1. Introduction
An estimated 175 zettabytes of data will be generated by 2025 globally, according to [
1]. Out of this, over 90 zettabytes are estimated to be created by IoT devices alone at the network edge including autonomous vehicles, factory automation, mobile devices, and so on. According to a report by Gartner Research [
2], an estimated 75% of all data will need analysis and further processing at the edge by 2025. This is due to several reasons:
First, there was an estimated 24 billion IoT devices in 2020 that generated a massive amount of data. The rate of data generation means that shipping such enormous volumes of data for analysis will face key challenges. These include latency, bandwidth costs, data privacy, and legal and ethical compliance issues. As a result, there is a growing need to process the data closer to the data generation source.
Second, while deep learning has shown tremendous success with large data and model sizes (billions of parameters), scaling compute and storage resources becomes critical. There are significant advances in compressing large models and still retaining the key performance benefits. Another rapidly emerging area is distributed training where either data or the model or a combination of both are split across several computing devices and trained without significant loss in performance.
Third, 5G is a key enabler to perform distributed learning at the edge. Not only does 5G promise peak data rates of 10 Gbps and five millisecond end-to-end latencies, it is also expected to support and operate a massive number of devices (millions per square kilometer). Further, 5G base stations are ideal choices for edge servers for orchestrating the machine learning task due to their ultra-low latency capabilities for end devices.
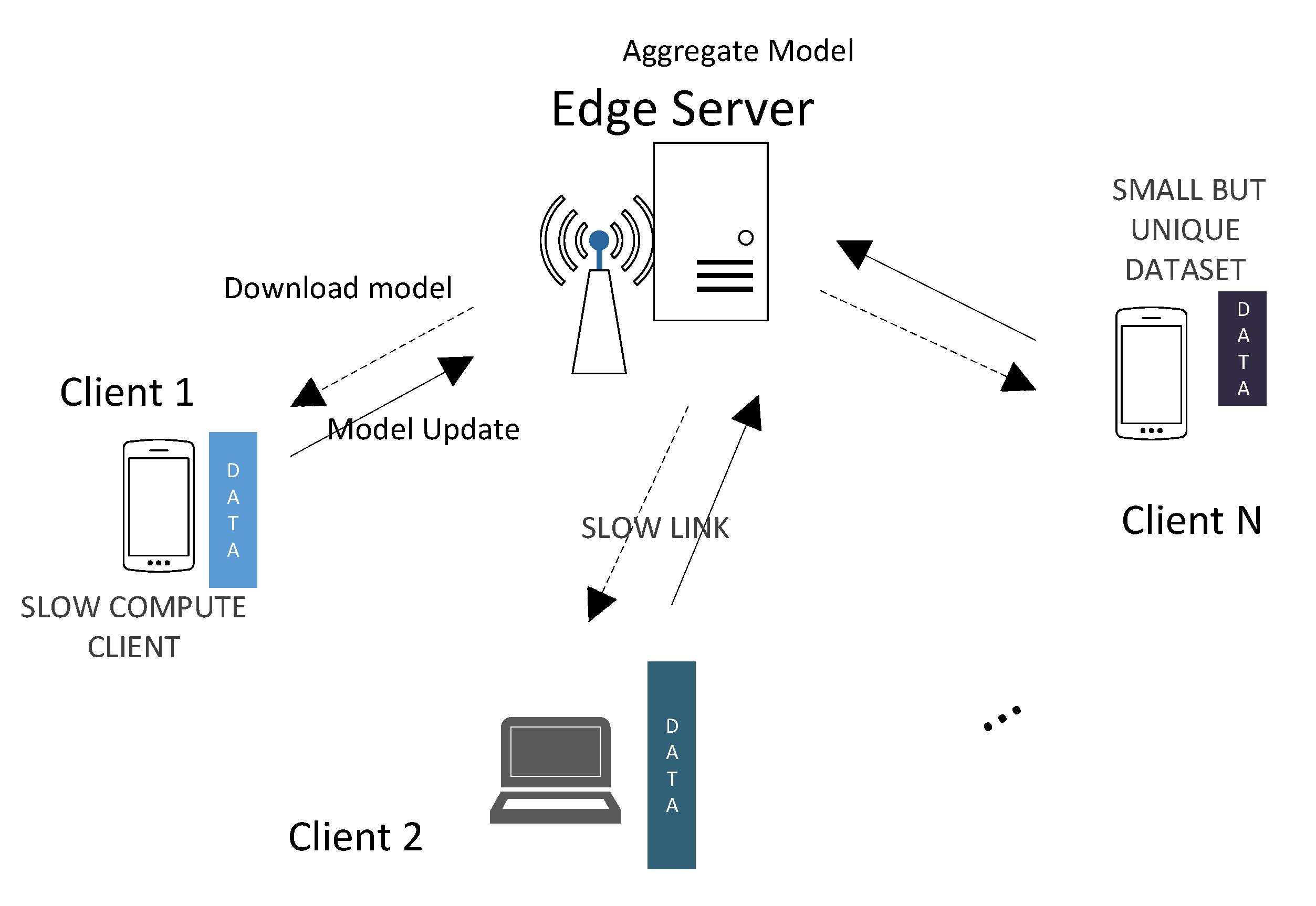
Owing to these factors, distributed learning at the network edge (beyond data centers) has recently emerged. A prime example for this is federated learning (FL) [
3] in which client devices collectively benefit from learning a shared model from all their data without the need for central storage or exchanging raw data among devices. An edge server coordinates the learning where clients exchange model updates with the server. FL has been applied successfully in many large-scale distributed smartphone use cases including models for face recognition, language models for text autocompletion (e.g., Google GBoard), and voice recognition (e.g., Siri in iOS 13). More recently, FL has also been successfully applied in the area of medicine where it facilitates multi-institutional collaborations without sharing patient data [
4]. Similarly, FL is a promising approach for sensor/IoT devices including wearables and autonomous vehicles where data privacy plays a key role.
The goal of federated learning based system is to learn a global model that performs well/has good accuracy for all clients while minimizing the overall training time. At the same time, it is crucial to allow clients to have a highly personalized model that can achieve high accuracy for end users. We highlight a subset of the challenges associated with federated learning, specifically when learning is performed over a diverse set of connected compute devices.
Compute heterogeneity: Client devices encompass a range of form-factors of devices, CPU clock rates, and memory read/write times. As a result, the model updates from difference clients can arrive at different times at the server.
Communication heterogeneity: Client devices experience different data rates depending on their wireless connectivities, location, and mobility characteristics. Further, such rates are also typically time-varying, which affects the overall training time.
Statistical heterogeneity: Finding a good global model that performs well across different client data distributions will be a major challenge. Moreover, the different clients may also have unbalanced data with different numbers of training examples. This leads to variance in the model updates across the clients.
Personalization and generalization for clients: The global model learned is an average of the local models and hence may not be optimal for individual clients. Further, there are no guarantees on the model performance even if clients are allowed to fine-tune or personalize the global model further based on local data. Furthermore, the generalization of the learned global model across a range of client data distributions is an open challenge.
Several of the above challenges motivate resource management techniques that are efficient in the presence of resource constraints at the edge including communication resources (e.g., bandwidth), computational resources (e.g., compute cycles, battery use), and data resources (dataset at clients). Efficient resource management can be viewed as an ensemble of approaches that aim to maximize distributed training performance by jointly factoring these diverse resource constraints and optimizing several training parameters such as the participating clients, time taken to complete one training iteration, etc.
This article focuses on our recent research findings on resource management and resource-efficient model personalization for federated learning. On the one hand, we develop a novel method for client selection utilizing importance sampling to jointly addresses compute, communication, and data heterogeneity. On the other hand, we develop a resource-efficient approach to perform model personalization when clients’ data distributions are different that has superior per-client performance over federated learning benchmarks. To this end, we make an observation that although there exists heterogeneity in the clients’ data distributions, clusters of clients are likely to form, which allows us to learn a federated meta-model from a subset of the overall clients, providing significant savings in communication and computation time.
The rest of work is organized as follows: In
Section 2, we present the system model, provide a detailed review of the related literature, and highlight the open challenges addressed in this paper. In
Section 3, we detail the proposed importance sampling based federated learning, as well as a resource-efficient federated meta-learning approach that identifies and exploits client clustering. We, present through extensive experiments, the benefits of performing resource management and resource-efficient personalization for federated learning in
Section 4. We summarize our conclusions and also identify related open research challenges in
Section 5.
3. Resource Management and Model Personalization for Federated Learning
3.1. Resource Management through Importance Sampling
The sampling of K out of N clients to optimize a performance objective such as maximizing a utility or minimizing the regret is well known in the scheduling literature as a combinatorial problem. One of the challenges to solving such problems is that they are NP-hard by nature. Additionally, pre-training must be conducted on at least a small amount of the dataset to determine the utility of different allocation policies. We develop a new approach to the client selection problem by considering it as a Monte Carlo sampling problem. The federated averaging algorithm aims to approximate an expectation of gradients by randomly sampling a subset of clients such that each client takes approximate gradient steps on local losses that are on average equal to the true gradient of the overall loss. However, due to the non-IID nature of data, the gradients computed at each client are not close approximations of the true gradients.
Importance sampling belongs to a set of Monte Carlo methods where an expectation with respect to a target distribution is approximated using a weighted average of sample draws from a different distribution. The application of importance sampling to stochastic gradient descent has received significant attention in recent years. The key idea is to focus the gradient computations on the “most informative” set of training data instead of providing equal priority to all training data. For example, humans are able to learn complex concepts from a small set of examples. Importance sampling methods for stochastic gradient descent and mini-batch gradient descent that achieve training speedup through variance reduction were proposed earlier, such as in [
15]. While such approaches achieve training speedup in the number of global training epochs, the previously proposed importance sampling distributions do not account for the wall clock time to train each epoch.
3.2. Federated Learning with Importance Sampling
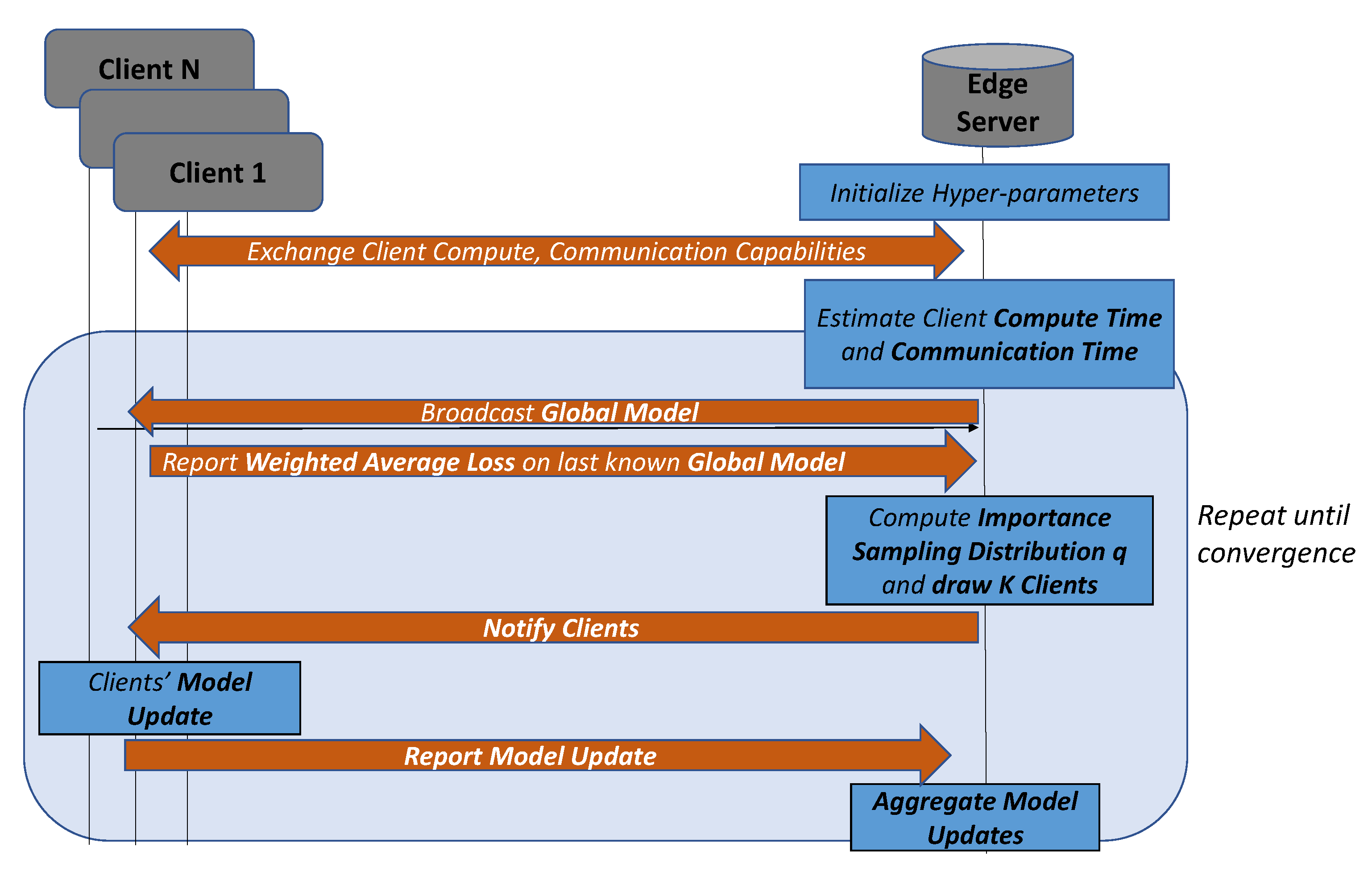
We developed an importance sampling method for federated learning that adaptively assigns sampling probabilities to clients in each training round based on the clients’ compute, communication, and data resources to not only achieve training speedup in the number of training rounds, but also to reduce the wall clock training time. This is because the training time per epoch of federated learning depends on the clients’ communication and compute times. Secondly, when the number of local epochs , importance sampling must be performed correctly in order to obtain unbiased gradients at each step. We addressed these two key issues in our importance sampling approach for federated learning.
Computing the importance sampling distribution from the loss with respect to each training example was proposed in [
16]. Since the target loss function to be minimized is the aggregate of the losses across all training examples, intuitively, the examples with the largest losses require more training iterations. It is, however, impractical to compute gradients on a per-sample basis for federated learning as the number of communication rounds needed to exchange model updates can scale with the number of training examples per client. Instead, we treated the data at each client as a batch and considered the weighted average training loss across a clients’ dataset
as a proxy to indicate a client’s priority. Here,
is the size of the training set and
is the average loss across the
examples. The weighting allows proportionally weighing the losses based on the number of training examples at the clients.
Such an approach, by itself, cannot reduce the wall clock training time as the compute and communication times can vary significantly between the clients. If the clients’ upload time can be estimated, representing the aggregate of the compute time and communication time , this will allow computing importance sampling probabilities accounting for not only the harder to train clients, but also the clients with short upload times. One such approach is to normalize the weighted loss by the upload time to compute the importance sampling distribution where represents the sampling probability for client k. The clients are sampled based on the importance sampling distribution s. At the end of each training round, is re-computed based on the updated quantities.
As noted earlier, in FL, the number of local gradient steps
can be greater than one. As the clients are sampled from a different distribution
s instead of the original distribution
, gradient correction is applied at each local step to un-bias the resulting gradient. Specifically, the gradient computed at each step at client
k is multiplied by the likelihood ratio
before the next local gradient descent step. The final updated local model computed after
local steps is shared with the edge server. The server aggregates the local updates from the
K clients that were sampled to obtain the global model for the next epoch. The proposed federated learning with importance sampling (FedIS) algorithm is described in
Figure 2, and more details can be found in [
17]. While the computation of the importance sampling distribution requires additional computational and communication overhead, our extensive empirical results demonstrate that the proposed method converges faster than the baseline approaches in spite of the overheads.
Fairness in federated learning is crucial where the goal of fair federated learning over wireless networks is to minimize the worst-case loss of clients while satisfying the compute and communication time constraints. We note that the proposed federated learning with importance sampling approach assigns a higher sampling probability to clients with larger weighted loss. Due to the adaptive nature of the importance sampling approach, clients with larger weighted loss in each global epoch obtain priority in the FL training. This also led to a higher degree of fairness for the proposed approach.
3.3. Model Personalization and Task Generalization in Federated Learning
In federated learning, the goal is to find a global model that “on-average” minimizes the weighted loss across clients. Although several approaches have been proposed to address the non-IID issue, it is important to note the fundamental limitation of treating the federated learning problem as the minimization of the average local losses. This is due to the following reasons:
Distance of client distributions: When client data are highly non-IID, learning a single average model may achieve sub-optimal personalized performance for individual clients.
Ability to fine-tune: The performance of the resulting model by fine-tuning the global model is also not necessarily optimal.
Clustered client behavior: While clients have varying data distributions, it is possible to find cluster regions where clients have comparable data distributions. However, current approaches are agnostic of such cluster formations and are unable to take advantage of the client clusters to improve the training efficiency or provision personalization, especially under resource constraints.
In meta-learning, instead of training a single model on a variety of tasks, the goal is to instead train a meta-initializer over the task distribution. The meta-initializer is trained such that when a new task is encountered, a few training steps on a small amount of data from the new task are sufficient to fine-tune the meta-model for maximal performance on the new task. We utilize this important insight for a federated learning scenario under resource constraints.
3.4. Federated Meta-Learning with Client Clustering
Meta-learning can be applied for federated learning across a broad set of clients with heterogeneous datasets. As a result, each task in a federated meta-learning setting can refer to a client or a set of clients that have nearly identical datasets. Therefore, in federated meta-learning, given a set of tasks, the goal is not to find a global model that performs well on-average on the tasks. Instead, the approach relies on learning a meta-initializer such that both existing and new clients can fine-tune the meta-model with only a few training steps and a small amount of data.
While it is true that each client can also fine-tune a model obtained by the federated averaging algorithm, as will be shown later, the federated meta-model acts as a superior initializer compared to the federated averaging model and requires significantly fewer resources (data points and fine-tuning steps) in order to achieve maximal performance for the clients. This is due to the fundamental formulation of the federated meta-learning problem to obtain the optimal meta-model
as the solution to:
where
is the expectation operator with respect to a distribution
of clients.
As can be noted above, the optimizer aims to find a meta-model initializer such that the loss of the fine-tuned model on average is minimized. In other words, the optimizer’s goal is such that when clients perform a single gradient descent update using a learning rate on the meta-model , the resulting average loss across clients is minimized. Federated meta-learning, therefore, is a more powerful goal of achieving model personalization as we are interested in how the resulting meta-model can be tuned for achieving maximal performance for the clients.
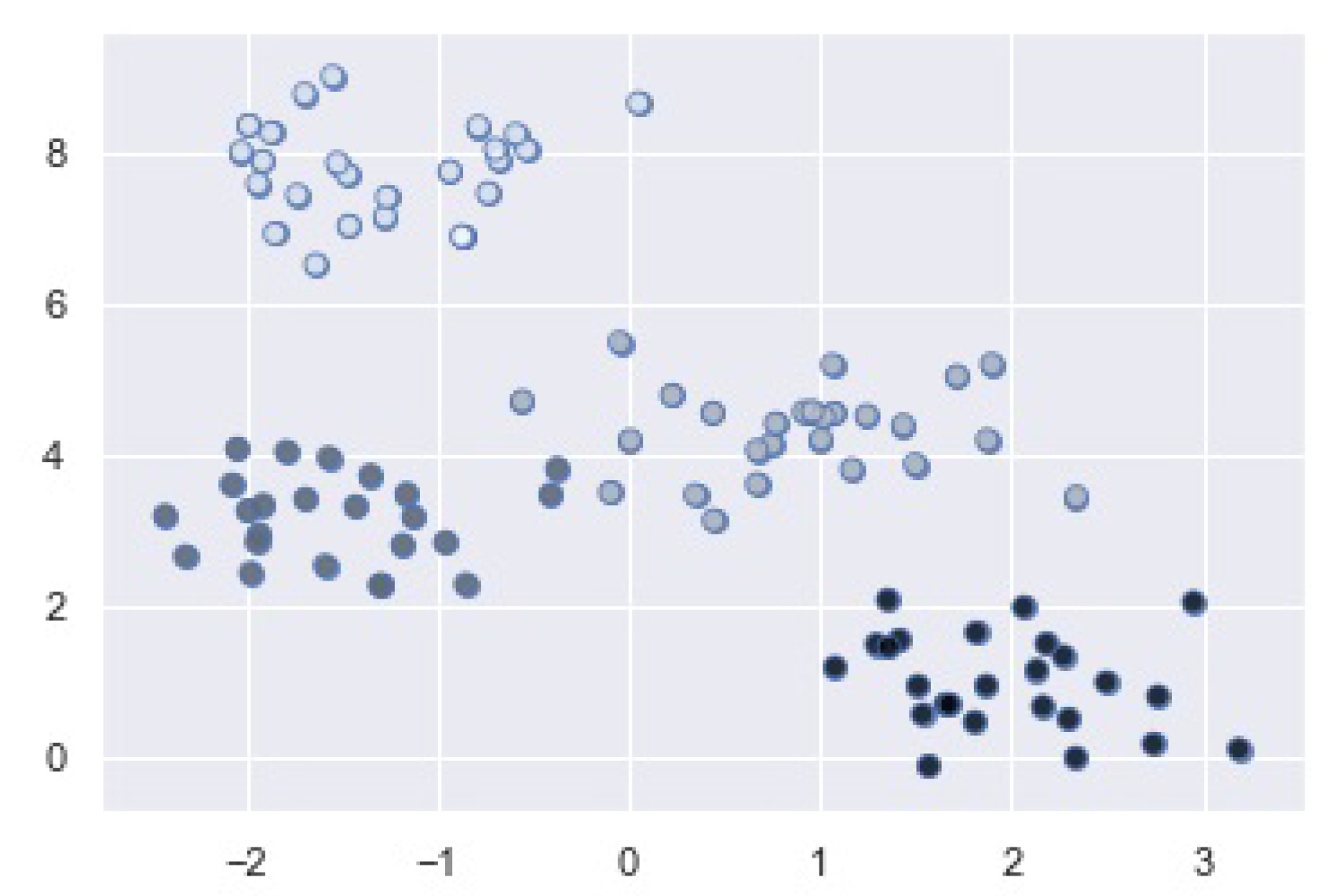
We take this further to argue that a resource-efficient meta-model can be trained if we can identify client clusters. Client clusters are not uncommon in the federated learning setting where user groups can be observed, as shown in
Figure 3. For example, in learning language models, distinct user groups can be formed based on the users’ native languages. We propose to utilize the fact that clients form clusters to perform resource-efficient federated meta-learning.
To this end, we first allow grouping of the clients based on their data distribution. In one approach, each client can share a distribution over its training examples or labels. In a supervised learning setting, in order to reduce the dimensionality of this communication, the clients may simply send the probability mass function of their data labels . Alternatively, clients can transform (linear or non-linear) their data to a different dimension and share the distribution over their examples with the server. Given a set of N clients, where each client k has a unique data distribution , clusters of clients are determined based on the similarity of their distributions.
The edge server can apply a clustering algorithm based on the received vectors from the clients in order to determine distinct client clusters/tasks, as shown in
Figure 3. Once clients are assigned to clusters, we apply a federated meta-learning algorithm such that we train only on a subset of the clients to obtain the meta-initializer subject to the communication and compute resource constraints. The resulting meta-initializer model is, in turn, utilized by clients to fine-tune on a small set of training examples using a few training steps. The federated meta-learning with clustering is described in Algorithm 1.
| Algorithm 1 Federated meta-learning with clustering. S: MECserver, C: clients.
|
- 1:
S: Initialize N, K, , , initial model , target task distribution if available - 2:
C: Initialize datasets and for gradient and meta-update steps, respectively - 3:
C: Report the PMF of local data points (or labels) to the server. - 4:
S: Determine cluster groups where each cluster is identified by a distribution . - 5:
S: Optional step: prune the client set by selecting of clients per cluster for training - 6:
for all global epochs do - 7:
S: Broadcast global weight - 8:
S: Draw K clients for meta-model update - 9:
for each client k = 1, 2,…, K do - 10:
for each local epochs e = 1, 2,…, do - 11:
Compute model update on the global model using data to obtain a local model - 12:
Compute its Hessian . The Hessian may be computed on a separate dataset as long as it is IID drawn from - 13:
Evaluate the gradient corresponding to the using the computed local weights as - 14:
Compute the local meta update as - 15:
end for - 16:
Report to the server - 17:
end for - 18:
S: Compute the global weight at the server as - 19:
end for
|
There are two major advantages of the proposed methods. First, sample-efficient learning can be performed from a subset of clients from each cluster to optimize communication and computational resources (e.g., clients that can speed up the wall clock time). Second, this allows a generalization of the learning of the model over a set of tasks where a task can represent a certain client group of interest. If a distribution over the client groups is known, the federated meta-learning algorithm can learn to generalize over the task distribution.

 ,
, 



{kind=link}
{kind=link}
{kind=link}