Automated Conflation of Digital Elevation Model with Reference Hydrographic Lines


Abstract
:1. Introduction
2. Related Research
3. Method
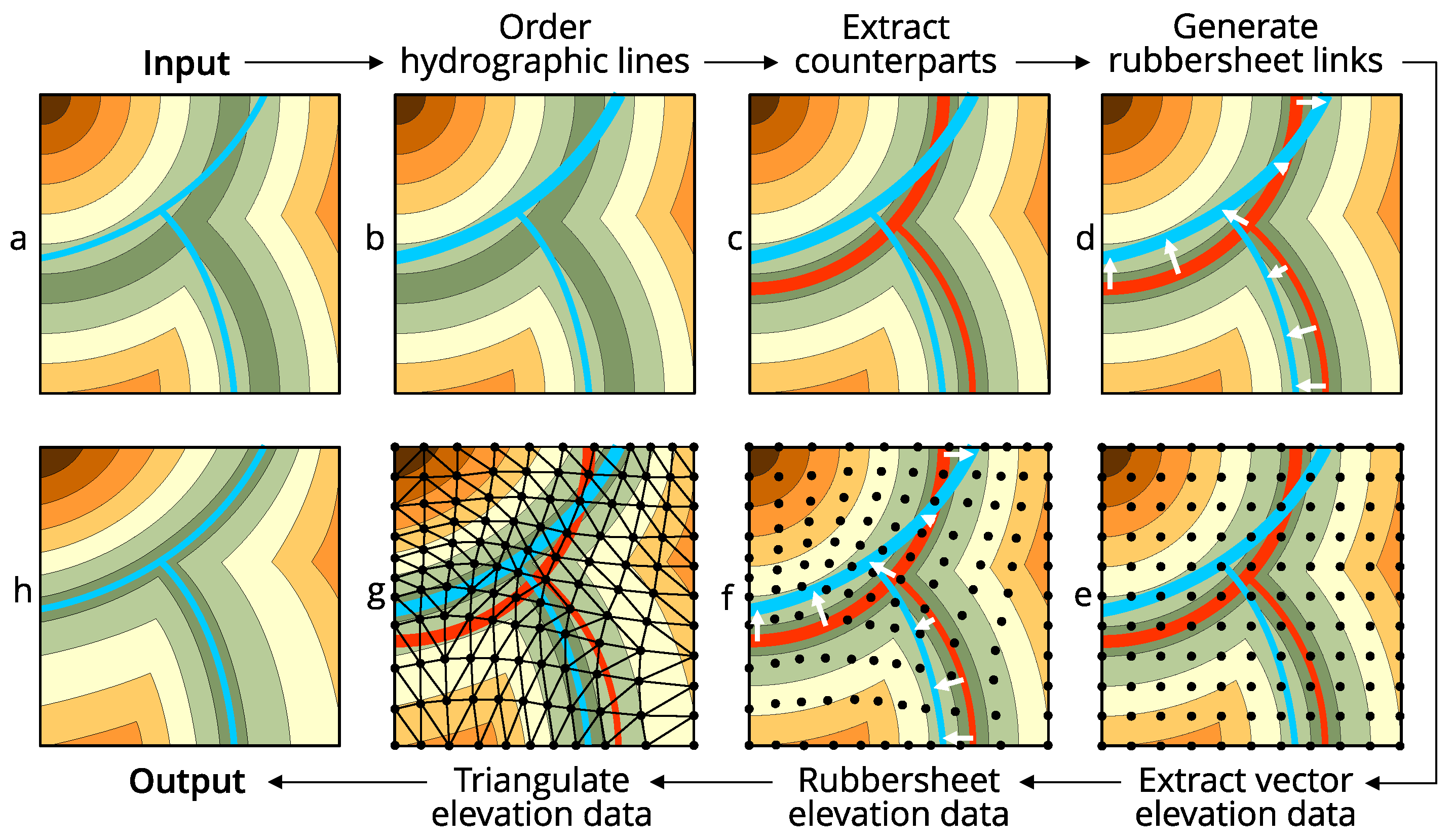
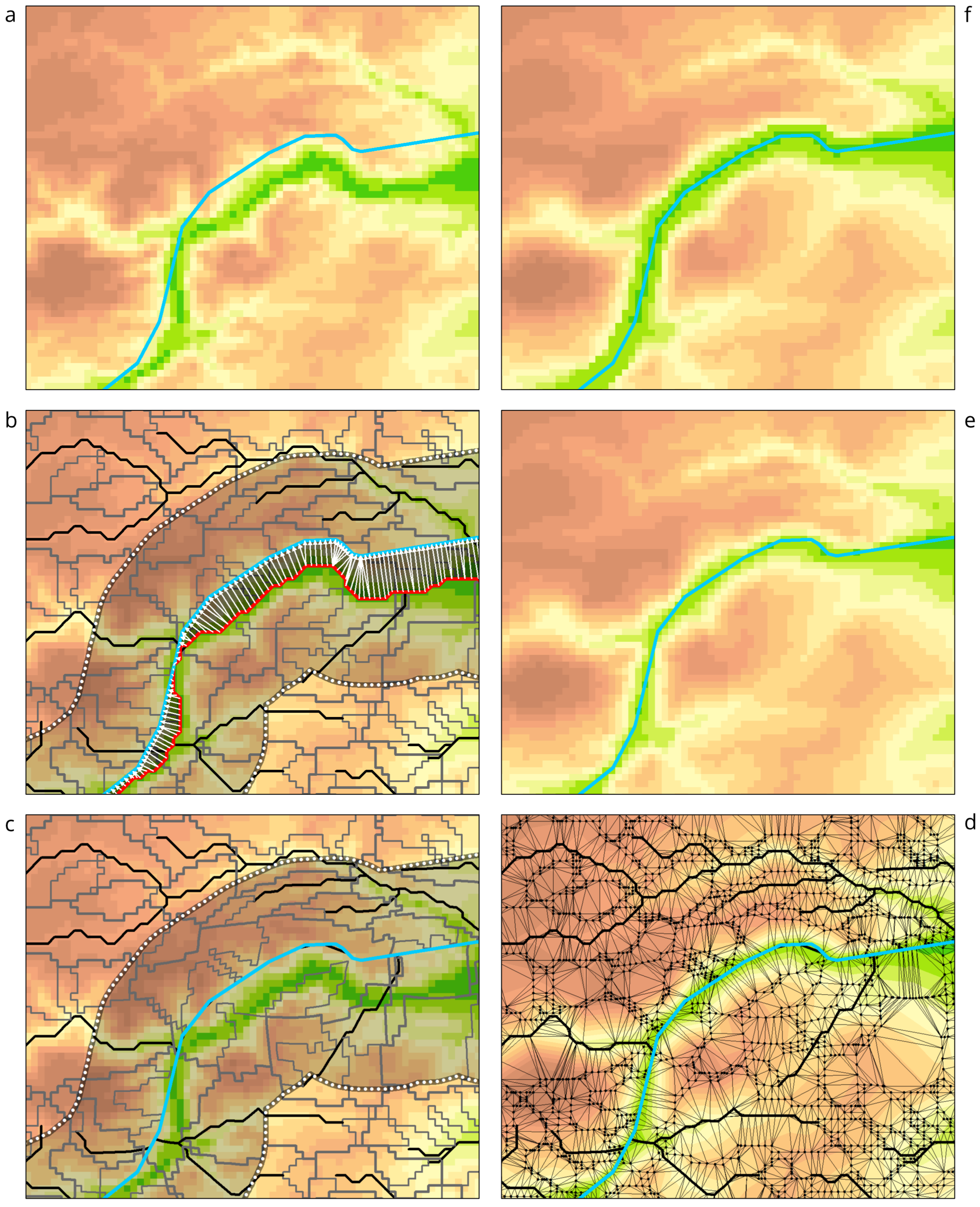
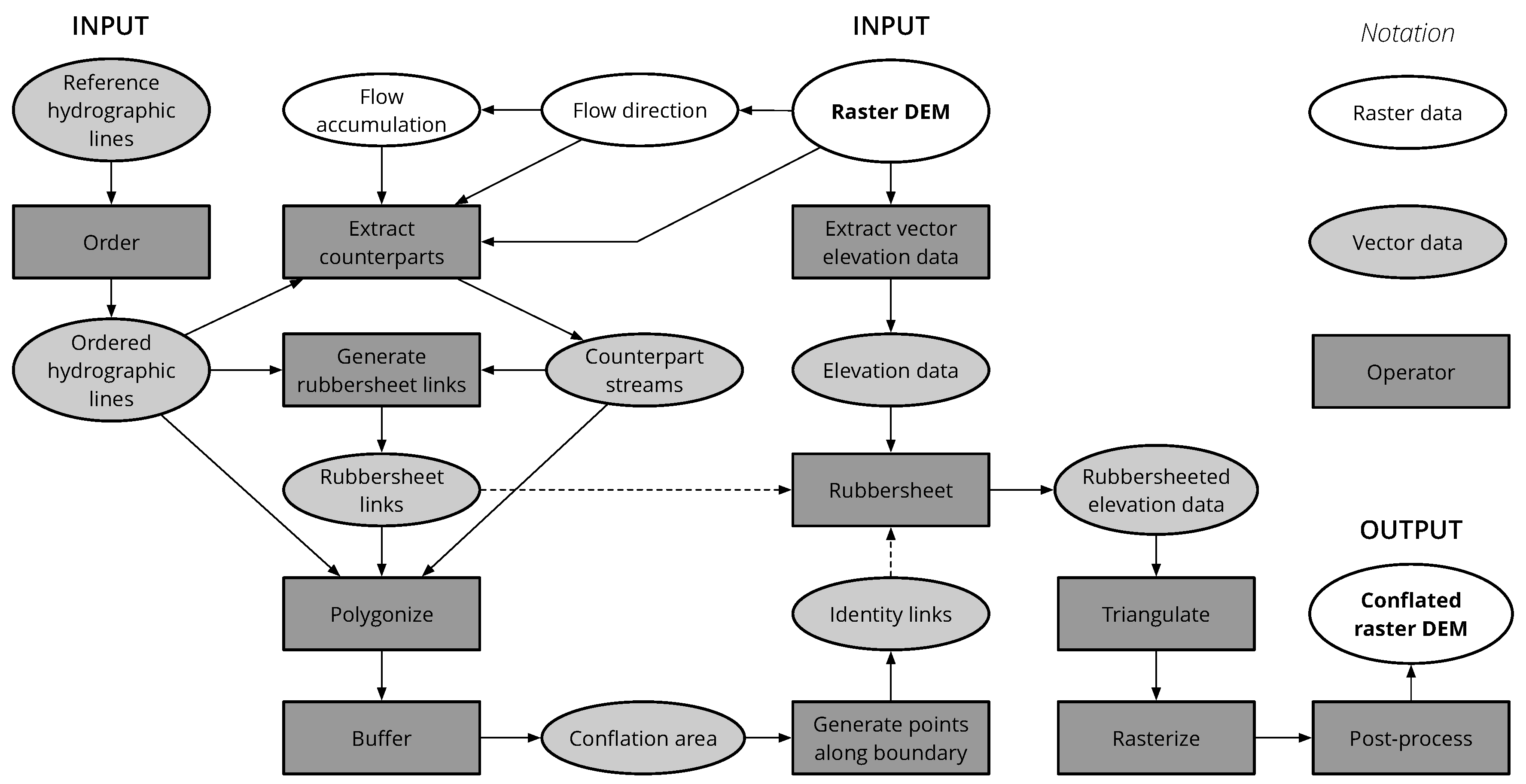
3.1. General Principles and Workflow
- A resulting terrain surface represented by elevations in conflated DEM must be spatially adjusted with reference hydrographic lines.
- Conflation is performed by displacing the elevation data. No new terrain features are created or burned into the surface. Reference lines are not considered to be of a better quality than DEM, but have primary importance in the conflation process and therefore remain at their locations.
- Elevation data must be represented by vector features, either points or lines. Both raster and triangulated DEMs can be easily represented as a set of elevation points and lines without loss of information. Also, linear representation can be used when breaklines represent a structural skeleton of the surface extracted from the source DEM to derive its generalized version. Thus, vector-based representation abstracts the format of elevation input and serves different conflation scenarios.
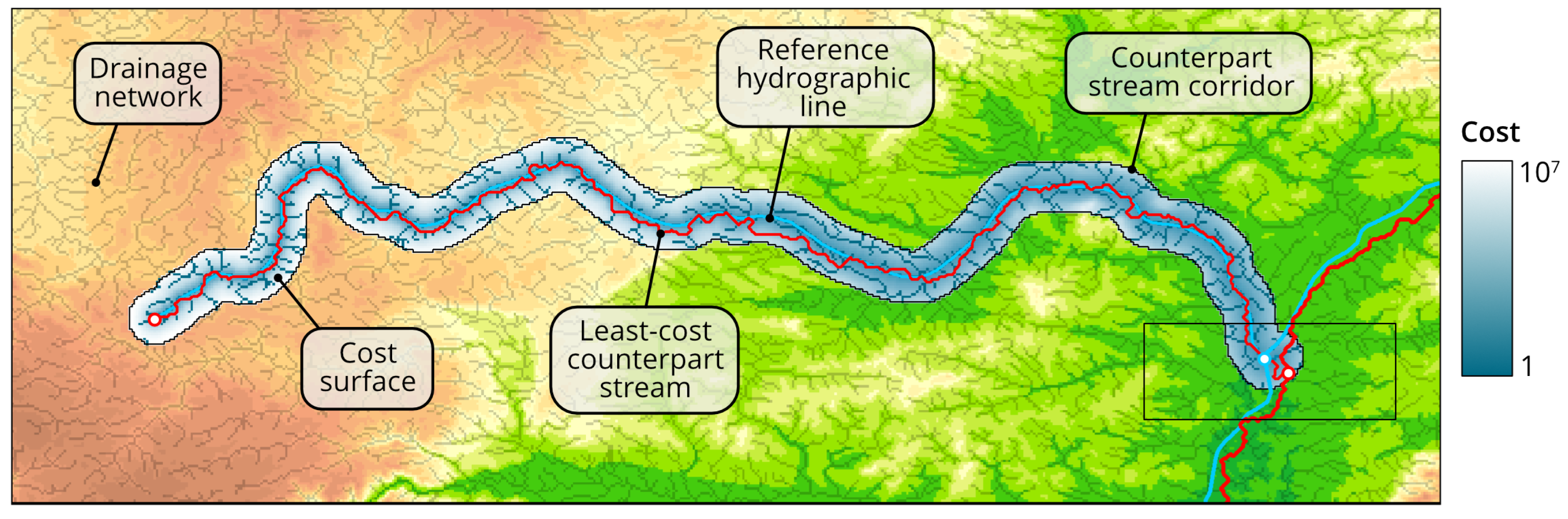
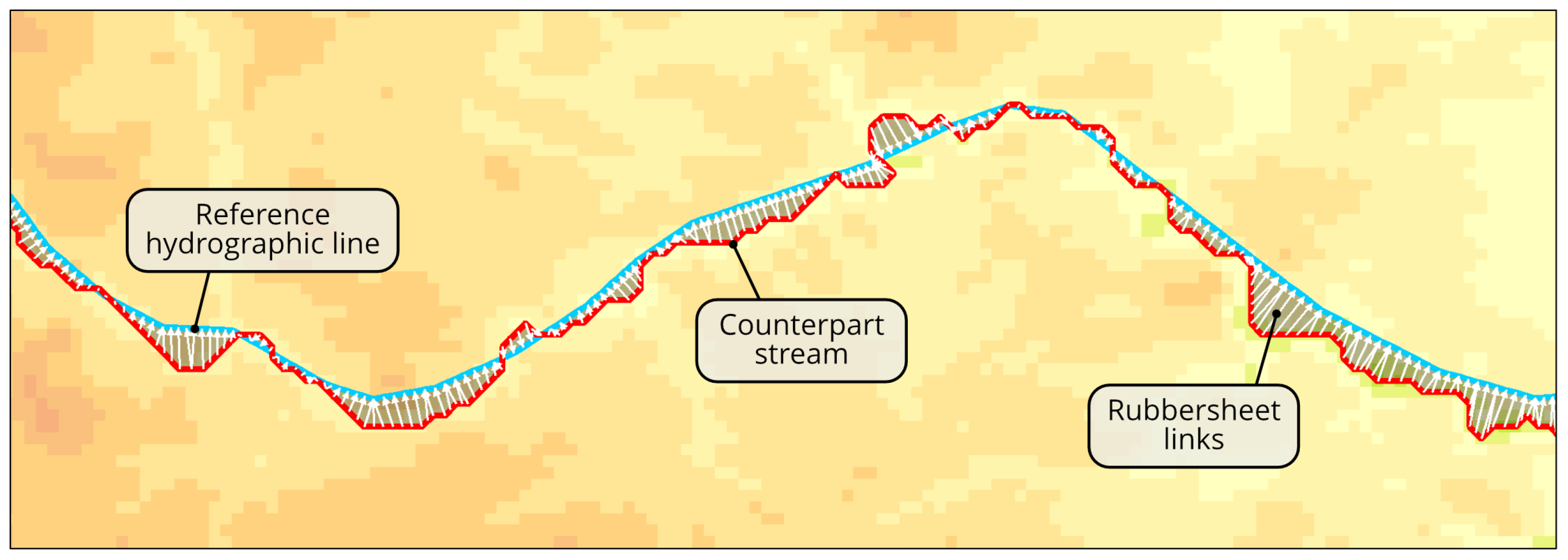
- Displacing the elevation data is performed by rubbersheeting the corresponding vector features along links directed towards reference hydrographic lines and originating from the most similar paths on the DEM surface—counterpart streams (or counterparts). Each reference hydrographic line is associated with one counterpart stream.
- Counterpart streams are automatically extracted from the source DEM and must comprise a topologically correct network similar to the network of the ordered reference lines. A method of extraction of counterpart streams must be robust in case of existing errors in DEM and hydrographic lines (artificial depressions, incorrect line directions) as well as in cases of non-standard stream configurations (braided streams, deltas, channels).
- Conflated DEM is reconstructed from the rubbersheeted elevation data.
- Order reference hydrographic lines (Figure 2b).
- Trace counterpart streams (Figure 2c).
- Generate rubbersheet links (Figure 2d).
- Extract elevation data as vector features (Figure 2e).
- Rubbersheet elevation data (Figure 2f).
- Create triangulated DEM (TIN) from rubbersheeted elevation data (Figure 2g).
- Reconstruct conflated DEM from TIN (Figure 2h).
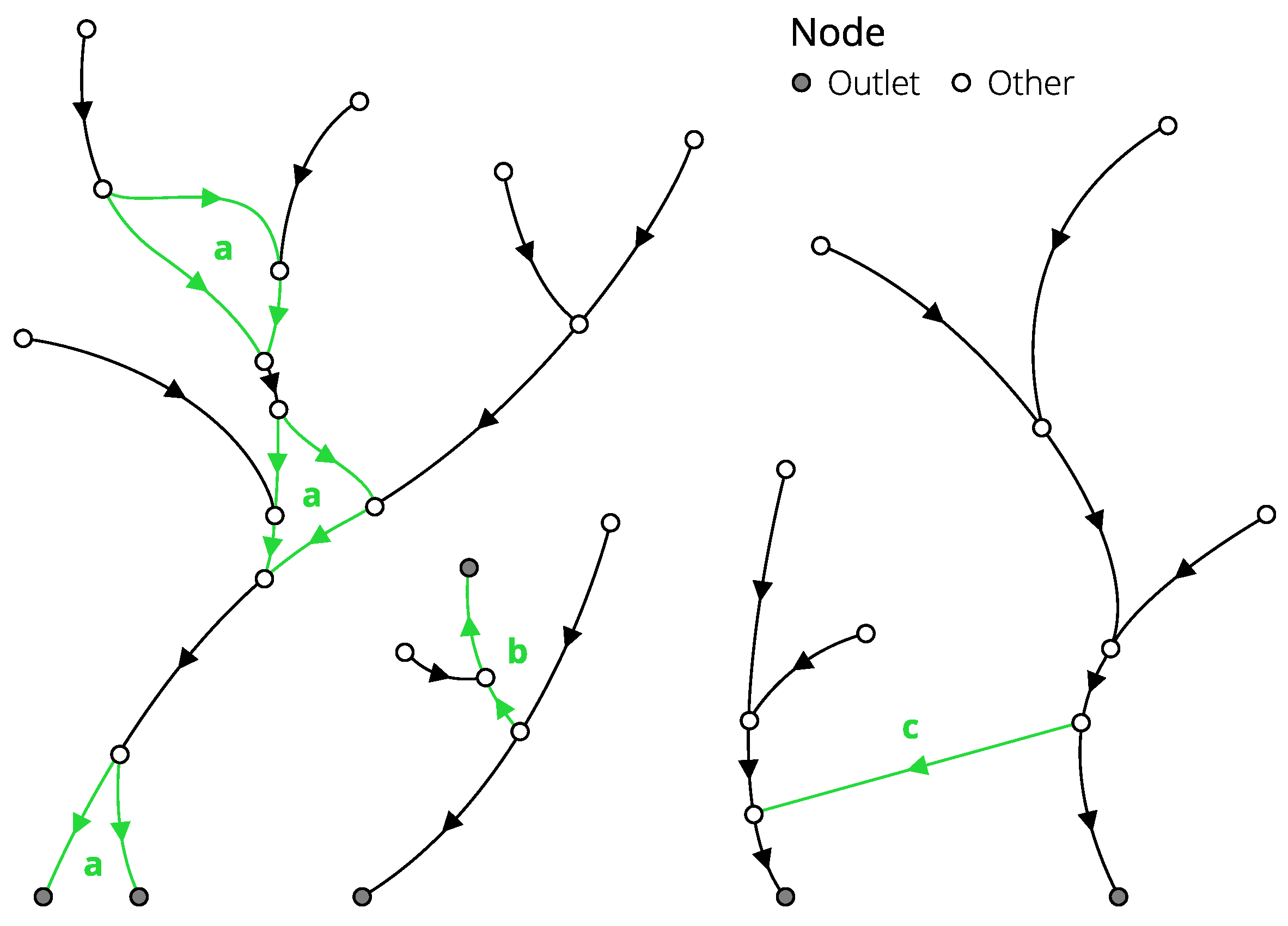
3.2. Ordering of Reference Hydrographic Lines
- Split hydrographic lines at intersections and construct a raw stream network with stream relations and outlet nodes identified.
- Reorganize the raw stream network using the modified Hack ordering.
- Describe the topological structure of the resulting network in a tabular form.
- ID (unique identifier of the stream);
- CONFL (ID of the stream that current stream outflows to);
- BIFUR (ID of inflowing stream to the current stream);
- ITER (number of iteration during which a counterpart for the current stream should be extracted);
- ORDER (modified Hack order);
- TYPE (stream type with respect to bifurcation process).
- outlet (end node of the stream with );
- source (start node of the stream with );
- confluence (end node of the stream with );
- bifurcation (start node of the stream with )
- main (streams with );
- distributary (streams with ).
3.3. Extraction of Counterpart Streams
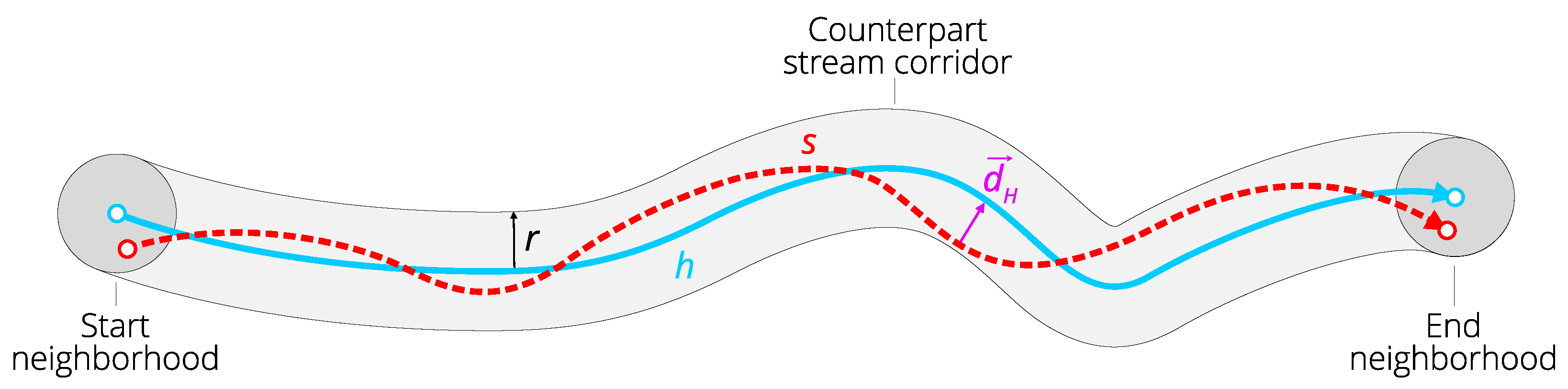
3.3.1. Distances
3.3.2. Single Reference Line
- strong: ;
- regular: ;
- weak: .
3.3.3. Multiple Reference Lines
3.4. Generation of Rubbersheet Links
3.5. Extraction of Vector Elevation Data
- Primary streams.
- Watersheds of primary streams.
- Watersheds of secondary streams (which are direct tributaries of primary streams).
3.6. Rubbersheeting
3.7. Reconstruction of Conflated DEM
3.8. Post-Processing
3.9. General Workflow
4. Results
5. Discussion
5.1. Parameterization
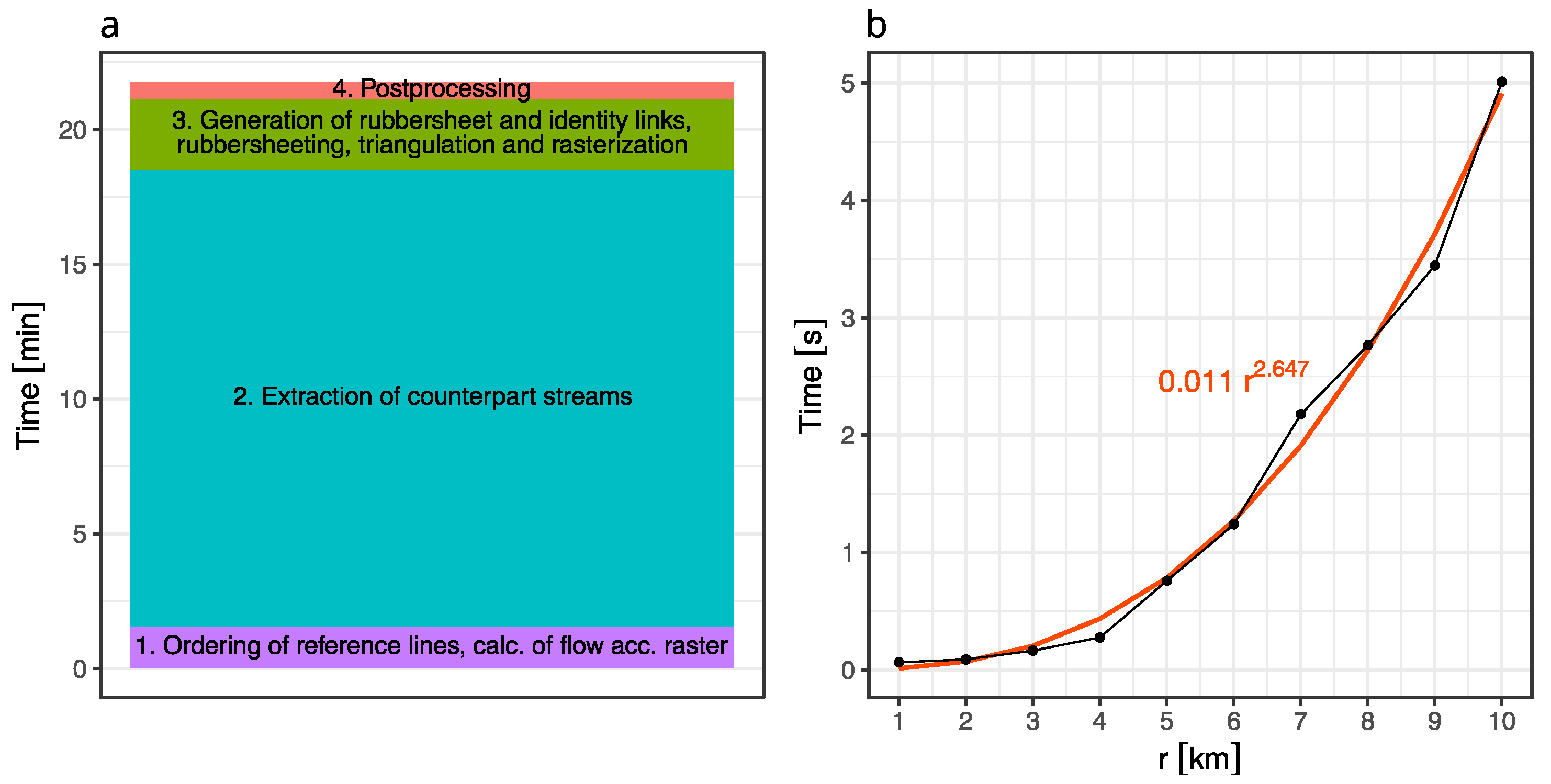
5.2. Processing Time
5.3. Displacement and Accuracy
5.4. Robustness
6. Conclusions
- The conflation process can be based on identification of the streams on DEM surface most similar to reference hydrographic lines—counterpart streams. Multiple measures can be used to estimate similarity and constrain counterpart candidates, including the Directed Hausdorff, the Hausdorff and the Fréchet distance, but the weakest constraint (the Directed Hausdorff) can be used by default for practical reasons.
- To preserve topological relations of reference hydrographic lines they must be ordered. A proper ordering allows establishing unambiguous sequence of counterpart extraction, during which the subordinate and superordinate relations reflecting the topology of reference network can be ensured. We find Hack ordering to be convenient for this purpose, with refinement on distributary streams in braided river sections. This ordering also minimizes the number of counterparts to be traced.
- A combination of flowline and least-cost approaches allows extraction of counterpart streams in a variety of cases, including the non-standard ones, such as braided streams and wrong direction of hydrographic lines.
- Topological relations between ordered reference hydrographic lines can be reflected by the network of counterpart streams using a series of topological rules. These rules ensure the correct location of counterpart stream junctions.
- Performing conflation on vectorized elevation data (points or structural lines) allows abstracting from the DEM format and applying the standard rubbersheeting algorithms. Another advantage of vector-based approach is easy integration of conflation stage into structural DEM generalization workflow.
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| DEM | Digital Elevation Model |
| GIS | Geographical Information System |
| IQR | Interquartile Range |
| TIN | Triangulated Irregular Network |
Appendix A. Algorithms for Extraction of Counterpart Streams
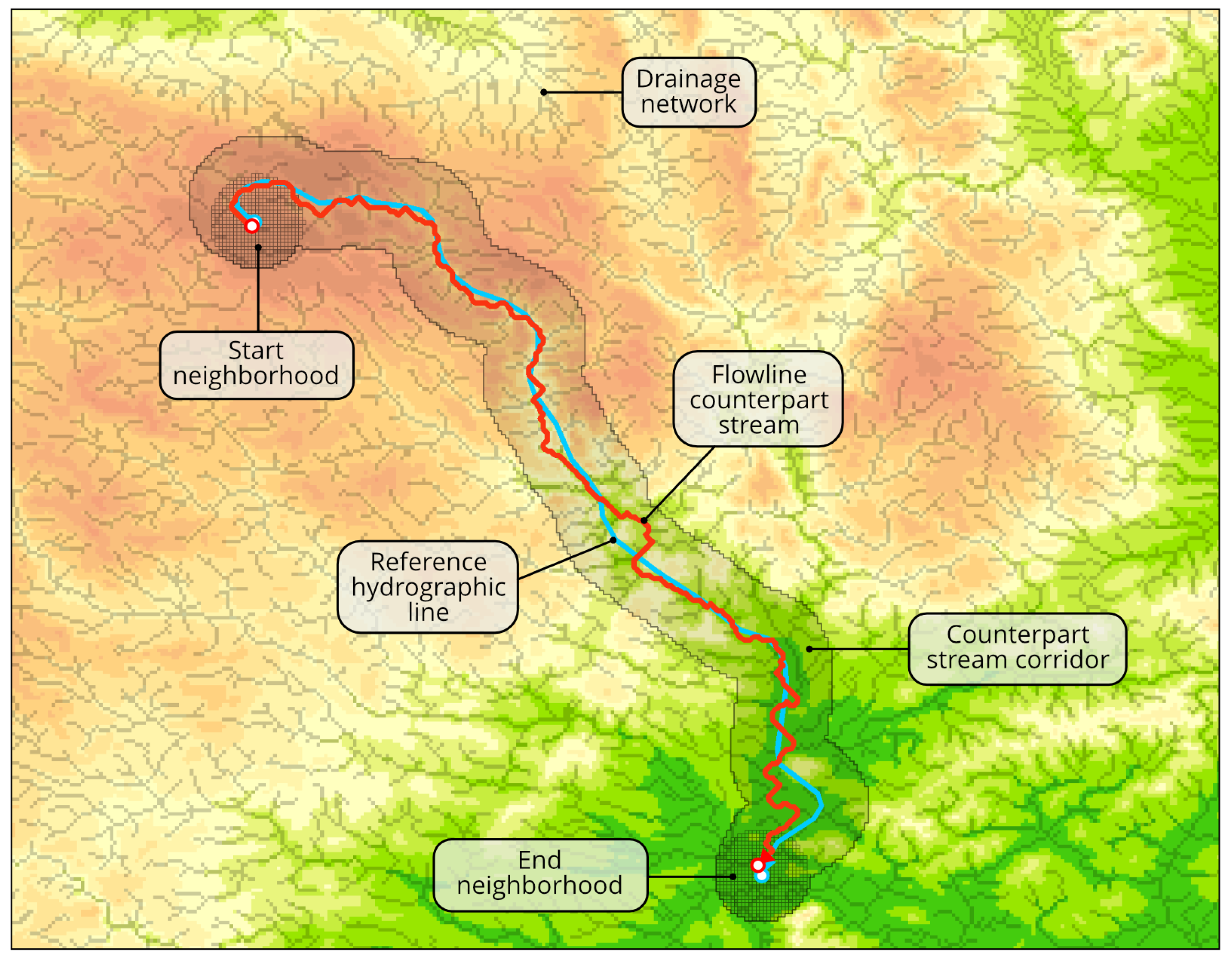
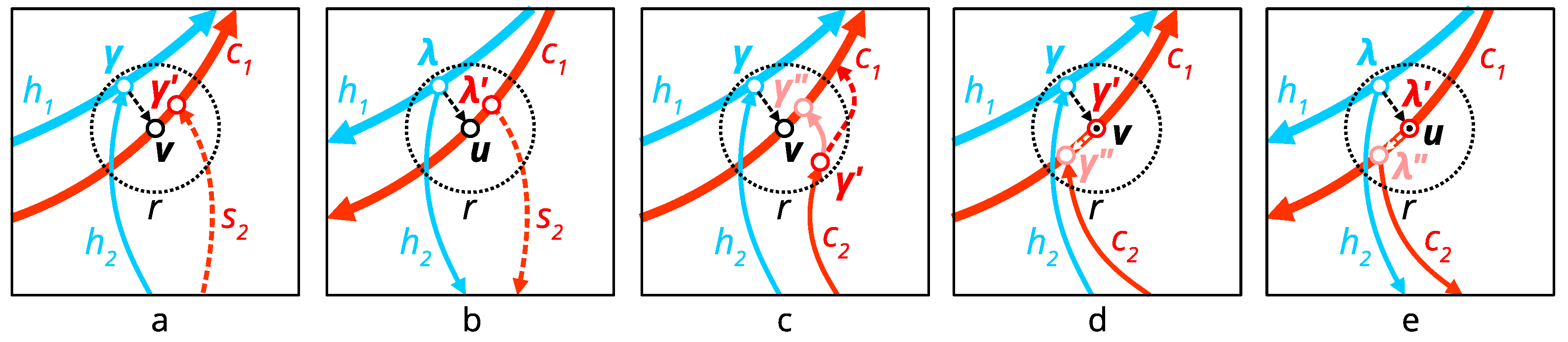
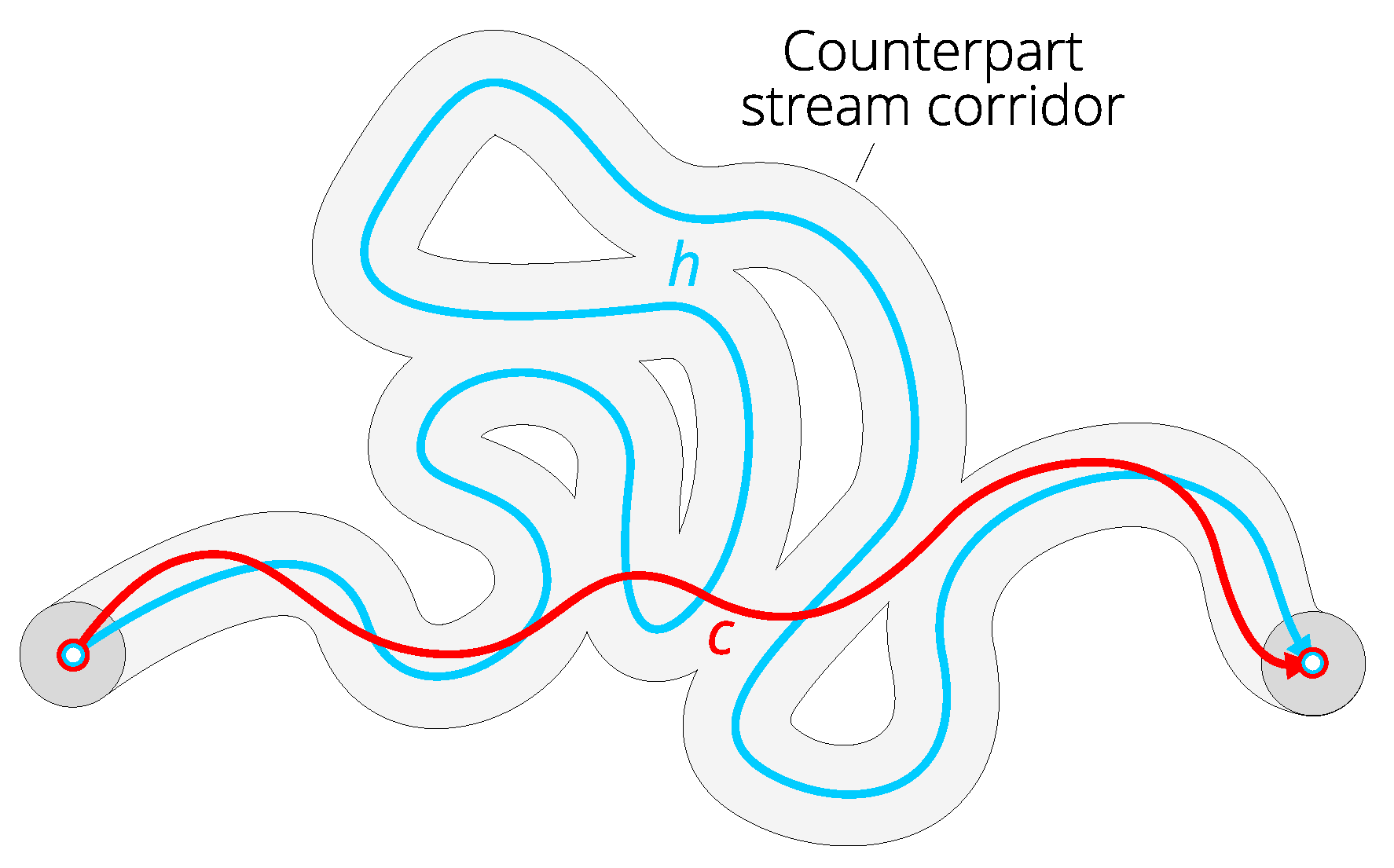
- Generate start and end neighborhoods and of radius r around start () and end () point of a reference line (Algorithm A1, lines 7–8). See the function in Algorithm A5 for the reference. Example neighborhoods are indicated in Figure 6.
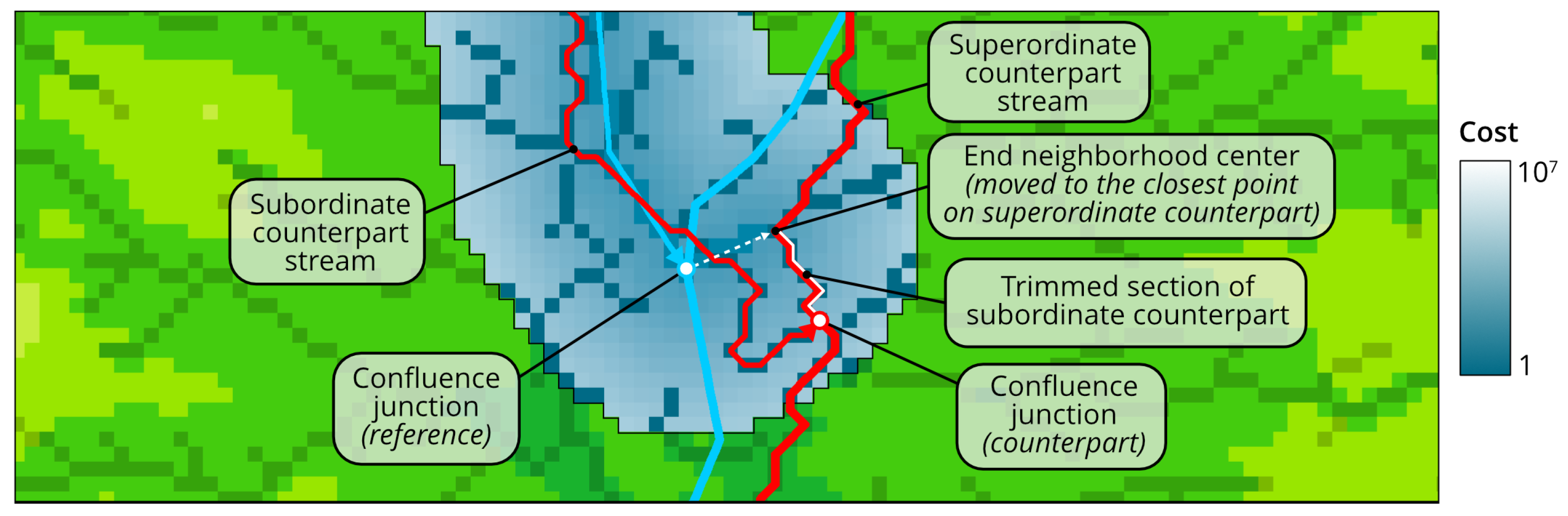
- If the current stream is tributary, then replace with similar pixel neighborhood around the closest point p on superordinate downstream counterpart (Algorithm A1, lines 9–14). Since coordinate tuples returned by function are always sorted by the distance to the central pixel, the procedure of a linear search for p can be finished at the first pixel in which is a member of as well. This step is the implementation of topological rule 1.
- If the current stream is distributary, then replace with a similar pixel neighborhood around the closest point on superordinate upstream counterpart (Algorithm A1, lines 15–20). This step is the implementation of topological rule 2 and uses the logic similar to the previous one.
- Calculate the Euclidean distance raster E for , which is needed on steps 6 and 7 (Algorithm A1, line 21).
- Trace a flowline counterpart stream c which satisfies the conditions in Equation (2) (Algorithm A1, line 22). See explanations on the function below and its representation in Algorithm A2.
- If c is flowline, extend it to its superordinate counterpart (Algorithm A1, lines 25–29). See explanations on the function below and its representation in Algorithm A3. This step is the implementation of topological rule 3.
- Ensure that c does not have intersections with its superordinate counterparts between its start and end point (line 30). See explanations on the function below and its representation in Algorithm A3. This step is the implementation of topological rules 4 and 5.
- Append c to (Algorithm A1, line 31).
- If flow accumulation at p is larger than minimum value a, then proceed to the next step (Algorithm A2, line 5).
- Trace counterpart stream candidate s starting from p using the function (Algorithm A2, line 6). If the stream does not reach the end neighborhood , then empty set is returned. See explanations on the function below and its representation in Algorithm A2.
- If s is not empty and , then proceed to the next step (Algorithm A2, line 7). If only regular or strong candidates are of interest, then should be replaced with or respectively at this stage.
- Calculate (Algorithm A2, line 8). If , then proceed to the next step (Algorithm A2, line 9).
- Replace c with s (Algorithm A2, line 10) and D with (Algorithm A2, line 11).
- If the current pixel p belongs to , then it is checked if p is closer to the center of than any previously traced pixel in s. If so, then its number is stored in as the end point of the stream. In addition, the end mode indicating that we entered is set up by (Algorithm A2, lines 18–23).
- If the current pixel p does not belong to , but previously we have entered it (), then iterations stop (Algorithm A2, lines 24–25).
- Append p to s. Find the next pixel downslope by function, which expects the D8 pointer raster generated according to [27]. If , then iterations stop, else set (Algorithm A2, lines 26–27).
| Algorithm A1: Main program. |
|
 |
| Algorithm A2: Flowline counterpart tracing. |
 |
| Algorithm A3: Least-cost counterpart tracing and post-processing. |
 |
| Algorithm A4: Generation of rubbersheet links. |
|
 |
| Algorithm A5: List of functions. |
|
References
- de Smith, M.J.; Goodchild, M.F.; Longley, P.A. Geospatial Analysis: A Comprehensive Guide to Principles, Techniques and Software Tools, 6th ed.; Troubador Publishing Ltd.: Winchelsea, UK, 2018. [Google Scholar]
- Saalfeld, A. Conflation. Automated Map Compilation. Int. J. Geogr. Inf. Syst. 1988, 2, 217–228. [Google Scholar] [CrossRef]
- White, M.S.; Griffin, P. Piecewise Linear Rubber-Sheet Map Transformation. Am. Cartographer 1985, 12, 123–131. [Google Scholar] [CrossRef]
- Stanislawski, L.V.; Nelson, C.; Hamann, M. Automated Conflation of Reach Data for the National Hydrography Dataset. In Proceedings of the 22nd Annual Esri International User Conference, San Diego, CA, USA, 8–12 July 2002. [Google Scholar]
- Cobb, M.A.; Chung, M.J.; Foley III, H.; Petry, F.E.; Shaw, K.B.; Miller, H.V. A Rule-Based Approach for the Conflation of Attributed Vector Data. Geoinformatica 1998, 2, 7–35. [Google Scholar] [CrossRef]
- Walter, V.; Fritsch, D. Matching Spatial Data Sets: A Statistical Approach. Int. J. Geogr. Inf. Sci. 1999, 13, 445–473. [Google Scholar] [CrossRef]
- Li, L.; Goodchild, M.F. An Optimisation Model for Linear Feature Matching in Geographical Data Conflation. Int. J. Image Data Fusion 2011, 2, 309–328. [Google Scholar] [CrossRef]
- Lei, T.; Lei, Z. Optimal Spatial Data Matching for Conflation: A Network Flow-based Approach. Trans. GIS 2019, 23, 1152–1176. [Google Scholar] [CrossRef]
- Gheibi, A.; Maheshwari, A.; Sack, J.R. Minimizing Walking Length in Map Matching. In Topics in Theoretical Computer Science; Hajiaghayi, M.T., Mousavi, M.R., Eds.; Series Title: Lecture Notes in Computer Science; Springer International Publishing: Cham, Germany, 2016; Volume 9541, pp. 105–120. [Google Scholar] [CrossRef] [Green Version]
- Chambers, E.; Fasy, B.T.; Wang, Y.; Wenk, C. Map-Matching Using Shortest Paths. ACM Trans. Spatial Algorithms Syst. 2020, 6, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.C.; Knoblock, C.A.; Shahabi, C. Automatically Conflating Road Vector Data with Orthoimagery. GeoInformatica 2006, 10, 495–530. [Google Scholar] [CrossRef] [Green Version]
- Mustière, S.; Devogele, T. Matching Networks with Different Levels of Detail. GeoInformatica 2008, 12, 435–453. [Google Scholar] [CrossRef]
- Lou, Y.; Zhang, C.; Zheng, Y.; Xie, X.; Wang, W.; Huang, Y. Map-Matching for Low-Sampling-Rate GPS Trajectories. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 4–6 November 2009; p. 352. [Google Scholar] [CrossRef] [Green Version]
- Bergman, C.; Oksanen, J. Conflation of OpenStreetMap and Mobile Sports Tracking Data for Automatic Bicycle Routing. Trans. GIS 2016, 20, 848–868. [Google Scholar] [CrossRef] [Green Version]
- Duchêne, C.; Baella, B.; Brewer, C.A.; Burghardt, D.; Buttenfield, B.P.; Gaffuri, J.; Käuferle, D.; Lecordix, F.; Maugeais, E.; Nijhuis, R.; et al. Generalisation in Practice Within National Mapping Agencies. In Abstracting Geographic Information in a Data Rich World; Burghardt, D., Duchêne, C., Mackaness, W., Eds.; Springer International Publishing: Cham, Germany, 2014; pp. 329–391. [Google Scholar] [CrossRef]
- Revell, P.; Regnauld, N.; Bulbrooke, G. OS VectorMapTM District: Automated Generalisation, Text Placement and Conflation in Support of Making Pubic Data Public. In Proceedings of the 25th International Cartographic Conference, Paris, France, 3–8 July 2011; p. 13. [Google Scholar]
- Kyriakidis, P.C.; Shortridge, A.M.; Goodchild, M.F. Geostatistics for Conflation and Accuracy Assessment of Digital Elevation Models. Int. J. Geogr. Inf. Sci. 1999, 13, 677–707. [Google Scholar] [CrossRef]
- Adams, B.; Li, L.; Raubal, M.; Goodchild, M.F. A General Framework for Conflation. In Proceedings of the GIScience 2010, Zurich, Switzerland, 14–17 September 2010. [Google Scholar]
- Goodchild, M.F.; Li, L. Assuring the Quality of Volunteered Geographic Information. Spatial Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Wallgrün, J.O.; Wolter, D.; Richter, K.F. Qualitative Matching of Spatial Information. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010. [Google Scholar] [CrossRef]
- OpenStreetMap. Available online: https://www.openstreetmap.org/ (accessed on 10 May 2020).
- Borges, K.A.V.; Laender, A.H.F.; Davis, C.A. Spatial Data Integrity Constraints in Object Oriented Geographic Data Modeling. In Proceedings of the 7th ACM International Symposium on Advances in Geographic Information Systems, Kansas City, MO, USA, 28–29 November 2007. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.; Yang, W.; Ahmed, N. Conflation in Geoprocessing Framework – Case Studies Recent Development and Looking Ahead. In Proceedings of the Geoprocessing 2014, Barcelona, Spain, 23–27 March 2014. [Google Scholar] [CrossRef]
- Dalang, O. VectorBender. Available online: https://github.com/olivierdalang/VectorBender (accessed on 10 May 2020).
- Hootenanny Conflates Multiple Maps into a Single Seamless Map. Available online: https://github.com/ngageoint/hootenanny (accessed on 10 May 2020).
- L3Harris Technologies, I. MapMerger™ Geospatial Vector Conflation. Available online: https://www.harris.com/solution/mapmerger-geospatial-vector-conflation (accessed on 10 May 2020).
- O’Callaghan, J.F.; Mark, D.M. The Extraction of Drainage Networks from Digital Elevation Data. Comput. Vision Graphics Image Process. 1984, 28, 323–344. [Google Scholar] [CrossRef]
- Jenson, S.K.; Domingue, J.O. Extracting Topographic Structure from Digital Elevation Data for Geographic Information System Analysis. Photogramm. Eng. Remote Sens. 1988, 54, 1593–1600. [Google Scholar]
- Lindsay, J.B. The Practice of DEM Stream Burning Revisited. Earth Surf. Process. Landf. 2016, 41, 658–668. [Google Scholar] [CrossRef]
- GEBCO 2019 Grid. Available online: https://www.bodc.ac.uk/data/published_data_library/catalogue/10.5285/836f016a-33be-6ddc-e053-6c86abc0788e/ (accessed on 10 May 2020).
- Natural Earth. Free Vector and Raster Map Data at 1:10m, 1:50m, and 1:110m Scales. Available online: https://www.naturalearthdata.com (accessed on 30 April 2020).
- Stanislawski, L.V.; Buttenfield, B.P.; Doumbouya, A. A Rapid Approach for Automated Comparison of Independently Derived Stream Networks. Cartogr. Geogr. Inf. Sci. 2015, 42, 435–448. [Google Scholar] [CrossRef]
- Stanislawski, L.V.; Survila, K.; Wendel, J.; Liu, Y.; Buttenfield, B.P. An Open Source High-Performance Solution to Extract Surface Water Drainage Networks from Diverse Terrain Conditions. Cartogr. Geogr. Inf. Sci. 2018, 45, 319–328. [Google Scholar] [CrossRef]
- Saunders, W. Preparation of DEMs for Use in Environmental Modeling Analysis. Available online: https://proceedings.esri.com/library/userconf/proc99/proceed/papers/pap802/p802.htm (accessed on 10 May 2020).
- Soille, P.; Vogt, J.; Colombo, R. Carving and Adaptive Drainage Enforcement of Grid Digital Elevation Models. Water Resour. Res. 2003, 39. [Google Scholar] [CrossRef]
- Getirana, A.C.V.; Bonnet, M.P.; Rotunno Filho, O.C.; Mansur, W.J. Improving Hydrological Information Acquisition from DEM Processing in Floodplains. Hydrol. Process. 2009, 23, 502–514. [Google Scholar] [CrossRef]
- Wu, T.; Li, J.; Li, T.; Sivakumar, B.; Zhang, G.; Wang, G. High-Efficient Extraction of Drainage Networks from Digital Elevation Models Constrained by Enhanced Flow Enforcement from Known River Maps. Geomorphology 2019, 340, 184–201. [Google Scholar] [CrossRef]
- Wang, L.; Liu, H. An Efficient Method for Identifying and Filling Surface Depressions in Digital Elevation Models for Hydrologic Analysis and Modelling. Int. J. Geogr. Inf. Sci. 2006, 20, 193–213. [Google Scholar] [CrossRef]
- Arundel, S.T.; Thiem, P.T.; Constance, E.W. Automated Extraction of Hydrographically Corrected Contours for the Conterminous United States: The US Geological Survey US Topo Product. Cartogr. Geogr. Inf. Sci. 2018, 45, 31–55. [Google Scholar] [CrossRef] [Green Version]
- Hutchinson, M. A New Procedure for Gridding Elevation and Stream Line Data with Automatic Removal of Spurious Pits. J. Hydrobiol. 1989, 106, 211–232. [Google Scholar] [CrossRef]
- Yadav, B.; Hatfield, K. Stream Network Conflation with Topographic DEMs. Environ. Modell. Softw. 2018, 102, 241–249. [Google Scholar] [CrossRef]
- Guilbert, E.; Gaffuri, J.; Jenny, B. Terrain Generalisation. In Abstracting Geographic Information in a Data Rich World; Burghardt, D., Duchêne, C., Mackaness, W., Eds.; Springer International Publishing: Cham, Germany, 2014; pp. 227–258. [Google Scholar] [CrossRef]
- Weibel, R. An Adaptive Methodology for Automated Relief Generalization. In Proceedings of the AutoCarto 8, Baltimore, MD, USA, 29 March–3 April 1987. [Google Scholar]
- Fan, Q.; Yang, L.; Hu, P. DEM Generalization Based on Analysis of Geometry and Landscape Context. Int. Symp. Multispectral Image Process. Pattern Recognit. 2007, 6790, 679035–679038. [Google Scholar] [CrossRef]
- Leonowicz, A.M.; Jenny, B.; Hurni, L. Automatic Generation of Hypsometric Layers for Small-Scale Maps. Comput. Geosci. 2009, 35, 2074–2083. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Wilson, J.P.; Zhu, Q.; Zhou, Q. Comparison of Drainage-Constrained Methods for DEM Generalization. Comput. Geosci. 2012, 48, 41–49. [Google Scholar] [CrossRef]
- Zhou, Q.; Chen, Y. Generalization of DEM for Terrain Analysis Using a Compound Method. ISPRS J. Photogramm. Remote Sens. 2011, 66, 38–45. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Q.; Yang, B. Multi-Resolution Representation of Digital Elevation Models With Topographical Features Preservation. ISPRS J. Photogramm. Remote Sens. 2008, XXXVII, 7. [Google Scholar]
- Jordan, G. Adaptive Smoothing of Valleys in DEMs Using TIN Interpolation from Ridgeline Elevations: An Application to Morphotectonic Aspect Analysis. Comput. Geosci. 2007, 33, 573–585. [Google Scholar] [CrossRef]
- Ai, T.; Li, J. A DEM Generalization by Minor Valley Branch Detection and Grid Filling. ISPRS J. Photogramm. Remote Sens. 2010, 65, 198–207. [Google Scholar] [CrossRef]
- Samsonov, T. Multiscale Hypsometric Mapping. In Advances in Cartography and GIScience. Vol.1: Selection from ICC-2011, Paris; Ruas, A., Ed.; Springer: Berlin, Germany, 2011. [Google Scholar]
- Chen, Y.; Ma, T.; Chen, X.; Chen, Z.; Yang, C.; Lin, C.; Shan, L. A New DEM Generalization Method Based on Watershed and Tree Structure. PLoS ONE 2016, 11, e0159798. [Google Scholar] [CrossRef] [PubMed]
- Gaffuri, J. Field Deformation in an Agent-Based Generalisation Model: The GAEL Model. In Proceedings of the 5th Geographic Information Days, Münster, Germany, 10–12 September 2007. [Google Scholar]
- Danielson, J.; Gesch, D. Global Multi-Resolution Terrain Elevation Data 2010 (GMTED2010). Available online: https://pubs.usgs.gov/of/2011/1073/pdf/of2011-1073.pdf (accessed on 10 May 2020).
- Hack, J.T. Studies of Longitudinal Stream Profiles in Virginia and Maryland. Available online: https://pubs.usgs.gov/pp/0294b/report.pdf (accessed on 10 May 2020).
- Hausdorff, F. Grundzüge der Megenlehre; OCLC: 468230296; Veit: Leipzig, Germany, 1914. [Google Scholar]
- Dubuisson, M.P.; Jain, A. A Modified Hausdorff Distance for Object Matching. In Proceedings of the 12th International Conference on Pattern Recognition, Jerusalem, Israel, 9–13 October 1994. [Google Scholar] [CrossRef]
- Fréchet, M. Sur Quelques Points Du Calcul Fonctionnel. Rendiconti del Circolo Matematico di Palermo 1906, 22, 1–74. [Google Scholar] [CrossRef] [Green Version]
- Alt, H.; Godau, M. Computing the Fréchet Distance Between Two Polygonal Curves. Int. J. Comput. Geom. Appl. 1995, 05, 75–91. [Google Scholar] [CrossRef]
- Eiter, T.; Mannila, H. Computing Discrete Fréchet Distance. Available online: http://www.kr.tuwien.ac.at/staff/eiter/et-archive/cdtr9464.pdf (accessed on 10 May 2020).
- Oliphant, T.E. A Guide to NumPy. Available online: https://web.mit.edu/dvp/Public/numpybook.pdf (accessed on 10 May 2020).
- What Is ArcPy? Available online: https://desktop.arcgis.com/en/arcmap/latest/analyze/arcpy/what-is-arcpy-.htm (accessed on 10 May 2020).
- Samsonov, T. Generalize DEM: ArcGIS Python Toolbox for Automated Structural Generalization and Conflation of Digital Elevation Models. Zenodo 2020. [Google Scholar] [CrossRef]
- Lindsay, J.B. Efficient Hybrid Breaching-Filling Sink Removal Methods for Flow Path Enforcement in Digital Elevation Models. Hydrol. Processes 2016, 30, 846–857. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychological Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Tomlin, D. GIS and Cartographic Model, 2nd ed.; ESRI Press: Redlands, CA, USA, 2012. [Google Scholar]
- Douglas, D.H. Least-Cost Path in GIS Using an Accumulated Cost Surface and Slopelines. Cartogr. Int. J. Geogr. Inf. Geovisualization 1994, 31, 37–51. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | CONFL | BIFUR | ITER | ORDER | TYPE |
|---|---|---|---|---|---|
| 1 | −1 | −1 | 1 | 1 | Main |
| 2 | −1 | 1 | 2 | 1 | Distributary |
| 3 | 1 | −1 | 2 | 2 | Main |
| 4 | 1 | −1 | 2 | 2 | Main |
| 5 | 1 | −1 | 2 | 2 | Main |
| 6 | 1 | 1 | 2 | 2 | Distributary |
| 7 | 4 | −1 | 3 | 3 | Main |
| 8 | 3 | 1 | 3 | 3 | Distributary |
| 9 | −1 | −1 | 1 | 1 | Main |
| 10 | −1 | 9 | 2 | 1 | Distributary |
| 11 | 10 | −1 | 3 | 2 | Main |
| 12 | −1 | −1 | 1 | 1 | Main |
| 13 | −1 | 12 | 2 | 1 | Distributary |
| 14 | 12 | −1 | 2 | 2 | Main |
| 15 | 12 | −1 | 2 | 2 | Main |
| 16 | 12 | −1 | 2 | 2 | Main |
| 17 | 14 | −1 | 3 | 3 | Main |
| ID | CONFL | BIFUR | ITER | ORDER | TYPE | COUNTERPART | , m | , m | , m | QUALITY |
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 6 | −1 | 2 | 2 | Main | Least-cost | 4065 | 4065 | 4065 | Strong |
| 3 | −1 | −1 | 1 | 1 | Main | Flowline | 3202 | 3202 | 3202 | Strong |
| 6 | −1 | −1 | 1 | 1 | Main | Flowline | 4412 | 4384 | 4384 | Strong |
| 7 | −1 | −1 | 1 | 1 | Main | Least-cost | 4705 | 4472 | 4472 | Strong |
| 8 | 7 | −1 | 2 | 2 | Main | Least-cost | 2809 | 2809 | 2809 | Strong |
| 9 | 32 | 32 | 2 | 2 | Distributary | Least-cost | 2357 | 2357 | 2356 | Strong |
| 11 | 32 | −1 | 2 | 2 | Main | Least-cost | 2375 | 2375 | 2375 | Strong |
| 12 | 32 | −1 | 2 | 2 | Main | Flowline | 5166 | 5136 | 5136 | Strong |
| 13 | 36 | −1 | 5 | 4 | Main | Flowline | 4586 | 4477 | 4477 | Strong |
| 14 | 35 | −1 | 3 | 3 | Main | Least-cost | 3307 | 3307 | 3307 | Strong |
| 15 | 32 | −1 | 2 | 2 | Main | Least-cost | 6264 | 6264 | 4277 | Weak |
| 16 | 15 | −1 | 3 | 3 | Main | Least-cost | 2884 | 2884 | 2884 | Strong |
| 17 | 3 | −1 | 2 | 2 | Main | Flowline | 4737 | 4737 | 4737 | Strong |
| 18 | 2 | −1 | 3 | 3 | Main | Least-cost | 2501 | 2501 | 1754 | Strong |
| 19 | 2 | −1 | 3 | 3 | Main | Flowline | 2510 | 2510 | 2510 | Strong |
| 20 | 32 | −1 | 2 | 2 | Main | Least-cost | 3341 | 3341 | 2581 | Strong |
| 21 | 6 | −1 | 2 | 2 | Main | Least-cost | 1987 | 1987 | 1987 | Strong |
| 22 | 32 | −1 | 2 | 2 | Main | Flowline | 4604 | 4604 | 4604 | Strong |
| 23 | −1 | −1 | 1 | 1 | Main | Flowline | 1378 | 1378 | 1378 | Strong |
| 25 | 32 | −1 | 2 | 2 | Main | Flowline | 2519 | 2519 | 2320 | Strong |
| 26 | 32 | −1 | 2 | 2 | Main | Least-cost | 4185 | 4185 | 4185 | Strong |
| 27 | 16 | −1 | 4 | 4 | Main | Least-cost | 4408 | 4408 | 4408 | Strong |
| 28 | 32 | −1 | 2 | 2 | Main | Least-cost | 2998 | 2998 | 2998 | Strong |
| 30 | −1 | −1 | 1 | 1 | Main | Flowline | 4059 | 4059 | 4059 | Strong |
| 32 | −1 | −1 | 1 | 1 | Main | Least-cost | 4206 | 4206 | 4206 | Strong |
| 34 | 12 | −1 | 3 | 3 | Main | Least-cost | 4417 | 4417 | 4417 | Strong |
| 35 | 32 | −1 | 2 | 2 | Main | Least-cost | 3689 | 3689 | 3689 | Strong |
| 36 | 2 | 34 | 4 | 3 | Distributary | Least-cost | 4032 | 4032 | 4032 | Strong |
| ID | ||||
|---|---|---|---|---|
| 2 | 0.758 | 0.015 | 0.991 | 0.003 |
| 3 | 0.830 | 0.018 | 0.992 | 0.004 |
| 6 | 0.560 | 0.024 | 0.993 | 0.003 |
| 7 | 0.415 | 0.018 | 0.998 | 0.001 |
| 8 | 0.457 | 0.021 | 0.966 | 0.006 |
| 9 | 0.433 | 0.047 | 1.000 | 0.000 |
| 11 | 0.620 | 0.018 | 0.992 | 0.003 |
| 12 | 0.396 | 0.022 | 0.998 | 0.002 |
| 13 | 0.577 | 0.029 | 1.000 | 0.000 |
| 14 | 0.539 | 0.026 | 0.977 | 0.007 |
| 15 | 0.457 | 0.021 | 0.982 | 0.005 |
| 16 | 0.382 | 0.024 | 0.929 | 0.010 |
| 17 | 0.470 | 0.033 | 0.977 | 0.008 |
| 18 | 0.549 | 0.050 | 1.000 | 0.000 |
| 19 | 0.509 | 0.027 | 1.000 | 0.000 |
| 20 | 0.463 | 0.027 | 0.985 | 0.005 |
| 21 | 0.646 | 0.030 | 1.000 | 0.000 |
| 22 | 0.567 | 0.024 | 0.997 | 0.002 |
| 23 | 0.591 | 0.059 | 0.978 | 0.015 |
| 25 | 0.862 | 0.031 | 0.877 | 0.030 |
| 26 | 0.621 | 0.030 | 1.000 | 0.000 |
| 27 | 0.513 | 0.026 | 0.993 | 0.004 |
| 28 | 0.553 | 0.028 | 1.000 | 0.000 |
| 30 | 0.820 | 0.021 | 0.964 | 0.010 |
| 32 | 0.449 | 0.013 | 0.997 | 0.001 |
| 34 | 0.589 | 0.021 | 0.994 | 0.003 |
| 35 | 0.484 | 0.018 | 0.958 | 0.006 |
| 36 | 0.556 | 0.019 | 0.985 | 0.004 |
| Variable | Rubbersheet Links | Displacement Vectors |
|---|---|---|
| dx [m] | ||
| Mean (SD) | −49 (761) | −28 (397) |
| Median (Q1, Q3) | −16 (−302, 225) | −4 (−126, 92) |
| Range | [−5404, 6210] | [−4461, 3747] |
| dy [m] | ||
| Mean (SD) | 301 (926) | 179 (533) |
| Median (Q1, Q3) | 256 (−111, 803) | 98 (−22, 389) |
| Range | [−4675, 4390] | [−4675, 4390] |
| dxy [m] | ||
| Mean (SD) | 936 (808) | 467 (506) |
| Median (Q1, Q3) | 726 (334, 1259) | 302 (114, 643) |
| Range | [4, 6264] | [0, 5137] |
| dz [m] | ||
| Mean (SD) | - | 0.07 (13.77) |
| Median (Q1, Q3) | - | 0.03 (−1.52, 1.76) |
| Range | - | [−466.49, 390.49] |
| Total number | 22,606 | 393,622 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samsonov, T.E. Automated Conflation of Digital Elevation Model with Reference Hydrographic Lines. ISPRS Int. J. Geo-Inf. 2020, 9, 334. https://doi.org/10.3390/ijgi9050334
Samsonov TE. Automated Conflation of Digital Elevation Model with Reference Hydrographic Lines. ISPRS International Journal of Geo-Information. 2020; 9(5):334. https://doi.org/10.3390/ijgi9050334
Chicago/Turabian StyleSamsonov, Timofey E. 2020. "Automated Conflation of Digital Elevation Model with Reference Hydrographic Lines" ISPRS International Journal of Geo-Information 9, no. 5: 334. https://doi.org/10.3390/ijgi9050334
APA StyleSamsonov, T. E. (2020). Automated Conflation of Digital Elevation Model with Reference Hydrographic Lines. ISPRS International Journal of Geo-Information, 9(5), 334. https://doi.org/10.3390/ijgi9050334