An Open-Source Framework of Generating Network-Based Transit Catchment Areas by Walking



Abstract
:1. Introduction
- We propose a methodological framework to generate the network-based TCAs by walking.
- We propose a method to evaluate the geospatial accuracy of the network-based TCAs.
- We provide an open-source implementation of our framework.
2. Methods
2.1. Problem Definition and Assumptions
Given a road network graph and a set of facilities . Each facilityhas an associated cut-off distance . The aim is to design a method to generate n TCAs for these facilities in an efficient and accurate way.
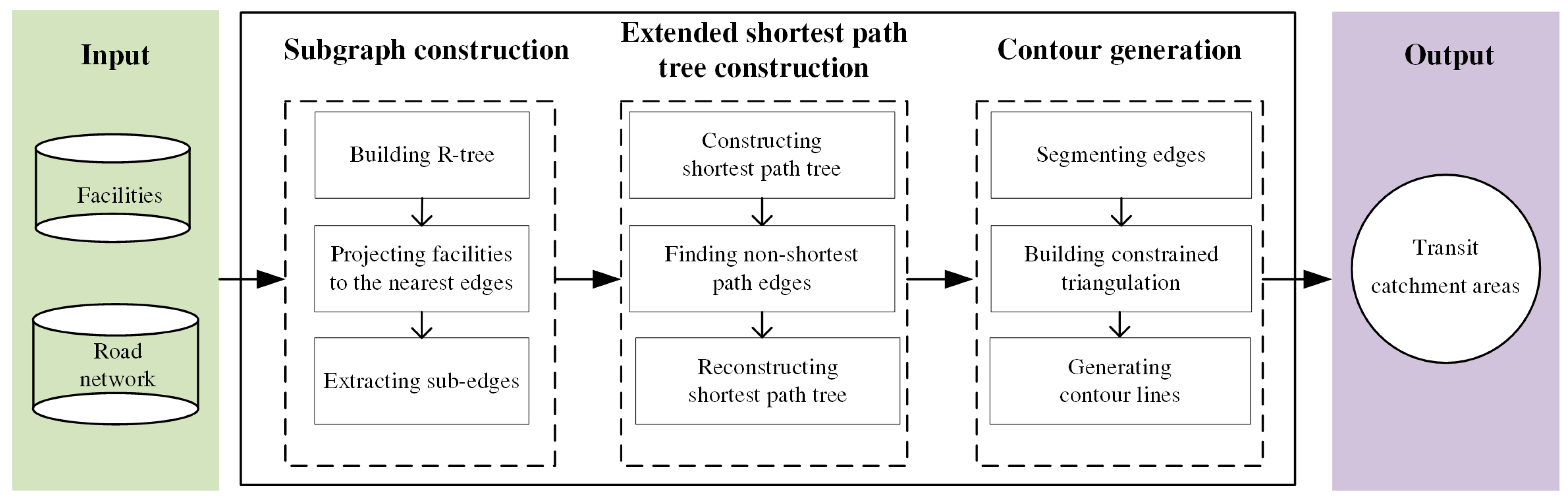
2.2. Framework of Generating Network-Based Transit Catchment Areas (TCAs)
2.2.1. Subgraph Construction
- Building R-tree. Based on the input road network edges, an R-tree [32] is built to accelerate the nearest road searching and sub-edge extraction.
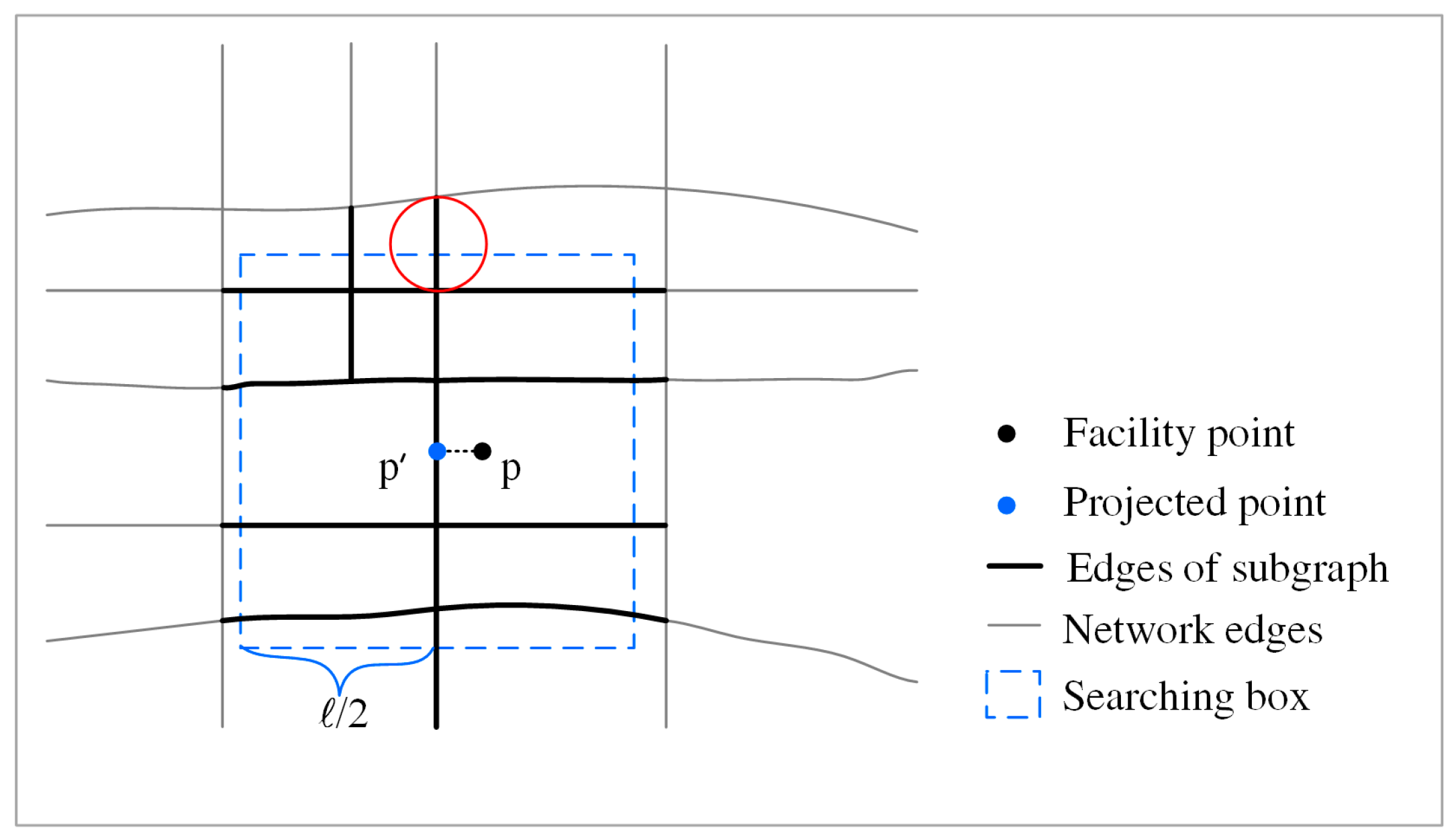
- Projecting facilities to the nearest edges. In order to measure the distance from/to a facility, each facility point is projected to its nearest edge. The nearest edge of a facility is retrieved using the nearest neighbor query of R-tree [33]. Then, each facility is projected to its nearest edge by using a linear reference algorithm, which iterates through every segment (i.e., a line connecting two neighboring points of an edge) of the edge to determine the nearest segment [34]. As illustrated in Figure 2, is the corresponding projected point of the facility.
- Extracting sub-edges. Based on the projected points obtained, a set of edges around each projected point can be identified. Given a facility with its projected point and the cut-off distance, a square searching box with a width of and centered at is created (Figure 2). The sub-edges of each facility are then extracted by finding the edges that intersect with its searching box with the assistance of the intersection query of R-Tree. Based on the extracted sub-edges of each facility, the corresponding subgraph for a facility can be constructed. Additionally, the projected point is inserted into as a new node. The parameter setting of needs to satisfy two requirements: (1) all the accessible edges (i.e., edges whose distance to/from are less than or equal to should be included in ; and (2) some edges beyond the distance of need to be included in , which will be used to interpolate additional boundary points of the catchment area (see Section 2.2.3). Therefore, should satisfy the following formulawhere is the Euclidean distance between and , is the given cut-off distance of . Under the condition of these two requirements being satisfied, should be as small as possible to improve the computation efficiency. We set to be for three reasons. First, the detour ratios of roads are generally bigger than 1. Second, is usually bigger than 0. Third, boundary edges with distances to larger than are naturally included in the subgraph because we use the “intersection query” to extract sub-edges (e.g., the edge marked by the red circle in Figure 2).
2.2.2. Extended Shortest Path Tree Construction
- Constructing SP tree. Given a node as the root node, the SP tree starting from a root node can be constructed by employing Dijkstra’s algorithm.
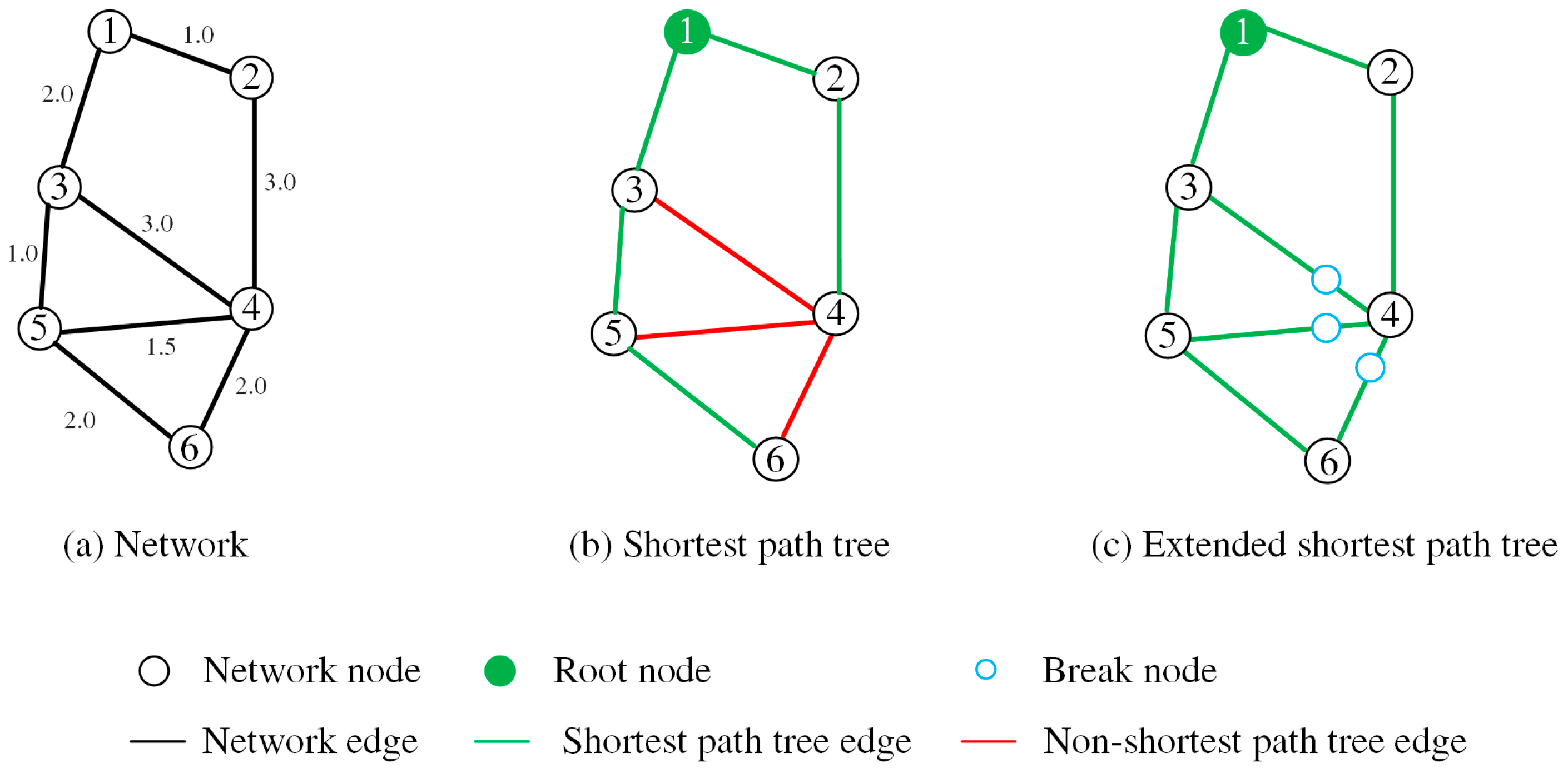
- Finding the non-SP tree edges. As illustrated by an example in Figure 3. Some edges (the red edges in Figure 3b) are not included in the SP tree, which are termed non-SP tree edges. In order to construct an extended SP tree that includes these non-SP tree edges, we need to insert additional points into them. According to [36], if a given edge is a non-SP tree edge, there must be a point (termed as break point) on this edge that satisfies the following:where are the network distances from the root node to nodes and , and are the network distances between point and nodes and . How to efficiently find the non-SP tree edges and the corresponding break points is the key issue of constructing the extended SP tree. We represent a non-SP tree edge as a tuple , where . Algorithm 1 describes the means of identifying the non-SP tree edges of a facility (denoted as , see Figure 4). The input of this algorithm is the output of the Dijkstra’s algorithm (i.e., the output of the preceding step), including the sequence of the examined nodes of the Dijkstra’s algorithm (denoted as ), the predecessors of the examined node (denoted as), and the shortest distances of the examined nodes to the root node (denoted as ). By iterating the examined nodes in a backward direction, the non-SP tree edges can be efficiently identified (Lines 4–12 in Algorithm 1).
- Reconstructing SP tree. Each non-SP tree edge is split into two edges at its break point , namely edge and edge . Although and have the same location, there are regarded as two distinct nodes to avoid circular roads in the graph after inserting the break points [36]. After the insertion of every single non-SP tree edge, an updated graph can be obtained. Then, by re-running Dijkstra’s algorithm on this updated graph, the corresponding extended SP tree can be generated (Figure 3c).
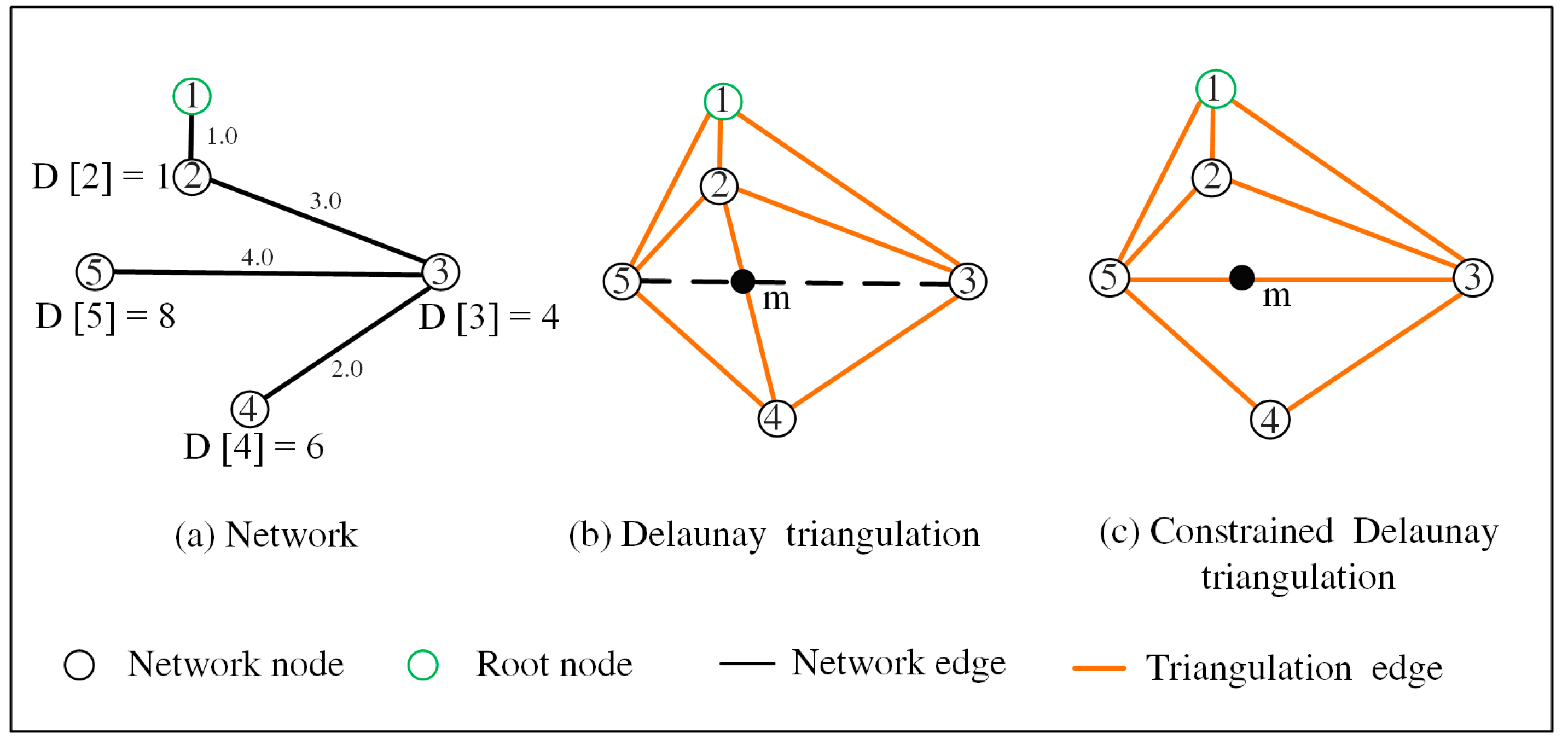
2.2.3. Contour Generation
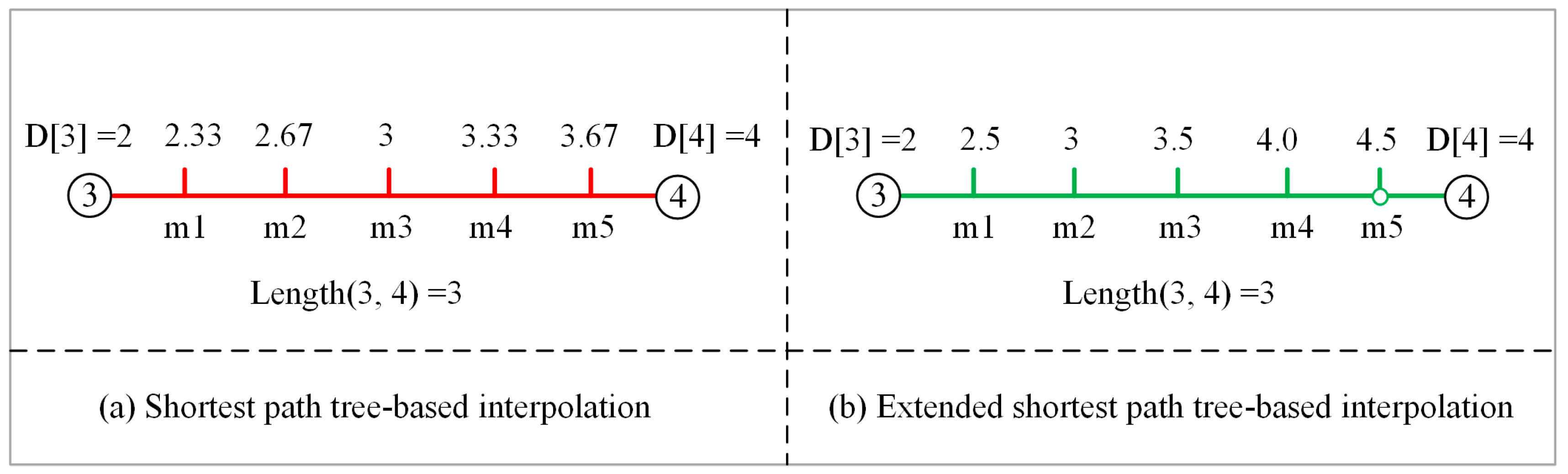
- Segmenting edges. Given an edge represented by point sequence, where to are intermediate points of edge . We divide the edge into segments and add them as constraints during the triangulation (their endpoints thus act as the vertices of the triangulation). Since every single edge is included in the extended SP tree, the distance from a root node to an intermediate point can be calculated by the following formula.where is the distance from the root node to the intermediate point , is the distance from the root node to node , is the distance from node to the intermediate point .
- Building constrained triangulation. Based on the constrained segments obtained in the previous step, a constrained Delaunay triangulation is built for each extended SP tree by using the Computational Geometry Algorithms Library [37].
- Generating contour lines. Using the constrained triangulation as input, the contour lines specified at the cut-off distance (i.e., ) are generated by employing a tracing-based contour generation algorithm [38].
2.3. Generalization of the Framework
2.3.1. Generalization to the Directed Road Network
2.3.2. Generalization to Non-Point Facilities
2.4. Geospatial Accuracy Metrics
2.5. Implementation
3. Case Study and Evaluation
3.1. Data Description and Experimental Set-up
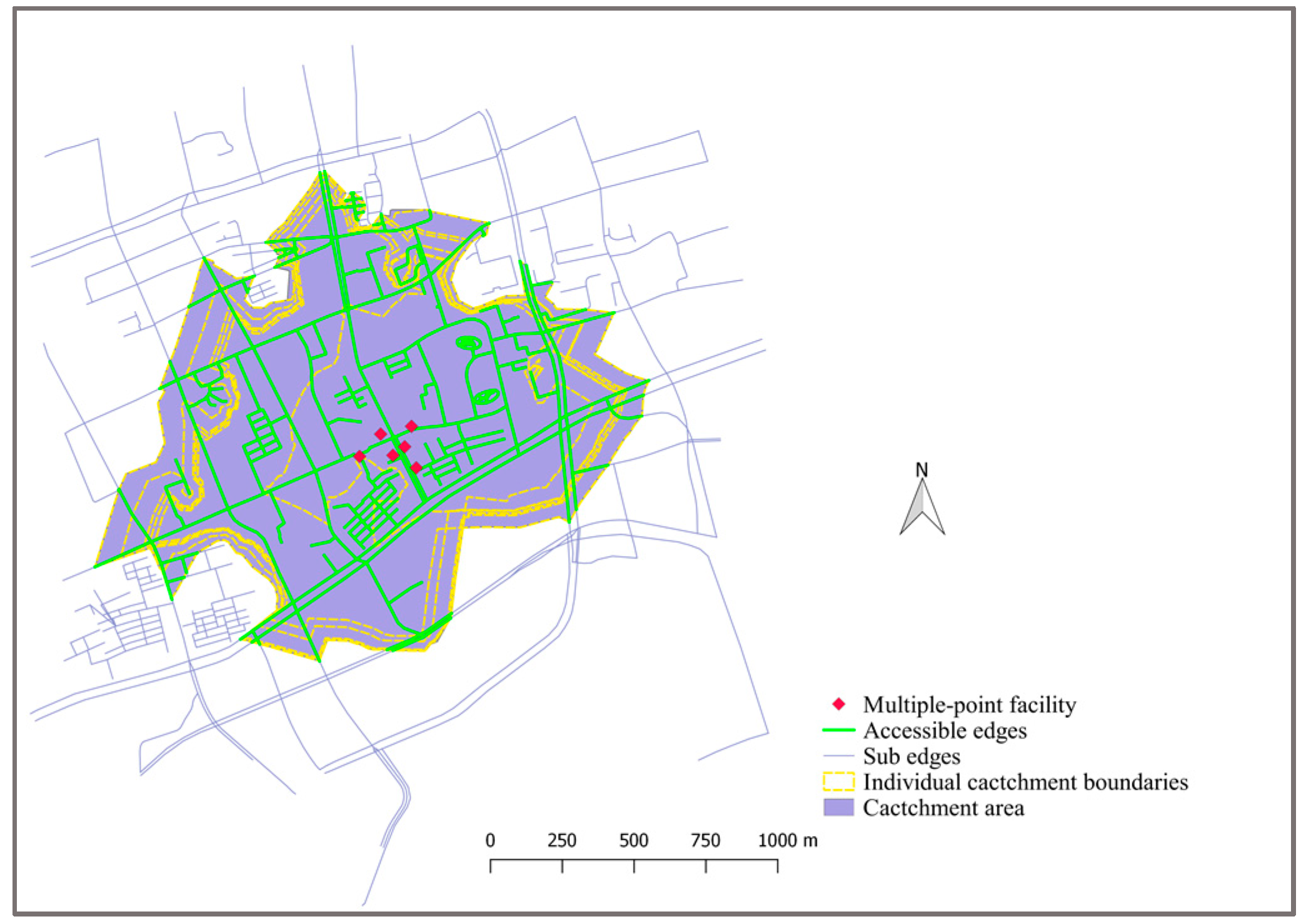
3.2. Case Study
3.2.1. Undirected Graph with Point-Based Facility
3.2.2. Directed Graph and Non-Point Facilities
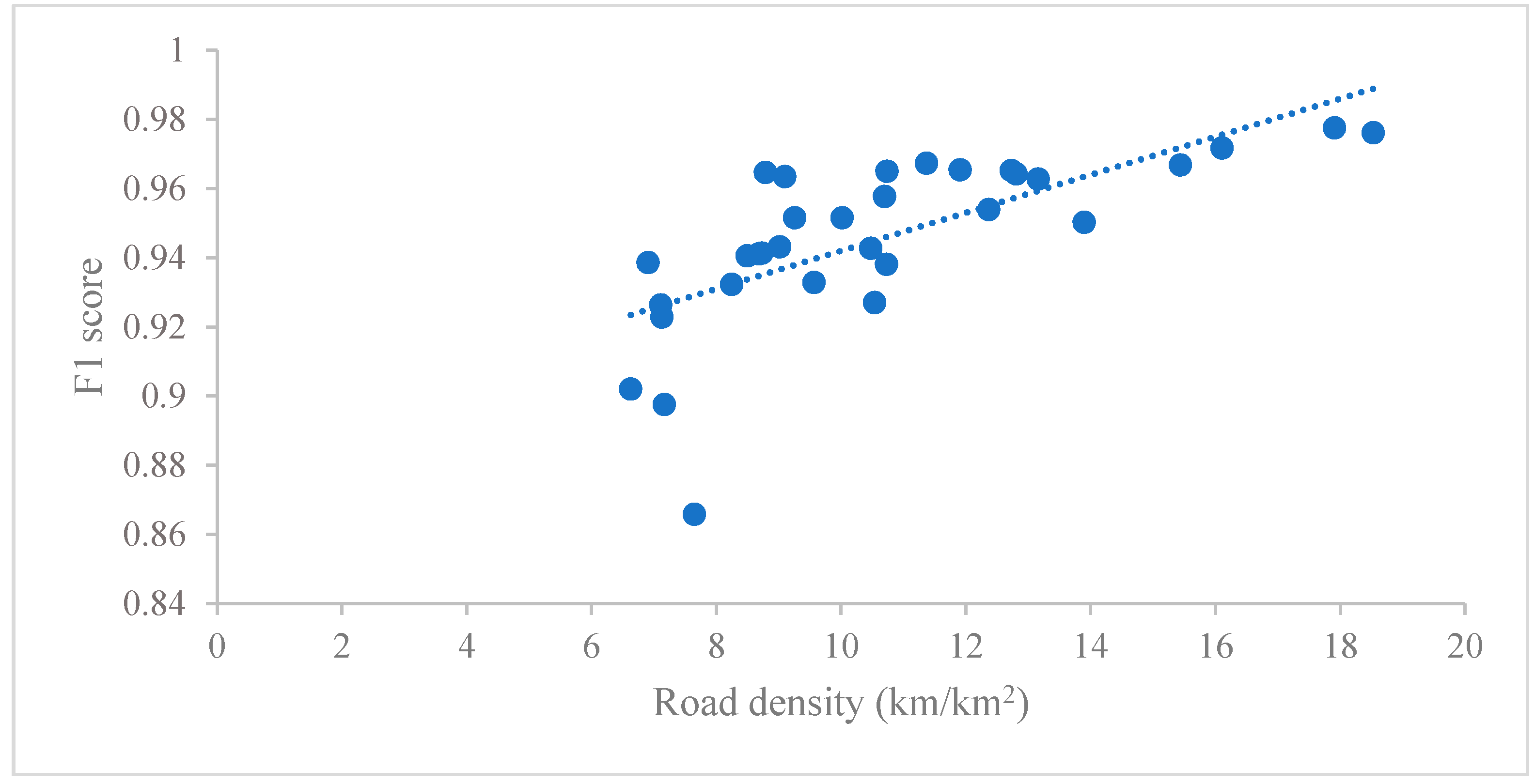
3.3. Geospatial Accuracy Evaluation
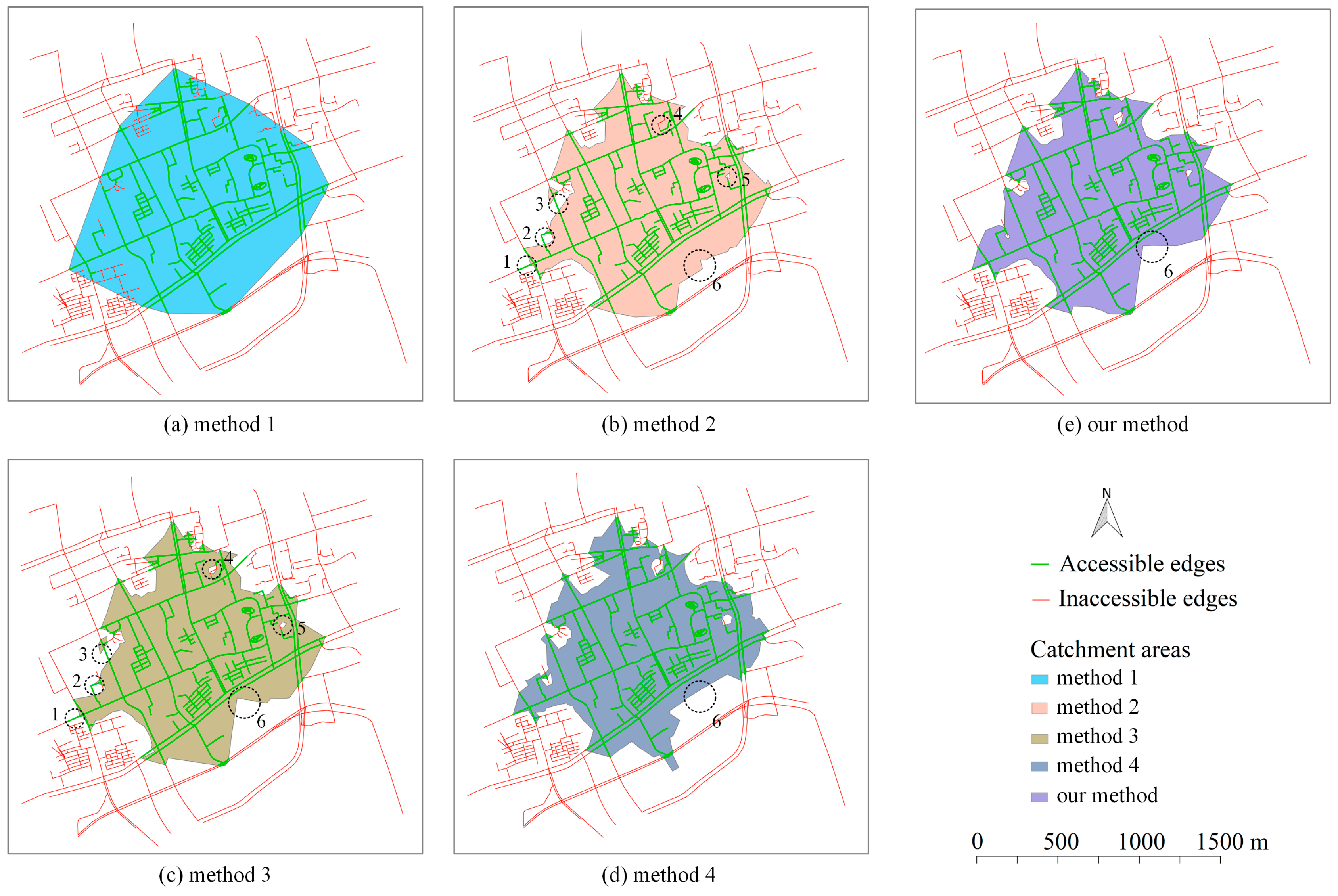
3.3.1. Visual Comparison
3.3.2. Quantitative Evaluation
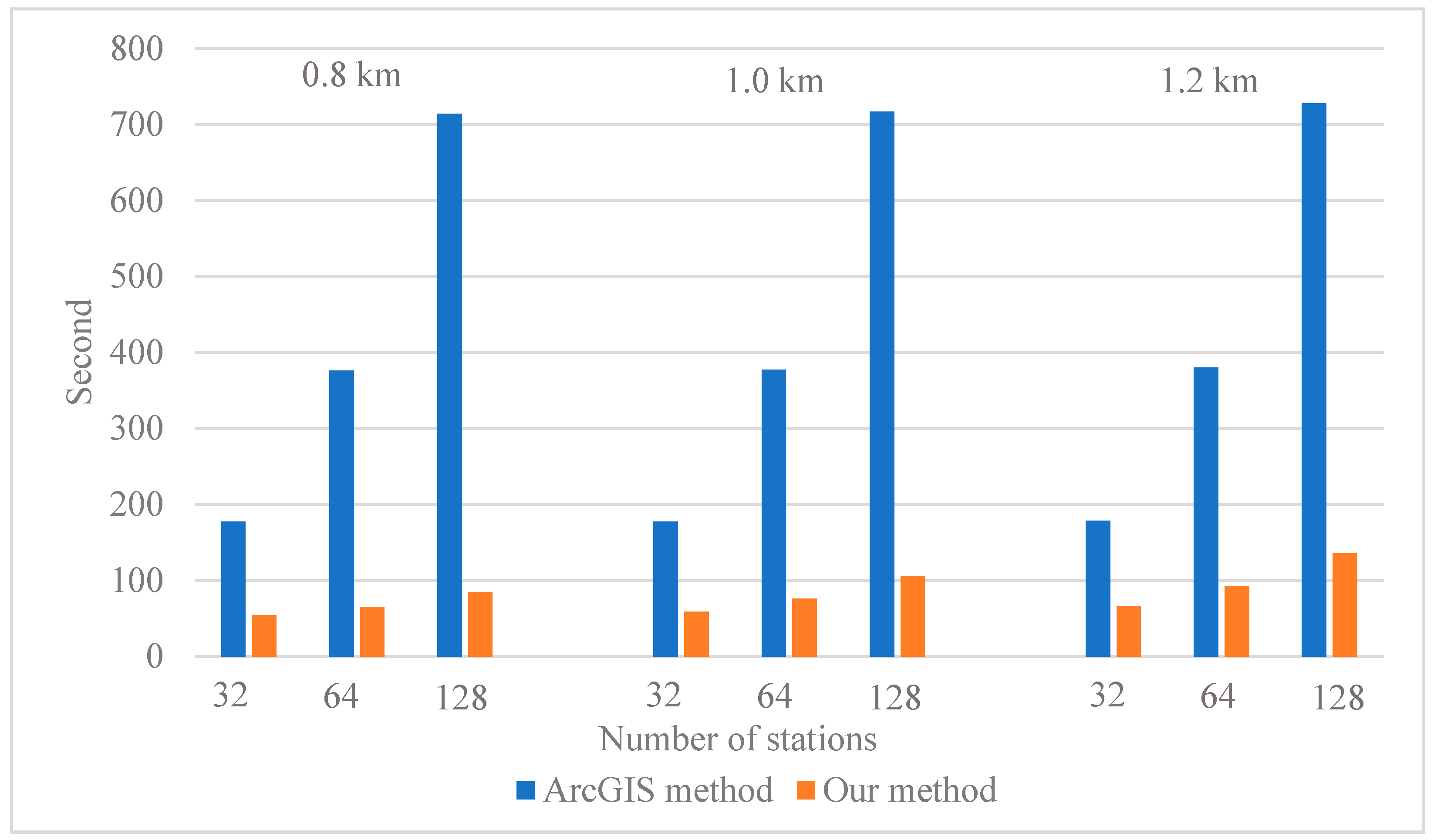
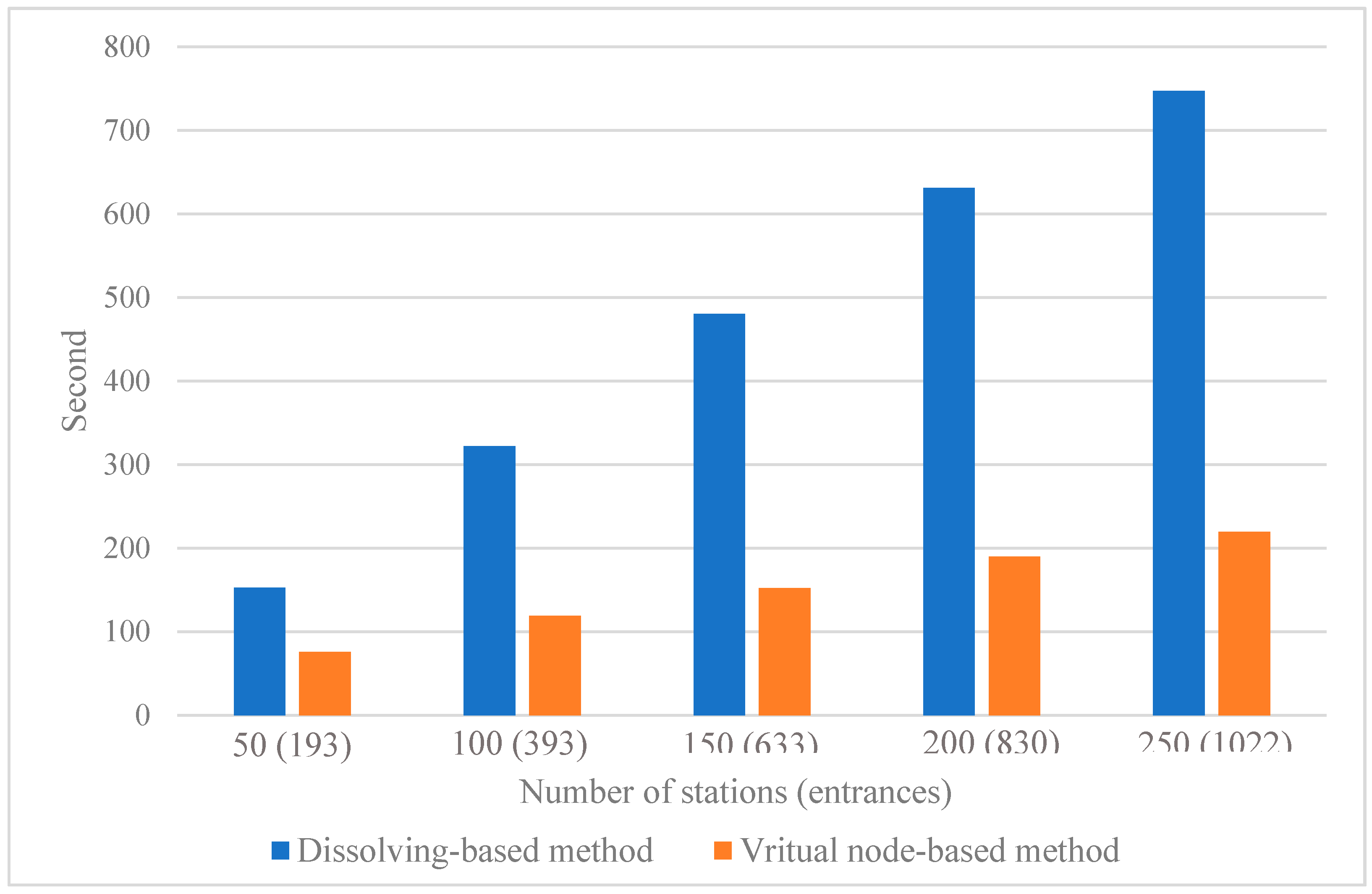
3.4. Computation Efficiency Evaluation
3.4.1. Point-Based Facility
3.4.2. Non-Point Facility
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lin, T.G.; Xia, J.C.; Robinson, T.P.; Olaru, D.; Smith, B.; Taplin, J.; Cao, B. Enhanced Huff model for estimating Park and Ride (PnR) catchment areas in Perth, WA. J. Transp. Geogr. 2016, 54, 336–348. [Google Scholar] [CrossRef] [Green Version]
- Dolega, L.; Pavlis, M.; Singleton, A. Estimating attractiveness, hierarchy and catchment area extents for a national set of retail centre agglomerations. J. Retail. Consum. Serv. 2016, 28, 78–90. [Google Scholar] [CrossRef] [Green Version]
- Lieshout, R. Measuring the size of an airport’s catchment area. J. Transp. Geogr. 2012, 25, 27–34. [Google Scholar] [CrossRef]
- Kimpel, T.J.; Dueker, K.J.; El-Geneidy, A.M. Using GIS to Measure the Effect of Overlapping Service Areas on Passenger Boardings at Bus Stops. Urban Reg. Inf. Syst. Assoc. J. 2007, 19, 5–11. [Google Scholar]
- Gutiérrez, J.; García-Palomares, J.C. Distance-measure impacts on the calculation of transport service areas using GIS. Environ. Plan. B Plan. Des. 2008, 35, 480–503. [Google Scholar] [CrossRef]
- García-Palomares, J.C.; Sousa Ribeiro, J.; Gutiérrez, J.; Sá Marques, T. Analysing proximity to public transport: The role of street network design. Boletín Asoc. Geógrafos Españoles 2018, 102–130. [Google Scholar] [CrossRef] [Green Version]
- Riggs, W.; Chamberlain, F. The TOD and smart growth implications of the LA adaptive reuse ordinance. Sustain. Cities Soc. 2018, 38, 594–606. [Google Scholar] [CrossRef]
- Zacharias, J.; Zhao, Q. Local environmental factors in walking distance at metro stations. Public Transp. 2018, 10, 91–106. [Google Scholar] [CrossRef]
- Gutiérrez, J.; Cardozo, O.D.; García-Palomares, J.C. Transit ridership forecasting at station level: An approach based on distance-decay weighted regression. J. Transp. Geogr. 2011, 19, 1081–1092. [Google Scholar] [CrossRef]
- Lee, S.; Yi, C.; Hong, S.P. Urban structural hierarchy and the relationship between the ridership of the Seoul Metropolitan Subway and the land-use pattern of the station areas. Cities 2013, 35, 69–77. [Google Scholar] [CrossRef]
- Langford, M.; Fry, R.; Higgs, G. Measuring transit system accessibility using a modified two-step floating catchment technique. Int. J. Geogr. Inf. Sci. 2012, 26, 193–214. [Google Scholar] [CrossRef]
- El-Geneidy, A.; Grimsrud, M.; Wasfi, R.; Tétreault, P.; Surprenant-Legault, J. New evidence on walking distances to transit stops: Identifying redundancies and gaps using variable service areas. Transportation 2014, 41, 193–210. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, F.; Xu, T. Interchange between Metro and Other Modes: Access Distance and Catchment Area. J. Urban Plan. Dev. 2016, 142, 04016012. [Google Scholar] [CrossRef]
- Páez, A.; Scott, D.M.; Morency, C. Measuring accessibility: Positive and normative implementations of various accessibility indicators. J. Transp. Geogr. 2012, 25, 141–153. [Google Scholar] [CrossRef]
- Hsiao, S.; Lu, J.; Sterling, J.; Weatherford, M. Use of geographic information system for analysis of transit pedestrian access. Transp. Res. Rec. 1997, 50–59. [Google Scholar] [CrossRef]
- O’Sullivan, S.; Morrall, J. Walking Distances to and from Light-Rail Transit Stations. Transp. Res. Rec. 1996, 1538, 19–26. [Google Scholar] [CrossRef]
- Zhao, J.; Deng, W. Relationship of Walk Access Distance to Rapid Rail Transit Stations with Personal Characteristics and Station Context. J. Urban Plan. Dev. 2013, 139, 311–321. [Google Scholar] [CrossRef]
- Jun, M.J.; Choi, K.; Jeong, J.E.; Kwon, K.H.; Kim, H.J. Land use characteristics of subway catchment areas and their influence on subway ridership in Seoul. J. Transp. Geogr. 2015, 48, 30–40. [Google Scholar] [CrossRef]
- Macias, K. Alternative methods for the calculation of pedestrian catchment areas for public transit. Transp. Res. Rec. 2016, 2540, 138–144. [Google Scholar] [CrossRef]
- Xi, Y.; Saxe, S.; Miller, E. Accessing the subway in Toronto, Canada: Access mode and catchment areas. Transp. Res. Rec. 2016, 2543, 52–61. [Google Scholar] [CrossRef]
- Bhat, C.; Bricka, S.; La Mondia, J.; Kapur, A.; Guo, J.; Sen, S. Metropolitan Area Transit Accessibility Analysis Tool; No. Report No. 0-5178-P3; Public Transportation Service: Austin, TX, USA, 2006. [Google Scholar]
- Foda, M.; Osman, A. Using GIS for Measuring Transit Stop Accessibility Considering Actual Pedestrian Road Network. J. Public Transp. 2010, 13, 23–40. [Google Scholar] [CrossRef] [Green Version]
- Young, M. Defining probability-based rail station catchments for demand modelling. In Proceedings of the 48th Annual UTSG Conference, Bristol, UK, 6–8 January 2016; pp. 1–12. [Google Scholar]
- Haggett, P.; Cliff, A.D.; Frey, A. Locational Analysis in Human Geography, 1st ed.; Edward Arnold: London, UK, 1977. [Google Scholar]
- Delamater, P.L.; Messina, J.P.; Shortridge, A.M.; Grady, S.C. Measuring geographic access to health care. Int. J. Health Geogr. 2012, 11, 15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Upchurch, C.; Kuby, M.; Zoldak, M.; Barranda, A. Using GIS to generate mutually exclusive service areas linking travel on and off a network. J. Transp. Geogr. 2004, 12, 23–33. [Google Scholar] [CrossRef]
- Lin, D.; Zhang, Y.; Zhu, R.; Meng, L. The analysis of catchment areas of metro stations using trajectory data generated by dockless shared bikes. Sustain. Cities Soc. 2019, 101598. [Google Scholar] [CrossRef]
- Service Area Analysis—Help|Documentation. Available online: https://desktop.arcgis.com/en/arcmap/latest/extensions/network-analyst/service-area.htm (accessed on 18 June 2020).
- Edler, D.; Husar, A.; Keil, J.; Vetter, M.; Dickmann, F. Virtual reality (VR) and open source software: A workflow for constructing an interactive cartographic VR environment to explore urban landscapes. Kartogr. Nachr. 2018, 5–13. [Google Scholar] [CrossRef]
- Garnett, R.; Kanaroglou, P. Qualitative GIS: An open framework using spatialite and open source GIS. Trans. GIS 2016, 20, 144–159. [Google Scholar] [CrossRef]
- Coetzee, S.; Ivánová, I.; Mitasova, H.; Brovelli, M.A. Open geospatial software and data: A review of the current state and a perspective into the future. ISPRS Int. J. GeoInf. 2020, 9, 90. [Google Scholar] [CrossRef] [Green Version]
- Guttman, A. R-trees: A dynamic index structure for spatial searching. In Proceedings of the 1984 ACM SIGMOD International Conference on Management of Data—SIGMOD, New York, NY, USA, 1 June 1984; ACM Press: New York, NY, USA, 1984. [Google Scholar] [CrossRef]
- Roussopoulos, N.; Kelley, S.; Vincent, F. Nearest neighbor queries. In Proceedings of the ACM SIGMOD international conference on Management of data, San Jose, CA, USA, 22 May 1995; Michael, C., Donovan, S., Eds.; Association for Computing Machinery: New York, NY, USA, 1995; pp. 71–79. [Google Scholar] [CrossRef]
- Yang, C.; Gidófalvi, G. Fast map matching, an algorithm integrating hidden Markov model with precomputation. Int. J. Geogr. Inf. Sci. 2018, 32, 547–570. [Google Scholar] [CrossRef]
- Okabe, A.; Okunuki, K.I.; Shiode, S. The SANET toolbox: New methods for network spatial analysis. Trans. GIS 2006, 10, 535–550. [Google Scholar] [CrossRef]
- Okabe, A.; Sugihara, K. Spatial Analysis along Networks: Statistical and Computational Methods, 1st ed.; Wiley: New Jersey, NJ, USA, 2012. [Google Scholar]
- Boissonnat, J.; Devillers, O.; Pion, S.; Teillaud, M.; Boissonnat, J.; Devillers, O.; Pion, S.; Teillaud, M.; Yvinec, M.; Boissonnat, J. Triangulations in CGAL. Comput. Geom. 2007, 22, 5–19. [Google Scholar] [CrossRef] [Green Version]
- Watson, D. Contouring: A Guide to the Analysis and Display of Spatial Data, 1st ed.; Pergamon: Oxford, UK, 1992. [Google Scholar]
- Boeing, G. OSMnx: New methods for acquiring, constructing, analyzing, and visualizing complex street networks. Comput. Environ. Urban Syst. 2017, 65, 126–139. [Google Scholar] [CrossRef] [Green Version]
- Van Soest, D.; Tight, M.R.; Rogers, C.D.F. Exploring the distances people walk to access public transport. Transp. Rev. 2020, 40, 160–182. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cut-off Distance (km) | Average Number of Grid Points in the TCAs | Average Precision | Average Recall | Average F1 Score | ||||
|---|---|---|---|---|---|---|---|---|
| ArcGIS | Ours | ArcGIS | Ours | ArcGIS | Ours | ArcGIS | Ours | |
| 0.8 | 9271 | 10217 | 0.932 | 0.908 | 0.885 | 0.954 | 0.904 | 0.928 |
| 1.0 | 15120 | 16798 | 0.948 | 0.916 | 0.891 | 0.962 | 0.914 | 0.937 |
| 1.2 | 22480 | 25049 | 0.955 | 0.921 | 0.899 | 0.973 | 0.924 | 0.946 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, D.; Zhu, R.; Yang, J.; Meng, L. An Open-Source Framework of Generating Network-Based Transit Catchment Areas by Walking. ISPRS Int. J. Geo-Inf. 2020, 9, 467. https://doi.org/10.3390/ijgi9080467
Lin D, Zhu R, Yang J, Meng L. An Open-Source Framework of Generating Network-Based Transit Catchment Areas by Walking. ISPRS International Journal of Geo-Information. 2020; 9(8):467. https://doi.org/10.3390/ijgi9080467
Chicago/Turabian StyleLin, Diao, Ruoxin Zhu, Jian Yang, and Liqiu Meng. 2020. "An Open-Source Framework of Generating Network-Based Transit Catchment Areas by Walking" ISPRS International Journal of Geo-Information 9, no. 8: 467. https://doi.org/10.3390/ijgi9080467
APA StyleLin, D., Zhu, R., Yang, J., & Meng, L. (2020). An Open-Source Framework of Generating Network-Based Transit Catchment Areas by Walking. ISPRS International Journal of Geo-Information, 9(8), 467. https://doi.org/10.3390/ijgi9080467