1. Introduction
In recent years, many nations worldwide have recognised the increasing importance to protect their key infrastructures (such as power plants, bridges, highways, airports, and so on). For example, in 2008, the European Council issued Directive 2008/114/EC, which required the Member States to identify European critical infrastructures and assess the needs for their protection. This Directive defined “critical infrastructure” as: an asset, system or part thereof located in Member States which is essential for the maintenance of vital societal functions, health, safety, security, economic or social well-being of people, and the disruption or destruction of which would have a significant impact in a Member State as a result of the failure to maintain those functions. Setola et al. [
1] provide an up-to-date report of the initiatives of several governments about the protection and resilience of their critical infrastructures.
The protection of the States’ critical infrastructures is the focus of the present paper, where they are called assets. The need to protect the assets arises because of the multiple hazards (e.g., earthquakes, floods, landslides) they are exposed [
2]. In the present study, the attention is focused on landslides which play a very important role in many countries of the world [
3]. In Italy landslides are frequent and cause considerable damage and many casualties each year [
4,
5]. According to the outcome of a study carried out by Jaedicke et al. [
6], “Italy has the highest number of people exposed to landslide hazard among the European countries.”
Landslides become a hazard when they interact with the so-called “elements at risk”. The evaluation of the side effects caused by landslides is usually referred to as risk assessment. In mathematical terms, the risk can be computed as in [
6]:
=
×
. Vegetation cover, soil moisture, slope, and lithology are usual susceptibility factors, while precipitation is the prominent triggering factor. Vulnerability denotes the extent of the damage to an element at risk, expressed in a scale from 0 (no damage) to 1 (total destruction). The quantification of the Hazard parameter induced by landslides is a complex task; reference [
6] proposes a method for its determination.
Many publications are available about the assessment of the vulnerability of elements at risk (for example, [
7,
8,
9]), as well as on the assessment of the risk caused by landslides (for example, [
6,
10,
11,
12]). In all the proposals, the identification of the elements at risk of landslides is carried out by computing the intersection of the geometries modeling the assets and the hazard area (e.g., [
13]). The consequence is that the elements in the region of study are split into two disjoint categories: one containing the elements that are exposed to the landslide hazard, while the other contains the remaining ones. Notice that the elements in the former category are all “ex-aequo” with respect to the “level of exposure” to the landslide hazard.
When the number of assets to be monitored is large (for example, in Italy there are 72,355 schools located in 43,643 separate buildings, while the total number of public buildings is far greater), returning to the practitioners in risk mitigation the ranking of the assets they are in charge of guides them in prioritizing the controls on the field. In fact, in that scenario they may limit the detailed risk assessment to the assets with a value of the exposure above a given threshold (briefly the top-N assets). This way the overall processing time required for the computation of the vulnerability, and hence of the risk, is reduced dramatically.
The present study focuses on assets modeled both as points (i.e., buildings, of any kind), and as lines (e.g., roads, highways, railway lines, pipelines, power lines). To a preliminary and, necessarily, high level of abstraction, the problems that are studied can be described as follows. Given a reference territory (for example an Italian region) and:
The set of buildings of a given category (for example the railway stations), return their ranking with respect to the level of exposure to the landslide hazard;
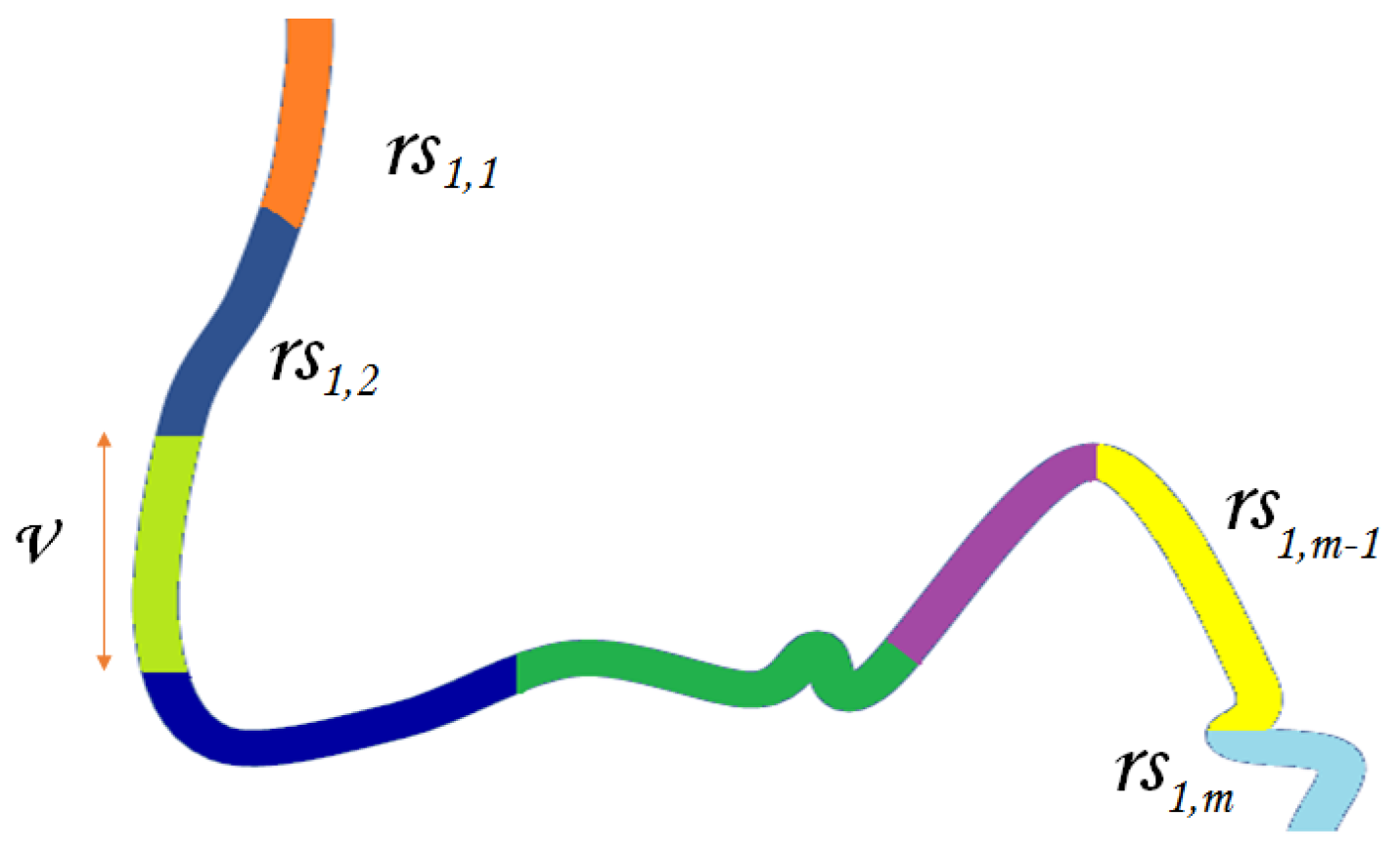
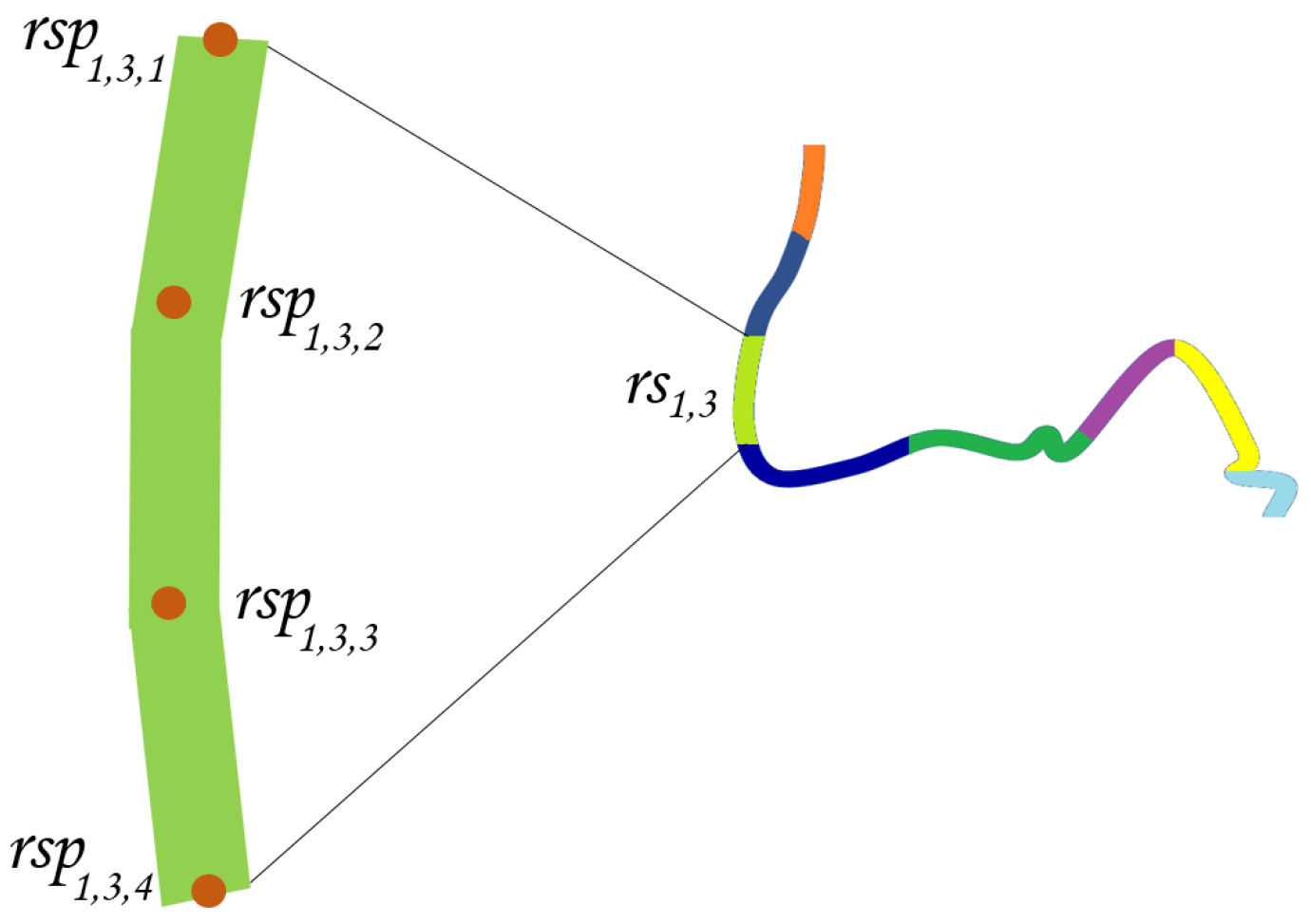
The set of lines (for example the railway lines) that cross it, return, for each of them, the ranking of their stretches with respect to the level of exposure to the landslide hazard.
In reference [
14], the authors studied the landslide exposure of buildings. Starting from vector data about the elements at risk, they derive raster data. The latter are used to output a multilayer-exposure map about potential hotspots for an in-depth analysis of vulnerability and consequent risk. The disadvantage of this method is that a ranking of hotspots is not possible. The ranking problem has origin in the Information Retrieval domain, while methods for the ranking of buildings have been proposed much more recently. In [
15], for example, a method has been proposed to construct the ranking of buildings with respect to the fire hazard, while [
16] formalizes a method to rank the illegal buildings located close to rivers. Another method for ranking the buildings with respect to their environmental performance can be found in [
17]. To the best of our knowledge, Refs. [
18,
19] are the first attempt to introduce a method for ranking the buildings present in a large territory, with respect to the level of exposure to the landslide hazard.
For both the problems studied, the following are given: (a) a theoretical solution, (b) its implemention with open source GIS software, (c) experimentation through case studies, (d) a preliminary validation of the proposed methods and, finally, (e) the discussion of the results. The formalization of the two novel methods is the actual contribution of the present paper.
The manuscript is structured in two parts, each is a paper in itself. The first one (
Section 2,
Section 3 and
Section 4) focuses on assets modeled as points, while the remaining pages concern assets modeled as lines. The sections about assets modeled as points extend a previous paper [
20], by adding the formalization of the method to compute the ranking and its validation.
In detail,
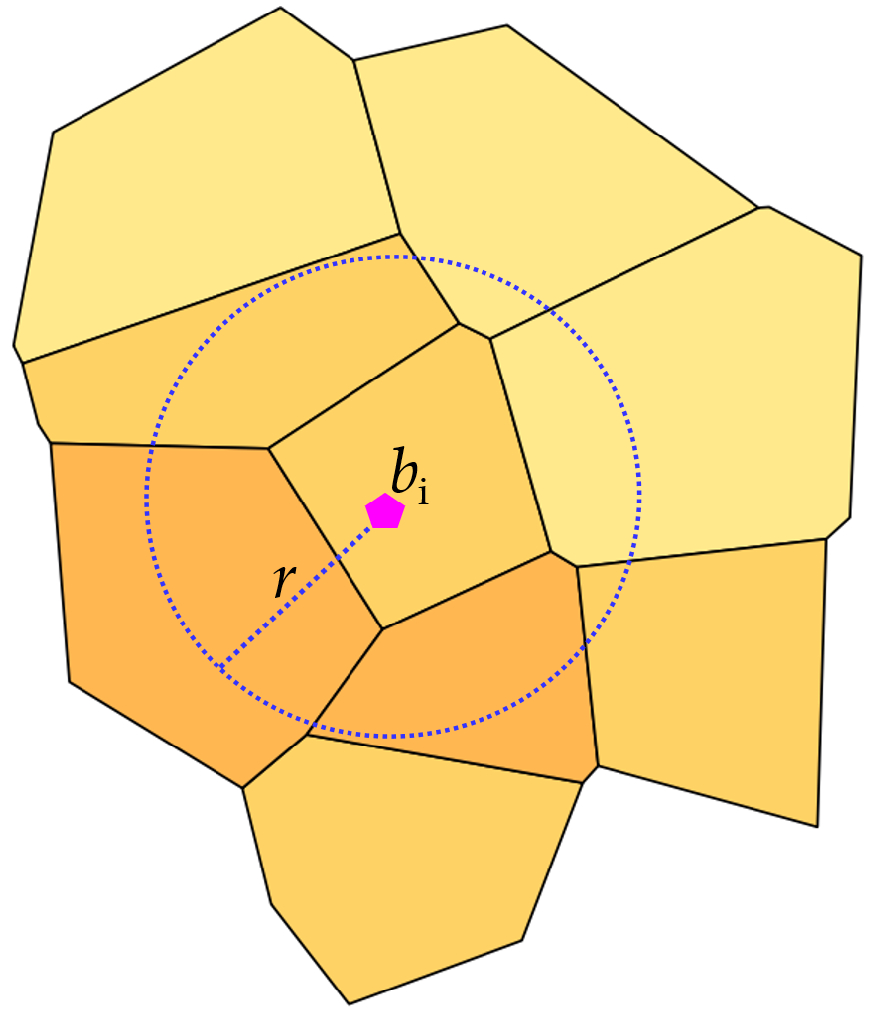
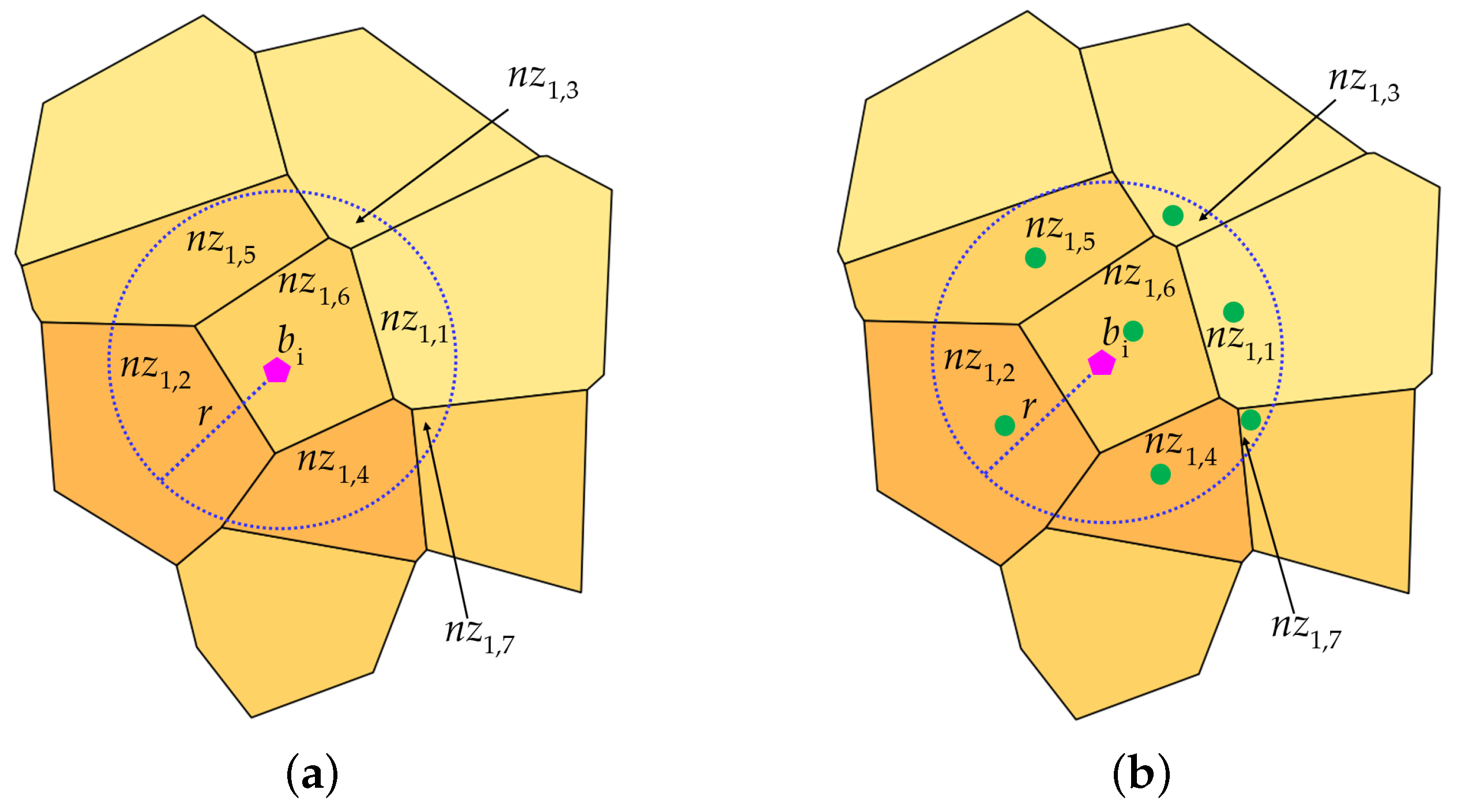
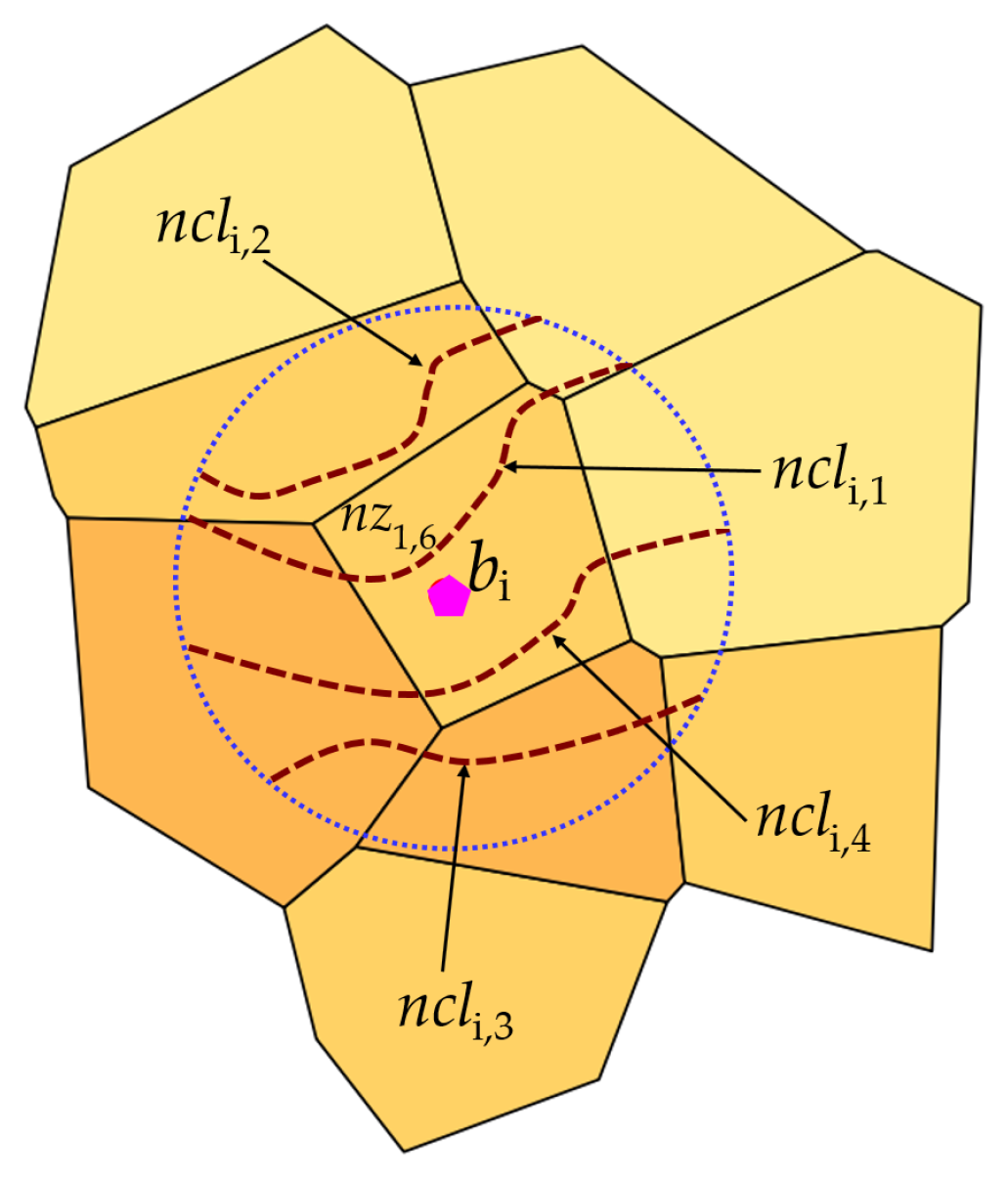
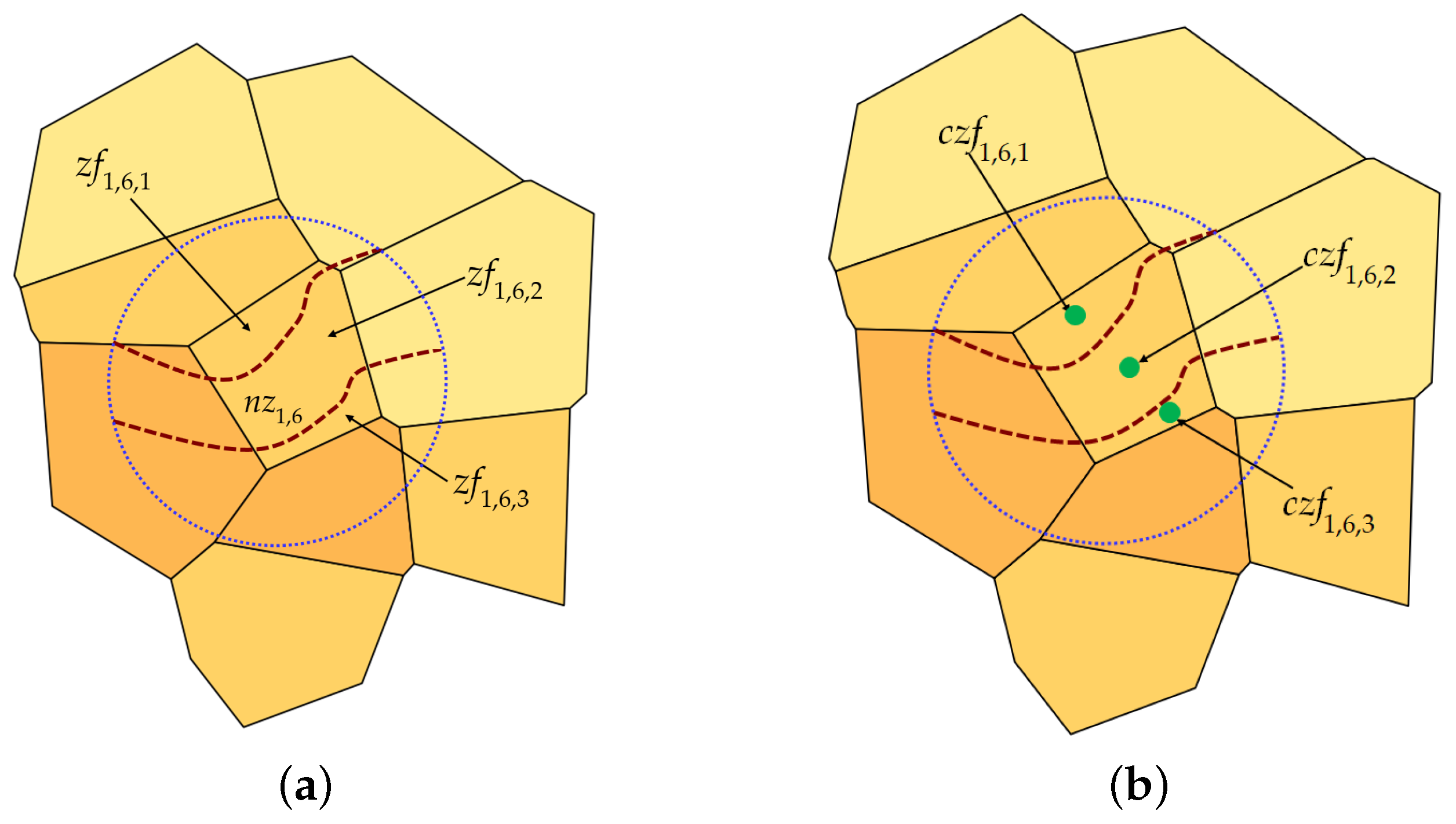
Section 2.1 concerns the formalization of the definitions and notations on which is based the method for calculating the ranking of buildings, located in the reference territory, with respect to the level of the potential hazard of being hit by landslides.
Section 2.2 proposes the equations for calculating the level of exposure to the landslide hazard of buildings located within the study area.
Section 2.3 touches on the way the theory was implemented. The core component of the solution is the DataBase Management System equipped with a Spatial extension (briefly Spatial DBMS). Moreover, the section lists the tables of the Spatial DataBase (briefly SpatialDB) and the names of the User Defined Functions that implement the proposed method.
Section 3 presents a case study about the 114 railway stations of the Abruzzo region (Italy).
Section 4 concerns the validation of the results of the case study and, hence, a preliminary evaluation of the method.
Section 5 focuses on the problem of calculating the ranking, with respect to the landslide hazard, of assets modeled through the geometric primitive “line”.
The case study adopted for the experimentation of the proposed method (
Section 6) concerned the nine railway lines crossing the Abruzzo region.
Section 7 closes the paper by making a balance between the initial objectives and the results.
4. Validation of the Method for Ranking Assets Modeled as Points
In the Machine Learning domain the notion of “confusion matrix” (also called “contingency table”) was introduced to assess the performance of a classification algorithm with respect to some test data. It is a two-dimensional matrix, indexed in one dimension by the true class of an object and in the other by the class that the classifier assigns [
35].
The simplest way to validate the proposed ranking algorithm is to reduce the problem of the classification of experimental values to the case of binary contingency tables; that is, to the case in which only one class at a time is involved. Therefore, the validation problem can be formulated as follows.
Given n values (, , …, ) and a class (C), construct the binary contingency table that summarizes how those values are classified both in the real world and as estimated by the algorithm of which we want to “measure" the effectiveness. Evidently, the value may fall in C or not, the same holds for , …, .
The main diagonal of the contingency table has the number of elements predicted correctly. The total number of elements belonging to a real class is equal to the sum of the values on the corresponding row of the table. The total number of the elements present in the set involved in the classification operation is equal to the sum of all the totals.
Table 2 shows the structure of a generic binary contingency table. In the following the terms true positives, false positives, true negatives, and false negatives are defined (they are positive integers):
True Positives (TP). This quantity denotes the cases that the classification algorithm has recognized correctly belonging to the class.
False Positives (FP). This quantity denotes the cases of wrong classification. In practical terms, a false positive constitutes a false alarm.
True Negatives (TN). This quantity denotes the cases that the algorithm has recognized correctly not belonging to the class.
False Negatives (FN). This quantity denotes the cases for which the algorithm has confused the class to which an element belongs to. In the context of this article, these are cases of non-alarm. An error of enormous potential gravity.
4.1. Validation Metrics
Many metrics have been proposed to judge the goodness of an algorithm that reconstructs the observed reality (reference [
36] is an authoritative source on the subject). The most common of them are listed below. The value of the metrics expresses a marginal probability, between 0 and 1.
The True Positive Rate (TPR, often called Recall) is defined as the percentage of positive cases correctly recognized as such (by the adopted classification method). In formulas:
The True Negative Rate (TNR) denotes the percentage of actual negatives that are correctly identified as such. In formulas:
The Precision (P) is defined as:
The Accuracy (Acc) is defined as:
4.2. The Expected Ranking
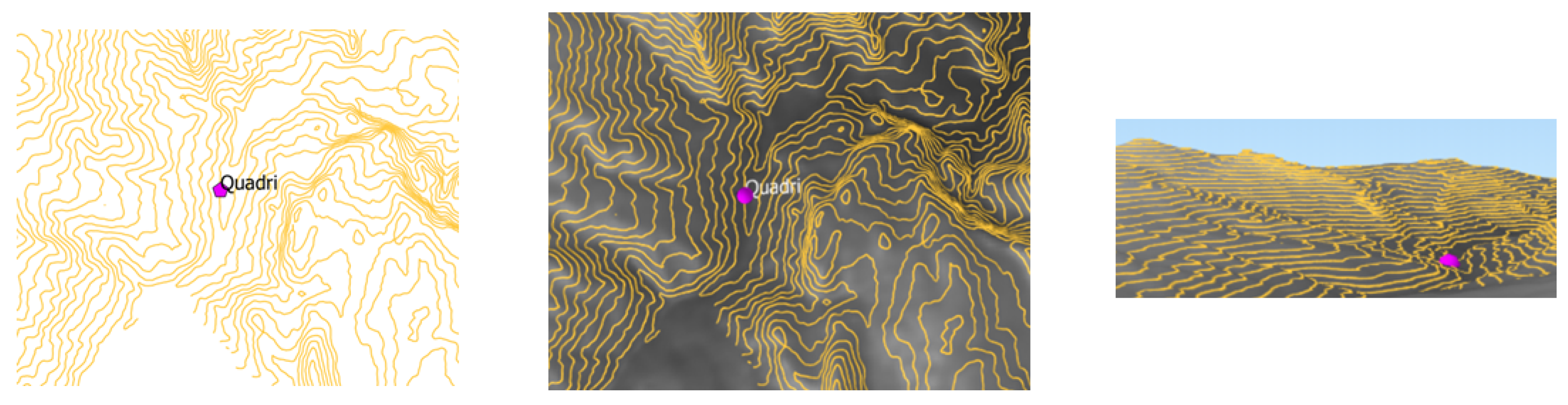
The 114 railway stations of the case study were classified, with respect to level of exposure to the landslide hazard, by exploiting the high degree of detail of the territory offered by Google. The buildings located on steep terrain were placed in the High class, in the Low class those located on flat land; while the Medium class was attributed to the hybrid situations (
Table 3). In
Table 3, the stations are identified by the ID internal to the SpatialDB. The match between the ID and the name is shown in
Table 4 for the six stations that fall in the High class of exposure.
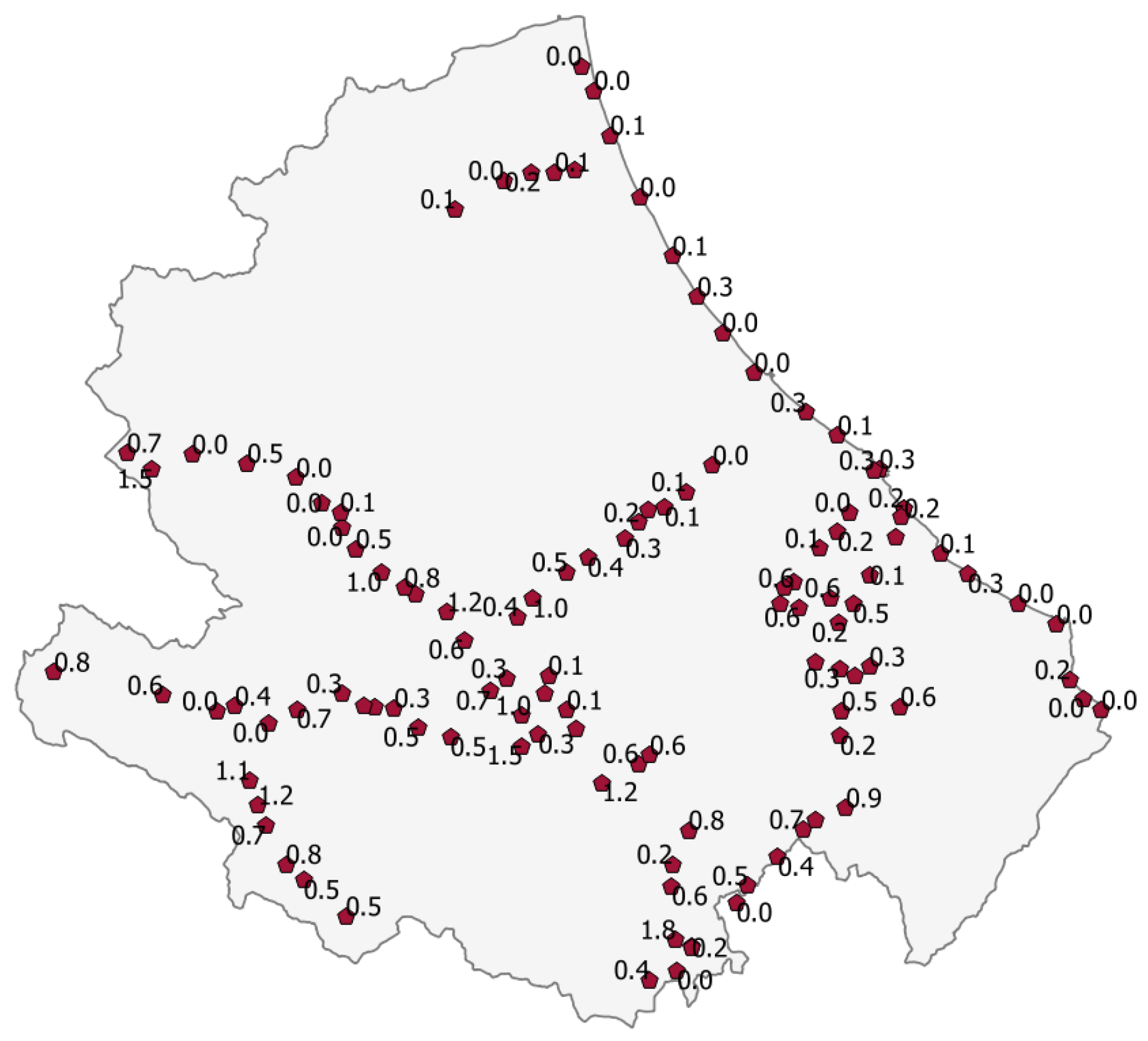
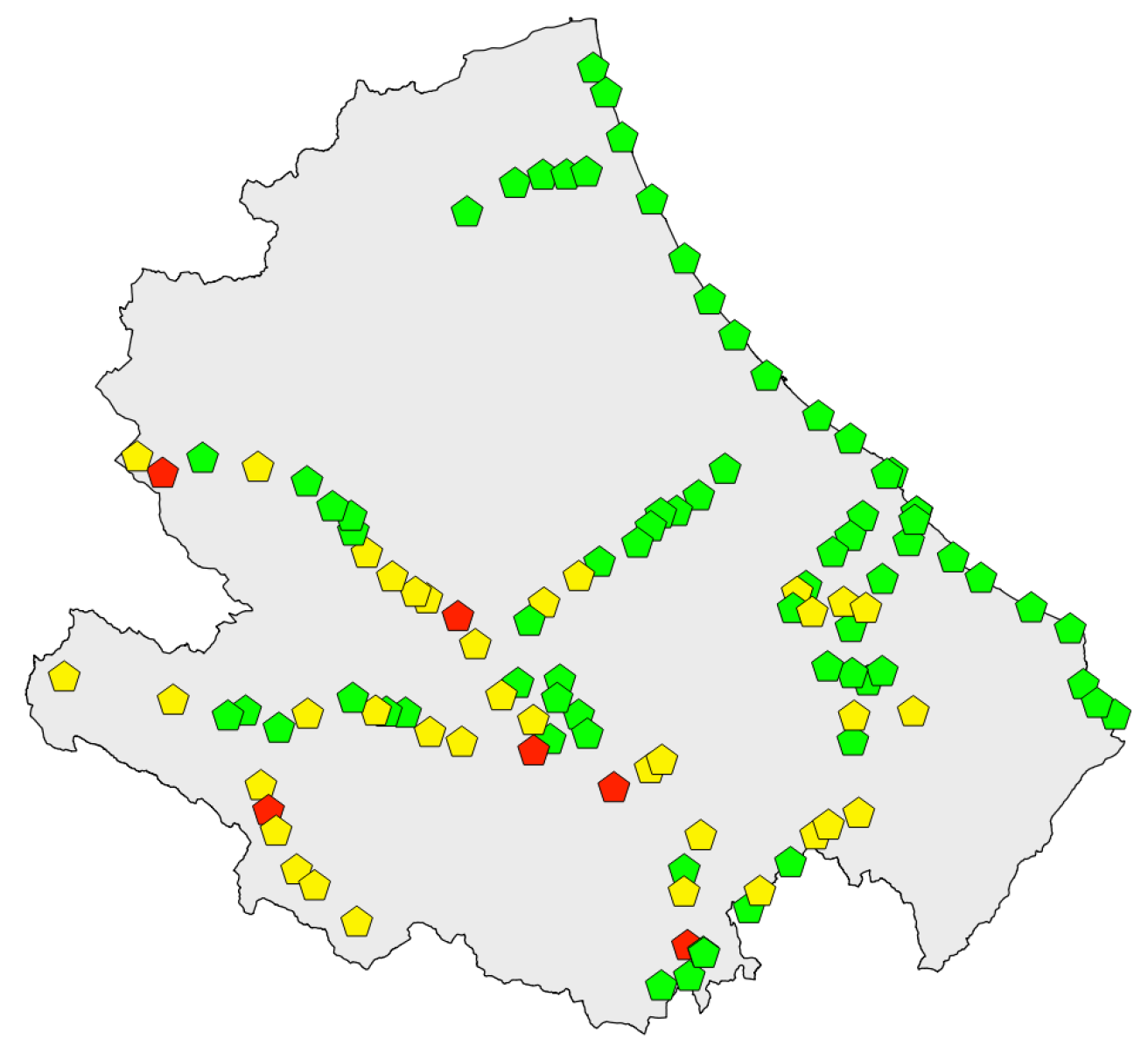
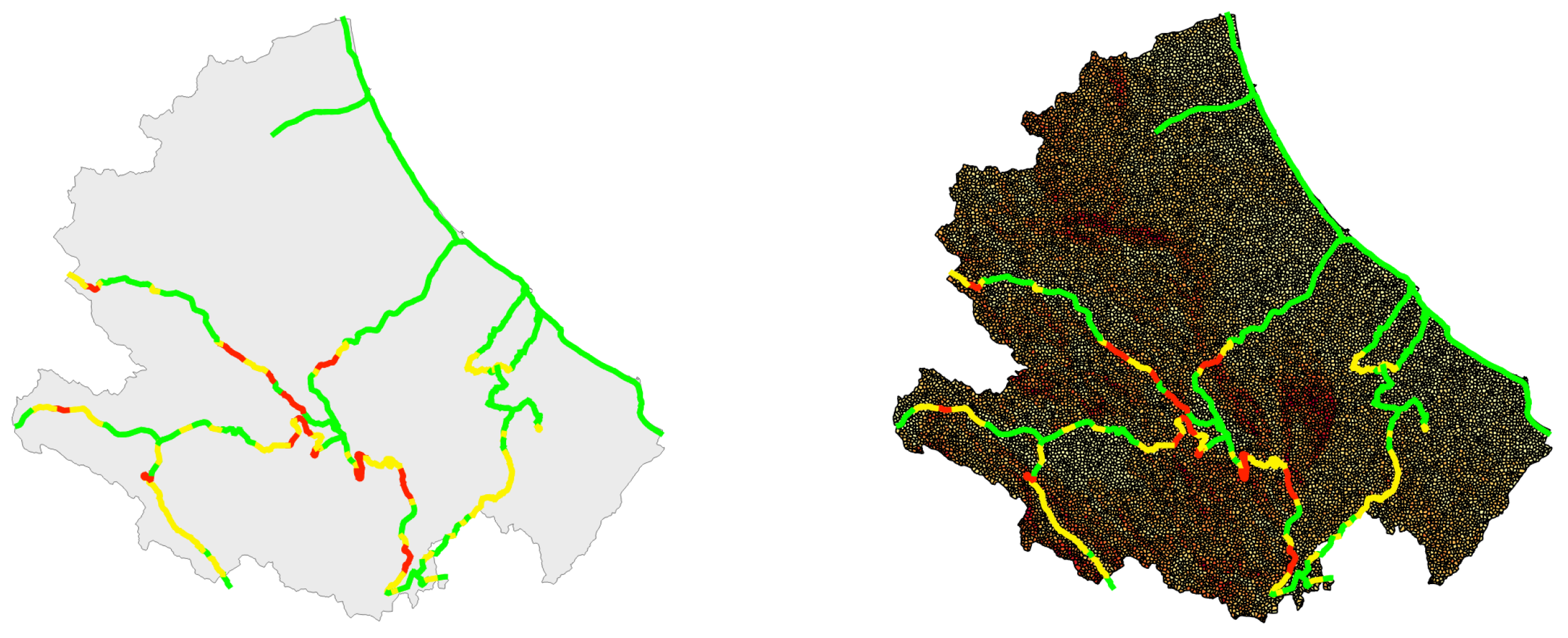
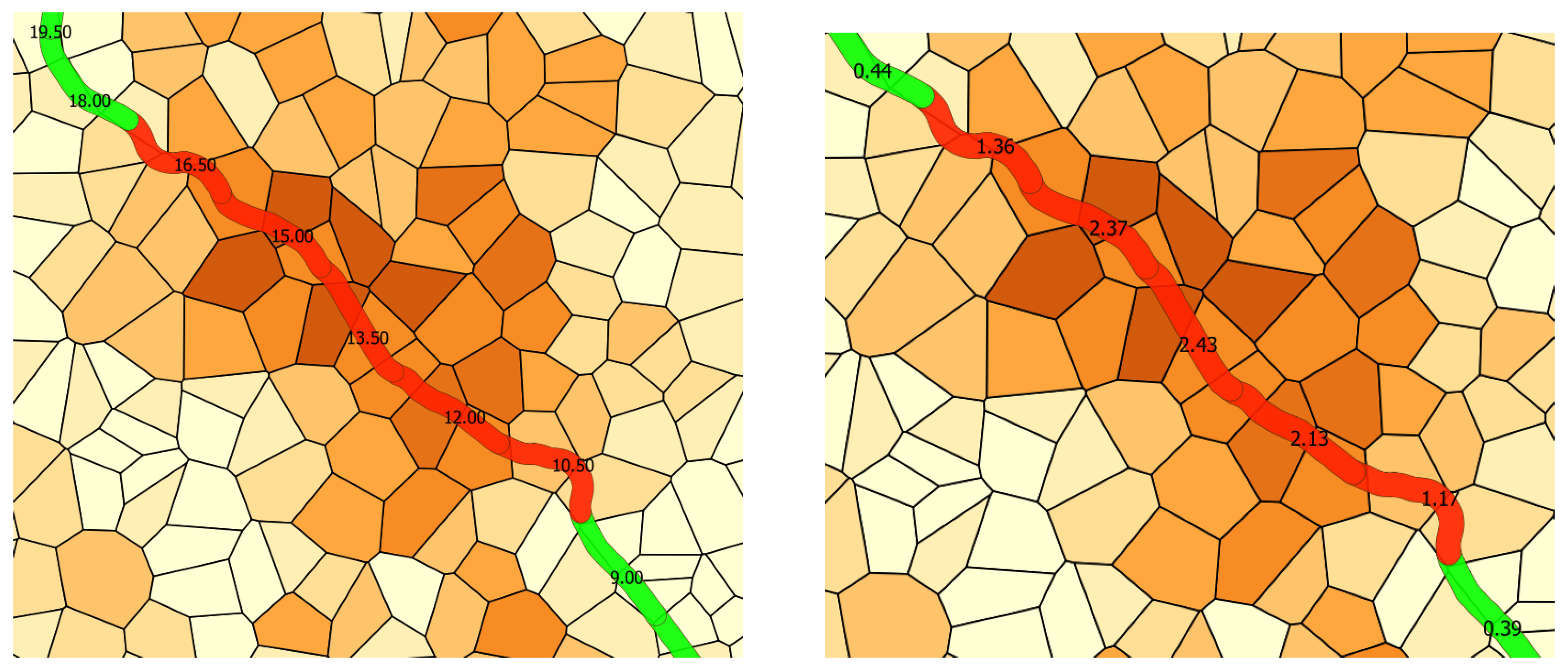
The map of
Figure 12 shows the 114 stations and their level of exposure (highlighted by the color) to the landslide hazard. Comparing this map with the knowledge of the elevation of the terrain of the Abruzzo region, there is a first confirmation of what was reasonable to expect, namely that the stations located on the part of the Region that faces the Adriatic sea do not run any landslide hazard and this because the ground is flat. Moreover, from this map we learn that the number of the most exposed stations is low (six out of 114) and, as it was predictadable, they are located in the hinterland of the Region that is mountainous and, therefore, subject to landslides during prolonged rains.
4.3. Evaluation of the Stations’ Ranking
The 3-class contingency table of
Table 5 summarizes the result of the comparison between the manual ranking (
Table 3) with that returned by the proposed classification algorithm (
Table 1). Overall, 13 cases (out of 114) of classification mismatch arise from the comparison. In detail, from
Table 5 it follows that the proposed algorithm:
Classifies correctly 64 stations (out of 72) as belonging to the Low actual class, while it assigns the remaining eight to the Medium class;
Classifies correctly 31 stations (out of 36) as belonging to the Medium actual class, while it puts two stations in the Low class and three in the High class;
Classifies correctly the six stations belonging to the High actual class.
From
Table 5 it is possible to derive the binary contingency
Table 6,
Table 7 and
Table 8, and from them
Table 9. The latter reports the quantitative assessment of the goodness of the results returned by the proposed ranking method as expressed by the metrics of
Section 4.1.
The value of metric TPR is very good for the classes Low and Medium, optimal for the class High. The value of the TNR metric is also very good for the three classes. The Precision is very satisfactory for the class Low, while it decreases for the other two classes. The lowest value of the Precision (p = 0.667) occurs for the class High, although in that case the number of False Positives is not the highest of the three classes. This effect is determined by the fact that the most exposed stations are much less than those categorized in the Low and Medium classes (six vs. 72 and six vs. 36, respectively).
As usual, also in our proposal the result of the validation phase depends on
the numeric values are grouped into the classes. For example, let us suppose that the criteria for grouping the 114 numeric values of
Table 1 are modified as follows: the assets whose exposure is above 1.10 go to the High class, the assets whose exposure is below 0.4 go to the Low class, all the remaining assets go to the Medium class.
Table 10 shows how the 3-class contingency table (
Table 5) is affected by the criteria. Now, 10 cases (out of 114) of classification mismatch arise. Most relevant is the fact that there are no more false positives about the assets of the High class.
Table 11 shows the values of the four metrics based on the values in
Table 10. From the comparison of the two pairs of tables (i.e.,
Table 10 vs.
Table 5 and
Table 11 vs.
Table 9) it emerges that the second hypothesis of classification is better than the previous one. Unfortunately, given a generic case study, it is not possible to know in advance what would be the best classification criteria to be used. Our experience suggests to pay attention to the values of the interval about the High class. This is because it is a more desirable situation having false positives than false negatives for the assets in the top positions of the ranking, since a false positive means a false alarm, while a false negative means a missing alarm.
7. Conclusions
The article’s aim was the computation of the ranking of the assets present in a large territory with respect to their level of exposure to the landslide hazard. Assets that can be modeled as points and as lines were taken into account. For both the problems studied, an original method of resolution was proposed. The solution of the first problem is an important step for the solution of the second. Both the proposals constitute an improvement of what is already known in the literature on the subject.
The work began with the study of the state of the art, then it continued with the formalization of the two problems by means of equations, their transformation into algorithms, and their subsequent implementation. Then, the experimental phase was conducted at a geographical scale allowing a preliminary validation of the proposed methods. The ranking returned by the proposed methods is dramatically affected by the completeness and the quality of set
. In simple words, the ranking does not make much sense if, for the area of interest, there is not available a dataset
built in terms of slope units as defined, for instance, in [
26]. In the near future, we plan to carry out further case studies, as soon as other Italian regions will make available the shapefile implementing the
dataset. The final goal is to make an accurate validation of the two prososed methods.
Our approach implements the adage “do more with less”, well-known to public administrations which are experiencing budgetary contractions from many years. The list of the top-N assets most exposed to the landslide hazard appears the only viable way for these administrations to make the need for safety coexist with the containment of the time of controls and interruptions in service delivery and, therefore, with the costs to be paid.
Being able to use the results provided by methods such as those proposed in this paper is also of interest to private companies responsible for the safety at the national scale. For example, the Italian Railway Company operates a railway network of 16,734 km and more than 3000 stations located throughout the country (301,340 km2). Implementing a periodic prevention business plan for each station and each kilometer of the railway network seems impractical.
Future work will focus on the integration of the GIS and the Wireless Sensor Network technology to set up a cooperating framework for the monitoring of the lines. In doing so, the ranking of the hotspots’ level of landslide hazard will become dynamic, following environmental events in real-time.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}