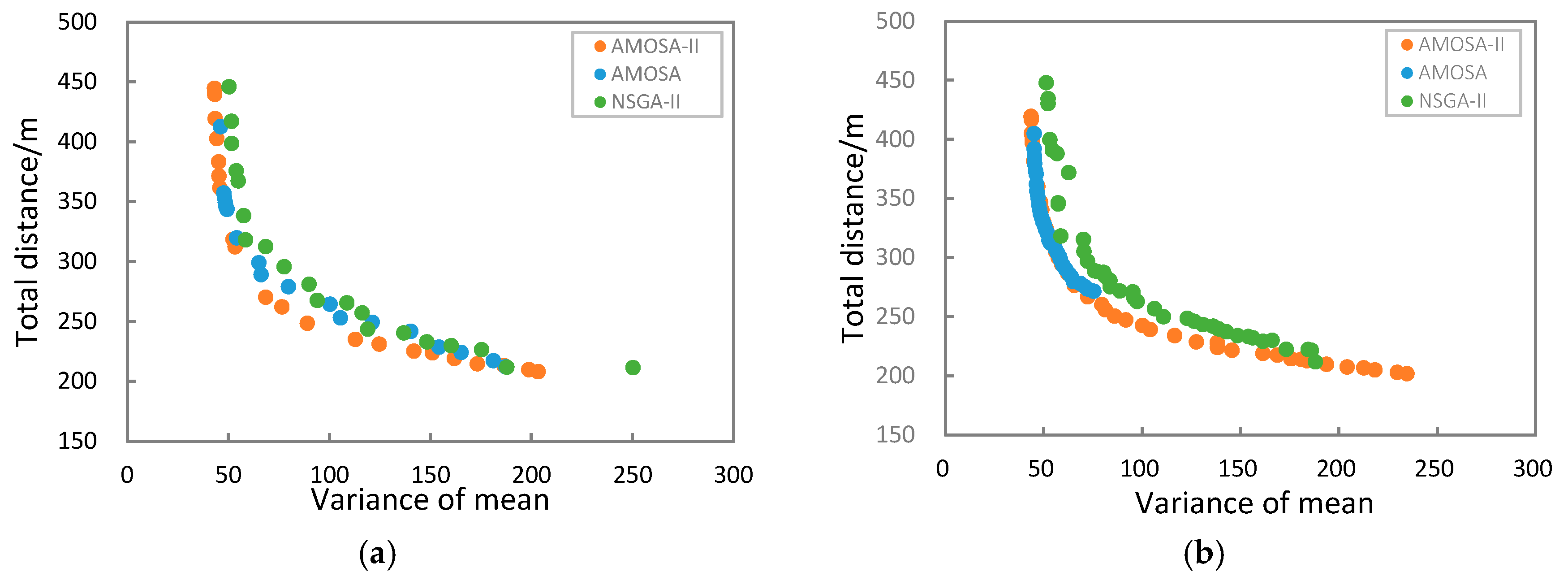
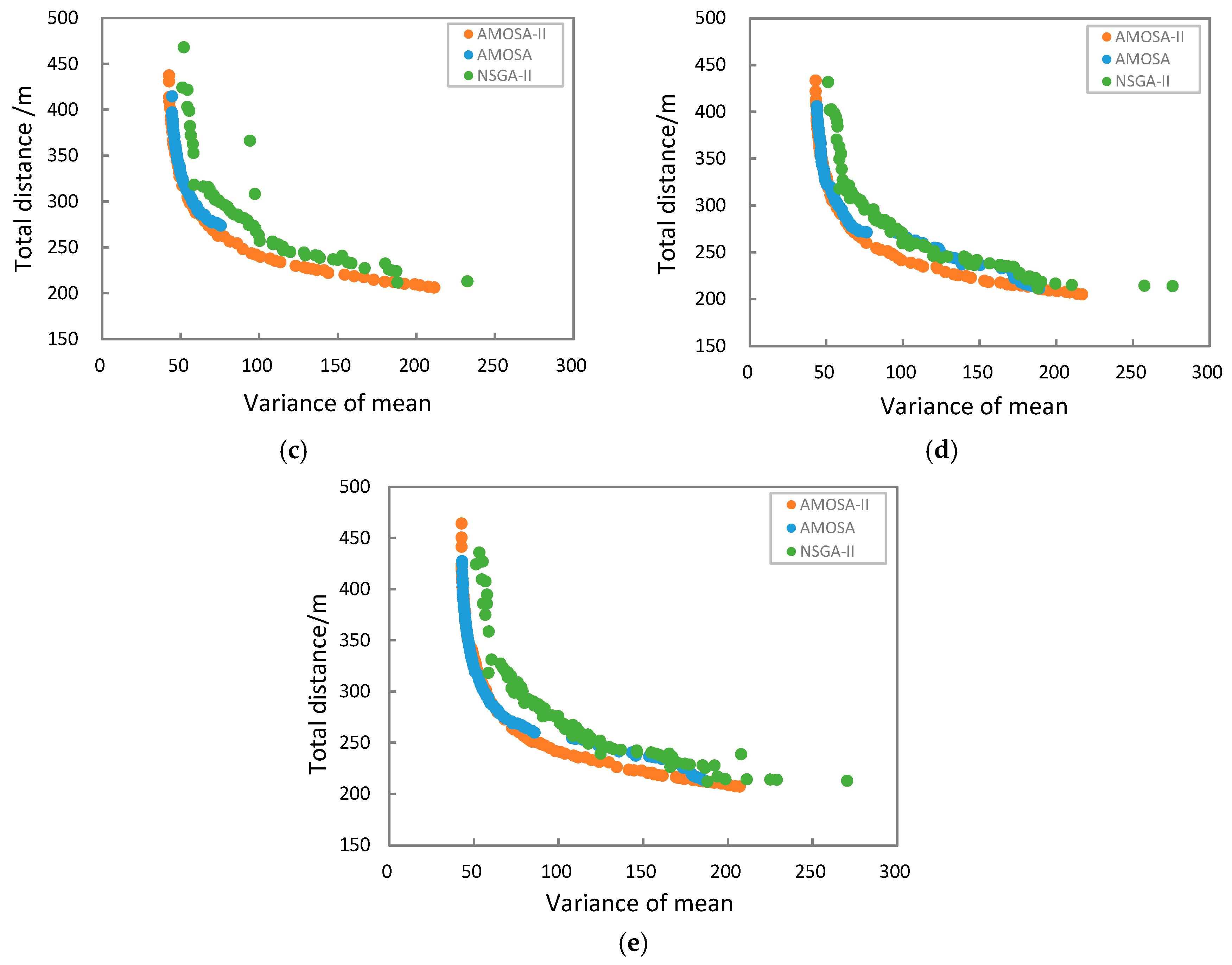
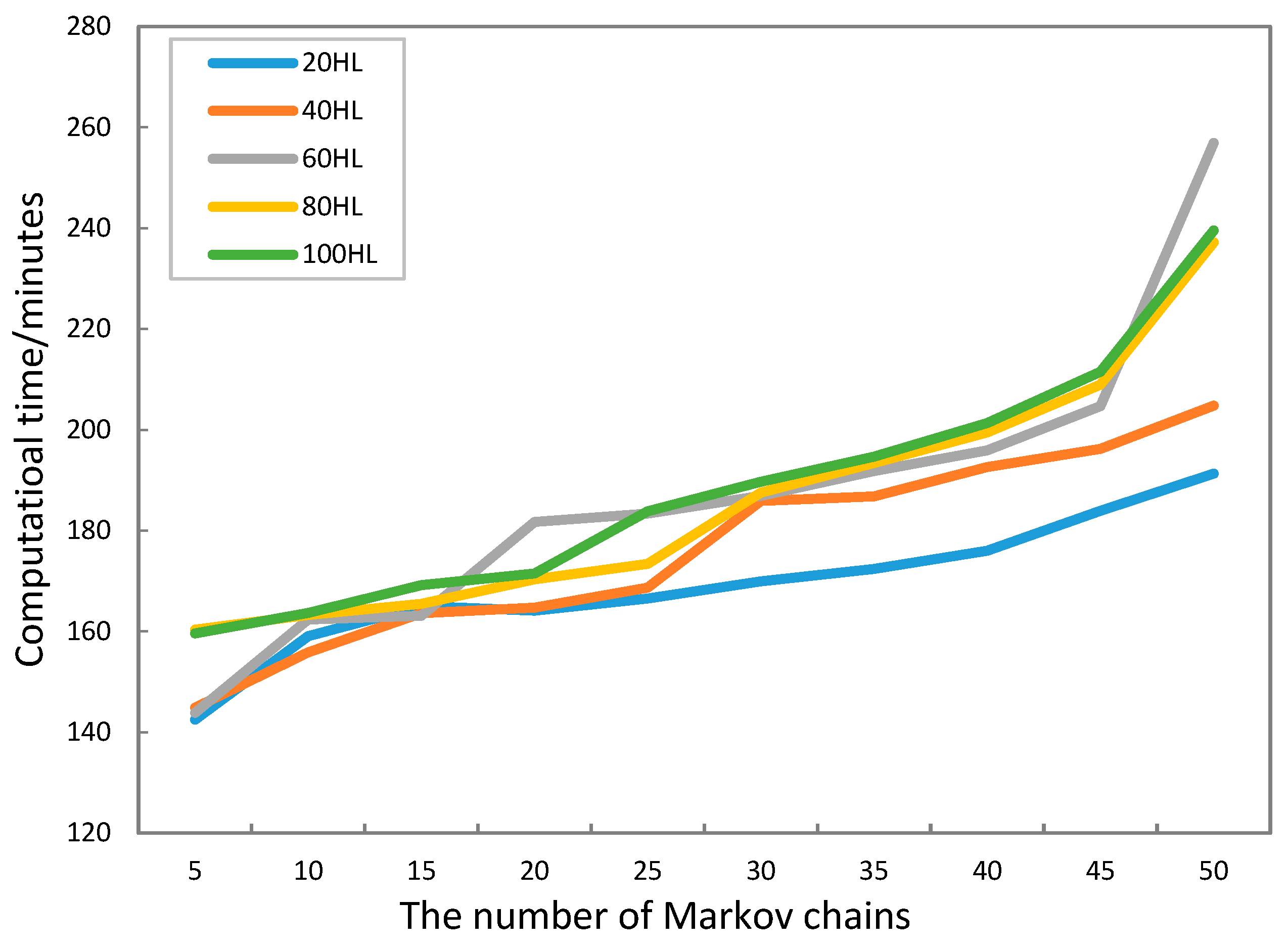
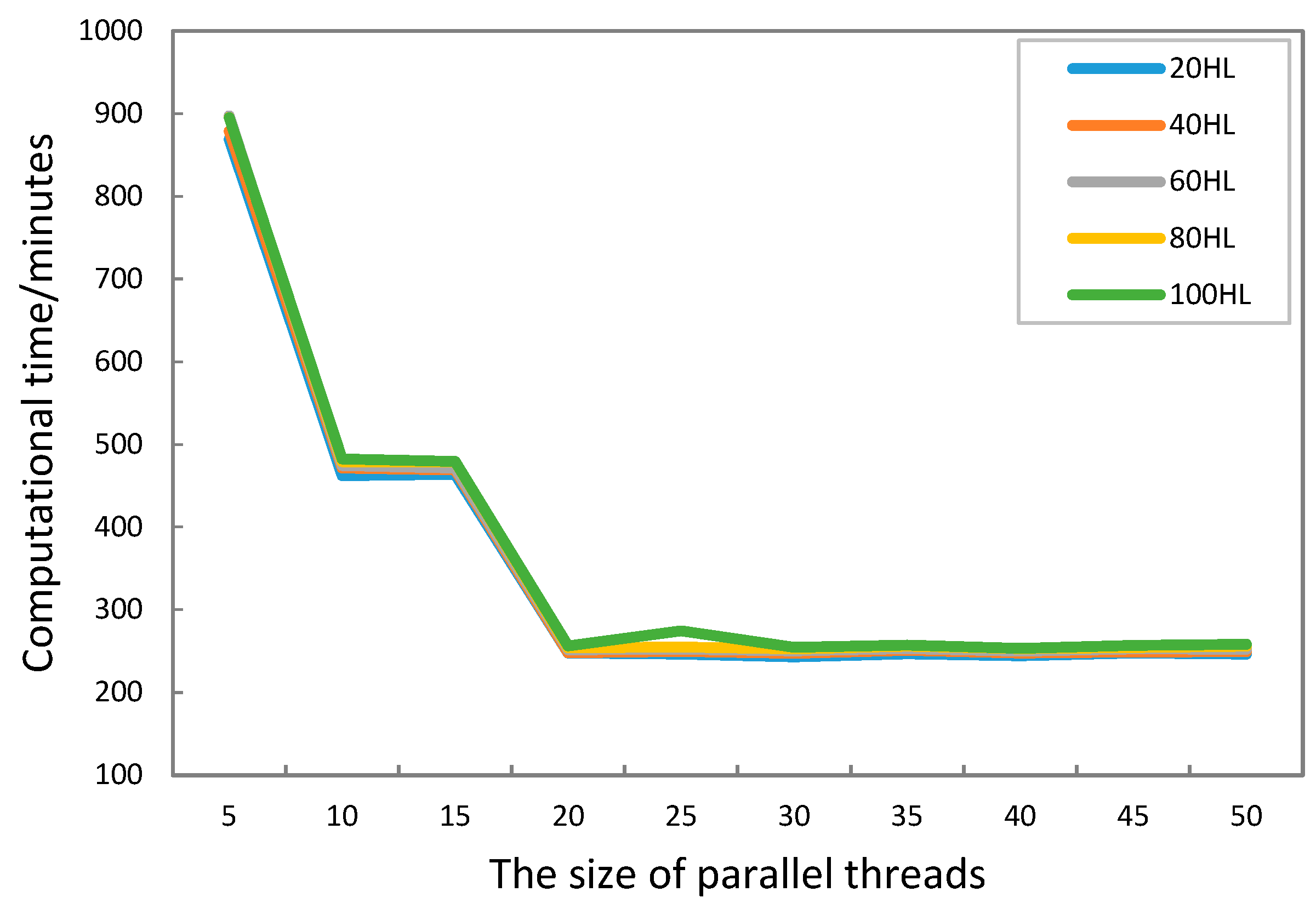
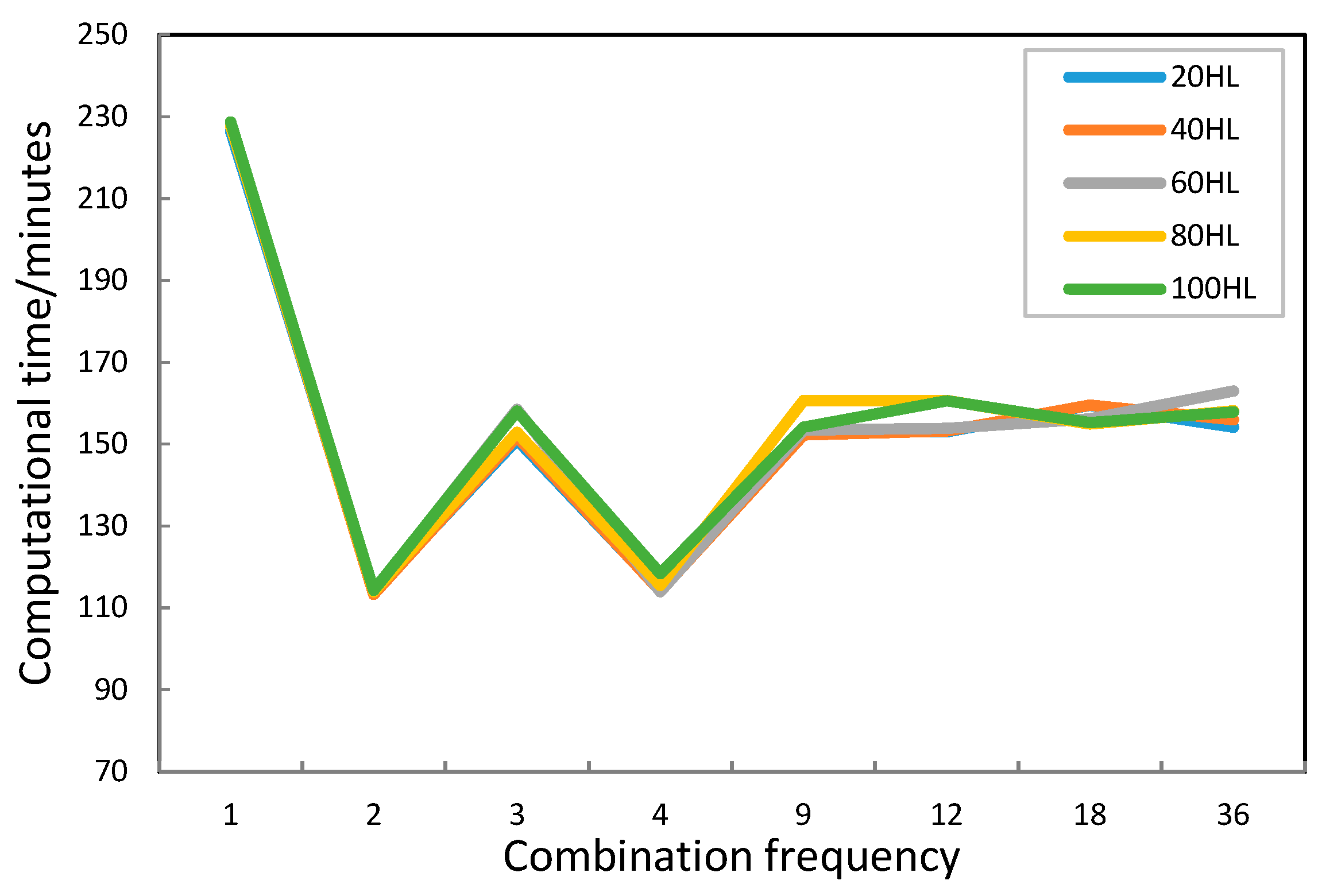
5.3. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- De Gruijter, J.J.; Brus, D.J.; Bierkens, M.F.P.; Knotters, M. Sampling for Natural Resource Monitoring; Springer: Berlin, Germany, 2006. [Google Scholar]
- Zimmerman, D.L. Optimal network design for spatial prediction, covariance parameter estimation, and empirical prediction. Environmetics 2006, 17, 635–652. [Google Scholar] [CrossRef]
- Heuvelink, G.B.M.; Brus, D.J.; de Gruijter, J.J. Opimization of sample configurations for digital mapping of soil properties with universal kriging. In Digital Soil Mapping. An Introductory Perspective; Lagacherie, P., Mcbratney, A.B., Voltz, M., Eds.; Elisevier: Oxford, UK, 2007; pp. 137–154. [Google Scholar]
- Szatmári, G.; László, P.; Takács, K.; Szabó, J.; Bakacsi, Z.; Koós, S.; Pásztor, L. Optimization of second-phase sampling for multivariate soil mapping purposes: Case study from a wine region, Hungary. Geoderma 2018, 352, 373–384. [Google Scholar] [CrossRef]
- Vašát, R.; Heuvelink, G.B.M.; Borůvka, L. Sampling design optimization for multivariate soil mapping. Geoderma 2010, 155, 147–153. [Google Scholar] [CrossRef]
- Ballari, D.; de Bruin, S.; Bregt, A.K. Value of information and mobility constraints for sampling with mobile sensors. Comput. Geosci. 2012, 49, 102–111. [Google Scholar]
- Zhu, Z.; Stein, M.L. Spatial sampling design for prediction with estimated parameters. J. Agric. Biol. Environ. Stat. 2006, 11, 24–44. [Google Scholar] [CrossRef] [Green Version]
- Brus, D.J.; Heuvelink, G.B.M. Optimization of sample patterns for universal kriging of environmental variables. Geoderma 2007, 138, 86–95. [Google Scholar] [CrossRef]
- Carlos, M.F.; Peter, J.F. An overview of evolutionary algorithms in multiobjective optimization. Evol. Comput. 1995, 3, 1–16. [Google Scholar]
- Srinivas, N.; Deb, K. Multiobjective optimization using nondominated sorting in genetic algorithms. Evol. Comput. 1995, 2, 221–248. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Joshua, D.K.; David, W.C. Approximating the nondominated front using the Pareto archived evolution strategy. Evol. Comput. 2000, 8, 149–172. [Google Scholar]
- David, C.; Nick, R.J.; Joshua, D.K.; Martin, J.O. PESA-II: Region-based selection in evolutionary multiobjective. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO-2001), San Francisco, CA, USA, 7–11 July 2001; pp. 283–290. [Google Scholar]
- Suman, B. Multiobjective simulated annealing-a metaheuristic technique for multiobjective optimization of a constrained problem. Found. Comput. Decis. Sci. 2002, 27, 171–191. [Google Scholar]
- Suman, B. Study of simulated annealing based algorithms for multiobjective optimization of a constrained problem. Comput. Chem. Eng. 2004, 28, 1849–1871. [Google Scholar]
- Bandyopadhyay, S.; Saha, S.; Maulik, U.; Deb, K. A simulated annealing-based multiobjective optimization algorithm: AMOSA. IEEE Trans. Evol. Comput. 2008, 12, 269–283. [Google Scholar] [CrossRef] [Green Version]
- Lark, R.M. Multi-objective optimization of spatial sampling. Spat. Stat. 2016, 18, 412–430. [Google Scholar] [CrossRef]
- Cheng, C.X.; Shi, P.J.; Song, C.Q.; Gao, J.B. Geographic big-data: A new opportunity for geography complexity study. Acta Geogr. Sin. 2018, 73, 1397–1406. [Google Scholar]
- Shen, S.; Ye, S.J.; Cheng, C.X.; Song, C.Q.; Gao, J.B.; Yang, J.; Ning, L.X.; Su, K.; Zhang, T. Persistence and Corresponding Time Scales of Soil Moisture Dynamics During Summer in the Babao River Basin, Northwest China. J. Geophys. Res. Atmos. 2018, 123, 8936–8948. [Google Scholar] [CrossRef]
- Zhang, T.; Shen, S.; Cheng, C.X.; Song, C.Q.; Ye, S.J. Long-range correlation analysis of soil temperature and moisture on A’rou Hillsides, Babao River Basin. Atmospheres 2018, 123, 12606–12620. [Google Scholar] [CrossRef]
- Burgess, T.M.; Webster, R.; Mcbratney, A.B. Optimal interpolation and isarithmic mapping of soil properties: IV. Sample strategy. Eur. J. Soil Sci. 1981, 32, 643–659. [Google Scholar] [CrossRef]
- Mcbratney, A.B.; Webster, R.; Burgess, T.M. The design of optimal sampling schemes for local estimation and mapping of regionalized variables.1. Theory and method. Comput. Geosci. 1981, 7, 331–334. [Google Scholar]
- Juang, K.; Liao, W.; Liu, T.; Tsui, L.; Lee, D. Additional sampling based on regulation threshold and kriging variance to reduce the probability of false delineation in a contaminated site. Sci. Total Environ. 2008, 389, 20–28. [Google Scholar] [CrossRef]
- Meirvenne, M.V.; Goovaerts, P. Evaluating the probability of exceeding a site-specific soil cadmium contamination threshold. Geoderma 2001, 102, 75–100. [Google Scholar] [CrossRef]
- Hengl, T.; David, G.R.; Stein, A. Soil sampling strategies for spatial prediction by correlation with auxiliary. Aust. J. Soil Res. 2003, 41, 1403–1422. [Google Scholar] [CrossRef]
- Gao, B.B.; Pan, Y.C.; Chen, Z.Y.; Wu, F.; Ren, X.H.; Hu, M.G. A spatial conditioned latin hypercube sampling method for mapping using ancillary data. Trans. GIS 2016, 20, 735–754. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.P.; Chu, H.J.; Huang, Y.L.; Tang, C.H.; Rouhani, S. Monitoring and identification of spatiotemporal landscape changes in multiple remote sensing images by using a stratified conditional Latin hypercube sampling approach and geostatistical simulation. Environ. Monit. Assess. 2011, 177, 353–373. [Google Scholar] [CrossRef]
- Ge, Y.; Wang, J.H.; Heuvelink, G.B.M.; Jin, R.; Li, X.; Wang, J.F. Sampling design optimization of a wireless sensor network for monitoring ecohydrological processes in the Babao River basin, China. Int. J. Geogr. Inf. Sci. 2014, 29, 92–110. [Google Scholar] [CrossRef]
- Van Groenigen, J.W.; Stein, A. Constrained optimization of spatial sampling using continuous simulated annealing. J. Environ. Qual. 1998, 27, 1078–1086. [Google Scholar] [CrossRef]
- Van Groenigen, J.W.; Siderius, W.; Stein, A. Constrained optimisation of soil sampling for minimisation of the kriging variance. Geoderma 1999, 87, 239–259. [Google Scholar] [CrossRef]
- Van Groenigen, J.W. The influence of variogram parameters on optimal sampling schemes for mapping by kriging. Geoderma 2000, 97, 223–236. [Google Scholar] [CrossRef]
- Richard, W.; Murray, L. Filed Sampling for Environmental Science and Management; Routledge: Oxon, UK, 2013. [Google Scholar]
- Wadoux, A.; Brus, D.J.; Heuvelink, G.B.M. Sampling design optimization for soil mapping with random forest. Geoderma 2019, 355, 11. [Google Scholar] [CrossRef]
- Tavakoli-Someh, S.; Rezvani, M.H. Multi-objective virtual network function placement using NSGA-II meta-heuristic approach. J. Supercomput. 2019, 75, 6451–6487. [Google Scholar] [CrossRef]
- Xue, Y. Mobile robot path planning with a non-dominated sorting genetic algorithm. Appl. Sci. Basel 2018, 8, 2253. [Google Scholar] [CrossRef] [Green Version]
- Rayat, F.; Musavi, M.; Bozorgi-Amiri, A. Bi-objective reliable location-inventory-routing problem with partial backordering under disruption risks: A modified AMOSA approach. Appl. Soft Comput. 2017, 59, 622–643. [Google Scholar] [CrossRef]
- Memari, A.; Rahim, A.R.A.; Hassan, A.; Ahmad, R. A tuned NSGA-II to optimize the total cost and service level for a just-in-time distribution network. Neural Comput. Appl. 2017, 28, 3413–3427. [Google Scholar]
- Rabiee, M.; Zandieh, M.; Ramezani, P. Bi-objective partial flexible job shop scheduling problem: NSGA-II, NRGA, MOGA and PAES approaches. Int. J. Prod. Res. 2012, 50, 7327–7342. [Google Scholar] [CrossRef]
- Kaveh, A.; Moghanni, R.M.; Javadi, S.M. Ground motion record selection using multi-objective optimization algorithms: A comparative study. Period. Polytech. Civ. Eng. 2019, 63, 812–822. [Google Scholar] [CrossRef] [Green Version]
- Saadatpour, M.; Afshar, A.; Khoshkam, H. Multi-objective multi-pollutant waste load allocation model for rivers using coupled archived simulated annealing algorithm with QUAL2Kw. J. Hydroinform. 2019, 21, 397–410. [Google Scholar] [CrossRef]
- An, H.; Green, D.; Johrendt, J.; Smith, L. Multi-objective optimization of loading path design in multi-stage tube forming using MOGA. Int. J. Mater. Form. 2013, 6, 125–135. [Google Scholar] [CrossRef]
- Arora, R.; Kaushik, S.C.; Arora, R. Multi-objective and multi-parameter optimization of two-stage thermoelectric generator in electrically series and parallel configurations through NSGA-II. Energy 2015, 91, 242–254. [Google Scholar] [CrossRef]
- Pang, J.; Zhou, H.; Tsai, Y.-C.; Chou, F.-D. A scatter simulated annealing algorithm for the bi-objective scheduling problem for the wet station of semiconductor manufacturing. Comput. Ind. Eng. 2018, 123, 54–66. [Google Scholar]
- 44. Daniel, P.; Christoph, B.; Martin, K.; Marta, G.; Menéndez, M.; Sainz-Palmero, G.I.; Bertrand, C.M.; Klawonn, F.; Benitez, J.M. Multiobjective optimization for railway maintenance plans. J. Comput. Civ. Eng. 2018, 32, 1–11. [Google Scholar]
- Chandy, J.A.; Sungho, K.; Ramkumar, B.; Parkes, S.; Banerjee, P. An evaluation of parallel simulated annealing strategies with application to standard cell placement. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 1997, 16, 398–410. [Google Scholar] [CrossRef] [Green Version]
- Borin, E.; Devloo, P.R.B.; Vieira, G.S.; Shauer, N. Accelerating engineering software on modern multi-core processors. Adv. Eng. Softw. 2015, 84, 77–84. [Google Scholar] [CrossRef]
- Ray, R.; Gurung, A.; Das, B.; Bartocci, E.; Bogomolov, S.; Grosu, R. XSpeed: Accelerating reachability analysis on multi-core processors. In Hardware and Software: Verification and Testing. HVC 2015. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Mannuel, J.A.E.; Jochen, K.; Christine, P.; Markus, S.; Esmeralda, V. Hands-on tutorial for parallel computing with R. Comput. Stat. 2011, 26, 219–239. [Google Scholar]
- Glover, F.; Taillard, E. A Users Guide to Tabu Search. Ann. Oper. Res. 1993, 41, 1–28. [Google Scholar] [CrossRef]
- Deb, K. Multi-objective_optimization Using Evolutionary Algorithms; Wiley: Wiltshire, UK, 2001. [Google Scholar]
- Sanghamitra, B.; Pal, S.K.; Aruna, B. Multiobjective GAs, quantitative indices, and pattern classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2004, 34, 2088–2099. [Google Scholar]
- Sanghamitra, B.; Sriparna, S. Unsupervised Classification: Similarity Measures, Classical and Metaheuristic Approaches, and Applications; Springer: Berlin, Germany, 2013. [Google Scholar]
- Deb, K.; Thiele, L.; Laumanns, M.; Zitzler, E. Scalable Multi-Objective Optimization Test Problems. In Proceedings of the 2002 Congress on Evolutionary Computation. CEC’02 (Cat. No.02TH8600), Honolulu, HI, USA, 12–17 May 2002; pp. 825–830. [Google Scholar]
- Turkson, R.F.; Yan, F.; Ali, M.K.A.; Liu, B.; Hu, J. Modeling and multi-objective optimization of engine performance and hydrocarbon emissions via the use of a computer aided engineering code and the NSGA-II genetic algorithm. Sustainability 2016, 8, 72. [Google Scholar] [CrossRef] [Green Version]
- Arshad, M.H.; Abido, M.A.; Salem, A.; Elsayed, A.H. Weighting factors optimization of model predictive torque control of induction motor using NSGA-II With TOPSIS decision making. IEEE Access 2019, 7, 177595–177606. [Google Scholar] [CrossRef]
- Bandyopadhyay, S.; Pal, S.K. Classification and Learning Using Genetic Algorithms Applications in Bioinformatics and Web Intelligence; Springer: Heidelberg/Berlin, Germany, 2007. [Google Scholar]
- Goldberg, D.E. Genetic Algorithms in Search, Opimization and Machine Learning; Addison-Wesley: New York, NY, USA, 1989. [Google Scholar]
- Webster, R.; Oliver, M.A. Statistical Methods in Soil and Land Resource Survey; Oxford University: Oxford, UK, 1991; Volume 86, pp. 1149–1150. [Google Scholar]
- Michael, H.; Kurt, H. TSP-Infrastructure for the traveling salesperson problem. J. Stat. Softw. 2007, 23. [Google Scholar]
- Suman, B.; Kumar, P. A survey of simulated annealing as a tool for single and multiobjective optimization. J. Oper. Res. Soc. 2006, 57, 1143–1160. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Performance Indices | Formula | Parameters’ Description |
|---|---|---|
| Computational time | is the beginning time, is the terminating time. | |
| Convergence [11] | is the number of solutions in the set , is the solution in the set R, is the true Pareto front, is the Euclidean distance of the solution from the true Pareto front . | |
| Purity [51] | is the number of algorithms used to obtain optimal solutions; is the algorithm; is the solution listed in the set; is the solution set obtained based on the algorithm; is the solution set obtained based on the all algorithms by combining all solutions of all sets and retaining the nondominated solutions; is the number of solutions in the set obtained based on the algorithm; is the number of solutions which not only in the set but also in the set . | |
| Spacing [51] | is the and solution in the obtained optimal solution set; is the number of solutions in the obtained optimal solution set; is the number of objectives, is the of objectives; are the normalized values that indicate the objective values of the and solution in the optimal solution set, is the sequence of the values that are the minimum sums of the absolute values of the difference between the respective objective normalized values of the and that of the other solutions in the set; is the mean value of all the . | |
| Min-spacing [51] | is the solution in the obtained optimal solution set; is the solution ranked in the sequence; is such a sequence of solutions: the solution is treated as the seed and marked; the unmarked solution is identified in the obtained optimal solution set that has the minimum distance to the seed and then the found solution is treated as seed and marked. Repeat the process until all unmarked solutions are treated as seed once; such a solution sequence is called the sequence of the solution; is the number of objectives; is the of objectives; and are the normalized values which indicate the objective values of the and solution in the sequence; is the sequence of the values which are the minimum sums of the absolute values of the difference between the respective objective normalized values of the and solution in the sequence; is the corresponding sequence that has the minimum sum; is the mean value of all the | |
| Displacement [52] | is the solution in the true Pareto front, is the solution in the obtained optimal solution set, is the number of solutions in the true Pareto front, Q is the number of solutions in the obtained optimal solution set, is the Euclidean distance between the solution in the true Pareto front and solution of the obtained optimal solution set. |
| Test Problem | Objective Functions | Pareto Front | Pareto Front Traits |
|---|---|---|---|
| ZDT1 [50] | Two objective functions: |  | Convex, continuous, uniform |
| ZDT2 [50] | Two objective functions: |  | Nonconvex, continuous, uniform |
| ZDT3 [50] | Two objective functions: |  | Nonconvex, discontinuous |
| ZDT4 [50] | Two objective functions: |  | Convex |
| ZDT6 [50] | Two objective functions: |  | Nonconvex, non-uniform |
| DTLZ2 [53] | Three objective functions: |  | Convex |
| Parameters | AMOSA-II | AMOSA | NSGA-II |
|---|---|---|---|
| Sample points | 20 | 20 | 20 |
| Markov chains | 20 | 1 | 1 |
| Parallelization threads | 20 | 1 | 1 |
| Combination frequency | 8 | 0 | 0 |
| Item | Parameters | Value |
|---|---|---|
| Experiment A. The effect of the number of Markov chains on operating efficiency | Sample points | 20 |
| Markov chains | 5, 10, 15, 20, 25, 30, 35, 40, 45, 50 | |
| Parallelization threads | 50 | |
| Combination frequency | 8 | |
| Experiment B. The effect of the number of parallelization threads on operating efficiency | Sample points | 20 |
| Markov chains | 20 | |
| Parallelization threads | 5, 10, 15, 20, 25, 30, 35, 40, 45, 50 | |
| Combination frequency | 8 | |
| Experiment C. The effect of combination frequency on operating efficiency | Sample points | 20 |
| Markov chains | 20 | |
| Parallelization threads | 20 | |
| Combination frequency | 1, 2, 3, 4, 9, 12, 18, 36 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Gao, B.; Bai, Z.; Pan, Y.; Gao, Y. An Improved Parallelized Multi-Objective Optimization Method for Complex Geographical Spatial Sampling: AMOSA-II. ISPRS Int. J. Geo-Inf. 2020, 9, 236. https://doi.org/10.3390/ijgi9040236
Li X, Gao B, Bai Z, Pan Y, Gao Y. An Improved Parallelized Multi-Objective Optimization Method for Complex Geographical Spatial Sampling: AMOSA-II. ISPRS International Journal of Geo-Information. 2020; 9(4):236. https://doi.org/10.3390/ijgi9040236
Chicago/Turabian StyleLi, Xiaolan, Bingbo Gao, Zhongke Bai, Yuchun Pan, and Yunbing Gao. 2020. "An Improved Parallelized Multi-Objective Optimization Method for Complex Geographical Spatial Sampling: AMOSA-II" ISPRS International Journal of Geo-Information 9, no. 4: 236. https://doi.org/10.3390/ijgi9040236
APA StyleLi, X., Gao, B., Bai, Z., Pan, Y., & Gao, Y. (2020). An Improved Parallelized Multi-Objective Optimization Method for Complex Geographical Spatial Sampling: AMOSA-II. ISPRS International Journal of Geo-Information, 9(4), 236. https://doi.org/10.3390/ijgi9040236