
A Study on Sensor System Latency in VR Motion Sickness




Abstract
:1. Introduction
2. Technical Factors Related to the Motion Sickness in Virtual Environment
2.1. Motion Sickness (MS) Incidence, Symptoms, and Theories
2.2. Field of View
2.3. Latency
2.4. Sensors
2.5. Tracking
2.6. Rendering
2.7. Display
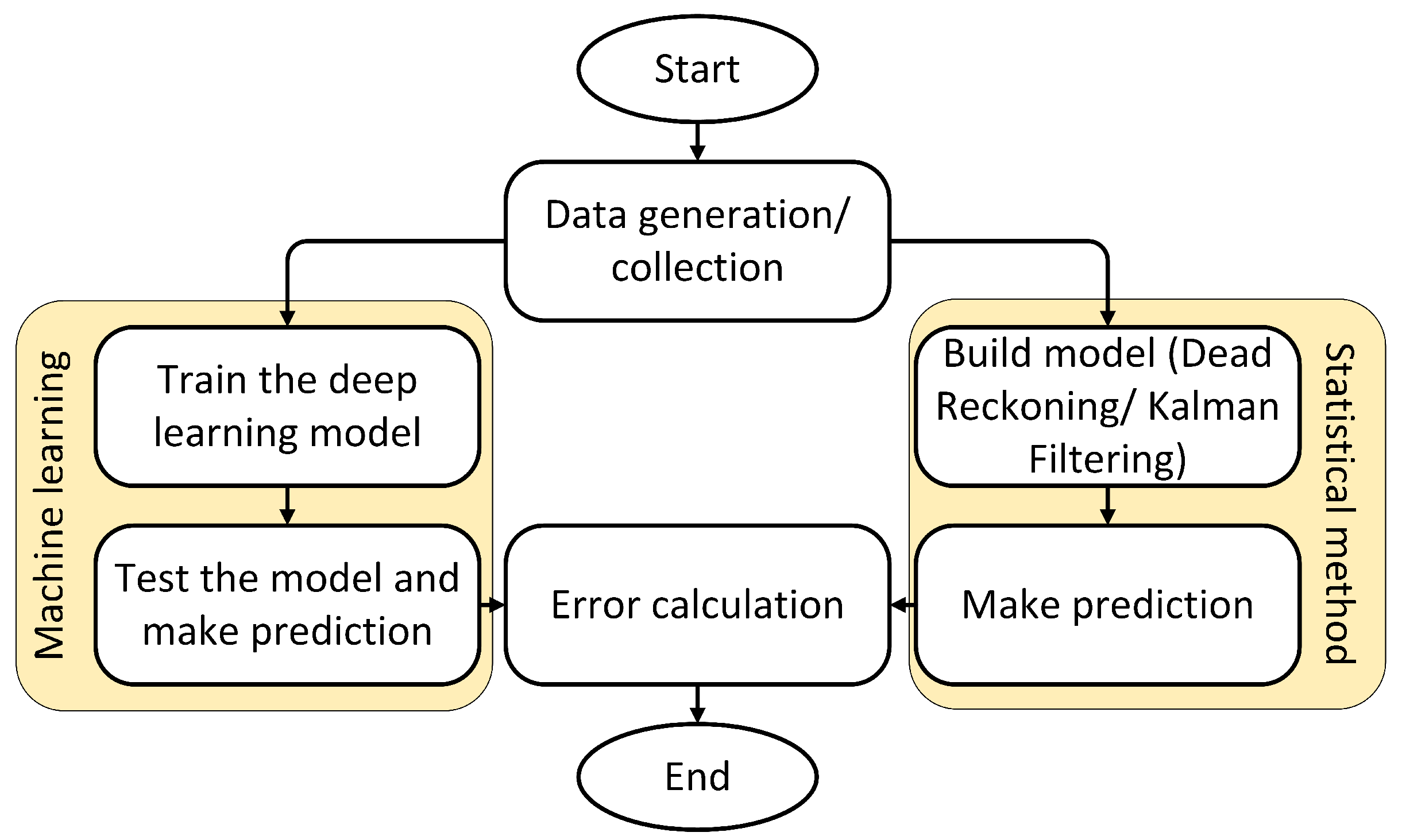
3. Common Prediction Algorithm for Predictive Tracking
3.1. Statistical Methods of Prediction
3.1.1. Dead Reckoning
3.1.2. Alpha-Beta-Gamma
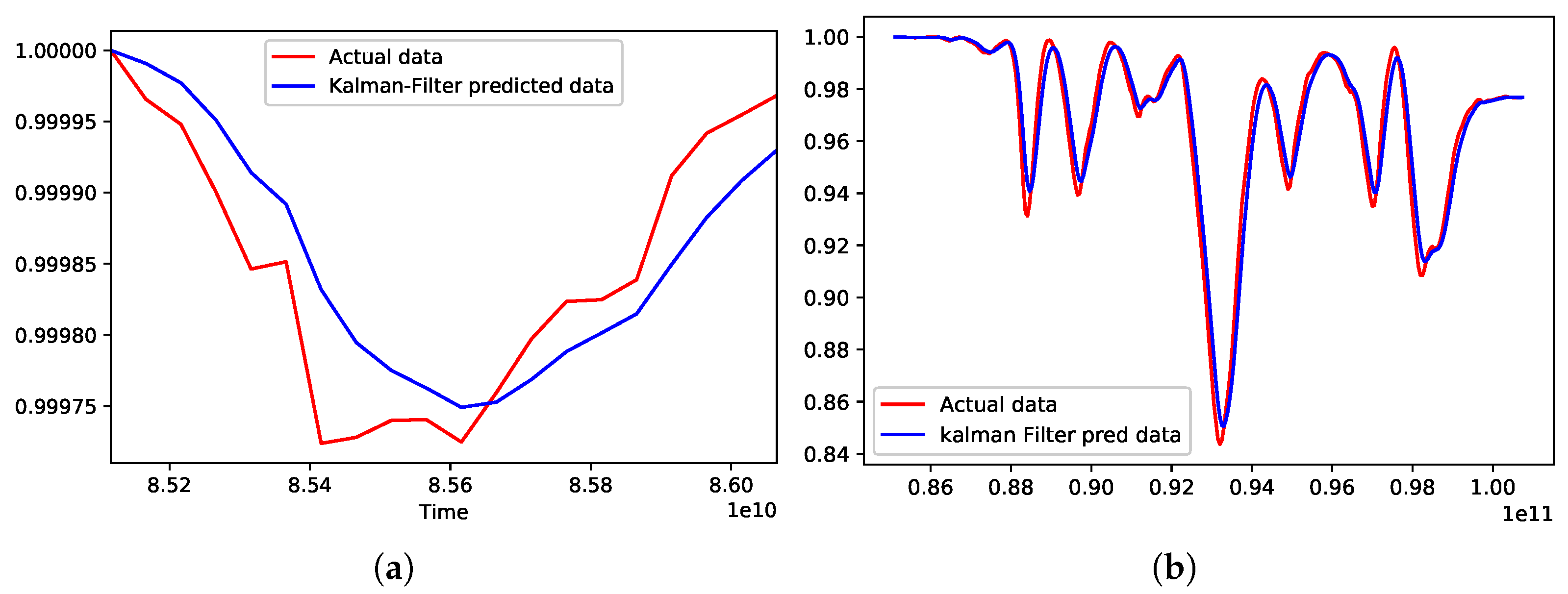
3.1.3. Kalman Filtering
3.2. Machine Learning-Based Approach
3.2.1. Recurrent Neural Networks (RNN)
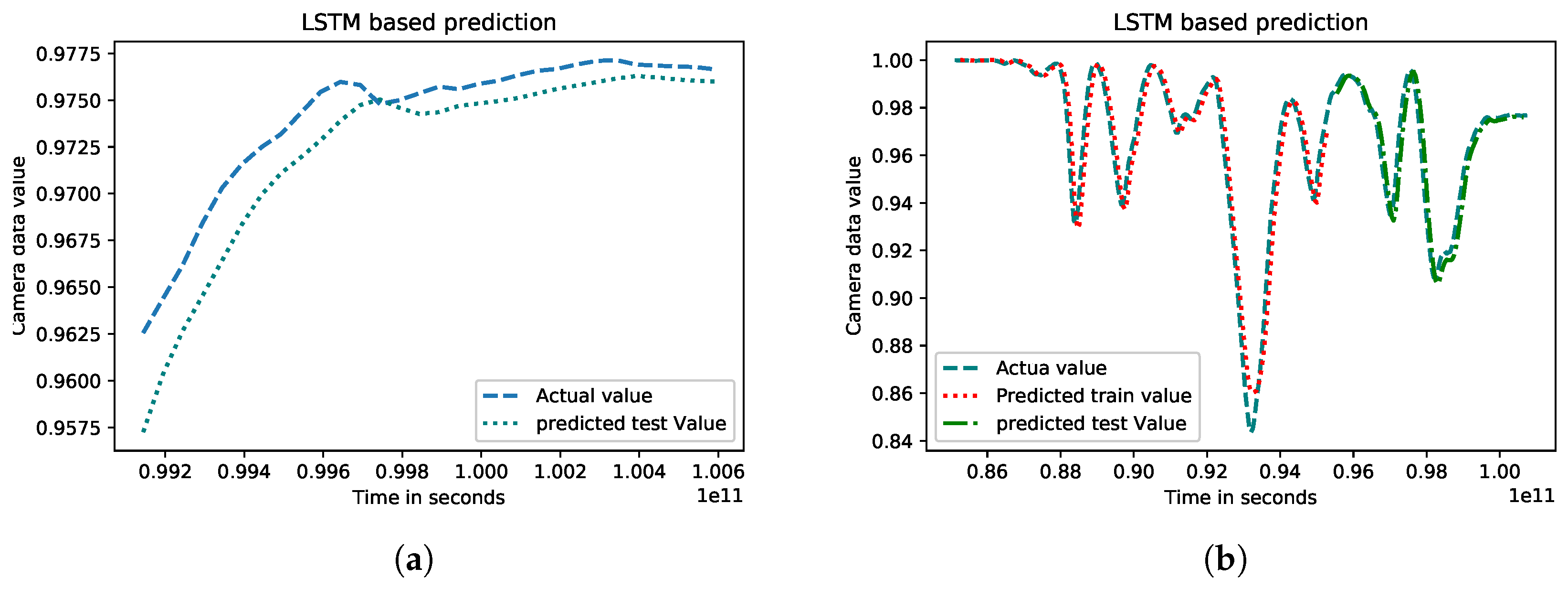
3.2.2. Long Short-Term Memory (LSTM)
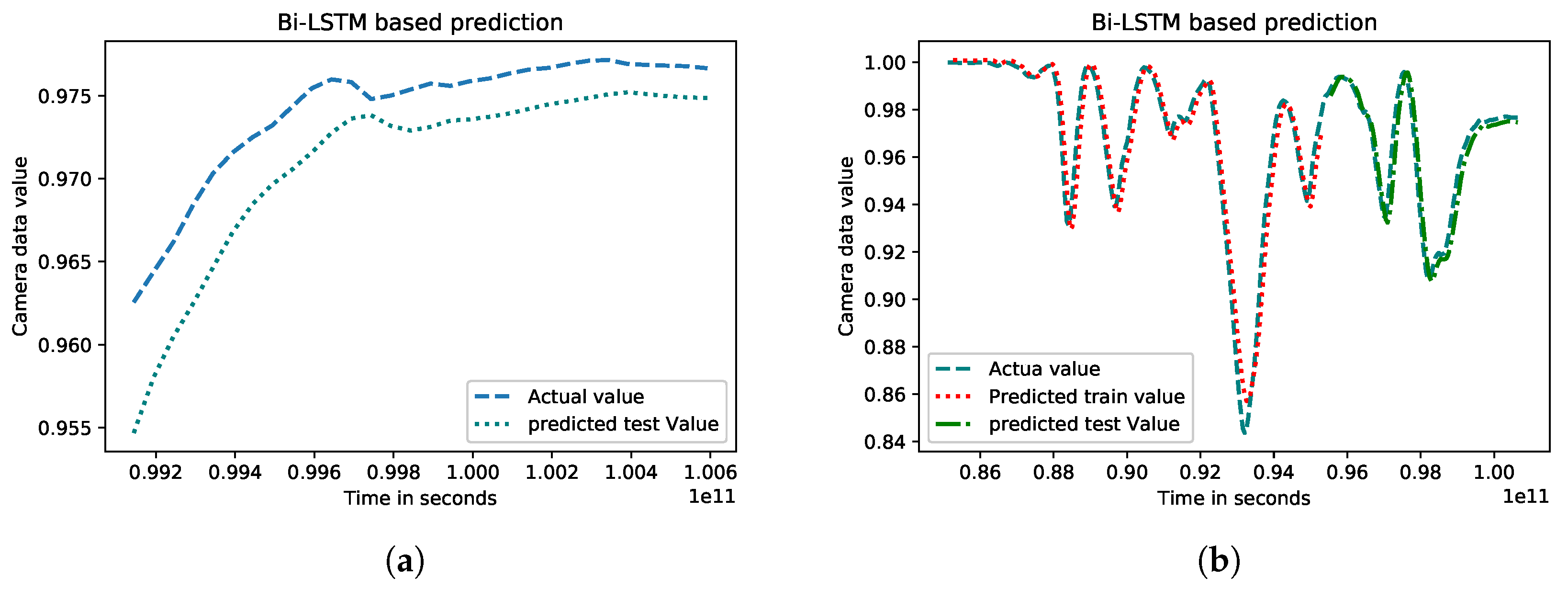
3.2.3. Bidirectional Long Short-Term Memory (BLSTM)
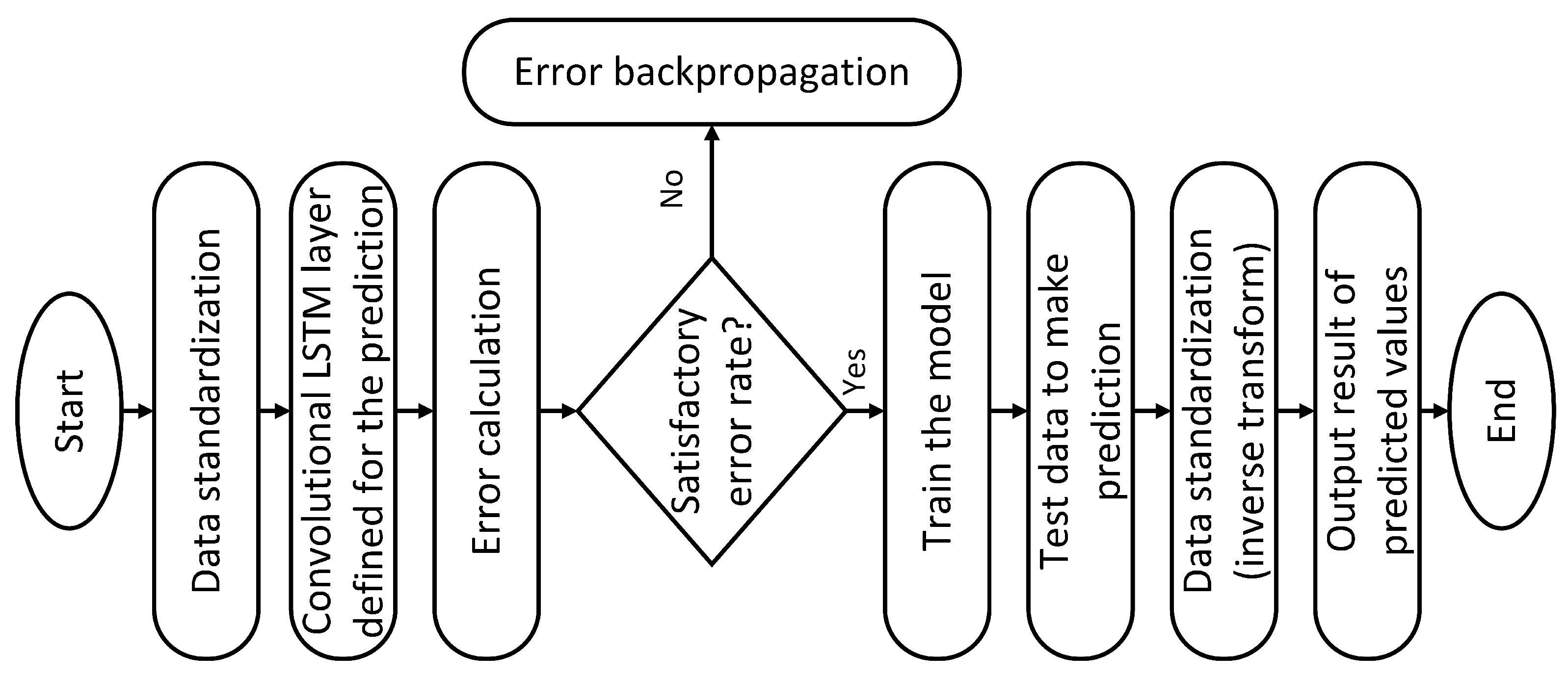
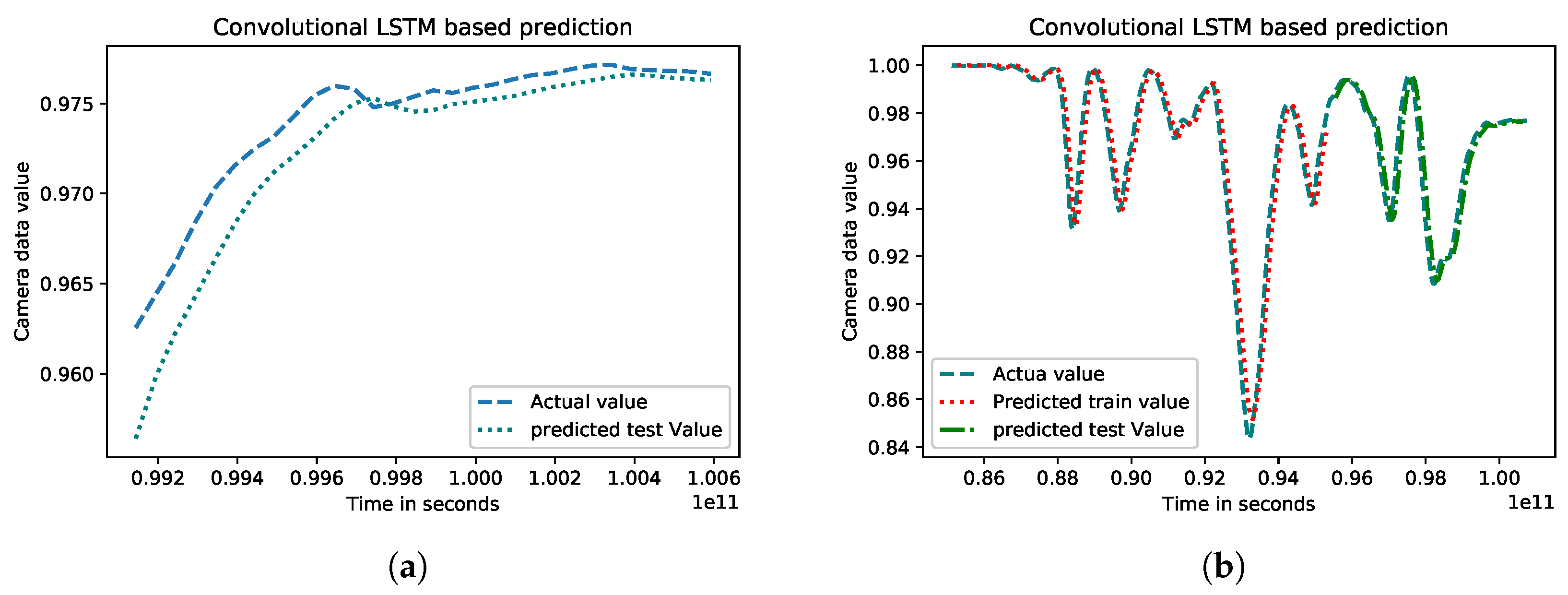
3.2.4. Convolutional LSTM
- Input data: Input the data needed for Convolutional LSTM training.
- Data standardization: To better train the neural network model, the MinMax scaler-based data standardization technique is used to normalize the data. This technique is to re-scale features with a distribution value between 0 and 1.
- Convolutional LSTM layer calculation: A Convolutional LSTM defined by adding CNN layers on the front end followed by LSTM layers with a Dense layer on the output. Where the input data are subsequently transferred through the convolution layer and pooling layer in the CNN layer, the feature extraction of the input data is carried out, and the output value is obtained. Finally, the CNN layer output data are calculated, and an output value is obtained through the LSTM layer.
- Error calculation: To determine the corresponding error, the output value calculated by the output layer is compared to the real value of this group of data.
- Error back-propagation: Proceed to step 3 to continue training the network by propagating the estimated error in the opposite way, updating the weight and bias of each layer and so on.
- Train and test the model and make a prediction. Save the trained model and make a prediction of that model with the testing data.
- Data standardization (inverse transform): The output value obtained through the Convolutional LSTM is the standardized value, and the standardized value is restored to the original value by inverse transform.
- Output result of the predicted values: Output the restored results to complete the prediction process.
3.2.5. Evaluation Metrics for LSTM, Bidirectional LSTM, Convolutional LSTM
- Root Mean Square Error (RMSE):
- Mean Absolute Error (MAE):
4. Experimental Analysis
4.1. Experimental Setup
4.2. Result Analysis
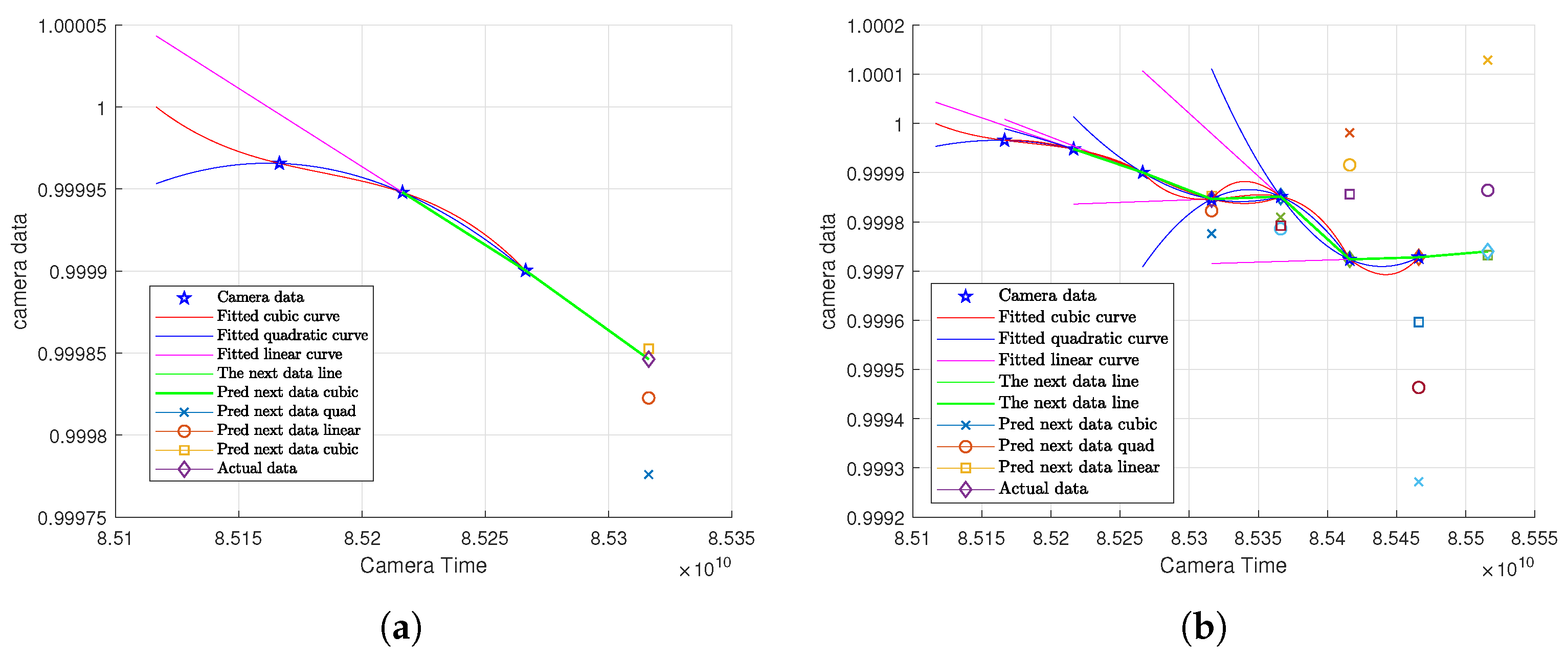
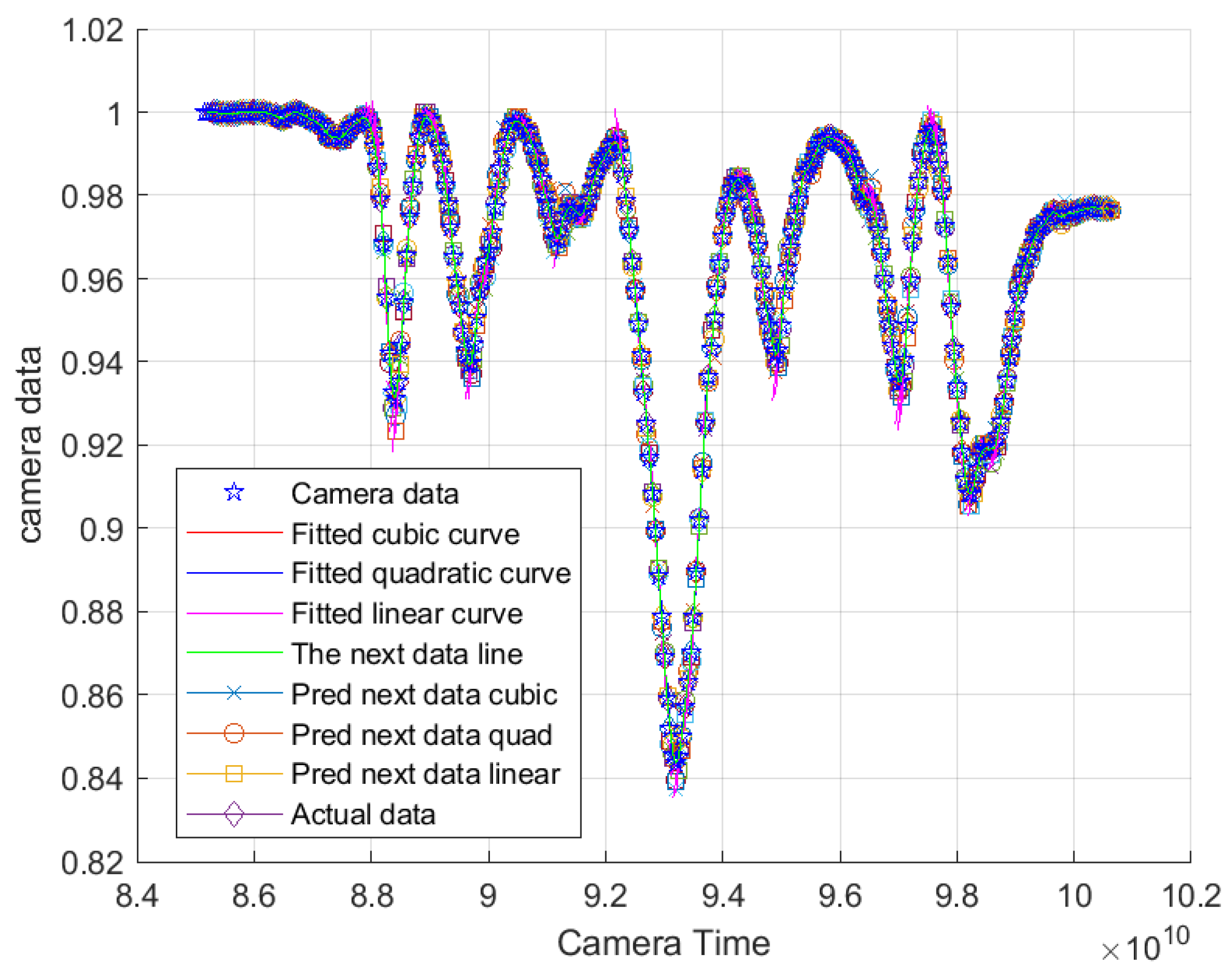
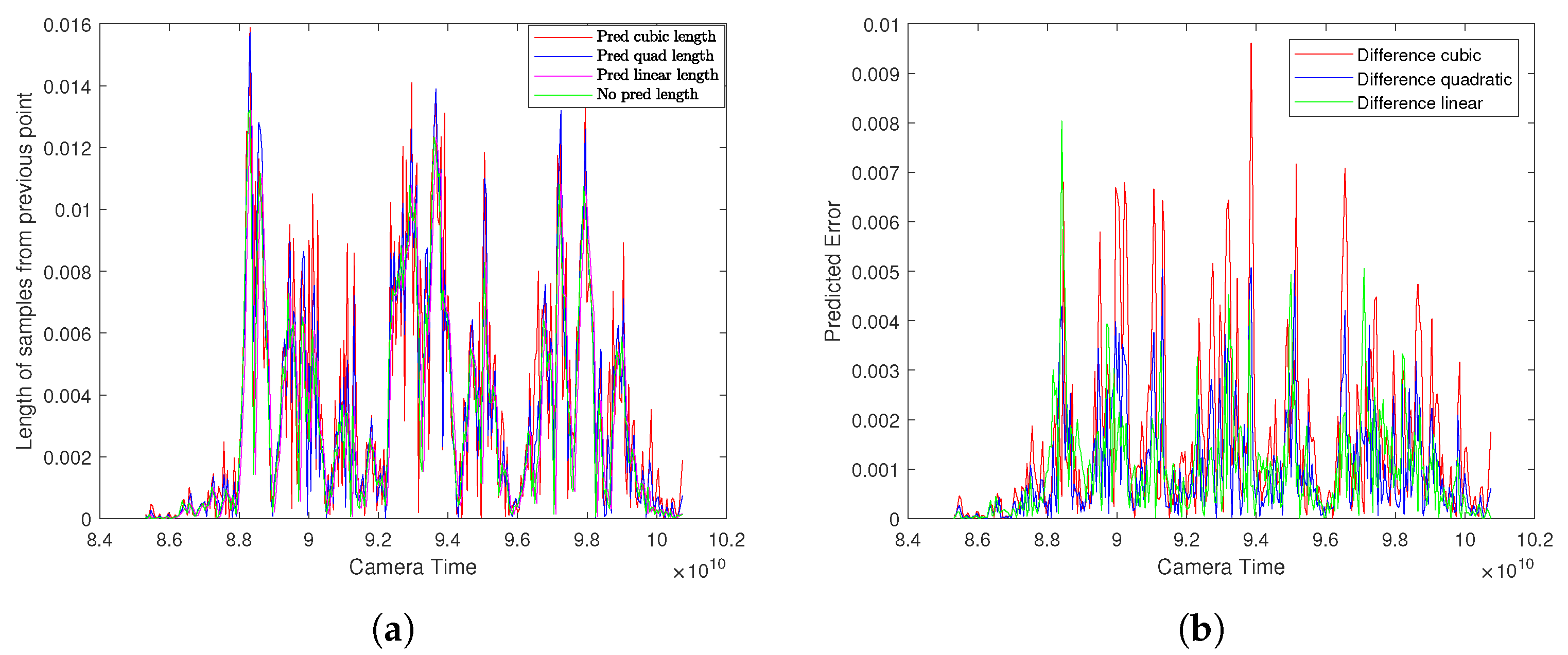
4.2.1. Experimental Results for Statistical Methods-Based Prediction
4.2.2. Experimental Results for Machine Learning-Based Prediction
4.2.3. Comparison of Error
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lawson, B.D. Motion Sickness Symptomatology and Origins. 2014. Available online: https://www.taylorfrancis.com/chapters/mono/10.1201/b17360-33/motion-sickness-symptomatology-origins-kelly-hale-kay-stanney (accessed on 1 September 2020).
- Wood, C.D.; Kennedy, R.E.; Graybiel, A.; Trumbull, R.; Wherry, R.J. Clinical Effectiveness of Anti-Motion-Sickness Drugs: Computer Review of the Literature. JAMA 1966, 198, 1155–1158. [Google Scholar] [CrossRef]
- Azad Balabanian, P.L. Motion Sickness in VR: Adverse Health Problems in VR Part I. 2016. Available online: https://researchvr.podigee.io/5-researchvr-005 (accessed on 5 August 2020).
- Reason, J.T. Motion sickness adaptation: A neural mismatch model. J. R. Soc. Med. 1978, 71, 819–829. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wiker, S.; Kennedy, R.; McCauley, M.; Pepper, R. Susceptibility to seasickness: Influence of hull design and steaming direction. Aviat. Space Environ. Med. 1979, 50, 1046–1051. [Google Scholar]
- Paul, S.; Ni, Z.; Ding, F. An Analysis of Post Attack Impacts and Effects of Learning Parameters on Vulnerability Assessment of Power Grid. In Proceedings of the 2020 IEEE Power Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 17–20 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Sunny, M.R.; Kabir, M.A.; Naheen, I.T.; Ahad, M.T. Residential Energy Management: A Machine Learning Perspective. In Proceedings of the 2020 IEEE Green Technologies Conference(GreenTech), Oklahoma City, OK, USA, 1–3 April 2020; pp. 229–234. [Google Scholar] [CrossRef]
- Paul, S.; Ding, F.; Kumar, U.; Liu, W.; Ni, Z. Q-Learning-Based Impact Assessment of Propagating Extreme Weather on Distribution Grids. In Proceedings of the 2020 IEEE Power Energy Society General Meeting (PESGM), Montreal, QC, Canada, 3–6 August 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Ni, Z.; Paul, S. A Multistage Game in Smart Grid Security: A Reinforcement Learning Solution. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2684–2695. [Google Scholar] [CrossRef]
- Paul, S.; Ni, Z.; Mu, C. A Learning-Based Solution for an Adversarial Repeated Game in Cyber–Physical Power Systems. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4512–4523. [Google Scholar] [CrossRef]
- Alsamhi, S.; Ma, O.; Ansari, S. Convergence of Machine Learning and Robotics Communication in Collaborative Assembly: Mobility, Connectivity and Future Perspectives. J. Intell. Robot. Syst. 2020, 98. [Google Scholar] [CrossRef]
- Maity, N.G.; Das, S. Machine learning for improved diagnosis and prognosis in healthcare. In Proceedings of the 2017 IEEE Aerospace Conference, Big Sky, MT, USA, 4–11 March 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Ahad, M.T.; Soma, F.A.; Paul, S.; Chowdhury, A.; Luna, S.A.; Yazdan, M.M.S.; Rahman, A.; Siddique, Z.; Huebner, P. Detecting SARS-CoV-2 From Chest X-Ray Using Artificial Intelligence. IEEE Access 2021, 9, 35501–35513. [Google Scholar] [CrossRef]
- Ünal, Z. Smart Farming Becomes Even Smarter With Deep Learning—A Bibliographical Analysis. IEEE Access 2020, 8, 105587–105609. [Google Scholar] [CrossRef]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar]
- Martinez, J.; Black, M.J.; Romero, J. On human motion prediction using recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2891–2900. [Google Scholar]
- Hou, X.; Dey, S.; Zhang, J.; Budagavi, M. Predictive view generation to enable mobile 360-degree and VR experiences. In Proceedings of the 2018 Morning Workshop on Virtual Reality and Augmented Reality Network, Budapest, Hungary, 24 August 2018; pp. 20–26. [Google Scholar]
- Fan, C.L.; Lee, J.; Lo, W.C.; Huang, C.Y.; Chen, K.T.; Hsu, C.H. Fixation prediction for 360 video streaming in head-mounted Virtual Reality. In Proceedings of the 27th Workshop on Network and Operating Systems Support for Digital Audio and Video, Taipei, Taiwan, 20–23 June 2017; pp. 67–72. [Google Scholar]
- Hou, X.; Lu, Y.; Dey, S. Wireless VR/AR with edge/cloud computing. In Proceedings of the 2017 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017; pp. 1–8. [Google Scholar]
- Perfecto, C.; Elbamby, M.S.; Ser, J.D.; Bennis, M. Taming the Latency in Multi-User VR 360°: A QoE-Aware Deep Learning-Aided Multicast Framework. IEEE Trans. Commun. 2020, 68, 2491–2508. [Google Scholar] [CrossRef] [Green Version]
- Elbamby, M.S.; Perfecto, C.; Bennis, M.; Doppler, K. Toward low-latency and ultra-reliable Virtual Reality. IEEE Netw. 2018, 32, 78–84. [Google Scholar] [CrossRef] [Green Version]
- Tiiro, A. Effect of Visual Realism on Cybersickness in Virtual Reality. Univ. Oulu 2018, 350. Available online: http://urn.fi/URN:NBN:fi:oulu-201802091218 (accessed on 5 August 2020).
- Kennedy, R.S.; Lane, N.E.; Berbaum, K.S.; Lilienthal, M.G. Simulator sickness questionnaire: An enhanced method for quantifying simulator sickness. Int. J. Aviat. Psychol. 1993, 3, 203–220. [Google Scholar] [CrossRef]
- Sensory Conflict Theory. Available online: https://www.oxfordreference.com/view/10.1093/oi/authority.20110803100454911 (accessed on 24 November 2020).
- Lu, D. Virtual Reality Sickness during Immersion: An Investigation Ofpotential Obstacles towards General Accessibility of VR Technology. 2016. Available online: https://www.diva-portal.org/smash/get/diva2:1129675/FULLTEXT01.pdf (accessed on 12 January 2021).
- Rouse, M. Field of View (FOV). 2017. Available online: https://whatis.techtarget.com/definition/field-of-view-FOV (accessed on 5 August 2020).
- Wilson, M.L. The Effect of Varying Latency in a Head-Mounted Display on Task Performance and Motion Sickness. 2016. Available online: https://tigerprints.clemson.edu/cgi/viewcontent.cgi?article=2689&context=all_dissertations (accessed on 20 September 2020).
- Wagner, D. Motion to Photon Latency in Mobile AR and VR. 2018. Available online: https://medium.com/@DAQRI/motion-to-photon-latency-in-mobile-ar-and-vr-99f82c480926 (accessed on 5 August 2020).
- Hunt, C.L.; Sharma, A.; Osborn, L.E.; Kaliki, R.R.; Thakor, N.V. Predictive trajectory estimation during rehabilitative tasks in augmented reality using inertial sensors. In Proceedings of the 2018 IEEE Biomedical Circuits and Systems Conference (BioCAS), Cleveland, OH, USA, 17–19 October 2018; pp. 1–4. [Google Scholar]
- Zheng, F.; Whitted, T.; Lastra, A.; Lincoln, P.; State, A.; Maimone, A.; Fuchs, H. Minimizing latency for augmented reality displays: Frames considered harmful. In Proceedings of the 2014 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 10–12 September 2014; pp. 195–200. [Google Scholar]
- Boger, Y. Understanding Predictive Tracking and Why It’s Important for AR/VR Headsets. 2017. Available online: https://www.roadtovr.com/understanding-predictive-tracking-important-arvr-headsets/ (accessed on 7 August 2020).
- Richter, F.; Zhang, Y.; Zhi, Y.; Orosco, R.K.; Yip, M.C. Augmented Reality Predictive Displays to Help Mitigate the Effects of Delayed Telesurgery. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal Convention Center, Montreal, QC, Canada, 20–24 May 2019; pp. 444–450. [Google Scholar]
- Azuma, R.T. Predictive Tracking for Augmented Reality. Ph.D. Thesis, University of North Carolina, Chapel Hill, NC, USA, 1995. [Google Scholar]
- Akatsuka, Y.; Bekey, G.A. Compensation for end to end delays in a VR system. In Proceedings of the IEEE 1998 Virtual Reality Annual International Symposium (Cat. No.98CB36180), Atlanta, GA, USA, 14–18 March 1998; pp. 156–159. [Google Scholar]
- Butepage, J.; Black, M.J.; Kragic, D.; Kjellstrom, H. Deep representation learning for human motion prediction and classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6158–6166. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal lstm with trust gates for 3d human action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 816–833. [Google Scholar]
- Graves, A.; Mohamed, A.r.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Jain, A.; Zamir, A.R.; Savarese, S.; Saxena, A. Structural-rnn: Deep learning on spatio-temporal graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5308–5317. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Duan, Y.; Yisheng, L.; Wang, F.Y. Travel time prediction with LSTM neural network. In Proceedings of the 2016 IEEE 19th international conference on intelligent transportation systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 1053–1058. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y.; Sa, J.; Chung, Y.; Park, D.; Lee, S. Resource-efficient pet dog sound events classification using LSTM-FCN based on time-series data. Sensors 2018, 18, 4019. [Google Scholar] [CrossRef] [Green Version]
- Hashida, S.; Tamura, K. Multi-channel mhlf: Lstm-fcn using macd-histogram with multi-channel input for time series classification. In Proceedings of the 2019 IEEE 11th International Workshop on Computational Intelligence and Applications (IWCIA), Hiroshima, Japan, 9–10 November 2019; pp. 67–72. [Google Scholar]
- Zhou, Q.; Wu, H. NLP at IEST 2018: BiLSTM-attention and LSTM-attention via soft voting in emotion classification. In Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Brusssels, Belgium, 31 October–1 November 2018; pp. 189–194. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Zhao, Y.; Yang, R.; Chevalier, G.; Shah, R.C.; Romijnders, R. Applying deep bidirectional LSTM and mixture density network for basketball trajectory prediction. Optik 2018, 158, 266–272. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Xu, R.; He, Y.; Wang, X. Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN. Expert Syst. Appl. 2017, 72, 221–230. [Google Scholar] [CrossRef] [Green Version]
- Qin, L.; Yu, N.; Zhao, D. Applying the convolutional neural network deep learning technology to behavioural recognition in intelligent video. Tehnički Vjesn. 2018, 25, 528–535. [Google Scholar]
- Hu, Y. Stock market timing model based on convolutional neural network—A case study of Shanghai composite index. Financ. Econ. 2018, 4, 71–74. [Google Scholar]
- Rachinger, C.; Huber, J.B.; Müller, R.R. Comparison of convolutional and block codes for low structural delay. IEEE Trans. Commun. 2015, 63, 4629–4638. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Wu, X. On cross correlation based-discrete time delay estimation. In Proceedings of the Proceedings, (ICASSP ’05), IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 23–25 March 2005; pp. 981–984. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Function Name | Maximum Error | Minimum Error | Average Error | Standard Deviation Error |
|---|---|---|---|---|
| Cubic function | ||||
| Quadratic function | ||||
| Linear function | ||||
| No prediction |
| Predicted Function Name | Maximum Error | Minimum Error | Average Error | Standard Deviation Error |
|---|---|---|---|---|
| Kalman filter | 0.0193 | 0.0049 | 0.0050 | |
| Actual data | 0.9999 | 0.8436 | 0.9686 | 0.0331 |
| Predicted Deep Learning Model Name | Train RMSE | Train MAE | Test RMSE | Test MAE |
|---|---|---|---|---|
| LSTM | 0.02 | 0.01 | 0.01 | 0.001 |
| Bidirectional LSTM | 0.01 | 0.01 | 0.011 | 0.001 |
| Convolutional LSTM | 0.01 | 0.00 | 0.012 | 0.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kundu, R.K.; Rahman, A.; Paul, S. A Study on Sensor System Latency in VR Motion Sickness. J. Sens. Actuator Netw. 2021, 10, 53. https://doi.org/10.3390/jsan10030053
Kundu RK, Rahman A, Paul S. A Study on Sensor System Latency in VR Motion Sickness. Journal of Sensor and Actuator Networks. 2021; 10(3):53. https://doi.org/10.3390/jsan10030053
Chicago/Turabian StyleKundu, Ripan Kumar, Akhlaqur Rahman, and Shuva Paul. 2021. "A Study on Sensor System Latency in VR Motion Sickness" Journal of Sensor and Actuator Networks 10, no. 3: 53. https://doi.org/10.3390/jsan10030053
APA StyleKundu, R. K., Rahman, A., & Paul, S. (2021). A Study on Sensor System Latency in VR Motion Sickness. Journal of Sensor and Actuator Networks, 10(3), 53. https://doi.org/10.3390/jsan10030053