
Networking for Cloud Robotics: The DewROS Platform and Its Application




Abstract
:1. Introduction
2. Related Works
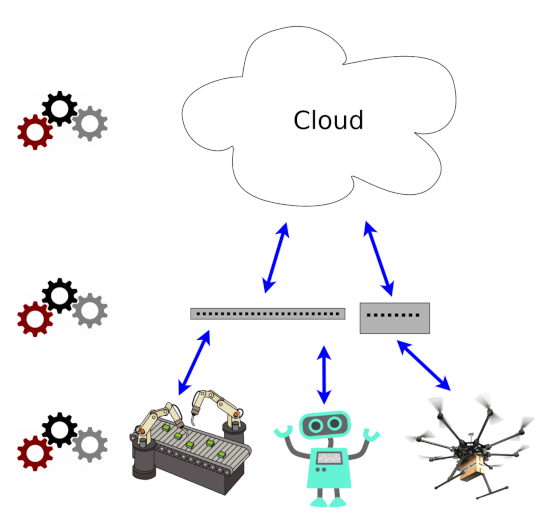
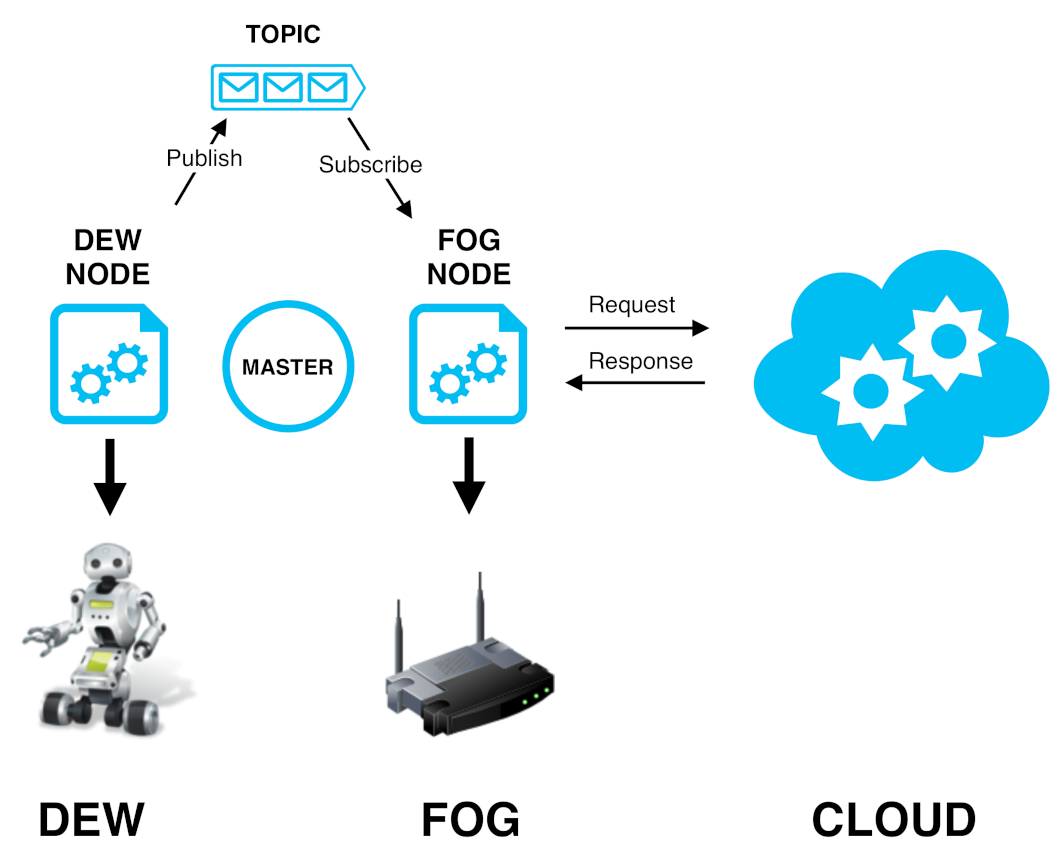
3. DewROS: Our Dew Robotics Platform
General Idea
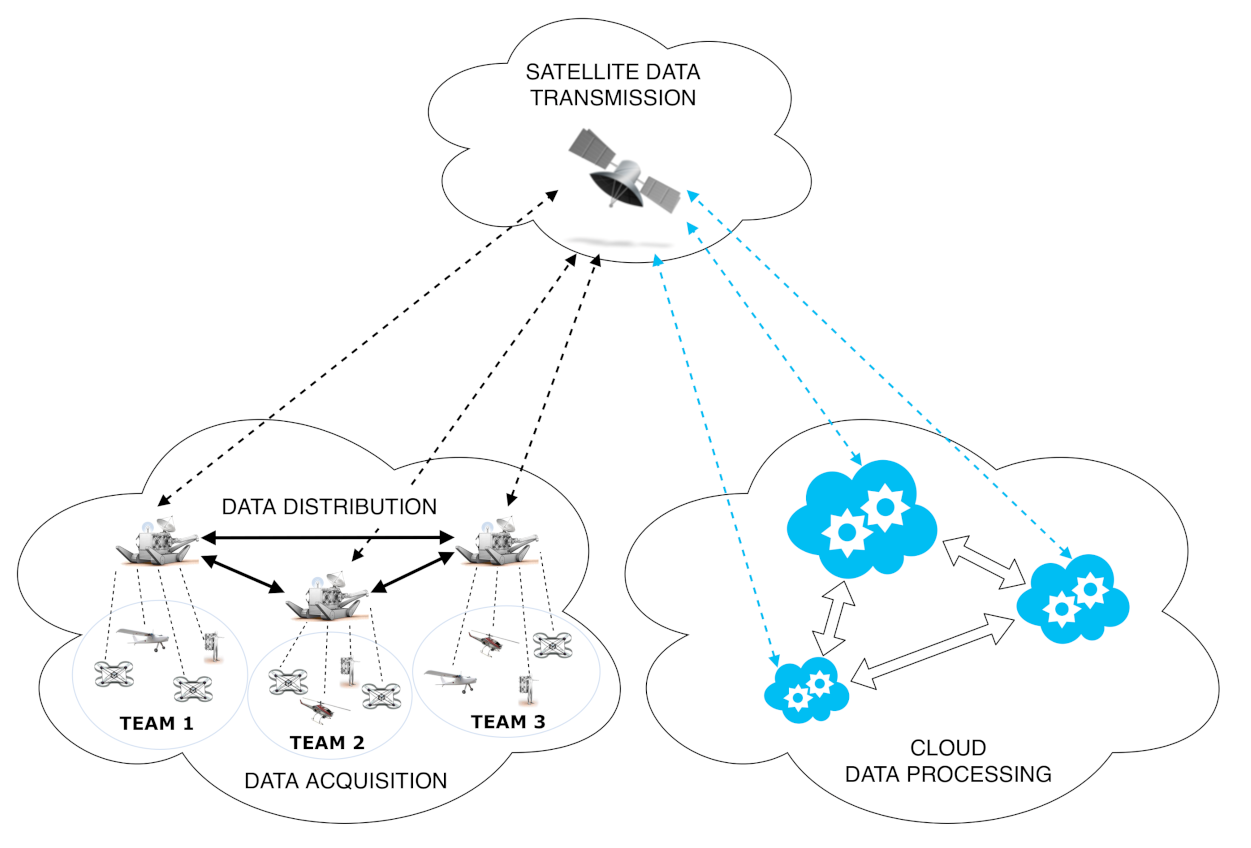
4. Our Use Case: The SHERPA Project
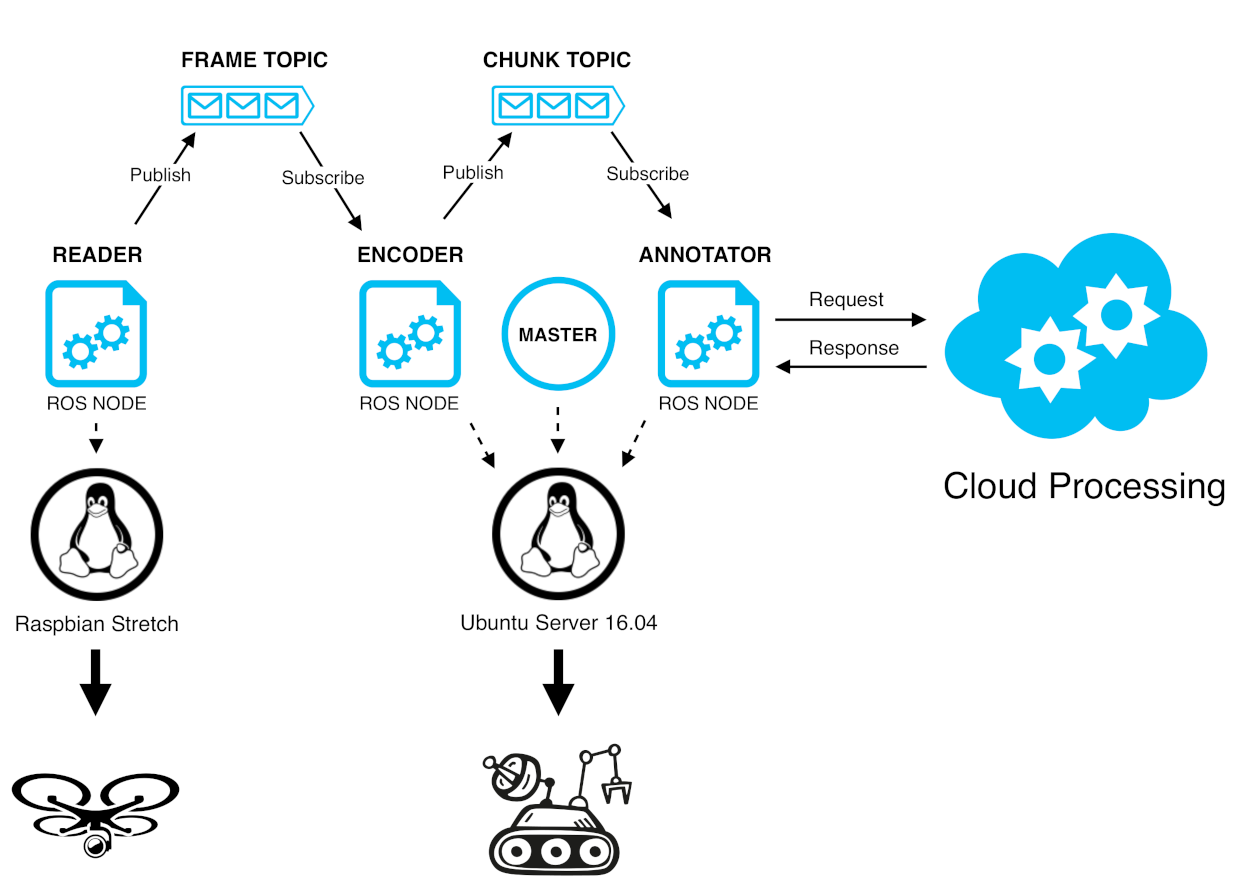
5. DewROS for SHERPA
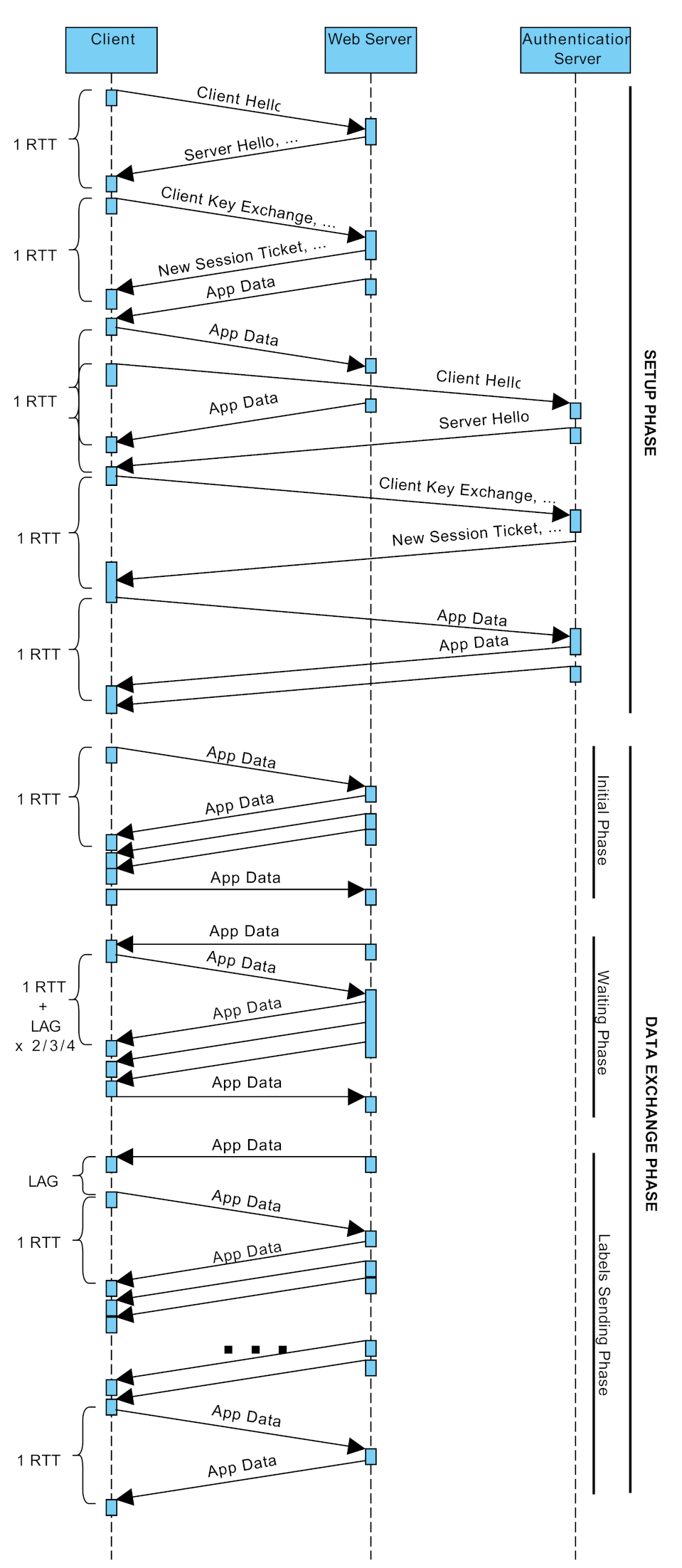
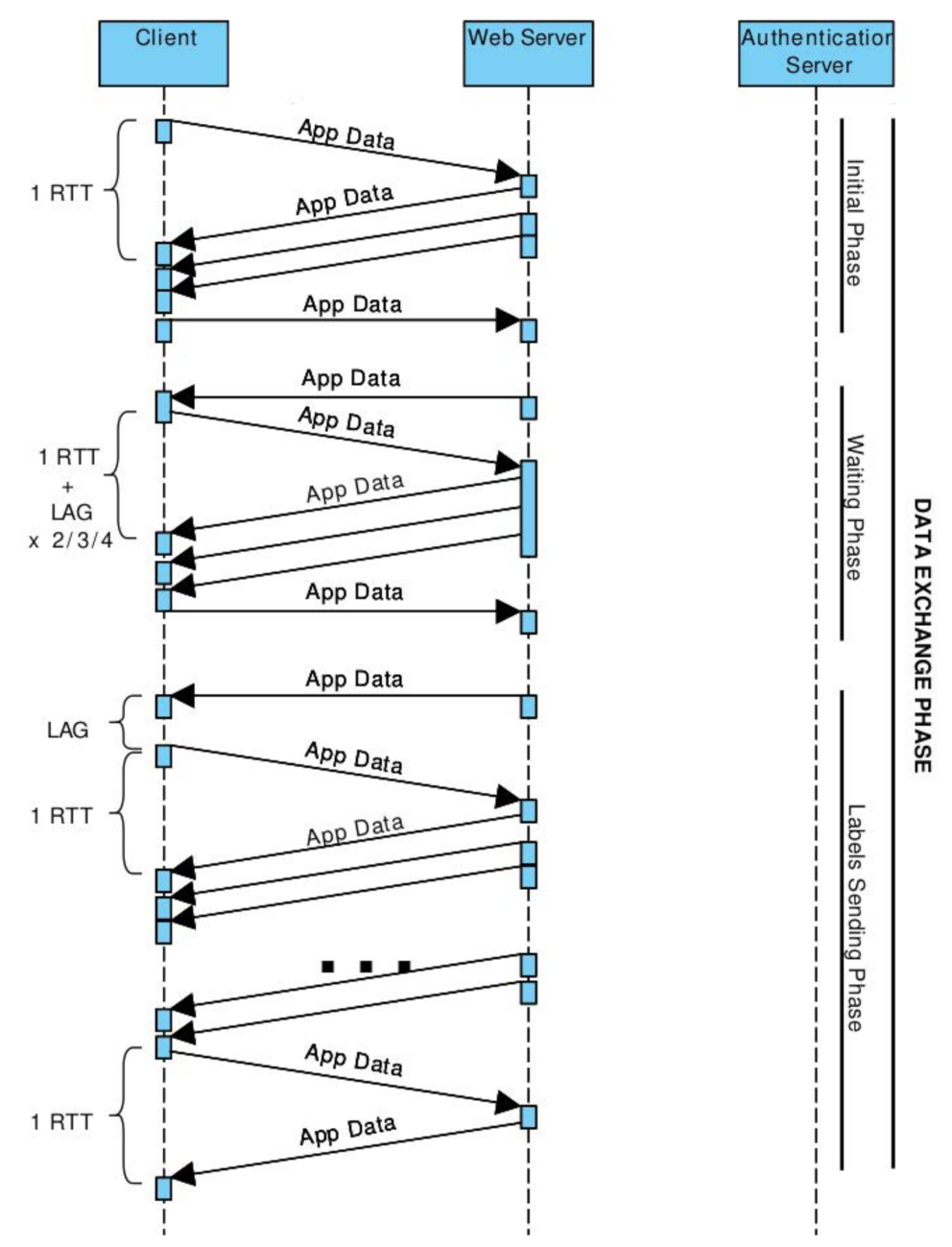
6. Experimental Evaluation
6.1. Tools and Methodology
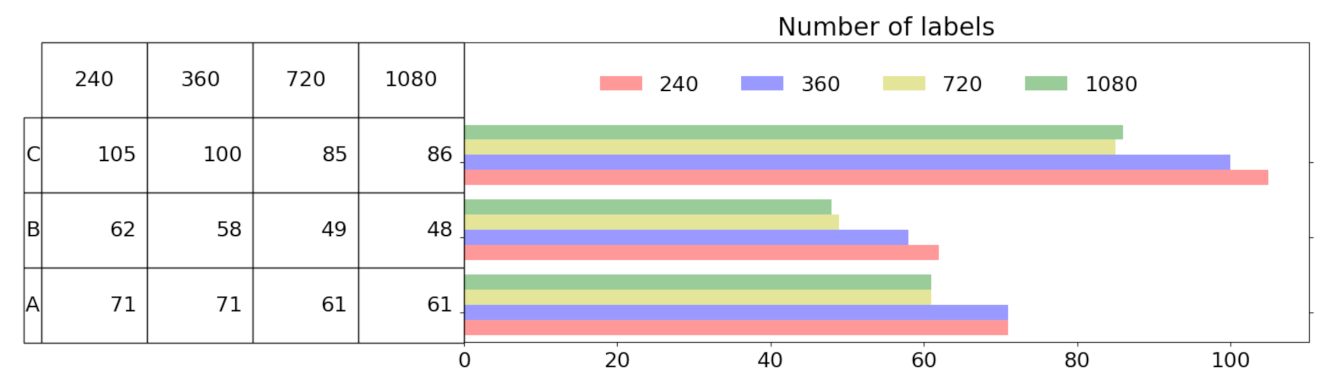
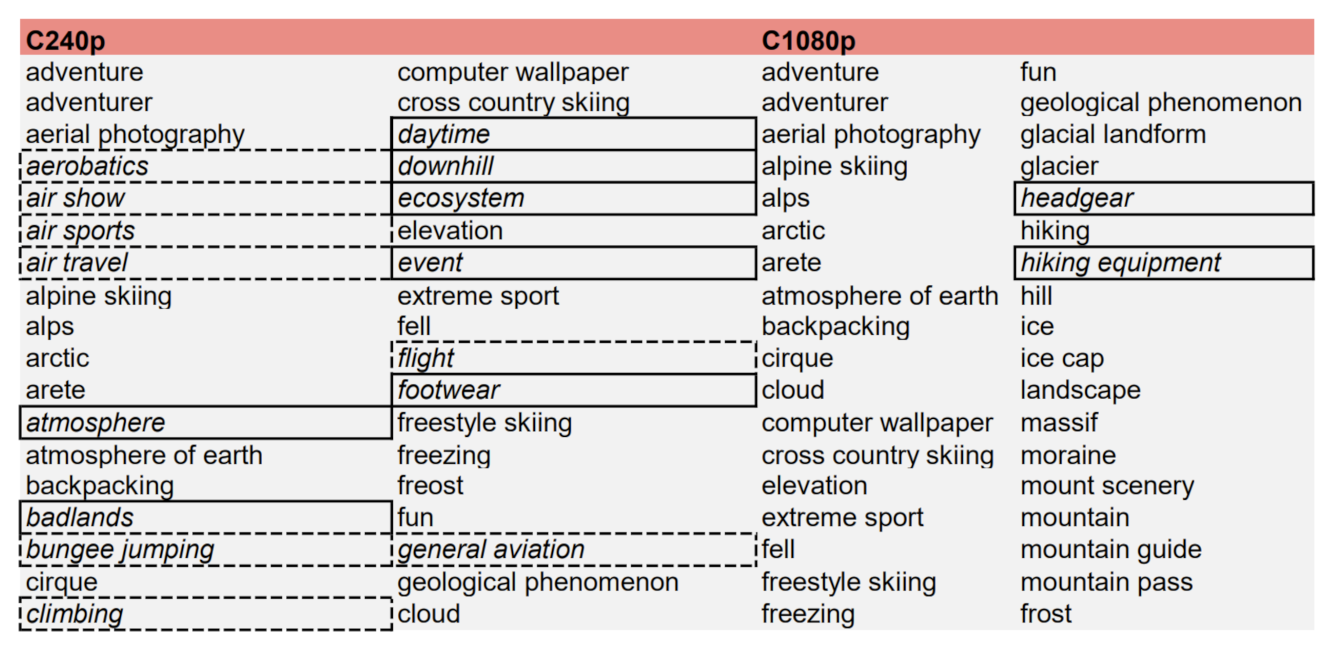
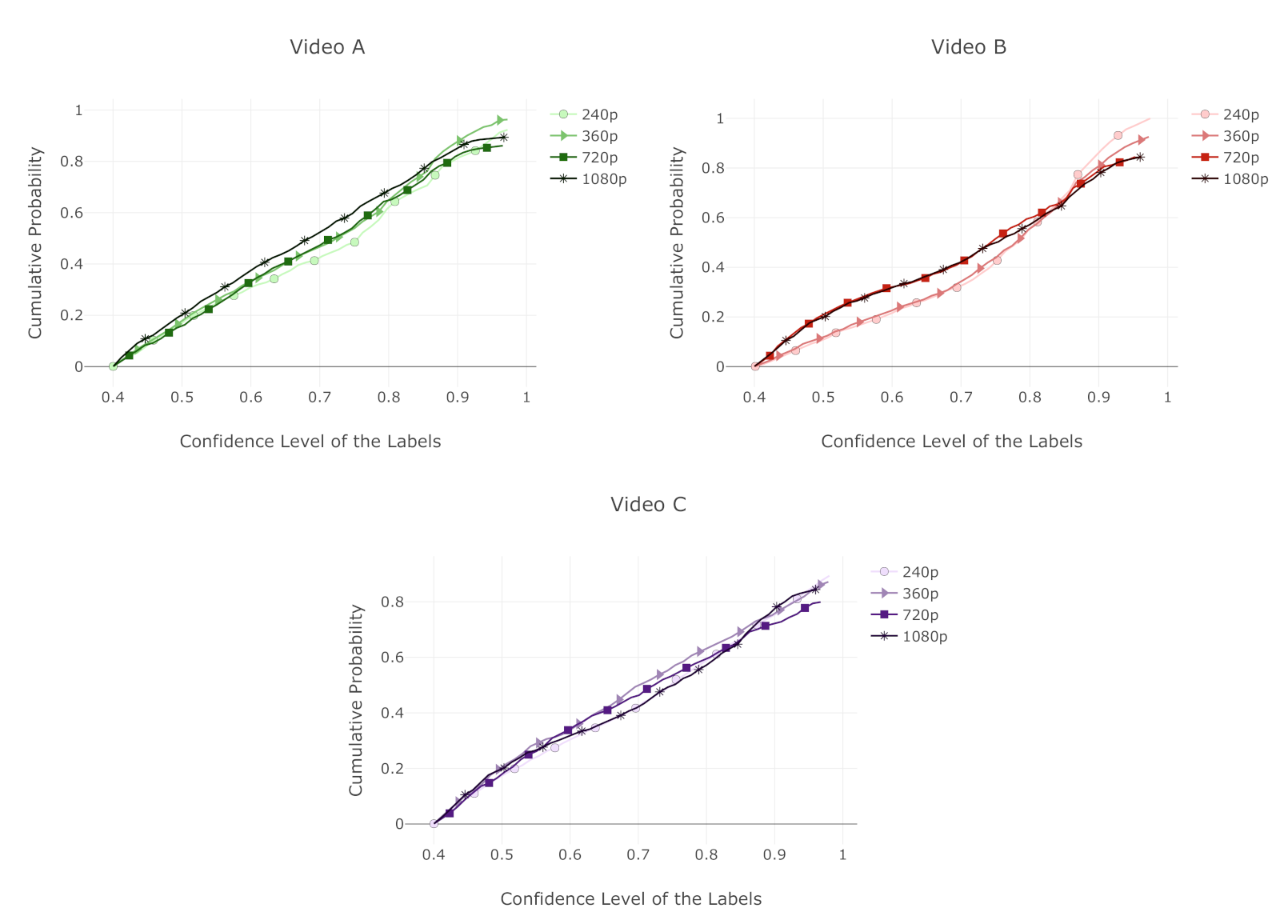
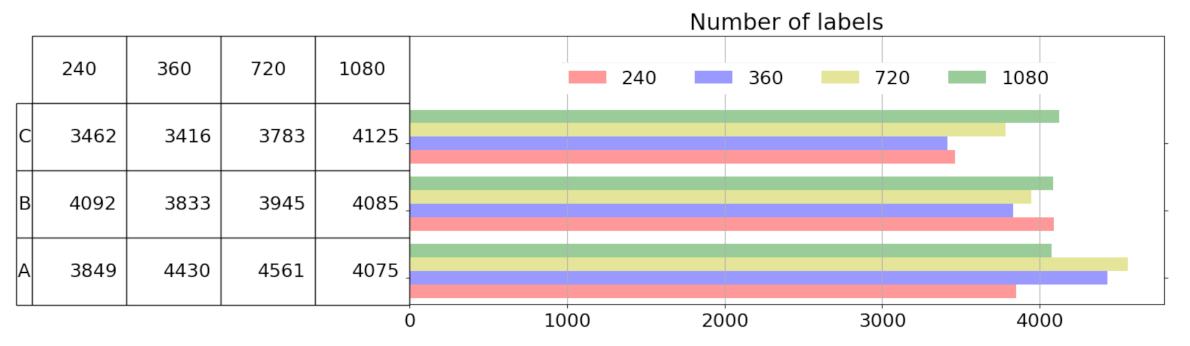
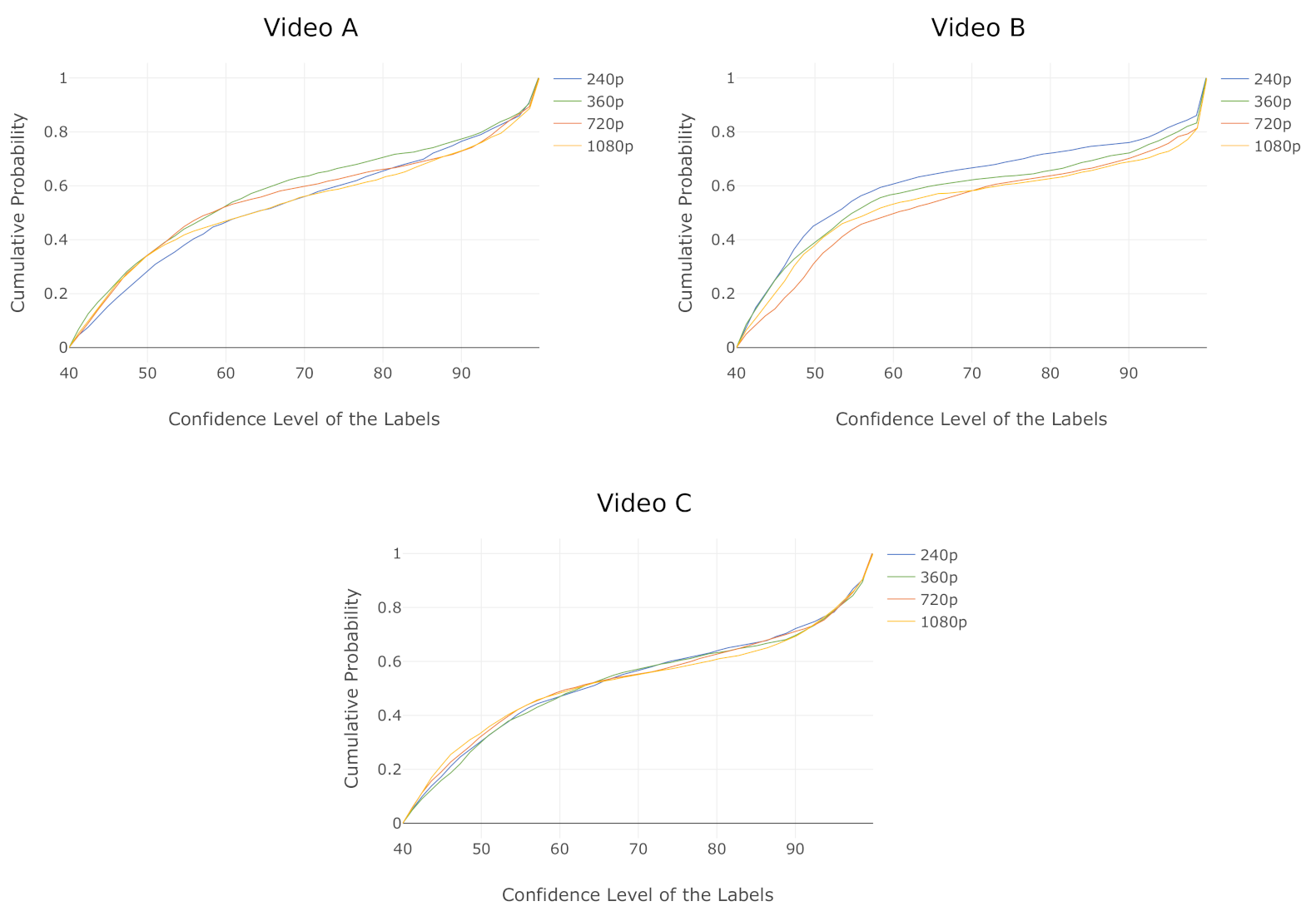
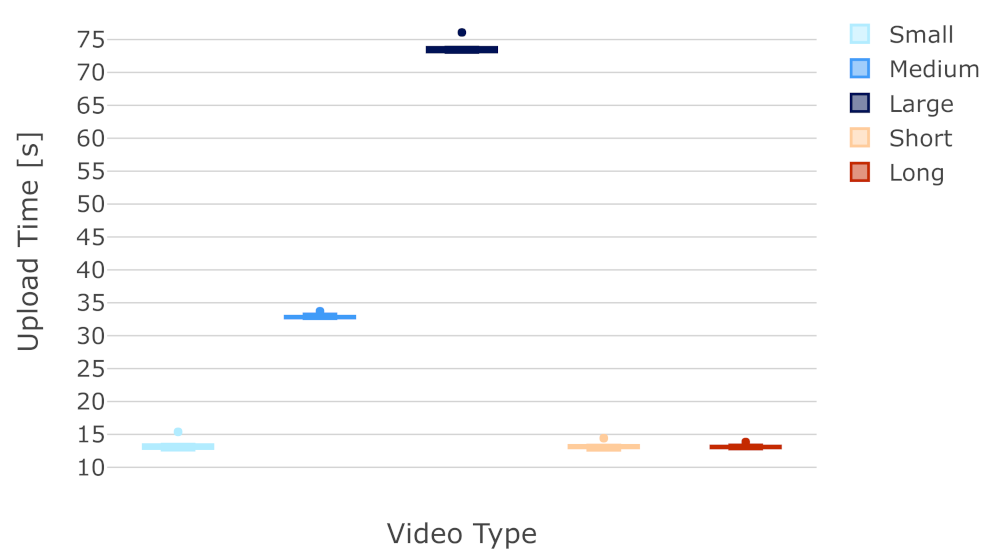
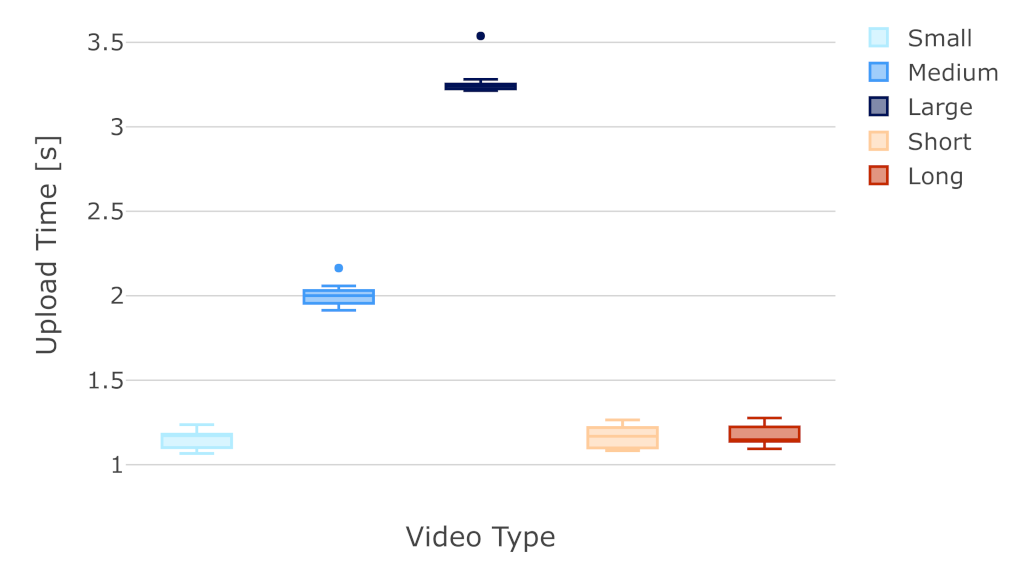
6.2. Analysis of Labels Detected
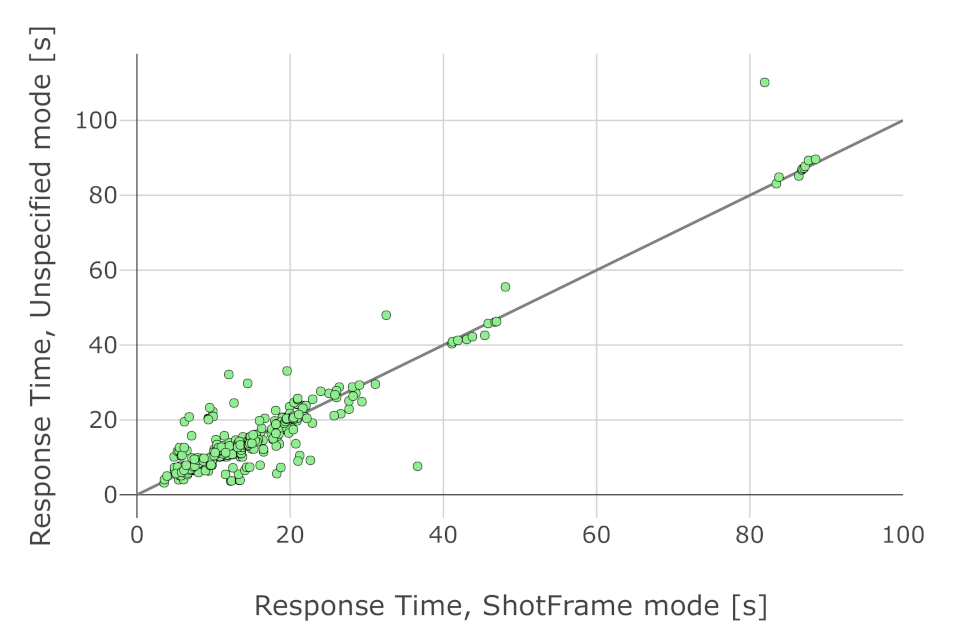
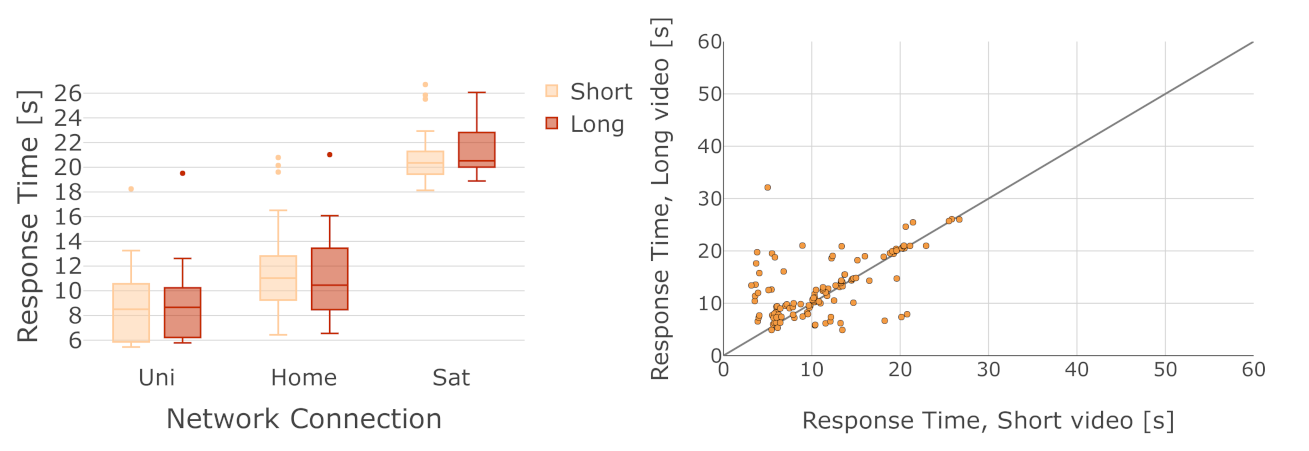
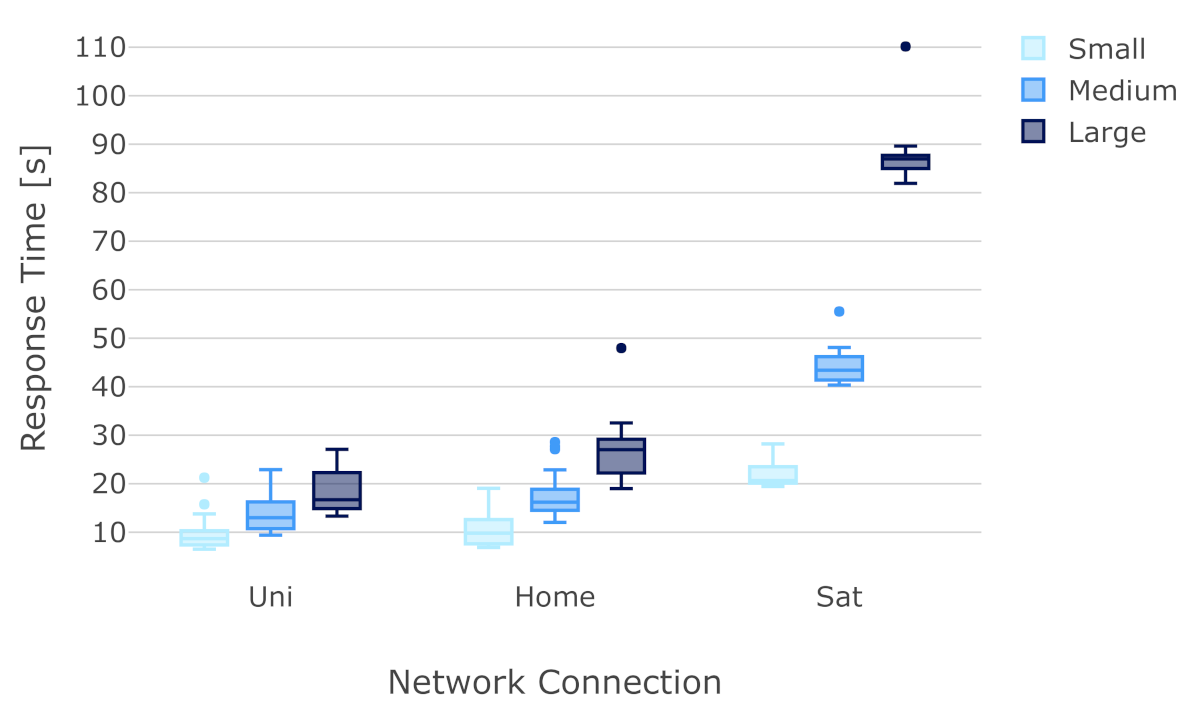
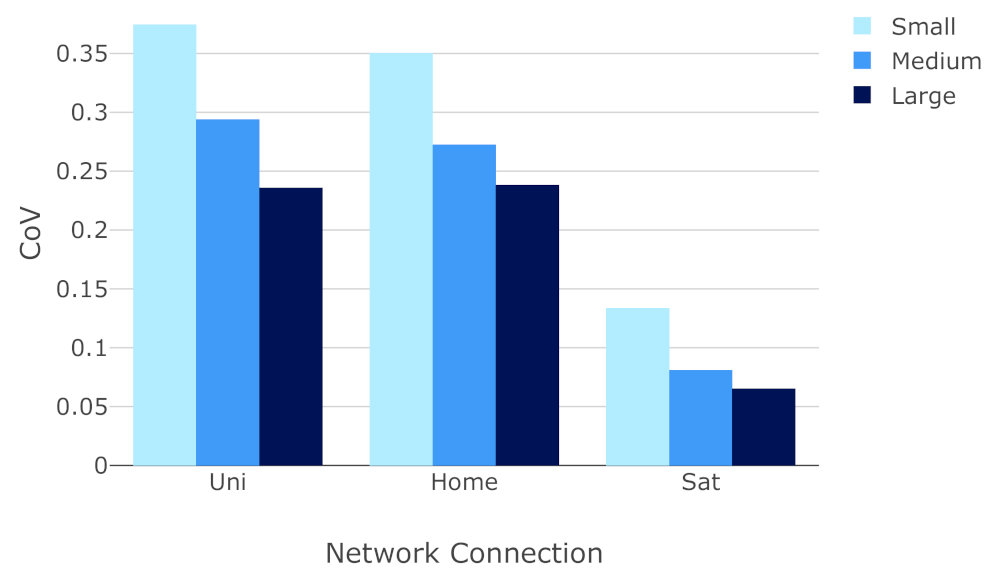
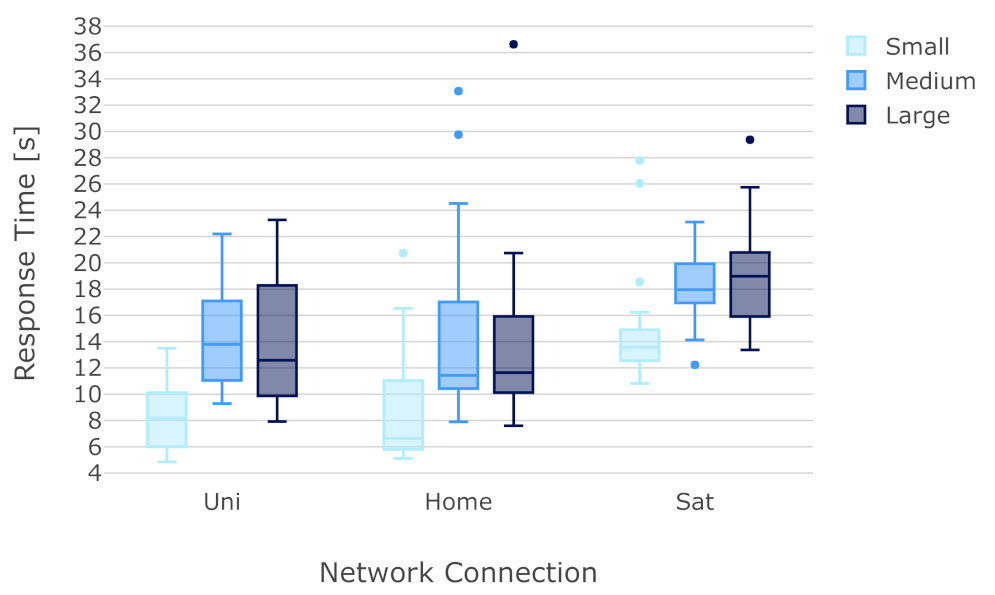
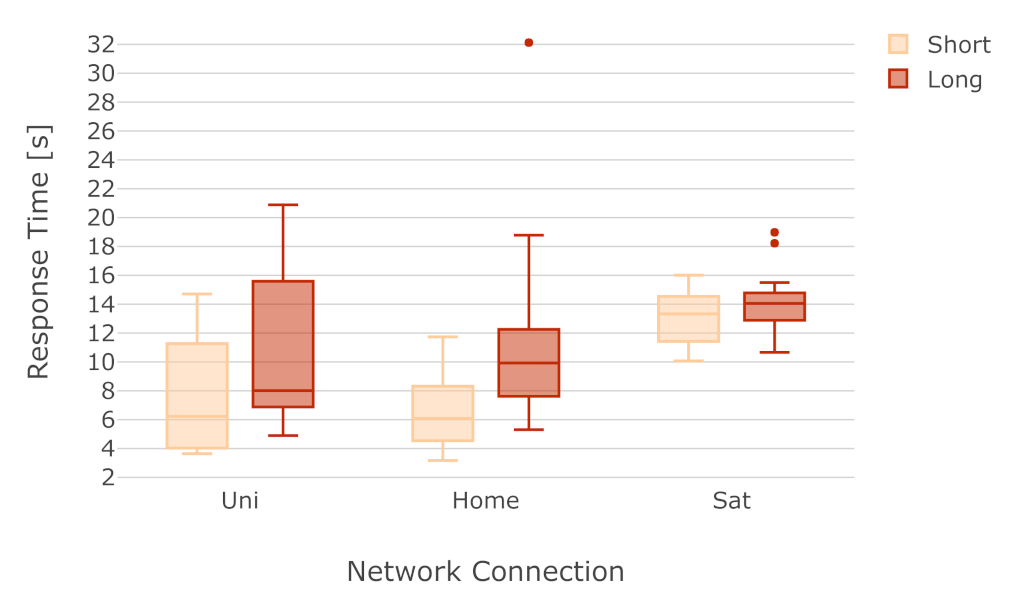
6.3. Analysis of Response Time
7. Discussion and Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RTT | Round Trip Time |
| ROS | Robot Operating System |
| VM | Virtual Machine |
| UAV | Unmanned Aerial Vehicle |
| S&R | Search and Rescue |
| IoT | Internet of Things |
| API | Application Program Interface |
| Wi-Fi | Wireless Fidelity or IEEE 802.11 |
| P2P | Peer-to-Peer |
| OpenCv | Open Computer Vision |
| GPS | Global Positioning System |
| CVI | Cloud Video Intelligence |
| AR | Amazon Rekognition |
| FTTH | Fiber To The Home |
| HD | High Definition |
| SD | Standard Definition |
| DC | Dew Computing |
| WLAN | IEEE 802.11 wireless LAN |
| WAN | Wide Area Network |
| GCS | Google Cloud Storage |
References
- Aceto, G.; Botta, A.; Pescape, A.; Westphal, C. Efficient Storage and Processing of High-Volume Network Monitoring Data. IEEE Trans. Netw. Serv. Manag. 2013, 10, 162–175. [Google Scholar] [CrossRef]
- Botta, A.; Gallo, L.; Ventre, G. Cloud, Fog, and Dew Robotics: Architectures for next generation applications. In Proceedings of the the Seventh IEEE International Conference on Mobile Cloud Computing, Services, and Engineering (IEEE Mobile Cloud 2019), Newark, CA, USA, 4–9 April 2019. [Google Scholar]
- ROS. Robot Operating System. Available online: http://www.ros.org (accessed on 11 June 2021).
- Marconi, L.; Melchiorri, C.; Beetz, M.; Pangercic, D.; Siegwart, R.; Leutenegger, S.; Carloni, R.; Stramigioli, S.; Bruyninckx, H.; Doherty, P.; et al. The SHERPA project: Smart collaboration between humans and ground-aerial robots for improving rescuing activities in alpine environments. In Proceedings of the 2012 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), College Station, TX, USA, 5–8 November 2012; pp. 1–4. [Google Scholar] [CrossRef]
- Botta, A.; Cacace, J.; Lippiello, V.; Siciliano, B.; Ventre, G. Networking for Cloud Robotics: A case study based on the Sherpa Project. In Proceedings of the International Conference on Cloud and Robotics ICCR2017, Saint Quentin, France, 23 November 2017. [Google Scholar]
- Du, Z.; He, L.; Chen, Y.; Xiao, Y.; Gao, P.; Wang, T. Robot Cloud: Bridging the power of robotics and cloud computing. Future Gener. Comput. Syst. 2017, 74, 337–348. [Google Scholar] [CrossRef]
- Du, Z.; Garcà a-Acosta, M.; Chen, Y. Robot as a Service in Cloud Computing. In Proceedings of the IEEE Fifth International Symposium on Service-Oriented System Engineering, Nanjing, China, 4–5 June 2010; IEEE Computer Society: Los Alamitos, CA, USA, 2010; pp. 151–158. [Google Scholar] [CrossRef]
- Thompson, E.A.; McIntosh, C.; Isaacs, J.; Harmison, E.; Sneary, R. Robot communication link using 802.11n or 900MHz OFDM. J. Netw. Comput. Appl. 2015, 52, 37–51. [Google Scholar] [CrossRef]
- Curiac, D.I. Towards wireless sensor, actuator and robot networks: Conceptual framework, challenges and perspectives. J. Netw. Comput. Appl. 2016, 63, 14–23. [Google Scholar] [CrossRef]
- Hadid, N.; Guitton, A.; Misson, M. Exploiting a meeting channel to interconnect mobile robots. J. Netw. Comput. Appl. 2012, 35, 1436–1445. [Google Scholar] [CrossRef]
- Akkaya, K.; Senturk, I.F.; Vemulapalli, S. Handling large-scale node failures in mobile sensor/robot networks. J. Netw. Comput. Appl. 2013, 36, 195–210. [Google Scholar] [CrossRef]
- Wan, J.; Tang, S.; Yan, H.; Li, D.; Wang, S.; Vasilakos, A.V. Cloud robotics: Current status and open issues. IEEE Access 2016, 4, 2797–2807. [Google Scholar] [CrossRef]
- Hu, G.; Tay, W.P.; Wen, Y. Cloud robotics: Architecture, challenges and applications. IEEE Netw. 2012, 26, 21–28. [Google Scholar] [CrossRef]
- Kehoe, B.; Patil, S.; Abbeel, P.; Goldberg, K. A survey of research on cloud robotics and automation. IEEE Trans. Autom. Sci. Eng. 2015, 12, 398–409. [Google Scholar] [CrossRef]
- Angelopoulos, G.; Baras, N.; Dasygenis, M. Secure Autonomous Cloud Brained Humanoid Robot Assisting Rescuers in Hazardous Environments. Electronics 2021, 10, 124. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, W.; Liu, D.; Jin, X.; Jiang, J.; Chen, K. Enabling Edge-Cloud Video Analytics for Robotics Applications. In Proceedings of the IEEE International Conference on Computer Communications, Virtual Conference, 10–13 May 2021. [Google Scholar]
- Liu, B.; Chen, Y.; Blasch, E.; Pham, K.; Shen, D.; Chen, G. A holistic cloud-enabled robotics system for real-time video tracking application. In Future Information Technology; Springer: Berlin/Heidelberg, Germany, 2014; pp. 455–468. [Google Scholar]
- Agostinho, L.; Olivi, L.; Feliciano, G.; Paolieri, F.; Rodrigues, D.; Cardozo, E.; Guimaraes, E. A Cloud Computing Environment for Supporting Networked Robotics Applications. In Proceedings of the 2011 IEEE Ninth International Conference on Dependable, Autonomic and Secure Computing, Sydney, Australia, 12–14 December 2011; pp. 1110–1116. [Google Scholar] [CrossRef]
- Miratabzadeh, S.A.; Gallardo, N.; Gamez, N.; Haradi, K.; Puthussery, A.R.; Rad, P.; Jamshidi, M. Cloud robotics: A software architecture: For heterogeneous large-scale autonomous robots. In Proceedings of the 2016 World Automation Congress (WAC), Rio Grande, PR, USA, 31 July–4 August 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, J.; Zhou, F.; Yin, L.; Wang, Y. A Novel Cloud Platform For Service Robots. IEEE Access 2019, 7, 182951–182961. [Google Scholar] [CrossRef]
- Mohanarajah, G.; Hunziker, D.; D’Andrea, R.; Waibel, M. Rapyuta: A Cloud Robotics Platform. IEEE Trans. Autom. Sci. Eng. 2015, 12, 481–493. [Google Scholar] [CrossRef] [Green Version]
- Kehoe, B.; Matsukawa, A.; Candido, S.; Kuffner, J.; Goldberg, K. Cloud-based robot grasping with the google object recognition engine. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 4263–4270. [Google Scholar] [CrossRef] [Green Version]
- Arumugam, R.; Enti, V.R.; Bingbing, L.; Xiaojun, W.; Baskaran, K.; Kong, F.F.; Kumar, A.S.; Meng, K.D.; Kit, G.W. DAvinCi: A cloud computing framework for service robots. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 3084–3089. [Google Scholar] [CrossRef]
- Cacace, J.; Finzi, A.; Lippiello, V.; Loianno, G.; Sanzone, D. Aerial Service Vehicles for Industrial Inspection: Task Decomposition and Plan Execution. In Recent Trends in Applied Artificial Intelligence. In Proceedings of the 26th International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, IEA/AIE 2013, Amsterdam, The Netherlands, 17–21 June 2013; pp. 302–311. [Google Scholar] [CrossRef] [Green Version]
- Waharte, S.; Trigoni, N. Supporting Search and Rescue Operations with UAVs. In Proceedings of the 2010 International Conference on Emerging Security Technologies, EST ’10, Canterbury, UK, 6–7 September 2010; IEEE Computer Society: Washington, DC, USA, 2010; pp. 142–147. [Google Scholar] [CrossRef]
- Goodrich, M.A.; Cooper, J.L.; Adams, J.A.; Humphrey, C.; Zeeman, R.; Buss, B.G. Using a Mini-UAV to Support Wilderness Search and Rescue Practices for Human-Robot Teaming. In Proceedings of the IEEE International Conference on Safety, Security and Rescue Robotics, Rome, Italy, 22–26 September 2007. [Google Scholar]
- Cacace, J.; Finzi, A.; Lippiello, V.; Furci, M.; Mimmo, N.; Marconi, L. A control architecture for multiple drones operated via multimodal interaction in search & rescue mission. In Proceedings of the 2016 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Lausanne, Switzerland, 23–27 October 2016; pp. 233–239. [Google Scholar] [CrossRef]
- Cacace, J.; Caccavale, R.; Finzi, A.; Lippiello, V. Attentional multimodal interface for multidrone search in the Alps. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016; pp. 1178–1183. [Google Scholar] [CrossRef]
- Waibel, M.; Beetz, M.; Civera, J.; D’Andrea, R.; Elfring, J.; Gálvez-López, D.; Häussermann, K.; Janssen, R.; Montiel, J.M.M.; Perzylo, A.; et al. RoboEarth. IEEE Robot. Autom. Mag. 2011, 18, 69–82. [Google Scholar] [CrossRef] [Green Version]
- Bogue, R. Robots for monitoring the environment. Ind. Robot. Int. J. 2011, 38, 560–566. [Google Scholar] [CrossRef]
- Wang, L. Wise-ShopFloor: An Integrated Approach for Web-Based Collaborative Manufacturing. IEEE Trans. Syst. Man Cybern. Part C 2008, 38, 562–573. [Google Scholar] [CrossRef]
- Pouliot, N.; Montambault, S. LineScout Technology: From inspection to robotic maintenance on live transmission power lines. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 1034–1040. [Google Scholar] [CrossRef]
- Persico, V.; Marchetta, P.; Botta, A.; Pescape, A. On Network Throughput Variability in Microsoft Azure Cloud. In Proceedings of the 2015 IEEE Global Communications Conference (GLOBECOM), San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Botta, A.; Emma, D.; Pescapé, A.; Ventre, G. Systematic performance modeling and characterization of heterogeneous IP networks. J. Comput. Syst. Sci. 2006, 72, 1134–1143. [Google Scholar] [CrossRef] [Green Version]
- Ray, P.P. An Introduction to Dew Computing: Definition, Concept and Implications. IEEE Access 2018, 6, 723–737. [Google Scholar] [CrossRef]
- Ray, P.P. Minimizing dependency on internetwork: Is dew computing a solution? Trans. Emerg. Telecommun. Technol. 2019, 30, e3496. [Google Scholar] [CrossRef] [Green Version]
- Sojaat, Z.; Skalaa, K. The dawn of Dew: Dew Computing for advanced living environment. In Proceedings of the 2017 40th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 22–26 May 2017; pp. 347–352. [Google Scholar]
- Cao, Y.; Xu, Z.; Qin, P.; Jiang, T. Video Processing on the Edge for Multimedia IoT Systems. arXiv 2018, arXiv:1805.04837. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Platform | ROS-Enabled | Cloud | Edge | Video | Experimental | Search |
|---|---|---|---|---|---|---|
| Support | Support | Processing | Validation | and Rescue | ||
| Liu et al. [17] | ✓ | ✓ | ✗ | ✓ | ✓ | ✗ |
| Agostinho et al. [18] | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ |
| Miratabzadeh et al. [19] | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ |
| Liu et al. [20] | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ |
| Mohanarajah et al. [21] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ |
| Kehoe et al. [22] | ✓ | ✓ | ✗ | ✓ | ✓ | ✗ |
| Arumugam et al. [23] | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ |
| Waibel et al. [29] | ✓ | ✓ | ✗ | ✓ | ✓ | ✗ |
| Cacace et al. [24] | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ |
| Waharte et al. [25] | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ |
| Goodrich et al. [26] | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ |
| Cacace et al. [27] | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| Cacace et al. [28] | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| Wang [31] | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ |
| DewROS | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Network Connection | Label Detection Mode | Video Type | Video Location | |
|---|---|---|---|---|
| Size | Length | |||
| University Ethernet (UNI) | Unspecified | Small (2.1 MB—52 s) | Short (2.1 MB—3 s) | Local (LOC) |
| Residential FTTH (HOME) | Shot & Frame | Medium (8.8 MB—53 s) | Long (2.2 MB—71 s) | Google Cloud Storage (GCS) |
| Satellite (SAT) | Large (23.7 MB—55 s) | |||
| Network | Upload Bandwidth | Download Bandwidth |
|---|---|---|
| UNI | 90 Mbps | 90 Mbps |
| HOME | 20 Mbps | 180 Mbps |
| SAT | 3 Mbps | 9 Mbps |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Botta, A.; Cacace, J.; De Vivo, R.; Siciliano, B.; Ventre, G. Networking for Cloud Robotics: The DewROS Platform and Its Application. J. Sens. Actuator Netw. 2021, 10, 34. https://doi.org/10.3390/jsan10020034
Botta A, Cacace J, De Vivo R, Siciliano B, Ventre G. Networking for Cloud Robotics: The DewROS Platform and Its Application. Journal of Sensor and Actuator Networks. 2021; 10(2):34. https://doi.org/10.3390/jsan10020034
Chicago/Turabian StyleBotta, Alessio, Jonathan Cacace, Riccardo De Vivo, Bruno Siciliano, and Giorgio Ventre. 2021. "Networking for Cloud Robotics: The DewROS Platform and Its Application" Journal of Sensor and Actuator Networks 10, no. 2: 34. https://doi.org/10.3390/jsan10020034
APA StyleBotta, A., Cacace, J., De Vivo, R., Siciliano, B., & Ventre, G. (2021). Networking for Cloud Robotics: The DewROS Platform and Its Application. Journal of Sensor and Actuator Networks, 10(2), 34. https://doi.org/10.3390/jsan10020034