
Tomato Leaf Disease Recognition on Leaf Images Based on Fine-Tuned Residual Neural Networks



Abstract
:1. Introduction
- A double form of data augmentation, using image transformations and the implementation of CutMix as a secondary form of data augmentation for model generalization.
- The effect of the train/test data split size ratio of our dataset on the network model for disease recognition on tomato leaf images. Train/test data split ratios of sizes 40/60, 50/50, 60/40, 70/30, and 80/20 were adopted and studied.
- The effect of varying batch sizes in training our network to correctly recognize tomato leaf diseases. According to the capacity of the GPU available, batch sizes of 40, 50, 60, 70, 80, 90, and 100 were adopted.
- The role of network depth in the effective recognition of tomato leaf disease. Residual networks with varying depths of 18, 34, 50, 101, and 152 layers were studied.
- The effect of tuning the learning rate while training the network and identification of a threshold to obtain suitable learning rates to effectively train the network to recognize tomato leaf diseases. The implementation of a discriminative learning rate for efficient training of residual models.
2. Related Work
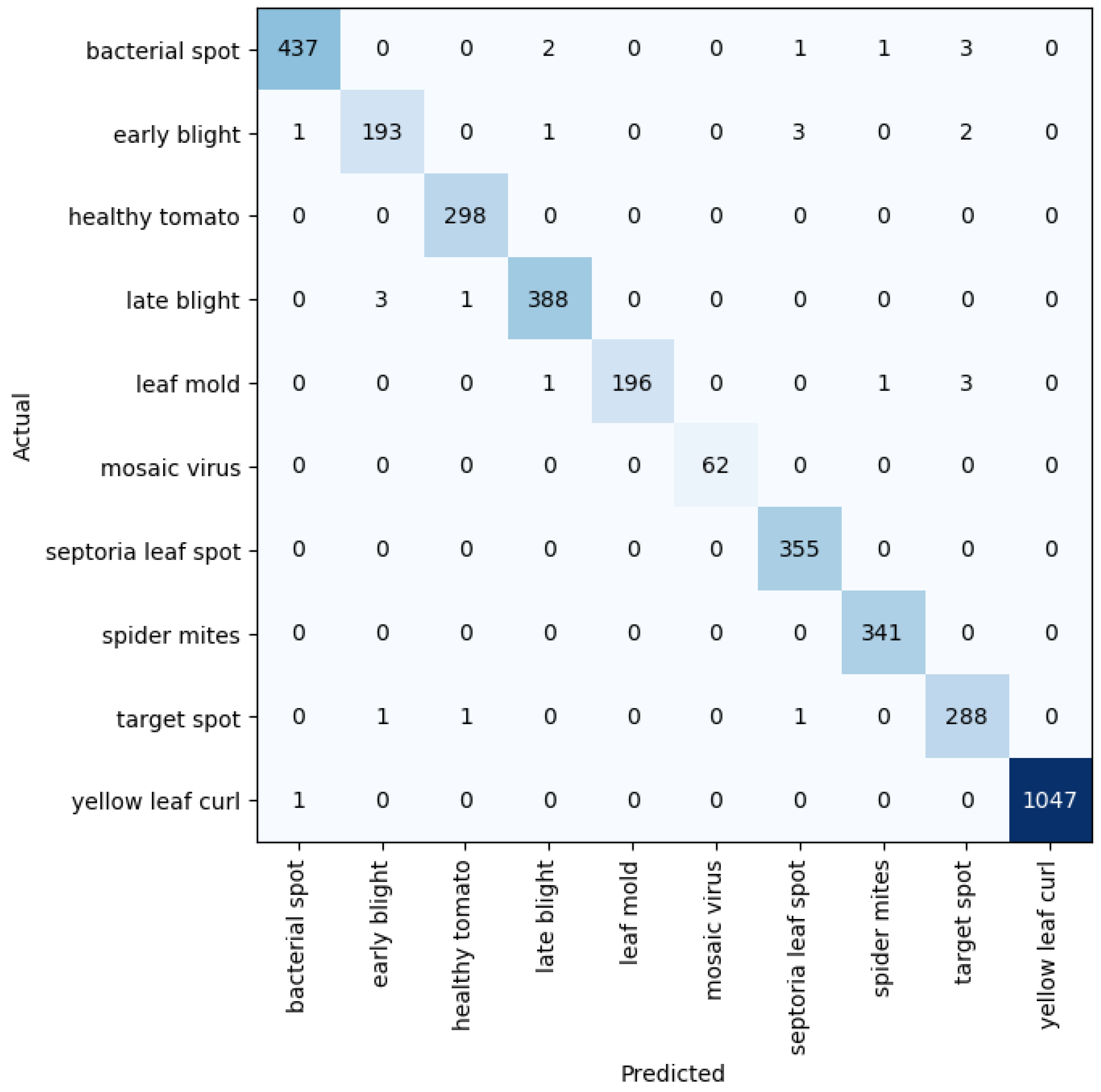
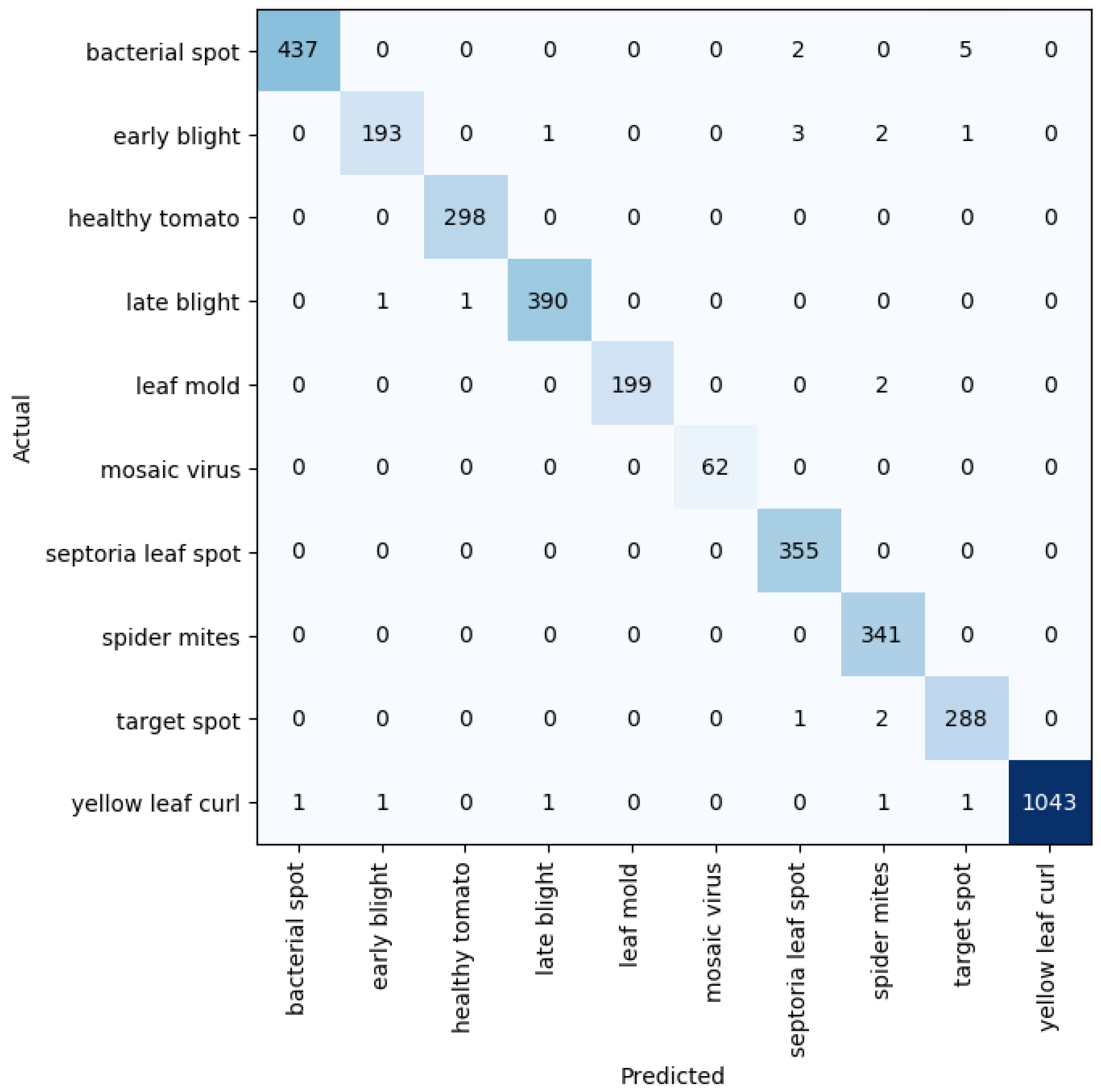
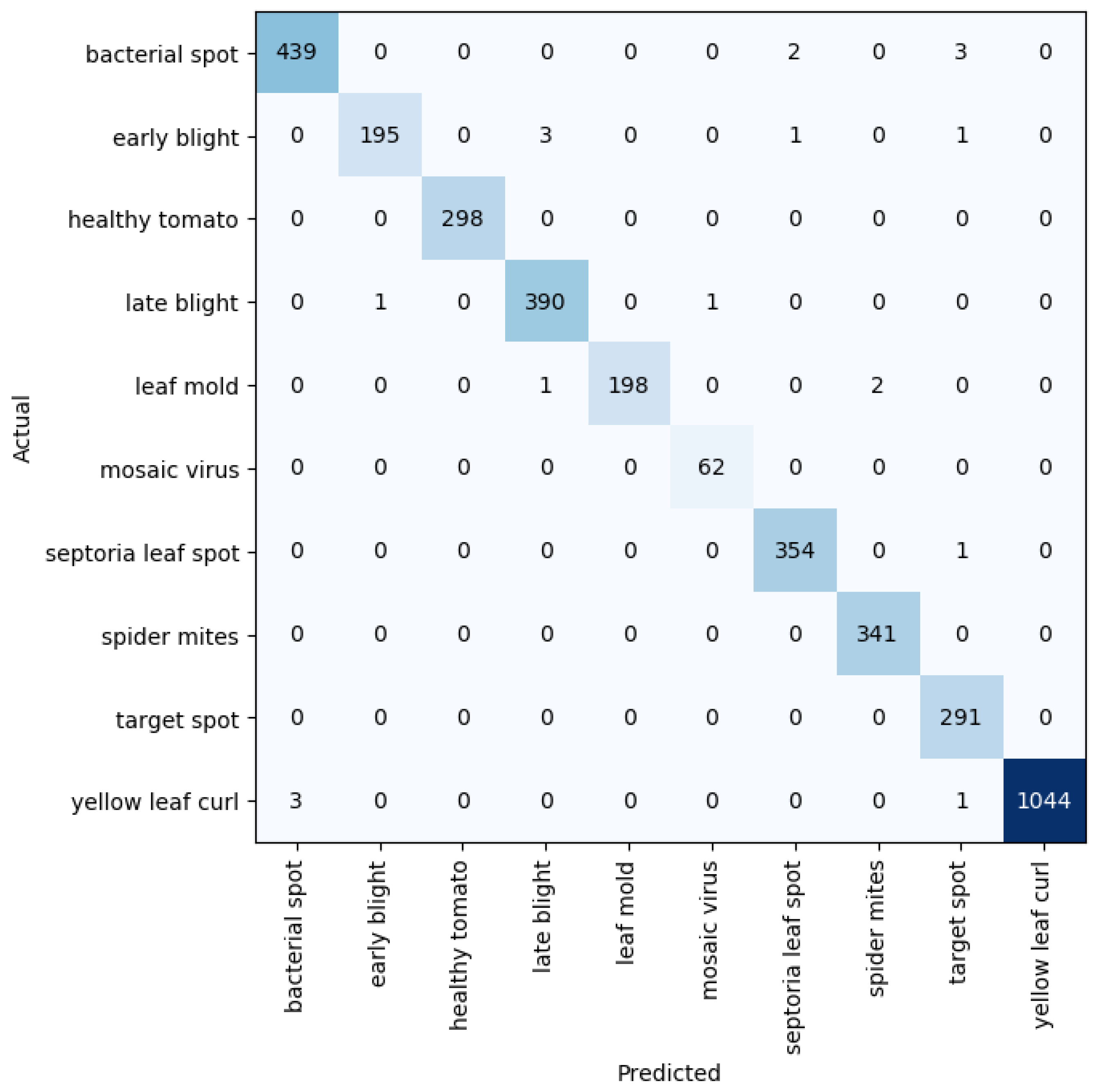
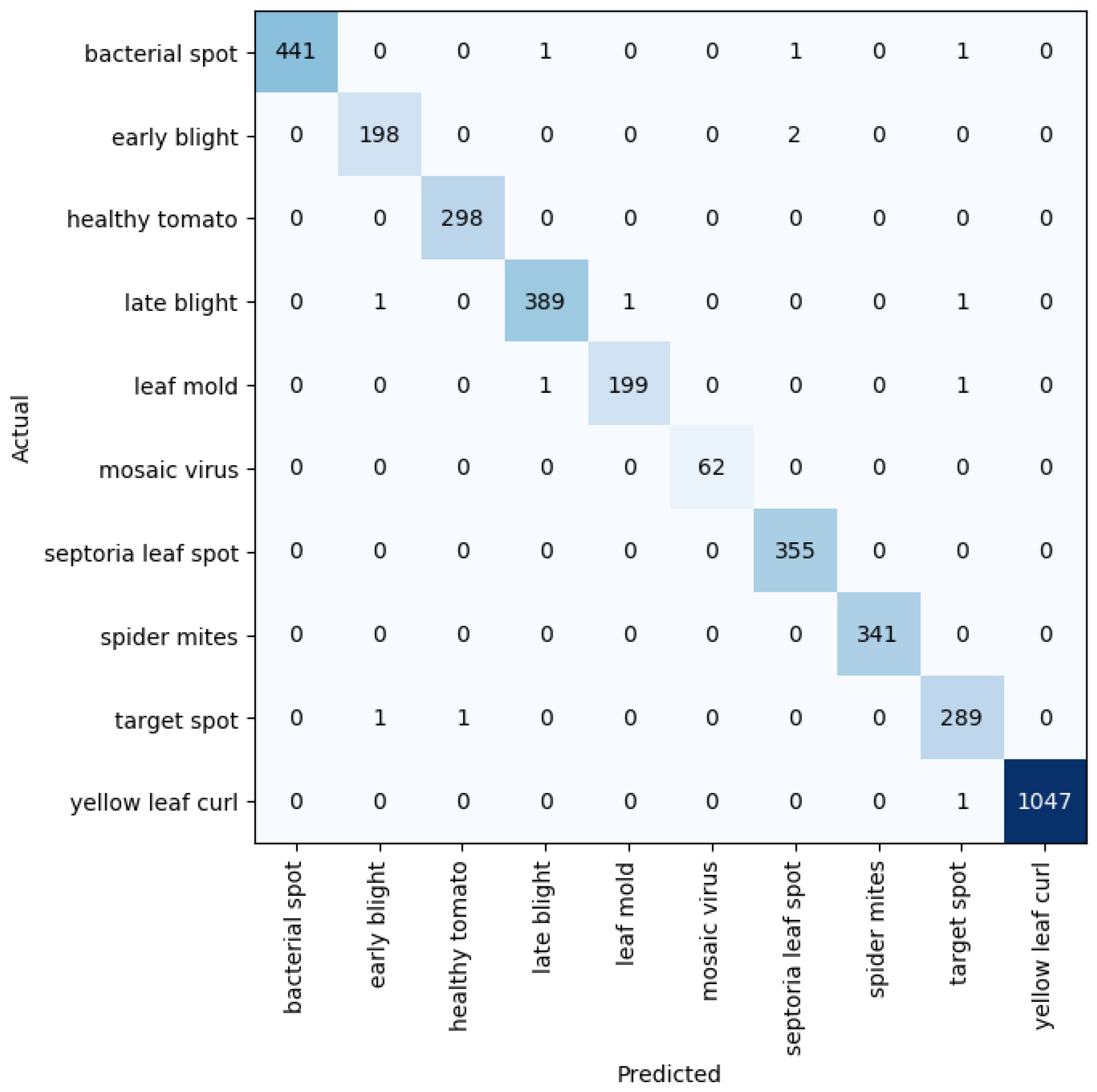
3. Evaluation Metrics, Results, and Discussion
3.1. Evaluation Metrics
- Accuracy: Accuracy is the number of right predictions that are made by the model with respect to the total number of predictions that were made. It is mathematically represented by Equation (1).
- Precision: Precision is defined as the number of true positive results (TP) divided by the number of positive results (TP + FP) that are predicted by the model. The range of the precision is between 0 and 1 and is calculated using Equation (2). It is used to find the proportion of positive identifications that is true.
- Recall: The recall is the number of true positives (TP) divided by the number of all relevant sample data (TP + FN). Equation (3) represents the mode of calculation of the recall. It is used to determine the proportion of actual positives that were correctly identified. These concepts are represented mathematically by Equations (2) and (3), respectively:
- F1 Score: Being one of the widely used metrics for the performance evaluation of machine learning algorithms, the F1 score is the harmonic mean of precision and recall. The range of the F1 score is between 0 and 1, and it is calculated as shown by Equation (4). It reflects the number of instances that are correctly classified by the learning model.
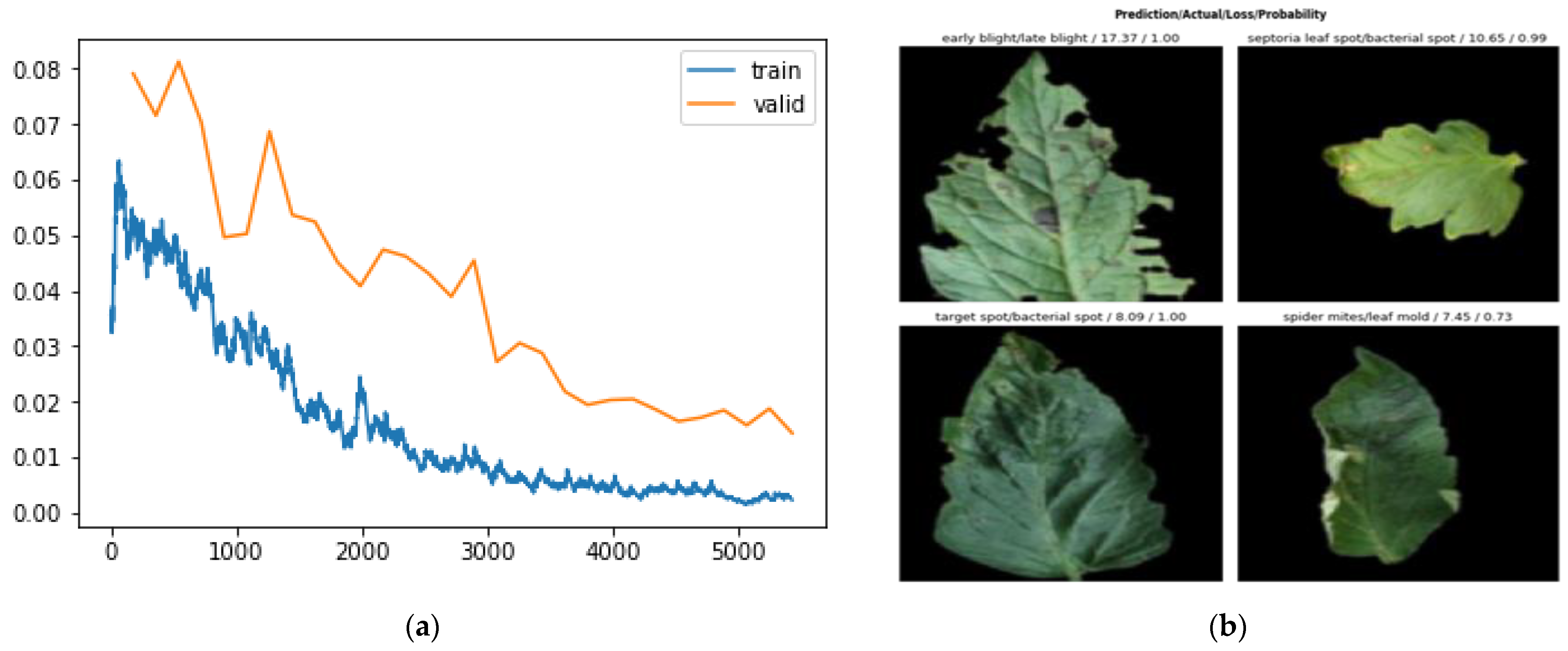
3.2. Results and Discussion
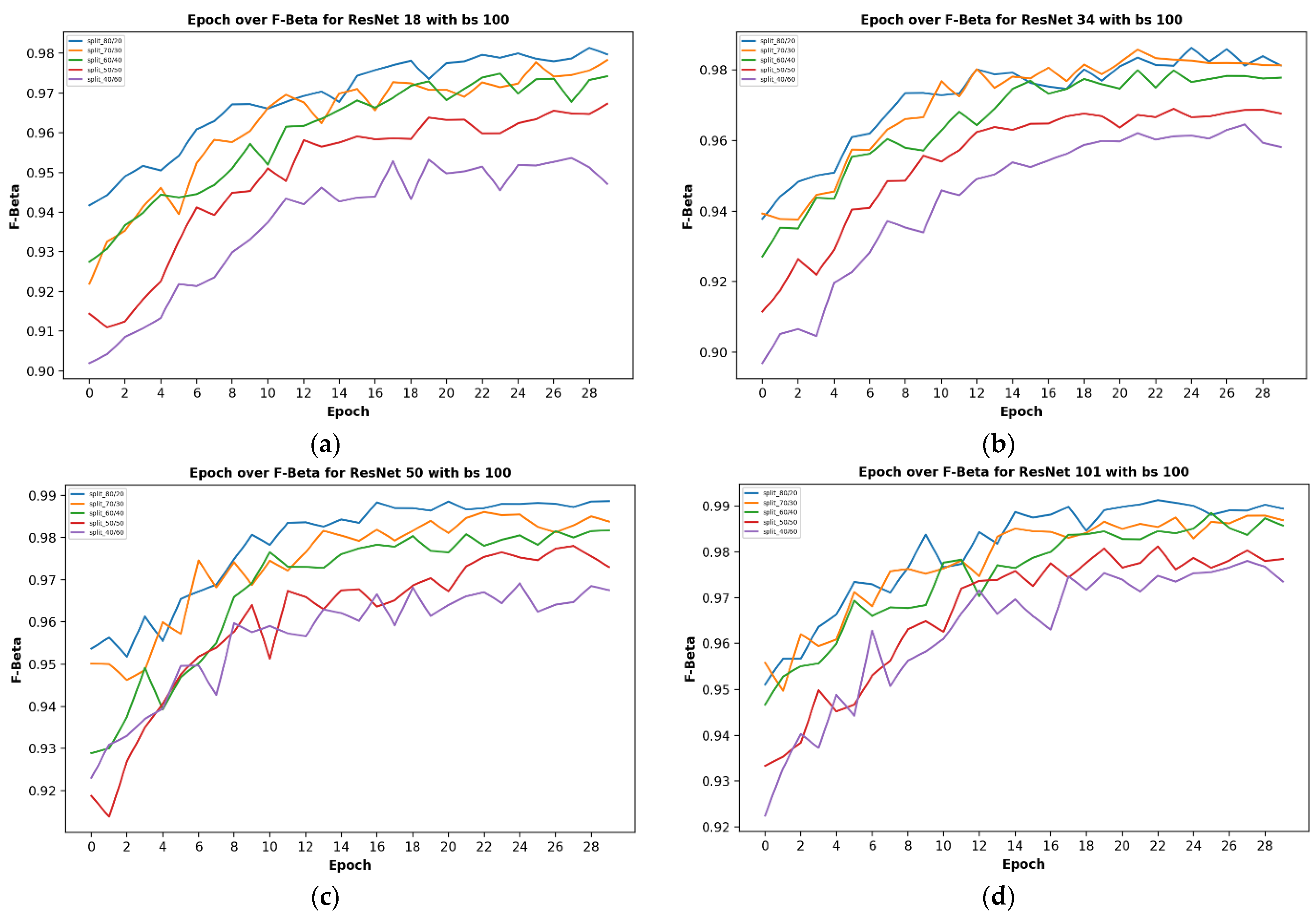
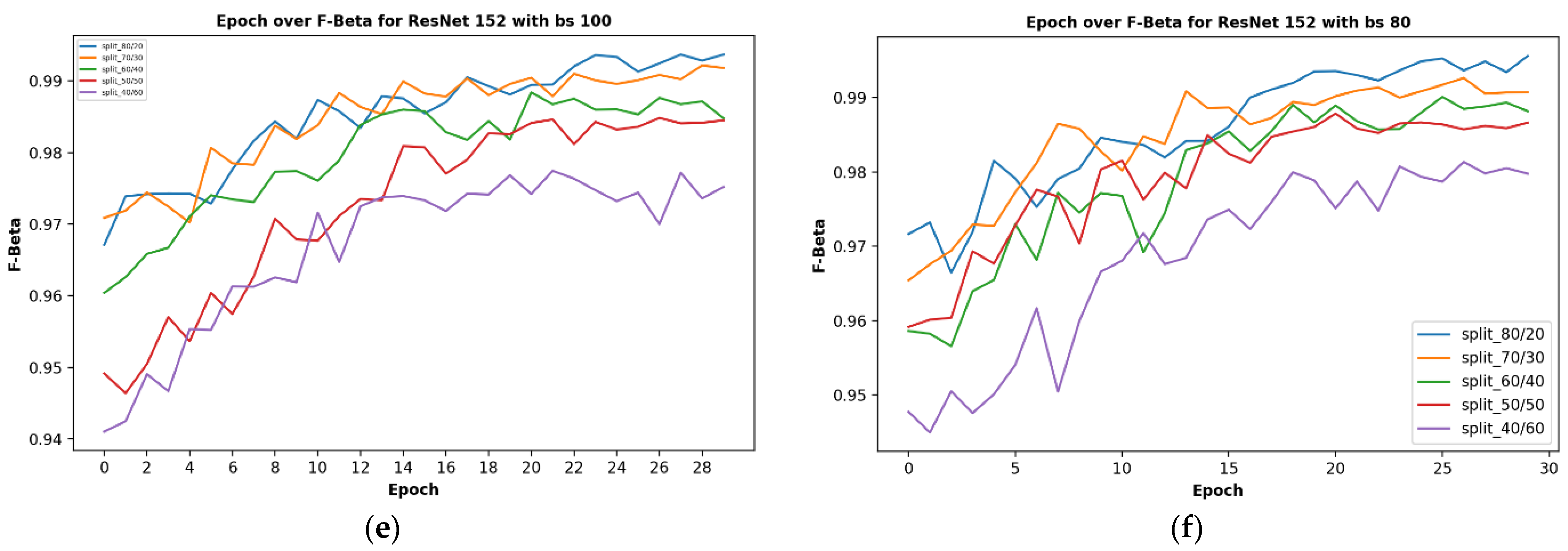
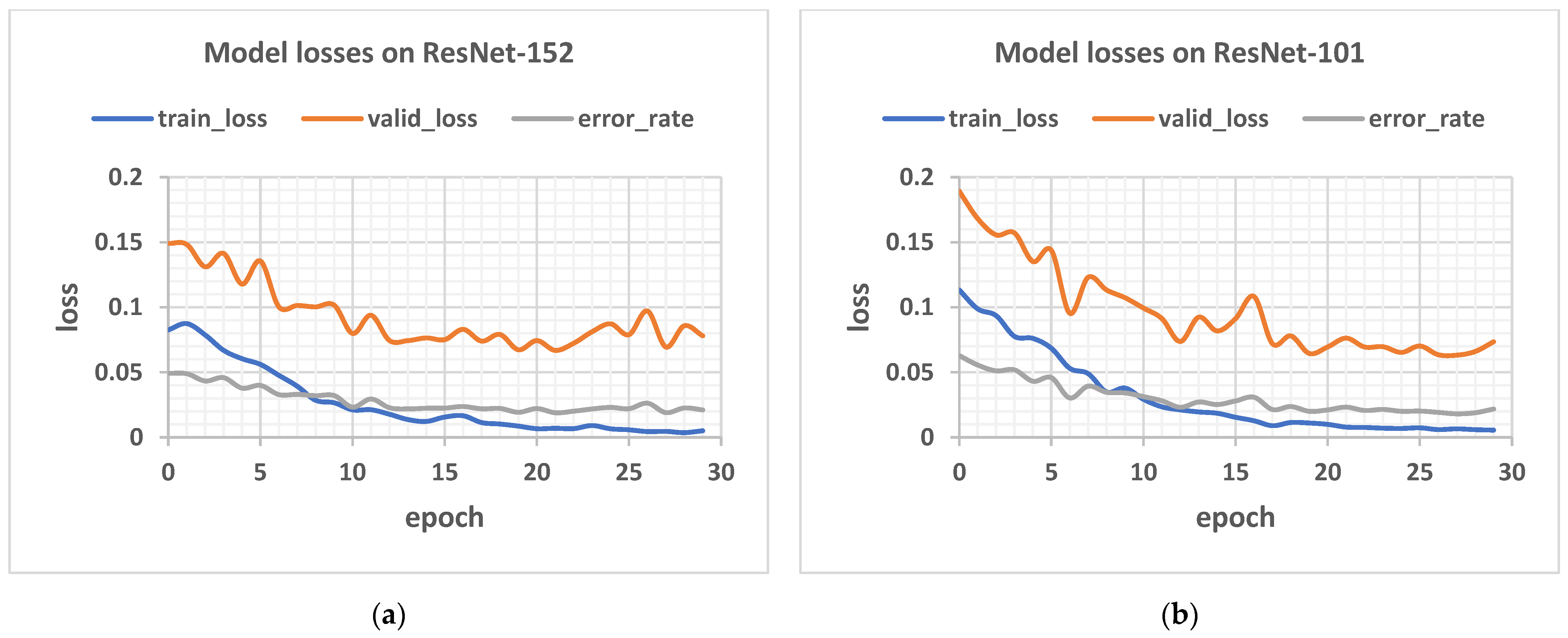
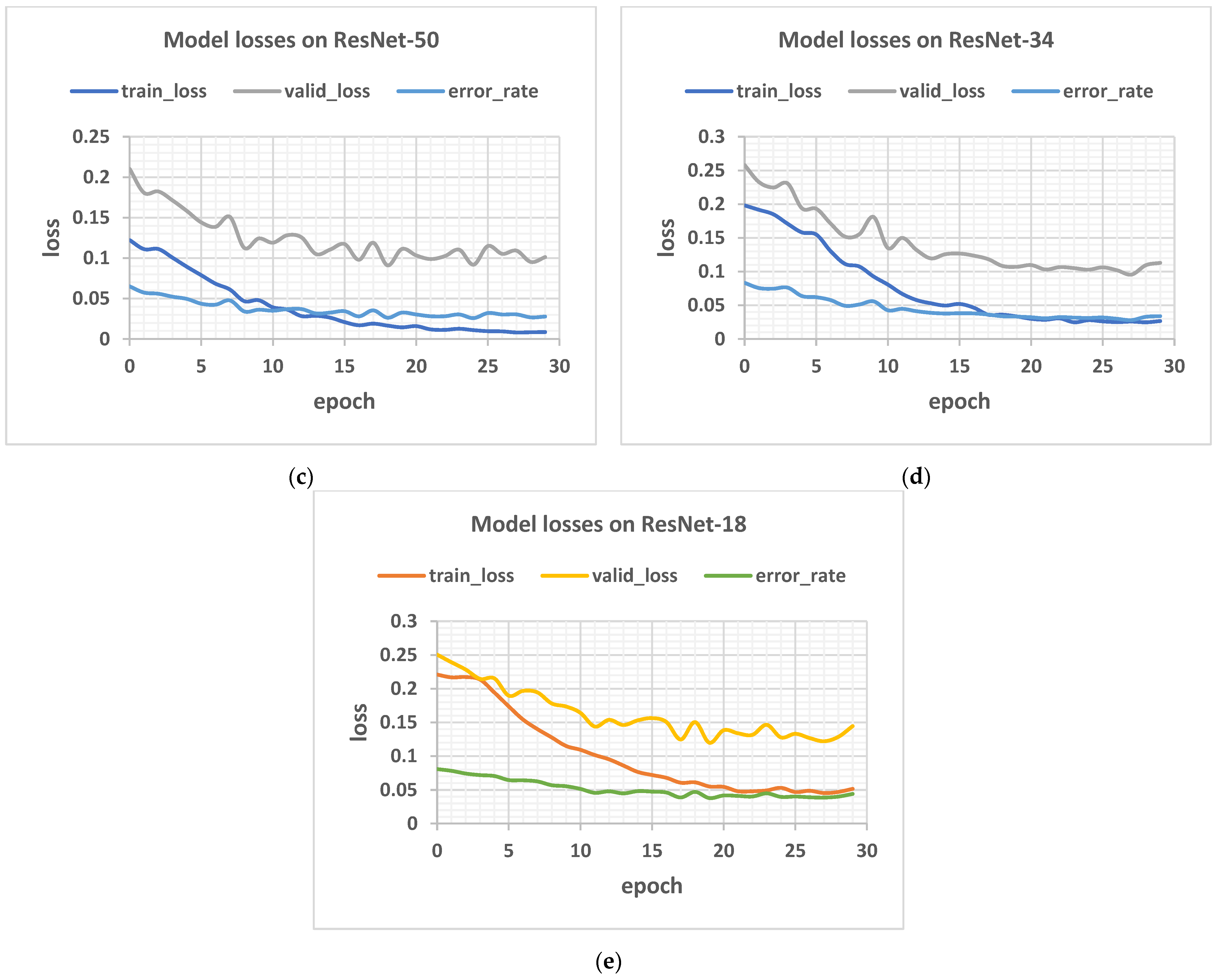
3.2.1. Results on Varied Network Depth
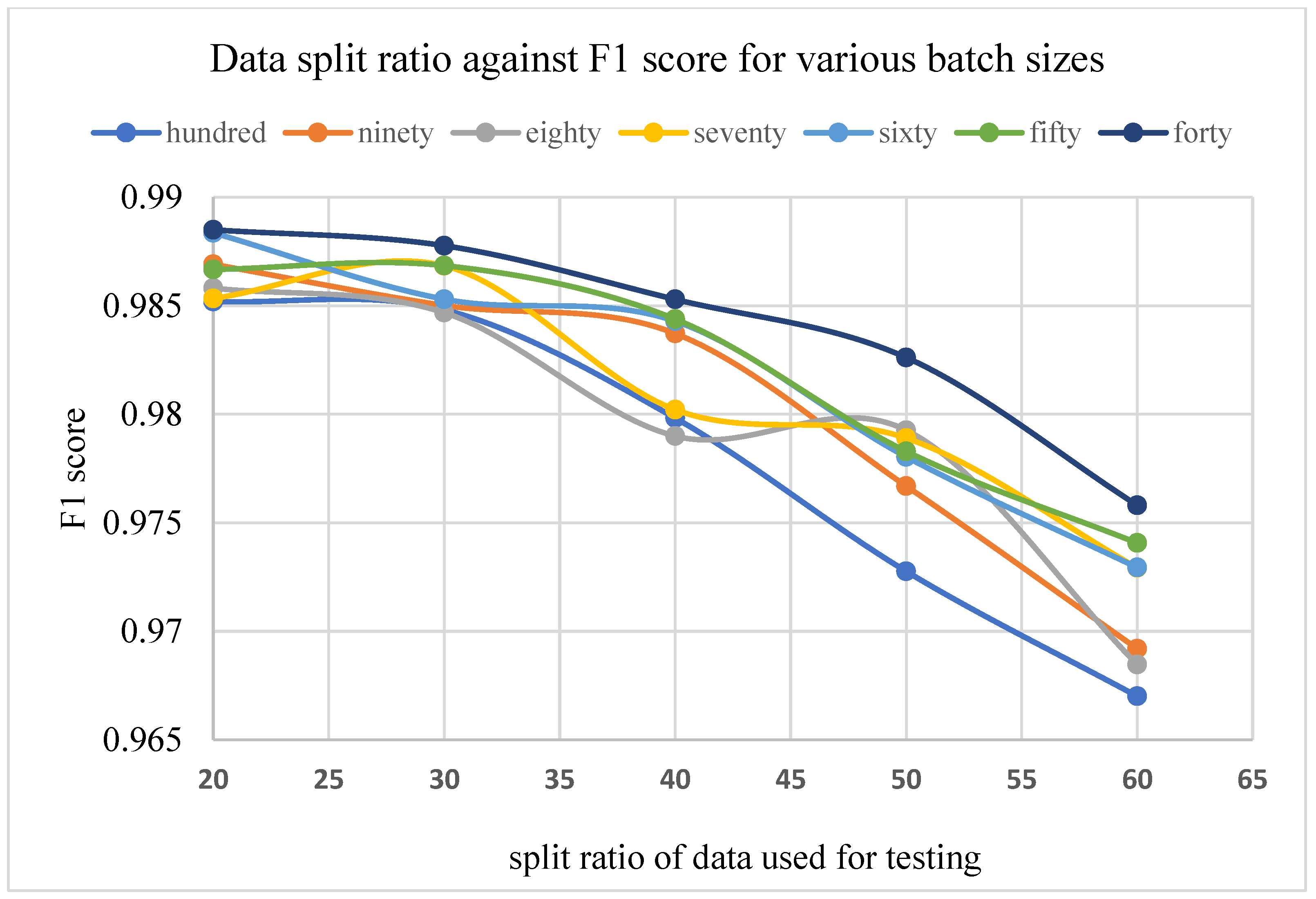
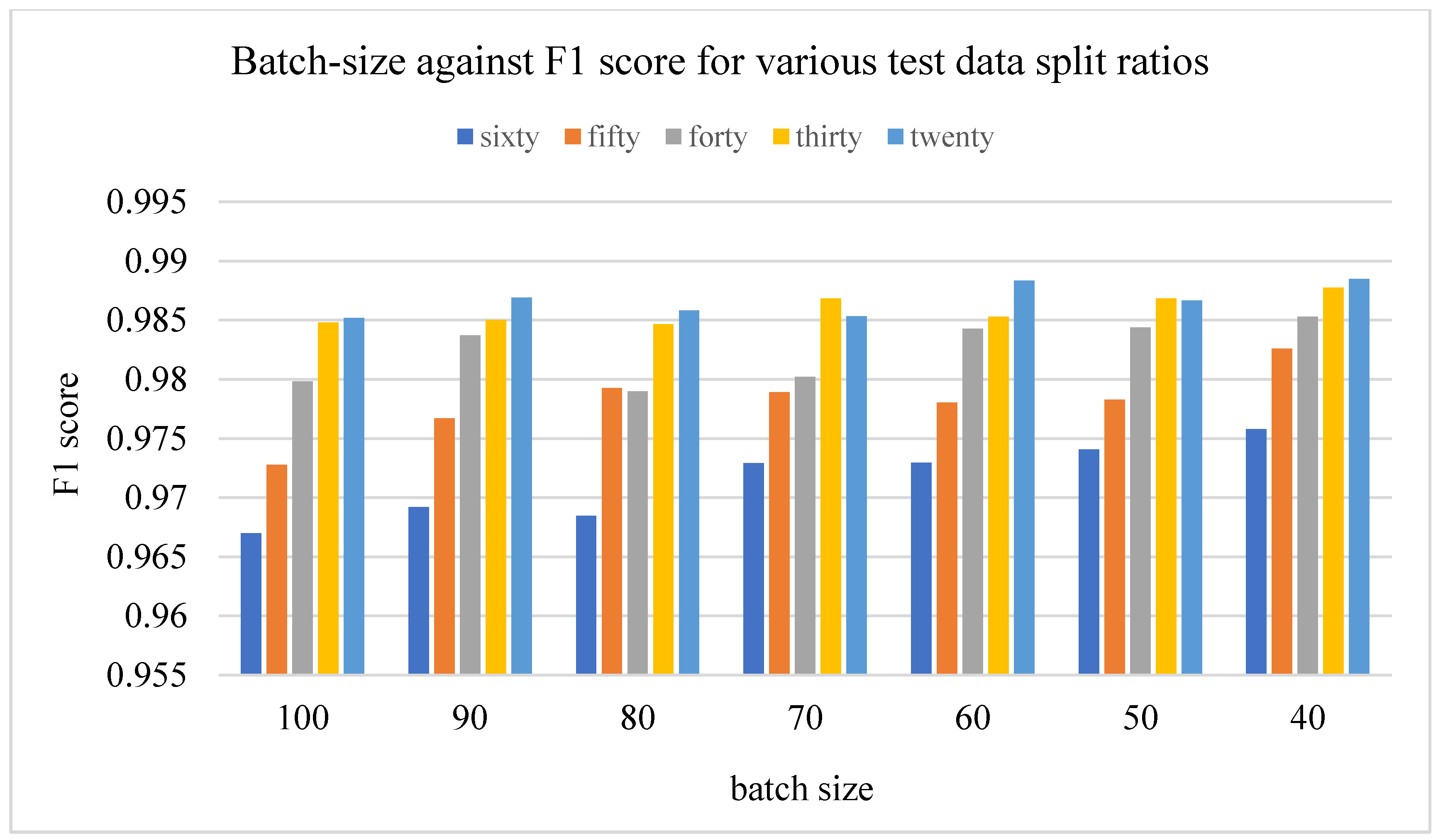
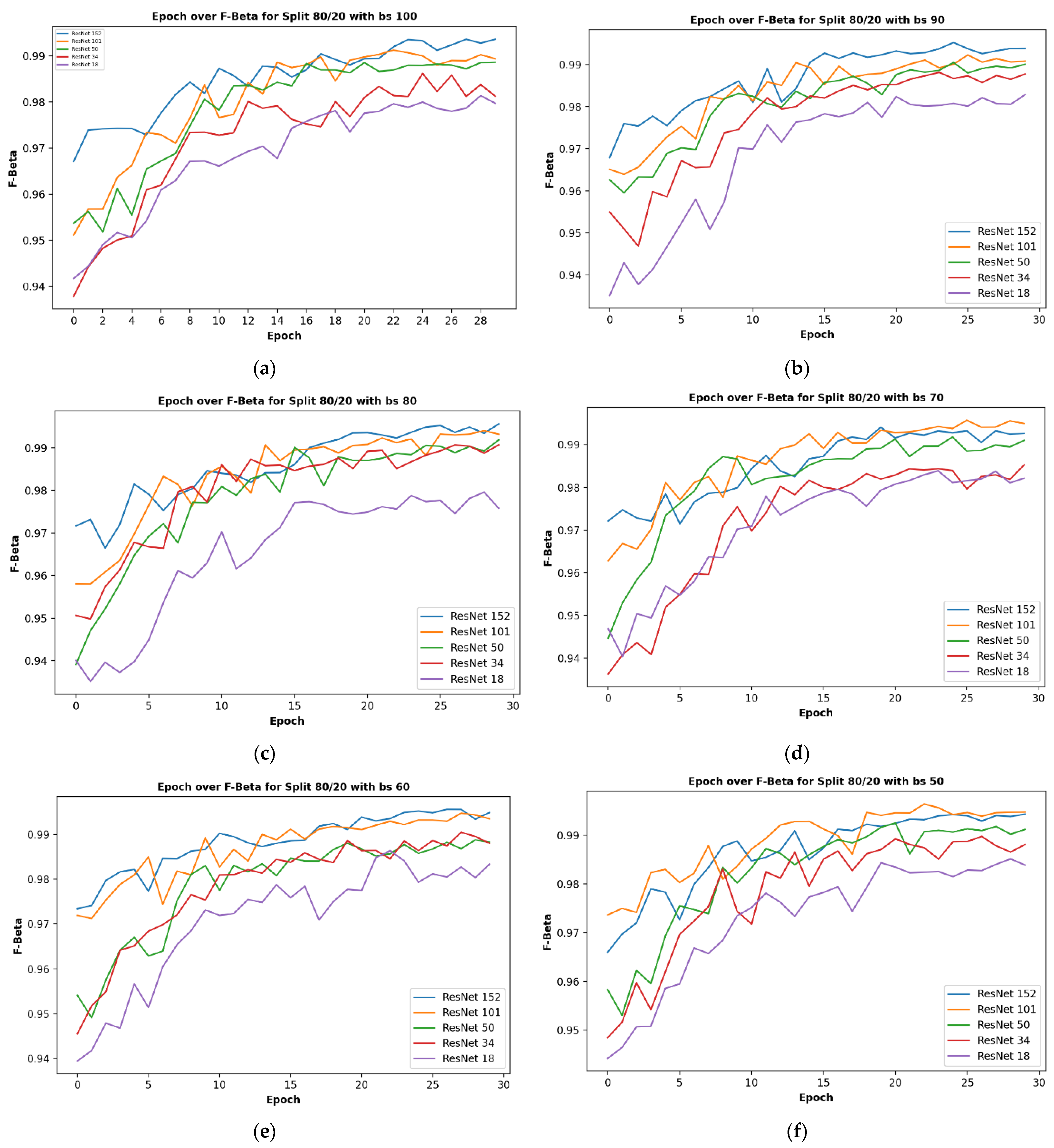
3.2.2. Results on Varied Train-Validation Data Split Ratios
3.2.3. Results on Different Batch Sizes
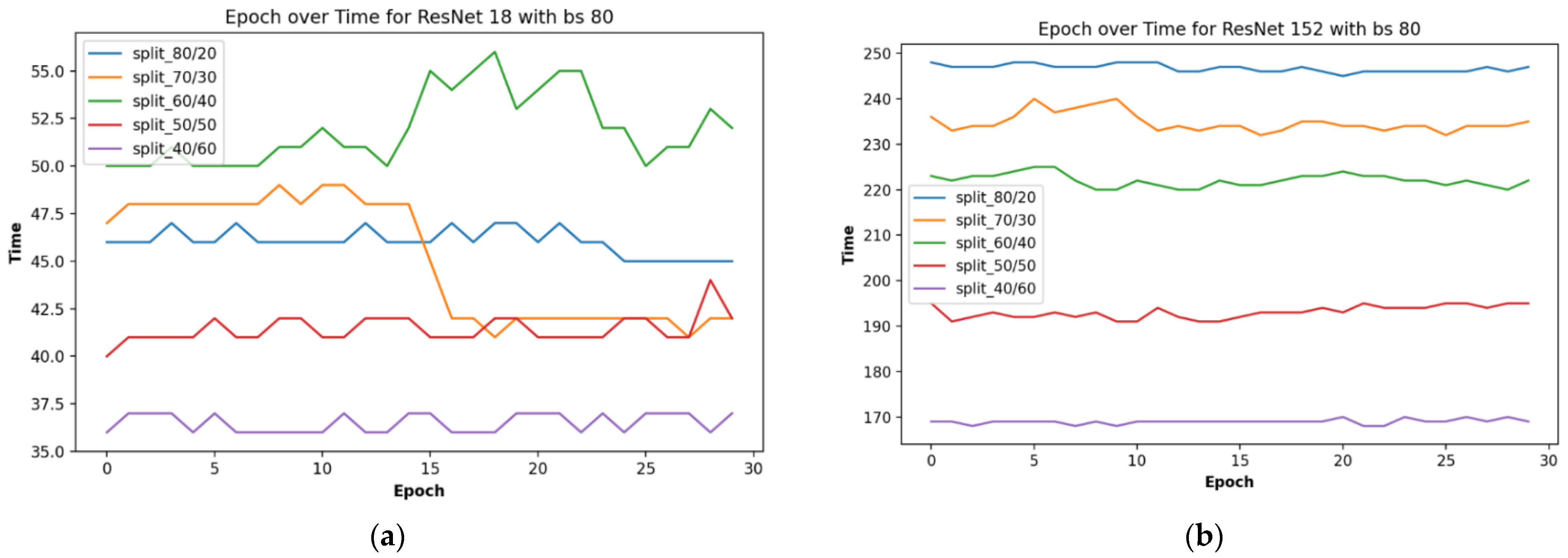
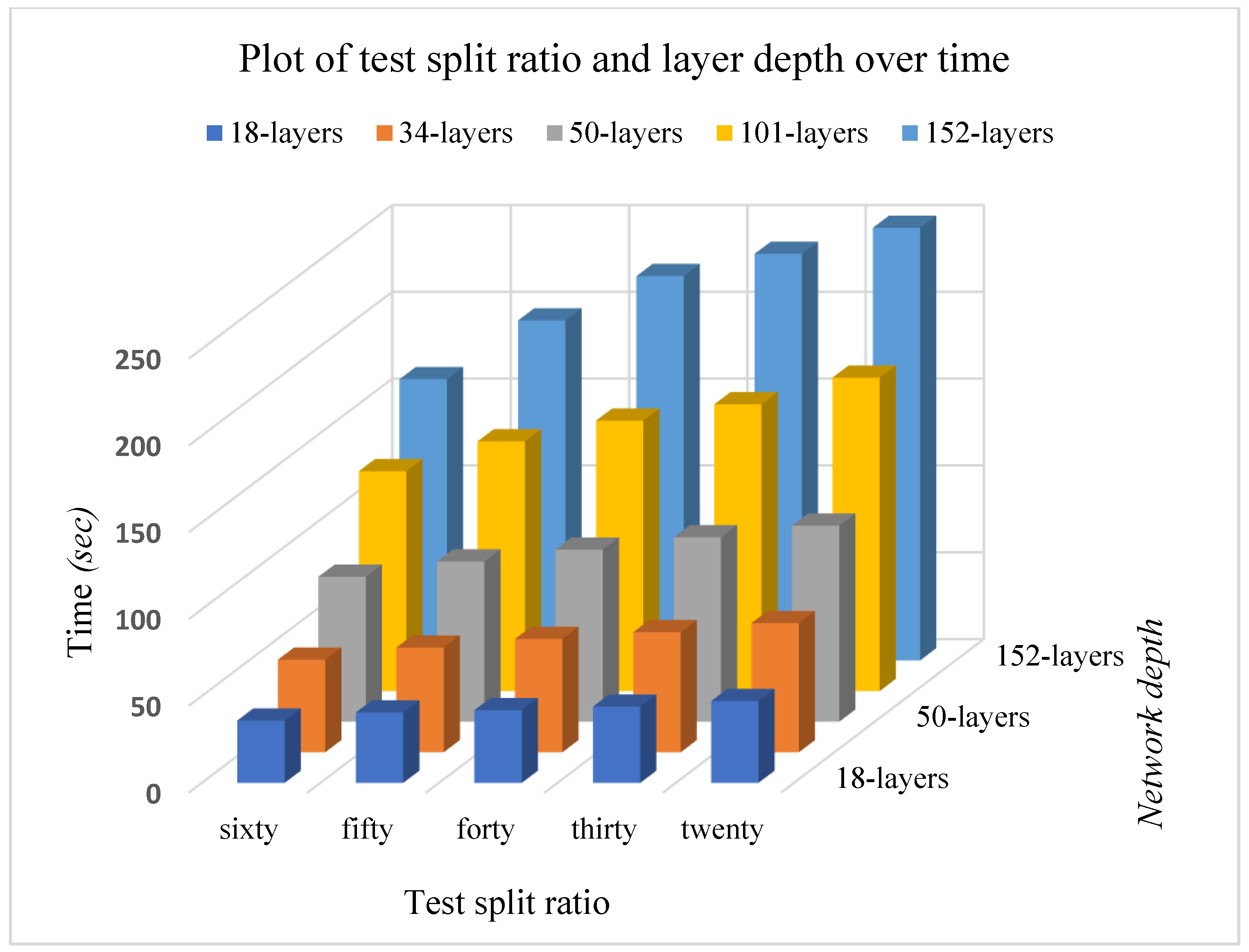
3.2.4. Results on Computing Time
3.2.5. Benchmark against Other Models
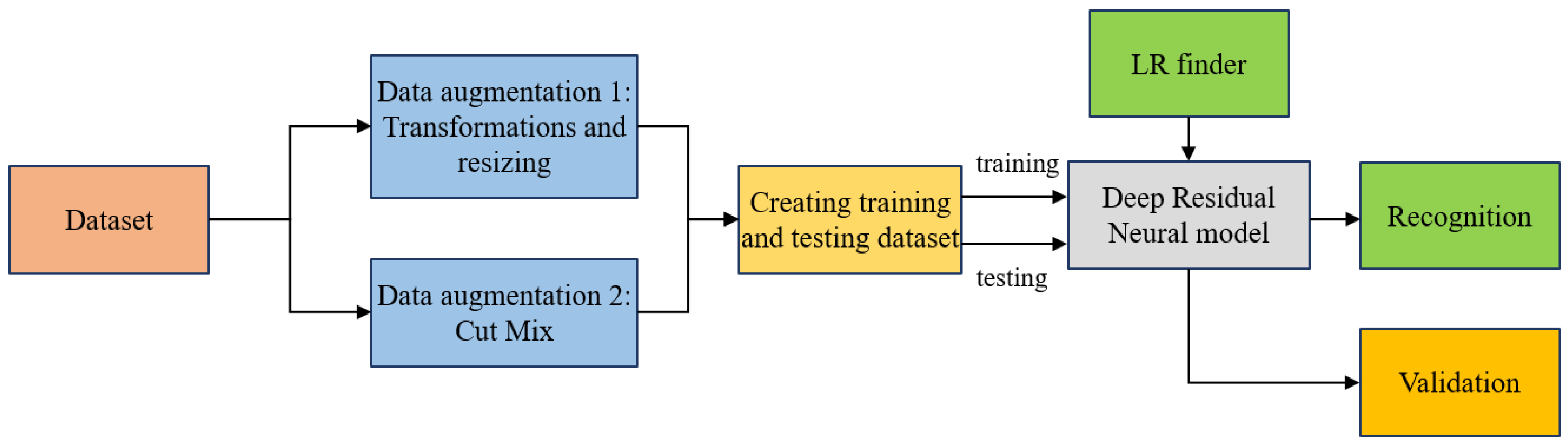
4. Materials and Methods
4.1. Data Acquisition and Pre-Processing
4.1.1. Datasets
- The Flavia leaf dataset
- 2.
- The tomato leaf dataset
- Early blight is a fungal infection, and symptoms start as oval-shaped lesions with a yellow chlorotic region across the lesion; concentric leaf lesions may be seen on infected leaves.
- Late blight, being another fungal infection, affects all aerial parts of the tomato plant; initial symptoms of the disease appear as water-soaked green to black areas on leaves which rapidly change to brown lesions; fluffy white fungal growth may appear on infected areas and leaf undersides during wet weather.
- The leaf spot is another fungal infection. Infected plants exhibit bronzing or purpling of the upper sides of young leaves and develop necrotic spots; leaf spots may resemble those caused by bacterial spots, but a bacterial ooze test will be negative; leaves may cup downwards, and shoot tips may begin to die back.
- Septoria leaf spot is yet another fungal disease. Symptoms may occur at any stage of tomato development and begin as small, water-soaked spots or circular grayish-white spots on the underside of older leaves; spots have a grayish center and a dark margin, and they may coalesce.
- Leaf mold is still another fungal infection. The older leaves exhibit pale greenish to yellow spots (without distinguishable margins) on the upper surface, whereas, the lower portion of these spots exhibits green to brown velvety fungal growth. As the disease progresses, the spots may coalesce and appear brown. The infected leaves wither and die but stay attached to the plant.
- Bacterial spots are bacterial diseases, and lesions start as small water-soaked spots; lesions become more numerous and coalesce to form necrotic areas on the leaves giving them a blighted appearance; leaves drop from the plant, and severe defoliation can occur leaving the fruit susceptible to sunscald; mature spots have a greasy appearance and may appear transparent when held up to a light source; centers of lesions dry up and fall out of the leaf; blighted leaves often remain attached to the plant and give it a blighted appearance.
- Spider mites (two-spotted spider mites). Leaves stippled with yellow; leaves may appear bronzed; webbing covering leaves; mites may be visible as tiny moving dots on the webs or underside of leaves, best viewed using a hand lens; usually not spotted until there are visible symptoms on the plant; leaves turn yellow and may drop from the plant.
- Target spot is also caused by a fungus. The fungus infects all parts of the plant. Infected leaves show small, pinpoint, water-soaked spots initially. As the disease progresses, the spots enlarge to become necrotic lesions with conspicuous concentric circles, dark margins, and light brown centers. Whereas the fruits exhibit brown, slightly sunken flecks in the beginning, later the lesions develop a large, pitted appearance.
- Tomato mosaic virus is a viral infection. Symptoms can occur at any growth stage and any part of the plant can be affected; infected leaves generally exhibit a dark green mottling or mosaic; some strains of the virus can cause yellow mottling on the leaves; young leaves may be stunted or distorted; severely infected leaves may have raised green areas; dark necrotic streaks may appear on the petioles’ leaves.
- Tomato yellow leaf curl disease is another viral infection. The infected leaves become reduced in size, curl upward, appear crumpled, and show yellowing of veins and leaf margins.
4.1.2. Data Pre-Processing
- 1.
- Data Augmentation 1—Image Transformations
- 2.
- Data Augmentation 2—CutMix
4.2. Our Proposed Method
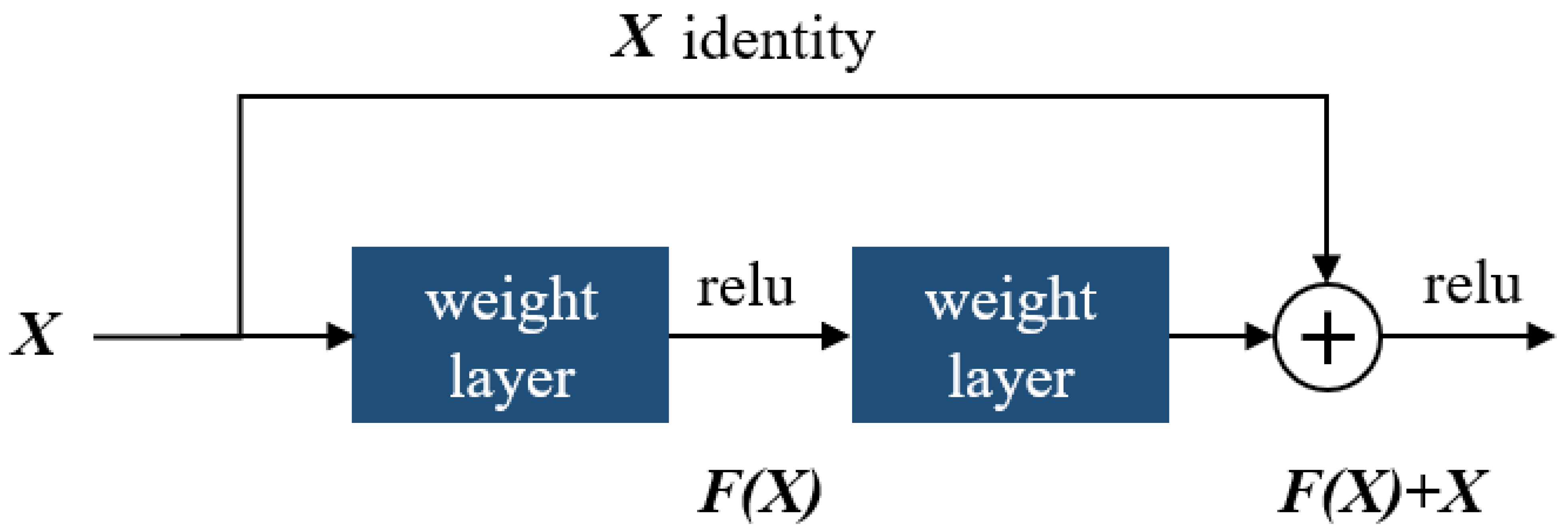
4.2.1. Convolutional Neural Networks
- 1.
- Convolutional Layer
- 2.
- Pooling Layer
- 3.
- Fully Connected Layer
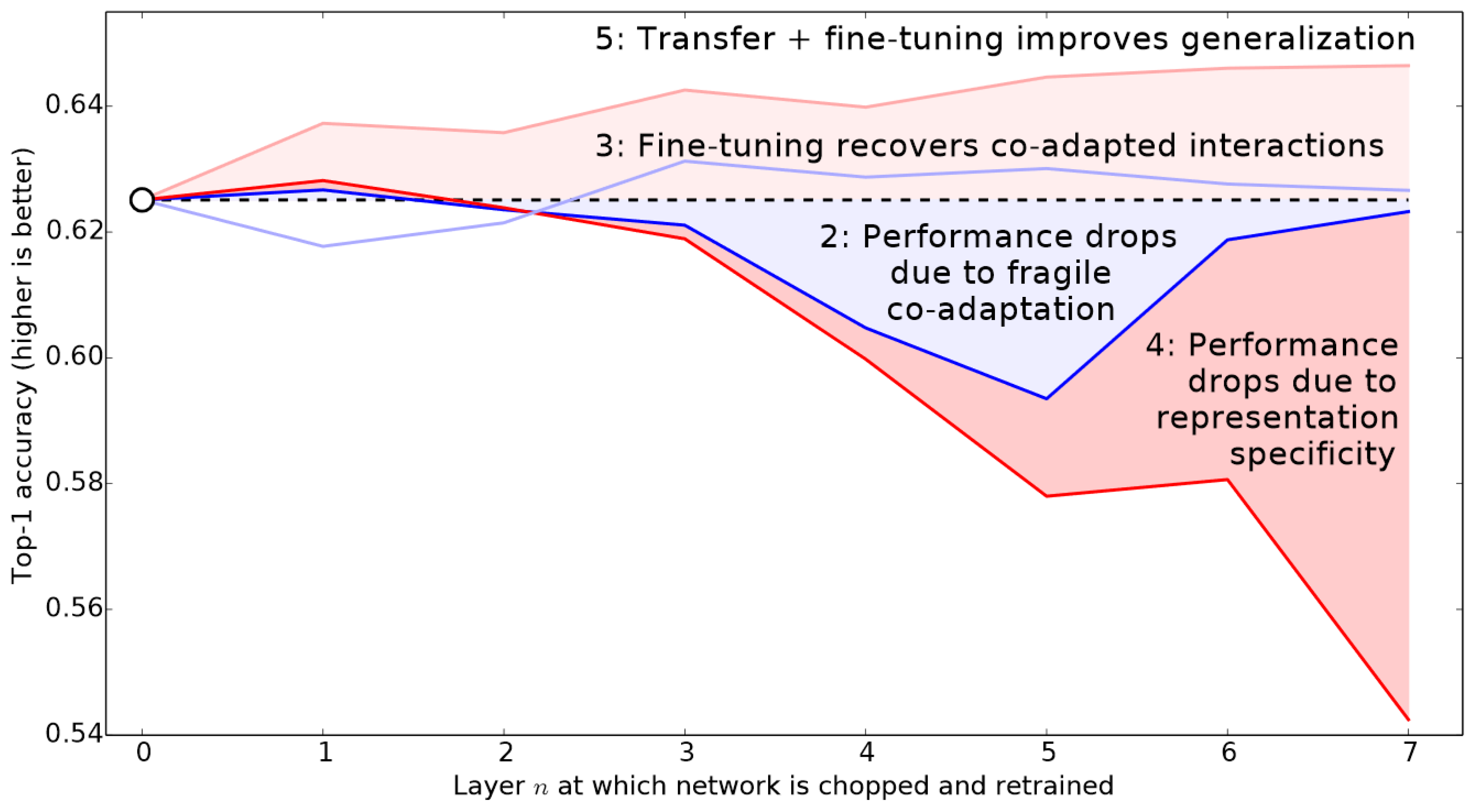
4.2.2. Transfer Learning Approach
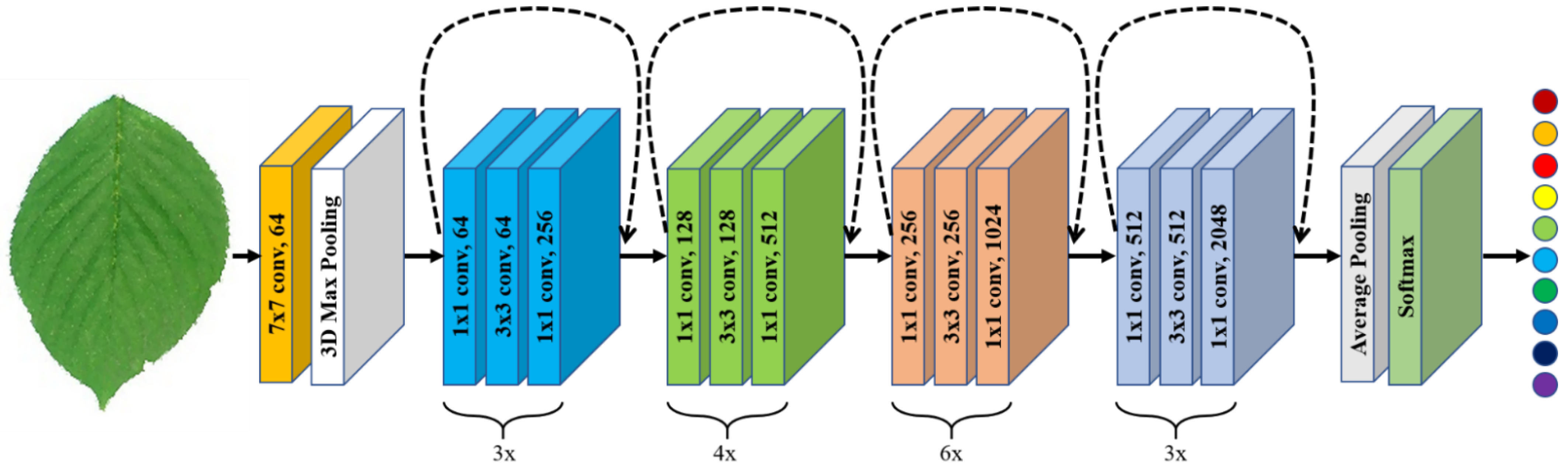
4.2.3. Overall Architecture of the Proposed Method
- To research the role of depth on the performance of such models, various residual convolutional neural networks, having different layers, such as ResNet-18, ResNet-34, ResNet-50, ResNet-102, and ResNet-152 were tested.
- Various train/test data split ratios were experimented on to determine the optimum value of the train/test split ratio for such a research area.
- Different batch sizes were selected based on the capacity of the GPU system obtainable in the laboratory to test for the influence of batch size on the training and if so on the result of the training and test processes of the model.
- The discriminative learning process was studied to determine the best learning rates to select in re-training the various models to achieve an optimal training process from one domain of data to a new domain of datasets: specific to this research is the tomato plant leaf dataset for disease recognition.
4.3. Training Procedure
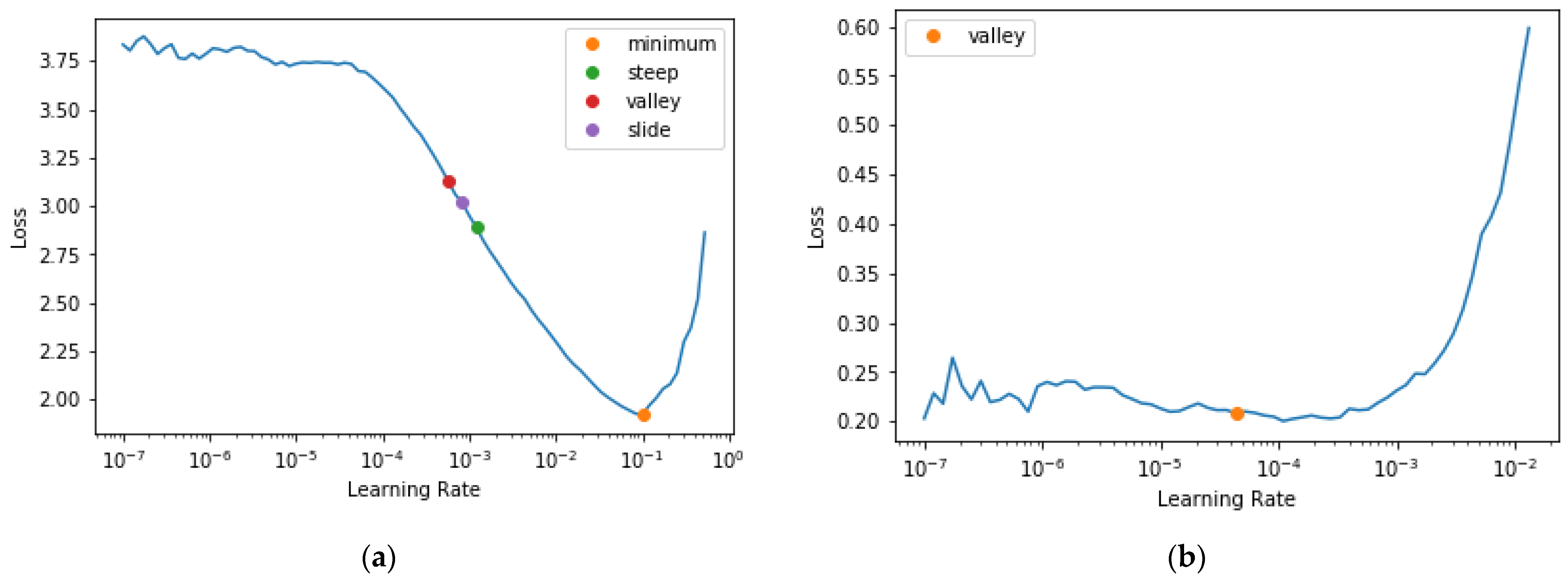
4.3.1. Tuning the Learning Rate Schedule
4.3.2. Unfreezing and Re-Tuning the Learning Rate Schedule
4.4. Experimental Setup
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hughes, D.P.; Salathe, M. An Open Access Repository of Images on Plant Health to Enable the Development of Mobile Disease Diagnostics. arXiv 2015, arXiv:1511.08060. [Google Scholar]
- Food and Agriculture Organization of the United Nations. Plant Pests and Diseases. Available online: https://www.fao.org/emergencies/emergency-types/plant-pests-and-diseases/en/ (accessed on 13 November 2021).
- FAOSTAT. 2019. Available online: http://www.fao.org/faostat/en/#data/QC (accessed on 13 November 2021).
- Panno, S.; Davino, S.; Caruso, A.G.; Bertacca, S.; Crnogorac, A.; Mandić, A.; Noris, E.; Matić, S. A Review of the Most Common and Economically Important Diseases That Undermine the Cultivation of Tomato Crop in the Mediterranean Basin. Agronomy 2021, 11, 2188. [Google Scholar] [CrossRef]
- Das, S. Over View of Septoria Diseases on Different Crops and Its Management. Int. J. Agric. Environ. Biotechnol. 2020, 13, 361–370. [Google Scholar] [CrossRef]
- Gilardi, G.; Matic, S.; Guarnaccia, V.; Garibaldi, A.; Gullino, M.L. First Report of Fusarium Clavum Causing Leaf Spot and Fruit Rot on Tomato in Italy. Plant Dis. 2021, 105, 2250. [Google Scholar] [CrossRef]
- Infantino, A.; Loreti, S. Malattie. In Il Pomodoro; Angelini, R., Ed.; Collana Coltura & Cultura, Bayer CropScience: Bologna, Italy, 2010; pp. 194–219. [Google Scholar]
- Barba, M.; Martelli, G.; Tomassoli, L.; Galllitelli, D.; Di Serio, F.; Pasquini, G. Virosi e Fitoplasmosi. In Proceedings of the AA.VV. Il Pomodoro; Bayer CropScience: Bologna, Italy, 2010; pp. 220–235. [Google Scholar]
- Zaagueri, T.; Mnari-Hattab, M.; Moussaoui, N.; Accotto, G.P.; Noris, E.; Marian, D.; Vaira, A.M. Chickpea Chlorotic Dwarf Virus Infecting Tomato Crop in Tunisia. Eur. J. Plant Pathol. 2019, 154, 1159–1164. [Google Scholar] [CrossRef]
- Williams’, C.E.; Clair, D.A.S.; Williams, C.E.; St, N.D.; Clair, D.A. Phenetic Relationships and Levels of Variability Detected by Restriction Fragment Length Polymorphism and Random Amplified Polymorphic DNA Analysis of Cultivated and Wild Accessions of Lycopersicon Esculentum. Genome 2011, 36, 619–630. [Google Scholar] [CrossRef]
- Bai, Y.; Im, P.; In, L.; Ut, D.O. Domestication and Breeding of Tomatoes: What Have We Gained and What Can We Gain in the Future? Ann. Bot. 2007, 100, 1085–1094. [Google Scholar] [CrossRef]
- Blanca, J.; Montero-Pau, J.; Sauvage, C.; Bauchet, G.; Illa, E.; Díez, M.J.; Francis, D.; Causse, M.; van der Knaap, E.; Cañizares, J. Genomic Variation in Tomato, from Wild Ancestors to Contemporary Breeding Accessions. BMC Genom. 2015, 16, 257. [Google Scholar] [CrossRef] [Green Version]
- King, K.C.; Lively, C.M. Does Genetic Diversity Limit Disease Spread in Natural Host Populations? Heredity 2012, 109, 199–203. [Google Scholar] [CrossRef] [Green Version]
- Singh, V.K.; Singh, A.K.; Kumar, A. Disease Management of Tomato through PGPB: Current Trends and Future Perspective. 3 Biotech 2017, 7, 255. [Google Scholar] [CrossRef]
- Khirade, S.D.; Patil, A.B. Plant Disease Detection Using Image Processing. In Proceedings of the 2015 International Conference on Computing Communication Control and Automation, Pune, India, 26–27 February 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 768–771. [Google Scholar]
- Bharate, A.A.; Shirdhonkar, M.S. A Review on Plant Disease Detection Using Image Processing. In Proceedings of the Proceedings of the International Conference on Intelligent Sustainable Systems, ICISS 2017, Palladam, India, 7–8 December 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 103–109. [Google Scholar] [CrossRef]
- Song, Z.; Cai, C.; Yan, Y. Automatic Identification of Grape Varieties Based on Leaf Morphological Characteristics. Comput. Simul. 2012, 29, 307–310. [Google Scholar]
- Wang, L.I.; Shao-Xian, T. Review of Crop Diseases Recognition Based on Image Processing. Hunan Agric. Mach. 2012, 1, 176–178. [Google Scholar]
- Tao, H.; Zhao, L.; Xi, J.; Yu, L.; Wang, T. Fruits and Vegetables Recognition Based on Color and Texture Features. Trans. Chin. Soc. Agric. Eng. 2014, 30, 305–311. [Google Scholar]
- Sladojevic, S.; Arsenovic, M.; Anderla, A.; Culibrk, D.; Stefanovic, D. Deep Neural Networks Based Recognition of Plant Diseases by Leaf Image Classification. Comput. Intell. Neurosci. 2016, 2016, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Zhou, G.; Zhang, W.; Chen, A.; He, M.; Ma, X. Rapid Detection of Rice Disease Based on FCM-KM and Faster R-CNN Fusion. IEEE Access 2019, 7, 143190–143206. [Google Scholar] [CrossRef]
- Durmus, H.; Gunes, E.O.; Kirci, M. Disease Detection on the Leaves of the Tomato Plants by Using Deep Learning. In Proceedings of the 2017 6th International Conference on Agro-Geoinformatics, Fairfax, VA, USA, 7–10 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Antonellis, G.; Gavras, A.G.; Panagiotou, M.; Kutter, B.L.; Guerrini, G.; Sander, A.C.; Fox, P.J. Shake Table Test of Large-Scale Bridge Columns Supported on Rocking Shallow Foundations. J. Geotech. Geoenviron. Eng. 2015, 141, 04015009. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef] [Green Version]
- Rangarajan, A.K.; Purushothaman, R.; Ramesh, A. Tomato Crop Disease Classification Using Pre-Trained Deep Learning Algorithm. Procedia Comput. Sci. 2018, 133, 1040–1047. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Karthik, R.; Hariharan, M.; Anand, S.; Mathikshara, P.; Johnson, A.; Menaka, R. Attention Embedded Residual CNN for Disease Detection in Tomato Leaves. Appl. Soft Comput. 2020, 86, 105933. [Google Scholar] [CrossRef]
- Anand, R.; Veni, S.; Aravinth, J. An Application of Image Processing Techniques for Detection of Diseases on Brinjal Leaves Using K-Means Clustering Method. In Proceedings of the 2016 International Conference on Recent Trends in Information Technology (ICRTIT), Chennai, India, 8–9 April 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, H.; Huang, W.; You, Z. Plant Diseased Leaf Segmentation and Recognition by Fusion of Superpixel, K-Means and PHOG. Optik 2018, 157, 866–872. [Google Scholar] [CrossRef]
- Rani, F.A.P.; Kumar, S.; Fred, A.L.; Dyson, C.; Suresh, V.; Jeba, P. K-Means Clustering and SVM for Plant Leaf Disease Detection and Classification. In Proceedings of the 2019 International Conference on Recent Advances in Energy-Efficient Computing and Communication (ICRAECC), Nagercoil, India, 7–8 March 2019; Fred, A.L., Dyson, C., Suresh, V., Eds.; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Kumari, C.U.; Jeevan Prasad, S.; Mounika, G. Leaf Disease Detection: Feature Extraction with K-Means Clustering and Classification with ANN. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1095–1098. [Google Scholar]
- Liu, B.; Tan, C.; Li, S.; He, J.; Wang, H. A Data Augmentation Method Based on Generative Adversarial Networks for Grape Leaf Disease Identification. IEEE Access 2020, 8, 102188–102198. [Google Scholar] [CrossRef]
- Lv, M.; Zhou, G.; He, M.; Chen, A.; Zhang, W.; Hu, Y. Maize Leaf Disease Identification Based on Feature Enhancement and DMS-Robust Alexnet. IEEE Access 2020, 8, 57952–57966. [Google Scholar] [CrossRef]
- Jiang, D.; Li, F.; Yang, Y.; Yu, S. A Tomato Leaf Diseases Classification Method Based on Deep Learning. In Proceedings of the Proceedings of the 32nd Chinese Control and Decision Conference, CCDC 2020, Hefei, China, 22–24 August 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; pp. 1446–1450. [Google Scholar] [CrossRef]
- Waheed, A.; Goyal, M.; Gupta, D.; Khanna, A.; Hassanien, A.E.; Pandey, H.M. An Optimized Dense Convolutional Neural Network Model for Disease Recognition and Classification in Corn Leaf. Comput. Electron. Agric. 2020, 175, 105456. [Google Scholar] [CrossRef]
- Huang, S.; Liu, W.; Qi, F.; Yang, K. Development and Validation of a Deep Learning Algorithm for the Recognition of Plant Disease. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Zhangjiajie, China, 10–12 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1951–1957. [Google Scholar] [CrossRef]
- Chen, X.; Zhou, G.; Chen, A.; Yi, J.; Zhang, W.; Hu, Y. Identification of Tomato Leaf Diseases Based on Combination of ABCK-BWTR and B-ARNet. Comput. Electron. Agric. 2020, 178, 105730. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Sethy, P.K.; Barpanda, N.K.; Rath, A.K.; Behera, S.K. Deep Feature Based Rice Leaf Disease Identification Using Support Vector Machine. Comput. Electron. Agric. 2020, 175, 105527. [Google Scholar] [CrossRef]
- Oyewola, D.O.; Dada, E.G.; Misra, S.; Damaševičius, R. Detecting Cassava Mosaic Disease Using a Deep Residual Convolutional Neural Network with Distinct Block Processing. PeerJ Comput. Sci. 2021, 7, e352. [Google Scholar] [CrossRef]
- Zeng, W.; Li, M. Crop Leaf Disease Recognition Based on Self-Attention Convolutional Neural Network. Comput. Electron. Agric. 2020, 172, 105341. [Google Scholar] [CrossRef]
- Chen, J.J.; Chen, J.J.; Zhang, D.; Sun, Y.; Nanehkaran, Y.A. Using Deep Transfer Learning for Image-Based Plant Disease Identification. Comput. Electron. Agric. 2020, 173, 105393. [Google Scholar] [CrossRef]
- Li, Y.; Nie, J.; Chao, X. Do We Really Need Deep CNN for Plant Diseases Identification? Comput. Electron. Agric. 2020, 178, 105803. [Google Scholar] [CrossRef]
- Ramcharan, A.; Baranowski, K.; McCloskey, P.; Ahmed, B.; Legg, J.; Hughes, D.P. Deep Learning for Image-Based Cassava Disease Detection. Front. Plant Sci. 2017, 8, 1852. [Google Scholar] [CrossRef] [Green Version]
- Ramcharan, A.; McCloskey, P.; Baranowski, K.; Mbilinyi, N.; Mrisho, L.; Ndalahwa, M.; Legg, J.; Hughes, D.P. A Mobile-Based Deep Learning Model for Cassava Disease Diagnosis. Front. Plant Sci. 2019, 10, 272. [Google Scholar] [CrossRef] [Green Version]
- Adedoja, A.; Owolawi, P.A.; Mapayi, T. Deep Learning Based on NASNet for Plant Disease Recognition Using Leave Images. In Proceedings of the 2019 International Conference on Advances in Big Data, Computing and Data Communication Systems (icABCD), Winterton, South Africa, 5–6 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Devi, S.N.; Muthukumaravel, A. A Novel Salp Swarm Algorithm With Attention-Densenet Enabled Plant Leaf Disease Detection And Classification. In Precision Agriculture, Proceedings of the 2022 International Conference on Advanced Computing Technologies and Applications (ICACTA), Coimbatore, India, 4–5 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Bhujel, A.; Kim, N.-E.; Arulmozhi, E.; Basak, J.K.; Kim, H.-T. A Lightweight Attention-Based Convolutional Neural Networks for Tomato Leaf Disease Classification. Agriculture 2022, 12, 228. [Google Scholar] [CrossRef]
- Zhao, Y.; Sun, C.; Xu, X.; Chen, J. RIC-Net: A Plant Disease Classification Model Based on the Fusion of Inception and Residual Structure and Embedded Attention Mechanism. Comput. Electron. Agric. 2022, 193, 106644. [Google Scholar] [CrossRef]
- Keivani, M.; Mazloum, J.; Sedaghatfar, E.; Tavakoli, M.B. Automated Analysis of Leaf Shape, Texture, and Color Features for Plant Classification. Traitement du Signal 2020, 37, 17–28. [Google Scholar] [CrossRef]
- Li, J.; Yang, J. Supervised Classification of Plant Image Based on Attention Mechanism. In Proceedings of the 2021 7th International Conference on Systems and Informatics (ICSAI), Chongqing, China, 13–15 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Kanda, P.S.; Xia, K.; Sanusi, O.H. A Deep Learning-Based Recognition Technique for Plant Leaf Classification. IEEE Access 2021, 9, 162590–162613. [Google Scholar] [CrossRef]
- Thanikkal, J.G.; Dubey, A.K.; Thomas, M. Importance of Image Morphological Features in Continues Learning. In Proceedings of the 2022 International Mobile and Embedded Technology Conference (MECON), Noida, India, 10–11 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 372–376. [Google Scholar] [CrossRef]
- Twum, F.; Missah, Y.M.; Oppong, S.O.; Ussiph, N. Textural Analysis for Medicinal Plants Identification Using Log Gabor Filters. IEEE Access 2022, 10, 83204–83220. [Google Scholar] [CrossRef]
- Gajjar, V.K.; Nambisan, A.K.; Kosbar, K.L. Plant Identification in a Combined-Imbalanced Leaf Dataset. IEEE Access 2022, 10, 37882–37891. [Google Scholar] [CrossRef]
- Goyal, N.; Gupta, K.; Kumar, N. Clustering-Based Hierarchical Framework for Multiclass Classification of Leaf Images. IEEE Trans. Ind. Appl. 2022, 58, 4076–4085. [Google Scholar] [CrossRef]
- Ganguly, S.; Bhowal, P.; Oliva, D.; Sarkar, R. BLeafNet: A Bonferroni Mean Operator Based Fusion of CNN Models for Plant Identification Using Leaf Image Classification. Ecol. Inform. 2022, 69, 101585. [Google Scholar] [CrossRef]
- Li, M.; Zhou, G.; Chen, A.; Yi, J.; Lu, C.; He, M.; Hu, Y. FWDGAN-Based Data Augmentation for Tomato Leaf Disease Identification. Comput. Electron. Agric. 2022, 194, 106779. [Google Scholar] [CrossRef]
- Too, E.C.; Yujian, L.; Njuki, S.; Yingchun, L. A Comparative Study of Fine-Tuning Deep Learning Models for Plant Disease Identification. Comput. Electron. Agric. 2019, 161, 272–279. [Google Scholar] [CrossRef]
- Hu, G.; Wu, H.; Zhang, Y.; Wan, M. A Low Shot Learning Method for Tea Leaf’s Disease Identification. Comput. Electron. Agric. 2019, 163, 104852. [Google Scholar] [CrossRef]
- Wang, G.; Sun, Y.; Wang, J. Automatic Image-Based Plant Disease Severity Estimation Using Deep Learning. Comput. Intell. Neurosci. 2017, 2017, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, M.; Gupta, S.K.; Biswas, K.K. Development of Efficient CNN Model for Tomato Crop Disease Identification. Sustain. Comput. Inform. Syst. 2020, 28, 100407. [Google Scholar] [CrossRef]
- Gandhi, R.; Nimbalkar, S.; Yelamanchili, N.; Ponkshe, S. Plant Disease Detection Using CNNs and GANs as an Augmentative Approach. In Proceedings of the 2018 IEEE International Conference on Innovative Research and Development (ICIRD), Bangkok, Thailand, 11–12 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Elhassouny, A.; Smarandache, F. Smart Mobile Application to Recognize Tomato Leaf Diseases Using Convolutional Neural Networks. In Proceedings of the 2019 International Conference of Computer Science and Renewable Energies (ICCSRE), Agadir, Morocco, 22–24 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Darwish, A.; Ezzat, D.; Hassanien, A.E. An Optimized Model Based on Convolutional Neural Networks and Orthogonal Learning Particle Swarm Optimization Algorithm for Plant Diseases Diagnosis. Swarm Evol. Comput. 2020, 52, 100616. [Google Scholar] [CrossRef]
- Mishra, S.; Sachan, R.; Rajpal, D. Deep Convolutional Neural Network Based Detection System for Real-Time Corn Plant Disease Recognition. Procedia Comput. Sci. 2020, 167, 2003–2010. [Google Scholar] [CrossRef]
- Lamba, M.; Gigras, Y.; Dhull, A. Classification of Plant Diseases Using Machine and Deep Learning. Open Comput. Sci. 2021, 11, 491–508. [Google Scholar] [CrossRef]
- Zhao, S.; Peng, Y.; Liu, J.; Wu, S. Tomato Leaf Disease Diagnosis Based on Improved Convolution Neural Network by Attention Module. Agriculture 2021, 11, 651. [Google Scholar] [CrossRef]
- Paymode, A.S.; Malode, V.B. Transfer Learning for Multi-Crop Leaf Disease Image Classification Using Convolutional Neural Network VGG. Artif. Intell. Agric. 2022, 6, 23–33. [Google Scholar] [CrossRef]
- Islam, M.S.; Sultana, S.; Al Farid, F.; Islam, M.N.; Rashid, M.; Bari, B.S.; Hashim, N.; Husen, M.N. Multimodal Hybrid Deep Learning Approach to Detect Tomato Leaf Disease Using Attention Based Dilated Convolution Feature Extractor with Logistic Regression Classification. Sensors 2022, 22, 6079. [Google Scholar] [CrossRef]
- Tarek, H.; Aly, H.; Eisa, S.; Abul-Soud, M. Optimized Deep Learning Algorithms for Tomato Leaf Disease Detection with Hardware Deployment. Electronics 2022, 11, 140. [Google Scholar] [CrossRef]
- Tej, B.; Nasri, F.; Mtibaa, A. Detection of Pepper and Tomato Leaf Diseases Using Deep Learning Techniques. In Proceedings of the 2022 5th International Conference on Advanced Systems and Emergent Technologies (IC_ASET), Hammamet, Tunisia, 22–25 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 149–154. [Google Scholar] [CrossRef]
- Ozbilge, E.; Ulukok, M.K.; Toygar, O.; Ozbilge, E. Tomato Disease Recognition Using a Compact Convolutional Neural Network. IEEE Access 2022, 10, 77213–77224. [Google Scholar] [CrossRef]
- Mukherjee, G.; Chatterjee, A.; Tudu, B. Identification of the Types of Disease for Tomato Plants Using a Modified Gray Wolf Optimization Optimized MobileNetV2 Convolutional Neural Network Architecture Driven Computer Vision Framework. Concurr. Comput. Pract. Exp. 2022, 34, e7161. [Google Scholar] [CrossRef]
- Wu, S.G.; Bao, F.S.; Xu, E.Y.; Wang, Y.X.; Chang, Y.F.; Xiang, Q.L. A Leaf Recognition Algorithm for Plant Classification Using Probabilistic Neural Network. In Proceedings of the ISSPIT 2007—2007 IEEE International Symposium on Signal Processing and Information Technology, Giza, Egypt, 15–18 December 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 11–16. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Neyshabur, B.; Sedghi, H.; Zhang, C. What Is Being Transferred in Transfer Learning? Adv. Neural Inf. Process. Syst. 2020, 33, 512–523. [Google Scholar]
- Saini, D.; Chand, T.; Chouhan, D.K.; Prakash, M. A Comparative Analysis of Automatic Classification and Grading Methods for Knee Osteoarthritis Focussing on X-ray Images. Biocybern. Biomed. Eng. 2021, 41, 419–444. [Google Scholar] [CrossRef]
- Cai, C.; Wang, S.; Xu, Y.; Zhang, W.; Tang, K.; Ouyang, Q.; Lai, L.; Pei, J. Transfer Learning for Drug Discovery. J. Med. Chem. 2020, 63, 8683–8694. [Google Scholar] [CrossRef]
- Achicanoy, H.; Chaves, D.; Trujillo, M. StyleGANs and Transfer Learning for Generating Synthetic Images in Industrial Applications. Symmetry 2021, 13, 1497. [Google Scholar] [CrossRef]
- Zhu, C. Pretrained language models. In Machine Reading Comprehension; Elsevier: Amsterdam, The Netherlands, 2021; pp. 113–133. ISBN 978-0-323-90118-5. [Google Scholar]
- Bashath, S.; Perera, N.; Tripathi, S.; Manjang, K.; Dehmer, M.; Streib, F.E. A Data-Centric Review of Deep Transfer Learning with Applications to Text Data. Inf. Sci. 2022, 585, 498–528. [Google Scholar] [CrossRef]
- Hussain, M.; Bird, J.J.; Faria, D.R. A Study on CNN Transfer Learning for Image Classification. In Advances in Computational Intelligence Systems, Proceedings of the Contributions Presented at the 18th UK Workshop on Computational Intelligence, Nottingham, UK, 5–7 September 2018; Springer: Cham, Switzerland, 2019; Volume 840, pp. 191–202. [Google Scholar] [CrossRef]
- Howard, J.; Gugger, S. Deep Learning for Coders with Fastai and PyTorch; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2020; Volume 66, ISBN 978-1-492-04552-6. [Google Scholar]
- Bengio, Y. Practical Recommendations for Gradient-Based Training of Deep Architectures. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2012; Volume 7700, pp. 437–478. ISBN 9783642352881. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-Tuning for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 1, pp. 328–339. [Google Scholar] [CrossRef] [Green Version]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How Transferable Are Features in Deep Neural Networks? In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 8–13 December 2014; Neural Information Processing Systems Foundation: La Jolla, CA, USA, 2014; Volume 4, pp. 3320–3328. [Google Scholar] [CrossRef]
- Howard, J.; Gugger, S. Fastai: A Layered API for Deep Learning. Information 2020, 11, 108. [Google Scholar] [CrossRef] [Green Version]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Computer Vision—ECCV 2014, Proceedings of the3th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; Volume 8689, pp. 818–833. [Google Scholar] [CrossRef]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pathogen Group | Pathogen Name | Reference |
|---|---|---|
| Fungi | Alternaria solani, Botrytis cinerea, Cladosporium fulvum, Colletotrichum coccodes, Fusarium oxysporum, Fusarium clavum, Leveillula taurica, Oidium lycopersici, Pseudoidium neolycopersici, Pyrenochaeta lycopersici, Rhizoctonia solani, Septoria lycopersici, Sclerotinia sclerotiorum, Sclerotium rolfsii, Stemphylium spp., Verticillium dahliae | [4,6] |
| Oomycetes | Phytophthora infestans, Phytophthora nicotianae, Phytophtora cryptogea, Pythium debaryanum, Pythium sylvaticum | [7] |
| Bacteria | Clavibacter michiganensis subsp. michiganensis, Erwinia carotovora subsp. carotovora, Pseudomonas corrugata, Pseudomonas mediterranea, Pseudomonas syringae pv. tomato, Ralstonia solanacearum, Xanthomonas axonopodis pv. vesicatoria | [7] |
| Phytoplasma | Candidatus Phytoplasma solani | [8] |
| Viruses | Alfalfa mosaic virus, Chickpea chlorotic dwarf virus, Cucumber mosaic virus, Eggplant mottled dwarf virus, Parietaria mottle virus, Pelargonium zonate spot virus, Pepino mosaic virus, Potato virus Y, Southern tomato virus, Tobacco mosaic virus, Tomato brown rugose fruit virus, Tomato chlorosis virus, Tomato infectious chlorosis virus, Tomato leaf curl New Delhi virus, Tomato mosaic virus, Tomato spotted wilt virus, Tomato torrado virus, Tomato yellow leaf curl virus, Tomato yellow leaf curl Sardinia virus | [4,9] |
| Viroids | Potato spindle tuber viroid, Tomato apical stunt viroid | [8] |
| Batch Size | Performance (%) | ||||
|---|---|---|---|---|---|
| 40/60 | 50/50 | 60/40 | 70/30 | 80/20 | |
| 100 | 0.977447 | 0.984816 | 0.988378 | 0.992139 | 0.993655 |
| 90 | 0.97957 | 0.987927 | 0.993078 | 0.99241 | 0.99521 |
| 80 | 0.981349 | 0.987848 | 0.990103 | 0.992641 | 0.995611 |
| 70 | 0.984734 | 0.986958 | 0.988716 | 0.994496 | 0.994071 |
| 60 | 0.984338 | 0.987595 | 0.994316 | 0.993444 | 0.995579 |
| 50 | 0.987115 | 0.9893 | 0.993566 | 0.994769 | 0.994317 |
| 40 | 0.985295 | 0.990085 | 0.993045 | 0.994083 | 0.995048 |
| Batch Size | Time (s) | ||||
|---|---|---|---|---|---|
| 40/60 | 50/50 | 60/40 | 70/30 | 80/20 | |
| 100 | 162 | 196 | 221 | 234 | 249 |
| 90 | 179 | 188 | 218 | 237 | 253 |
| 80 | 169 | 193 | 222 | 235 | 247 |
| 70 | 176 | 188 | 211 | 232 | 240 |
| 60 | 172 | 193 | 217 | 236 | 259 |
| 50 | 188 | 208 | 221 | 242 | 275 |
| 40 | 200 | 204 | 226 | 248 | 281 |
| Train Split (%) | Validation Split (%) | Train Loss | Valid Loss | Accuracy | Recall | Precision | F1 Score |
|---|---|---|---|---|---|---|---|
| 90 | 10 | 0.052291 | 0.07908 | 0.976046 | 0.972897 | 0.972338 | 0.97166 |
| 80 | 20 | 0.049548 | 0.071533 | 0.976597 | 0.973958 | 0.973845 | 0.97321 |
| 70 | 30 | 0.045366 | 0.081245 | 0.97109 | 0.967464 | 0.966935 | 0.966463 |
| 60 | 40 | 0.042245 | 0.070298 | 0.975771 | 0.972307 | 0.97289 | 0.971938 |
| 50 | 50 | 0.033666 | 0.049622 | 0.984857 | 0.981165 | 0.982264 | 0.981518 |
| 40 | 60 | 0.002324 | 0.014366 | 0.996421 | 0.995781 | 0.995451 | 0.995611 |
| Network Depth | Error Rate | F1 Score | Time (s) |
|---|---|---|---|
| 18 | 0.037812 | 0.953628 | 35 |
| 34 | 0.028084 | 0.964552 | 53 |
| 50 | 0.025881 | 0.96916 | 83 |
| 101 | 0.01808 | 0.977994 | 126 |
| 152 | 0.018906 | 0.977447 | 160 |
| Network Depth | Error Rate | F1 Score | Time (s) |
|---|---|---|---|
| 18 | 0.027423 | 0.967306 | 40 |
| 34 | 0.024559 | 0.968959 | 59 |
| 50 | 0.018612 | 0.978017 | 91 |
| 101 | 0.015419 | 0.981207 | 139 |
| 152 | 0.013216 | 0.984816 | 187 |
| Network Depth | Error Rate | F1 Score | Time (s) |
|---|---|---|---|
| 18 | 0.021338 | 0.974903 | 41 |
| 34 | 0.015694 | 0.979904 | 63 |
| 50 | 0.015556 | 0.98172 | 97 |
| 101 | 0.010187 | 0.988444 | 152 |
| 152 | 0.009637 | 0.988378 | 217 |
| Network Depth | Error Rate | F1 Score | Time (s) |
|---|---|---|---|
| 18 | 0.016153 | 0.978283 | 43 |
| 34 | 0.011013 | 0.985728 | 69 |
| 50 | 0.011197 | 0.986037 | 105 |
| 101 | 0.009728 | 0.987897 | 160 |
| 152 | 0.006608 | 0.992139 | 228 |
| Network Depth | Error Rate | F1 Score | Time (s) |
|---|---|---|---|
| 18 | 0.015419 | 0.981407 | 47 |
| 34 | 0.011564 | 0.986212 | 73 |
| 50 | 0.009086 | 0.988667 | 112 |
| 101 | 0.006883 | 0.991295 | 179 |
| 152 | 0.005507 | 0.993655 | 243 |
| Technique | Year | Objective | # Images | Methods | Accuracy (%) |
|---|---|---|---|---|---|
| Keivani et al. [50] | 2020 | Flavia dataset | 1907 | Decision Tree | 98.58 |
| Li et al. [51] | 2021 | Flavia dataset | 1907 | DenseNet201 | 98.69 |
| Kanda et al. [52] | 2021 | Flavia dataset | 1907 | DL + Logistic Regression | 99.0 |
| Thanikkal et al. [53] | 2022 | Flavia dataset | 1907 | DL | 99.0 |
| Twum et al. [54] | 2022 | Flavia dataset | 1907 | Log Gabor Filters | 97.0 |
| Gajjar et al. [55] | 2022 | Flavia dataset | 1907 | Extreme learning machines | 99.10 |
| Goyal et al. [56] | 2022 | Flavia dataset | 1907 | Hierarchical cluster | 96.24 |
| Ganguly et al. [57] | 2022 | Flavia dataset | 1907 | ResNet + Bonferroni mean operator | 98.7 |
| Proposed Network | 2022 | Flavia dataset | 1907 | ResNet + Discriminative Learning | 99.23 |
| Technique | Year | Objective | # Images | Methods | Accuracy (%) |
|---|---|---|---|---|---|
| Too et al. [59] | 2019 | Plant leaf disease | 54,306 | VGG16 | 81.83 |
| Gensheng et al. [60] | 2019 | Tea leaf disease | 4980 | VGG16 | 90 |
| Wang et al. [61] | 2017 | Plant leaf disease | 54,306 | VGG16 | 90.4 |
| Agarwal et al. [62] | 2020 | Tomato leaf disease | 18,160 | VGG16 | 93.5 |
| Wang et al. [61] | 2017 | Plant leaf disease | 54,306 | Inception-V3 | 80 |
| Gandhi et al. [63] | 2018 | Plant leaf disease | 56,000 | Inception-V3 | 88.6 |
| Agarwal et al. [62] | 2020 | Tomato leaf disease | 18,160 | Inception-V3 | 77.5 |
| Elhassouny & Smarandache [64] | 2019 | Tomato leaf disease | 7176 | MobileNet | 88.4 |
| Gandhi et al. [63] | 2018 | Plant leaf disease | 56,000 | Mobilenet | 92 |
| Agarwal et al. [62] | 2020 | Tomato leaf disease | 18,160 | Mobilenet | 82.6 |
| Darwish et al. [65] | 2019 | Maize leaf disease | 15,408 | VGG19 | 98.2 |
| Karthik et al. [27] | 2020 | Tomato leaf disease | 5452 (4 classes) | ResNet + DenseNet | 98 |
| Mishra et al. [66] | 2020 | Corn leaf disease | 3703 | CNN | 98.4 |
| Lamba et al. [67] | 2021 | Tomato leaf disease | 16,012 | CNN | 98.2 |
| Agarwal et al. [62] | 2020 | Tomato leaf disease | 18,160 | CNN | 98.4 |
| Zhao et al. [68] | 2021 | Tomato leaf disease | 18,160 (10 classes) | ResNet50 + SeNet | 96.81 |
| Li et al. [58] | 2022 | Tomato leaf disease | 4240 | FWDGAN + B-ARNet | 98.75 |
| Paymode et al. [69] | 2022 | Tomato leaf disease | VGG16 | 95.71 | |
| Devi et al. [47] | 2022 | Tomato leaf disease | 9281 | DensNet + Attention mechanism | 97.56 |
| Bhujel et al. [48] | 2022 | Tomato leaf disease | 19,510 | Lightweight Attention-Based CNN | 99.34 |
| Zaho et al. [49] | 2022 | Tomato leaf disease | 18,160 | Spatial attention with CNN | 95.20 |
| Islam et al. [70] | 2022 | Tomato leaf disease | 15,989 | cGAN + CNN + Logistic Regression | 100 |
| Tarek et al. [71] | 2022 | Tomato leaf disease | 16,004 | MobileNetV3 | 99.81 |
| Tej et al. [72] | 2022 | Pepper and Tomato leaf diseases | 488 | CNN | 98.85 |
| Özbılge et al. [73] | 2022 | Tomato leaf disease | 18,160 | Compact CNN | 98.49 |
| Mukherjee et al. [74] | 2022 | Tomato leaf disease | 10,839 (7 classes) | Gray Wolf + MobileNetV2 | 98 |
| Proposed Technique | 2022 | Tomato leaf disease | 18,160 | ResNet + Discriminative Learning | 99.51 |
| Name | Parameter |
|---|---|
| Memory | 32 GB |
| Processor | Intel(R) Xeon(R) Silver 4114 CPU @ 2.20 GHz |
| Server model | DELL PowerEdge T640 Tower Server |
| Graphics | CUDA-based video cards 4X 1080TI; GPU Video memory of 11 Gb |
| OS | Linux |
| Language | Python 3 |
| Framework | Pytorch |
| Name | Parameter |
|---|---|
| Solver type | Adam |
| Batch sizes | 20, 30, 40, 50, 60, 70, 80, 90, 100 |
| Image input size | 256 × 256 |
| Train/Test-split ratio | 40/60, 50/50, 60/40, 70/30, 80/20 |
| Learning rate | Discriminative ranges |
| Drop out | 0.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kanda, P.S.; Xia, K.; Kyslytysna, A.; Owoola, E.O. Tomato Leaf Disease Recognition on Leaf Images Based on Fine-Tuned Residual Neural Networks. Plants 2022, 11, 2935. https://doi.org/10.3390/plants11212935
Kanda PS, Xia K, Kyslytysna A, Owoola EO. Tomato Leaf Disease Recognition on Leaf Images Based on Fine-Tuned Residual Neural Networks. Plants. 2022; 11(21):2935. https://doi.org/10.3390/plants11212935
Chicago/Turabian StyleKanda, Paul Shekonya, Kewen Xia, Anastasiia Kyslytysna, and Eunice Oluwabunmi Owoola. 2022. "Tomato Leaf Disease Recognition on Leaf Images Based on Fine-Tuned Residual Neural Networks" Plants 11, no. 21: 2935. https://doi.org/10.3390/plants11212935
APA StyleKanda, P. S., Xia, K., Kyslytysna, A., & Owoola, E. O. (2022). Tomato Leaf Disease Recognition on Leaf Images Based on Fine-Tuned Residual Neural Networks. Plants, 11(21), 2935. https://doi.org/10.3390/plants11212935